Abstract
With the advent of large-scale data, the demand for information is increasing, which makes signal sampling technology and digital processing methods particularly important. The utilization of 1-bit compressive sensing in sparse recovery has garnered significant attention due to its cost-effectiveness in hardware implementation and storage. In this paper, we first leverage the minimax concave penalty equipped with the least squares to recover a high-dimensional true signal with k-sparse from n-dimensional 1-bit measurements and discuss the regularization by combing the nonconvex sparsity-inducing penalties. Moreover, we give an analysis of the complexity of the method with minimax concave penalty in certain conditions and derive the general theory for the model equipped with the family of sparsity-inducing nonconvex functions. Then, our approach employs a data-driven Newton-type method with stagewise steps to solve the proposed method. Numerical experiments on the synthesized and real data verify the competitiveness of the proposed method.
MSC:
65J20; 47J06; 65F22
1. Introduction
With the advent of big data, people’s demand for signal processing is increasing, which drives the need for simpler signal processing technology. In the past decade or two, compressive sensing (CS), as a high-efficiency tool in signal processing, has garnered a lot of interest. However, classical CS faces substantial computing challenges when dealing with larger-dimensional signals due to storage bottlenecks, high transmission bandwidth requirements, and algorithmic inefficiencies. To mitigate these computing costs, it is often effective to quantize measurements by using a finite number of bits. A quantized signal collection method for high-dimensional sparse data processing and storage is 1-bit compressive sensing [1], which transforms the measurements to a single bit, i.e., with , captures the sign of , and the element is 1 or −1, , , , n and p are positive integers. Such 1-bit compressive sensing lowers transmission costs, resulting in a significant decrease for hardware implementation. A 1-bit quantizer only needs the sign of the measurements, and thus, is admissible to nonlinear distortion. Furthermore, 1-bit CS can be used effectively in computation due to the binary measurements. The 1-bit CS is suitable for various fields including wireless sensing network and radar analysis [2,3], and in domains like machine learning research, scientific studies, and industrial application. Researchers need to deal with quantized data for producing portable devices, which are necessary in modern life.
In their pioneering work [1], Boufounos and Baraniuk firstly took into account 1-bit noiseless measurements and studied the -norm optimization problem to recover with two constraints , where the sign “≥” represents the element-wise inequality and the Hadamard product is represented by ⊙. Jacques et al. [4] considered -norm instead of -norm to enhance sparsity, and established the binary iterative hard thresholding (BIHT or BIHT-) algorithm for 1-bit noisy measurements , . Matsumoto et al. [5] studied a noisy version with iterative hard thresholding, where a fraction of the measurements can be flipped. Yan et al. [6] considered sign flips in 1-bit measurements by using an adaptive outlier pursuit (AOP) algorithm that was a modified version of BIHT. Plan et al. [7] discussed a combination between the linear loss and -constraint, just as and . Ref. [8] studied the Lagrange optimization of the linear loss and -norm and attained the analysis solution . Dai et al. [9] considered the one-sided objective model for the noisy 1-bit CS model. Subsequently, Ref. [10] introduced the pitball loss (it involves both -norm and -norms), and proposed the PBAOP algorithm to decode from binary noisy data. Aiming at solutions with better sparsity, Ref. [11] introduced the nonconvex minimax concave penalty (MCP) with linear loss. Refs. [12,13] extended this to the family of nonconvex sparsity-inducing penalties with analytical solutions. However, Refs. [12,13] did not give the estimation error. Ref. [14] considered projected least squares and proposed the LinProj algorithm to decode unknown signals. Huang et al. [15] studied -regularized least squares to decode from 1-bit noisy compressive measurements, and, respectively, proposed PDASC algorithms. Ref. [16] considered nonconvex least-squares loss with constrained with a higher sparsity level. To attain the target signal with more sparsity, Ref. [17] used the double sparsity of the unknown signal and the measurement to solve 1-bit CS optimization. The above works use the assumption of a sparse signal. In practice, there are other signals such as the gradient sparse signal or block sparse signal. Hou and Liu [18] studied the L1-TV model to solve signals possessing both element sparse and gradient sparse properties. Zhong et al. [19] proposed total variation minimization in the binary setting. Inspired by [20,21], the family of noncovex sparsity reducing penalties has been shown to enjoy good performance when it approximates -norm in conventional CS. In this paper, we try to study the least squares with minimax concave penalty (MCP) and other nonconvex sparsity-inducing penalties to decode from 1-bit CS measurements.
We end this section by giving the structure of this paper as follows. Section 2 gives some notation and preliminaries. Section 3 proposes the least-squares loss equipped with MCP and other nonconvex sparsity-inducing penalties, and discusses the estimation of the non-asymptotical error and the complexity. It then utilizes a Newton-type algorithm with a data-driven parameter voting rule to implement the proposed approach. In Section 4, experiments on synthetic and real datasets are implemented to verify the superiority of the proposed model, and illustrate the robustness and high efficiency of our method. Section 5 gives a short conclusion.
2. Preliminaries
In our work, the 1-bit CS measurement is generally modeled as [15,22]
where is the Gaussian measurement matrix, is the unknown signal to recover, the measurement , is the random Gauss noise sampled from with noise level , is the sign flip, and ⊙ is the Hadamard product. Due to binary nature of the sign function, (1) is nonlinear, and so it is challenging to decode the unknown signal from the noisy and sign-flipped data.
We then introduce assumptions and notation in the sequel. The unknown recovered signal is assumed up to a positive constant. Since only the signs of real-valued measurements are preserved, scaling will not make changes to the measurements, i.e., with , which indicates that the best way is to recover up to a scale factor. The measurement matrix is a random matrix, whose rows , is independently distributed (i.i.d.) from , where is the unknown covariance matrix. For , the -norm is defined as , with . is the infinity norm. Let be the target signal with k sparse level. And the true is given. We use to denote the integer set, i.e., . For a subset with the cardinality of , is the supplementary set of , i.e., . and , where is the jth column of the measurement matrix A. For the entries of sign flips , it is assumed that the probability of positive signs is and that of negative signs is . A, , and are mutually independent. denotes that a positive numerical constant is ignored. Next, we give the definition and the theoretical basis.
Definition 1
([20,23]). The mapping is called Newton differentiable in the open subset if there exists a family of mappings such that
The mapping G is called a Newton derivative for F in U.
This definition can be used to analyze and solve the proposed model.
Lemma 1
([20]). Let be the 1-bit model (1) at the population level, where the elements , , , and in model (1) are random variables with the same distributions as those of , , , and , respectively. Let , , . It follows that
where and is the true signal.
Based on this lemma, is a multiple of . Note that
and
Meanwhile, if is invertible, though y consists of a flipped signal,
where indicates the least-squares loss can be used as a loss function if .
3. The Least-Squares Approach with MCP Regularized
3.1. Combination of Least Squares and MCP
In this subsection, we try to recover the sparse signal from the 1-bit CS model (1) with . -norm is the best choice to use for sparsity recovery. Nonetheless, the -norm optimization problem is generally difficult because of the nonconvexity and nonsmoothness. MCP regression models have the oracle property and produce unbiased solutions [24]. Based on these advantages, we combine MCP with least-squares loss to decode the unknown signal from the binary measurements as follows:
where is the minimum of model (2), the element is denoted by , , is defined by
with a regularization parameter , and , where t is a scalar. The form of MCP after integration is generally used, namely,
Then, can be formulated as the sum of the -penalty and a concave part for all . Even though is nonconvex and nonsmooth, is differentiable. MCP satisfies the following unbiasedness, selection features, and bounded properties:
- (a)
- ;
- (b)
- , where denotes that the variable approaches 0 from the right;
- (c)
- .
When , MCP coincides with the -penalty; when , MCP approaches the -penalty. Further, these properties are suitable for the SCAD function. As we know, this is the first time the least-squares loss has been combined with MCP regularization in a 1-bit CS setting.
To solve the nonlinear model problem (2), we adopt the concentration of measure theorem and use the linear model to approximate the measurement data. First, we give one assumption.
Assumption 1
(-null consistency condition). Assume that and , the least-squares model with the nonconvex sparsity-inducing regularization, i.e.,
has the
-null consistency condition if it satisfies
This condition guarantees that the global minimizer by the model is achievable at if the target signal . The null consistency condition is used to attain the -regularity condition [25] for large-scale optimization.
Lemma 2.
Assume that is a global minimizer of (2). Let , where is the given true signal with k sparse level. ; ; ; and . If Assumption (1) holds, then it has
Proof.
Since is the minimizer of the problem (2), satisfies the following inequality
We put and into the above inequality (5), and obtain
Next, applying -null consistency, we have
Using and and (6), we have
Finally, by , this gives the conclusion. □
Due to Lemma 2, with the error of the model (2) satisfies
In order to give the bound of the random measurement matrix, we find the property of the measurement matrix. Here, an -regularization condition is needed, which is used for concave penalty functions in other works.
Definition 2.
Let , ; a cone invertibility factor (CIF) is defined by [25]
Definition 3.
Let ; denotes any penalty function; the restricted invertibility factor is defined as [25]
Comparing the definitions of the above invertibility factors, the factor is more general than the factor. When is specifically the -norm penalty function, . For the MCP function , there is a relationship between and described in the following proposition.
Lemma 3.
If is increasing when , then it holds that
Hence, when , is an regularity condition for the measure matrix A, where the notation denotes f asymptotically approaching 1. Since is concave in , then is increasing in t. Lemma 3 is applicable to MCP, SCAD, and other nonconvex sparsity-inducing functions.
From this proposition, we know that if the lower bound of exists, then the lower bound of exists, and therefore, the upper bound of exists. When , the sparse eigenvalue of the measurement is uniformly bound from below in terms of [26]. Thus, there exists a constant with respect to the sparse eigenvalue of the given measurements, such that
Let and , with (7); for , we attain the property of the measurement matrix as follows:
Then, we give the non-asymptotic error estimates of the model (2).
Theorem 1.
Let be the true signal with k-sparse level and and . If the ν-consistency condition (1) holds, as , then with probability at least , it holds that
where and are generic positive constants depending on the maximum sub-Gaussian norm of rows of A, respectively, (see details in Lemma B.2 of [15]) and .
Proof.
As is a minimizer of the model (2), from the optimization conditions of vector extremum problems, satisfies the following inequality:
From the KKT optimal condition, it has . And we define . Moreover, due to , we obtain
Due to (10) and Lemma 2, it holds that
where the third inequality uses the trigonometric inequality for the infinite norms, the right item of the fourth inequality uses Lemma D.2. in [15], and the fifth inequality applies Formula (12). Let , and then,
Since , we have
i.e.,
This gives a conclusion. □
Remark 1.
Through Theorem 1, we know that for any , if , the estimated signal decoded from (2) belongs to the δ-neighborhood of . Based on Theorem 1, we attain the same order of sample complexity with [8,15,17]. The least-squares model based on the MCP penalty function has lower sample complexity than that of the -constrained least-squares model [16], which coincides with less computational time in experiments.
Remark 2.
MCP belongs to a class of nonconvex penalty functions that can reduce the sparsity, which are proved to satisfy the ν-null consistency (see details of [25]). The SCAD function also has the special property Section 3.1. Hence, under the ν-null consistency assumption and the definition of RIF for the least squares based on the SCAD penalty function, we can arrive at a similar upper bound for the reconstruction error.
Finally, we obtain the estimated error of a one-class sparsity-inducing nonconvex penalty. Here, as a convenience, we concentrate all regularization parameters in the penalty function on one parameter . For the 1-bit noisy and sign-flipped compressive sensing measurement, the least-squares model based on the sparse nonconvex penalty function is written as
Theorem 2.
Let and , . Suppose that is a minimum of model (13). If the ν-null consistency condition 1 holds, it has
where , , and .
Proof.
Let and . Due to the given conditions, we have that if Assumption 1 holds, then it has
Therefore, it holds that
and
Since the lower bound of exists, we obtain , and
So, we give a conclusion about the reconstruction error that
□
Remark 3.
The above theorem gives the estimated error under the general cases. That is, there exists a upper bound for the least-squares loss with a class of sparsity-inducing nonconvex penalty functions. Theorem 1 gives a more precise calculation for the reconstruction error. We can extend the result of the linear measurement model to the nonlinear 1-bit measurement model.
For the comparison, Table 1 is reported.

Table 1.
The complexity of 1-bit compressive sensing for many methods.
3.2. Algorithm for (2)
For the proposed method, MCP and other penalties are nonconvex. This is not easy to compute effectively. Fortunately, these noncovex sparsity-inducing functions equipped with the least-squares loss obtain the thresholding operator [20]. We first give the description of the thresholding operator and derive the Karush–Kuhn–Tucker (KKT) equations of the minimizer solution and necessary condition for the global minimizer of (2). Specifically, we show that the global minimizer satisfies the Karush–Kuhn–Tucker (KKT) equations.
Theorem 3.
Let be the global minimizer of (2). Then,
where is the thresholding operator of the MCP function, defined as
Proof.
The proof refers to Lemma 3.4 of [20]. □
Then, based on the KKT system, we let , and introduce a nonlinear operator as
Let be the root of . We use the Newton-type to find the root. Denote the derivative function of as by
From (15), we can derive that
For an initial and given [20], we implement the following procedure to update the l-th iterated value . Let an active set and an inactive set . Then, we use the Newton update as
which, after some algebra computation, becomes
with
To obtain the effective solution, we introduce the weight into the active set, i.e., .
The method is a Newton-type method, and therefore, it heavily relies on the input value and the Lagrange multiplier to obtain a meaningful result. So, the continuation technique [15,20] is used to attain the initial value and a proper tuning parameter is simultaneously selected by using a decreasing sequence and majority-vote strategy. Specifically, from a decreasing sequence , the output of the -problem is used as the initial value of the -problem. Let , since is a minimizer to the model (2), and , , . By using the series (a scalar), we conduct the algorithm until the stopping criterion is satisfied, i.e., , where and the symbol represents the largest integer smaller than itself. The algorithm on is conducted to obtain a solution path and select a by using the majority-vote rule [28], i.e.,
Then, we solve the proposed model by Algorithm 1 below, for simplicity termed MCPWP.
| Algorithm 1 MCPWP |
4. Experiments
We conduct all experiments on MATLAB 2018a running on a PC with Intel(R) Core (TM)i5-8265 CPU (1.60 GHz) and RAM with 8 GB. For the code of the proposed algorithm, refer to “https://github.com/cjia80/mcpwp” (accessed on 12 June 2024).
4.1. Testing Examples
Example (correlated covariance [15]). The rows of a random Gaussian measurement matrix are independently and identically distributed (i.i.d.) from with . The nonzero true signal vector is generated from the normal Gaussian distribution. To avoid negligible entries of the true signal, we modify , while ensuring that the number of nonzero elements is k. The noise term b is sampled from the Gaussian distribution, i.e., , where represents the noise level. The sign flips with the probability are also given. Then, the measurement data y are generated by . Additionally, for the data-driven selection method, we divide the interval into L subintervals, i.e., to choose the parameter and obtain a good initial value of our Newton-type algorithm. All the 1-bit recovered signals need to be normalized for comparison. Furthermore, based on previous studies [6,8,15], we set all experiments with 100 epochs, and manually adjust values of and w in subsequent epochs. For the comparison of the recovered performance, we choose the computational (CPU) time, the exact recovery probability (PrE; defined as the frequency of the number of trials where the estimated support coincides with the true support), and the signal-to-noise ratio (SNR; denoted by in dB (where is the recovered signal) or estimated error ( ).
4.2. Implementation and the Effect of Parameter Selection
We firstly consider the effect of the probability of the sparsity k, the noise level , and the sign flip probability when using the MCPWP algorithm to solve the model (2). We run MCPWP under the following three cases: , with various sparsity k, noise level , and probability of sign flips . The experiment results are plotted accordingly in Figure 1. Let us take a close look at the results. From Figure 1a, the proposed method has an accuracy of PrE if the target is very sparse and is above if . In Figure 1b, the recovery probability changes very little if the noise level is below 0.8. The same result is shown in terms of various sign flip rates in Figure 1c. This figure implies that our method is robust to the sparsity, noise level, and sign flips.
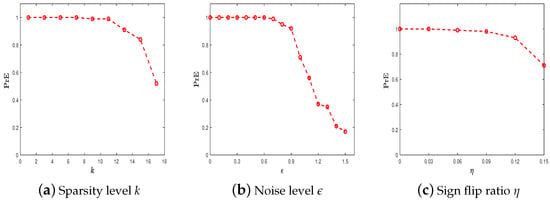
Figure 1.
The robustness of MCPWP for various k, , under . (a) ; (b) ; (c) = 0:0.03:0.15.
4.3. Benchmark Methods
In this test, we try to verify the superiority of our method in comparison with other methods with respect to SNR, the exact probability (PrE(%)), and average computational time (CPU time (s)). The benchmark methods consist of BIHT [4], AOP [6], PBAOP [10], LinProj [29,30], PDASC [15], MCP [12], WPDASC [16], and [17]. Although GPSP is an effective method to improve sparsity in synthesis experiments, GPSP needs the two priors of sparsity. And the first four algorithms and MCP require the prior knowledge of sparsity. In addition, the sign flip rate is specified in AOP and PBAOP. Our method, PDASC, and WPDASC do not need priors. The performance is illustrated in Figure 2 and Figure 3 through the three indexes SNR, PrE, and CPU time when the experiments are conducted at various sparsity level settings. Figure 2 shows that MCPWP and WPDASC exhibit superior performance, while GPSP, MCP, and BIHT are more likely to fail as the sparsity increases. In Figure 3a, MCPWP demonstrates a higher exact recovery probability compared to all other methods except for WPDASC. Meanwhile, it is evident that MCPWP requires less CPU time than WPDASC from Figure 3b. These findings highlight that our method MCPWP is an optimal choice in terms of both performance metrics here. Then, the performance of different methods on the various noise levels with others’ fixed is depicted in Figure 4 and Figure 5. As is plotted, MCPWP generally exhibits a higher SNR than other methods across most scenarios. Notably, for the three noise levels, MCPWP demonstrates the highest SNR, which reveals the robustness of the proposed method. When the sign flip rate becomes larger, our method has a higher SNR and less CPU time, as illustrated in Figure 6 and Figure 7. In addition, with high noise and a high sign flip rate , MCPWP has a higher SNR than the benchmark methods. Additionally, as the sparsity k increases, MCPWP surpasses the other approaches in CPU time except for LinProj (due to its lower computational time as a convex approach). Thus, the above experiments demonstrate that MCPWP is robust against noise, sign flips, and sparsity level, and also outperforms other methods. More higher-dimensional experiments are reported in Table 2. By comparison with other methods, our model is superior.
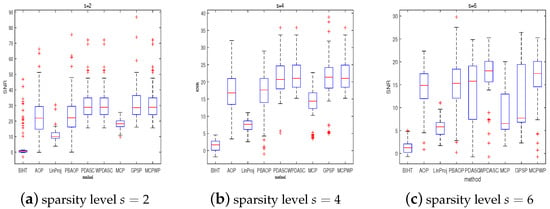
Figure 2.
The SNR for different methods with different sparsities. = 2:2:6, .
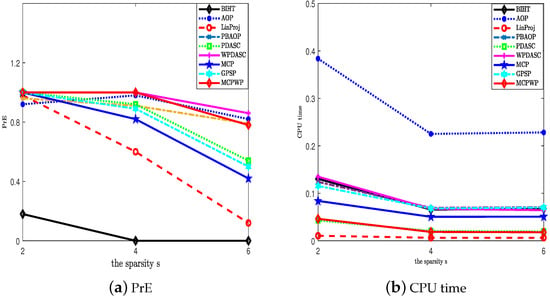
Figure 3.
The exact probability and CPU time for different methods with different sparsities. = 2:2:6, .
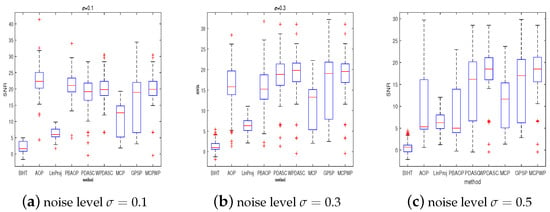
Figure 4.
The SNR for different methods with different sparsities. .
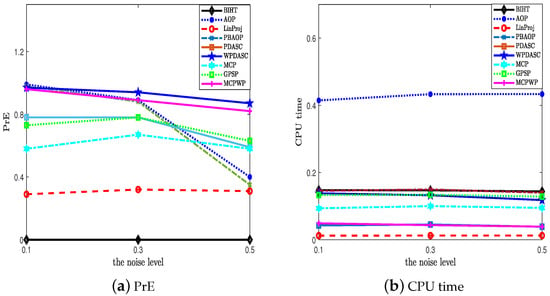
Figure 5.
The exact probability and CPU time for different methods with different sparsities. .
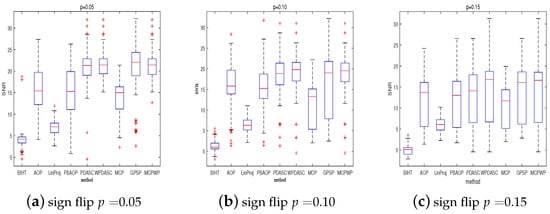
Figure 6.
The SNR for different methods with different sparsities. = 0.05:0.05:0.15.
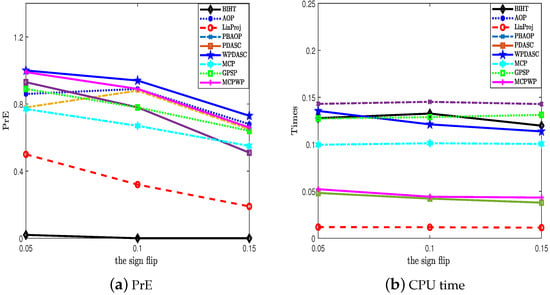
Figure 7.
The exact probability and CPU time for different methods on the different sparsity. = 0.05:0.05:0.15.
Table 2.
Comparison of many methods under higher-dimension situations.
4.4. Numerical Comparisons on 1-D Real Data
In this section, we aim to decode a 1-dimensional signal from real-world data with under the wavelet basis “Db1” [31]. There is a random Gaussian and an inverse wavelet transform in measurement matrix with the noise level and sign flip ratio . It should be noted that since GPSP is not suitable for real data, it has been omitted from our analysis. The behaviors of the aforementioned methods are reported in Table 3 and Figure 8. Among three indexes, the peak signal-to-noise ratio (PSNR) is defined as , in which M is the absolute value of the maximum in the true vector. In Table 3, as shown in our findings, MCPWP has both higher PSNR values and smaller recovery errors compared to other methods while maintaining a faster CPU time. These results demonstrate the superiority of our decoder.
Table 3.
Comparison of methods for 1-D real signal. .
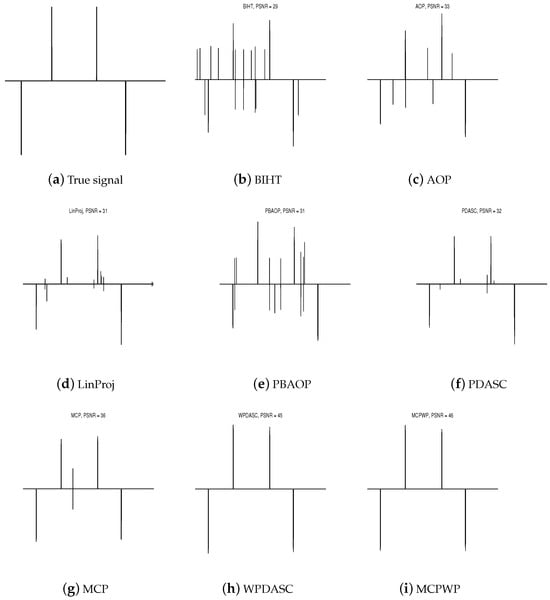
Figure 8.
Comparison of different methods under 1-D real signal. .
Finally, we conduct an investigation into the performance of the sparsity-inducing nonconvex regularization function, which contains , MCP, SCAD, and Capped-. We utilize the data-driven semi-smooth Newton algorithm equipped with continuity described in [20]. The recovery performance with different regularization functions is presented in Table 4. It is worth noting that the CPU time is very similar across all cases, indicating that the least-squares method with sparsity-inducing nonconvex functions proves to be efficient for 1-bit compressive sensing.
Table 4.
Comparison of penalty functions under different situations.
5. Conclusions
In this work, we have analyzed the least-squares regularization approach with MCP and other nonconvex sparsity-inducing functions to reconstruct the signal from 1-bit CS data with added noise and sign flips. We have obtained the competitive complexity of the proposed method, i.e., with the accuracy as long as . A data-driven Newton type with an active set and majority-vote selection rule are utilized to implement the unknown signal. Through a lot of numerical simulations, we validate that the proposed model surpasses other state-of-the-art methods.
Author Contributions
Conceptualization, C.J. and L.Z.; methodology, C.J.; validation, C.J.; writing—original draft preparation, C.J.; writing—review and editing, L.Z.; funding acquisition, C.J. and L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by OF FUNDER, grant number Y202147627, Provincial Department of Education/Research Program.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Boufounos, P.T.; Baraniuk, R.G. 1-bit compressive sensing. In Proceedings of the 2008 42nd Annual Conference on Information Sciences and Systems, Princeton, NJ, USA, 19–21 March 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 16–21. [Google Scholar]
- Fan, X.; Wang, Y.; Huo, Y.; Tian, Z. 1-bit compressive sensing for efficient federated learning over the air. IEEE Trans. Wirel. Commun. 2022, 22, 2139–2155. [Google Scholar] [CrossRef]
- Qing, C.; Ye, Q.; Cai, B.; Liu, W.; Wang, J. Deep learning for 1-bit compressed sensing-based superimposed CSI feedback. PLoS ONE 2022, 17, e0265109. [Google Scholar] [CrossRef]
- Laurent, J.; Jason N., L.; Petros T., B.; Richard G., B. Robust 1-bit compressive sensing via binary stable embeddings of sparse vectors. IEEE Trans. Inf. Theory 2013, 59, 2082–2102. [Google Scholar]
- Matsumoto, N.; Mazumdar, A. Robust 1-bit Compressed Sensing with Iterative Hard Thresholding. In Proceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms. Society for Industrial and Applied Mathematics, Alexandria, VA, USA, 7–10 January 2024; pp. 2941–2979. [Google Scholar]
- Yan, M.; Yang, Y.; Osher, S. Robust 1-bit compressive sensing using adaptive outlier pursuit. IEEE Trans. Signal Process. 2012, 60, 3868–3875. [Google Scholar] [CrossRef]
- Plan, Y.; Vershynin, R. Robust 1-bit compressed sensing and sparse logistic regression: A convex programming approach. IEEE Trans. Inf. Theory 2012, 59, 482–494. [Google Scholar] [CrossRef]
- Zhang, L.; Yi, J.; Jin, R. Efficient algorithms for robust one-bit compressive sensing. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 820–828. [Google Scholar]
- Dai, D.Q.; Shen, L.; Xu, Y.; Zhang, N. Noisy 1-bit compressive sensing: Models and algorithms. Appl. Comput. Harmon. Anal. 2016, 40, 1–32. [Google Scholar] [CrossRef]
- Huang, X.; Shi, L.; Yan, M.; Suykens, J.A. Pinball loss minimization for one-bit compressive sensing: Convex models and algorithms. Neurocomputing 2018, 314, 275–283. [Google Scholar] [CrossRef]
- Zhu, R.; Gu, Q. Towards a lower sample complexity for robust one-bit compressed sensing. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 739–747. [Google Scholar]
- Huang, X.; Yan, M. Nonconvex penalties with analytical solutions for one-bit compressive sensing. Signal Process. 2018, 144, 341–351. [Google Scholar] [CrossRef]
- Xiao, P.; Liao, B.; Li, J. One-bit compressive sensing via Schur-concave function minimization. IEEE Trans. Signal Process. 2019, 67, 4139–4151. [Google Scholar] [CrossRef]
- Plan, Y.; Vershynin, R. The generalized lasso with non-linear observations. IEEE Trans. Inf. Theory 2016, 62, 1528–1537. [Google Scholar] [CrossRef]
- Huang, J.; Jiao, Y.; Lu, X.; Zhu, L. Robust Decoding from 1-Bit Compressive Sampling with Ordinary and Regularized Least Squares. SIAM J. Sci. Comput. 2018, 40, A2062–A2086. [Google Scholar] [CrossRef]
- Fan, Q.; Jia, C.; Liu, J.; Luo, Y. Robust recovery in 1-bit compressive sensing via Lq-constrained least squares. Signal Process. 2021, 179, 107822. [Google Scholar] [CrossRef]
- Zhou, S.; Luo, Z.; Xiu, N.; Li, G.Y. Computing One-bit Compressive Sensing via Double-Sparsity Constrained Optimization. IEEE Trans. Signal Process. 2013, 61, 5777–5788. [Google Scholar] [CrossRef]
- Hou, J.; Liu, X. 1-bit compressed sensing via an l1-tv regularization method. IEEE Access 2022, 10, 116473–116484. [Google Scholar] [CrossRef]
- Zhong, Y.; Xu, C.; Zhang, B.; Hou, J.; Wang, J. One-bit compressed sensing via total variation minimization method. Signal Process. 2023, 207, 108939. [Google Scholar] [CrossRef]
- Huang, J.; Jiao, Y.; Jin, B.; Liu, J.; Lu, X.; Yang, C. A unified primal dual active set algorithm for nonconvex sparse recovery. Statist. Sci. 2021, 36, 215–238. [Google Scholar] [CrossRef]
- Shen, L.; Suter, B.W.; Tripp, E.E. Structured sparsity promoting functions. J. Optim. Theory Appl. 2019, 183, 386–421. [Google Scholar] [CrossRef]
- Plan, Y.; Vershynin, R. One-Bit Compressed Sensing by Linear Programming. Commun. Pure Appl. Math. 2013, 66, 1275–1297. [Google Scholar] [CrossRef]
- Hintermüller, M.; Ito, K.; Kunisch, K. The primal-dual active set strategy as a semismooth Newton method. SIAM J. Optim. 2002, 13, 865–888. [Google Scholar] [CrossRef]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Zhang, C.H.; Zhang, T. A general theory of concave regularization for high-dimensional sparse estimation problems. Stat. Sci. 2012, 27, 576–593. [Google Scholar] [CrossRef]
- Ye, Y.; Zhang, C.H. Rate minimaxity of the Lasso and Dantzig selector for the ℓq loss in ℓr balls. J. Mach. Learn. Res. 2010, 11, 3519–3540. [Google Scholar]
- Gopi, S.; Netrapalli, P.; Jain, P.; Nori, A. One-bit compressed sensing: Provable support and vector recovery. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; pp. 154–162. [Google Scholar]
- Kim, Y.; Kwon, S.; Choi, H. Consistent model selection criteria on high dimensions. J. Mach. Learn. Res. 2012, 13, 1037–1057. [Google Scholar]
- Plan, Y.; Vershynin, R.; Yudovina, E. High-dimensional estimation with geometric constraints. Inf. Inference A J. IMA 2016, 6, 1–40. [Google Scholar]
- Vershynin, R. Estimation in high dimensions: A geometric perspective. In Sampling Theory, a Renaissance; Springer: Berlin/Heidelberg, Germany, 2015; pp. 3–66. [Google Scholar]
- Mallat, S. A Wavelet Tour of Signal Processing: The Sparce Way, 3rd ed.; AP Professional: London, UK, 2009. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).