
A Rapid Detection Method for Coal Ash Content in Tailings Suspension Based on Absorption Spectra and Deep Feature Extraction


Abstract
1. Introduction
- Our method focuses on the absorption spectrum of tailings suspensions, marking the first study in the field to detect ash content in coal slurry flotation tailings. This approach not only meets the demands for industrial rapidity but also provides more comprehensive data.
- Traditional sequential preprocessing methods fail to effectively capture the temporal relationships inherent in the settling phenomena of tailings suspension samples. To address this, we propose an inverse time weight function (ITWF) that emphasizes differences at earlier time points, while still considering information from later time points.
- Considering the unique characteristics of the absorption spectrum of tailings suspension, we designed the DSFN (DeepSpectraFusionNet) model. This model effectively captures the location-dependent features and time memory features of the tailings suspension absorption spectrum, yielding promising results.
2. Related Work
2.1. Radiation Method
2.2. Image Method
2.2.1. Image Method Based on Machine Learning
2.2.2. Image Method Based on Deep Learning
2.3. Spectral Analysis
3. Materials and Methods
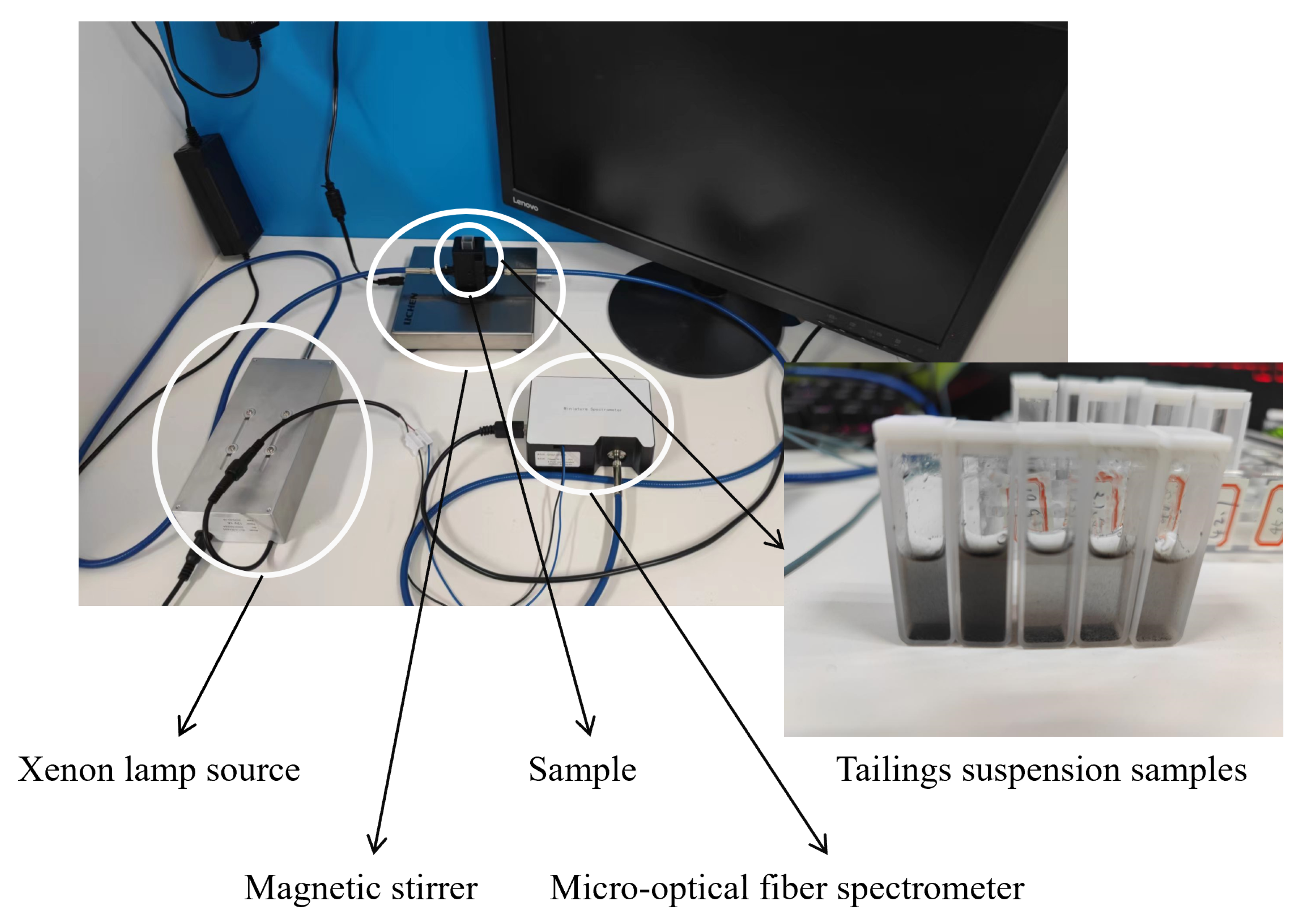
3.1. Data Description and Preprocessing
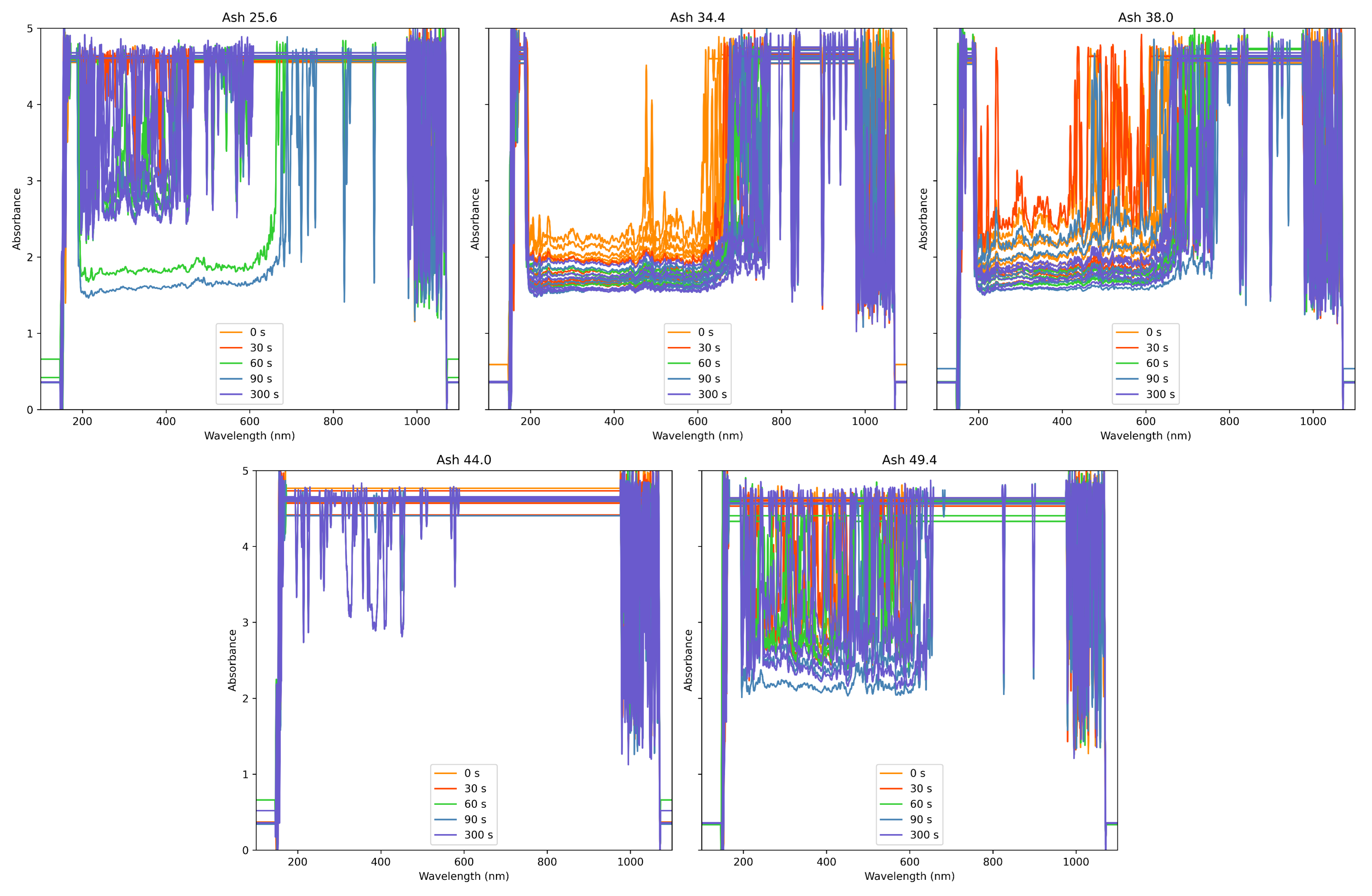
3.1.1. Data Preprocessing
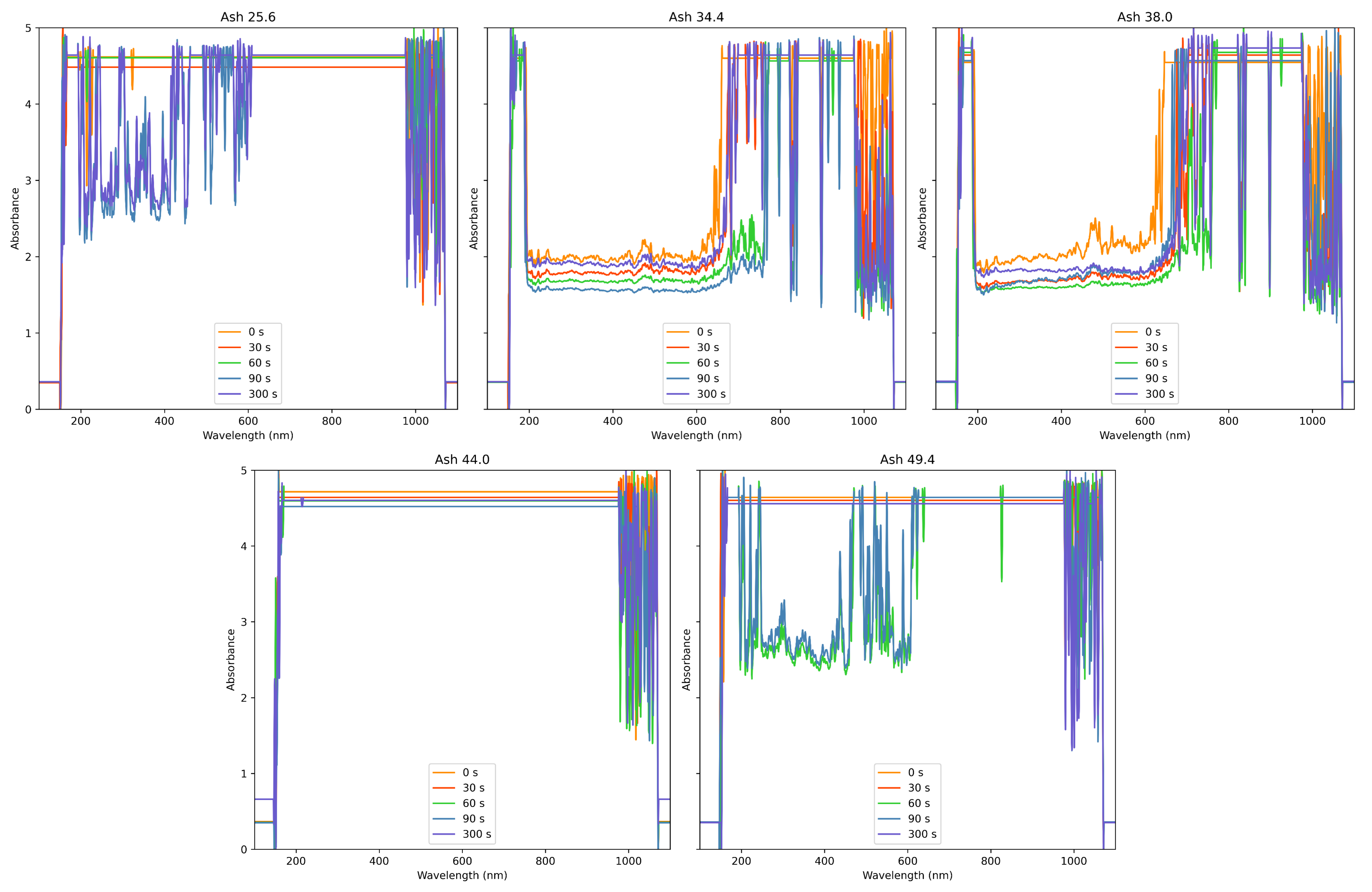
3.1.2. Inverse Time Weight Function
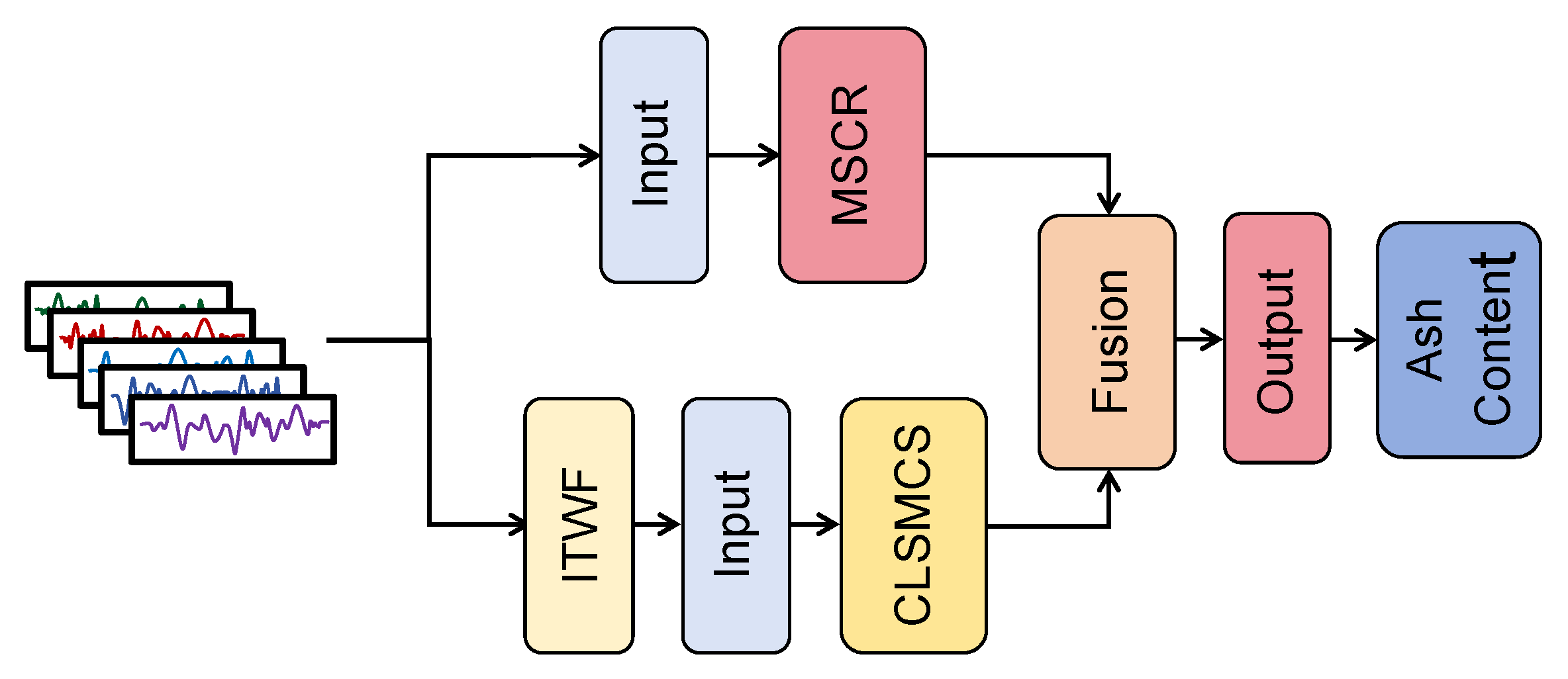
3.2. Model Framework
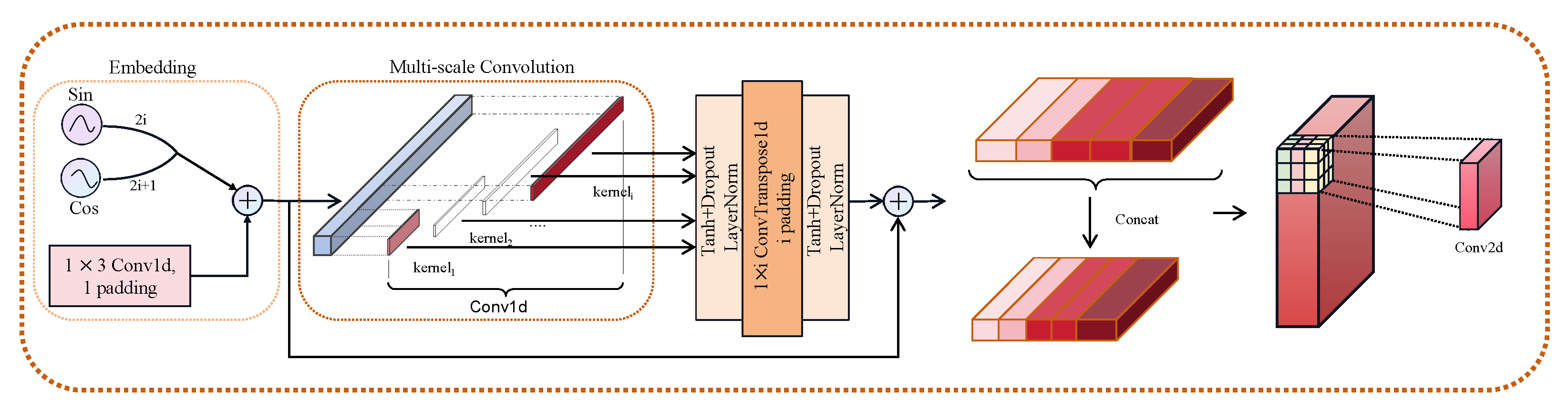
3.2.1. Multi-Scale Convolutional Residual Module
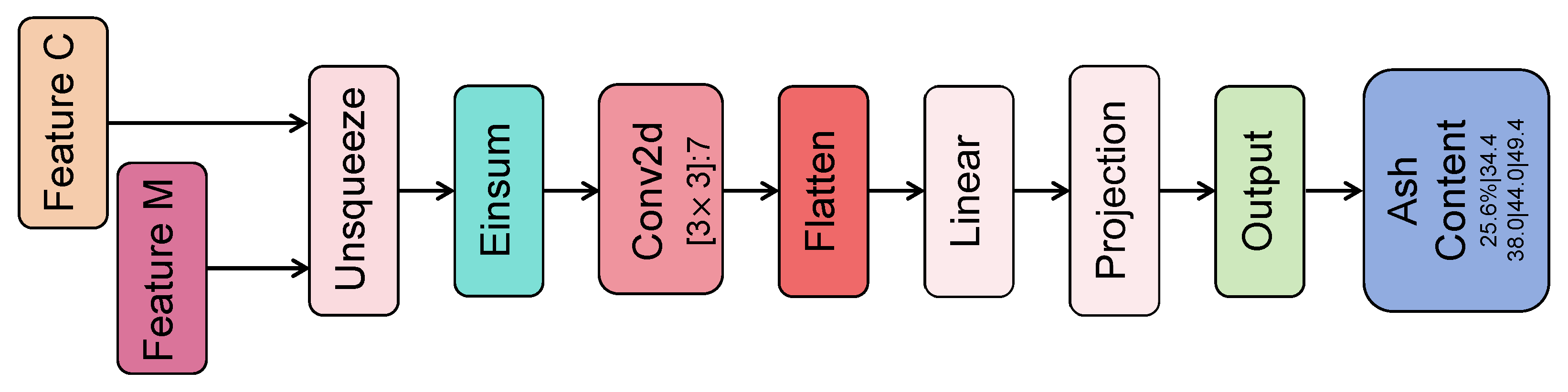
3.2.2. Convolutional Long-Short Memory with Candidate States Module
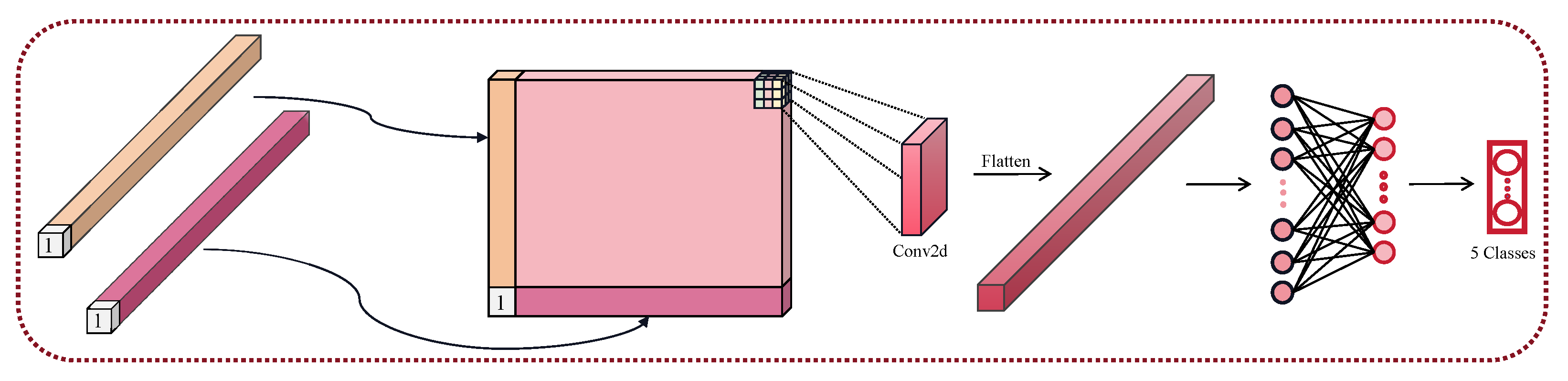
3.2.3. Fusion Convolutional Deep Classifier
4. Experiment
4.1. Comparison of Preprocessing Methods
4.2. Model Comparison Experiment
4.3. Ablation Study
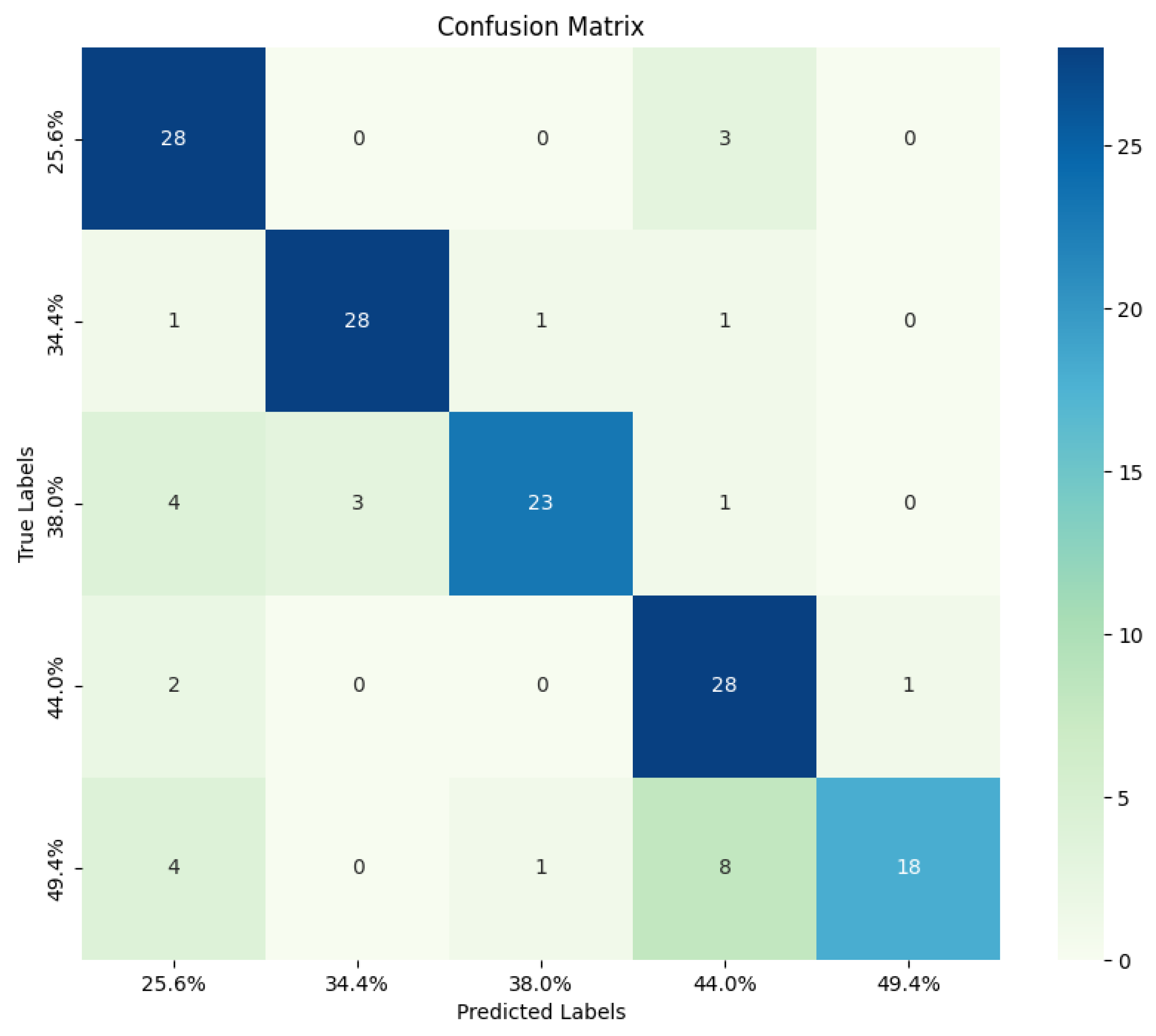
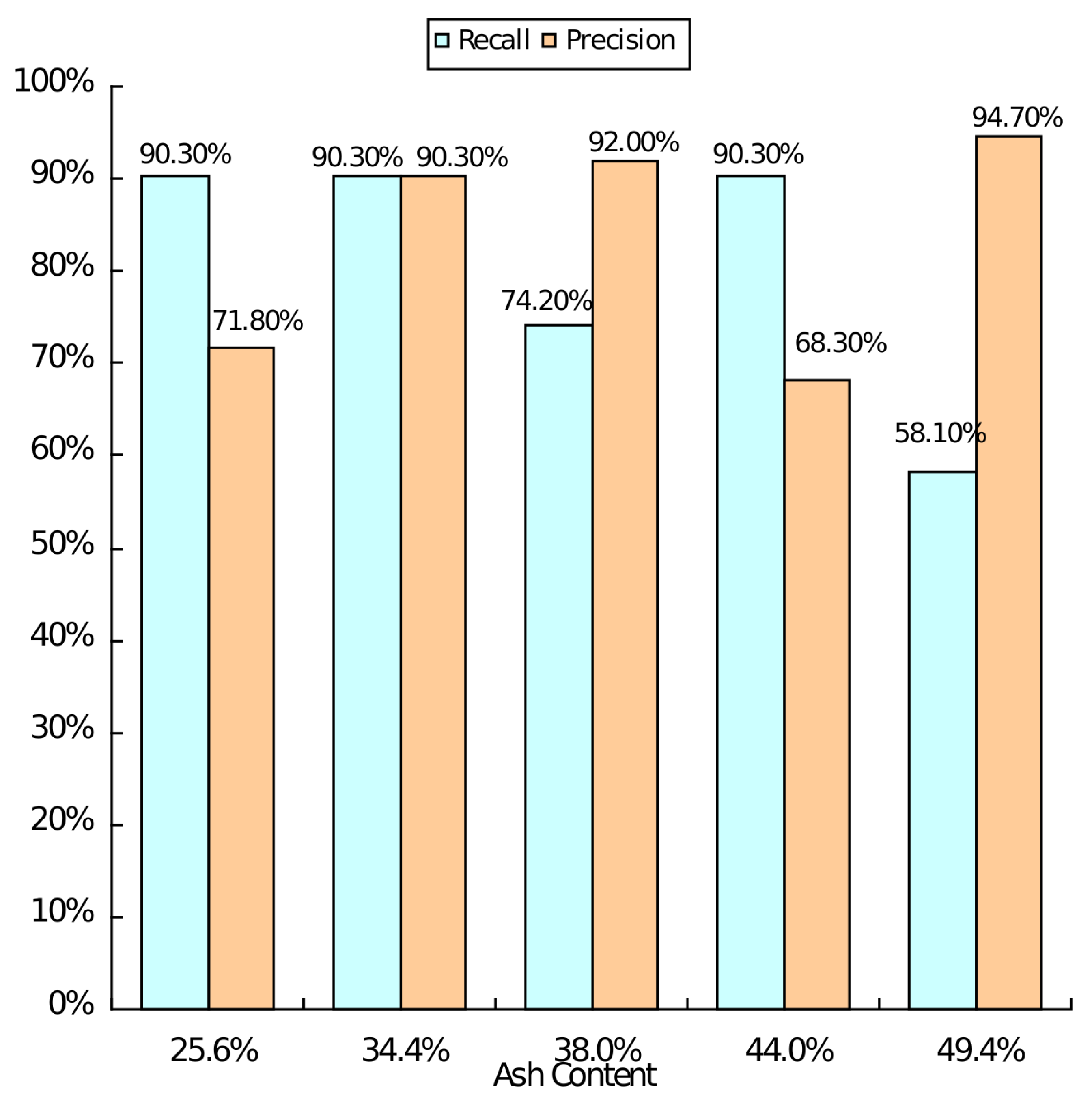
4.4. Performance Evaluation of Each Category
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liang, H.; Li, Y. Analyses of influencing factors of fine coal flotation. Coal Process. Compr. Util. 2023, 20–24. [Google Scholar] [CrossRef]
- Fookes, R.; Gravitis, V.; Watt, J.; Hartley, P.; Campbell, C.; Howells, E.; McLennan, T.; Millen, M. On-line determination of the ash content of coal using a “Siroash” gauge based on the transmission of low and high energy γ-rays. Int. J. Appl. Radiat. Isot. 1983, 34, 63–69. [Google Scholar] [CrossRef]
- Vardhan, R.H.; Giribabu. On-Line Coal-Ash Monitoring Technologies in Coal Washaries—A Review. Procedia Earth Planet. Sci. 2015, 11, 49–55. [Google Scholar] [CrossRef]
- Li, J.; Zhang, J.; Ge, L.; Zhou, W.; Zhong, D. Software design method and application of Monte Carlo simulation of NaI detector natural γ spectrum. Nucl. Electron. Detect. Technol. 2005, 423–425. [Google Scholar]
- Huang, X.; Wang, G.; Sun, P.; Yang, D.; Ma, Y. Low-energy γ-ray backscatter method for measuring coal ash. Nucl. Tech. 2005, 72–75. [Google Scholar]
- Bona, M.; Andrés, J. Coal analysis by diffuse reflectance near-infrared spectroscopy: Hierarchical cluster and linear discriminant analysis. Talanta 2007, 72, 1423–1431. [Google Scholar] [CrossRef]
- Gui, W.; Yang, C.; Xu, D.; Lu, M.; Xie, Y. Research progress on mineral flotation process monitoring technology based on machine vision. Acta Autom. Sin. 2013, 39, 1879–1888. [Google Scholar] [CrossRef]
- Zhao, B.; Hu, S.; Zhao, X.; Zhou, B.; Li, J.; Huang, W.; Chen, G.; Wu, C.; Liu, K. The application of machine learning models based on particles characteristics during coal slime flotation. Adv. Powder Technol. 2022, 33, 103363. [Google Scholar] [CrossRef]
- Tan, L.; Zhang, Z.; Zhao, W.; Zhang, R.; Zhang, K. Research progress on mineral flotation foam monitoring based on machine vision. Min. Res. Dev. 2020, 40, 123–130. [Google Scholar] [CrossRef]
- Wang, J.; Wang, R.; Fu, X.; Wu, T. Research on soft measurement of flotation tail coal ash based on color image processing. Coal Eng. 2020, 52, 137–142. [Google Scholar]
- Ding, J.; Bai, F.; Ren, X.; Fan, M. Ash content prediction system of clean coal based on flotation foam image recognition. Coal Prep. Technol. 2022, 50, 89–93. [Google Scholar] [CrossRef]
- Guo, X.; Wei, L.; Yang, C. Study on coal slime flotation tailings ash detection method based on deep convolutional network. Coal Technol. 2020, 39, 144–146. [Google Scholar] [CrossRef]
- Wen, Z.; Zhou, C.; Pan, J.; Nie, T.; Zhou, C.; Lu, Z. Deep learning-based ash content prediction of coal flotation concentrate using convolutional neural network. Miner. Eng. 2021, 174, 107251. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, K.; Ni, C.; Cao, H.; Thé, J.; Xie, G.; Tan, Z.; Yu, H. Ash determination of coal flotation concentrate by analyzing froth image using a novel hybrid model based on deep learning algorithms and attention mechanism. Energy 2022, 260, 125027. [Google Scholar] [CrossRef]
- Han, Y.; Wang, L.; Liu, Q.; Gui, X. Intelligent detection method of flotation tail coal ash based on CNN-BP. Ind. Min. Autom. 2023, 49, 100–106. [Google Scholar] [CrossRef]
- Manley, M. Near-infrared spectroscopy and hyperspectral imaging: Non-destructive analysis of biological materials. Chem. Soc. Rev. 2014, 43, 8200–8214. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Wang, J.; Lu, G.; Fei, S.; Yan, T.; Zhang, C.; Lu, X.; Yu, Z.; Li, W.; Tang, X. TeaNet: Deep learning on Near-Infrared Spectroscopy (NIR) data for the assurance of tea quality. Comput. Electron. Agric. 2021, 190, 106431. [Google Scholar] [CrossRef]
- Chang, Y.T.; Hsueh, M.C.; Hung, S.P.; Lu, J.M.; Peng, J.H.; Chen, S.F. Prediction of specialty coffee flavors based on near-infrared spectra using machine-and deep-learning methods. J. Sci. Food Agric. 2021, 101, 4705–4714. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Fan, P.; Li, Z.; Chen, G.; Qiu, H.; Hou, G. Soil classification based on deep learning algorithm and visible near-infrared spectroscopy. J. Spectrosc. 2021, 2021, 1508267. [Google Scholar] [CrossRef]
- Xiao, D.; Vu, Q.H.; Le, B.T. Salt content in saline-alkali soil detection using visible-near infrared spectroscopy and a 2D deep learning. Microchem. J. 2021, 165, 106182. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, J.; Tan, Z.; Hou, Q.; Liu, R. Detecting the content of the bright blue pigment in cream based on deep learning and near-infrared spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 270, 120757. [Google Scholar] [CrossRef] [PubMed]
- Bai, X.; Zhang, L.; Kang, C.; Quan, B.; Zheng, Y.; Zhang, X.; Song, J.; Xia, T.; Wang, M. Near-infrared spectroscopy and machine learning-based technique to predict quality-related parameters in instant tea. Sci. Rep. 2022, 12, 3833. [Google Scholar] [CrossRef] [PubMed]
- Ravichandran, P.; Viswanathan, S.; Ravichandran, S.; Pan, Y.J.; Chang, Y.K. Estimation of grain quality parameters in rice for high-throughput screening with near-infrared spectroscopy and deep learning. Cereal Chem. 2022, 99, 907–919. [Google Scholar] [CrossRef]
- Lee, P.H.; Torng, C.C.; Lin, C.H.; Chou, C.Y. Control chart pattern recognition using spectral clustering technique and support vector machine under gamma distribution. Comput. Ind. Eng. 2022, 171, 108437. [Google Scholar] [CrossRef]
- Ma, Y.; Lan, Y.; Xie, Y.; Yu, L.; Chen, C.; Wu, Y.; Dai, X. A Spatial–Spectral Transformer for Hyperspectral Image Classification Based on Global Dependencies of Multi-Scale Features. Remote Sens. 2024, 16, 404. [Google Scholar] [CrossRef]
- Le, B.T.; Xiao, D.; Mao, Y.; He, D. Coal analysis based on visible-infrared spectroscopy and a deep neural network. Infrared Phys. Technol. 2018, 93, 34–40. [Google Scholar] [CrossRef]
- Mao, Y.; Le, B.T.; Xiao, D.; He, D.; Liu, C.; Jiang, L.; Yu, Z.; Yang, F.; Liu, X. Coal classification method based on visible-infrared spectroscopy and an improved multilayer extreme learning machine. Opt. Laser Technol. 2019, 114, 10–15. [Google Scholar] [CrossRef]
- Xiao, D.; Le, B.T. Rapid analysis of coal characteristics based on deep learning and visible-infrared spectroscopy. Microchem. J. 2020, 157, 104880. [Google Scholar] [CrossRef]
- Xiao, D.; Le, T.T.G.; Doan, T.T.; Le, B.T. Coal identification based on a deep network and reflectance spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 270, 120859. [Google Scholar] [CrossRef]
- Xiao, D.; Yan, Z.; Li, J.; Fu, Y.; Li, Z. Rapid proximate analysis of coal based on reflectance spectroscopy and deep learning. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2023, 287, 122042. [Google Scholar] [CrossRef]
- Li, B.; Xiao, D.; Xie, H.; Huang, J.; Yan, Z. Coal Classification Based on Reflection Spectroscopy and the IAT-TELM Algorithm. ACS Omega 2023, 8, 35232–35241. [Google Scholar] [CrossRef]
- Li, Z.; Wang, D.; Zhu, T.; Ni, C.; Zhou, C. SCNet: A deep learning network framework for analyzing near-infrared spectroscopy using short-cut. Infrared Phys. Technol. 2023, 132, 104731. [Google Scholar] [CrossRef]
- Hua, Y.; Zhao, Z.; Li, R.; Chen, X.; Liu, Z.; Zhang, H. Deep learning with long short-term memory for time series prediction. IEEE Commun. Mag. 2019, 57, 114–119. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Object Type | Image Data | Spectral Data | ||
| Coal Powder Solid Image | Coal Slurry Flotation Foam Image | Reflectance Spectrum | Absorption Spectrum | |
 |  |  |  | |
| Advantages |
|
|
|
|
| Limitations |
|
|
|
|
| Common points | Its quality is greatly affected by lighting factors | Less susceptible to external interference | ||
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Data Type | Univariate Sequence | Learning Rate | 0.0001 |
| Data Proportion | Balance | Batch Size | 32 |
| Data Partition | 8:2 | Epochs | 60 |
| Dropout Rate | 0.5 | Optimizer | Adam |
| Methods | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|
| GA | 0.6452 | 0.6301 | 0.6333 | 0.6548 |
| SWA | 0.7424 | 0.7343 | 0.7564 | 0.7452 |
| DTF | 0.6323 | 0.6207 | 0.6241 | 0.6314 |
| OD | 0.6774 | 0.6703 | 0.6710 | 0.6833 |
| ITWF | 0.8065 | 0.8045 | 0.8343 | 0.8065 |
| Methods | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|
| RF | 0.6581 | 0.6392 | 0.6565 | 0.6433 |
| SVM | 0.6193 | 0.6086 | 0.6108 | 0.6233 |
| ELM | 0.7548 | 0.7549 | 0.7554 | 0.7548 |
| TELM | 0.7545 | 0.7556 | 0.7615 | 0.7599 |
| PCA_ELM | 0.7161 | 0.7188 | 0.7191 | 0.7209 |
| CNN + ELM | 0.7871 | 0.7849 | 0.7831 | 0.7871 |
| LSTM | 0.6839 | 0.6736 | 0.7023 | 0.6839 |
| TCN | 0.7201 | 0.7167 | 0.7842 | 0.7205 |
| Transformer | 0.7742 | 0.7514 | 0.8089 | 0.7571 |
| DSFN | 0.8065 | 0.8045 | 0.8343 | 0.8065 |
| Methods | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|
| DSFN-A | 0.7552 | 0.7554 | 0.7574 | 0.7560 |
| DSFN-B | 0.7806 | 0.7801 | 0.7934 | 0.7806 |
| DSFN-AB | 0.7345 | 0.7331 | 0.7335 | 0.7345 |
| DSFN | 0.8065 | 0.8045 | 0.8343 | 0.8065 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, W.; Zhang, X.; Zhu, Z.; Fu, W.; Liu, N.; Zhang, Z. A Rapid Detection Method for Coal Ash Content in Tailings Suspension Based on Absorption Spectra and Deep Feature Extraction. Mathematics 2024, 12, 1685. https://doi.org/10.3390/math12111685
Zhu W, Zhang X, Zhu Z, Fu W, Liu N, Zhang Z. A Rapid Detection Method for Coal Ash Content in Tailings Suspension Based on Absorption Spectra and Deep Feature Extraction. Mathematics. 2024; 12(11):1685. https://doi.org/10.3390/math12111685
Chicago/Turabian StyleZhu, Wenbo, Xinghao Zhang, Zhengjun Zhu, Weijie Fu, Neng Liu, and Zhengquan Zhang. 2024. "A Rapid Detection Method for Coal Ash Content in Tailings Suspension Based on Absorption Spectra and Deep Feature Extraction" Mathematics 12, no. 11: 1685. https://doi.org/10.3390/math12111685
APA StyleZhu, W., Zhang, X., Zhu, Z., Fu, W., Liu, N., & Zhang, Z. (2024). A Rapid Detection Method for Coal Ash Content in Tailings Suspension Based on Absorption Spectra and Deep Feature Extraction. Mathematics, 12(11), 1685. https://doi.org/10.3390/math12111685