Abstract
In this short paper, we describe natural logit population games dynamics that explain equilibrium models of origin-destination matrix estimation and (stochastic) traffic assignment models (Beckmann, Nesterov–de Palma). Composition of the proposed dynamics allows to explain two-stages traffic assignment models.
Keywords:
Beckmann model; origin-destination matrix estimation; logit-dynamic; maximum entropy principle; Hoeffding’s inequality in Hilbert space; Cheeger’s inequality; concentration of measure phenomenon MSC:
93-10
1. Introduction
The first traffic assignment model was proposed for about 70 years ago in the work of M. Beckmann [1], see also [2]. Nowadays Beckmann’s type models are rather well studied [3,4,5,6,7]. The entropy-based origin–destination matrix models are also well developed nowadays [7,8,9]. Moreover, as was mentioned in [10], both of these two types of models can be considered as macrosystem equilibrium for logit (best-response) dynamics in corresponding congestion games [11].
In this paper, we popularise the results of [10] for English-reading people (The paper [10] was written in Russian and has not been translated yet) and refine the results on the convergence rate. Moreover, we propose superposition of the considered dynamics to describe equilibrium in two-stage traffic assignment model [12,13].
One of the main results of the paper is Theorem 1, where it is proved that the natural logit-choice and best-response Markovian population dynamics in traffic assignment model (congested population game) converge to equilibrium. By using Cheeger’s inequality we first time show that mixing time (the time required to reach equilibrium) of these dynamics is proportional to , where N is a total number of agents. Note, that in related works analogues of this theorem were proved without estimating of [9,11,13]. We confirm Theorem 1 by numerical experiments.
Another important result is a saddle-point reformulation of two-stages traffic assignment model. We explain how to apply results of Theorem 1 to this model.
2. Traffic Assignment: Problem Statement
Following [14] we describe the problem statement.
Let the urban road network be represented by a directed graph , where vertices V correspond to intersections or centroids [4] and edges E correspond to roads, respectively. Suppose we are given the travel demands: namely, let (veh/h) be a trip rate for an origin–destination pair w from the set . Here, is the set of all possible origins of trips, and is the set of destination nodes. For OD pair denote by the set of all simple paths from i to j. Respectively, is the set of all possible routes for all OD pairs. Agents travelling from node i to node j are distributed among paths from , i.e., for any there is a flow (i.e., ) along the path p, and . Flows from vertices from the set O to vertices from the set D create the traffic in the entire network G, which can be represented by an element of
Note that set X can have extremely large number of paths (routes): e.g., for Manhattan network up to a logarithmic factor. Note, that to describe a state of the network we do not need to know an entire vector x, but only flows on arcs: , where . Let us introduce a matrix such that for , , so in vector notation we have . To describe an equilibrium we use both path- (route-) and link-based notations or .
Beckmann model. An important idea behind the Beckmann model is that the cost (e.g., travel time) of passing a link e is the same for all agents and depends only on the flow along it. We denote this cost for a given flow by . Another essential point is a behavioral assumption (the first Wardrop’s principle): each agent knows the state of the whole network and chooses a path p minimizing the total cost
We consider to be continuous, non-decreasing, and non-negative. In this case , is an equilibrium state, i.e., it satisfies conditions
if, and only if, is a minimum of the potential function:
and [2].
According to [5,13], we can construct a dual problem for the potential function in the following way:
where
is the Legendre—Fenchel conjugate function of , . At the end we obtain the dual problem, which solution is :
We can reconstruct primal variable f from the current dual variable t:
This condition reflects the fact that every driver choose the shortest route [5]. Another condition can be equivalently rewrite as . This condition with the condition form the optimization problem (1).
If Beckmann’s model will turn into Nesterov–de Palma model [13,15].
Population games dynamic for (stochastic) Beckmann model. Let us consider each driver to be an agent in population game, where , is a set of types of agents. All agent (drivers) of type can choose one of the strategy with cost function . Assume that every driver/agent independently of anything (in particular of any other drivers) is considering the opportunity to reconsider his choice of route/strategy p in time interval with probability , where is the same for all drivers/agents. It means that with each driver we relate its own Poisson process with parameter . If in moment of time t (when the flow distribution vector is ) the the driver of type decides to reconsider his route, than he choose the route with probability
where are i.i.d. and satisfy Gumbel max convergence theorem [16] when with the parameter (e.g., has (sub)exponential tails at ∞). It means that asymptotically (when ) has Gumbel distribution , where is Euler constant. Note that , . In (2) it means that every driver try to choose the best route. However, the only available information are noise corrupted values . So the driver try to choose the best route focused on the worst forecasts for each route.
One of the main results of Discrete Choice Theory is as follows [17]
where was previously defined in (2).
Note that the described above dynamic degenerates into the best-response dynamic when [11].
Theorem 1.
Let . For all there exists such a constant that for all and :
where
Proof.
The first important observation is that the described Markov process is reversible. That is, it satisfies Kolmogorov’s detailed balance condition (see also [18]) with stationary (invariant) measure
where [11]. The result of type (4) for holds true due to Hoeffding’s inequality in a Hilbert space [19]. We can apply this inequality for multinomial part . The rest part may only strength the concentration phenomenon, especially when is small. The Sanov’s theorem [20] says that from (5) asymptotically () describe the proportions in maximum probability state, that is
To estimate the mixing time of the considered Markov process we will put it in accordance with this continuous-time process discrete-time process with step , which corresponds to the expectation time between two nearest events in continuous-time dynamic. Additionally, we consider this discrete Markov chain as a random walk on a proper graph with starting point corresponds to the vertex s and transition probability matrix . According to a Cheeger’s inequality mixing time for such a random walk, which approximate stationary measure with accuracy (in this case ), is
where Cheeger’s constant is determined as
where [21]. Since G and P correspond to reversible Markov chain with stationary measure that exponentially concentrate around one can prove that isoperimetric problem of finding optimal set of vertexes S has the following solution, which we described below roughly up to a numerical constant: S is a set of such states that . Since the the ratio of sphere volume of radius to the volume of the ball of the same radius is , we can obtain that . So up to a (we put it into ) mixing time is indeed . □
Note that the describe above approach assumes that we first and then . If we firstly take than due to Kurtz’s theorem [22] satisfies (for all , )
where , . Note that Sanov’s type function from (5) will be Boltzmann–Lyapunov type function for this system of ordinary differential equations (SODE), that is decrees along the trajectory of SODE. This result is a particular case of the general phenomenon: Sanov’s type function for invariant measure obtained from Markovian dynamics is Boltzmann–Lyapunov type function for deterministic Kurtz’s kinetic dynamics [18,23,24].
3. Origin–Destination Matrix Estimation
Origin–destination matrix estimation model can be considered as a particular case of the traffic assignment model. The following interpretation goes back to [10,13]. Indeed, let us consider fictive origin o and fictive destination d. So , . Let us draw fictive edges from o to real origins of trips O. The cost of the trip at edge is —an average price that each agent pays to live at this origin region . Analogously, let us draw edges from the vertexes of the real destination set D to d. The cost of the trip at edge is , minus average salary that each agent obtains in destination region . So the set of all possible routes (trips) from o to d can be described by pairs . Each route consist of three edges with cost , edge with cost (is available as an input of the model) and edge with cost . So equilibrium origin-destination matrix (up to a scaling factor) can be find from entropy-linear programming problem
In real life, and are typically unknown. However, at the same time, the following agglomeration characters are available
The key observation is that (6) can be considered as Lagrange multipliers principle for constraint entropy-linear programming problem
where and are Lagrange multipliers for (7) and (8) correspondingly. The last model is called Wilson’s entropy origin–destination matrix model [8,9].
The result of Theorem 1 can be applied to this model due to the mentioned above reduction.
4. Two-Stages Traffic Assignment Model
From the Section 2 we may know that Beckmann’s model requires origin-destination matrix as an input . So Beckmann’s model allows to calculate . At the same time, from Section 3, we may know that Wilson’s entropy origin–destination model requires cost matrix as an input, where . So Wilson’s model allows to calculate . The solution of the system is called two-stage traffic assignment model [12]. Following [7,13] we can reduce this problem to the following one (see (1) and (9))
The problem (10) can be rewritten as a convex-concave (if ) saddle-point problem (SPP)
This SPP can be efficiently solved numerically [7].
Note that, if we consider best-response dynamics from Section 2, with the parameter and logit dynamic with the parameter for the origin–destination matrix estimation and assume that than such a dynamic will converge to the stationary (invariant) measure that is concentrated around the solution of the SPP problem (11). This result can be derived from the more general result related with hierarchical congested population games [7].
5. Numerical Experiments
The main result of the paper is Theorem 1. The main new result of this theorem is a statement that mixing time of the considered Markovian logit-choice and best-response dynamics is approximately , where N is a number of agents.
We consider Braess’s paradox example [25], see Figure 1. This picture is taken from Wikipedia. Here, Origin is START and Destination is END. We have one OD-pair and put , the number of agents. The <<paradox>> arises when . In this case when there is no road from A to B we have two routes (START, A, END) and (START, B, END) with 2000 agents at each route. So the equilibrium time costs at each route will be 65. When the road AB is present (this road has time costs 0) all agents will use the route (START, A, B, END) and this equilibrium has time costs 80. That is paradoxically larger than it was without road AB.
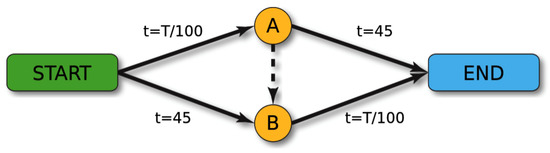
Figure 1.
Braess’s paradox graph.
In series of experiments (see Figure 2, Figure 3 and Figure 4) the dependence of mixing time from was investigated. Details see in https://github.com/ZVlaDreamer/transport_flows_project (accessed on 1 November 2022).
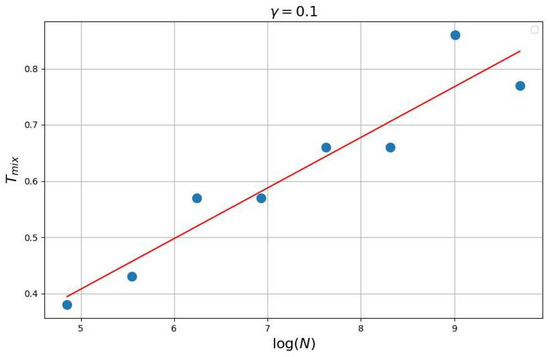
Figure 2.
Logit-choice dynamic .
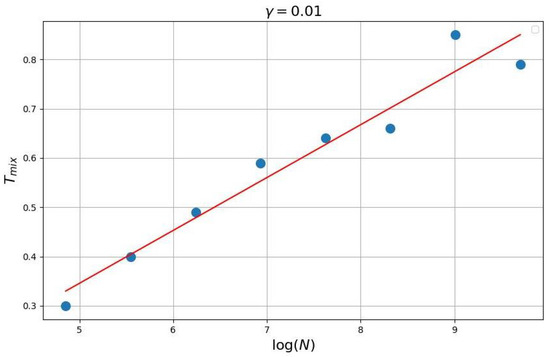
Figure 3.
Logit-choice dynamic .
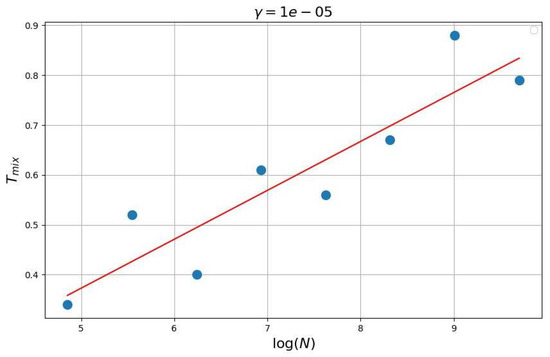
Figure 4.
Best response dynamic (as a limit of logit-choice dynamics ).
Numerical experiments confirm Theorem 1. Note that in [9] it was described a real-life experiment oraganized with MIPT students in Experimental Economics Lab. The students were agents and play in repeated Braess’s paradox game. The result of experiments from [9] is also well agreed with the described above numerical experiments.
6. Conclusions
In this paper, we investigate logit-choice and best-response population Markovian dynamics converges to equilibrium in corresponding traffic assignment model. We show that mixing time is proportional to logarithm from the number of agent. Numerical experiments confirm that the dependence is probably unimprovable. We also consider two-stage traffic assignment model and describe how to interpret equilibrium for this model in an evolutionary manner.
Author Contributions
Conceptualization, A.G. and Y.K.; Methodology, Y.K.; Software, A.Z.; Formal analysis, E.G. and A.G.; Investigation, E.G. and A.Z.; Data curation, A.Z.; Writing—original draft, E.G.; Supervision, A.G.; Project administration, A.G. All authors have read and agreed to the published version of the manuscript.
Funding
The work of E. Gasnikova was supported by the Ministry of Science and Higher Education of the Russian Federation (Goszadaniye) 075-00337-20-03, project No. 0714-2020-0005. The work of A. Gasnikov was supported by the strategic academic leadership program <<Priority 2030>> (Agreement 075-02-2021-1316 30 September 2021).
Data Availability Statement
Not applicable.
Acknowledgments
We dedicate this paper to our colleague Vadim Alexandrovich Malyshev (13 April 1938–30 September 2022). We express our gratitude to Leonid Erlygin (MIPT) and Vladimir Zholobov (MIPT) who conducted numerical experiments.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Beckmann, M. A continuous model of transportation. Econom. J. Econom. Soc. 1952, 20, 643–660. [Google Scholar] [CrossRef]
- Beckmann, M.J.; McGuire, C.B.; Winsten, C.B. Studies in the Economics of Transportation; Technical Report; The National Academies of Sciences, Engineering, and Medicine: Washington, DC, USA, 1956. [Google Scholar]
- Patriksson, M. The Traffic Assignment Problem: Models and Methods; Courier Dover Publications: Mineola, NY, USA, 2015. [Google Scholar]
- Sheffi, Y. Urban Transportation Networks; Prentice-Hall: Englewood Cliffs, NJ, USA, 1985; Volume 6. [Google Scholar]
- Nesterov, Y.; De Palma, A. Stationary dynamic solutions in congested transportation networks: Summary and perspectives. Netw. Spat. Econ. 2003, 3, 371–395. [Google Scholar]
- Baimurzina, D.R.; Gasnikov, A.V.; Gasnikova, E.V.; Dvurechensky, P.E.; Ershov, E.I.; Kubentaeva, M.B.; Lagunovskaya, A.A. Universal method of searching for equilibria and stochastic equilibria in transportation networks. Comput. Math. Math. Phys. 2019, 59, 19–33. [Google Scholar]
- Gasnikov, A.; Gasnikova, E. Traffic Assignment Models. Numerical Aspects; MIPT: Dolgoprudny, Russia, 2020. [Google Scholar]
- Wilson, A. Entropy in Urban and Regional Modelling (Routledge Revivals); Routledge: Oxfordshire, UK, 2013. [Google Scholar]
- Gasnikov, A.; Klenov, S.; Nurminskiy, Y.; Kholodov, Y.; Shamray, N. Vvedenie v matematicheskoe modelirovanie transportnykh potokov. In Introduction to Mathematical Modeling of Traffic Flows: Textbook; MCCME: Moscow, Russia, 2013. [Google Scholar]
- Gasnikov, A.V.; Gasnikova, E.V.; Mendel’, M.A.; Chepurchenko, K.V. Evolutionary interpretations of entropy model for correspondence matrix calculation. Mat. Model. 2016, 28, 111–124. [Google Scholar]
- Sandholm, W.H. Population Games and Evolutionary Dynamics; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- de Dios Ortúzar, J.; Willumsen, L.G. Modelling Transport; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Gasnikov, A.V.; Dorn, Y.V.; Nesterov, Y.E.; Shpirko, S.V. On the three-stage version of stable dynamic model. Mat. Model. 2014, 26, 34–70. [Google Scholar]
- Kubentayeva, M.; Gasnikov, A. Finding equilibria in the traffic assignment problem with primal-dual gradient methods for Stable Dynamics model and Beckmann model. Mathematics 2021, 9, 1217. [Google Scholar] [CrossRef]
- Kotlyarova, E.V.; Krivosheev, K.Y.; Gasnikova, E.V.; Sharovatova, Y.I.; Shurupov, A.V. Proof of the connection between the Backman model with degenerate cost functions and the model of stable dynamics. Comput. Res. Model. 2022, 14, 335–342. [Google Scholar] [CrossRef]
- Leadbetter, M.; Lindgren, G.; Rootzén, H. Asymptotic Distributions of Extremes. In Extremes and Related Properties of Random Sequences and Processes; Springer: Berlin/Heidelberg, Germany, 1983. [Google Scholar]
- Anderson, S.P.; De Palma, A.; Thisse, J.F. Discrete Choice Theory of Product Differentiation; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Malyshev, V.A.; Pirogov, S.A. Reversibility and irreversibility in stochastic chemical kinetics. Russ. Math. Surv. 2008, 63, 1. [Google Scholar] [CrossRef]
- Boucheron, S.; Lugosi, G.; Massart, P. Concentration Inequalities: A Nonasymptotic Theory of Independence; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley Series in Telecommunications and Signal Processing; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Levin, D.A.; Peres, Y. Markov Chains and Mixing Times; American Mathematical Society: Providence, RI, USA, 2017; Volume 107. [Google Scholar]
- Ethier, S.N.; Kurtz, T.G. Markov Processes: Characterization and Convergence; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Batishcheva, Y.G.; Vedenyapin, V.V. The 2-nd low of thermodynamics for chemical kinetics. Mat. Model. 2005, 17, 106–110. [Google Scholar]
- Gasnikov, A.V.; Gasnikova, E.V. On entropy-type functionals arising in stochastic chemical kinetics related to the concentration of the invariant measure and playing the role of Lyapunov functions in the dynamics of quasiaverages. Math. Notes 2013, 94, 854–861. [Google Scholar] [CrossRef]
- Frank, M. The braess paradox. Math. Program. 1981, 20, 283–302. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).