Abstract
As one of the top ten security threats faced by artificial intelligence, the adversarial attack has caused scholars to think deeply from theory to practice. However, in the black-box attack scenario, how to raise the visual quality of an adversarial example (AE) and perform a more efficient query should be further explored. This study aims to use the architecture of GAN combined with the model-stealing attack to train surrogate models and generate high-quality AE. This study proposes an image AE generation method based on the generative adversarial networks with dual discriminators and a single generator (DDSG-GAN) and designs the corresponding loss function for each model. The generator can generate adversarial perturbation, and two discriminators constrain the perturbation, respectively, to ensure the visual quality and attack effect of the generated AE. We extensively experiment on MNIST, CIFAR10, and Tiny-ImageNet datasets. The experimental results illustrate that our method can effectively use query feedback to generate an AE, which significantly reduces the number of queries on the target model and can implement effective attacks.
Keywords:
artificial intelligence; security threat; adversarial attacks; adversarial examples; generative adversarial networks MSC:
68T07
1. Introduction
With the emergence of deep neural networks, the security issues of artificial intelligence (AI) have become increasingly prominent. Because of the wide application of deep learning technology, the security of deep neural networks has also been increasingly questioned. The existence of an AE makes deep neural networks (DNN) cause disastrous consequences in many fields, such as the occurrence of traffic accidents in the field of automatic driving [1], malicious code successfully escaping detection [2], etc. AE is a major obstacle that various machine learning systems and even artificial intelligence (AI) must overcome. Its existence not only makes the output results of the model deviate greatly but can even make this deviation inevitable. This indicates that machine learning models rely on unreliable features to maximize performance. If the features are disturbed, it will lead to the misclassification of the model. For example, FGSM [3] enables a machine-learning model that classifies the original image as a panda with a probability of 57.7% but classifies its AE as a gibbon with a very high probability of 99.3%.
The vulnerability of DNN to AE has led to adversarial learning. On the one hand, studying an AE is to understand the mechanism of adversarial attacks to better develop corresponding defense technologies and construct more robust deep learning models. In addition, the existence of an AE reveals the serious security threat of DNN. Research on AE can provide a more comprehensive index for evaluating the robustness of DNN.
In adversarial attacks, because different models own different information access rights, the attackers need to consider different attack scenarios to design AE. Adversarial attacks contain two categories: white-box and black-box attacks.
In white-box attacks, adversaries can acquire the structure and parameter information of the target model. Therefore, they can use the target model’s gradient information to construct the AE. However, black-box attacks are more challenging to implement. In a black-box attack, the attackers can only interact with the target model through the input, which increases the difficulty of constructing AE. Still, it is more consistent with real-world attack scenarios.
Black-box attacks contain query-based and transfer-based attacks. Although the former can achieve a good attack effect, the query complexity is high, the query results are not fully utilized in the current attack methods, and masses of queries are easily resisted by defense mechanisms. The latter attack avoids the query to the target model. However, its attack effect is not ideal.
Combining transfer-based and query-based attacks, we design a generative adversary network (GAN) with dual discriminators and a single generator (DDSG-GAN) to generate an AE with better attack performance. We use the generator of the DDSG-GAN to generate the adversarial perturbation, and the trained discriminator can act as a surrogate model of the target model . The discriminator is used to distinguish whether the input image is original. We experimentally evaluate our method on the MNIST [4], CIFAR10 [5], and Tiny-ImageNet [6] datasets and compare it with the state-of-the-art (SOTA) experimental results. The experiment results demonstrate that the proposed method has a high attack success rate and greatly reduces the number of queries to the target model. The generated AE with our proposed method has a higher visual quality. The main contributions are the following:
- (1)
- This study presents a novel image AE generation method based on the GANs of dual discriminators. The generator generates adversarial perturbation, and two discriminators constrain the generator in different aspects. The constraint of discriminator guarantees the success of the attack, and the constraint of discriminator ensures the visual quality of the generated AE.
- (2)
- This study designs a new method to train the surrogate model; we use original images and AEs to train our substitute model together. The training process contains two stages: pre-training and fine-tuning. To make the most of the query results of the AE, we put the query results of the AEs into the circular queue for the subsequent training, which greatly reduces the query requirement of the target model and makes efficient use of the query results.
- (3)
- This study introduces a clipping mechanism so that the generated AEs are within the neighborhood of the original image.
The remainder of our paper is organized as follows. Section 2 introduces the related work of adversarial attacks. The proposed method of generating AE is described in Section 3. Section 4 demonstrates the effectiveness of the attack method through extensive experiments. Section 5 summarizes this paper.
2. Related Work
AEs can exist in many areas of artificial intelligence (AI), such as images, voice, text, and malware, and bring many potential risks to people’s lives. This study mainly focuses on adversarial attacks in image classification tasks. Adversarial attacks mainly contain white-box and black-box attacks. This section will summarize and review the relevant studies of adversarial attacks.
2.1. White-Box attack
In a white-box attack, the adversaries can acquire the structure and parameter information of the attacked target model, while in a black-box attack, the adversaries can only gain the prediction results of the target model about the input. The white-box attack has been developed earlier and is simpler to implement. At present, it can achieve a good attack effect.
White-box attacks mainly include three categories, which are summarized as follows:
(1) Optimize the objective function directly: Szegedy et al. [7] proposed directly optimizing the objective function with the box-constrained L-BFGS algorithm to generate adversarial perturbation. C&W [8] put forward three optimization-based attack methods after the defense distillation, successfully broke the defense distillation, and made the white-box attack reach a new height. Although the optimization-based methods can achieve a good attack effect, the optimization process takes a long time.
(2) Gradient-based attack method: FGSM [3] maintains that the existence of AEs is mainly due to the linear nature of the neural network and can add perturbations in the direction of the maximum gradient change of DNN to increase the classification loss of images. Due to FGSM being a one-step attack algorithm, the attack effect has yet to be improved. The success of FGSM has based on the hypothesis that the loss function is locally linear. If it is nonlinear, the attack’s success cannot be guaranteed. Based on this, Kurakin Alexey et al. [9] put forward I-FGSM, which obtains AEs through continuous iteration of the FGSM algorithm. Compared to FGSM, the I-FGSM can construct a more accurate perturbation, but from the performance of AEs in transfer attacks, I-FGSM is less effective than FGSM. Similar to the I-FGSM attack, the PGD [10] attack has more iterations and a better attack effect, whose disadvantage is its poor transfer attack ability.
(3) The attack method based on the generated neural network can train the neural network to generate AEs. Once the network training is completed, it can generate AEs in batches. For example, ATN [11] can convert an input image into AEs against the target model. It also has a strong attack capability, but the effect of a transfer attack is poor. AdvGAN [12] introduced the GANs into the method of generating AEs based on the generative neural network for the first time, and the trained AdvGAN network can convert random noise into AEs.
Other white-box attack algorithms, such as DeepFool [13], are based on the consideration of how to add the minimum perturbation to the original image. It is by reducing the distance between the image and the decision boundary of the target model to iteratively generate the minimum perturbation that can make the target model misclassified, which is relatively simple to implement and can achieve a good attack effect. One-pixel attack [14] is based on differential evolution. Each attack attempt to modify one pixel of data of an example achieves the result of model misclassification. This method has a good attack performance on less pixel information datasets, but for the datasets with a larger pixel space, the performance of the algorithm declined. The current white-box attack methods have been relatively mature and have achieved a good attack effect in MNIST, CIFAR10, ImageNet [6], and other datasets.
2.2. Black-Box attack
Compared with a white-box attack, a black-box attack is more difficult to implement. In the black-box attack setting, the adversary can only interact with the target model through input, which increases the difficulty of constructing the AEs. Black-box attacks are divided into query-based attacks and transfer-based attacks. Querying different target models will get different types of feedback results. According to the query results of the target model, query-based attacks can be divided into score-based attacks and decision-based attacks.
In the query-based attacks, by interacting with the target model, the Zero Order Optimization (ZOO) attack [15] uses the confidence score of the model’s feedback to estimate the target model’s gradient. Then, it uses the estimated gradient information to generate AEs. AutoZOOM [16] is the improved version of the ZOO attack, which introduces an autoencoder structure and greatly reduces the cost of useless pixel search. At the same time, AutoZOOM adopts a dynamic attack mechanism to further reduce the number of queries. After that, Bandits attack [17] uses the gradient prior information to improve the black-box attacks and introduces data-dependent and time-dependent priors to improve the query efficiency. However, the above methods are used for high-precision gradient estimation, so these inevitably require a lot of time and computing storage. Guo et al. put forward SimBA [18], which does not need to estimate the gradient of the target model and generates query samples by continuously greedily adding randomly sampled perturbation to the original image. According to the query results, it is decided to add or remove the perturbation on the target image. LeBA [19] combined transfer-based and query-based attacks to optimize SimBA further and achieve more efficient attacks.
With the outstanding performance of meta-learning in various classification tasks, Meta attacks [20] first combine adversarial attacks, and meta-learning First uses meta-learning to train a general Meta attack model. Then, it uses real attack information to fine-tune the Meta attack model, which greatly improves the query efficiency. The Simulator attack [21] further improves the attack model based on the Meta attack, which realizes the accurate simulation of any unknown target model. It improves the overall query efficiency of the model. However, because the model is relatively complex, there are comparatively high requirements for computer hardware configuration, and the training time is pretty long. Query-based black-box attacks can achieve a higher success rate. Still, this type of attack requires many query requirements and computing storage, and a large number of queries are easily resisted by the defense mechanism. Therefore, how to improve the efficiency of the query is the key to the current research.
Biggio et al. [22] found that the AEs generated against a certain machine learning model can be used to attack other models, which led researchers to think about transfer attacks. The goal of the transfer-based attack is that the AEs generated for one model can still attack other models. The core idea of the transfer-based black-box attack method [23,24] is to generate AEs on the source model and then transfer them to the target model. This method does not need to know the network structure and the parameters of the target model, nor does it need to query the target model. However, because there is a large distance between the source model and the target model, the attack effect is not satisfactory. The precondition for the realization of transfer-based attacks is the transfer ability of AE. Therefore, training a surrogate model that can highly simulate the target model will improve the AEs’ transferability. Therefore, the model-stealing attacks [25,26,27] are gradually applied to adversarial attacks. The model-stealing attacks obtain the labels of input data by querying the target model and then using the input and query results to train the black-box model’s surrogate model. The surrogate model trained by model stealing attacks can more accurately fit the target model and greatly improve the success rate of transfer attacks.
In recent research, many scholars have applied GANs [28] to the adversarial attack. Zhao et al. [29] built the semantic space of images on the architecture of GANs to obtain more natural AE. Xiao et al. [12] first introduced the idea of GANs in the attack algorithm based on neural networks to generate AE. They proposed a network architecture including a generator, discriminator, and target model. The trained generator can efficiently generate AEs for any input image, but it can only generate AEs for a single target class. Later, Zhou et al. [30] proposed a data-free surrogate model training based on GAN’s architecture to attack the target model. This method does not need a training data set but needs to combine a white-box attack algorithm, such as FGSM or PGD, to generate AE, and the training time is very long. Because it needs a lot of queries, this attack is easy to be avoided by the defense mechanism. In this paper, we focus on the black-box attack, based on the architecture of GANs, and combine it with the model-stealing attack to generate adversarial samples with a higher attack success rate and better visual quality.
3. Methodology
3.1. Preliminaries
3.1.1. Adversarial Examples and Adversarial Attack
Modifying the original images in a human-imperceptible way so that the modified images can be misclassified by the machine learning model, and the modified images are called AE. For a victim image classification model , we use as the original image-label pair. The goal of the adversarial attack is to generate an AE so that target model can misclassify it. For the untargeted attack setting, it can be formulated as follows:
For the targeted attack setting, it can be formulated as follows:
where denotes the norm, is the target class in the targeted attack, and is the upper bound of the perturbation.
3.1.2. Attack Scenarios
In this paper, we consider the adversarial attack in the black-box scenario. Query-based black-box attacks can be divided into decision-based attacks and score-based attacks. In this paper, we focus on a decision-based attack scenario.
- (1)
- Score-based attacks. In this scenario, the attacker is unknown to any structure and parameter information of the target model, but for any input, the adversary can acquire the classification confidence.
- (2)
- Decision-based attacks. Similar to the attack scenario of score-based attacks, the adversary doesn’t know any structure and parameter information of the target model, but for any input, the attacker can acquire the classification label.
3.2. Model Architecture
In this section, we will introduce the method of generating AEs based on the dual discriminators and single generator of GAN (DDSG-GAN). This paper introduces the model architecture of GAN and designs a GAN with dual discriminators and a single generator to generate AEs. DDSG-GAN uses generator to generate adversarial perturbations and uses discriminators and to constrain the generated perturbations. Then, the trained discriminator can be used as a surrogate model of the target model , and the overall structure of DDSG-GAN is shown in Figure 1. The input of Generator is the original image , and the output is perturbation vector . Adding the perturbation vector to the original image and clipping it to obtain the query sample . Input and into the target model to acquire the output and . Discriminator uses image-output pairs and for training, and Discriminator uses image-output pairs and for training.
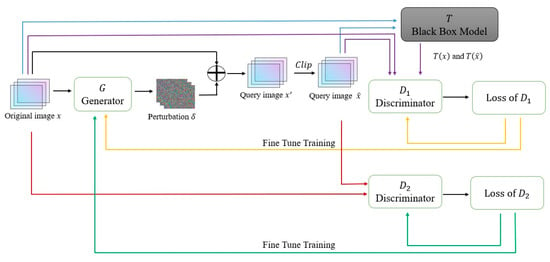
Figure 1.
The proposed DDSG-GAN model.
In DDSG-GAN, is the victim image classification black-box model. The generator will generate the perturbation vector of the input image and add to . Then, through clip operation, we can get query sample . The ’s query result is used to train discriminator , and discriminator is used to identify whether the input is the original image. Both discriminators, and , will constrain the generated perturbations.
In this training process, the generator and discriminator play a game relationship with each other. In each iteration, target model and discriminators and will calculate corresponding prediction results for each input. The discriminator fits the target model according to the output of the target model . With the increasing of iterations, the fitting ability of the discriminator to is constantly enhanced so that the attack ability of generator to target model continues to increase. At the same time, the discriminator is increasingly capable of classifying true and fake samples so that generator will generate AEs closer to the original data distribution. This training process forms discriminators and with generator to keep playing games and making progress.
3.2.1. The Training of Discriminator
The input of generator is the original image , and the output is the perturbation vector about the original image . Add the generated perturbation vector to to get the query sample . To ensure that the generated sample is within the neighborhood of the original image, we clip or to get the final query sample . In the norm attack,
where denotes the norm between and , and is the upper bound of the perturbation.
In the norm attack,
where and are the upper bound and lower bound of clipping respectively. The final query sample .
The adversarial attack’s goal is to make the target model misclassify the AE. It can be formulated as follows:
For the convenience of training, we convert (5) to maximize the following objective function:
where measures the difference between the output of target model and .
In the process of solving the optimization problem (6), it is necessary to continuously query the target model to obtain . However, this will make the query calculation very large, which is easily avoided by the defense mechanism. In the cause of reducing the number of queries to the target model, we train the discriminator as a surrogate model for so that the query of can be transferred to , which will greatly reduce the number of queries to the target model.
The training goal of the discriminator is to make it to be used as a surrogate model to simulate the function of model . For the purpose of improving the fitting ability of , we use the original image and the generated query sample to train together. The loss function for training the discriminator is as follows:
where and are the query results obtained by inputting and into the target model respectively, is the parameters of model , is the predicting result of the discriminator about the query sample , and is the predicting result of the discriminator about the original image . and are the weight factors used to control the relative importance. In this paper, we set .
For the decision-based black-box attack, the loss function of can be formulated as follows:
where denotes the cross-entropy function between and .
For the score-based black-box attack, the adversary is obtained through query to get the classification probability for each class. So, we can convert the obtained by the query into the corresponding label value and bring it into (8) to calculate the loss function of in this attack setting. Algorithm 1 presents the training procedure of .
| Algorithm 1 | Training procedure of the Discriminator |
| Input: | Training dataset and , where is the original image and is the sample after adding perturbation, target model , the discriminator and its parameters , the generator and its parameters ; loss function is defined in Equation (7). |
| Parameters: | Batch number , learning rate , iterations , weight factor and , clipping upper bound and lower bound . |
| Output: | The trained Discriminator . |
| 1: | for to do |
| 2: | for to do |
| 3: | |
| 4: | if do |
| 5: | |
| 6: | |
| 7: | elifdo |
| 8: | |
| 9: | |
| 10: | end if |
| 11: | |
| 12: | |
| 13: | |
| 14: | end for |
| 15: | end for |
| 16: | return |
3.2.2. The Training of Discriminator
We train the discriminator as a surrogate model for , so most of the queries on can be transferred to discriminator . When the attack is successful, the AEs must be close to , so discriminator can be set to distinguish whether the sample is sampled from the original images. If it is the original image, the label is 1. If it is the AE, the label is 0. The objective function for training the discriminator is:
where is the data distribution of the original image , denotes the calculation of the mean of the expression, is the parameters of model , is the predicting result of the discriminator about the original image , and is the predicting result of the discriminator about the query sample .
The discriminator is used to judge whether the sample is true or fake and uses to train a good generator to fool so that the distribution of the generated AE can be closer to the original image. Algorithm 2 presents the training procedure of .
| Algorithm 2 | Training procedure of the Discriminator |
| Input: | Training dataset and , where is the original image and are the query samples, the discriminator and its parameters , loss function is defined in Equation (9). |
| Parameters: | Batch number , Learning rate , iterations . |
| Output: | The trained Discriminator . |
| 1: | for to do |
| 2: | for to do |
| 3: | |
| 4: | |
| 5: | end for |
| 6: | end for |
| 7: | return |
3.2.3. The Training of Generator
The input of generator is the original image , and the output is the perturbation vector about . On behalf of making the generated AE to fool the target model , which needs to maximize the objective function (6). In this way, each update of generator needs to query , and the parameter information of target model needs to be used in the backpropagation process, which does not conform to the scenario settings of black-box attacks. Therefore, we replace the target model with the discriminator and approximate (6) as follows (10):
where is the cross-entropy function. Since the output of has passed softmax, the denominator of (11) will not be 0, and (10) is equivalent to the following (11):
generator ’s loss function regarding discriminator can be defined as follows (12):
While the attack is successful in ensuring that the generated AEs are closer to the distribution of the original image, the loss function of the generator , with respect to the discriminator , is defined as (13):
To obtain a high attack success rate, it is necessary to continuously input into the target model and use the loss of output with the ground truth (untargeted attack) or the target class (targeted attack) to optimize generator . The objectivate loss function of the attack can be formulated as follows:
where denotes the prediction probability of for the target class in the targeted attack or the prediction probability of for the real class in the untargeted attack, and denotes the maximum value among the predicted probabilities of other classes by .
To reduce the number of queries and be more consistent with the black-box setting, we use discriminator instead of to optimize the training process. The objectivate loss function can be formulated as follows:
where denotes the prediction probability of for the target class in the targeted attack or the prediction probability of for the real class in the untargeted attack, and denotes the maximum value among the predicted probabilities of other classes by .
We train the generator by minimizing the following objectivate function:
where is the weight factor of the three losses, which controls the relative importance of the three losses. makes the generated AE deceive discriminator step by step. makes generated AEs to be closer to the actual data distribution. is the attack loss, and its optimization produces a better attack effect. In this paper, the generator and discriminators and are obtained by solving the minimax function .
3.2.4. Improved Model
We can find from the training of discriminator that every training update of needs to query . To reduce the number of queries to while ensuring the fitting ability of , we design a circular queue to limit the training of . We divide the training process of into two stages: model pre-training and fine-tuning.
First, when the number of iterations , setting and . We use to train according to the Equation (7). When the number of iterations and , we add the query result of this iteration to circular queue . So, when , setting and and when using , the query result is saved in the circular queue to fine-tuned according to the Equation (7).
In each iteration training, since we constantly use the query results of to train , and are highly approximate. Therefore, the ultimate goal of generator can be converted to realize the discriminator ’s misclassification of AE. If the AE can successfully lead to misclassifying them, we can think that the AE can also successfully fool the target model with a high probability. Therefore, in the whole training process, we also trained a surrogate model that can highly simulate the target model while generating the adversarial perturbation, combining GANs and model-stealing attacks to improve the transferability of the AEs. Algorithm 3 presents the training procedure of the whole model.
| Algorithm 3 | Training procedure of the DDSG-GAN. |
| input: | Target model , generator and it’s parameters , discriminator and its parameters , discriminator and it’s parameters , original image–label pair the learning rate , and . |
| output: | The trained generator . |
| 1: | Initialize the model of , and . |
| 2: | for to do |
| 3: | for to do |
| 4: | |
| 5: | if do |
| 6: | |
| 7: | |
| 8: | elif do |
| 9: | |
| 10: | |
| 11: | end if |
| 12: | query example |
| 13: | if and do |
| 14: | Input into the targeted model to get the query result |
| Add to the circular queue | |
| 16: | end if |
| 17: | if do pre-training of |
| 18: | |
| 19: | elif do fine tuning of |
| 20: | is taken from the circular queue |
| 21: | end if |
| 22: | |
| 23: | end for |
| 24: | for to do |
| 25: | |
| 26: | |
| 27: | end for |
| 28: | for to do |
| 29: | |
| 30: | |
| 31: | end for |
| 32: | end for |
| 33: | return |
3.2.5. Generate Adversarial Examples
Firstly, according to algorithm 3, the adversary trains the generator for the target model under a specific attack setting. Secondly, we input the original image into the trained generator to obtain the corresponding perturbation vector , and then add to the original sample to get the initial AE . In order to ensure that the perturbation of the AE is within a small range, we perform the corresponding clipping operation on to obtain the AE . If it is a norm attack, the clipping operation is performed according to the formula (3). If it is a norm attack, the clipping operation is performed according to the formula (4). Input the AE to the corresponding target model to attack.
Figure 2 shows the specific attack process of the MNIST dataset. As shown in Figure 2, after the training of DDSG-GAN, we input the original image into the trained generator to make AE . Then, input into the corresponding target model to attack. The generator designed in this paper consists of an encoder and a decoder. The encoder is a 5-layer convolution network, and the decoder is a 3-layer convolution network. For different target models, DDSG-GAN will train different generators and get different attack results.
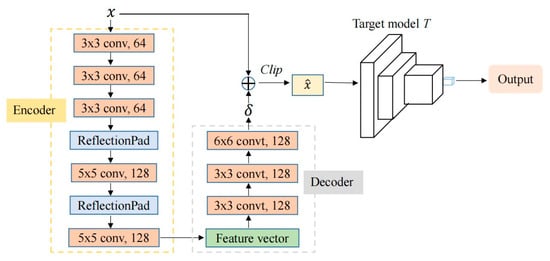
Figure 2.
The attack procedure on MNIST dataset.
4. Experiment
4.1. Experiment Setting
In this section, we will introduce the specific details of the experiment, including datasets, target model architecture, method settings, and evaluation indicators.
Dataset: We evaluate the effectiveness of the proposed method through experimental results on MNIST, CIFAR10, and Tiny-ImageNet. For these datasets, we select images with the correct classification of the target model in their testing sets as their respective testing sets for evaluation. The number of selected images is 1000, 1000, and 1600, respectively.
Attack scenario: We use a decision-based attack in the black-box attack setting to evaluate the proposed method. The attackers can acquire the output results of the target model but cannot obtain any structure and parameter information about the target model.
Target model architecture: In the norm attack, for the MNIST dataset, we follow the advGAN [12] trained three image classification models for attack testing. Models A and B are from the paper [31], and model C is from the paper [8]. In the norm attack, we trained model D as the target model. The structure of these models is shown in Table 1.

Table 1.
MNIST classification model.
For the CIFAR10 dataset, we perform an norm attack. We also follow advGAN to train ResNet32 as the target model. In a Tiny-ImageNet dataset, we train the ResNet34 classification model as the target model, and perform norm attack.
DDSG-GAN model details: The DDSG-GAN model contains dual discriminators and a single generator. The generator consists of an encoder and a decoder. For MNIST and CIFAR10 data sets, we design the same generator structure. The encoder is a 5-layer convolutional network, and the decoder is a 3-layer convolutional network. Refer to Figure 2 for the specific generator structure. For the Tiny-ImageNet, we add a convolution layer in the encoder and generator, respectively. For the MNIST data set, the discriminator is a 4-layer convolutional neural network. The discriminator for the CIFAR10 data set is ResNet18 without pre-training. For the Tiny-ImageNet data set, there are two types of discriminators , ResNet18 and ResNet50, which are pre-trained. We design the same discriminator for all data sets. The discriminator is a 2-classification network model composed of a 4-layer convolutional network, which is used to distinguish whether the sample is sampled from the original images.
Method setting: Multiple classification models are trained for MNIST, CIFAR10, and Tiny-ImageNet datasets. First, algorithm 3 is used to train the generator . Then, the trained is used to generate the adversarial perturbation. Then, it is added to the original sample, and the AE is obtained by clipping operation. Finally, we use these AEs to attack classification models. In the targeted attack, the target class is set to , where is the ground truth, and is the total number of categories.
Evaluation indicators: (1) Attack success rate. In the untargeted attack, it is the proportion of the AE successfully divided into any other classes. In the targeted attack, it is the probability of classifying the image into a specific target class. (2) The magnitude of the perturbation. We conduct attack experiments under the and norm and set the corresponding perturbation threshold.
4.2. Experiments on MNIST
In this section, we use the and norms to perform targeted and untargeted attacks on MNIST, respectively. Table 2 shows the specific parameter settings. The untargeted attack aims to generate AEs that make the classification result of the target model different from the ground truth. The targeted attack aims to generate AEs that make the classification result of the target model in the specified category. The experimental results are shown in Table 3, Table 4 and Table 5.
Table 2.
Experimental parameter setting of MNIST.
Table 3.
Training results of the surrogate model.
Table 4.
Experimental results of untargeted attack under norm (ASR: the attack success rate).
Table 5.
Experimental results of targeted attack under norm.
First, we attack the target models under norm. We train discriminator as a ’s surrogate model. We calculate the classification accuracy and similarity with the model (the proportion of the same number of output results of the surrogate model and that of the target model) against the MNSIT test set. The experimental results are shown in Table 3. The classification accuracy of several surrogate models and the similarity between them and the target model is close to above 99%, indicating that the surrogate model we trained can replace the target model’s function.
In the norm attack, we set the maximum perturbation threshold to evaluate the proposed approach. We compare DDSG-GAN with surrogate model-based black-attack, DaST, and advGAN. The surrogate model is trained by two methods, respectively. The first is to train the surrogate model according to [32]. This method uses 150 images in the test set as the original training set , which sets the Jacobian augmentation parameter , and runs 30 Jacobian augmentation iterations. The second is to use the trained discriminator as the surrogate model and combine FGSM and PGD for the black-box attacks. We set an upper bound on the number of queries to the target model in the DaST method. For MNIST data sets, the query of each image is set to 1000. Under this premise, the total query upper bound of the DaST method is .
For a surrogate model-based attack, we use the same DNN model as the surrogate model and attack the target model by combining FGSM and PGD attack algorithms. To make the surrogate model trained by the first method have a better attack effect, set , and the perturbation thresholds of other methods are set to . Table 4 shows that our proposed method (DDSG-GAN) achieves an attack success rate of nearly 100%, which is much higher than black-box attacks based on surrogate models and DaST. At the same time, we also calculated the average query numbers of the target model. For the target models A, B, and C, the query numbers of each image in the train set were 15, 20, and 28, respectively, which ensured a low query quantity. Because the target model is unknown, black-box attacks based on the surrogate model have a low success rate. If is the surrogate model, compared with the surrogate model trained by [32], if combined with the FGSM algorithm to attack, the attack success rate is increased by 3.8% (4.7%, 2.4%, 4.3%) on average. If combined with the PGD algorithm to attack, the attack success rate is increased by 19.4% (22.2%, 12.2%, 23.9%) on average, and the attack effect is significantly improved. It demonstrates that the surrogate model we trained can replace the target model to a large extent, and this method can also achieve a good attack effect.
Table 5 shows the result of the targeted attack under the norm, and we also compare it with the advGAN method. Compared with advGAN, the attack success rate of DDSG-GAN is 4.23% (6.5%, 7.5%, 0.58%) higher than advGAN on average, and three–four times higher than DaST. It also is much higher than the surrogate-model-based black-box attack. For target models A, B, and C, each image query numbers in the train set are 70, 75, and 109 times, respectively, also maintained at a low level. If is the surrogate model, compared with the surrogate model trained by [32], if combined with the FGSM algorithm to attack, the ASR is increased by 7.17% (7%, 7.5%, 7%) on average. If combined with the PGD algorithm to attack, the ASR is increased by 31.17% (25.4%, 31.6%, 36.5%) on average. The attack effect has also been significantly improved. In this attack setting, we visualize the generated AEs by DDSG-GAN on MNIST, which is shown in Figure 3. The top row shows the original samples of each class randomly selected from the training set. Other rows show the AEs generated by DDSG-GAN for the corresponding target model. The probability that each AE is classified into the target class is shown below the image.

Figure 3.
Visualization of the AE in targeted attack.
We also carried out an untargeted attack under the norm, and the results are shown in Table 6. In the norm attack, DDSG-GAN achieved comparable ASR and perturbation size to other attack methods but reduced the number of queries.
Table 6.
Experimental results of untargeted attack under norm.
4.3. Experiments on CIFAR10 and Tiny-ImageNet
We perform the untargeted and targeted attacks on CIFAR10 under norm. Different from the setting of experimental parameters of MNIST, we set , , , and the maximum length of is set to 50,001. The target model of the attack is ResNet32, and its classification accuracy is 92.4%. In the targeted attack, the classification accuracy of the trained for the test set reaches 54.82%, and the similarity with the target model is 73.26%. The classification accuracy of the surrogate model trained by DaST is only 20.35%, and the accuracy of is 2.69 times higher. To verify the effectiveness of DDSG-GAN, we also compare it with DaST, advGAN, and the black-box attack based on the surrogate model on CIFAR10. The results are shown in Table 7.
Table 7.
Attack results under norm on CIFAR10.
Under the setting of a targeted attack and untargeted attack, we have realized FGSM and PGD attacks based on the surrogate model. For FGSM, we set , as it is shown to be effective in [32]. For the other attack methods, we uniformly set the perturbation threshold to . We also set an upper bound on the number of queries to the target model in the DaST method on CIFAR10. We set the query of each image to 1000. Under this premise, the total query upper bound of the DaST method is . As can be seen from Table 7, DDSG-GAN has an obvious advantage over the other attack methods. Compared with advGAN, DDSG-GAN’s ARS in targeted attack is improved by 0.93%, and it is much higher than the black box attack based on the surrogate model and DaST. At the same time, the surrogate model we trained also achieved a good fitting effect. In the untargeted attack (targeted attack), if as the surrogate model combined with the FGSM algorithm to attack the target model, the ASR is 4.9% (10.9%) higher than the surrogate trained by [32], and the ASR combined with the PGD algorithm is increased by 10% (8.1%). The attack effect has obviously been improved. In the untargeted attack setting, visualization of AE generated by DDSG-GAN is shown in Figure 4. Figure 4a denotes original samples randomly selected from the training set. Figure 4b denotes AE generated by DDSG-GAN for the corresponding target model.

Figure 4.
Visualization of AE generated by DDSG-GAN for attacking the ResNet32 on CIFAR10. (a) original samples randomly selected from the training set; (b) AE generated by DDSG-GAN for the corresponding target model.
We perform an untargeted attack on Tiny-ImageNet under norm. Because the Tiny-ImageNet data set is large, only about 1/3 of the training set, that is, 32,000 pictures, are randomly selected for training in each iterative training. We set , , , and . The maximum length of is set to 32,001. The pre-trained ResNet18 and ResNet50 are used as discriminators . The classification accuracy of the trained for the test set is 52.3% and 45.8%, respectively. The results are shown in Table 8. As can be seen from Table 8, the more complex the surrogate model, the better the attack effect. Therefore, in order to improve the attack effect, the complexity of the surrogate model can be appropriately increased.
Table 8.
Attack results under norm on Tiny-ImageNet.
4.4. Model Analysis
As can be seen from the above experimental results, compared with the black-box attack based on the surrogate model (under norm), DDSG-GAN has great advantages and a significantly higher attack success rate. In a black-box attack experiment based on the surrogate model, the surrogate model trained in this paper has a higher success rate of attack. In the norm attack, we can find that the query requirement of the target model is greatly reduced, and the success rate is kept at a high level. In addition, the attack effect of the model depends largely on the network architecture of the generator and the discriminator. When we use a fully connected neural network as the generator to perform algorithm 3, the ASR of the untargeted attack is only 80%. Therefore, designing a better network architecture helps improve the attack ability of the model.
5. Conclusions
Based on the structure of GAN, we design the architecture of generating AE with dual discriminators and a single generator and use the generator to generate the adversarial perturbation. Two discriminators constrain the generated perturbation, respectively. While ensuring the attack success rate and low image distortion, it also ensures a low query level. While training the generator, the discriminator gradually fits the target model, and, finally, it is trained as a surrogate model that can highly simulate the target model. In this way, combined with the white-box attack algorithm can carry out a black-box attack based on a surrogate model, and this attack method reaches a higher attack level, which shows that the surrogate model we trained has a good effect. When training the discriminator , we added the structure of a circular queue to save the query results, which made efficient use of the query results and greatly reduced the query requirements. In future work, we will consider adding perturbation in key areas to ensure the attack effect and reduce unnecessary image distortion. At the same time, it is considered to select a broader data set, such as ImageNet, to improve the universality of the method.
Author Contributions
Methodology, F.W., Z.M. and X.Z.; validation, Z.M. and Q.L.; formal analysis, F.W., Z.M. and C.W.; investigation, F.W. and Z.M.; data curation, Z.M. and Q.L.; writing—original draft preparation, F.W., Z.M. and X.Z.; writing—review and editing, F.W., C.W. and Q.L.; visualization, Z.M.; supervision, F.W. and C.W.; funding acquisition, F.W. and C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by NSFC under Grant 61572170, Natural Science Foundation of Hebei Province under Grant F2021205004, Science and Technology Foundation Project of Hebei Normal University under Grant L2021K06, Science Foundation of Returned Overseas of Hebei Province Under Grant C2020342, and Key Science Foundation of Hebei Education Department under Grant ZD2021062.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The MNIST dataset is available at http://yann.lecun.com/exdb/mnist/ (accessed on 10 January 2023). The CIFAR10 dataset is available at http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz (accessed on 10 January 2023). The Tiny-ImageNet dataset is available at http://cs231n.stanford.edu/tiny-imagenet-200.zip (accessed on 8 February 2023).
Acknowledgments
We would like to thank Yong Yang, Dongmei Zhao, and others for helping us check the details and providing us with valuable suggestions for this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- McAllister, R.; Gal, Y.; Kendall, A.; Van Der Wilk, M.; Shah, A. Concrete problems for autonomous vehicle safety: Advantages of bayesian deep learning. In Proceedings of the Twenty-Sixth International Joint Conferences on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4745–4753. [Google Scholar]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial perturbations against deep neural networks for malware classification. arXiv 2016, arXiv:1606.04435. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572.2014. [Google Scholar]
- LeCun, Y. The Mnist Database of Handwritten Digits. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 10 January 2023).
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, CA, USA, 2009. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Roman, V.Y., Ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Baluja, S.; Fischer, I. Adversarial Transformation Networks: Learning to Generate Adversarial Examples. arXiv 2017, arXiv:1703.09387. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.Y.; He, W.; Liu, M.; Song, D. Generating Adversarial Examples with Adversarial Networks. arXiv 2018, arXiv:1801.02610. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Tu, C.C.; Ting, P.; Chen, P.Y.; Liu, S.; Zhang, H.; Yi, J.; Cheng, S.M. Autozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 February 2019; pp. 742–749. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Madry, A. Prior convictions: Black-box adversarial attacks with bandits and priors. arXiv 2018, arXiv:1807.07978. [Google Scholar]
- Guo, C.; Gardner, J.; You, Y.; Wilson, A.G.; Weinberger, K. Simple black-box adversarial attacks. In Proceedings of the International Conference on Machine Learning, Boca Raton, FL, USA, 16–19 December 2019; pp. 2484–2493. [Google Scholar]
- Yang, J.; Jiang, Y.; Huang, X.; Ni, B.; Zhao, C. Learning black-box attackers with transferable priors and query feedback. In Proceedings of the NeurIPS 2020, Advances in Neural Information Processing Systems 33, Beijing, China, 6 December 2020; pp. 12288–12299. [Google Scholar]
- Du, J.; Zhang, H.; Zhou, J.T.; Yang, Y.; Feng, J. Query efficient meta attack to deep neural networks. arXiv 2019, arXiv:1906.02398. [Google Scholar]
- Ma, C.; Chen, L.; Yong, J.H. Simulating unknown target models for query-efficient black-box attacks. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11835–11844. [Google Scholar]
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B.; Šrndić, N.; Laskov, P. Evasion attacks against machine learning at test time. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 22–26 September 2013; pp. 387–402. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving transferability of adversarial examples with input diversity. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2730–2739. [Google Scholar]
- Demontis, A.; Melis, M.; Pintor, M.; Matthew, J.; Biggio, B.; Alina, O.; Roli, F. Why do adversarial attacks transfer? explaining transferability of evasion and poisoning attacks. In Proceedings of the 28th USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019; pp. 321–338. [Google Scholar]
- Kariyappa, S.; Prakash, A.; Qureshi, M.K. Maze: Data-free model stealing attack using zeroth-order gradient estimation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 18–24 June 2022; pp. 13814–13823. [Google Scholar]
- Wang, Y.; Li, J.; Liu, H.; Wang, Y.; Wu, Y.; Huang, F.; Ji, R. Black-box dissector: Towards erasing-based hard-label model stealing attack. In Proceedings of the 2021 European Conference on Computer Vision, Montreal, Canada, 11 October 2021; pp. 192–208. [Google Scholar]
- Yuan, X.; Ding, L.; Zhang, L.; Li, X.; Wu, D.O. ES attack: Model stealing against deep neural networks without data hurdles. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 1258–1270. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhao, Z.; Dua, D.; Singh, S. Generating Natural Adversarial Examples. arXiv 2017, arXiv:1710.11342. [Google Scholar]
- Zhou, M.; Wu, J.; Liu, Y.; Liu, S.; Zhu, C. Dast: Data-Free Substitute Training for Adversarial Attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 234–243. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. arXiv 2017, arXiv:1712.04248. [Google Scholar]
- Cheng, M.; Le, T.; Chen, P.Y.; Yi, J.; Zhang, H.; Hsieh, C.J. Query efficient hard-label black-box attack: An optimization based approach. arXiv 2018, arXiv:1807.04457. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).