
Scheduling of Software Test to Minimize the Total Completion Time †


Abstract
:1. Introduction
2. Problem Definition and Literature Review
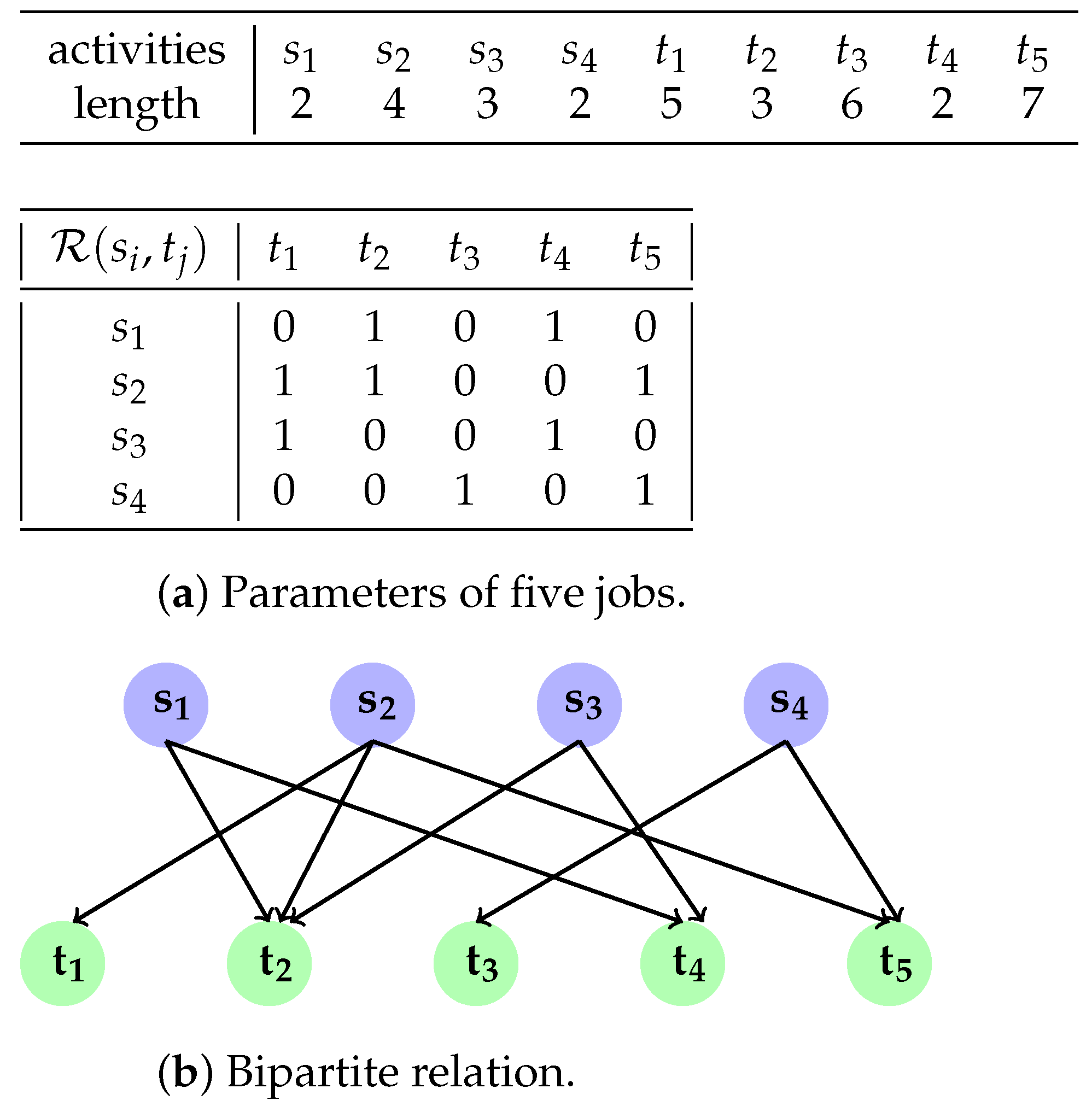
2.1. Problem Statements
| n | number of jobs; |
| m | number of setup operations; |
| set of jobs to be processed; | |
| set of setup operations; | |
| relation indicating whether the setup operation | |
| is required for each job ; | |
| processing time of job on the machine; | |
| processing time of setup on the machine; | |
| particular sequence of the jobs; | |
| optimal schedule sequence; | |
| completion time of job ; | |
| total job completion time under schedule . |
2.2. Literature Review
3. Integer Programming Models
3.1. Position-Based IP
3.2. Sequence-Based IP
4. Branch-and-Bound Algorithm
4.1. Upper Bound
4.2. Lower Bound
| Algorithm 1: LowerBound |
 |
4.3. Dominance Property
| Algorithm 2: Check Property |
 |
4.4. Tree Traversal
4.5. Depth-First Search (DFS)
| Algorithm 3: Depth-First Search |
 |
4.6. Breadth-First Search (BFS)
| Algorithm 4: Breadth-First Search |
 |
4.7. Best-First Search (BestFS)
5. Ant Colony Optimization (ACO)
| Algorithm 5: Ant Colony Optimization |
 |
6. Computational Experiments
6.1. Data Generation Scheme
- Six different numbers of jobs and different numbers of setup operations .
- A binary support relation array of a size is randomly generated. If belongs to , denoted by , then job cannot start unless setup is completed. The probability for is set to be 0.5, i.e., if a generated random number , then . Note that when for all i and j, the problem can be solved by simply arranging the job in the shortest processing time (SPT) order.
- The processing times of jobs were generated from the uniform distribution .
- The processing times of setups were generated from the uniform distribution .
- For each job number, three independent instances were generated. In total, 18 datasets will be tested, as shown in Table 1.
6.2. Results of Integer Programming Models
6.3. Results of Branch-and-Bound Algorithm
6.4. Results of DFS Algorithm
6.5. Results of ACO Algorithm
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Leung, J.Y.T. Handbook of Scheduling: Algorithms, Models, and Performance Analysis; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Pinedo, M. Scheduling; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Kononov, A.V.; Lin, B.M.T.; Fang, K.T. Single-machine scheduling with supporting tasks. Discret. Optim. 2015, 17, 69–79. [Google Scholar] [CrossRef]
- Graham, R.; Lawler, E.L.; Lenstra, J.K.; Kan, A.R. Optimization and approximation in deterministic sequencing and scheduling: A survey. Ann. Discret. Math. 1979, 5, 287–326. [Google Scholar]
- Brucker, P. Scheduling Algorithms; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Baker, K.E. Single Machine Sequencing with Weighting Factors and Precedence Constraints. Unpublished papers. 1971. [Google Scholar]
- Adolphson, D.; Hu, T.C. Optimal linear ordering. Siam J. Appl. Math. 1973, 25, 403–423. [Google Scholar] [CrossRef]
- Lawler, E.L. Sequencing jobs to minimize total weighted completion time subject to precedence constraints. Ann. Discret. Math. 1978, 2, 75–90. [Google Scholar]
- Hassin, R.; Levin, A. An approximation algorithm for the minimum latency set cover problem. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3669, pp. 726–733. [Google Scholar]
- Shafransky, Y.M.; Strusevich, V.A. The open shop scheduling problem with a given sequence of jobs on one machine. Nav. Res. Logist. 1998, 41, 705–731. [Google Scholar] [CrossRef]
- Hwang, F.J.; Kovalyov, M.Y.; Lin, B.M.T. Scheduling for fabrication and assembly in a two-machine flowshop with a fixed job sequence. Ann. Oper. Res. 2014, 27, 263–279. [Google Scholar] [CrossRef]
- Cheng, T.C.E.; Kravchenko, S.A.; Lin, B.M.T. Server scheduling on parallel dedicated machines with fixed job sequences. Nav. Res. Logist. 2019, 66, 321–332. [Google Scholar] [CrossRef]
- Brucker, P.; Jurisch, B.; Sievers, B. A branch and bound algorithm for the job-shop scheduling problem. Discret. Appl. Math. 1994, 49, 107–127. [Google Scholar] [CrossRef]
- Hadjar, A.; Marcotte, O.; Soumis, F. A branch-and-cut algorithm for the multiple sepot Vehicle Scheduling Problem. Oper. Res. 2006, 54, 130–149. [Google Scholar] [CrossRef]
- Kunhare, N.; Tiwari, R.; Dhar, J. Particle swarm optimization and feature selection for intrusion detection system. Sādhanā 2020, 45, 109. [Google Scholar] [CrossRef]
- Kunhare, N.; Tiwari, R.; Dhar, J. Intrusion detection system using hybrid classifiers with meta-heuristic algorithms for the optimization and feature selection by genetic algorithms. Comput. Ind. Eng. 2022, 103, 108383. [Google Scholar] [CrossRef]
- Luo, L.; Zhang, Z.; Yin, Y. Simulated annealing and genetic algorithm based method for a bi-level seru loading problem with worker assignment in seru production systems. J. Ind. Manag. Optim. 2021, 17, 779–803. [Google Scholar] [CrossRef]
- Ansari, Z.N.; Daxini, S.D. A state-of-the-art review on meta-heuristics application in remanufacturing. Arch. Comput. Methods Eng. 2022, 29, 427–470. [Google Scholar] [CrossRef]
- Rachih, H.; Mhada, F.Z.; Chiheb, R. Meta-heuristics for reverse logistics: A literature review and perspectives. Comput. Ind. Eng. 2019, 127, 45–62. [Google Scholar] [CrossRef]
- Blum, C.; Sampels, M. An ant colony optimization algorithm for shop scheduling problems. J. Math. Model. Algorithms 2004, 3, 285–308. [Google Scholar] [CrossRef]
- Yang, J.; Shi, X.; Marchese, M.; Liang, Y. An ant colony optimization method for generalized TSP problem. Prog. Nat. Sci. 2008, 18, 1417–1422. [Google Scholar] [CrossRef]
- Xiang, W.; Yin, J.; Lim, G. An ant colony optimization approach for solving an operating room surgery scheduling problem. Comput. Ind. Eng. 2015, 85, 335–345. [Google Scholar] [CrossRef]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Positive Feedback as a Search Strategy; Technical Report 91–016; Dipartimento di Elettronica, Politecnico di Milano: Milan, Italy, 1991. [Google Scholar]
- Dorigo, M. Optimization, Learning and Natural Algorithms. Ph.D. Thesis, Dipartimento di Elettronica, Politecnico di Milano, Milan, Italy, 1992. (In Italian). [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Datasets | n | m |
|---|---|---|
| 5 | 4 | |
| 10 | 8 | |
| 20 | 18 | |
| 30 | 25 | |
| 40 | 35 | |
| 50 | 45 |
| Datasets | Position-Based | Sequence-Based | Best Solution | |||||
|---|---|---|---|---|---|---|---|---|
| obj. | Time | gap | obj. | Time | gap | |||
| 5 | 101 | 0.09 | 0% | 101 | 0.10 | 0% | 101 | |
| 128 | 0.09 | 0% | 128 | 0.10 | 0% | 128 | ||
| 122 | 0.08 | 0% | 122 | 0.10 | 0% | 122 | ||
| 10 | 461 | 246.11 | 0% | 461 | - | 19% | 461 | |
| 423 | 46.10 | 0% | 423 | - | 21% | 423 | ||
| 457 | 355.95 | 0% | 457 | - | 25% | 457 | ||
| 20 | 2055 | - | 44% | 2052 | - | 53% | 2052 | |
| 1822 | - | 34% | 1820 | - | 58% | 1820 | ||
| 1670 | - | 46% | 1662 | - | 57% | 1662 | ||
| 30 | 3609 | - | 50% | 3602 | - | 61% | 3597 | |
| 3985 | - | 50% | 4007 | - | 62% | 3985 | ||
| 4448 | - | 62% | 4469 | - | 66% | 4424 | ||
| 40 | 8196 | - | 72% | 8168 | - | 66% | 8168 | |
| 7395 | - | 68% | 7402 | - | 67% | 7390 | ||
| 7975 | - | 70% | 7935 | - | 66% | 7935 | ||
| 50 | 12,882 | - | 76% | 12,963 | - | 66% | 12,880 | |
| 12,305 | - | 73% | 12,374 | - | 67% | 12,305 | ||
| 10,891 | - | 72% | 10,953 | - | 66% | 10,871 | ||
| Datasets | DFS | BFS | BestFS | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| obj. | node_cnt | Time | dev | obj. | node_cnt | Time | dev | obj. | node_cnt | Time | dev | ||
| 5 | 101 | 25 | 0.00 | 0.00 | 101 | 67 | 0.00 | 0.00 | 101 | 16 | 0.00 | 0.00 | |
| 128 | 22 | 0.00 | 0.00 | 128 | 44 | 0.00 | 0.00 | 128 | 12 | 0.00 | 0.00 | ||
| 122 | 27 | 0.00 | 0.00 | 122 | 68 | 0.01 | 0.00 | 122 | 20 | 0.00 | 0.00 | ||
| 10 | 461 | 203 | 0.06 | 0.00 | 461 | 4141 | 0.39 | 0.00 | 461 | 283 | 0.04 | 0.00 | |
| 423 | 246 | 0.04 | 0.00 | 423 | 2518 | 0.27 | 0.00 | 423 | 128 | 0.02 | 0.00 | ||
| 457 | 1055 | 0.25 | 0.00 | 457 | 34,646 | 2.57 | 0.00 | 457 | 1788 | 0.18 | 0.00 | ||
| 20 | 2052 | 34,798 | 69.07 | 0.00 | 7839 | 1,940,323 | - | 2.82 | 2052 | 33,393 | 22.62 | 0.00 | |
| 1820 | 44,844 | 77.49 | 0.00 | 6651 | 2,081,103 | - | 2.65 | 1820 | 44,166 | 22.03 | 0.00 | ||
| 1662 | 201,418 | 314.67 | 0.00 | 6211 | 2,078,269 | - | 2.74 | 1662 | 172,094 | 96.32 | 0.00 | ||
| 30 | 3605 | 440,015 | - | 0.00 | 18,533 | 1,482,922 | - | 4.15 | 18,533 | 1,903,404 | - | 4.15 | |
| 4053 | 385,433 | - | 0.02 | 22,005 | 1,083,532 | - | 4.52 | 22,055 | 1,064,974 | - | 4.53 | ||
| 4470 | 392,869 | - | 0.01 | 22,990 | 1,165,534 | - | 4.20 | 22,990 | 1,423,640 | - | 4.20 | ||
| 40 | 8357 | 189,796 | - | 0.02 | 51,610 | 846,721 | - | 5.32 | 51,610 | 769,918 | - | 5.32 | |
| 7564 | 176,723 | - | 0.02 | 44,779 | 873,638 | - | 5.06 | 44,779 | 1,112,645 | - | 5.06 | ||
| 8074 | 185,522 | - | 0.02 | 49,102 | 888,079 | - | 5.19 | 49,102 | 1,094,652 | - | 5.19 | ||
| 50 | 13,007 | 74,873 | - | 0.01 | 106,541 | 856,905 | - | 7.27 | 106,541 | 954,605 | - | 7.27 | |
| 12,527 | 84,980 | - | 0.02 | 97,383 | 933,536 | - | 6.91 | 97,383 | 1,047,559 | - | 6.91 | ||
| 11,255 | 90,908 | - | 0.04 | 87,545 | 1,055,329 | - | 7.05 | 87,545 | 1,181,533 | - | 7.05 | ||
| Datasets | DFS | DFS + LB | DFS + LB + Property | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| obj. | node_cnt | Time | dev | obj. | node_cnt | Time | dev | obj. | node_cnt | Time | dev | ||
| 5 | 101 | 325 | 0.00 | 0.00 | 101 | 28 | 0.00 | 0.00 | 101 | 25 | 0.00 | 0.00 | |
| 128 | 325 | 0.00 | 0.00 | 128 | 48 | 0.00 | 0.00 | 128 | 22 | 0.00 | 0.00 | ||
| 122 | 325 | 0.00 | 0.00 | 122 | 27 | 0.00 | 0.00 | 122 | 27 | 0.00 | 0.00 | ||
| 10 | 461 | 9,864,100 | 173.53 | 0.00 | 461 | 614 | 0.11 | 0.00 | 461 | 203 | 0.07 | 0.00 | |
| 423 | 9,864,100 | 174.60 | 0.00 | 423 | 626 | 0.09 | 0.00 | 423 | 246 | 0.05 | 0.00 | ||
| 457 | 9,864,100 | 182.09 | 0.00 | 457 | 2381 | 0.51 | 0.00 | 457 | 1055 | 0.25 | 0.00 | ||
| 20 | 2174 | 27,177,572 | - | 0.06 | 2052 | 135,187 | 230.35 | 0.00 | 2052 | 34,798 | 69.07 | 0.00 | |
| 2145 | 28,810,807 | - | 0.18 | 1820 | 287,087 | 429.71 | 0.00 | 1820 | 44,844 | 77.49 | 0.00 | ||
| 1904 | 29,472,356 | - | 0.15 | 1662 | 1,006,390 | 1405.52 | 0.00 | 1662 | 201,418 | 314.67 | 0.00 | ||
| 30 | 4229 | 14,013,551 | - | 0.18 | 3679 | 426,340 | - | 0.02 | 3605 | 440,015 | - | 0.00 | |
| 4757 | 13,668,237 | - | 0.19 | 4211 | 462,562 | - | 0.06 | 4053 | 385,433 | - | 0.02 | ||
| 5087 | 14,077,620 | - | 0.15 | 4530 | 443,418 | - | 0.02 | 4470 | 392,869 | - | 0.01 | ||
| 40 | 9557 | 7,184,349 | - | 0.17 | 8405 | 169,550 | - | 0.03 | 8357 | 189,796 | - | 0.02 | |
| 8505 | 7,327,087 | - | 0.15 | 7645 | 210,938 | - | 0.03 | 7564 | 176,723 | - | 0.02 | ||
| 9131 | 7,111,936 | - | 0.15 | 8250 | 210,891 | - | 0.04 | 8074 | 185,522 | - | 0.02 | ||
| 50 | 14,629 | 4,136,372 | - | 0.14 | 13,196 | 104,445 | - | 0.02 | 13,007 | 74,873 | - | 0.01 | |
| 14,272 | 4,189,689 | - | 0.16 | 12,911 | 119,416 | - | 0.05 | 12,527 | 84,980 | - | 0.02 | ||
| 12,901 | 4,254,099 | - | 0.19 | 11,522 | 114,774 | - | 0.06 | 11,255 | 90,908 | - | 0.04 | ||
| Datasets | DFS | ACO | DFS + ACO | ||||||
|---|---|---|---|---|---|---|---|---|---|
| obj. | node_cnt | Time | obj. | dev | obj. | node_cnt | Time | ||
| 5 | 101 | 25 | 0.00 | 101 | 0.00 | 101 | 5 | 0.00 | |
| 128 | 22 | 0.00 | 128 | 0.00 | 128 | 7 | 0.00 | ||
| 122 | 27 | 0.00 | 122 | 0.00 | 122 | 4 | 0.00 | ||
| 10 | 461 | 203 | 0.06 | 461 | 0.00 | 461 | 112 | 0.06 | |
| 423 | 246 | 0.04 | 427 | 0.01 | 423 | 75 | 0.04 | ||
| 457 | 1055 | 0.25 | 464 | 0.02 | 457 | 954 | 0.25 | ||
| 20 | 2052 | 34,798 | 69.07 | 2058 | 0.00 | 2052 | 32,861 | 64.83 | |
| 1820 | 44,844 | 77.49 | 1868 | 0.03 | 1820 | 43,257 | 72.69 | ||
| 1662 | 201,418 | 314.67 | 1668 | 0.00 | 1662 | 157,071 | 243.59 | ||
| 30 | 3605 | 440,015 | - | 3616 | 0.01 | 3597 | 433,789 | - | |
| 4053 | 385,433 | - | 3986 | 0.00 | 3985 | 373,573 | - | ||
| 4470 | 392,869 | - | 4424 | 0.00 | 4424 | 357,690 | - | ||
| 40 | 8357 | 189,796 | - | 8282 | 0.01 | 8282 | 159,727 | - | |
| 7564 | 176,723 | - | 7390 | 0.00 | 7390 | 131,500 | - | ||
| 8074 | 185,522 | - | 7967 | 0.00 | 7967 | 145,476 | - | ||
| 50 | 13,007 | 74873 | - | 12,880 | 0.00 | 12,880 | 69,077 | - | |
| 12,527 | 84,980 | - | 12,587 | 0.02 | 12,527 | 83,440 | - | ||
| 11,255 | 90,908 | - | 10,871 | 0.00 | 10,871 | 71,311 | - | ||
| Datasets | BFS | ACO | BFS + ACO | ||||||
|---|---|---|---|---|---|---|---|---|---|
| obj. | node_cnt | Time | obj. | Deviation | obj. | node_cnt | Time | ||
| 5 | 101 | 67 | 0.00 | 101 | 0.00 | 101 | 4 | 0.00 | |
| 128 | 44 | 0.00 | 128 | 0.00 | 128 | 3 | 0.00 | ||
| 122 | 68 | 0.01 | 122 | 0.00 | 122 | 4 | 0.00 | ||
| 10 | 461 | 4141 | 0.39 | 461 | 0.00 | 461 | 96 | 0.04 | |
| 423 | 2518 | 0.27 | 427 | 0.01 | 423 | 118 | 0.03 | ||
| 457 | 34,646 | 2.57 | 464 | 0.02 | 457 | 2578 | 0.40 | ||
| 20 | 7839 | 1,940,323 | - | 2058 | 0.00 | 2052 | 43,231 | 33.67 | |
| 6651 | 2,081,103 | - | 1868 | 0.03 | 1868 | 3,185,673 | - | ||
| 6211 | 2,078,269 | - | 1668 | 0.00 | 1662 | 79,117 | 124.83 | ||
| 30 | 18,533 | 1,482,922 | - | 3616 | 0.01 | 3616 | 782,158 | - | |
| 22,005 | 1,083,532 | - | 3986 | 0.00 | 3986 | 394,009 | - | ||
| 22,990 | 1,165,534 | - | 4424 | 0.00 | 4424 | 485,726 | - | ||
| 40 | 51,610 | 846,721 | - | 8282 | 0.01 | 8282 | 649,800 | - | |
| 44,779 | 873,638 | - | 7390 | 0.00 | 7390 | 532,584 | - | ||
| 49,102 | 888,079 | - | 7967 | 0.00 | 7967 | 702,847 | - | ||
| 50 | 106,541 | 856,905 | - | 12,880 | 0.00 | 12,880 | 682,047 | - | |
| 97,383 | 933,536 | - | 12,587 | 0.02 | 12,587 | 927,886 | - | ||
| 87,545 | 1,055,329 | - | 10,871 | 0.00 | 10,871 | 820,528 | - | ||
| Datasets | BestFS | ACO | BestFS + ACO | ||||||
|---|---|---|---|---|---|---|---|---|---|
| obj. | node_cnt | Time | obj. | Deviation | obj. | node_cnt | Time | ||
| 5 | 101 | 16 | 0.00 | 101 | 0.00 | 101 | 4 | 0.00 | |
| 128 | 12 | 0.00 | 128 | 0.00 | 128 | 3 | 0.00 | ||
| 122 | 20 | 0.00 | 122 | 0.00 | 122 | 4 | 0.00 | ||
| 10 | 461 | 283 | 0.04 | 461 | 0.00 | 461 | 96 | 0.04 | |
| 423 | 128 | 0.02 | 427 | 0.01 | 423 | 61 | 0.02 | ||
| 457 | 1788 | 0.18 | 464 | 0.02 | 457 | 1333 | 0.18 | ||
| 20 | 2052 | 33,393 | 22.62 | 2058 | 0.00 | 2052 | 13,380 | 24.48 | |
| 1820 | 44,166 | 22.03 | 1868 | 0.03 | 1820 | 39,031 | 25.69 | ||
| 1662 | 172,094 | 96.32 | 1668 | 0.00 | 1662 | 71,082 | 100.10 | ||
| 30 | 18,533 | 1,903,404 | - | 3616 | 0.01 | 3616 | 1,350,098 | - | |
| 22,055 | 1,064,974 | - | 3986 | 0.00 | 3986 | 518,619 | - | ||
| 22,990 | 1,423,640 | - | 4424 | 0.00 | 4424 | 648,245 | - | ||
| 40 | 51,610 | 769,918 | - | 8282 | 0.01 | 8282 | 790,216 | - | |
| 44,779 | 1,112,645 | - | 7390 | 0.00 | 7390 | 971,168 | - | ||
| 49,102 | 1,094,652 | - | 7967 | 0.00 | 7967 | 1,087,057 | - | ||
| 50 | 106,541 | 954,605 | - | 12,880 | 0.00 | 12,880 | 888,985 | - | |
| 97,383 | 1,047,559 | - | 12,587 | 0.02 | 12,587 | 1,078,245 | - | ||
| 87,545 | 1,181,533 | - | 10,871 | 0.00 | 10,871 | 1,181,376 | - | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chao, M.-T.; Lin, B.M.T. Scheduling of Software Test to Minimize the Total Completion Time. Mathematics 2023, 11, 4705. https://doi.org/10.3390/math11224705
Chao M-T, Lin BMT. Scheduling of Software Test to Minimize the Total Completion Time. Mathematics. 2023; 11(22):4705. https://doi.org/10.3390/math11224705
Chicago/Turabian StyleChao, Man-Ting, and Bertrand M. T. Lin. 2023. "Scheduling of Software Test to Minimize the Total Completion Time" Mathematics 11, no. 22: 4705. https://doi.org/10.3390/math11224705
APA StyleChao, M.-T., & Lin, B. M. T. (2023). Scheduling of Software Test to Minimize the Total Completion Time. Mathematics, 11(22), 4705. https://doi.org/10.3390/math11224705