


Structure-Aware Low-Rank Adaptation for Parameter-Efficient Fine-Tuning


Abstract
:1. Introduction
2. Backgound
3. Method
3.1. Problem Formalization
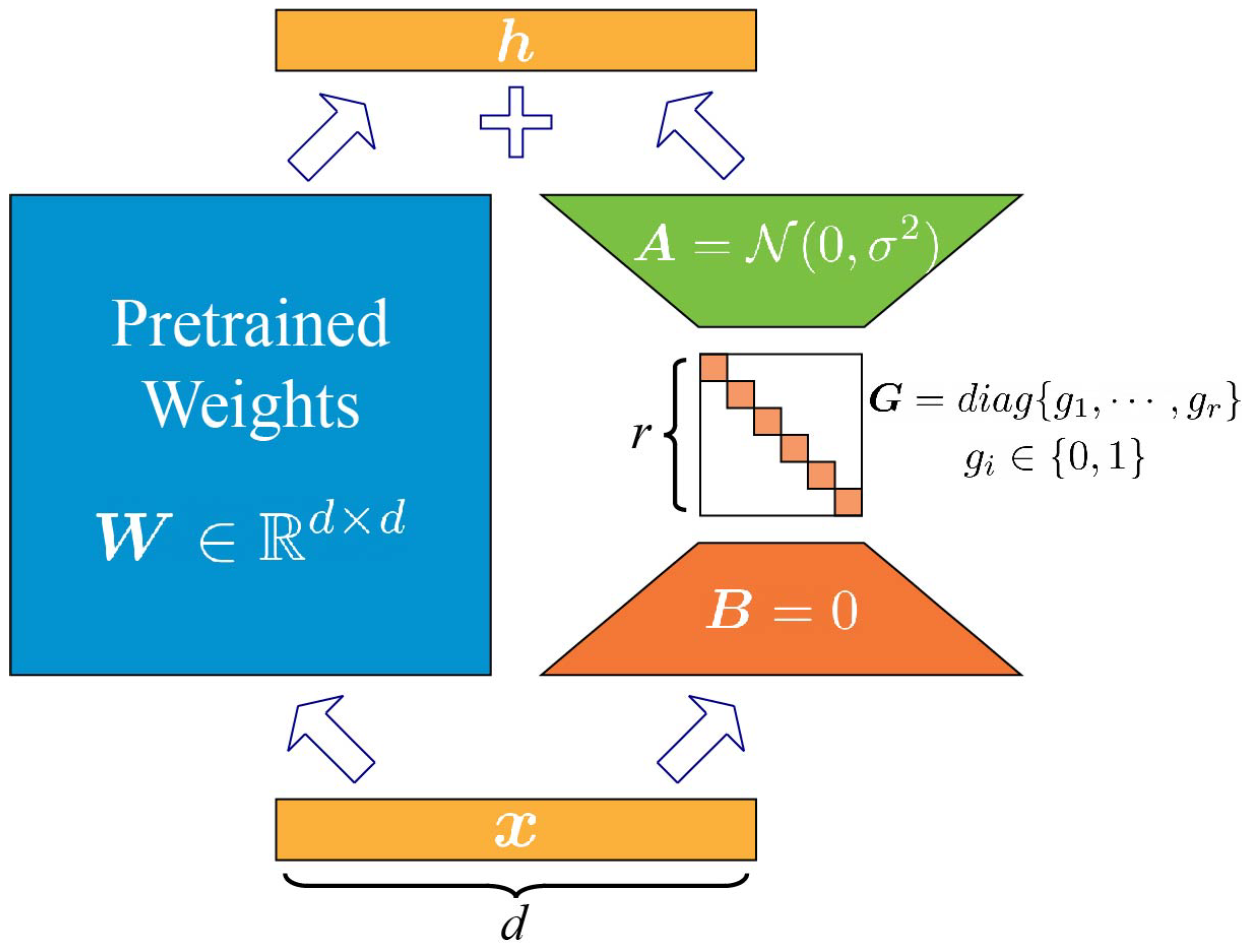
3.2. Structure-Aware Intrinsic Rank Using Norm
3.3. Enhanced Stability Using Orthogonal Regularization
3.4. Controlled Budget Using Lagrangian Relaxation
| Algorithm 1 SaLoRA |
|
3.5. Inference
4. Experiments
- Fine-tuning (FT) is the most common approach for adaptation. To establish an upper bound for the performance of our proposed method, we fine-tuned all parameters within the model.
- Adapting tuning, as proposed by Houlsby et al. [25], incorporates adapter layers between the self-attention module (and the MLP module) and the subsequent residual connection. Each adapter module consists of two fully connected layers with biases and a nonlinearity in between. This original design is referred to as AdapterH. Recently, Pfeiffer et al. [11] introduced a more efficient approach, applying the adapter layer only after the MLP module and following a LayerNorm. We call it AdapterP.
- Prefix-tuning (Prefix) [12] prepends a sequence of continuous task-specific activations to the input. During tuning, prefix-tuning freezes the model parameters and only backpropagates the gradient to the prefix activations.
- Prompt-tuning (Prompt) [13] is a simplified version of prefix-tuning, allowing the additional k tunable tokens per downstream task to be prepended to the input text.
- LoRA, introduced by Hu et al. [15], is a state-of-the-art method for parameter-efficient fine-tuning. The original implementation of LoRA applied the method solely to query and value projections. However, empirical studies [16,35] have shown that extending LoRA to all matrices, including , , , , and , can further improve its performance. Therefore, we compare our approach with this generalized LoRA configuration to maximize its effectiveness.
- AdaLoRA, proposed by Zhang et al. [16], utilizes singular value decomposition (SVD) to adaptively allocate the parameter budget among weight matrices based on their respective importance scores. However, this baseline involves computationally intensive operations, especially for large matrices. The training cost can be significant, making it less efficient for resource-constrained scenarios.
4.1. Task-Oriented Performance
4.2. Task-Agnostic Performance
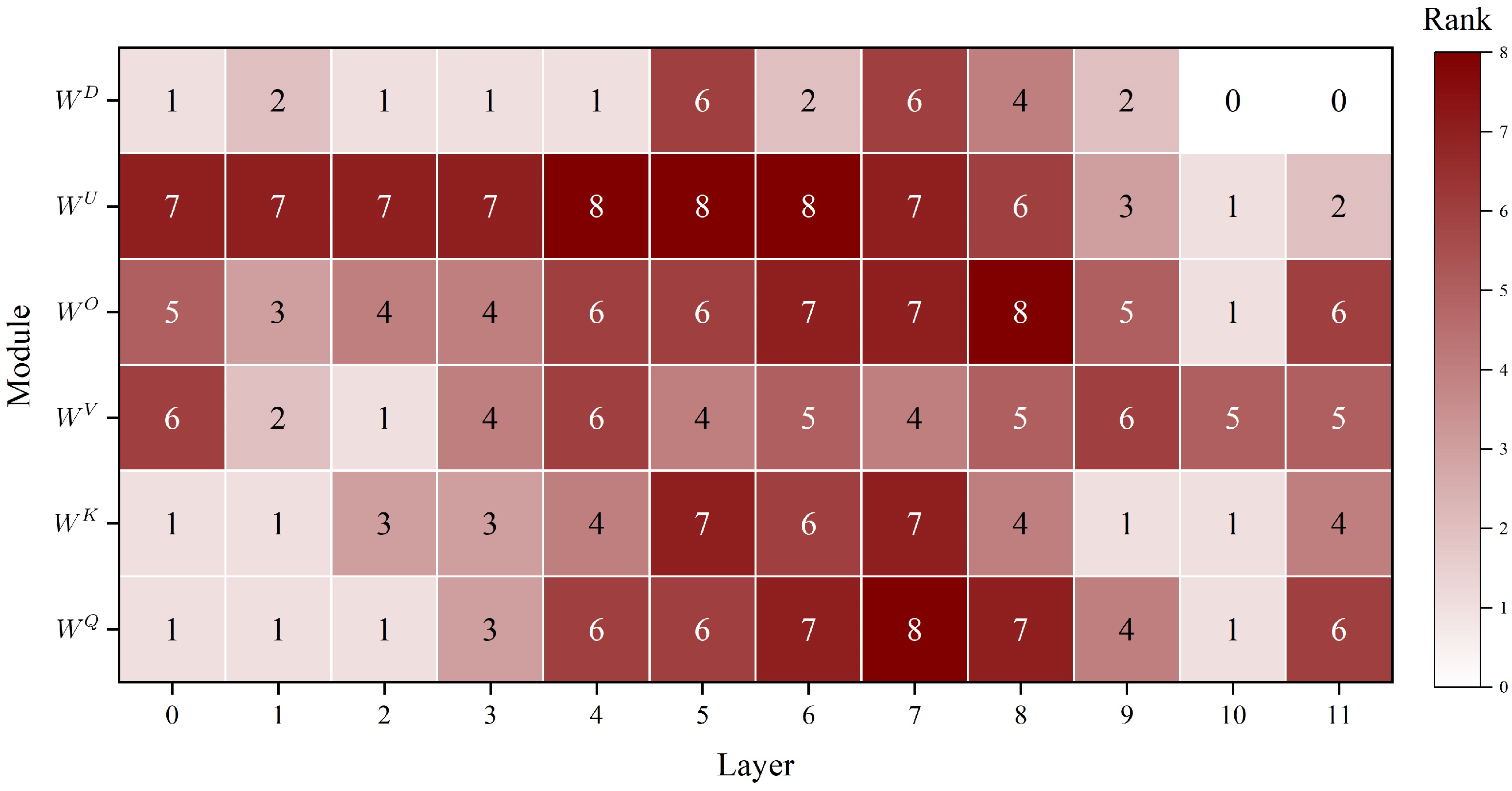
4.3. Analysis
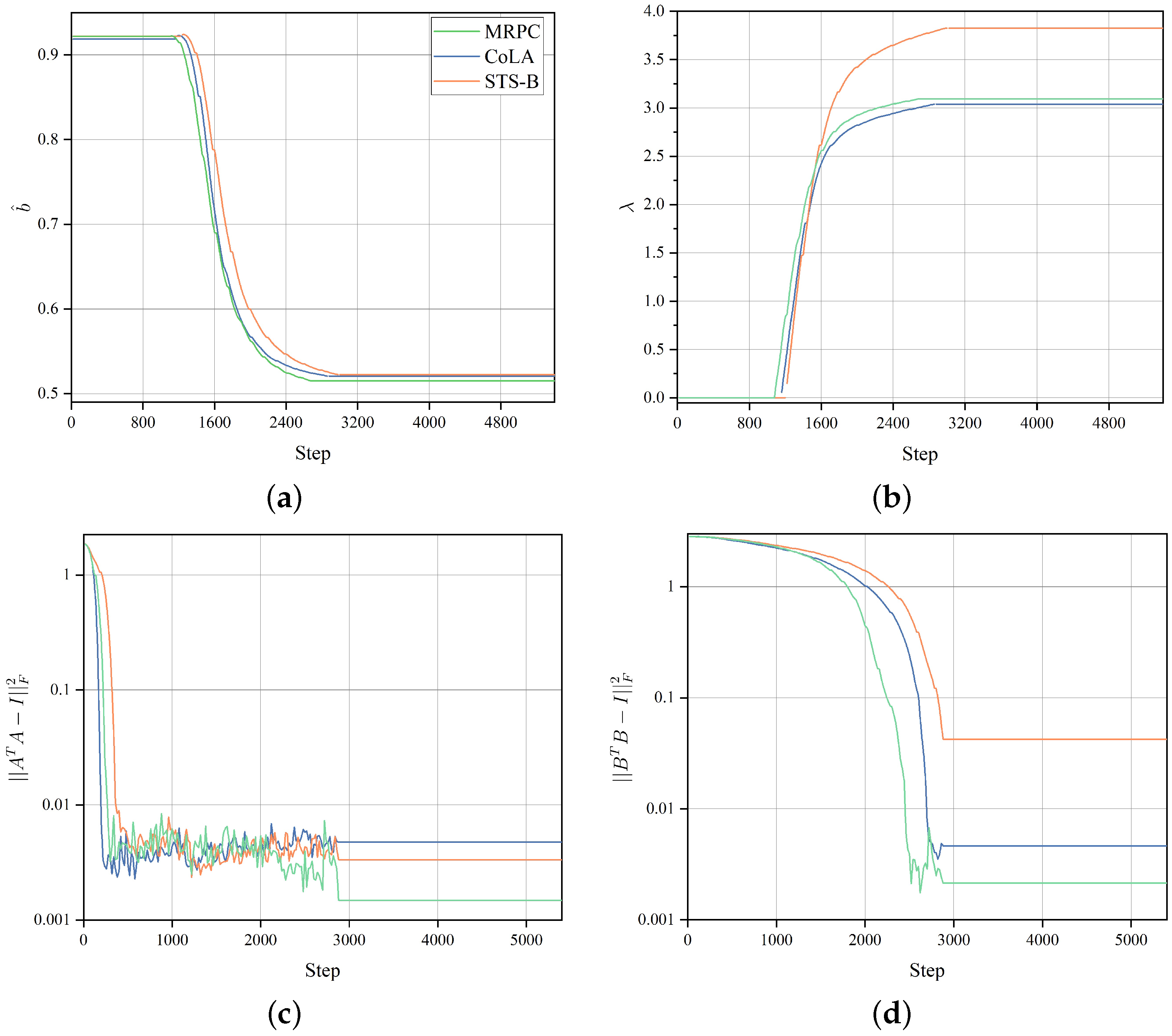
- Without Lagrangian relaxation, the parameter budget was uncontrollable, being , and on the three datasets, respectively. Such results highlight the pivotal role that Lagrangian relaxation plays in controlling the allocation of the parameter budget. Nonetheless, it is worth noting that omitting Lagrange relaxation may lead to slight enhancements in performance. However, given the emphasis on control over the parameter budget, this incremental enhancement should be disregarded.
- Without orthogonal regularization, the performance of SaLoRA degenerated. These results validate that incorporating orthogonal regularization into SaLoRA ensures the independence of doublets from one another, leading to a significant enhancement in its performance.
- The expected sparsity decreased from 0.92 to about 0.50, and the Lagrangian multiplier kept increasing during training. The results indicate that the SaLoRA algorithm placed more emphasis on satisfying the constraints, eventually reaching a trade-off between satisfying the constraints and optimizing the objective function.
- The values of and could be optimized to a highly negligible level (e.g., 0.001). Therefore, this optimization process enforced orthogonality upon both matrices A and B, guaranteeing the independence of doublets from one another.
- The GPU memory usages of both methods were remarkably similar. Such results demonstrate that SaLoRA does not impose significant memory overhead. The reason behind this is that SaLoRA only introduces gate matrices in contrast to LoRA. The total number of parameters was . In this experiment, r denotes the rank of the incremental matrix (set at 8), L corresponds to the number of layers within the model (12 for and 24 for ) and M stands for the number of modules in each layer (set at 6).
- The training time of SaLoRA increased by 11% when using a batch size of 32 compared with LoRA. This suggests that the additional computational requirements introduced by SaLoRA are justified by its notable gains in performance. This is because SaLoRA is only utilized during a specific training phase ( to ) comprising 30% of the overall training time. With the remaining 70% being equivalent to LoRA, the overall impact on training time remains manageable.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| PLMs | Pre-trained language models |
| LLMs | Large language models |
| NLP | Natural language process |
| LoRA | Low-rank adaptation |
| MHA | Multi-head self-attention |
| FFN | Feed-forward network |
| FT | Fine-tuning |
| PEFT | Parameter-efficient fine-tuning |
| HC | Hard-concrete distribution |
Appendix A. Description of Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Description | Train | Valid | Test | Metrics |
|---|---|---|---|---|---|
| GLUE Benchmark | |||||
| MNLI | Inference | 393.0k | 20.0k | 20.0k | Accuracy |
| SST-2 | Sentiment analysis | 7.0k | 1.5k | 1.4k | Accuracy |
| MRPC | Paraphrase detection | 3.7k | 408 | 1.7k | Accuracy |
| CoLA | Linguistic acceptability | 8.5k | 1.0k | 1.0k | Matthews correlation |
| QNLI | Inference | 108.0k | 5.7k | 5.7k | Accuracy |
| QQP | Question answering | 364.0k | 40.0k | 391k | Accuracy |
| RTE | Inference | 2.5k | 276 | 3.0k | Accuracy |
| STS-B | Textual similarity | 7.0k | 1.5k | 1.4k | Pearson correlation |
| Text Style Transfer | |||||
| Yelp-Negative | Negative reviews of restaurants and businesses | 17.7k | 2.0k | 500 | Accuracy Similarity Fluency |
| Yelp-Positive | Positive reviews of restaurants and businesses | 26.6k | 2.0k | 500 | Accuracy Similarity Fluency |
| GYAFC-Informal | Informal sentences from the Family and Relationships domain | 5.2k | 2.2k | 1.3k | Accuracy Similarity Fluency |
| GYAFC-Formal | Formal sentences from the Family and Relationships domain | 5.2k | 2.8k | 1.0k | Accuracy Similarity Fluency |
Appendix B. Training Details
| Model | MNLI | SST-2 | CoLA | QQP | QNLI | RTE | MRPC | STS-B | |
|---|---|---|---|---|---|---|---|---|---|
| # Epoch | 15 | 20 | 20 | 20 | 15 | 40 | 40 | 30 | |
| 15 | 20 | 20 | 20 | 15 | 40 | 40 | 30 | ||
Appendix C. Prompts
| Yelp: Negative → Positive |
|---|
| “Below is an instruction that describes a task. Write a response that appropriately completes the request. |
| ### Instruction: |
| {Please change the sentiment of the following sentence to be more positive.} |
| ### Input: |
| {$Sentence} |
| ### Response:” |
| Yelp: Positive → Negative |
| “Below is an instruction that describes a task. Write a response that appropriately completes the request. |
| ### Instruction: |
| {Please change the sentiment of the following sentence to be more negative.} |
| ### Input: |
| {$Sentence} |
| ### Response:” |
| GYAFC: Informal → Formal |
| “Below is an instruction that describes a task. Write a response that appropriately completes the request. |
| ### Instruction: |
| {Please rewrite the following sentence to be more formal.} |
| ### Input: |
| {$Sentence} |
| ### Response:” |
| GYAFC: Formal → Informal |
| “Below is an instruction that describes a task. Write a response that appropriately completes the request. |
| ### Instruction: |
| {Please rewrite the following sentence to be more informal.} |
| ### Input: |
| {$Sentence} |
| ### Response:” |
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. Glm-130b: An open bilingual pre-trained model. arXiv 2022, arXiv:2210.02414. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Pavlyshenko, B.M. Financial News Analytics Using Fine-Tuned Llama 2 GPT Model. arXiv 2023, arXiv:2308.13032. [Google Scholar] [CrossRef]
- Kossen, J.; Rainforth, T.; Gal, Y. In-Context Learning in Large Language Models Learns Label Relationships but Is Not Conventional Learning. arXiv 2023, arXiv:2307.12375. [Google Scholar] [CrossRef]
- Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Wu, Z.; Chang, B.; Sun, X.; Xu, J.; Li, L.; Sui, Z. A Survey on In-context Learning. arXiv 2022, arXiv:2301.00234. [Google Scholar] [CrossRef]
- Li, C.; Farkhoor, H.; Liu, R.; Yosinski, J. Measuring the Intrinsic Dimension of Objective Landscapes. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Aghajanyan, A.; Gupta, S.; Zettlemoyer, L. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 7319–7328. [Google Scholar] [CrossRef]
- Ding, N.; Qin, Y.; Yang, G.; Wei, F.; Yang, Z.; Su, Y.; Hu, S.; Chen, Y.; Chan, C.; Chen, W.; et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nat. Mac. Intell. 2023, 5, 220–235. [Google Scholar] [CrossRef]
- Pfeiffer, J.; Kamath, A.; Rücklé, A.; Cho, K.; Gurevych, I. AdapterFusion: Non-Destructive Task Composition for Transfer Learning. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 487–503. [Google Scholar] [CrossRef]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 4582–4597. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3045–3059. [Google Scholar] [CrossRef]
- Ben Zaken, E.; Goldberg, Y.; Ravfogel, S. BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 22–27 May 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Zhang, Q.; Chen, M.; Bukharin, A.; He, P.; Cheng, Y.; Chen, W.; Zhao, T. Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning. In Proceedings of the the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Louizos, C.; Welling, M.; Kingma, D.P. Learning Sparse Neural Networks through L_0 Regularization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, Z.; Wohlwend, J.; Lei, T. Structured Pruning of Large Language Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 8–12 November 2020; pp. 6151–6162. [Google Scholar] [CrossRef]
- Gallego-Posada, J.; Ramirez, J.; Erraqabi, A.; Bengio, Y.; Lacoste-Julien, S. Controlled Sparsity via Constrained Optimization or: How I Learned to Stop Tuning Penalties and Love Constraints. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 29 November–1 December 2022; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 1253–1266. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Stanford Alpaca: An Instruction-Following LLaMA Model. 2023. Available online: https://github.com/tatsu-lab/stanford_alpaca (accessed on 14 March 2023).
- Li, J.; Jia, R.; He, H.; Liang, P. Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 1865–1874. [Google Scholar] [CrossRef]
- Rao, S.; Tetreault, J. Dear Sir or Madam, May I Introduce the GYAFC Dataset: Corpus, Benchmarks and Metrics for Formality Style Transfer. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 129–140. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-Efficient Transfer Learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 2790–2799. [Google Scholar]
- Mo, Y.; Yoo, J.; Kang, S. Parameter-Efficient Fine-Tuning Method for Task-Oriented Dialogue Systems. Mathematics 2023, 11, 3048. [Google Scholar] [CrossRef]
- Lee, J.; Tang, R.; Lin, J. What Would Elsa Do? Freezing Layers during Transformer Fine-Tuning. arXiv 2019, arXiv:1911.03090. [Google Scholar] [CrossRef]
- Guo, D.; Rush, A.; Kim, Y. Parameter-Efficient Transfer Learning with Diff Pruning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 4884–4896. [Google Scholar] [CrossRef]
- Valipour, M.; Rezagholizadeh, M.; Kobyzev, I.; Ghodsi, A. DyLoRA: Parameter-Efficient Tuning of Pre-trained Models using Dynamic Search-Free Low-Rank Adaptation. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–6 May 2023; pp. 3274–3287. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the 1st International Conference on Machine Learning, Bejing, China, 22–24 June 2014; Xing, E.P., Jebara, T., Eds.; PMLR: Bejing, China, 2014; Volume 32, pp. 1278–1286. [Google Scholar]
- Brock, A.; Lim, T.; Ritchie, J.; Weston, N. Neural Photo Editing with Introspective Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Lin, T.; Jin, C.; Jordan, M. On Gradient Descent Ascent for Nonconvex-Concave Minimax Problems. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020; Daumé, H., III, Singh, A., Eds.; PMLR: Vienna, Austria, 2020; Volume 119, pp. 6083–6093. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- He, J.; Zhou, C.; Ma, X.; Berg-Kirkpatrick, T.; Neubig, G. Towards a Unified View of Parameter-Efficient Transfer Learning. In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Mangrulkar, S.; Gugger, S.; Debut, L.; Belkada, Y.; Paul, S. PEFT: State-of-the-Art Parameter-Efficient Fine-Tuning Methods. 2022. Available online: https://github.com/huggingface/peft (accessed on 6 July 2023).
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 3–5 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Heafield, K. KenLM: Faster and Smaller Language Model Queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Edinburgh, UK, 30–31 July 2011; pp. 187–197. [Google Scholar]
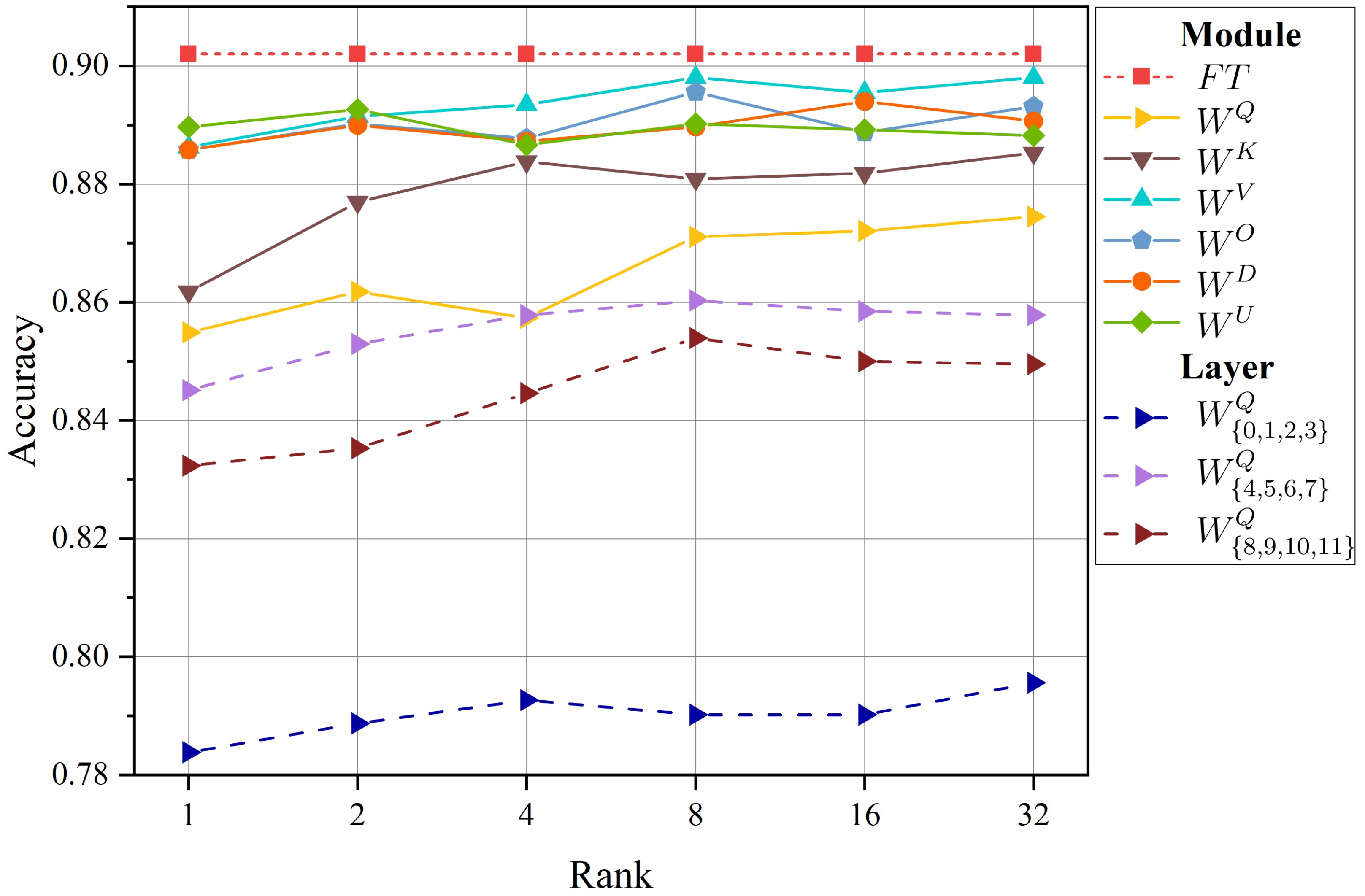

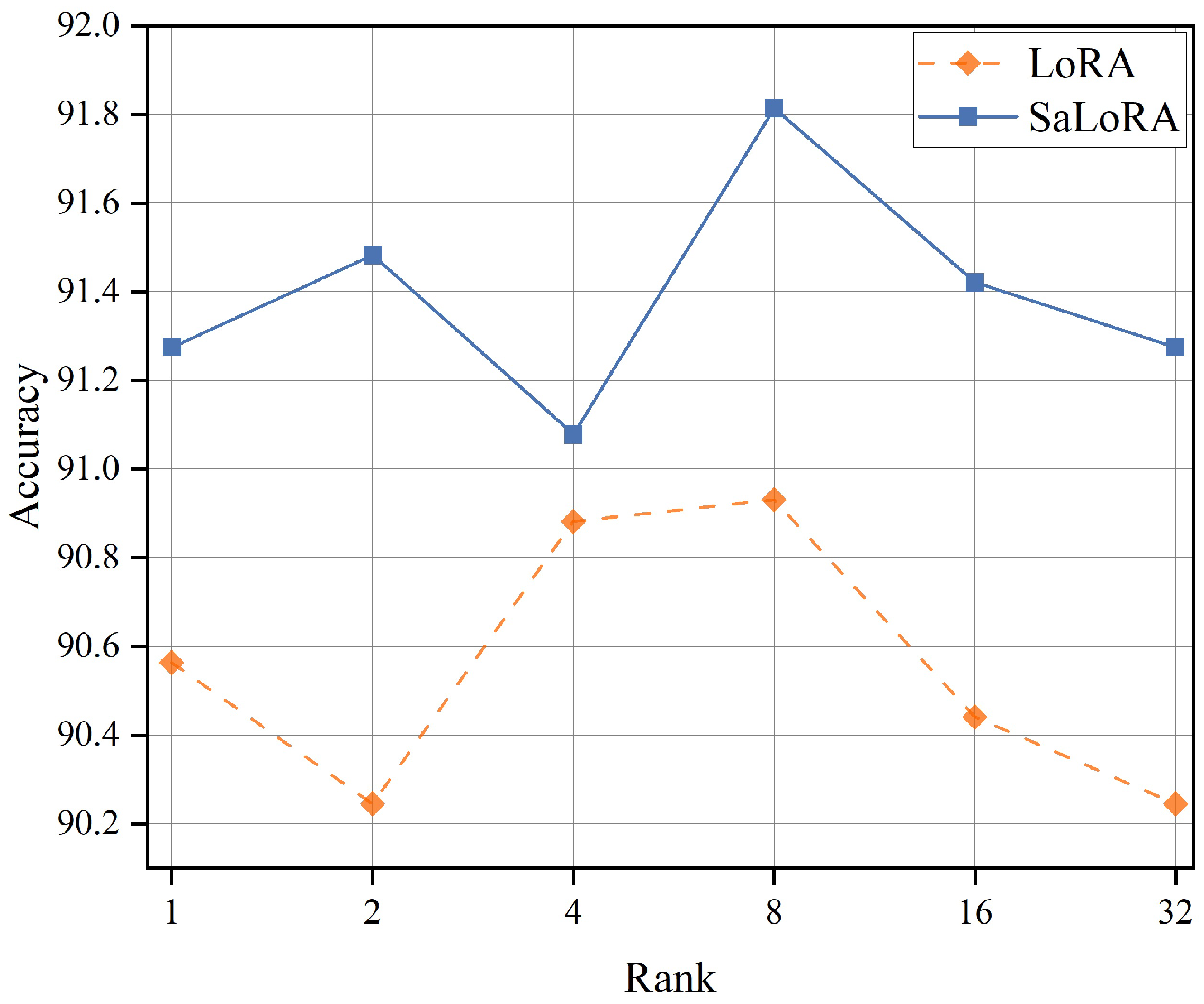
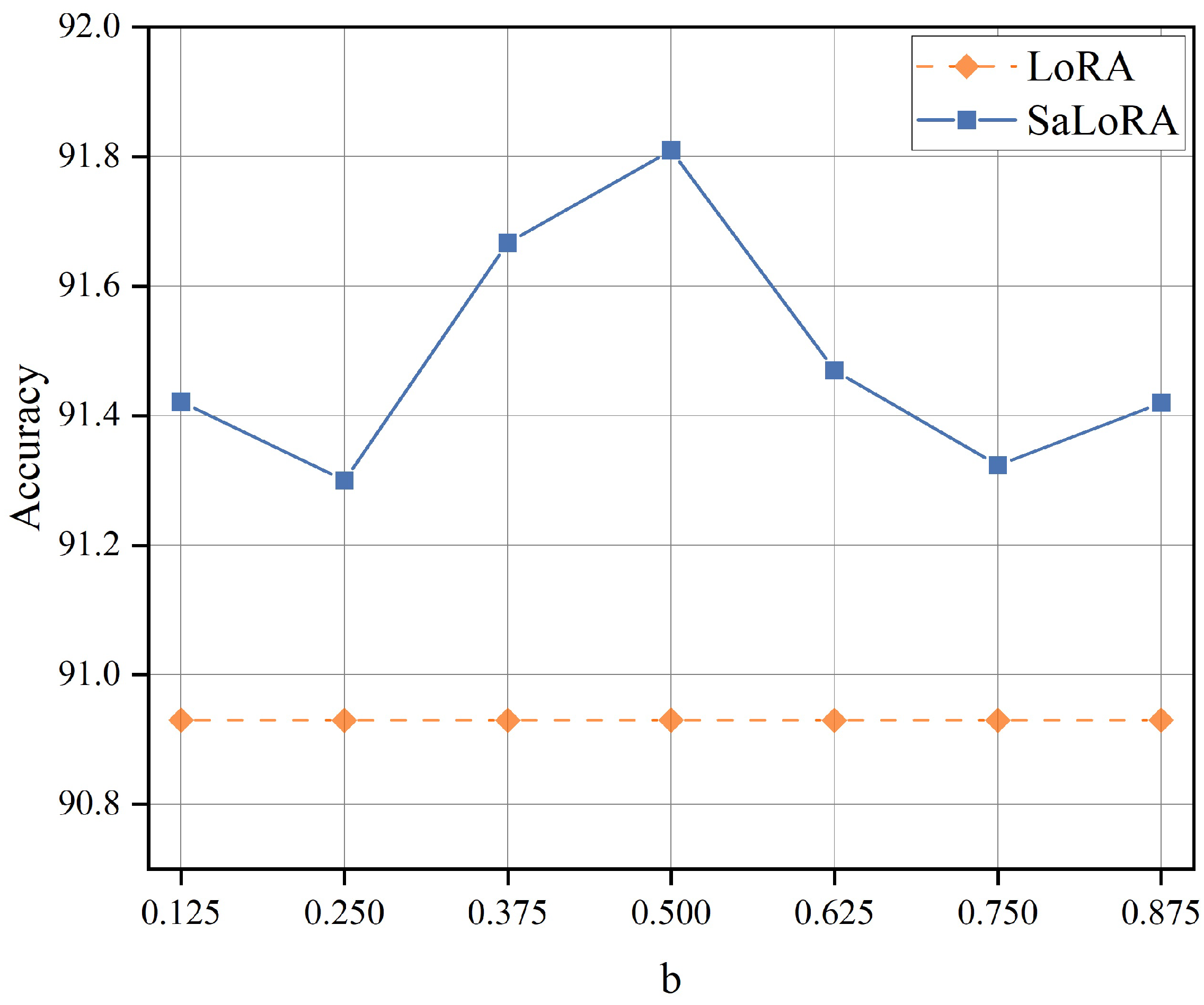
| Model and Method | # Trainable | MNLI | SST-2 | CoLA | QQP | QNLI | RTE | MRPC | STS-B | ALL |
|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | ACC | ACC | Mathew | ACC | ACC | ACC | ACC | Pearson | Avg | |
| † | 125.00 M | 87.6 | 94.8 | 63.6 | 91.9 | 92.8 | 78.7 | 90.2 | 91.2 | 86.4 |
| 1.33 M | 78.70 | |||||||||
| 0.62 M | 70.77 | |||||||||
| 1.33 M | 85.91 | |||||||||
| 1.33 M | 85.00 | |||||||||
| 1.33 M | 86.64 | |||||||||
| † | 356.05 M | 90.2 | 96.4 | 68.0 | 92.2 | 94.7 | 86.6 | 90.9 | 92.4 | 88.9 |
| † | 4.05 M | 88.4 | ||||||||
| † | 7.05 M | 87.8 | ||||||||
| 3.02 M | 84.71 | |||||||||
| 1.09 M | 77.53 | |||||||||
| 3.41 M | 88.38 | |||||||||
| 3.54 M | 88.64 | |||||||||
| 3.54 M | 89.33 |
| Model and Method | Yelp | GYAFC | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Negative to Positive | Positive to Negative | Informal to Formal | Formal to Informal | |||||||||
| ACC↑ | BLEU↑ | PPL↓ | ACC↑ | BLEU↑ | PPL↓ | ACC↑ | BLEU↑ | PPL↓ | ACC↑ | BLEU↑ | PPL↓ | |
| Reference | 64.60 | 100 | 102.62 | 93.80 | 100 | 77.53 | 88.44 | 100 | 66.86 | 87.63 | 100 | 105.28 |
| StyTrans | 88.40 | 25.85 | 173.35 | 94.20 | 24.90 | 141.88 | 32.81 | 54.91 | 144.15 | 80.86 | 27.69 | 201.78 |
| StyIns | 92.40 | 25.98 | 116.01 | 89.60 | 26.08 | 105.79 | 54.73 | 60.87 | 96.53 | 80.57 | 30.25 | 132.54 |
| TSST | 91.20 | 28.95 | 112.86 | 94.40 | 28.83 | 101.92 | 65.62 | 61.83 | 87.04 | 85.87 | 33.54 | 128.78 |
| 2.20 | 33.58 | 208.69 | 0.80 | 31.12 | 156.14 | 12.01 | 60.18 | 189.78 | 7.75 | 34.61 | 145.43 | |
| 71.00 | 25.96 | 82.20 | 92.80 | 31.83 | 83.03 | 89.34 | 61.06 | 68.52 | 34.45 | 41.59 | 82.96 | |
| 73.20 | 24.76 | 76.49 | 94.60 | 31.96 | 87.41 | 89.63 | 61.76 | 67.53 | 39.04 | 40.91 | 79.54 | |
| Method | MRPC | STS-B | CoLA | |||
|---|---|---|---|---|---|---|
| ACC | SPS | ACC | SPS | ACC | SPS | |
| SaLoRA | ||||||
| SaLoRA | ||||||
| SaLoRA | ||||||
| Model | BS | Method | GPU Mem | Time |
|---|---|---|---|---|
| 16 | LoRA | 3.54 GB | 15 min | |
| SaLoRA | 3.54 GB | 20 min | ||
| 32 | LoRA | 5.34 GB | 14 min | |
| SaLoRA | 5.35 GB | 15 min | ||
| 64 | LoRA | 9.00 GB | 13 min | |
| SaLoRA | 9.00 GB | 14 min | ||
| 16 | LoRA | 7.44 GB | 44 min | |
| SaLoRA | 7.46 GB | 53 min | ||
| 32 | LoRA | 12.16 GB | 40 min | |
| SaLoRA | 12.18 GB | 44 min | ||
| 64 | LoRA | 21.80 GB | 38 min | |
| SaLoRA | 21.82 GB | 41 min |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Xie, Y.; Wang, T.; Chen, M.; Pan, Z. Structure-Aware Low-Rank Adaptation for Parameter-Efficient Fine-Tuning. Mathematics 2023, 11, 4317. https://doi.org/10.3390/math11204317
Hu Y, Xie Y, Wang T, Chen M, Pan Z. Structure-Aware Low-Rank Adaptation for Parameter-Efficient Fine-Tuning. Mathematics. 2023; 11(20):4317. https://doi.org/10.3390/math11204317
Chicago/Turabian StyleHu, Yahao, Yifei Xie, Tianfeng Wang, Man Chen, and Zhisong Pan. 2023. "Structure-Aware Low-Rank Adaptation for Parameter-Efficient Fine-Tuning" Mathematics 11, no. 20: 4317. https://doi.org/10.3390/math11204317
APA StyleHu, Y., Xie, Y., Wang, T., Chen, M., & Pan, Z. (2023). Structure-Aware Low-Rank Adaptation for Parameter-Efficient Fine-Tuning. Mathematics, 11(20), 4317. https://doi.org/10.3390/math11204317