1. Introduction
CDMs are widely used in the field of educational and psychological assessments. These models are used to extract the examinees’ latent binary random vectors, which can provide rich and comprehensive information about examinees. Different CDMs are proposed for different test scenarios. The popular CDMs include Deterministic Input, Noisy “And” gate (DINA) model [
1], Deterministic Input, Noisy “Or” gate (DINO) model [
2], Noisy Inputs, Deterministic “And” gate (NIDA) model [
3], Noisy Inputs, Deterministic “Or” gate (NIDO) model [
2], Reduced Reparameterized Unified Model (RRUM) [
4,
5] and Log-linear Cognitive Diagnosis Model (LCDM) [
6]. The differences among the above-mentioned CDMs are the modeling methods of the positive response probabilities. CDMs can be summarized in more flexible frameworks such as the Generalized Noisy Inputs, Deterministic “And” gate (GDINA) model [
7] and the General Diagnostic Model (GDM) [
8]. The simplicity and interpretability of the DINA model have positioned it as one of the most popular CDMs.
The DINA model, also known as the latent classes model [
9,
10,
11,
12,
13], is a mixture model, so it still suffers from the drawbacks of the mixture model. Too many latent classes may overfit the data, which means that data should have been characterized by a simpler model. Too few latent classes cannot characterize the true underlying data structure well and yield poor inference. In practical terms, identifying the empty latent classes will improve the model’s interpretability and explain the data well. Chen [
14] showed that the theoretical optimal convergence rate of the mixture model with the unknown number of classes is slower than the optimal convergence rate with the known number of classes. This means that the inference would strongly benefit from the known number of classes. Therefore, from both practical and theoretical views, eliminating the empty latent classes is a crucial issue in the DINA model.
Common reasons for empty attribute profiles include small sample sizes or highly correlated attributes. Let us explore a few examples to illustrate further. In a scenario where the sample size is smaller than the number of attribute profiles, it is inevitable that some attribute profiles will be empty. In another scenario with two attributes
and
, the relation is assumed that
if and only if
. Under the assumption of extremely correlated attributes, attribute profiles
and
do not appear. Situations with empty attribute profiles can occur in various scenarios [
15].
The hierarchical diagnostic classification model [
15,
16] is a well-known method to eliminate empty attribute profiles. In the literature, directed acyclic graphs are employed to describe the relationships among the attributes, and the directions of edges impose strict constraints on attributes. If there is a directed edge from
to
, the attribute profile
is forbidden. Gu and Xu [
15] utilized penalized EM to select the true attribute profiles, avoid overfitting, and learn attribute hierarchies. Wang and Lu [
17] compared two exploratory approaches of learning attribute hierarchies in the LCDM and DINA models. In essence, the attribute hierarchy can be regarded as a specific family of correlated attributes that can be effectively represented and described through a graph model.
The penalized methods have been widely researched in many statistical problems. In the regression model, the least absolute shrinkage and selection operator (LASSO) and its variants are analyzed by [
18,
19,
20]. Fan and Li [
21] proposed a nonconcave penalty smoothly clipped absolute deviation (SCAD) to reduce the bias of estimators. In the Gaussian mixture model, Ma and Wang, Huang et al. [
22,
23] proposed penalized likelihood methods to determine the number of components. In CDMs, Chen et al. [
10] used SCAD to obtain the sparse item parameters and recovery
Q matrix. Xu and Shang [
11] applied a “
norm” penalty to CDM and suggested a truncated “
norm” penalty as the approximate calculation.
In the hierarchical diagnostic classification model, directed acyclic graphs of attributes often need to be specified in advance. A limitation of this model is that it is difficult to specify a graph in real scenarios. The penalty of the penalized EM proposed by Gu and Xu [
15] involves two tuning parameters that complicate the implementation. Therefore, we hope to propose a method that does not require specifying a directed acyclic graph in advance and has a concise penalty term.
This paper makes two primary contributions. Firstly, it introduces an entropy-based penalty, and secondly, it develops the corresponding algorithms to utilize this penalty. This paper proposes a novel approach for estimating the DINA model, combining Shannon entropy and the penalized method. In information theory, “uncertainty” can be interpreted informally as the negative logarithm of probability, and Shannon entropy is the average effect of the “uncertainty”. Shannon entropy can be used to characterize the distribution of attribute profiles. By utilizing the proposed method, the empty attribute profiles can be eliminated. We further develop the EM algorithm for the proposed method and conduct some simulations to verify the proposed method.
The rest of the paper is organized as follows. In
Section 2, we give an overview of the DINA model and the estimation method. A definition of the feasible domain is defined to characterize the latent classes.
Section 3 introduces the entropy penalized method, and the EM algorithm is employed to estimate the DINA model. The numerical studies of the entropy penalized method are shown in
Section 4.
Section 5 presents real data analysis based on the fractions–subtraction data. The summary of the paper and future research are given in
Section 6. The details of the EM algorithm and proof are given in
Appendix A,
Appendix B and
Appendix C.
2. DINA Model
2.1. Review of DINA Model
Firstly, some useful notations are introduced. For the examinee , the attribute profile , also known as the latent class, is a K-dimensional binary vector , and the corresponding response data to J items is a J-dimensional binary vector , where “⊤” is the transpose operation. Let and denote the collection of all and , respectively. The Q matrix is a binary matrix, where if item j requires the attribute k, then the element is 1, otherwise, the element is 0. The j-th row vector is denoted by . Given the fixed K, there are latent classes. We use a multinomial distribution with the probability to describe the attribute profile , where , and the population parameter denotes the collection of probabilities for all attribute profiles.
The DINA model [
1] supposes that, in an ideal scenario, the examinees with all required attributes will provide correct answers. For examinee
i and item
j, the ideal response is defined as
, where
is defined as 1. The slipping and guessing parameters are defined by conditional probabilities
and
, respectively. The parameters
and
are the collections of all
and
, respectively.
In the DINA model, the positive response probability
can be constructed as
If both
and
are observed, the likelihood function is
Given data
and attribute profile
, the parameters
and
can be directly estimated by the maximum likelihood estimators:
where
is the indicator function. When
is latent, by integrating out
, the marginal likelihood is
which is the primary focus of this paper.
2.2. Estimation Methods
EM and Markov chain Monte Carlo (MCMC) are two estimation methods for the DINA model. De la Torre [
24] discussed the marginal maximum likelihood estimation for the DINA model, and the EM algorithm was employed where the objective function was Equation (
4). Gu and Xu [
15] proposed a penalized expectation–maximization (PEM) with the penalty
where
controls the sparsity of
and
is a small threshold parameter the same order as
, the constant
. There are two tuning parameters
and
in PEM. Additionally, a variational EM algorithm is proposed as an alternative approach.
Culpepper [
25] proposed a Bayesian formulation for the DINA model and used Gibbs sampling to estimate parameters. The algorithm can be implemented by the R package “dina”. The Gibbs sampling can be extended by a sequential method in the DINA and GDINA with many attributes [
26], which provides an alternative approach to the traditional MCMC. As the focus of this paper does not revolve around the MCMC, we refrain from details.
2.3. The Property of DINA as Mixture Model
For a fixed K, the DINA model can be viewed as a mixture model comprising latent classes (i.e., components). In contrast to the Gaussian mixture model, where a change in the number of components will introduce or remove the mean and covariance parameters, the DINA model behaves differently. Specifically, a change in the number of latent classes does not necessarily affect the presence of item parameters. This means that there are two cases: (i) the latent classes have changed while the structure of the item parameters does not change, and (ii) the latent classes and the structure of the item parameters change simultaneously. To account for the two cases, a formal definition of the feasible domain of latent classes is introduced.
Definition 1. Given the subset of latent classes. If for any or , , there exist some latent classes in , whose response function (i.e., the distribution of response data), is determined by or . We say that is a feasible subset of latent classes and all feasible s make up the feasible domain .
If all
, the probability of
is strictly 0. There exist some subsets
that will spoil the item parameter space. Let us see the following examples
Assume the response vector
. If
is from
, then for
,
, we have
which means that the
’s response function is determined by
. For
,
, we have
which means that the
’s response function is determined by
. The Equations (
7) and (
8) are obtained by calculating the ideal responses. To determine the response function of
and
, all item parameters
and
are required. Based on similar discussions,
’s response function is determined by
, and
’s response function is determined by
. To determine the response function of
and
, all item parameters
and
are required.
Then, a different case is presented. If
is from
,
’s response function is determined by
,
’s response function is determined by
, and
’s response function is determined by
. The item parameter
cannot affect the response function of any attribute profile. Hence,
is called a redundant parameter. Meanwhile, this indicates that there does not exist a slipping behavior for item 4, and we can let the redundant parameter
. If
is from
, the item parameter space collapses from 8-dimensional to 7-dimensional. It is obvious that the subset
will not spoil item parameter space, and the feasible domain
depends on
Q. However, a lemma can be given as follows. The proof is deferred to
Appendix A.
Lemma 1. If contains and , then always lies in the feasible region , where and are K-dimensional vectors with all 0 and 1, respectively.
5. Real Data Analysis
In this section, fraction–subtraction data are analyzed. For more about the data, please refer to the literature [
7,
32,
33]. This data set contains responses of
middle school students to
items, where the responses are coded as 0 or 1. The test measures
attributes, so there are
possible latent classes. The
Q-matrix and item contents are shown in
Table 2.
Because the sample size
is not significantly larger than possible latent classes
, we cannot ensure there are enough latent classes to guarantee that true
is feasible. Algorithm 2 is suggested for analyzing the real data. Firstly, EBIC is used to select the penalty parameter
. The results around the optimal EBIC are shown in
Table 3, which is based on a stable interval of EBIC. We observe that when
, the EBIC achieves the minimum. If
, the number
changes from 76 to 20, and two guessing parameters disappear. For
, if
slightly increases, the model will be more complicated. Based on this fact, we discard the
s that are not less than
.
Next, the evaluation is based on Theorem 1 and estimators
,
,
. We note that
does not satisfy Theorem 1, so the corresponding estimator eliminates many classes.
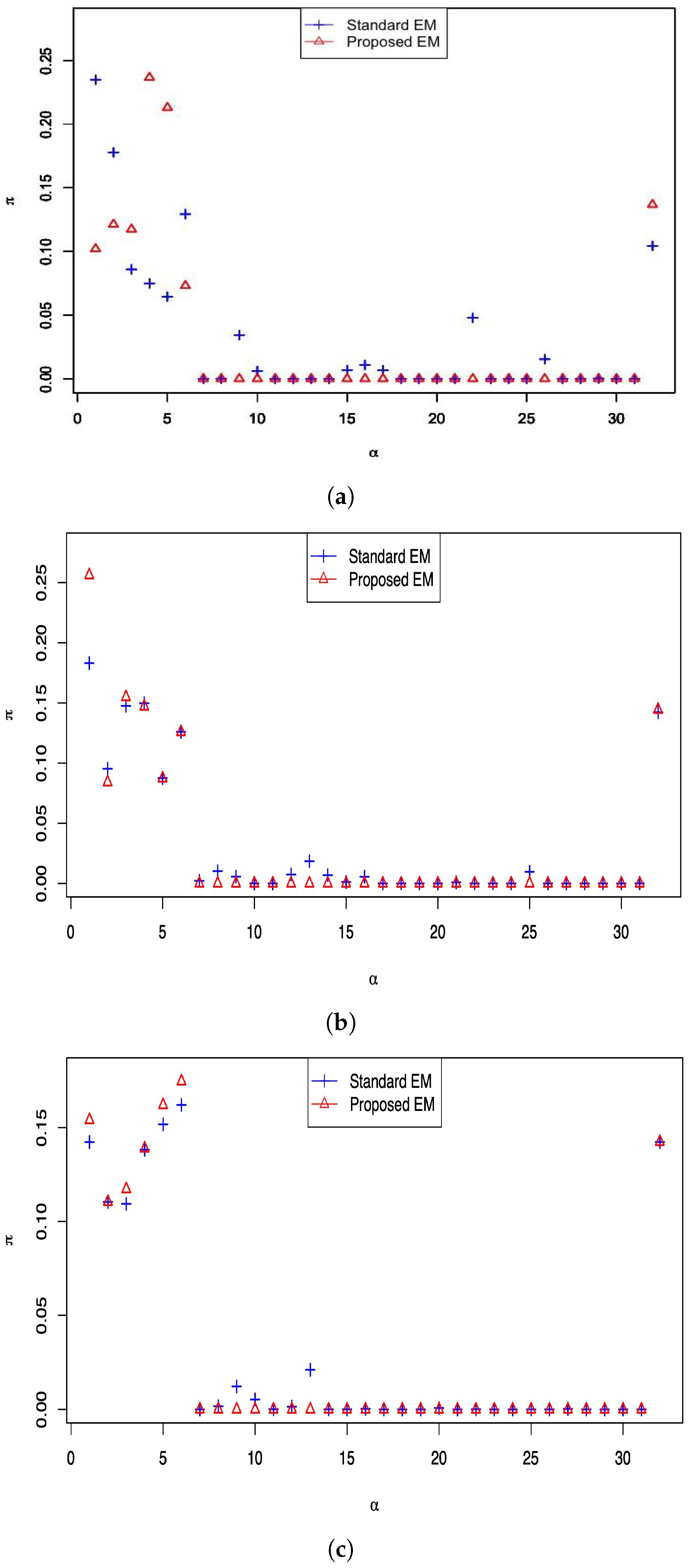
Figure 3 presents the estimated
for different
, and we can see that the results of
Figure 3a are consistent with the conclusion of Theorem 1. The conclusion is that the
s no larger than
are discarded. In addition, combined with
Figure 3a–c, we know that attribute 7 is the most basic attribute.
Figure 4a,b display the estimators of guessing and slipping parameters, respectively. According to the estimated
, the results of
strongly shifted on items 2, 3, 5, 9, and 16. For different
s, the behavior of estimated
is too complex, and significant differences are found in items 8, 9, and 13.
Until now, the candidate penalties are and . The penalty supports the criteria EBIC, and prefers a simpler model. Furthermore, a denser grid between will give more detailed results.
6. Discussion
In this paper, we study the penalized method for the DINA model. There are two contributions. Firstly, the entropy penalized method is proposed for the DINA model. The feasible domain is defined to describe the relation between latent classes and the parameter space of item parameters. This framework allows for distinguishing irrelevant attribute profiles. Second, based on the definition of the feasible domain, two modified EM algorithms are developed. In practice, it is recommended to perform exploratory analyses using Algorithm 2 before proceeding further, which can provide valuable insights and guidance to understand the data structure.
While this paper focuses on the DINA model, a natural extension would be the application of the entropy penalized method to other CDMs. Additionally, it is worth noting that this paper study involves situations with a maximum dimension of , which is relatively low. In high-dimensional cases of K, improving the power and performance of the entropy-penalized method is an interesting topic. A more challenging question is indicating how the specification of irrelevant latent classes may affect the classification accuracy and the estimation of the model. Those topics are left for future research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}