1. Introduction
The explosive growth of equipment maintenance data has not only changed the norm for the research and analysis of maintenance but has also brought new opportunities and challenges to the way in which maintenance is carried out [
1]. In the field of equipment maintenance, these two requirements place considerable workload and stress on the maintenance engineer. The first requires proper maintenance to optimize equipment performance during the safety period, while the second involves accurate repairs that speed up equipment restoration within a shorter time frame. In practice, this means that the maintainer must regularly verify the operation status of all parts of the device and carry out appropriate servicing to reduce the wear and tear of these components. In addition, the maintenance worker needs to be able to quickly determine the site of the fault and to repair it when the machine appears to be malfunctioning [
2]. Obviously, the traditional approach to equipment maintenance still relies heavily on the knowledge and experience of maintainers and specialists in related fields [
3,
4,
5], which requires them to repeatedly study, memorize and consult a great quantity of maintenance procedures and to repair manuals in a textual form [
6,
7]. On the one hand, this is a rather inefficient approach, which not only makes it easy to have inappropriate care and to miss the inspection of certain parts but also makes it difficult to share and transmit the experience of trouble-shooting [
8], which leads to poor accuracy and standardization of machine maintenance; on the other hand, a large amount of first-hand knowledge is yet to be managed and utilized effectively, which limits knowledge dissemination and is a waste of data resources. For this reason, there is an urgent demand for a set of strong interpretive Artificial Intelligence technologies to improve the knowledge management of machine maintenance.
As an emerging technology, a knowledge graph (KG) delivers a new scheme to handle equipment maintenance data. The key technologies for building knowledge graphs are Named Entity Recognition (NER) and Relationship Extraction (RE). These technical approaches can be divided into two main categories: pipeline models and joint models. Traditionally, the pipeline approach treats named entity recognition and relationship extraction as a two-step process, first performing the entity recognition and then extracting relationships on the recognized entities. NER aims to identify and classify entities with specific meaning from text, such as the names of people, places, organizations, etc. Rules and manual feature engineering approaches have been the mainstay of early NER research. However, these methods rely on manually defined rules and features, require customization for different languages and domains and are difficult to adapt to large data sets and complex language structures. With the emergence of deep learning, neural network-based approaches are beginning to make significant progress in NER tasks. Among them, Recurrent Neural Network (RNN)-based models, such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), are widely used in NER tasks. These models are able to capture contextual information and to achieve entity recognition by learning feature representations. In addition, with the development of pre-trained language models (PLMs) such as BERT, GPT, etc., the NER task has been further improved. These models can be fine-tuned for downstream NER tasks by being pre-trained on large corpora and by learning rich language representations. RE is concerned with extracting relationships between entities from text. Traditional methods of relation extraction are mainly based on manually designed rules and pattern matching, where relationships are extracted by means of keyword matching, grammar patterns and other means. These methods have the advantage of being highly interpretable, but they require a significant amount of manual work and domain knowledge, and they have difficulty in adapting to complex language structures and diverse types of text. With the growth of machine-learning techniques, machine-learning-based relationship extraction methods have gradually emerged.
However, while the above-mentioned pipeline approach is simple and intuitive, it is susceptible to the propagation of errors and to false matches. To address the problems with the pipeline approach, researchers have proposed the use of joint models. These models treat entity recognition and relation extraction as a unified task and enhance the overall performance through joint optimization. Early methods of entity and relation extraction have relied mainly on rules and pattern matching. These methods depend on manually created rules and patterns, which limit their applicability and ability to be generalized. With the advent of machine learning, researchers have begun to explore the use of machine-learning algorithms to solve the entity relation extraction problem. The first methods used feature-based classifiers, such as Support Vector Machines (SVM) and Maximum Entropy models. These processes extract features from text and train classifiers to predict entity and relationships. In recent years, the rise of deep learning has brought new breakthroughs in knowledge extraction. Researchers started to use neural network models to learn text representations and to perform relation classifications. They achieved high performance by learning feature representations and relation classifiers through end-to-end training. To enhance the performance, researchers started to optimize the objective functions of entity recognition and relation classification together, allowing the two sub-tasks to reinforce each other and improve overall performance. Joint training, shared representation and sequence annotation are common approaches to joint modelling. In addition, researchers have gradually introduced attention mechanisms to extract key information and the use of pre-trained language models to enhance representation learning.
Additionally, there is a significant amount of redundancy in the extracted entities and relationships. Redundant knowledge takes up a lot of storage space, which can lead to repetition in the computational process and thus reduce efficiency. Additionally, it can produce incorrect and ambiguous knowledge, which significantly affects the quality of the knowledge graph. Therefore, it is necessary to eliminate redundant knowledge before the construction of the knowledge graph. Common techniques include manual review, entity disambiguation and relationship merging. However, manual review is a labor-intensive and time-consuming task. Entity disambiguation and relationship merging methods are widespread. Therefore, methods for resolving entity ambiguity and merging relationships are commonly employed. These can apply predefined rules and heuristic methods to determine whether entities represent the same concept. Alternatively, they can perform similarity-based entity and relationship fusion by calculating the similarity between entities and merging ones with similarity above a threshold.
KGs have the ability to organize and store large amounts of knowledge and can be divided into two categories: general KGs and domain KGs [
9], of which general KGs are not limited to specific domains and cover a very wide range of knowledge, while domain-specific KGs are for specific domains such as finance, e-commerce or healthcare [
2]. In comparison with general knowledge graphs, domain-specific knowledge graphs can be highly accurate due to their in-depth research and specialized knowledge, as they can capture the details and complexities of specific domains, which can provide more precise results. Consequently, domain-specific knowledge graphs require a larger and more rapidly expanding source of knowledge. Given the diversity of personnel in the industry, with different roles and corresponding operational and business scenarios, domain knowledge graphs need to have a certain level of depth and completeness. Also, they require higher quality standards for knowledge as they are used to support various complex analysis and decision support applications. Moreover, domain knowledge graphs can be presented to users through visualization tools, allowing them to understand and explore domain knowledge more intuitively. They can be used in various scenarios such as knowledge management, intelligent search and recommendation systems.
Currently, there are several challenges in applying KGs in the field of equipment maintenance: on the one hand, equipment maintenance data is large in quantity, knowledge-intensive and involves a series of decision-making activities, most of which are highly dependent on expert knowledge and equipment resources accumulated over a long period of time from working on related projects [
1]. This, in turn, results in the diversity of formats and heterogeneity of the relevant knowledge, making it difficult to share and reuse it effectively. As a result, traditional KGs often have to be constructed manually, which is time-consuming and laborious, and this can hardly meet the requirements of an automated KG. On the other hand, the knowledge redundancy problem occurs during automated KG construction, which reduces the KG quality and affects subsequent system [
10] development and applications.
Consequently, to address the above issues, the focus of this thesis is to develop a framework for a knowledge graph-based device maintenance system that supports automated construction and the associated design activities. The main contributions of this research can be summarized as follows:
A maintenance domain-specific word embedding system is trained and a joint extraction model based on BERT-Bi-LSTM-CRF is used to extract entities and relationships.
A knowledge ontology is designed by exploiting maintenance manuals and analysis reports with predefined relationships and tags to address the problem of ambiguous entity boundaries within this domain.
An advanced edit distance algorithm has been introduced, which employs Word2vec and a combination of IDF and Cosine for semantic similarity calculations.
A maintenance system based on a KG using a Browser/Server (B/S) architecture has been developed for equipment maintenance.
The structure of this paper is as follows:
Section 2 reviews the relevant work on automatic construction techniques for domain KGs.
Section 3 introduces the method of entity and relation joint extraction in the process of constructing domain KGs in Chinese, focusing on the elimination of redundancy in the KG by improving the similarity judgment through the edit distance in the knowledge fusion.
Section 4 provides the validation of the application and the extraction effectiveness of the domain KG by developing a prototype system.
Section 5 presents the conclusions.
3. Constructing a Knowledge Graph for Equipment Maintenance
3.1. Knowledge Extraction Based on a Joint Model
The idea of this thesis is to design a knowledge ontology based on the characteristics of equipment maintenance knowledge in order to structure and organize complex domain knowledge and to support the construction of more reliable and accurate KGs in the future. Compared with English, the Chinese character set has a large number of characters and does not have clear delimiters. There is also a lack of explicit part-of-speech tags in Chinese vocabulary, and the boundaries of entities are often unclear. Therefore, in order to solve the problem of fuzzy entity boundaries in the field of equipment maintenance, this paper combines the ontology with predefined relationships and labels to better perform entity and relationship extraction on Chinese texts. Moreover, the choice of the joint model based on BERT-Bi-LSTM-CRF for knowledge extraction is due to the following reasons:
First, considering the high ambiguity and diversity of Chinese texts and the problem of understanding context semantics, we chose the BERT model tailored for Chinese. It has been pre-trained on a large Chinese corpus, making it adaptable to Chinese texts and able to capture the characteristics as well as the patterns of the Chinese language. In addition, BERT, which emphasizes the meaning of words in context as opposed to other models such as Word2vec and Glove, was chosen due to the ambiguity and diversity of natural language, and it has been trained on domain-specific word embedding for equipment maintenance knowledge, potentially improving the quality of subsequent extractions. Second, due to its bidirectional and synchronous nature, Bi-LSTM further emphasizes the importance of semantics. Finally, in the decoding part, CRF can improve the accuracy of label prediction by learning the rules of NER, in contrast to the traditional Soft-max method, which simply takes the predicted labels with the highest predictor scores.
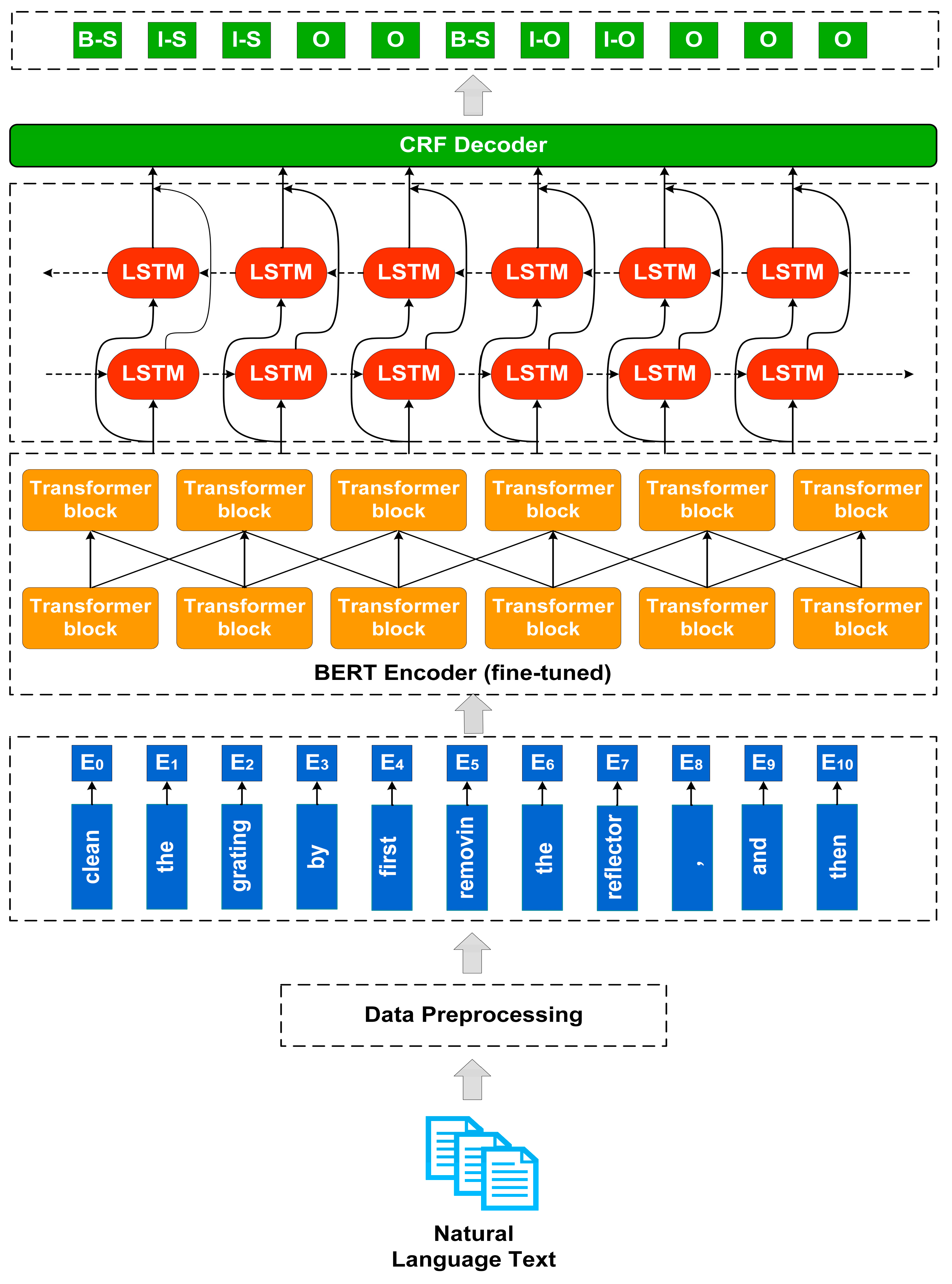
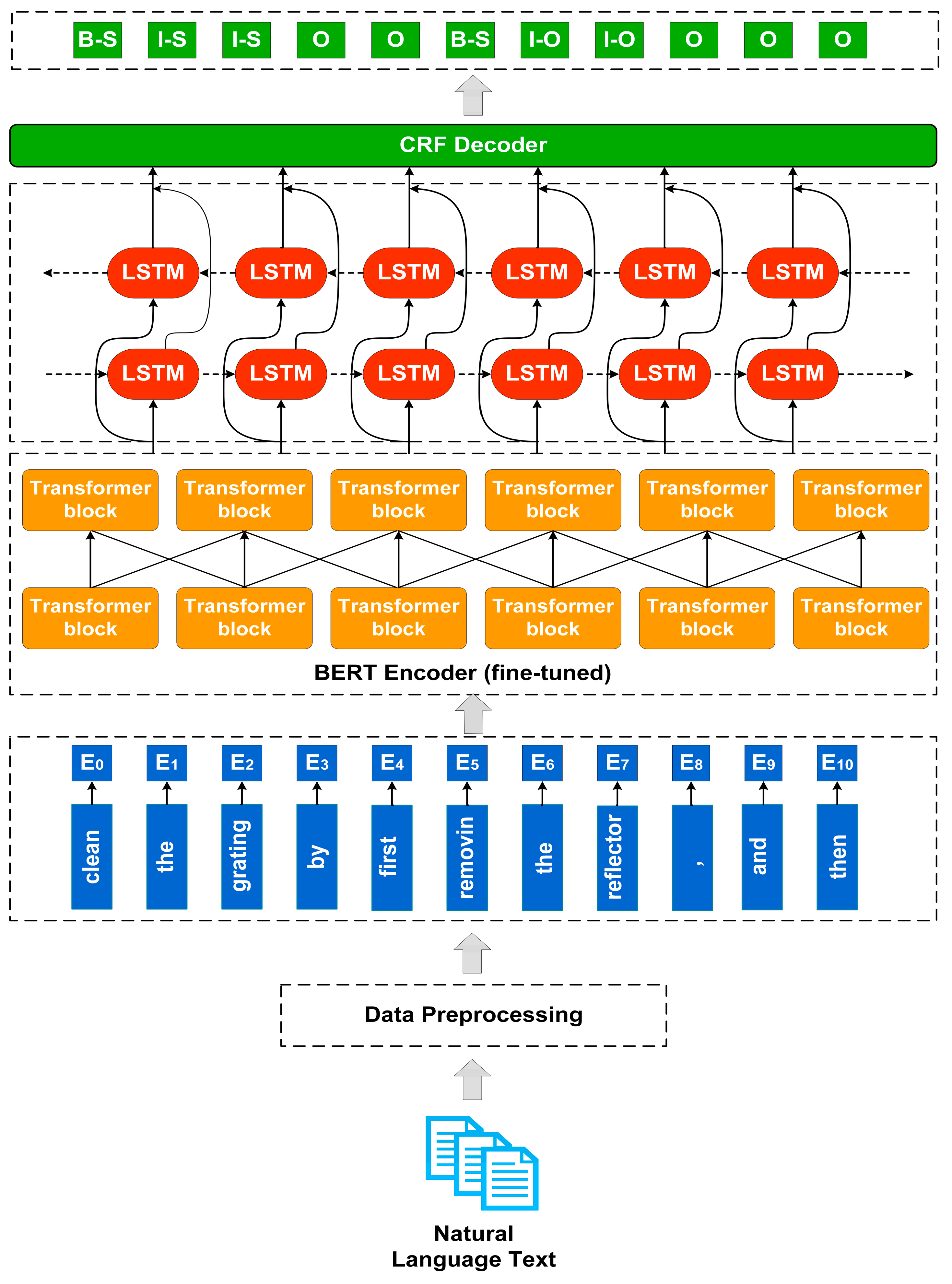
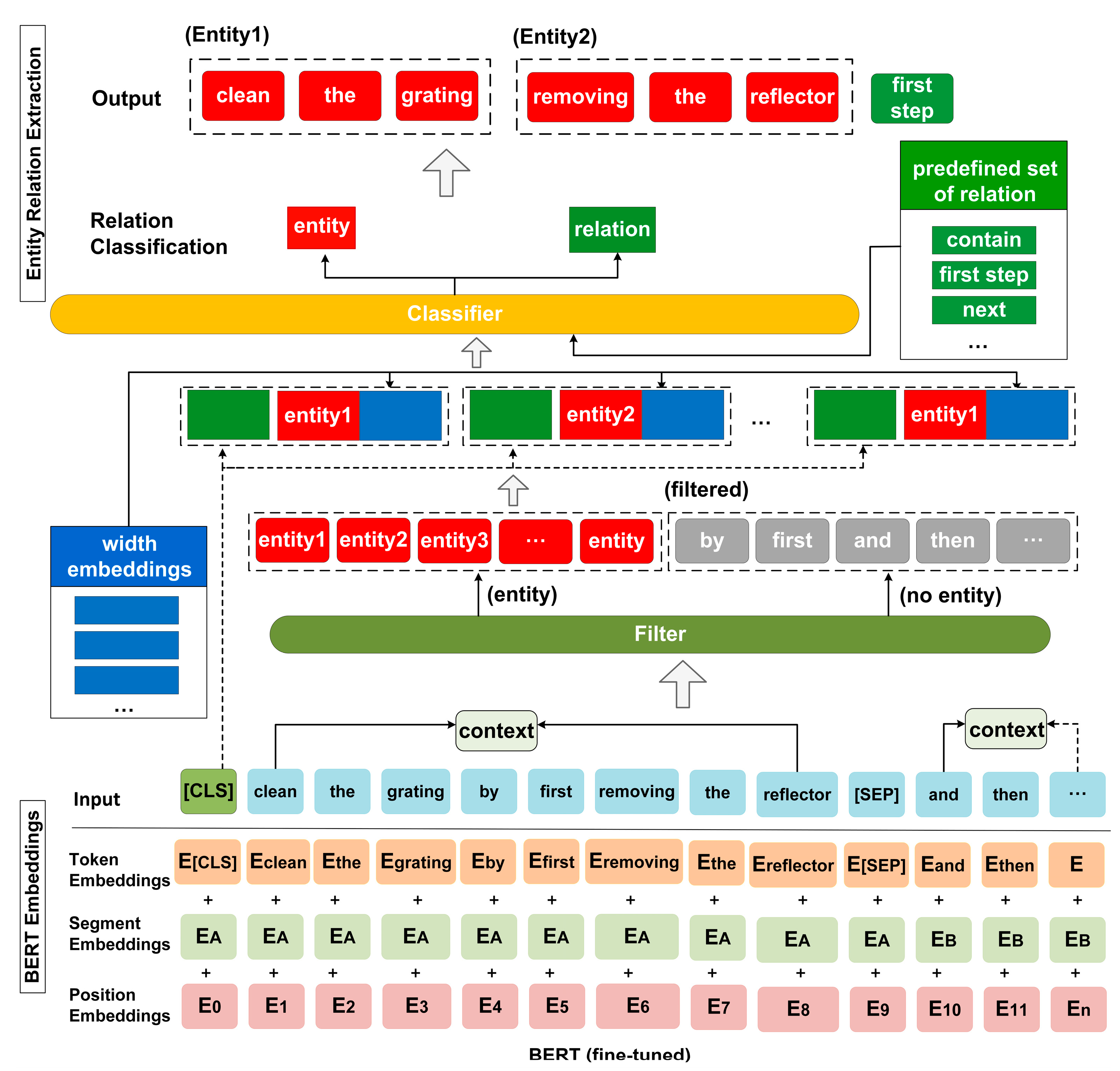
However, it was found that the pipelined method not only suffered from the cumulative propagation of mistakes, but it also ignored the connection between NER and RE characters and lost potentially valid information, severely affecting the extraction performance. Therefore, to solve the above problems, a joint multi-stage neural network model for knowledge extraction was implemented in the maintenance domain, with several stages of this architecture shown in
Figure 1.
3.1.1. Text Preprocessing Based on Ontology
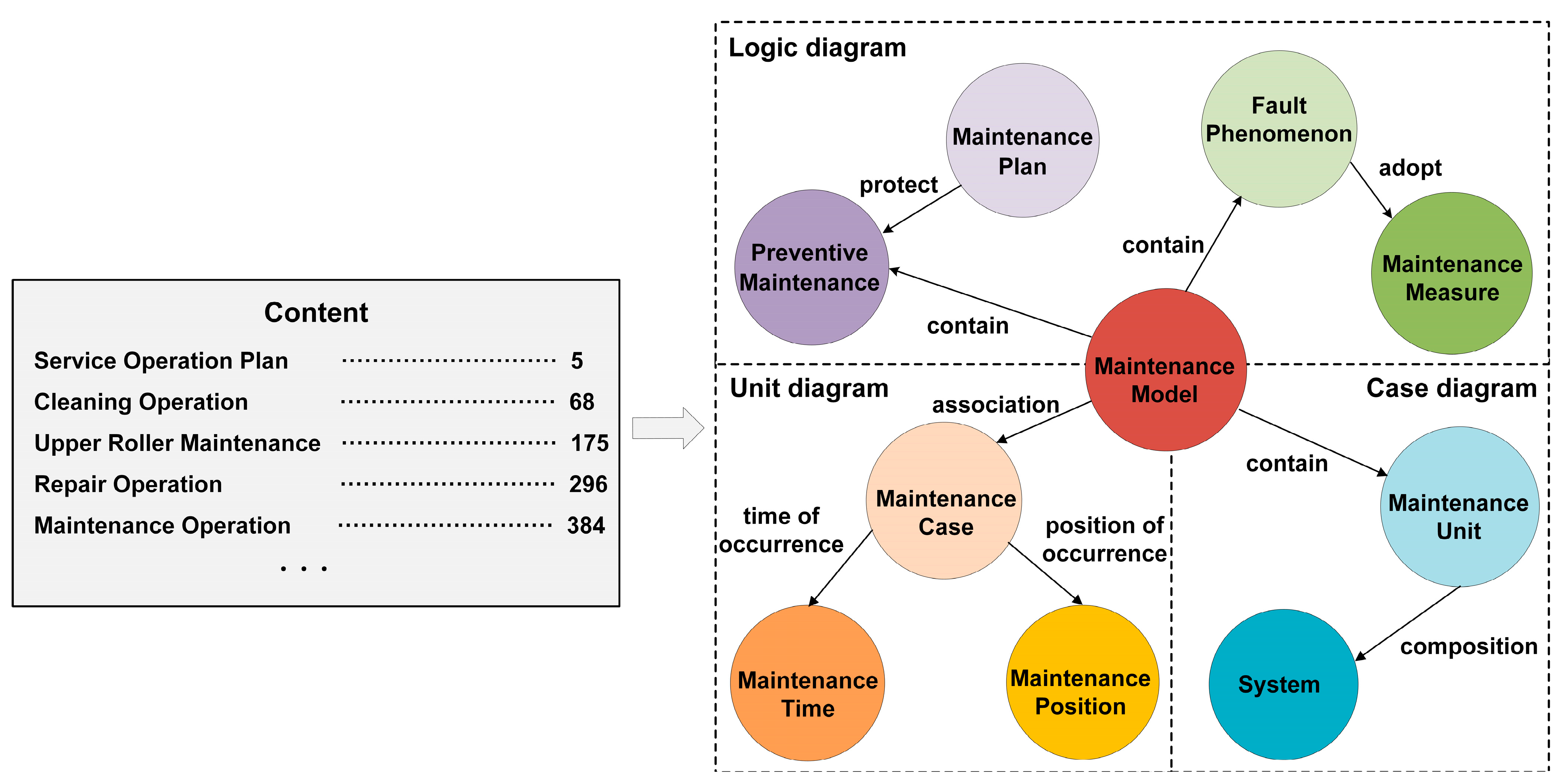
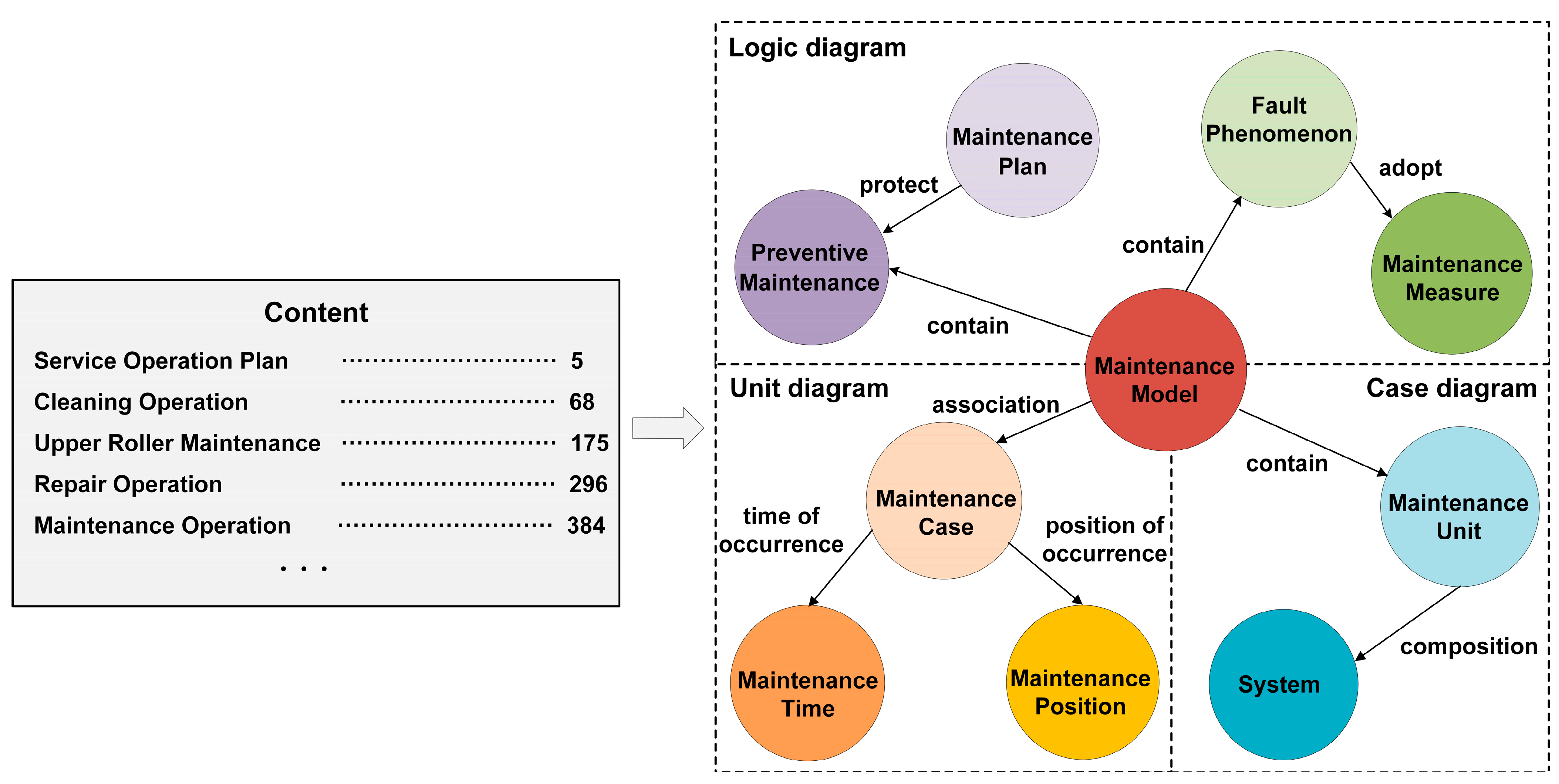
Ontology is a conceptualization related to a specific domain, which is an important foundation for building a reliable and sustainable KG that can improve data quality, reduce semantic ambiguity and provide clear and shareable characteristics. This paper focuses on the design of ontology for maintenance manuals and analysis reports in the maintenance domain, as these documents contain detailed information about the equipment and are rigorously reviewed to ensure accuracy. Moreover, the content is categorized, which helps to clarify the hierarchy of knowledge and promotes knowledge sharing. Therefore, based on the characteristics of the extracted text and through a combination of top-down and bottom-up approaches, we designed a basic model of maintenance knowledge ontology and optimized the model under the guidance of experts and maintenance personnel, as shown in
Figure 2. The natural text is complex and irregularly arranged in maintenance manuals and analysis reports. It is difficult to obtain knowledge extraction results satisfactorily if information extraction methods are used directly. Therefore, a set of relationship types was predefined based on ontology to assure its accuracy, which can solve the problem of blurred entity boundaries in Chinese, and the text was annotated according to the ontology on the Doccano platform in order to effectively identify and locate valuable knowledge. An example of partial annotation results is shown in
Table 1, which includes entities, entity attributes, relationships between entities, where “contains”, “first step” and “next step” are predefined relationships, and subject and object are entities.
3.1.2. The BERT Embedding Layer
After the text pre-processing described above, we divided the labeled dataset into a training dataset, a test dataset and an evaluation dataset (for evaluation of the best model). The model was initially refined by trying different segmentation ratios for debugging purposes, and after comparing their performance, we settled on a ratio of 8:1:1 for the three subsets. In summary, a maintenance corpus with a sufficient amount of data was obtained.
The BERT-based Chinese pre-training model was employed to generate contextually relevant word vectors, which processes text from two directions during training, thus solving the one-way problem of most current word vector generation models and enabling a better understanding of the context and meaning of the text. Moreover, we fine-tuned the BERT model and build a word vector representation layer specifically for the maintenance domain knowledge extraction problem to address the error accumulation and exposure bias problems associated with pipeline models.
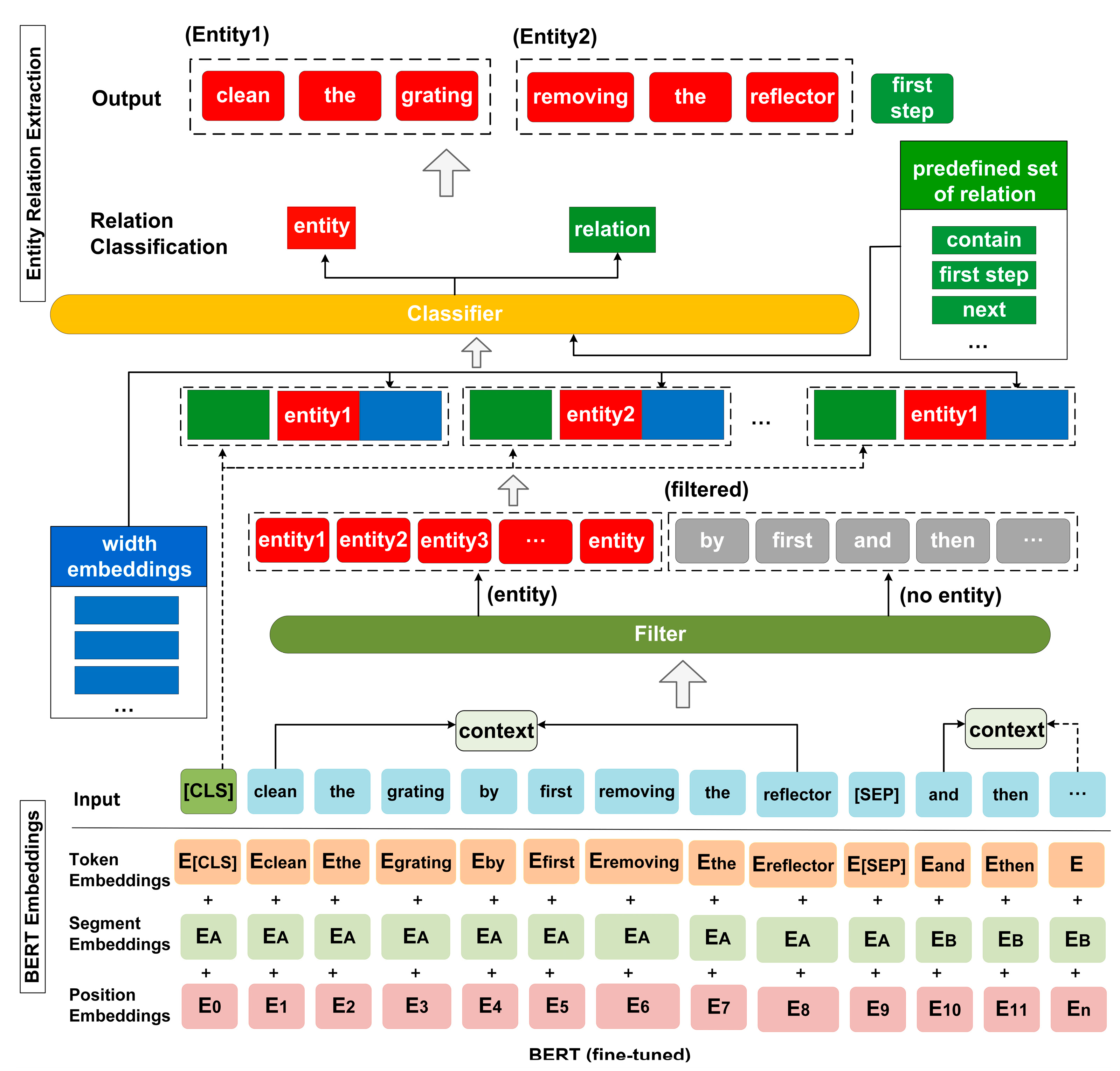
First of all, we split the input sequence by adding an identifier (CLS) at the beginning of the sequence and also by using the identifier (SEP) to separate two adjacent clauses. In this case, the output embedding of each word in the sequence consists of three parts: Token Embedding, Segment Embedding and Position Embedding. To jointly extract entities and relations, we added classifier tokens to classify entity and relation, where the relation types are obtained from a set of predefined relations. In addition, we added filters to clean out the non-entity types, as shown in
Figure 3. Thus, we obtained a sequence containing both entity labels and relationship labels, and then the sequence vector was fed into the bidirectional Transformer for feature extraction, which yields a sequence vector with rich semantic features. The Transformer is a deep network based on a “self-attentive mechanism”, which mainly adjusts the weight coefficient matrix to capture word characteristics by the degree of association between words in the same sentence:
where
,
and
are the word vector matrices and
is the embedding dimension.
means to transpose; specifically, transpose here means to adjust the elements of row
and column
of
to row
and column
, respectively. In contrast to the single-headed attention mechanism, the multi-headed attention mechanism involves the projection of
,
and
by several different linear transformations, so that the model can jointly obtain information from different spaces in different locations K, and finally the different results are stitched together as in formulas (2) and (3):
where
,
and
are the three trainable parameter matrices. The input matrix
is multiplied by
,
and
to produce
,
and
respectively, which is equivalent to a linear transformation. After obtaining each word vector in the sentence, the sequence of word vector outputs from the BERT layer is fed into the Bi-LSTM module for semantic encoding.
3.1.3. The Bi-LSTM Encoding Layer
For the problem of long-range dependency in knowledge extraction, this work employs Bi-LSTM to overcome the obstacle. The basic idea of Bi-LSTM is to take a forward LSTM and a backward LSTM for each sequence of words, and then to merge the results at the same time. In this way, both the forward and the backward information is available at any point in time. It not only solves the problem of exploding and disappearing gradients that occurs when training RNNs, but it also allows for the inability of the one-way LSTM model to process contextual information simultaneously. Assuming that the input sequence is denoted by
, the Bi-LSTM model consists of two separate LSTM layers: one for processing the forward input sequence and another for the backward sequence. The outputs from these two layers are then concatenated across time steps to generate the final output sequence
. The output of each Bi-LSTM layer can be represented by
where
and
denote the output of each hidden layer in the two opposite directions of LSTM,
is the number of words in the sentence. At this point, we obtain the complete sequence of hidden states, and then we derive the features of the sentence. Bi-LSTM suffers from not handling dependencies between adjacent labels yet. Therefore, the next step is to use a CRF layer for labels to compensate for these drawbacks.
3.1.4. The CRF Decoding Layer
CRF is a graphical model of joint probability distributions represented by an undirected graph, which can effectively constrain the interactions between prediction labels and model the label sequences. It calculates the probability distribution of the entire sequence and normalizes the local features to the global features to obtain a globally optimal prediction sequence. We assume that
is the output score matrix of Bi-LSTM, where
is of size
,
is the number of words,
is the number of labels, and
denotes the score of the corresponding label. We define the sequence of labels
and use it to score the input sequence
to get the score function as
where
is the transfer score matrix and
is the transfer score from label
to label
. CRF allows the calculation of the probability between label transformations to avoid an incorrect label order; for example, that the I-place will not be connected to the B-person, and the I-label will not be at the beginning of a name entity. All true label sets are also defined as
, and formula 6 is used to calculate the conditional probability of the CRF, where
denotes the
-th true label value in
. During training, the predicted sequence of the input sequence
is obtained by maximizing the log-likelihood function, then the sequence is decoded by using the Viterbi algorithm, and, finally, the sequence with the highest output prediction score is generated.
where
is the score of the optimal path.
3.2. Eliminating Redundancy Based on Knowledge Fusion
From the above procedure, it is not hard to see that knowledge extracted from unstructured equipment maintenance texts may contain a lot of duplicate or similar information. If stored directly in a database, redundant knowledge will increase the size of the KG, thereby reducing the efficiency of querying and increasing the load placed on the system. In addition, redundant knowledge can be a source of unnecessary confusion and misunderstanding, as well as reduce the accuracy of the knowledge graph. If an entity has several different descriptions, these descriptions may be in conflict with each other, with a consequent reduction in the quality of the KG. For instance, given two knowledge triples and in a knowledge graph with the same and similar entities , or , , respectively, as the number of knowledge extracted entities grows, the knowledge graph becomes increasingly redundant if similar knowledge triples are not removed. Indeed, in order to effectively fuse and unify this redundant knowledge, knowledge fusion is required when considering the knowledge quality of the KG database. In this paper, we improve the traditional edit distance calculation based on semantic similarity and combine the IDF with the cosine distance to determine the similarity score of entities to derive the final similarity score.
Calculation of Similarity Based on Improved Edit Distance
The traditional edit distance cannot determine the degree of similarity at the semantic level, which is particularly important for the semantics of domain KGs, as it can only determine the degree of match of string literal d by measuring the distance of the string. For this reason, we have introduced Word2vec [
34] for unsupervised learning in the traditional editing distance, in which word vectors are trained for specialized domains.
It is commonly desired that the core word match between two similar, but different, entities is correct in their entity similarity matching; in other words, that the core word plays a slightly larger role in the similarity calculation, and that the IDF will evaluate the importance of a word. Thus, the value can be used as a weight to engage in the calculation, using the formula for the computation of word
and the sentence vector as follows:
where
is the number of sentences in the corpus,
is the number of sentences in which the word occurs,
denotes the vector of
in the sentence and
is the value of the
-th word.
Cosine similarity is assessed by calculating the cosine of the angle between two vectors to assess their similarity. Usually, the more similar the semantics, the higher the cosine score. Assuming that
and
are two n-dimensional vectors calculated by the above formula, i.e.,
and
, the cosine formula is as follows:
where
represents the similarity of entities
and
.
4. Prototype System and Analysis
4.1. Prototype System
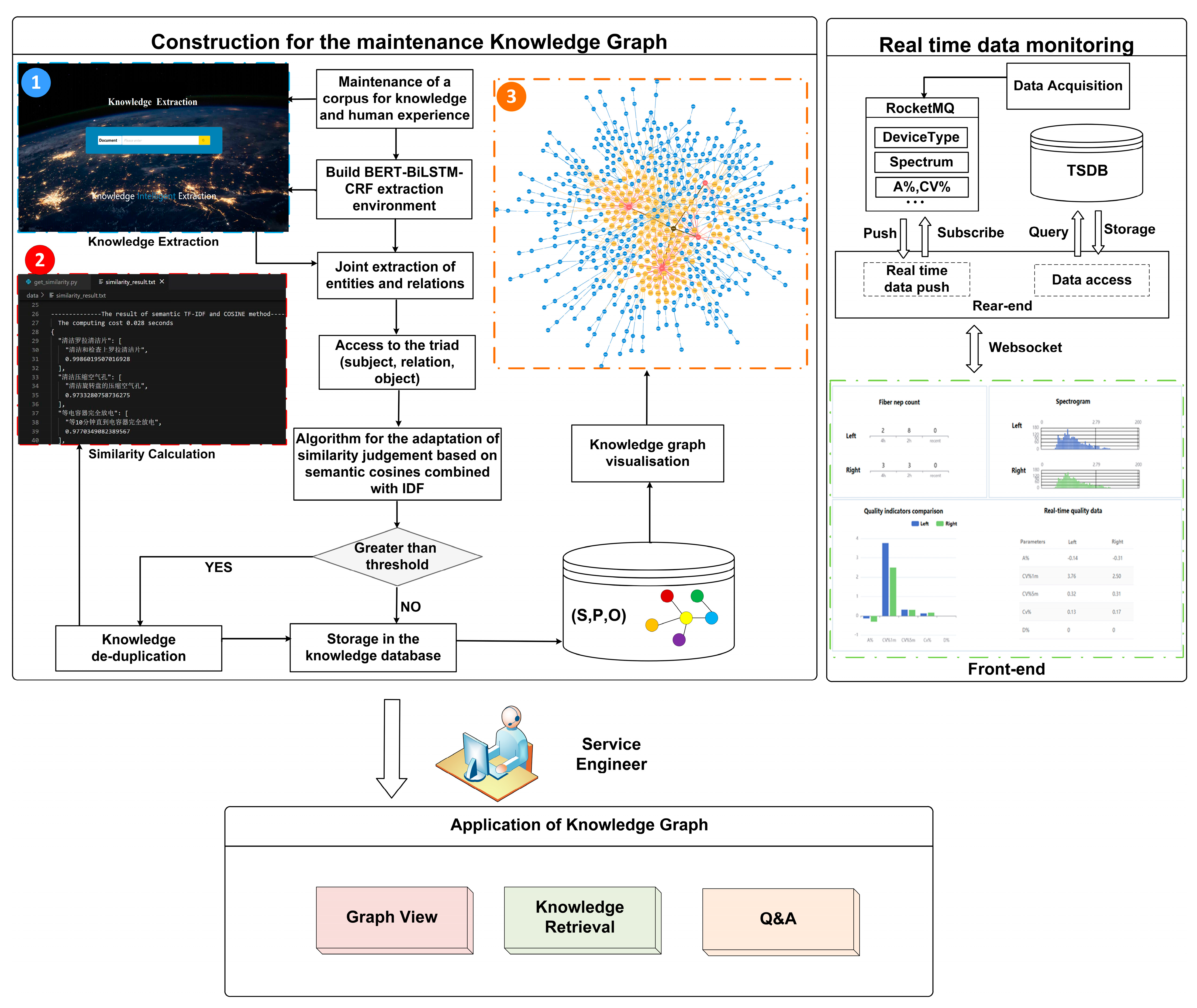
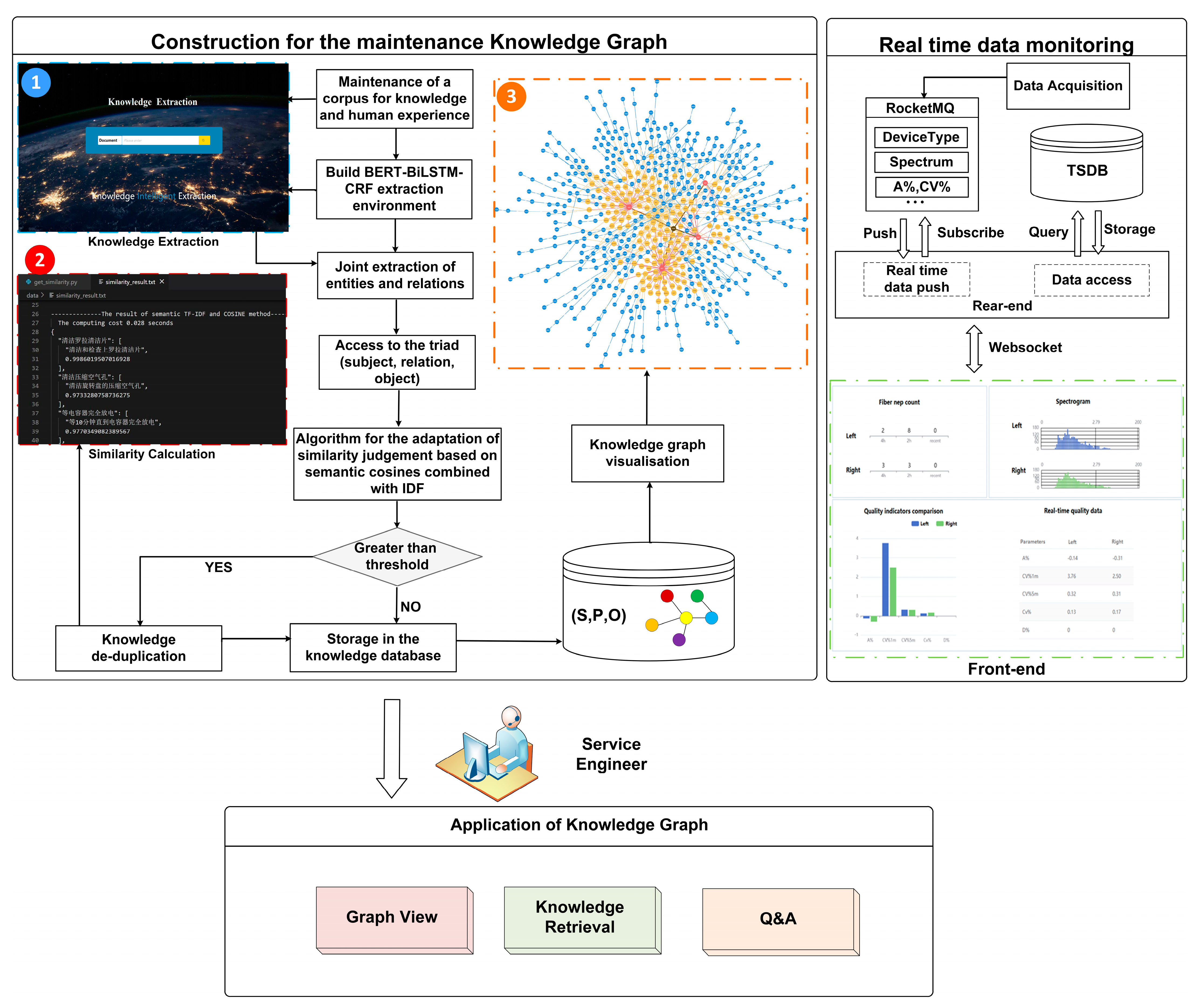
As a means of validating the efficiency of the approach proposed in this paper, we developed a prototype equipment maintenance system based on a KG, which was implemented by adopting a B/S design architecture with integrated Python and Neo4j, enabling easy extension to update the system. The system realizes knowledge extraction, visualization of extraction results, knowledge retrieval and knowledge question and answer. In addition, the system covers the process of data acquisition (real time equipment status data) and storage in a database to support the subsequent establishment of bidirectional data and knowledge-driven maintenance decision. The overall structure is shown in
Figure 4.
In this work, the equipment maintenance knowledge and data used in the construction of the system are mainly derived from textile machinery industry standard data, maintenance manuals, maintenance analysis reports and maintenance data accumulated by the research team over the years. According to the system of KGs built for equipment maintenance shown in
Figure 4, it is clear that the construction of the KG is mainly divided into two aspects. On the one hand, entities and relations are extracted from unstructured text and represented as triples in the environment of the joint model. On the other hand, redundancy reduction is performed in the knowledge fusion phase. The redundant knowledge from the previous extraction is effectively removed by introducing semantics into the traditional edit distance algorithm as well as by combining the IDF and Cosine to compute similarity, which is finally stored in the KG. Following the above steps, the quality of the KG can be upgraded, thus providing a foundation for reasoning about applying the graph in downstream tasks.
Naturally, experiments were carried out to evaluate the performance of the prototype system by investigating (1) the quality of the constructed KG of equipment maintenance and (2) the application of KG in the maintenance field.
4.2. Quality Analysis of Knowledge Extraction
In this paper, the joint model was used for knowledge extraction for Chinese text in the maintenance domain. To verify the efficiency of the proposed method, appropriate parameter adjustments were made in this aper according to the training of the joint model, and the learning rate was set
to better stabilize and control the training process of the model after multiple trainings. Moreover, the Adam optimizer was selected, which has better performance and convergence speed in the training of the neural network and is especially suitable for the training of such large data and complex models as Chinese text, helping to speed up the convergence and jump out of the local optimal solution. The detailed parameter settings are shown in
Table 2. Next, in this work, the Chinese corpus was divided into training, test and validation sets in the ratio of 8:1:1. Then, the joint model based on BERT-Bi-LSTM-CRF was trained on the same dataset with the pipeline model [
39], the CNN-Bi-LSTM-CRF model and the Bi-LSTM-CRF model with the elimination of the BERT module, and the experimental results are shown in
Table 3. From the experimental results, the Accuracy, Recall and F1 scores of the joint model are higher than those of the other three models, indicating that the joint model achieves better extraction performance for Chinese text in the domain of maintenance. The reasons are analyzed as follows:
The pipeline model has drawbacks, including a high dependency on the previous trained model, which can cause errors to accumulate, and it is hard to train end-to-end. Also, each component needs to be tuned and optimized separately, thus increasing the complexity. In this paper, the joint model based on the BERT Chinese pre-trained model was employed, as it is an end-to-end model that can be trained directly from raw text to label sequences. Compared with the pipeline model, it requires no manual construction and processing of intermediate results, which decreases the risk of error transmission. Meanwhile, end-to-end training can better exploit the overall capability of the model and increase its performance. This approach fully considers the influence of contextual information on entities, which is beneficial for extracting features from Chinese text. The BERT model used in this paper also includes a classifier for relations and entities as well as a filter for non-entities to improve the predictive ability of the model for entities and relations. Furthermore, to reduce the burden of manual analysis, improve the reliability and accuracy of knowledge extraction and to facilitate the automatic identification of specific types of entities and the extraction of predefined relationships, a set of relationships was predefined and integrated into the contextual representation, effectively avoiding the problem of entity boundary ambiguity in the domain of equipment maintenance. This information was used as input for Bi-LSTM to generate predictions, and the final entity and relationship information was obtained by extracting the globally optimal label sequence of the target sentence from the CRF layer.
On the other hand, for Chinese texts in the domain of equipment maintenance, the model employed in this paper outperforms the CNN-Bi-LSTM-CRF model. The reason is that the CNN model can only capture contextual information through local features and cannot fully understand the complexity of the Chinese language. Not only does the CNN module use fixed window sizes for convolutional kernels when processing text, which restricts its ability to flexibly learn representations of words of different lengths, it also has poorer ability to handle out-of-vocabulary words and spelling errors due to the use of static word vector representations. In contrast, the joint model used in this paper can carry out global context modeling on input sequences and utilizes character-level WordPiece embedding. Compared with the CNN-Bi-LSTM-CRF model, it has substantial benefits in terms of contextual understanding, word vector representation and feature extraction capabilities.
Compared with the Bi-LSTM-CRF model, the BERT module used in this paper can learn broader semantic word representations, thereby improving the performance in extraction tasks. BERT, based on the Transformer architecture, can consider the context information both before and after a word simultaneously, resulting in a better understanding of the relationships between entities. The ability to understand context allows the joint model to better capture the semantic and contextual information in sentences, thereby raising the accuracy of extraction. As can be seen from
Table 3, the joint model used in this paper achieves much higher accuracy in extraction than the Bi-LSTM-CRF model.
4.3. Assessment of the Entity Similarity Algorithm
In the process of building a knowledge graph, there are often many duplicate or similar pieces of information in the triple data obtained from knowledge extraction. If these redundant pieces of knowledge are stored directly in the database, they can cause unnecessary confusion and misunderstanding. Moreover, if an entity has several different descriptions, the knowledge graph may generate ambiguous or contradictory knowledge, which can greatly reduce its accuracy and trustworthiness. Therefore, using the triple data generated by the aforementioned knowledge extraction process as an example, this paper proposes the use of semantics combined with the IDF and Cosine to compute entity similarity.
According to the experimental results shown in
Table 4, it is clear that the method employed in this paper performs better than that of Jaccard and Cosine [
40] in determining the similarity between entities. For similar entities, the method proposed in this work gives higher values of similarity, while for confusing entities, this method is able to distinguish between them in a better way. The reason for this is that the method weights each word in the text, thereby converting different words into vector representations with similar semantics, thus avoiding errors in similarity calculations caused by different expressions and overcoming the problem of lexical diversity. In addition, this method also decreases the effect of differences in text length. Following several sets of extensive experimental data, the threshold
is set to 0.8 in this study. If the calculation is greater than
, the entity is considered redundant and must be de-duplicated. To demonstrate the importance and effectiveness of the algorithm, a statistical analysis was performed comparing the total number of nodes in the KG and the number of redundant nodes with and without the implementation of the three redundancy removal methods mentioned above. The results are presented in
Table 5. It is evident that the knowledge graph without any redundancy removal has the highest ratio of redundant nodes to the total nodes, indicating the highest degree of redundancy. This significantly reduces the quality and credibility of the knowledge graph, as well as increasing the storage space and query time, affecting the performance and response speed of the subsequent system. In comparison, the proposed algorithm shows the most substantial reduction in redundancy compared with the other two methods, which greatly improves the quality of the KG and increases the efficiency of storage and querying.
4.4. Case Study
In this article, an equipment maintenance system is set up to provide a detailed demonstration of the construction and application of the KG in the maintenance process, as shown in
Figure 4. In
Figure 4, ➀ represents the page used for knowledge extraction, where maintenance engineers can upload texts related to equipment maintenance, such as maintenance manuals, maintenance reports or textual descriptions of their practical experience. The uploaded texts are processed by the BERT-Bi-LSTM-CRF joint model to extract entities and relationships, which are then represented as triplets. Each triplet consists of a head entity, a tail entity and the relationship between them. At this stage, ambiguous or conflicting knowledge may be found in the extracted triplets due to high redundancy. Not only does this take up a large amount of storage space, but it also has a major impact on the quality and timeliness of the subsequent construction of the KG. Hence, to calculate the similarity between entities, the semantic-based Cosine similarity algorithm is used in combination with the IDF, which is shown in ➁. If the calculated similarity exceeds a predefined threshold, it is determined that these entities are redundant and need to be de-duplicated, i.e., only one entity is retained while the rest of the similar entities are discarded. This process eliminates the effects of redundant knowledge and enables the construction of a concise and accurate KG. Once the above steps have been completed, the de-duplicated triplets are stored in the database (➂). At this point, the equipment maintenance KG is constructed and can be accessed by the system to implement maintenance functionalities.
This paper takes the maintenance manual and maintenance report of the warping machine as an example. It contains operations such as top roller maintenance, overhaul, cleaning and repair. Entities and relationships are extracted using a joint model, and the similarity between entities is computed for de-duplication. The data is then stored in a graph database. Neo4j was chosen for this project because it can better represent the associations and attributes between entities. It also offers good flexibility and scalability, making it suitable for dealing with the characteristics of the constantly growing and changing textual data in equipment maintenance. In addition, Neo4j provides support for Atomicity, Consistency, Isolation and Durability (ACID) transactions. This means that Neo4j can ensure data integrity and consistency as data is modified, which is critical for a reliable and consistent asset maintenance system. The overall graph representation shown in
Figure 5a,b specifically lists the extracted entities and relationships (the objects extracted in this paper are Chinese texts, partially translated into English for a more intuitive understanding). It can be seen that each node represents an entity and that the relationships between nodes are from subject to object. For example, top roller maintenance and cleaning operations are two aspects of warping machine maintenance, while cleaning operations include more specific units such as cleaning, grating and cleaning the filter sieve. Each unit has specific operating procedures. Specifically, the original text “Cleaning grating requires first clean dust off the grating and then remove dust from reflector” is extracted by the joint model. “Cleaning grating”, “ Clean dust off grating” and “ Remove dust from reflector” are entities, while “first step” and “next step” are predefined relationships between different entities. It is obvious that the “first step” of “Cleaning grating” is “Clean dust off grating” and the “next step” of “Clean dust off grating” is “Remove dust from reflector”.
In summary, the construction of the KG for maintaining the warping machine is complete, and the system is ready for use. To provide a comfortable interactive experience for service engineers, the system offers a convenient knowledge search, avoiding the drawbacks of poor readability and the lack of flexibility in Cypher. Maintenance personnel can quickly find the information they need, improving work efficiency. The system also provides a basic knowledge question-and-answer function, allowing maintainers to ask questions about maintenance-related knowledge of the machine and providing guidance and support. There is a description of the system based on specific examples. In
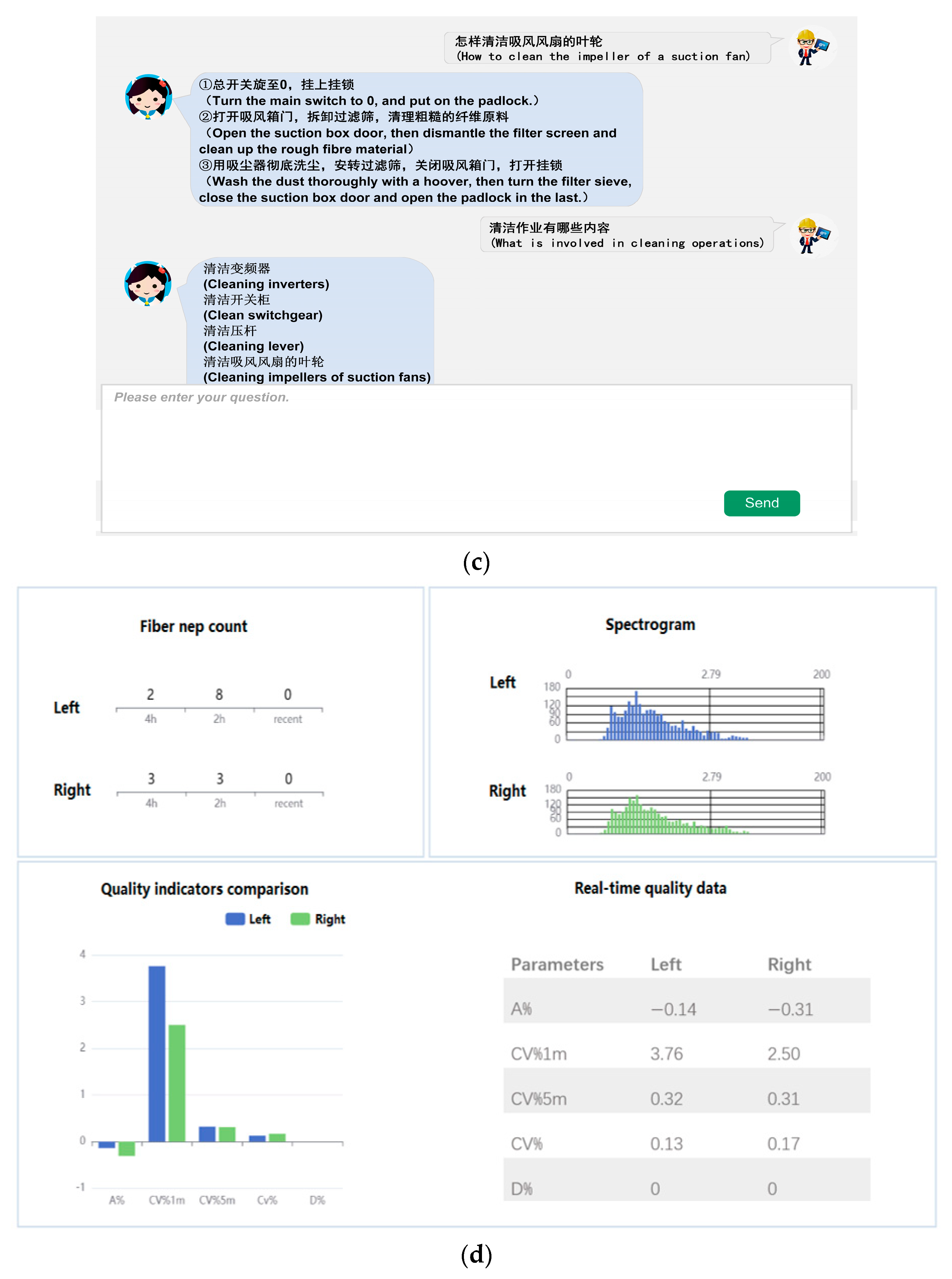
Figure 6a, the graph shows all the cleaning units involved in the cleaning operation, and the content of each unit is displayed in the “Detailed Information” panel, making it convenient for maintainers to view.
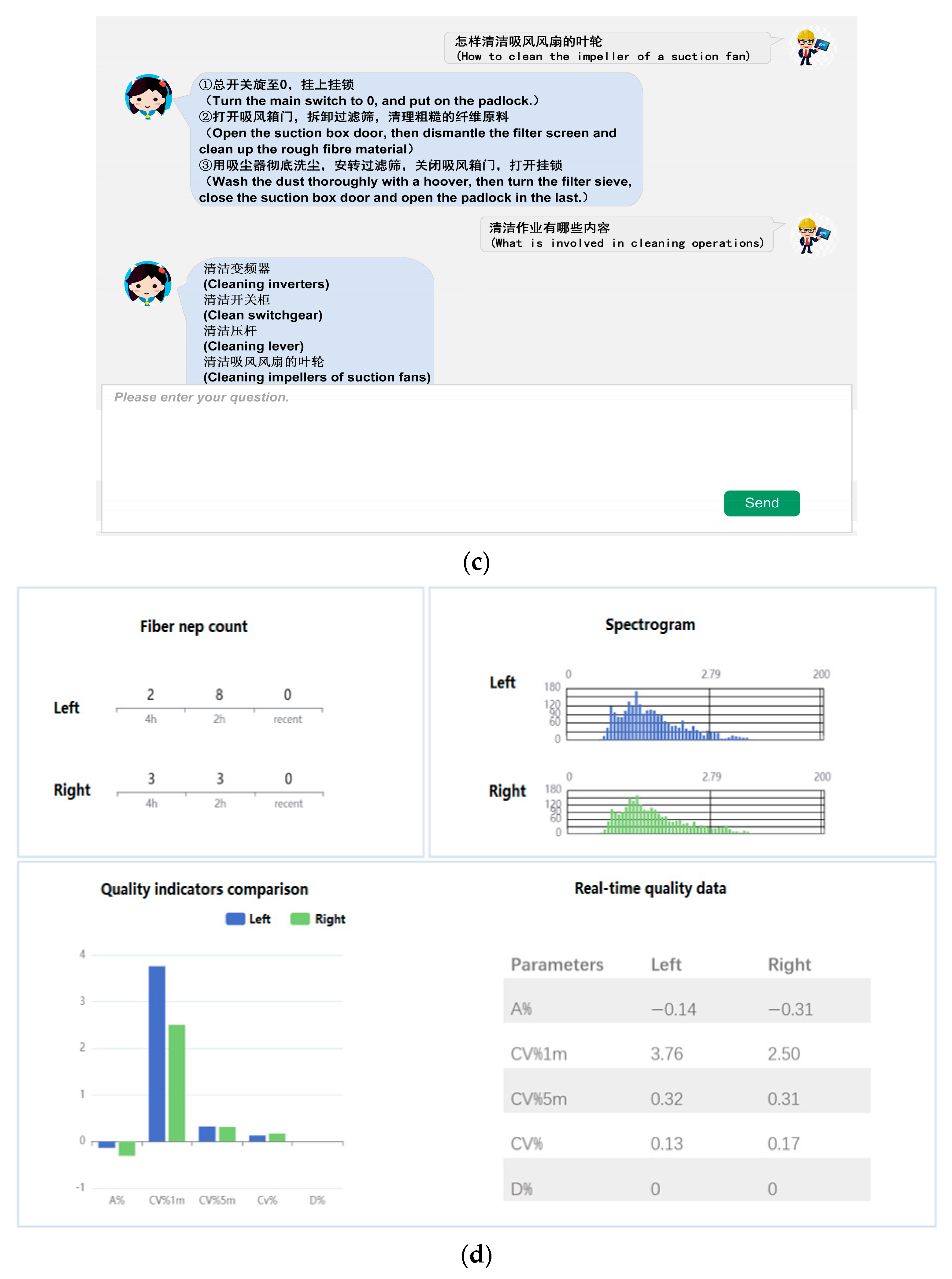
Figure 6b shows the graph of the cleaning of the exhaust fan, and the entities and relationships in the graph are transformed into natural language and displayed in the “Detailed Information” panel, making it easier to read. Here are the specific steps for cleaning the exhaust fan.
Figure 6c shows the question-and-answer page, where enquiries can be made about the entities and relationships in the KG, such as “What does “cleaning operation” involve?” and “How do you clean the exhaust fan?” Furthermore, the system has added an important real-time data monitoring function, which monitors key parameters such as CV, AV and spectrum. It provides real-time feedback on the warping machine’s operating status, providing reliable data collection for future bidirectional knowledge and data driving.
5. Conclusions
Current equipment maintenance methods rely heavily on the knowledge and experience of maintenance personnel and experts in related fields. They must repeatedly study, memorize and refer to a number of text-based maintenance manuals and analysis reports. Not only is this inefficient, but it also makes it difficult to share and transfer troubleshooting experience. Compared with the above discussed pipeline model based on BERT-Bi-LSTM-CRF, the CNN-Bi-LSTM-CRF model and the Bi-LSTM-CRF model without the BERT module, the joint model in this paper achieves the highest accuracy, recall and F1 scores. This indicates that the joint model performs well for Chinese texts in the maintenance domain and eliminates redundancy to build a high-quality KG, thereby improving knowledge management in equipment maintenance and greatly enhancing the sharing of equipment maintenance knowledge and the efficiency. Previous studies have often relied on expert interviews or manual methods to construct KGs, especially in the face of global events such as COVID-19, where traditional face-to-face activities may undergo significant changes.
Consequently, the focus of this paper was to develop an automatic framework for constructing a Chinese KG specifically for equipment maintenance. This framework effectively manages knowledge and provides a case to demonstrate how it can assist service engineers in equipment maintenance. In summary, the approach has the following advantages:
(1) Domain-specific word embedding is trained for the maintenance function, and a joint extraction model based on BERT-Bi-LSTM-CRF is used to extract entities and relationships. This architecture improves the performance of knowledge extraction by avoiding the accumulation of errors caused by pipeline models, which allows the capture and representation of knowledge in the maintenance domain. In addition, a knowledge ontology is designed based on maintenance manuals and analysis reports. Combining these with the ontology-added tags and predefined relationships to the knowledge, this solves the problem of ambiguous entity boundaries in this domain.
(2) An enhanced edit distance algorithm that introduces semantics and combines the IDF and Cosine is proposed to eliminate knowledge redundancy and promote the quality of the KG.
(3) A system adopts a B/S design architecture, which can be flexibly extended to update the system, and includes convenient knowledge retrieval, detailed information display, knowledge question and answer and real-time data monitoring functions to facilitate the interaction of maintenance engineers.
In future work, we will consider analyzing the real-time data collected and the signs from the equipment to establish links and to support decision making based on both knowledge and data.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}