Abstract
Sentiment analysis aims to systematically study affective states and subjective information in digital text through computational methods. Aspect Sentiment Triplet Extraction (ASTE), a subtask of sentiment analysis, aims to extract aspect term, sentiment and opinion term triplets from sentences. However, some ASTE’s extracted triplets are not self-contained, as they reflect the sentence’s sentiment toward the aspect term, not the sentiment between the aspect and opinion terms. These triplets are not only unhelpful to people, but can also be detrimental to downstream tasks. In this paper, we introduce a more nuanced task, Aspect–Sentiment–Opinion Triplet Extraction (ASOTE), which also extracts aspect term, sentiment and opinion term triplets. However, the sentiment in a triplet extracted with ASOTE is the sentiment of the aspect term and opinion term pair. We build four datasets for ASOTE. A Position-aware BERT-based Framework (PBF) is proposed to address ASOTE. PBF first extracts aspect terms from sentences. For each extracted aspect term, PBF generates an aspect term-specific sentence representation, considering the aspect term’s position. It then extracts associated opinion terms and predicts the sentiments of the aspect–opinion term pairs based on the representation. In the experiments on the four datasets, PBF has set a benchmark performance on the novel ASOTE task.
Keywords:
aspect–sentiment–opinion triplet extraction; aspect sentiment triplet extraction; aspect-based sentiment analysis MSC:
68T50
1. Introduction
Sentiment analysis, an important task in natural language understanding is to systematically study affective states and subjective information in digital text through computational methods [1,2]. This field has received much attention from both academia and industry due to its wide range of applications, such as the voice of the customer (VOC) in marketing [3] and gaining insights from social media posts [4]. General sentiment analysis determines if the emotional tone of a text is positive, negative or neutral. Aspect-based sentiment analysis (ABSA) [5,6,7,8] is a fine-grained sentiment analysis task and can provide more detailed information than general sentiment analysis. To solve the ABSA task, many subtasks have been proposed, such as Aspect Term Extraction (ATE), Aspect Term Sentiment Analysis (ATSA) and Target-oriented Opinion Words Extraction (TOWE) [9]. An aspect term (aspect for short) is a word or phrase that refers to an entity discussed in a sentence. An opinion term (opinion for short) is a word or phrase that expresses a subjective attitude. ATE extracts aspects from sentences. Given a sentence and an aspect in the sentence, ATSA and TOWE predict the sentiment and opinions associated with the aspect. These subtasks can work together to tell a complete story, i.e., the discussed aspect, the sentiment of the aspect and the cause of the sentiment. However, no previous ABSA study has tried to provide a complete solution in one shot. Peng et al. [10] proposed the Aspect Sentiment Triplet Extraction (ASTE) task, which attempted to provide a complete solution for ABSA. A triplet extracted from a sentence via ASTE contains an aspect, the sentiment that the sentence expresses toward the aspect and one opinion associated with the aspect. The example in Figure 1 shows the inputs and outputs of the tasks mentioned above.
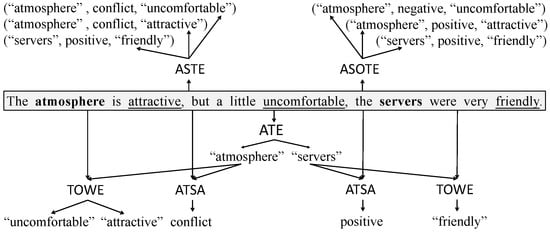
Figure 1.
An example showing the inputs and outputs of the tasks. For each arrow, when the head is a task name, the tail is an input of the task; when the tail is a task name, the head is an output of the task. The bold words are aspects. The underlined words are opinions.
However, the triplets extracted from a sentence with ASTE are not self-contained when the sentence has multiple opinions about the aspect and these opinions express different sentiments toward the aspect. This is because the sentiment in a triplet extracted with ASTE is the sentiment that the sentence expresses toward the aspect rather than the sentiment of the aspect and opinion pair. The third column in Figure 2 shows the extraction results of ASTE for the corresponding sentences. The triplets whose sentiments are marked in red are not only unhelpful to people, but can also be detrimental to downstream tasks such as opinion summarization (opinion summarization is generated by aggregating the extraction triplets. When extracted triplets are erroneous, the opinion summarization built based on these triplets will not be accurate) [6].

Figure 2.
Differences between ASOTE and ASTE. In the third sentence, the negative sentiment toward the aspect “Food” is expressed without an annotatable opinion. The triplets whose sentiments are marked in red are not only unhelpful to people, but can also be detrimental to downstream tasks.
In this paper, we introduce a more fine-grained Aspect–Sentiment–Opinion Triplet Extraction (ASOTE) task. ASOTE also extracts aspect, sentiment and opinion triplets. In the triplet extracted with ASOTE, the sentiment is the sentiment of the aspect and opinion pair. The fourth column in Figure 2 shows the extraction results of the ASOTE task for the corresponding sentences. In addition, we build four datasets for ASOTE based on several popular ABSA benchmarks.
Additionally, we propose a Position-aware BERT-based Framework (PBF) to address ASOTE. PBF first extracts aspects from sentences. For each extracted aspect, PBF then extracts associated opinions and predicts the sentiments of the aspect and opinion pairs. PBF obtains triplets by merging the results. Since a sentence may contain multiple aspects associated with different opinions, to extract the corresponding opinions of a given aspect, similar to previous models proposed for the TOWE task [9,11,12], PBF generates aspect-specific sentence representations. To accurately generate aspect-specific sentence representations, both the meaning and the position of the aspect are important. Some methods have been proposed to integrate the position information of aspects into non-BERT based models for some ABSA subtasks, such as refs. [13,14] for ATSA. However, how to integrate the position information of aspects into BERT [15]-based modes has not been studied well. PBF generates aspect-specific sentence representations considering both the meaning and the position of the aspect. We explore several methods which integrate the position information of aspects into PBF.
Our contributions are summarized as follows:
- We introduce a new aspect-based sentiment analysis subtask: Aspect–Sentiment–Opinion Triplet Extraction (ASOTE).
- We build four datasets for ASOTE and release the datasets for public use as a benchmark.
- We propose a Position-aware BERT-based Framework (PBF) to address ASOTE.
- In the experiments on the four datasets, PBF has set a benchmark performance on the novel ASOTE task.
2. Related Work
Aspect-based sentiment analysis (ABSA) [5,6,7,8] is a fine-grained sentiment analysis task. ABSA has many subtasks, such as Aspect Term Extraction (ATE), Opinion Term Extraction (OTE) (OTE extracts opinions from sentences), Aspect Term Sentiment Analysis (ATSA) and Target-oriented Opinion Words Extraction (TOWE) [9]. Many methods have been proposed for these subtasks. Most methods only solve one subtask, such as [16,17,18,19,20] for ATE, refs. [21,22,23,24,25,26,27,28,29,30] for ATSA and refs. [9,11,12,31] for TOWE. Some studies also attempted to solve two or three of these subtasks jointly. Refs. [32,33] jointly modeled ATE and ATSA, then generated aspect–sentiment pairs. Refs. [34,35,36] jointly modeled ATE and OTE, then output the aspect set and opinion set. The extracted aspects and opinions are not in pairs. Refs. [37,38] jointly modeled ATE and TOWE, then generated aspect–opinion pairs. Refs. [39,40] jointly modeled ATE, OTE and ATSA, then output the aspect–sentiment pairs and opinion set. However, the extracted aspects and opinions are also not in pairs; that is, the aspects, sentiments and opinions do not form triplets. The Aspect Sentiment Triplet Extraction (ASTE) task proposed by [10] extracts aspects, the sentiments of the aspects and opinions, which could form triplets. However, ASTE has the problem mentioned in Section 1.
Many methods have been proposed for ASTE [10,41,42,43,44,45,46,47]. Since most of these methods for ASTE do not utilize the fact that the sentiment of an ASTE triplet is the sentiment of the entire sentence toward the aspect term and may be from more than one opinion term and predict the sentiment of the aspect–opinion triplet as the triplet sentiment, these methods can be directly used for our proposed ASOTE task. For example, ref. [41] proposed an end-to-end model with a novel position-aware tagging scheme for ASTE. This model is capable of jointly extracting the triplets and can obtain better performance compared with previous pipeline approaches. However, this model has at most one triplet for an aspect term. The sentiment of a triplet is predicted only based on the extracted opinion term of the aspect term. Ref. [44] proposed a Grid Tagging Scheme (GTS) for ASTE. GTS first predicts the relationships between the words in a sentence, then decodes triplets from the relationships. The relationships includes the sentiment polarities. That is, the sentiment of an ASTE triplet is predicted based on the words in the aspect term and the opinion term and is the sentiment of the aspect–opinion pair. Different from these studies, we proposed a Position-aware BERT-based Framework (PBF) to address ASOTE.
3. Dataset Construction
Data Collection. We annotate four datasets (i.e., 14res, 14lap, 15res, 16res) for our proposed Aspect–Sentiment–Opinion Triplet Extraction (ASOTE) task. First, we construct four Aspect Sentiment Triplet Extraction (ASTE) datasets. Similar to previous studies [10,41], we obtain four ASTE datasets by aligning the four SemEval Challenge datasets [7,8] and the four Target-oriented Opinion Words Extraction (TOWE) datasets [9]. The four SemEval Challenge datasets are restaurant and laptop datasets from SemEval 2014 and restaurant datasets from SemEval 2015 and SemEval 2016. The four SemEval Challenge datasets provide the annotation of aspect terms and the corresponding sentiments and the four TOWE datasets were obtained by annotating the corresponding opinion terms for the annotated aspect terms in the four SemEval Challenge datasets. Compared with the ASTE datasets used in previous studies [10,41], the ASTE datasets we generate (1) keep the triplets with conflict sentiments and (2) keep all the sentences in the four SemEval Challenge datasets. That is, the sentences that do not contain triplets and therefore are not included in the ASTE datasets used in previous studies [10,41] are included in the ASTE datasets we generate. We believe datasets including these sentences can better evaluate the performance of ASOTE methods, since ASOTE methods can encounter this type of sentences in real-world scenarios.
Data Annotation. We invited a researcher who works in natural language processing (NLP) and an undergraduate student to annotate the sentiments of the aspect–opinion pairs in the triplets of the four ASTE datasets. The annotation tool we used is brat [48]. Each time, we only provided the annotators only with triplets of one aspect term. For each aspect term, not only the aspect term and its corresponding opinion terms but also the sentiment of the aspect term were provided to the annotators. Figure 3a shows an example of what we provided to the annotators and Figure 3b shows the results of annotation. When annotating the sentiment of an aspect–opinion pair, the annotators need to consider both the opinion itself and the context of the opinion. For example, given the sentence, “The decor is night tho…but they REALLY need to clean that vent in the ceiling…its quite un-appetizing and kills your effort to make this place look sleek and modern” (the triplets extracted with ASOTE from this sentence, i.e., (“place”, negative, “sleek”) and (“place”, negative, “modern”), are also not self-contained, since the sentiment shifter expression is complicated and therefore is not annotated as part of the opinions. One simple solution to this problem is to add a reversing word (e.g.,“not”) to this kind of opinion (e.g., “not sleek” and “not modern”) when we annotate opinions, which is left for future exploration) and one aspect–opinion pair, (“place”, “sleek”), the sentiment should be negative, even though the sentiment of “sleek” is positive. The kappa statistic [49] between the annotations of the two annotators is 0.85. The conflicts have been checked by another researcher who works in NLP.
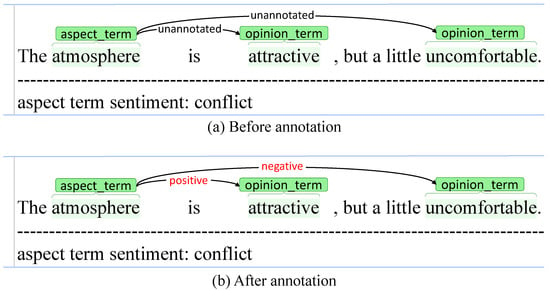
Figure 3.
An example of annotating the sentiments of the aspect and opinion pairs on the ASTE triplets for the ASOTE task. The annotated sentiments are marked in red.
Dataset Analysis. The statistics of the four ASOTE datasets are summarized in Table 1. Since #diff_s2 is always greater than 0, the annotators have to annotate the sentiments of the triplets in which the aspect only has one triplet and the sentiment of the aspect is not conflicting. That is, we cannot treat the sentiment of the aspect in these triplets as the sentiment of these triplets. For example, for the third sentence in Figure 2, the aspect “Food” has a negative sentiment, while the correct sentiment of its only one triplet, (“Food”, neutral, “average”), is neutral.

Table 1.
Statistics of our ASOTE datasets. #zero_t, #one_t and #m_t represent the number of aspects without triplet, with one triplet and with multiple triplets, respectively. #d_s1 represents the number of aspects that have multiple triplets with different sentiments. #d_s2 represents the number of aspects which only have one triplet and whose sentiments are not in conflict and are different from the sentiment of the corresponding triplet. #t_d represents the number of the triplets whose sentiments are different from the sentiments of the aspects in them.
4. Method
In this section, we describe our Position-aware BERT-based Framework (PBF) for Aspect–Sentiment–Opinion Triplet Extraction (ASOTE).
4.1. Task Definition
Given a sentence containing n words, ASOTE aims to extract a set of triplets , where a is an aspect, o is an opinion, s is the sentiment of the aspect–opinion pair and T is the number of triplets in the sentence. When a sentence does not contain triplets, .
4.2. PBF
Figure 4 shows the overview of PBF. PBF contains three models. Given a sentence , the Aspect Term Extraction (ATE) model first extracts a set of aspects . For each extracted aspect, , the Target-oriented Opinion Words Extraction (TOWE) model then extracts its opinions , where is the number of opinions with respect to the j-th aspect and . Finally, for each extracted aspect–opinion pair , the Aspect–Opinion Pair Sentiment Classification (AOPSC) model predicts its sentiment . PBF obtains the triplets by merging the results of the three models: . In PBF, all three models use BiLSTM [50] with BERT [15] as sentence encoder.
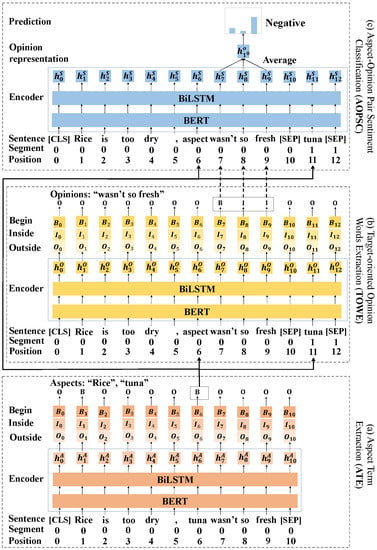
Figure 4.
Our proposed Position-aware BERT-based Framework (PBF). The parameters of the ATE, TOWE and AOPSC models are different.
4.3. Input
The input of PBF is a sentence consisting of n words.
Given the sentence, to obtain the inputs of the ATE model (Figure 4a), we first convert the sentence S to a new sentence, , where is “[CLS]” and is “[SEP]”. We then generate segment indices and position indices for the new sentence.
Since a sentence may contain multiple aspects associated with different opinions, to extract the associated opinions of a particular aspect, the TOWE model generates aspect-specific sentence representations for the aspect. It is intuitive that both the meaning and the position of the aspect are important for producing aspect-specific sentence representations. In other words, we need to tell the TOWE model what the aspect is and where the aspect is in the sentence. Given the sentence S and an aspect in the sentence, we first replace the words of the aspect with the word “aspect”, which tells the TOWE model where the aspect is in the sentence. We then append the words of the aspect to the end of the sentence, which tells the model what the aspect is. Finally, we obtain a new sentence . We also generate segment indices and position indices for the new sentence. The encoder of the TOWE model (Figure 4b) takes , and as inputs and can generate aspect-specific sentence representations.
To predict the sentiment of an aspect–opinion pair, the AOPSC model (Figure 4c) also generates aspect-specific sentence representations for the aspect. The inputs of the AOPSC model are the same as the TOWE model.
4.4. ATE
We formulate ATE as a sequence-labeling problem. The encoder takes , and as inputs and outputs the corresponding sentence representation, . The ATE model uses to predict the tag (B: Begin, I: Inside, O: Outside) of the word . It can be regarded as a three-class classification problem at each position of . We use a linear layer and a softmax layer to compute prediction probability :
where and are learnable parameters.
The cross-entropy loss of the ATE task can be defined as follows:
where denotes the ground truth label. is an indicator function. If , = 1; otherwise, = 0. We minimize to optimize the ATE model.
Finally, the ATE model decodes the tag sequence of the sentence and outputs a set of aspects .
4.5. TOWE
We aslo formulate TOWE as a sequence-labeling problem. The TOWE model has the same architecture as the ATE model, but they do not share the parameters. The TOWE model takes , and as inputs and outputs the opinions of the aspect .
4.6. AOPSC
Given an aspect and its opinions , the AOPSC model predicts the sentiments of all aspect–opinion pairs, , at once. The encoder of the AOPSC model takes the new sentence , the segment indices and the position indices as inputs and outputs the aspect-specific sentence representation, . We then obtain the representation of an opinion by averaging the hidden representations of the words in the opinion. The representation of opinion is used to make sentiment prediction of opinion :
where and are learnable parameters.
The loss of the AOPSC task is the sum of all opinions’ cross entropy of the aspect:
where denotes the ground truth label. We minimize to optimize the AOPSC model.
5. Experiments
5.1. Datasets and Metrics
We evaluate our method on two types of datasets:
TOWE-data [9] are used to compare our method with previous methods proposed for the Target-oriented Opinion Words Extraction (TOWE) task on the TOWE task. TOWE-data only include the sentences that contain pairs of aspect and opinion and the aspect associated with at least one opinion. Following previous works [9,11], we randomly select 20% of the training set as a development set for tuning hyper-parameters and early stopping.
ASOTE-data are the data we built for our Aspect–Sentiment–Opinion Triplet Extraction (ASOTE) task and are used to compare the methods on the ASOTE task. ASOTE-data can also be used to evaluate the TOWE models on the TOWE task. Compared with TOWE-data, ASOTE-data additionally include the sentences that do not contain aspect–opinion pairs and include the aspects without opinions. Since methods can encounter these kinds of examples in real-world scenarios, ASOTE-data are more appropriate for evaluating methods on the TOWE task.
We use precision (P), recall (R) and F1-score (F1) as the evaluation metrics. For the ASOTE task, an extracted triplet is regarded as correct only if the predicted aspect spans, sentiment, opinion spans and ground truth aspect spans, sentiment and opinion spans exactly match.
5.2. Our Methods
We provide the comparisons of several variants of our Position-aware BERT-based Framework (PBF). The difference between these variants is the way they generate the new sentence , the segment indices and the position indices .
PBF -w/o A does not append the words of the aspect to the end of the original sentence. In other words, this variant does not know what the aspect is.
PBF -w/o P does not replace the words of the aspect with the word “aspect”; namely, this variant does not know where the aspect is. This model has been used on some aspect-based sentiment analysis subtasks to generate aspect-specific sentence representations [26,51].
PBF -w/o AP neither appends the words of the aspect to the end of the original sentence, nor replaces the words of the aspect with the word “aspect”.
PBF-M1 does not replace the words of the aspect with the word “aspect”. To inform the model about the position of the aspect, the words of the aspect in the original sentence and the words of the aspect appended to the original sentence share the same position indices. This method has been used on relation classification [52].
PBF-M2 does not replace the words of the aspect with the word “aspect”. To inform the model about the position of the aspect, the position indices of the words of the aspect in the original sentence are marked as 0 and the position indices of other words are the relative distance to the aspect. This method has been utilized in the aspect-term sentiment analysis task [13].
PBF-M3 modifies the original sentence S by inserting the special token # at the beginning of the aspect and the special token $ at the end of the aspect. Special tokens were first used by [53] to incorporate target entity information into BERT for the relation classification task.
Figure 5 displays input examples for PBF-M1, PBF-M2 and PBF-M3.
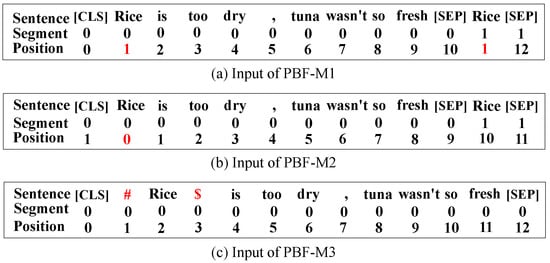
Figure 5.
The inputs of PBF-M1, PBF-M2 and PBF-M2, given the sentence “Rice is too dry, tuna was n’t so fresh” and the aspect “Rice”. The symbols marked in red indicate the positions of the aspect terms.
5.3. Implementation Details
We implement our models in PyTorch [54]. We use the uncased basic pre-trained BERT. The BERT is fine-tuned during training. The batch size is set to 32 for all models. All models are optimized with the Adam optimizer [55]. The learning rate is set to 0.00002. We apply a dropout of after the BERT and BiLSTM layers. We apply early stopping in training and the patience is 10. We run all models five times and report the average results on the test datasets. For the baseline models of the ASOTE task, we first convert our datasets into datasets that have the same format as the inputs of the baseline models, then run the code released by the authors on the converted datasets.
5.4. Exp-I: ASOTE
5.4.1. Comparison Methods
On the ASOTE task, we compare our methods with several methods proposed for the Aspect Sentiment Triplet Extraction (ASTE) task. These methods also extract aspect, sentiment, opinion triplets from sentences. These methods include MTL from Zhang et al. [45] (https://github.com/l294265421/OTE-MTL-ASOTE accessed on 1 January 2021), JET, JETo, JET and JET where from Xu et al. [41] (https://github.com/l294265421/Position-Aware-Tagging-for-ASOTE accessed on 1 January 2021), GTS-CNN, GTS-BiLSTM and GTS-BERT from Wu et al. [44] (https://github.com/l294265421/GTS-ASOTE accessed on 1 January 2021). All these baselines are joint models, which are jointly trained to extract the three elements of ASOTE triplets.
5.4.2. Results
The results of the ASOTE task are shown in Table 2. We have several observations from Table 2. First, MTL outperforms JET on all datasets, because JET can extract at most one triplet for an aspect. Although JETo can extract at most one triplet for an opinion, JETo outperforms JET on all datasets and surpasses MTL on 3 of 4 datasets, because there are fewer opinions belonging to multiple triplets than aspects belonging to multiple triplets. Second, GTS-CNN and GTS-BiLSTM outperform both JET and JETo on all datasets and GTS-BERT also achieves better performance than JET and JET. GTS-BERT is the best baseline model. Third, our proposed PBF surpasses GTS-BERT on all datasets. Since the Aspect Term Extraction (ATE) model and the Aspect–Opinion Pair Sentiment Classification (AOPSC) model in PBF are vanilla, compared with previous models, the advantages of PBF are from the TOWE model. However, GTS-BERT cannot be applied to the TOWE task directly, so we compare PBF with GTS-BERT on the aspect–Opinion Pair Extraction (OPE) [44] task. The results of OPE are shown in Table 3, which shows that PBF also outperforms GTS-BERT on all datasets. Fourth, PBF outperforms PBF -w/o P on all datasets, indicating that integrating position information of aspects can boost the model performance. Fifth, compared with PBF -w/o A, PBF obtains better performance on 14res and 16res, similar performance on 14lap and worse performance on 15res. Similar phenomenon can also be observed from the TOWE results in Table 4. This indicates that the meaning of the aspect is useful but the method used to combine the position information with the aspect meaning in PBF is not perfect. We leave the exploration of more effective combination methods for future work. Sixth, PBF outperforms PBF-M1 in 3 of 4 datasets (14res, 15res and 16res) and surpasses PBF-M2 on all datasets, which shows that our method of incorporating aspect position information is more effective. Although the method used by PBF-M2 to integrate the position information of aspects into it has been successfully applied to non-BERT based models, it is not effective enough for BERT-based models. Moreover, PBF-M1 is a little better than PBF on the 14lap dataset. This indicates it is necessary for PBF to explore more effective methods of incorporating aspect position information. Seventh, PBF outperforms PBF-M3, indicating our method is more effective than the method of integrating the position information and meaning of an aspect into a model by inserting special aspect markers for the aspect. The possible reason is that the additional special tokens may destroy the syntax knowledge learned by BERT. Last but not least, PBF -w/o AP obtains the worst performance among all variants, which further demonstrates that both the position and the meaning of an aspect are important.
Table 2.
Results of ASOTE task. The bold F1 scores are the best scores among PBF and the baselines. The underlined F1 scores are the best scores among PBF and its variants.
Table 3.
Results of the OPE task in terms of F1. The bold F1 scores are the best scores among PBF and the baseline.
Table 4.
Results of the TOWE task in terms of F1 on the ASOTE-data. The bold F1 scores are the best scores among PBF and the variants.
5.4.3. Case Study
To further understand the effect of the position and the meaning of an aspect, we perform a case study on two sentences, as displayed in Figure 6. In the first sentence, the bold “food” and underlined “food” are different aspects. The positions of the aspects help PBF and PBF -w/o A to extract different opinions for aspects with the same meaning. In the second sentence, with the help of the meaning of the aspect “crust”, PBF and PBF -w/o P do not extract “raw” and “cold” as the opinions of “crust”.
Figure 6.
Case study. Red triplets are incorrect predictions. The bold aspect term “food” and underlined aspect term “food” are different aspect terms.
5.5. Exp-II: TOWE
5.5.1. Comparison Methods
On the TOWE task, we compare our methods with (1) three non-BERT models: IOG [9], LOTN [11], ARGCN [31]; (2) two BERT-based models: ARGCN [31] and ONG [12].
5.5.2. Results
The results for ASOTE-data are shown in Table 4 and the results for TOWE-data are shown in Table 5. We draw the following conclusions from the results. First, PBF outperforms all baselines proposed for TOWE on the TOWE-data, indicating the effectiveness of our method. Second, PBF -w/o P also surpasses all baselines on the TOWE-data. To the best of our knowledge, no previous study evaluates the performance of this method on TOWE. Third, regarding PBF and its variants, we can obtain conclusions from Table 4 similar to the conclusions obtained from Table 2, because the differences in these models’ performance on ASOTE are mainly due to the differences in their performances on TOWE. Fourth, since the methods (i.e., PBF, PBF -w/o A, PBF -w/o P and PBF -w/o AP) obtain better performance on TOWE-data than on ASOTE-data, the ASOTE-data dataset is a more challenging dataset for TOWE. Fifth, on the 14res dataset, PBF does not surpasses its variants PBF -w/o A and PBF -w/o P, further indicating that it is necessary for PBF to explore more effective methods of combining the position information with the aspect meaning in the future.
Table 5.
Results of the TOWE task in terms of F1 on TOWE-data. The results of the baselines are from the original papers. The bold F1 scores are the best.
6. Conclusions
In this paper, we introduce the Aspect–Sentiment–Opinion Triplet Extraction (ASOTE) task. ASOTE is more fine-grained than Aspect Sentiment Triplet Extraction (ASTE). The sentiment of a triplet extracted with ASOTE is the sentiment of the aspect–opinion pair in the triplet. We manually annotate four datasets for ASOTE. Moreover, we propose a Position-aware BERT-based Framework (PBF) to address ASOTE. Although PBF is a pipeline method, it obtains better performance than several joint models, which demonstrates the effectiveness of our method.
Since Aspect Term Extraction (ATE) and Target-oriented Opinion Words Extraction (TOWE) are highly correlated with each other and TOWE and Aspect–Opinion Pair Sentiment Classification (AOPSC) are also highly correlated with each other, we can improve PBF by turning it into a joint model which jointly trains the ATE model, the TOWE model and the AOPSC model. However, it is not easy to jointly train the ATE model and the TOWE model, since we need to use the aspects that the ATE model extracts to modify the sentences that the TOWE model takes as input. In the future, we will explore how to jointly train the ATE model and the TOWE model.
Author Contributions
Conceptualization, Y.L., F.W. and S.-h.Z.; methodology, Y.L., F.W. and S.-h.Z.; software, Y.L. and F.W.; validation, Y.L., F.W. and S.-h.Z.; formal analysis, Y.L., F.W. and S.-h.Z.; investigation, Y.L., F.W. and S.-h.Z.; resources, Y.L., F.W. and S.-h.Z.; data curation, Y.L., F.W. and S.-h.Z.; writing—original draft preparation, Y.L., F.W. and S.-h.Z.; writing—review and editing, Y.L., F.W. and S.-h.Z.; visualization, Y.L., F.W. and S.-h.Z.; supervision, S.-h.Z.; project administration, S.-h.Z.; funding acquisition, S.-h.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Natural Science Foundation of Guangdong Province (2023A1515012685, 2023A1515011296), Open Research Fund from Guangdong Laboratory of Artificial Intelligence and Digital Economy (SZ) under Grant No. GMLKF-22-28, and National Natural Science Foundation of China (62002230).
Data Availability Statement
Data and code are available at https://github.com/l294265421/ASOTE.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Nasukawa, T.; Yi, J. Sentiment Analysis: Capturing Favorability Using Natural Language Processing. In Proceedings of the 2nd International Conference on Knowledge Capture, K-CAP ’03, Island, FL, USA, 23–25 October 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 70–77. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar]
- Griffin, A.; Hauser, J.R. The voice of the customer. Mark. Sci. 1993, 12, 1–27. [Google Scholar] [CrossRef]
- Barbieri, F.; Camacho-Collados, J.; Espinosa Anke, L.; Neves, L. Tweeteval: Unified Benchmark and Comparative Evaluation for Tweet Classification. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 1644–1650. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and Summarizing Customer Reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’04, Seattle, WA, USA, 22–25 August 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 168–177. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. Semeval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (Semeval 2014), Dublin, Ireland, 23–24 August 2014; Association for Computational Linguistics: Dublin, Ireland, 2014; pp. 27–35. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. Semeval-2015 Task 12: Aspect Based Sentiment Analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (Semeval 2015), Denver, CO, USA, 4–5 June 2015; Association for Computational Linguistics: Denver, CO, USA, 2015; pp. 486–495. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. Semeval-2016 Task 5: Aspect Based Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (Semeval-2016), San Diego, CA, USA, 16–17 June 2016; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 19–30. [Google Scholar] [CrossRef]
- Fan, Z.; Wu, Z.; Dai, X.; Huang, S.; Chen, J. Target-oriented opinion words extraction with target-fused neural sequence labeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MO, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MO, USA, 2019; pp. 2509–2518. [Google Scholar]
- Peng, H.; Xu, L.; Bing, L.; Huang, F.; Lu, W.; Si, L. Knowing What, How and Why: A Near Complete Solution for Aspect-based Sentiment Analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Wu, Z.; Zhao, F.; Dai, X.Y.; Huang, S.; Chen, J. Latent Opinions Transfer Network for Target-Oriented Opinion Words Extraction. arXiv 2020, arXiv:2001.01989. [Google Scholar] [CrossRef]
- Pouran Ben Veyseh, A.; Nouri, N.; Dernoncourt, F.; Dou, D.; Nguyen, T.H. Introducing Syntactic Structures into Target Opinion Word Extraction with Deep Learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 8947–8956. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, L.; Hou, Y.; Song, Y. A Position-aware Bidirectional Attention Network for Aspect-level Sentiment Analysis. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; Association for Computational Linguistics: Santa Fe, NM, USA, 2018; pp. 774–784. [Google Scholar]
- Li, L.; Liu, Y.; Zhou, A. Hierarchical Attention Based Position-Aware Network for Aspect-Level Sentiment Analysis. In Proceedings of the 22nd Conference on Computational Natural Language Learning, Brussels, Belgium, 31 October–1 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 181–189. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MO, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Yin, Y.; Wei, F.; Dong, L.; Xu, K.; Zhang, M.; Zhou, M. Unsupervised word and dependency path embeddings for aspect term extraction. arXiv 2016, arXiv:1605.07843. [Google Scholar]
- Li, X.; Bing, L.; Li, P.; Lam, W.; Yang, Z. Aspect term extraction with history attention and selective transformation. arXiv 2018, arXiv:1805.00760. [Google Scholar]
- Xu, H.; Liu, B.; Shu, L.; Philip, S.Y. Double Embeddings and CNN-based Sequence Labeling for Aspect Extraction. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 592–598. [Google Scholar]
- Wei, Z.; Hong, Y.; Zou, B.; Cheng, M.; Jianmin, Y. Don’t Eclipse Your Arts Due to Small Discrepancies: Boundary Repositioning with a Pointer Network for Aspect Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3678–3684. [Google Scholar]
- Li, K.; Chen, C.; Quan, X.; Ling, Q.; Song, Y. Conditional Augmentation for Aspect Term Extraction via Masked Sequence-to-Sequence Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7056–7066. [Google Scholar] [CrossRef]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive recursive neural network for target-dependent twitter sentiment classification. In Proceedings of the 52nd annual meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 23–25 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 49–54. [Google Scholar]
- Nguyen, T.H.; Shirai, K. PhraseRNN: Phrase Recursive Neural Network for Aspect-based Sentiment Analysis. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 2509–2514. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for Target-Dependent Sentiment Classification. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; Technical Papers. The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 3298–3307. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. arXiv 2017, arXiv:1709.00893. [Google Scholar]
- Xue, W.; Li, T. Aspect Based Sentiment Analysis with Gated Convolutional Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 2514–2523. [Google Scholar] [CrossRef]
- Jiang, Q.; Chen, L.; Xu, R.; Ao, X.; Yang, M. A Challenge Dataset and Effective Models for Aspect-Based Sentiment Analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 6280–6285. [Google Scholar] [CrossRef]
- Tang, H.; Ji, D.; Li, C.; Zhou, Q. Dependency Graph Enhanced Dual-transformer Structure for Aspect-based Sentiment Classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6578–6588. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. arXiv 2020, arXiv:2004.12362. [Google Scholar]
- Zhao, P.; Hou, L.; Wu, O. Modeling sentiment dependencies with graph convolutional networks for aspect-level sentiment classification. Knowl.-Based Syst. 2020, 193, 105443. [Google Scholar] [CrossRef]
- Dai, J.; Yan, H.; Sun, T.; Liu, P.; Qiu, X. Does syntax matter? A strong baseline for Aspect-based Sentiment Analysis with RoBERTa. arXiv 2021, arXiv:2104.04986. [Google Scholar]
- Jiang, J.; Wang, A.; Aizawa, A. Attention-based Relational Graph Convolutional Network for Target-Oriented Opinion Words Extraction. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 1986–1997. [Google Scholar]
- Li, X.; Bing, L.; Li, P.; Lam, W. A unified model for opinion target extraction and target sentiment prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6714–6721. [Google Scholar]
- Phan, M.H.; Ogunbona, P.O. Modelling Context and Syntactical Features for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3211–3220. [Google Scholar]
- Wang, W.; Pan, S.J.; Dahlmeier, D.; Xiao, X. Recursive neural conditional random fields for aspect-based sentiment analysis. arXiv 2016, arXiv:1603.06679. [Google Scholar]
- Wang, W.; Pan, S.J.; Dahlmeier, D.; Xiao, X. Coupled multi-layer attentions for co-extraction of aspect and opinion terms. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Dai, H.; Song, Y. Neural Aspect and Opinion Term Extraction with Mined Rules as Weak Supervision. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5268–5277. [Google Scholar]
- Zhao, H.; Huang, L.; Zhang, R.; Lu, Q.; Xue , H. SpanMlt: A Span-based Multi-Task Learning Framework for Pair-wise Aspect and Opinion Terms Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3239–3248. [Google Scholar]
- Chen, S.; Liu, J.; Wang, Y.; Zhang, W.; Chi, Z. Synchronous Double-channel Recurrent Network for Aspect–Opinion Pair Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6515–6524. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. An Interactive Multi-Task Learning Network for End-to-End Aspect-Based Sentiment Analysis. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 504–515. [Google Scholar]
- Chen, Z.; Qian, T. Relation-Aware Collaborative Learning for Unified Aspect-Based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3685–3694. [Google Scholar]
- Xu, L.; Li, H.; Lu, W.; Bing, L. Position-Aware Tagging for Aspect Sentiment Triplet Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 2339–2349. [Google Scholar] [CrossRef]
- Sutherland, A.; Bensch, S.; Hellström, T.; Magg, S.; Wermter, S. Tell Me Why You Feel That Way: Processing Compositional Dependency for Tree-LSTM Aspect Sentiment Triplet Extraction (TASTE). In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2020, Bratislava, Slovakia, 15–18 September 2020; Farkaš, I., Masulli, P., Wermter, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 660–671. [Google Scholar]
- Chen, P.; Chen, S.; Liu, J. Hierarchical Sequence Labeling Model for Aspect Sentiment Triplet Extraction. In Proceedings of the Natural Language Processing and Chinese Computing, Zhengzhou, China, 14–18 October 2020; Zhu, X., Zhang, M., Hong, Y., He, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 654–666. [Google Scholar]
- Wu, Z.; Ying, C.; Zhao, F.; Fan, Z.; Dai, X.; Xia, R. Grid Tagging Scheme for Aspect-oriented Fine-grained Opinion Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 2576–2585. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Q.; Song, D.; Wang, B. A Multi-task Learning Framework for Opinion Triplet Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 819–828. [Google Scholar] [CrossRef]
- Mao, Y.; Shen, Y.; Yu, C.; Cai, L. A Joint Training Dual-MRC Framework for Aspect Based Sentiment Analysis. arXiv 2021, arXiv:2101.00816. [Google Scholar] [CrossRef]
- Chen, S.; Wang, Y.; Liu, J.; Wang, Y. Bidirectional Machine Reading Comprehension for Aspect Sentiment Triplet Extraction. arXiv 2021, arXiv:2103.07665. [Google Scholar] [CrossRef]
- Stenetorp, P.; Pyysalo, S.; Topić, G.; Ohta, T.; Ananiadou, S.; Tsujii, J. brat: A Web-based Tool for NLP-Assisted Text Annotation. In Proceedings of the Demonstrations at the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012; Association for Computational Linguistics: Avignon, France, 2012; pp. 102–107. [Google Scholar]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.r.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar] [CrossRef]
- Li, Y.; Yin, C.; Zhong, S.h.; Pan, X. Multi-Instance Multi-Label Learning Networks for Aspect-Category Sentiment Analysis. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 3550–3560. [Google Scholar] [CrossRef]
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Joint Entity and Relation Extraction. arXiv 2020, arXiv:2010.12812. [Google Scholar]
- Wu, S.; He, Y. Enriching pre-trained language model with entity information for relation classification. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2361–2364. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 1 January 2021).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).