Abstract
This paper investigates the financial default model with stochastic intensity by incomplete data. On the strength of the process-designated point process, the likelihood function of the model in the parameter estimation can be decomposed into the factor likelihood term and event likelihood term. The event likelihood term can be successfully estimated by the filtered likelihood method, and the factor likelihood term can be calculated in a standardized manner. The empirical study reveals that, under the filtered likelihood method, the first model outperforms the other in terms of parameter estimation efficiency, convergence speed, and estimation accuracy, and has a better prediction effect on the default data in China’s financial market, which can also be extended to other countries, which is of great significance in the default risk control of financial institutions.
Keywords:
incomplete observable data; financial default markets; marked point process; self-exciting process; filtered likelihood method MSC:
91G30; 91G40; 91G80
1. Introduction
Generalized from stochastic processes, marked point processes have been widely applied in fields such as informatics, physics, and finance. A marked point process can be used to describe common bond defaults in financial markets [1], where the marker variable can be seen as the cumulative value of the default amount from zero to the corresponding moment [2]. Financial default models have been studied extensively by foreign academics. For example, Gordy et al. [3] developed the notion of rating-based bank capital risk and presented a single financial default model affected by visible systematic risk. Das et al. [4] and Duffie et al. [5] examined US financial default data from 1979 to 2004 and discovered that, in addition to observable systematic risk, all enterprises are vulnerable to unobservable systematic risk. Based on this, we present a model of the financial default with unobservable latent factors and an O-U process for studying the effect of latent variables on default intensity. Our study reveals that the model with latent variables is more accurate in depicting default events than the model with simply observable systematic risk. Azizpour et al. [6] also discovered that cluster contagion plays a crucial role in the dynamics of model parameters, and they put forward a financial default model that includes cluster contagion and latent variables. In this model, the latent variables are described by the conventional CIR model, and the cluster contagion is described by Hawkes’ standard self-excited process model [7]. The financial default model with the self-excited term outperforms the classic model when it comes to describing default events. Meanwhile, Chen et al. [8] applied the financial default model with the cluster contagion factor to give a derivation of the CDS pricing strategy based on this model, and proved that the financial default model with the cluster contagion factor also has better performance in the portrayal of default events in the supply chain system. Wang et al. [9] investigated how the non-financial sector affects the financial system, extended default clustering estimates to the non-financial sector using data on listed companies, and documented significant time-varying and cross-sectional changes in default clustering across different non-financial sectors in China. Finally, it was found that stock market volatility, fixed asset investment and credit-GDP gaps are key determinants of changes in time-series default clusters. Li et al. [10] proposed a simplified model for the embedded credit risk of corporate bonds. They specified the default risk rate as an affine function of a set of influencing variables and, in order to capture the clustering properties in certain extreme cases, employed a Hawkes jump-diffusion process to model these variables to derive a semi-analytical pricing formula for default bonds. Kai Xing et al. [11] found that macro indicators and NBER recession indicators are significant in explaining and predicting default clusters, even with a lag of 3 months.
The explanatory variables determining the default intensity in different financial default models are often different, and hence the estimation methods of the model parameters often differ from each other. On this premise, Ogata [12] proposed a point-process default model based on the experience of each state under complete data and proved the asymptotic property and convergence of its parameter estimation method on this basis. Fernando et al. [13] investigated the situation in which the model’s default intensity is based on the proportional risk equation with complete data. However, in the default model generated from incomplete observable data (partially observable or unobservable explanatory variables), the discrete information flow of partially observable variables and the path dependence of endogenous variables cause the filtering problem of discontinuous information flow due to the interaction of explanatory variables and point-process paths in the intensity parameters. Most researchers utilize interpolation to make the trajectories of some observable variables continuous in the filtering problem. For example, Lando [14] extended the COX model to give parameter estimates for a financial default model based on default intensity with latent variables under incomplete observable data. In previous studies, it was found that using the interpolation method to solve the likelihood function does not lead to a closed-form solution, and the properties of the resulting parameter estimation method are not well described. Thus, it is reasonable to attempt methods other than interpolation to solve the filtering equations controlling the maximum likelihood estimation. Elliott et al. [15] used a stochastic EM technique to solve the filtering equations and provide asymptotic estimates of the filtering control equations. Giesecke et al. [16] suggested a method for estimating the default intensity based on filtered likelihood estimation and obtained an analytical solution for parameter estimation. The filtered likelihood technique outperforms other methods for solving the filtered equations in terms of parameter estimation accuracy and asymptotic efficiency in numerical simulations. This method can be seen as a good answer to the default model’s parameter estimation problem with incomplete observable data.
Clusters of corporate defaults can have catastrophic economic effects, such as a sudden drop in consumption [17]. The default behavior is one of the most important indicators for credit rating review in the financial market. However, financial default modeling and estimation methods in China are still in their infancy, relying primarily on basic models and Monte Carlo simulation approaches. The filtered likelihood estimation approach is rarely employed in China since there is a lack of the effective creation of explanatory variables affecting financial default events. Studying financial default, particularly bond default, is critical both theoretically and practically for avoiding financial risk and establishing a stable financial environment. Based on incomplete observable data, a filtered likelihood estimation method is utilized in this research to estimate the parameters of the marked point process under the influence of self-excitation and jump-diffusion processes on the default intensity [18]. We also compare and analyze the parameter estimation and model-fitting effects of the two models, as well as investigating and analyzing China’s financial default problem and development trend, using financial default data from 2014 to 2020 [19], and find that our first model has better results in portraying the small sample data of the Chinese bond default market. Other references are also of great help to this paper [20,21,22,23,24].
2. Explanation of Related Concepts
2.1. The CIR Process
The O-U process is a stochastic process, also known as the Ornstein–Uhlenbeck process, which describes a stochastic process with a tendency to regress to the mean. Originally invented by Ornstein and Uhlenbeck in the 1930s, the O-U process is widely used in finance, physics, chemistry, biology, and other fields. The O-U process is usually described by the following differential equation:
where is the value of the stochastic process at time t, and , and represent the regression intensity, mean, standard deviation, and Wiener process, respectively. The Wiener process is a continuous, constantly changing stochastic process, which is the noise source of the O-U process and represents the stochastic fluctuations in the system.
In the O-U process, the random variable fluctuates up and down around the mean value , but when deviates from the mean, the regression force tends to pull it back to the mean. Thus, the O-U process has the property of regression to the mean, which makes it useful in describing random walks (i.e., random wanderings).
The O-U process and the CIR process are solutions of stochastic differential equations, and they both have the property of regression to the mean, which can be used to describe the evolution of stochastic processes, and therefore they both have a wide range of applications in the field of finance. In fact, the CIR process can be regarded as an extension of the O-U process, and there are certain connections and similarities between them. Specifically, the CIR process can be obtained by applying some transformations to the O-U process. Suppose we have a random variable that conforms to the O-U process, which can be expressed as
where is the regression intensity, is the mean, is the standard deviation, and is the Wiener process. We can transform it as follows:
Substituting the differential equation for into the above equation, we obtain
The simplification gives
This equation is very similar to the form of the equation for the CIR process, and by simply considering as the random variable of the CIR process, , , and , we can obtain the form of the equation for the CIR process as follows
Therefore, the CIR process can be regarded as an extension of the O-U process, an extended model based on the O-U process, which is widely used in finance for interest rate modeling, option pricing, etc.
2.2. The Cox Process
The Cox model is a statistical model for analyzing survival data, which was originally proposed by David Cox in 1972 and is widely used in survival analysis in medicine, public health, finance, etc. The Cox model is a semi-parametric model that can handle right-hand truncated survival data and does not require any assumptions about the time distribution. The ratio comparison analyzes the effect of a factor on survival time by comparing the risk ratio of two groups on that factor. The basic form of the Cox model is as follows:
where represents the risk function at time t given the covariates X, is the underlying risk function, and are the coefficients of the covariates . The core of the Cox model is the assumption that the risk function can be decomposed into an exponential function of the underlying risk function and covariates, which allows the Cox model to handle a variety of different risk factors and does not require any assumptions to be made about the underlying risk function.
2.3. The Hawkes Process
The Hawkes process (Hawkes process) is a stochastic process, which was proposed by Hawkes in 1971 to describe the stochastic process of a class of events occurring. The Hawkes process is often used to describe the occurrence and evolution of events, such as social networks, financial markets, and earthquakes. The Hawkes process has the property of self-excitation, that is, the occurrence of one event affects the occurrence probability of subsequent events.
The basic form of the Hawkes process is as follows:
where represents the intensity function at time t, is the underlying intensity function, is the event count in the time interval , and is the activation function that affects the probability of subsequent events. The central idea of the Hawkes process is that when an event occurs, it has an effect on the probability of occurrence of subsequent events, and this effect can be described by the activation function . The activation function represents the effect of an event occurring at time on an event after time t, and it is usually a non-negative function with respect to the time difference .
The model parameters of the Hawkes process can be estimated by the maximum likelihood estimation, which can be implemented using the Hawkes package in the R language. The model parameters of the Hawkes process include the underlying intensity function and the activation function , etc. By studying these parameters, the pattern of event occurrence can be obtained, and the occurrence of future events can be predicted.
In conclusion, the Hawkes process is a stochastic process used to describe the occurrence of events, which has the property of self-excitation and can be used to describe the occurrence and evolution of events such as social networks, financial markets, and earthquakes. The estimation and prediction of the Hawkes process model parameters can be achieved by the maximum likelihood estimation and analysis of the activation function.
3. Financial Default Marked Point Process Model
A complete probability space and a right continuous and complete filtration are fixed, and a marked point process is conducted. The is a strictly increasing sequence of positive stopping times that represent the arrival times of events. The is measurable mark variables that take values in a subset of the Euclidean space. The marked point processes provide information about the arrival of events. One of the random processes is also called the counting process used to calculate the number of event arrivals:
Because contains the same information as the stop-time sequence, it can act as a replacement for the stop-time sequence. has a right continuous time-dependent violation strength :
where is a function determined by the parameter , denotes a Markov process taking values in . The initial value of this process and the transfer probability are determined by the parameter . The conditional distribution function of the marker variable is determined by the parameter :
After the initial values and the corresponding state transfer probabilities are given, the intensity of the default event arrival and the process of the explanatory variable are dynamically changed. Here, and are interacting. In particular, can appear as a constituent element in , or and have the same jump or self-excited behavior. Specifically, the structure of the explanatory variable stochastic process can be set as , where X represents the observable explanatory variable and the path of X in can take values in , Y represents the partially observable explanatory variable and the path of Y in takes values in , and Z represents the unobservable latent variable and the path of Z in takes values in , which is shown in Equation (4). Order is the time of the first default:
Since the default intensity of financial default events arrival is influenced by macro- and micro-economic factors, observable systematic risk variables, and unobservable systematic risk variables, the structure of the default intensity is constructed as shown in Equation (4) in the setting of the default intensity:
4. Filter Likelihood Method
The filtered likelihood asymptotic method was proposed by Giesecke et al. [16]. On the one hand, it solves the problems of difficulty in describing the nature of the solution results and difficulty in controlling the convergence speed when the traditional interpolation method is used for parameter estimation of the violation intensity of the marked point process. On the other hand, it also solves the problems of path dependence and discontinuous information flow when the partially observable variable is calculated under incomplete data. The filtered likelihood method is superior in terms of parameter accuracy, parameter convergence speed and asymptotic efficiency. Therefore, the filtered likelihood method is used as the parameter estimation method for the financial default intensity model.
First let the parameters be estimated for the explanatory variables in the point process with default intensity as . The true unknown parameters , and denote the probability and expectation operators, respectively. Then, the likelihood function of the data under the parameter comes from the Radon–Nikodym derivative of the distribution. Under incomplete data, the likelihood function is a projection of , so we have
Set the random variable and the distribution function of the marker term. When in Equation (7) satisfies the condition, a new measure can be obtained. The counting process in the point process under the new measure obeys the standard Poisson distribution, and the distribution function of the marker term is also independent of [16]:
Therefore, when the parameters are estimated under incomplete data, can be calculated by splitting it into the product of the point process term and the explanatory variable term. See Theorem 1 and Equation (8):
In the calculation of Equation (8), a more standardized solution for the term is already available [8,14]. However, it is more difficult to calculate the direct solution for . Thus, the likelihood asymptotic is performed using the filtered likelihood method for the term in the following Equation (9):
According to Theorem 1, when , can be calculated. Therefore, we divide the state space by and the time interval by to obtain as its likelihood approximation. The specific result is shown in (10):
and in Equation (10) are given in a more complicated form ([14]) and are not given here. can be viewed as an approximation of based on the multidimensional rectangular orthogonal Leberg integral. In the calculation of , if the orbits (realizations) are multiplied, finding the parameter estimate that maximizes the probability of all states occurring is difficult to achieve. Therefore, the filtered likelihood algorithm is used to adjust the construction order of the likelihood function, and the transfer probability matrix is constructed from the transfer probabilities p of all states at each moment t. The term is solved by the dot product of the matrix and the multiplication of the matrix, and the local optimal solution of the log-likelihood function is finally solved by the simplex method.
First the vector is constructed, where is the component of , . Next, since the asymptotic essence of is the integral of all realization paths based on a sufficiently small time interval and the division of the state space. For each initial state of with a probability of that, the integral of the realization path term that should be obtained is shown in (11):
Therefore, the matrix calculation is used, and the specific calculation process is divided into two steps.
First, the explanatory variables transfer probability matrix is constructed as shown in (12). The integral of the realized path is calculated up to moment . Then is updated:
Next, the operation in Equation (13) is performed to construct the probability function matrix at moment and accordingly calculate the integral of the realized path at moment and update it for :
The final summation of the realized path integrals for all initial states yields an approximation for , which is shown in Equation (14).
After the algorithm is constructed, the state space and the time interval are divided into and intervals. Then, the unobservable explanatory variables and the partially observable explanatory variables are transformed into matrices (the expressions are available in the subsequent sections). The orbits (realizations) of the point process are combined and logarithmically manipulated, which are also combined with the log-likelihood function for the explanatory variables part of the processed incomplete data to derive the filtered likelihood asymptotic for the point process events and the stopping time part. The local optimal solution of the log-likelihood function is found via the downhill simplex method. The parameter estimates obtained by the filter likelihood method can be obtained.
5. Properties and Proofs of Filtered Likelihood Estimation
Since it is known that it is difficult to solve directly after the Radon–Nikodym transformation, the random variable and the distribution function of the marker term are set. The likelihood function can be calculated in two parts when the condition is satisfied. The sum of the two independently calculated parts, i.e., the event term and the factor term , which is positively correlated with the initial maximum likelihood function , i.e., the direction of the optimal solution parameters, is the same. The following theorem applies:
Theorem 1.
Assume that the following conditions hold:
(1) On parameter space Θ, is satisfied for all ;
(2) For all , given the event data under measure , the conditional likelihood function for the factor data exists and is strictly positive a.s., then the likelihood function is satisfied:
The above theorem gives a method for estimating the posterior probability and the posterior mean of the filtered likelihood based on incomplete data. The results of the parameter estimation of the filtered likelihood have the same optimization direction as the original maximum likelihood function, which is proved as follows.
Proof of Theorem 1.
From condition (1) and the definition of the measure , we have , so for any , the measure and the measure can be transformed as in (16):
According to the Radon–Nikodym theorem, the measure is absolutely continuous with respect to measure under the Radon–Nikodym derivative, so Equation (17) is established:
Then, according to the Bayesian formula, the measure of the data under is equal to the product of the measure of the event term under and the posterior conditional probability of the factor data under the given event term
Since the event term does not depend on the parameter under the measure , the counting process N is normalized. Also, the density function of the labeled term under the measure does not depend on parameters and , so Equation (19) holds:
Equation (20) can be obtained by condition (2):
Since is in the form of a product of measures as shown in Equation (18), it is obtained by combining Equation (19) with (20) and using Fubini’s theorem:
In summary, the filtered likelihood function has the same optimization direction as the original likelihood function, i.e.,
□
6. Two Intensity Parameter Models
The default intensity can usually be expressed in the form of Equation (23), where p represents the arrival rate of a default event in time h. We multiply it by the number of defaults, divide it by the time interval h, and take the limit, the average arrival rate of defaults in a given time [8]:
The intensity parameter is influenced by, partly, measurable macro variables (e.g., GDP, PPI, and CPI), systemic risk factors, and endogenous variables, such as default events. Therefore, can provide a better understanding of the scale and frequency of financial default events at a macro level, which is of high reference value for the evaluation of the macro-financial environment [6].
6.1. The First Model
Ignoring the contagion factor caused by the cluster default in traditional financial default models often leads to an overestimation of the impact of unobservable systematic risk variables on default intensity, resulting in large errors in model parameter estimation. Furthermore, ignoring cluster default contagion results in extreme values of the marker amount at the time of the financial default event’s arrival, causing a high level of bias in the model’s representation of the financial default event. The probability of another financial default occurring immediately after a marked large-volume financial default increases significantly. Therefore, it is appropriate to include a self-excitation term in the model to characterize the effect of the contagion factor on the default intensity and marker amount, as well as its decaying effect with increasing lags. Moreover, it is necessary to study the optimization of the explanatory variables’ parameter settings and the model-fitting effect under extreme values [25]. As a result, the first model studied in this paper is shown in (24):
The COX model, CIR model, and Hawkes models are used to treat the model’s parameter settings, accordingly. According to the analysis of Azizpour et al. [6], among the variables such as short-term treasury yields, bond credit ratings, and broad market indices, only the GDP variable passed the significance test. Thus, the variable in the partially observable term in the first model was selected, considering only the effect of the GDP factor. Also, for the form of the composition of the effect of the partially observable variable on the intensity parameter, the standard proportional risk COX model is used. As for the control of the systematic risk variable , the standard mean reversion CIR model is chosen. Since the CIR model has better performance in reflecting the treasury yield curve, which has a relatively good effect in portraying the macroeconomic boom, it makes good economic sense to use this model to portray the unobservable systematic risk variables. In the construction of the fully observable explanatory variable , a self-exciting term factor with the Hawkes model is added to portray the contagious effect of the cluster event because the effect of a high default event on subsequent default stops is a gradually decaying positive effect. Accordingly, the model is set where is monotonically increasing, representing the effect of the size of the default event marker (amount) on it, while the model front of the exponential term is monotonically decreasing, depicting the half decay of the default amount impact over time. According to Azizpour et al. [6], it is found that as the value of the default marker increases, the probability of the occurrence of a cluster event rises, along with the probability of another default event rising. Also, as increases, the effect of the occurrence of a default event at moment gradually decays. The same Azizpour et al. [6] also found that ignoring the effect of the contagious factor in the model causes problems, such as overestimating the effect of the unobservable variable . Therefore, the settings in the model make better economic sense [26].
6.2. The Second Model
In the setup of the intensity parameter model based on incomplete data, the partially observable term and the unobservable explanatory variable are crucial. Since the unobservable systematic risk variable contains stochastic components, the inclusion of Brownian motion at the stochastic wandering scale in the inscription of can better fit the stochastic nature of the model. As for the setting of the partially observable term using only the diffusion process to describe it would ignore the jump characteristics of the term time series. Therefore, we consider adding the jump process to the diffusion, i.e., the term is constructed as a diffusion process with a jump. The second model is constructed as shown in (25):
This model is the one used in Giesecke et al. [16] for simulations with the filtered likelihood method. It can be considered an extension of the first model. Each variable in this model satisfies the stochastic differential equation shown in (26), where :
and the parameters , , and R to be estimated for the stochastic differential equation, as shown in (27):
Bringing the corresponding parameters in (27) into the stochastic differential Equation (26) leads to the analytical solution of the explanatory variables in the intensity parameter model as shown in Equation (28):
where is a diffusion process with jumps, which are driven by the counting process , which is used to describe the effect of the self-excitation caused by the contagion term on the financial default event, and is the geometric Brownian motion. The fully observable variables in the model are , , , where , are two pure jump processes that integrate over the counting process, and is a one-dimensional variable t representing the stopping time of the default event. According to the constructed form of the pair of jump processes in Equation (28), the three elements , , and in the fully observable vector are combined to obtain , and with the combination , one can obtain a partially observable variable of the form shown in .
A comparison with the first model reveals that the two models are similar in the form of the fully observable variable , while the second model lacks the self-excitation effect caused by the cluster contagion factor due to the neglect of the marker term . In dealing with the latent variable , the components of the two models differ significantly: the first model uses the standard mean reversion CIR model, which has only a numerical solution to the stochastic differential equation, while the second model uses the geometric Brownian motion, which has a clearer analytical solution. The second model uses the summation of and for the partial observable vector, while the first model uses the COX risk ratio form for the GDP variable to depict the effect of macro variables on the default intensity.
In the following, the algorithm for filtering the likelihood function of this model is processed to obtain the closed expression for in Equation (12). From Equation (28), we can see that consists of a geometric Brownian motion with log-normal probability density function and a pure jump process. also follows a log-normal distribution, and the model uses a random variable with log-normal conditional probability distribution to characterize the transfer probability of the variable. Also, the variable is logarithmicized to have mean and standard deviation at each fixed interval . Therefore, its transfer probability is shown in (29), and the treatment of the transfer probability is described in more detail in Section 6.2:
and
where the parameters, is , is , is , is the density of a normal distribution with mean a and standard deviation b. and denote the division interval, where the variable and are transferred to the next state. The function is a jump process that can be expressed as . Also, the model is constructed in a form more similar to that of the model obtained by combining with . And in the application, is a partially observable variable in months, so can be taken at 30-day time intervals.
6.3. Nature of Parameter Estimation for Both Models
Theorem 2
(Convergence Theorem for Parameter Estimation). Suppose the conditions of Theorem 1 in Giesecke et al. [16] hold, and also that holds almost everywhere on the parameter space Θ, then, if there is a parameter , the likelihood function maximizes the following equation
Also, for any , the parameter estimation obtained under the n division maximizes the likelihood function in (32):
Then, for any fixed , holds almost everywhere, and also for any data , converges to the parameter estimation such that the likelihood function achieves the global optimum. This theorem illustrates that the parameters obtained under the filtered likelihood method of the first model estimates under the filtered likelihood method of the first model has the property of global convergence.
Proof of Theorem 2.
First taking , it follows from Giesecke et al. [13] that there exists that depends only on . Equation (33) holds for all and :
Since holds almost everywhere, we have that
holds almost everywhere. Definition since is the parameter estimation that maximizes . Therefore, the value space can be expressed by Equation (35) under n division:
Therefore, when , holds, and the proof is complete. □
Theorem 3
(Asymptotic properties of parameter estimation). Assume that all the conditions of Theorem 2 hold, and the following conditions also hold:
(1) The exact maximum likelihood estimates of any of the original parameters are consistent and asymptotically normal, i.e., on the probability space , when , there is . Also on the probability space when we have , where is: .
(2) The parameter estimation of the maximum likelihood function to obtain the global optimal solution does not reach the boundary of the parameter space Θ.
(3) For any , the Hessian matrix of the asymptotic likelihood function is positive definite in the neighborhood of the filtered likelihood estimate , while for any , when , let the sequence satisfy the following equation
Then when , the sequence of parameter estimation derived from the discretization satisfies
(1) On the probability space , when we have
(2) Under the distribution, when we have . Here is the same as in condition (1).
Proof of Theorem 3.
For any fixed , it follows from Theorem 2 that there is a limit to the filter estimate when n tends to infinity. Let this limit be . If is the global optimal solution of the likelihood function, i.e., , then we have
Since is a globally optimal solution that does not take values at the boundary of the parameter space , then the first-order derivative of is 0, i.e.,
Meanwhile, from the asymptotic normality of the global optimal parameter of as shown in the following equation, the second-order derivative of the limiting parameter can be obtained. The Taylor expansion of can be performed around
According to Giesecke et al. [15], the series of parameter estimation generated by dividing n when and the parameter estimation that lead to the global optimization of the likelihood function satisfy the following equation:
For each parameter in the domain of , there is a second-order Taylor expansion of the great likelihood function around the point satisfying the following equation:
Since for any , the Hessian matrix of the asymptotic likelihood function is positive definite over the domain of the filtered likelihood estimate , it follows that the second-order derivative of the likelihood function is finite, i.e.,
So when , and holds, we have the following conclusion:
□
7. Model Comparison and Empirical Analysis
Due to the late development of China’s financial market and the emergence of financial defaults (bond defaults) in actual practice only in recent years, there are few sample data available for the study of financial default models and parameter estimation. As China’s structural deleveraging continues to advance, the financing environment as a whole has tightened, making it more difficult for enterprises to raise funds, and the tight credit environment has exacerbated the structural problems in the fund transmission process, while the declining risk appetite of investors in the bond market has further increased the difficulty of financing for issuers with low credit quality to the extent that the number of bond defaults increased in the second half of 2018 as well as in 2019. In this chapter, we use the bond default data of China from 5 March 2014 to 24 June 2020 in the Wind Database to study the trend of quarterly cumulative default amount and daily default amount, the correlation of the quarterly average default arrivals and quarterly GDP data, as well as the correlation of daily default marker amount and daily average default arrival rate by using R language software to analyze them. We also study their normality, lagging and spikes. A comparative analysis of the first model and the second model is also conducted. The coefficient of determination , the AIC criterion, the degree of model fit, and the significance analysis of model parameters are utilized to derive a model that is more consistent with the portrayal of China’s bond default data in the case of small samples. Since the default data are tagged with large amounts, the tagged amounts are reduced by a factor of 10,000 to facilitate observation and analysis. Figure 1 first shows the trend of quarterly cumulative default amount and daily default amount.
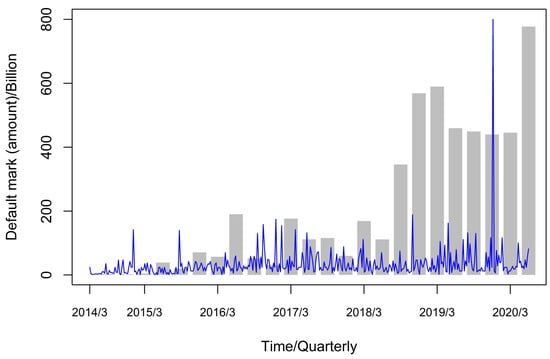
Figure 1.
Trend graph of quarterly cumulative default amount (bar) and daily default amount.
7.1. Model Variable Study
From Figure 2, the average default intensity arrival rate (day) fluctuates in the interval [0, 25]. Due to the distribution of the average default arrival rate exhibiting characteristics similar to a normal distribution, it is reasonable to assume that there is an unobserved systematic risk factor that affects the average default event rate that can be fitted by the geometric Brownian motion under a random walk scale. The results of the J-B test on the true value of the average intensity of financial default arrival parameter show that p-value , indicating that the series test of the average arrival times of default rejects the normality hypothesis, as shown in the Table 1. Combined with the peak and thick tail shape of the average default arrival rate image, it shows that the extreme value phenomenon of the distribution of the average occurrence rate of financial default events is significant. The probability of the occurrence of financial default events is relatively high. At the same time, the influence of contagion factors is obvious in Figure 2. After the default event occurs, the probability of another default event increases. Therefore, the default event is not completely determined by the random walk scale. Under the Brownian motion interpretation, there is also a strong contagion factor.
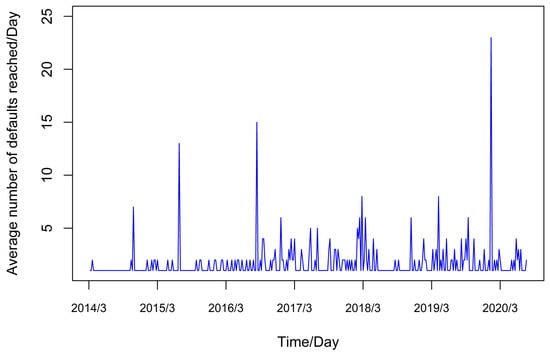
Figure 2.
Trend of the average number of default arrivals.

Table 1.
J-B test result.
In Figure 3, the solid line depicts quarterly GDP statistics, whereas the dotted line depicts quarterly average default arrivals. The link between GDP and the quarterly average default arrival rate reveals a p-value of 0.05, as shown in the Table 2. As a result, it seems appropriate to include GDP, a partially observable quantity, in the explanation of the intensity parameter model, implying that the macro-financial environment has a greater impact on the financial default arrival rate. The macroeconomic environment substantially impacts the pace at which financial defaults arrive. It can be utilized to fit the underlying pattern features of changes in the intensity parameter. Defaults tend to climb in tandem with the general financial environment’s volume, but the average growth rate of defaults is more moderate or even declining.
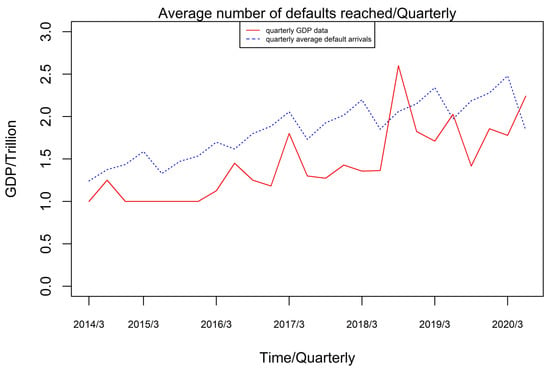
Figure 3.
Average default arrivals (quarterly) vs. GDP data (quarterly) trend graph.
Table 2.
Results of the correlation test between GDP and quarterly average default arrival rate.
Figure 4 shows that when a contagion event occurs, the default amount (dashed line) and the average daily default arrivals (solid line) have a fairly consistent trend and periodicity. Therefore, it is reasonable to use to build a Hawkes model that simulates the effect of the contagion factor on the average default arrival rate at the random travel scale using a model with the half-decayed self-excitation effect. Although the self-excited effect accounts for a small proportion of the model description, at moment T when the contagion effect causes extreme marker values, the self-excited term can better describe the fluctuation of the average default arrival rate affected by infectious factors. Thus, the setting of the self-excited term can better describe the model in extreme value situations.
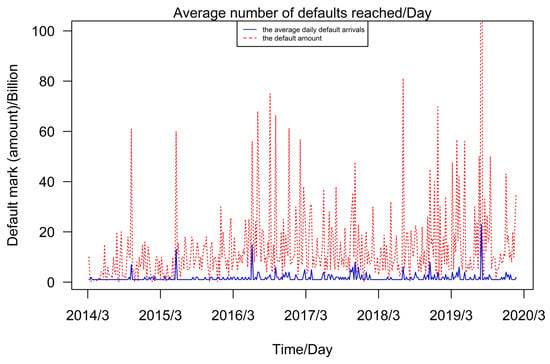
Figure 4.
Default marker (amount) vs. average default arrival rate trend.
7.2. Comparative Analysis of the Model
The filtered likelihood algorithm is used to estimate the parameters of the model. Compared with the Monte Carlo method, the filtered likelihood algorithm greatly reduces the computational burden of estimating the a posteriori mean of the intensity parameter likelihood function; compared with the EM algorithm, the filtered likelihood algorithm enhances the efficiency of parameter estimation without increasing the estimation error so that the model can converge better and has a better fit. The parameters are . Since the unobservable variable in the second model is inscribed by a random variable whose conditional probability distribution is log-normal with respect to its transfer probability, the logarithmization of this variable yields its mean and standard deviation at each fixed interval . In the case where the state is at moment is known, the next moment state is the transfer probability obtained by integrating over all states of as shown in (44):
where is a normally distributed probability density function with mean a and standard deviation b, and is a subinterval after partitioning the state space. Also, after we analyze the unobservable variables of the first model, it is evident that since the factors set in the first model to capture the variables of systematic risk are standard mean-reverting CIR models, the initial values of the model are set to obey, and the shape parameter is a non-centered chi-square distribution with scale parameter . Meanwhile, it is easy to know through a calculation that its initial values can be set to the shape parameter and scale parameter . Therefore, with the conditional transfer probability under time division , state division can be calculated by Equation (45):
where, for parameters, c is and q is ; for variables, u is and v is ; and is the q-order first class modified Sebel function .
The asymptotic estimation of the intensity parameter likelihood function using the filtered likelihood algorithm and the locally optimal parameter estimation of the second model, and the first model likelihood function obtained by the simplex method, as shown in Table 3. For the design of the initial values of the model, on the one hand, we refer to the relevant literature, and on the other hand, we consider the weight of the parameters in the model. For example, parameters and of the latent variable in the first model are set to consider the variation of per unit time t and the variation of Brownian motion relative to at each moment, respectively. From the analysis of the parameters, we can see that the contagious factor and the unobservable latent variable have a positive influence on the model but the proportion is relatively small, while the partially observable explanatory variable has a positive influence on the model by decaying the period with a relatively large proportion.
Table 3.
Financial default model parameter estimation.
The right panel of Figure 5 shows the fit of the second model to the average default arrival rate. The figure shows that the second model better describes the overall trend of the average default arrival rate and has a better fit for the contagion factors of default events. The left panel of Figure 5 shows the fit of the first model to the average default arrival rate. It can be seen that the first model reflects the overall trend of the average default arrival rate better than the second model. The first model has a better fit for the “spikes thick tail” of the default arrival rate distribution because it takes into account the influence of the contagion factors depicted by the Hawkes model represented by . The fit also matches the moment of default, the change in decay and the magnitude of the event. Combined with the higher values of the coefficient of determination and AIC of the first model, it can be concluded that the first model is a better fit for the stochastic average default intensity arrival rate of financial default events in China in the case of small samples, as shown in the Table 4.
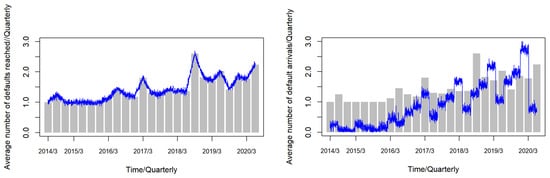
Figure 5.
Default marker (amount) vs. average default arrival rate trend.
Table 4.
Comparison of financial default model values.
8. Conclusions and Recommendations
From a macro perspective, financial default data can indicate the stability and risk level of the national financial environment. The timing of financial defaults and the regularity of the accumulated default amount can be used as a benchmark for the stability and future predictions of the financial market’s development. Two default intensity parameters models are investigated in this paper. Because the first model accounts for the self-excitation impact of cluster default factors, it does not overstate the influence of latent variables on the model and hence has a better fit for small samples of data, such as China’s bond default market. In this paper, we estimate the default intensity parameters in these two models based on the filtered likelihood method with great likelihood, which enhances the interpretation of the parameter solution and the efficiency of the model parameter solution, and, to some extent, reduces the estimation errors caused by the nature of the filtered likelihood method [27]. The default intensity model can be improved in the future study by selecting relevant explanatory factors that are more appropriate for China’s national conditions, allowing it to play a stronger role in the early warning and prediction of China’s financial default market.
Author Contributions
Conceptualization, X.L. (Xiangdong Liu); Methodology, X.L. (Xianglong Li); Software, J.W. The theoretical proof and empirical analysis of this article were written by three authors. All authors have read and agreed to the published version of the manuscript.
Funding
The research is supported Support by National Natural Science Foundation of China (No. 71471075), Fundamental Research Funds for the Central University (No. 19JNLH09), Innovation Team Project in Guangdong Province, P.R. China (No. 2016WCXTD004) and Industry -University- Research Innovation Fund of Science and Technology Development Center of Ministry of Education, P.R. China (No. 2019J01017).
Data Availability Statement
Not Applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shreve, S. Stochastic Calculus for Finance-Continuous Times Models; Springer: New York, NY, USA, 2003; pp. 125–251. [Google Scholar]
- Bremnud, P. Point Process and Queues-Martingale Dynamics; Springer: New York, NY, USA, 1980; pp. 150–233. [Google Scholar]
- Gordy, M.B. A Risk-Factor Model Foundation for Ratings-Based Bank Capital Rules. Journey Financ. Intermediat. 2003, 12, 199–232. [Google Scholar] [CrossRef]
- Das, S.; Duffie, D.; Kapadia, N.; Saita, L. Common Failings: How Corporate Defaults are Correlated. J. Financ. 2006, 62, 93–117. [Google Scholar] [CrossRef]
- Duffie, D.; Saita, L.; Wang, K. Multi-period corporate default prediction with stochastic covariates. J. Financ. Econ. 2007, 83, 635–665. [Google Scholar] [CrossRef]
- Azizpour, S.; Giesecke, K.; Schwenkler, G. Exploring the sources of default Clustering. J. Financ. Econ. 2018, 129, 154–183. [Google Scholar] [CrossRef]
- Hawkes, A.G. Spectra of some self-exciting and mutually exciting point processes. Biometrika 1971, 58, 83–90. [Google Scholar] [CrossRef]
- Chen, Y.S.; Zou, H.W.; Cai, L.X. Credit Default Swap Pricing Based on Supply Chain Default Transmission. South China Financ. 2018, 8, 33–42. [Google Scholar]
- Wang, X.; Hou, S.; Shen, J. Default clustering of the nonfinancial sector and systemic risk: Evidence from China. Econ. Model. 2021, 96, 196–208. [Google Scholar] [CrossRef]
- Li, C.; Ma, Y.; Xiao, W.L. Pricing defaultable bonds under Hawkes jump-diffusion processes. Financ. Res. Lett. 2022, 47, 102738. [Google Scholar]
- Xing, K.; Luo, D.; Liu, L. Macroeconomic conditions, corporate default, and default clustering. Econ. Model. 2023, 118, 106079. [Google Scholar] [CrossRef]
- Ogata, Y. The Asymptotic Behavior Of MaxiumLikehood Estimators for Stationary Point Processes. Ann. Inst. Stat. Math. 1978, 30, 243–261. [Google Scholar] [CrossRef]
- Fernando, B.P.W.; Sritharan, S.S. Nonlinear Filtering of Stochastic Navier-Stokes Equation with Ito-Levy Noise. Stoch. Anal. Appl. 2013, 31, 381–426. [Google Scholar] [CrossRef]
- Lando, D. On Cox Processes and Credit Risky Securities. Rev. Deriv. Res. 1998, 2, 99–120. [Google Scholar] [CrossRef]
- Elliott, R.J.; Chuin, C.; Siu, T.K. The Discretization Filter: On filtering and estimation of a threshold stochastic volatility model. Appl. Math. Comput. 2011, 218, 61–75. [Google Scholar]
- Giesecke, K.; Schwenkler, G. Filtered likelihood for point processes. J. Econom. 2018, 204, 33–53. [Google Scholar] [CrossRef]
- Gourieroux, C.; Monfort, A.; Mouabbi, S.; Renne, J.P. Disastrous defaults. Rev. Financ. 2021, 25, 1727–1772. [Google Scholar] [CrossRef]
- Duffie, D.; Eckner, A.; Horel, G. Frailty Correlated Default. J. Financ. 2009, 64, 2089–2123. [Google Scholar] [CrossRef]
- Chakrabarty, B.; Zhang, G. Credit contagion channels: Market microstructure evidence from Lehman Brothers’ bankruptcy. Financ. Manag. 2012, 41, 320–343. [Google Scholar] [CrossRef]
- Collin-Dufresn, P.; Goldstein, R.S.; Martin, J.S. The Determinants of Credit Spread Changes. J. Financ. 2001, 68, 2177–2207. [Google Scholar] [CrossRef]
- Liu, X.D.; Jin, X.J. Parameter estimation via regime switching model for high frequency data. J. Shenzhen Univ. (Sci. Eng.) 2018, 35, 432–440. [Google Scholar] [CrossRef]
- Liu, X.D.; Wang, X.R. Semi-Markov regime switching interest rate term structure models—Based on minimal Tsallis entropy martingale measure. Syst. Eng.-Theory Pract. 2017, 37, 1136–1143. [Google Scholar]
- Xu, Y.X.; Wang, H.W.; Zhang, X. Application of EM algorithm to eatimate hyper parameters of the random parameters of Wiener process. Syst. Eng. Electron. 2015, 37, 707–712. [Google Scholar]
- Giesecke, K.; Schwenkler, G. Simulated likelihood estimators for discretely observed jump–diffusions. J. Econom. 2019, 213, 297–320. [Google Scholar] [CrossRef]
- Duffie, D.; Pan, J.; Singleton, K.J. Transform Analysis and Asset Pricing for Affine Jump-diffusions. Econometrica 2000, 68, 1343–1376. [Google Scholar] [CrossRef]
- Hou, Z.T.; Ma, Y.; Liu, L. Estimation of the stationary distribution parameters based on the forward equation. Acta Math. Sci. 2016, 36, 997–1009. [Google Scholar]
- Wang, S.W.; Wen, C.L. The Wavelet Packet Maximum Likelihood Estimation Method of Long Memory Process Parameters. J. Henan Univ. (Nat. Sci.) 2006, 2, 79–84. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).