Abstract
This work will address the problem of estimating the parameters for the Nadaraj ah–Haghighi (NH) distribution using progressive Type-1 censoring (PT1C) utilizing Bayesian and non-Bayesian approaches. To apply PT1C, censoring times for each stage of censoring needed to be known before the experiment started. To solve this issue of censoring time selection, qauntiles from the NH lifetime distribution will be used as PT1C censoring time points. Maximum likelihood (ML) estimators (MLEs) and asymptotic confidence intervals (ACoIs) are produced with a focus on the censoring technique. Bayes estimates (BEs) and accompanying maximum posterior density (PD) credible interval estimations are also created via the squared error (SEr) loss function. The BEs are evaluated using the Markov Chain Monte Carlo (MCMC) technique and the Metropolis–Hasting (MH) algorithm. An analysis of an actual data set demonstrates the theoretical implications of MLEs and BEs for defined schemes of PT1C samples. Finally, simulation results will be used to compare the performance of the various recommended estimators.
Keywords:
progressive Type-1 censoring; Nadaraj ah–Haghighi distribution; Bayesian estimation; Markov Chain Monte Carlo; method of maximum likelihood MSC:
60E05; 62E15; 62F10
1. Introduction
Expanding continuous univariate distributions through adding a few more shape parameters is an important way of better exploring the skewness and tail weights, as well as other features of the produced distributions. Due to the recent trend, applied statisticians may now create more extended distributions that yield superior goodness-of-fit metrics whenever fitted to real data rather than just the classical distributions. The exponential (Ex) model is likely the most commonly used statistical distribution for analysis of survival and reliability concerns. The above model was the earliest in the lifetime literature about which statistical methods became substantially explored. Ref. [1] recently presented a generalization of the Ex distribution known as the Nadaraj ah–Haghighi (NH) distribution. Both distribution function (cdf) and probability density function (pdf) are computed on the basis of
and
The quantile function (quf) of random variable (R-V) Z are
In terms of fitting real-life data, the NH distribution is a fairly flexible lifespan model. The NH distribution, like the standard Weibull distribution, gamma distribution, or modified exponential distribution, may simulate decreasing, increasing, or constant hazard rates. Furthermore, this model is a subset of the generalized power Weibull distribution, which was presented in [2]. In the literature, the NH distribution has attracted a great attention and has already been researched by a lot of scientists. Consider, for instance, [3,4] works. Furthermore, the NH distribution is also known as the extended Ex distribution in certain other publications, which including [5,6]. Ref. [1] discovered that even if certain data sets had the number zero, an NH model may still produce adequate fits. Furthermore, under this distribution, the trend of the hazard rate function (hrf) is sensitive on . For example, when , the hrf tends to grow (reduce). However, when is set to 1, the hrf becomes a constant. At this point, (1) also becomes the Ex distribution.
There is some material available about estimation of the NH distribution. Regarding the estimate of unknown parameters, Ref. [7] has studied the maximum likelihood (ML) and Bayes estimations using progressive type-2 censored (PT2C) samples with binomial removals. Subsequently, Ref. [8] looked at PT2C data. They computed MLEs using the Newton–Raphson technique and BEs using the MCMC methodology. Asymptotic confidence intervals (ACoIs) and highest PD (HPD) intervals were also estimated. Several sources, such as [5,6], also focused on the issues of order statistics (OS) of an NH distribution. They jointly developed on moment recurrence formulations for OS. The former, on the other hand, dealt with the problem in PT2C, whilst the latter concentrated on the entire sample set. In addition, Ref. [9] explored MLEs and BEs using the Lindley approximation for the unknown parameters. Non-Bayesian and Bayesian predictions were also used to make point and interval forecasts for future data. Furthermore, Ref. [10] investigated the MLEs and BEs for the two unknown parameters and lifespan parameters of survival and hrfs using the gradually first-failure censored NH model. They also proposed an optimum filtering strategy based on several optimality criteria. The MLEs and BEs for the constant stress partly accelerated life tests under PT2C were explored in ref. [11]. The estimate and prediction of the NH distribution under PT2C were addressed in ref. [12].
Censored data occurs in real-world testing trials when studies, including the lifespan of test units, must be ended before complete observation. Censoring is a typical and inevitable practice action for a variety of reasons, including time constraints and cost savings. Censorship of various forms has been thoroughly investigated, with Type-1 and Type-2 censorship being the most common. In comparison to traditional censorship designs, a generalized style of censorship known as PC schemes has lately received significant attention in the works due to its effective use of available resources. One of these PC schemes is PT1C. This trend is observed when a specific number of lifespan test units are consistently excluded from the test at the end of each post-test period of time. The capacity to determine the termination time realistically and additional design freedom by allowing test units to be terminated during non-terminal time periods [13]. Bayesian and classical inference for odd Lindley Burr XII model are proposed in [14] and Topp-Leone NH distribution are proposed in [15].
Assume a life testing experiment has n units. Presume that represent the lifetime of all n units taken from a population. Suppose that denotes the respective ordered lifespan recorded from the life test. At the end of the preset period of censoring , items are excluded from the surviving items in accordance with Qs, , where m signifies the number of testing phase, and .
The quantities should always be determined ahead of time:
- Predicated on the experimenter’s past knowledge and skills with the objects under consideration [16], or
- The Qs of the lifetimes distribution, th, which possibly calculated by using the provided expression
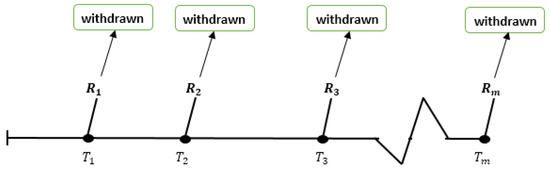
Figure 1.
PT1C Scheme.
Complete samples, as well as the Type-1 censoring scheme, can indeed be viewed as special examples of this censoring technique.
The PT1C technique for the Weibull distribution was introduced in reference [17]. The MLEs and BEs for the unknown parameters of the generalized inverse Ex distribution under PT1C were obtained in [19]. For the PT1C, there are two publications that are closely linked. The first was the MLEs and ACI estimates for the parameters of the extended inverse Ex model, predicated on the premise that there are two kinds of failures [20]. The second were the MLEs and BEs for the unknown parameters of the extended inverse Ex model [21]. Ref. [22] investigates the statistical inference of the inverse Weibull model under PT1C.
The goal of this work is to examine the PT1C scheme where each lifetime has its own NH model. We employ two independent approaches to drive the MLEs and BEs, and then use MCMC to calculate the ACI of these various parameters. We examine simulation results as well as actual data sets to evaluate how the various models work in practice. The next thing is how the entire article is structured: the second The section discusses the MLE and confidence intervals. The Metropolis–Hasting (MH) method is utilized in the third section to investigate the Bayesian estimation approach, which completely certifies the gamma model as a prior distribution for unknown parameters. The fourth section uses simulated results and a real data set to show the theoretical findings. Finally, there are some closing remarks and a summary.
2. Maximum Likelihood Approach
This section examines the MLE estimation strategy based on the PT1C strategy for the unknown parameters of the NH distribution. It is how the PT1C approach is suitable:
- In a real-world experiment, test a random sample of n units with the next lifespan NH(,) model.
- Prefix s censoring time points , at which fixed quantity of surviving items are eliminated from the test at randomized. The censoring times are chosen equivalent to , where Z∼ NH(,) and is the Qs () in terms of the desired lifetime distribution.
- The life test ends at just before a predetermined time .
As a result, using the same censoring process, one may generate PT1C samples indicating the reported lifetime of r units.
Using (2) of NH model in (4) of L-L function under PT1C, the linked L-L function of and given the PT1C data, , might be regarded as
By taking the logarithm function of L-L to obtain log-L-L () as
First partial derivatives of in regard to and are calculated in the following manner:
and
where , and .
Equating and to 0, The MLEs of and are the empirical solutions of the preceding two equations for and .
3. Bayesian Estimation
In this part, we will look at how to use Bayesian estimation to estimate the parameters of an NH model using the PT1C method. The standard error (SEr) loss function will be used for Bayesian estimation. It is feasible to employ distinct gamma priors for the NH model parameters and with pdfs
and
Pursuant to the data compiled, the appropriate PD could be represented in fact as
The PD function has been written in the form
where
As just an outcome, the PD could be changed as tries to follow:
The Bayes estimator about any function, such like , is supplied by the SEr
As a result, Equation (10) cannot be computed for generic . As an outcome, we propose that you employ the most often used estimated BEs of and MCMC.
3.1. Metropolis–Hasting Algorithm
To perform the MH method for the NH distribution, we must supply the NH model and initial values for the unknown parameters and . For the suggestion model, we investigate a bivariate normal distribution, that is , We might receive unfavorable feedback, which really is undesired, if describes the variance-covariance matrix. To establish the initial values, we apply the MLE for and , that is . The MH technique uses the following stages to select a sample from the PD provided by Equation (10) are delivered in the prescribed sequence:
- Step I Set the initial magnitude of to .
- Step II For the following phases must be reproduced:
- 2.1: Set .
- 2.2: Make a new value for the contender parameter from .
- 2.3: Set .
- 2.4: Compute , where is the PD.
- 2.5: Create a sample u through using uniform distribution.
- 2.6: Accept or reject the specific request premised on
Consequently, to use the PD’s random samples of size M, a portion of the original samples might well be removed (burn-in), and the remaining samples can really be utilized to generate BEs. The Equation (10) can really be approximated more exactly as
where is the overall amount of burn-in samples.
3.2. Highest Posterior Density (HDP)
We establish HPD intervals for the unknown parameters and of the NH distribution under PT1C using the samples obtained by the suggested MH approach in the preceding paragraph. Considering the next case study: and be the th Q of and , respectively, that is,
where and is the PD of and . It should be noted that for a given and , an accurate estimator based on simulation of might well be computed as
Here is the indicator function. The proper estimate is then determined as
where and are the ordered values of . Now, for , may be estimated by
Furthermore, let us determine a HPD credible interval for and
for , here represents indicates the largest integer that . Need to choose from one of many ’s with the narrowest width.
4. Numerical Outcomes
The purpose of this section is to compare the performance of the various estimating methods outlined in the previous sections. For illustrative purposes, we investigate a real data set; moreover, a simulation experiment is performed to test the statistical performances of the estimators under the PT1C scheme as well as the conduct of the recommended techniques. For calculations, we employed the R-statistical software.
4.1. Results of Simulation
Inside this section, we utilize computer simulations to test the efficiency of estimation methodologies, specifically MLE and Bayesian estimation, for something like the NH distribution using the PT1C scheme. We generate 1000 data points from the NH model with the standard procedures for such MLEs:
- and , i.e., .
- Sample sizes are , and .
- Number of stages of PT1C are .
- Censoring times (CT) are discussed and recommendations:
- = (0.25, 0.55, 2)
where . The patterns of CT can be classified according to m. In our study, and are used when and and are used when . - Removed items are assumed at different sample size n as shown in Table 1 where and r is the number of failure items.
 Table 1. Numerous patterns for removing items from life test at numerous number of stages.
Table 1. Numerous patterns for removing items from life test at numerous number of stages.
It is indicate that scheme PT1C1 and PT1C8 are represent Type-1 censoring scheme as a special case with number of failure items and CT is . We compute MLEs and related 95% ACoI relying on the generated data. When calculating MLEs, the initial estimate values are assumed to be much like the genuine parameter values.
We compute BEs utilizing the MH algorithm with informative priors for the Bayesian estimation approach. As previous examples, we construct 1000 complete samples of size 60 from the model, and the hyper parameter values are .
The aforementioned informative prior values are used to compute the required estimations. When using the MH approach, we use the MLEs as starting guess values, as well as the corresponding variance–covariance matrix of . Subsequently, we removed 2000 burn-in samples from the total 10,000 samples generated by the PD, and then used the approach to derive BEs and HPD interval estimates of [23].
Table 2, Table 3 and Table 4 shows all of the average estimates including both approaches for samples size , , and , respectively. Furthermore, the first row shows average estimations (Avg. ), whereas the second row reflects corresponding means square errors (MSErs). For CoIs, we have ACoI for MLEs and HPD for BEs premised on the MCMC results shown in Table 5, Table 6 and Table 7 for samples size , , and , respectively. In addition, the first row indicates average interval lengths (AvILs), whereas the second row reflects corresponding coverage probabilities (CPrs).
Table 2.
Average estimated values and MSErs of the ML and BEs for NH model with and under various censoring schemes at .
Table 3.
Average estimated values and MSErs of the ML and BEs for NH model with and under various censoring schemes at .
Table 4.
Average estimated values and MSErs of the ML and BEs for NH model with and under various censoring schemes at .
Table 5.
AvILs and CPr(in %) values and MSErs of the ML and BEs for NH model with and under various censoring schemes at .
Table 6.
AvILs and CPr(in %) values and MSErs of the ML and BEs for NH model with and under various censoring schemes at .
Table 7.
AvILs and CPr(in %) values and MSErs of the ML and BEs for NH model with and under various censoring schemes at .
According to the tabulated figures, greater values of n lead to better estimations depending on MSErs. It is also worth noting that MLEs outperform informative Bayes estimates. Furthermore, MSErs and AvILs of linked interval estimations are often lower when units are eliminated early in the process. The convergence of MCMC estimation for and could be reported in two figures. First, Figure 2 for and pattern of censoring PT1C3 and for choosing sample size . Secondm Figure 3 for and pattern of censoring PT1C10 and for choosing sample size .
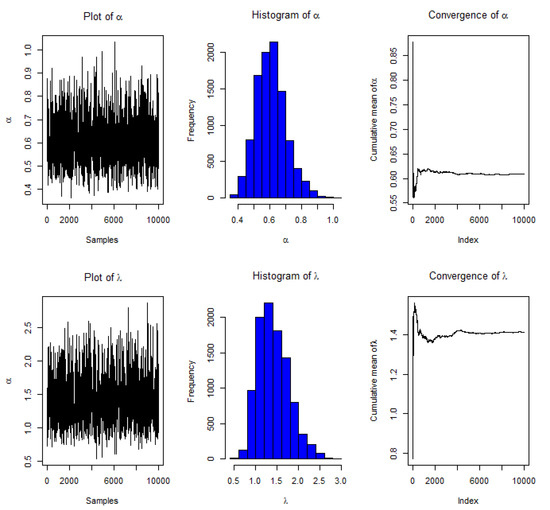
Figure 2.
Convergence of MCMC estimates for and using MH algorithm under PT1C3 and where and .
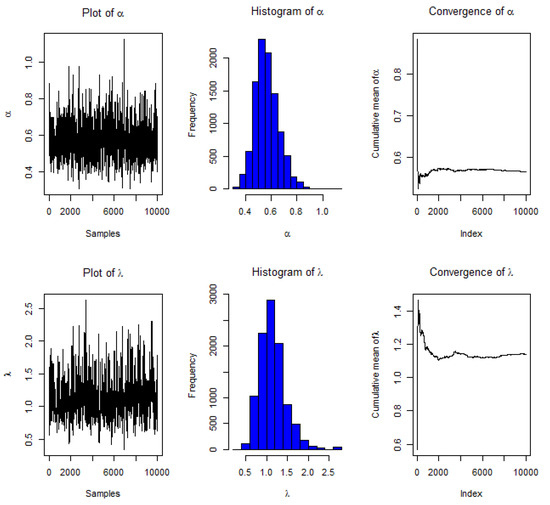
Figure 3.
Plots of convergence of MCMC estimates for and by using MH algorithm under PT1C10 and where and .
4.2. Real Data Analysis
The accompanying data set contains actual data on total yearly rainfall (inches) in January from 1880 to 1916. This is data was first analyzed by [9]. There were 37 observations listed below:
We begin by determining if the NH distribution is appropriate for evaluating this data set. The computed Kolmogorov–Smirnov (K-S) for the NH model for the given data set is 0.091 and its p-value is 0.9 where and this implies that this distribution (NH) is a suitable model for the current data set.1.33, 1.43, 1.01, 1.62, 3.15, 1.05, 7.72, 0.20, 6.03, 0.25, 7.83, 0.25, 0.88, 6.29, 0.94, 5.84, 3.23, 3.70, 1.26, 2.64, 1.17, 2.49, 1.62, 2.10, 0.14, 2.57, 3.85, 7.02, 5.04, 7.27, 1.53, 6.70, 0.07, 2.01, 10.35, 5.42, 13.3.
From the original data we generate different PT1C samples. Removed items are considered as in simulation study in Table 1 for . In addition, different stages of censoring are proposed at and and four CT proposed as follows:
where . As discussed in simulation study, patterns and for and and for
We compute the MLErs of the parameters and , as well as their corresponding 95% ACoI estimates. We also compute BEs under the informative prior using the MH technique. It should be noted that the non-informative prior is assumed for . It is said that while using the MH method to generate samples from the posterior distribution, starting values of are taken into account as , where and are the MLEs of the parameters and , respectively. As a result, we investigated the variance–covariance matrix of , which is readily produced using the delta approach. Ultimately, among many of the total 10,000 samples generated by the PD, we excluded 2000 burn-in samples and derived BEs and HPD interval estimates using the approach of [23].
All the estimated values of MLEs and ACoI and standard errors (St.Er) are mentioned in Table 8 and Table 9 for and , receptively. In addition, Bayesian estimate using MCMC using the MH method, as well as accompanying HPD intervals and St.Er, are determined.
Table 8.
ML and BEs with associated St.Er (in practices) and CoIs based on various PT1C schemes for given real data set at .
Table 9.
ML and BEs with associated St.Er (in practices) and CoIs based on various PT1C schemes for given real data set at .
5. Summary and Conclusions
Throughout this paper, we looked at the NH distribution estimate and prediction under PT1C from both a classical and a Bayesian approach. We obtained maximum likelihood estimates and ACIs for the unknown parameters of the NH distribution. Then, using informative priors, we generated Bayes estimates using MCMC approach as well as the corresponding HPD interval estimates. Furthermore, when an informative prior is used, a discussion of how to choose the values of hyper-parameters for a Bayesian estimate based on historical samples is discussed. The simulation results show that MLEs informative Bayes estimates under informative prior utilizing MCMC outperform MLEs. For future work, we will employ Bayesian estimation using the squared error loss function, although other loss functions can also be used. Furthermore, the current methodology might be extended to the development of an optimal progressive censoring sample strategy, as well as alternate censoring strategies.
Author Contributions
Conceptualization, I.E., N.A., S.A.A., M.E. and A.R.E.-S.; methodology, I.E., N.A., S.A.A., M.E. and A.R.E.-S.; validation, I.E., N.A., S.A.A., M.E. and A.R.E.-S.; writing—review and editing, I.E., N.A., S.A.A., M.E. and A.R.E.-S. All authors have read and agreed to the published version of the manuscript.
Funding
The authors extend their appreciation to the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University for funding this work through Research Group no. RG-21-09-08.
Data Availability Statement
Interested parties can reach out to the author in order to receive a numerical dataset used to perform the research described in the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Nadarajah, S.; Haghighi, F. An extension of the exponential distribution. Stat. J. Theor. Appl. Stat. 2011, 45, 543–558. [Google Scholar] [CrossRef]
- Nikulin, M.; Haghighi, F. A chi-squared test for the generalized power Weibull family for the head-and-neck cancer censored data. J. Math. Sci. 2006, 133, 1333–1341. [Google Scholar] [CrossRef]
- Haghighi, F. Optimal design of accelerated life tests for an extension of the exponential distribution. Reliab. Eng. Syst. Saf. 2014, 131, 251–256. [Google Scholar] [CrossRef]
- Dey, S.; Zhang, C.; Asgharzadeh, A.; Ghorbannezhad, M. Comparisons of methods of estimation for the NH distribution. Ann. Data Sci. 2017, 4, 441–455. [Google Scholar] [CrossRef]
- Kumar, D.; Dey, S.; Nadarajah, S. Extended exponential distribution based on order statistics. Commun. Stat. Theory Methods 2017, 46, 9166–9184. [Google Scholar] [CrossRef]
- Kumar, D.; Malik, M.R.; Dey, S.; Shahbaz, M.Q. Recurrence relations for moments and estimation of parameters of extended exponential distribution based on progressive type-II right-censored order statistics. J. Stat. Theory Appl. 2019, 18, 171–181. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.; Singh, U.; Kumar, M.; Vishwakarma, P. Classical and Bayesian inference for an extension of the exponential distribution under progressive type-II censored data with binomial removals. J. Stat. Appl. Probab. Lett. 2014, 1, 75–86. [Google Scholar] [CrossRef]
- Singh, U.; Singh, S.K.; Yadav, A.S. Bayesian estimation for extension of exponential distribution under progressive type-II censored data using Markov Chain Monte Carlo method. J. Stat. Appl. Probab. 2015, 4, 275–283. [Google Scholar]
- Selim, M.A. Estimation and prediction for Nadaraj ah–Haghighi distribution based on record values. Pak. J. Stat. 2018, 34, 77–90. [Google Scholar]
- Ashour, S.K.; El-Sheikh, A.A.; Elshahhat, A. Inferences and optimal censoring schemes for progressively first-failure censored Nadarajah–Haghighi distribution. Sankhya A 2020, 1–39. [Google Scholar] [CrossRef]
- Dey, S.; Wang, L.; Nassar, M. Inference on Nadarajah–Haghighi distribution with constant stress partially accelerated life tests under progressive type-II censoring. J. Appl. Stat. 2021, 1–22. [Google Scholar] [CrossRef]
- Wu, M.; Gui, W. Estimation and Prediction for NadarajahHaghighi Distribution under Progressive Type-II Censoring. Symmetry 2021, 13, 999. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Han, D.; Iliopoulos, G. Exact inference for progressively type-I censored exponential failure data. Metrika 2011, 73, 335–358. [Google Scholar] [CrossRef]
- Korkmaz, M.C.; Yousof, H.M.; Rasekhi, M.; Hamedan, G.G. The odd Lindley Burr XII model: Bayesian analysis, classical inference and characterizations. J. Data Sci. 2018, 16, 327–354. [Google Scholar] [CrossRef]
- Yousof, H.M.; Korkmaz, M.C. Topp-Leone Nadaraj ah–Haghighi distribution. İstatistikçiler Dergisi İstatistik ve Aktüerya 2017, 10, 119–128. [Google Scholar]
- Balasooriya, U.; Low, C.K. Competing causes of failure and reliability tests for Weibull lifetimes under type I progressive censoring. IEEE Trans. Reliab. 2004, 53, 29–36. [Google Scholar] [CrossRef]
- Cohen, A.C. Progressively censored samples in life testing. Technometrics 1963, 5, 327–329. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Cramer, E. The Art of Progressive Censoring: Applications to Reliability and Quality; Springer: New York, NY, USA, 2010. [Google Scholar]
- Mahmoud, R.M.; Muhammed. H.Z.; El-Saeed, A.R. Inference for generalized inverted exponential distribution under progressive Type-I censoring scheme in presence of competing risks model. Sankhya A Indian J. Stat. 2021. [Google Scholar] [CrossRef]
- Mahmoud, R.M.; Muhammed, H.Z.; El-Saeed, A.R. Analysis of progressively Type-I censored data in competing risks models with generalized inverted exponential distribution. J. Stat. Appl. Probab. 2020, 9, 109–117. [Google Scholar]
- Mahmoud, R.M.; Muhammed, H.Z.; El-Saeed, A.R.; Abdellatif, A.D. Estimation of parameters of the GIE distribution under progressive Type-I censoring. J. Stat. Theory Appl. 2021, 20, 380–394. [Google Scholar] [CrossRef]
- Algarni, A.; Elgarhy, M.; Almarashi, A.M.; Fayomi, A.; El-Saeed, A.R. Classical and Bayesian Estimation of the Inverse WeibullDistribution: Using Progressive Type-I Censoring Scheme. Adv. Civ. Eng. 2021, 2021, 5701529. [Google Scholar]
- Chen, M.H.; Shao, Q.M. Monte Carlo estimation of Bayesiancredible and HPD intervals. J. Comput. Graph. Stat. 1999, 6, 69–92. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).