
Single Image Super-Resolution with Arbitrary Magnification Based on High-Frequency Attention Network



Abstract
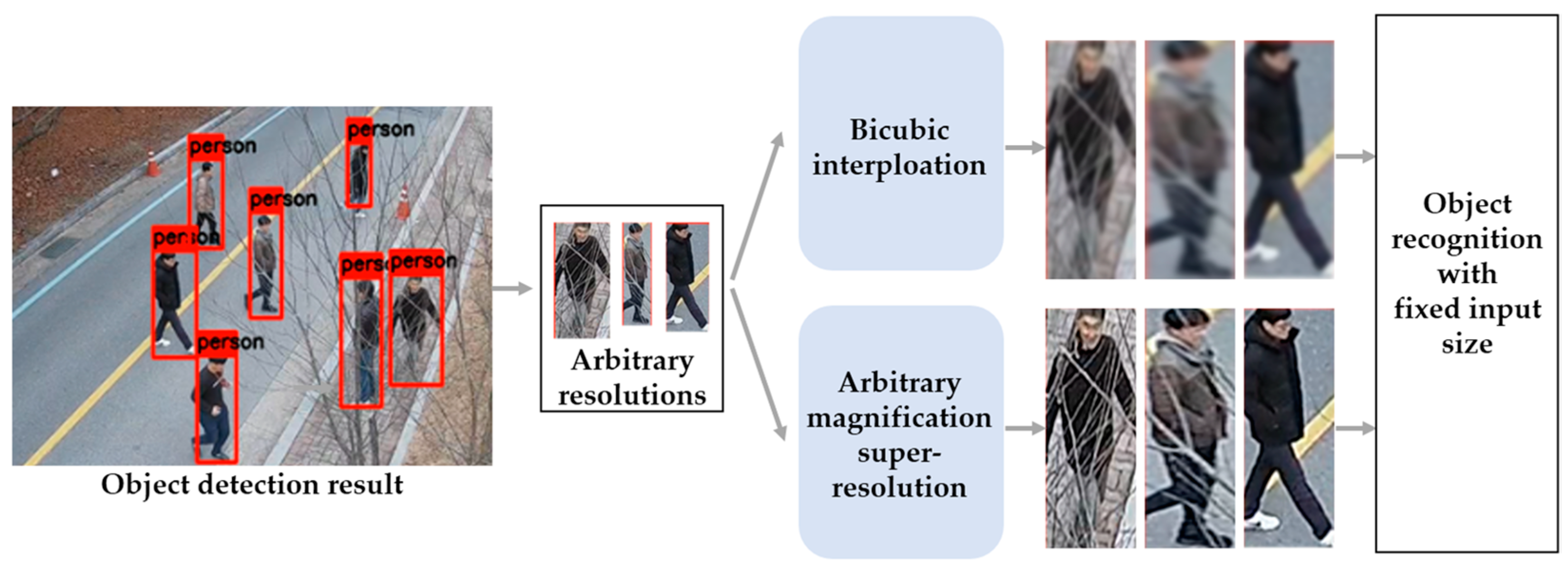
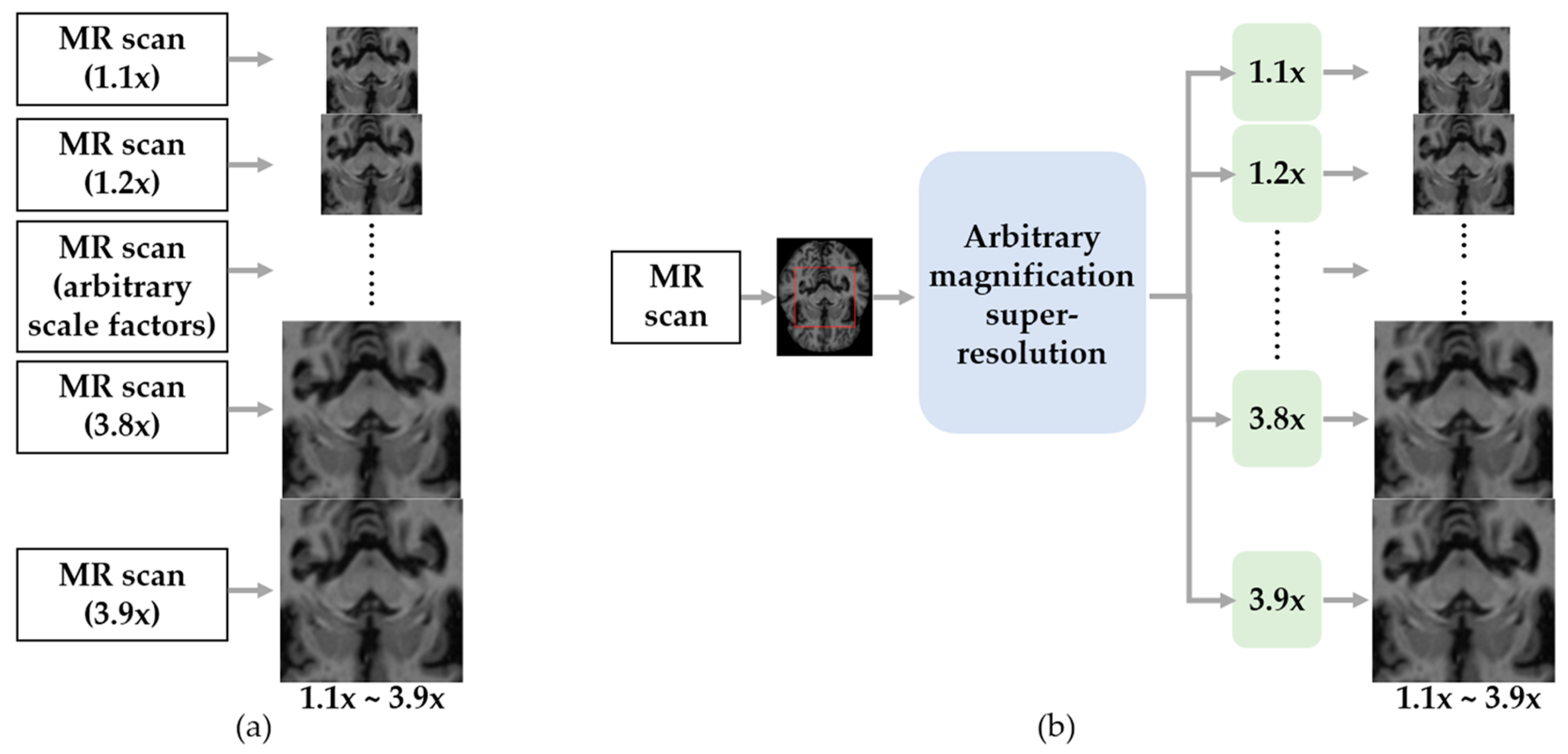
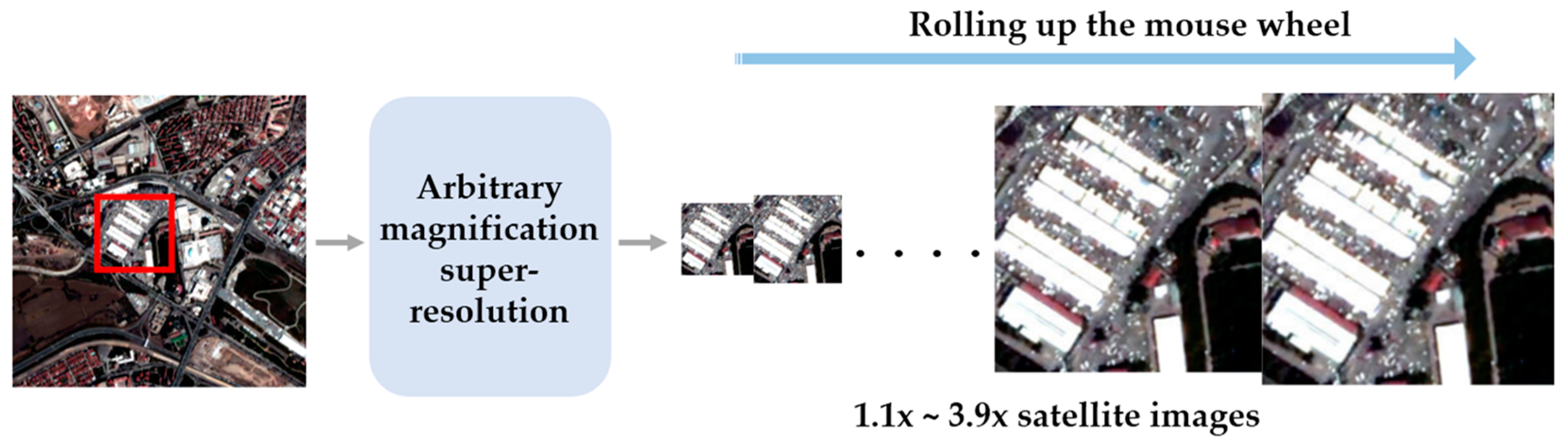
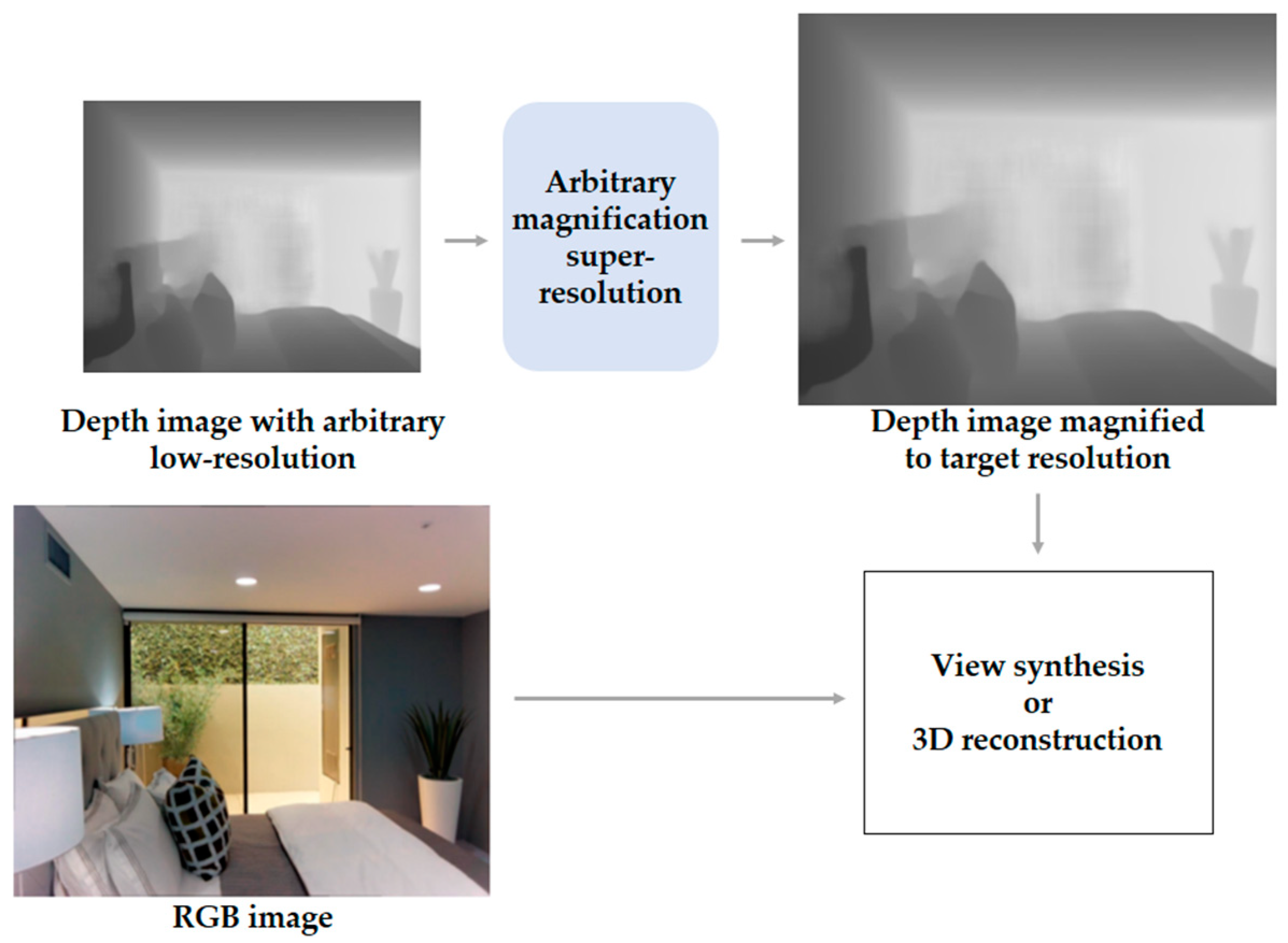
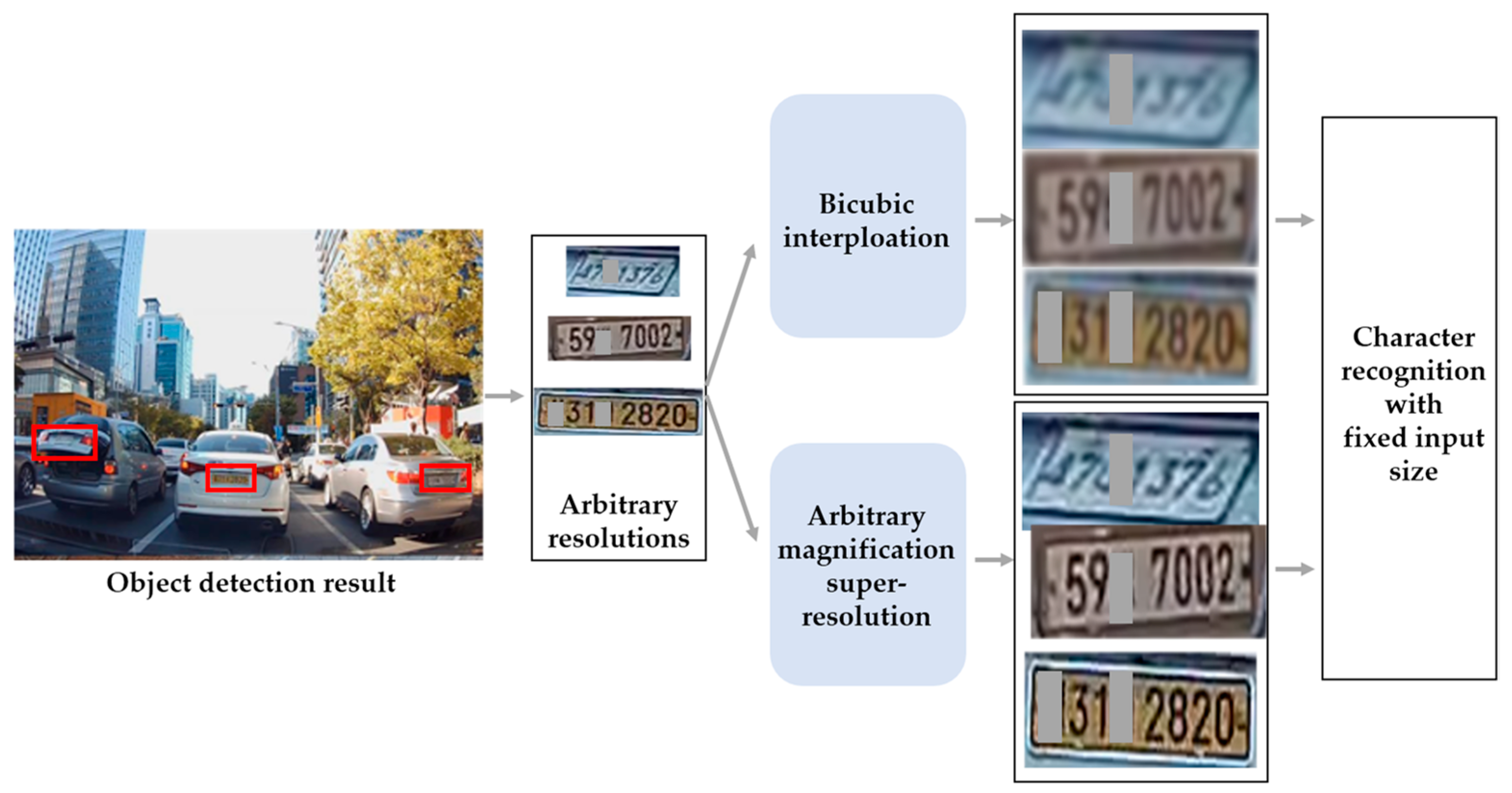
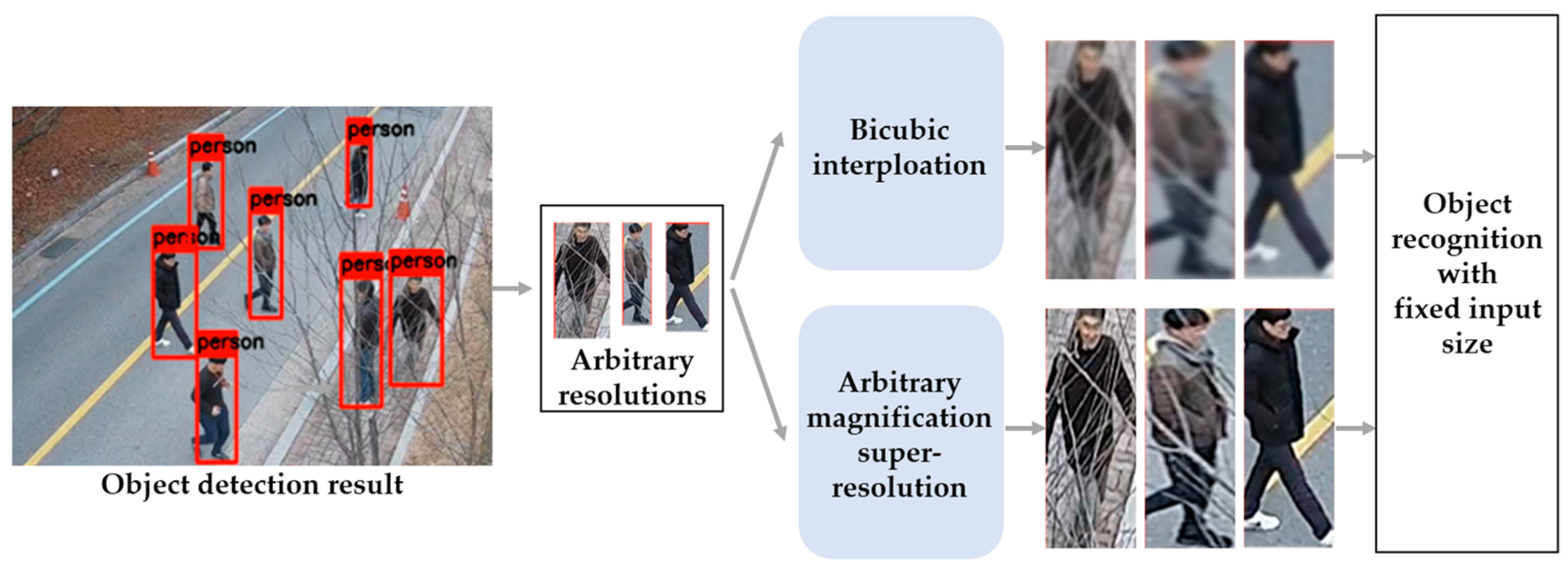
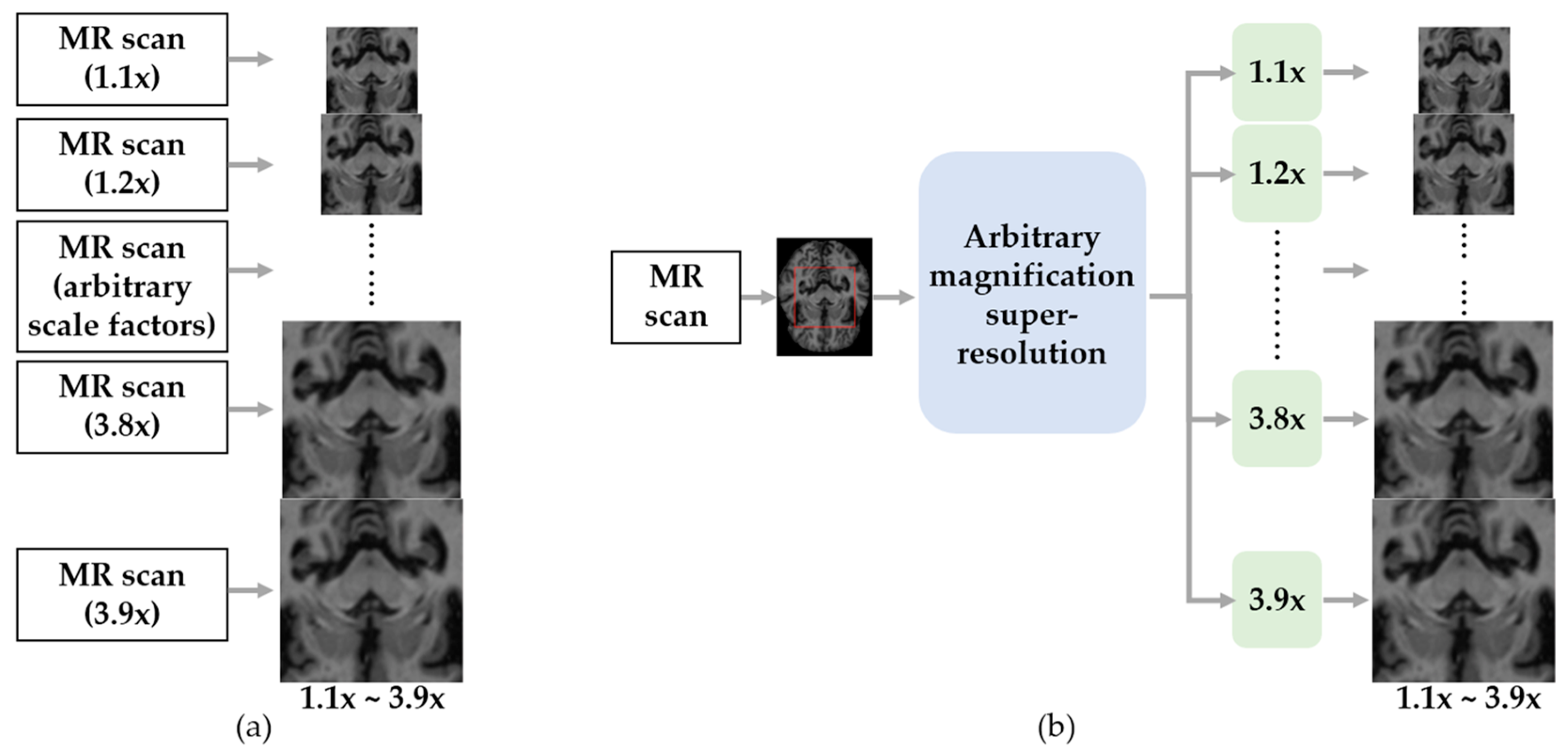
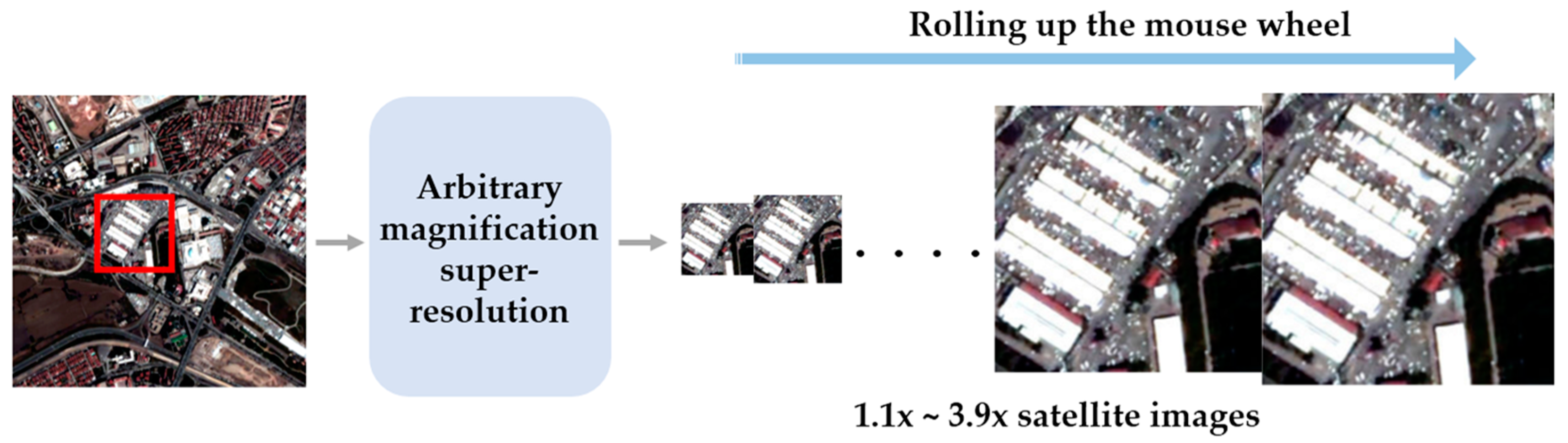
:1. Introduction
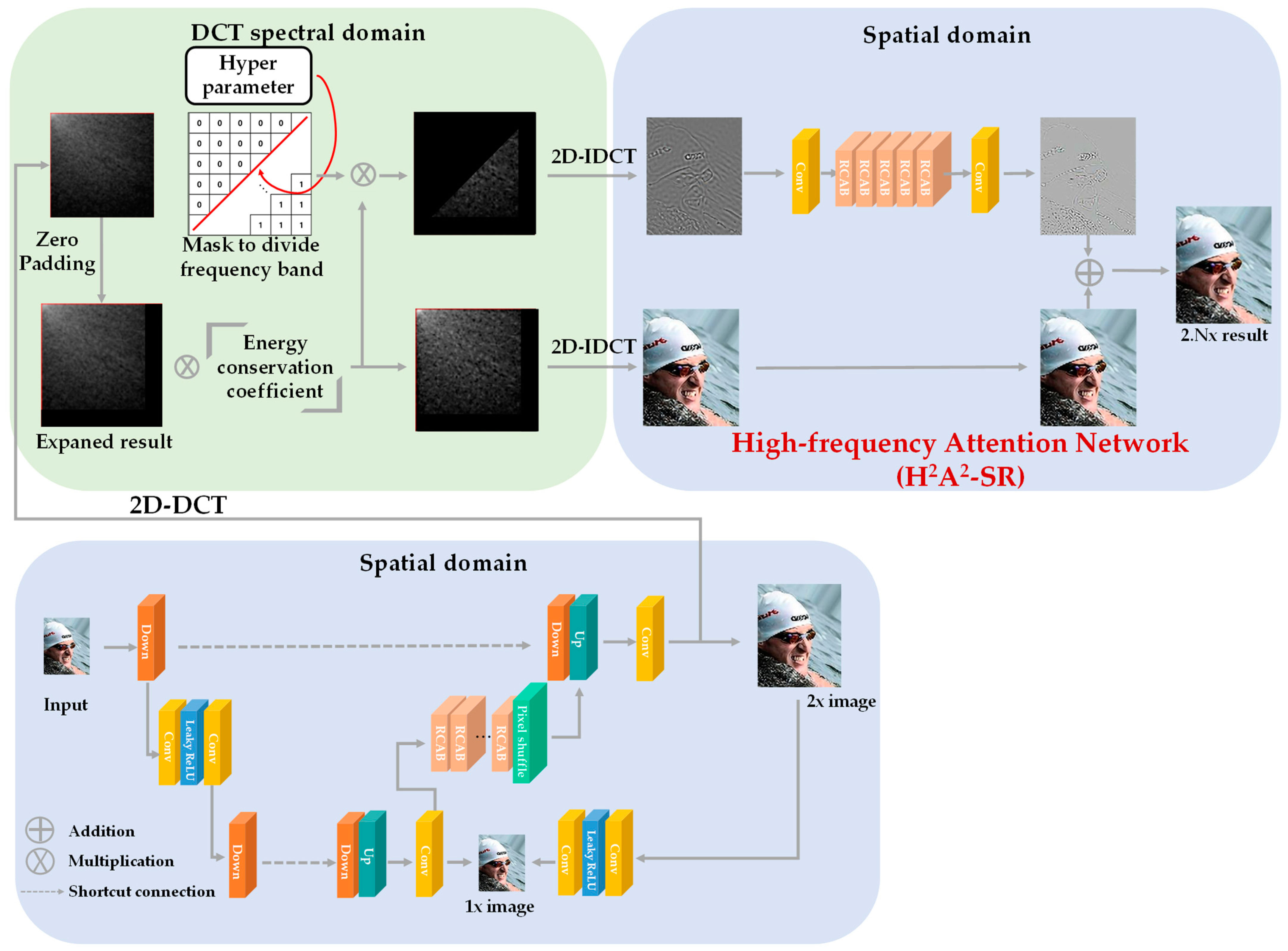
- The image is enlarged to target resolution in the DCT spectral domain.
- The high frequency, which is insufficient owing to the DCT spectral domain spatial expansion, is restored through the spatial domain high-frequency concentration network.
- The proposed model preserves the superiority of the existing integer super-resolution model. By simply adding the hybrid-domain high-frequency model without modifying and additionally training on the existing integer super-resolution model, our model’s arbitrary magnification restoration performance is better than that of state-of-the-art models.
2. Related Works
2.1. Conventional Single Image Super-Resolution
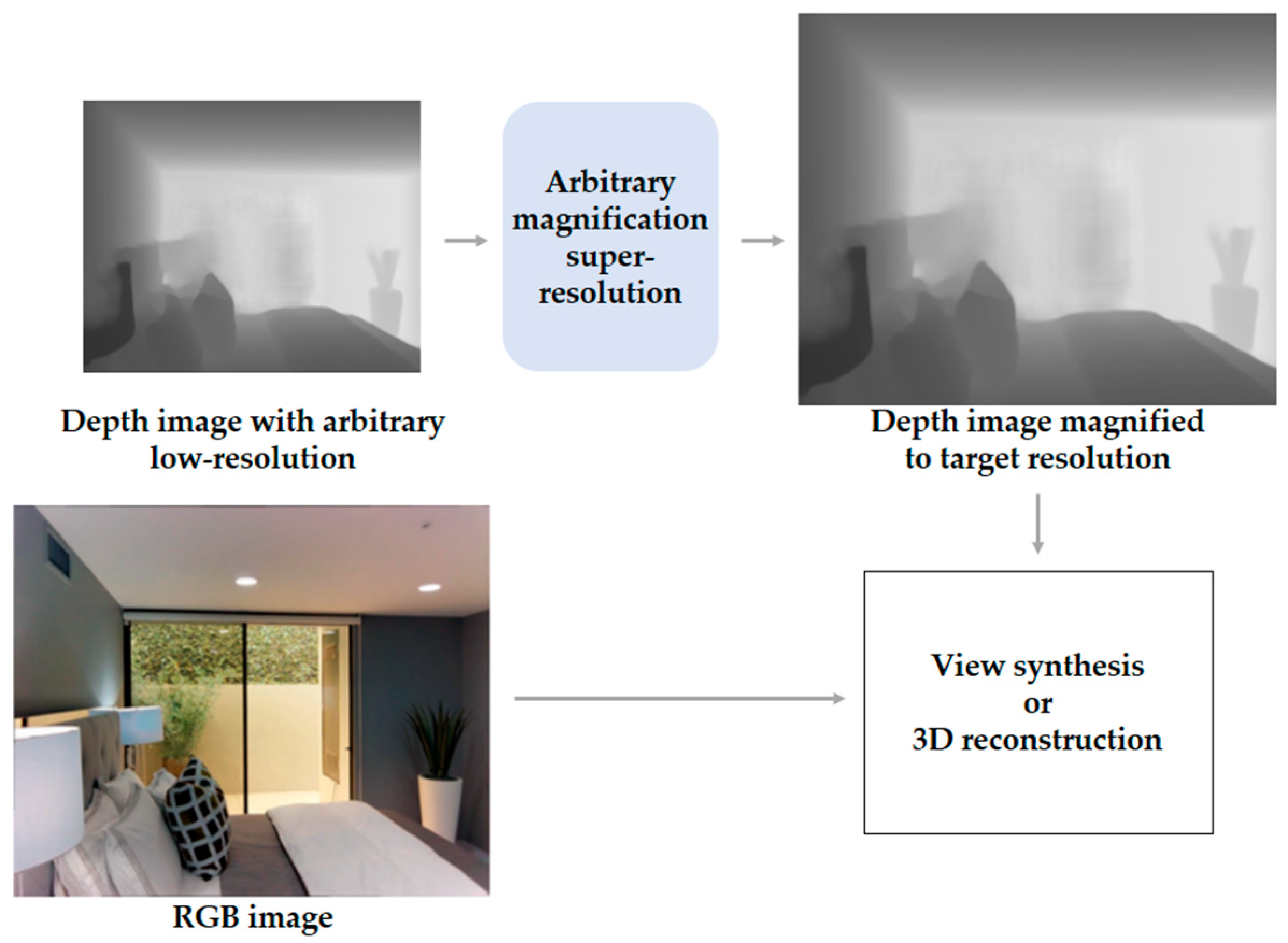
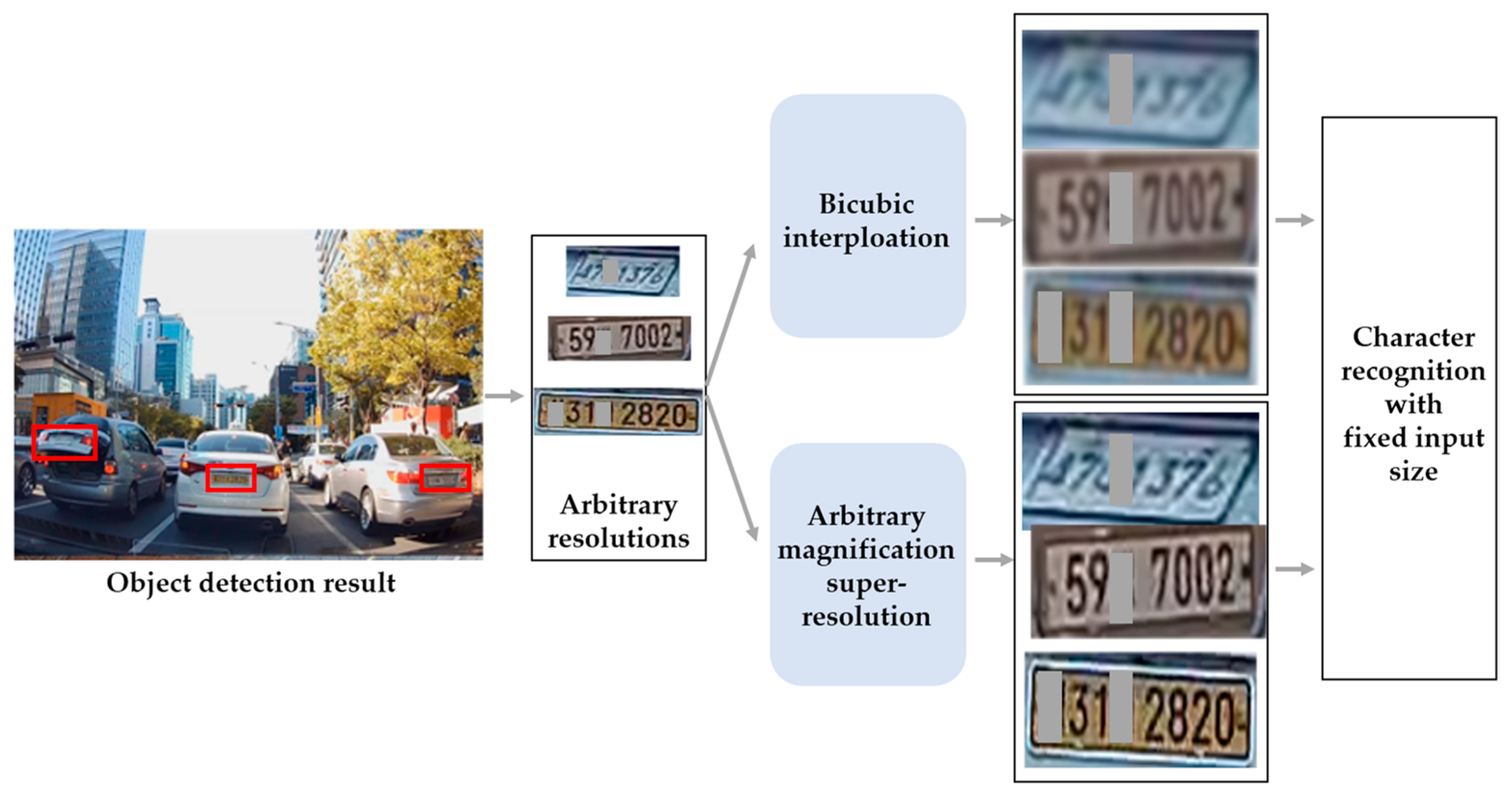
2.2. Arbitrary Magnification Single Image Super-Resolution
2.3. Frequency Domain Super-Resolution
2.4. State-of-the-Art Task-Driven Arbitrary Magnification Super-Resolution
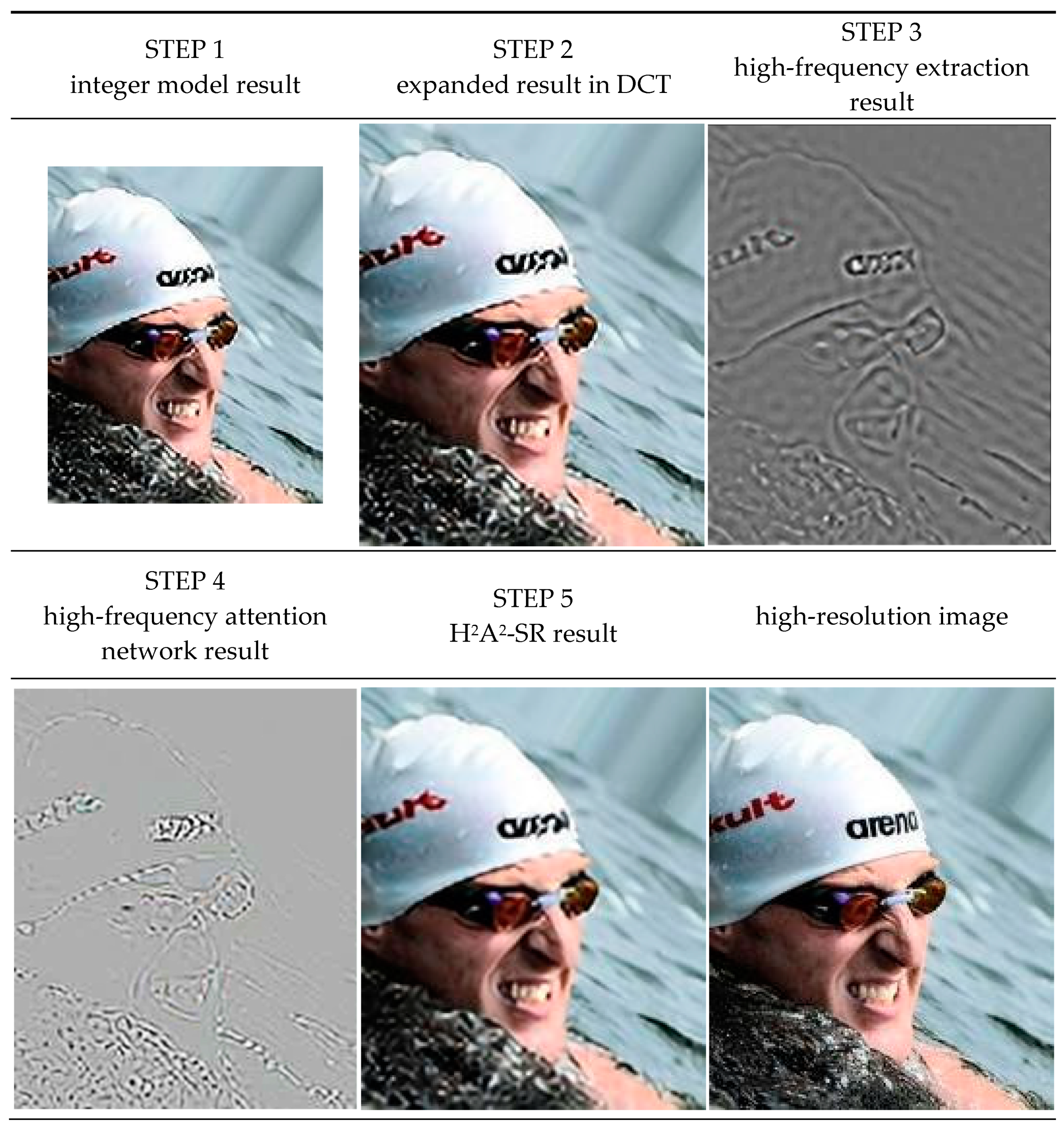
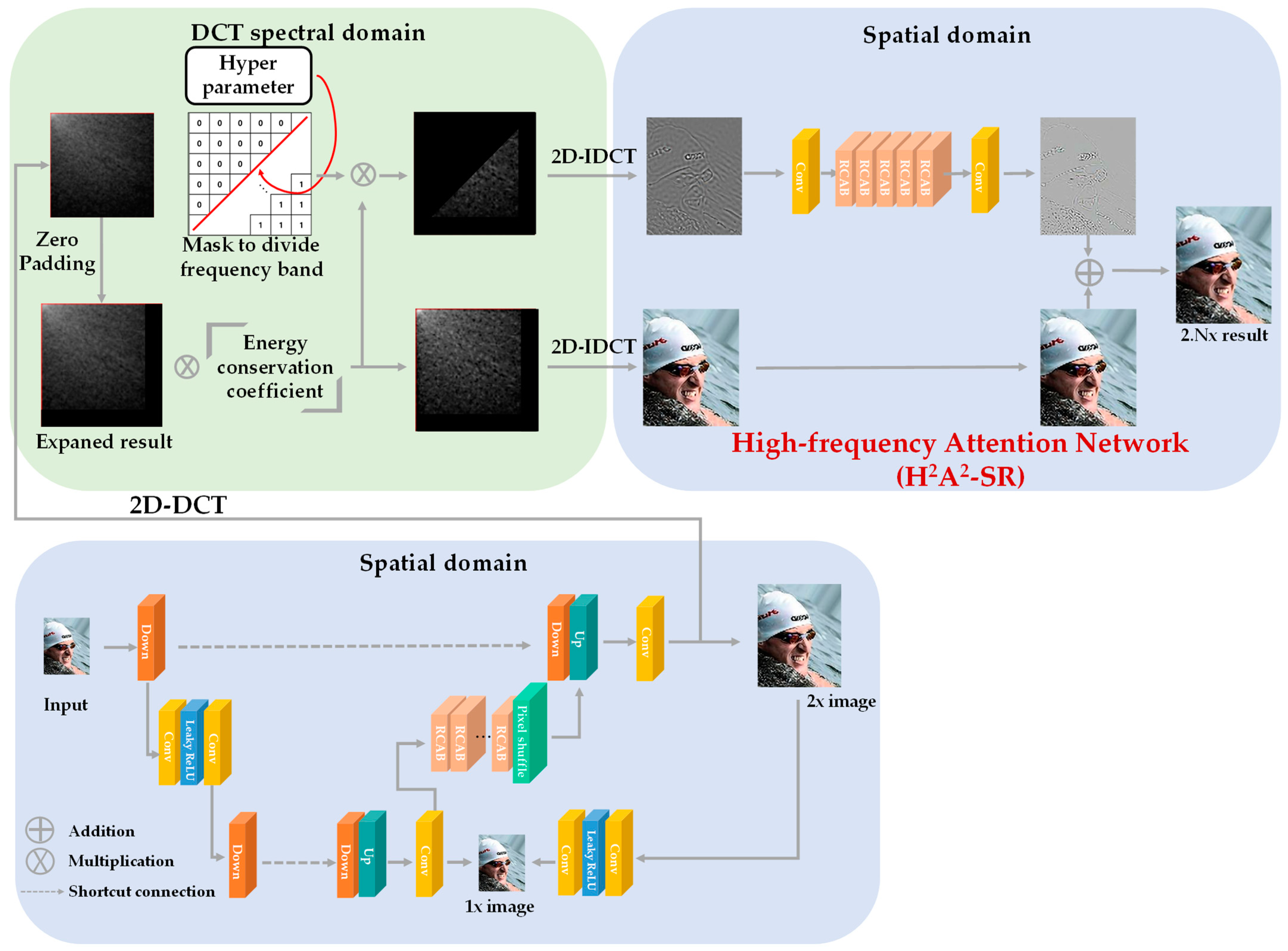
3. Proposed Method
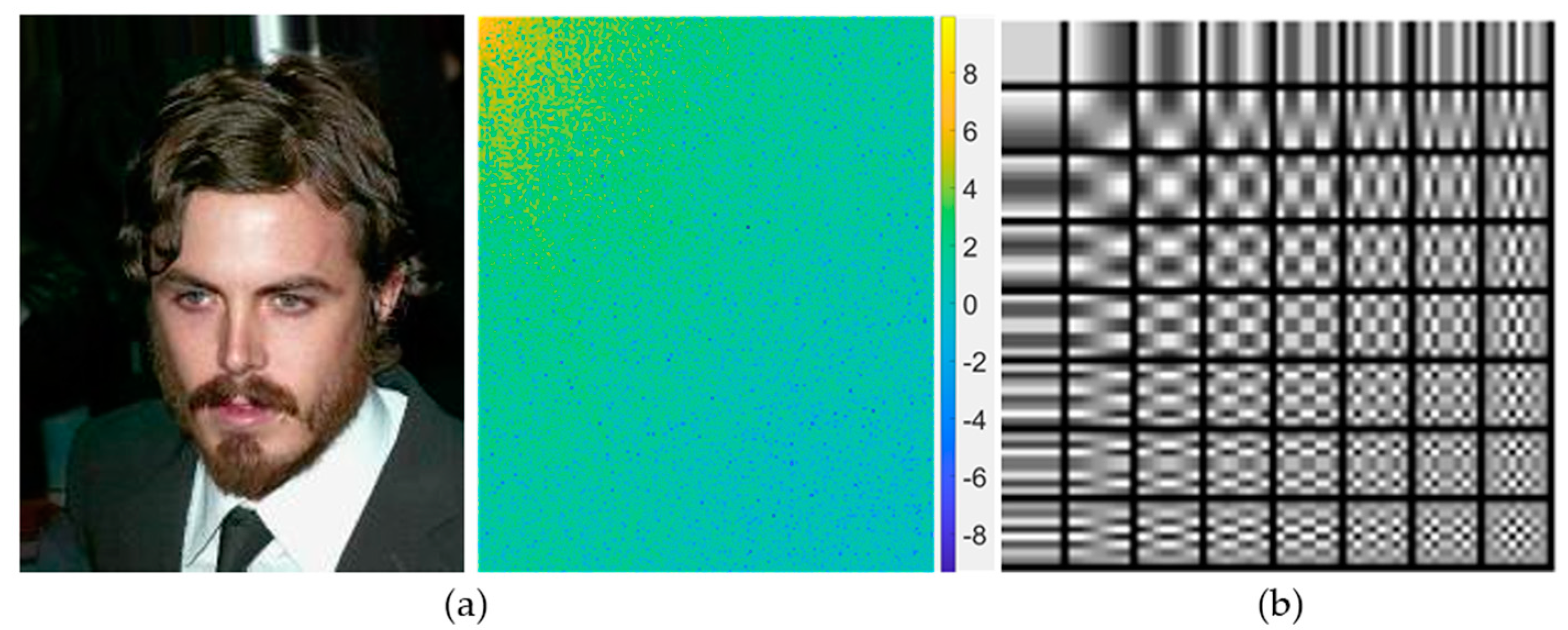
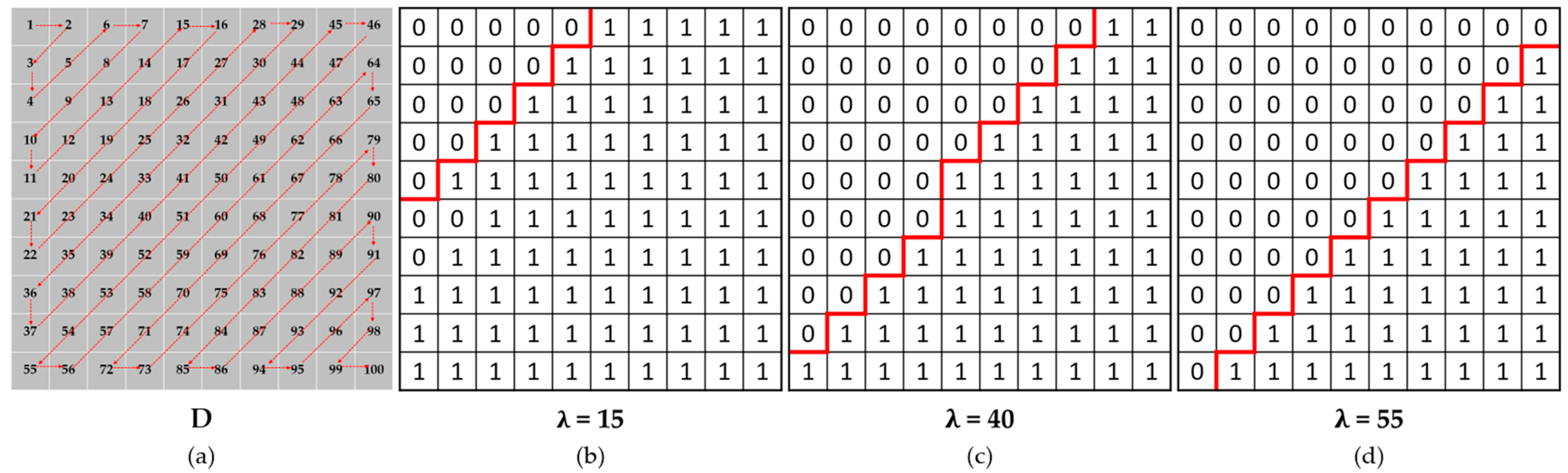
3.1. Discrete Cosine Transform (DCT)
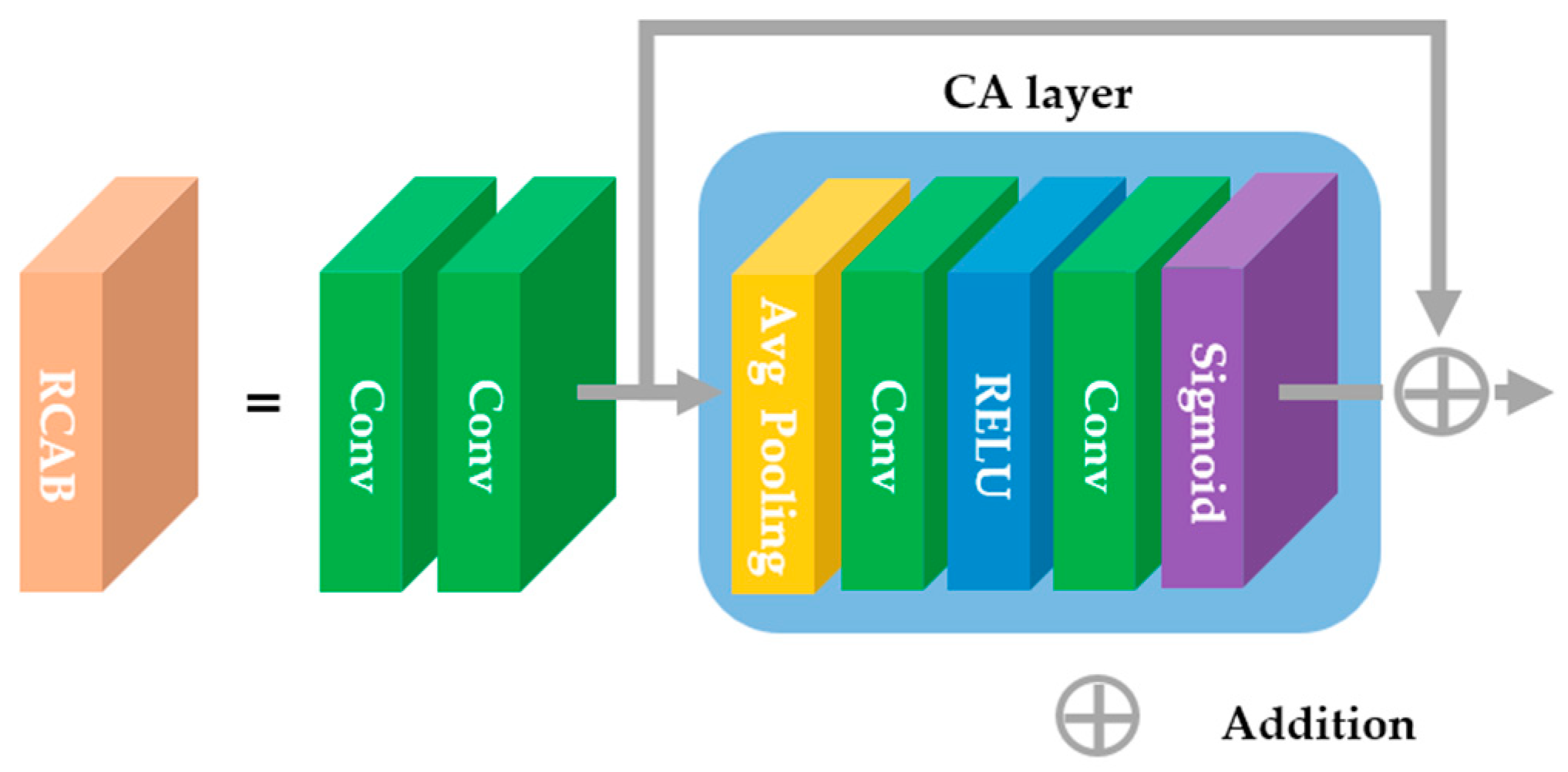
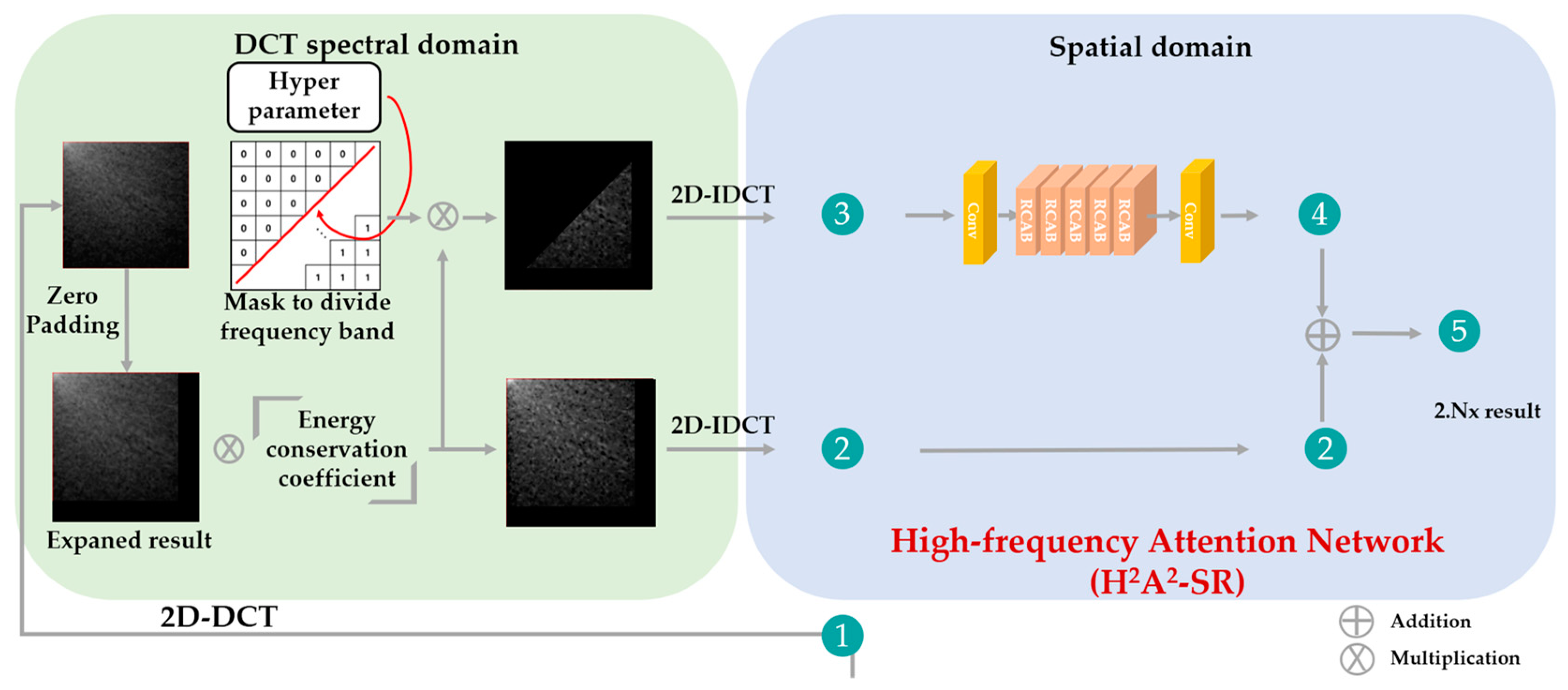
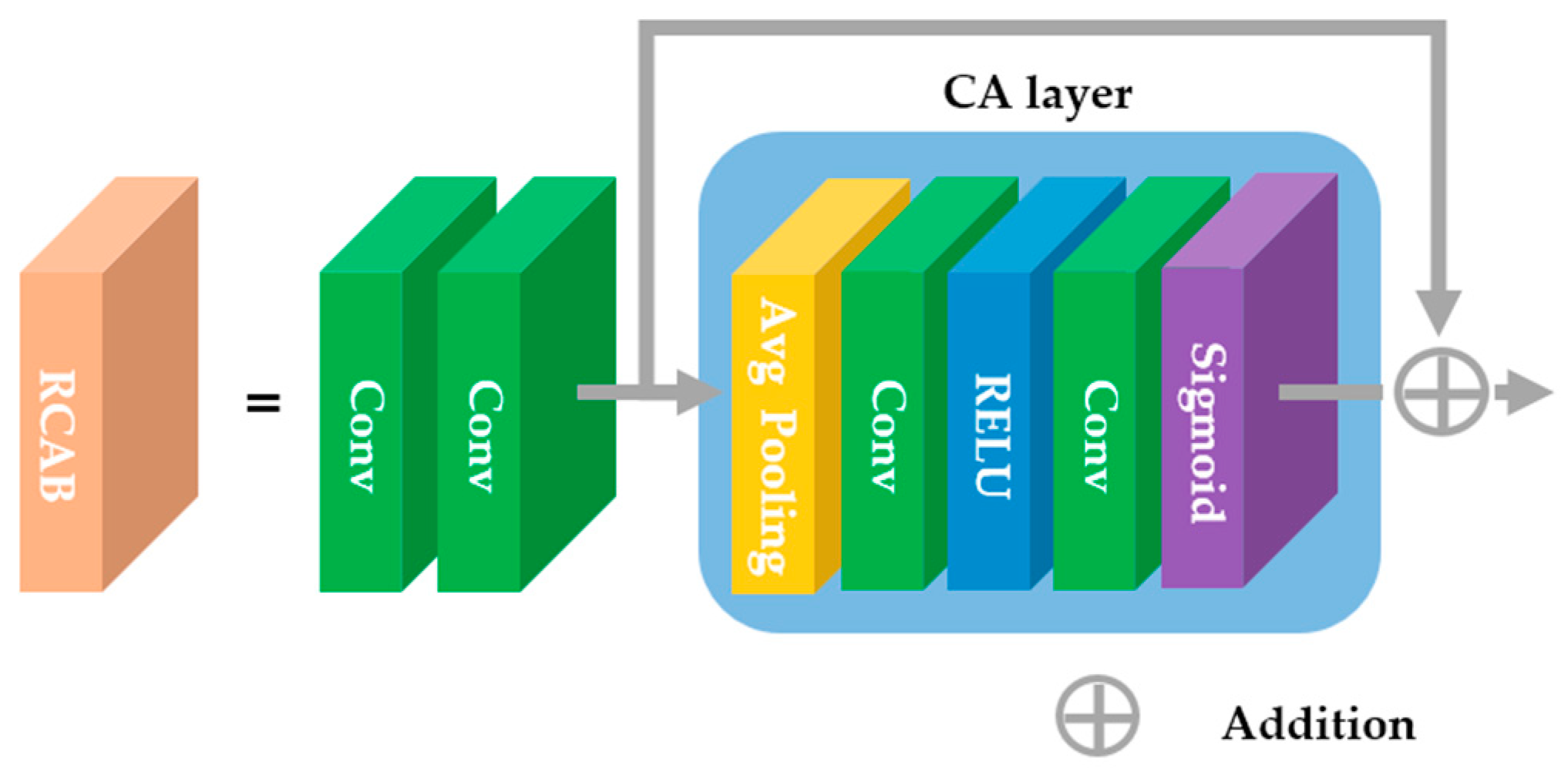
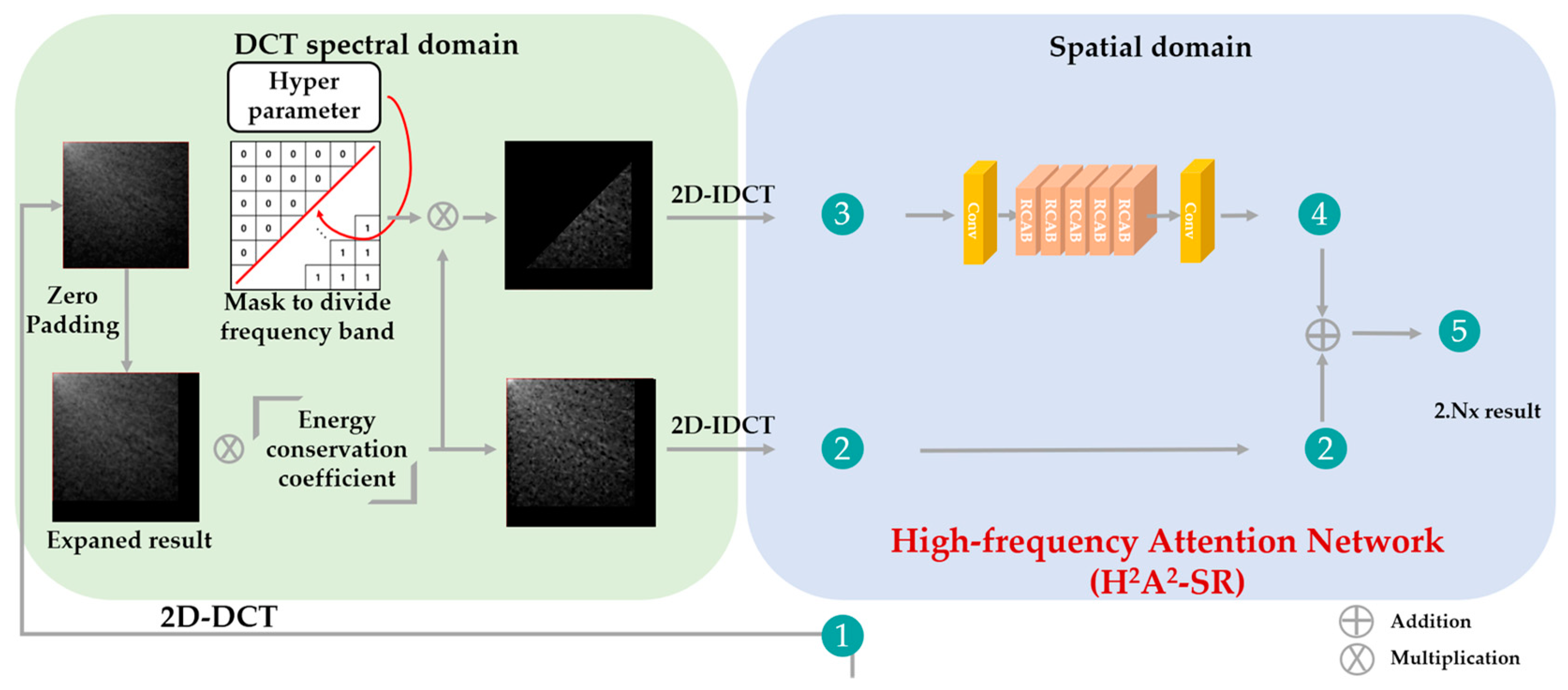
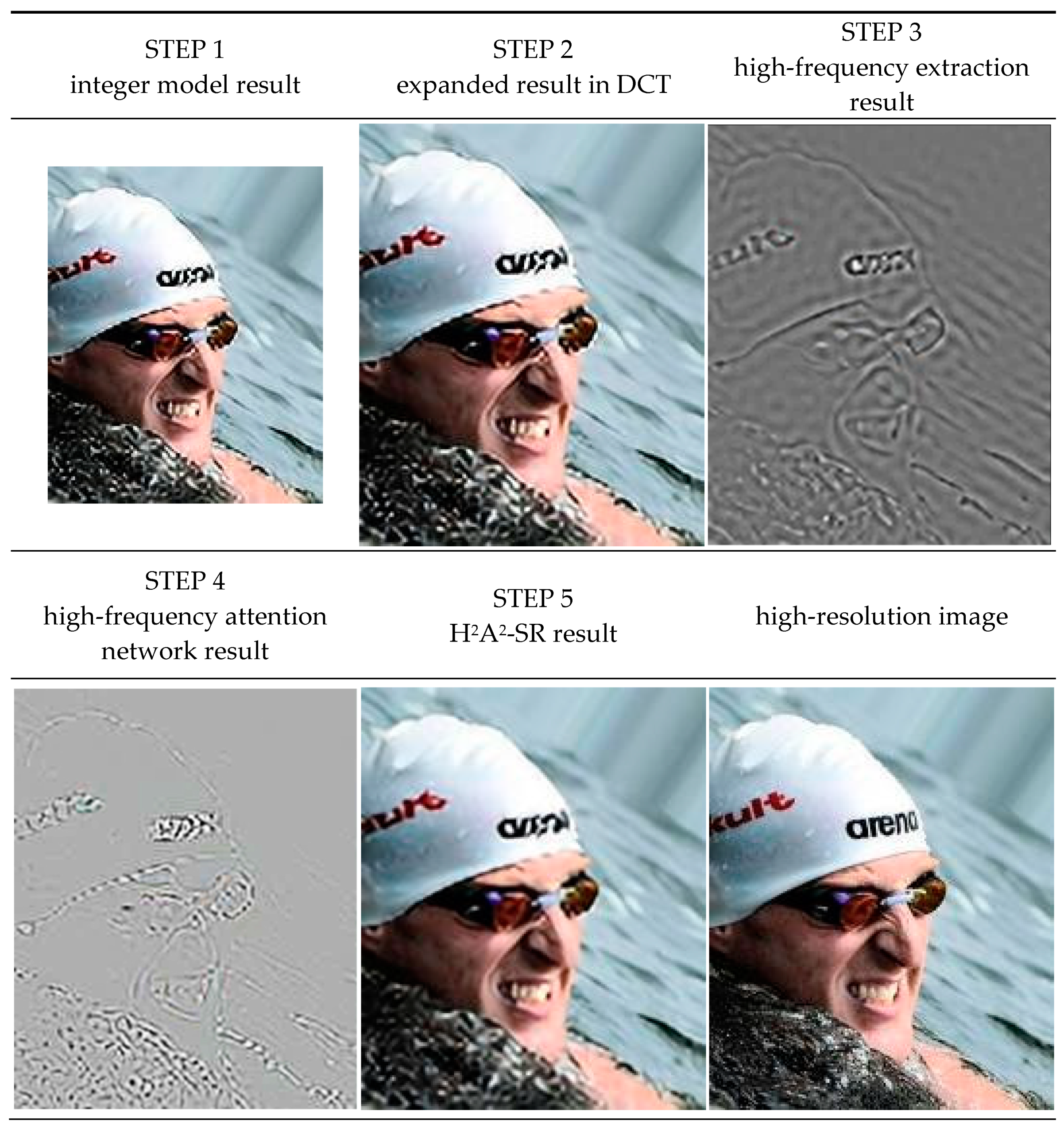
3.2. Hybrid-Domain High-Frequency Attention Network
| Algorithm 1 H2A2-SR model |
| INPUT: low-resolution image (L), target magnification factor (s). OUTPUT: arbitrary magnification image result (O). Step 1: Obtain integer magnification image (I) from L by using the baseline SR model. Step 2: Transform I into the DCT domain. Step 3: Expand to residual decimal magnification (r = s/(s – floor(s))) in the DCT domain. Step 4: Multiply the energy conservation factor (r2) to the expanded image (E). Step 5: Generate a mask (M) according to Equation (6). Step 6: Multiply E and M for high-frequency (H) extraction. Step 7: Convert E and H into the spatial domain through IDCT. Step 8: Make H into 64 channels through the conv layer. Step 9: Recover high-frequency (Hr) through 64 channels and 5 RCAB layers. Step 10: Make Hr into 3 channels through the conv layer. Step 11: Obtain O by adding E and the attention network’s result. |
3.3. Loss Function for High-Frequency Attention Network
4. Experimental Results
4.1. Network Training
4.2. Performance Comparison of Meta-SR and the Proposed Method
4.3. Performance Comparison of the Existing Arbitrary Magnification Method and the Proposed Method
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, S.-J.; Yoo, S.B. Super-resolved recognition of license plate characters. Mathematics 2021, 9, 2494. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 391–407. [Google Scholar]
- Kim, J.W.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Guo, Y.; Chen, J.; Wang, J.; Chen, Q.; Cao, J.; Deng, Z.; Xu, Y.; Tan, M. Closed-loop matters: Dual regression networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5407–5416. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11065–11074. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Gool, L.V.; Timofte, R. Srflow: Learning the super-resolution space with normalizing flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 715–732. [Google Scholar]
- Jo, Y.H.; Yang, S.J.; Kim, S.J. Srflow-da: Super-resolution using normalizing flow with deep convolutional block. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 364–372. [Google Scholar]
- Kim, Y.G.; Son, D.H. Noise conditional flow model for learning the super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 424–432. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van, G.; Timofte, R. SwinIR: Image restoration using swin transformer. In Proceedings of the IEEE International Conference on Computer Vision, Montréal, QC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Stephen, L.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. arXiv 2021, arXiv:2103.14030. Available online: https://arxiv.org/abs/2103.14030 (accessed on 6 November 2021).
- Mei, Y.; Fan, Y.; Zhou, Y.; Huang, L.; Huang, T.S.; Shi, H. Image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5690–5699. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1575–1584. [Google Scholar]
- Son, S.H.; Lee, K.M. SRWarp: Generalized image super-resolution under arbitrary transformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7782–7791. [Google Scholar]
- Wang, L.; Wang, Y.; Lin, Z.; Yang, J.; An, W.; Guo, Y. Learning a single network for scale-arbitrary super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Montréal, QC, Canada, 11–17 October 2021; pp. 4801–4810. [Google Scholar]
- Kumar, N.; Verma, R.; Sethi, A. Convolutional neural networks for wavelet domain super resolution. Pattern Recognit. Lett. 2017, 90, 65–71. [Google Scholar] [CrossRef]
- Li, J.; You, S.; Kelly, A.R. A frequency domain neural network for fast image super-resolution. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Xue, S.; Qiu, W.; Liu, F.; Jin, X. Faster image super-resolution by improved frequency-domain neural networks. Signal Image Video Process. 2019, 14, 257–265. [Google Scholar] [CrossRef]
- Aydin, O.; Cinbiş, R.G. Single-image super-resolution analysis in DCT spectral domain. Balk. J. Electr. Comput. Eng. 2020, 8, 209–217. [Google Scholar] [CrossRef]
- Zhu, J.; Tan, C.; Yang, J.; Yang, G.; Lio, P. Arbitrary Scale Super-Resolution for Medical Images. Int. J. Neural Syst. 2021, 31, 2150037. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; He, D. A unified network for arbitrary scale super-resolution of video satellite images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 8812–8825. [Google Scholar] [CrossRef]
- Truong, A.M.; Philips, W.; Veelaert, P. Depth Completion and Super-Resolution with Arbitrary Scale Factors for Indoor Scenes. Sensors 2021, 21, 4892. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Large-Scale CelebFaces Attributes (CelebA) Dataset. p. 11. Available online: https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html (accessed on 15 August 2018).
- Timofte, R.; Agustsson, E.; Gool, L.V.; Yang, M.H.; Zhang, L.; Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the European Conference on Computer Vision, Glasgow, Scotland, 23–28 August 2020; pp. 191–207. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages (Characteristics) | Shortcomings |
|---|---|---|
| SRCNN | Uses only three convolutional layers and enhances the performance of super-resolution. | Perform integer super-resolution only and should utilize interpolation methods to perform the arbitrary magnification super-resolution. |
| VDSR | Cascades small filters many times; information over an image is exploited in an efficient way. | |
| ESPCNN | Effectively replacing the bicubic filter, computing cost is reduced. | |
| DBPN | Concatenates the features of the repeated upsampling and downsampling, super-solution performance improved. | |
| RCAN | Bypasses multiple skip connections and focuses on learning high-frequency information. | |
| DRN | Estimates kernel and utilizes it to restore low-resolution images. | |
| RDN | Learns hierarchical representation and stabilizes the training process. | |
| SAN | Rescales the features adaptively and learns feature expressions and feature correlation. | |
| SRGAN | Uses adversarial learning and recovers heavily downsampled images. | |
| SRFlow-DA | Enlarges the receptive field and takes more expressive power. | |
| NCSR | Adds the noise conditional layer and extends diversity. | |
| SwinIR | Applies a Swin transformer and utilizes interactions between image content and attention weights. | |
| CSNLN | Finds and utilizes more cross-scale feature correlations. |
| Method | Advantages (Characteristics) | Shortcomings |
|---|---|---|
| Meta-SR | Upscales images with arbitrary scale factors through a single model. | Cannot preserve the integer super-resolution performance due to the replacement of the upscale module. |
| SRWarp | Uses a multiscale blending and handles numerous possible deformations. | Focuses on the warp of the image and is similar to Meta-SR performance. |
| Wang et al.’s | Uses multiple scale-aware feature adaption blocks and a scale-aware upsampling layer. | Needs additional training of integer super-resolution model due to the replacement of the existing module. |
| Method | Advantages (Characteristics) | Shortcomings |
|---|---|---|
| CNNW SR | Predicts the wavelet coefficients of three images that can be used for image restoration. | Provide lower performance than other spatial domain super-resolution models despite the fast speed. |
| FNNSR | Applies Fourier transform to super-resolution and is faster than the alternatives. | |
| IFNNSR | Learns the basic features in transformed images. | |
| Aydin et al.’s | Predicts DCT coefficients and reconstruct an image in the DCT spectral domain. |
| PSNR (dB)/SSIM on CelebA with Arbitrary Scale Factors | |||||||
|---|---|---|---|---|---|---|---|
| Method | Metric | ×2.2 | ×2.5 | ×2.8 | ×3.2 | ×3.5 | ×3.8 |
| DRN + Meta-SR | PSNR SSIM | 29.02 0.7268 | 31.37 0.7665 | 31.33 0.7696 | 27.51 0.6494 | 28.14 0.6533 | 28.00 0.6437 |
| DRN + Meta-SR* | PSNR SSIM | 33.80 0.8462 | 32.91 0.8142 | 31.80 0.7787 | 31.94 0.7618 | 31.41 0.7487 | 30.20 0.7024 |
| DRN + H2A2-SR (ours) | PSNR SSIM | 35.23 0.8766 | 33.98 0.8476 | 32.98 0.8201 | 32.22 0.7978 | 31.52 0.7788 | 30.77 0.7543 |
| PSNR (dB)/SSIM on B100 with Arbitrary Scale Factors | |||||||
|---|---|---|---|---|---|---|---|
| Method | Metric | ×2.2 | ×2.5 | x2.8 | ×3.2 | ×3.5 | ×3.8 |
| RDN + bicubic | PSNR SSIM | 27.34 0.8087 | 26.87 0.7849 | 26.25 0.7586 | 25.88 0.7086 | 25.33 0.6906 | 24.86 0.6728 |
| HAN + bicubic | PSNR SSIM | 28.39 0.8180 | 27.42 0.7852 | 26.51 0.7563 | 25.88 0.7102 | 25.26 0.6914 | 24.77 0.6731 |
| CSNLN + bicubic | PSNR SSIM | 29.52 0.8471 | 28.21 0.8072 | 26.28 0.7221 | 24.89 0.6739 | 24.377 0.6639 | 24.28 0.6543 |
| SwinIR + bicubic | PSNR SSIM | 28.50 0.8162 | 27.28 0.7954 | 26.75 0.7866 | 25.86 0.6973 | 25.40 0.6961 | 24.47 0.6639 |
| RDN + Meta-SR* | PSNR SSIM | 28.51 0.8262 | 28.19 0.8063 | 27.41 0.7801 | 27.01 0.7530 | 26.50 0.7315 | 25.95 0.7075 |
| RDN + H2A2-SR | PSNR SSIM | 29.52 0.8473 | 28.31 0.8097 | 27.63 0.7819 | 27.34 0.7638 | 26.81 0.7433 | 26.32 0.7237 |
| PSNR (dB) on CelebA with Arbitrary Scale Factors | |||||||
|---|---|---|---|---|---|---|---|
| Method | Metric | ×2.2 | ×2.5 | ×2.8 | ×3.2 | ×3.5 | ×3.8 |
| Without high-frequency attention model | PSNR | 30.89 | 29.62 | 28.48 | 31.73 | 30.90 | 30.15 |
| DRN + H2A2-SR (ours) | PSNR | 35.23 | 33.98 | 32.98 | 32.22 | 31.52 | 30.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yun, J.-S.; Yoo, S.-B. Single Image Super-Resolution with Arbitrary Magnification Based on High-Frequency Attention Network. Mathematics 2022, 10, 275. https://doi.org/10.3390/math10020275
Yun J-S, Yoo S-B. Single Image Super-Resolution with Arbitrary Magnification Based on High-Frequency Attention Network. Mathematics. 2022; 10(2):275. https://doi.org/10.3390/math10020275
Chicago/Turabian StyleYun, Jun-Seok, and Seok-Bong Yoo. 2022. "Single Image Super-Resolution with Arbitrary Magnification Based on High-Frequency Attention Network" Mathematics 10, no. 2: 275. https://doi.org/10.3390/math10020275
APA StyleYun, J.-S., & Yoo, S.-B. (2022). Single Image Super-Resolution with Arbitrary Magnification Based on High-Frequency Attention Network. Mathematics, 10(2), 275. https://doi.org/10.3390/math10020275