Abstract
A non-iterative method for the difference of means is presented to calculate the log-Euclidean distance between a symmetric positive-definite matrix and the mean matrix on the Lie group of symmetric positive-definite matrices. Although affine-invariant Riemannian metrics have a perfect theoretical framework and avoid the drawbacks of the Euclidean inner product, their complex formulas also lead to sophisticated and time-consuming algorithms. To make up for this limitation, log-Euclidean metrics with simpler formulas and faster calculations are employed in this manuscript. Our new approach is to transform a symmetric positive-definite matrix into a symmetric matrix via logarithmic maps, and then to transform the results back to the Lie group through exponential maps. Moreover, the present method does not need to compute the mean matrix and retains the usual Euclidean operations in the domain of matrix logarithms. In addition, for some randomly generated positive-definite matrices, the method is compared using experiments with that induced by the classical affine-invariant Riemannian metric. Finally, our proposed method is applied to denoise the point clouds with high density noise via the K-means clustering algorithm.
1. Introduction
The difference of means method is usually employed in detection problems. Its procedure can be described as Figure 1: for the detected element , the distance between and the mean of the reference elements , is computed. If the distance is bigger than the present value, we can conclude that can be distinguished from the reference elements. For example, the difference of means method is applied to detect abnormal conditions in clustered enterprise middleware systems [1,2,3]. In [4], an algorithm is proposed to detect the change-points of rigid body motions, which is defined as the difference of means method in the special Euclidean group. Based on the difference of means method, a geometric approach is developed for high-resolution Doppler processing and shows the existence of targets in fixed directions of some elements [5].
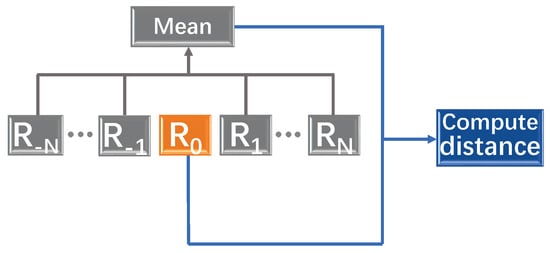
Figure 1.
The difference of means method.
In the field of coastal radars, the issue of detecting small targets and stealth targets in a non-uniform clutter environment is vital. Recently, a high-resolution Doppler detector was proposed by Ref. [6] using the difference of means method, and the X-band radar experiments at Paris Airport show that the performance of Doppler imaging and Doppler detection has been improved. Their purpose of target detection is to judge whether there are targets in some cells according to the observed values. Based on the affine-invariant Riemannian metric, they developed an iterative algorithm for the Riemannian mean of some symmetric positive-definite Hermitian matrices.
In this paper, we propose a non-iterative method to compute the distance between a symmetric positive-definite matrix and the mean matrix on the Lie group of symmetric positive-definite matrices. Although affine-invariant Riemannian metrics, which avoid the drawbacks of Euclidean inner product, have a perfect theoretical framework, their complex formulas also lead to sophisticated and time-consuming algorithms [7,8]. Therefore, we use log-Euclidean metrics to obtain simpler formulas and faster calculations [9,10,11]. As the Lie algebra of the Lie group is the space of symmetric matrices, we transform the Riemannian computations on the Lie group into Euclidean computations on its Lie algebra. Finally, our proposed method is applied to denoise the point clouds with high density noise via the K-means clustering algorithm.
Our first contribution is that a non-iterative method for calculating the log-Euclidean distance between a symmetric positive-definite matrix and the mean matrix is obtained, and the mean matrix does not need to be calculated. Our second contribution is applied our proposed method to denoise the point clouds with high density noise via the K-means clustering algorithm, and the denoising effect of the method is evaluated by three criteria: Accuracy, Recall and Precision.
The remaining sections of this paper are as follows: Section 2 reviews the geometry on the space of symmetric positive-definite matrices, including metrics, geodesics and geodesic distances. In Section 3, a non-iterative method is presented to compute the distance between a matrix and the mean matrix on the Lie group of symmetric positive-definite matrices, and the method is compared with classical algorithms using simulations. Section 4 shows the effectiveness of our developed method to denoise the point clouds with high density noise.
2. Preliminaries
In this section, we introduce some concepts, including Euclidean metrics, affine-invariant Riemannian metrics and log-Euclidean metrics on the space of symmetric positive-definite matrices. More details are discussed in Refs. [12,13,14,15].
2.1. Exponential Map and Logarithmic Map
The set of all invertible real matrices is known as the general linear group . The set of all real matrices is denoted by , where is a differentiable manifold and is the Lie algebra . Exponential maps and logarithmic maps can transmit the information between and . Here, the exponential map of a matrix is and expressed by the convergent series
On the other hand, the logarithmic map is the local inverse of the exponential map, denoted by log and the logarithmic map of a matrix is the solution of the equation . When all eigenvalues of A are non-negative, there exists a unique real logarithm, whose spectrum is just in the scope of the complex plane [16]. Furthermore, if A is in a neighborhood of the identity matrix I, then the series converges to . The logarithmic map is shown in
Let us denote the set of all the symmetric matrices by
and the set of all the symmetric positive-definite matrices by
where implies that the quadratic form for all non-zero n-dimensional vectors x. For a general invertible matrix, the uniqueness and existence of logarithmic maps may not be available. The logarithm of a symmetric positive-definite matrix is well defined and is a symmetric matrix. Moreover, since the exponential map from to is one-to-one and onto, the exponential map of any symmetric matrix is symmetric positive-definite.
2.2. Frobenius Inner Product
On , the Frobenius inner product is
where is the trace of , hence with the metric (5) is taken as a manifold. The tangent space at the point is written as . Since is an open subset of , the tangent space at A can be identified with . The geodesic at A in the direction of with the metric (5) is a straight line
with , where t is sufficiently small so that the geodesic (6) remains on . The associated norm defines the Euclidean distance on as follows
2.3. Affine-Invariant Riemannian Metric
The Riemannian metric at point A is defined by
with , where with the metric (8) is a Riemannian manifold.
At point , the geodesic in the direction is given by
which is entirely contained on . It is noted that with the metric (8) is geodesically complete [17], then a geodesic curve can be obtained for any given matrices , which satisfies that , and the initial velocity . The Riemannian distance between A and B is represented as
The following action of a matrix is defined by
This group action describes the influence of the general affine change of coordinates on the matrix . In addition, this action is naturally extended to tangent vectors in the same way. For example, if is a curve passing through A with tangent vector V, then the curve passes through with tangent vector . Moreover, is isometric for any invertible matrix U, namely
so the Riemannian metric (8) is affine-invariant.
2.4. Log-Euclidean Riemannian Metric
Here, becomes a Lie group by defining a logarithmic multiplication ⊙ as follows
The log-Euclidean metric between tangent vectors and at the point is given by
where denotes the differential map at the point A. Then, the geodesic between A and B is given by
and it can see that is a straight line in the domain of matrix logarithms. From (14), the log-Euclidean distance between A and B is written as
It is evident that the Formula (16) corresponds to the Euclidean distance in the logarithmic domain. From the above formulas, we can see that the framework of the log-Euclidean metric is simpler than that of the affine-invariant metric (8).
Moreover, the log-Euclidean metrics satisfy the following invariance property
with . Although the log-Euclidean metrics do not entirely satisfy affine-invariant conditions, they are similarity invariant by an orthogonal transformation
where is an orthogonal matrix and is a scaling factor.
3. Non-Iterative Method for the Difference of Means on
In this section, for given matrices on , we present a non-iterative method to calculate the distance between a matrix and the mean of the remaining matrices. As an introduction, we first review the concept of the mean matrix associated with different metrics.
3.1. Mean Matrices Associated with Different Metrics
For a given metric, the associated mean of m matrices on is defined as the matrix minimizing the cost function
where corresponds to the metric.
First, the mean matrix induced by the Frobenius inner product (5) is represented as
which is the usual arithmetic mean. Via the convexity of , the Frobenius inner product can still be used, but utilizing with this flat metric dose not result in a geodesically complete space. Because of this, it may not be appropriate to adopt the arithmetic mean on this manifold (see Ref. [6]).
The Riemannian mean associated with the affine-invariant metric (8) is not explicit, as denoted by . It can only be computed by the following iterative algorithm [6]
where means the k-th iteration of and is the learning rate.
Next, the Riemannian mean in the log-Euclidean case is given. The following lemmas are useful for calculating the Riemannian mean [12,18].
Lemma 1.
Let denote function-valued matrices and A be a constant matrix. We have
Moreover, if the matrix X is invertible and all its eigenvalues are positive, then
Lemma 2.
Let denote a scalar function of matrix X. We have the following properties
is equivalent to
where stands for the gradient of at X.
By the above lemmas, we get the Riemannian mean with the log-Euclidean metric as follows.
Lemma 3.
For m given matrices on , the Riemannian mean with the associated log-Euclidean metric (14) is obtained by
Proof.
Using Lemma 1, the differential of the cost function at A is
By means of Lemma 2 and the symmetry of matrices on , we can obtain the gradient of at A as
The necessary condition and sufficient condition for A to be the minimum of is
and the explicit expression of A is given by
With this, the proof is completed. □
3.2. Non-Iterative Method for the Difference
With the above work, a non-iterative method is proposed to calculate the Riemannian distance between a matrix and the mean of some matrices.
For given on , plays the role of being detected matrices in the algorithms proposed by Refs. [1,5,6].
Since the affine-invariant Riemannian framework with the iterative Formula (21) contains matrix exponential, logarithm, square root and inverse operations, it is time-consuming in practical applications. Although several other scholars have also proposed gradient descent algorithms for the Riemannian mean [6,19,20], all these algorithms are iterative. Therefore, the log-Euclidean Riemannian framework is adopted in our method so that computations on the Lie group being a Riemannian manifold is transformed to calculations on being a Euclidean space in the domain of matrix logarithms.
Initially, we transform all the matrices into symmetric matrices by the matrix logarithm
where . Then, let and
stands for the right weighted mean of after and stands for the left weighted mean of before . Therefore, we can represent the log-Euclidean distance between and by the following theorem, where stands for .
Theorem 1.
For given on , the log-Euclidean distance between and the mean of the remain matrices is obtained by
Proof.
From Lemma 3 and (17), the log-Euclidean distance between and the mean of the remain ing matrices is given by
We can rewrite the Formula (39) as follows
This means that can be expressed by the difference of the right mean and the left mean .
This completes the proof of Theorem 1. □
Obviously, the Formula (38) for calculating the log-Euclidean distance between and the mean of the remain matrices is non-iterative, and the Riemannian mean does not need to be computed. with the log-Euclidean metric (14) is isomorphic and isometric with the corresponding Euclidean [15], therefore the calculation in the Log-Euclidean framework should be time-efficient.
3.3. Numerical Examples
Three examples are provided in the present subsection. One illustrates the difference of the arithmetic mean, the affine-invariant mean and the log-Euclidean mean on . Two other examples demonstrate the numerical behavior of our proposed method for the calculation of and compares the performance with the algorithm proposed by Ref. [6].
In the following simulations, the error criterion of the iterative Formula (21) is
and all samples on are generated by the rule
where is a random matrix so that .
Example 1.
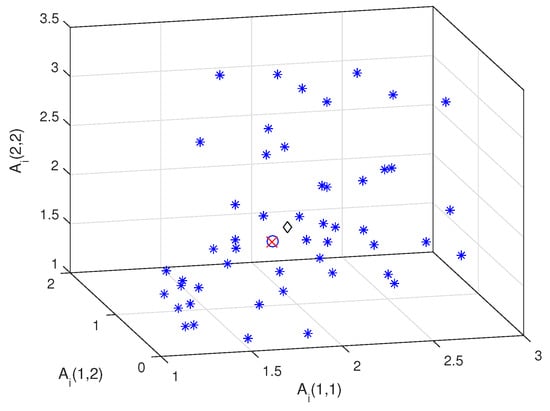
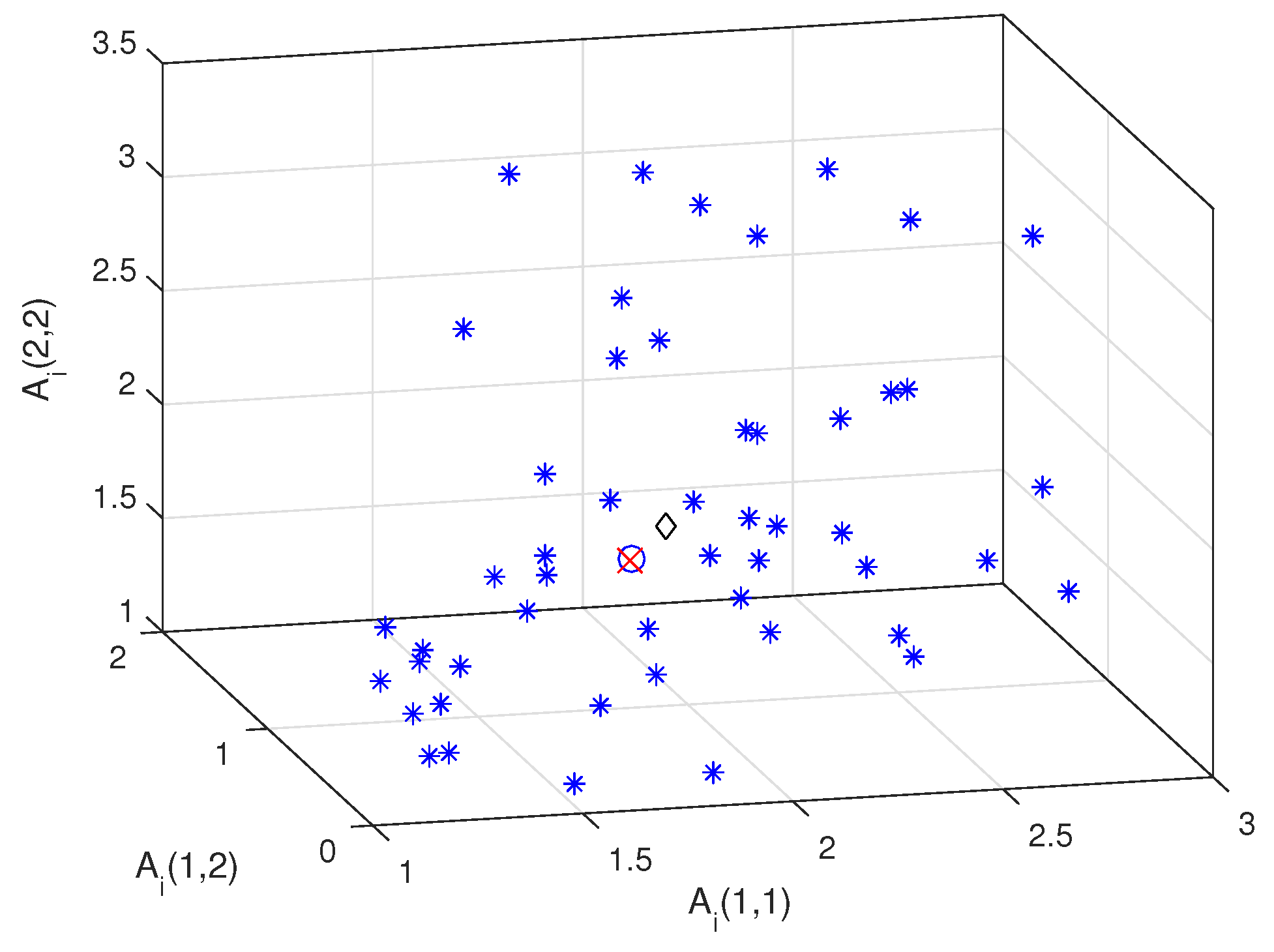
First, we consider a 3-dimensional manifold to display symmetric positive-definite matrices in the XYZ system. Figure 2 shows the arithmetic mean (diamond), the affine-invariant mean (circle) and the log-Euclidean mean (cross) of 50 randomly generated matrices (asterisk). It can be seen that the locations of the log-Euclidean mean are very close to that of the affine-invariant mean.
Figure 2.
Mean of 50 samples.
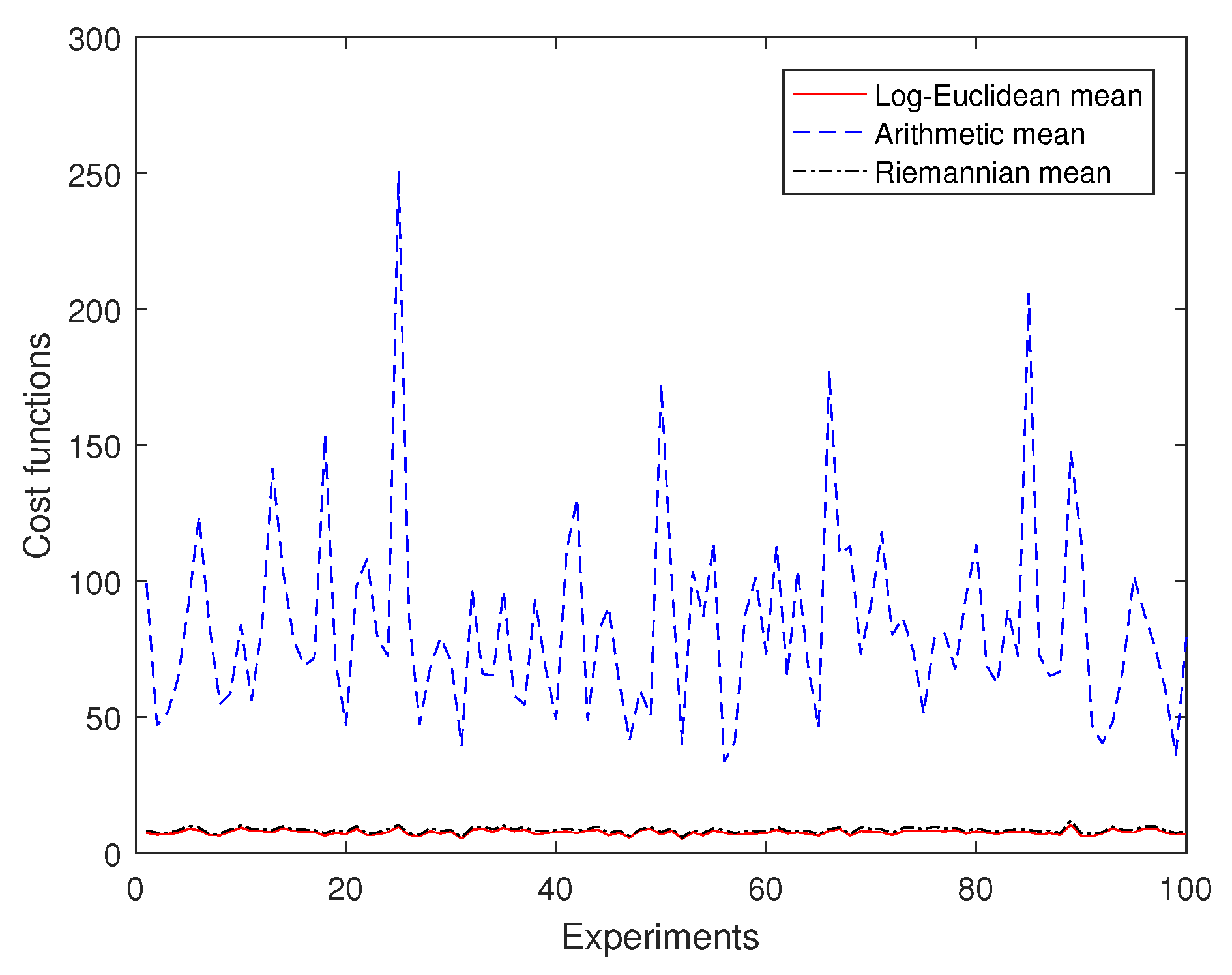
Then, for 10 randomly generated samples on , we use 50 experiments to compare the cost functions of the arithmetic mean, the affine-invariant mean and the log-Euclidean mean. Figure 3 shows that the cost function of the log-Euclidean mean is the smallest of them, and that the cost function of the arithmetic mean is much larger than the others. It can be seen that the cost function of the log-Euclidean mean is very close to that of the Riemannian mean, and the difference between them is less than 1.3 for this set of experimental data.
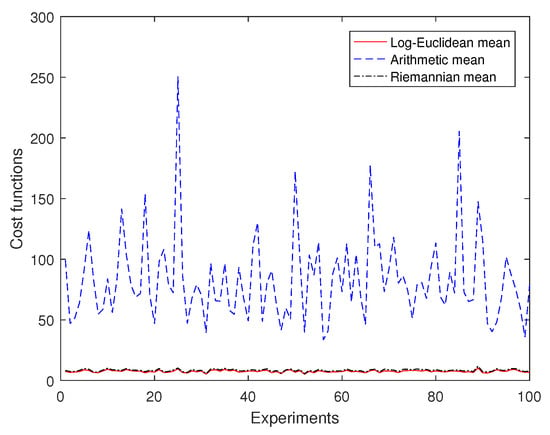
Figure 3.
Comparison of cost functions.
Therefore, it is shown that the log-Euclidean mean and the Riemannian mean are more suitable than the arithmetic mean on .
Example 2.
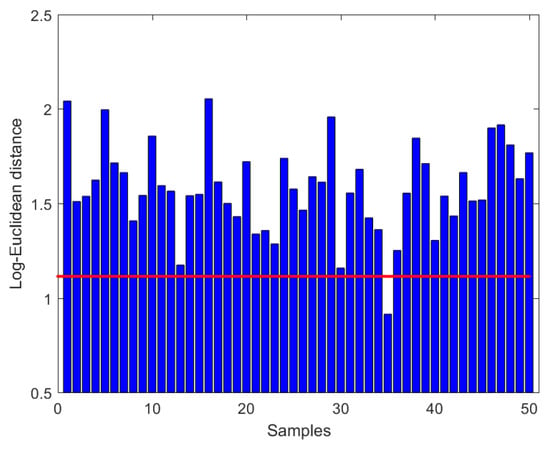
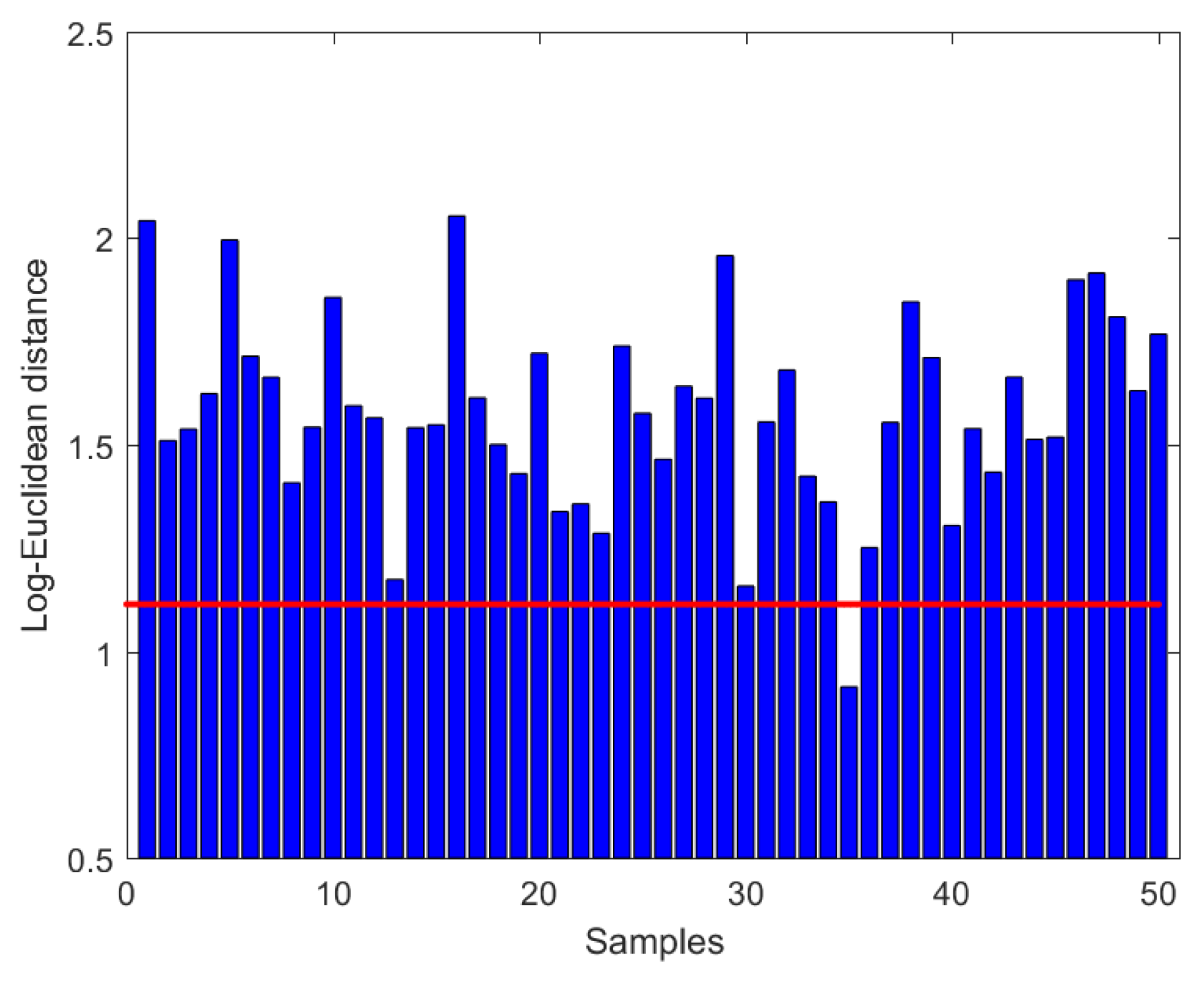
Let and in Theorem 1, 51 randomly generated samples on are then employed to verify the effectiveness of our method. Figure 4 shows that the log-Euclidean distance between and the mean is 1.1141 (straight line) and the bar graphs denote the log-Euclidean distance from the log-Euclidean mean to each sample.
Figure 4.
Log-Euclidean distance to samples.
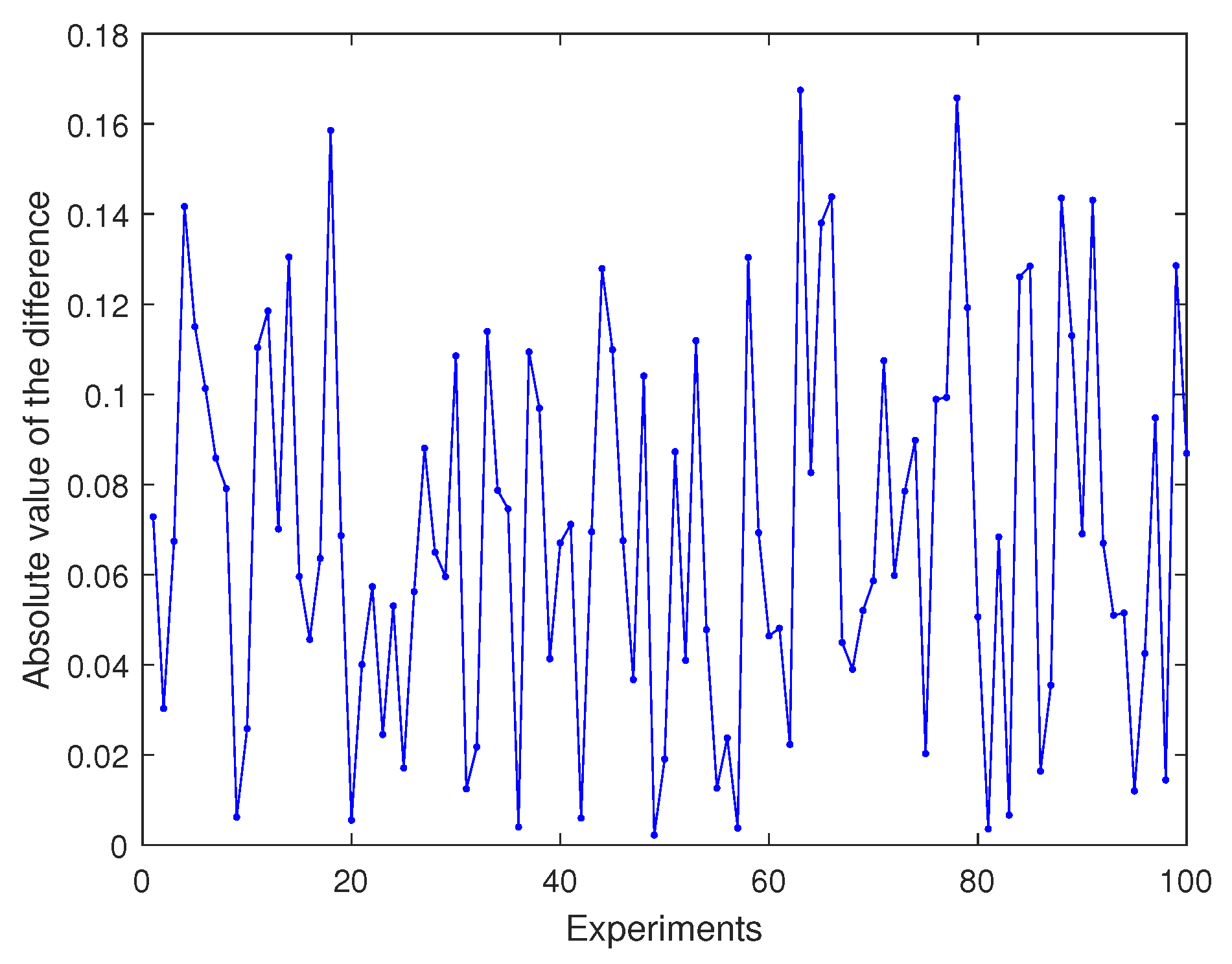
Then, we use 100 experiments to compare our method with that developed by Ref. [6]. Figure 5 shows that the absolute value Moreover, our method is non-iterative, and the log-Euclidean framework is simpler than that of Ref. [6]. It is obvious that our approach is more time-efficient. Thus, we do not compare the computing time of the two methods in the above simulations.
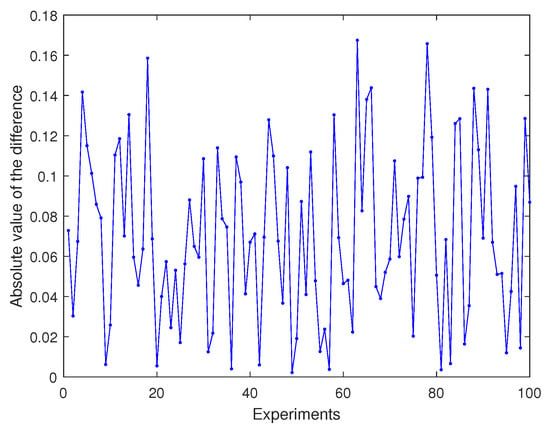
Figure 5.
Absolute value of the difference gotten by two methods.
In conclusion, our non-iterative method in log-Euclidean framework is effective, and the calculation results are very close to those of the classical method proposed by Ref. [6].
Example 3.
In this example, the difference of means method is used to judge whether there are target matrices in detected matrices.
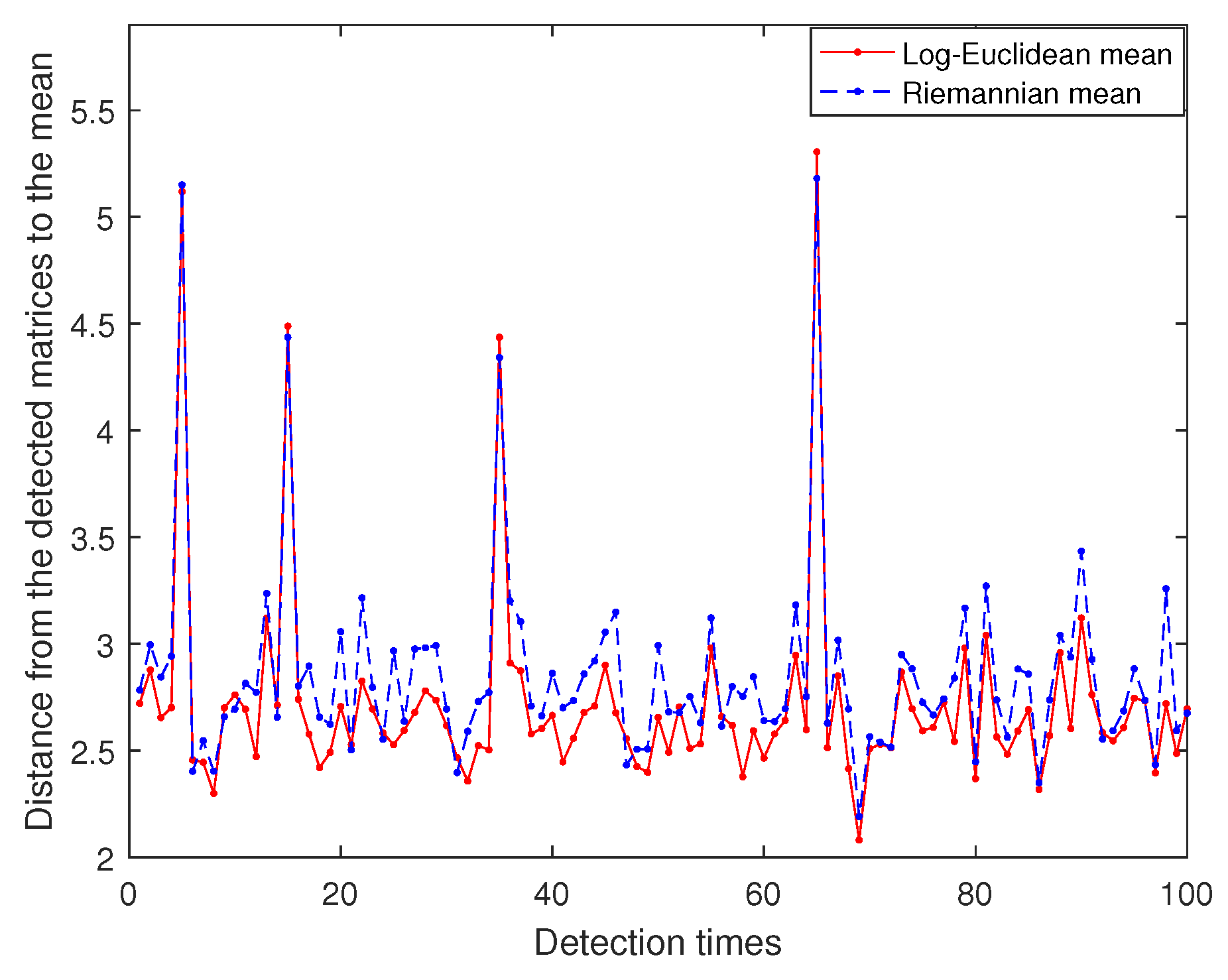
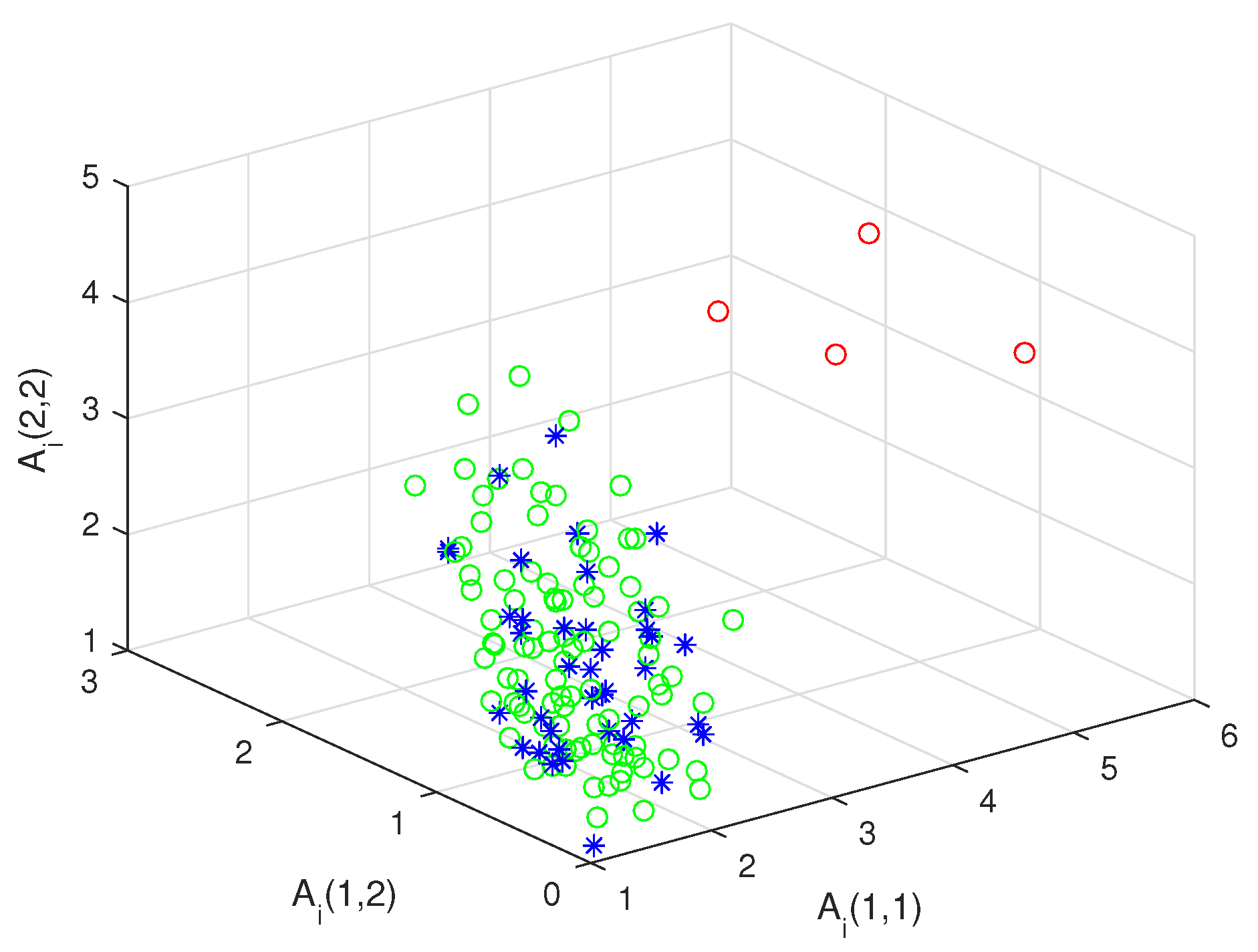
First, let and , we could get 100 random detected matrices and 40 randomly reference matrices , on , where are obtained by adding to random symmetric positive-definite matrices matrices. For each detected matrix , the distance between and the mean of the reference matrices is, respectively, calculated by our non-iterative method in Theorem 1 and the algorithm proposed by Ref. [6]. Figure 6 shows the distance curves produced by the two methods are in good agreement and can be clearly distinguished from the reference matrices. Then, similar to the above process, we set and display 100 randomly detected matrices ( circle) and 40 randomly reference matrices (blue asterisk) in XYZ system. In Figure 7, it is seen that (red circle) are far from the reference matrices. Consequently, our deference of means method is more valid to seek the target matrices than the algorithm developed by Ref. [6].
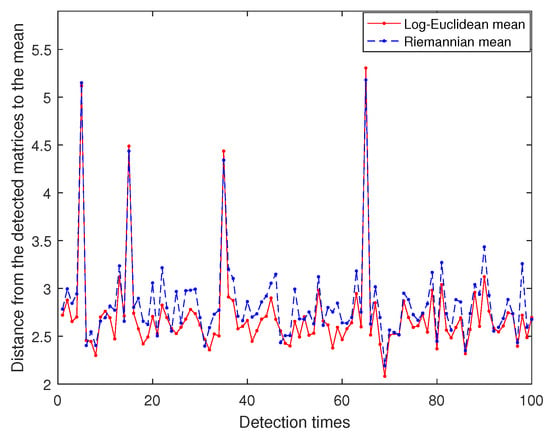
Figure 6.
Distance from the detected matrices to the mean.
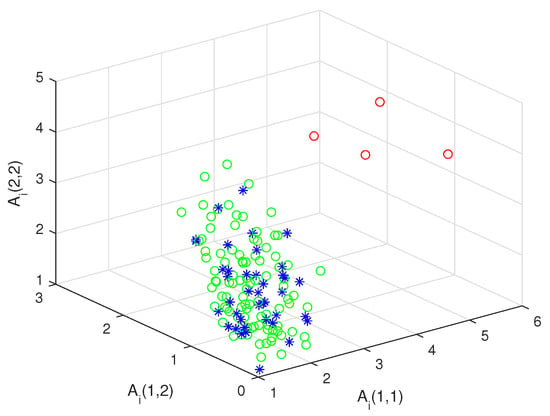
Figure 7.
Target matrices.
4. Application to Point Cloud Denoising
In this section, the method for the difference of means is applied to denoise the point clouds with high density noise via the K-means clustering algorithm. When there is a considerable distance between data within a cluster, the traditional clustering algorithm will suffer from difficulties, making it difficult to distinguish the random noise from the effective data [21]. In Ref. [22,23], clustering is carried out according to the neighborhood density of each data. It is noted that the local statistical structures of noise and effective data are different, so the data with similar local statistics should be grouped into the same cluster. Afterwards, all point clouds are projected into the parameter distribution families to obtain the parameter point clouds, which contain the local information of the origin point cloud. Then, the original point cloud is classified according to the clustering results of the parameter point clouds.
4.1. Algorithm for Point Cloud Denoising
First, the original data point clouds are mapped to the normal distribution family manifolds, whose expectation and covariance matrix are calculated by the k-nearest neighbors of each point cloud, such that the parameter point clouds are formed. In , we denote the point clouds with scale l as
For any , the k-nearest neighbor method is used to select the neighborhood , which is abbreviated as N. Then, the expectation and covariance matrix of the data points in N is calculated. Finally, the data points are represented as parameter points on an n-ary normal distribution family manifold , where
Thus, the local statistical mapping is defined by
which satisfies
Under the local statistical mapping , the image of the point cloud is called the parameter point cloud [24]. The barycenter of the parameter point cloud is defined as follows
Moreover, the barycenter , that is, the geometric mean, depends on the selection of the distance functions on . To avoid the complex iterative calculation, the Euclidean distance (7) and the log-Euclidean distance (17) are used, respectively, in the following. Because and are topologically homeomorphic [25], the geometric structure on can be induced by defining the metrics on . In one case, is embedded into , the distance function on is obtained from the Euclidean metric
From (20), the geometric mean is the arithmetic mean
Another case is to define the log-Euclidean metric (14) on , then the distance function on is expressed as
According to Lemma 1, the geometric mean is the arithmetic mean in the logarithmic domain as follows
Note that the local statistical structure of signal is very different from that of random noise, so we will cluster into two categories: signal and noise. Due to the statistical properties of the n-ary normal distribution parameter family, the efficiency of the algorithm depends on the selection of distance functions on . Algorithm for clustering signal and noise is as follows.
In the process of clustering, Theorem 1 is used to calculate the log-Euclidean distance between the geometric mean of the category and each data point in the parameter point cloud . In addition, when clustering based on the distance function obtained by the log-Euclidean metric, the difference between the old and new barycenters is compared in the logarithmic domain to avoid calculating exponential mapping.
4.2. Numerical Examples
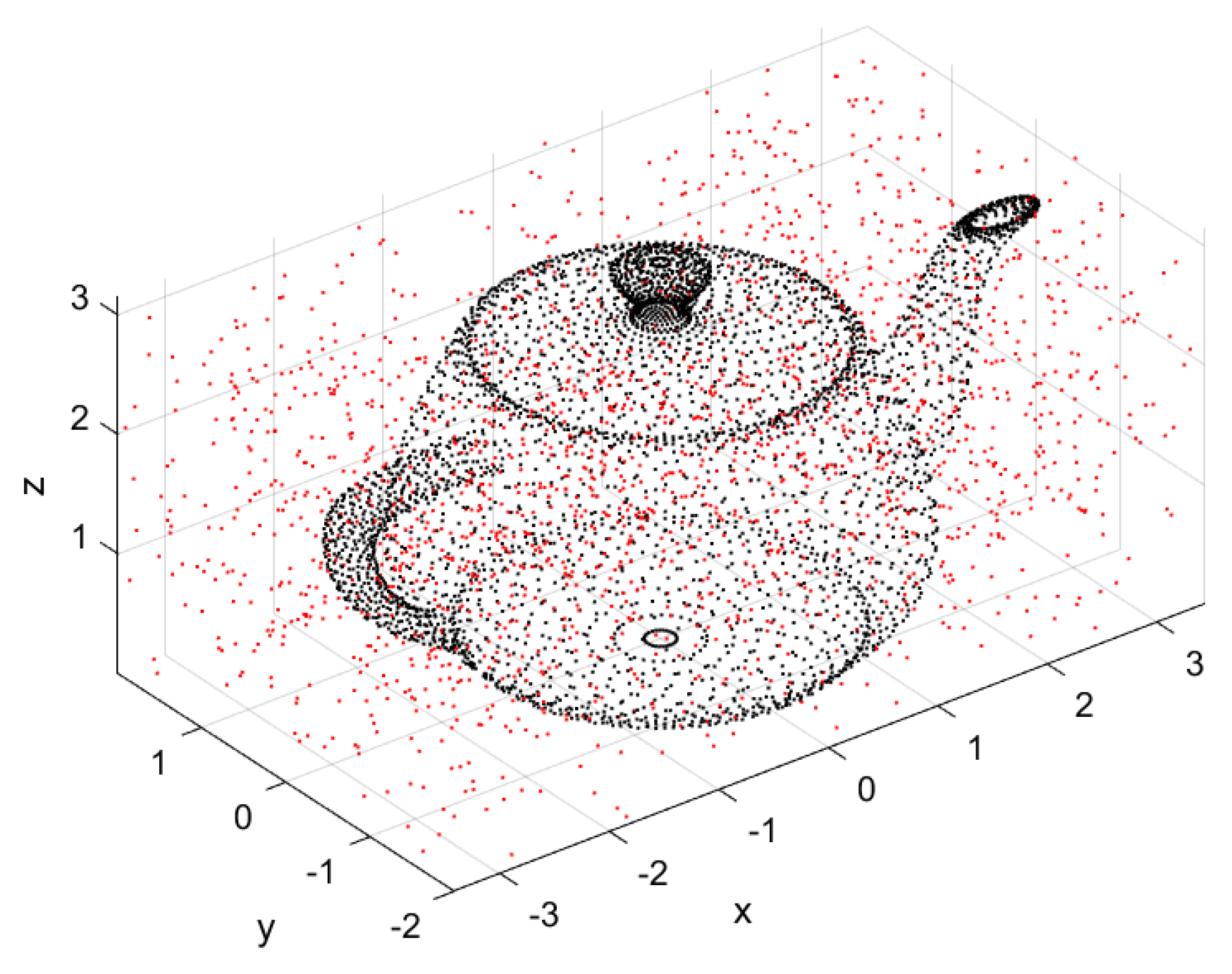
This subsection verifies the effectiveness of Algorithm 1 in removing high-density noise, and compares the denoising effect of the distance function obtained by the Euclidean metric and that of the log-Euclidean metric. The experimental data adopts the 3-dimensional point cloud of Teapot, and the background noise is uniformly distributed, where the signal-to-noise ratio (SNR) is 4148:1000, as shown in Figure 8.
| Algorithm 1 Algorithm for clustering signal and noise. |
Inputs: Point clouds , value of k and convergence threshold . Output: Two categories of point clouds . Main loop:
|
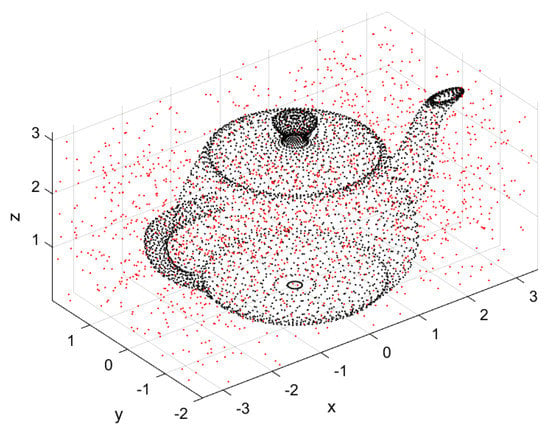
Figure 8.
Original data cloud.
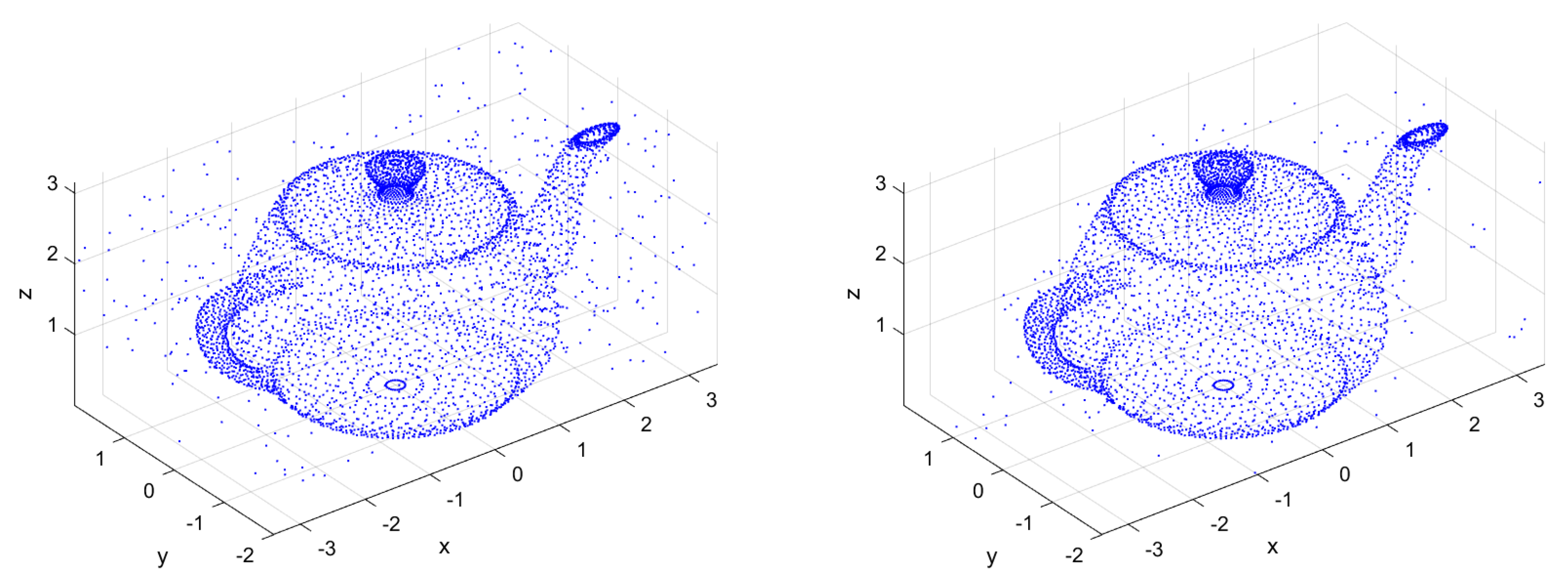
Take and , Figure 9 is the denoised images of the original point cloud by Algorithm 1, based on the Euclidean metric and the log-Euclidean metric, respectively. Obviously, Algorithm 1 based on the log-Euclidean metric is more effective.
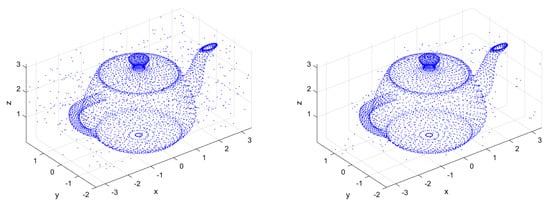
Figure 9.
Point cloud after denoising based on Euclidean metric (left) and log-Euclidean metric (right).
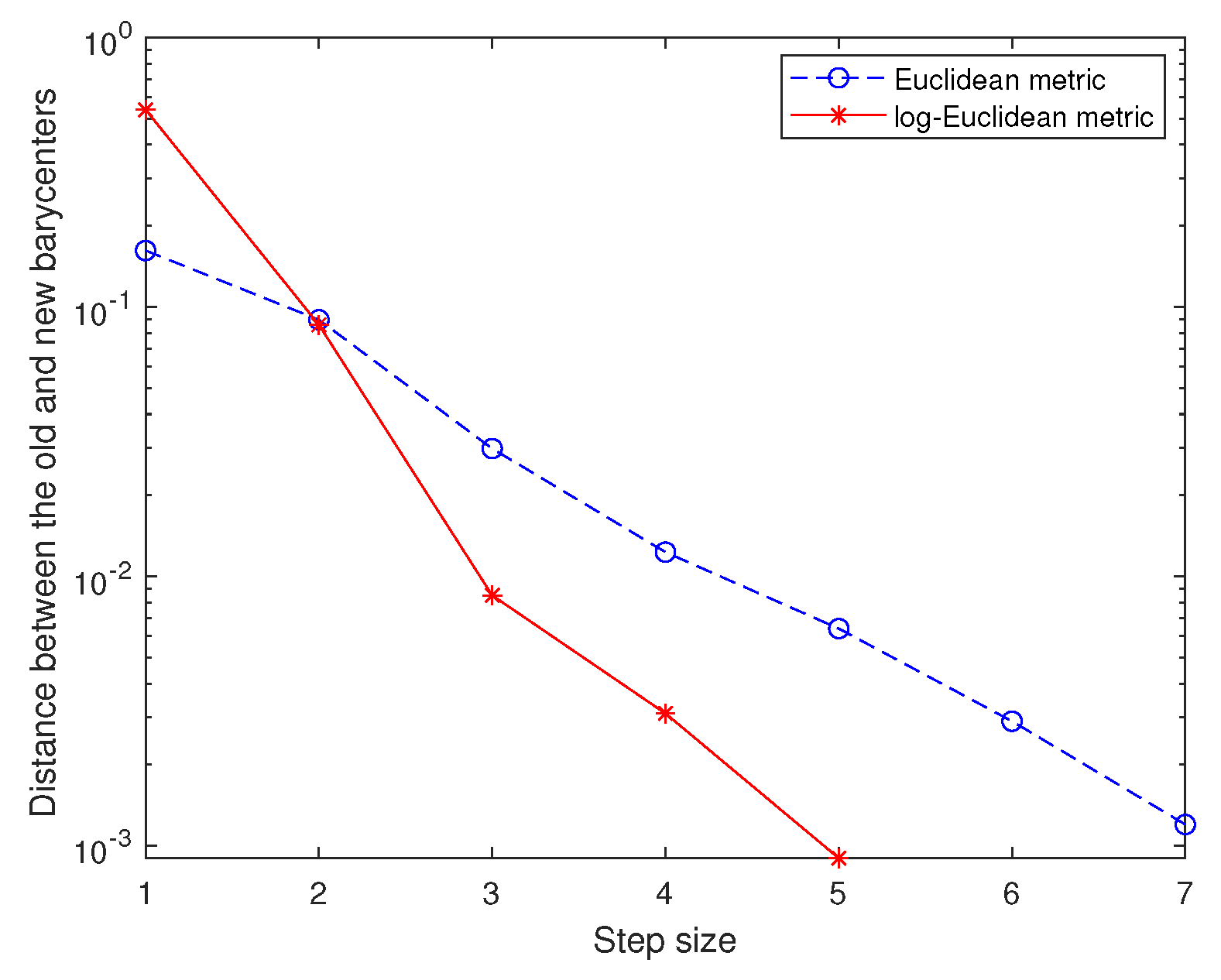
The efficiency and the convergence of Algorithm 1 is shown by Figure 10. It also demonstrates that Algorithm 1 using the log-Euclidean metric has faster convergence speed. To compare the denoising effects of different metrics, we adopt three criteria: Accuracy, Recall and Precision. For different SNR, the experimental results are shown in Table 1. In conclusion, Algorithm 1 based on the distance obtained by the log-Euclidean metric has obvious denoising effect for high-density noise, which is a successful application of our proposed method (Theorem 1). Furthermore, it is proved again that the Euclidean metric can not well describe the geometric structure on manifolds.
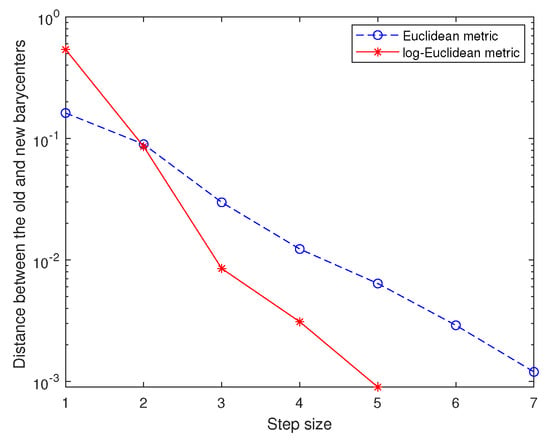
Figure 10.
Denoising effects of different metrics (log scale).

Table 1.
Comparison of denoising effects.
5. Conclusions
On the Lie group of symmetric positive-definite matrices, we present a non-iterative method to calculate the distance between a matrix and the mean matrix. Based on log-Euclidean metrics, we transform computations on the Lie group into computations on the space of symmetric matrices in the domain of matrix logarithms, and obtained the conclusion that this distance can be represented by the Euclidean distance between the right weighted mean and the left weighted mean. Our proposed method is simpler and more efficient than the classical iterative approach induced by affine-invariant Riemannian metrics in Ref. [6]. In addition, one example shows that the log-Euclidean mean and the Riemannian mean are more suitable than the arithmetic mean on the space of symmetric positive-definite matrices, and the other two examples illustrate that our method in Theorem 1 is more effective than the approach developed by Ref. [6]. Finally, the method for the difference of means is applied to denoise the point clouds with high density noise via the K-means clustering algorithm, and the experimental results show that Algorithm 1, which is based on the distance induced by the log-Euclidean metric has an obvious denoising effect.
Author Contributions
Investigation, X.D.; Methodology, X.J. and H.S.; Software, H.G.; Writing—original draft, X.D.; Writing—review and editing, X.J., X.D., H.S. and H.G. All authors have read and agreed to the published version of the manuscript.
Funding
The present research is supported by the National Natural Science Foundation of China (No. 61401058, No. 61179031).
Acknowledgments
The authors would like to thank the anonymous reviewers as well as Xinyu Zhao for their detailed and careful comments, which helped improve the quality of presentation and the simulations for Section 4.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Agarwal, M.; Gupta, M.; Mann, V.; Sachindran, N.; Anerousis, N.; Mummert, L. Problem determination in enterprise middleware systems using change point correlation of time series data. In Proceedings of the 2006 IEEE/IFIP Network Operations and Management Symposium NOMS 2006, Vancouver, BC, Canada, 3–7 April 2006; pp. 471–482. [Google Scholar]
- Cheng, Y.; Wang, X.; Morelande, M.; Moran, B. Information geometry of target tracking sensor networks. Inf. Fusion 2013, 14, 311–326. [Google Scholar] [CrossRef]
- Li, X.; Cheng, Y.; Wang, H.; Qin, Y. Information Geometry Method of Radar Signal Processing; Science Press: Beijing, China, 2014. [Google Scholar]
- Merckel, L.; Nishida, T. Change-point detection on the lie group SE(3). In Proceedings of the International Conference on Computer Vision, Imaging and Computer Graphics, Angers, France, 17–21 May 2010; Springer: Berlin, Germany, 2010; pp. 230–245. [Google Scholar]
- Arnaudon, M.; Barbaresco, F.; Yang, L. Riemannian medians and means with applications to Radar signal processing. IEEE J. Sel. Top. Signal Process. 2013, 7, 595–604. [Google Scholar] [CrossRef]
- Barbaresco, F. Interactions between Symmetric Cone and Information Geometries: Bruhat-Tits and Siegel Spaces Models for High Resolution Autoregressive Doppler Imagery, Emerging Trends in Visual Computing; Springer: Berlin, Germany, 2008. [Google Scholar]
- Duan, X.; Zhao, X.; Shi, C. An extended Hamiltonian algorithm for the general linear matrix equation. J. Math. Anal. Appl. 2016, 441, 1–10. [Google Scholar] [CrossRef]
- Luo, Z.; Sun, H. Extended Hamiltonian algorithm for the solution of discrete algebraic Lyapunov equations. Appl. Math. Comput. 2014, 234, 245–252. [Google Scholar] [CrossRef]
- Chen, W.; Chena, S. Application of the non-local log-Euclidean mean to Radar target detection in nonhomogeneous sea clutter. IEEE Access 2019, 99, 36043–36054. [Google Scholar] [CrossRef]
- Wang, B.; Hu, Y.; Gao, J.; Ali, M.; Tien, D.; Sun, Y.; Yin, B. Low rank representation on SPD matriceswith log-Euclidean metric. Pattern Recognit. 2016, 76, 623–634. [Google Scholar] [CrossRef]
- Liu, Q.; Shao, G.; Wang, Y.; Gao, J.; Leung, H. Log-Euclidean metrics for contrast preserving decolorization. IEEE Trans. Image Process. 2017, 26, 5772–5783. [Google Scholar] [CrossRef]
- Moakher, M. A differential geometric approach to the geometric mean of symmetric positive-definite matrices. SIAM J. Matrix Anal. Appl. 2005, 26, 735–747. [Google Scholar] [CrossRef]
- Moakher, M. On the averaging of symmetric positive-definite tensors. J. Elast. 2006, 82, 273–296. [Google Scholar] [CrossRef]
- Batchelor, P.G.; Moakher, M.; Atkinson, D.; Calamante, F.; Connelly, A. A rigorous framework for diffusion tensor calculus. Magn. Reson. Med. 2005, 53, 221–225. [Google Scholar] [CrossRef] [PubMed]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Log-Euclidean metrics for fast and simple calculus on diffusion tensors. Magn. Reson. Med. 2006, 56, 411–421. [Google Scholar] [CrossRef]
- Curtis, M.L. Matrix Groups; Springer: Berlin, Germany, 1979. [Google Scholar]
- Jost, J. Riemannian Geometry and Geometric Analysis, 3rd ed.; Springer: Berlin, Germany, 2002. [Google Scholar]
- Jorgen, W. Matrix diferential calculus with applications in statistics and econometrics. De Economist 2000, 148, 130–131. [Google Scholar]
- Fiori, S. Learning the Fréchet mean over the manifold of symmetric positive-definite matrices. Cogn. Comput. 2009, 1, 279–291. [Google Scholar] [CrossRef] [Green Version]
- Duan, X.; Sun, H.; Peng, L. Application of gradient descent algorithms based on geodesic distances. Sci. China Inf. Sci. 2020, 63, 152201:1–152201:11. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K. Data clustering. 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Zhu, Y.; Ting, K.M. Carman, M.J. Density-ratio based clustering for discovering clusters with varying densities. Pattern Recognit. 2016, 60, 983–997. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 334, 1492–1496. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, H.; Song, Y.; Luo, Y.; Sun, F. A clustering algorithm based on statistical manifold. Trans. Beijing Inst. Technol. 2021, 41, 226–230. [Google Scholar]
- Amari, S. Information Geometry and Its Applications; Springer: Tokyo, Japan, 2016. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).