1. Introduction
In recent years, we have seen a considerable interest in formulating new families of distributions for modeling proportional data: for example, illiteracy and mortality rates, the proportion of eggs hatched in the production of cuttings, percentage of defective items, etc. One of the most common distributions in this context is the beta distribution [
1], which was also extended to a regression [
2]. There are several extensions of the beta regression in Simas et al. [
3], Ospina Ferrari [
4], Ospina Ferrari [
5], Carrasco et al. [
6], and Figueroa-Zúñiga et al. [
7].
Some other alternatives have appeared in the literature. For example, Qiu et al. [
8] defined a simplex regression [
9], Bayes et al. [
10] introduced a parametric quantile regression from the Kumaraswamy distribution [
11], Lemonte and Bazán [
12] proposed a regression based on an extended Johnson
distribution [
13,
14] introduced a family by compounding the cumulative distribution function (cdf) of a model with the quantile function (qf) of a second one. Cancho et al. [
15] constructed a regression model by extending the Johnson
distribution with a shape parameter controlling the asymmetry.
Let
be the baseline cdf of a random variable (rv)
X with real support
, and the transformation:
where
is a cdf of an rv with support
,
, and
. Then,
for
, where
. The probability density function (pdf) of
Y follows from (
1) as:
where
.
Let
have the standard normal cdf
, and
the standard logistic cdf. Thus, the Johnson
density follows from (
2), for
,
where
is the standard normal density, and:
is the logistic qf [
14].
We define a new family by compounding a baseline standard normal with the qf of the generalized extreme value (GEV). Let
Z be an rv having a GEV distribution [
16] having cdf with zero location and unit scale parameter, namely:
where
for
,
for
and
for
.
This article is organized in six sections.
Section 2 defines a new model called the
normal-generalized extreme value (Normal-GEV) distribution, and provides some of its structural properties.
Section 3 constructs a new regression model from this distribution, and addresses Bayesian inferential procedures.
Section 4 performs several simulations under different scenarios to study the behavior of the estimators. An application to colorectal cancer data in
Section 5 shows the importance of the proposed regression. Some conclusions are given in
Section 6.
2. The Normal-GEV Distribution
The pdf of the rv
follows by inserting (
6) in Equation (
3):
Note that the above pdf includes both cases of Equation (
6), i.e., the cases for
and
.
Proof. Setting
, the Normal-GEV pdf (
7) can be expressed as:
By using the known inequality:
the expression on the right-hand side of (
8) reduces to:
That is, . We have , , since the exponential grows faster than the polynomial. Then, since ⟺ from the squeeze (or sandwich) theorem, we get . This proves that , .
Again, by using (
8) and inequality (
9), we have:
For , from the inequality above and by the rapid growth of the exponential in comparison to polynomials, we have . Therefore, , .
On the other hand, note that ⟺. Again, from the inequality and the rapid growth of the exponential, , we get . Hence, .
Finally, if
, then
in (
7) gives:
Then, it is clear that (by the continuity of ), . □
The proof of the next result is immediate and hence omitted.
Proposition 2. Let , and . The cdf of Y iswhereis as in (
6).
2.1. Behavior of the Normal-GEV Distribution
In this subsection, some distributional properties such as unimodality and monotonicity of the Normal-GEV pdf are analyzed.
To determine the number of modes of a pdf, f, it is necessary to locate its critical points. By definition, a critical point of a function f is a point on the graph of f where the derivative is zero or infinite.
Proposition 3. All critical points y of the new pdf (
7)
satisfy:
where is given in (
6).
Proof. Adopting the notation of Proposition 2,
and
, we have (dashes mean derivatives)
. Differentiating
with respect to
y gives:
where:
By combining (
10) and (
11), we obtain:
Then, the proof follows. □
Theorems 1 and 2 show that governs the shape of the new distribution.
Theorem 1. Ifwith, the pdf of Y is:
Decreasing-increasing-decreasing (DID) or decreasing (D) whenever.
Unimodal whenever and .
Proof. By replacing
with
in equation of Proposition 3, all critical points
y of the pdf of
Y satisfy:
If
, then
is a polynomial of degree
. By Descartes’ rule of signs [
17],
has two sign changes (regardless of the sign of
) and then two or zero positive roots. If
has two positive roots
and
, the pdf of
Y has two critical points
and
in
. On the other hand, if
has zero positive roots, it has no critical points in
. Finally, since
and
, the statement of Item 1 follows.
If
,
can be written in terms of
In this case, is a polynomial of degree . Again, by Descartes’ rule of signs, has only one sign change, and this polynomial has only one positive root, say . Then, the pdf of Y has only one critical point on . Since and , where is the Kronecker delta, the unimodality stated in Item 2 follows. □
Theorem 2 provides the explicit critical points of the Normal-GEV pdf () whenever a constraint on parameters and is imposed. Further, this theorem shows that the form of the pdf is continuous monotone at three disjoint intervals.
Theorem 2. If and , the pdf of Y is decreasing-increasing-decreasing (DID) whenever: Moreover,are the minimum and maximum points of the pdf of Y, respectively. For some integer k, denotes the Lambert W function. Proof. By replacing the definition of
with
in the equation of Proposition 3, all critical points
y of the pdf of
Y satisfy:
Since the function
has a (global) minimum
at the point
, the above equation can be solved for
only if
. Since
, assuming the condition (
12), the two values
and
in (
13) are obtained. Finally,
and
are minimum and maximum points of the pdf of
Y, respectively, because
and
, and
. □
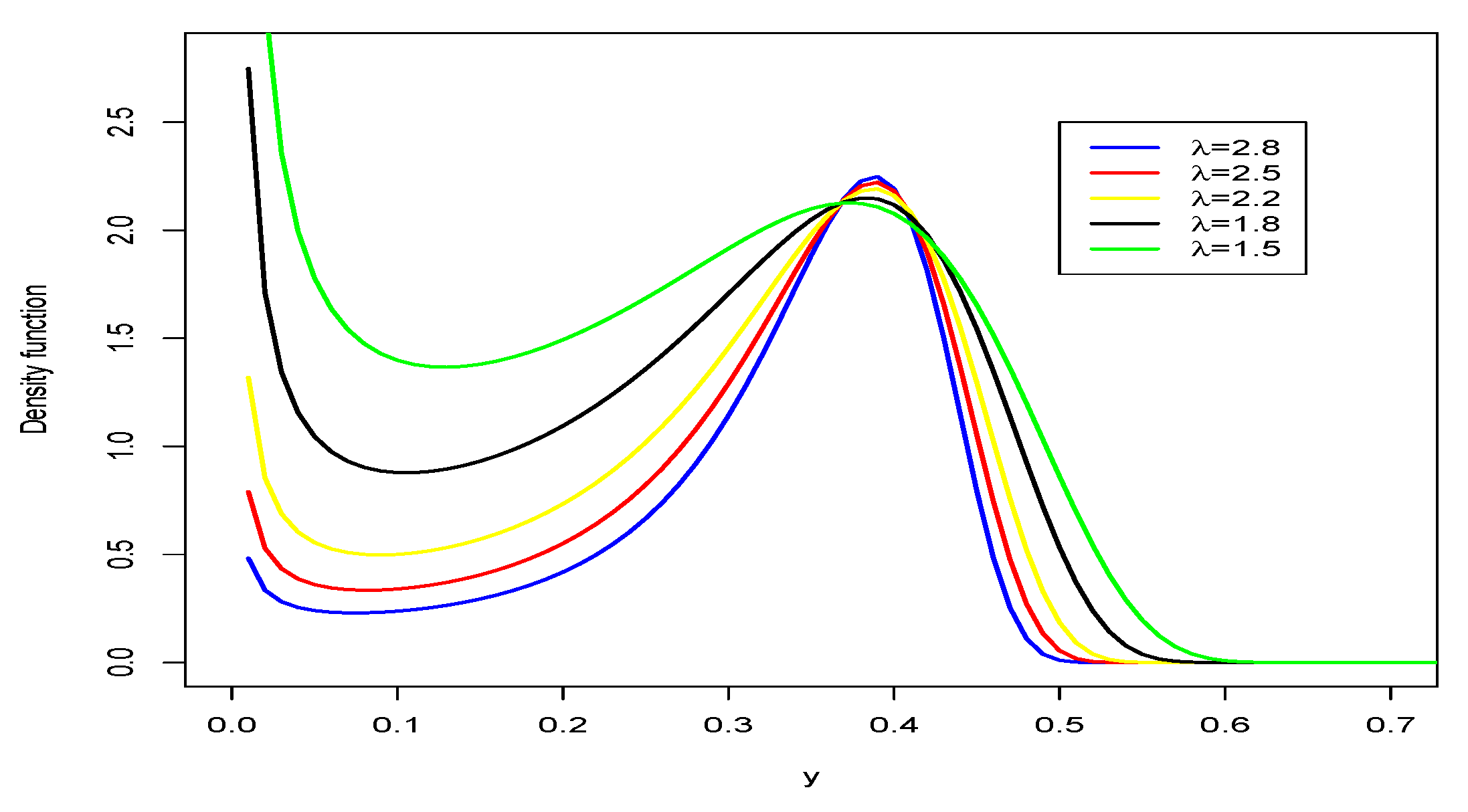
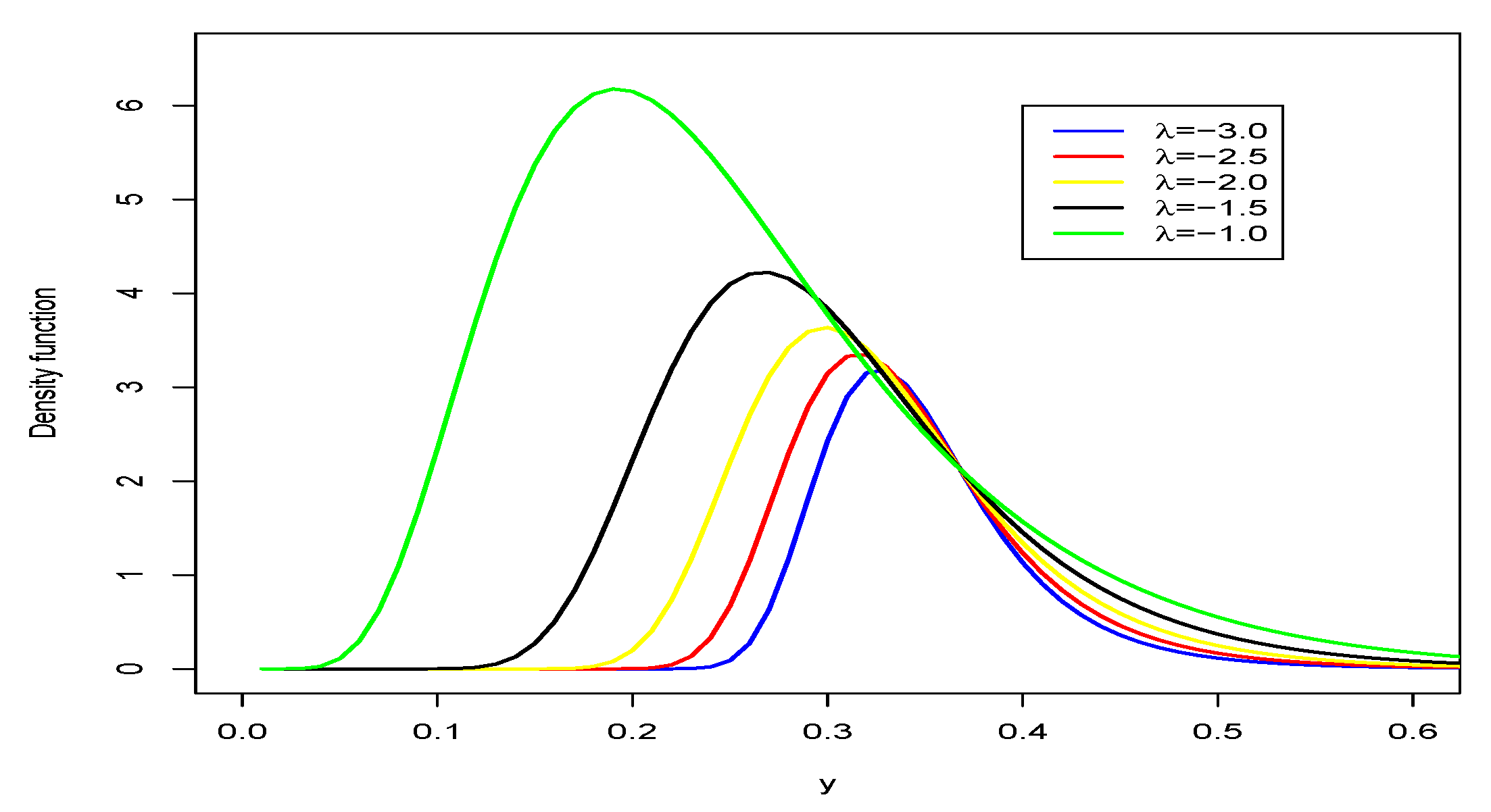
Figure 1 and
Figure 2 reveal different types of asymmetrical. For negative values of the parameter
we have positive asymmetry (and unimodality), for positive values of
we have decreasing, increasing and decreasing behavior.
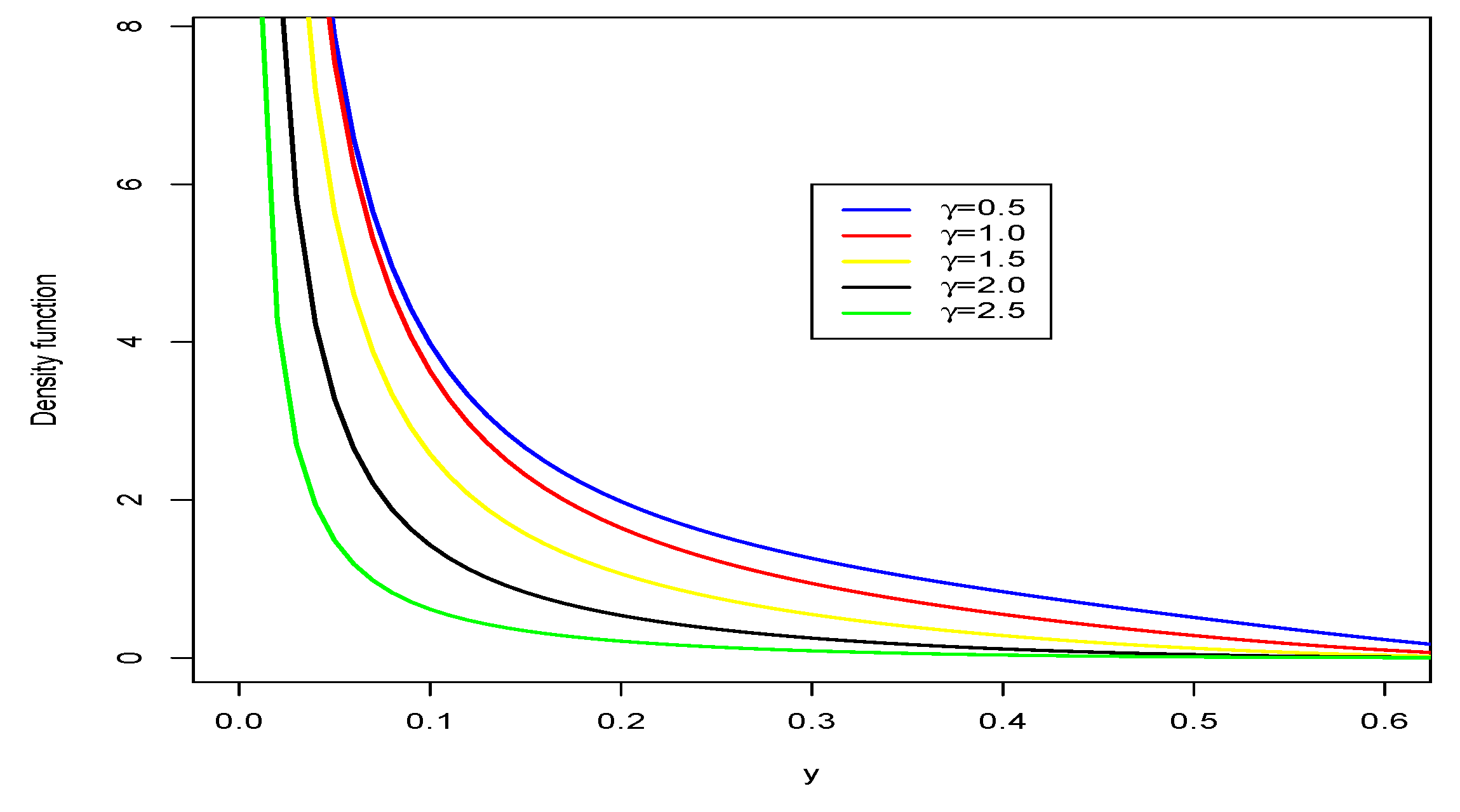
Figure 3 shows that cases of decreasing strict monotonicity can appear in the Normal-GEV pdf.
2.2. Related Distributions
Proposition 4. If, then (for anyand):
Normal distribution: .
Log-normal distribution: .
Folded normal distribution: .
χ distribution with one degree of freedom (df): .
Noncentral distribution: .
Lévy distribution: .
Proof. The proof of this proposition follows by using well-known properties of the normal distribution with Equation (
1). Hence, details are omitted. □
Proposition 5. distribution with n df: If,
,
are independent rvs, then: Student t-distribution withdf: If,
,
are independent rvs, then:where.
F-distribution withdf: If,
,
,
,
are independent rvs, then:
Proof. The proof follows by combining known properties of the normal distribution with Equation (
1). □
2.3. The New Model as a Limit Distribution
Let
be the sample mean of
n samples drawn from a population with mean
and standard deviation
. The central limit theorem leads to the well-known result:
where “
” denotes convergence in the distribution. Let
be the transformation defined in Proposition 2. Since
is a continuous map, by applying the continuous mapping theorem, we have:
From Equation (
1),
, where
and
is the GEV cdf given in (
5).
Then, for
:
and, for
,
2.4. Moments, Quantile and Other Measures
Proposition 6. The rth real moment of is (whenever it makes sense):where,and is the generating function of X. For example, for , . Proof. The proof is immediate since
Y follows Equation (
1) with
given in (
5). □
The moments of
Y are finite since its support is limited, and the integral in (
14) can be numerically computed via the software R, Mathematica, and Maple, among others. Specifically, the mean and variance are calculated using the integrate function of the R software. This approximation is based on the adaptive quadrature of functions of one variable over a finite interval; for more details, see Piessens et al. [
18].
Table 1 reports the mean and variance of
Y for some parameters obtained numerically using the
integrate function of the R software. We note in the second and third columns that the mean and variance do not change for different values of
. However, there is some variation of the variance for different values of
with the other parameters fixed. So, the parameter
is responsible for the location of the model and the parameter
for the dispersion.
Proposition 7. Let . Then, the qth quantile of Y is:where is the qth standard normal quantile (for ). Proof. The proof is immediate and then omitted. □
The median
of the Normal-GEV distribution follows from Proposition 7:
where
is the median of the standard normal distribution. Furthermore, from Proposition 7, the random values for
Y can be easily generated.
Further, the Bowley’s skewness of
Y is:
where
and
are the quantile values.
Figure 4 displays the skewness of
Y for some parameters, which indicates that the distribution is symmetric when
and
. Thus, the parameters
and
govern the skewness of
Y.
3. Bayesian Inference for the Normal-GEV Regression
The Normal-GEV median can be expressed from (
15) as:
where
is given by (
6). Therefore, it has a simple form to construct a regression model. In this context, we obtain a reparameterized density of
Y by replacing the above expression in Equation (
2),
where
,
, and
works as a dispersion parameter.
Let
be
n observations from
, where two systematic components are constructed for the median
and dispersion
. The Normal-GEV regression model is defined by (
16) and the systematic components:
where
and
are vectors of covariates,
,
are vectors of unknown coefficients (
), and
and
are strictly monotonic and twice differentiable link functions. There are several possible choice for the link functions
and
. For example, some useful link functions for the median are: logit
; probit
, where
is the standard normal quantile function; complementary log–log
; log–log
; and Cauchy
. Some possible choice dispersion link are: logarithmic
; square root
; identity
(with
); among others. The relationship between
and
and
and
is equivalent to a canonical link for
( location parameter) and
(dispersion parameter) in setting generalized linear model.
Further, let
and
be matrices of full ranks
p and
q, respectively. The likelihood function for the parameters given the observed data
has the form:
Maximizing (
17) provides the maximum likelihood estimates (MLEs) of the parameters. However, we consider the Bayesian method with the common proper prior distributions:
where
,
, and
are assumed independent. Combining (
17) and (
18), the joint posterior density for
reduces to:
The Metropolis–Hastings algorithm consists of the steps:
- (1)
Initialize from trial and set ;
- (2)
Construct the transitional kernel to generate a new point , where is evaluated at ;
- (3)
Update to with probability , or set with probability ;
- (4)
Steps (2) and (3) are repeated until the process becomes stationary.
The script can be obtained from the authors upon request. For more details on the Metropolis–Hastings algorithm, we refer to Chib et al. [
19].
4. Simulation Study
We determine the accuracy of the Bayesian estimates in the new regression model. One thousand samples of sizes , and 400 are generated from under the systematic components and , and . The covariate is produced from the uniform distribution with , , , and .
We obtain the posterior summaries and 95% highest probability density (HPD) intervals of the parameters for each trial. We generate 25,000 MCMC posterior samples for the parameters, from which 5000 observations are discarded to eliminate the effect of the initial values. To avoid correlation between the generates values, we took a spacing of size 5, leading to samples of size 2000. Therefore, the final sample has size 2000 to record the convergence of the Gibbs samples [
20]. For each configuration, we perform 1000 replicates to determine from the estimates: the average (MC mean), standard deviation (SD), mean root square error (MC RMSE), and coverage probability (CP).
Table 2 reports the simulations results, which reveal that the RMSEs decay when
n increases (as expected), and the coverage probabilities approximate the nominal level.
5. Application: Colorectal Cancer Data
We analyze data on patients with colorectal cancer [
21] from 50 American States, where the mortality rate is the response variable. We consider
observations after deleting states with incomplete data. The variables below were collected:
: mortality rate ();
: sex (0 = man, 1 = woman);
: race (non-Hispanic white, non-Hispanic black, Hispanic).
Figure 5 displays boxplots of mortality rate by sex (left panel) and race (right panel). They indicate that it is different for men and women, and Hispanic patients have a lesser mortality rate than the other patients.
We fit the regression mode described in
Section 3 to these data with all covariates on the median of the mortality rate (
), and dispersion parameter (
) with the link functions: logistic, probit, complement log–log for the median, and logarithmic for the dispersion, i.e.,
where the race covariate (
) requires two dummy variables:
We consider 250,000 MCMC posterior samples from which 50,000 were excluded to eliminate the effect of the initial values. The autocorrelations of theses sampled values are reduced by taking a spacing of size five, yielding a final sample of size 4000. The trace plots for parameters of the new regression model with complementary log–log link are reported in
Figure 6, thus indicating convergence of the chains [
20].
For model comparison, we consider the deviance Information criterion (DIC [
22]), the expected Akaike information criterion (EAIC, [
23]), the expected Bayesian (or Schwarz) information criterion (EBIC, [
24]), and the log pseudo marginal likelihood (LPML [
25]). The last criteria is the one derived from the Conditional Predictive Ordinate (CPO) [
26]. The Monte Carlo estimates of the DIC, EAIC, EBIC, and LPML criteria in
Table 3 confirm that the proposed regression with complementary log–log link (com-log-log) (short Normal-GEV-CLL) is the best model.
The Bayesian estimates under quadratic and absolute losses of the parameters of the Normal-GEV-CLL and Johnson’s
regression models and the
HPD intervals are reported in
Table 4. All covariates are statistically significant at the significance level of 5% for all models.
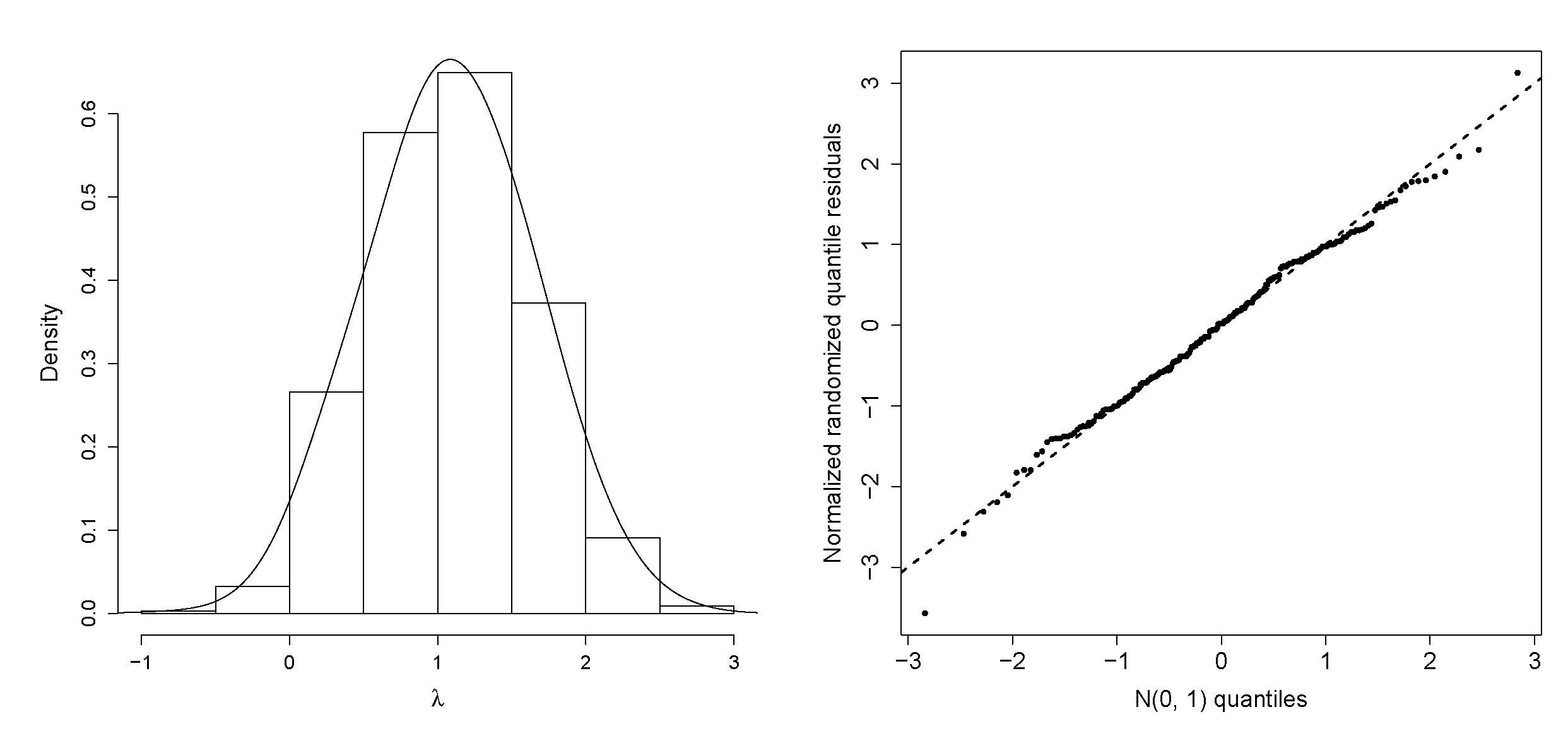
Figure 7 (left panel) displays the marginal posterior density of
in the Normal-GEV-CLL regression model, which is symmetric.
Table 4 reveals that the posterior mean of
is 1.088, and a 95% HPD interval is
. We fit the GJS-Student-t regression model [
12] with four degrees of freedom and log–log link to the current data.
Table 5 reports the Monte Carlo estimates of DIC, EAIC, EBIC, and LPML for Jhonson’s
and GJS-Student-t regression models. They indicate that the second regression is better than the first for these data, but it does not provide a better fit than the Normal-GEV-CLL regression model. The quantile–quantile (QQ) plot of the posterior normalized randomized quantile residuals for the last regression in
Figure 7 (right panel) proves an acceptable fit [
27,
28].
We consider a Bayesian global influence methodology to identify the presence of outliers and/or influential observations under the general divergence measure [
29]. Let
be the
-divergence between
and
, where
denotes the posterior distribution of
for the full dataset, and
the posterior distribution of
without the
ith observation, namely:
where
is a convex function with
. Different choices of
are addressed by Dey and Birmiwal [
30] and Pardo [
31]. Here,
defines the Kullback–Leibler (K-L) divergence,
gives the
J-distance,
provides
norm, and
yields the
-square divergence. The divergence measure to verify whether a small subset of observations from the full data is influential or not follows the criterion by Peng and Dey [
29] and Weiss [
32]; see also Cancho et al. [
15,
33,
34].
We calculate the Monte Carlo estimates of the divergence measures K-L, J, , and for the posterior distribution of the parameters of the Normal-GEV-CLL regression models to detect possible influential points.
They are plotted in
Figure 8 and identify the cases 39, 54, and 122 as possible influential observations in the posterior distribution.
Table 6 presents subjects having large K-L, J,
, and
.
For some cases, we refit the regression model to determine the impact of these observations on the posterior distribution of the parameters [
15]. We eliminate each case individually and then two and three cases. The relative change (RC) of each estimate is
, where
is the posterior mean of
(for
) when the set I of observations is removed.
Table 7 reports the RCs after removing some observations, and the lower (L) and upper (U) limits of the
HPD intervals of the new estimates. In general, the significance of the parameter estimates does not change after removing set
I at the level of 5%.
We estimate the median of the mortality rate for eight patients A, B, C, D, E, and F with specified characteristics in
Table 8. These numbers refer to the Bayes estimates under the quadratic and absolute loss functions and the
HPD intervals for the median mortality. For example, the median mortality rates are 0.147 and 0.276 for patient
A of gender male and race Hispanic and patient
E of gender male and race Hispanic, respectively. This difference can be seen in
Figure 9, and in the posterior distribution of the median mortality rate of the other patients.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}