Abstract
Constant-specified and exponential concentration inequalities play an essential role in the finite-sample theory of machine learning and high-dimensional statistics area. We obtain sharper and constants-specified concentration inequalities for the sum of independent sub-Weibull random variables, which leads to a mixture of two tails: sub-Gaussian for small deviations and sub-Weibull for large deviations from the mean. These bounds are new and improve existing bounds with sharper constants. In addition, a new sub-Weibull parameter is also proposed, which enables recovering the tight concentration inequality for a random variable (vector). For statistical applications, we give an -error of estimated coefficients in negative binomial regressions when the heavy-tailed covariates are sub-Weibull distributed with sparse structures, which is a new result for negative binomial regressions. In applying random matrices, we derive non-asymptotic versions of Bai-Yin’s theorem for sub-Weibull entries with exponential tail bounds. Finally, by demonstrating a sub-Weibull confidence region for a log-truncated Z-estimator without the second-moment condition, we discuss and define the sub-Weibull type robust estimator for independent observations without exponential-moment conditions.
Keywords:
constants-specified concentration inequalities; exponential tail bounds; heavy-tailed random variables; sub-Weibull parameter; lower bounds on the least singular value MSC:
60E15; 62F25; 62F99
1. Introduction
In the last two decades, with the development of modern data collection methods in science and techniques, scientists and engineers can access and load a huge number of variables in their experiments. Over hundreds of years, probability theory lays the mathematical foundation of statistics. Arising from data-driving problems, various recent statistics research advances also contribute to new and challenging probability problems for further study. For example, in recent years, the rapid development of high-dimensional statistics and machine learning have promoted the development of the probability theory and even pure mathematics, such as random matrices, large deviation inequalities, and geometric functional analysis, etc.; see [1]. More importantly, the concentration inequality (CI) quantifies the concentration of measures that are at the heart of statistical machine learning. Usually, CI quantifies how a random variable (r.v.) X deviates around its mean by presenting as one-side or two-sided bounds for the tail probability of
The classical statistical models are faced with fixed-dimensional variables only. However, contemporary data science motivates statisticians to pay more attention to studying random Hessian matrices (or sample covariance matrices, [2]) with , arising from the likelihood functions of high-dimensional regressions with covariates in . When the model dimension increases with sample size, obtaining asymptotic results for the estimator is potentially more challenging than the fixed dimensional case. In statistical machine learning, concentration inequalities (large derivation inequalities) are essential in deriving non-asymptotic error bounds for the proposed estimator; see [3,4]. Over recent decades, researchers have developed remarkable results of matrix concentration inequalities, which focuses on non-asymptotic upper and lower bounds for the largest eigenvalue of a finite sum of random matrices. For a more fascinated introduction, please refer to the book [5].
Motivated from sample covariance matrices, a random matrix is a specific matrix with its entries drawn from some distributions. As , random matrix theory mainly focuses on studying the properties of the p eigenvalues of , which turn out to have some limit law. Several famous limit laws in random matrix theory are different from the CLT for the summation of independent random variables since the p eigenvalues are dependent and interact with each other. For convergence in distribution, some pioneering works are the Wigner’s semicircle law for some symmetric Gaussian matrices’ eigenvalues, the Marchenko-Pastur law for Wishart distributed random matrices (sample covariance matrices), and the Tracy-Widom laws for the limit distribution for maximum eigenvalues in Wishart matrices. All these three laws can be regarded as the CLT of random matrix versions. Moreover, the limit law for the empirical spectral density is some circle distribution, which sheds light on the non-communicative behaviors of the random matrix, while the classic limit law in CLT is for normal distribution or infinite divisible distribution. For strong convergence, Bai-Yin’s law complements the Marchenko-Pastur law, which asserts that almost surely convergence of the smallest and largest eigenvalue for a sample covariance matrix. The monograph [2] thoroughly introduces the limit law in random matrices.
This work aims to extend non-asymptotic results from sub-Gaussian to sub-Weibull in terms of exponential concentration inequalities with applications in count data regressions, random matrices, and robust estimators. The contributions are:
- (i)
- We review and present some new results for sub-Weibull r.v.s, including sharp concentration inequalities for weighted summations of independent sub-Weibull r.v.s and negative binomial r.v.s, which are useful in many statistical applications.
- (ii)
- Based on the generalized Bernstein-Orlicz norm, a sharper concentration for sub-Weibull summations is obtained in Theorem 1. Here we circumvent Stirling’s approximation and derive the inequalities more subtly. As a result, the confidence interval based on our result is sharper and more accurate than that in [6] (For example, see Remark 2) and [7] (see Proposition 1 with unknown constants) gave.
- (iii)
- By sharper sub-Weibull concentrations, we give two applications. First, from the proposed negative binomial concentration inequalities, we obtain the (up to some log factors) estimation error for the estimated coefficients in negative binomial regressions under the increasing-dimensional framework and heavy-tailed covariates. Second, we provide a non-asymptotic Bai-Yin’s theorem for sub-Weibull random matrices with exponential-decay high probability.
- (iv)
- We propose a new sub-Weibull parameters, which is enabled of recovering the tight concentration inequality for a single non-zero mean random vector. The simulation studies for estimating sub-Gaussian and sub-exponential parameters show these parameters could be estimated well.
- (v)
- We establish a unified non-asymptotic confidence region and the convergence rate for general log-truncated Z-estimator in Theorem 5. Moreover, we define a sub-Weibull type estimator for a sequence of independent observations without the second-moment condition, beyond the definition of the sub-Gaussian estimator.
2. Sharper Concentrations for Sub-Weibull Summation
Concentration inequalities are powerful in high-dimensional statistical inference, and it can derive explicit non-asymptotic error bounds as a function of sample size, sparsity level, and dimension [3]. In this section, we present preparation results of concentration inequalities for sub-Weibull random variables.
2.1. Properties of Sub-Weibull norm and Orlicz-Type Norm
In empirical process theory, sub-Weibull norm (or other Orlicz-type norms) is crucial to derive the tail probability for both single sub-Weibull random variable and summation of random variables (by using the Chernoff’s inequality). A benefit of Orlicz-type norms is that the concentration does not need the zero mean assumption.
Definition 1
(Sub-Weibull norm). For , the sub-Weibull norm of X is defined as
The is also called the -norm. We define X as a sub-Weibull random variable with index if it has a bounded -norm (denoted as ). Actually, the sub-Weibull norm is a special case of Orlicz norms below.
Definition 2
(Orlicz Norms). Let be a non-decreasing convex function with . The “g-Orlicz norm” of a real-valued r.v. X is given by
Using exponential Markov’s inequality, we have
by Definition 2. For example, let , which leads to sub-Weibull norm for .
Example 1
(-norm of bounded r.v.). For a r.v. , we have
In general, we have following corollary to determine based on moment generating functions (MGF). It would be useful for doing statistical inference of -norm.
Corollary 1.
If , then for the MGF .
Remark 1.
If we observe i.i.d. data from a sub-Weibull distribution, one can use the empirical moment generating function (EMGF, [8]) to estimate the sub-Weibull norm of X. Since the EMGF converge to MGF in probability for t in a neighbourhood of zero, the value of the inverse function of EMGF at 2. Then, under some regularity conditions, , is a consistent estimate for .
In particular, if we take , we get the sub-exponential norm of X, which is defined as . For independent r.v.s , if and , by Proposition 4.2 in [4], we know
Example 2.
An explicitly calculation of the sub-exponential norm is given in [9], they show that Poisson r.v. has sub-exponential norm . And Example 1 with triangle inequality implies
based on following useful results.
Proposition 1
(Lemma A.3 in [9]). For any and any r.v.s we have and
where , if and if .
To extend Poisson variables, one can also consider concentration for sums of independent heterogeneous negative binomial variables with probability mass functions:
where are variance-dependence parameters. Here, the mean and variance of are respectively. The MGF of are for . Based on (3), we obtain following results.
Corollary 2.
For any independent r.v.s satisfying , , and non-random weight , we have
In particular, if is independently distributed as , we have
where with
Corollary 2 can play an important role in many non-asymptotic analyses of various estimators. For instance, recently [10] uses the above inequality as an essential role for deriving the non-asymptotic behavior of the penalty estimator in the counting data model.
Next, we study moment properties for sub-Weibull random variables. Lemma 1.4 in [11] showed that if , then we have: (a). the tail satisfies for any ; (b). The (a) implies that moments and . We extend Lemma 1.4 in [11] to sub-Weibull r.v. X satisfying following properties.
Corollary 3
(Moment properties of sub-Weibull norm). (a). If , then for all ; and then for all . (2). Let , for all we have
Particularly, sub-Weibull r.v.s reduce to sub-exponential or sub-Gaussian r.v.s when = 1 or 2. It is obvious that the smaller is, the heavier tail the r.v. has. A r.v. is called heavy-tailed if its distribution function fails to be bounded by a decreasing exponential function, i.e.,
(the tail decays slower than some exponential r.v.s);
see [12]. Hence for sub-Weibull r.v.s, we usually focus on the the sub-Weibull index . A simple example that the heavy-tailed distributions arises when we work more production on sub-Gaussian r.v.s. Via a power transform of , the next corollary explains the relation of sub-Weibull norm with parameter and , which is similar to Lemmas 2.7.6 of [1] for sub-exponential norm.
Corollary 4.
For any if , then . Moreover,
Conversely, if , then with .
By Corollary 4, we obtain that d-th root of the absolute value of sub-Gaussian is by letting . Corollary 4 can be extended to product of r.v.s, from Proposition D.2 in [6] with the equality replacing by inequality, we state it as the following proposition.
Proposition 2.
If are (possibly dependent) r.vs satisfying ∞ for some then
For multi-armed bandit problems in reinforcement learning, [7] move beyond sub-Gaussianity and consider the reward under sub-Weibull distribution which has a much weaker tail. The corresponding concentration inequality (Theorem 3.1 in [7]) for the sum of independent sub-Weibull r.v.s is illustrated as follows.
Proposition 3
(Concentration inequality for sub-Weibull distribution). Suppose are independent sub-Weibull random variables with . Then there exists absolute constants and only depending on θ such that with probability at least :
The weakness in the Proposition 3 is that the upper bound of is up to a unknown constants . In the next section, we will give a constants-specified and high probability upper bound for , which improve Proposition 3 and is sharper than Theorem 3.1 in [6].
2.2. Main Results: Concentrations for Sub-Weibull Summation
Based on the exponential moment condition, the Chernoff’s tricks implies the following sub-exponential concentrations from Proposition 4.2 in [4].
Proposition 4.
For any independent r.v.s satisfying , , and non-random weight , we have
But it is not easy to extend to sub-Weibull distributions. From Corollary 4, . The MGF of satisfies for some constant . The bound of with or 2 is not directly applicable for deriving the concentration of by using the independence and Chernoff’s tricks, since the MGF of Weibull r.v. do not has closed form as exponential function. Thanks to the tail probability derived by Orlicz-type norms, instead of using the upper bound for MGF, an alternative method is given by [6] who defines the so-called Generalized Bernstein-Orlicz (GBO) norm. And the GBO norm can help us to derive tail behaviours for sub-Weibull r.v.s.
Definition 3
(GBO norm). Fix and . Define the function as the inverse function The GBO norm of a r.v. X is then given by
The monotone function is motivated by the classical Bernstein’s inequality for sub-exponential r.v.s. Like the sub-Weibull norm properties Corollary 3, the following proposition in [6] allows us to get the concentration inequality for r.v. with finite GBO norm.
Proposition 5.
If , then
With an upper bound of GBO norm, we could easily derive the concentration inequality for a single sub-Weibull r.v. or even the sum of independent sub-Weibull r.v.s. The sharper upper bounds for the GBO norm is obtained for the sub-Weibull summation, which refines the constant in the sub-Weibull concentration inequality. Let for all integer . First, by truncating more precisely, we obtain a sharper upper bound for , comparing to Proposition C.1 in [6].
Corollary 5.
If for and constants , , then
where and is the minimal solution of
The proof can be seen in the Appendix A. In below, we need the moment estimation for sums of independent symmetric r.v.s.
Lemma 1
(Khinchin-Kahane Inequality, Theorem 1.3.1 of [13]). Let be a finite non-random sequence, be a sequence of independent Rademacher variables and Then
Lemma 2
(Theorem 2 of [14]). Let be a sequence of independent symmetric r.v.s, and . Then, where with
Lemma 3
(Example 3.2 and 3.3 of [14]). Assume X be a symmetric r.v. satisfying . For any , we have
- (a)
- If is concave, then .
- (b)
- For convex , denote the convex conjugate function and Then .
With the help of three lemmas above, we can obtain the main results concerning the shaper and constant-specified concentration inequality for the sum of independent sub-Weibull r.v.s.
Theorem 1
(Concentration for sub-Weibull summation). Let γ be given in Corollary 5. If are independent centralized r.v.s such that for all and some , then for any weight vector , the following bounds holds true:
- (a)
- The estimate for GBO norm of the summation:,where , withand where and . For the case , β is the Hölder conjugate satisfying .
- (b)
- Concentration for sub-Weibull summation:
- (c)
- Another form of for :
Remark 2.
The constant in Theorem 1 can be improved as under symmetric assumption of sub-Weibull r.v.s . Moreover, by the improved symmetrization theorem (Theorem 3.4 in [15]), one can replace the constant in Theorem 1 by a sharper constant . Theorem 1 (b) also implies a potential empirical upper bound for for independent sub-Weibull r.v.s , because the only unknown variable in is . From Remark 1, estimating is possible for i.i.d. observation .
Remark 3.
Compared with the newest result in [6], our method do not use the crude String’s approximation will give sharper concentration. For example, suppose are i.i.d. r.v.s with mean μ and . Here we set , X is heavy-tailed (for example set the density of X as ). We find that , , and . Hence, confidence interval in our method will be
while the 95% confidence interval in Theorem 3.1 of [6] is evaluated as
In this example, it can be seen that our method does give a much better (tighter) confidence interval.
Remark 4.
Theorem 1 (b) generalizes the sub-Gaussian concentration inequalities, sub-exponential concentration inequalities, and Bernstein’s concentration inequalities with Bernstein’s moment condition. For in Theorem 1 (c), the tail behaviour of the sum is akin to a sub-Gaussian tail for small t, and the tail resembles the exponential tail for large t; For , the tail behaves like a Weibull r.v. with tail parameter θ and the tail of sums match that of the sub-Gaussian tail for large t. The intuition is that the sum will concentrate around zero by the Law of Large Number. Theorem 1 shows that the convergence rate will be faster for small deviations from the mean and will be slower for large deviations from the mean.
Remark 5.
Recently, similar result presented in [16] is that
where is some constants only depends on X and θ ( can be obtained by Proposition 3). But it is obvious to see this large derivation result cannot guarantee a -convergence rate (as presented in Proposition 3) whereas our result always give a -convergence rate, as presented in Theorem 1 (c) and Proposition 3.
2.3. Sub-Weibull Parameter
In this part, a new sub-Weibull parameters is proposed, which is enable of recovering the tight concentration inequality for single non-zero mean random vector. Similar to characterizations of sub-Gaussian r.vs. in Proposition 2.5.2 of [1], sub-Weibull r.vs. has the equivalent definitions.
Proposition 6
(Characterizations of sub-Weibull r.v., [17]). Let X be a r.v., then the following properties are equivalent. (1). The tails of X satisfy ; (2). The moments of X satisfy ; (3). The MGF of satisfies for ; (4).
From the upper bound of in Proposition 6(2), an alternative definition of the sub-Weibull norm is given by [17]. Let . An alternative definition of the sub-exponential norm is see Proposition 2.7.1 of [1]. The sub-exponential r.v. X satisfies equivalent properties in Proposition 6 (Characterizations of sub-exponential with ). However, these definition is not enough to obtain the sharp parameter as presented in the sub-Gaussian case. Here, we redefine the sub-Weibull parameter by our Corollary 3(a).
Definition 4
(Sub-Weibull r.v.,). Define the sub-Weibull norm
We denote the sub-Weibull r.v. as if for a given . For , the is a norm which satisfies triangle inequality by Minkowski’s inequality: , comparing to Proposition 1. Definition 4 is free of bounding MGF, and it avoids Stirling’s approximation in the proof of the tail inequality. We obtain following main results for this moment-based norm.
Corollary 6.
If , then
Theorem 2
(sub-Weibull concentration). Suppose that there are n independent sub-Weibull r.v.s for . We have
and . Moreover, we have
The proof of Theorem 2 can be seen in Appendix A.8. The concentration in this Theorem 2 will serve a critical role in many statistical and machine learning literature. For instance, the sub-Weibull concentrations in [7] contain unknown parameters, which makes the algorithm for general sub-Weibull random rewards is infeasible. However, when using our results, it will become feasible as we give explicit constants in these concentrations.
Importantly, the sub-exponential parameter is a special case of sub-Weibull norm by letting . Denote the sub-exponential parameter for r.v X as
.
We denote if . For exponential r.v. , the moment is and . Another case of sub-Weibull norm is , which defines sub-Gaussian parameter:
.
Like the generalized method of moments, we can give the higher-moment estimation procedure for the norm . Unfortunately, the method in Remark 1 for estimating MGF is not stable in the simulation since the exponential function has a massive variance in some cases.
- Estimation procedure for and . Consideras a discrete optimization problem. We can take big enough to minimizeon .
At the first glimpse, the bigger p is, the larger n is required in this method. Nonetheless, often, most of common distributions only require a median-size of p to give a relatively good result, then only the median-size of n in turn is required. For standard Gaussian random, centralized Bernoulli (successful probability ), and uniform distributed (on ) variable X,
It can be shown that The Figure 1, Figure 2 and Figure 3 show the estimated value from different n under estimate method (8) for the three distributions mentioned above. The estimate method (8) is a correct estimated method for sub-Gaussian parameter to our best knowledge.
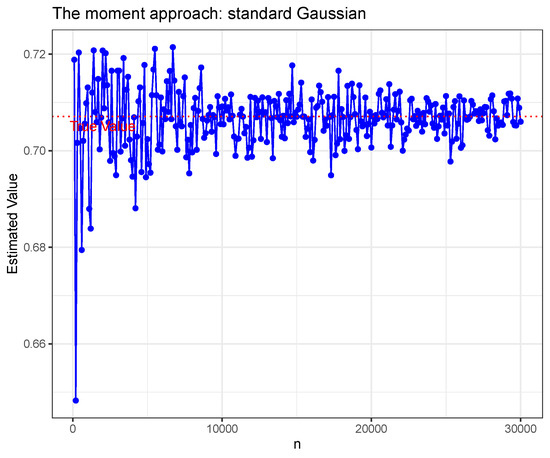
Figure 1.
Standard Gaussian.
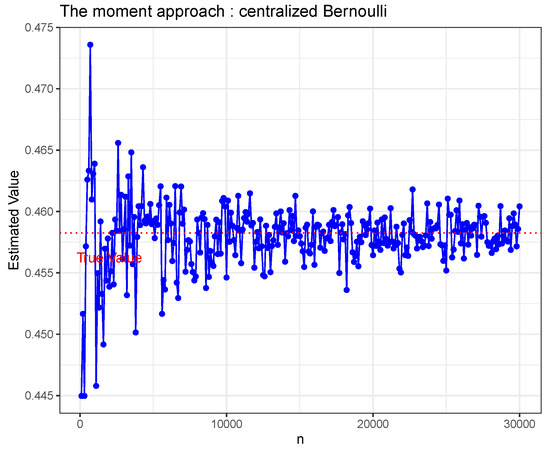
Figure 2.
Centralized Bernoulli.
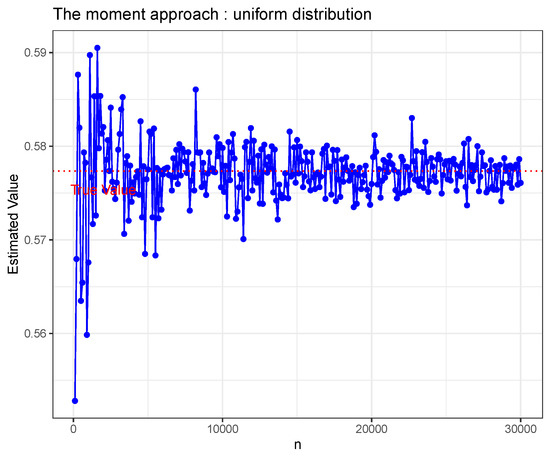
Figure 3.
Uniform on .
For centralized negative binomial, and centralized Poisson () variable X, respectively. The Figure 4 and Figure 5 show the estimated value from different n under estimate method (8) for the four distributions mentioned above.
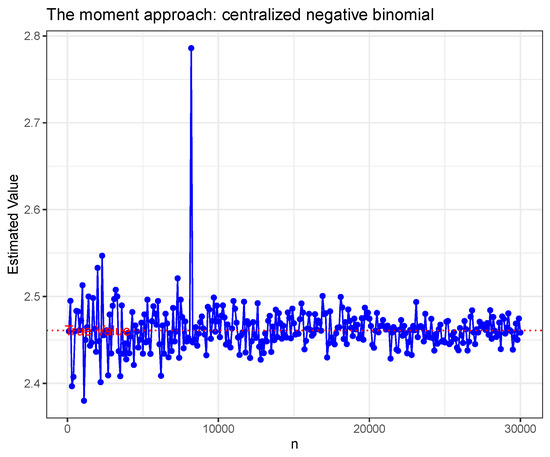
Figure 4.
Centralized negative binomial.
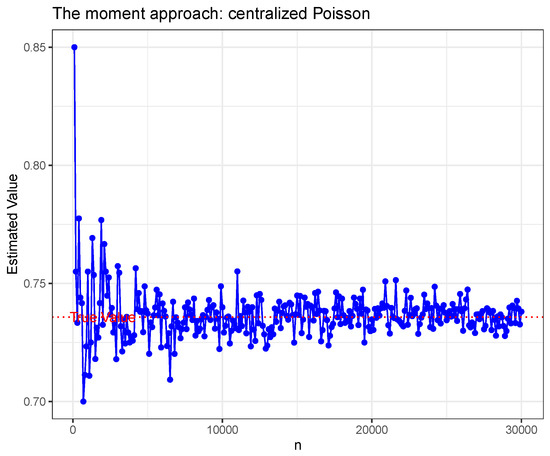
Figure 5.
Centralized Poisson.
The five figures mentioned above show litter bias between the estimated norm and true norm. It is worthy to note that the norm estimator for centralized negative binomial case has a peak point. This is caused by sub-exponential distributions having relatively heavy tails, and hence the norm estimation may not robust as that in sub-Gaussian under relatively small sample sizes.
Moreover, sub-Gaussian and sub-exponential parameter is extensible for random vectors with values in a normed space , we define norm-sub-Gaussian parameter and norm-sub-exponential parameter: The norm-sub-Gaussian parameter:
;
the norm-sub-exponential parameter:
We denote and for , respectively.
3. Statistical Applications of Sub-Weibull Concentrations
3.1. Negative Binomial Regressions with Heavy-Tail Covariates
In statistical regression analysis, the responses in linear regressions are assume to be continuous Gaussian variables. However, the category in classification or grouping may be infinite with index by the non-negative integers. The categorical variables is treated as countable responses for distinction categories or groups; sometimes it can be infinite. In practice, random count responses include the number of patients, the bacterium in the unit region, or stars in the sky and so on. The responses with covariates belongs to generalized linear regressions. We consider i.i.d. random variables . By the methods of the maximum likelihood or the M-estimation, the estimator is given by
where the loss function is convex and twice differentiable in the first argument.
In high-dimensional regressions, the dimension may be growing with sample size n. When belongs to the exponential family, [18] studied the asymptotic behavior of in the generalized linear models (GLMs) as is increasing. In our study, we focus on the case that the covariates is heavy-tailed for .
The target vector is assumed to be the loss under the population expectation, comparing to (9). Let , and . Finally, define the score function and Hessian matrix of the empirical loss function are and , respectively. The population version of Hessian matrix is . The following so-called determining inequalities guarantee the -error for the estimator obtained from the smooth M-estimator defined as (9).
Lemma 4
(Corollary 3.1 in [19]). Let for . If is a twice differentiable function that is convex in the first argument and for some : . Then there exists a vector satisfying as the estimating equation of (9),
Applications of Lemma 4 in regression analysis is of special interest when X is heavy tailed, i.e., the sub-Weibull index . For the negative binomial regression (NBR) with the known dispersion parameter , the loss function is
Thus we have , see [20] for details.
Further computation gives and it implies that Therefore, condition in Lemma 4 leads to
This condition need the assumption of the design space for .
In NBR with loss (10), one has
and .
To guarantee that approximates well, some regularity conditions are required.
- •
- (C.1): For , assume and the heavy-tailed covariates are uniformly sub-Weibull with for .
- •
- (C.2): The vector is sparse or bounded. Let with a slowly increasing function , we have .
In addition, to bound , the sub-Weibull concentration determines:
by using Corollary 3. Hence, we define the event for the maximum designs:
To make sure that the optimization in (9) has a unique solution, we also require the minimal eigenvalue condition.
- •
- (C.3): Suppose that is satisfied for all .
In the proof, to ensure that the random Hessian function has a non-singular eigenvalue, we define the event
Theorem 3
(Upper bound for -error). In the NBR with loss (10) and , let
and . Under the event , for any , if the sample size n satisfies
Let with , then
A few comment is made on this theorem. First, in order to get , we need under sample size restriction (11) with . Second, note that the in provability depends on the models size and the fluctuation of the design by the event .
3.2. Non-Asymptotic Bai-Yin’s Theorem
In statistical machine learning, exponential decay tail probability is crucial to evaluate the finite-sample performance. Unlike Bai-Yin’s law with the fourth-moment condition that leads to polynomial decay tail probability, under sub-Weibull conditions of data, we provide a exponential decay tail probability on the extreme eigenvalues of a random matrix.
Let be an random matrix whose entries are independent copies of a r.v. with zero mean, unit variance, and finite fourth moment. Suppose that the dimensions n and p both grow to infinity while the aspect ratio converges to a constant in . Then Bai-Yin’s law [21] asserted that the standardized extreme eigenvalues satisfying
Next we introduce a special counting measure for measuring the complexity of a certain set in some space. The is called an ε-net of K in if K can be covered by balls with centers in K and radii (under Euclidean distance). The covering number is defined by the smallest number of closed balls with centers in K and radii whose union covers K.
For purposes of studying random matrices, we need to extend the definition of sub-Weibull r.v. to sub-Weibull random vectors. The n-dimensional unit Euclidean sphere , is denoted by We say that a random vector in is sub-Weibull if the one-dimensional marginals are sub-Weibull r.v.s for all . The sub-Weibull norm of a random vector is defined as Similarly, define the spectral norm for any matrix as . Spectral norm has many good properties, see [1] for details.
Furthermore, for simplicity, we assume that the rows in random matrices are isotropic random vectors. A random vector in is called isotropic if Equivalently, is isotropic if In the non-asymptotic regime, Theorem 4.6.1 in [1] study the upper and lower bounds of maximum (minimum) eigenvalues of random matrices with independent sub-Gaussian entries which are sampled from high-dimensional distributions. As an extension of Theorem 4.6.1 in [1], the following result is a non-asymptotic versions of Bai-Yin’s law for sub-Weibull entries, which is useful to estimate covariance matrices from heavy-tailed data [, ].
Theorem 4 (Non-asymptotic Bai-Yin’s law).
Let be an matrix whose rows are independent isotropic sub-Weibull random vectors in with covariance matrix and . Then for every , we have
where
where if and if ; , and defined in Theorem 1a.
Moreover, the concentration inequality for extreme eigenvalues hold for
3.3. General Log-Truncated Z-Estimators and sub-Weibull Type Robust Estimators
Motivated from log-truncated loss in [22,23], we study the almost surely continuous and non-decreasing function for truncating the original score function
where is a high-order function [23] of which is to be specified. For example, a plausible choose for in (13) should have following form
For (14), we get for sufficiently smaller x and for larger x. Under (13), now we show that must obey a key inequality. For all , it suffices to verify , which is equivalent to check , namely
For independent r.v.s , using the score function (14), we define the score function of data
for any .
Then the influence of the heavy-tailed outliers is weaken by by choosing an optimal . We aim to estimate the average mean: for non-i.i.d. samples . Define the Z-estimator as
where is the tuning parameter (will be determined later).
To guarantee consistency for log-truncated Z-estimators (15), we require following assumptions of .
- •
- (C.1): For a constant , the satisfies weak triangle inequality and scaling property,for satisfies(C.1.3): and are non-constant increasing functions and .
Remark 6.
Note that and we could put . However, does not satisfy (C.1.3) since and are constant functions of t.
In the following theorem, we establish the finite sample confidence interval and the convergence rate of the estimator .
Theorem 5.
Let be independent samples drawn from an unknown probability distribution on . Consider the estimator defined as (15) with (C.1), and . Let and . Let be the smallest solution of the equation and be the largest solution of .
(a). We have with the -confidence intervals
for any satisfies the sample condition:
where is a constant such that .
(b). Moreover, picking , one has
The (17) in Theorem 5 is a fundamental extension of Lemma 2.1 (see Theorem 16 in [24]) with from i.i.d. sample to independent sample. Let , for i.i.d. sample, Theorem 5 implies Lemmas 2.3, 2.4 and Theorem 2.1 in [22]. The in Theorem 5(b) gives a theoretical guarantee for choosing the tuning parameter .
Proposition 7
(Theorem 2.1 in [22]). Let be a sequence of i.i.d. samples drawn from an unknown probability distribution on . We assume for a certain and denote . Given any and positive integer , let Then, with probability at least ,
Comparing to the convergence rate in (18), put for . It implies
For example, let us deal with the Pareto distribution with shape parameter and scale parameter , and the density function is . For , has infinite variance, and it does not belong to the sub-Weibull distribution, so do the sample mean of i.i.d. Pareto distributed data. Proposition 7 shows that the estimator error for robust mean estimator enjoys sub-Weibull concentration as presented in Proposition 3, without finite sub-Weibull norm assumption of data. With the Weibull-tailed behavior, it motivates us to define general sub-Weibull estimators having the non-parametric convergence rate in Proposition 3 for , even if the data do not have finite sub-Weibull norm.
Definition 5
(Sub-Weibull estimators). An estimator based on i.i.d. samples from an unknown probability distribution P with mean , is called - if
For example, in Proposition 7, is - with in Definition 5. When , [25] defined sub-Gaussian estimators (includes Median of means and Catoni’s estimators) for certain heavy-tailed distributions and discussed the nonexistence of sub-Gaussian mean estimators under -moment condition for the data ().
4. Conclusions
Concentration inequalities are far-reaching useful in high-dimensional statistical inferences and machine learnings. They can facilitate various explicit non-asymptotic confidence intervals as a function of the sample size and model dimension.
Future research includes sharper version of Theorem 2 that is crucial to construct non-asymptotic and data-driven confidence intervals for the sub-Weibull sample mean. Although we have obtained sharper upper bounds for sub-Weibull concentrations, the lower bounds on tail probabilities are also important in some statistical applications [26]. Developing non-asymptotic and sharp lower tail bounds of Weibull r.v.s is left for further study. For negative binomial concentration inequalities in Corollary 2, it is of interesting to study concentration inequalities of COM-negative binomial distributions (see [27]).
Author Contributions
Conceptualization, H.Z. and H.W.; Formal analysis, H.Z. and H.W.; Funding acquisition, H.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by National Natural Science Foundation of China Grant (12101630) and the University of Macau under UM Macao Talent Programme (UMMTP-2020-01). This work is also supported in part by the Key Project of Natural Science Foundation of Anhui Province Colleges and Universities (KJ2021A1034), Key Scientific Research Project of Chaohu University (XLZ-202105).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
The authors thank Guang Cheng for the discussion about doing statistical inference in the non-asymptotic way and Arun Kumar Kuchibhotla for his help about the proof of Theorem 1. The authors also thank Xiaowei Yang for his helpful comments on Theorem 5.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1
Proof of Corollary 1.
is continuous for t a neighborhood of zero, by the definition, Since , the MGF is monotonic increasing. Hence, inverse function exists and So . □
Appendix A.2
Proof of Corollary 2.
The first inequality is the direct application of (3) by observing that for any constant , and r.v. Y with , , and . The second inequality is obtained from (3) by considering two rate in separately. For (5), we only need to note that
Then the third inequality is obtained by the first inequality and the definition of . □
Appendix A.3
Proof of Corollary 3.
The first and second part of this proposition were shown in Lemma 2.1 of [28]. For the third result, using the bounds of Gamma function [see [29]:
it gives
□
Appendix A.4
Proof of Corollary 4.
By the definition of -norm, . Then The result follows by the definition of -norm again. Moreover,
which verifies (6). If , then , which means that with
□
Appendix A.5
Proof of Corollary 5.
Set so that holds for all . By Markov’s inequality for t-th moment , we have
So, for any ,
Note the definition of shows holds for all and assumption for all . It gives . This inequality with (A1) gives
Take , and define for a certain constant ,
Therefore, with defined as the smallest solution of the inequality . An approximate solution is . □
Appendix A.6
The main idea in the proof is by the sharper estimates of the GBO norm of the sum of symmetric r.v.s.
Proof of Theorem 1.
- (a)
- Without loss of generality, we assume . Define , then it is easy to check that implies . For independent Rademacher r.v. , the symmetrization inequality gives Note that is identically distributed as ,From Lemma 2, we are going to handle the first term in (A3) with the sum of symmetric r.v.s. Since , thenfor symmetric independent r.v.s satisfying and for all .Next, we proceed the proof by checking the moment conditions in Corollary 5.Case : is concave for . From Lemmas 2 and 3 (a), for ,where the last inequality we use HenceandUsing homogeneity, we can assume that . Then and . Therefore, for ,where the last inequality follows form the fact that for any . HenceFollowing Corollary 5, we havewhere , , and .Finally, take Indeed, the positive limit can be argued by (2.2) in [30]. Then by the monotonicity property of the GBO norm, it givesCase : In this case is convex with By Lemmas 2 and 3(b), for , we havewith mentioned in the statement. Therefore, for , Equation (A3) impliesThen the following result follows by Corollary 5,,where , , and .Note that , we can conclude (a).
- (b)
- It is followed from Proposition 5 and (a).
- (c)
- For easy notation, put in the proof. When , by the inequality for , we havePut , we haveFor , we obtain Let , it givesSimilarly, for , it impliesif ,and if . □
Appendix A.7
Proof of Corollary 6.
Using the definition of , it yields
if which implies that the minimal c is . That is to say we have . Applying (2), we have
□
Appendix A.8
Proof of Theorem 2.
Minkowski’s inequality for and definition of imply
where the last inequality by letting in Corollary 3b.
From Markov’s inequality, it yields
Let , it gives
and .
Therefore, for , we have
So
Let and . Then
For , note that moment monotonicity show that is a non-decreasing function of , i.e.,
The -inequality implies . Using Markov’s inequality again, we have
Put and Then, we obtain
This completes the proof. □
Appendix A.9
Proof of Theorem 3.
Note that for , it yields
Consider the decomposition
For the first term, we have under the with
where we use and the second last inequality is from Corollary 2.
For the second term, by Theorem 1 and we have
where .
Then we have by conditioning on
By , Corollary 2 implies for any ,
Let
We bound and under the event . Note that , then (C.1) and (C.2) gives
Furthermore, under , it gives the condition of n: (11). □
Appendix A.10
Proof of Theorem 4.
For convenience, the proof is divided into three steps.
Step 1. Adopting the lemma
Lemma A1 (Computing the spectral norm on a net, Lemma 5.4 in [1])
Let be an matrix, and let be an ε-net of for some . Then
Then show that . Indeed, note that . By setting in Lemma 4, we can obtain:
Step 2. Let fix any . Observe that . The fact that are with . Then by Corollary 4, are independent r.v.s with . The norm triangle inequality (Lemma A.3 in [9]) gives
where if and if .
Denote in Theorem 1. With (A11), we have
and .
For , we obtain
.
Write as the constant defined in Theorem 1(a). Then,
Hence
Therefore, . Let for constant c, then
Step 3. Consider the follow lemma for covering numbers in [1].
Lemma A2 (Covering numbers of the sphere).
For the unit Euclidean sphere , the covering number satisfies for every .
Then, we show the concentration for , and (12) follows by the definition of largest and least eigenvalues. The conclusion is drawn by Step 1 and 2:
where the last inequality follows by Lemma A2 with . When the , then , and the (12) is proved.
Moreover, note that
implies that
.
Similarly, for the minimal eigenvalue, we have
This implies . So we obtain that the two events satisfy
Then we obtain the second conclusion in this theorem. □
Appendix A.11
Proof of Theorem 5
By independence and (13),
For convenience, let
and . Therefore, Equation (A12) and the Markov’s inequality show
and . These two inequality yield
The implies the map is non-increasing. If , we have from (A13). As n is sufficient large and , in , from (C.1.2) the term converges to 0 by (C.1.3). Then, there must be a constant such that . So under (16), it implies that has a solution and denote the smallest solution . Similarly, for , we have . The condition (16) implies , then has a solution and denote the largest solution . Note that is a continuous and non-increasing function, the estimating equation has a solution such that with a probability at least . Recall that
has the smallest solution under the condition (16). We have
which implies
Put , i.e., The scaling assumption gives
and thus . Let . Moreover, Equation (A16) and the value yields
Solve the above inequality in terms of , we obtain
Similarly, for , one has . Then we obtain that (17) holds with probability at least . □
References
- Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science; Cambridge University Press: Cambridge, UK, 2018; Volume 47. [Google Scholar]
- Bai, Z.; Silverstein, J.W. Spectral Analysis of Large Dimensional Random Matrices; Springer: New York, NY, USA, 2010; Volume 20. [Google Scholar]
- Wainwright, M.J. High-Dimensional Statistics: A Non-Asymptotic Viewpoint; Cambridge University Press: Cambridge, UK, 2019; Volume 48. [Google Scholar]
- Zhang, H.; Chen, S.X. Concentration Inequalities for Statistical Inference. Commun. Math. Res. 2021, 37, 1–85. [Google Scholar]
- Tropp, J.A. An introduction to matrix concentration inequalities. Found. Trends Mach. Learn. 2015, 8, 1–230. [Google Scholar] [CrossRef]
- Kuchibhotla, A.K.; Chakrabortty, A. Moving beyond sub-Gaussianity in high-dimensional statistics: Applications in covariance estimation and linear regression. Inf. Inference J. Imag. 2022. ahead of print. [Google Scholar] [CrossRef]
- Hao, B.; Abbasi-Yadkori, Y.; Wen, Z.; Cheng, G. Bootstrapping Upper Confidence Bound. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Gbur, E.E.; Collins, R.A. Estimation of the Moment Generating Function. Commun. Stat. Simul. Comput. 1989, 18, 1113–1134. [Google Scholar] [CrossRef]
- Götze, F.; Sambale, H.; Sinulis, A. Concentration inequalities for polynomials in α-sub-exponential random variables. Electron. J. Probab. 2021, 26, 1–22. [Google Scholar] [CrossRef]
- Li, S.; Wei, H.; Lei, X. Heterogeneous Overdispersed Count Data Regressions via Double-Penalized Estimations. Mathematics 2022, 10, 1700. [Google Scholar] [CrossRef]
- Rigollet, P.; Hütter, J.C. High Dimensional Statistics. 2019. Available online: http://www-math.mit.edu/rigollet/PDFs/RigNotes17.pdf (accessed on 20 April 2022).
- Foss, S.; Korshunov, D.; Zachary, S. An Introduction to Heavy-Tailed and Subexponential Distributions; Springer: New York, NY, USA, 2011. [Google Scholar]
- De la Pena, V.; Gine, E. Decoupling: From Dependence to Independence; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Latala, R. Estimation of moments of sums of independent real random variables. Ann. Probab. 1997, 25, 1502–1513. [Google Scholar] [CrossRef]
- Kashlak, A.B. Measuring distributional asymmetry with Wasserstein distance and Rademacher symmetrization. Electron. J. Stat. 2018, 12, 2091–2113. [Google Scholar] [CrossRef]
- Vladimirova, M.; Girard, S.; Nguyen, H.; Arbel, J. Sub-Weibull distributions: Generalizing sub-Gaussian and sub-Exponential properties to heavier tailed distributions. Stat 2020, 9, e318. [Google Scholar] [CrossRef]
- Wong, K.C.; Li, Z.; Tewari, A. Lasso guarantees for β-mixing heavy-tailed time series. Ann. Stat. 2020, 48, 1124–1142. [Google Scholar] [CrossRef]
- Portnoy, S. Asymptotic behavior of likelihood methods for exponential families when the number of parameters tends to infinity. Ann. Stat. 1988, 16, 356–366. [Google Scholar] [CrossRef]
- Kuchibhotla, A.K. Deterministic inequalities for smooth m-estimators. arXiv 2018, arXiv:1809.05172. [Google Scholar]
- Zhang, H.; Jia, J. Elastic-net regularized high-dimensional negative binomial regression: Consistency and weak signals detection. Stat. Sin. 2022, 32, 181–207. [Google Scholar] [CrossRef]
- Bai, Z.D.; Yin, Y.Q. Limit of the smallest eigenvalue of a large dimensional sample covariance matrix. In Advances In Statistics; World Scientific: Singapore, 1993; pp. 1275–1294. [Google Scholar]
- Chen, P.; Jin, X.; Li, X.; Xu, L. A generalized catoni’s m-estimator under finite α-th moment assumption with α∈(1,2). Electron. J. Stat. 2021, 15, 5523–5544. [Google Scholar] [CrossRef]
- Xu, L.; Yao, F.; Yao, Q.; Zhang, H. Non-Asymptotic Guarantees for Robust Statistical Learning under (1+ε)-th Moment Assumption. arXiv 2022, arXiv:2201.03182. [Google Scholar]
- Lerasle, M. Lecture notes: Selected topics on robust statistical learning theory. arXiv 2019, arXiv:1908.10761. [Google Scholar]
- Devroye, L.; Lerasle, M.; Lugosi, G.; Oliveira, R.I. Sub-gaussian mean estimators. Ann. Stat. 2016, 44, 2695–2725. [Google Scholar] [CrossRef]
- Zhang, A.R.; Zhou, Y. On the non-asymptotic and sharp lower tail bounds of random variables. Stat 2020, 9, e314. [Google Scholar] [CrossRef]
- Zhang, H.; Tan, K.; Li, B. COM-negative binomial distribution: Modeling overdispersion and ultrahigh zero-inflated count data. Front. Math. China 2018, 13, 967–998. [Google Scholar] [CrossRef]
- Zajkowski, K. On norms in some class of exponential type Orlicz spaces of random variables. Positivity 2019, 24, 1231–1240. [Google Scholar] [CrossRef]
- Jameson, G.J. A simple proof of Stirling’s formula for the gamma function. Math. Gaz. 2015, 99, 68–74. [Google Scholar] [CrossRef][Green Version]
- Alzer, H. On some inequalities for the gamma and psi functions. Math. Comput. 1997, 66, 373–389. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).