Abstract
Large language models (LLMs) exhibit strong semantic reasoning capabilities for autonomous driving decision-making; however, their substantial inference latency poses a critical challenge for real-time closed-loop vehicle control. This study proposes an engineering-oriented framework to enable latency-constrained LLM-based decision-making by integrating bird’s-eye-view (BEV) structured perception with low-bit quantized inference. The BEV perception module compresses multi-view visual inputs into structured semantic representations, thereby reducing input redundancy and enhancing inference efficiency. In addition, 4-bit post-training quantization (PTQ), combined with an optimized inference engine, is employed to alleviate computational and memory bandwidth constraints during autoregressive decoding. Experiments conducted on the CARLA simulation platform under car-following, overtaking, and mixed driving scenarios—validated through 500 independent trials—demonstrate that the proposed framework substantially reduces end-to-end inference latency while maintaining stable decision-making performance. The results indicate that the system satisfies the 10 Hz real-time control requirement and significantly improves control quality, as evidenced by reduced collision rates and lower Average Jerk compared with both traditional imitation learning (Behavioral Cloning, BC) and the Transformer-based TransFuser baseline. Furthermore, sensitivity analyses confirm the robustness of the framework under environmental degradation and perception noise, underscoring the practical feasibility of deploying LLMs for safe and reliable closed-loop autonomous driving.
1. Introduction
Autonomous driving systems operate in complex traffic environments via the closed-loop integration of environmental perception, behavioral decision-making, and vehicle control [1]. With advances in deep learning, data-driven planning frameworks have become a major research focus, effectively addressing the limited adaptability of traditional rule-based models in unstructured scenarios [2,3]. However, corner cases persist in urban road environments with frequent multi-agent interactions and complex scene semantics [4]. Enhancing the semantic understanding and logical reasoning capabilities of the decision-making layer while maintaining overall system stability remains a key challenge for the large-scale deployment of autonomous driving technologies [5].
In recent years, large language models (LLMs) have demonstrated notable strengths in natural language processing and multimodal information fusion, offering a new technical paradigm for high-level autonomous driving decision-making [6]. Existing studies have explored the integration of LLMs into the driving decision loop, leveraging their rich world knowledge to improve generalization and behavioral interpretability in complex interactive scenarios [7,8]. Although LLMs perform well in offline evaluations, most studies focus on decision-making effectiveness while neglecting real-time constraints in closed-loop control systems [9].
Autonomous driving systems, particularly at the execution and control layers, typically require decision-making modules to operate at high update frequencies (e.g., above 10 Hz) to respond effectively to dynamic environmental changes [10]. However, due to their large parameter scales and the substantial computational overhead associated with autoregressive inference in Transformer architectures, LLMs generally exhibit excessive inference latency in practical deployments [11]. This latency can lead to a spatiotemporal mismatch between perceived information and executed actions, whereby the scene state used for decision-making has significantly evolved by the time the control action is applied. This mismatch degrades closed-loop stability and heightens safety risks [12].
From an engineering perspective, this challenge cannot be addressed solely by increasing computational resources. Directly feeding high-dimensional visual features or raw images into LLMs introduces substantial redundant information, resulting in long token sequences and increased inference burden [13]. Moreover, vehicle-mounted computing platforms are constrained by power consumption and thermal limitations, making real-time inference with full-precision models difficult to sustain [14]. Consequently, reducing inference complexity through efficient feature representation and model compression, while preserving essential semantic information, has emerged as a critical bottleneck [15].
To address the real-time constraints that fundamentally hinder the deployment of large language models (LLMs) in closed-loop autonomous driving systems, this study investigates the system-level feasibility of LLM-based decision-making under strict latency requirements. Although state-of-the-art end-to-end and hybrid planners—such as TransFuser, UniAD, and PlanT—have achieved impressive performance through multi-modal fusion and unified task modeling, they primarily rely on reactive pattern matching mechanisms. Such approaches often lack the explicit logical reasoning and common-sense knowledge required for complex multi-agent interactions. In contrast, the proposed framework leverages the reasoning capabilities of LLMs to provide a form of “logical buffering” for perception-driven planners, thereby enhancing decision stability in ambiguous or safety-critical scenarios.
The primary contributions of this work are summarized as follows:
- We propose an engineering-oriented framework that integrates bird’s-eye-view (BEV) structured perception with a low-bit quantized LLM reasoning engine, specifically optimized for real-time closed-loop control.
- We implement and systematically evaluate a 4-bit post-training quantization (PTQ) strategy based on GPTQ, achieving a 75% reduction in memory footprint while preserving the semantic fidelity required for autonomous decision-making.
- We establish a comprehensive evaluation protocol on the CARLA platform, incorporating safety-critical metrics—namely Collision Rate and Average Jerk—as well as statistical significance testing across 500 independent trials.
- We conduct an extensive sensitivity analysis to validate system robustness under environmental degradation and perception noise, providing empirical evidence for the practical feasibility of deploying LLMs on resource-constrained vehicle-mounted platforms.
The remainder of this paper is organized as follows. Section 2 reviews related work, with particular emphasis on LLM-based autonomous driving and the evolution of planners such as UniAD and PlanT. Section 3 describes the overall system architecture and the BEV-based structured perception module. Section 4 details the experimental results of BEV perception and the LLM-based decision module, including comparative and ablation studies. Section 5 discusses the speed–accuracy trade-offs, safety implications, and current limitations of the study. Finally, Section 6 concludes the paper and outlines directions for future research.
2. Related Work
2.1. Large Language Models in Autonomous Driving
The rapid advancement of large language models (LLMs) and multimodal large models (MLMs) has driven a paradigm shift in autonomous vehicle decision-making. By leveraging extensive pre-trained world knowledge and strong semantic reasoning capabilities, these models address inherent limitations of traditional rule-based systems. Li et al. [16] presented a comprehensive review demonstrating that the integration of LLMs across perception, prediction, and human–machine interaction modules enhances both system intelligence and operational safety. To bridge the gap between abstract reasoning and practical vehicle control, Wang et al. [17] proposed the “Drive as Veteran” framework. By fine-tuning a LLaMA-7B model on high-quality driving datasets, they showed that domain-adapted LLMs can achieve highway driving performance comparable to experienced human drivers while maintaining acceptable inference efficiency.
Further investigating model generalization, Xiong et al. [18] employed the Dilu framework to evaluate LLM-based decision-making in complex traffic scenarios, including roundabouts and intersections. Their results indicate that augmenting the number of “memory items” through few-shot learning significantly improves adaptive stability in multi-agent environments.
The integration of symbolic reasoning with sensory inputs has also attracted increasing attention. Azarafza et al. [19] introduced a hybrid reasoning architecture that combines common-sense knowledge with arithmetic logic, enabling LLMs to generate accurate longitudinal and lateral control commands. From an architectural perspective, Shao et al. [20] developed LMDrive, an end-to-end closed-loop framework capable of processing multi-modal sensor data and natural language instructions to achieve language-guided autonomous navigation.
Beyond performance improvements, safety and ethical alignment remain critical considerations. Kong et al. [21] proposed a “superalignment” framework based on multi-agent LLM verification to ensure that generated plans comply with traffic regulations and privacy constraints. For trajectory refinement, Zhang et al. [22] presented DAPlanner, a dual-agent architecture that separates trajectory generation from discriminative evaluation, achieving state-of-the-art results on the nuScenes dataset. More recently, Han et al. [23] leveraged hierarchical Chain-of-Thought (CoT) reasoning to enhance perception robustness, while Ge et al. [24] introduced the VLA-MP system to map semantic latent states to physics-constrained motion trajectories.
Collectively, these studies highlight the potential of LLMs to address long-tail and semantically complex scenarios. Nevertheless, real-time deployment remains a substantial engineering challenge due to the computational demands of autoregressive inference limitation that the present study seeks to mitigate through low-bit quantization.
2.2. End-to-End and Hybrid Planning Architectures
In parallel with the rise of LLM-based approaches, end-to-end planning architectures have evolved to mitigate error propagation in traditional modular pipelines. Chu et al. [25] surveyed the application of Transformer architectures in autonomous driving, emphasizing the critical role of self-attention mechanisms in modeling long-range spatiotemporal dependencies.
For spatial representation, Zhao et al. [26] proposed the BETAV framework, which integrates Bird’s-Eye-View (BEV) Transformer encoding with Bézier curve optimization to improve perception accuracy and trajectory smoothness. Addressing challenges in unstructured environments, Su et al. [27] developed a perception model based on Global Context Vision Transformers (GCViT), demonstrating its effectiveness in detecting temporary roads and generating feasible real-time paths.
Efficiency and computational overhead are key considerations in deploying dense BEV-based planners. Chen et al. [28] introduced HiPro-AD, a sparse trajectory planning framework employing hybrid spatiotemporal attention to reduce latency to approximately 67 ms without sacrificing decision quality. To accelerate convergence, Qian et al. [29] explored pre-training strategies using multi-behavior optimal datasets, facilitating rapid adaptation to complex car-following scenarios.
Advances in feature fusion are reflected in the works of Cheng et al. [30] and Liu et al. [31]. The former combined SENet with Vision Transformers to achieve deep spatiotemporal feature coupling, whereas the latter proposed the MSTF model to reconstruct incomplete trajectories caused by sensor occlusions. At the system integration level, Lyu et al. [32] demonstrated that unifying sensor fusion and motion planning within a consistent BEV representation significantly enhances perception robustness. Furthermore, Jun et al. [33] conducted a comparative optimization study on BEV segmentation, revealing that the use of InternImage-T encoders with FP16 precision can reduce memory consumption by 32.2% while preserving accuracy.
These developments in hardware-efficient perception and planning provide an important technical foundation for the present study. Building upon these insights, our work aims to balance the high-level semantic reasoning capability of LLMs with the stringent real-time requirements of closed-loop vehicle control through structured perception and low-bit quantized inference.
3. Materials and Methods
3.1. System Architecture Overview
To meet the requirements of real-time performance and stability in autonomous driving closed-loop control, a layered modular design is adopted to construct a closed-loop execution framework comprising perception, inference, and control. The framework integrates a BEV structured perception module with an LLM-based decision-making inference module. Together, these modules support a continuous decision-making process, spanning from environmental perception to the generation of control commands.
We collect environmental images and vehicle state labels via the CARLA simulation platform to train the BEV perception model. This training process enables the model to extract geometric attributes of vehicles directly from raw visual inputs. After training, the BEV perception module transforms environmental images into low-redundancy, structured semantic representations of the scene, which are output in a unified data format to provide a standardized input interface for subsequent decision-making inference.
Within the decision-making inference module, structured scene information and corresponding vehicle control signals are obtained through CARLA’s autopilot mode to construct training samples for model fine-tuning. Each sample contains the state information of surrounding traffic participants and the associated control action sequences. Supervised fine-tuning (SFT) is then applied to the LLM using these data, enabling the model to learn to infer and generate reasonable control strategies based on structured scene semantics. After fine-tuning, the model is able to output continuous low-level control commands given perception results and specific driving task instructions, thereby linking semantic understanding with action execution.
During system operation, environmental images are first processed by the BEV perception module to estimate the spatial positions and dimensions of traffic participants. The resulting structured scene information is then provided to the fine-tuned LLM for inference. The control commands generated by the model are subsequently applied to the vehicle through the CARLA interface, forming a perception–inference–execution closed-loop control flow. The overall execution framework of the proposed method is illustrated in Figure 1.
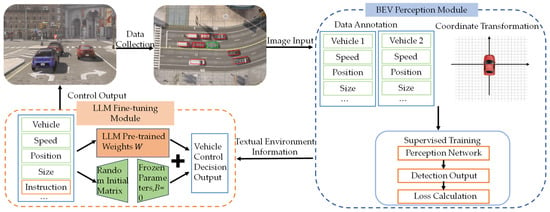
Figure 1.
Flowchart of the proposed real-time autonomous driving system. The framework consists of three main stages: perception, decision-making, and control. In the perception stage, multi-view camera images are processed by a bird’s-eye-view (BEV) structured perception module to extract spatial and geometric attributes of surrounding traffic participants. In the decision-making stage, the structured scene representation, together with ego-vehicle states and task instructions, is provided to a large language model (LLM) for supervised fine-tuning and inference. In the control stage, the LLM generates low-level control commands, which are executed in the CARLA simulator to form a closed-loop perception–decision–control pipeline.
3.2. BEV Perception Module
The training of autonomous driving perception and decision-making algorithms depends on high-quality, multimodal, and fully annotated datasets [34]. The data acquisition and processing pipeline consists of coordinate system transformation, heading angle conversion, image–label temporal synchronization, and label cropping and filtering. This pipeline is designed to provide spatiotemporally consistent and semantically coherent training samples for the upper-layer perception and decision-making modules [35].
First, the mapping relationships among the world coordinate system, the ego-vehicle coordinate system, and the bird’s-eye-view (BEV) coordinate system are established. Let the position vector of the surrounding vehicle in the world coordinate system be:
The position vector of the ego vehicle in the world coordinate system is defined as:
where (xs, ys) and (xe, ye) denote the two-dimensional planar position coordinates of the surrounding vehicle and the ego vehicle, respectively.
Then, the relative position of the surrounding vehicle in the ego-vehicle coordinate system can be expressed as:
where the rotation matrix R defined as:
where prel = [xrel, yrel]T denotes the relative position vector of the surrounding vehicle in the ego-vehicle coordinate system, and θ represents the heading angle of the ego vehicle. We map the ego-vehicle coordinate system to the BEV pixel coordinate system through vertical-axis rotation, scaling, and pixel translation. Here, the x-axis points rightward and the y-axis forward.
The heading angles of traffic participants are converted accordingly, and the relative heading angle in the ego-vehicle coordinate system is defined as:
where Ψrel denotes the orientation angle of the surrounding vehicle relative to the ego vehicle, and Ψw represents the heading angle of the surrounding vehicle in the world coordinate system. Ψrel is normalized to the interval [−180°, 180°] to maintain numerical continuity and stability of the heading angle.
During the image acquisition phase, a top-down camera is positioned at a height of 20 m above the ego vehicle within the simulation environment. A synchronous data acquisition mechanism is employed to ensure strict alignment between images and labels. At each simulation step, RGB images and state information for the ego vehicle and surrounding traffic participants are captured simultaneously and stored using the CARLA frame number as a unique index for synchronization.
In the label processing stage, to maintain consistency between inputs and annotations during perception model training, only information from traffic participants within the BEV field of view is retained. Given the camera height h and the horizontal field of view fovx, the lateral and longitudinal visible ranges of the BEV are calculated as:
where xrange and yrange the lateral and longitudinal visible ranges of the BEV plane, respectively; h denotes the camera height, and fovx and fovy represent the horizontal and vertical fields of view, respectively. Traffic participants outside this range, or targets that appear only partially within the field of view, are removed or retained according to predefined filtering modes. The cropped label files therefore include only targets visible in the BEV image, thereby reducing noise caused by discrepancies between image content and annotations.
Based on this procedure, a multimodal dataset comprising RGB images and synchronized traffic participant labels is constructed, providing data support for training the BEV perception and decision-making models [36]. Figure 2 illustrates the overall schematic of the data acquisition process.

Figure 2.
Schematic diagram of the data collection process in the CARLA simulation environment under different traffic scenarios: (a) Intersection straight-ahead maneuver; (b) Intersection right-turn maneuver; (c) High-density urban congestion scenario.
The perception layer uses a bird’s-eye-view (BEV)-based approach to parse geometric and spatial features of traffic participants from environmental images. This module directly constructs BEV representations from imagery captured by a high-mounted top-down camera [37]. Under the evaluated settings, it supports object detection and attribute inference through four main stages: data preprocessing, feature extraction and spatial alignment, Transformer-based representation learning, and object prediction and optimization [38,39,40].
The input images are subjected to data augmentation operations, including random cropping, rotation, horizontal flipping, and color jittering, to improve robustness to variations in complex traffic environments [41]. The input samples are represented as:
where Ii denotes the i-th RGB image, H and W represent image height and width, and N is the batch size. Corresponding structured labels record the 2D position and scale attributes of traffic participants, forming the attribute vector for training:
where aj denotes the attribute vector of the j-th traffic participant, xj and yj represent the center coordinates, wj and lj correspond to the vehicle width and length, respectively, and M is the number of traffic participants in the scene.
For feature extraction, ResNet34 is employed as the backbone network, with the final classification layer removed to preserve the convolutional feature maps. The resulting output is:
where fbackbone(·) denotes the feature extraction function, C = 512 is the number of channels, and H′, W′ represent the downsampled spatial resolutions. A 1 × 1 convolution is applied to project the channels to the Transformer input dimension dmodel = 256, which is combined with learnable positional embeddings to form the input sequence:
where P represents the position encoding tensor.
In the representation learning stage, a Transformer encoder–decoder architecture is introduced [42]. The encoder performs global modeling of the feature sequence, while the decoder extracts latent target representations based on a fixed number of query vectors , where n denotes the number of queries. The decoder output is expressed as:
where fdecoder(·) is the decoding function and H represents the target-level feature representation. In the prediction stage, a Multi-Layer Perceptron (MLP) outputs the vehicle existence probability and attribute regression results:
where is the existence probability for the k-th query, σ(•) is the Sigmoid function, and is the predicted attribute vector.
The loss function is defined as a weighted sum of the object existence loss and attribute regression loss:
where Lobj is the existence loss based on weighted Binary Cross Entropy (BCE) with a balance weight λobj = 0.3 is the weighted Lattr loss for attribute prediction:
where ⊙ denotes element-wise multiplication, and w = [1.0, 1.0, 0.8, 0.8]T is the weight vector designed to improve position accuracy and suppress overfitting in scale prediction.
3.3. Large Language Model–Based Decision Module
To facilitate the integration of semantic and geometric information derived from BEV perception into the reasoning process of the Large Language Model (LLM), traffic scenes are represented in a structured format. This representation includes the ego-vehicle state, which is composed of the longitudinal velocity v, the lateral offset from the lane center Δy, and other relevant dynamic variables [43]; surrounding participant information, where for each detected traffic participant, the relative position p = [x, y]T and dimensions s = [w, l]T are recorded; and task instructions, which specify high-level commands such as “lane keeping” or “overtaking”. The input scene can be formalized as:
where t denotes the current time step; vt represents the ego-vehicle’s longitudinal velocity; Δy is the lateral offset relative to the lane center; and is the set of surrounding traffic participants, where .
The LLM module conducts reasoning based on the structured scene descriptions and outputs continuous vehicle control commands [44]. These command values lie within the range [−1, 1], corresponding to control actions such as throttle, braking, and steering.
We discretize continuous control commands into fixed-resolution bins to enable likelihood-based optimization in the autoregressive LLM framework before supervised fine-tuning. Each discretized control dimension is encoded as a categorical token, enabling the control output to be modeled as a sequence of discrete tokens compatible with standard token-level probability modeling. The output is defined as:
where vcontrol denotes the target longitudinal velocity; θcontrol represents the desired steering wheel angle; and reason provides a brief textual explanation. As the training samples contain only scene states and corresponding control signals without linguistic explanations, the reason field is not included in supervised learning during the fine-tuning phase. Instead, it is generated autonomously by the model during inference based on the input scene and task instructions. This process maps the perception space St to high-level planning instructions, thereby forming the LLM-driven decision module.
Within the CARLA platform, the built-in autopilot model is employed to execute driving maneuvers such as lane changes and car-following [45]. During execution, perception outputs, ego-vehicle states, the actual sequence of executed control actions Pt, and driving task instructions task are recorded synchronously. Consequently, training samples with explicit “instruction–action” alignment are constructed as:
Supervised fine-tuning (SFT) is adopted to organize each sample into instruction–response pairs, where the input consists of the scene state St, and the output corresponds to the ground-truth control action Pt. After discretization, the ground-truth control action Pt is represented as a sequence of discrete control tokens, and the training objective is formulated over their conditional likelihood. The objective aims to minimize the discrepancy between the generated actions and the ground-truth actions, with the loss function defined as:
where ω denotes the parameters of the LLM. To further encourage consistency between the model outputs and the specified driving tasks, a joint loss function is introduced:
where λ is a weight coefficient and Ltask measures whether the predicted action aligns with the task instruction.
To ensure the comparability of experimental results, all selected LLMs (as listed in Table 1) are fine-tuned using the LoRA technique under a unified dataset and fine-tuning pipeline. In addition, traditional Behavioral Cloning (BC) and the Transformer-based TransFuser are adopted as baseline methods to systematically evaluate the advantages of LLM-based reasoning in comparison with representative state-of-the-art end-to-end planning approaches. Although high-performance end-to-end models such as TransFuser have been proposed, the primary objective of this study is not to pursue state-of-the-art (SOTA) performance on individual task metrics. Rather, it aims to examine the feasibility of real-time LLM inference in resource-constrained vehicular environments and to assess the potential semantic reasoning advantages in long-tail corner cases. Accordingly, the BC method is mainly used as a baseline for evaluating semantic reasoning capability. The research focus remains on systematically validating the practical effectiveness of the proposed engineering acceleration strategies through a comparative analysis of full-precision (FP16) and low-bit quantized (Int4) models.

Table 1.
Selected large language models (LLMs) and their main characteristics.
The deployment of 7B-parameter large language models (LLMs) on vehicle-mounted computing platforms is challenging due to their substantial memory footprint and inference latency when operating in standard half-precision (FP16) mode [46]. Existing system-level analyses indicate that FP16 inference for models at this scale requires a large amount of GPU memory to accommodate parameter storage and runtime overheads [47]. In addition, the autoregressive nature of Transformer-based generation is known to be strongly constrained by GPU memory bandwidth, which can lead to significant inference delays on resource-limited platforms. Such characteristics make it difficult to satisfy the real-time requirements of closed-loop autonomous driving systems, which typically operate at update frequencies of 10 Hz or higher.
To address these practical deployment constraints, an inference acceleration strategy is adopted by combining low-bit weight compression with an efficient inference engine [48]. Specifically, 4-bit post-training quantization (PTQ) based on the GPTQ algorithm is employed to compress model weights to INT4 precision. An asymmetric quantization scheme with per-channel granularity is utilized to minimize numerical errors across Transformer layers.
To balance the trade-off between computational throughput and reasoning accuracy, a group size of 128 is selected. The quantization parameters are calibrated using 128 representative driving sequences (each with a length of 2048 tokens) collected from the CARLA simulation environment, ensuring that the scaling factors are well aligned with realistic driving scenarios.
In parallel, the vLLM inference framework is integrated to optimize key–value cache management through the Paged Attention mechanism. Combined with compressed weights, this strategy significantly alleviates memory bandwidth pressure and improves token generation efficiency. This design is motivated by the need to preserve semantic reasoning capability while substantially enhancing inference speed.
Preliminary evaluations indicate that the quantized configuration (Qwen-Int4) maintains strong structural integrity, exhibiting only a 1.5% increase in perplexity compared with the FP16 baseline. This result demonstrates that LLM-based decision-making can be successfully aligned with the 10 Hz real-time requirement of closed-loop autonomous driving control. The specific hyperparameter settings used in the quantization process are summarized in Table 2.
Table 2.
Detailed hyperparameter configurations for GPTQ 4-bit quantization.
3.4. Simulation Environment and Settings
To validate the proposed method, experiments were conducted on the CARLA simulation platform, with detailed hardware and software configurations summarized in Table 3.
Table 3.
Configuration of the experimental environment.
To systematically assess the engineering effectiveness of the proposed inference acceleration strategy under practical deployment conditions, two inference configuration schemes were established for comparative evaluation. The high-precision baseline configuration (Baseline-FP16) loads the original model and performs standard half-precision (FP16) inference, serving as a reference for the system’s perception accuracy and decision-making performance in the absence of quantization effects. The real-time deployment configuration (Ours-Int4) incorporates the proposed acceleration strategy by applying 4-bit low-bit quantization to the model and deploying it using an efficient inference engine. This configuration is designed to emulate the resource constraints of vehicle-mounted edge computing environments, with particular emphasis on evaluating real-time responsiveness and task robustness while meeting the 10 Hz closed-loop control frequency requirement.
The experimental evaluation is conducted in two sequential stages to ensure both performance transparency and system reliability. In the first stage, the baseline perception and decision-making capabilities are assessed under standard simulation conditions, with results reported in Section 4.1, Section 4.2, Section 4.3 and Section 4.4. Following this baseline evaluation, the second stage examines system robustness by introducing environmental degradation and semantic noise to emulate real-world uncertainties. These robustness assessments—including adverse weather simulations and a structured-data sensitivity analysis—are presented in Section 4.5. To rigorously evaluate control quality under stress conditions, safety-critical metrics are incorporated at this stage, with particular emphasis on Collision Rate and Average Jerk to quantify driving safety and control smoothness, respectively.
4. Results
4.1. Performance of BEV Structured Perception
To validate the effectiveness of the BEV perception module for vehicle identification, visualization experiments were conducted using the trained model. Figure 3 presents representative detection results in a test traffic scenario. The results show accurate identification of vehicle positions and dimensions, with high overlap between predicted bounding boxes and actual vehicle bodies.

Figure 3.
Representative detection results of the bird’s-eye-view (BEV) perception module under varying traffic densities in the CARLA environment: (a) Low traffic density; (b) Medium traffic density; (c) High traffic density.
As shown in Figure 4, the convergence behavior indicates that the proposed BEV perception network can be optimized in a stable and efficient manner. Such training stability is important for downstream decision-making tasks, as reliable and consistent scene representations provide a foundation for semantic reasoning and control generation.
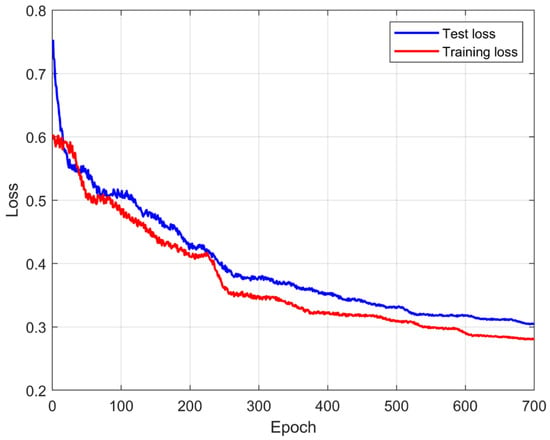
Figure 4.
Training loss curves of the bird’s-eye-view (BEV) perception module over the training process.
To quantitatively evaluate perception accuracy, a statistical analysis was performed on the validation set. The results show that, under an Intersection over Union (IoU) threshold of 0.5, the detection recall of the BEV perception module reaches 94.2%, indicating effective target coverage and a low rate of missed detections under the evaluated settings.
In addition, the mean position error between the predicted center points and the ground truth converges to 0.28 m, while the mean size error remains within 0.15 m. These results suggest that the module produces structured outputs with a high level of geometric accuracy, providing reliable spatial semantic inputs for the downstream LLM-based decision-making module and reducing the impact of perception uncertainty on subsequent decision processes.
4.2. Performance of LLM-Based Decision-Making
To systematically assess the generalization performance of the proposed method under diverse dynamic operating conditions, three representative task scenarios were designed: car-following, overtaking, and mixed driving. Detailed parameter configurations for these scenarios are provided in Table 4.
Table 4.
Parameter settings of experimental task scenarios.
Figure 5 presents the testing workflow developed to evaluate the LLM’s comprehensive decision-making and control capabilities across multi-task scenarios. During experimentation, dynamic driving instructions were applied, including modes such as car-following, lane changing, and mixed tasks. In mixed-task conditions, the model is capable of switching between tasks based on driver instructions, enabling the assessment of robustness and response efficiency during task transitions and instruction changes.
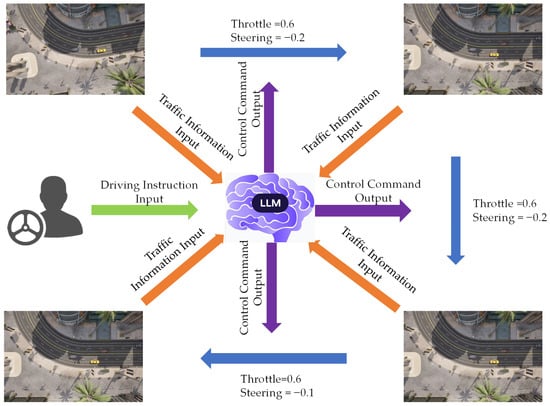
Figure 5.
Schematic representation of the real-time closed-loop testing procedure for the large language model (LLM) agent in the CARLA environment. High-level driving instructions and structured multi-source traffic information are encoded as LLM inputs, based on which the agent performs reasoning and decision-making to generate low-level control commands (throttle and steering), which are executed by the simulator and fed back to the perception module for continuous closed-loop interaction.
During execution, the ego-vehicle continuously acquires environmental semantic information through the BEV perception system. This information, together with the vehicle’s dynamic state, is provided as input to the LLM for inference. Based on this input, the model produces structured control outputs, establishing an end-to-end closed-loop mapping from environmental perception to action generation.
Figure 6 summarizes the interaction interface between the perception module and the LLM agent.

Figure 6.
Schematic representation of the input and output interface for the large language model (LLM) agent based on the structured scene representation, including the system prompt, the JSON-formatted environment input, and the low-level control command output.
For ease of comparison and analysis, success rate, single-step inference latency (defined as the end-to-end duration from BEV input to high-level intent generation and action mapping), and peak memory usage are adopted as the primary evaluation metrics [49,50]. To ensure statistical rigor, each method was subjected to five independent experimental groups, with each group containing 100 repetitive trials, totaling 500 trials per task category. Table 5 presents the experimental results for the various models across these three task types.
Table 5.
Performance of different models across three task types.
The 4-bit quantized and accelerated Qwen-Int4 achieved success rates of 89.0% in car-following tasks and 84.0% in mixed driving tasks, representing improvements of approximately 12 percentage points over the Behavioral Cloning (BC) method and about 5 percentage points over the Transformer-based TransFuser under the evaluated scenarios. These results suggest that supervised regression-based imitation in BC models may be insufficient for dynamic environments characterized by complex interactions and extended planning horizons. Meanwhile, perception–fusion architectures such as TransFuser still exhibit limitations in modeling high-level decision dependencies. In contrast, the proposed framework, which integrates BEV-based structured perception with LLM-driven reasoning, leverages explicit environmental semantics. This design is associated with enhanced generalization capability and improved robustness in multi-agent interaction scenarios.
Regarding real-time performance and system responsiveness, although LLaVA-1.5 and Mistral-7B achieved higher task success rates than the BC method and TransFuser, their large parameter sizes and FP16 inference precision introduce substantial computational overhead. Their single-step inference latencies generally exceed 400 ms (approximately 2.5 Hz), which may be associated with a spatiotemporal mismatch between perception and execution, particularly in high-speed dynamic scenarios.
The Qwen-Int4 model reduces end-to-end inference latency to approximately 87.0 ms, substantially alleviating real-time constraints when deploying large models for closed-loop control. In car-following tasks that require extremely fast reaction times, Qwen-Int4 achieved a higher success rate than Mistral-7B due to its lower control-loop latency, highlighting the importance of low inference latency alongside model accuracy in time-sensitive driving scenarios.
As task complexity increases, the performance of all models degrades to varying extents. In mixed tasks—where different driving behaviors must be dynamically switched—the increased logical complexity imposes greater demands on the decision-making module. Although success rates declined across all methods, Qwen-Int4 and Mistral-7B maintained relatively high performance levels, achieving success rates of approximately 84%. In contrast, the success rate of the Behavioral Cloning (BC) method dropped markedly to 71.4%, while that of the Transformer-based TransFuser decreased to 80.0%. These results highlight the limitations of imitation learning and end-to-end perception–fusion architectures in handling nonlinear and logically complex driving tasks.
To further assess the statistical reliability of the performance gains achieved by the proposed Qwen-Int4 framework, a formal comparative analysis was conducted using independent two-sample t-tests against the BC and TransFuser baselines. The results, summarized in Table 6, verify whether the observed improvements in decision-making success are statistically significant across varying levels of task complexity.
Table 6.
Statistical Significance Analysis (t-test) for Success Rate Improvements.
The statistical evaluation presented in Table 6 demonstrates the decision-making advantages of the Qwen-Int4 framework over established baselines. For the Overtaking and Car-following tasks, independent two-sample t-tests yielded t-statistics ranging from 4.061 to 6.559, with p-values consistently below 0.01. These metrics indicate statistically significant improvements in success rates over both the BC and TransFuser baselines.
In the Mixed task, the comparison with the BC method remained highly significant (t = 6.332, p = 0.0002). However, the comparison with TransFuser produced a p-value of 0.1553, suggesting that the mean performance difference did not reach conventional levels of statistical significance in this specific scenario. Nevertheless, Qwen-Int4 exhibited a substantially lower variance (4.50) than TransFuser (27.98). This marked reduction in performance fluctuation underscores the superior operational stability of our framework under complex, multi-agent conditions, where it provides more predictable and reliable control than Transformer-based fusion models.
Figure 7 illustrates the performance trends and statistical stability of the evaluated models as task complexity increases. In the overtaking task, which requires high-level spatial reasoning, both Qwen-Int4 and Mistral-7B achieve peak success rates exceeding 88%. Notably, the shaded confidence bands for Qwen-Int4 are substantially narrower than those of the baseline models, visually indicating superior decision-making consistency despite the potential precision loss introduced by 4-bit quantization.
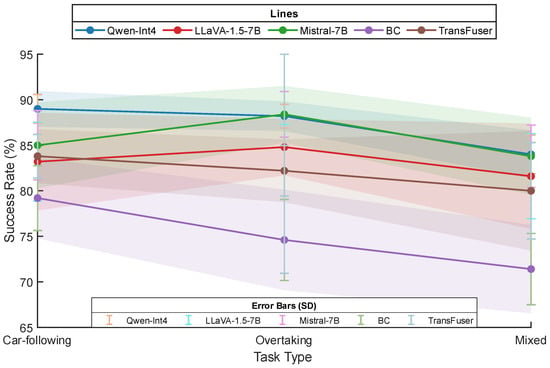
Figure 7.
Comparison of task success rates among the evaluated models across car-following, overtaking, and mixed driving scenarios in the CARLA environment. The vertical error bars represent the standard deviation (SD), reflecting operational consistency, while the shaded envelopes denote the 95% confidence interval (CI) calculated across n = 5 independent experimental groups (N = 500 total episodes per model/task category).
In the car-following task, where real-time responsiveness is critical, a clear performance gap emerges. Qwen-Int4 maintains a success rate of nearly 89%, significantly outperforming higher-latency models such as Mistral-7B and LLaVA-1.5-7B. The relatively small error bars associated with Qwen-Int4 suggest that its millisecond-level inference latency effectively mitigates delayed control responses, which are reflected in the broader statistical dispersion observed for the full-precision baselines.
As the evaluation transitions to mixed-task scenarios, all models exhibit some degree of performance degradation. However, while the success rates of Behavioral Cloning (BC) and TransFuser decline markedly (to approximately 71% and 80%, respectively), Qwen-Int4 remains comparatively robust at 84%. The 95% confidence intervals shown in Figure 7 further indicate that, although TransFuser demonstrates substantial variance under complex task-switching conditions, the proposed framework maintains a more compact and stable performance range. These observations support the conclusion that the framework effectively balances high-level semantic reasoning capability with the real-time constraints necessary for stable closed-loop control.
4.3. Impact of Model Quantization on Decision Performance
To further investigate the specific mechanisms by which model inference latency and semantic accuracy impact closed-loop driving performance, an ablation study was conducted. This study compared the performance of the Qwen2.5-7B model between full-precision (FP16) and 4-bit quantization (Int4) modes. Table 7 presents the specific performance results for both configurations across different tasks.
Table 7.
Ablation study on the performance of full-precision and quantized models across different task types.
Experimental data indicate that system response speed plays a critical role in dynamic driving tasks, in addition to single-inference accuracy. The performance disparity is most evident in the car-following task, where the success rate of the proposed Ours (Int4) configuration increased by 6 percentage points (from 83% to 89%) compared to the Baseline (FP16). Due to the extreme sensitivity of car-following scenarios to real-time longitudinal control, the Baseline model—despite retaining full-precision parametric details—suffers from latency exceeding 400 ms. This excessive delay can introduce a significant “perception–execution” temporal lag when encountering transient changes, such as sudden braking by the lead vehicle, which may adversely affect timely braking responses. In contrast, the quantized model increases the control loop frequency to above 10 Hz, effectively reducing control blind spots and contributing to improved control stability under the evaluated conditions.
In overtaking tasks involving complex spatial games, the gains from low latency similarly offset the negative impacts of quantization noise. Although 4-bit quantization could theoretically reduce the model’s ability for fine-grained spatial reasoning, experimental results show that the success rate of Ours (Int4) increased from 87% to 88%. This suggests that, in dynamic game environments, a higher decision refresh rate allows the control system to more rapidly correct trajectory deviations and respond to the uncertain behaviors of surrounding vehicles. Such a high-frequency feedback mechanism effectively compensates for minor accuracy losses that may occur during single-frame inference. Combined with the 3% performance improvement observed in mixed tasks, it is clear that under the constraints of limited vehicle-mounted computing resources, sacrificing a marginal amount of quantization precision in exchange for a significant increase in inference speed represents a practical and effective strategy for optimizing LLM-based closed-loop control performance under computational constraints. This observation underscores the central role of fast system response in enhancing the robustness of autonomous driving systems under dynamic conditions.
4.4. Impact of Scene Representation on Decision Performance
To verify the necessity of the bird’s-eye-view (BEV) structured perception module in the autonomous driving decision-making system, an ablation experiment was conducted focusing on scene representation methods. The experiment compared a “simplified state input,” which omits explicit spatial modeling and only provides the model with one-dimensional numerical information—such as the ego-vehicle’s dynamic state (velocity and acceleration) and the relative motion parameters of the lead vehicle (relative distance and relative velocity)—against the “BEV structured semantic input” proposed in this study, which includes complete two-dimensional spatial distributions and geometric attributes. To ensure a fair comparison, both scene representation methods were evaluated using the same Qwen-Int4 model under an identical set of test scenarios. The evaluation criteria, including success definitions and task durations, were kept consistent across both configurations. This controlled experimental design ensures that any observed performance differences can be attributed exclusively to variations in environmental encoding rather than to model or procedural discrepancies. The comparative test results, based on the Qwen-Int4 model, are presented in Table 8.
Table 8.
Impact of different scene representations on decision-making performance.
Experimental data show that by introducing the BEV structured representation, the overall success rate of the system in multi-task scenarios significantly increased from 62% to 92%. The substantial increase in success rate highlights an inherent limitation of one-dimensional state inputs: they fail to capture lane-level topology and the spatial interaction context required for complex multi-agent scenarios. In the “Simplified” configuration, the model frequently fails in mixed-task settings because it cannot reliably infer the relative priority of surrounding vehicles based solely on distance–velocity pairs. In contrast, the BEV-based structured input provides a global representation of the intersection geometry, enabling the LLM to leverage its pre-trained knowledge to better anticipate the intentions of other agents. This richer spatial encoding contributes to more informed decision-making and reduces collision-prone control behaviors.
The introduction of the BEV perception module inevitably increased computational overhead, causing the end-to-end inference latency to rise from approximately 69 ms with simplified input to 85 ms. However, this latency remains well within the 100 ms real-time closed-loop threshold. In summary, although structured perception adds some computational load, the qualitative improvement in decision-making performance provided by the inclusion of critical spatial semantics demonstrates that this module plays a central role in constructing a reliable autonomous driving planning framework.
Although the BEV-based representation increases the average input length from approximately 125 tokens to 458 tokens, this additional token budget is not redundant. The enriched sequence encodes the relative spatial geometry and heading information of all traffic participants, which is critical for enabling the LLM’s self-attention mechanism to capture multi-agent dependencies effectively. The resulting increase in inference latency (from 69 ms to 85 ms) remains moderate and within real-time constraints. This latency overhead represents a reasonable trade-off for the substantial improvement in reasoning accuracy and overall decision reliability.
4.5. Robustness and Sensitivity Analysis
To further examine the boundary performance of the proposed autonomous driving decision-making system under both ideal simulation conditions and more challenging real-world-like environments, this section presents a comprehensive robustness and sensitivity analysis of the Qwen-Int4 model in the logically complex “Mixed Driving” scenario. This scenario, characterized by frequent task switching and intensive multi-agent interactions, provides a rigorous testbed for evaluating the resilience of the decision module when confronted with imperfect perception inputs. In addition to task success rate, safety-critical metrics—Collision Rate and Average Jerk—are incorporated to enable a more fine-grained assessment of control quality and driving smoothness.
As summarized in Table 9, the system exhibits strong stability under adverse weather conditions in the CARLA simulation environment. In the “Heavy Rain” and “Dense Fog” scenarios, despite degraded sensor input quality, the average success rates remain at 81.4 ± 2.8% and 78.2 ± 3.4%, respectively. Although collision rates increase to 7.2% and 9.6%, the Average Jerk remains relatively low (below 3.0 m/s3), indicating that the LLM preserves satisfactory control smoothness even when perception reliability is reduced. These findings suggest that the integrated BEV-based perception and LLM-driven reasoning framework effectively abstracts structured semantic information, thereby maintaining logical consistency under environmental degradation.
Table 9.
Performance of Qwen-Int4 under perception noise in the Mixed Driving scenario.
In the second stage of the sensitivity analysis, the model’s tolerance to perception uncertainty is evaluated by injecting Gaussian noise with varying standard deviations (σ) into the spatial coordinates of traffic participants. Considering that the BEV module exhibits an inherent mean positional error of 0.28 m, additional noise in the range of 0.2–1.0 m is introduced to simulate increasing perception disturbances. The results show that at σ = 0.2 m, the success rate remains at 82.8 ± 2.1%, and the Average Jerk (2.4 m/s3) increases only marginally compared with the baseline. Even when the noise level rises to σ = 0.5 m, the success rate decreases only moderately to 78.6%. The relative stability of both success rate and control smoothness can be attributed to the fine-tuned LLM’s capacity to leverage semantic priors to preserve safety margins, thereby mitigating oscillatory control behaviors commonly observed in purely reactive planners. However, when σ reaches 1.0 m, a clear performance inflection point emerges: the success rate declines to 65.0 ± 4.8%, and the Average Jerk increases substantially to 4.8 m/s3. This result indicates that perception deviations beyond this magnitude exceed the model’s ability to compensate through logical reasoning, thereby defining a practical operational boundary for reliable closed-loop control.
5. Discussion
The experimental results highlight a fundamental speed–accuracy trade-off in deploying LLMs for autonomous driving. Although 4-bit quantization may introduce slight precision degradation, it substantially reduces inference latency—from over 400 ms in full-precision configurations to approximately 85 ms—thereby enabling the real-time responsiveness required for stable closed-loop control. In vehicle control systems, latency frequently has a greater impact on safety and stability than marginal gains in numerical precision, as even minor delays can induce spatiotemporal mismatches between perception and execution. The findings indicate that increasing the decision frequency to 10 Hz leads to smoother control behavior, as reflected by a significantly lower Average Jerk compared with reactive baseline methods. These observations suggest that the “logical compensation” capability of LLM-based reasoning, when combined with high-frequency feedback, can effectively offset minor quantization-induced noise and preserve overall control stability.
Despite these encouraging results, several limitations should be acknowledged. First, all evaluations were conducted within the CARLA simulation environment, and validation on real vehicles remains an important direction for future work. Second, although the NVIDIA GeForce RTX 4090 GPU employed in this study does not represent a typical vehicle-mounted edge computing platform, the adoption of 4-bit GPTQ quantization provides a practical approximation of resource-constrained inference conditions. Specifically, quantization reduces the memory footprint of a 7B-parameter model from approximately 14 GB to 3.5 GB—a 75% reduction—thereby improving the feasibility of deployment on automotive-grade hardware.
Moreover, the robustness and sensitivity analyses presented in Section 4.5 constitute an initial step toward understanding how LLM-based planners respond to perception degradation and domain shifts. Future research will focus on real-world validation through integration with the Autoware framework and on investigating more aggressive compression strategies, such as 2-bit quantization, to further reduce hardware requirements while maintaining acceptable decision quality.
6. Conclusions
To address the challenges of high inference latency and the difficulty of satisfying real-time requirements when deploying large language models (LLMs) in closed-loop autonomous driving control, this study proposes a decision-making framework that integrates bird’s-eye-view (BEV) structured perception with low-bit quantized inference. By reducing semantic redundancy through structured scene representation and combining it with GPTQ-based 4-bit quantization, the proposed method effectively alleviates the computational and latency bottlenecks associated with autoregressive LLM reasoning.
Experimental evaluations conducted on the CARLA platform over 500 independent trials demonstrate that the proposed framework reduces end-to-end inference latency to approximately 85 ms while maintaining high decision-making success rates. Beyond task completion metrics, the incorporation of safety-critical indicators further shows that the framework achieves improved control quality, characterized by lower collision rates and smoother acceleration profiles (i.e., reduced Average Jerk) compared with traditional imitation learning and Transformer-based baselines.
Moreover, sensitivity analyses confirm that LLM-based semantic reasoning provides a degree of robustness against environmental degradation and perception noise. Overall, the Qwen-Int4 configuration satisfies the 10 Hz real-time requirement for closed-loop control while preserving high-level reasoning capability, offering a balanced and practically feasible engineering solution for LLM-driven autonomous driving under current computational constraints.
Author Contributions
Conceptualization, G.S. and X.S.; methodology, G.S.; software, G.S.; validation, G.S., M.Y. and X.S.; formal analysis, G.S.; investigation, G.S.; resources, G.S.; data curation, G.S.; writing—original draft preparation, G.S.; writing—review and editing, X.S.; visualization, G.S.; supervision, X.S.; project administration, G.S.; funding acquisition, G.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the 2026 School-level Scientific Research Project of Shandong Vocational University of Foreign Affairs, “Research on Autonomous Driving Methods Based on Large Language Model Inference”, grant number 2026ZD21.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting the findings of this study are available on figshare and can be accessed via a private link provided to the editor and reviewers during the peer-review process. The data will be made publicly available upon acceptance of the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Teng, S.; Hu, X.; Deng, P.; Li, B.; Li, Y.; Ai, Y.; Yang, D.; Li, L.; Xuanyuan, Z.; Zhu, F.; et al. Motion planning for autonomous driving: The state of the art and future perspectives. IEEE Trans. Intell. Veh. 2023, 8, 3692–3711. [Google Scholar] [CrossRef]
- Hu, Y.; Yang, J.; Chen, L.; Li, K.; Sima, C.; Zhu, X.; Chai, S.; Du, S.; Lin, T.; Wang, W.; et al. Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 17853–17862. [Google Scholar]
- Wu, J.; Huang, C.; Huang, H.; Lv, C.; Wang, Y.; Wang, F.Y. Recent advances in reinforcement learning-based autonomous driving behavior planning: A survey. Transp. Res. Part C Emerg. Technol. 2024, 164, 104654. [Google Scholar] [CrossRef]
- Sima, C.; Renz, K.; Chitta, K.; Chen, L.; Zhang, H.; Xie, C.; Beißwenger, J.; Luo, P.; Geiger, A.; Li, H. Drivelm: Driving with graph visual question answering. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2024; pp. 256–274. [Google Scholar]
- Chen, L.; Wu, P.; Chitta, K.; Jaeger, B.; Geiger, A.; Li, H. End-to-end autonomous driving: Challenges and frontiers. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10164–10183. [Google Scholar] [CrossRef] [PubMed]
- Cui, C.; Ma, Y.; Cao, X.; Ye, W.; Zhou, Y.; Liang, K.; Chen, J.; Lu, J.; Yang, Z.; Liao, K.-D.; et al. A survey on multimodal large language models for autonomous driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2024; pp. 2950–2959. [Google Scholar]
- Xu, Z.; Zhang, Y.; Xie, E.; Zhao, Z.; Guo, Y.; Wong, K.-Y.K. DriveGPT4: Interpretable end-to-end autonomous driving via large language model. IEEE Robot. Autom. Lett. 2024, 9, 5118–5125. [Google Scholar] [CrossRef]
- Hou, J.; Wang, H.; Li, T.; Dong, E. An explainable end-to-end autonomous driving framework based on large language model and vision modality fusion: Design and application of DriveLLM-V. Transp. Res. Part C Emerg. Technol. 2025, 181, 105368. [Google Scholar] [CrossRef]
- Chen, M.; Li, Y.; Yang, Y.; Yu, S.; Lin, B.; He, X. Automanual: Constructing instruction manuals by llm agents via interactive environmental learning. Adv. Neural Inf. Process. Syst. 2024, 37, 589–631. [Google Scholar]
- Hang, P.; Lv, C.; Xing, Y.; Hu, Z. Human-like decision making for autonomous driving: A non-cooperative game theoretic approach. IEEE Trans. Intell. Transp. 2023, 24, 12345–12358. [Google Scholar] [CrossRef]
- Pope, R.; Douglas, S.; Chowdhury, A.; Devlin, J.; Bradbury, J.; Heek, J.; Xiao, K.; Agrawal, S.; Dean, J. Efficiently scaling transformer inference. In Proceedings of the 5th Conference on Machine Learning and Systems (MLSys), Miami, FL, USA, 4–8 June 2023. [Google Scholar]
- Ji, X.A.; Avedisov, S.S.; Khan, M.I.; Vörös, I.; Altintas, O.; Orosz, G. On the effects of latency in teleoperated driving: Stability and performance analysis. Veh. Syst. Dyn. 2025, 1–23. [Google Scholar] [CrossRef]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. Adv. Neural Inf. Process. Syst. 2023, 36, 34892–34916. [Google Scholar]
- Zheng, Y.; Chen, Y.; Qian, B.; Lee, Y.J. A review on edge large language models: Design, execution, and applications. ACM Comput. Surv. 2025, 57, 209. [Google Scholar] [CrossRef]
- Zhu, X.; Li, J.; Liu, Y.; Ma, C.; Wang, W. A survey on model compression for large language models. Trans. Assoc. Comput. Linguist. 2024, 12, 1556–1577. [Google Scholar] [CrossRef]
- Li, J.; Li, J.; Yang, G.; Yang, L.; Chi, H.; Yang, L. Applications of Large Language Models and Multimodal Large Models in Autonomous Driving: A Comprehensive Review. Drones 2025, 9, 238. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, Z.; Liu, Q.; Zheng, Y.; Hong, J.; Chen, J.; Xiong, L.; Gao, B.; Chen, H. Drive as veteran: Fine-tuning of an onboard large language model for highway autonomous driving. In Proceedings of the 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 502–508. [Google Scholar]
- Xiong, G.; Liu, S.; Yan, Y.; Li, Q.; Li, H. Efficacy of autonomous vehicle’s adaptive decision-making based on large language models across multiple driving scenarios. IEEE Access 2025, 13, 16789–16801. [Google Scholar] [CrossRef]
- Azarafza, M.; Nayyeri, M.; Steinmetz, C.; Staab, S.; Rettberg, A. Hybrid reasoning based on large language models for autonomous car driving. In Proceedings of the 2024 12th International Conference on Control, Mechatronics and Automation (ICCMA), Luxembourg City, Luxembourg, 13–15 November 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 14–22. [Google Scholar]
- Shao, H.; Hu, Y.; Wang, L.; Song, G.; Waslander, S.L.; Liu, Y.; Li, H. Lmdrive: Closed-loop end-to-end driving with large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 15120–15130. [Google Scholar]
- Kong, X.; Bräunl, T.; Fahmi, M.; Wang, Y. A superalignment framework in autonomous driving with large language models. In Proceedings of the 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1715–1720. [Google Scholar]
- Zhang, P.; Lin, K.; Li, D.; Fu, Z.; Cai, Y.; Li, B.; Yu, H.; Li, M. DAPlanner: Dual-agent framework with multi-modal large language model for autonomous driving motion planning. Appl. Soft Comput. 2025, 168, 113625. [Google Scholar] [CrossRef]
- Han, Y.; Wu, K.; Shao, Q.; Xiao, R.; Wang, Z.; Jiang, C.; Xiao, Y.; Hu, L.; Lou, Y. AppleVLM: End-to-End Autonomous Driving with Advanced Perception and Planning-Enhanced Vision-Language Models. arXiv 2026, arXiv:2602.04256. [Google Scholar] [CrossRef]
- Ge, M.; Ohtani, K.; Niu, Y.; Zhang, Y.; Takeda, K. VLA-MP: A vision-language-action framework for multimodal perception and physics-constrained action generation in autonomous driving. Sensors 2025, 25, 6163. [Google Scholar] [CrossRef]
- Chu, F.; Li, H.; Xie, L.; Zhao, J. A survey of transformer architectures for autonomous driving. Expert Syst. Appl. 2025, 265, 130338. [Google Scholar] [CrossRef]
- Zhao, R.; Chen, Z.; Fan, Y.; Gao, F.; Men, Y. BETAV: A Unified BEV-Transformer and Bézier Optimization Framework for Jointly Optimized End-to-End Autonomous Driving. Sensors 2025, 25, 3336. [Google Scholar] [CrossRef]
- Su, Q.; Xie, M.; Wang, L.; Song, Y.; Cui, A.; Xie, Z. An End-to-End autonomous driving model based on visual perception for temporary roads. PeerJ Comput. Sci. 2025, 11, e3152. [Google Scholar] [CrossRef]
- Chen, B.; Wang, G.; Yang, J.; Huang, S.; Qian, X.; Huang, B.; Guo, G. HiPro-AD: Sparse Trajectory Transformer for End-to-End Autonomous Driving with Hybrid Spatiotemporal Attention. Sensors 2025, 26, 185. [Google Scholar] [CrossRef]
- Qian, Z.; Jiang, K.; Zhou, W.; Wen, J.; Jing, C.; Cao, Z.; Yang, D. An end-to-end autonomous driving pre-trained transformer model for multi-behavior-optimal trajectory generation. In Proceedings of the 26th IEEE International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–27 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 4730–4737. [Google Scholar]
- Cheng, R.; An, X.; Xu, Y. Vit-Traj: A Spatial–Temporal Coupling Vehicle Trajectory Prediction Model Based on Vision Transformer. Systems 2025, 13, 147. [Google Scholar] [CrossRef]
- Liu, Z.; Li, C.; Yang, N.; Wang, Y.; Ma, J.; Cheng, G.; Zhao, X. Mstf: Multiscale transformer for incomplete trajectory prediction. In Proceedings of the 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 573–580. [Google Scholar]
- Lyu, Y.; Tan, X.; Yu, Z.; Fan, Z. Sensor fusion and motion planning with unified bird’s-eye view representation for end-to-end autonomous driving. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–8. [Google Scholar]
- Jun, W.; Lee, S. A Comparative Study and Optimization of Camera-Based BEV Segmentation for Real-Time Autonomous Driving. Sensors 2025, 25, 2300. [Google Scholar] [CrossRef]
- Li, C.; Liu, Z.; Yang, N.; Li, W.; Zhao, X. Regional attention network with data-driven modal representation for multimodal trajectory prediction. Expert Syst. Appl. 2023, 232, 120808. [Google Scholar] [CrossRef]
- Zhao, J.; Shi, J.; Zhuo, L. BEV perception for autonomous driving: State of the art and future perspectives. Expert Syst. Appl. 2024, 258, 125103. [Google Scholar] [CrossRef]
- Yu, J.; Lu, C.; Meng, X.; Shao, F.; Jiang, Q. Identifying Unobserved Road Regions in Bird’s-Eye View for Single-Vehicle Perception. IEEE Robot. Autom. Lett. 2026, 11, 2410–2417. [Google Scholar] [CrossRef]
- Ping, P.; Zhang, X.; Tao, L.; Shi, Q.; Tian, Y.; Yan, J.; Ding, W. A comprehensive survey on multi-sensor information processing and fusion for BEV perception in autonomous vehicles. Inf. Fusion 2025, 115, 103653. [Google Scholar] [CrossRef]
- Philion, J.; Fidler, S. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3D. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 194–210. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Feng, Q.; Zhao, C.; Liu, P.; Zhang, Z.; Jin, Y.; Tian, W. LST-BEV: Generating a long-term spatial–temporal bird’s-eye-view feature for 3D object detection. Sensors 2025, 25, 4040. [Google Scholar] [CrossRef]
- Li, Y.; Huang, B.; Chen, Z.; Cui, Y.; Liang, F.; Shen, M.; Liu, F.; Xie, E.; Sheng, L.; Ouyang, W.; et al. Fast-BEV: A fast and strong bird’s-eye view perception baseline. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 8665–8679. [Google Scholar] [CrossRef]
- Li, H.; Zhao, Y.; Zhong, J.; Wang, B.; Sun, C.; Sun, F. Delving into the secrets of BEV 3D object detection in autonomous driving: A comprehensive survey. IEEE Trans. Intell. Transp. Syst. 2025, 27, 119–144. [Google Scholar] [CrossRef]
- Cui, Y.; Huang, S.; Zhong, J.; Liu, Z.; Wang, Y.; Sun, C.; Li, B.; Wang, X.; Khajepour, A. DriveLLM: Charting the path toward full autonomous driving with large language models. IEEE Trans. Intell. Veh. 2024, 9, 1450–1464. [Google Scholar] [CrossRef]
- Chi, F.; Wang, Y.; Nasiopoulos, P.; Leung, V.C. Multi-Agent Collaborative Decision-Making Using Small Vision-Language Models for Autonomous Driving. IEEE Internet Things J. 2025, 12, 55344–55355. [Google Scholar] [CrossRef]
- Ansarinejad, M.; Gaweesh, S.M.; Ahmed, M.M. Assessing the efficacy of pre-trained large language models in analyzing autonomous vehicle field test disengagements. Accid. Anal. Prev. 2025, 220, 108178. [Google Scholar] [CrossRef]
- Lu, S.; He, L.; Li, S.E.; Luo, Y.; Wang, J.; Li, K. Hierarchical end-to-end autonomous driving: Integrating bev perception with deep reinforcement learning. In Proceedings of the 2025 IEEE International Conference on Robotics and Automation (ICRA), Atlanta, GA, USA, 19–23 May 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 8856–8863. [Google Scholar]
- Kim, T.; Wang, Y.; Chaturvedi, V.; Gupta, L.; Kim, S.; Kwon, Y.; Ha, S. LLMem: Estimating GPU memory usage for fine-tuning pre-trained LLMs. arXiv 2024, arXiv:2404.10933. [Google Scholar]
- Yang, S.; Wang, Z.; Ortiz, D.; Burbano, L.; Kantarcioglu, M.; Cardenas, A.; Xie, C. Probing Vulnerabilities of Vision-LiDAR Based Autonomous Driving Systems. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 11–15 June 2025; pp. 3561–3569. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the 1st Conference on Robot Learning (CoRL 2017), Mountain View, CA, USA, 13–15 November 2017; PMLR: Cambridge, MA, USA, 2017; Volume 78, pp. 1–16. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.