

The Influence of Heritage Language Experience on Perception and Imitation of Prevoicing

Abstract
1. Introduction
2. Materials and Methods
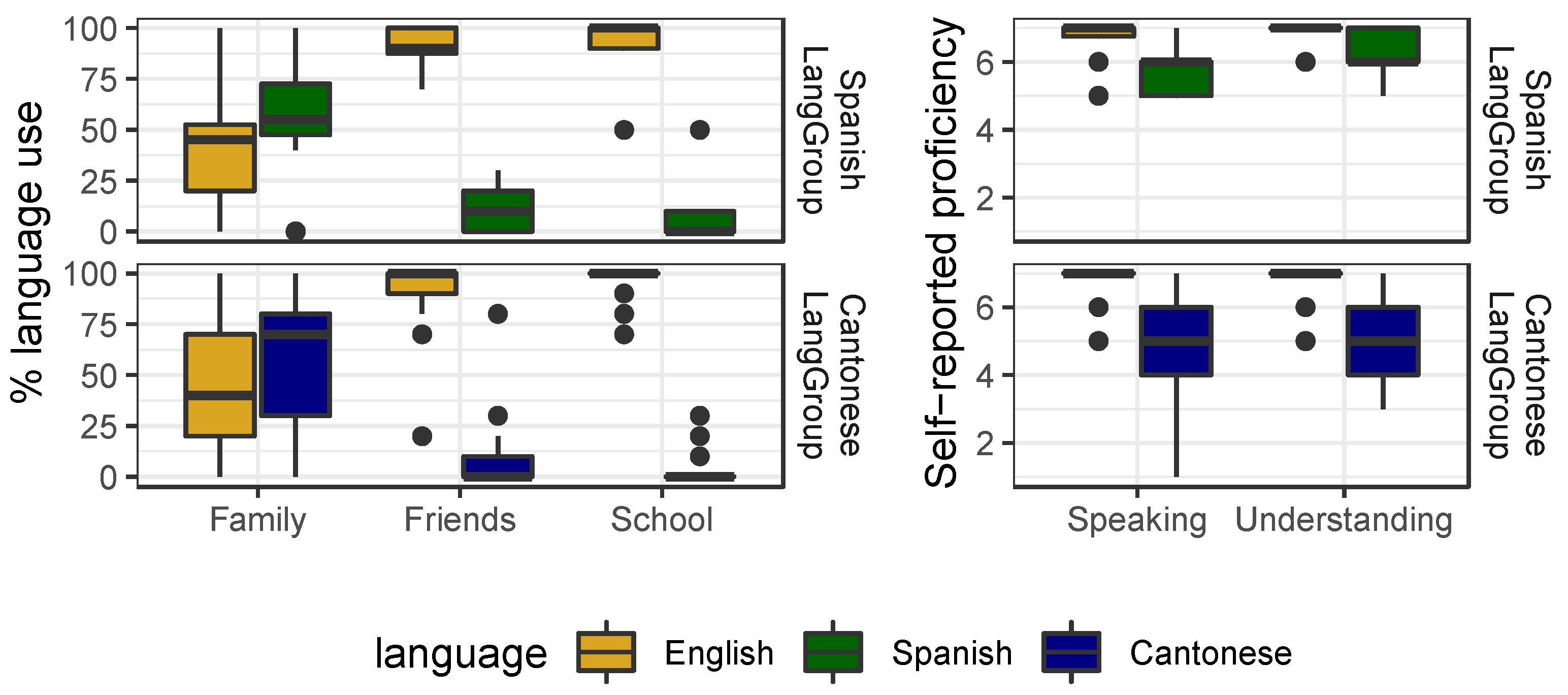
2.1. Participants
2.2. Materials
2.3. Procedure
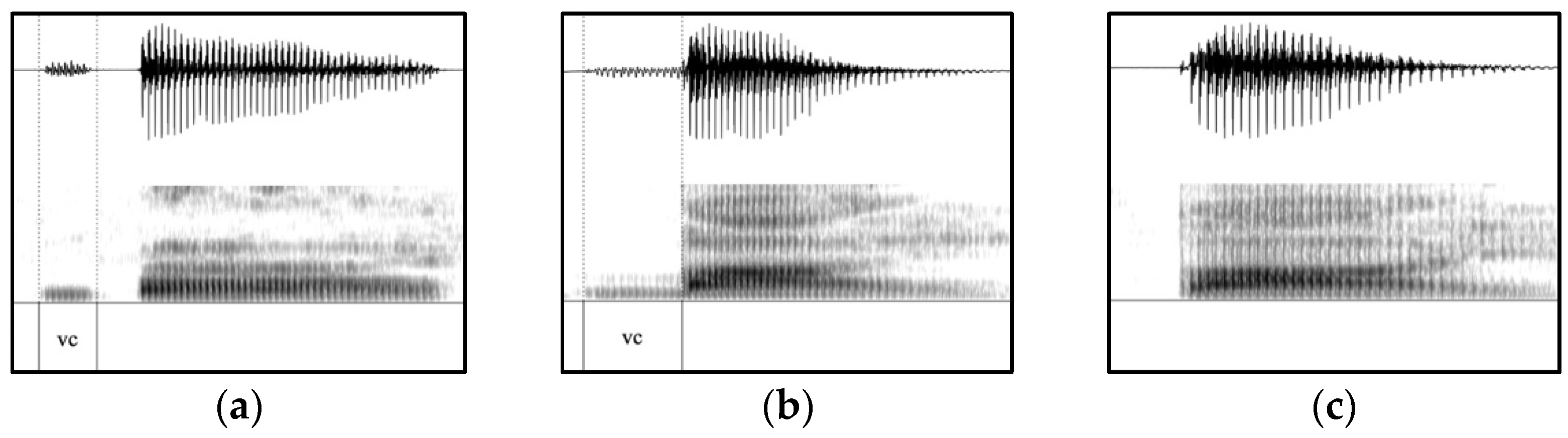
2.4. Data Processing, Phonetic Annotation and Measurements
2.5. Statistical Analysis
3. Results
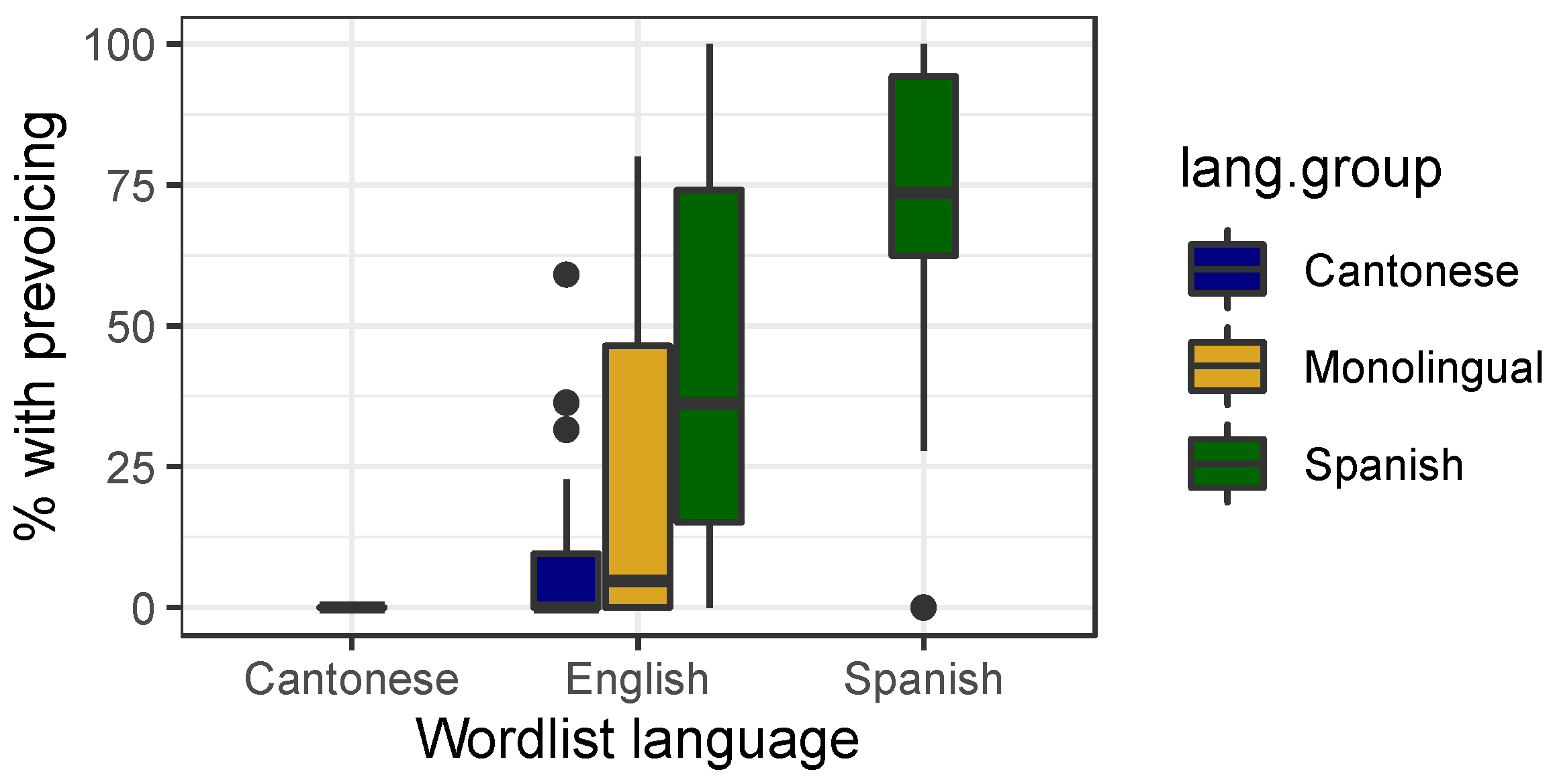
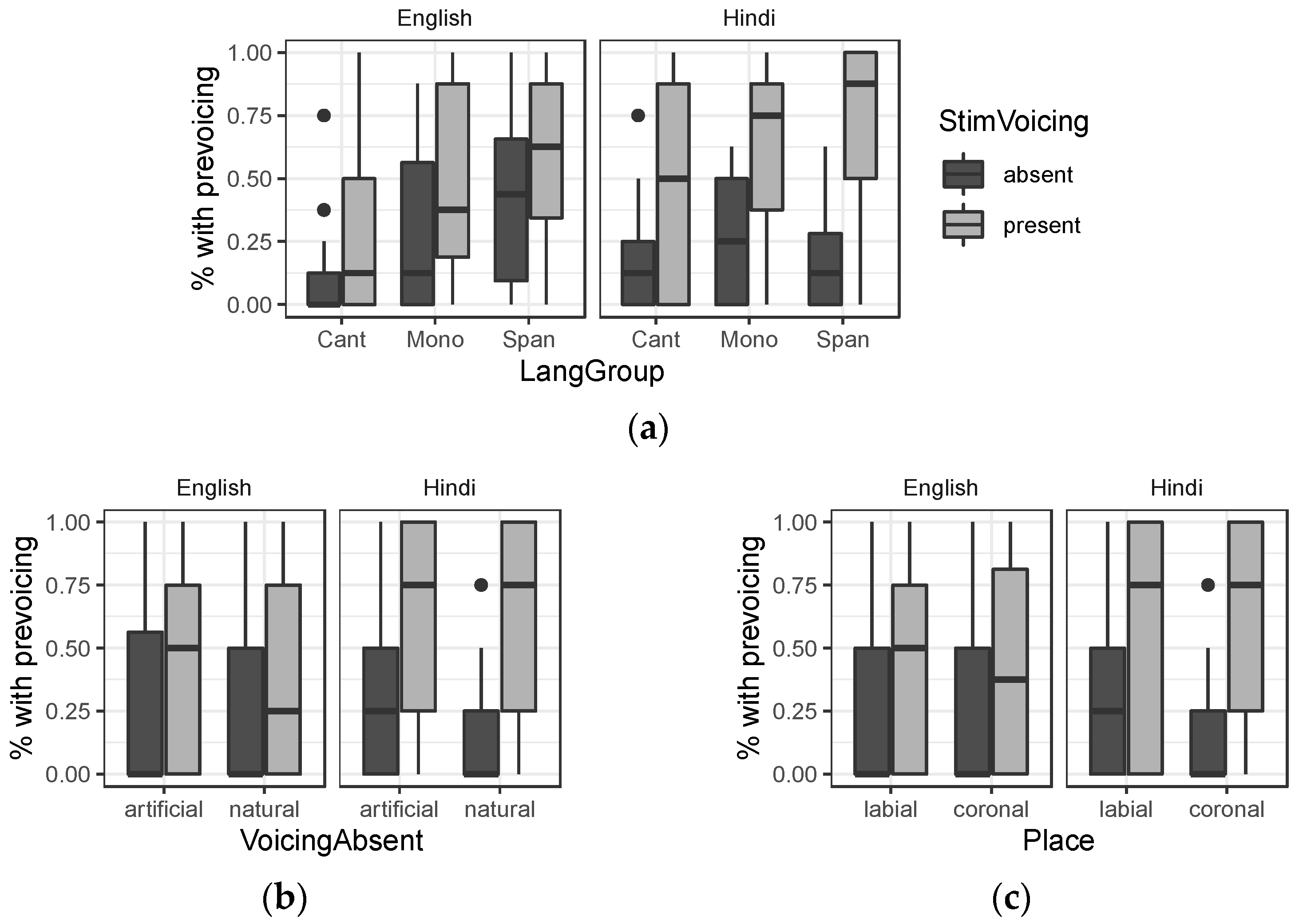
3.1. Baseline Wordlist
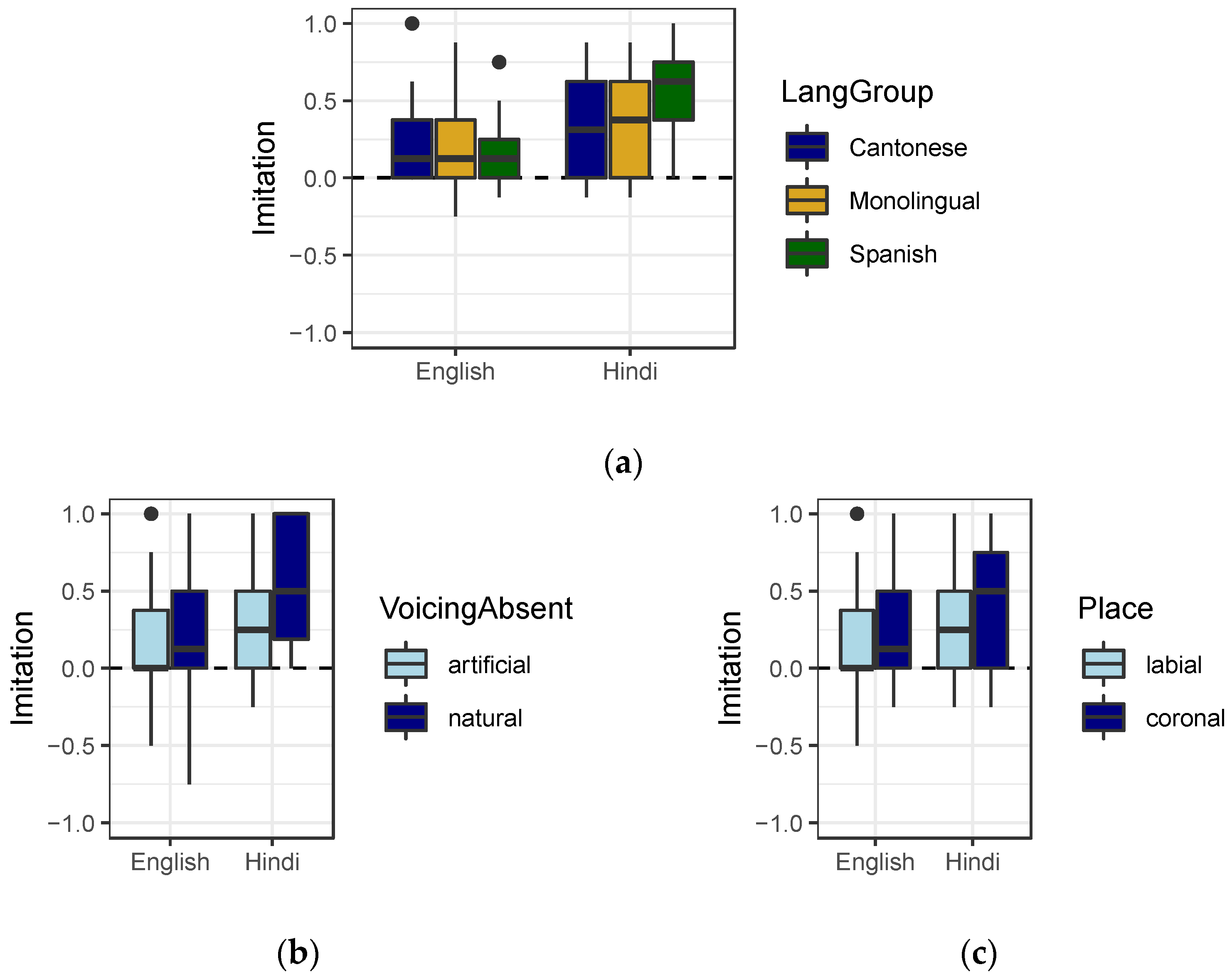
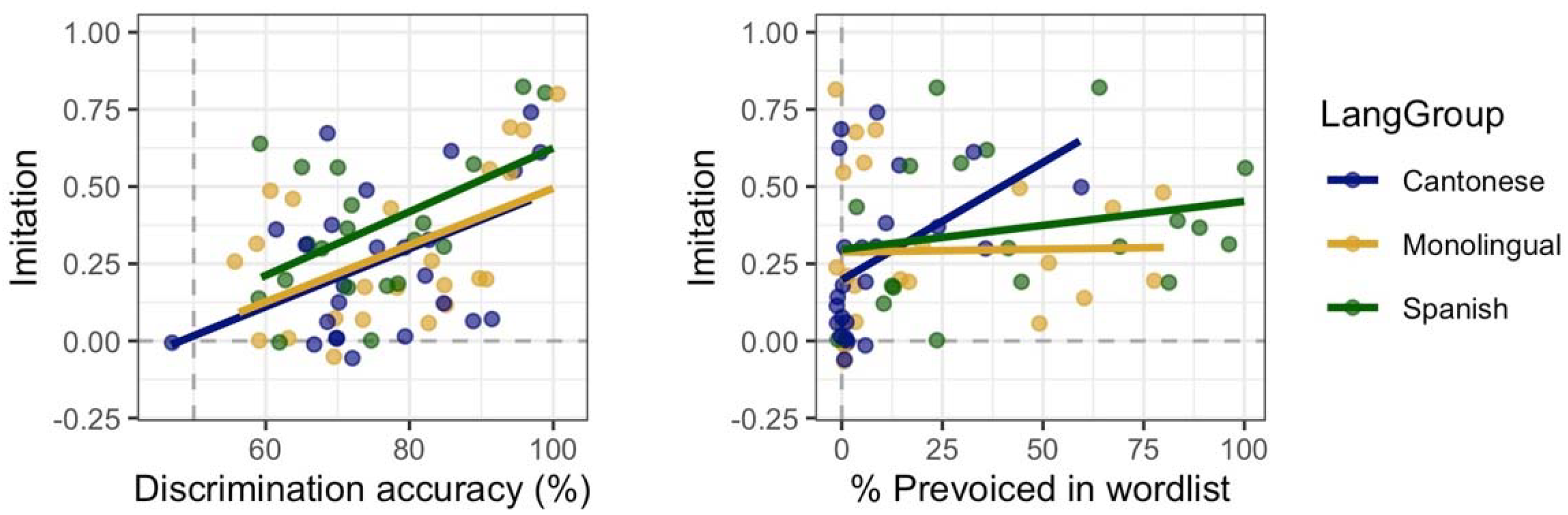
3.2. Imitation
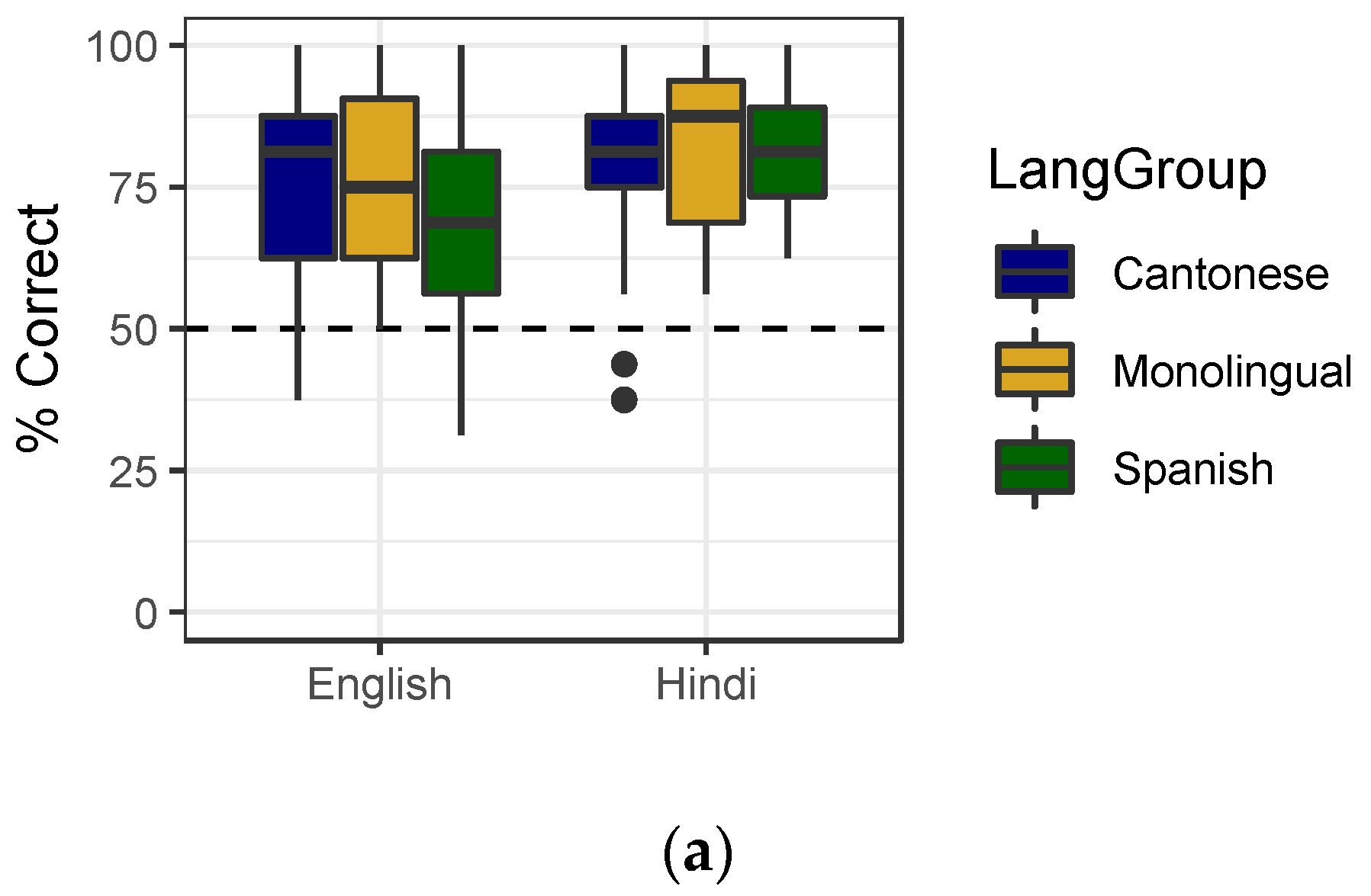
3.3. Discrimination
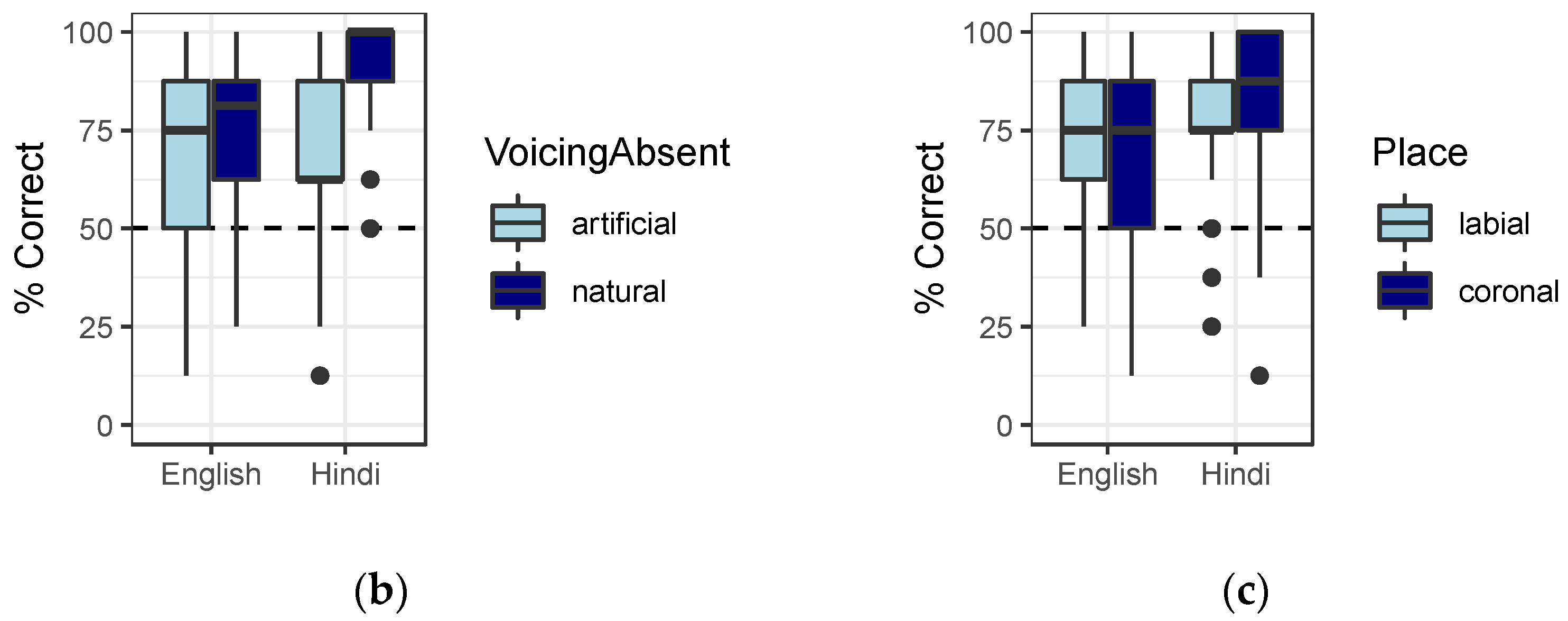
3.4. Individual Predictors of Imitation: Discrimination and Baseline Voicing
4. Discussion
4.1. Summary of Results
4.2. Influence of Language Background and Language Mode on Imitation and Discrimination
4.3. Sensitivity to Prevoicing: An Understudied Domain
4.4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| English | Spanish | Cantonese | |||
|---|---|---|---|---|---|
| /bɑt/ | bot | /base/ | base ‘base’ | /ba1hɐn4/ | 疤痕 ‘scar’ |
| /bitʃ/ | beach | /bisi/ | bici ‘bike’ | /bin3fa3/ | 变化 ‘change’ |
| /bum/ | boom | /buska/ | busca ‘search’ | /bun1ʊk1/ | 搬屋 ‘to move house’ |
| /dɑt/ | dot | /dato/ | dato ‘date’ | /da2tsi6/ | 打字 ‘to type’ |
| /dip/ | deep | /digo/ | digo ‘I say’ | /din6si6/ | 电视 ‘TV’ |
| /dun/ | dune | /dutʃa/ | ducha ‘shower’ | /dʊŋ1tin1/ | 冬天 ‘winter’ |
| /ɡɑt/ | got | /ɡafas/ | gafas ‘glasses’ | /ɡa1tɪŋ4/ | 家庭 ‘family’ |
| /ɡis/ | geese | /ɡia/ | guía ‘guide’ | /ɡin6hɔŋ1/ | 健康 ‘health’ |
| /ɡun/ | goon | /ɡusto/ | gusto ‘taste’ | /ɡu1tsɛ1/ | 姑妈 ‘father’s older sister’ |
| /pɑt/ | pot | /pasa/ | pasa ‘happens’ | /pa4san1/ | 爬山 ‘to climb a mountain’ |
| /pitʃ/ | peach | /piso/ | piso ‘floor’ | /pin1fʊk1/ | 蝙蝠 ‘bat (animal)’ |
| /pul/ | pool | /puso/ | puso ‘I put’ | /pun4gwɐt1/ | 盆骨 ‘pelvis’ |
| /tɑt/ | tot | /tako/ | taco ‘taco’ | /ta1mun4/ | 他们 ‘they/them’ |
| /tiθ/ | teeth | /tiɡɾe/ | tigre ‘tiger’ | /tin1hei3/ | 天气 ‘weather’ |
| /tun/ | tune | /tuve/ | tuve ‘I had’ | /tʊŋ4hɔk6/ | 同学 ‘classmate’ |
| /kɑp/ | cop | /kasa/ | casa ‘house’ | /ka1tʊŋ1/ | 卡通 ‘cartoon’ |
| /kip/ | keep | /kinse/ | quince ‘fifteen’ | /kit3hiu2/ | 揭晓 ‘to disclose/reveal’ |
| /kul/ | cool | /kuvo/ | cubo ‘cube’ | /ku1ŋa4/ | 箍牙 ‘to get braces’ |
| /baj/ | buy | ||||
| /daj/ | die | ||||
| /paj/ | pie | ||||
| /taj/ | tie | ||||
| English | Hindi | ||
|---|---|---|---|
| Place | Manipulation | Aspiration Present ~ Absent | Aspiration Present ~ Absent |
| labial | natural | [pʰaj] ~ [paj] | [pʰɑl] ~ [pɑl] |
| artificial | [pʰaj] ~ [p˭aj] | [pʰɑl] ~ [p˭ɑl] | |
| coronal | natural | [tʰaj] ~ [taj] | [tʰɑl] ~ [tɑl] |
| artificial | [tʰaj] ~ [t˭aj] | [tʰɑl] ~ [t˭ɑl] |
Appendix B
| English | Hindi | ||||||
|---|---|---|---|---|---|---|---|
| Word | VOT (ms) | Prevoicing Duration (ms) | Peak Intensity of Voicing (dB) | Word | VOT (ms) | Prevoicing Duration (ms) | Peak Intensity of Voicing (dB) |
| [baj] | 13 | 122 | 67.81 | [bɑl] | 5 | 106 | 70.66 |
| [daj] | 13 | 125 | 68.42 | [dɑl] | 8 | 122 | 70.04 |
| [paj] | 15 | 0 | - | [pɑl] | 7 | 0 | - |
| [taj] | 13 | 0 | - | [dɑl] | 11 | 0 | - |
| [pʰaj] | 71 | 0 | - | [pʰɑl] | 131 | 0 | - |
| [tʰaj] | 47 | 0 | - | [tʰɑj] | 127 | 0 | - |
Appendix C

| 1 | While not always the case, the language of the wider community is often the dominant language of heritage speakers, and this is the case in the participants in our study. For simplicity, in this work we use “dominant language” to refer to the language of the wider community, and “monolinguals” to refer to non-heritage native speakers of this wider community language. |
| 2 | We chose Hindi for the foreign language because the stop laryngeal contrast includes both prevoicing and aspiration, resulting in a four-way phonemic distinction between [b], [bʰ], [p], and [pʰ] (Hussain 2018). As detailed in the Methods section, our stimulus manipulations required natural baseline stimuli including both prevoicing and aspiration. |
| 3 | We chose to use percent accuracy for its transparency and for consistency with comparable work (Nielsen and Scarborough 2015), and because we the ABX task we used eliminates much of the potential response bias present in AX discrimination tasks, reducing the need for a measure like d-prime that corrects for this bias. |
| 4 | We chose to use by-participant indices (i.e., an aggregate measure) as our response variable, instead of the raw data, for two reasons. First, it allowed for a more direct comparison between participants’ perception and production, and because the models using raw data with the appropriate random effects structures failed to converge, indicating that more data is likely needed to support such models. |
| 5 | The difference between Cantonese and Monolingual groups, not tested directly in this model, was also non-significant: (estimate = 0.03, SE = 0.071, t = 0.43, p = 0.904), as calculated by using the emmeans package in R (Lenth 2022). |
| 6 | One possibility was that the better imitative performance by Spanish speakers in Hindi was driven by naturally produced trials; in order to test this, we compared an additional model that included the three-way interaction between Language Group, VoicingAbsent Type, and StimulusLanguage. None of the interactions involving Language Group and VoicingAbsent type were significant, and this model was not significantly different than the one used in our analysis, indicating that the effect was not driven by the natural stimuli. |
| 7 | The difference between Cantonese and Monolingual groups, not tested directly in this model, was also non-significant: (estimate = 0.02, SE = 0.036, t = 0.555, p = 0.844), as calculated by using the emmeans package in R (Lenth 2022). |
References
- Antoniou, Mark, Catherine T. Best, Michael D. Tyler, and Christian Kroos. 2010. Language context elicits native-like stop voicing in early bilinguals’ productions in both L1 and L2. Journal of Phonetics 38: 640–53. [Google Scholar] [CrossRef]
- Antoniou, Mark, Michael D. Tyler, and Catherine T. Best. 2012. Two ways to listen: Do L2-dominant bilinguals perceive stop voicing according to language mode? Journal of Phonetics 40: 582–94. [Google Scholar] [CrossRef] [PubMed]
- Anwyl-Irvine, Alexander L., Jessica Massonnié, Adam Flitton, Natasha Kirkham, and Jo K. Evershed. 2020. Gorilla in our midst: An online behavioral experiment builder. Behavior Research Methods 52: 388–407. [Google Scholar] [CrossRef] [PubMed]
- Baese-Berk, Melissa, and Matthew Goldrick. 2009. Mechanisms of interaction in speech production. Language and Cognitive Processes 24: 527–54. [Google Scholar] [CrossRef]
- Balukas, Colleen, and Christian Koops. 2015. Spanish-English bilingual voice onset time in spontaneous code-switching. International Journal of Bilingualism 19: 423–43. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Maechler, Ben Bolker, and Steve Walker. 2015. Lme4: Linear Mixed-Effects Models Using Eigen and S4. Available online: https://cran.r-project.org/web/packages/lme4/index.html (accessed on 14 November 2022).
- Benkí, José R. 2005. Perception of VOT and first formant onset by Spanish and English speakers. In Proceedings of the 4th International Symposium on Bilingualism. Edited by James Cohen, Kara McAlister, Kellie Rolstad and Jeff MacSwan. Somerville: Cascadilla Press, pp. 240–48. [Google Scholar]
- Birdsong, David, Libby M. Gertken, and Mark Amengual. 2012. Bilingual Language Profile: An Easy-to-Use Instrument to Assess Bilingualism. Austin: COERLL, University of Texas at Austin. Available online: https://sites.la.utexas.edu/bilingual/ (accessed on 14 November 2022).
- Caramazza, A., G. Yeni-Komshian, and E. B. Zurif. 1974. Bilingual switching: The phonological level. Canadian Journal of Psychology/Revue Canadienne de Psychologie 28: 310–18. [Google Scholar] [CrossRef]
- Casillas, Joseph V., and Miquel Simonet. 2018. Perceptual categorization and bilingual language modes: Assessing the double phonemic boundary in early and late bilinguals. Journal of Phonetics 71: 51–64. [Google Scholar] [CrossRef]
- Catford, John Cunnison. 2001. A Practical Introduction to Phonetics, 2nd ed. Oxford: Oxford University Press. [Google Scholar]
- Chang, Charles B. 2016. Bilingual perceptual benefits of experience with a heritage language. Bilingualism: Language and Cognition 19: 791–809. [Google Scholar] [CrossRef]
- Chang, Charles B. 2018. Perceptual attention as the locus of transfer to nonnative speech perception. Journal of Phonetics 68: 85–102. [Google Scholar] [CrossRef]
- Chang, Charles B. 2021. Phonetics and phonology of heritage languages. In The Cambridge Handbook of Heritage Languages and Linguistics. Edited by Silvina Montrul and Maria Polinsky. Cambridge: Cambridge University Press, pp. 581–612. [Google Scholar] [CrossRef]
- Cho, Taehong, and Peter Ladefoged. 1999. Variation and universals in VOT: Evidence from 18 languages. Journal of phonetics 27: 207–29. [Google Scholar] [CrossRef]
- De Rosario-Martínez, Helios. 2015. “Package ‘Phia’”. Available online: https://CRAN.R-project.org/package=phia (accessed on 14 November 2022).
- Dmitrieva, Olga. 2019. Transferring perceptual cue-weighting from second language into first language: Cues to voicing in Russian speakers of English. Journal of Phonetics 73: 128–43. [Google Scholar] [CrossRef]
- Dmitrieva, Olga, Fernando Llanos, Amanda A. Shultz, and Alexander L. Francis. 2015. Phonological status, not voice onset time, determines the acoustic realization of onset f0 as a secondary voicing cue in Spanish and English. Journal of Phonetics 49: 77–95. [Google Scholar] [CrossRef]
- Drager, Katie. 2010. Sociophonetic variation in speech perception. Language and Linguistics Compass 4: 473–80. [Google Scholar] [CrossRef]
- Dufour, Sophie, and Noël Nguyen. 2013. How much imitation is there in a shadowing task? Frontiers in Psychology 4: 346. [Google Scholar] [CrossRef] [PubMed]
- Flege, James Emil, and Wieke Eefting. 1988. Imitation of a VOT continuum by native speakers of English and Spanish: Evidence for phonetic category formation. The Journal of the Acoustical Society of America 83: 729–40. [Google Scholar] [CrossRef]
- Gonzales, Kalim, and Andrew J. Lotto. 2013. A Bafri, un Pafri. Psychological Science 24. [Google Scholar] [CrossRef] [PubMed]
- Herd, Wendy. 2020. Sociophonetic voice onset time variation in Mississippi English. The Journal of the Acoustical Society of America 147: 596. [Google Scholar] [CrossRef]
- Hussain, Qandeel. 2018. A typological study of Voice Onset Time (VOT) in Indo-Iranian languages. Journal of Phonetics 71: 284–305. [Google Scholar] [CrossRef]
- Kang, Yoonjung, Sneha George, and Rachel Soo. 2016. Cross-language Influence in the Stop Voicing Contrast in Heritage Tagalog. Heritage Language Journal. [Google Scholar] [CrossRef]
- Kharlamov, Viktor. 2022. Phonetic effects in the perception of VOT in a prevoicing language. Brain Sciences 12: 427. [Google Scholar] [CrossRef]
- Kuznetsova, Alexandra, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef]
- Kwon, Harim. 2019. The role of native phonology in spontaneous imitation: Evidence from Seoul Korean. Laboratory Phonology: Journal of the Association for Laboratory Phonology 10: 10. [Google Scholar] [CrossRef]
- Kwon, Harim. 2021. A non-contrastive cue in spontaneous imitation: Comparing mono- and bilingual imitators. Journal of Phonetics 88: 101083. [Google Scholar] [CrossRef]
- Ladefoged, Peter, and Keith Johnson. 2014. A Course in Phonetics, 7th ed. Belmont: Wadsworth Publishing. ISBN 1285463404. [Google Scholar]
- Lenth, Russell V. 2022. Emmeans: Estimated Marginal Means, aka Least-Squares Means, Version 1.8.1-1. Available online: https://CRAN.R-project.org/package=emmeans (accessed on 14 November 2022).
- Lisker, Leigh, and Arthur S. Abramson. 1964. A Cross-Language Study of Voicing in Initial Stops: Acoustical Measurements. WORD 20: 384–422. [Google Scholar] [CrossRef]
- Nagy, Naomi. 2015. A sociolinguistic view of null subjects and VOT in Toronto heritage languages. Lingua. International Review of General Linguistics. Revue Internationale de Linguistique Generale 164: 309–27. [Google Scholar] [CrossRef]
- Newlin-Łukowicz, Luiza. 2014. From interference to transfer in language contact: Variation in voice onset time. Language Variation and Change 26: 359–85. [Google Scholar] [CrossRef]
- Nielsen, Kuniko Y., and Rebecca Scarborough. 2015. Perceptual asymmetry between greater and lesser vowel nasality and VOT. Paper presented at ICPhS, Glasgow, UK, August 10–14. [Google Scholar]
- Oh, Janet S., Terry Kit-Fong Au, and Sun-Ah Jun. 2010. Early childhood language memory in the speech perception of international adoptees. Journal of Child Language 37: 1123–32. [Google Scholar] [CrossRef]
- Ohala, Manjari. 1994. Hindi. Journal of the International Phonetic Association 24: 35–38. [Google Scholar] [CrossRef]
- Olmstead, Annie J., Navin Viswanathan, M. Pilar Aivar, and Sarath Manuel. 2013. Comparison of native and non-native phone imitation by English and Spanish speakers. Frontiers in Psychology 4: 475. [Google Scholar] [CrossRef]
- Pallier, Christophe, Stanislas Dehaene, J.-B. Poline, Denis LeBihan, A.-M. Argenti, Emmanuel Dupoux, and Jacques Mehler. 2003. Brain imaging of language plasticity in adopted adults: Can a second language replace the first? Cerebral Cortex 13: 155–61. [Google Scholar] [CrossRef]
- Podlipský, Václav Jonás, and Sárka Šimáčková. 2015. Phonetic imitation is not conditioned by preservation of phonological contrast but by perceptual salience. Paper presented at ICPhS, Glasgow, UK, August 10–14. [Google Scholar]
- Schertz, Jessamyn, and Sarah Khan. 2020. Acoustic cues in production and perception of the four-way stop laryngeal contrast in Hindi and Urdu. Journal of Phonetics 81: 100979. [Google Scholar] [CrossRef]
- Schertz, Jessamyn, Kathy Carbonell, and Andrew J. Lotto. 2020. Language Specificity in Phonetic Cue Weighting: Monolingual and Bilingual Perception of the Stop Voicing Contrast in English and Spanish. Phonetica 77: 186–208. [Google Scholar] [CrossRef] [PubMed]
- Schwartz, Geoffrey. 2022. Asymmetrical cross-language phonetic interaction. Linguistic Approaches to Bilingualism 12: 103–32. [Google Scholar] [CrossRef]
- Tees, Richard C., and Janet F. Werker. 1984. Perceptual flexibility: Maintenance or recovery of the ability to discriminate non-native speech sounds. Canadian Journal of Psychology 38: 579–90. [Google Scholar] [CrossRef]
- van Alphen, Petra M., and Roel Smits. 2004. Acoustical and perceptual analysis of the voicing distinction in Dutch initial plosives: The role of prevoicing. Journal of Phonetics 32: 455–91. [Google Scholar] [CrossRef]
- Walker, Abby. 2020. Voiced stops in the command performance of Southern US English. The Journal of the Acoustical Society of America 147: 606. [Google Scholar] [CrossRef] [PubMed]
- Williams, Lee. 1974. Speech Perception and Production as a Function of Exposure to a Second Language. Ph.D. thesis, Harvard University, Cambridge, MA, USA. [Google Scholar]
- Williams, Lee. 1977a. The perception of stop consonant voicing by Spanish-English bilinguals. Perception & Psychophysics 21: 289–97. [Google Scholar] [CrossRef]
- Williams, Lee. 1977b. The voicing contrast in Spanish. Journal of Phonetics 5: 169–84. [Google Scholar] [CrossRef]
- Woods, Kevin J. P., Max H. Siegel, James Traer, and Josh H. McDermott. 2017. Headphone screening to facilitate web-based auditory experiments. Attention, Perception & Psychophysics 79: 2064–72. [Google Scholar] [CrossRef]







| Language | Phonological Voiced Series | Phonological Voiceless Series | Prevoicing in Voiced Series | Primary Cue to Contrast |
|---|---|---|---|---|
| English | [b] or [p] | [pʰ] | variable | aspiration |
| Spanish | [b] | [p] | always present | prevoicing |
| Cantonese | [p] | [pʰ] | always absent | aspiration |
| LangGroup | N | Age | Gender | Current Residence | English AoA |
|---|---|---|---|---|---|
| Spanish/English | 20 | 22 (18–30) | 14F, 4M, 2NB | US (19), Canada (1) | 4 (0–8) |
| Cantonese/English | 25 | 25 (19–37) | 20F, 5M | US (7), Canada (18) | 3 (0–6) |
| Monolingual English | 23 | 25 (18–30) | 9F, 13M, 1NB | US (18), Canada (5) | 0 |
| English | Hindi | ||
|---|---|---|---|
| Place | Manipulation | Prevoicing Present ~ Absent | Prevoicing Present ~ Absent |
| labial | natural | [baj] ~ [paj] | [bɑl] ~ [pɑl] |
| artificial | [baj] ~ [b̥aj] | [bɑl]~ [b̥ɑl] | |
| coronal | natural | [daj] ~ [taj] | [dɑl] ~ [tɑl] |
| artificial | [daj] ~ [d̥aj] | [dɑl] ~ [d̥ɑl] |
| Phase | A | B | X |
|---|---|---|---|
| LISTEN: you will listen to two words of English. Try to pay attention to the differences. | [baj] | [paj] | -- |
| [baj] | [paj] | -- | |
| IMITATE: Now you will be asked to repeat the words. After you hear each word, please repeat it out loud, trying to imitate it as closely as possible. | [baj] | [paj] | -- |
| [baj] | [paj] | -- | |
| DECIDE: Please decide whether the third word sounds more like the first or second word you heard. | [baj] | [paj] | [baj] |
| [baj] | [paj] | [paj] | |
| [baj] | [paj] | [baj] | |
| [baj] | [paj] | [paj] |
| Estimate | SE | t | p | |
|---|---|---|---|---|
| (Intercept) | 0.306 | 0.030 | 10.158 | <0.001 |
| Stimulus Language (Hindi vs. English) | 0.199 | 0.032 | 6.248 | <0.001 |
| Language Group (Monolingual vs. Spanish) | −0.075 | 0.076 | −0.994 | 0.324 |
| Language Group (Cantonese vs. Spanish) | −0.106 | 0.074 | −1.423 | 0.160 |
| VoicingAbsent Type (natural vs. artificial) | 0.137 | 0.032 | 4.309 | <0.001 |
| Place of Articulation (coronal vs. labial) | 0.089 | 0.032 | 2.802 | 0.005 |
| StimLang * LangGroup (Mono vs. Spanish) | −0.207 | 0.080 | −2.597 | 0.010 |
| StimLang * LangGroup (Cantonese vs. Spanish) | −0.225 | 0.079 | −2.869 | 0.004 |
| StimLang * VoicingAbsent Type | 0.213 | 0.063 | 3.358 | 0.001 |
| StimLang * Place | 0.132 | 0.063 | 2.083 | 0.038 |
| Estimate | SE | t | p | |
|---|---|---|---|---|
| (Intercept) | 0.762 | 0.015 | 50.454 | <0.001 |
| Stimulus Language (Hindi vs. English) | 0.078 | 0.019 | 4.111 | <0.001 |
| Language Group (Monolingual vs. Spanish) | 0.035 | 0.038 | 0.912 | 0.365 |
| Language Group (Cantonese vs. Spanish) | 0.015 | 0.037 | 0.395 | 0.694 |
| VoicingAbsent Type (natural vs. artificial) | 0.155 | 0.019 | 8.201 | <0.001 |
| Place of Articulation (coronal vs. labial) | −0.028 | 0.019 | −1.504 | 0.133 |
| StimLang * LangGroup (Mono vs. Spanish) | −0.069 | 0.048 | −1.448 | 0.148 |
| StimLang * LangGroup (Cantonese vs. Spanish) | −0.099 | 0.047 | −2.121 | 0.034 |
| StimLang * VoicingAbsent Type | 0.131 | 0.038 | 3.445 | 0.001 |
| StimLang * Place | 0.094 | 0.038 | 2.475 | 0.014 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Clare, E.J.; Schertz, J. The Influence of Heritage Language Experience on Perception and Imitation of Prevoicing. Languages 2022, 7, 302. https://doi.org/10.3390/languages7040302
Clare EJ, Schertz J. The Influence of Heritage Language Experience on Perception and Imitation of Prevoicing. Languages. 2022; 7(4):302. https://doi.org/10.3390/languages7040302
Chicago/Turabian StyleClare, Emily J., and Jessamyn Schertz. 2022. "The Influence of Heritage Language Experience on Perception and Imitation of Prevoicing" Languages 7, no. 4: 302. https://doi.org/10.3390/languages7040302
APA StyleClare, E. J., & Schertz, J. (2022). The Influence of Heritage Language Experience on Perception and Imitation of Prevoicing. Languages, 7(4), 302. https://doi.org/10.3390/languages7040302