1. Introduction
Research in language acquisition has demonstrated that adult language learners often differ from monolingual speakers of the language that they learn in various linguistic aspects (
Cook 1999). Among these differences is the production and perception of second language sounds by adult second-language (L2) learners, who have been shown to be influenced by their first language when they produce and perceive L2 sounds (
Flege et al. 1997). It has been proposed that this difficulty in the learning of a second language sound system is perceptually driven and based on the sound inventory of one’s native language (
Best and Tyler 2007). Much research has been dedicated to this idea under the Perceptual Assimilation Model for L2 learners (PAM-L2;
Best and Tyler 2007). In this view, the use of contrasts in the L1 predicts the relative ease or difficulty of learning sound contrasts in the L2. A body of research has come to support the notion that, at near first exposure to a new language, speakers have difficulty contrasting L2 phonemes that do not make word distinctions in their L1. This body of research has largely not considered whether this effect of a native language is due to some special status of a native language (relative to late learned ones) or whether its impact on novel language sound perception occurs simply because a monolingual’s native language is the only source of phonology available to them. Bilingual speakers, on the other hand, have two language specific phonological systems that could plausibly be used to account for new language sounds.
Across many linguistic domains, L3 research has investigated how L2 and L3 learning might be distinct. A traditional view subsumes L3 learning as another instance of L2 learning by assuming that L1 categories, rather than all known language categories, should influence subsequent language learning. The field of L3 acquisition has suggested that this is not the case. In one of the first attempts to model L3 acquisition in the domain of morphosyntax,
Flynn et al. (
2004) provided evidence that the L1 does not play a privileged role in the production of L3 restrictive relative clauses by L1 Kazakh-L2 Russian-L3 English speakers. The authors interpreted this result as evidence that language learners can be influenced by both their L1 and L2 during acquisition of a new language, referring to language learning as cumulative process and formally introducing this idea as the Cumulative Enhancement Model of Language Acquisition (CEM). However, the influence of the syntactic structure in question was common in the L2 and L3 of the speakers in this case, and the data presented did not directly demonstrate that the L3 speakers treated other structures as L1-like.
Taking an alternative interpretation of the data reported in
Flynn et al. 2004;
Bardel and Falk (
2007) proposed the L2 Status Factor Model (L2SF). In this view, the second language is a privileged source of transfer and influences the third language, while inhibiting access to the L1. Evidence for this argument was provided in this initial study, in which learners of an L3 V2 language were less successful in L3 word order tasks when their L2 was not a V2 language. This result provided important counter-evidence for the CEM, since, while showing that L3 learners had access to their L2, this influence was not helpful, which the CEM would predict.
Future studies would propose additional models which aimed to predict how L3 learners are influenced by their previously known languages. In a study examining adjective order by L3 learners of Spanish and Brazilian Portuguese,
Rothman (
2010) proposed the Typological Primacy Model (TPM), based on the finding that L3 learners were influenced in some cases by their L1 and by their L2 in others. This difference in L1 or L2 influence was proposed to be due to structural similarity in the known languages. That is, a speaker learning L3 Brazilian Portuguese is thought to be influenced by their Spanish whether it is their L1 or L2 instead of their other known language (such as English). Again, the data presented in
Rothman (
2010) provided counterevidence for the predictions of the previous model, the L2SF, since it showed that L1 influence or L2 influence can occur during L3 learning. This model was further elucidated in future work (
Rothman 2011;
Rothman 2013;
Rothman 2015), in which it is proposed that L3 learners are, at some point during development, influenced by the transfer of one entire language system (wholesale transfer) as a reflex of cognitive economy. This influence is argued for within the framework of the Full Access/Full Transfer Hypothesis (
Schwartz and Sprouse 1996), where the initial state of the L3 is either the L1 or L2 system.
While also positing that structural similarity influences L3 learning and that L3 learners can be influenced by either the L1 or L2, more recent models of L3 acquisition have argued that language structures are influenced by the L1 and the L2 based on their underlying structural similarity, and that full-language transfer (and blocking of the non-transferred language) does not occur. These models are the Linguistic Proximity Model (LPM;
Westergaard et al. 2017;
Westergaard 2021) and the Scalpel Model (
Slabakova 2017). Initial evidence for the LPM was reported in
Westergaard et al. (
2017), in which L3 English learners (Russian-Norwegian) were compared to two groups of L2 English learners (L1 Russian and L1 Norwegian). The results of a Grammaticality Judgment Task found that the percentage of correct responses of the L3 group fell between the two bilingual groups, where the L1 Norwegian group was the least successful in noticing errors, followed by the L3 group, and the L1 Russian group was the most successful. The authors took this result as evidence of incremental, property-by-property learning of an L3, in which individual structures are subject to influence by both languages simultaneously.
Importantly, there is evidence in the literature for all views. In a recent systematic review of L3 transfer studies,
Rothman et al. (
2019) reviewed and coded a total of 92 studies which investigated how the L1 or L2 impacted the L3. The results suggested that many studies could be explained by typological transfer (n = 51), while 23 were explained by L2 status, 18 could be explained by hybrid transfer, and finally 15 could be explained by L1 transfer. Importantly, some studies were coded as providing evidence for more than one view. That is, it was possible for a study to be explained by both L2 status and typology in the systematic review.
The relationship between L3 models of morphosyntax and L3 phonology has not yet been addressed in much detail. For example,
Westergaard et al. 2017 does not discuss whether the LPM’s predictions could be extended to L3 phonology. The TPM (
Rothman 2011;
Rothman 2013;
Rothman 2015) suggests that phonological cues in L3 input aids in triggering the wholesale transfer of one language system, but does not explicitly state that this “one language system” includes phonology or refers to syntax alone. When discussing Full Access/Full trasfer in the context of L3 acquistiion,
Schwartz and Sprouse (
2021) state that Full Transfer includes all abstract categories of the source language, but not the “phonetic matrices” of lexical or morphological models (p. 3). This description could lead one to posit that, at for the least the TPM, that Full Transfer refers to phonology, which some studies in L3 phonology have assumed (
Cabrelli and Pichan 2021, p. 8). As a result, it is unclear if these current general models of L3A could apply to third language phonology overall, and to perception in particular.
Work in L3 phonology has yielded mixed results and most studies to date have focused on production. In particular, some studies have found that L2 influence has a greater impact on L3 global accent production (
Wrembel 2010), vowels (
Kamiyama 2007), speech rhythm (
Gut 2010), and VOT (
Llama et al. 2010). On the other hand, some studies have found an L1 influence on global accent production production despite L3 proficiency (
Wrembel 2012), or in VOT in advanced L3 learners (
Llama and Cardoso 2018). Finally, other studies have found evidence that L3 VOT falls between L1 and L2 values. For example,
Wrembel (
2014) measured VOT and aspiration in all languages of participants with two different language combinations: L1 Polish, L2 English, and L3 French; (2) L1 Polish, L2 English, and L3 German. The results showed that each language had a specific stop-value, and that the L3 VOT productions were intermediate, falling between the L1 and L2 values. Similarly,
Wrembel (
2011) examined thirty-two learners of L3 French with L1 Polish and L2 English who were recorded reading lists of words in carrier phrases. As in previous studies (e.g.,
Wrembel 2014), combined transfer from the L1 and the L2 in VOT productions was found. Findings of combined L1 and L2 influence in VOT productions were also reported by
Wunder (
2010) in L3 Spanish speakers, and by
Blank and Zimmer (
2009) in L3 English speakers who spoke L1 Brazilian Portuguese and L2 French.
Sypiańska (
2016) found that the L3 vowels of L1 Polish, L2 Danish and L3 English speakers were produced on target, perhaps due to the combined influence of both their L1 Polish and L2 Danish.
The source of this variety of findings in the research is not yet clear. One possible cause is the risk for sampling error that is associated with low sample studies (
Brysbaert 2020). That is, when sample size is low, as it has been in many studies on multilingualism, the likelihood of a proposed difference between groups being due to a false positive result increases. In other words, differences observed in small groups may have to do with the differences in individual participants more than it does the difference in their underlying group membership.
Following the suspicion that intermediate values might have to do with either sampling issues or proficiency effects,
Parrish (
2022) examined Mexican Spanish-English bilinguals who produced voiceless stop-initial French words in isolation near first exposure to the language. The results found that the relative VOT of the L3 fell between their own L1 and L2 values, in line with previous research, and that suggested that intermediate values were less likely to have been seen in previous studies as a result of small samples or proficiency effects. However, a subsequent analysis of the data suggested that wide individual variation existed, in which some participants produced L3 French as L1 Spanish like, and others produced intermediate, L2-like values. This result suggests that higher samples could reveal group trends and provide better insights into individual variation in crosslinguistic influence, as opposed to assuming that a single group trend exists.
It is also not known whether the trends seen in production might also be found in perception. By carrying out perception studies, it is possible to examine whether the predictions of L3 models apply more generally to L3 phonological acquisition, or whether there is discord between perception and production.
Even fewer studies have been carried out in L3 perception than in production, but have mostly found that the L2 plays a role in L3 perception.
Wrembel et al. (
2019) examined the categorization and discrimination of L3 vowels by 10 young trilinguals who spoke L1 German-L2 English-L3 Polish. To test categorization, a cross-linguistic similarity task was used in which participants heard minimal pairs of sounds and had to rate how similar sounds were on a 1–7 Likert scale. The results showed evidence that participants assimilated L3 sounds to both L1 and L2 categories, but preferred the L2. In a second experiment, an AX discrimination task was given to participants to evaluate whether retroflex and palato-alveolar consonants, a feature of Polish, but not English nor German, could be distinguished in L3 words. The results revealed that discrimination of the L3 Polish contrast was very good (84% accuracy). This language specific phonetic discrimination was attended to by even L3 beginners.
Balas (
2018) also used the PAM as a perceptual framework to work in and adapted it to L3 learners. The study recruited three groups of Polish L1 speakers, including two L3 groups (L1 Polish-L2 English-L3 Dutch and L1 English-L2 Polish-L3 Dutch). The third group spoke only English as an L2. All three groups listened to Dutch vowels and were asked to categorize them given Polish vowel categories. The L3 groups were not given L2 English categories as options during this task, so the results of this study cannot directly provide evidence that L3 learners categorize L3 sounds using both the L1 and L2 categories. The same study also conducted an AXB discrimination task of 8 Dutch vowels and found that discrimination was at ceiling for all vowels involved.
Nelson (
2020) compared the perception of the /v-w/ contrast in L1 German-L2 English-L3 Polish adults and young people and found that adults better discriminated this contrast that was present in the L2 and L3, but not the L1.
The Present Study
Building on this work, the present study adapts methods commonly used in studies in L2 bilingual phonology to investigate how the phonetic vowel categories of adults language learners impact their categorization of unknown language vowels near first exposure. The term “near first exposure” is used to describe these speakers, rather than “at first exposure”, since it is likely that most speakers have heard French and German to some degree throughout their life. Thus, their exposure to these languages in the context of the present study would not truly be their very first exposure to the language, but “near first exposure”, since they also have not meaningfully begun the process of acquiring these languages. In particular, methods are adopted from studies which have tested the predictions of the Perceptual Assimilation Model for L2 learners (PAM-L2;
Best and Tyler 2007). The model predicts that perception drives L2 phonological acquisition, and that, broadly, the (dis)similarity between sound contrasts in the L1 and L2 predicts how difficult the acquisition of a particular phoneme will be for the learner. To test these predictions, speakers of a particular language are asked to categorize sounds in a language that they do not speak given the categories of their native language. The present study presented similar tasks to those used in L2 studies, but included both L1 and L2 categories. Here, a fully combined design of Spanish-English bilinguals (i.e., two bilinguals groups and two monolingual groups will be exposed to the same languages, where the bilingual groups have the opposite order of acquisition but know the same languages) categorized vowel sounds in both French and German. Importantly, all the participants in the present study did not speak French or German.
The languages of French and German were chosen as L3s since they correspond historically to Spanish and English respectively. Spanish and French are both Romance languages and German and English are both Germanic. This historical relationship likely corresponds to global typological similarity between these language pairs, and the present design includes vowel conditions (e.g., /i/, which is present in all languages in the current study), which arguably allow for a bias to be observed. That is, if participants categorized the L3 sound /i/ in L3 French as Spanish-like more often than English like, and the the L3 sound /i/ in German as English-like more often than Spanish-like, despite the acoustic overlap in the stimuli, this would be interpreted as evidence for bias based on global typological effects as the TPM would predict. Additionally, the vowel spaces of the chosen languages varies sufficiently to create four scenarios, which are operationalized in the vowel conditions covered in more detail in the method section of this paper. Specifically, a situation is created in which (1.) the sound is present in all four languages, (2.) a sound is present in all languages except for English, (3.) a sound is present in all language except for Spanish, and (4.) a sound is present neither in English nor in Spanish.
The present study includes a fully-combined design (see
Westergaard et al. 2022) which combines the idea of the mirror-image group (
Foote 2009), with a subtractive group design (
Westergaard et al. 2017). The mirror-image design is intended to tease apart typological influence from language status by recruiting two groups of participants who speak the same languages, but who acquired the L1 and L2 in the opposite order (L1 English-L2 Spanish and L1 Spanish-L2 English). This way, if the groups treat the same L3 in similar manner, this would be taken as evidence that the structural similarity of one’s background languages, not the order of their acquistion, predicts which background language impacts a third language. The subtractive design compares an L3 group and an L2 group where the groups have the same L1 and the L3 of one group is the L2 of the other group (L1 English-L2 Spanish-L3 French and L1 English-L2 French). This design is intended to isolate the impact of the L2, such that differences between these groups in L3 tasks (or L2 tasks in the case of the bilingual group) are assumed to be due to L2 influence. The fully combined design uses both mirror image and subtractive groups, creating a total of four groups. In the present study, the fully combined design includes a group of (a.) L1 English-L2 Spanish speakers, (b.) L1 Spanish-L2 English speakers, (c.) L1 English monolingual speakers, and (d.) L1 Spanish monolingual speakers who are all naïve speakers of French and German.
In addition to the advantages of a fully-combined design, examining L3 learners near first exposure offers at least two additional advantages. First, acquisition and influence can better be teased apart when perception is target-like, and second a larger sample can be recruited in which L3 input can be better experimentally controlled for. As opposed to traditional L3 studies, where participants are actively learning a third language and may vary in L3 proficiency, exposure to input and daily L3 use, absolute beginners have almost no exposure to the L3 in a learning setting. As a result, initial exposure learners are an ideal population to examine cross-linguistic influence that could not be readily explained by other variables associated with distinct language learning outcomes. Second, a much larger sample can be recruited, which may strengthen the findings of the present study by reducing the risk of sampling error as a possible cause of the results.
In summary, the present study is guided by the following research questions:
RQ1: Overall, do Spanish-English bilinguals prefer their L1 or L2 when categorizing a new language?
RQ2: Does the L3 that they learn impact their categorization of similar vowel sounds cross-linguistically?
RQ3: When a language is chosen, do bilingual and monolingual speakers differ in their phoneme of choice?
The present study is pseudo-exploratory or hypothesis generating, in that specific predictions are not made in regard to these research questions. This is the case due to the lack of comparable studies in L3 perception in the literature, although a recent study was conducted on the production of initial state (near first exposure) L3 learners of Brazilian Portuguese and Italian who were Spanish-English bilinguals (
Cabrelli and Pichan 2021). This study found that Spanish influenced the production of intervocalic stops in the L3, even though English would be the more appropriate choice, and was taken as evidence that global structural similarity modulated this influence.
It is important, additionally, to point out that L3 models would be able to explain specific categorization patterns related to these research questions. That is, if French and German sounds are categorized as L2 or L1 sounds exclusively by all groups, then this would imply that language status is a more important predictor than cross-language similarity at a segmental level and support the L2SF or views that the L1 or dominant language predict new language perception (see e.g.,
Hermas 2010;
Best and Tyler 2007).
On the other hand, if just one language is used to categorize French and German sounds, but is not exclusively the L1 or L2 (e.g., if any group categorizes all German sounds using English categories but Spanish as French categories, whether or not English is their L1 or L2), the TPM would best explain these results. Finally, the LPM would explain if participants categorize French and German sounds using both Spanish and English sounds.
For RQ2, the TPM would predict a difference in categorization as a function of the third language being learned. That is, it would predict that very similar sounds between two languages (in this case French and German) should be differently categorized. In particular, global typological relationships should drive the bias of categorizations that are acoustically similar. On the other hand, the LPM would predict that the sound itself, rather than the language it belongs to, should predict patterns of categorization. In the present case, the phoneme /i/ is one case which will provide evidence to sort out the predictions of these models. If, in the both languages and given the phoneme /i/, participants are equally likely to choose and English or Spanish category, it will support the LPM. On the other hand, if a clear bias can be observed when the phoneme /i/ is played given a particular L3, the TPM would receive support. For example, if the German /i/ is categorized as English more often than Spanish, this would be taken as evidence of a bias. The L2SF and L1/dominance view would predict that the L3 being learned does not make a difference in terms of which source language impacts it, and that either the L2 or the L1 would influence the L3.
For RQ3, the present study will make use of conditional probability to investigate whether, for example, when the L1 Spanish group picks a Spanish category given a particular stimulus, whether they differ from the monolingual groups. Conditional probability will be calculated by taking the probability of a particular choice and dividing it by the sum of the probability of all of a given language’s choices.
For L2 bilingual phonology, the PAM-L2 emphasizes the term “native language” when describing its predictions, but does not directly engage how naïve bilingual speakers might categorize new language sounds. In the event that these bilingual speakers categorize new language sounds using both L1 and L2 categories, it would inform the PAM-L2 and suggest that the term “native language” could be replaced with “known languages”, since it would not be that case that solely native, and not L2, phonology is used to categorize new language sounds.
4. Discussion
The present study examined the categorization of vowel sounds in two unknown languages by Spanish-English bilinguals in both orders of acquisition. Although there was an overall preference for English, the results suggested that bilinguals do have access to both their L1 and L2 during L3 perception and categorization, a finding which single-language access models, such as the TPM and L2SF cannot account for. In several instances, L3 sounds had a similar probability of being assimilated to English or Spanish sound, such as in 3 out of 4 cases with the phoneme /i/. The results were mixed in terms of whether the L3 that the participants heard impacted their preference for English or Spanish categories. In total, there were three cases in which the L3 did result in the preference for an English or Spanish category out of 16 possible. In particular, the L1 Spanish group showed a slight preference for the English /i/ (the choice feel) when they heard /i/ in German, but not in French. Additionally, the L1 Spanish group also categorized the phoneme /y/ differently when they heard it in L3 French than when they heard it in L3 German. In particular, the L3 French /y/ was assimilated to Spanish /u/ (su) and the L3 German /y/ was assimilated to English /u/ (fool).
These results are best explained by the LPM (
Westergaard et al. 2017;
Westergaard 2021), which suggests that L3 learners have access to both their L1 and L2 during L3 acquisition. On the other hand, the TPM (
Rothman 2010;
Rothman 2011;
Rothman 2013;
Rothman 2015) suggests that, while bilinguals have access to both their languages near first exposure, this access is lost at some point during what the model refers to as the “initial stages” of L3 acquisition. While the present data does not necessarily provide counter-evidence to the TPM, it provides a starting point for future research by providing a picture of the categorization patterns of L3 phonemes in two languages by Spanish-English bilinguals which could be examined in a longitudinal design. If the TPM is correct, a distinct change in categorization would be expected to reflect a bias for a single language’s category. The present study provides a basis of comparison, and evidence that bilinguals do have access to both the L1 and L2 near first exposure. However, in six out of eight cases, global typological similarity (English and German vs. French and Spanish), did not result in any obvious bias in categorization. This result is in line with previous research, which reported that global typological effects do not guide L3 production (
Llama et al. 2010), At the same time, this result is at odds with the findings of
Cabrelli and Pichan (
2021), who concluded that the global typological similarity between Spanish and Italian/BP guided the (non-facilitative) production of intervocalic stops.
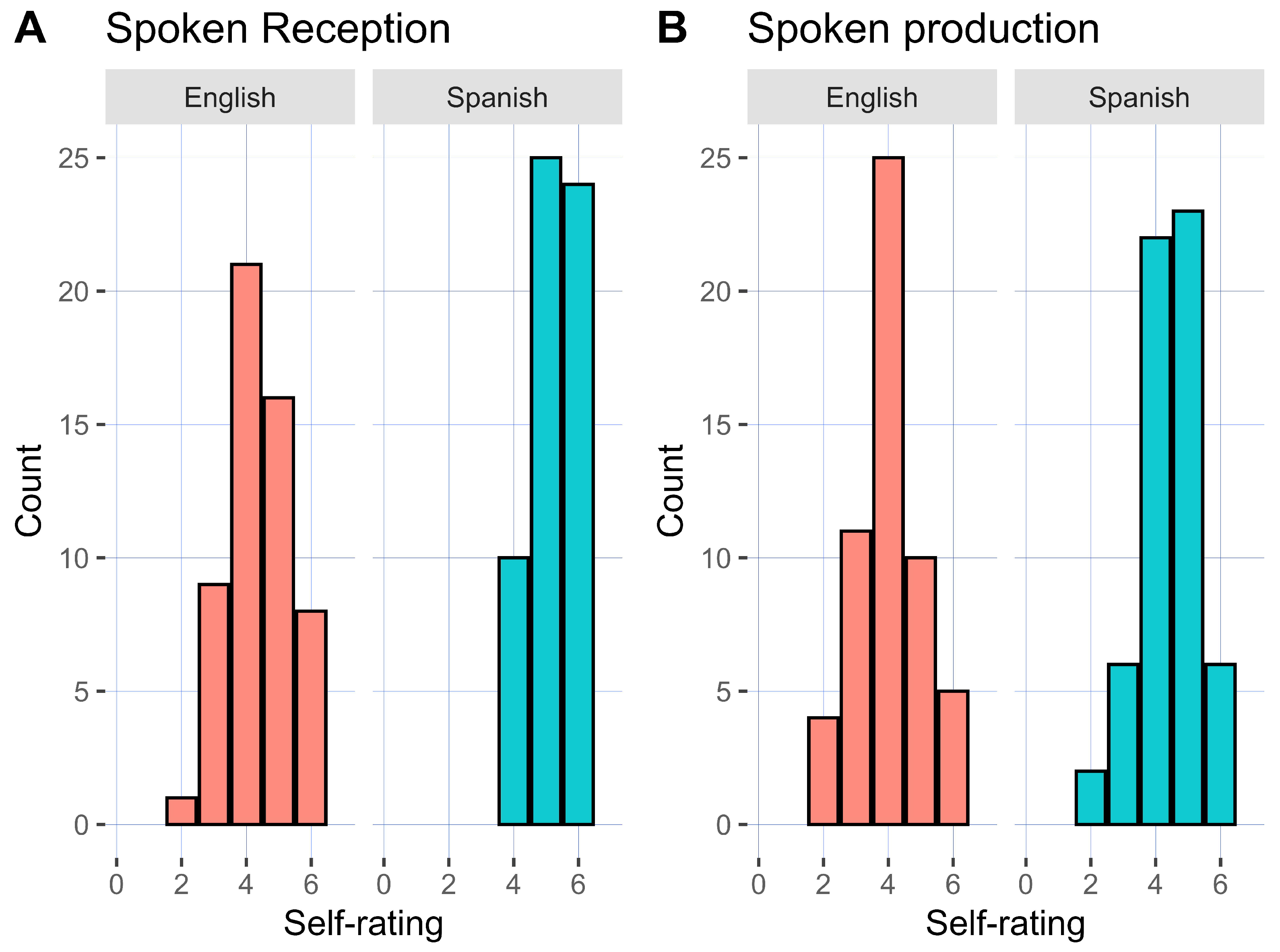
It is unclear why the L1 Spanish group seemed to be sensitive to which L3 they heard, where the L1 English group was not. It is worth noting that there are differences between the groups in self-rated proficiency and age of onset and acquisition; the L1 Spanish group rated themselves as more proficient on average in spoken and perceptual abilities and had an earlier age of onset and acquisition on average. The role of proficiency has been addressed in L3 models, but its precise role in influence is not yet clear. The TPM has stated that the L2 must be sufficiently proficient to be a source of influence. In the TPM studies to date, this has been taken to mean “advanced proficiency”. Though the present study was not interested in the effect of L2 proficiency on L3 categorizations, it is worth noting that the group differences in proficiency might have impacted the results, although it is difficult to say exactly how. This notion of the impact of L2 proficiency CLI could be further investigated, in which the more traditional categorical grouping of proficiency (e.g., novice, intermediate, advanced) could also be examined in a continuous fashion and corroborated across measures. In other words, it is unclear for the purpose of the present study, and likely with many proficiency measures, where the TPM’s cutoff for “advanced” should be.
The results of this study also have implications for models of L2 phonology, such as the PAM-L2 (
Best and Tyler 2007), in that they provide evidence that language learners are not simply influenced by their native language, but rather, at least their L1 and L2, and arguably all languages that they know. Future research examining of L2 perception should take care to examine the linguistic background of what has traditionally been assumed to be an L2 learner, since it is likely that speakers who are bilingual have a distinct developmental trajectory compared to monolinguals when they learn a new language.
The present study also had limitations. Firstly, online studies offers unique challenges and limitations. One potential issue is the lack of the ability to control the participant’s environment outside of the instructions and experiment itself. As a result, language mode effects (
Grosjean 1998;
Casillas and Simonet 2018) cannot be completely ruled out. Additionally, headphone quality, speaker quality, background noise and volume level are all variables within the participant’s control that could not be reasonably controlled for in the context of online data collection. Second, self-reported proficiency, while convenient and fast, is a subjective measure of language ability that would likely be improved by a more objective proficiency measure such as the LexTALE (
Lemhöfer and Broersma 2012). Additionally, all participants first heard all French and then all German sounds during the new language block, rather than a counter-balanced order. Although it is generally desirable to counter-balance, the lack of online measures in the present study arguably minimize the importance of a task effect. That is, since there is, for example, no reaction time data being analyzed here, but rather offline categorization, it is argued that the task order does not meaningfully impact the categorization patterns of these speakers. Finally, the use of some language category choices did not follow the consonant-vowel structure of the auditory stimuli, such as the case with the Spanish
su, a CV choice, while the auditory stimuli were all CVC, and the choice of consonant was not consistent between auditory stimulus and answer choice. This was limited by the lexicons of the source languages, but ideally could have been more tightly controlled in the event that the allophonic variation of the vowel category in the carrier word and auditory stimulus impacted how close the listeners treated them. Ideally, all language category choices and auditory stimuli would follow a similar syllabic structure to avoid any confounds of syllable structure’s impact on vowel quality. Whether the inconsistency in the consonant frames impacted these categorizations could be question for future research.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}