3.1. Distribution of Quotatives
The overall distribution of quotatives found in the corpus of the 14 Chinese L2 English learners was compared to
Rodriguez Louro (
2013), which looked at the spontaneous conversations of 47 native AusE speakers (22 women, 25 men) in Perth with ages ranging from 11 to 63. The results are shown in
Table 5 and are broken down by the age groups in
Rodriguez Louro (
2013). (
Rodriguez Louro (
2013) did not code for
DM like or quotative
feel in her data, thus they have been marked as n/a in the table).
Rodriguez Louro’s (
2013) 18–26 age group is the most comparable with the Chinese L2 participants, who were mostly in their mid-20s except for two participants (003F, 004F) who were in their 30s. Among AusE speakers, the use of
be like was especially notable among younger speakers, particularly in the 11–16 and 18–26 cohorts, with the highest number of
be like tokens (278; 79.4%) found among the 11–16 age group, and
be like being used at the highest frequency (81.5%) among the 18–26 age group. These numbers differ dramatically from our Chinese L2 speakers, despite the similarity in age, who used
be like just 7.4% of the time.
For the AusE 18–26 age group,
be like (81.5%) and
say (8.4%) were the two most frequently used quotative variants, followed by
think (3.7%) at a distant third. In line with
Buchstaller and D’Arcy (
2009, p. 320),
Rodriguez Louro (
2013) has explained the decrease in the frequency of
think in apparent time in her data by people choosing to use
be like instead of
think to express inner thoughts (p. 60). In other words, she claims that
think is in direct competition with
be like and has been overtaken by
be like for reporting inner thoughts.
In the L2 corpus, think was the third most frequently used quotative, amounting to 7.4% of the total, with a noticeable lower frequency compared to second place zero (25.9%) and the most frequent quotative, say (34.3%). However, it remains to be seen whether think was in direct competition with be like for reporting inner thoughts among the L2 speakers, as the two variants had the same number of tokens (N = 16).
Half of all
be like tokens (
N = 8) in the L2 corpus were used to report inner thoughts (see
Section 3.4.1), which could indicate that they were being used in a similar way to quotative
think, which can only be used to report inner thoughts. The use of
be like was also concentrated among a small number of participants (
N = 4), while
think was used among a slightly higher number of participants (
N = 6). This makes it difficult to assess whether the L2 speakers were really using
be like in favor of
think (7.4%). Nonetheless, among the four participants who used
be like, their frequency of
think was mostly nonexistent or very low (only one participant, 030M, used it once), which could indicate that they were using
be like instead of
think. To shed further light on these issues,
Table 6 provides a breakdown of the frequency of quotatives used by each Chinese L2 participant.
In
Table 5 and
Table 6, we note that quotatives with token numbers of less than four were grouped together under ‘other’, except for
go, which is displayed separately for comparative purposes, due to its prevalence in the AusE data (
Rodriguez Louro 2013). Quotative
tell includes
tell + that and
be includes
is,
it is, and
it isn’t. Quotatives in the ‘other’ category include semantically richer quotatives, or “graphic introducers”, which function as an evaluative device to describe elements in oral narratives (
Labov 1972 cited in
Tannen 1986, p. 322).
Tannen (
1986) defines these as any verbs other than
say,
tell,
think,
ask,
go or
be like (p. 322). In the present study, the ‘other’ category included the following:
know (
N = 1),
speak (
N = 1),
ask (
N = 3),
write (
N = 1),
find (
N = 2),
pronounce (
N = 2),
wonder (
N = 1),
call (
N = 2),
believe (
N = 2),
answer (
N = 2), and
mean (
N = 1). The presence and variety of these graphic introducers could be an outcome of the formal education settings in which the participants learned English (
Section 2.3) as they tend to be more common in written rather than spoken English.
Quotative
feel, as in (5), was well-represented in the L2 data at 4.2% of quotatives used. In our coding schema, quotative
feel also includes the “transitional” (
Macaulay 2001;
Buchstaller 2008, p. 30) quotative form
feel + like’.
| 5. | I can’t understand but I felt “oh, it’s so touching,” and I was very nervous and I stood up, and raised the Coke (016F, 36:18) |
Feel was not part of the native AusE quotative system documented by
Rodriguez Louro (
2013) and it was also not included in her miscellaneous ‘other’ category. Unlike native AusE speakers, Chinese L2 learners were, to a certain extent, using
feel to report inner thoughts (perhaps in the place of
be like) which could also have affected their frequency of quotative
think. The reason why L2 speakers were using
feel to express inner thoughts and whether it is in competition with
think or
be like would naturally require confirmation through further research with a larger dataset.
Overall, L1 influence is another future issue to be addressed, as recent studies such as
Yang (
2021) show that
gǎnjué ‘feel’ and
juéde ‘think’ are highly frequent in Mandarin conversation and have a stance-taking function. This may have influenced the frequency of use of
feel and
think as quotatives by the Chinese L2 learners in the present study. Furthermore, Mandarin Chinese does not have an equivalent of the
be like quotative and tends to rely on quotatives such as
shuō (说) ‘say’ (
Le 2013, p. 106),
biǎo shì (表示) ‘express/indicate’ (
Zhang 2020, p. 24) or
wèn (问) ‘ask’. This means that the acquisition of quotative
be like could present more difficulties for Chinese learners of English than learners with an L1 that has a
be like equivalent (see
Buchstaller and Van Alphen 2012).
Chinese L2 learners were also found to be using
like without a copula (‘be’) to introduce direct speech, as in (6). Here,
like is a DM, functioning as an exemplifier to introduce an example (see
Diskin 2017,
Diskin-Holdaway 2021), but at the same time, the example introduced is what someone else has said. As such,
like is functioning both as a DM and as a quotative.
| 6. | yeah, and like uh “how you going today?” (017F, 22:42) |
Diskin and Levey (
2019) distinguish DM
like (p. 66) as a separate quotative variant from
be like in their corpus of native Irish English (IrE) speakers. They report that DM
like amounted to approximately 6% of the 222 quotative tokens found in their corpus of six IrE speakers, compared to 25% for
be like. In other words, DM
like was used approximately once every four times
be like was used among native IrE speakers. The usage rates for
be like (7.4%) for the Chinese L2 corpus analyzed here are lower but are similar for DM
like as compared to native IrE usage at 5.1%. The AusE data could not be directly compared with the Chinese L2 data as
Rodriguez Louro (
2013) did not look at DM
like as a separate quotative variant, and the variant was also not included in her ‘other’ category, which included
write,
ask,
yell,
tell,
read,
scream, and
realize.
Nonetheless, the relatively high rate of DM
like among the Chinese L2 group, especially in comparison to their use of
be like, may be due to the fact that DM
like could be easier to acquire for non-native speakers. This is supported by the fact that even lower proficiency speakers (017F, 019F) were using it as a quotative. Furthermore,
Diskin-Holdaway (
2021) found that, with a different cohort of Chinese migrants residing in Ireland, their acquisition of DM
like did not differ in terms of frequency as compared to the L1 (Irish English) benchmark. In the present study, since 032M, who had the longest LoR and was part of the higher proficiency cohort, was the only one to use both DM
like and quotative
be like frequently, we cautiously propose that the acquisition of DM
like may have occurred ahead of quotative
be like for these speakers.
3.2. Comparison between Chinese L2 and Polish L2 Groups
To compare quotative acquisition among different L2 groups, the Chinese L2 data were compared with Polish L2 English speakers in Ireland from
Diskin and Levey (
2019). As the two studies were commensurate in data collection method and participants, a comparison of quotative distribution is expected to provide a robust comparison of what kind of quotative choices L2 English learners are making when reporting speech or thought.
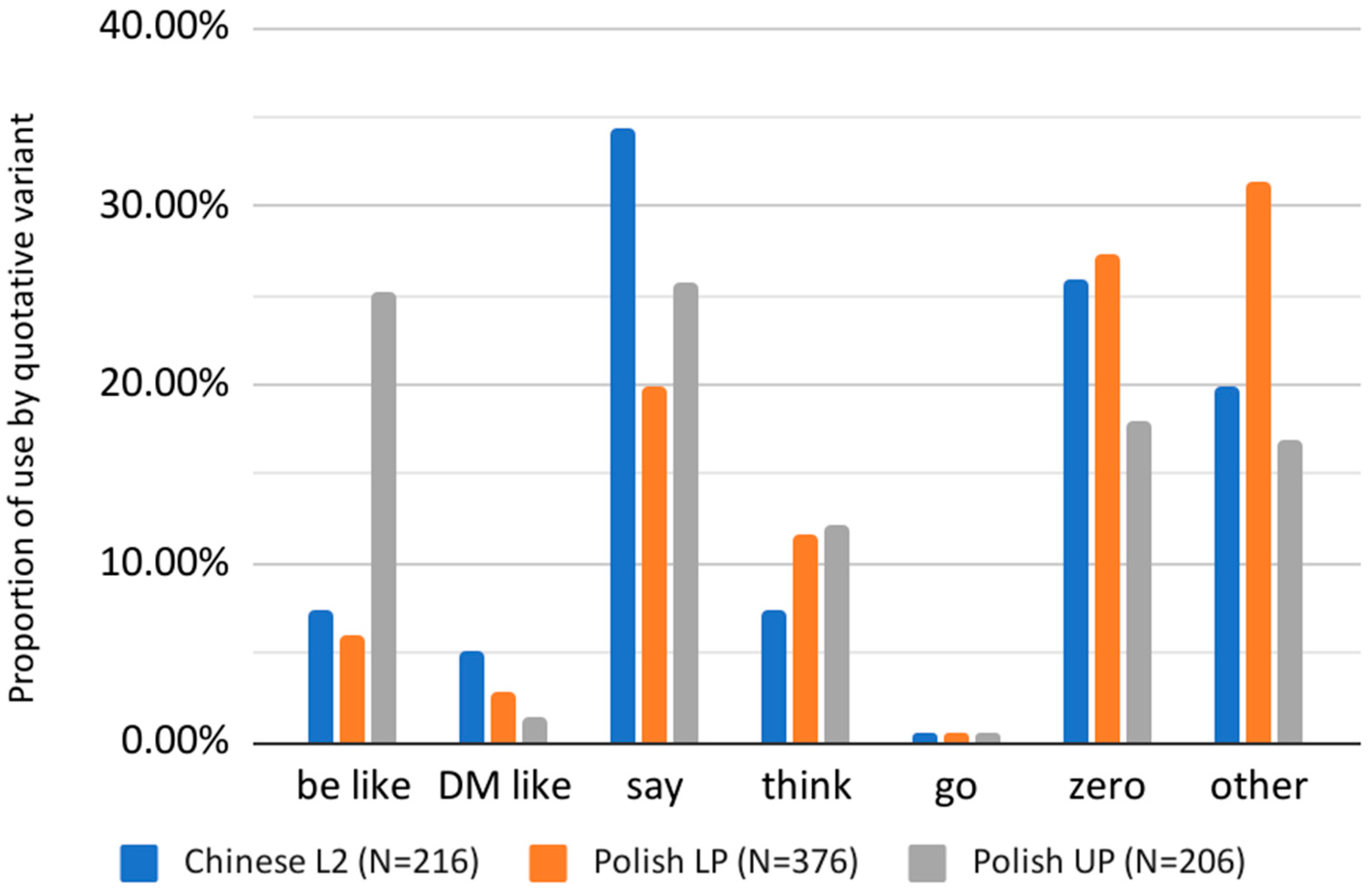
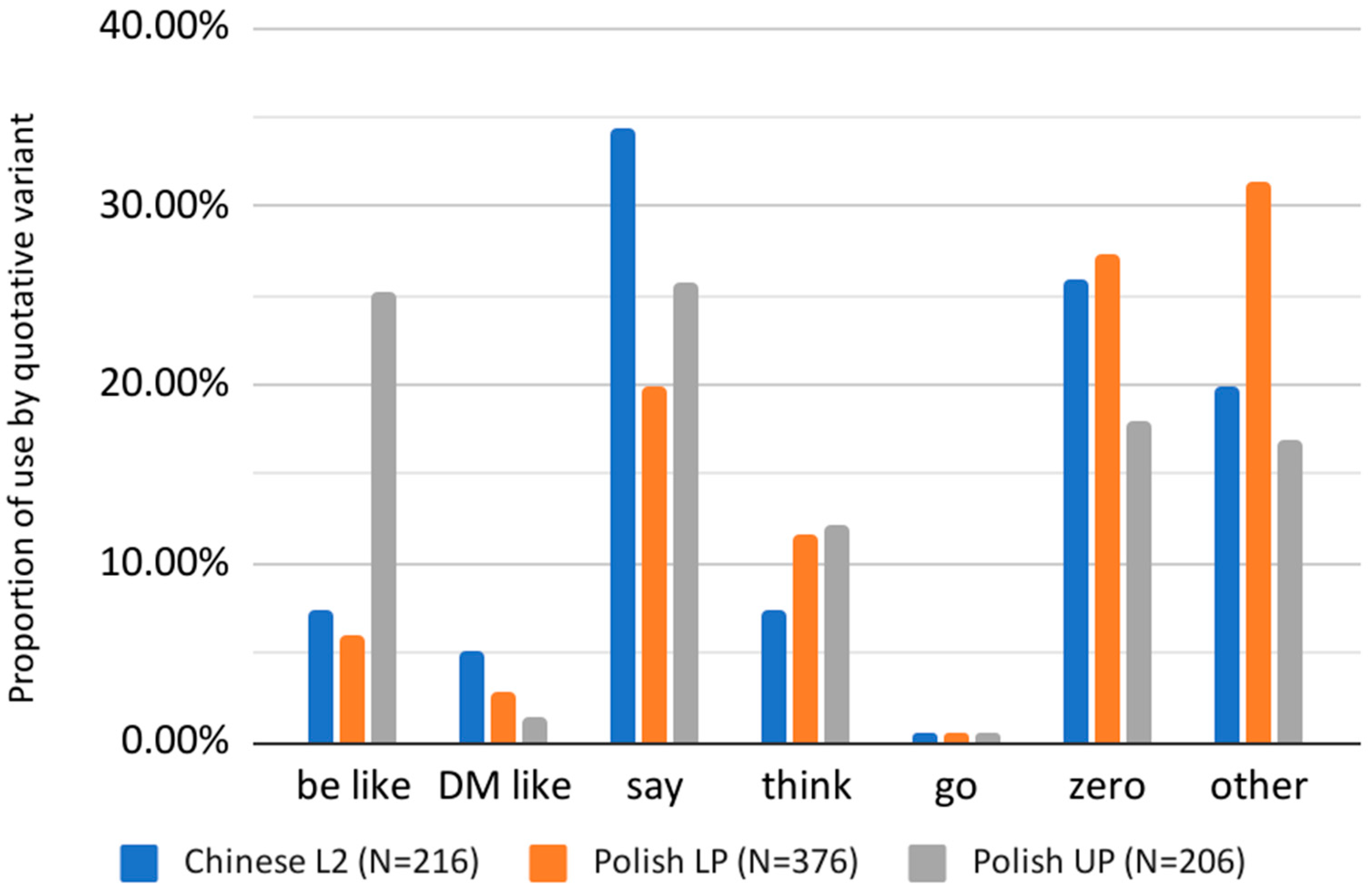
Figure 1 shows a comparison of the most frequently used quotatives among the Chinese L2 learners and
Diskin and Levey’s (
2019) Polish L2 speakers, who were divided into two proficiency groups: upper (Polish UP) and lower (Polish LP).
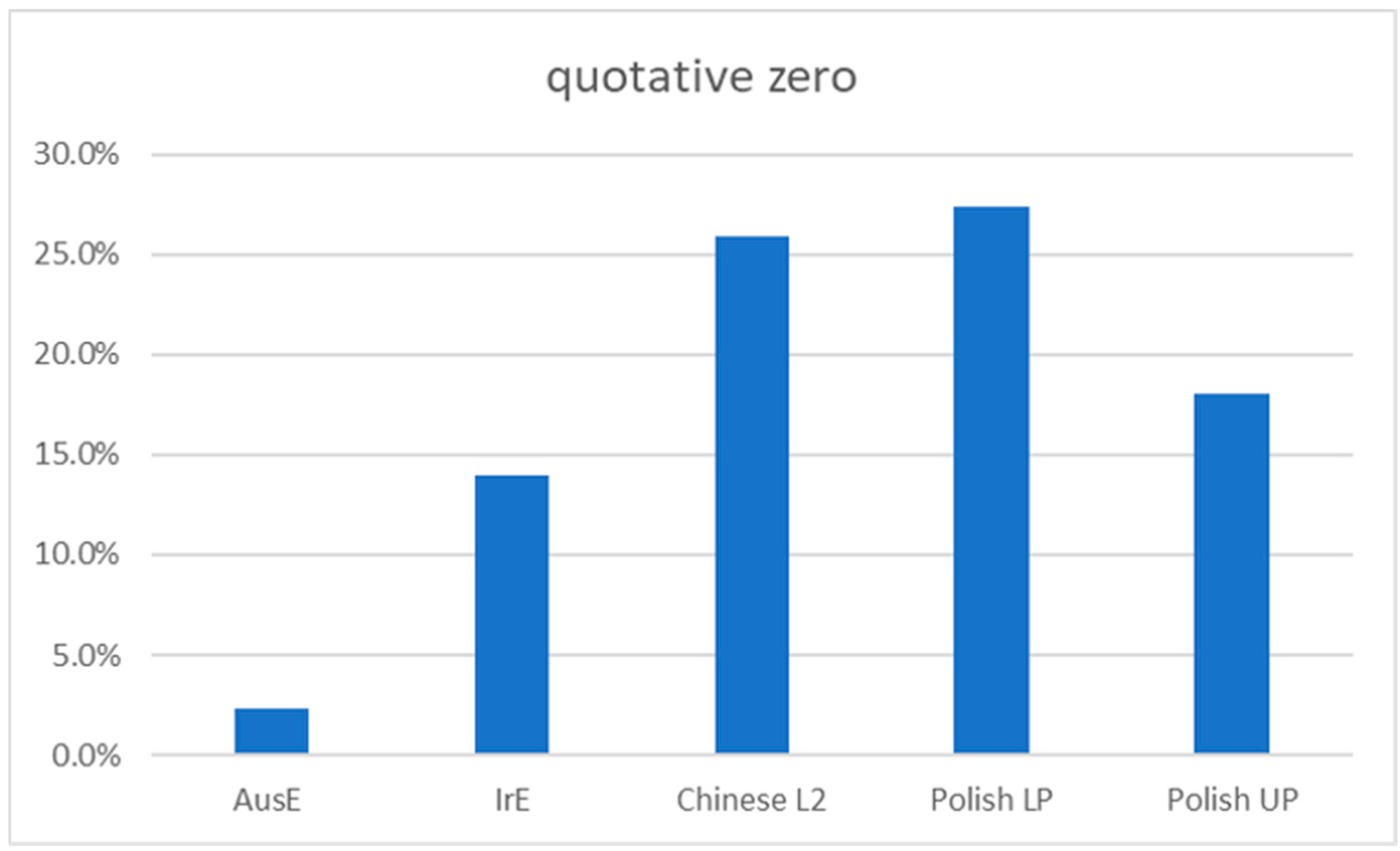
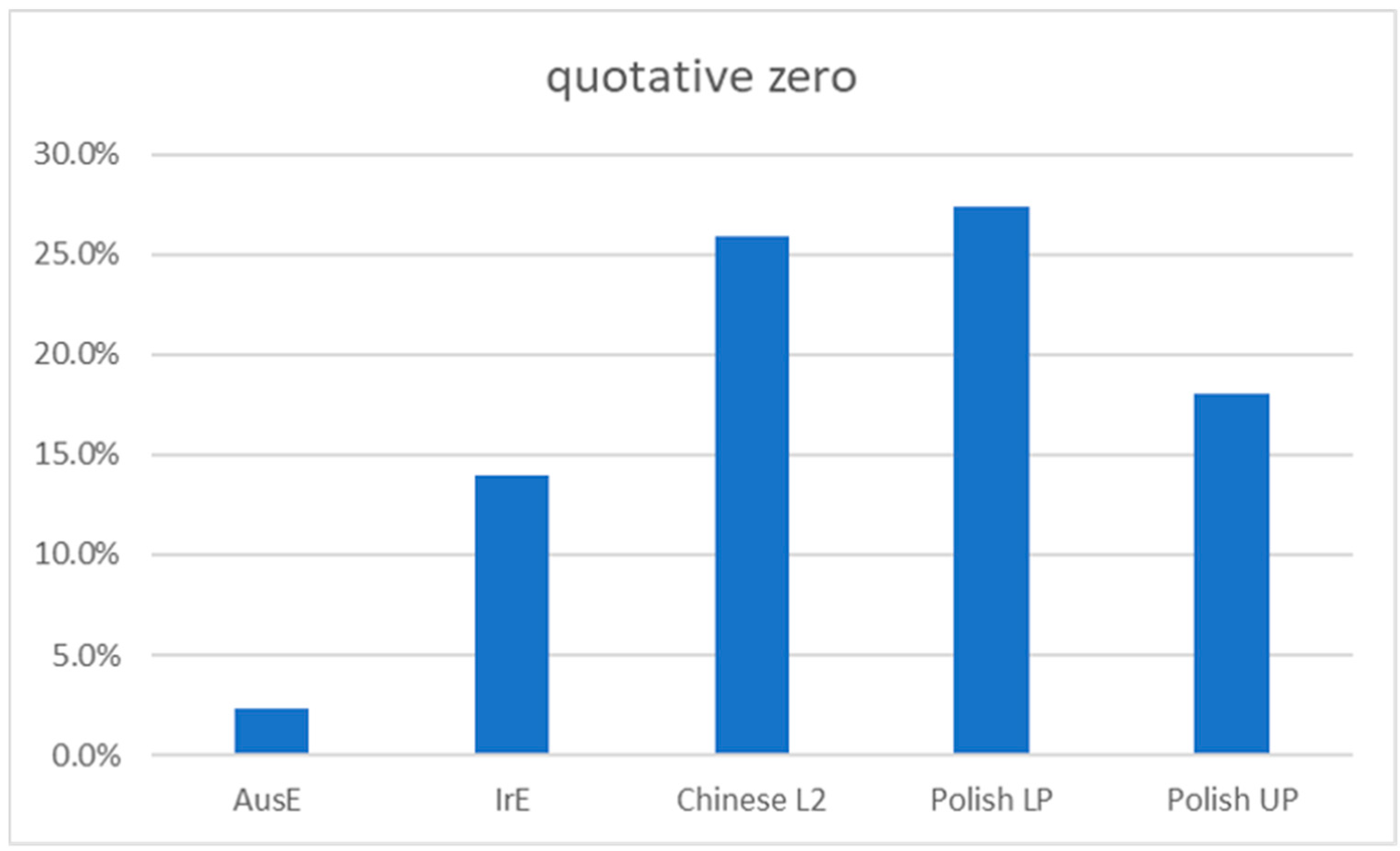
As shown in
Figure 1, there was a high frequency of use for the zero quotative among all L2 groups. Similar to the Chinese L2 learners, where zero accounted for 25.9% of all quotatives, Polish L2 learners, and in particular the lower proficiency group (Polish LP), show a high proportion of the zero quotative (27%), which is in sharp contrast to the frequency of zero quotatives for native AusE speakers (2.3%;
Rodriguez Louro 2013) and still higher than native IrE speakers (14%;
Diskin and Levey 2019) as shown in
Figure 2 below.
Diskin and Levey (
2019) explain the disproportionate representation of the zero quotative, which occurred at nearly double the rate for the Polish LP group compared to the native speaker group (IrE), as a strategy used by L2 speakers to avoid some of the difficulties of selecting a “verb in the quotative frame which typically requires speakers to attend to grammatical person and number, tense and aspect as well as (irregular) verb morphology” (p. 69). In other words, as the zero quotative, argued to be a universal quotative option (
Güldemann 2008), mostly relies on voice modulation rather than syntactic aspects to differentiate speaker voices, it may be an efficient strategy for lower proficiency speakers when reporting someone else’s speech or thought.
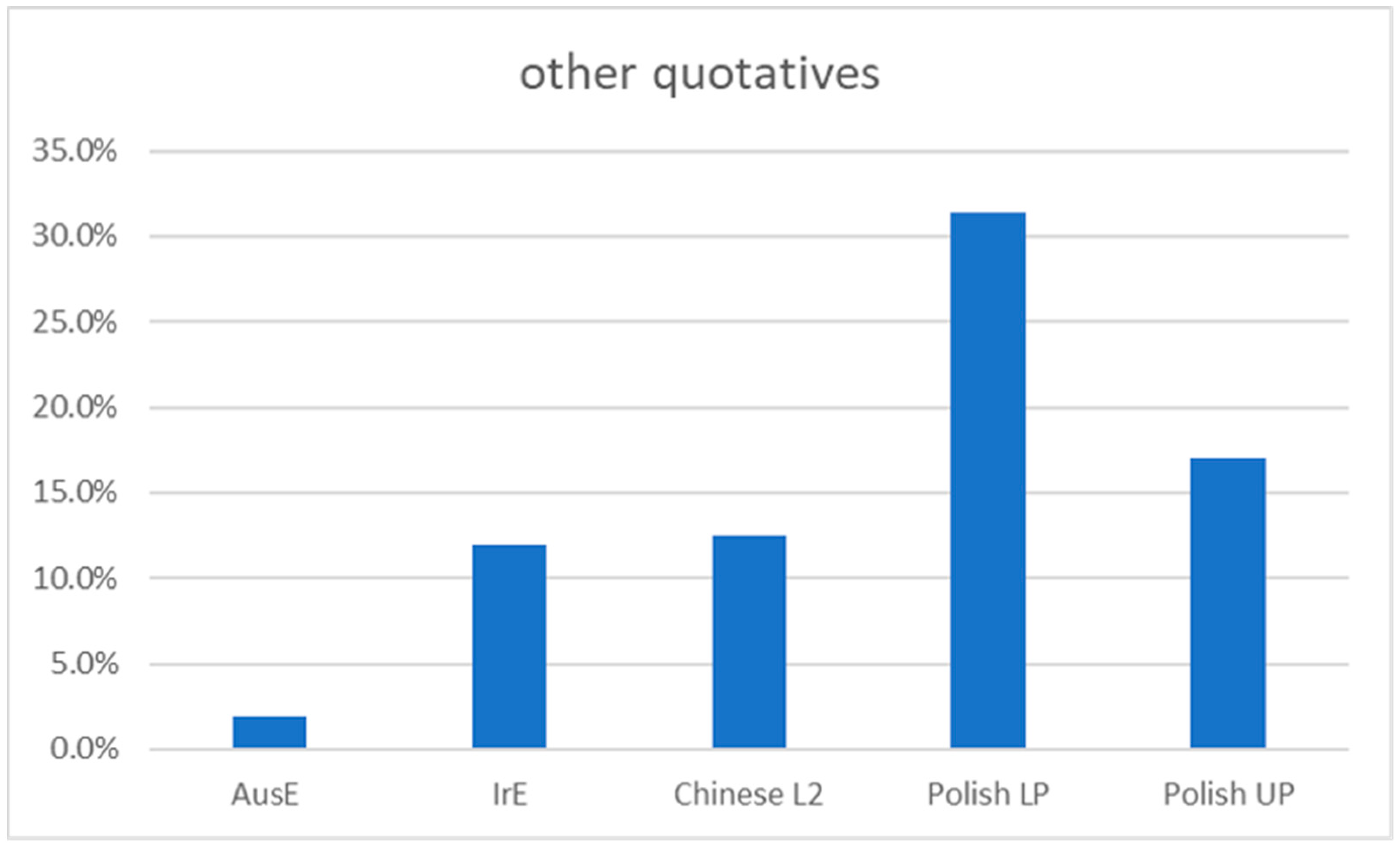
Meanwhile, the ‘other’ category accounted for 12.4% of the Chinese L2 learner corpus, which was much larger than the proportion of ‘other’ quotatives (1.9%) for native AusE speakers from
Rodriguez Louro (
2013).
Figure 3 shows a comparison of the ‘other’ category between native speaker groups and L2 groups from
Rodriguez Louro (
2013) and
Diskin and Levey (
2019).
It is of note that the Chinese L2 corpus had a similar frequency of ‘other’ quotatives to native IrE speakers and upper-proficiency Polish L2 English speakers in
Diskin and Levey (
2019). This may be because the participants in the Chinese L2 corpus were mostly highly proficient English speakers with a mean IELTS score of 7.5. Only four out of 14 participants had scores lower than IELTS band 6.5, and the lowest score was 6.0, which is still considered to be a “competent user” (
IELTS n.d.). This can go some way to explaining why their patterns of use of ‘other’ quotatives resemble that of native speakers and other high proficiency L2 speakers. Further, it has already been noted in
Section 3.1 that the presence of these semantically richer ‘other’ quotatives could be an outcome of the formal education settings in which the participants learned English. Conversely, the overall low rates of ‘other’ quotatives in the AusE corpus (
Rodriguez Louro 2013) could be explained by the fact that the corpus has a high proportion of informal speech and narratives, where quotatives such as
be like or
say may be preferred.
3.3. Comparison between Proficiency Levels for L2 Groups
The participants in this study were divided into upper (UP) and lower proficiency (LP) groups based on their IELTS scores (see
Table 4 in
Section 2.3).
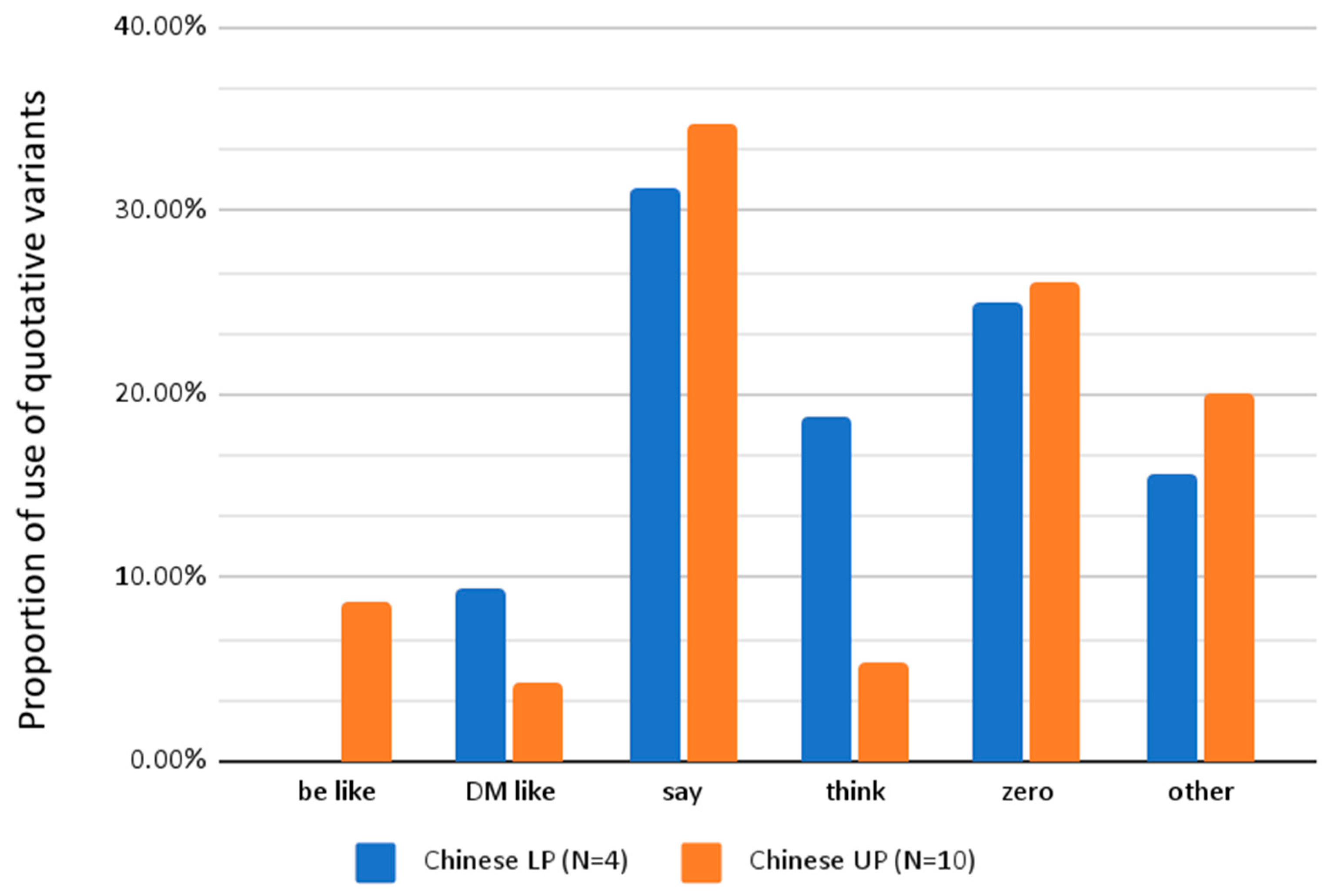
Figure 4 shows the distribution of the most frequently used quotative variants by participants in the L2 Chinese corpus according to their respective proficiency groups.
As shown in
Figure 4, the two proficiency groups (LP and UP) had similar proportions of quotatives, apart from
think and
be like, with
think being favored by the LP group and
be like by the UP group (there were no tokens of
be like in the LP group). As mentioned in
Section 3.1, the higher frequency of
think in the LP group may have been because they did not use
be like to report inner thoughts. This becomes more evident when comparing the Chinese and Polish L2 groups (
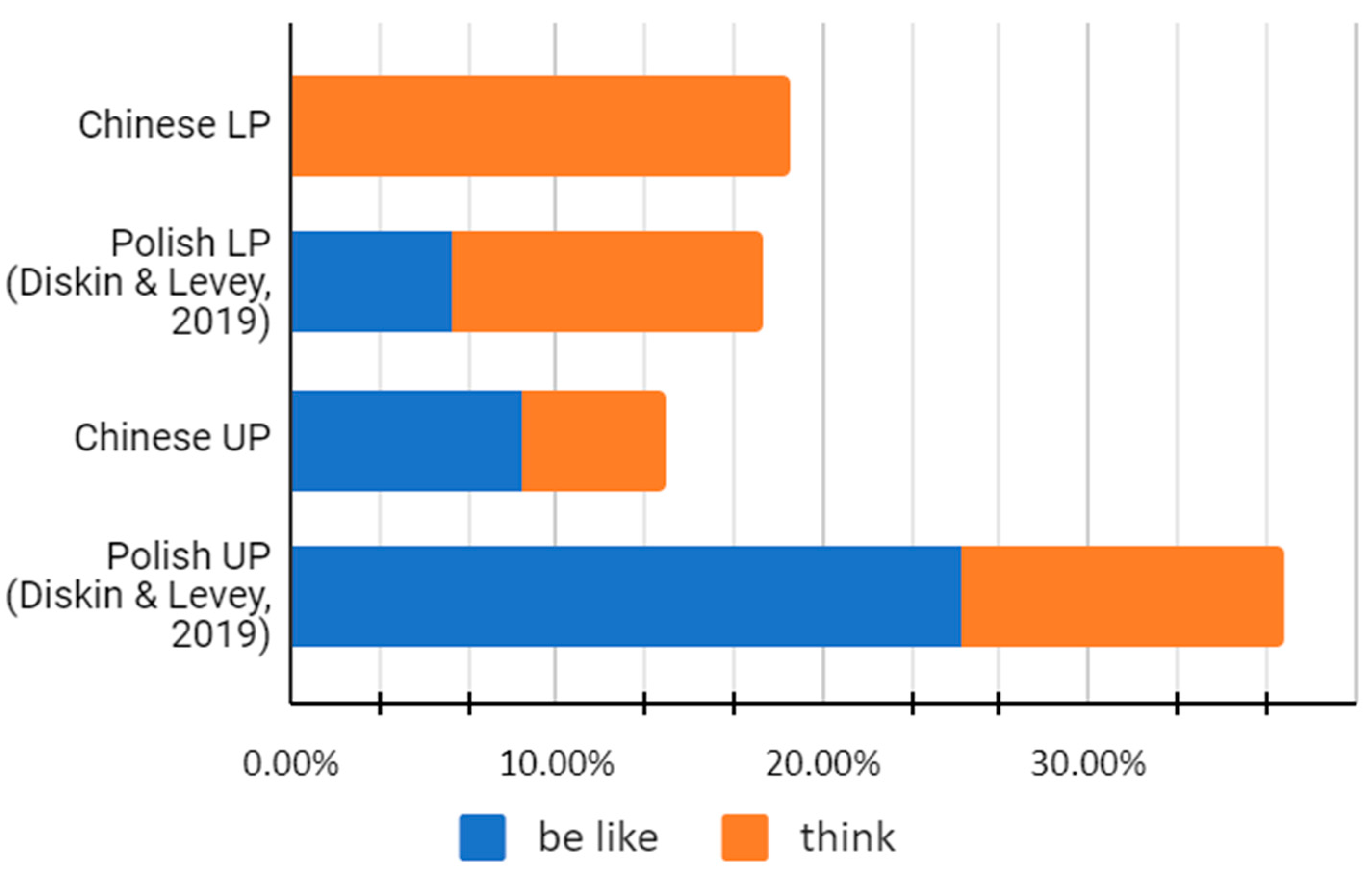
Figure 5).
The UP groups for both Chinese and Polish L2 learners show similar proportions for the two quotatives, where
be like is used slightly more than
think. Meanwhile, between the two LP groups, the proportion of
think is lower for the Polish LP group, which uses some
be like, compared to the Chinese LP group, which does not. It is difficult to make direct comparisons, as the Chinese LP group did not produce any
be like tokens; however, the results could indicate that even among L2 speakers,
think could be in direct competition with
be like (
Rodriguez Louro 2013, p. 60), similar to the trend noticed in native English speakers.
3.5. Analysis of Individual Lower and Upper-Proficiency Speakers
The quantitative results shown above provide a broad view of the overall quotative system for Chinese L2 English learners in Australia. As speaker proficiency and length of residence (LoR) emerged as two social factors influencing the use of be like in the data, this paper will now focus on two participants for further analysis. One participant will be from the high proficiency group with longer LoR (participant 032M) and one will be from the lower proficiency group with shorter LoR (participant 019F).
3.5.1. Upper Proficiency Speaker 032M
Participant 032M stood out in the data as he had the longest LoR (88 months), which was much higher than the mean LoR (34.43 months). He was also the only participant who had attended high school in Australia and had over six years of education (two years of high school and four years of university) at Australian educational institutions. This meant he had come to Australia at an earlier age (i.e., at 17), compared to the rest of the group who had arrived in Australia past the age of 20, with the exception of 021M, who had arrived at 18.
Participant 032M was an outlier, in the sense that he produced the largest number of quotative
be like tokens (
N = 10) in the data, which amounted to 62.5% of all
be like tokens (
N = 16) produced in the corpus. Individually,
be like amounted to 20.4% of 032M’s total quotative tokens. He also displayed robust usage of quotative
say and zero (see
Table 6). Age of onset (or perhaps more accurately: age of immersion in an English-speaking environment) was not a factor that was originally considered in the research design of this study. All participants had arrived in Australia past the age of puberty and there was little variation among participants, with only two participants arriving before the age of 20 as compared to the remaining participants who had arrived in Australia between the ages of 21 and 28. However, as 032M was exposed to native AusE at a relatively younger age compared to the other participants, and his use of
be like stood out in the data, we can cautiously suggest that age of onset/exposure may be an important factor influencing the acquisition of quotatives and quotative
be like in particular. Meanwhile, considering that 032M (and 021M) had a longer LoR compared to other participants, coupled with higher proficiency, more research would be needed to determine whether the age of onset, proficiency, and LoR are collinear.
Due to his long LoR and high proficiency, 032M was also unique in using quotative variants that other participants did not use, but which were found in
Rodriguez Louro’s (
2013) data. For example, 032M was the only participant to use quotative
go, as in example (8), although this was just once.
| 8. | and I think, in the beginning, I just, I go, “okay okay” they’re like, “dip, dip,” I was like, “okay,” uh <LAUGHTER> (032M, 21:10) |
Rodriguez Louro’s (
2013) findings also document the use of
go among native AusE speakers, which amounted to 4.2% of the overall distribution of quotatives and 1.3% among the 18–26 age group. Participant 032M was also among the few participants who used quotative
be (example 9), also reported in
Rodriguez Louro (
2013).
| 9. | that is “ohhhhh my god” <LAUGHTER> kind of thing, and I- I think have a little bit of that, I will have a conversation, but um (.) in terms, as for, having a relationship? it really depends on, what that situation what the circumstances, yeah (032M, 39:03) |
In
Rodriguez Louro’s (
2013) overall distribution of quotatives, quotative
be takes up 1.4% for all age groups and 3.4% for the 18–26 age group, whereas 032M’s use of
be amounted to 2.04% of his overall quotative distribution.
3.5.2. Lower Proficiency Speaker 019F
We now take a closer look at 019F from the lower proficiency group, who had scored a 6.5 on her IELTS and had been living in Australia for 22 months. In comparison with 032M, a difference in proficiency is noted, which was also noticed in her interaction with the interviewers. Throughout the interview, 019F needed some questions to be repeated or rephrased as she did not understand what the interviewers were asking. Furthermore, incorrect grammatical forms (e.g., verb inflections) emerged frequently in her speech.
In 019F’s quotative distribution, there was a near equal distribution of zero (N = 4), say (N = 4) and think (N = 4) which each amounted to 23.5% of the total number of her quotative tokens (N = 17). Although she did not use quotative be like, she used DM like (11.8%), tell (11.8%), and pronounce (5.9%). Compared to the other three participants in the lower-proficiency group, she had the highest number of total quotative tokens and was the only one to use tell (or tell + complementizer ‘that’) to report speech or thought.
Indeed, although 019F had a higher number of quotatives compared to others in the lower-proficiency group, she still reported speech or thought using indirect quotes with complementizer ‘that’, which is a common way of reporting speech or thought taught in EFL contexts (
Barbieri and Eckhardt 2007). The frequent use of indirect quotation was also noted among other lower proficiency speakers, such as 018F, with most of the lower-frequency group having less than 10 quotatives per person (
N = 3 for 018F;
N = 5 for 017F;
N = 7 for 026M).
Looking at the use of indirect quotations in more detail, it seemed 019F did not have full competence in reporting speech or thought both directly and indirectly. In 10a, she uses complementizer ‘that’ to report what someone else has said indirectly. However, in 10b, she also uses complementizer ‘that’ to report what someone has said directly. The direct speech is characterized by a shift in pitch, indicating mimicry of her teacher’s voice. Meanwhile, in 10c, she begins by using
say to reconstruct a dialogue with her parents, in what appears to be a reporting of direct speech: “if you really do want to do that”. However, as she follows this with “they will support me”, the grammatical person switches from ‘you’ to ‘me,’ and the utterance turns into an indirect report of what was said.
| 10. | a. | and they told me that mm it seems like from her point of view? what we have done is on the right track. (019F, 05:47) |
| | b. | but mm. they told me that <HIGHER PITCH> “why do show me that. I don’t tell you do the an- competitor analysis”. (019F, 05:09) |
| | c. | but they said “if you really do want to do that” they will support me. (019F, 27:35) |
Although example 10 does not provide a complete view of 019F’s quotative system and what she has acquired, we can infer that she does not have full mastery in reporting strategies for direct speech, and, as an alternative strategy, uses complementizer ‘that’ accompanied by voice modulation indicating direct speech. This is a strategy that has not, to the best of our knowledge, previously been documented among native speakers.
Finally, although 019F did not use quotative
be like, she did use DM
like to report speech or thought, as in example 11 where she is providing an example of an accent she has heard. Here, DM
like is used as an ‘exemplifier’ similar to other cases of DM
like found in the data.
| 11. | but some like they say “toilet?” like <HARSH VOICE> “doilet”. (019F, 36:47) |
As DM
like functions as an exemplifier (see
Diskin 2017), it is arguably a less challenging strategy for L2 learners (similar to the zero quotative) to report examples of what they have heard, as compared to quotative
be like. DM
like has also been found to be relatively unproblematically acquired by Chinese L2 learners in Ireland (
Diskin-Holdaway 2021). Regardless of the circumstances of its use, the fact that both lower proficiency speakers (e.g., 017F) and participants with shorter LoR (e.g., 016F) were using DM
like more frequently, indicates that it may be easier to acquire than quotative
be like.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}