1. Introduction
The present study is an investigation into the acoustic vowel space defined in terms of the first three spectral formants and of the acoustic duration of the seven Romanian stressed vowels [i e a o u ɨ ə]. The Romanian language is endowed with seven stressed vowels, namely, five peripheral vowels and two central vowels: a high vowel [ɨ], which is represented by means of the graphemes
î and
â in writing, and a mid vowel [ə], which is represented with the grapheme
ă. All of these vowels have phonemic status (
Chitoran, 2001) with the inclusion of the high and mid central vowels as demonstrated by the following minimal pairs: [pɨr] onomatopeia/[pәr] ‘hair’, [vɨr] ‘I thrust’/[vәr] ‘cousin’, [rɨw] ‘river’/[rәw] ‘bad’ and [tsɨr
j] ‘sea mackerels’/[tsər
j] ‘lands’. Regarding other Romance languages, this central vowel scenario is similar to that of European Portuguese, in which, however, [ɨ] and [ə] (the latter vowel is often transcribed as [ɐ] in this language variety) are found in unstressed instead of in stressed syllables.
This acoustic study is especially relevant in view of the comparatively little attention that phoneticians have devoted to the only Romance language endowed with two stressed central vowels, and to the fact that Romanian is the only major Romance language that does not yet have an article in the Illustrations of the IPA series in the Journal of the International Phonetic Association. Only a few acoustic studies of Romanian vowels exist, and, as pointed out later in this section, they do not control for phonological context in a stringent manner, and do not report vowel duration values. These previous acoustic studies include that of
Teodorescu (
1985), which reports unnormalized formant frequency values for these seven vowels as produced in nonsense VCV sequences with the consonant [p] by three males, and
Renwick (
2012, pp. 142–147;
2014, pp. 114–115), which presents unnormalized formant frequency data for stressed [i e a o u ɨ ə] as produced in real words in various syllable structure and contextual consonant conditions by fourteen female speakers and three males.
Moreover, the present investigation complements with new acoustic data previous research on the phonetic characteristics of stressed schwa in the world’s languages that was carried out by the first author. The two stressed central vowels [ɨ] and [ə] occur in languages and dialects from other language families such as Battambang Khmer, Madurese, Sundanese, Cheju, Thai, Amharic and Northern Welsh. As shown subsequently, these languages and dialects exhibit vowel systems of a similar size and quality to that of Romanian, including the two central vowels, which are considered to be phonemic, or to exhibit a high frequency of occurrence, whenever they are in complementary distribution or their phonemic status is not mentioned in existing monographs: Battambang Khmer [i e a ɨ ə ɔ o u] and Wa Mon Khmer [i e ɛ a ɨ ə ɔ o u] (
Huffman, 1967;
Pinnow, 1979); Madurese [i ɛ a ɨ ə ɔ ɤ u] (
Stevens, 1964); Sundanese [i e a ɨ ə o u] (
Van Syoc, 1959); Cheju [i e æ a ɨ ə ʌ o u] (
Yang et al., 2020); Thai [i e æ ɨ ə a ɔ o u] (
Abramson, 1962); Amharic [i e a ɨ ə o u] (
Leslau, 1995); and Northern Welsh [i e a ɨ ə o u] (
Jones, 1984). Several phonetic aspects of the central vowels of Romanian and of these other languages and dialects will be subject to comparison in this and the following sections of the present study.
The research goals of the present investigation are as follows.
Firstly, we will focus on the placement of mid and central vowels in the vowel space, and, more specifically, on the degree of vowel height for the mid vowels [e] and [o], and the degree of vowel height and fronting for the central vowels [ɨ] and [ə].
Concerning stressed schwa and as reported for a considerable number of languages exhibiting this vowel in their vowel inventory (
Recasens, 2021), it is expected that the first formant or F1 (which is inversely correlated with vowel height and thus is higher for low vs. high vowels) occurs ca. 500 Hz, and that the second formant or F2 (which is positively correlated with vowel fronting and thus is higher for front vs. back vowels) is found ca. 1500 Hz. These formant frequency values, i.e., 500 Hz for F1 and 1500 Hz for F2, correspond to a 17.5 cm long vocal tract with no tongue constriction (
Fant, 1960) while, as pointed out to us by a reviewer, the F1/F2 ratio should also be 1 to 3 for other vocal tract lengths. As mentioned more explicitly below, the actual phonetic realization of stressed schwa is, however, quite variable when evaluated across different positional and contextual conditions, which accounts for the fact that this vowel has often been transcribed not only as [ə], but also as a mid back unrounded vowel, whether [ɤ] or [ʌ], in phonetic studies of other languages such as Thai, Wa, Chantyal, Scottish Gaelic and Bulgarian (see
Recasens, 2021). Regarding Romanian, stressed schwa has been labelled as mid central [ə] (
Chitoran, 2001) and mid back unrounded [ʌ] (
Renwick, 2014), the issue being which one of these two IPA symbols is more appropriate in the light of formant frequency data for a representative number of subjects. As shown in
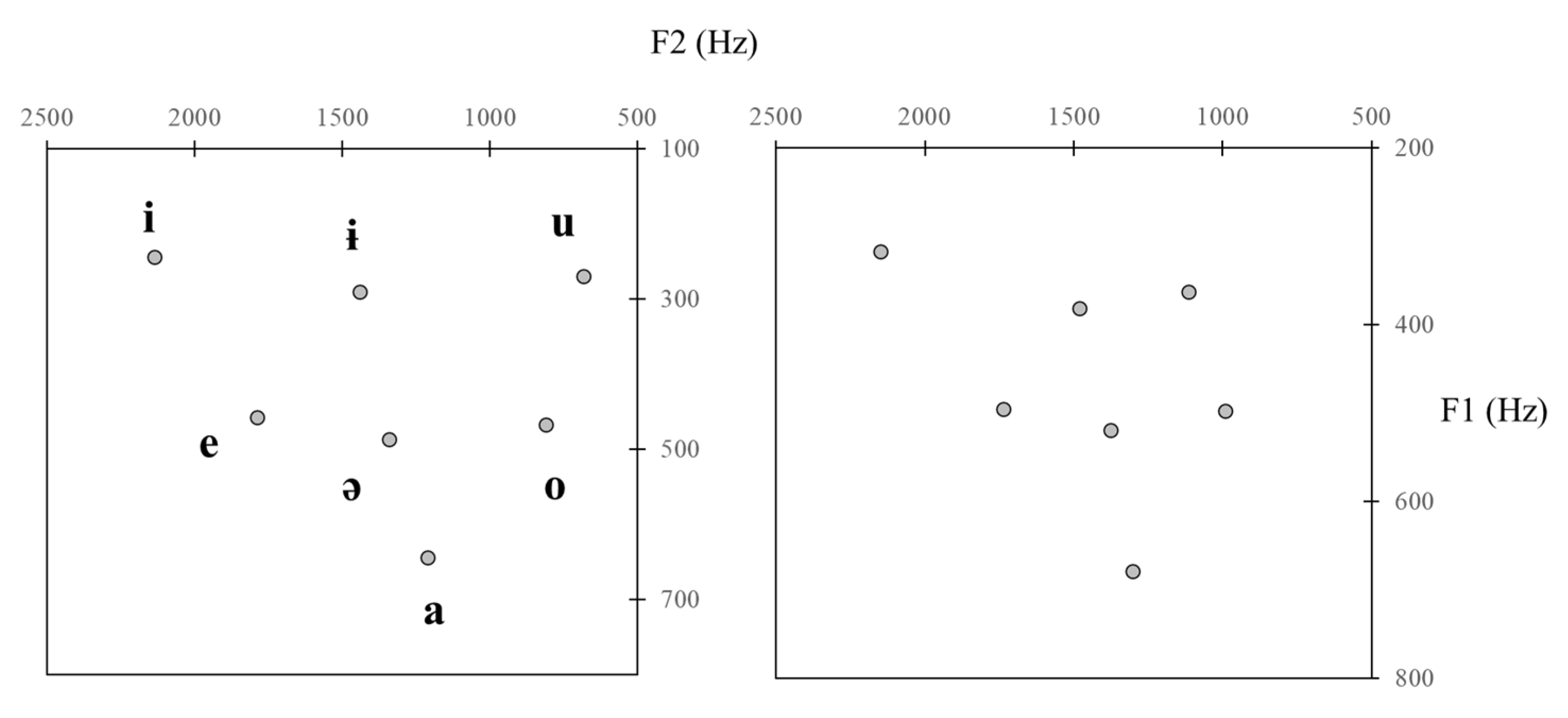
Figure 1, the F1 and F2 frequencies for Romanian vowels reported by
Teodorescu (
1985) and
Renwick (
2014) reveal the following: the two peripheral mid vowels [e] and [o] are placed about halfway between [i u] and [a]; and [ɨ] and [ə] are lined up with the high and mid vowels, respectively, and placed mid way between the front and back vowels. Based on these formant frequency data, the most suitable IPA symbol for Romanian stressed schwa should probably be [ə], not the symbols [ɤ] or [ʌ], which, as pointed out above, are also used by scholars for transcribing the mid central vowel in the world’s languages. An analogous scenario, i.e., one in which [ɨ] and [ə] are roughly equidistant from the front and back vowels and occur at the high and mid regions of the vowel space, respectively, may be inferred from formant frequency data for most of the non-Romance languages listed above: Battambang Khmer long vowels (
Wayland, 1998), Wa Mon Khmer (
Svantesson, 1993;
Watkins, 2002), Sundanese (
Yusuf, 1993), Cheju (
Cho et al., 2001), Thai (
Abramson, 1962;
Apiluck, 1996) and Amharic (
Iwatsuki, 2012). Alternatively, the vowels in question lie closer to the back vowels than to the front vowels in Madurese (
Cohn & Lockwood, 1994), while the opposite is true for Northern Welsh (
Mayr & Davies, 2011).
In the light of the evidence from other languages endowed with stressed schwa that have just been described, and based on the position that this vowel occupies within the vowel space in Romanian, our concern is whether the mid central vowel in question ought to be transcribed as central ([ə]) or as mid back unrounded ([ʌ]). The argument provided in
Renwick (
2014, p. 13) for transcribing the mid central vowel with the symbol [ʌ] instead of with [ə] appears to be either only phonological or both phonetic and phonological. The phonetic aspect may be inferred by the use for stressed and unstressed schwa of not only the notation /ʌ/ (
Renwick, 2012,
2014), but also [ʌ] (
Renwick et al., 2016) and both /ʌ/ and [ʌ] (
Renwick, 2021). Regarding the phonological aspect, the symbol [ʌ] would be preferable to [ə], since [ə] is usually used for reduced mid vowels (
Maddieson, 1984, p. 252;
Silverman, 2011), these vowels being often the end product of phonological neutralizations in prosodically weak positions, which is not what happens in Romanian, where the mid central vowel may function synchronically as a full vowel.
A second research issue concerns acoustic variability. A salient characteristic of stressed schwa in the world’s languages is its high degree of spectral variability as a function of segmental context, and therefore its high degree of sensitivity to coarticulatory effects in tongue and lip position exerted by its flanking consonants. In particular, the F2 frequency ranges for this vowel often exceed those for all or most other vowels in the language, as has been reported to be the case, for example, for Enganno, Iaai, Javanese, Khonoma Angami, Albanian, Arrernte and Kabardian, which is why a number of different context-dependent allophones have been identified for stressed schwa in some Salishan languages and also in Sharwa, Cheremis, Amharic and Macedonian (see
Recasens, 2021 for details). The reason for this appears to be the lack of a well-defined constriction location for central vowels in general, and for [ə] in particular, which nevertheless appears to be specified for a mid tongue position (i.e., F1 values for this vowel rarely extend into the vowel spaces for high and low vowels), and, at least in the case of English, could even exhibit some postdorsal constriction at the pharynx rather than being fully unconstricted (
Browman & Goldstein, 1992;
Kondo, 1995;
Gick, 2002). Moreover, these positive articulatory properties should hold for stressed schwa rather than for unstressed schwa, which is often the outcome of vowel reduction, and during whose production the tongue is likely to be placed in the breathing position, and thus roughly equidistant from all regions of the vocal tract.
The possibility that stressed central vowels including schwa may be produced with some active tongue configuration, and consequently turn out to be less variable than expected, should hold precisely in languages like Romanian, in which [ɨ] and [ə] have phonemic status. In other words, the need to avoid intelligibility problems could very well cause the two central vowels in question to exhibit different articulatory goals and a moderate degree of articulatory variability, at least in F1 frequency, and thus along the vowel height dimension. An aspect which is closely related to this need is functional load, i.e., phoneme pairs undergoing merging distinguish significantly fewer minimal pairs in the lexicon than those which avoid the merging process (
Wedel et al., 2013;
Tse, 2024). With regard to this issue, a look at the frequency of occurrence of the two Romanian central vowels reveals that [ɨ] is the least frequent of all vowels of the vowel system, followed by schwa (
Renwick, 2014, p. 22), one of the reasons for this being the limited contextual origin of both stressed [ɨ] and [ə] in native words: [ə] comes from Latin /e/, after labials and the alveolar trill ([pəɾ] PILU ‘hair’, [rəw] REU ‘bad’), and [ɨ], probably through intermediate [ə], from /i/ after [r] ([ˈrɨpə] RIPA ‘ravine’, [ˈrɨde] RIDET ‘(s)he laughs’) and from non-back vowels before a nasal consonant ([ˈlɨnə] LANA ‘wool’, [kɨmp] CAMPU ‘field’, [ˈvɨnə] VENA ‘vein’) (
Nandris, 1963). The two vowels may also be found in other consonantal contexts in loanwords from Hungarian and Turkish, and also from the Slavic languages, such as [sfɨnt]
sfânt “saint, holy” and [ɡɨskə]
gâscă “goose”. In spite of their limited contextual occurrence, the two vowels of interest are endowed with a relatively high morphological load (
Chitoran, 2001): [ɨ] appears in common function words such as pronouns ([ɨl] ‘him’, [ɨm
j] ‘to me, dative’), the preposition [ɨn] ‘in’ and the infinitive ending of fourth conjugation verbs ([uˈrɨ]
urî ‘to hate’); and [ə] is the non-definite nominative/accusative ending of many feminine singular nouns ([ˈkasə] CASA ‘a house’), and may be also found in pronouns ([mə] ‘me, accusative’) and in verb paradigms. In view of these historical and synchronic scenarios, it may be hypothesized that the two Romanian vowels [ɨ] and [ə] are kept phonemically distinct, since they are involved in a number of minimal pairs and play a relevant morphological role.
Data on vowel dispersion for 14 female speakers reported by
Renwick (
2012) are consistent with this assumption. Indeed, they show that, when evaluated across syllable and consonant context conditions, Romanian [ɨ] and [ə] overlap very little along the F1 dimension, and are thus quite distinct from one another regarding vowel height, which appears to be in agreement with their independent phonemic status in the language. Also in
Renwick (
2012), on the other hand, these two vowels happen to be more variable along the F2 dimension than all five peripheral vowels [i e a o u], with their ranges amounting to ca. 1000–2000 Hz ([ɨ]) and 1200–1800 Hz ([ə]) in the case of female speakers, and ca. 1100–1750 Hz ([ɨ]) and 1100–1650 Hz ([ə]) in the case of male speakers. These figures also reveal a higher degree of F2 variability for [ɨ] than for [ə]. As revealed by vowel acoustic data for schwa from other languages such as English and Catalan, changes in F2 frequency for central vowels typically result from coarticulatory effects in tongue, jaw and lip position exerted by palatal and certain dentoalveolar consonants, which cause the vowel F2 to rise, vs. those exerted by labials, other alveolars (/r/ mostly if realized as a trill, and dark /l/) and possibly velars, which cause F2 to lower (
Kondo, 1995;
Recasens & Espinosa, 2006). Moreover, also according to
Renwick (
2012), perceptual identification data show that the two central vowels are not inherently more difficult to identify than the five peripheral vowels, with [ə] being more prone to confusion with [ɨ] than the reverse. All in all, even though they are highly variable in terms of fronting degree, the two central vowels appear to be well integrated in the Romanian vowel system, and perhaps more so [ɨ] than [ə]. Minimal overlap between stressed [ɨ] and [ə] has also been reported consistently in F1 (and thus in oral opening and tongue dorsum height), but not in F2 (and thus in tongue raising and fronting), for Battambang and Wa Mon Khmer, Madurese, Sundanese, Cheju (when adjacent to /t/, but not when flanked by /k/;
Cho et al., 2001), Thai, Amharic (in the context of /d/;
Iwatsuki, 2012) and Northern Welsh by the studies mentioned earlier in this section. In particular, the cross-language F1 frequency averages for stressed [ɨ] and [ə] provided by these studies amount to 414.7 Hz (sd = 49.6) for the former vowel and to 568.2 Hz (sd = 78.2) for the latter, which follows from [ə] being a lower vowel than [ɨ]; as for the F2 frequency data, the cross-language values are slightly higher for [ɨ] (1490.4 Hz, sd = 210.2) than for [ə] (1410.3 Hz, sd = 164.6).
It must be pointed out that this scenario is less valid for spontaneous speech than for laboratory speech. In contrast with laboratory speech conditions, it has been found that [ɨ] and [ə] may overlap more or less considerably along the F1 dimension in spontaneous speech, in which [ɨ] is often produced with a higher F1 and thus a more schwa-like realization than expected (
Vasilescu et al., 2016). In line with previous experimental evidence (
Wedel et al., 2018), it may be true that in laboratory speech tasks speakers hyperarticulate words with [ɨ] in order to distinguish them from competitors endowed with schwa and perhaps other peripheral vowels as well. Moreover, it appears that the F1 frequency, and thus the acoustic cue that better sets the two central vowels in contrast, is chosen for this purpose.
Another reason for carrying out an analysis of vowel dispersion and overlap in the present study stems from the fact that in the lexical items subject to analysis in
Renwick (
2012), the Romanian stressed vowels were often preceded and followed by consonants specified for different places of articulation, and, in addition, were produced in words differing in their number of syllables and endowed with various syllable structures (CV, VC, CVC, CCCVC, CVCC). Thus, for example, only [ɨ] and [ə] occurred in CV words. More importantly, regarding the former variable, contextual /r/ was over-represented in words with the two central vowel nuclei, but not in those with the five peripheral vowels. In sum, based on Renwick’s data, it is still not perfectly clear whether the two Romanian mid vowels, and especially schwa, are highly variable acoustically, which would be in line with other world’s languages, or else whether they exhibit a restricted acoustic variability, at least along the F1 frequency dimension, which would be determined by their phonological status.
A final goal of the present investigation is to compare the duration of the two central vowels [ɨ] and [ə] with those of the five peripheral vowels [i e a o u]. This appears to be a novel contribution insofar as no duration values for each of the seven stressed vowels of Romanian are reported in
Teodorescu (
1985) and
Renwick (
2012,
2014). It should be recalled in this respect that vowel duration increases with vowel opening, such that high vowels are shorter than mid vowels, and mid vowels shorter than low vowels (
Lehiste, 1970, pp. 18–19). Moreover, vowel duration data for the world’s languages reported in
Recasens (
2021) reveal that stressed schwa is often the shortest of all stressed vowels, or as short as high vowels, which, as just mentioned, are typically shorter than lower vowels in vowel systems. It thus appears that the lack of a clear-cut constriction location, at least for schwa, may go hand in hand with a short vowel duration, which again is prone to occurring if the vowel is unstressed rather than if it is stressed. A partial exception appears to take place precisely in Romanian, in which, according to
Estill (
2010), vowel duration varies in the progression [i u] > [e o] > [a], and [ə] and [ɨ] are slightly shorter than [e o], but longer than [i u]. In view of Estill’s data, it may then turn out to be the case that, given their phonological characteristics, and in parallel to the corresponding formant frequency values, the two Romanian central vowels (or just one of them) are longer than expected because they are produced with some sort of articulatory target. Insofar as Estill’s study is merely exploratory (the only piece of information about the experimental setup provided in it is that the data were recorded from two Romanian newsreaders), a more controlled dataset is warranted in order to verify whether this prediction holds or not.
To summarize, by using a more controlled experimental setup than in previous studies, and given the existence and the phonological status of the two central vowels [ɨ] and [ə] in Romanian, the present study seeks to determine whether the following are true: (a) in contrast with other languages in which stressed schwa is the only stressed central vowel, Romanian stressed schwa has a vowel space of its own, exhibits less variation than reduced vowels and shows a similar duration to [e] and [o]; and (b) in parallel to other languages endowed with stressed [ɨ] and [ə], there is minimal overlap between these two central vowels. Moreover, the position occupied by stressed schwa relative to the other vowels in the vowel space should allow for ascertaining which is the most suitable IPA symbol for phonetically transcribing this Romanian vowel.
2. Materials and Methods
In order to explore the research issues identified in the
Section 1, acoustic data were recorded and analyzed for the seven Romanian stressed vowels [i e a o u ɨ ə] in the contextual, word type and sentence conditions referred to below. In light of differences in vowel overlap between [ɨ] and [ə] depending on elicitation conditions reported in earlier studies, data for vowels embedded in meaningful and nonsense words were recorded and processed separately.
(a) Recordings were made of meaningful words in which the target vowel was preceded and followed by consonants exhibiting the same place of articulation (see
Appendix A). There were four contextual conditions overall, i.e., labial/labiodental ([p b f v]), dental/alveolar ([t s]), palatoalveolar ([ʃ ʒ tʃ dʒ]) and alveolar lateral [l]. A partial exception was the palatoalveolar consonant condition, since due to lexical restrictions, the consonant placed on the other side of the vowel was [s] in the lexical items [ʃes], [tʃas] and [ʒos]; this other contextual setup should not differ considerably from the symmetrical one in view of the articulatory similarity between alveolars and palatoalveolars. On the other hand, the reason why [l] was included as a separate contextual group is because, in spite of being ‘clear’ in Romanian (and thus produced with a similar tongue fronting gesture to other dentals and alveolars), it may involve some tongue dorsum and jaw lowering and perhaps a slight tongue body retraction due to the laterality requirement involved (
Lindblad & Lundqvist, 2003). Real words were uttered in meaningful sentences and conformed to the syllable structures CVC([ɾ])V (20 cases) and, to a much lesser extent, CVC(C) (6 cases) and CVCCV(C) (2 cases). The stressed vowel subject to analysis thus occurred in open CV syllables (20 cases) rather than in closed CVC syllables (8 cases). All subjects who took part in the recording procedure were familiar with the chosen regional words, which are available in the real word list reproduced in
Appendix A. In order to render these words more familiar to the reader, they were presented in distinctive sentences; thus, for example,
băbci appears in the sentence
nu ştiu ce sunt băbci “I don’t know the meaning of the word băbci”, and
sătă appears in the sentence
se zicea şi sătă “sătă was said as well”.
(b) Nonsense CVC[ə] words with identical prevocalic and postvocalic consonants were also recorded in the meaningful sentence frame
spun…
aşa “I say…so” (see
Appendix B). There were six contextual conditions in this case, i.e., bilabial ([p]), dental ([t]), palatoalveolar ([ʃ]), velar ([k]), alveolar lateral ([l]) and alveolar rhotic ([r] word-initially, [ɾ] intervocalically). The reason why the alveolar rhotic was included as a separate contextual group is because, due to manner of articulation requirements, and mostly in the case of the trill, it may be articulated with a somewhat lowered tongue predorsum and blade and some tongue body retraction (see for Spanish rhotics,
Proctor, 2009). It also needs to be said that Romanian velars are realized as purely velars before low and back vowels, and exhibit a (post)palatal realization before front vowels (
Rosetti, 1967, p. 77). Some linguists consider that these fronted velars are allophones of the palatalized phonemes /kʲ/ and /ɡʲ/ (
Vasiliu, 1989, p. 5). The subjects were informed that some of the words appearing in the nonsense word list could be equal or similar to existing words. Even though a small number of these words have a meaning in Romanian, they must have been treated as nonsense by the subjects who took part in the acoustic recordings, insofar as they were read together with all the other nonsense words in the sentence
spun…
aşa.
The speech material was read by three males (THE, SEB, RAD) and three females (SIM, NIC, LIV). Subjects SIM and THE were 39 and 45 years old, respectively, and were born and have always lived in Bucharest. Subjects SEB and LIV were 55 and 54 years old, respectively, were born in Piatra Neamţ in the historical Romanian region of Moldova, have lived in Spain since the early 1990s and speak Romanian regularly as a couple and with their friends and family. NIC was 56 years old, was born in Iaşi (also placed in Moldova) and has been living in Spain since 2013. RAD was born in Buzău, which is located in the historical region of Muntenia, was 40 years old and lived in Romania until the age of 28. Both NIC and RAD used the Romanian language at work and with their family and friends. Sentences were recorded 5 times each at a 48 kHz sampling rate using an AKG PERCEPTION 200 microphone and a Marantz PMD660 recorder. Recordings were carried out in a quiet room at the Faculty of Philology of the University of Salamanca.
The four last repetitions of the meaningful and nonsense words were analyzed acoustically using Praat (
Boersma & Weenink, 2024). For all vowel tokens, the following landmarks were used for identifying the vowel onset and offset times on 0–5 kHz spectrographic displays: the onset of voicing after the burst of the preceding stop and closure onset for the following stop; the high intensity vowel formant edges bordering the frication period for fricatives; the low intensity formants for [l], and also for [r] if realized as an approximant; and the short closure period whenever contextual [r] was implemented as an alveolar tap or as an alveolar trill. The segmentation criteria for contextual stops and fricatives were used in order to identify the onset and offset times for vowels in the context of affricate consonants. After segmentation, the first author measured the F1, F2 and F3 frequency values of the target vowels at their midpoint by placing the cursor manually in the middle of the vowel. The Praat LPC formant tracker was used to assist in formant measurement in specific cases: whenever formant displays were visually unclear; whenever two formants came close to each other, as in the case of F1 and F2 for [a], and F2 and F3 for [i]; and whenever F1 for high vowels approached the voicing bar. The formant tracking procedure was set up for six formants and a 0.015 ms window length.
The formant frequency data were subjected to the Lobanov vowel normalization method in order to compare vowel formant frequencies across speakers (see
Adank et al., 2004 for details). This transformation was carried out because it is known that absolute formant frequency values are influenced by individual differences in a speaker’s vocal anatomy. The Lobanov method has been characterized as vowel-extrinsic, since it uses acoustic information distributed across more than one vowel category of a given speaker, i.e., the overall mean formant frequencies across all vowels for that speaker, as a correction factor for the frequencies of the individual vowels. It is computed separately for each formant and speaker using the formula Fn[V]N = (Fn[V]−X̅n)/σn, where Fn[V]N is the normalized value for the formant n of vowel V, and X̅n and σn are the mean and standard deviation values for formant n for the speaker in question.
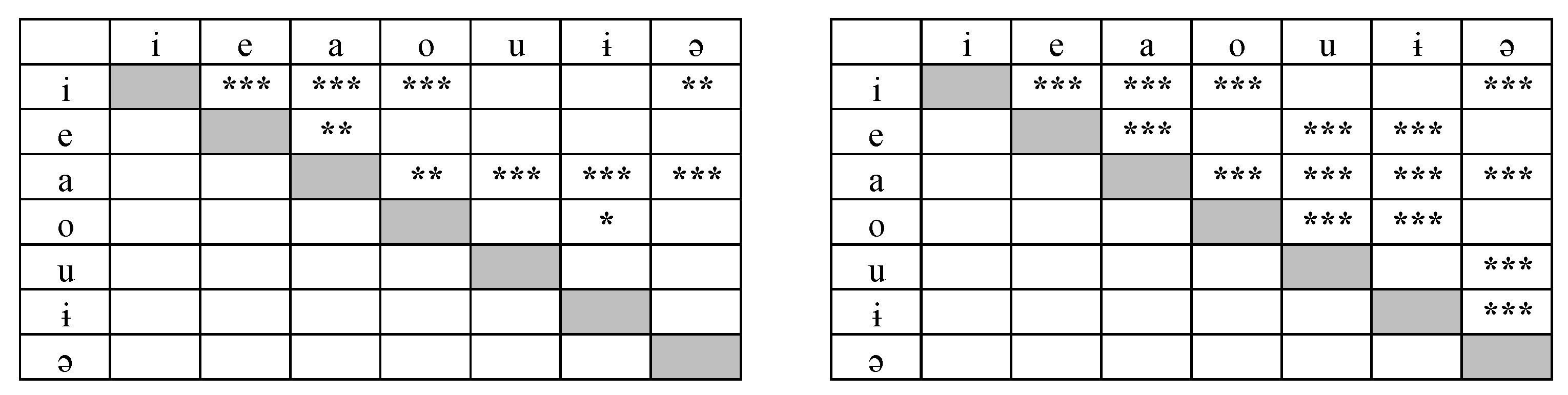
Several statistical tests were carried out in order to evaluate whether the two central vowels [ɨ] and [ə] differed significantly in F1 and F2 frequency, and also the extent to which duration differences among the seven Romanian vowels achieved statistical significance. For this purpose, main effects and vowel × consonant interactions for the formant frequency data, and main effects for the duration data, were computed by means of a linear mixed model (LMM) analysis, with vowel and contextual consonant as fixed factors and subject as a random factor, using SAS 9.4 (SAS Institute Inc., Cary, NC, USA). Separate tests were carried out for the meaningful and nonsense word conditions. Tukey-Kramer post-hoc tests were used for determining whether pairwise comparisons between contextual consonants were significant or not. In all statistical tests, the significance level was set at p < 0.05.
4. Discussion
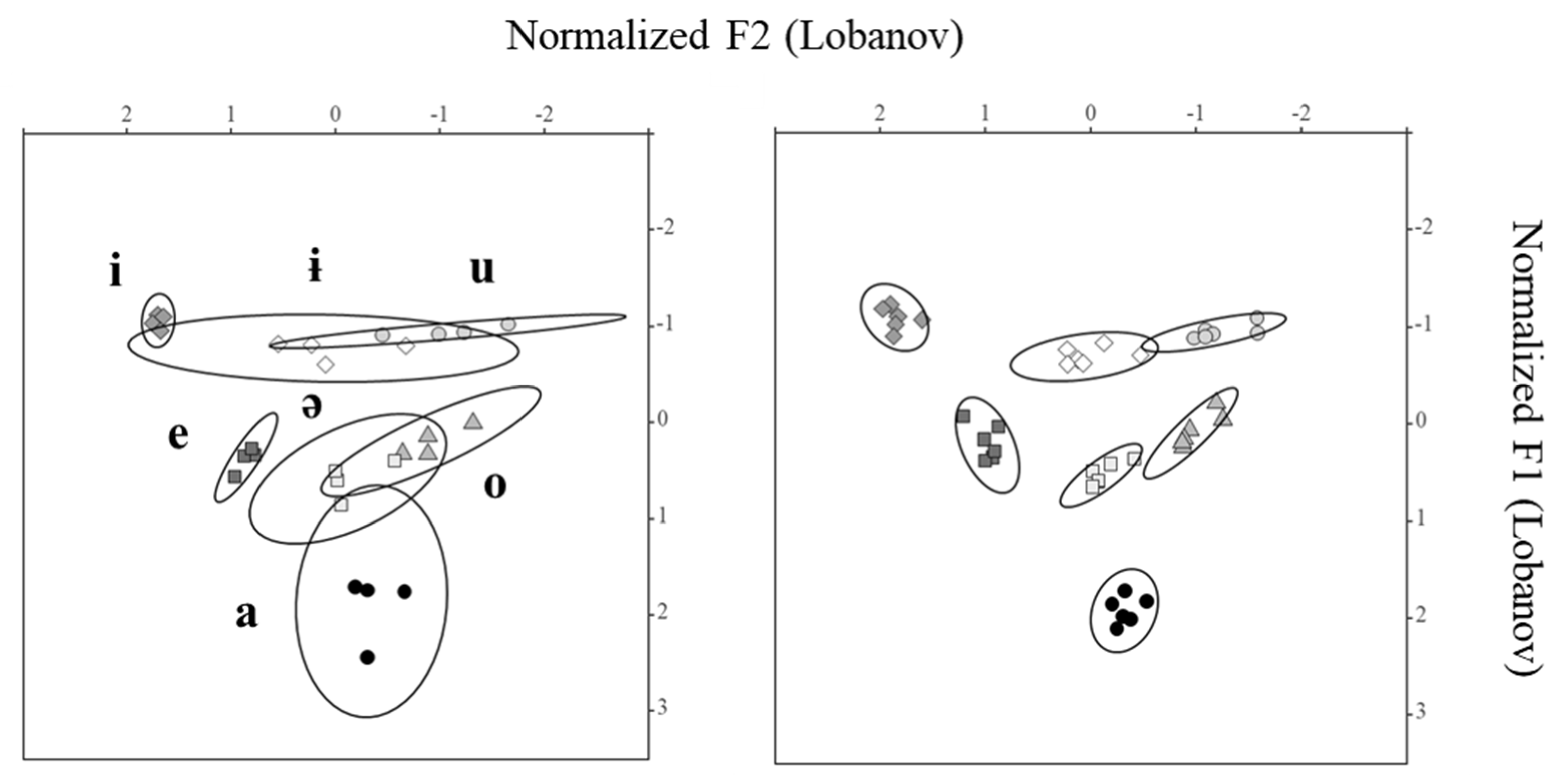
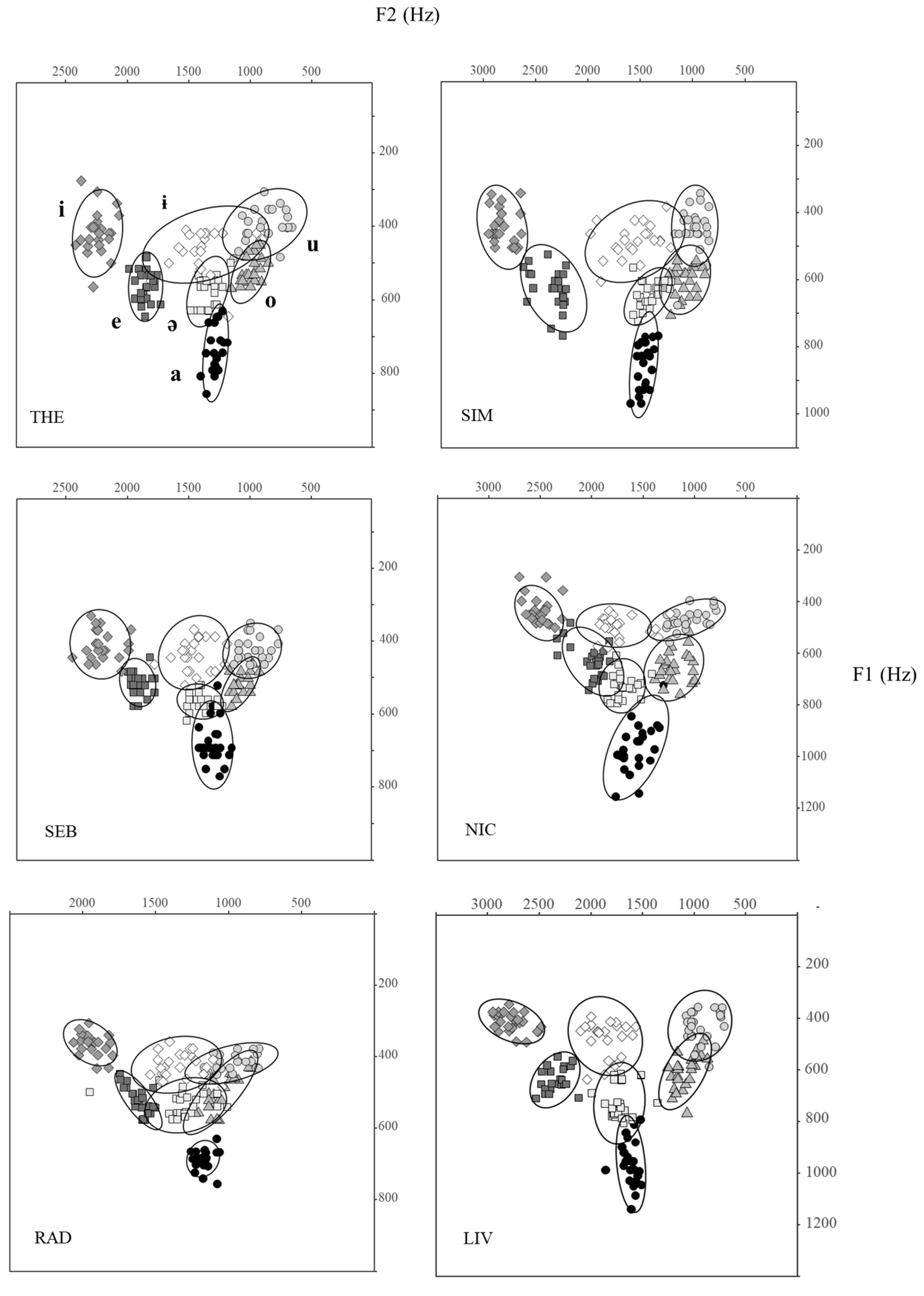
The acoustic data for the Romanian stressed vowels [i e a o u ɨ ə] produced by six speakers reveal that [e] and [o] are roughly midway between the high and low vowels, though they are closer to [i] and [u] than to [a]. As for the two central vowels, while [ɨ] may be characterized as high central and [ə] as mid central, both [ɨ] and [ə] (and [ə] more than [ɨ]) may occur closer to the back vowels than to the front vowels in the vowel space. The latter finding is in accordance with other world’s languages whose stressed schwa is also central but leaning towards the space occupied by [ʌ]. Regarding phonetic transcription, and based solely on phonetic considerations, [ə] appears to be the most suitable IPA symbol for Romanian stressed schwa, since retracted [ʌ]-like realizations of this vowel appear to occur in specific consonantal contexts only. In any case, the symbol [ʌ] used in
Renwick (
2012,
2014,
2021) cannot be entirely rejected until data from more speakers are taken into consideration. It should be mentioned, in this respect, that both the symbols [ə] and [ɤ] or [ʌ] have been used in the literature for the phonetic representation of the stressed mid central vowel in phonetic studies of other languages and dialects. The precise nature of the articulatory configuration during the production of the two Romanian central vowels should be ascertained with data on tongue configuration recorded with ultrasound or MRI (magnetic resonance imaging). Apparently, in the spirit of Renwick, another reason for not rejecting the symbol [ʌ], which is of no concern to the present study, is for purely phonological reasons, in view of the phonemic status of this vowel in Romanain (see our comments on this issue in
Section 1).
Our data agree with
Renwick (
2012) in showing that there is often a more variable F2 frequency for [ɨ] than for [ə] and for the peripheral vowels, which, analogously to the back rounded vowels, is mostly associated with the tongue fronting and unrounding coarticulatory effects exerted by palatoalveolar and palatal consonants on the high central vowel. Stressed schwa, on the other hand, turns out to be generally more variable in vowel opening (F1) than in vowel fronting (F2), and may thus be somewhat higher or lower, with, analogously to the low vowel [a], the highest F1 occurring next to [l r], and the highest F2 next to palatals and palatoalveolars. This scenario contrasts with that of other languages with stressed schwa and no [ɨ], showing that this vowel is more variable acoustically than all or most peripheral vowels, while suggesting that it has an articulatory target in Romanian, presumably since it must be distinguished from [ɨ]. Another relevant finding is that mid, back and low vowels were more variable and thus exposed to greater consonant-to-vowel coarticulatory effects, in the case of the meaningful vs. the nonsense word condition.
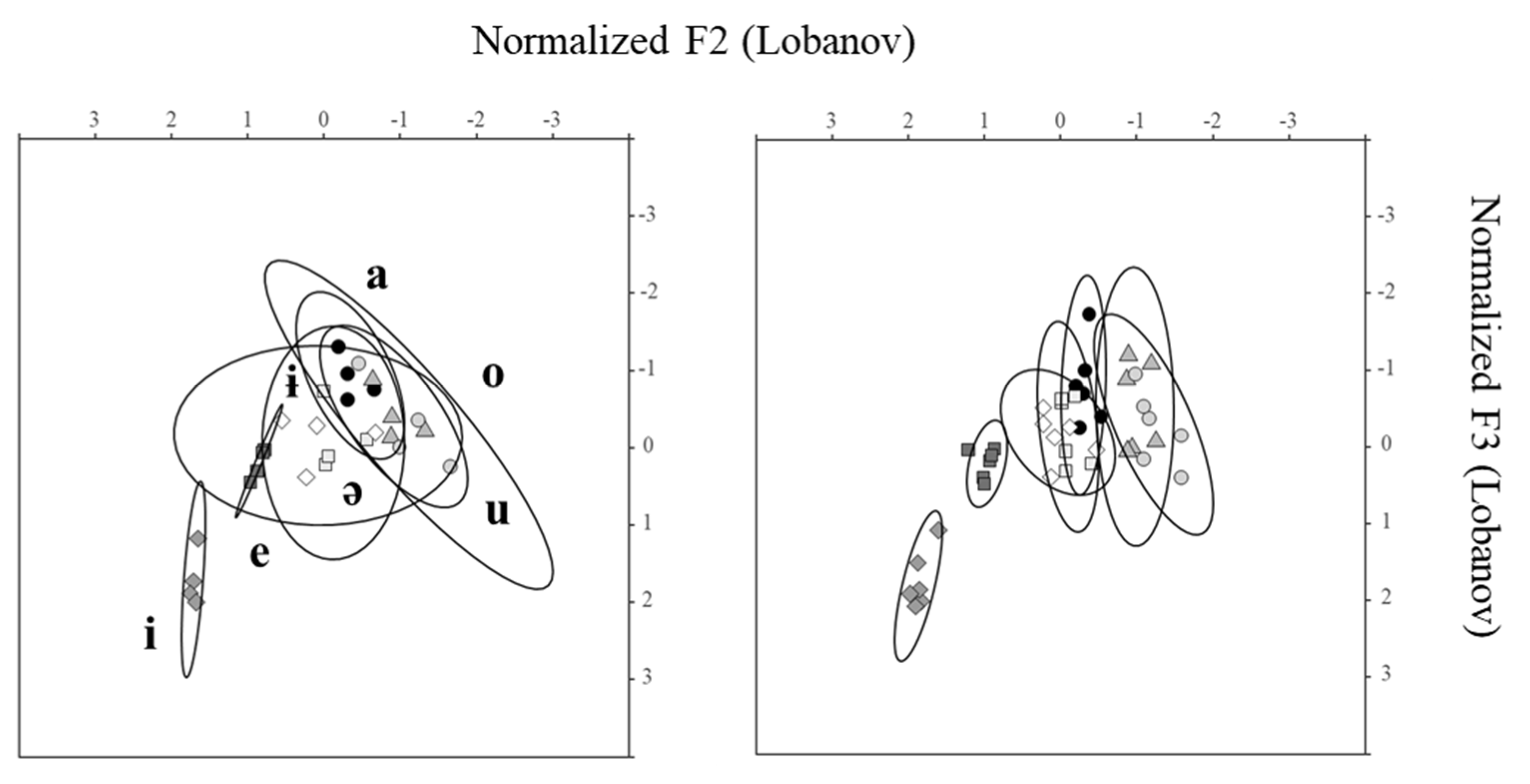
Of special relevance to the relationship between phonetics and phonology is the absence or minimal presence of F1 overlap between the vowel spaces for [ɨ] and [ə] for those speakers whose acoustic data were subjected to analysis in the present study, which may nevertheless intersect to a greater or lesser extent with the vowel spaces of neighbouring peripheral back vowels. The validity of this finding, which has also been reported to occur for other languages endowed with [ɨ] and [ə], supports the view that overlap in production is avoided because the two vowels have a distinctive phonological status in the Romanian language. As found by
Vasilescu et al. (
2016), while holding for the laboratory speech condition, this clear-cut acoustic distinction does not necessarily operate in spontaneous speech, where the two mid vowels are not hyperarticulated.
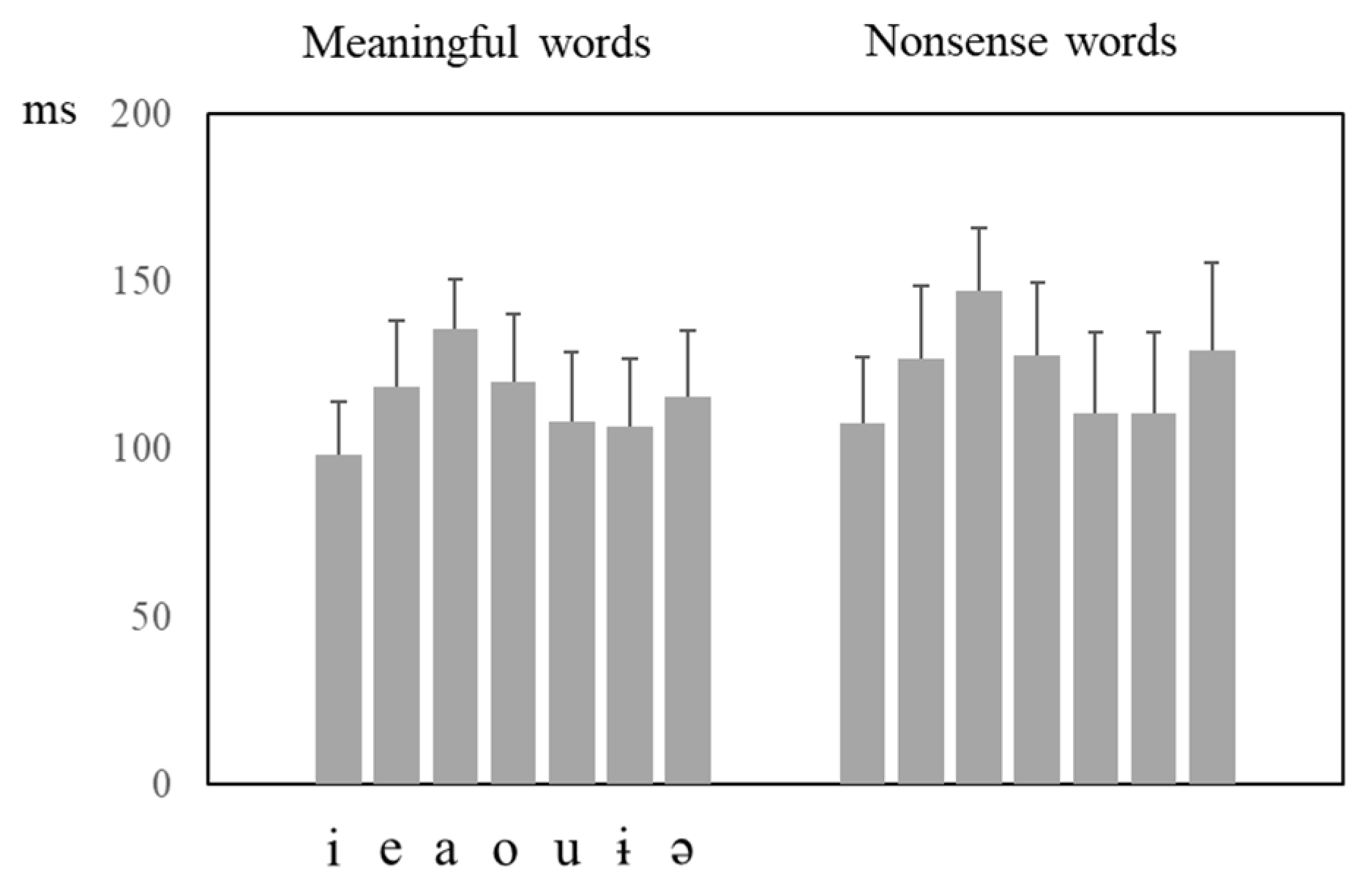
The duration data for the two Romanian central vowels reported in the present study reveal that [ɨ] is shorter than [ə], the two vowel durations being in the range of the high and mid vowels, respectively. This difference in duration, which is in contrast with other languages with stressed schwa, is in accordance with the difference in formant frequency variability reported above, insofar as the vowel showing the greatest variability (i.e., [ɨ]) is also the shorter one of the two, while suggesting, at the same time, that the tongue body configuration for stressed schwa may be subject to active articulatory control by Romanian speakers. Moreover, duration differences between the central and peripheral vowels, and also between [ɨ] and [ə], turned out to be greater in the nonsense vs. the meaningful word condition (see
Figure 7).
To summarize, the data for the two Romanian central vowels reveal that [ɨ] is more variable and shorter than schwa, while schwa differs from other languages in being longer and not too variable. A reason for this finding may be the need to set in contrast the two central vowels phonologically. It is important to stress that even though the high central vowel [ɨ] has a marginal occurrence status in Romanian, it appears to be phonetically different from all the other Romanian vowels. As for stressed schwa, its formant frequency and duration characteristics suggest that it is articulated not only with a mid tongue position (and thus is neither too high nor too low), but also with some tongue body approximation towards the back of the vocal tract.
The acoustic characteristics of Romanian vowels differed as a function of word type condition: generally speaking, they were shorter, less contrastive (both regarding vowel quality and duration) and spectrally more disperse, and thus more sensitive to consonant coarticulatory effects, in meaningful vs. nonsense words, presumably because they were more hyperarticulated in the latter word type condition than in the former one. Moreover, it is worth noticing that, while the central vowels [ɨ] and [ə] turned out to be closer to each other in duration and more spectrally variable in meaningful vs. nonsense words, they did not exhibit greater overlap in F1 frequency in the former vs. the latter word type condition. Indeed, the statistical results showed significant F1 differences between [ɨ] and [ə] when produced both in meaningful words and in nonsense words. This piece of evidence may be attributed again to the need to set in contrast the two central vowels on the part of the Romanian speakers.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}