Abstract
This paper estimates the drift parameters in the fractional Vasicek model from a continuous record of observations via maximum likelihood (ML). The asymptotic theory for the ML estimates (MLE) is established in the stationary case, the explosive case, and the boundary case for the entire range of the Hurst parameter, providing a complete treatment of asymptotic analysis. It is shown that changing the sign of the persistence parameter changes the asymptotic theory for the MLE, including the rate of convergence and the limiting distribution. It is also found that the asymptotic theory depends on the value of the Hurst parameter.
Keywords:
maximum likelihood estimate; fractional Vasicek model; asymptotic distribution; stationary process; explosive process; boundary process JEL Classification:
C15; C22; C32
1. Introduction
Since Vasicek (1977) introduced a model to describe the evolution of short-term interest rates, the so-called Vasicek model has enjoyed a wide range of applications. Jamshidian (1989) used it to price bond options. Scott (1987) used it to model the evolution of the instantaneous volatility of stock price and to price European call options.
Many extensions have been made to generalize the specification of Vasicek. For example, motivated by the phenomenon of long-range dependence found in the data of hydrology, geophysics, climatology, telecommunication, economics, and finance, the Brownian motion in the Vasicek model has been replaced by a fractional Brownian motion (fBm), leading to the following fractional Vasicek model (fVm):
where is a positive constant, , is an fBm with being the Hurst parameter, and with defined at the end of this section. An fBm is a zero mean Gaussian process, defined on a complete probability space , with the following covariance function:
The process is self-similar in the sense that , . It becomes the standard Brownian motion when and can be represented as a stochastic integral with respect to the standard Brownian motion. It is negatively correlated when . When , it has long-range dependence in the sense that . In this case, the positive (negative) increments are likely to be followed by positive (negative) increments. The parameter H, which is also called the self-similarity parameter, measures the intensity of the long-range dependence.
Parameter is often referred to as the persistence parameter. When , is stationary and ergodic. In this case, is the unconditional mean of and is the mean-reversion parameter. When , is explosive and hence non-ergodic. When , is the boundary case, and the drift term disappears. Therefore, is superfluous in this case. The ergodic fVm was used to model the evolution of instantaneous volatility in Comte and Renault (1998), the evolution of quadratic variation in Aït-Sahalia and Mancini (2008), and the evolution of realized variance in Gatheral et al. (2018). The explosive fVm was used to model the NASDAQ index in Lui et al. (2020). The explosive OU was used to model the log real estate price in Chen et al. (2017).
An alternative to and perhaps slightly more general specification than Model (1) is:
In Model (3), even when , the drift term does not vanish, and it is . This alternative specification for the drift term was used in Chan et al. (1992) and Yu and Phillips (2001). When in (3) is known (without loss of generality, it is assumed to be zero), (3) becomes the fractional Ornstein–Uhlenbeck (fOU) process. A unique path-wise solution to the stochastic differential equation in (3) is:
where the stochastic integral, , is the path-wise Riemann–Stieltjes integral, and the solution is unique (Proposition A.1 in Cheridito et al. 2003).
Assuming that a continuous record of observations is available for with , a number of studies have introduced methods to estimate and (or ) and developed asymptotic distributions for the proposed estimators under the scheme of .1 When and , borrowing the idea of Hu and Nualart (2010) and Hu et al. (2019), Xiao and Yu (2019a) considered the ergodic-type estimates of and . Xiao and Yu (2019b) extended the results of Xiao and Yu (2019a) from the case where to where . Assuming and , Nourdin and Tran (2019) extended the results of Xiao and Yu (2019a, 2019b) to a model where the fBm is replaced with a Hermite process. Using the Malliavin calculus, Es-Sebaiy and Viens (2019) studied the estimation problem for the drift parameter for some stochastic differential equations driven by fBm. Lohvinenko and Ralchenko (2017) considered the maximum likelihood (ML) estimates of and when and . Moreover, Lohvinenko and Ralchenko (2019) considered the maximum likelihood (ML) estimates of and when and .
Our paper also focuses on the MLE of and . We aim to develop the asymptotic distributions for the MLE of and under the following scenarios: (1) and ; (2) and ; (3) and . Therefore, together with Lohvinenko and Ralchenko (2017), a complete coverage of asymptotic theory for all possible cases is provided to the MLE of and .
Other estimation methods and alternative sampling schemes are possible. A recent study by Ng and Wirjanto (2019) investigated the bias property of the least squares estimator (LS) of based on discrete-sampled data. It is shown that the bias depends on the Hurst parameter and the true value of . While the assumption of a continuous-time record is practically too strong, it allows us to obtain the ML estimates in closed-form. Moreover, the results obtained in our paper will serve as the benchmark for those based on discrete-sampled data.
Several recent applications of Model (1) can be found in economics and finance. Gatheral et al. (2018) assumed and found the evidence of in the log realized volatility (RV) of a DAX contract, the Bund futures contract, the S&P 500 index, and the NASDAQ index. Bennedsen et al. (2017) documented the evidence of in the log RV of a large number of U.S. equities. Wang et al. (2019) found the evidence of and in the log RV, the realized kernel and bipower variation of the S&P500, NASDAQ, and DJIA, and in the log RV of three exchange rates. Fukasawa et al. (2019) found the log RV of several stock indices indicating that H is smaller than . Lui et al. (2020) reported the evidence of and in the S&P500 in the 1990s. Unfortunately, none of these empirical studies used the ML method to estimate .
The rest of the paper is organized as follows. Section 2 introduces the MLE of and . Section 3 is devoted to the asymptotic theory for the stationary case (i.e., ), but . Section 4 studies the asymptotic properties of the MLE in the boundary case (i.e., ) and for the entire range for the Hurst parameter . In Section 5, we establish the asymptotic behaviors of the MLE for the non-ergodic case (i.e., ) and for the entire range for the Hurst parameter . Section 6 contains some concluding remarks and gives directions for further research. All the proofs are collected in Appendix A.
We use the following notations throughout the paper: O, o, , , , , , and ∼ denote the same order, the smaller order, the same order in probability, the smaller order in probability, convergence in probability, convergence almost surely, convergence in the distribution, and asymptotic equivalence, respectively, as . Throughout this paper, the constant C only depends on H, whose values can differ at different places.
2. ML Estimation
Following Kleptsyna et al. (2000), by applying the Girsanov theorem for the fBm developed in Norros et al. (1999), one can get the expression for the continuous-record log-likelihood function for Model (3) as follows:
where:
Taking the derivatives of the log-likelihood function with respect to and and setting them to zero, Lohvinenko and Ralchenko (2017) obtained the following expressions for the MLE of and :
where:
Using the idea of Kleptsyna and Le Breton (2002), Lohvinenko and Ralchenko (2017) obtained the following results:
The process , the so-called fundamental martingale, is a Gaussian martingale with the variance function being . Moreover, the natural filtration of the martingale coincides with the natural filtration of the fBm. Based on (19) and (20), the MLE of and can be represented as:
When a continuous record of observations of is available, Lohvinenko and Ralchenko (2017) studied the consistency and the asymptotic normality of the MLE defined by (10) and (11) when and . The goal of the present paper is to establish the asymptotic theory for the MLE of and for all the other cases, including and , and , and and .
3. Asymptotic Theory When
In this section, inspired by Lohvinenko and Ralchenko (2017), we extend the asymptotic properties of and from the case of to the case of . For the sake of comparison, we first introduce the main result of Lohvinenko and Ralchenko (2017). When , Lohvinenko and Ralchenko (2017) obtained the asymptotic normality for the MLE of and , i.e.,
Remark 1.
We can use the ergodic property to estimate α and κ (denoted by and , respectively). Following the idea of Equation (1.3) in Nourdin and Tran (2019) or Equations (2.9) and (2.10) in Xiao and Yu (2019a), we can easily obtain the following results by the ergodic theorem:
Solving these two equations for α and κ, we obtain the ergodic-type estimators of κ and μ as:
with .
Using Theorem 1.3 in Nourdin and Tran (2019) or Theorem 3.3 in Xiao and Yu (2019a), we can easily obtain:
for and:
for and .
Similarly, using Theorem 1.3 in Nourdin and Tran (2019) or Theorem 3.3 in Xiao and Yu (2019a), we can obtain:
for .
Using Theorem 1.3 in Nourdin and Tran (2019) or Theorem 3.3 in Xiao and Yu (2019a), again, for , we have:
where is the Rosenblatt distribution with .
Comparing (23) with (27), we can see that the convergence rate of is the same as that of . However, is more efficient than because of for . Similarly, comparing (24) with (28), we can see that the convergence rate of is the same as that of when . In this case, the asymptotic variance of depends on H while the asymptotic variance of is always . Since , is more efficient than . When , the convergence rate of is slower than that of . Let us also mention that is asymptotically more efficient than the LS estimator of κ when ; see Xiao and Yu (2019a) for details about the LS estimator of κ. When , and the LS estimator of κ are asymptotically equivalent. For more comparison of the LS estimator and MLE, see Tanaka (2020).
The objective of this section is to obtain the consistency and the asymptotic normality of and when . Since the asymptotic laws of are different when from those when , we need to treat them separately.
3.1. Asymptotic Theory When
Before presenting the asymptotic properties of and for , we first state a useful technical lemma.
Lemma 1.
We can now describe the asymptotic laws of and as .
Theorem 1.
Remark 2.
Comparing the asymptotic theory with that obtained in Lohvinenko and Ralchenko (2017), the asymptotic normality continues to hold for both estimators. Moreover, comparing (39) with (24), we can see that the asymptotic theory for is the same regardless of or . Comparing (38) with (23), we can see that the asymptotic variance of depends on H. The asymptotic variance is with the consistency order if , whereas it does not depend on H with the consistency order as T becomes large if .
Remark 3.
The asymptotic theory for the MLE of κ in the fOU when has been developed in the literature; see, for example, Theorem 2 in Brouste and Kleptsyna (2010). It is the same as in (39). Therefore, having to estimate an additional parameter α, there is no efficiency loss in estimating κ asymptotically.
Remark 4.
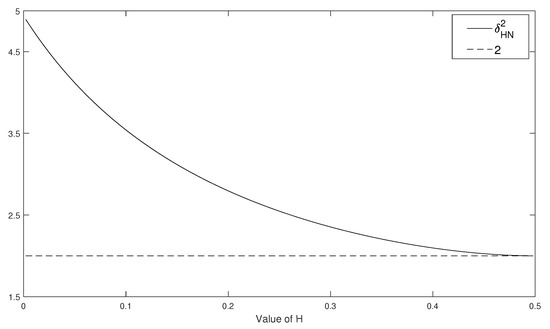
Following Hu et al. (2019), Xiao and Yu (2019b) considered the ergodic-type estimate of κ defined in (25) when and showed that:
where . Figure 1 compares the asymptotic variances of and by plotting against twofor . It can be seen that is more efficient than . The smaller H is, the larger the relative asymptotic efficiency in . The two estimators have the same asymptotic variance when .
Figure 1.
Plots of against two as functions of H.
3.2. Asymptotic Theory When
When , , which is a standard Brownian motion, and the fVm becomes the standard Vasicek model. In this case, it can be shown that fundamental martingale becomes a standard Brownian motion. Consequently, the MLE reduces to the LS estimates and can be rewritten as:
where the stochastic integration is interpreted as an Itô integral. The asymptotic theory in (42) and (43) has been studied in the literature; see, for example, Kubilius et al. (2018) and Kutoyants (2004). From page 64 of Kutoyants (2004), we can easily show that and are consistent and asymptotically normally distributed. Hence, we only provide the asymptotic laws of and for without proof.
Theorem 2.
Remark 6.
When , we can summarize the three sets of asymptotic theory for the MLE of α as follows:
where the last asymptotic theory was obtained in Theorem 3.4 of Lohvinenko and Ralchenko (2017). While the three sets of asymptotic theory for are identical, the three sets of asymptotic theory for are different. When H changes from a value in to , while the rate of convergence stays the same (i.e., ), the asymptotic variance changes from to . When H changes from a value in to , both the rate of convergence and the asymptotic variance change.
Remark 7.
When α is known and assumed to be zero and , the asymptotic theory for the MLE of κ was obtained in Brown and Hewitt (1975) and in Feigin (1976). The two sets of asymptotic theory are the same, suggesting that there is no efficiency loss in estimating κ when α is estimated or not.
4. Asymptotic Theory When
In this section, we consider the asymptotic laws of and for the entire range for the Hurst parameter, i.e., . Note that when , we have:
For the model , it is well known that the MLE of can be expressed as:
where .
Before considering the asymptotic properties of and , we first introduce a lemma, which will be used to derive the asymptotic theory.
We can now describe the asymptotic behavior of and as .
Remark 8.
In the case of and , we can see that . A straightforward algebraic calculation shows , , and that:
Then, by the scaling properties of the Brownian motion, (21) and (58)–(60), we deduce that:
which is identical to (56) with . Moreover, using (22) and (58)–(60), we can write:
which is identical to (57) with being assumed.
Remark 9.
In the case of and , with α and κ being estimated, by the scaling properties of the Brownian motion, we have:
Thus, the limiting distributions of and are not normal. In particular, the asymptotic distribution of is a Dickey–Fuller–Phillips-type distribution with the rate of convergence being T. Hence, when is unknown, the value of α plays an important role in the study of asymptotic laws for the MLE.
5. Asymptotic Theory When
When , the model given by (3) is non-ergodic or explosive. Since the proofs of the asymptotic theory of and when are different from those when , we first consider the case of . For the sake of notational simplicity, we introduce the process for . Obviously, . Moreover, using (17) and the definition of , we can easily obtain:
Since , we can obtain:
Moreover, let be a zero mean Gaussian process. Since , we have . Consequently, we can obtain:
where and are two independent random variables.
5.1. Asymptotic Theory When
Now, we can state the key results of the asymptotic theory for and when .
Theorem 4.
where and are two independent random variables.
Remark 10.
In (66), if we set , the limiting distribution of becomes a standard Cauchy variate. This limiting distribution is the same as that in the Vasicek model driven by a standard Brownian motion (see, e.g., Feigin 1976). The asymptotic theory in (66) is similar to that in the explosive discrete-time and continuous-time models when discretely-sampled data are available (see, e.g., White 1958; Anderson 1959; Phillips and Magdalinos 2007; Wang and Yu 2015, 2016).
5.2. Asymptotic Theory When
We now turn to the case when assuming . The limiting theory is the most difficult to derive in our paper and, hence, is the main technical contribution to the literature. First, we can have the following lemma.
Lemma 3.
Now, we can state the asymptotic theory for and for and .
Theorem 5.
Remark 11.
For the entire range of , the asymptotic distribution of is normal with the rate of convergence of and variance . This asymptotic distribution is the same as that of the LS estimate (see Theorem 3.5 in Xiao and Yu (2019a) and Section 3 in Xiao and Yu (2019b)).
Remark 12.
According to (76), the asymptotic law of is the standard Cauchy times . For , , suggesting that as H draws further away from , κ is estimated with higher accuracy. Moreover, with , from Theorem 3.5 in Xiao and Yu (2019a, 2019b), we can see that the LS estimator of κ, which is denoted by , has the asymptotic law , where C is the standard Cauchy distribution. Since the second moment of the Cauchy distribution is infinite, we cannot use the variances to measure the asymptotic relative efficiency. From Theorem 2 in Tanaka (2020) and based on the asymptotic concentration probability, we can see that the MLE is always more efficient asymptotically than the LS estimator for . For , the MLE is asymptotically the same as the LS estimator.
Remark 13.
When , using Lemma 3, we can obtain:
In this case, to obtain the asymptotic distribution of , one needs to calculate the Laplace transform of . On the other hand, for , using the moment generating function of , , , and , Lohvinenko and Ralchenko (2019) provided the joint asymptotic normality of MLE of the vector parameter :
where , , and , which generalizes (76) for particular .
6. Concluding Remarks and Future Directions
The fVm has found more and more applications in practice. In this paper, we consider the MLE of parameters in the drift term when a continuous record of observations is available. The ML estimation is made possible due to the presence of the fundamental martingale and the generalized Girsanov theorem. The asymptotic theory is based on the assumption that .
It is shown that the MLE of is asymptotically normal regardless of the sign of . However, the asymptotic law of the MLE of critically depends on the sign of . More precisely, when and , we have shown that the asymptotic distribution of the MLE of is normal with the rate of convergence being . The asymptotic variance is , which is independent of H. When and , the asymptotic distribution of the MLE of is normal with the rate of convergence being . The asymptotic variance depends on H. When and , the asymptotic distribution of the MLE of is a Dickey–Fuller–Phillips distribution with the rate of convergence being T. When , it is shown that the limiting distribution is a Cauchy-type with the rate of convergence being . If one further assumes that , the limiting distribution becomes a standard Cauchy variate multiplied by . Table 1 summarizes the asymptotic laws of and for different ranges of H and , where , , , , and are two independent random variables and X and Y are two independent random variables. Moreover, we assume for and .

Table 1.
Summary of the asymptotic laws of and for different ranges of H and .
This study also suggests several important directions for future research. First, it is worth investigating generalizing the results in this paper to nonlinear stochastic differential equations driven by the fBm. The ergodic theorem, fractional calculus, and Malliavin calculus will be employed for obtaining the asymptotic properties of both the MLE and the LS estimators.
Second, in this paper, H and are assumed to be known. In practice, both H and are almost always unknown. Although many approaches have been proposed to estimate the Hurst coefficient and the volatility parameter from discrete time observations, how to estimate H and in fVm with a continuous record of observations is an open question. It is interesting to realize that we can use the generalized quadratic variation to estimate both the Hurst parameter and the volatility parameter in fVm. For and any ,
It would be interesting to study the asymptotic properties of these estimators mentioned above, which will be reported in later work.
Third, this paper assumes that a continuous record of an increasing time span is available for the development of asymptotic theory. In practice, data are typically observed at discrete time points with where h is the sampling interval and T is the time span. When high frequency data over a long spanning time period are available, one may consider using a double asymptotic scheme by assuming and . The discretized model corresponding to (3) is given by:
where L is the lag operator, . As shown in Wang and Yu (2016), under the double asymptotic scheme, where as and as . This implies an autoregressive (AR) model with the AR root moderately deviating from unity and with a fractionally integrated error term with . This model is closely related to a model considered in Magdalinos (2012) where it is assumed that . Developing double asymptotic theory based on discretely-sampled data will allow one to extend the results of Magdalinos (2012) to the case where . The development of the MLE and the asymptotic theory is beyond the scope of this paper and will be reported in later work.
Author Contributions
Three authors make the equal contribution to the paper. All authors have read and agreed to the published version of the manuscript.
Funding
Xiao gratefully acknowledges the financial support of the National Natural Science Foundation of China (No. 71871202); Yu wishes to thank the Singapore Ministry of Education for Academic Research Fund under grant number MOE2013-T3-1-009 and acknowledges the financial support from the Lee Foundation.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1. Proof of Lemma 1
We first consider (30). Let us introduce the modified Bessel functions of the first kind (see, e.g., Abramowitz and Stegun 1972), which are defined as:
From page 377 in Abramowitz and Stegun (1972), we can see that the asymptotic behavior of is:
Then, as , using arguments similar to those in Lemma 4.2 of Lohvinenko and Ralchenko (2017), we can obtain:
which yields (31).
By the proof of Theorem 3 in Tanaka (2013), we can easily obtain (32) and (33). The result of (34) follows directly from and (see the proof of Lemma 4.7 in Lohvinenko and Ralchenko 2017).
Next, we consider (35). Let . Then, using Lemma 2 in Lohvinenko and Ralchenko (2019) and replacing with , we have:
where , , is the moment generating function defined by Lemma 1 in Lohvinenko and Ralchenko (2019). Using Lemma 1 in Lohvinenko and Ralchenko (2019) again, we can obtain:
where and is defined by Equation (10) in Lohvinenko and Ralchenko (2019).
Now, we consider (36). Using the Cauchy–Schwarz inequality, (33) and (34), we obtain:
which implies (36).
Finally, we are left with (37). Using (34), we can obtain:
which implies (37) directly.
Appendix A.2. Proof of Theorem 1
Moreover, using (14), we get:
According to Corollary 5.2 of Jost (2006), for , we have the relationship between and ,
Using (A14), following Equation (34) in Brouste and Kleptsyna (2010), we can transform Model (1) to the following model,
where . When and , hence, the results in (4.4) and (4.5) of Lohvinenko and Ralchenko (2017) are valid for all .
Appendix A.3. Proof of Lemma 2
From the proof of Theorem 2 in Tanaka (2013), we can easily obtain (48) and (49). A simple calculation shows that:
Similarly, a standard calculation yields:
Combining (49) with the Cauchy–Schwarz inequality, we have:
Using (49), (51) and the Cauchy–Schwarz inequality, we obtain:
Now, we consider (54). Form the definition of , we conclude that:
Finally, we deal with (55). A standard calculation yields:
where , and the proof of this lemma is complete.
Appendix A.4. Proof of Theorem 3
Using (13), (46) and (55), we have:
where . Using (49)–(53) and (A16), we have:
Similarly, combining (50) with (52) leads to:
Moreover, using (48) and (A16), we have:
According to (A17) and (A18), we get:
Similarly, applying (A17) and (A19), we have:
Using (A21), we can see that:
Appendix A.5. Proof of Theorem 4
Using (17), (61) and (62), we can obtain:
Similarly, using (17), (61) and (62) again, we can easily have:
A straightforward calculation shows:
Appendix A.6. Proof of Lemma 3
We first consider (67). Applying (14) and (15), we can obtain:
where is the modified Bessel function of the first kind defined in (A1) and we used the asymptotic behavior of (A2).
Let us observe that (68) can be obtained easily from Theorem 2 in Tanaka (2015), and the details are omitted here. For (69), using (68), we have:
which implies (69) directly.
Let be the confluent hypergeometric function of the first kind. From (A29) and the well-known result of the confluent hypergeometric function (see, for example, Equation 3.383 (1) in Gradshteyn and Ryzhik 2007; Bateman 1953, p. 278), we have:
which yields (70).
We now deal with (71). Let . Then, using Lemma 2.2 of El Machkouri et al. (2016), as , we have:
Using (6), (17), (A30) and the property of the confluent hypergeometric function (see, for example, Equation 3.383 (1) in Gradshteyn and Ryzhik 2007; Bateman 1953, p. 278), we have:
which implies (71).
We now turn to the term (72). Using (A29), we can easily obtain:
which yields (72).
Using the Cauchy–Schwarz inequality, (68) and (72), we obtain:
which implies (73).
Similarly, using (72), we have:
which yields (74), and we complete the proof.
Appendix A.7. Proof of Theorem 5
Using (14), (68) and (70)–(73), we can obtain:
According to (14), (68), (70) and (71), we obtain:
From (14), (69) and (74), we can see that:
From (14) and the definition of , we can obtain:
Using (A31), we have:
References
- Abramowitz, Milton, and Irene A. Stegun. 1972. Handbook of Mathematical Functions. New York: Dover. [Google Scholar]
- Aït-Sahalia, Yacine, and Loriano Mancini. 2008. Out of sample forecasts of quadratic variation. Journal of Econometrics 147: 17–33. [Google Scholar] [CrossRef]
- Anderson, Theodore W. 1959. On asymptotic distributions of estimates of parameters of stochastic difference equations. Annals of Mathematical Statistics 30: 676–87. [Google Scholar] [CrossRef]
- Bateman, Harry. 1953. Higher Transcendental Functions. New York: McGraw-Hill Book Company, vol. I. [Google Scholar]
- Bennedsen, Mikkel, Asger Lunde, and Mikko S. Pakkanen. 2017. Decoupling the Short- and Long-Term Behavior of Stochastic Volatility. Working Paper. Aarhus, Denmark: CREATES, Aarhus University. [Google Scholar]
- Brouste, Alexandre, and Marina Kleptsyna. 2010. Asymptotic properties of MLE for partially observed fractional diffusion system. Statistical Inference for Stochastic Processes 13: 1–13. [Google Scholar] [CrossRef]
- Brown, Bruce M., and Jonathan I. Hewitt. 1975. Asymptotic likelihood theory for diffusion processes. Journal of Applied Probability 12: 228–38. [Google Scholar] [CrossRef]
- Chan, Kalok C., G. Andrew Karolyi, Francis A. Longstaff, and Anthony B. Sanders. 1992. An empirical comparison of alternative models of the short—Term interest rate. Journal of Finance 47: 1209–27. [Google Scholar] [CrossRef]
- Chen, Ye, Peter CB Phillips, and Jun Yu. 2017. Inference in continuous systems with mildly explosive regressors. Journal of Econometrics 201: 400–16. [Google Scholar] [CrossRef]
- Cheridito, Patrick, Hideyuki Kawaguchi, and Makoto Maejima. 2003. Fractional Ornstein–Uhlenbeck processes. Electronic Journal of Probability 8: 1–14. [Google Scholar] [CrossRef]
- Comte, Fabienne, and Eric Renault. 1998. Long memory continuous-time stochastic volatility models. Mathematical Finance 8: 291–323. [Google Scholar] [CrossRef]
- El Machkouri, Mohamed, Khalifa Es-Sebaiy, and Youssef Ouknine. 2016. Least squares estimator for non-ergodic Ornstein–Uhlenbeck processes driven by Gaussian processes. Journal of the Korean Statistical Society 45: 329–41. [Google Scholar] [CrossRef]
- Es-Sebaiy, Khalifa, and Frederi G. Viens. 2019. Optimal rates for parameter estimation of stationary Gaussian processes. Stochastic Processes and Their Applications 129: 3018–54. [Google Scholar] [CrossRef]
- Feigin, Paul David. 1976. Maximum likelihood estimation for continuous-time stochastic processes. Advances in Applied Probability 8: 712–36. [Google Scholar] [CrossRef]
- Fukasawa, Masaaki, Tetsuya Takabatake, and Rebecca Westphal. 2019. Is volatility rough? arXiv arXiv:1905.04852. [Google Scholar]
- Gatheral, Jim, Thibault Jaisson, and Mathieu Rosenbaum. 2018. Volatility is rough. Quantitative Finance 18: 933–49. [Google Scholar] [CrossRef]
- Gradshteyn, Izrail Solomonovich, and Iosif Moiseevich Ryzhik, eds. 2007. Table of Integrals, Series, and Products. Amsterdam: Elsevier. [Google Scholar]
- Hu, Yaozhong, and David Nualart. 2010. Parameter estimation for fractional Ornstein–Uhlenbeck processes. Statistics and Probability Letters 80: 1030–38. [Google Scholar] [CrossRef]
- Hu, Yaozhong, David Nualart, and Hongjuan Zhou. 2019. Parameter estimation for fractional Ornstein–Uhlenbeck processes of general Hurst parameter. Statistical Inference for Stochastic Processes 22: 111–42. [Google Scholar] [CrossRef]
- Jamshidian, Farshid. 1989. An exact bond option formula. Journal of Finance 44: 205–9. [Google Scholar] [CrossRef]
- Jost, Celine. 2006. Transformation formulas for fractional Brownian motion. Stochastic Processes and Their Applications 116: 1341–57. [Google Scholar]
- Kleptsyna, Marina L., and Alain Le Breton. 2002. Statistical analysis of the fractional Ornstein–Uhlenbeck type process. Statistical Inference for Stochastic Processes 5: 229–48. [Google Scholar] [CrossRef]
- Kleptsyna, Marina L., A. Le Breton, and Marie-Christine Roubaud. 2000. Parameter estimation and optimal filtering for fractional type stochastic systems. Statistical Inference for Stochastic Processes 3: 173–82. [Google Scholar] [CrossRef]
- Kubilius, Kestutis, Y. Mishura, and Kostiantyn Ralchenko. 2018. Parameter Estimation in Fractional Diffusion Models. Berlin/Heidelberg: Springer. [Google Scholar]
- Kutoyants, Yury A. 2004. Statistical Inference for Ergodic Diffusion Process. Springer Series in Statistics; London: Springer. [Google Scholar]
- Lohvinenko, Stanislav, and Kostiantyn Ralchenko. 2017. Maximum likelihood estimation in the fractional Vasicek model. Lithuanian Journal of Statistics 56: 77–87. [Google Scholar] [CrossRef][Green Version]
- Lohvinenko, Stanislav, and Kostiantyn Ralchenko. 2019. Maximum likelihood estimation in the non-ergodic fractional Vasicek model. Modern Stochastics: Theory and Applications 6: 377–95. [Google Scholar] [CrossRef]
- Lui, Yiu Lim, Weilin Xiao, and Jun Yu. 2020. Mild-Explosive Autoregression with Anti-Persistent Errors. Oxford Bulletin of Economics and Statistics. forthcoming. [Google Scholar]
- Magdalinos, Tassos. 2012. Mildly explosive autoregression under weak and strong dependence. Journal of Econometrics 169: 179–87. [Google Scholar] [CrossRef]
- Ng, Wai Man, and Tony S. Wirjanto. 2019. Bias of the Mean-Reversion Parameter in the Fractional Ornstein–Uhlenbeck Process. Working Paper. Waterloo: University of Waterloo. [Google Scholar]
- Norros, Ilkka, Esko Valkeila, and Jorma Virtamo. 1999. An elementary approach to a Girsanov formula and other analytical results on fractional Brownian motions. Bernoulli 5: 571–87. [Google Scholar] [CrossRef]
- Nourdin, Ivan, and T. T. Diu Tran. 2019. Statistical inference for Vasicek-type model driven by Hermite processes. Stochastic Processes and Their Applications 129: 3774–91. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., and Tassos Magdalinos. 2007. Limit theory for moderate deviations from a unit root. Journal of Econometrics 136: 115–30. [Google Scholar] [CrossRef]
- Scott, Louis O. 1987. Option pricing when the variance changes randomly: Theory, estimation, and an application. Journal of Financial and Quantitative Analysis 22: 419–38. [Google Scholar] [CrossRef]
- Tanaka, Katsuto. 2013. Distributions of the maximum likelihood and minimum contrast estimators associated with the fractional Ornstein–Uhlenbeck process. Statistical Inference for Stochastic Processes 16: 173–92. [Google Scholar] [CrossRef]
- Tanaka, Katsuto. 2015. Maximum likelihood estimation for the non-ergodic fractional Ornstein–Uhlenbeck process. Statistical Inference for Stochastic Processes 18: 315–32. [Google Scholar] [CrossRef]
- Tanaka, Katsuto. 2020. Comparison of the LS-based estimators and the MLE for the fractional Ornstein–Uhlenbeck process. Statistical Inference for Stochastic Processes 23: 415–434. [Google Scholar] [CrossRef]
- Vasicek, Oldrich. 1977. An equilibrium characterization of the term structure. Journal of Financial Economics 5: 177–88. [Google Scholar] [CrossRef]
- White, John S. 1958. The limiting distribution of the serial correlation coefficient in the explosive case. Annals of Mathematical Statistics 29: 1188–97. [Google Scholar] [CrossRef]
- Wang, Xiaohu, and Jun Yu. 2015. Limit theory for an explosive autoregressive process. Economics Letters 126: 176–80. [Google Scholar] [CrossRef]
- Wang, Xiaohu, Weilin Xiao, and Jun Yu. 2019. Estimation and Inference of Fractional Continuous-Time Model with Discrete-Sampled Data. Singapore Management University Economics and Statistics Working Paper Series; Paper No. 17-2019. Singapore: SMU School of Economics. [Google Scholar]
- Wang, Xiaohu, and Jun Yu. 2016. Double asymptotics for explosive continuous time models. Journal of Econometrics 193: 35–53. [Google Scholar] [CrossRef]
- Xiao, Weilin, and Jun Yu. 2019a. Asymptotic theory for estimating the drift parameters in the fractional Vasicek model. Econometric Theory 35: 198–231. [Google Scholar] [CrossRef]
- Xiao, Weilin, and Jun Yu. 2019b. Asymptotic theory for rough fractional Vasicek models. Economics Letters 177: 26–29. [Google Scholar] [CrossRef]
- Yu, Jun, and Peter C. B. Phillips. 2001. A Gaussian approach for continuous time models of the short–term interest rate. Econometrics Journal 4: 210–24. [Google Scholar] [CrossRef]
| 1. | When a continuous record of observations is available, H and can be recovered without estimation errors. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).