Maximum Likelihood Estimation for the Fractional Vasicek Model



Abstract
1. Introduction
2. ML Estimation
3. Asymptotic Theory When
3.1. Asymptotic Theory When
3.2. Asymptotic Theory When
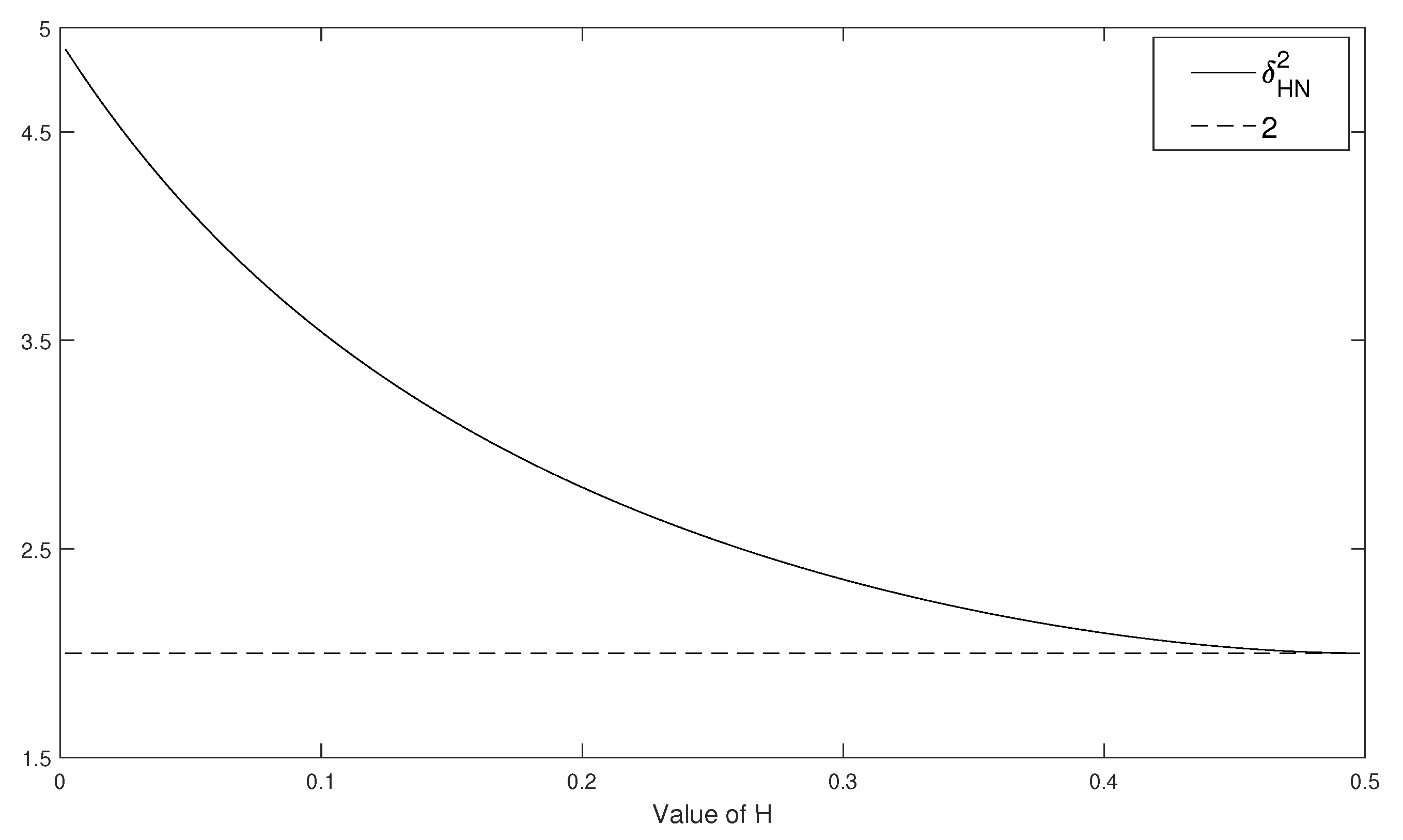
4. Asymptotic Theory When
5. Asymptotic Theory When
5.1. Asymptotic Theory When
5.2. Asymptotic Theory When
6. Concluding Remarks and Future Directions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix A.1. Proof of Lemma 1
Appendix A.2. Proof of Theorem 1
Appendix A.3. Proof of Lemma 2
Appendix A.4. Proof of Theorem 3
Appendix A.5. Proof of Theorem 4
Appendix A.6. Proof of Lemma 3
Appendix A.7. Proof of Theorem 5
References
- Abramowitz, Milton, and Irene A. Stegun. 1972. Handbook of Mathematical Functions. New York: Dover. [Google Scholar]
- Aït-Sahalia, Yacine, and Loriano Mancini. 2008. Out of sample forecasts of quadratic variation. Journal of Econometrics 147: 17–33. [Google Scholar] [CrossRef]
- Anderson, Theodore W. 1959. On asymptotic distributions of estimates of parameters of stochastic difference equations. Annals of Mathematical Statistics 30: 676–87. [Google Scholar] [CrossRef]
- Bateman, Harry. 1953. Higher Transcendental Functions. New York: McGraw-Hill Book Company, vol. I. [Google Scholar]
- Bennedsen, Mikkel, Asger Lunde, and Mikko S. Pakkanen. 2017. Decoupling the Short- and Long-Term Behavior of Stochastic Volatility. Working Paper. Aarhus, Denmark: CREATES, Aarhus University. [Google Scholar]
- Brouste, Alexandre, and Marina Kleptsyna. 2010. Asymptotic properties of MLE for partially observed fractional diffusion system. Statistical Inference for Stochastic Processes 13: 1–13. [Google Scholar] [CrossRef]
- Brown, Bruce M., and Jonathan I. Hewitt. 1975. Asymptotic likelihood theory for diffusion processes. Journal of Applied Probability 12: 228–38. [Google Scholar] [CrossRef]
- Chan, Kalok C., G. Andrew Karolyi, Francis A. Longstaff, and Anthony B. Sanders. 1992. An empirical comparison of alternative models of the short—Term interest rate. Journal of Finance 47: 1209–27. [Google Scholar] [CrossRef]
- Chen, Ye, Peter CB Phillips, and Jun Yu. 2017. Inference in continuous systems with mildly explosive regressors. Journal of Econometrics 201: 400–16. [Google Scholar] [CrossRef]
- Cheridito, Patrick, Hideyuki Kawaguchi, and Makoto Maejima. 2003. Fractional Ornstein–Uhlenbeck processes. Electronic Journal of Probability 8: 1–14. [Google Scholar] [CrossRef]
- Comte, Fabienne, and Eric Renault. 1998. Long memory continuous-time stochastic volatility models. Mathematical Finance 8: 291–323. [Google Scholar] [CrossRef]
- El Machkouri, Mohamed, Khalifa Es-Sebaiy, and Youssef Ouknine. 2016. Least squares estimator for non-ergodic Ornstein–Uhlenbeck processes driven by Gaussian processes. Journal of the Korean Statistical Society 45: 329–41. [Google Scholar] [CrossRef]
- Es-Sebaiy, Khalifa, and Frederi G. Viens. 2019. Optimal rates for parameter estimation of stationary Gaussian processes. Stochastic Processes and Their Applications 129: 3018–54. [Google Scholar] [CrossRef]
- Feigin, Paul David. 1976. Maximum likelihood estimation for continuous-time stochastic processes. Advances in Applied Probability 8: 712–36. [Google Scholar] [CrossRef]
- Fukasawa, Masaaki, Tetsuya Takabatake, and Rebecca Westphal. 2019. Is volatility rough? arXiv arXiv:1905.04852. [Google Scholar]
- Gatheral, Jim, Thibault Jaisson, and Mathieu Rosenbaum. 2018. Volatility is rough. Quantitative Finance 18: 933–49. [Google Scholar] [CrossRef]
- Gradshteyn, Izrail Solomonovich, and Iosif Moiseevich Ryzhik, eds. 2007. Table of Integrals, Series, and Products. Amsterdam: Elsevier. [Google Scholar]
- Hu, Yaozhong, and David Nualart. 2010. Parameter estimation for fractional Ornstein–Uhlenbeck processes. Statistics and Probability Letters 80: 1030–38. [Google Scholar] [CrossRef]
- Hu, Yaozhong, David Nualart, and Hongjuan Zhou. 2019. Parameter estimation for fractional Ornstein–Uhlenbeck processes of general Hurst parameter. Statistical Inference for Stochastic Processes 22: 111–42. [Google Scholar] [CrossRef]
- Jamshidian, Farshid. 1989. An exact bond option formula. Journal of Finance 44: 205–9. [Google Scholar] [CrossRef]
- Jost, Celine. 2006. Transformation formulas for fractional Brownian motion. Stochastic Processes and Their Applications 116: 1341–57. [Google Scholar]
- Kleptsyna, Marina L., and Alain Le Breton. 2002. Statistical analysis of the fractional Ornstein–Uhlenbeck type process. Statistical Inference for Stochastic Processes 5: 229–48. [Google Scholar] [CrossRef]
- Kleptsyna, Marina L., A. Le Breton, and Marie-Christine Roubaud. 2000. Parameter estimation and optimal filtering for fractional type stochastic systems. Statistical Inference for Stochastic Processes 3: 173–82. [Google Scholar] [CrossRef]
- Kubilius, Kestutis, Y. Mishura, and Kostiantyn Ralchenko. 2018. Parameter Estimation in Fractional Diffusion Models. Berlin/Heidelberg: Springer. [Google Scholar]
- Kutoyants, Yury A. 2004. Statistical Inference for Ergodic Diffusion Process. Springer Series in Statistics; London: Springer. [Google Scholar]
- Lohvinenko, Stanislav, and Kostiantyn Ralchenko. 2017. Maximum likelihood estimation in the fractional Vasicek model. Lithuanian Journal of Statistics 56: 77–87. [Google Scholar] [CrossRef][Green Version]
- Lohvinenko, Stanislav, and Kostiantyn Ralchenko. 2019. Maximum likelihood estimation in the non-ergodic fractional Vasicek model. Modern Stochastics: Theory and Applications 6: 377–95. [Google Scholar] [CrossRef]
- Lui, Yiu Lim, Weilin Xiao, and Jun Yu. 2020. Mild-Explosive Autoregression with Anti-Persistent Errors. Oxford Bulletin of Economics and Statistics. forthcoming. [Google Scholar]
- Magdalinos, Tassos. 2012. Mildly explosive autoregression under weak and strong dependence. Journal of Econometrics 169: 179–87. [Google Scholar] [CrossRef]
- Ng, Wai Man, and Tony S. Wirjanto. 2019. Bias of the Mean-Reversion Parameter in the Fractional Ornstein–Uhlenbeck Process. Working Paper. Waterloo: University of Waterloo. [Google Scholar]
- Norros, Ilkka, Esko Valkeila, and Jorma Virtamo. 1999. An elementary approach to a Girsanov formula and other analytical results on fractional Brownian motions. Bernoulli 5: 571–87. [Google Scholar] [CrossRef]
- Nourdin, Ivan, and T. T. Diu Tran. 2019. Statistical inference for Vasicek-type model driven by Hermite processes. Stochastic Processes and Their Applications 129: 3774–91. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., and Tassos Magdalinos. 2007. Limit theory for moderate deviations from a unit root. Journal of Econometrics 136: 115–30. [Google Scholar] [CrossRef]
- Scott, Louis O. 1987. Option pricing when the variance changes randomly: Theory, estimation, and an application. Journal of Financial and Quantitative Analysis 22: 419–38. [Google Scholar] [CrossRef]
- Tanaka, Katsuto. 2013. Distributions of the maximum likelihood and minimum contrast estimators associated with the fractional Ornstein–Uhlenbeck process. Statistical Inference for Stochastic Processes 16: 173–92. [Google Scholar] [CrossRef]
- Tanaka, Katsuto. 2015. Maximum likelihood estimation for the non-ergodic fractional Ornstein–Uhlenbeck process. Statistical Inference for Stochastic Processes 18: 315–32. [Google Scholar] [CrossRef]
- Tanaka, Katsuto. 2020. Comparison of the LS-based estimators and the MLE for the fractional Ornstein–Uhlenbeck process. Statistical Inference for Stochastic Processes 23: 415–434. [Google Scholar] [CrossRef]
- Vasicek, Oldrich. 1977. An equilibrium characterization of the term structure. Journal of Financial Economics 5: 177–88. [Google Scholar] [CrossRef]
- White, John S. 1958. The limiting distribution of the serial correlation coefficient in the explosive case. Annals of Mathematical Statistics 29: 1188–97. [Google Scholar] [CrossRef]
- Wang, Xiaohu, and Jun Yu. 2015. Limit theory for an explosive autoregressive process. Economics Letters 126: 176–80. [Google Scholar] [CrossRef]
- Wang, Xiaohu, Weilin Xiao, and Jun Yu. 2019. Estimation and Inference of Fractional Continuous-Time Model with Discrete-Sampled Data. Singapore Management University Economics and Statistics Working Paper Series; Paper No. 17-2019. Singapore: SMU School of Economics. [Google Scholar]
- Wang, Xiaohu, and Jun Yu. 2016. Double asymptotics for explosive continuous time models. Journal of Econometrics 193: 35–53. [Google Scholar] [CrossRef]
- Xiao, Weilin, and Jun Yu. 2019a. Asymptotic theory for estimating the drift parameters in the fractional Vasicek model. Econometric Theory 35: 198–231. [Google Scholar] [CrossRef]
- Xiao, Weilin, and Jun Yu. 2019b. Asymptotic theory for rough fractional Vasicek models. Economics Letters 177: 26–29. [Google Scholar] [CrossRef]
- Yu, Jun, and Peter C. B. Phillips. 2001. A Gaussian approach for continuous time models of the short–term interest rate. Econometrics Journal 4: 210–24. [Google Scholar] [CrossRef]
| 1. | When a continuous record of observations is available, H and can be recovered without estimation errors. |


{kind=link}
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tanaka, K.; Xiao, W.; Yu, J. Maximum Likelihood Estimation for the Fractional Vasicek Model. Econometrics 2020, 8, 32. https://doi.org/10.3390/econometrics8030032
Tanaka K, Xiao W, Yu J. Maximum Likelihood Estimation for the Fractional Vasicek Model. Econometrics. 2020; 8(3):32. https://doi.org/10.3390/econometrics8030032
Chicago/Turabian StyleTanaka, Katsuto, Weilin Xiao, and Jun Yu. 2020. "Maximum Likelihood Estimation for the Fractional Vasicek Model" Econometrics 8, no. 3: 32. https://doi.org/10.3390/econometrics8030032
APA StyleTanaka, K., Xiao, W., & Yu, J. (2020). Maximum Likelihood Estimation for the Fractional Vasicek Model. Econometrics, 8(3), 32. https://doi.org/10.3390/econometrics8030032