Forecasting Inflation Uncertainty in the G7 Countries


Abstract
1. Introduction
2. The STARFIMA-MSM Model
3. Statistical Properties
4. Maximum Likelihood Estimation and Optimal Forecasting
4.1. Maximum Likelihood Estimation
4.2. Optimal Forecasting
4.3. Monte Carlo Simulation
5. Empirical Application
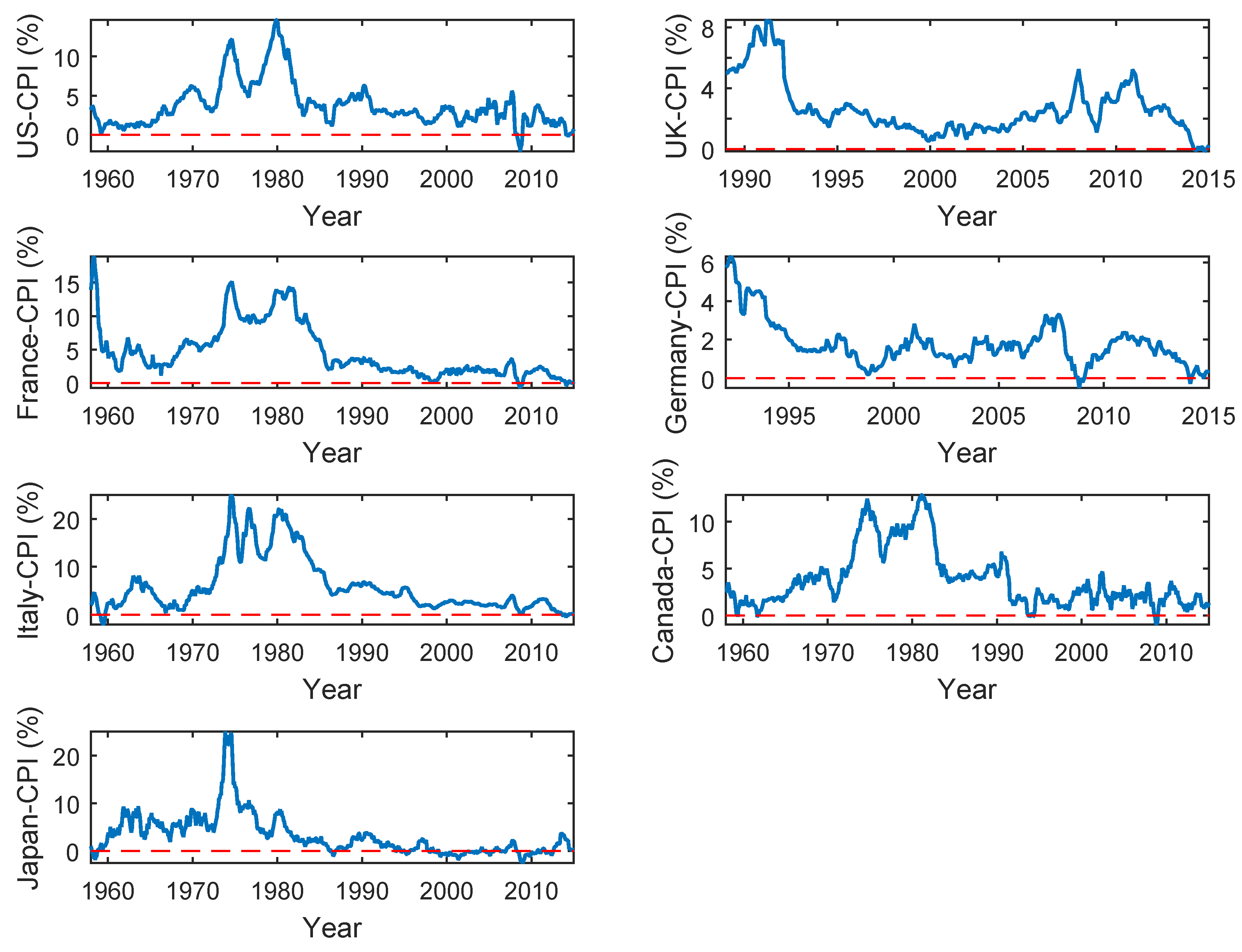
5.1. Data
5.2. Forecasting Methodology
5.3. Forecasting Results
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Baillie, Richard T., Ching-Fan Chung, and Margie A. Tieslau. 1996. Analyzing inflation by the fractionally integrated ARFIMA-GARCH model. Journal of Applied Econometrics 11: 23–40. [Google Scholar] [CrossRef]
- Baker, R. Scott, Nicholas Bloom, and Steven J. Davis. 2015. Measuring economic policy uncertainty. Quarterly Journal of Economics 136: 1593–636. [Google Scholar]
- Beran, Jan. 1994. Statistics for Long-memory Processes. New York: Chapman and Hall. [Google Scholar]
- Bernanke, Ben S. 1983. Irreversibility, uncertainty, and cyclical investment. Quarterly Journal of Economics 98: 85–106. [Google Scholar] [CrossRef]
- Bloom, Nicholas. 2009. The impact of uncertainty shocks. Econometrica 77: 623–85. [Google Scholar]
- Bloom, Nicholas. 2014. Fluctuations in uncertainty. Journal of Economic Perspectives 28: 153–76. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef]
- Calvet, Laurant E., and Adlai J. Fisher. 2001. Forecasting multifractal volatility. Journal of Econometrics 105: 27–58. [Google Scholar] [CrossRef]
- Calvet, Laurant E., and Adlai J. Fisher. 2004. Regime-switching and the estimation of multifractal processes. Journal of Financial Econometrics 2: 44–83. [Google Scholar] [CrossRef]
- Caporale, Guglielmo, Luca Onarante, and Paolo Paesani. 2012. Inflation uncertainty in Euro Aera. Empirical Economics 43: 597–615. [Google Scholar] [CrossRef][Green Version]
- Clements, Michael P. 2014. Forecast uncertainty—Ex ante and Ex post: US inflation and output growth. Journal of Business and Economic Statistics 32: 206–16. [Google Scholar] [CrossRef]
- Diebold, Francis X., and Roberto S. Mariano. 1995. Comparing predictive accuracy. Journal of Business and Economic Statistics 13: 253–63. [Google Scholar]
- Ding, Zhuanxin, Clive Granger, and Robert Engle. 1993. A long memory property of stock market returns and a new model. Journal of Empirical Finance 1: 83–106. [Google Scholar] [CrossRef]
- Engle, Robert F. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Fountas, Stilianos, Alexandra Ioannidis, and Menelaos Karanasos. 2004. Inflation, inflation uncertainty and a common European Monetary Policy. Manchester School 2: 221–42. [Google Scholar] [CrossRef]
- Glosten, Lawrence R., Ravi Jagannathan, and David E. Runkle. 1993. On the relation between the expected value and volatility of the nominal excess return on stocks. Journal of Finance 46: 1779–801. [Google Scholar] [CrossRef]
- Goodhart, Charles A. 1999. Central bankers and uncertainty. Bank of England Quarterly Bulletin 39: 102–21. [Google Scholar]
- Greenspan, Alan. 2003. Testimony before the Committee on Banking, Housing, and Urban Affairs. U.S. Senate, 16 July 2003. Technical Report, Federal Reserve Board’s Semiannual Monetary Policy Report to the Congress. Washington: Federal Reserve Board. [Google Scholar]
- Gurkaynak, Refet S., and Jonathan H. Wright. 2012. Macroeconomics and the term structure. Journal of Economic Literature 50: 331–67. [Google Scholar] [CrossRef]
- Hansen, Peter R. 2005. A test for superior predictive ability. Journal of Business and Economic Statistics 23: 365–80. [Google Scholar] [CrossRef]
- He, Changli, and Timo Terasvirta. 1999. Properties of moments of a family of GARCH processes. Journal of Econometrics 92: 173–92. [Google Scholar] [CrossRef]
- Henzel, Steffen R., and Malte Rengel. 2017. Dimensions of macroeconomic uncertainty: A common factor analysis. Economic Inquiry 55: 843–77. [Google Scholar] [CrossRef]
- Hillebrand, Eric, and Marcelo C. Medeiros. 2016. Nonlinearity, breaks and long-range dependence in time-series models. Journal of Business and Economic Statistics 34: 23–41. [Google Scholar] [CrossRef][Green Version]
- Hosking, Jonathan R. 1981. Fractional differencing. Biometrika 68: 165–76. [Google Scholar] [CrossRef]
- Jurado, Kyle, Sydney C. Ludvigson, and Serena Ng. 2015. Measuring uncertainty. American Economic Review 105: 1177–216. [Google Scholar] [CrossRef]
- Karanasos, Menelaos, and Stefanie Schurer. 2008. Is the relationship between inflation and its uncertainty linear? German Economic Review 9: 265–86. [Google Scholar] [CrossRef]
- Li, Wai Keung, and A. I. McLeod. 1986. Fractional time series modeling. Biometrika 73: 217–21. [Google Scholar] [CrossRef]
- Ling, Shiqing. 1999. On the probabilistic properties of a double threshold ARMA conditional heteroskedasticity model. Journal of Applied Probability 36: 1–18. [Google Scholar] [CrossRef]
- Ling, Shiqing, and Michael McAleer. 2002a. Necessary and sufficient moment conditions for the GARCH(r,s) and asymmetric power GARCH(r,s) models. Econometric Theory 18: 722–29. [Google Scholar] [CrossRef]
- Ling, Shiqing, and Michael McAleer. 2002b. Stationary and the existence of moments of a GARCH processes. Journal of Econometrics 106: 109–17. [Google Scholar] [CrossRef]
- Liu, Ruipeng, Tiziana di Matteo, and Thomas Lux. 2007. True and apparent scaling: The proximity of the Markov-switching multifractal model to long-range dependence. Physica A 383: 35–42. [Google Scholar] [CrossRef]
- Lundbergh, Stefan, and Timo Terasvirta. 1999. Modelling Economic High Frequency Time Series with STAR-STGARCH Models. SSE/EFI Working Paper Series in Economics and Finance, No. 291; Stockholm, Sweden: Stockholm School of Economics. [Google Scholar]
- Lux, Thomas. 2008. The Markov-switching multifractal model of asset returns: GMM estimation and linear forecasting of volatility. Journal of Business and Economic Statistics 26: 194–210. [Google Scholar] [CrossRef]
- Lux, Thomas, and Mawuli Segnon. 2018. Multifractal models in finance: Their origin, properties and applications. In OUP Handbook on Computational Economics and Finance. Edited by Shu-Heng Chen, Mak Kaboudan and Ye-Rong Du. Oxford: Oxford University Press. [Google Scholar]
- Lux, Thomas, Mawuli Segnon, and Rangan Gupta. 2016. Forecasting crude oil price volatility and value-at-risk: Evidence from historical and recent data. Energy Economics 56: 117–33. [Google Scholar] [CrossRef]
- Makarova, Svetlana. 2018. European central bank footprints on inflation forecast uncertainty. Economic Inquiry 56: 637–52. [Google Scholar]
- Nelson, Daniel B. 1991. Conditional heteroskedasticity in asset returns: A new approach. Econometrica 59: 347–70. [Google Scholar] [CrossRef]
- Pötscher, Benedikt, and Ingmar R. Prucha. 1997. Dynamic Nonlinear Econometric Models—Asymptotic Theory. New York: Springer. [Google Scholar]
- Segnon, Mawuli, Thomas Lux, and Rangan Gupta. 2017. Modeling and forecasting the volatility of carbon dioxide emission allowance prices: A review and comparison of modern volatility models. Renewable and Sustainable Energy Reviews 69: 692–704. [Google Scholar] [CrossRef]
- Sentana, Enrique. 1995. Quadratic ARCH models. Review of Economic Studies 62: 639–61. [Google Scholar] [CrossRef]
- Shiryaev, Albert. 1995. Probability (Graduate Texts in Mathematics), 2nd ed.Springer: New York. [Google Scholar]
- Stock, James H., and Mark W. Watson. 2012. Disentangling the Channels of the 2007-09 Recession. NBER Working Paper No. 18094. 1050 Massachusetts Ave., Cambridge, MA, USA: NBER. [Google Scholar]
- Van Dijk, Dick, Timo Terasvirta, and Phillip H. Franses. 2002. Smooth transition autoregressive models—A survey of recent developments. Econometric Reviews 21: 1–47. [Google Scholar] [CrossRef]
- Wang, Yudon, Congfeng Wu, and Li Yang. 2016. Forecasting crude oil market volatility: A Markov switching multifractal volatility approach. International Journal of Forecasting 32: 1–9. [Google Scholar] [CrossRef]
- White, Halbert. 2000. A reality check for data snooping. Econometrica 68: 1097–126. [Google Scholar] [CrossRef]
- Wooldridge, Jeffrey. 1994. Chapter Estimation and Inference for Dependent Processes. In Aspects of Modelling Nonlinear Time Series. Amsterdam: Elsevier Science, pp. 2639–738. [Google Scholar]
- Wright, Jonathan H. 2011. Term premia and inflation uncertainty: Empirical evidence from an international panel dataset. American Economic Review 101: 1514–34. [Google Scholar] [CrossRef]
- Žikeš, Filip, Jozef Baruník, and Nikhil Shenai. 2017. Modeling and forecasting persistent financial durations. Econometric Reviews 36: 1081–110. [Google Scholar] [CrossRef]
| 1 | See Lux and Segnon (2018) for details on the genesis and alternative applications of multifractal processes in finance. |
| 2 | Technical details on the determination of the optimal number of multipliers are available upon request. |


{kind=link}
| Binomial parameter | |||||||||
| Bias | −0.036 | −0.028 | −0.010 | −0.025 | −0.023 | −0.036 | −0.022 | −0.027 | −0.018 |
| MSE | 0.005 | 0.003 | 0.001 | 0.004 | 0.002 | 0.002 | 0.003 | 0.002 | 0.001 |
| Scaling factor | |||||||||
| Bias | −0.108 | −0.072 | −0.061 | −0.214 | −0.150 | −0.105 | −0.315 | −0.232 | −0.187 |
| MSE | 0.013 | 0.006 | 0.004 | 0.048 | 0.024 | 0.012 | 0.101 | 0.055 | 0.036 |
| G7 Countries | |||||||
|---|---|---|---|---|---|---|---|
| US | UK | France | Germany | Italy | Canada | Japan | |
| Mean | 1.659 × 10 | 9.152 × 10 | −5.509 × 10 | 4.574 × 10 | 0.001 | −1.472× 10 | −6.959 × 10 |
| Standard deviation | 0.283 | 0.260 | 0.317 | 0.224 | 0.281 | 0.365 | 0.737 |
| Skewness | −6.932 × 10 | 0.032 | −0.003 | 0.021 | 0.006 | 0.006 | −0.029 |
| Kurtosis | 4.369 | 7.130 | 5.627 | 5.775 | 8.202 | 4.686 | 8.380 |
| Hurst Exponent for the G7 Countries | |||||||
| 0.499 | 0.491 | 0.508 | 0.504 | 0.515 | 0.499 | 0.508 | |
| 0.673 | 0.814 | 0.780 | 0.772 | 0.867 | 0.694 | 0.901 | |
| 0.630 | 0.773 | 0.766 | 0.721 | 0.813 | 0.673 | 0.848 | |
| US | UK | France | Germany | Italy | Canada | Japan | |
|---|---|---|---|---|---|---|---|
| No. of Obs | 696 | 324 | 696 | 288 | 696 | 695 | 695 |
| Mean | 3.778 | 2.643 | 4.582 | 1.771 | 6.004 | 3.815 | 3.157 |
| Standard deviation | 2.864 | 1.802 | 3.980 | 1.171 | 5.739 | 3.082 | 4.264 |
| Skewness | 1.536 | 1.395 | 1.238 | 1.482 | 1.424 | 1.248 | 2.206 |
| Kurtosis | 5.428 | 4.624 | 3.728 | 5.993 | 4.105 | 3.687 | 10.080 |
| Tail index | 7.688 | 11.719 | 12.251 | 6.720 | 10.922 | 13.050 | 2.09 |
| 4.825 × 10 | 2.056 × 10 | 4.769 × 10 | 1.359 × 10 | 5.123 E× 10 | 5.030 × 10 | 4.712 × 10 | |
| ARCH(1) | 685.983 | 309.386 | 684.018 | 271.658 | 684.284 | 684.306 | 660.613 |
| Jarque-Bera | 444.528 | 140.674 | 193.272 | 213.002 | 207.722 | 194.039 | 2.095 × 10 |
| Country | PP | PP * | ST | ST * | |
|---|---|---|---|---|---|
| US | −2.044 | −1.876 | 3.634 | 6.001 | |
| UK | −1.851 | −1.669 | 2.101 | 3.963 | |
| France | −2.225 | −2.243 | 2.753 | 13.571 | |
| Germany | −3.357 | −3.363 | 1.148 | 3.495 | |
| Italy | −1.728 | −1.324 | 4.549 | 8.382 | |
| Canada | −2.052 | −1.798 | 4.356 | 8.033 | |
| Japan | −3.119 | −2.345 | 1.704 | 13.913 | |
| Forecasting Horizons | 1M | 2M | 3M | 4M | 5M | 6M | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Countries | GARCH | ||||||||||
| US | 0.179 | 0.184 | 0.187 | 0.183 | 0.178 | 0.173 | |||||
| UK | 0.110 | 0.115 | 0.120 | 0.123 | 0.124 | 0.126 | |||||
| France | 0.065 | 0.065 | 0.066 | 0.067 | 0.068 | 0.069 | |||||
| Germany | 0.078 | 0.077 | 0.076 | 0.069 | 0.068 | 0.066 | |||||
| Italy | 0.076 | 0.078 | 0.078 | 0.078 | 0.078 | 0.078 | |||||
| Canada | 0.213 | 0.210 | 0.210 | 0.211 | 0.209 | 0.209 | |||||
| Japan | 0.512 | 0.510 | 0.509 | 0.508 | 0.505 | 0.506 | |||||
| GJR | |||||||||||
| US | 0.196 | 0.201 | 0.206 | 0.204 | 0.198 | 0.192 | |||||
| UK | 0.117 | 0.119 | 0.121 | 0.125 | 0.128 | 0.130 | |||||
| France | 0.063 | 0.064 | 0.065 | 0.067 | 0.067 | 0.069 | |||||
| Germany | 0.082 | 0.081 | 0.079 | 0.073 | 0.072 | 0.071 | |||||
| Italy | 0.076 | 0.077 | 0.077 | 0.078 | 0.078 | 0.078 | |||||
| Canada | 0.213 | 0.210 | 0.210 | 0.211 | 0.210 | 0.209 | |||||
| Japan | 0.513 | 0.511 | 0.509 | 0.507 | 0.504 | 0.504 | |||||
| EGARCH | |||||||||||
| US | 0.169 | 0.171 | 0.171 | 0.169 | 0.162 | 0.156 | |||||
| UK | 0.117 | 0.115 | 0.116 | 0.116 | 0.116 | 0.117 | |||||
| France | 0.078 | 0.083 | 0.079 | 0.082 | 0.080 | 0.081 | |||||
| Germany | 0.085 | 0.084 | 0.082 | 0.077 | 0.075 | 0.073 | |||||
| Italy | 0.078 | 0.078 | 0.079 | 0.080 | 0.080 | 0.080 | |||||
| Canada | 0.215 | 0.210 | 0.210 | 0.210 | 0.211 | 0.211 | |||||
| Japan | 0.505 | 0.503 | 0.502 | 0.500 | 0.498 | 0.497 | |||||
| QGARCH | |||||||||||
| US | 0.180 | 0.183 | 0.185 | 0.183 | 0.177 | 0.171 | |||||
| UK | 0.103 | 0.104 | 0.106 | 0.107 | 0.108 | 0.110 | |||||
| France | 0.061 | 0.063 | 0.064 | 0.065 | 0.067 | 0.066 | |||||
| Germany | 0.083 | 0.082 | 0.080 | 0.072 | 0.071 | 0.069 | |||||
| Italy | 0.077 | 0.078 | 0.078 | 0.079 | 0.079 | 0.078 | |||||
| Canada | 0.213 | 0.210 | 0.210 | 0.211 | 0.209 | 0.208 | |||||
| Japan | 0.509 | 0.508 | 0.507 | 0.505 | 0.503 | 0.503 | |||||
| APGARCH | |||||||||||
| US | 0.203 | 0.209 | 0.216 | 0.212 | 0.206 | 0.201 | |||||
| UK | 0.120 | 0.123 | 0.123 | 0.128 | 0.128 | 0.125 | |||||
| France | 0.057 | 0.057 | 0.058 | 0.058 | 0.058 | 0.059 | |||||
| Germany | 0.086 | 0.086 | 0.086 | 0.078 | 0.076 | 0.075 | |||||
| Italy | 0.075 | 0.077 | 0.078 | 0.079 | 0.078 | 0.078 | |||||
| Canada | 0.214 | 0.212 | 0.213 | 0.214 | 0.212 | 0.211 | |||||
| Japan | 0.509 | 0.506 | 0.505 | 0.504 | 0.410 | 0.500 | |||||
| MSM | |||||||||||
| US | 0.153 | 0.157 | 0.156 | 0.154 | 0.151 | 0.150 | |||||
| UK | 0.104 | 0.104 | 0.103 | 0.105 | 0.106 | 0.106 | |||||
| France | 0.060 | 0.061 | 0.061 | 0.062 | 0.062 | 0.062 | |||||
| Germany | 0.082 | 0.081 | 0.080 | 0.075 | 0.074 | 0.073 | |||||
| Italy | 0.082 | 0.086 | 0.089 | 0.091 | 0.092 | 0.093 | |||||
| Canada | 0.219 | 0.215 | 0.215 | 0.216 | 0.214 | 0.214 | |||||
| Japan | 0.518 | 0.514 | 0.513 | 0.511 | 0.508 | 0.511 | |||||
| Forecasting Horizons | 1M | 2M | 3M | 4M | 5M | 6M | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Countries | GARCH | ||||||||||
| US | 0.140 | 0.142 | 0.144 | 0.142 | 0.139 | 0.137 | |||||
| UK | 0.083 | 0.088 | 0.091 | 0.094 | 0.093 | 0.096 | |||||
| France | 0.059 | 0.060 | 0.061 | 0.062 | 0.063 | 0.064 | |||||
| Germany | 0.063 | 0.064 | 0.064 | 0.060 | 0.060 | 0.060 | |||||
| Italy | 0.049 | 0.049 | 0.050 | 0.050 | 0.049 | 0.050 | |||||
| Canada | 0.151 | 0.148 | 0.150 | 0.151 | 0.150 | 0.149 | |||||
| Japan | 0.199 | 0.199 | 0.200 | 0.199 | 0.198 | 0.199 | |||||
| GJR | |||||||||||
| US | 0.150 | 0.151 | 0.152 | 0.152 | 0.148 | 0.145 | |||||
| UK | 0.091 | 0.093 | 0.092 | 0.093 | 0.096 | 0.098 | |||||
| France | 0.056 | 0.058 | 0.059 | 0.061 | 0.061 | 0.063 | |||||
| Germany | 0.066 | 0.066 | 0.066 | 0.063 | 0.062 | 0.061 | |||||
| Italy | 0.048 | 0.047 | 0.049 | 0.049 | 0.048 | 0.048 | |||||
| Canada | 0.151 | 0.150 | 0.150 | 0.152 | 0.151 | 0.149 | |||||
| Japan | 0.214 | 0.215 | 0.214 | 0.214 | 0.213 | 0.215 | |||||
| EGARCH | |||||||||||
| US | 0.133 | 0.133 | 0.132 | 0.132 | 0.128 | 0.125 | |||||
| UK | 0.092 | 0.091 | 0.089 | 0.088 | 0.088 | 0.089 | |||||
| France | 0.072 | 0.078 | 0.073 | 0.077 | 0.074 | 0.076 | |||||
| Germany | 0.070 | 0.070 | 0.069 | 0.066 | 0.065 | 0.064 | |||||
| Italy | 0.050 | 0.050 | 0.051 | 0.051 | 0.051 | 0.050 | |||||
| Canada | 0.144 | 0.137 | 0.139 | 0.140 | 0.141 | 0.142 | |||||
| Japan | 0.191 | 0.192 | 0.190 | 0.189 | 0.190 | 0.192 | |||||
| QGARCH | |||||||||||
| US | 0.140 | 0.140 | 0.140 | 0.140 | 0.136 | 0.133 | |||||
| UK | 0.077 | 0.078 | 0.079 | 0.079 | 0.080 | 0.080 | |||||
| France | 0.056 | 0.058 | 0.060 | 0.060 | 0.062 | 0.061 | |||||
| Germany | 0.067 | 0.067 | 0.066 | 0.063 | 0.061 | 0.060 | |||||
| Italy | 0.049 | 0.049 | 0.050 | 0.051 | 0.050 | 0.050 | |||||
| Canada | 0.151 | 0.149 | 0.149 | 0.151 | 0.150 | 0.148 | |||||
| Japan | 0.204 | 0.205 | 0.207 | 0.207 | 0.207 | 0.210 | |||||
| APGARCH | |||||||||||
| US | 0.154 | 0.155 | 0.158 | 0.156 | 0.152 | 0.150 | |||||
| UK | 0.089 | 0.090 | 0.087 | 0.090 | 0.091 | 0.090 | |||||
| France | 0.052 | 0.052 | 0.053 | 0.054 | 0.054 | 0.055 | |||||
| Germany | 0.071 | 0.072 | 0.072 | 0.068 | 0.067 | 0.067 | |||||
| Italy | 0.048 | 0.048 | 0.050 | 0.050 | 0.048 | 0.049 | |||||
| Canada | 0.155 | 0.154 | 0.155 | 0.157 | 0.154 | 0.154 | |||||
| Japan | 0.186 | 0.188 | 0.186 | 0.187 | 0.188 | 0.190 | |||||
| MSM | |||||||||||
| US | 0.123 | 0.126 | 0.127 | 0.126 | 0.123 | 0.122 | |||||
| UK | 0.080 | 0.082 | 0.081 | 0.082 | 0.084 | 0.086 | |||||
| France | 0.051 | 0.052 | 0.053 | 0.054 | 0.054 | 0.055 | |||||
| Germany | 0.067 | 0.068 | 0.068 | 0.066 | 0.065 | 0.064 | |||||
| Italy | 0.063 | 0.066 | 0.071 | 0.073 | 0.074 | 0.077 | |||||
| Canada | 0.162 | 0.159 | 0.161 | 0.163 | 0.161 | 0.161 | |||||
| Japan | 0.216 | 0.219 | 0.227 | 0.231 | 0.234 | 0.240 | |||||
| Forecasting Horizons | 1M | 2M | 3M | 4M | 5M | 6M | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Countries | GARCH | ||||||||||
| US | 0.176 | 0.181 | 0.184 | 0.179 | 0.173 | 0.169 | |||||
| UK | 0.108 | 0.113 | 0.112 | 0.114 | 0.118 | 0.120 | |||||
| France | 0.067 | 0.067 | 0.067 | 0.068 | 0.068 | 0.069 | |||||
| Germany | 0.080 | 0.080 | 0.079 | 0.072 | 0.071 | 0.070 | |||||
| Italy | 0.075 | 0.076 | 0.076 | 0.076 | 0.076 | 0.076 | |||||
| Canada | 0.206 | 0.203 | 0.203 | 0.204 | 0.203 | 0.203 | |||||
| Japan | 0.516 | 0.514 | 0.513 | 0.511 | 0.509 | 0.509 | |||||
| GJR | |||||||||||
| US | 0.192 | 0.197 | 0.203 | 0.202 | 0.195 | 0.190 | |||||
| UK | 0.121 | 0.115 | 0.117 | 0.122 | 0.125 | 0.129 | |||||
| France | 0.066 | 0.066 | 0.067 | 0.068 | 0.068 | 0.069 | |||||
| Germany | 0.082 | 0.083 | 0.081 | 0.076 | 0.075 | 0.074 | |||||
| Italy | 0.074 | 0.075 | 0.075 | 0.075 | 0.075 | 0.075 | |||||
| Canada | 0.205 | 0.203 | 0.202 | 0.205 | 0.203 | 0.204 | |||||
| Japan | 0.517 | 0.515 | 0.513 | 0.511 | 0.507 | 0.508 | |||||
| EGARCH | |||||||||||
| US | 0.169 | 0.171 | 0.172 | 0.170 | 0.163 | 0.157 | |||||
| UK | 0.117 | 0.117 | 0.118 | 0.119 | 0.119 | 0.122 | |||||
| France | 0.078 | 0.084 | 0.079 | 0.081 | 0.080 | 0.081 | |||||
| Germany | 0.086 | 0.085 | 0.083 | 0.077 | 0.075 | 0.078 | |||||
| Italy | 0.077 | 0.077 | 0.077 | 0.078 | 0.078 | 0.078 | |||||
| Canada | 0.209 | 0.203 | 0.203 | 0.204 | 0.204 | 0.205 | |||||
| Japan | 0.508 | 0.507 | 0.506 | 0.503 | 0.501 | 0.503 | |||||
| QGARCH | |||||||||||
| US | 0.176 | 0.179 | 0.181 | 0.180 | 0.173 | 0.167 | |||||
| UK | 0.105 | 0.105 | 0.107 | 0.109 | 0.110 | 0.112 | |||||
| France | 0.061 | 0.060 | 0.059 | 0.060 | 0.060 | 0.060 | |||||
| Germany | 0.085 | 0.085 | 0.082 | 0.076 | 0.075 | 0.074 | |||||
| Italy | 0.076 | 0.076 | 0.077 | 0.077 | 0.077 | 0.077 | |||||
| Canada | 0.206 | 0.203 | 0.202 | 0.204 | 0.202 | 0.202 | |||||
| Japan | 0.513 | 0.512 | 0.510 | 0.508 | 0.506 | 0.508 | |||||
| APGARCH | |||||||||||
| US | 0.193 | 0.202 | 0.210 | 0.204 | 0.198 | 0.194 | |||||
| UK | 0.111 | 0.118 | 0.121 | 0.126 | 0.130 | 0.128 | |||||
| France | 0.060 | 0.060 | 0.061 | 0.061 | 0.062 | 0.062 | |||||
| Germany | 0.086 | 0.086 | 0.092 | 0.084 | 0.082 | 0.082 | |||||
| Italy | 0.073 | 0.076 | 0.076 | 0.076 | 0.075 | 0.074 | |||||
| Canada | 0.205 | 0.204 | 0.206 | 0.206 | 0.204 | 0.204 | |||||
| Japan | 0.512 | 0.509 | 0.507 | 0.505 | 0.503 | 0.504 | |||||
| MSM | |||||||||||
| US | 0.155 | 0.158 | 0.158 | 0.155 | 0.152 | 0.151 | |||||
| UK | 0.103 | 0.103 | 0.102 | 0.104 | 0.104 | 0.105 | |||||
| France | 0.061 | 0.061 | 0.061 | 0.062 | 0.062 | 0.062 | |||||
| Germany | 0.083 | 0.084 | 0.083 | 0.078 | 0.077 | 0.076 | |||||
| Italy | 0.082 | 0.086 | 0.088 | 0.089 | 0.089 | 0.091 | |||||
| Canada | 0.213 | 0.208 | 0.208 | 0.210 | 0.208 | 0.208 | |||||
| Japan | 0.522 | 0.518 | 0.517 | 0.515 | 0.511 | 0.515 | |||||
| Forecasting Horizons | 1M | 2M | 3M | 4M | 5M | 6M | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Countries | GARCH | ||||||||||
| US | 0.136 | 0.138 | 0.138 | 0.136 | 0.133 | 0.131 | |||||
| UK | 0.081 | 0.087 | 0.086 | 0.088 | 0.091 | 0.093 | |||||
| France | 0.062 | 0.062 | 0.062 | 0.063 | 0.063 | 0.064 | |||||
| Germany | 0.064 | 0.064 | 0.064 | 0.061 | 0.061 | 0.060 | |||||
| Italy | 0.049 | 0.049 | 0.050 | 0.049 | 0.048 | 0.050 | |||||
| Canada | 0.152 | 0.149 | 0.150 | 0.151 | 0.150 | 0.149 | |||||
| Japan | 0.198 | 0.197 | 0.200 | 0.199 | 0.198 | 0.200 | |||||
| GJR | |||||||||||
| US | 0.142 | 0.144 | 0.146 | 0.145 | 0.142 | 0.141 | |||||
| UK | 0.095 | 0.091 | 0.090 | 0.094 | 0.097 | 0.097 | |||||
| France | 0.060 | 0.060 | 0.061 | 0.062 | 0.063 | 0.064 | |||||
| Germany | 0.065 | 0.066 | 0.066 | 0.063 | 0.062 | 0.061 | |||||
| Italy | 0.046 | 0.047 | 0.047 | 0.047 | 0.047 | 0.047 | |||||
| Canada | 0.150 | 0.149 | 0.149 | 0.152 | 0.152 | 0.151 | |||||
| Japan | 0.216 | 0.216 | 0.217 | 0.217 | 0.216 | 0.218 | |||||
| EGARCH | |||||||||||
| US | 0.128 | 0.129 | 0.129 | 0.128 | 0.123 | 0.121 | |||||
| UK | 0.093 | 0.093 | 0.092 | 0.091 | 0.092 | 0.093 | |||||
| France | 0.072 | 0.078 | 0.074 | 0.075 | 0.075 | 0.075 | |||||
| Germany | 0.071 | 0.070 | 0.068 | 0.067 | 0.066 | 0.067 | |||||
| Italy | 0.050 | 0.050 | 0.051 | 0.052 | 0.051 | 0.052 | |||||
| Canada | 0.147 | 0.140 | 0.142 | 0.143 | 0.144 | 0.145 | |||||
| Japan | 0.192 | 0.193 | 0.194 | 0.194 | 0.195 | 0.198 | |||||
| QGARCH | |||||||||||
| US | 0.132 | 0.132 | 0.134 | 0.134 | 0.130 | 0.127 | |||||
| UK | 0.081 | 0.080 | 0.083 | 0.083 | 0.084 | 0.084 | |||||
| France | 0.055 | 0.055 | 0.055 | 0.056 | 0.056 | 0.055 | |||||
| Germany | 0.067 | 0.068 | 0.066 | 0.064 | 0.063 | 0.061 | |||||
| Italy | 0.049 | 0.049 | 0.050 | 0.050 | 0.050 | 0.051 | |||||
| Canada | 0.151 | 0.149 | 0.149 | 0.152 | 0.150 | 0.149 | |||||
| Japan | 0.204 | 0.206 | 0.208 | 0.209 | 0.209 | 0.213 | |||||
| APGARCH | |||||||||||
| US | 0.144 | 0.149 | 0.151 | 0.146 | 0.143 | 0.143 | |||||
| UK | 0.085 | 0.091 | 0.088 | 0.091 | 0.094 | 0.093 | |||||
| France | 0.055 | 0.055 | 0.056 | 0.057 | 0.057 | 0.057 | |||||
| Germany | 0.072 | 0.073 | 0.075 | 0.070 | 0.070 | 0.069 | |||||
| Italy | 0.046 | 0.048 | 0.049 | 0.047 | 0.046 | 0.047 | |||||
| Canada | 0.153 | 0.151 | 0.154 | 0.156 | 0.152 | 0.152 | |||||
| Japan | 0.185 | 0.187 | 0.186 | 0.188 | 0.189 | 0.192 | |||||
| MSM | |||||||||||
| US | 0.123 | 0.126 | 0.126 | 0.124 | 0.122 | 0.122 | |||||
| UK | 0.081 | 0.082 | 0.081 | 0.082 | 0.084 | 0.085 | |||||
| France | 0.052 | 0.052 | 0.053 | 0.054 | 0.054 | 0.055 | |||||
| Germany | 0.067 | 0.068 | 0.068 | 0.066 | 0.065 | 0.064 | |||||
| Italy | 0.062 | 0.066 | 0.070 | 0.072 | 0.073 | 0.076 | |||||
| Canada | 0.163 | 0.159 | 0.161 | 0.162 | 0.159 | 0.160 | |||||
| Japan | 0.214 | 0.219 | 0.226 | 0.230 | 0.233 | 0.239 | |||||
| Forecasting Horizons | 1M | 2M | 3M | 4M | 5M | 6M | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Benchmark Models | US | ||||||||||
| GARCH | 0.088 | 0.066 | 0.047 | 0.070 | 0.049 | 0.045 | |||||
| GJR | 0.034 | 0.032 | 0.026 | 0.024 | 0.021 | 0.039 | |||||
| EGARCH | 0.055 | 0.088 | 0.081 | 0.072 | 0.143 | 0.284 | |||||
| QGARCH | 0.041 | 0.047 | 0.041 | 0.031 | 0.031 | 0.032 | |||||
| APGARCH | 0.038 | 0.038 | 0.031 | 0.031 | 0.033 | 0.043 | |||||
| MSM | 1.000 | 1.000 | 1.000 | 1.000 | 0.857 | 0.716 | |||||
| UK | |||||||||||
| GARCH | 0.110 | 0.255 | 0.094 | 0.031 | 0.164 | 0.109 | |||||
| GJR | 0.017 | 0.028 | 0.036 | 0.034 | 0.033 | 0.031 | |||||
| EGARCH | 0.046 | 0.122 | 0.086 | 0.134 | 0.161 | 0.100 | |||||
| QGARCH | 0.621 | 0.748 | 0.259 | 0.328 | 0.287 | 0.208 | |||||
| APGARCH | 0.070 | 0.051 | 0.058 | 0.061 | 0.057 | 0.109 | |||||
| MSM | 0.379 | 0.735 | 0.741 | 0.672 | 0.713 | 0.792 | |||||
| France | |||||||||||
| GARCH | 0.006 | 0.002 | 0.001 | 0.001 | 0.000 | 0.000 | |||||
| GJR | 0.053 | 0.026 | 0.020 | 0.010 | 0.002 | 0.001 | |||||
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| QGARCH | 0.080 | 0.006 | 0.004 | 0.001 | 0.000 | 0.000 | |||||
| APGARCH | 0.780 | 0.856 | 0.821 | 0.859 | 0.839 | 1.000 | |||||
| MSM | 0.274 | 0.172 | 0.224 | 0.179 | 0.161 | 0.145 | |||||
| Germany | |||||||||||
| GARCH | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| GJR | 0.020 | 0.049 | 0.076 | 0.016 | 0.034 | 0.037 | |||||
| EGARCH | 0.009 | 0.018 | 0.022 | 0.005 | 0.008 | 0.007 | |||||
| QGARCH | 0.012 | 0.021 | 0.064 | 0.037 | 0.075 | 0.091 | |||||
| APGARCH | 0.013 | 0.006 | 0.002 | 0.005 | 0.005 | 0.004 | |||||
| MSM | 0.055 | 0.049 | 0.101 | 0.010 | 0.011 | 0.016 | |||||
| Italy | |||||||||||
| GARCH | 0.240 | 0.367 | 0.232 | 0.474 | 0.553 | 0.476 | |||||
| GJR | 0.245 | 0.717 | 0.898 | 0.926 | 0.599 | 0.559 | |||||
| EGARCH | 0.092 | 0.202 | 0.144 | 0.151 | 0.061 | 0.109 | |||||
| QGARCH | 0.099 | 0.180 | 0.141 | 0.160 | 0.053 | 0.134 | |||||
| APGARCH | 0.781 | 0.770 | 0.312 | 0.387 | 0.765 | 0.785 | |||||
| MSM | 0.018 | 0.012 | 0.003 | 0.001 | 0.000 | 0.000 | |||||
| Canada | |||||||||||
| GARCH | 0.953 | 0.869 | 0.582 | 0.840 | 0.803 | 0.791 | |||||
| GJR | 0.727 | 0.521 | 0.630 | 0.450 | 0.431 | 0.416 | |||||
| EGARCH | 0.383 | 0.558 | 0.549 | 0.598 | 0.437 | 0.347 | |||||
| QGARCH | 0.802 | 0.838 | 0.951 | 0.870 | 0.993 | 0.998 | |||||
| APGARCH | 0.468 | 0.116 | 0.048 | 0.139 | 0.154 | 0.125 | |||||
| MSM | 0.004 | 0.059 | 0.025 | 0.041 | 0.033 | 0.005 | |||||
| Japan | |||||||||||
| GARCH | 0.210 | 0.267 | 0.217 | 0.238 | 0.114 | 0.172 | |||||
| GJR | 0.130 | 0.188 | 0.267 | 0.268 | 0.379 | 0.148 | |||||
| EGARCH | 0.749 | 0.733 | 0.993 | 0.993 | 0.853 | 0.764 | |||||
| QGARCH | 0.047 | 0.037 | 0.031 | 0.017 | 0.018 | 0.015 | |||||
| APGARCH | 0.373 | 0.492 | 0.451 | 0.400 | 0.541 | 0.350 | |||||
| MSM | 0.063 | 0.060 | 0.052 | 0.014 | 0.029 | 0.013 | |||||
| Forecasting Horizons | 1M | 2M | 3M | 4M | 5M | 6M | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Benchmark Models | US | ||||||||||
| GARCH | 0.075 | 0.032 | 0.014 | 0.026 | 0.025 | 0.018 | |||||
| GJR | 0.024 | 0.014 | 0.0150 | 0.017 | 0.017 | 0.028 | |||||
| EGARCH | 0.089 | 0.156 | 0.180 | 0.168 | 0.236 | 0.346 | |||||
| QGARCH | 0.053 | 0.076 | 0.036 | 0.052 | 0.078 | 0.051 | |||||
| APGARCH | 0.023 | 0.020 | 0.009 | 0.016 | 0.023 | 0.030 | |||||
| MSM | 1.000 | 0.844 | 0.820 | 0.832 | 0.764 | 0.678 | |||||
| UK | |||||||||||
| GARCH | 0.136 | 0.130 | 0.057 | 0.016 | 0.098 | 0.058 | |||||
| GJR | 0.007 | 0.004 | 0.014 | 0.012 | 0.003 | 0.002 | |||||
| EGARCH | 0.0122 | 0.020 | 0.051 | 0.073 | 0.050 | 0.036 | |||||
| QGARCH | 0.814 | 1.000 | 0.742 | 0.802 | 1.000 | 1.000 | |||||
| APGARCH | 0.058 | 0.043 | 0.159 | 0.058 | 0.049 | 0.091 | |||||
| MSM | 0.258 | 0.145 | 0.375 | 0.265 | 0.175 | 0.155 | |||||
| France | |||||||||||
| GARCH | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| GJR | 0.008 | 0.003 | 0.001 | 0.000 | 0.000 | 0.000 | |||||
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| QGARCH | 0.098 | 0.004 | 0.001 | 0.002 | 0.000 | 0.001 | |||||
| APGARCH | 0.359 | 0.537 | 0.470 | 0.544 | 0.542 | 0.578 | |||||
| MSM | 0.641 | 0.463 | 0.530 | 0.456 | 0.458 | 0.422 | |||||
| Germany | |||||||||||
| GARCH | 1.000 | 1.000 | 0.847 | 1.000 | 0.756 | 0.691 | |||||
| GJR | 0.161 | 0.154 | 0.204 | 0.123 | 0.188 | 0.229 | |||||
| EGARCH | 0.006 | 0.007 | 0.014 | 0.004 | 0.004 | 0.003 | |||||
| QGARCH | 0.086 | 0.105 | 0.250 | 0.220 | 0.393 | 0.484 | |||||
| APGARCH | 0.033 | 0.018 | 0.006 | 0.012 | 0.008 | 0.001 | |||||
| MSM | 0.009 | 0.010 | 0.020 | 0.010 | 0.016 | 0.031 | |||||
| Italy | |||||||||||
| GARCH | 0.272 | 0.204 | 0.249 | 0.402 | 0.271 | 0.200 | |||||
| GJR | 0.611 | 1.000 | 1.000 | 0.913 | 0.822 | 0.715 | |||||
| EGARCH | 0.062 | 0.065 | 0.063 | 0.082 | 0.052 | 0.133 | |||||
| QGARCH | 0.045 | 0.024 | 0.030 | 0.043 | 0.012 | 0.060 | |||||
| APGARCH | 0.630 | 0.281 | 0.063 | 0.374 | 0.559 | 0.462 | |||||
| MSM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| Canada | |||||||||||
| GARCH | 0.365 | 0.084 | 0.066 | 0.094 | 0.139 | 0.261 | |||||
| GJR | 0.268 | 0.078 | 0.087 | 0.096 | 0.112 | 0.200 | |||||
| EGARCH | 0.880 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| QGARCH | 0.388 | 0.091 | 0.092 | 0.102 | 0.155 | 0.337 | |||||
| APGARCH | 0.050 | 0.012 | 0.010 | 0.006 | 0.036 | 0.009 | |||||
| MSM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| Japan | |||||||||||
| GARCH | 0.121 | 0.162 | 0.092 | 0.140 | 0.179 | 0.175 | |||||
| GJR | 0.007 | 0.007 | 0.003 | 0.003 | 0.004 | 0.003 | |||||
| EGARCH | 0.433 | 0.469 | 0.271 | 0.373 | 0.377 | 0.542 | |||||
| QGARCH | 0.045 | 0.039 | 0.013 | 0.007 | 0.010 | 0.005 | |||||
| APGARCH | 0.731 | 0.704 | 0.729 | 0.627 | 0.623 | 0.651 | |||||
| MSM | 0.006 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| Forecasting Horizons | |||||||
|---|---|---|---|---|---|---|---|
| Model 1 | Model 2 | 1M | 2M | 3M | 4M | 5M | 6M |
| US | |||||||
| GARCH | MSM | 0.026 | 0.087 | 0.087 | 0.068 | 0.136 | 0.192 |
| GJR | 0.015 | 0.067 | 0.074 | 0.055 | 0.106 | 0.155 | |
| EGARCH | 0.045 | 0.140 | 0.142 | 0.066 | 0.169 | 0.308 | |
| QGARCH | 0.022 | 0.084 | 0.086 | 0.050 | 0.118 | 0.190 | |
| APGARCH | 0.012 | 0.064 | 0.066 | 0.061 | 0.113 | 0.154 | |
| UK | |||||||
| GARCH | MSM | 0.057 | 0.163 | 0.034 | 0.021 | 0.120 | 0.067 |
| GJR | 0.018 | 0.059 | 0.092 | 0.135 | 0.148 | 0.162 | |
| EGARCH | 0.054 | 0.089 | 0.079 | 0.158 | 0.194 | 0.167 | |
| QGARCH | 0.633 | 0.549 | 0.317 | 0.397 | 0.382 | 0.334 | |
| APGARCH | 0.037 | 0.073 | 0.107 | 0.144 | 0.168 | 0.204 | |
| France | |||||||
| GARCH | MSM | 0.011 | 0.020 | 0.010 | 0.023 | 0.002 | 0.002 |
| GJR | 0.009 | 0.020 | 0.012 | 0.004 | 0.000 | 0.000 | |
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| QGARCH | 0.395 | 0.349 | 0.278 | 0.322 | 0.192 | 0.251 | |
| APGARCH | 0.777 | 0.800 | 0.728 | 0.745 | 0.718 | 0.706 | |
| Germany | |||||||
| GARCH | MSM | 0.965 | 0.969 | 0.930 | 0.958 | 0.940 | 0.919 |
| GJR | 0.464 | 0.633 | 0.670 | 0.806 | 0.825 | 0.791 | |
| EGARCH | 0.040 | 0.136 | 0.225 | 0.360 | 0.403 | 0.402 | |
| QGARCH | 0.284 | 0.382 | 0.558 | 0.760 | 0.776 | 0.751 | |
| APGARCH | 0.127 | 0.126 | 0.083 | 0.343 | 0.380 | 0.363 | |
| Italy | |||||||
| GARCH | MSM | 0.947 | 0.968 | 0.979 | 0.985 | 0.987 | 0.9871 |
| GJR | 0.890 | 0.966 | 0.980 | 0.982 | 0.981 | 0.981 | |
| EGARCH | 0.783 | 0.929 | 0.956 | 0.963 | 0.959 | 0.966 | |
| QGARCH | 0.846 | 0.950 | 0.971 | 0.975 | 0.970 | 0.976 | |
| APGARCH | 0.969 | 0.967 | 0.968 | 0.971 | 0.981 | 0.984 | |
| Canada | |||||||
| GARCH | MSM | 0.995 | 0.972 | 0.977 | 0.978 | 0.974 | 0.996 |
| GJR | 0.997 | 0.951 | 0.959 | 0.927 | 0.926 | 0.972 | |
| EGARCH | 0.738 | 0.747 | 0.791 | 0.797 | 0.689 | 0.677 | |
| QGARCH | 0.995 | 0.966 | 0.978 | 0.967 | 0.975 | 0.996 | |
| APGARCH | 0.991 | 0.814 | 0.743 | 0.853 | 0.846 | 0.981 | |
| Japan | |||||||
| GARCH | MSM | 0.937 | 0.831 | 0.772 | 0.736 | 0.657 | 0.809 |
| GJR | 0.729 | 0.658 | 0.675 | 0.701 | 0.691 | 0.941 | |
| EGARCH | 0.988 | 0.985 | 0.968 | 0.976 | 0.917 | 0.996 | |
| QGARCH | 0.966 | 0.946 | 0.893 | 0.922 | 0.823 | 0.973 | |
| APGARCH | 0.996 | 0.987 | 0.931 | 0.879 | 0.877 | 0.986 | |
| Forecasting Horizons | |||||||
|---|---|---|---|---|---|---|---|
| Model 1 | Model 2 | 1M | 2M | 3M | 4M | 5M | 6M |
| US | |||||||
| GARCH | MSM | 0.015 | 0.085 | 0.099 | 0.128 | 0.185 | 0.225 |
| GJR | 0.010 | 0.064 | 0.089 | 0.108 | 0.158 | 0.206 | |
| EGARCH | 0.057 | 0.216 | 0.256 | 0.254 | 0.330 | 0.416 | |
| QGARCH | 0.021 | 0.126 | 0.159 | 0.173 | 0.237 | 0.293 | |
| APGARCH | 0.007 | 0.056 | 0.063 | 0.093 | 0.151 | 0.189 | |
| UK | |||||||
| GARCH | MSM | 0.246 | 0.149 | 0.054 | 0.045 | 0.188 | 0.102 |
| GJR | 0.024 | 0.086 | 0.142 | 0.191 | 0.199 | 0.200 | |
| EGARCH | 0.036 | 0.127 | 0.166 | 0.271 | 0.351 | 0.371 | |
| QGARCH | 0.834 | 0.835 | 0.696 | 0.724 | 0.775 | 0.764 | |
| APGARCH | 0.086 | 0.170 | 0.301 | 0.266 | 0.328 | 0.384 | |
| France | |||||||
| GARCH | MSM | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 |
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| QGARCH | 0.046 | 0.049 | 0.059 | 0.122 | 0.060 | 0.099 | |
| APGARCH | 0.324 | 0.515 | 0.464 | 0.515 | 0.514 | 0.532 | |
| Germany | |||||||
| GARCH | MSM | 0.999 | 0.993 | 0.963 | 0.957 | 0.930 | 0.891 |
| GJR | 0.833 | 0.917 | 0.917 | 0.935 | 0.956 | 0.939 | |
| EGARCH | 0.055 | 0.167 | 0.315 | 0.435 | 0.480 | 0.467 | |
| QGARCH | 0.494 | 0.641 | 0.804 | 0.844 | 0.855 | 0.826 | |
| APGARCH | 0.086 | 0.137 | 0.156 | 0.289 | 0.334 | 0.307 | |
| Italy | |||||||
| GARCH | MSM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| GJR | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| EGARCH | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| QGARCH | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| APGARCH | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| Canada | |||||||
| GARCH | MSM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| GJR | 1.000 | 0.999 | 0.999 | 0.997 | 0.991 | 0.997 | |
| EGARCH | 0.995 | 0.997 | 0.999 | 0.999 | 0.997 | 0.991 | |
| QGARCH | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| APGARCH | 0.996 | 0.958 | 0.976 | 0.986 | 0.998 | 0.999 | |
| Japan | |||||||
| GARCH | MSM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| GJR | 0.563 | 0.634 | 0.777 | 0.836 | 0.860 | 0.899 | |
| EGARCH | 0.997 | 0.991 | 0.994 | 0.996 | 0.995 | 0.999 | |
| QGARCH | 0.983 | 0.969 | 0.982 | 0.992 | 0.993 | 0.997 | |
| APGARCH | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| Forecasting Horizons | 1M | 2M | 3M | 4M | 5M | 6M | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Benchmark Models | US | ||||||||||
| GARCH | 0.108 | 0.068 | 0.051 | 0.099 | 0.058 | 0.038 | |||||
| GJR | 0.041 | 0.036 | 0.027 | 0.029 | 0.024 | 0.041 | |||||
| EGARCH | 0.081 | 0.111 | 0.094 | 0.081 | 0.142 | 0.292 | |||||
| QGARCH | 0.049 | 0.053 | 0.037 | 0.027 | 0.026 | 0.052 | |||||
| APGARCH | 0.058 | 0.047 | 0.035 | 0.052 | 0.045 | 0.055 | |||||
| MSM | 1.000 | 1.000 | 0.906 | 1.000 | 0.858 | 0.737 | |||||
| UK | |||||||||||
| GARCH | 0.197 | 0.099 | 0.088 | 0.044 | 0.080 | 0.063 | |||||
| GJR | 0.004 | 0.045 | 0.077 | 0.048 | 0.040 | 0.034 | |||||
| EGARCH | 0.026 | 0.046 | 0.066 | 0.080 | 0.092 | 0.062 | |||||
| QGARCH | 0.542 | 0.280 | 0.101 | 0.145 | 0.142 | 0.120 | |||||
| APGARCH | 0.217 | 0.080 | 0.050 | 0.068 | 0.055 | 0.101 | |||||
| MSM | 0.715 | 0.720 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| France | |||||||||||
| GARCH | 0.001 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| GJR | 0.029 | 0.012 | 0.006 | 0.003 | 0.001 | 0.000 | |||||
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| QGARCH | 0.623 | 0.817 | 0.719 | 0.776 | 0.758 | 0.833 | |||||
| APGARCH | 0.798 | 0.685 | 0.058 | 0.145 | 0.028 | 0.022 | |||||
| MSM | 0.422 | 0.360 | 0.318 | 0.254 | 0.283 | 0.195 | |||||
| Germany | |||||||||||
| GARCH | 1.000 | 0.901 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| GJR | 0.094 | 0.050 | 0.090 | 0.034 | 0.049 | 0.034 | |||||
| EGARCH | 0.023 | 0.056 | 0.095 | 0.040 | 0.090 | 0.005 | |||||
| QGARCH | 0.036 | 0.030 | 0.068 | 0.038 | 0.044 | 0.026 | |||||
| APGARCH | 0.150 | 0.171 | 0.007 | 0.007 | 0.001 | 0.004 | |||||
| MSM | 0.092 | 0.036 | 0.030 | 0.008 | 0.007 | 0.010 | |||||
| Italy | |||||||||||
| GARCH | 0.052 | 0.108 | 0.103 | 0.318 | 0.341 | 0.188 | |||||
| GJR | 0.263 | 1.000 | 1.000 | 0.942 | 0.542 | 0.397 | |||||
| EGARCH | 0.004 | 0.021 | 0.013 | 0.005 | 0.006 | 0.022 | |||||
| QGARCH | 0.044 | 0.023 | 0.019 | 0.013 | 0.004 | 0.019 | |||||
| APGARCH | 0.801 | 0.271 | 0.177 | 0.368 | 0.849 | 0.775 | |||||
| MSM | 0.007 | 0.006 | 0.003 | 0.000 | 0.001 | 0.000 | |||||
| Canada | |||||||||||
| GARCH | 0.638 | 0.801 | 0.350 | 0.914 | 0.875 | 0.722 | |||||
| GJR | 0.743 | 0.796 | 0.653 | 0.657 | 0.517 | 0.352 | |||||
| EGARCH | 0.356 | 0.612 | 0.510 | 0.622 | 0.447 | 0.381 | |||||
| QGARCH | 0.824 | 0.978 | 0.918 | 0.939 | 0.988 | 0.999 | |||||
| APGARCH | 0.795 | 0.453 | 0.108 | 0.529 | 0.419 | 0.512 | |||||
| MSM | 0.006 | 0.077 | 0.033 | 0.076 | 0.028 | 0.002 | |||||
| Japan | |||||||||||
| GARCH | 0.217 | 0.266 | 0.219 | 0.224 | 0.1456 | 0.198 | |||||
| GJR | 0.109 | 0.158 | 0.200 | 0.199 | 0.327 | 0.225 | |||||
| EGARCH | 0.712 | 0.680 | 0.985 | 0.987 | 0.907 | 0.995 | |||||
| QGARCH | 0.054 | 0.031 | 0.024 | 0.010 | 0.008 | 0.018 | |||||
| APGARCH | 0.430 | 0.561 | 0.543 | 0.514 | 0.459 | 0.388 | |||||
| MSM | 0.052 | 0.035 | 0.059 | 0.011 | 0.010 | 0.030 | |||||
| Forecasting Horizons | 1M | 2M | 3M | 4M | 5M | 6M | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | US | ||||||||||
| GARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| MSM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| UK | |||||||||||
| GARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| MSM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| France | |||||||||||
| GARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| MSM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| Germany | |||||||||||
| GARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| MSM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| Italy | |||||||||||
| GARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| MSM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| Canada | |||||||||||
| GARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| MSM | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| Japan | |||||||||||
| GARCH | 0.115 | 0.174 | 0.101 | 0.148 | 0.179 | 0.217 | |||||
| GJR | 0.006 | 0.007 | 0.004 | 0.004 | 0.006 | 0.008 | |||||
| EGARCH | 0.395 | 0.437 | 0.390 | 0.443 | 0.450 | 0.441 | |||||
| QGARCH | 0.041 | 0.046 | 0.022 | 0.016 | 0.020 | 0.014 | |||||
| APGARCH | 0.931 | 0.935 | 0.936 | 0.935 | 0.934 | 0.931 | |||||
| MSM | 0.229 | 0.243 | 0.239 | 0.244 | 0.252 | 0.257 | |||||
| Forecasting Horizons | |||||||
|---|---|---|---|---|---|---|---|
| Model 1 | Model 2 | 1M | 2M | 3M | 4M | 5M | 6M |
| US | |||||||
| GARCH | MSM | 0.030 | 0.094 | 0.096 | 0.081 | 0.149 | 0.210 |
| GJR | 0.023 | 0.081 | 0.086 | 0.070 | 0.119 | 0.163 | |
| EGARCH | 0.068 | 0.167 | 0.158 | 0.096 | 0.186 | 0.319 | |
| QGARCH | 0.040 | 0.112 | 0.105 | 0.064 | 0.134 | 0.215 | |
| APGARCH | 0.024 | 0.081 | 0.076 | 0.078 | 0.134 | 0.173 | |
| UK | |||||||
| GARCH | MSM | 0.093 | 0.056 | 0.045 | 0.069 | 0.073 | 0.086 |
| GJR | 0.001 | 0.072 | 0.118 | 0.136 | 0.152 | 0.161 | |
| EGARCH | 0.015 | 0.057 | 0.088 | 0.147 | 0.183 | 0.170 | |
| QGARCH | 0.277 | 0.306 | 0.153 | 0.233 | 0.264 | 0.262 | |
| APGARCH | 0.099 | 0.077 | 0.081 | 0.130 | 0.155 | 0.187 | |
| France | |||||||
| GARCH | MSM | 0.003 | 0.006 | 0.008 | 0.018 | 0.004 | 0.003 |
| GJR | 0.005 | 0.005 | 0.003 | 0.004 | 0.000 | 0.000 | |
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| QGARCH | 0.553 | 0.610 | 0.634 | 0.674 | 0.650 | 0.690 | |
| APGARCH | 0.587 | 0.600 | 0.493 | 0.587 | 0.493 | 0.554 | |
| Germany | |||||||
| GARCH | MSM | 0.970 | 0.981 | 0.963 | 0.968 | 0.953 | 0.934 |
| GJR | 0.651 | 0.700 | 0.771 | 0.866 | 0.864 | 0.823 | |
| EGARCH | 0.212 | 0.371 | 0.500 | 0.573 | 0.674 | 0.389 | |
| QGARCH | 0.245 | 0.357 | 0.577 | 0.727 | 0.740 | 0.706 | |
| APGARCH | 0.265 | 0.301 | 0.038 | 0.098 | 0.115 | 0.044 | |
| Italy | |||||||
| GARCH | MSM | 0.976 | 0.983 | 0.984 | 0.989 | 0.987 | 0.988 |
| GJR | 0.960 | 0.981 | 0.981 | 0.980 | 0.976 | 0.980 | |
| EGARCH | 0.899 | 0.964 | 0.965 | 0.957 | 0.955 | 0.968 | |
| QGARCH | 0.920 | 0.967 | 0.965 | 0.960 | 0.953 | 0.970 | |
| APGARCH | 0.988 | 0.973 | 0.966 | 0.973 | 0.977 | 0.985 | |
| Canada | |||||||
| GARCH | MSM | 0.994 | 0.966 | 0.971 | 0.970 | 0.969 | 0.995 |
| GJR | 0.994 | 0.935 | 0.951 | 0.878 | 0.876 | 0.902 | |
| EGARCH | 0.775 | 0.783 | 0.779 | 0.792 | 0.693 | 0.714 | |
| QGARCH | 0.995 | 0.958 | 0.974 | 0.947 | 0.974 | 0.996 | |
| APGARCH | 0.993 | 0.886 | 0.703 | 0.907 | 0.855 | 0.983 | |
| Japan | |||||||
| GARCH | MSM | 0.931 | 0.833 | 0.766 | 0.741 | 0.677 | 0.813 |
| GJR | 0.696 | 0.637 | 0.649 | 0.684 | 0.716 | 0.935 | |
| EGARCH | 0.980 | 0.986 | 0.972 | 0.989 | 0.959 | 0.988 | |
| QGARCH | 0.954 | 0.949 | 0.905 | 0.945 | 0.881 | 0.944 | |
| APGARCH | 0.997 | 0.994 | 0.964 | 0.947 | 0.897 | 0.969 | |
| Forecasting Horizons | |||||||
|---|---|---|---|---|---|---|---|
| Model 1 | Model 2 | 1M | 2M | 3M | 4M | 5M | 6M |
| US | |||||||
| GARCH | MSM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | |
| UK | |||||||
| GARCH | MSM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| France | |||||||
| GARCH | MSM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Germany | |||||||
| GARCH | MSM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Italy | |||||||
| GARCH | MSM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Canada | |||||||
| GARCH | MSM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| GJR | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| EGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| QGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| APGARCH | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Japan | |||||||
| GARCH | MSM | 0.738 | 0.738 | 0.736 | 0.742 | 0.746 | 0.759 |
| GJR | 0.684 | 0.679 | 0.680 | 0.684 | 0.692 | 0.711 | |
| EGARCH | 0.754 | 0.752 | 0.761 | 0.769 | 0.779 | 0.795 | |
| QGARCH | 0.719 | 0.714 | 0.711 | 0.713 | 0.717 | 0.726 | |
| APGARCH | 0.775 | 0.769 | 0.779 | 0.781 | 0.787 | 0.794 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Segnon, M.; Bekiros, S.; Wilfling, B. Forecasting Inflation Uncertainty in the G7 Countries. Econometrics 2018, 6, 23. https://doi.org/10.3390/econometrics6020023
Segnon M, Bekiros S, Wilfling B. Forecasting Inflation Uncertainty in the G7 Countries. Econometrics. 2018; 6(2):23. https://doi.org/10.3390/econometrics6020023
Chicago/Turabian StyleSegnon, Mawuli, Stelios Bekiros, and Bernd Wilfling. 2018. "Forecasting Inflation Uncertainty in the G7 Countries" Econometrics 6, no. 2: 23. https://doi.org/10.3390/econometrics6020023
APA StyleSegnon, M., Bekiros, S., & Wilfling, B. (2018). Forecasting Inflation Uncertainty in the G7 Countries. Econometrics, 6(2), 23. https://doi.org/10.3390/econometrics6020023