
Cascaded Residual Attention Enhanced Road Extraction from Remote Sensing Images

 , ,
, ,
Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
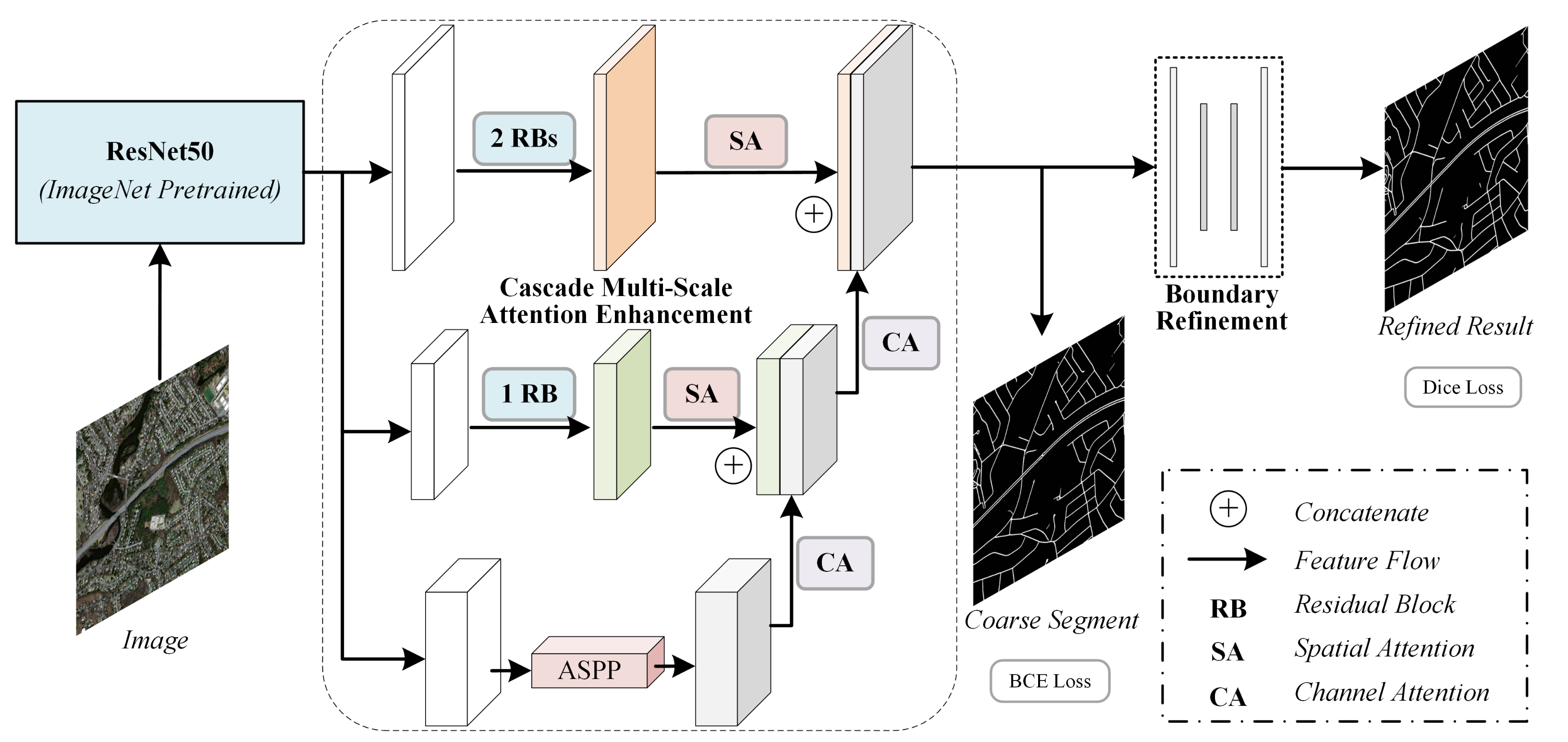
3.1. Overview
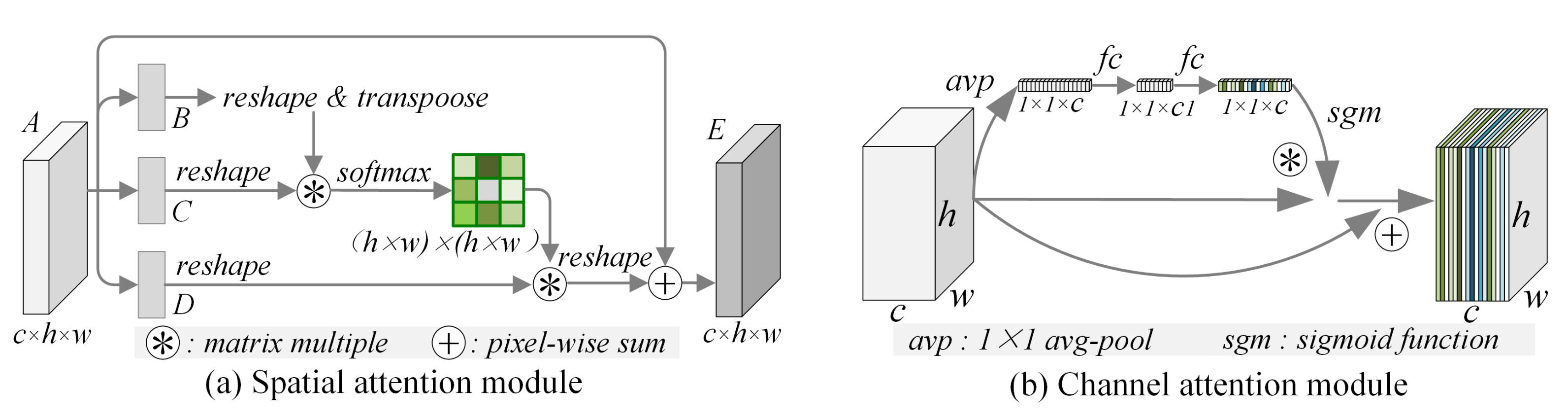
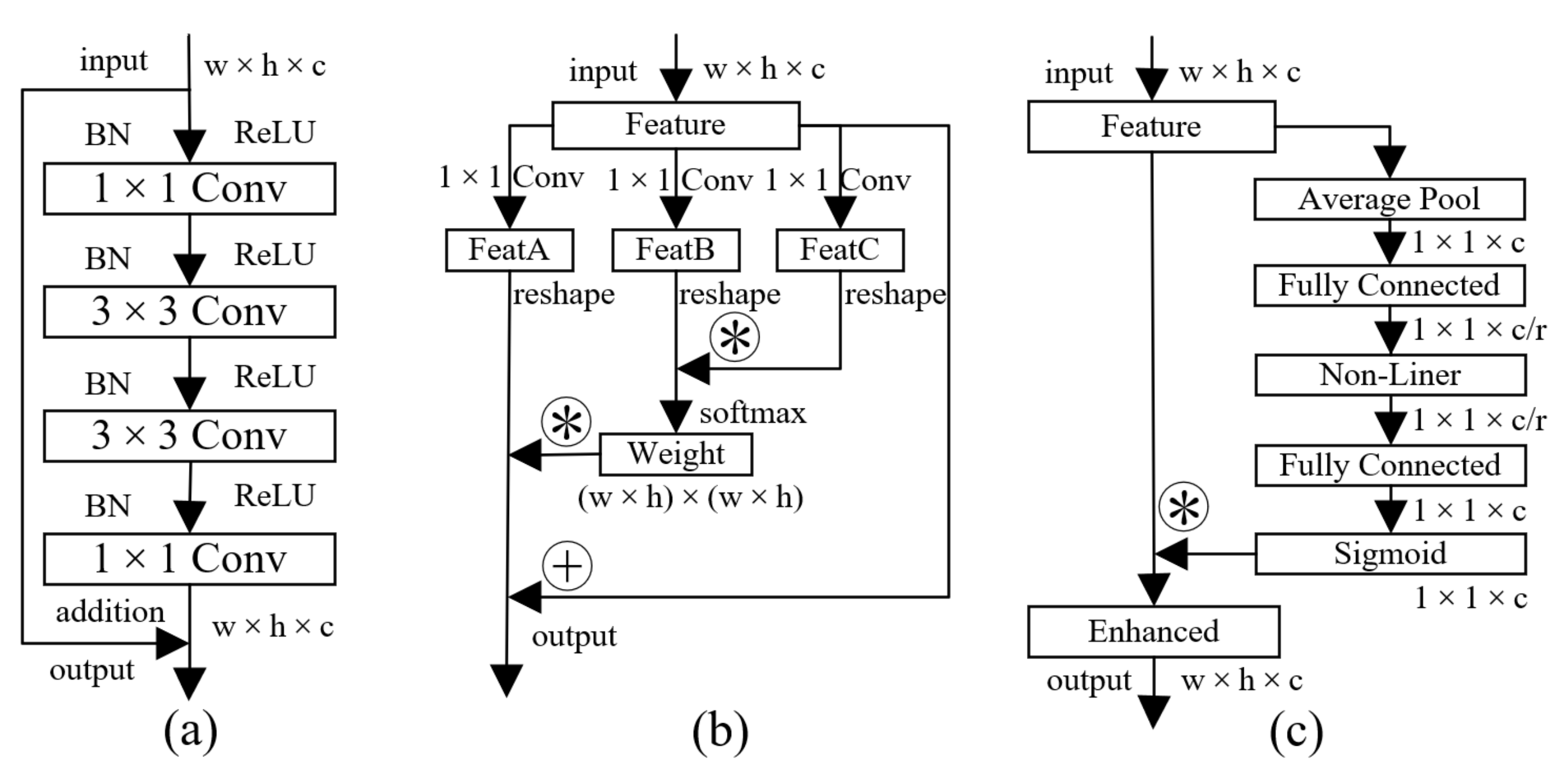
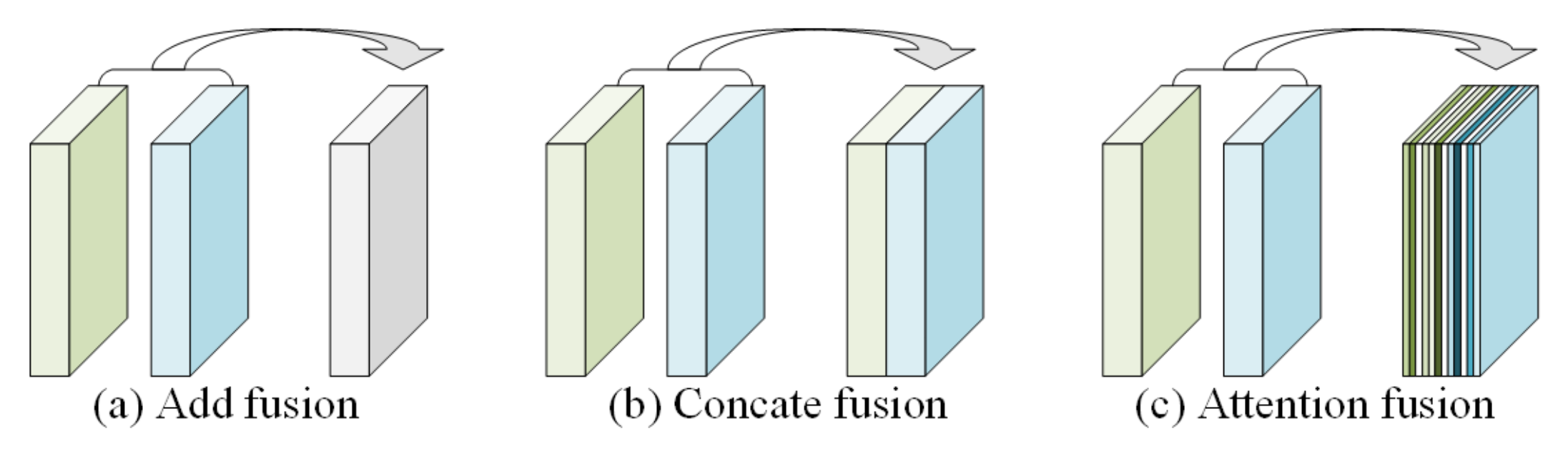
3.2. Cascaded Attention Feature Enhancement
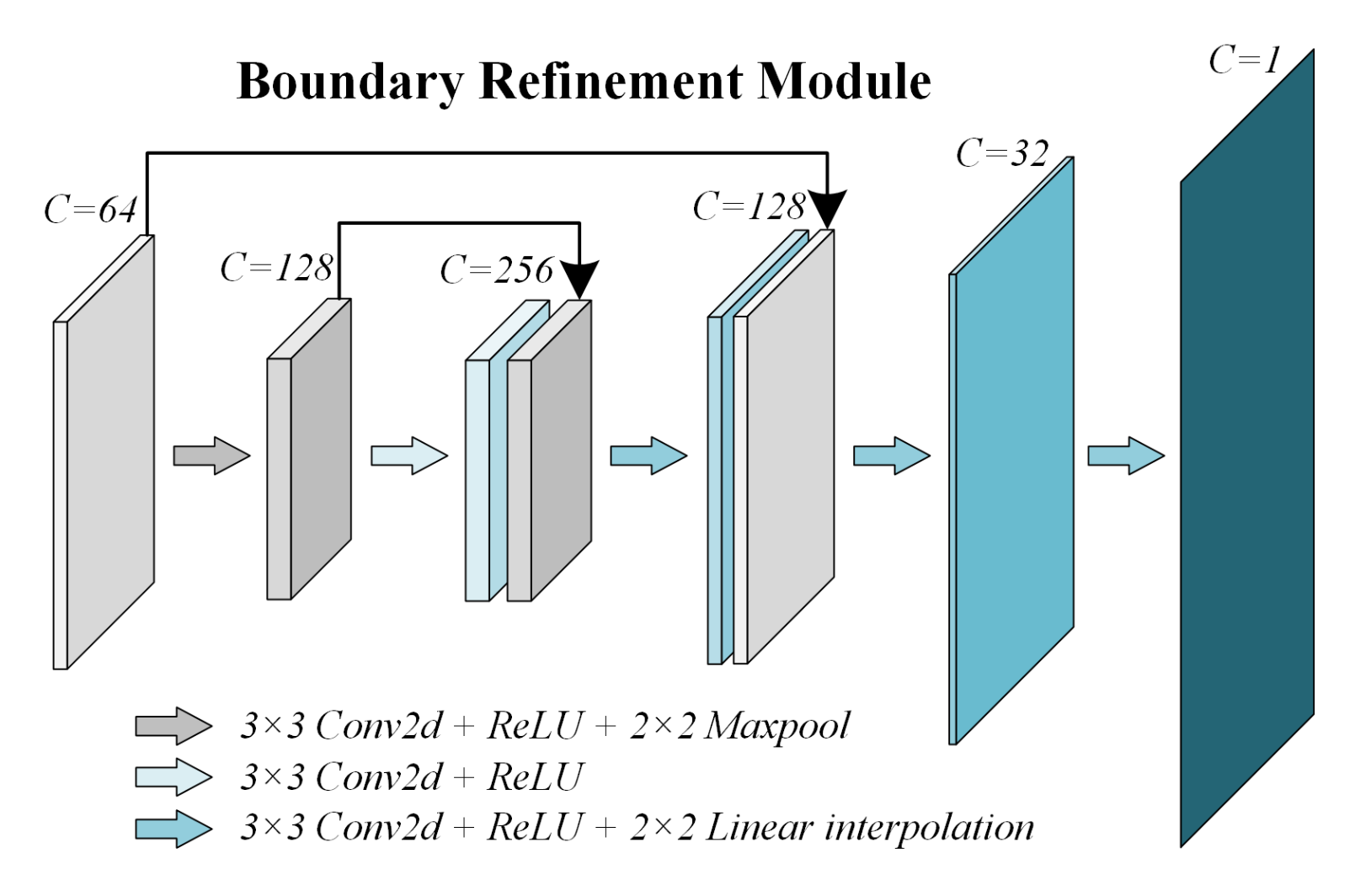
3.3. Coarse-to-Fine Boundary Optimization
3.4. Evaluation Metrics
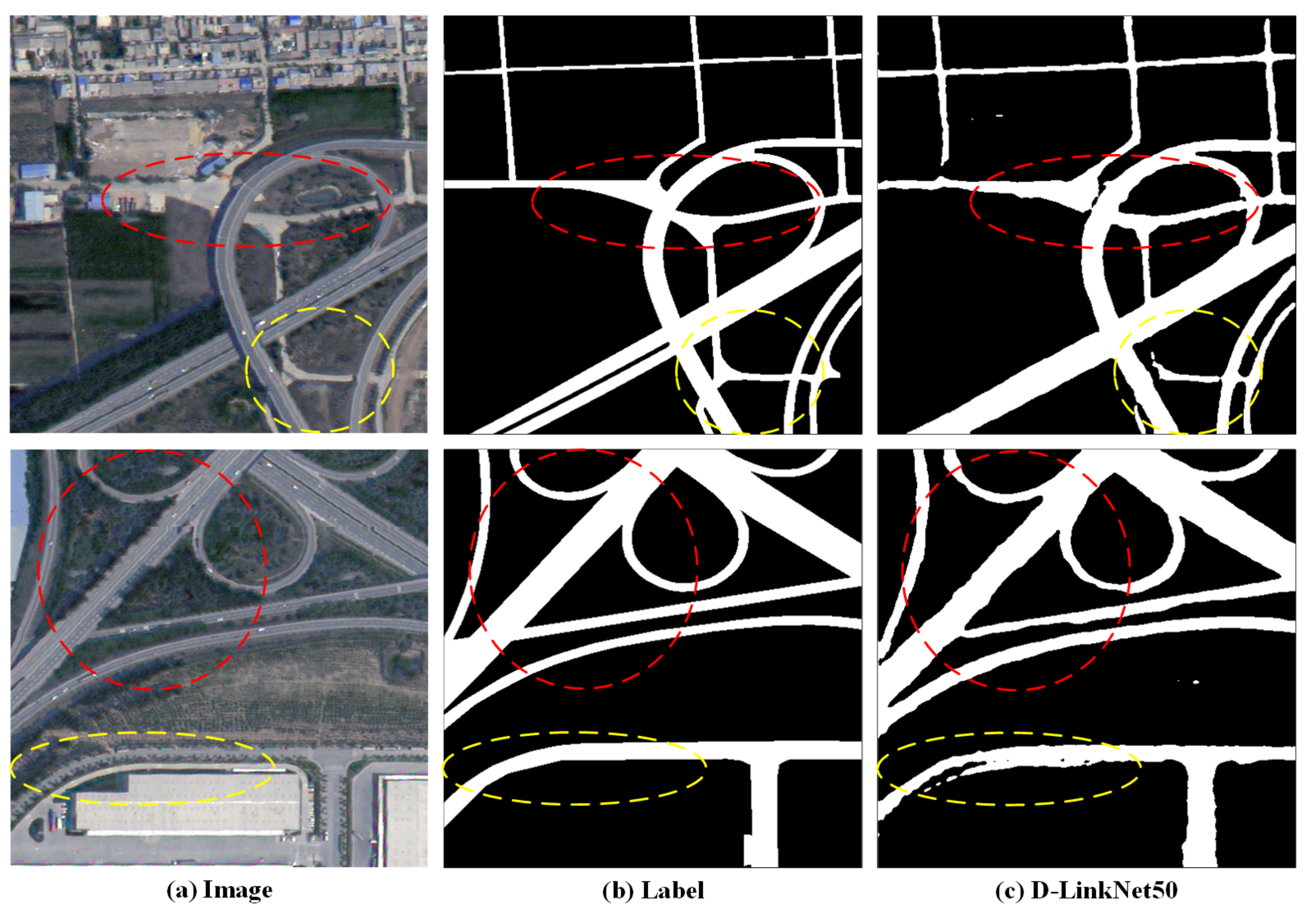
4. Experiments and Results
4.1. Datasets and Strategies
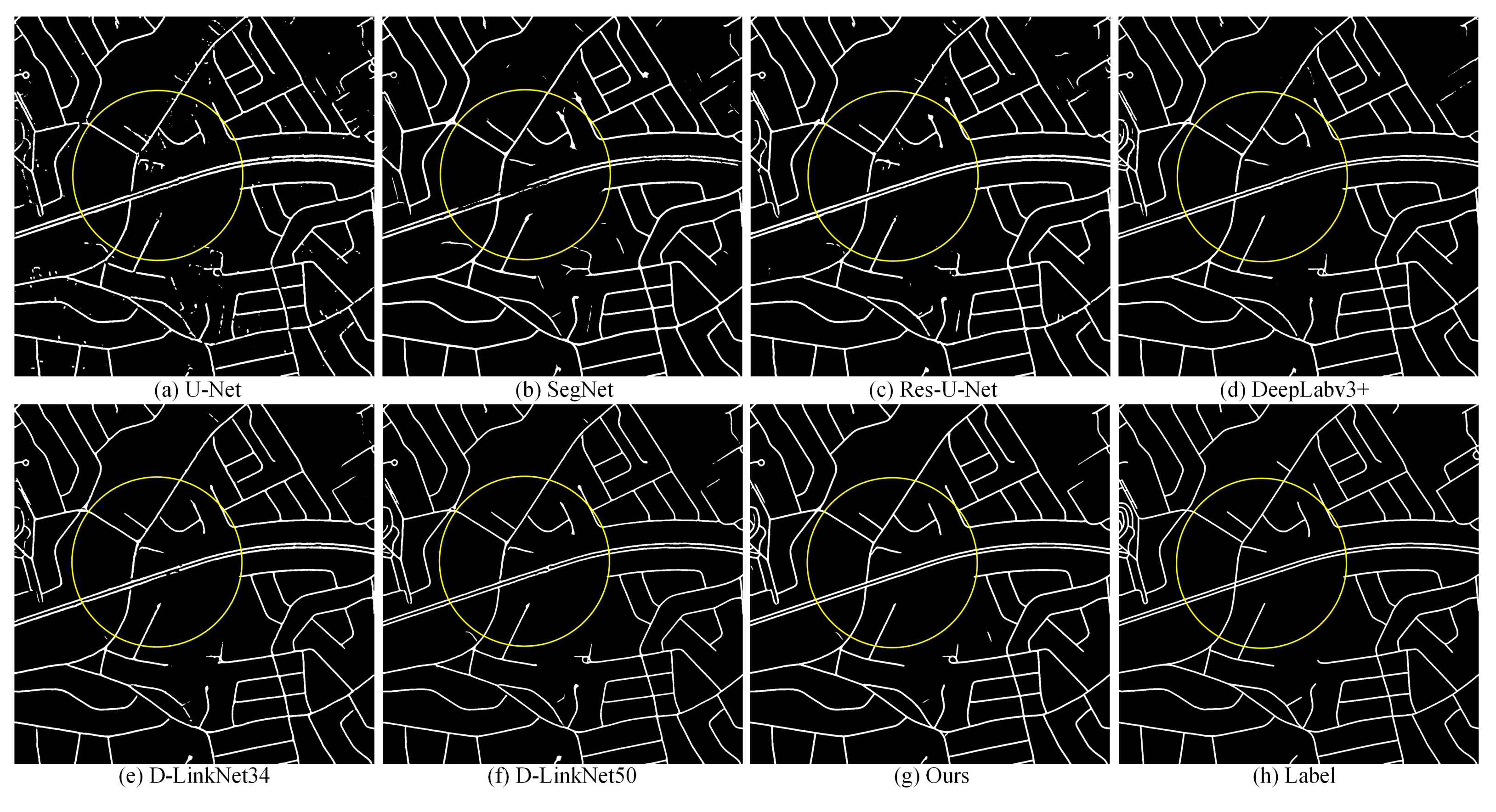
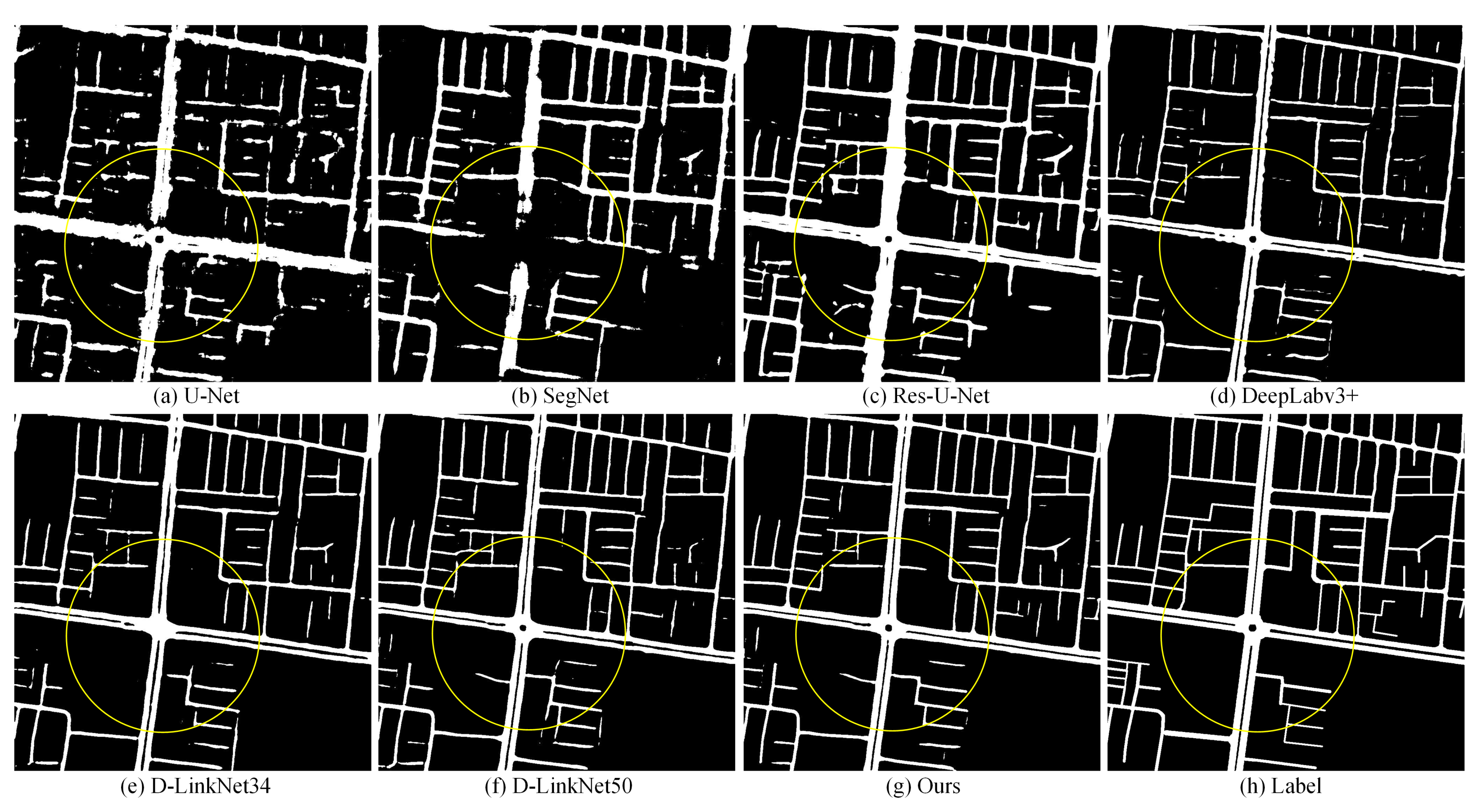
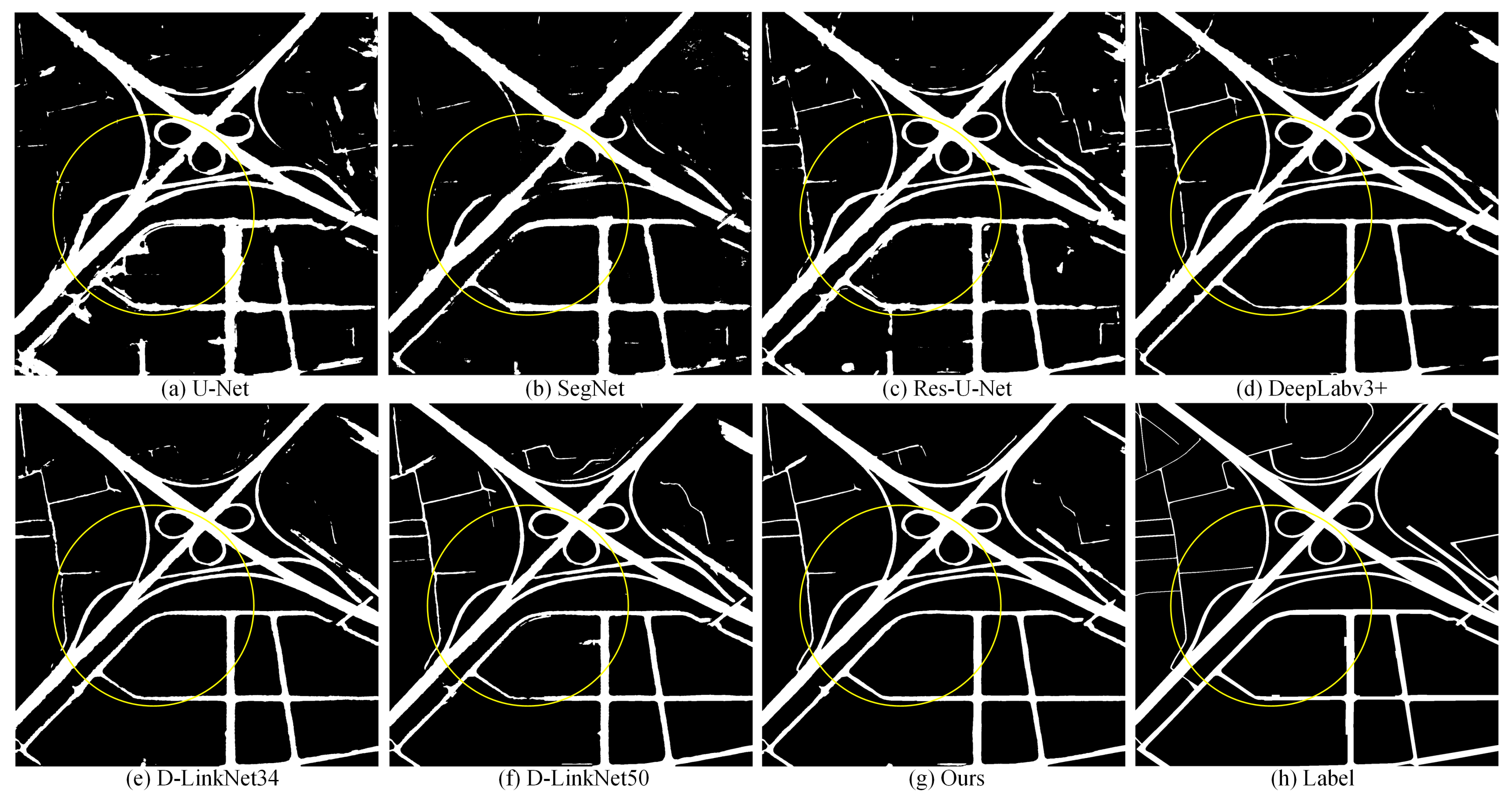
4.2. Performance on Massachusetts
4.3. Performance on DeepGlobe
4.4. Performance on Huawei Cloud
4.5. Ablation Study
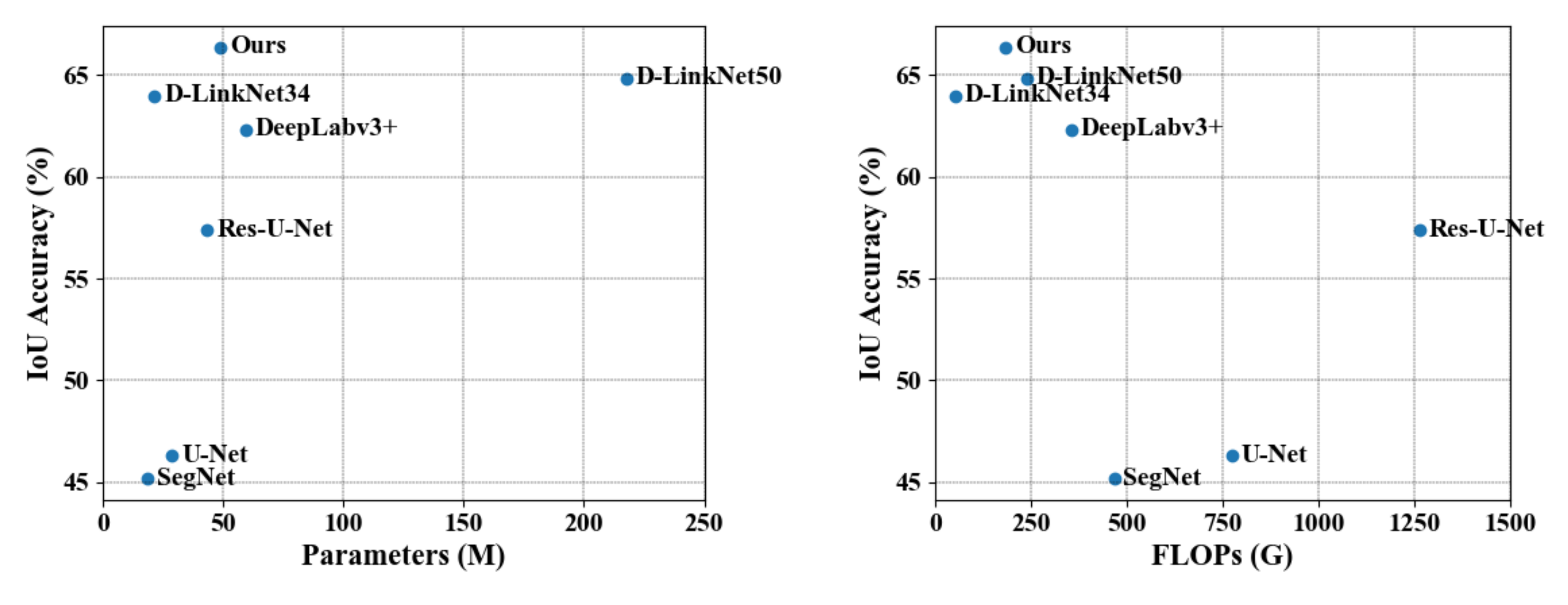
4.6. Efficiency Comparison
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. (Engl. Ed.) 2016, 3, 271–282. [Google Scholar] [CrossRef] [Green Version]
- Miao, Z.; Shi, W.; Gamba, P.; Li, Z. An Object-Based Method for Road Network Extraction in VHR Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4853–4862. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-of-the-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road Extraction Methods in High-Resolution Remote Sensing Images: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Chen, L.; Zhu, Q.; Xie, X.; Hu, H.; Zeng, H. Road Extraction from VHR Remote-Sensing Imagery via Object Segmentation Constrained by Gabor Features. ISPRS Int. J. Geo-Inf. 2018, 7, 362. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018; Series Title: Lecture Notes in Computer, Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 833–851. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road Extraction by Using Atrous Spatial Pyramid Pooling Integrated Encoder-Decoder Network and Structural Similarity Loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Mu, X.; Yang, D.; He, H.; Zhao, P. Road Extraction from Remote Sensing Images Using the Inner Convolution Integrated Encoder-Decoder Network and Directional Conditional Random Fields. Remote Sens. 2021, 13, 465. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Liu, Y.; Zhao, J.; Ma, A.; Yang, J. Multi-scale and multi-task deep learning framework for automatic road extraction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9362–9377. [Google Scholar] [CrossRef]
- Ding, L.; Bruzzone, L. DiResNet: Direction-Aware Residual Network for Road Extraction in VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 1–12. [Google Scholar] [CrossRef]
- Wu, Q.; Luo, F.; Wu, P.; Wang, B.; Yang, H.; Wu, Y. Automatic Road Extraction from High-Resolution Remote Sensing Images Using a Method Based on Densely Connected Spatial Feature-Enhanced Pyramid. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3–17. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, J.; Zhu, Q.; Xie, Y.; Li, W.; Fu, L.; Zhang, J.; Tan, J. The construction of personalized virtual landslide disaster environments based on knowledge graphs and deep neural networks. Int. J. Digit. Earth 2020, 13, 1637–1655. [Google Scholar] [CrossRef]
- Buslaev, A.; Seferbekov, S.; Iglovikov, V.; Shvets, A. Fully Convolutional Network for Automatic Road Extraction from Satellite Imagery. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 197–1973. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; DeWitt, D. RoadTracer: Automatic Extraction of Road Networks from Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 4720–4728. [Google Scholar] [CrossRef] [Green Version]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Shi, W.; Miao, Z.; Debayle, J. An Integrated Method for Urban Main-Road Centerline Extraction From Optical Remotely Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3359–3372. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, L.; Hu, H.; Pirasteh, S.; Li, H.; Xie, X. Unsupervised Feature Learning to Improve Transferability of Landslide Susceptibility Representations. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3917–3930. [Google Scholar] [CrossRef]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multiple Attending Path Neural Network for Building Footprint Extraction From Remote Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6169–6181. [Google Scholar] [CrossRef]
- Liao, C.; Hu, H.; Li, H.; Ge, X.; Chen, M.; Li, C.; Zhu, Q. Joint Learning of Contour and Structure for Boundary-Preserved Building Extraction. Remote Sens. 2021, 13, 1049. [Google Scholar] [CrossRef]
- Xie, Y.; Miao, F.; Zhou, K.; Peng, J. HsgNet: A road extraction network based on global perception of high-order spatial information. ISPRS Int. J. Geo-Inf. 2019, 8, 571. [Google Scholar] [CrossRef] [Green Version]
- Ding, C.; Weng, L.; Xia, M.; Lin, H. Non-Local Feature Search Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int. J. Geo-Inf. 2021, 10, 245. [Google Scholar] [CrossRef]
- Zhao, X.; Tao, R.; Li, W.; Philips, W.; Liao, W. Fractional Gabor Convolutional Network for Multisource Remote Sensing Data Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Series Title: Lecture Notes in Computer, Science; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote. Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Xin, J.; Zhang, X.; Zhang, Z.; Fang, W. Road Extraction of High-Resolution Remote Sensing Images Derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Wang, C.; Li, J.; Xie, N.; Han, Y.; Du, J. Reconstruction Bias U-Net for Road Extraction From Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2284–2294. [Google Scholar] [CrossRef]
- Ren, Y.; Yu, Y.; Guan, H. DA-CapsUNet: A dual-attention capsule U-Net for road extraction from remote sensing imagery. Remote Sens. 2020, 12, 2866. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Zhu, T.; Wang, Y.; Ma, R.; Fang, X. Road Extraction from High-Resolution Satellite Images Based on Multiple Descriptors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 227–240. [Google Scholar] [CrossRef]
- Wang, S.; Yang, H.; Wu, Q.; Zheng, Z.; Wu, Y.; Li, J. An Improved Method for Road Extraction from High-Resolution Remote-Sensing Images that Enhances Boundary Information. Sensors 2020, 20, 2064. [Google Scholar] [CrossRef] [Green Version]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. A Higher-Order CRF Model for Road Network Extraction. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; IEEE: Portland, OR, USA, 2013; pp. 1698–1705. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, Z.; Fan, W.; Zhong, B.; Li, J.; Du, J.; Wang, C. Corse-to-fine road extraction based on local Dirichlet mixture models and multiscale-high-order deep learning. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4283–4293. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, Z.; Zang, Y.; Wang, C.; Li, J.; Li, X. Topology-Aware Road Network Extraction via Multi-Supervised Generative Adversarial Networks. Remote Sens. 2019, 11, 1017. [Google Scholar] [CrossRef] [Green Version]
- Zhou, M.; Sui, H.; Chen, S.; Wang, J.; Chen, X. BT-RoadNet: A boundary and topologically-aware neural network for road extraction from high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 168, 288–306. [Google Scholar] [CrossRef]
- Sghaier, M.O.; Lepage, R. Road Extraction From Very High Resolution Remote Sensing Optical Images Based on Texture Analysis and Beamlet Transform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1946–1958. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R. Hierarchical graph-based segmentation for extracting road networks from high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2017, 126, 245–260. [Google Scholar] [CrossRef]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.; Paluri, M. Improved Road Connectivity by Joint Learning of Orientation and Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 10377–10385. [Google Scholar] [CrossRef]
- Tan, Y.Q.; Gao, S.H.; Li, X.Y.; Cheng, M.M.; Ren, B. VecRoad: Point-Based Iterative Graph Exploration for Road Graphs Extraction. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 8907–8915. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 3141–3149. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 7794–7803. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A Dual-Attention Network for Road Extraction from High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y.; Zhang, Y.; Zhang, Y. Cascaded Attention DenseUNet (CADUNet) for Road Extraction from Very-High-Resolution Images. ISPRS Int. J. Geo-Inf. 2021, 10, 329. [Google Scholar] [CrossRef]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic Segmentation using Adversarial Networks. arXiv 2016, arXiv:1611.08408. [Google Scholar]
- Costea, D.; Marcu, A.; Leordeanu, M.; Slusanschi, E. Creating Roadmaps in Aerial Images with Generative Adversarial Networks and Smoothing-Based Optimization. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy, 2017; pp. 2100–2109. [Google Scholar] [CrossRef]
- Zhang, X.; Han, X.; Li, C.; Tang, X.; Zhou, H.; Jiao, L. Aerial Image Road Extraction Based on an Improved Generative Adversarial Network. Remote Sens. 2019, 11, 930. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 192–1924. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 172–17209. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Stanford, CA, USA, 2016; pp. 565–571. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Ottawa, ON, Canada, 2013. [Google Scholar]
- Huawei Cloud Road Extraction Challenge 2020. Available online: https://competition.huaweicloud.com/information/1000041322/introduction (accessed on 26 December 2021).
- Geng, K.; Sun, X.; Yan, Z.; Diao, W.; Gao, X. Topological Space Knowledge Distillation for Compact Road Extraction in Optical Remote Sensing Images. Remote Sens. 2020, 12, 3175. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y. JointNet: A Common Neural Network for Road and Building Extraction. Remote Sens. 2019, 11, 696. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) |
|---|---|---|---|---|
| U-Net | 77.71 | 66.09 | 71.19 | 55.66 |
| SegNet | 78.89 | 67.73 | 72.25 | 57.02 |
| Res-U-Net | 80.76 | 71.49 | 75.69 | 61.21 |
| DeepLabv3+ | 75.47 | 77.97 | 76.43 | 62.25 |
| D-LinkNet34 | 72.77 | 79.53 | 75.75 | 61.35 |
| D-LinkNet50 | 73.38 | 82.66 | 77.51 | 63.63 |
| Ours | 80.04 | 79.35 | 79.52 | 66.27 |
| Methods | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) |
|---|---|---|---|---|
| TSKD-Road [60] | 69.85 | 79.38 | 74.15 | 59.16 |
| CDG [36] | 81.41 | 71.80 | 76.10 | 61.90 |
| DGRN [12] | 81.84 | 71.97 | 76.59 | 62.48 |
| JointNet [61] | 85.36 | 71.90 | 78.05 | 64.00 |
| RB-UNET [12] | 79.14 | 78.53 | 78.83 | 65.06 |
| Ours | 80.04 | 79.35 | 79.52 | 66.27 |
| Methods | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) |
|---|---|---|---|---|
| U-Net | 75.13 | 55.53 | 62.00 | 46.30 |
| SegNet | 54.45 | 76.38 | 60.00 | 45.45 |
| Res-U-Net | 84.97 | 64.13 | 71.95 | 57.36 |
| DeepLabv3+ | 78.20 | 76.24 | 75.69 | 62.33 |
| D-LinkNet34 | 77.74 | 78.65 | 77.04 | 63.98 |
| D-LinkNet50 | 80.18 | 77.46 | 77.72 | 64.85 |
| Ours | 79.12 | 80.39 | 78.75 | 66.38 |
| Methods | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) |
|---|---|---|---|---|
| U-Net | 60.48 | 66.01 | 61.35 | 46.25 |
| SegNet | 51.34 | 70.54 | 58.43 | 42.90 |
| Res-U-Net | 71.54 | 65.07 | 67.45 | 52.07 |
| DeepLabv3+ | 72.28 | 69.59 | 70.20 | 55.57 |
| D-LinkNet34 | 73.70 | 68.35 | 70.35 | 55.72 |
| D-LinkNet50 | 73.27 | 70.44 | 71.26 | 56.83 |
| Ours | 74.16 | 71.91 | 72.36 | 57.93 |
| Methods | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) |
|---|---|---|---|---|
| BaseLine | 80.18 | 77.46 | 77.72 | 64.85 |
| BaseLine+Att_B | 79.95 | 78.94 | 78.25 | 65.69 |
| BaseLine+Ref_B | 81.68 | 76.82 | 78.28 | 65.62 |
| Ours | 79.12 | 80.39 | 78.75 | 66.38 |
| Methods | Parameters (M) | FLOPs (%) | IoU (%) |
|---|---|---|---|
| U-Net | 28.94 | 774.09 | 46.30 |
| SegNet | 18.82 | 467.52 | 45.17 |
| Res-U-Net | 43.57 | 1263.01 | 57.36 |
| DeepLabv3+ | 59.34 | 354.97 | 62.33 |
| D-LinkNet34 | 21.64 | 54.70 | 63.98 |
| D-LinkNet50 | 217.65 | 240.36 | 64.85 |
| Ours | 49.18 | 184.31 | 66.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Liao, C.; Ding, Y.; Hu, H.; Jia, Y.; Chen, M.; Xu, B.; Ge, X.; Liu, T.; Wu, D. Cascaded Residual Attention Enhanced Road Extraction from Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2022, 11, 9. https://doi.org/10.3390/ijgi11010009
Li S, Liao C, Ding Y, Hu H, Jia Y, Chen M, Xu B, Ge X, Liu T, Wu D. Cascaded Residual Attention Enhanced Road Extraction from Remote Sensing Images. ISPRS International Journal of Geo-Information. 2022; 11(1):9. https://doi.org/10.3390/ijgi11010009
Chicago/Turabian StyleLi, Shengfu, Cheng Liao, Yulin Ding, Han Hu, Yang Jia, Min Chen, Bo Xu, Xuming Ge, Tianyang Liu, and Di Wu. 2022. "Cascaded Residual Attention Enhanced Road Extraction from Remote Sensing Images" ISPRS International Journal of Geo-Information 11, no. 1: 9. https://doi.org/10.3390/ijgi11010009
APA StyleLi, S., Liao, C., Ding, Y., Hu, H., Jia, Y., Chen, M., Xu, B., Ge, X., Liu, T., & Wu, D. (2022). Cascaded Residual Attention Enhanced Road Extraction from Remote Sensing Images. ISPRS International Journal of Geo-Information, 11(1), 9. https://doi.org/10.3390/ijgi11010009