
Automatic Identification of Addresses: A Systematic Literature Review




Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Sources and Search Strategies
2.2. Screening Procedures
- Exclusion of reviews, book chapters, reports, and other duplicates (e.g.,: articles published as book chapters in the Springer series “Studies in Computational Intelligence”);
- Exclusion of conferences not ranked as “A” (as of April 2021), according to the conference ranking provided in http://www.conferenceranks.com/ (accessed on 9 November 2021) (e.g.,: International Conference on Natural Computation);
- Exclusion of journals not ranked as Q1 or Q2 (as of April 2021), according to the SCImago Journal Rank indicator (https://www.scimagojr.com/ (accessed on 9 November 2021)) (e.g.,: Russian Journal of Forest Science);
- Exclusion of articles which were not in the scope of the research (e.g.,: articles dealing with inputs not related to addresses).
2.3. Tools
3. Results and Discussion
3.1. Results
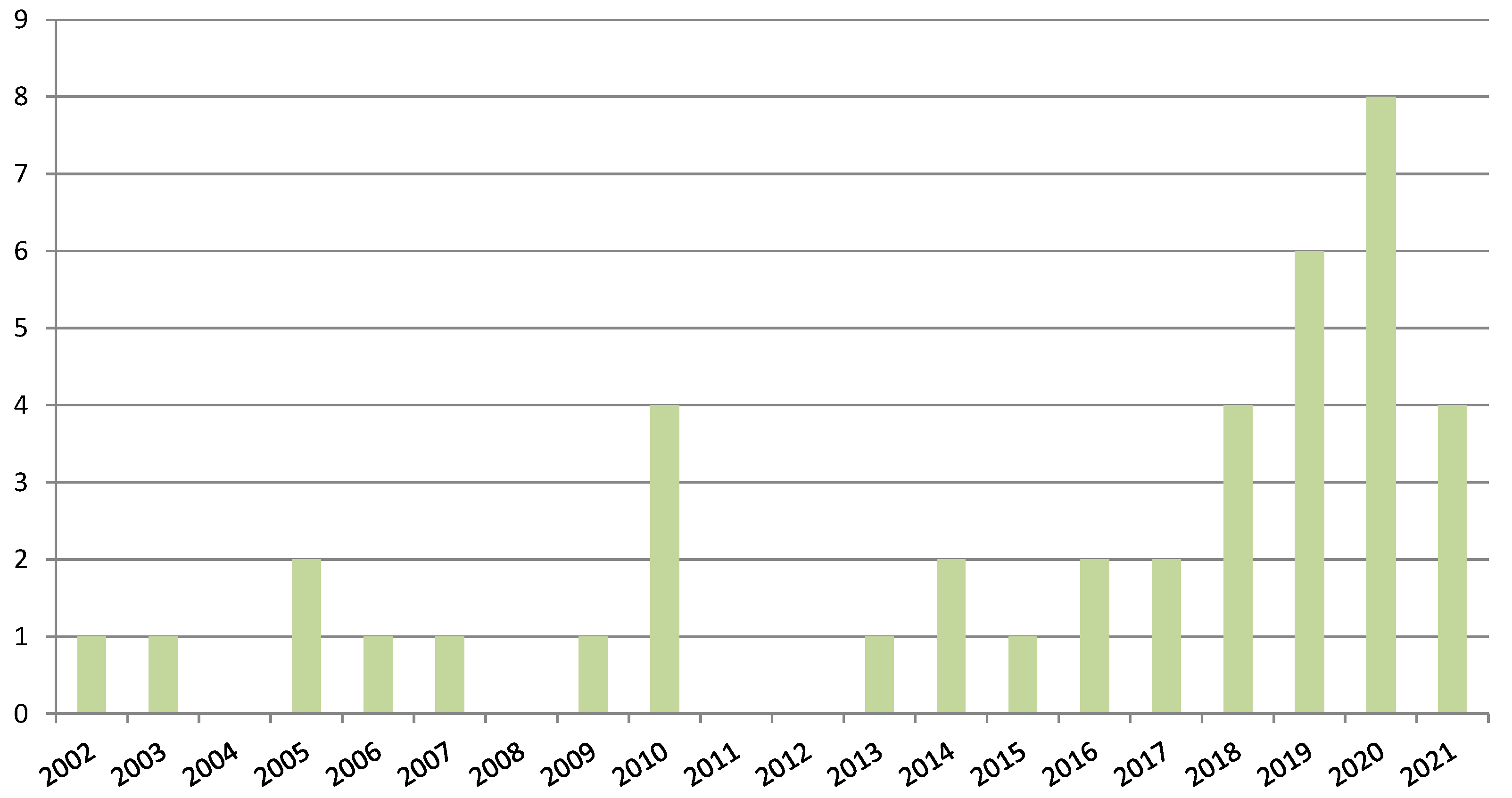
3.1.1. Publication Venues of the Selected Papers
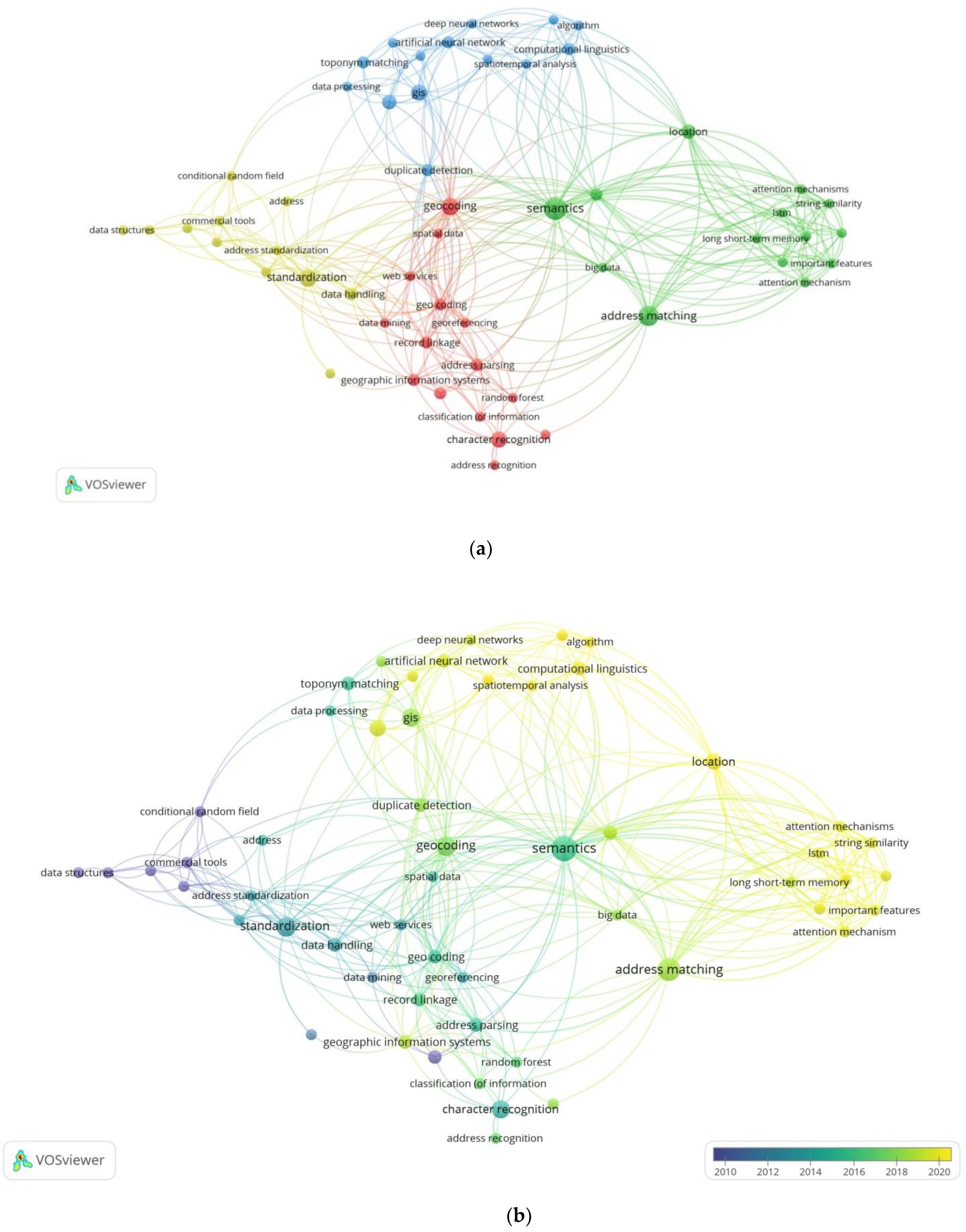
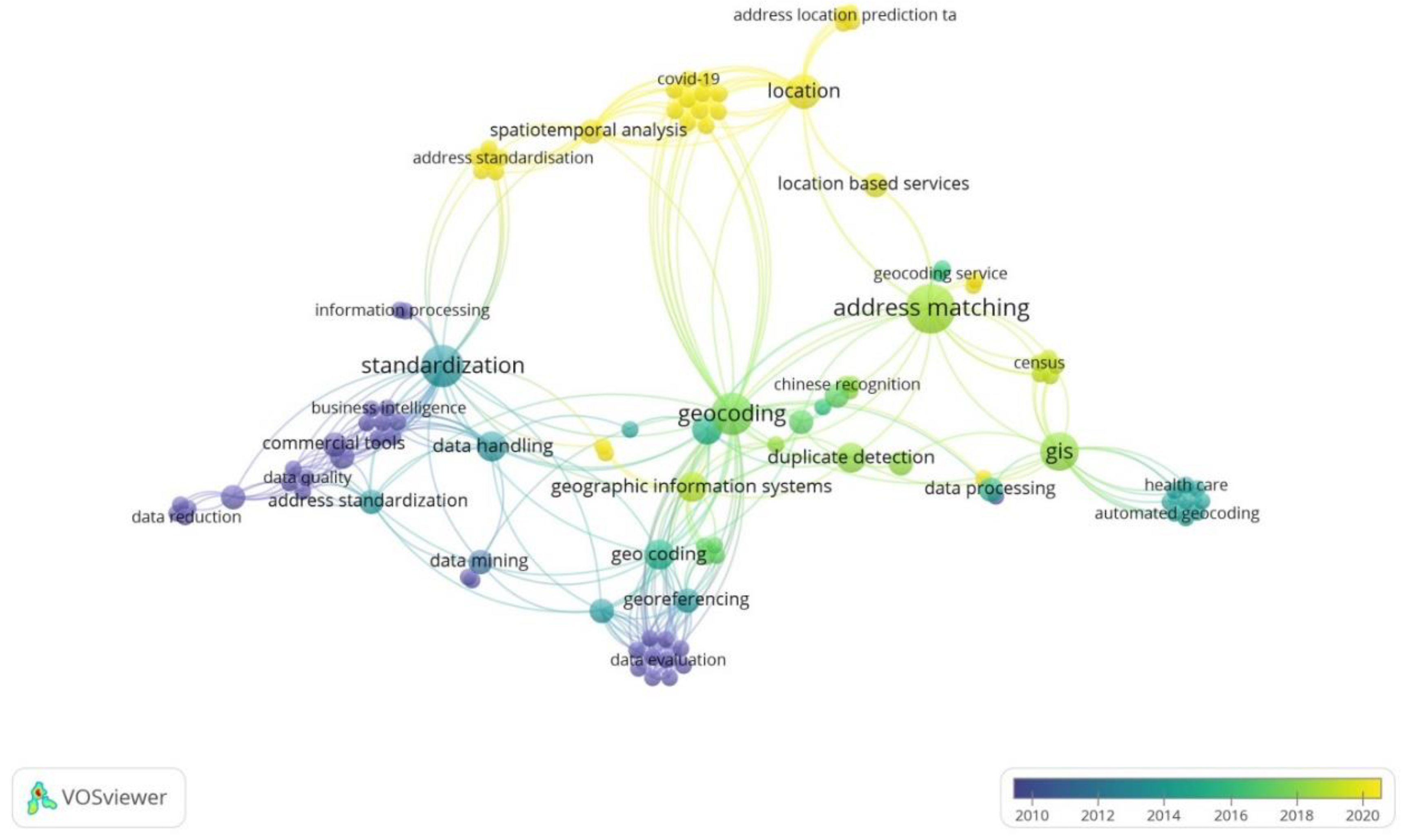
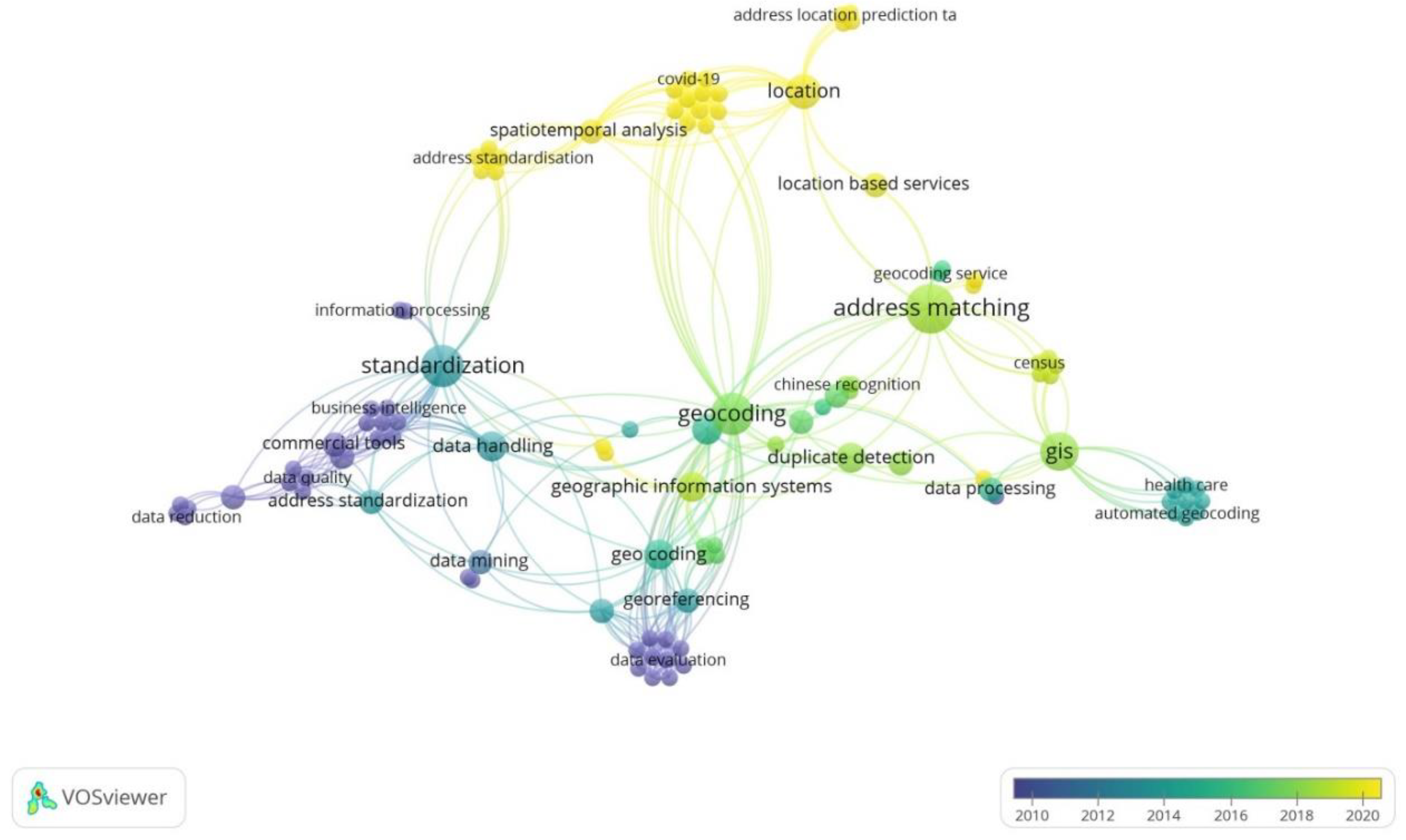
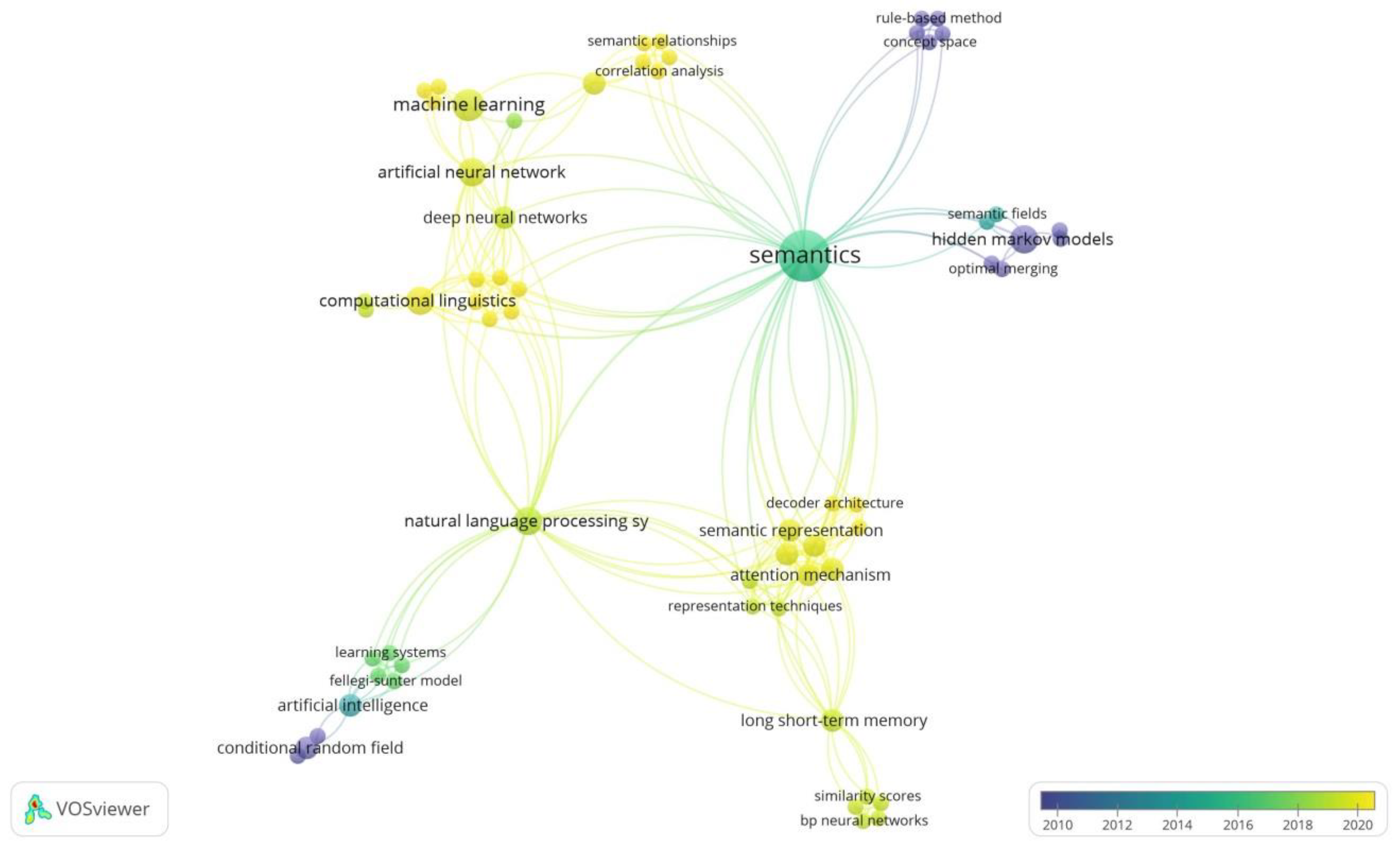
3.1.2. Keyword Occurrence Analysis
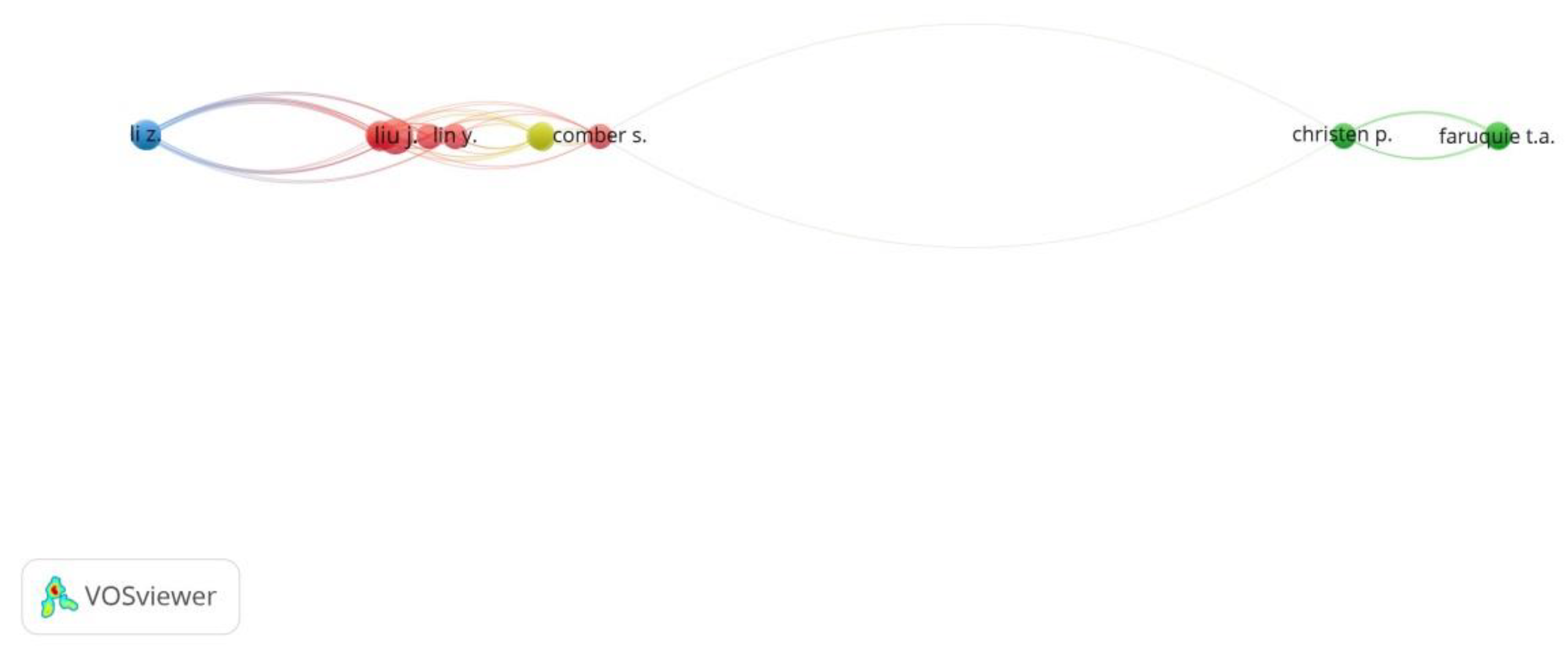
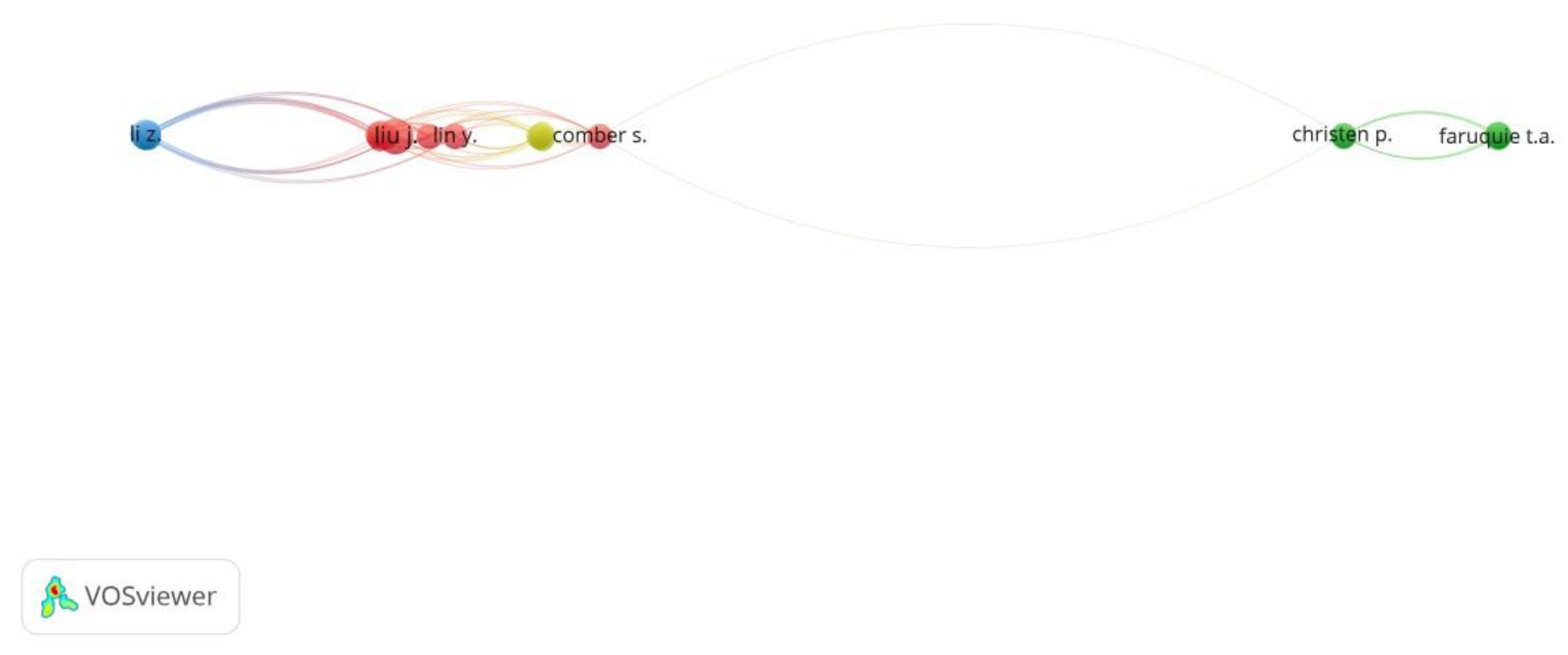
3.1.3. Co-Authorship Analysis
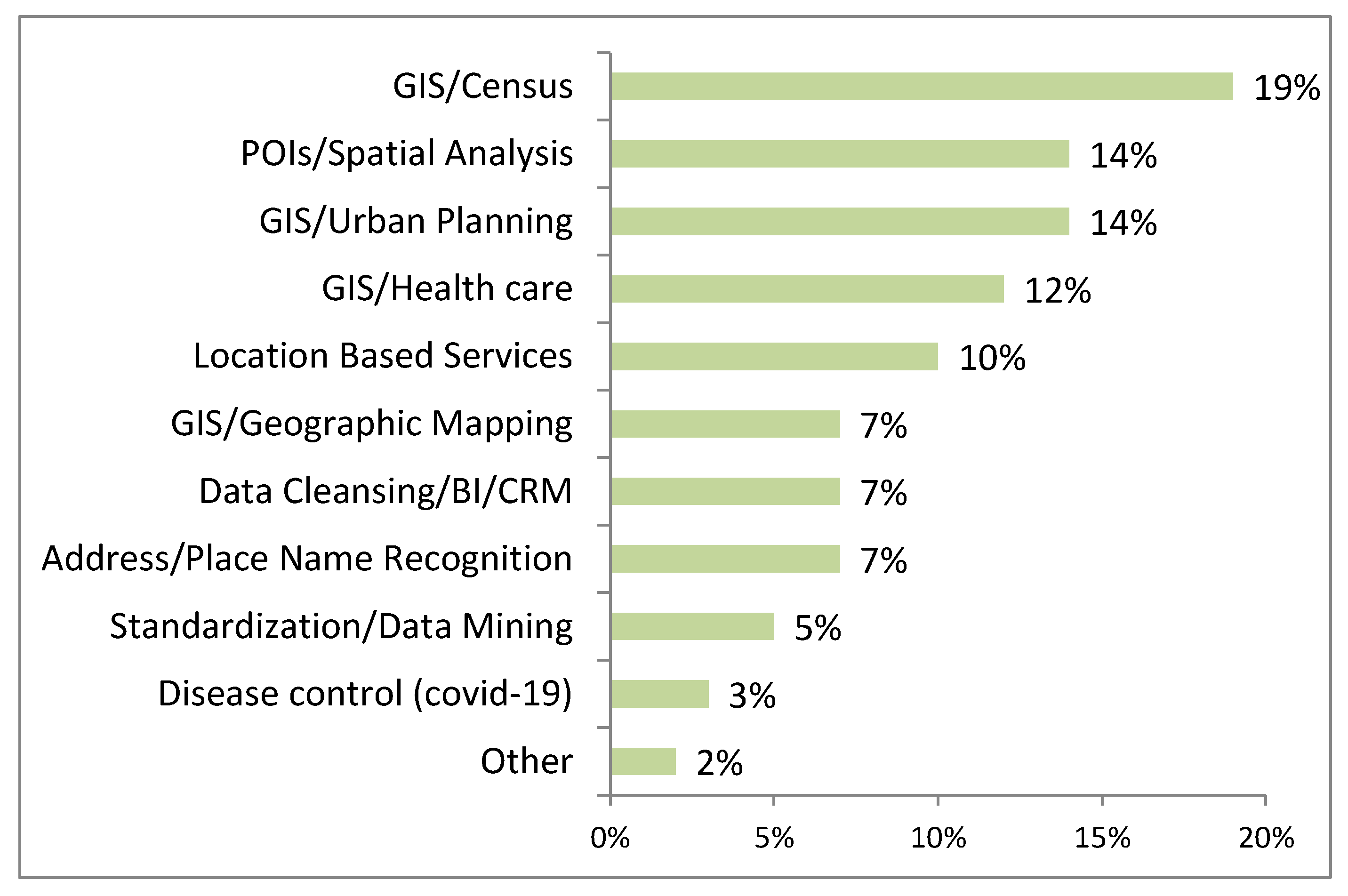
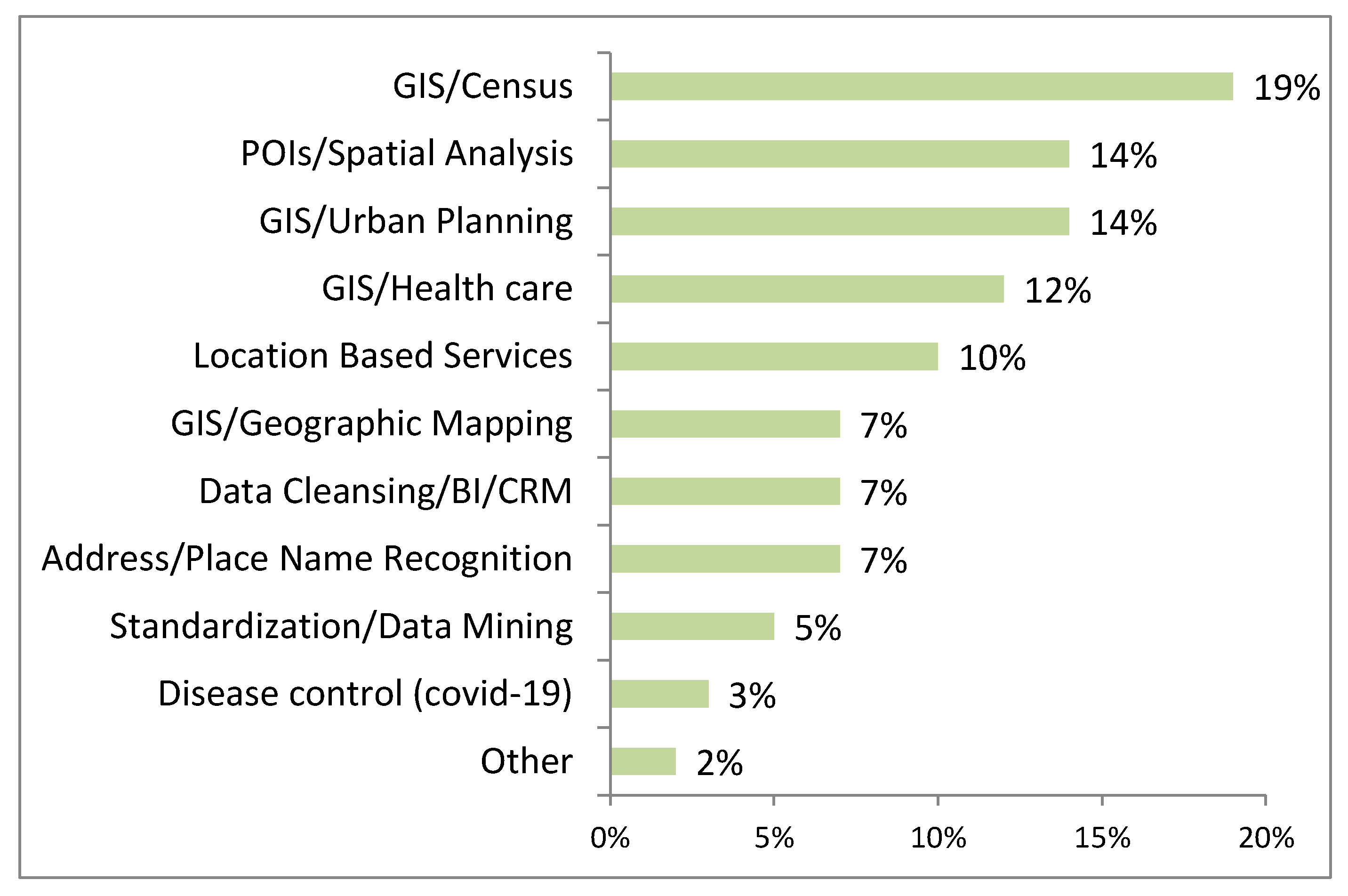
3.1.4. Application and Methods Analysis
3.2. Discussion and Future Research
3.2.1. Detailed Literature Review
- An input encoding layer, that encodes the input address vectors and extracts higher-level representations using the bidirectional long short-term memory (BiLSTM) model;
- A local inference modelling layer, that makes local inference of an address pair using a modified decomposable attention model [72];
- An inference composition layer, responsible for making a global inference between two compared address records based on their local inference, in which average and max pooling are used to summarize the local inference and output a final vector with a fixed length;
- Finally, a prediction layer, based on a multilayer perceptron (MLP) composed of three fully connected layers with rectified linear unit (ReLU), tanh and softmax activation functions, is used to output the predictive results of address pairs (that is, whether there is a match or not).
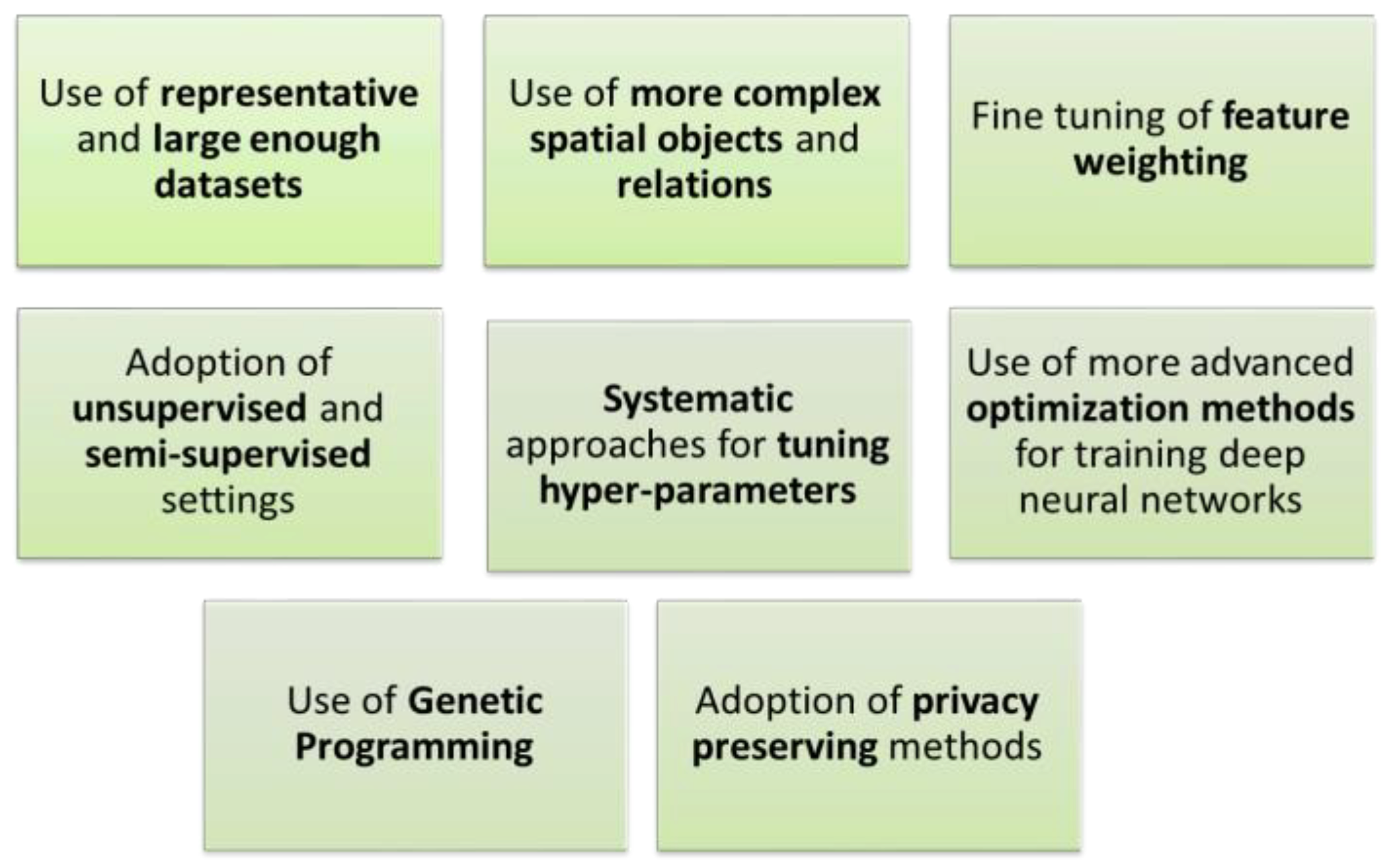
3.2.2. Research Gaps
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Application and Methods’ Analysis
| Id. [Ref.] | Authors, Pub. Year | Application | Methods |
| 1 [9] | Lin et al., 2019 | Geocoding | Word2vec; bi-directional LSTM (ESIM model) |
| 2 [52] | Fu et al., 2005 | Handwritten address character string segmentation and recognition | Hidden Markov Model (HMM) |
| 3 [55] | Dani et al., 2010 | Address standardization; data quality improvement | Ripple Down Rules (RDR); conditional random field (CRF) |
| 4 [51] | Christen et al., 2006 | Geocoding | Learning address parser based on hidden Markov models and a rule-based matching engine |
| 5 [62] | Jiang et al., 2007 | Address recognition system | Suffix tree based system |
| 6 [75] | Song, 2013 | Location-based services | Natural language understanding |
| 7 [61] | Guo et al., 2009 | Address standardization | Free-text address standardization method with latent semantic association (LaSA). |
| 8 [69] | P. Li et al., 2020 | Geocoding | Bidirectional gated recurrent unit (GRU) neural network |
| 9 [27] | Walford, 2019 | Geocoding historical census records | Four-stage semi-automated method to geocode historical census addresses |
| 10 [76] | Verma and Kaur, 2015 | Character recognition from handwritten document | Neural Networks |
| 11 [58] | J. Liu et al., 2019 | Financial anti-fraud | LM-LSTM-CRF |
| 12 [77] | Choi et al., 2017 | Probabilistic record linkage; Entity resolution | Similarity functions (ex. Jaro-Winkler); Fellegi-Sunter model |
| 13 [29] | Shan et al., 2019 | Location-based services | Encode-decoder architecture with two LSTM networks and an attention mechanism |
| 14 [54] | Comber, 2019 | Spatial socio-economic applications | CRF; string similarity functions; Random Forest |
| 15 [28] | Shah et al., 2014 | Geocoding for public health research | Geocoding methods |
| 16 [57] | Weinman, 2017 | Historical Map Alignment and Toponym Recognition | Semi-Markov CRF text recognizer; Caffe-based CNN |
| 17 [7] | Shan et al., 2020 | Location-based services | Encode-decoder architecture with two LSTM networks and an attention mechanism; GCN |
| 18 [20] | Xu et al., 2020 | Management and application of non-standard addresses | Bidirectional encoder representations from Transformers (BERT); high-dimensional clustering algorithm to fuse semantic and geospatial information |
| 19 [64] | Q. Liu et al., 2018 | Handwritten address character string recognition | Deep neural network for character recognition (CNNs); domain specific knowledge for address recognition |
| 20 [40] | X. Li et al., 2014 | Record linkage | HMM |
| 21 [1] | Javidaneh et al., 2020 | Evaluate the influence of formal addressing systems on spatial knowledge acquisition | Agent-based simulation of spatial knowledge acquisition |
| 22 [5] | Lee et al., 2020 | Geocoding | Regex for address parsing; support vector machine (SVM), random forest (RF), extreme gradient boosting (XGB) for address matching |
| 23 [44] | Santos et al., 2017 | Geographical information retrieval | 13 different string similarity metrics; supervised machine learning methods for combining the scores (Support Vector Machines, Random Forests, Extremely Randomized Trees, Gradient Boosted Trees) |
| 24 [3] | Comber and Arribas-Bel, 2019 | Record linkage | word2vec; CRFs |
| 25 [65] | H. Li et al., 2019 | Parsing of non-standard addresses | Neural structured prediction models with latent variables (latent tree structures and regular chain structures) |
| 26 [6] | Churches et al., 2002 | Record linkage | HMM |
| 27 [37] | Zhang et al., 2020 | Location-based services | BERT; CRF |
| 28 [22] | Wei et al., 2016 | Recognition of handwritten non-standard address | Word-level-tree (WLT) based method |
| 29 [56] | Tang et al., 2010 | Toponym resolution | Geo-parsing approach based on CRF; geo-coding approach based on partial fuzzy matching |
| 30 [78] | Nagabhushan et al., 2005 | Postal automation | Symbolic knowledge base supported address validation system |
| 31 [35] | Santos et al., 2018 | Toponym recognition | Bidirectional GRUs |
| 32 [59] | Kothari et al., 2010 | Address cleansing (with transfer of supervision) | Hierarchical Dirichlet process |
| 33 [63] | Tian et al., 2016 | Geocoding | Address tree model; Lucene fuzzy matching |
| 34 [21] | Peng et al., 2020 | COVID-19 Epidemic Prevention and Control | Word segmentation weighted address matching algorithm considering a variety of semantics |
| 35 [8] | Luo et al., 2021 | Address standardization of POIs | GRU; spatial correlation |
| 36 [70] | Chen et al., 2021 | Address semantic matching | Attention-Bi-LSTM-CNN |
| 37 [66] | Koumarelas et al., 2018 | Enhancing address matching | CRF; geocoding; similarity measures |
| 38 [68] | Cortes et al., 2021 | Improving geocoding matching rates of structured addresses | Regular expressions and dictionary-based methods for address standardization and enrichment; geocoding |
| 39 [67] | Cayo and Talbot, 2003 | Evaluation of positional error in automated geocoding of residential addresses | GIS |
| 40 [2] | Cheng et al., 2021 | Locating POIs in large datasets | Combination of multiple similarities (string, semantic and spatial); grid-based spatial reasoning algorithm |
| 41 [79] | Florczyk et al., 2010 | Urban management | Compound geocoding architecture, based on gazetteers, cadastral services and address geocoding services |
References
- Javidaneh, A.; Karimipour, F.; Alinaghi, N. How Much Do We Learn from Addresses? On the Syntax, Semantics and Pragmatics of Addressing Systems. ISPRS Int. J. Geo-Inf. 2020, 9, 317. [Google Scholar] [CrossRef]
- Cheng, R.; Liao, J.; Chen, J. Quickly Locating POIs in Large Datasets from Descriptions Based on Improved Address Matching and Compact Qualitative Representations. Trans. GIS 2021, 1–26. [Google Scholar] [CrossRef]
- Comber, S.; Arribas-Bel, D. Machine Learning Innovations in Address Matching: A Practical Comparison of Word2vec and CRFs. Trans. GIS 2019, 23, 334–348. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Ji, M.; Jin, F.; Wang, H. Public Responses to Air Pollution in Shandong Province Using the Online Complaint Data. ISPRS Int. J. Geo-Inf. 2021, 10, 126. [Google Scholar] [CrossRef]
- Lee, K.; Claridades, A.R.C.; Lee, J. Improving a Street-Based Geocoding Algorithm Using Machine Learning Techniques. Appl. Sci. 2020, 10, 5628. [Google Scholar] [CrossRef]
- Churches, T.; Christen, P.; Lim, K.; Zhu, J.X. Preparation of Name and Address Data for Record Linkage Using Hidden Markov Models. BMC Med. Inform. Decis. Mak. 2002, 2, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shan, S.; Li, Z.; Yang, Q.; Liu, A.; Zhao, L.; Liu, G.; Chen, Z. Geographical Address Representation Learning for Address Matching. World Wide Web. 2020, 23, 2005–2022. [Google Scholar] [CrossRef]
- Luo, A.; Liu, J.; Li, P.; Wang, Y.; Xu, S. Chinese Address Standardisation of POIs Based on GRU and Spatial Correlation and Applied in Multi-Source Emergency Events Fusion. Int. J. Image Data Fusion 2021, 12, 319–334. [Google Scholar] [CrossRef]
- Lin, Y.; Kang, M.; Wu, Y.; Du, Q.; Liu, T. A Deep Learning Architecture for Semantic Address Matching. Int. J. Geogr. Inf. Sci. 2019, 34, 559–576. [Google Scholar] [CrossRef]
- Wang, J.; Deng, H.; Liu, B.; Hu, A.; Liang, J.; Fan, L.; Zheng, X.; Wang, T.; Lei, J. Systematic Evaluation of Research Progress on Natural Language Processing in Medicine over the Past 20 Years: Bibliometric Study on Pubmed. J. Med. Internet Res. 2020, 22, e16816. [Google Scholar] [CrossRef] [PubMed]
- Melo, F.; Martins, B. Automated Geocoding of Textual Documents: A Survey of Current Approaches. Trans. GIS 2017, 21, 3–38. [Google Scholar] [CrossRef]
- Kayed, M.; Dakrory, S.; Ali, A.A. Postal Address Extraction from the Web: A Comprehensive Survey; Springer: Dordrecht, The Netherlands, 2021. [Google Scholar] [CrossRef]
- Barrington-Leigh, C.; Millard-Ball, A. The World’s User-Generated Road Map Is More than 80% Complete. PLoS ONE 2017, 12, e0180698. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yassine, M.; Beauchemin, D.; Laviolette, F.; Lamontagne, L. Leveraging Subword Embeddings for Multinational Address Parsing. In Proceedings of the 2020 6th IEEE Congress on Information Science and Technology (CiSt), Agadir-Essaouira, Morocco, 5–12 June 2021. [Google Scholar]
- Goldberg, D.W.; Wilson, J.P.; Knoblock, C.A. From Text to Geographic Coordinates: The Current State of Geocoding. URISA J. 2007, 19, 33–46. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. PLoS Med. 2021, 18, 372. [Google Scholar] [CrossRef]
- Van Eck, N.J.; Waltman, L. Software Survey: VOSviewer, a Computer Program for Bibliometric Mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef] [Green Version]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An Open Source Software for Exploring and Manipulating Networks. Icwsm 2009, 361–362. [Google Scholar]
- Lin, Y.; Kang, M.; He, B. Spatial Pattern Analysis of Address Quality: A Study on the Impact of Rapid Urban Expansion in China. Environ. Plan. B Urban Anal. City Sci. 2019, 48, 728–740. [Google Scholar] [CrossRef]
- Xu, L.; Du, Z.; Mao, R.; Zhang, F.; Liu, R. GSAM: A Deep Neural Network Model for Extracting Computational Representations of Chinese Addresses Fused with Geospatial Feature. Comput. Environ. Urban Syst. 2020, 81, 101473. [Google Scholar] [CrossRef]
- Peng, M.; Li, Z.; Liu, H.; Meng, C.; Li, Y. Weighted Geocoding Method Based on Chinese Word Segmentation and Its Application to Spatial Positioning of COVID-19 Epidemic Prevention and Control. Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomat. Inf. Sci. Wuhan Univ. 2020, 46, 808–815. [Google Scholar]
- Wei, X.; Lu, S.; Wen, Y.; Lu, Y. Recognition of Handwritten Chinese Address with Writing Variations. Pattern Recognit. Lett. 2016, 73, 68–75. [Google Scholar] [CrossRef]
- Bornmann, L.; Wohlrabe, K. Normalisation of Citation Impact in Economics; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 120. [Google Scholar] [CrossRef] [Green Version]
- Babalola, A.; Musa, S.; Akinlolu, M.T.; Haupt, T.C. A Bibliometric Review of Advances in Building Information Modeling (BIM) Research. J. Eng. Des. Technol. 2021. [Google Scholar] [CrossRef]
- Baraibar-Diez, E.; Luna, M.; Odriozola, M.D.; Llorente, I. Mapping Social Impact: A Bibliometric Analysis. Sustainability 2020, 12, 9389. [Google Scholar] [CrossRef]
- Liu, X. Co-Citation Analysis, Bibliographic Coupling, and Direct Citation: Which Citation Approach Represents the Research Front Most Accurately? J. Am. Soc. Inf. Sci. Technol. 2013, 64, 1852–1863. [Google Scholar] [CrossRef]
- Walford, N.S. Bringing Historical British Population Census Records into the 21st Century: A Method for Geocoding Households and Individuals at Their Early-20th-Century Addresses. Popul. Space Place 2019, 25, e2227. [Google Scholar] [CrossRef]
- Shah, T.I.; Bell, S.; Wilson, K. Geocoding for Public Health Research: Empirical Comparison of Two Geocoding Services Applied to Canadian Cities. Can. Geogr. 2014, 58, 400–417. [Google Scholar] [CrossRef] [Green Version]
- Shan, S.; Li, Z.; Qiang, Y.; Liu, A.; Xu, J. DeepAM: Deep Semantic Address Representation for Address Matching; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 3. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hochreiter, S.; Urgen Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 17351780. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Thekumparampil, K.K.; Wang, C.; Oh, S.; Li, L.J. Attention-Based Graph Neural Network for Semi-Supervised Learning. arXiv 2018, arXiv:1803.03735. [Google Scholar]
- Santos, R.; Murrieta-Flores, P.; Calado, P.; Martins, B. Toponym Matching through Deep Neural Networks. Int. J. Geogr. Inf. Sci. 2018, 32, 324–348. [Google Scholar] [CrossRef] [Green Version]
- Gori, M.; Monfardini, G.; Scarselli, F. A New Model for Learning in Graph Domains. Proc. Int. Jt. Conf. Neural Netw. 2005, 2, 729–734. [Google Scholar] [CrossRef]
- Zhang, H.; Ren, F.; Li, H.; Yang, R.; Zhang, S.; Du, Q. Recognition Method of New Address Elements in Chinese Address Matching Based on Deep Learning. ISPRS Int. J. Geo-Inf. 2020, 9, 745. [Google Scholar] [CrossRef]
- Rabiner, L.R. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Ghahramani, Z. An Introduction to Hidden Markov Models and Bayesian Networks. Int. J. Pattern Recognit. Artif. Intell. 2001, 15, 9–42. [Google Scholar] [CrossRef]
- Li, X.; Kardes, H.; Wang, X.; Sun, A. HMM-Based Address Parsing with Massive Synthetic Training Data Generation. Int. Conf. Inf. Knowl. Manag. Proc. 2014, 33–36. [Google Scholar] [CrossRef]
- Lafferty, J.; Mccallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data Abstract. In Proceedings of the 18th International Conference on Machine Learning 2001, San Francisco, CA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I.; Wallach, H.M.; Hinton, G.E.; Osindero, S.; Teh, Y.-W. Conditional Random Fields: An Introduction. Neural Comput. 2004, 18, 1–9. [Google Scholar] [CrossRef]
- Borgatti, S.P. Centrality and Network Flow. Soc. Netw. 2005, 27, 55–71. [Google Scholar] [CrossRef]
- Santos, R.; Murrieta-Flores, P.; Martins, B. Learning to Combine Multiple String Similarity Metrics for Effective Toponym Matching. Int. J. Digit. Earth 2017, 11, 913–938. [Google Scholar] [CrossRef]
- Levenshtein, V.I. Binary Codes Capable of Correcting Deletions, Insertions, and Reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar] [CrossRef]
- Jaro, M.A. Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida. J. Am. Stat. Assoc. 1989, 84, 414–420. [Google Scholar] [CrossRef]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. Proc. Sect. Surv. Res. Am. Stat. Assoc. 1990, 354–359. [Google Scholar]
- Forney, G.D. The Viterbi Algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- McCallum, A.; Freitag, D.; Pereira, F. Maximum Entropy Markov Models for Information Extraction and Segmentation. In Proceedings of the 17th International Conference on Machine Learning, 2000, San Francisco, CA, USA, 29 June–2 July 2000. [Google Scholar]
- Wang, M.; Haberland, V.; Yeo, A.; Martin, A.; Howroyd, J.; Bishop, J.M. A Probabilistic Address Parser Using Conditional Random Fields and Stochastic Regular Grammar. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016. [Google Scholar] [CrossRef]
- Christen, P.; Willmore, A.; Churches, T. A Probabilistic Geocoding System Utilising a Parcel Based Address File. In Data Mining; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3755, pp. 130–145. [Google Scholar] [CrossRef]
- Fu, Q.; Ding, X.Q.; Liu, C.S.; Jiang, Y. A Hidden Markov Model Based Segmentation and Recognition Algorithm for Chinese Handwritten Address Character Strings. Proc. Int. Conf. Doc. Anal. Recognit. ICDAR 2005, 2005, 590–594. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Comber, S. Demonstrating the Utility of Machine Learning Innovations in Address Matching to Spatial Socio-Economic Applications. Region 2019, 6, 17–37. [Google Scholar] [CrossRef]
- Dani, M.N.; Faruquie, T.A.; Garg, R.; Kothari, G.; Mohania, M.K.; Prasad, K.H.; Subramaniam, L.V.; Swamy, V.N. A Knowledge Acquisition Method for Improving Data Quality in Services Engagements. In Proceedings of the 2010 IEEE International Conference on Services Computing, Miami, FL, USA, 5–10 July 2010; pp. 346–353. [Google Scholar] [CrossRef]
- Tang, X.; Chen, X.; Zhang, X. Research on Toponym Resolution in Chinese Text. Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomat. Inf. Sci. Wuhan Univ. 2010, 35, 930–935. [Google Scholar]
- Weinman, J. Geographic and Style Models for Historical Map Alignment and Toponym Recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 957–964. [Google Scholar] [CrossRef]
- Liu, J.; Wang, J.; Zhang, C.; Yang, X.; Deng, J.; Zhu, R.; Nan, X.; Chen, Q. Chinese Address Similarity Calculation Based on Auto Geological Level Tagging Jing; Springer International Publishing: Cham, Switzerland, 2019; Volume 2. [Google Scholar] [CrossRef]
- Kothari, G.; Faruquie, T.A.; Subramaniam, L.V.; Prasad, K.H.; Mohania, M.K. Transfer of Supervision for Improved Address Standardization. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2178–2181. [Google Scholar] [CrossRef]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Hierarchical Dirichlet Processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Guo, H.; Zhu, H.; Guo, Z.; Zhang, X.X.; Su, Z. Address Standardization with Latent Semantic Association. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1155–1163. [Google Scholar] [CrossRef]
- Jiang, Y.; Ding, X.; Ren, Z. A Suffix Tree Based Handwritten Chinese Address Recognition System. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; Volume 1, pp. 292–296. [Google Scholar] [CrossRef]
- Tian, Q.; Ren, F.; Hu, T.; Liu, J.; Li, R.; Du, Q. Using an Optimized Chinese Address Matching Method to Develop a Geocoding Service: A Case Study of Shenzhen, China. ISPRS Int. J. Geo-Inf. 2016, 5, 65. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Wang, D.; Lu, H.; Li, C. Handwritten Chinese Character Recognition Based on Domain-Specific Knowledge; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; Volume 2, pp. 221–231. [Google Scholar] [CrossRef]
- Li, H.; Lu, W.; Xie, P.; Li, L. Neural Chinese Address Parsing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 3421–3431. [Google Scholar]
- Koumarelas, I.; Kroschk, A.; Mosley, C.; Naumann, F. Experience: Enhancing Address Matching with Geocoding and Similarity Measure Selection. J. Data Inf. Qual. 2018, 10, 1–16. [Google Scholar] [CrossRef]
- Cayo, M.R.; Talbot, T.O. Positional Error in Automated Geocoding of Residential Addresses. Int. J. Health Geogr. 2003, 2, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cortes, T.R.; da Silveira, I.H.; Junger, W.L. Improving Geocoding Matching Rates of Structured Addresses in Rio de Janeiro, Brazil. Cad. Saude Publica 2021, 37, e00039321. [Google Scholar] [CrossRef]
- Li, P.; Luo, A.; Liu, J.; Wang, Y.; Zhu, J.; Deng, Y.; Zhang, J. Bidirectional Gated Recurrent Unit Neural Network for Chinese Address Element Segmentation. ISPRS Int. J. Geo-Inf. 2020, 9, 635. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; She, X.; Mao, J.; Chen, G. Deep Contrast Learning Approach for Address Semantic Matching. Appl. Sci. 2021, 11, 7608. [Google Scholar] [CrossRef]
- Chen, Q.; Ling, Z.; Jiang, H.; Zhu, X.; Wei, S.; Inkpen, D. Enhanced LSTM for Natural Language Inference. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1657–1668. [Google Scholar] [CrossRef]
- Parikh, A.P.; Täckström, O.; Das, D.; Uszkoreit, J. A Decomposable Attention Model for Natural Language Inference. arXiv 2016, arXiv:1606.01933. [Google Scholar] [CrossRef] [Green Version]
- Koza, J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Araujo, L. Genetic Programming for Natural Language Processing. Genet. Program. Evolvable Mach. 2020, 21, 11–32. [Google Scholar] [CrossRef]
- Song, Z. Address Matching Algorithm Based on Chinese Natural Language Understanding. J. Remote Sens. 2013, 17, 788–801. [Google Scholar]
- Verma, A.; Kaur, G. Character Recognition from Handwritten Document Using Neural Networks. Int. J. Appl. Eng. Res. 2015, 10, 37574–37579. [Google Scholar]
- Choi, S.C.T.; Lin, Y.; Mulrow, E. Comparison of Public-Domain Software and Services for Probabilistic Record Linkage and Address Standardization. Lect. Notes Comput. Sci. 2017, 10344, 51–66. [Google Scholar] [CrossRef]
- Nagabhushan, P.; Angadi, S.A.; Anami, B.S. Symbolic Data Structure for Postal Address Representation and Address Validation through Symbolic Knowledge Base. Lect. Notes Comput. Sci. 2005, 3776, 388–394. [Google Scholar] [CrossRef] [Green Version]
- Florczyk, A.J.; López-Pellicer, F.J.; Muro-Medrano, P.; Nogueras-Iso, J.; Zarazaga-Soria, F.J. Semantic Selection of Georeferencing Services for Urban Management. Electron. J. Inf. Technol. Constr. 2010, 15, 111–121. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Journal | No. | Quartile | Publisher | Field(s) | Publisher Country |
|---|---|---|---|---|---|
| ISPRS International Journal of Geo-Information | 4 | Q1 | MDPI AG | Earth and Planetary Sciences; Social Sciences | Switzerland |
| International Journal of Geographical Information Science | 2 | Q1 | Taylor and Francis Ltd. | Computer Science; Social Sciences | United Kingdom |
| Applied Sciences (Switzerland) | 2 | Q1 | MDPI Multidisciplinary Digital Publishing Institute | Chemical Engineering; Computer Science; Engineering; Materials Science; Physics and Astronomy | Switzerland |
| Transactions in GIS | 2 | Q1 | Wiley-Blackwell Publishing Ltd. | Earth and Planetary Sciences | United Kingdom |
| Wuhan Daxue Xuebao (Xinxi Kexue Ban)/Geomatics and Information Science of Wuhan University | 2 | Q2 | Wuhan University | Computer Science; Earth and Planetary Sciences | China |
| Computers, Environment and Urban Systems | 1 | Q1 | Elsevier Ltd. | Environmental Science; Social Sciences | United Kingdom |
| BMC Medical Informatics and Decision Making | 1 | Q1 | BioMed Central Ltd. | Medicine | United Kingdom |
| International Journal of Digital Earth | 1 | Q1 | Taylor and Francis Ltd. | Computer Science; Earth and Planetary Sciences | United Kingdom |
| Pattern Recognition Letters | 1 | Q1 | Elsevier | Computer Science | Netherlands |
| Population, Space and Place | 1 | Q1 | John Wiley and Sons Ltd. | Social Sciences | United Kingdom |
| Region | 1 | Q2 | European Regional Science Association | Economics, Econometrics and Finance; Social Sciences | Belgium |
| World Wide Web | 1 | Q2 | Springer New York | Computer Science | United States |
| Yaogan Xuebao/Journal of Remote Sensing | 1 | Q2 | Science Press | Earth and Planetary Sciences; Physics and Astronomy; Social Sciences | China |
| Cadernos de Saude Publica | 1 | Q2 | Fundacao Oswaldo Cruz | Medicine | Brazil |
| Canadian Geographer | 1 | Q1 | Wiley-Blackwell Publishing Ltd. | Earth and Planetary Sciences; Social Sciences | United Kingdom |
| (Electronic) Journal of Information Technology in Construction | 1 | Q2 | International Council for Research and Innovation in Building and Construction | Computer Science; Engineering | Sweden |
| International Journal of Applied Engineering Research | 1 | Q2 | Research India Publications | Engineering | India |
| International Journal of Health Geographics | 1 | Q1 | BioMed Central Ltd. | Business, Management and Accounting; Computer Science; Medicine | United Kingdom |
| International Journal of Image and Data Fusion | 1 | Q2 | Taylor and Francis Ltd. | Computer Science; Earth and Planetary Sciences | United Kingdom |
| Journal of Data and Information Quality | 1 | Q2 | Association for Computing Machinery | Computer Science; Decision Sciences | United States |
| Conference Proceedings/Book Series | No. | Publisher Country | Field(s) |
|---|---|---|---|
| Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) | 6 | Germany | Computer Science; Mathematics |
| Proceedings of the International Conference on Document Analysis and Recognition, ICDAR | 3 | United States | Computer Science |
| International Conference on Information and Knowledge Management, Proceedings | 1 | United States | Business, Management and Accounting; Decision Sciences |
| NAACL HLT 2019 – 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies – Proceedings of the Conference | 1 | United States | Computer Science |
| Proceedings – 2010 IEEE 7th International Conference on Services Computing, SCC 2010 | 1 | United States | Computer Science; Mathematics |
| Proceedings – International Conference on Pattern Recognition | 1 | United States | Computer Science |
| Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining | 1 | United States | Computer Science |
| Journal Articles | No. of Publications | No. of Citations |
|---|---|---|
| International Journal of Health Geographics | 1 | 228 |
| BMC Medical Informatics and Decision Making | 1 | 70 |
| International Journal of Geographical Information Science | 2 | 38 |
| ISPRS International Journal of Geo-Information | 4 | 28 |
| International Journal of Digital Earth | 1 | 18 |
| Canadian Geographer | 1 | 16 |
| Conference Articles | No. of publications | No. of citations |
| Proceedings of the International Conference on Document Analysis and Recognition, ICDAR | 3 | 28 |
| Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) | 6 | 17 |
| Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining | 1 | 12 |
| Proceedings - 2010 IEEE 7th International Conference on Services Computing, SCC 2010 | 1 | 12 |
| Proceedings - International Conference on Pattern Recognition | 1 | 10 |
| International Conference on Information and Knowledge Management, Proceedings | 1 | 6 |
| Clusters | Co-Words |
|---|---|
| Address matching and NLP | address matching(s), big data, important features, location, location-based services, long short-term memory (lstm), natural language processing systems, search engines, semantic representation, semantics, string similarity |
| GIS/geocoding and machine learning | accuracy assessment, algorithm, artificial neural network, China, computational linguistics, data processing, deep neural networks, duplicate detection, geographic information retrieval, gis, machine learning, recurrent neural networks, spatiotemporal analysis, toponym matching |
| Address standardization | address, address standardization, article, artificial intelligence, commercial tools, conditional random field, data cleansing, data handling, data source, data structures, information analysis, standardization |
| Address recognition and parsing | address parsing, address recognition, character recognition, classification (of information), data mining, geocoding, geographic information systems, georeferencing, hidden markov models, neural networks, random forest, record linkage, spatial data, web services |
| Author | Cluster | Link Strength | Documents | Citations | Average Publication Year |
|---|---|---|---|---|---|
| Tanveer A. Faruquie | 1 | 8 | 2 | 22 | 2010 |
| Govind Kothari | 1 | 8 | 2 | 22 | 2010 |
| Mukesh K. Mohania | 1 | 8 | 2 | 22 | 2010 |
| K. Hima Prasad | 1 | 8 | 2 | 22 | 2010 |
| L. Venkata Subramaniam | 1 | 8 | 2 | 22 | 2010 |
| Jing Liu | 3 | 7 | 4 | 26 | 2019 |
| Zhigang Chen | 2 | 6 | 2 | 3 | 2020 |
| Zhixu Li | 2 | 6 | 3 | 3 | 2020 |
| An Liu | 2 | 6 | 2 | 3 | 2020 |
| Shuangli Shan | 2 | 6 | 2 | 3 | 2020 |
| Pengpeng Li | 3 | 6 | 2 | 4 | 2021 |
| An Luo | 3 | 6 | 2 | 4 | 2021 |
| Yong Wang | 3 | 6 | 2 | 4 | 2021 |
| Bruno Martins | 4 | 4 | 2 | 42 | 2018 |
| P. Murrieta-Flores | 4 | 4 | 2 | 42 | 2018 |
| Rui Santos | 4 | 4 | 2 | 42 | 2018 |
| Peter Christen | 5 | 2 | 2 | 80 | 2004 |
| Tim Churches | 5 | 2 | 2 | 80 | 2004 |
| Qingyun Du | 6 | 2 | 2 | 36 | 2018 |
| Yue Lin | 6 | 1 | 2 | 14 | 2019 |
| Sam Comber | 7 | 0 | 2 | 10 | 2019 |
| Yan Jiang | 8 | 0 | 2 | 21 | 2006 |
| Xiaoxun Zhang | 9 | 0 | 2 | 25 | 2010 |
| Keyword | No. | Avg. Pub. Year | Eigenvector (max.) | Betweenness (max.) |
|---|---|---|---|---|
| semantics | 20 | 2016 | 1.00 | 0.24 |
| natural language processing (nlp) | 5 | 2017 | 0.81 | 0.13 |
| attention mechanisms | 4 | 2020 | 0.54 | 0.00 |
| long short-term memory (lstm) | 4 | 2019 | 0.54 | 0.07 |
| artificial neural networks | 5 | 2019 | 0.47 | 0.05 |
| representation techniques | 1 | 2019 | 0.46 | 0.00 |
| vector spaces | 1 | 2019 | 0.46 | 0.00 |
| deep neural networks | 3 | 2019 | 0.46 | 0.01 |
| computational representations | 4 | 2020 | 0.43 | 0.03 |
| bidirectional encoder representations from transformer (bert) | 2 | 2020 | 0.42 | 0.00 |
| cluster analysis | 2 | 2020 | 0.42 | 0.00 |
| numerical model | 1 | 2020 | 0.42 | 0.00 |
| decoder architecture | 1 | 2020 | 0.34 | 0.00 |
| gcn | 1 | 2020 | 0.34 | 0.00 |
| word-embeddings | 1 | 2020 | 0.34 | 0.00 |
| recurrent neural networks | 2 | 2020 | 0.25 | 0.01 |
| correlation analysis | 1 | 2021 | 0.16 | 0.00 |
| gru | 1 | 2021 | 0.16 | 0.00 |
| spatial correlation | 2 | 2021 | 0.16 | 0.00 |
| machine learning | 5 | 2019 | 0.12 | 0.00 |
| concept space | 1 | 2009 | 0.12 | 0.00 |
| latent semantics | 1 | 2009 | 0.12 | 0.00 |
| rule-based approach | 2 | 2009 | 0.12 | 0.00 |
| supervised learning methods | 2 | 2014 | 0.12 | 0.00 |
| artificial intelligence | 2 | 2014 | 0.12 | 0.04 |
| hidden markov models (hmm) | 6 | 2012 | 0.12 | 0.03 |
| fellegi-sunter model | 1 | 2017 | 0.12 | 0.00 |
| learning algorithms | 1 | 2017 | 0.12 | 0.00 |
| learning systems | 1 | 2017 | 0.12 | 0.00 |
| probabilistic record linkage | 1 | 2017 | 0.12 | 0.00 |
| optimal merging | 1 | 2005 | 0.10 | 0.00 |
| bp neural networks | 1 | 2019 | 0.07 | 0.00 |
| conditional random fields (crf) | 3 | 2013 | 0.07 | 0.01 |
| lm-lstm-crf model | 1 | 2019 | 0.07 | 0.00 |
| word2vec | 1 | 2020 | 0.06 | 0.00 |
| latent variable | 1 | 2019 | 0.04 | 0.00 |
| linear chain | 1 | 2019 | 0.04 | 0.00 |
| random forests | 3 | 2017 | 0.03 | 0.01 |
| conditional functional dependencies | 1 | 2018 | 0.02 | 0.00 |
| decision trees | 1 | 2018 | 0.02 | 0.00 |
| back propagation algorithm | 1 | 2015 | 0.02 | 0.00 |
| ripple down rules | 1 | 2010 | 0.01 | 0.00 |
| learning address parsers | 1 | 2006 | 0.01 | 0.00 |
| probabilistic gis | 1 | 2006 | 0.01 | 0.00 |
| dirichlet process | 2 | 2010 | 0.01 | 0.00 |
| variational techniques | 1 | 2010 | 0.01 | 0.00 |
| contrast learning | 1 | 2021 | 0.00 | 0.00 |
| ensemble learning | 1 | 2018 | 0.00 | 0.00 |
| trees (mathematics) | 1 | 2016 | 0.00 | 0.00 |
| word-level-tree | 2 | 2016 | 0.00 | 0.00 |
| bi-gru neural network | 1 | 2020 | 0.00 | 0.00 |
| likelihood functions | 1 | 2017 | 0.00 | 0.00 |
| probabilistic modeling | 1 | 2017 | 0.00 | 0.00 |
| automated geocoding | 1 | 2014 | 0.00 | 0.00 |
| deep learning | 1 | 2018 | 0.00 | 0.00 |
| suffix trees | 1 | 2007 | 0.00 | 0.00 |
| symbolic object | 1 | 2005 | 0.00 | 0.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cruz, P.; Vanneschi, L.; Painho, M.; Rita, P. Automatic Identification of Addresses: A Systematic Literature Review. ISPRS Int. J. Geo-Inf. 2022, 11, 11. https://doi.org/10.3390/ijgi11010011
Cruz P, Vanneschi L, Painho M, Rita P. Automatic Identification of Addresses: A Systematic Literature Review. ISPRS International Journal of Geo-Information. 2022; 11(1):11. https://doi.org/10.3390/ijgi11010011
Chicago/Turabian StyleCruz, Paula, Leonardo Vanneschi, Marco Painho, and Paulo Rita. 2022. "Automatic Identification of Addresses: A Systematic Literature Review" ISPRS International Journal of Geo-Information 11, no. 1: 11. https://doi.org/10.3390/ijgi11010011
APA StyleCruz, P., Vanneschi, L., Painho, M., & Rita, P. (2022). Automatic Identification of Addresses: A Systematic Literature Review. ISPRS International Journal of Geo-Information, 11(1), 11. https://doi.org/10.3390/ijgi11010011