Analysis of Differentially Expressed Genes in Coronary Artery Disease by Integrated Microarray Analysis


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
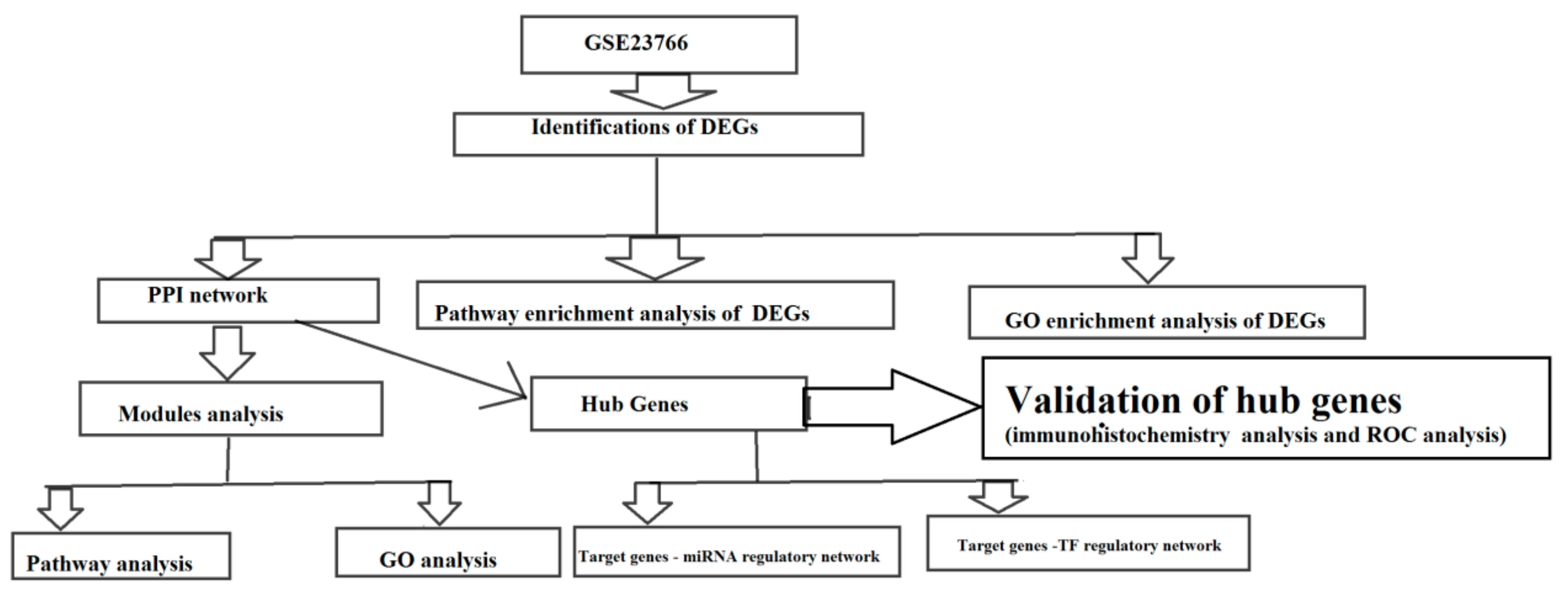
2. Materials and Methods
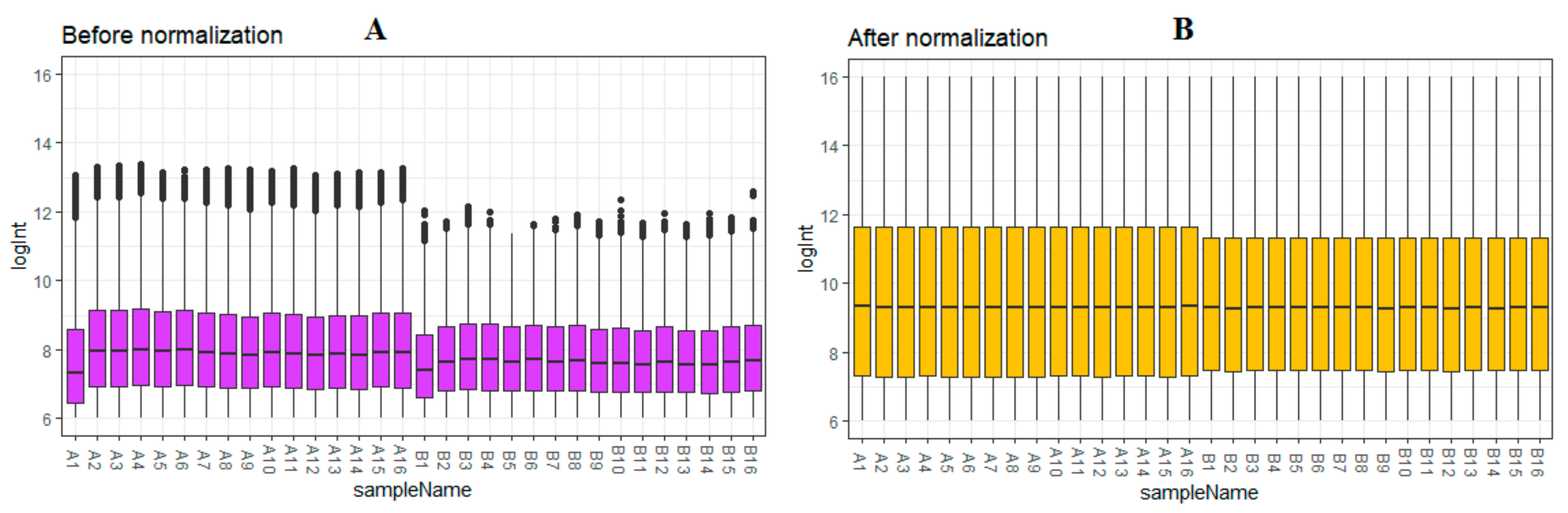
2.1. Microarray Data and Data Processing
2.2. Identification of DEGs between Male CAD and Female CAD Samples
2.3. Pathway Enrichment Analysis of DEGs
2.4. GO Enrichment Analysis of DEGs
2.5. Comprehensive Analysis of PPI Network and Modules
2.6. Construction of Target Genes-miRNA Regulatory Network
2.7. Construction of Target Genes-TF Regulatory Network
2.8. Hub Gene Expression Levels in CAD
2.9. Receiver Operating Characteristic Curve Analysis
3. Results
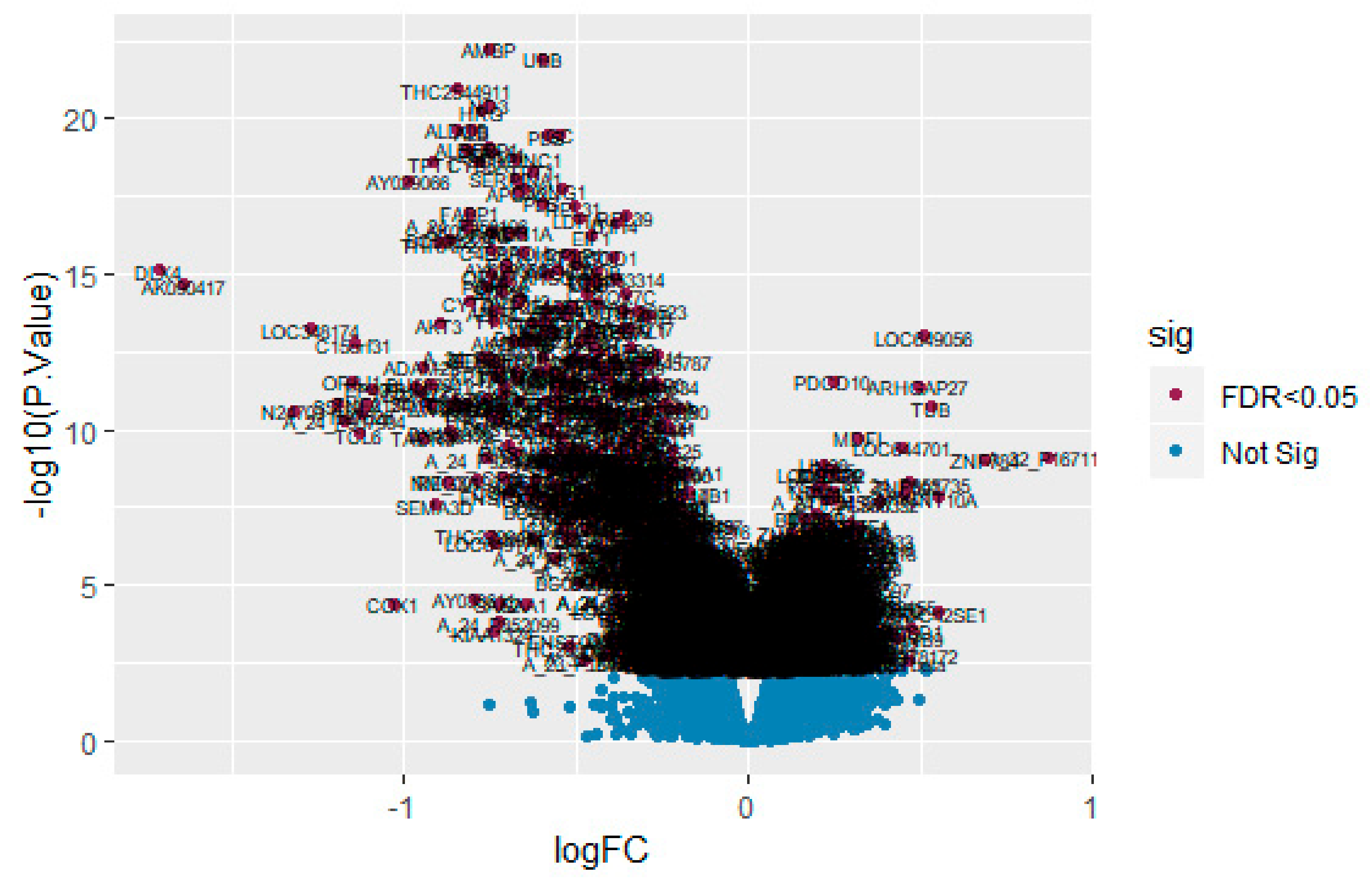
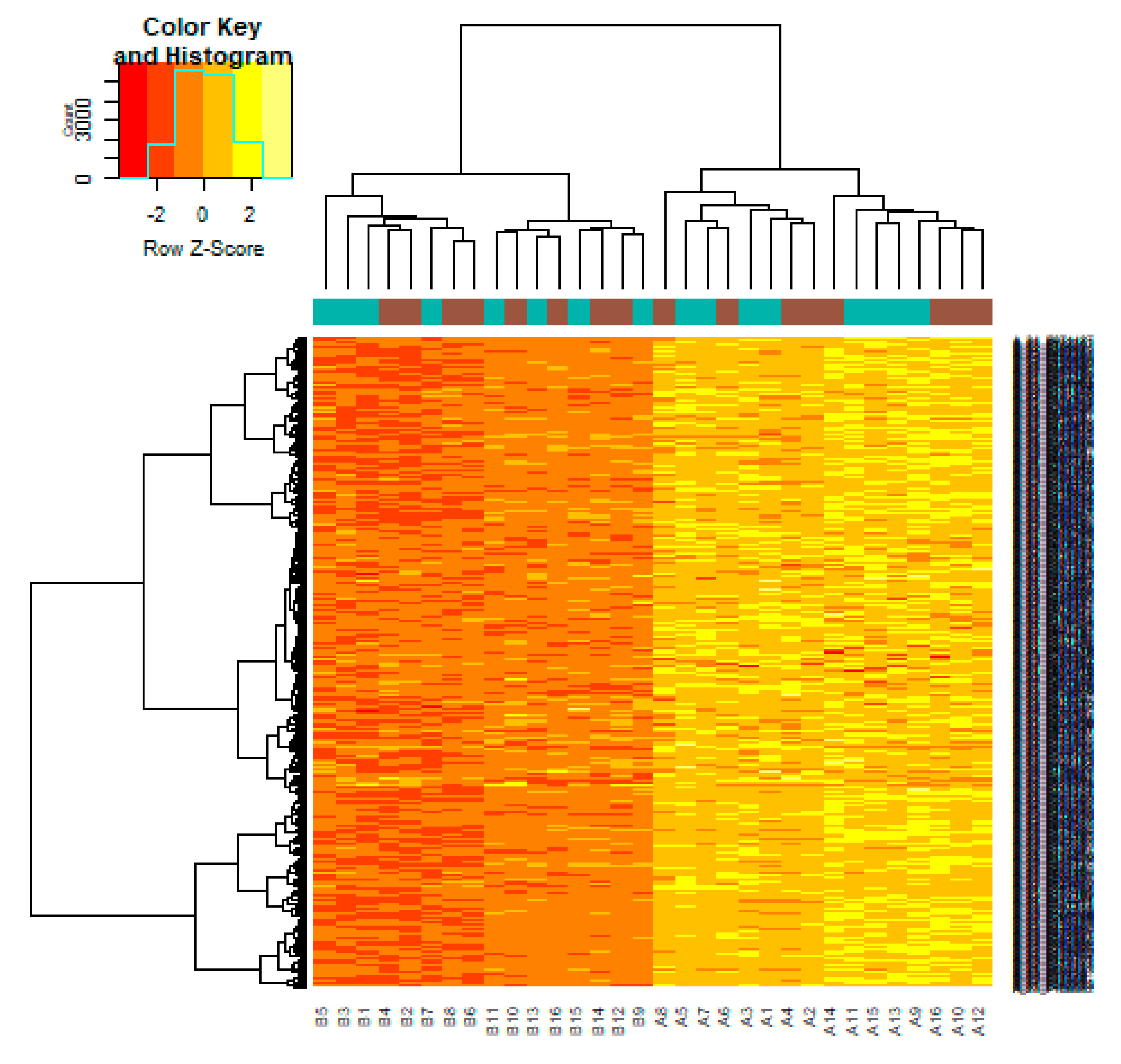
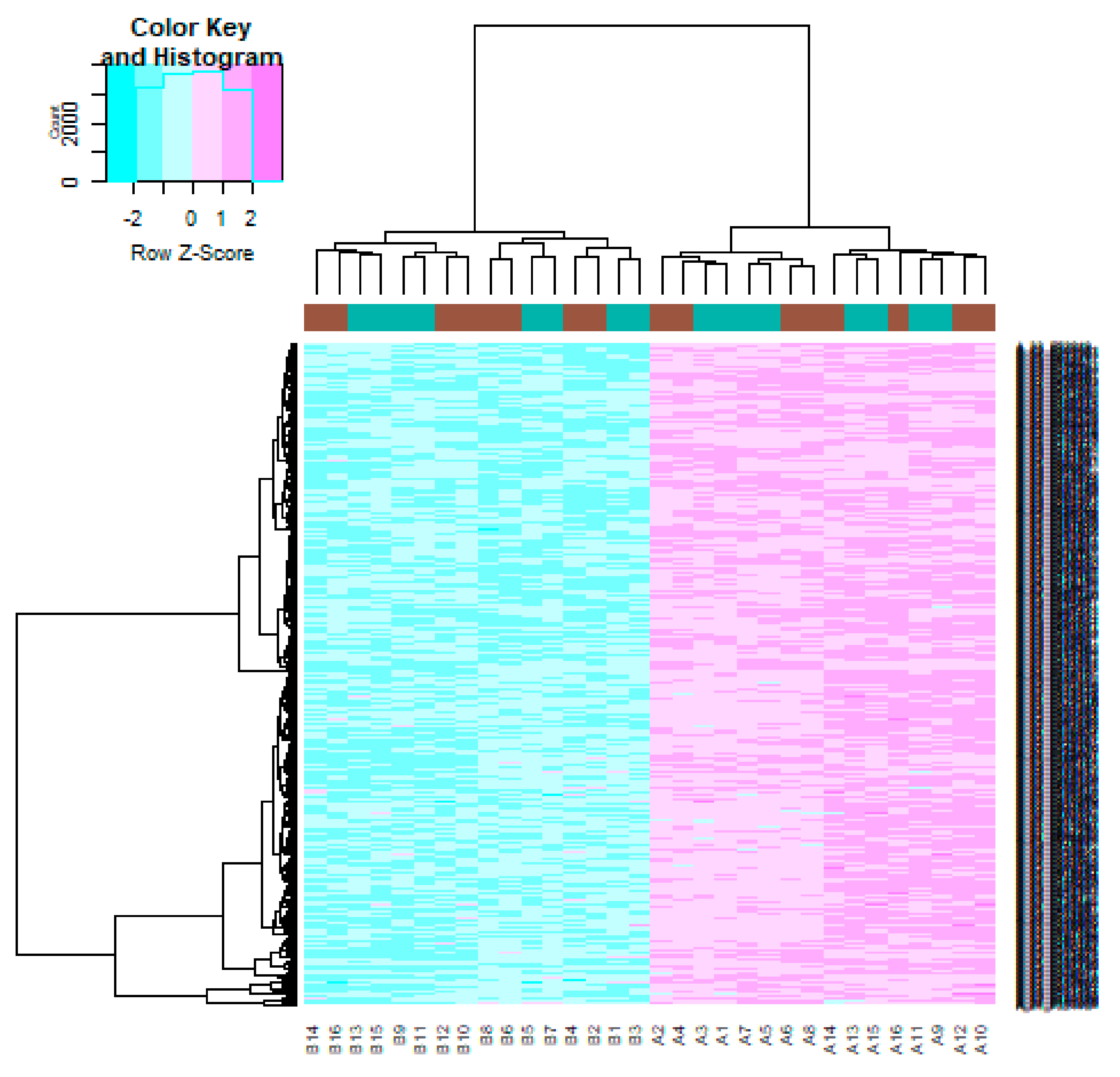
3.1. Identification of DEGs
3.2. Pathway Enrichment Analysis
3.3. GO Enrichment Analysis of DEGs
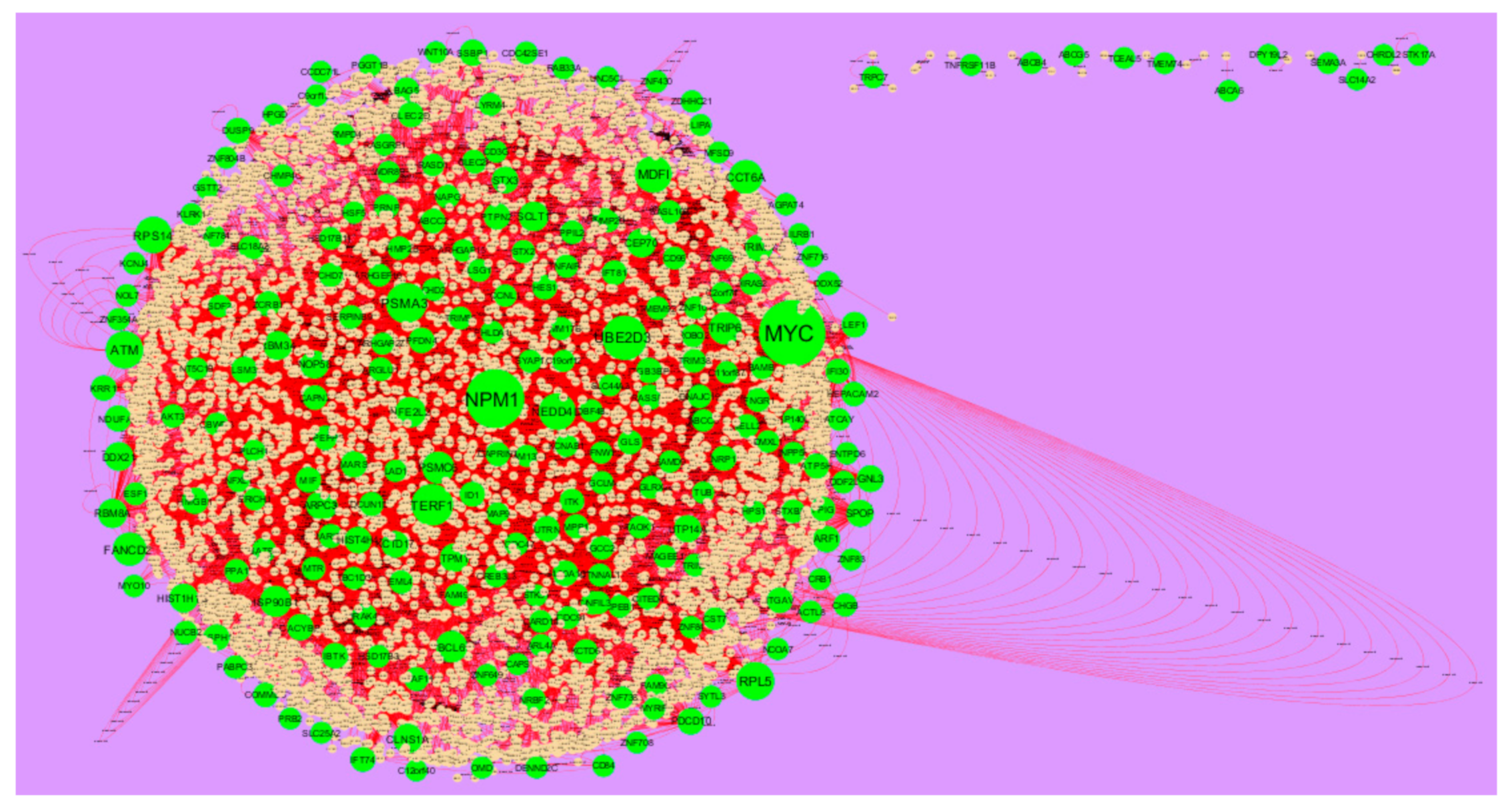
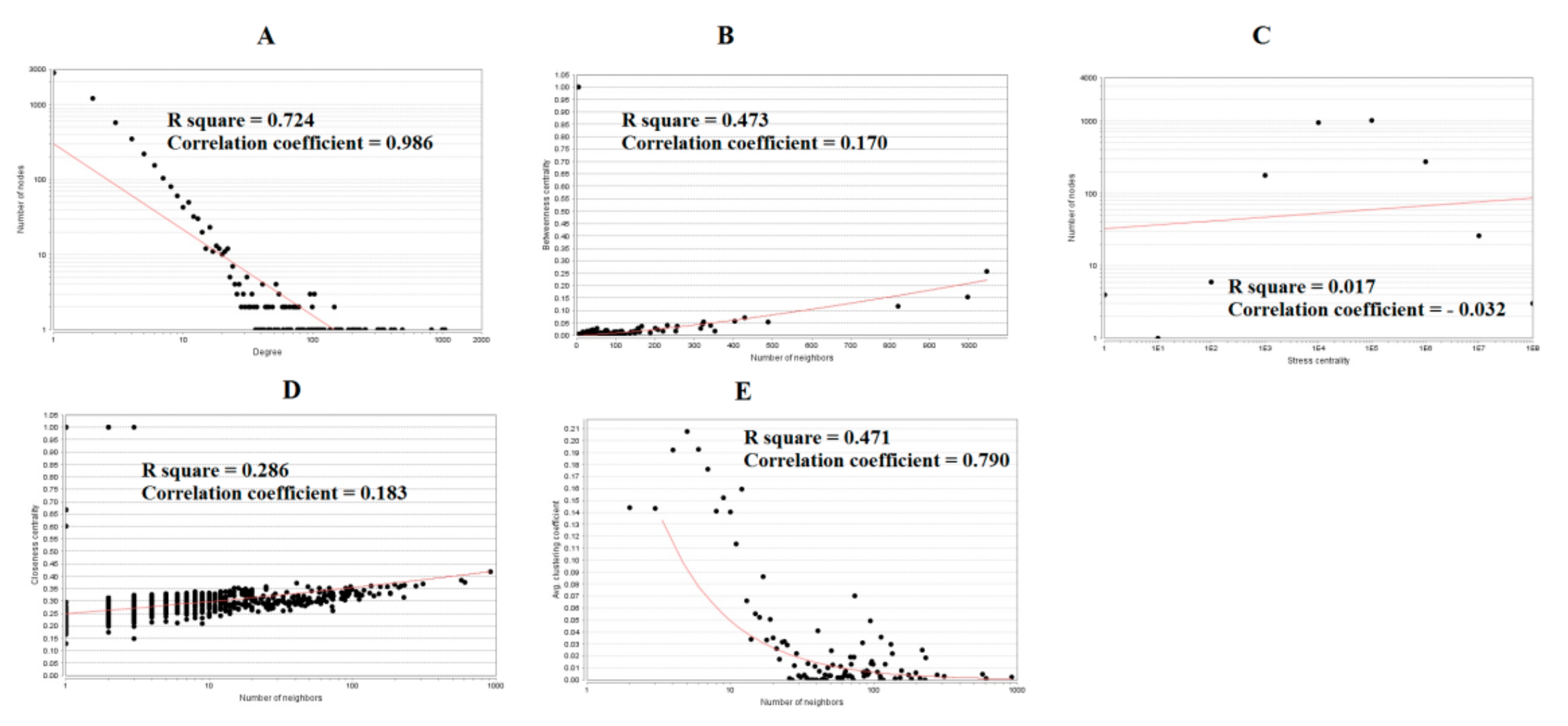
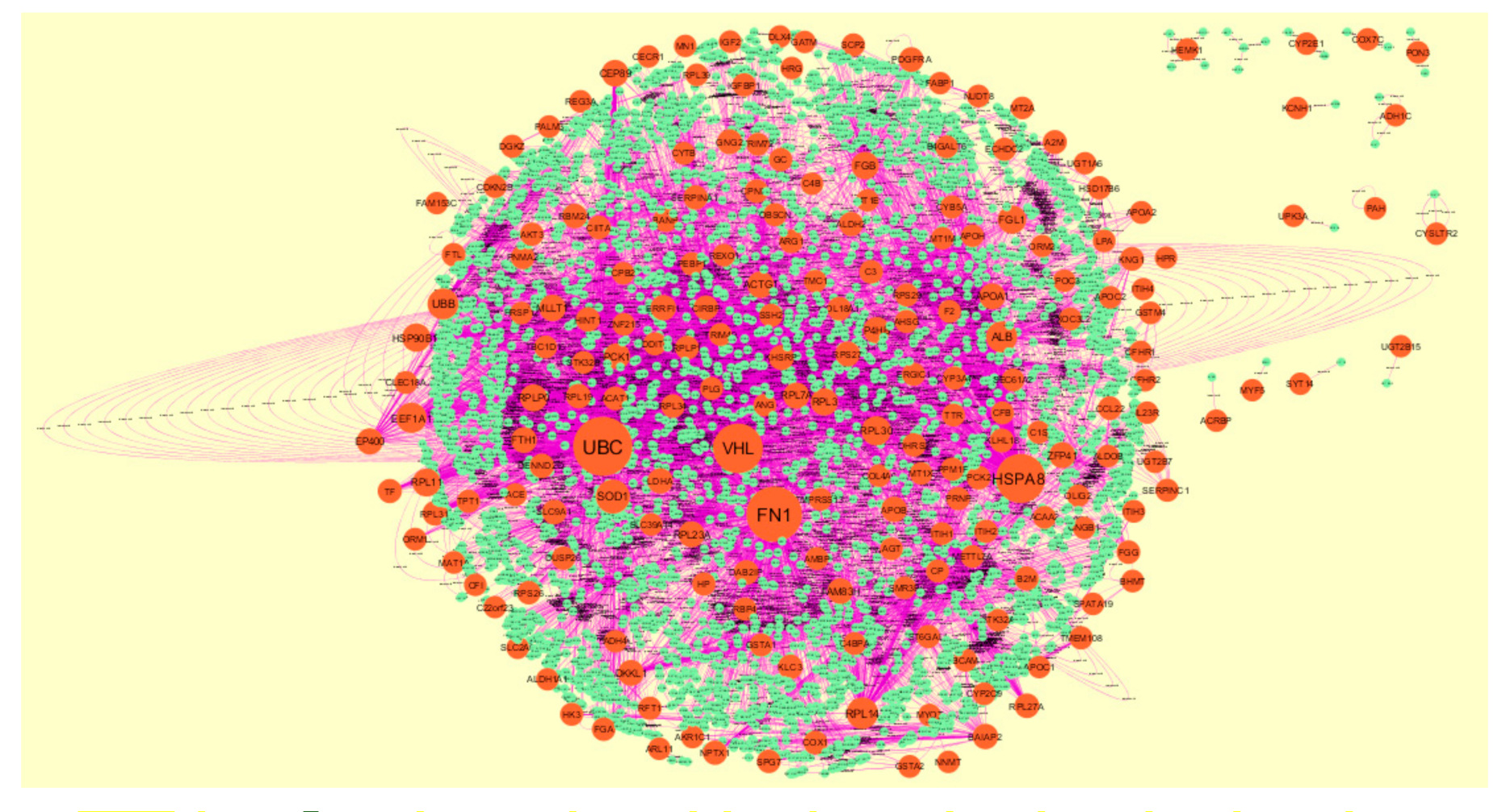
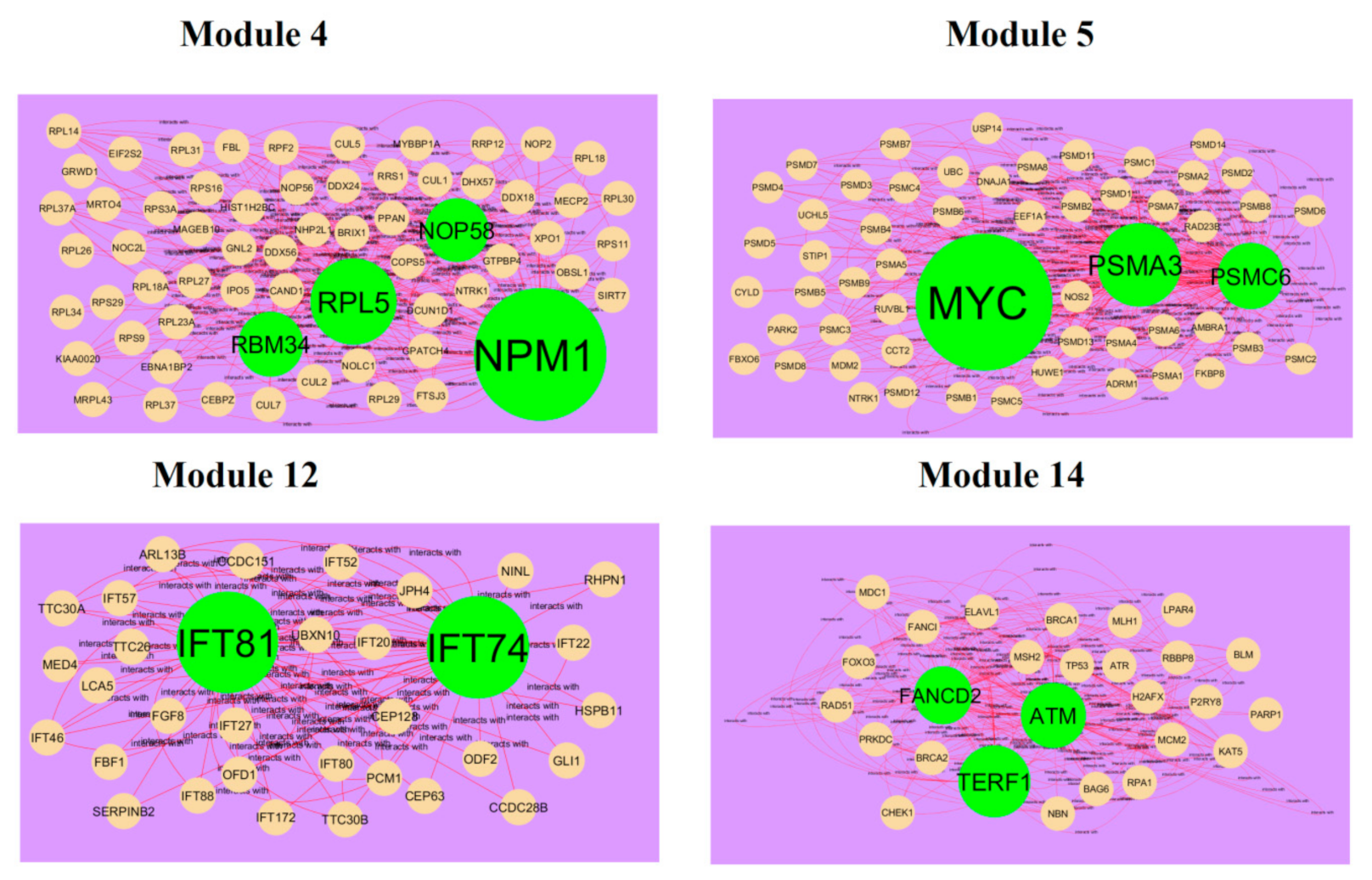
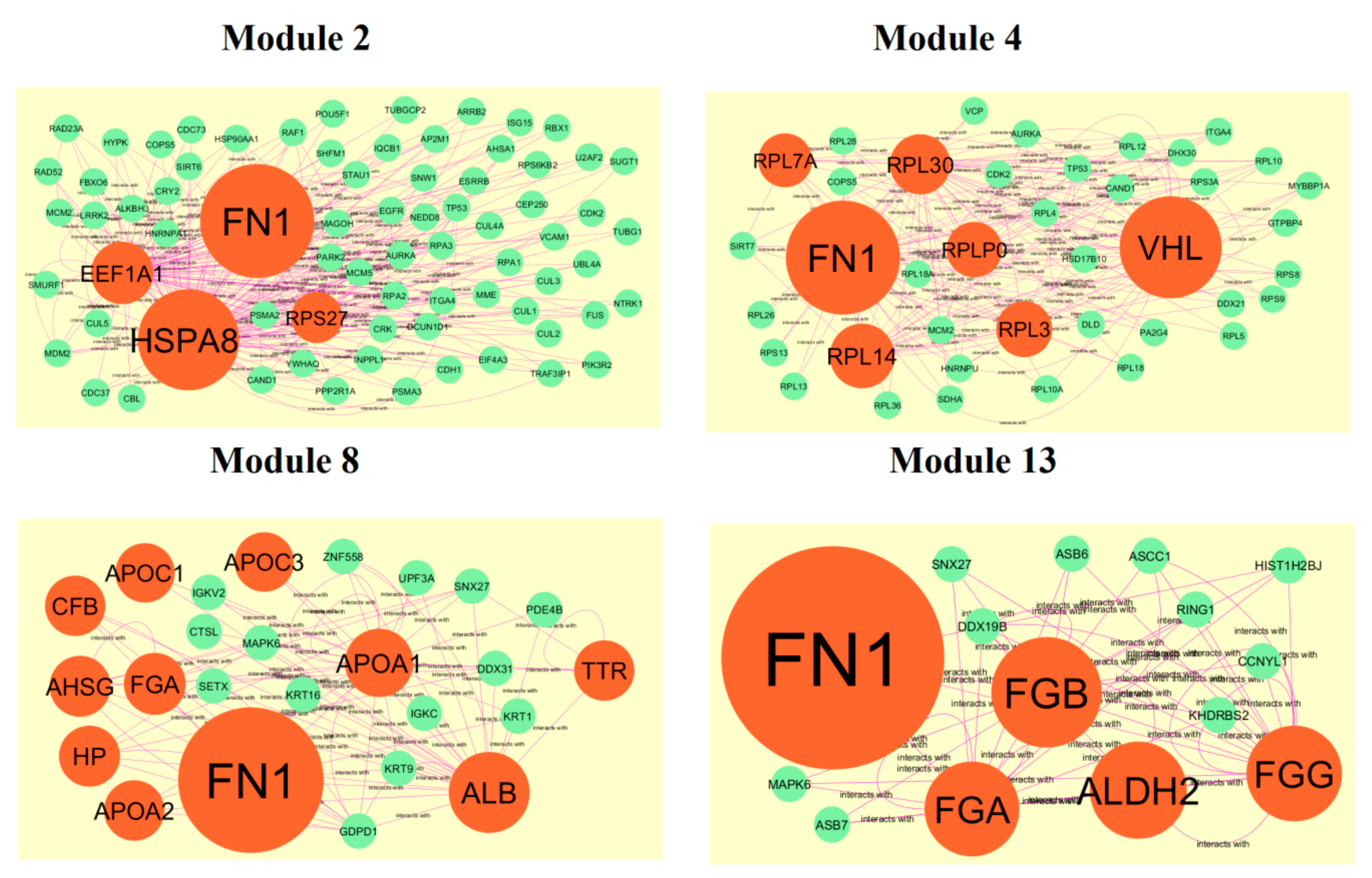
3.4. Comprehensive Analysis of PPI Network and Modules
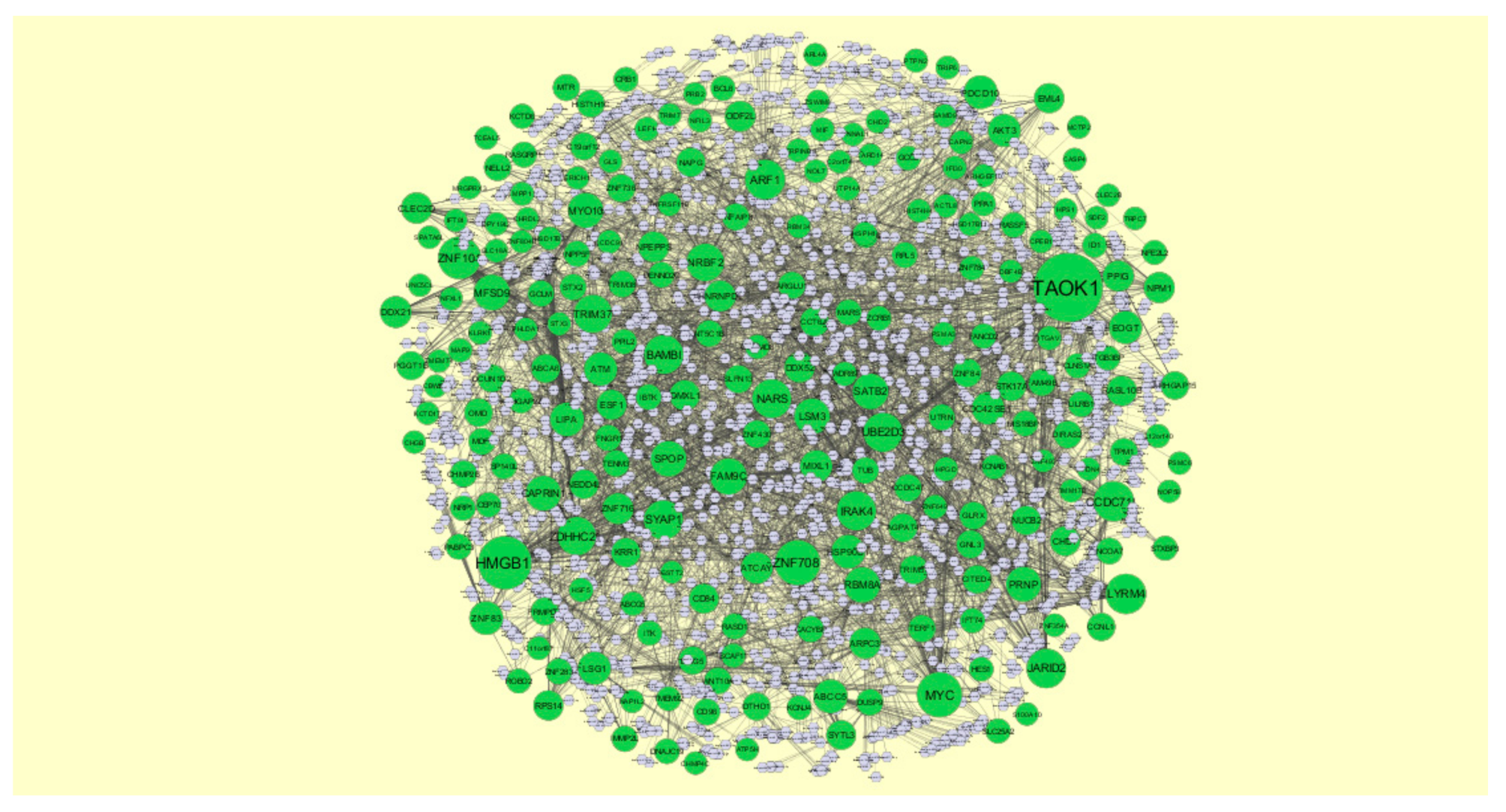
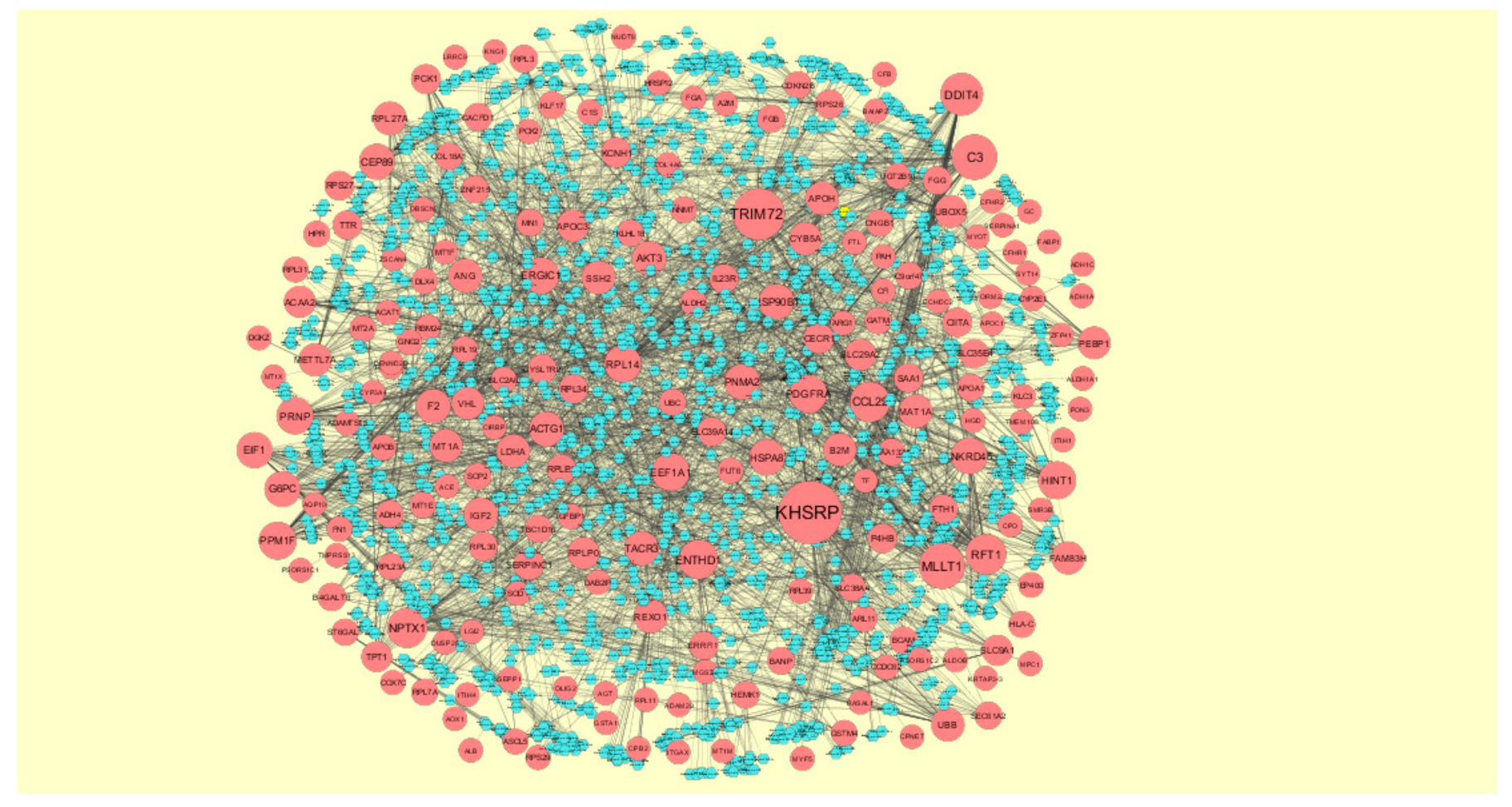
3.5. Construction of Target Genes-miRNA Regulatory Network
3.6. Construction of Target Genes–TF Regulatory Network
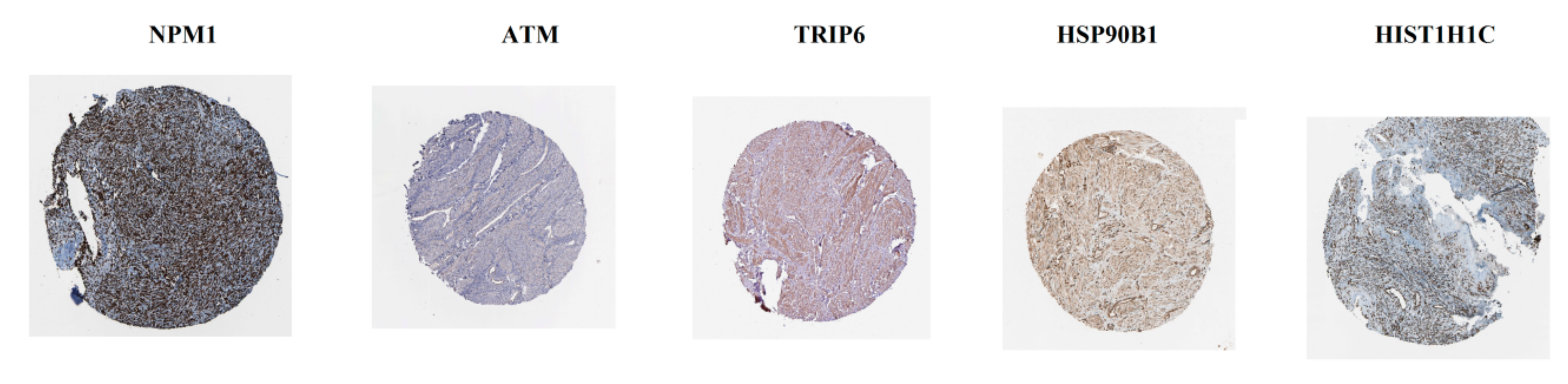
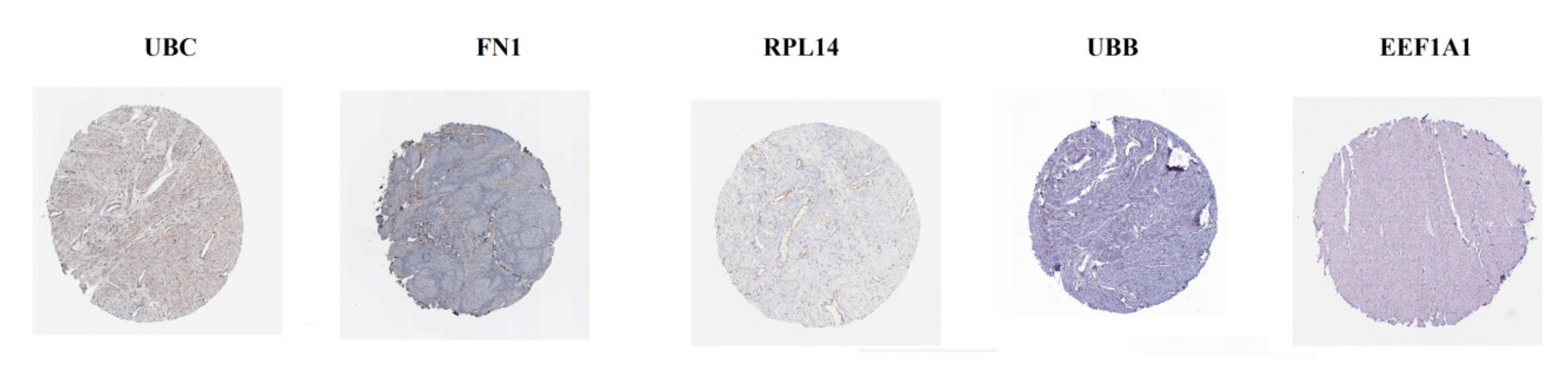
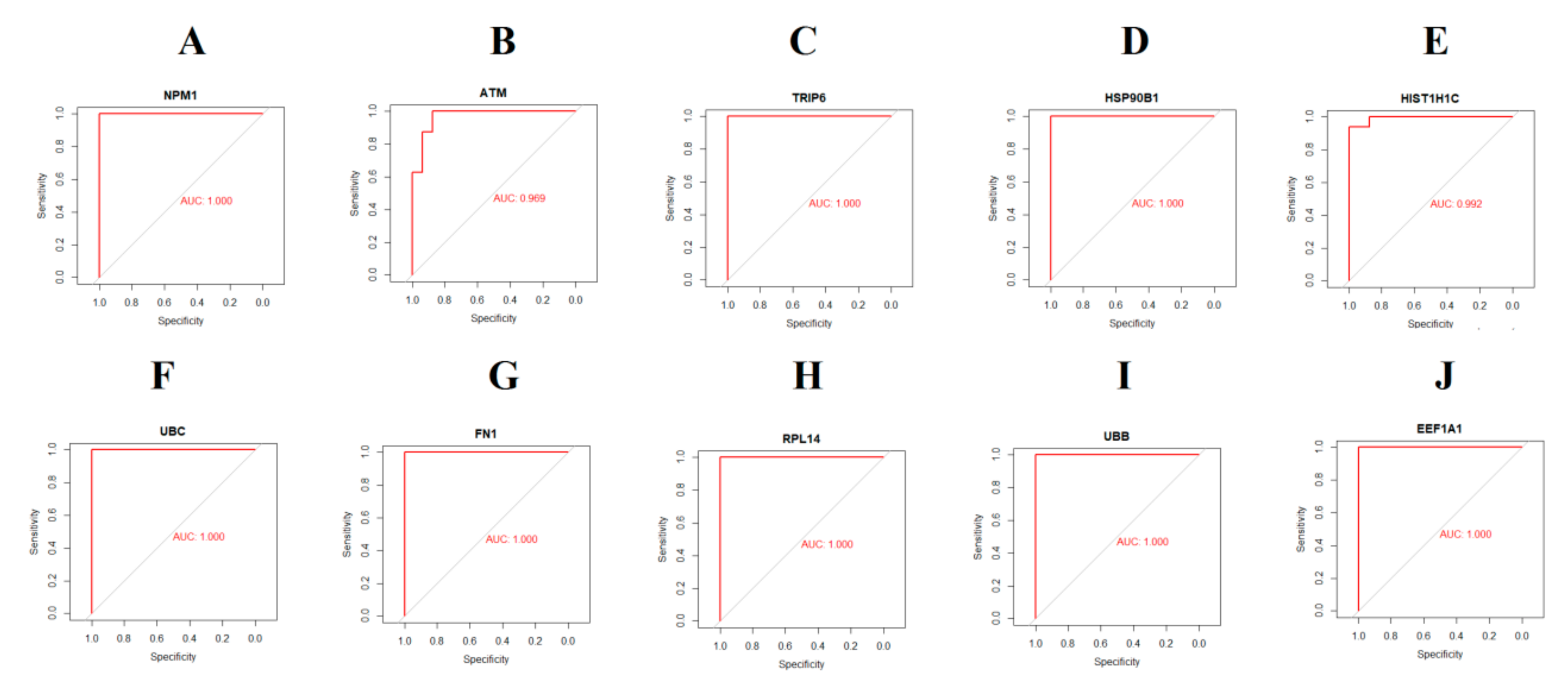
3.7. Validation of Hub Genes by Immunohistochemistry from HPA Database and Receiver Operating Characteristic Curve analysis
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Ethical Approval
Informed Consent
Availability of Data and Materials
Consent for Publication
References
- Diamond, G.A.; Forrester, J.S. Analysis of probability as an aid in the clinical diagnosis of coronary-artery disease. N. Engl. J. Med. 1979, 300, 1350–1358. [Google Scholar] [CrossRef] [PubMed]
- Ghassibe-Sabbagh, M.; Platt, D.E.; Youhanna, S.; Abchee, A.B.; Stewart, K.; Badro, D.A.; Haber, M.; Salloum, A.K.; Douaihy, B.; el Bayeh, H. Genetic and environmental influences on total plasma homocysteine and its role in coronary artery disease risk. Atherosclerosis 2012, 222, 180–186. [Google Scholar] [CrossRef] [PubMed]
- Howson, J.M.; Zhao, W.; Barnes, D.R.; Ho, W.K.; Young, R.; Paul, D.S.; Waite, L.L.; Freitag, D.F.; Fauman, E.B.; Salfati, E.L.; et al. Fifteen new risk loci for coronary artery disease highlight arterial-wall-specific mechanisms. Nat. Genet. 2017, 49, 1113–1119. [Google Scholar] [CrossRef] [PubMed]
- Aceña, Á.; Pello, A.M.; Carda, R.; Lorenzo, Ó.; Gonzalez-Casaus, M.L.; Blanco-Colio, L.M.; Martín-Ventura, J.L.; Palfy, J.; Orejas, M.; Rábago, R.; et al. Parathormone Levels Are Independently Associated with the Presence of Left Ventricular Hypertrophy in Patients with Coronary Artery Disease. J. Nutr. Health Aging 2016, 20, 659–664. [Google Scholar] [CrossRef] [PubMed]
- Samani, N.J.; Erdmann, J.; Hall, A.S.; Hengstenberg, C.; Mangino, M.; Maye, R.B.; Dixon, R.J.; Meitinger, T.; Braund, P.; Wichmann, H.E.; et al. Genomewide association analysis of coronary artery disease. N. Engl. J. Med. 2007, 357, 443–453. [Google Scholar] [CrossRef] [PubMed]
- Clee, S.M.; Zwinderman, A.H.; Engert, J.C.; Zwarts, K.Y.; Molhuizen, H.O.; Roomp, K.; Jukema, J.W.; van Wijland, M.; van Dam, M.; Hudson, T.J.; et al. Common genetic variation in ABCA1 is associated with altered lipoprotein levels and a modified risk for coronary artery disease. Circulation 2001, 103, 1198–1205. [Google Scholar] [CrossRef]
- Serrato, M.; Marian, A.J. A variant of human paraoxonase/arylesterase (HUMPONA) gene is a risk factor for coronary artery disease. J. Clin. Investig. 1995, 96, 3005–3008. [Google Scholar] [CrossRef]
- Behague, I.; Poirier, O.; Nicaud, V.; Evans, A.; Arveiler, D.; Luc, G.; Cambou, J.P.; Scarabin, P.Y.; Bara, L.; Green, F.; et al. Beta fibrinogen gene polymorphisms are associated with plasma fibrinogen and coronary artery disease in patients with myocardial infarction. The ECTIM Study. Etude Cas-Temoins sur l’Infarctus du Myocarde. Circulation 1996, 93, 440–449. [Google Scholar] [CrossRef]
- Ordovas, J.M.; Schaefer, E.J.; Salem, D.; Ward, R.H.; Glueck, C.J.; Vergani, C.; Wilson, P.W.; Karathanasis, S.K. Apolipoprotein A-I gene polymorphism associated with premature coronary artery disease and familial hypoalphalipoproteinemia. N. Engl. J. Med. 1986, 314, 671–677. [Google Scholar] [CrossRef]
- Kaneda, H.; Ohno, M.; Taguchi, J.; Togo, M.; Hashimoto, H.; Ogasawara, K.; Aizawa, T.; Ishizaka, N.; Nagai, R. Heme oxygenase-1 gene promoter polymorphism is associated with coronary artery disease in Japanese patients with coronary risk factors. Arterioscler. Thromb. Vasc. Biol. 2002, 22, 1680–1685. [Google Scholar] [CrossRef]
- Sanghera, D.K.; Aston, C.E.; Saha, N.; Kamboh, M.I. DNA polymorphisms in two paraoxonase genes (PON1 and PON2) are associated with the risk of coronary heart disease. Am. J. Hum. Genet. 1998, 62, 36–44. [Google Scholar] [CrossRef] [PubMed]
- Margaglione, M.; Cappucci, G.; Colaizzo, D.; Giuliani, N.; Vecchione, G.; Grandone, E.; Pennelli, O.; Di Minno, G. The PAI-1 gene locus 4G/5G polymorphism is associated with a family history of coronary artery disease. Arterioscler. Thromb. Vasc. Biol. 1998, 18, 152–156. [Google Scholar] [CrossRef] [PubMed]
- Lamblin, N.; Bauters, C.; Hermant, X.; Lablanche, J.M.; Helbecque, N.; Amouyel, P. Polymorphisms in the promoter regions of MMP-2, MMP-3, MMP-9 and MMP-12 genes as determinants of aneurysmal coronary artery disease. J. Am. Coll. Cardiol. 2002, 40, 43–48. [Google Scholar] [CrossRef]
- Inoue, N.; Kawashima, S.; Kanazawa, K.; Yamada, S.; Akita, H.; Yokoyama, M. Polymorphism of the NADH/NADPH oxidase p22 phox gene in patients with coronary artery disease. Circulation 1998, 97, 135–137. [Google Scholar] [CrossRef] [PubMed]
- Amant, C.; Hamon, M.; Bauters, C.; Richard, F.; Helbecque, N.; McFadden, E.P.; Escudero, X.; Lablanche, J.M.; Amouyel, P.; Bertrand, M.E. The angiotensin II type 1 receptor gene polymorphism is associated with coronary artery vasoconstriction. J. Am. Coll. Cardiol. 1997, 29, 486–490. [Google Scholar] [CrossRef]
- Ma, J.; Liew, C.C. Gene profiling identifies secreted protein transcripts from peripheral blood cells in coronary artery disease. J. Mol. Cell. Cardiol. 2003, 35, 993–998. [Google Scholar] [CrossRef]
- Archacki, S.R.; Angheloiu, G.; Tian, X.L.; Tan, F.L.; DiPaola, N.; Shen, G.Q.; Moravec, C.; Ellis, S.; Topol, E.J.; Wang, Q. Identification of new genes differentially expressed in coronary artery disease by expression profiling. Physiol. Genom. 2003, 15, 65–74. [Google Scholar] [CrossRef]
- Carvalho, B.S.; Irizarry, R.A. A framework for oligonucleotide microarray preprocessing. Bioinformatics 2010, 6, 2363–2367. [Google Scholar] [CrossRef]
- Ritchie, M.E.; Phipson, B.; Wu, D.; Hu, Y.; Law, C.W.; Shi, W.; Smyth, G.K. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015, 43, e47. [Google Scholar] [CrossRef]
- Chen, J.; Bardes, E.E.; Aronow, B.J.; Jegga, A.G. ToppGene Suite for gene list enrichment analysis and candidate gene prioritization. Nucleic Acids Res. 2009, 37, W305–W311. [Google Scholar] [CrossRef]
- Aoki-Kinoshita, K.F.; Kanehisa, M. Gene annotation and pathway mapping in KEGG. Methods. Mol. Biol. 2007, 396, 71–91. [Google Scholar] [CrossRef] [PubMed]
- Schaefer, C.F.; Anthony, K.; Krupa, S.; Buchoff, J.; Day, M.; Hannay, T.; Buetow, K.H. PID: The Pathway Interaction Database. Nucleic Acids Res. 2009, 37, D674–D679. [Google Scholar] [CrossRef] [PubMed]
- Croft, D.; O’Kelly, G.; Wu, G.; Haw, R.; Gillespie, M.; Matthews, L.; Caudy, M.; Garapati, P.; Gopinath, G.; Jassal, B.; et al. Reactome: A database of reactions, pathways and biological processes. Nucleic Acids Res. 2011, 39, D691–D697. [Google Scholar] [CrossRef] [PubMed]
- Liberzon, A.; Subramanian, A.; Pinchback, R.; Thorvaldsdóttir, H.; Tamayo, P.; Mesirov, J.P. Molecular signatures database (MSigDB) 3.0. Bioinformatics 2011, 27, 1739–1740. [Google Scholar] [CrossRef]
- Dahlquist, K.D.; Salomonis, N.; Vranizan, K.; Lawlor, S.C.; Conklin, B.R. GenMAPP, a new tool for viewing and analyzing microarray data on biological pathways. Nat. Genet. 2002, 31, 19–20. [Google Scholar] [CrossRef]
- Petri, V.; Jayaraman, P.; Tutaj, M.; Hayman, G.T.; Smith, J.R.; De Pons, J.; Laulederkind, S.J.; Lowry, T.F.; Nigam, R.; Wang, S.J.; et al. The pathway ontology-updates and applications. J. Biomed. Semant. 2014, 5, 7. [Google Scholar] [CrossRef]
- Mi, H.; Muruganujan, A.; Thomas, P.D. PANTHER in 2013: Modeling the evolution of gene function, and other gene attributes, in the context of phylogenetic trees. Nucleic Acids Res. 2013, 41, D377–D386. [Google Scholar] [CrossRef]
- Harris, M.A.; Clark, J.; Ireland, A.; Lomax, J.; Ashburner, M.; Foulger, R.; Eilbeck, K.; Lewis, S.; Marshall, B.; Mungall, C.; et al. The Gene Ontology (GO) database and informatics. Nucleic Acids Res. 2004, 32, D258–D261. [Google Scholar] [CrossRef]
- Oughtred, R.; Stark, C.; Breitkreutz, B.J.; Rust, J.; Boucher, L.; Chang, C.; Kolas, N.; O’Donnell, L.; Leung, G.; McAdam, R.; et al. The BioGRID interaction database: 2019 update. Nucleic Acids Res. 2019, 47, D529–D541. [Google Scholar] [CrossRef]
- Licata, L.; Briganti, L.; Peluso, D.; Perfetto, L.; Iannuccelli, M.; Galeota, E.; Sacco, F.; Palma, A.; Nardozza, A.P.; Santonico, E.; et al. MINT, the molecular interaction database: 2012 update. Nucleic Acids Res. 2012, 40, D857–D861. [Google Scholar] [CrossRef]
- Orchard, S.; Kerrien, S.; Abbani, S.; Aranda, B.; Bhate, J.; Bidwell, S.; Bridge, A.; Briganti, L.; Brinkman, F.S.; Chatr-Aryamontri, A.; et al. Protein interaction data curation: The International Molecular Exchange (IMEx) consortium. Nat. Methods 2012, 9, 345–350. [Google Scholar] [CrossRef] [PubMed]
- Salwinski, L.; Miller, C.S.; Smith, A.J.; Pettit, F.K.; Bowie, J.U.; Eisenberg, D. The Database of Interacting Proteins: 2004 update. Nucleic Acids Res. 2004, 32, D449–D451. [Google Scholar] [CrossRef] [PubMed]
- Cerami, E.G.; Gross, B.E.; Demir, E.; Rodchenkov, I.; Babur, O.; Anwar, N.; Schultz, N.; Bader, G.D.; Sander, C. Pathway Commons, a web resource for biological pathway data. Nucleic Acids Res. 2011, 39, D685–D690. [Google Scholar] [CrossRef] [PubMed]
- Razick, S.; Magklaras, G.; Donaldson, I.M. iRefIndex: A consolidated protein interaction database with provenance. BMC Bioinform. 2008, 9, 405. [Google Scholar] [CrossRef] [PubMed]
- Szklarczyk, D.; Gable, A.L.; Lyon, D.; Junge, A.; Wyder, S.; Huerta-Cepas, J.; Simonovic, M.; Doncheva, N.T.; Morris, J.H.; Bork, P.; et al. STRING v11: Protein-protein association networks with increased coverage, supporting functional discovery in genome-wide experimental datasets. Nucleic Acids Res. 2019, 47, D607–D613. [Google Scholar] [CrossRef]
- Clerc, O.; Deniaud, M.; Vallet, S.D.; Naba, A.; Rivet, A.; Perez, S.; Thierry-Mieg, N.; Ricard-Blum, S. MatrixDB: Integration of new data with a focus on glycosaminoglycan interactions. Nucleic Acids Res. 2019, 47, D376–D381. [Google Scholar] [CrossRef]
- Goll, J.; Rajagopala, S.V.; Shiau, S.C.; Wu, H.; Lamb, B.T.; Uetz, P. MPIDB: The microbial protein interaction database. Bioinformatics 2008, 24, 1743–1744. [Google Scholar] [CrossRef]
- Breuer, K.; Foroushani, A.K.; Laird, M.R.; Chen, C.; Sribnaia, A.; Lo, R.; Winsor, G.L.; Hancock, R.E.; Brinkman, F.S.; Lynn, D.J. InnateDB: Systems biology of innate immunity and beyond--recent updates and continuing curation. Nucleic Acids Res. 2013, 41, D1228–D1233. [Google Scholar] [CrossRef]
- Turner, B.; Razick, S.; Turinsky, A.L.; Vlasblom, J.; Crowdy, E.K.; Cho, E.; Morrison, K.; Donaldson, I.M.; Wodak, S.J. iRefWeb: Interactive analysis of consolidated protein interaction data and their supporting evidence. Database 2010, 2010, baq023. [Google Scholar] [CrossRef]
- Kotlyar, M.; Pastrello, C.; Sheahan, N.; Jurisica, I. Integrated interactions database: Tissue-specific view of the human and model organism interactomes. Nucleic Acids Res. 2016, 44, D536–D541. [Google Scholar] [CrossRef]
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D.; Amin, N.; Schwikowski, B.; Ideker, T. Cytoscape: A software environment for integrated models of biomolecular interaction networks. Genome Res. 2003, 3, 2498–2504. [Google Scholar] [CrossRef] [PubMed]
- Przulj, N. Biological network comparison using graphlet degree distribution. Bioinformatics 2007, 23, e177–e183. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Lonardi, S. A parallel edge-betweenness clustering tool for Protein-Protein Interaction networks. Int. J. Data Min. Bioinform. 2007, 1, 241–247. [Google Scholar] [CrossRef] [PubMed]
- Bi, D.; Ning, H.; Liu, S.; Que, X.; Ding, K. Gene expression patterns combined with network analysis identify hub genes associated with bladder cancer. Comput. Biol. Chem. 2015, 56, 71–83. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Q.; Wang, J.; Peng, X.; Wu, F.X.; Pan, Y. Identifying essential proteins from active PPI networks constructed with dynamic gene expression. BMC Genom. 2015, 16. [Google Scholar] [CrossRef] [PubMed]
- Asur, S.; Ucar, D.; Parthasarathy, S. An ensemble framework for clustering protein-protein interaction networks. Bioinformatics 2007, 23, i29–i40. [Google Scholar] [CrossRef]
- Zaki, N.; Efimov, D.; Berengueres, J. Protein complex detection using interaction reliability assessment and weighted clustering coefficient. BMC Bioinform. 2013, 14, 163. [Google Scholar] [CrossRef]
- Vlachos, I.S.; Paraskevopoulou, M.D.; Karagkouni, D.; Georgakilas, G.; Vergoulis, T.; Kanellos, I.; Anastasopoulos, I.L.; Maniou, S.; Karathanou, K.; Kalfakakou, D.; et al. DIANA-TarBase v7.0: Indexing more than half a million experimentally supported miRNA:mRNA interactions. Nucleic Acids Res. 2015, 43, D153–D159. [Google Scholar] [CrossRef]
- Chou, C.H.; Shrestha, S.; Yang, C.D.; Chang, N.W.; Lin, Y.L.; Liao, K.W.; Huang, W.C.; Sun, T.H.; Tu, S.J.; Lee, W.H.; et al. miRTarBase update 2018: A resource for experimentally validated microRNA-target interactions. Nucleic Acids Res. 2018, 46, D296–D302. [Google Scholar] [CrossRef]
- Zhou, G.; Soufan, O.; Ewald, J.; Hancock, R.E.W.; Basu, N.; Xia, J. NetworkAnalyst 3.0: A visual analytics platform for comprehensive gene expression profiling and meta-analysis. Nucleic Acids Res. 2019. [Google Scholar] [CrossRef]
- Khan, A.; Fornes, O.; Stigliani, A.; Gheorghe, M.; Castro-Mondragon, J.A.; van der Lee, R.; Bessy, A.; Chèneby, J.; Kulkarni, S.R.; Tan, G.; et al. JASPAR 2018: Update of the open-access database of transcription factor binding profiles and its web framework. Nucleic Acids Res. 2018, 46, D260–D266. [Google Scholar] [CrossRef] [PubMed]
- Uhlen, M.; Oksvold, P.; Fagerberg, L.; Lundberg, E.; Jonasson, K.; Forsberg, M.; Zwahlen, M.; Kampf, C.; Wester, K.; Hober, S.; et al. Towards a knowledge-based Human Protein Atlas. Nat. Biotechnol. 2010, 28, 1248–1250. [Google Scholar] [CrossRef]
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.C.; Müller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Z.; Hou, J.; Zhang, Q.; Zhong, W.; Li, B.; Li, C.; Liu, Z.; Yang, M.; Zhao, P. Circulating microRNA expression profiling and bioinformatics analysis of dysregulated microRNAs of patients with coronary artery disease. Medicine 2018, 97, e11428. [Google Scholar] [CrossRef] [PubMed]
- Bhagavatula, M.R.; Fan, C.; Shen, G.Q.; Cassano, J.; Plow, E.F.; Topol, E.J.; Wang, Q. Transcription factor MEF2A mutations in patients with coronary artery disease. Hum. Mol. Genet. 2004, 13, 3181–3188. [Google Scholar] [CrossRef][Green Version]
- Detrano, R.; Janosi, A.; Steinbrunn, W.; Pfisterer, M.; Schmid, J.J.; Sandhu, S.; Guppy, K.H.; Lee, S.; Froelicher, V. International application of a new probability algorithm for the diagnosis of coronary artery disease. Am. J. Cardiol. 1989, 64, 304–310. [Google Scholar] [CrossRef]
- Joshi, S.; Wei, J.; Bishopric, N.H. A cardiac myocyte-restricted Lin28/let-7 regulatory axis promotes hypoxia-mediated apoptosis by inducing the AKT signaling suppressor PIK3IP1. Biochim. Biophys. Acta 2016, 1862, 240–251. [Google Scholar] [CrossRef]
- Singh, G.B.; Raut, S.K.; Khanna, S.; Kumar, A.; Sharma, S.; Prasad, R.; Khullar, M. MicroRNA-200c modulates DUSP-1 expression in diabetes-induced cardiac hypertrophy. Mol. Cell. Biochem. 2017, 424, 1–11. [Google Scholar] [CrossRef]
- Sjakste, T.; Paramonova, N.; Osina, K.; Dokane, K.; Sokolovska, J.; Sjakste, N. Genetic variations in the PSMA3, PSMA6 and PSMC6 genes are associated with type 1 diabetes in Latvians and with expression level of number of UPS-related and T1DM-susceptible genes in HapMap individuals. Mol. Genet. Genom. 2016, 291, 891–903. [Google Scholar] [CrossRef]
- Wang, H.W.; Zhao, W.P.; Liu, J.; Tan, P.P.; Tian, W.S.; Zhou, B.H. ATP5J and ATP5H Proactive Expression Correlates with Cardiomyocyte Mitochondrial Dysfunction Induced by Fluoride. Biol. Trace Elem. Res. 2017, 180, 63–69. [Google Scholar] [CrossRef]
- Rekhter, M.; Staschke, K.; Estridge, T.; Rutherford, P.; Jackson, N.; Gifford-Moore, D.; Foxworthy, P.; Reidy, C.; Huang, X.D.; Kalbfleisch, M.; et al. Genetic ablation of IRAK4 kinase activity inhibits vascular lesion formation. Biochem. Biophys. Res. Commun. 2008, 367, 642–648. [Google Scholar] [CrossRef] [PubMed]
- Gorinstein, S.; Caspi, A.; Libman, I.; Katrich, E.; Lerner, H.T.; Trakhtenberg, S. Fresh israeli jaffa sweetie juice consumption improves lipid metabolism and increases antioxidant capacity in hypercholesterolemic patients suffering from coronary artery disease: Studies in vitro and in humans and positive changes in albumin and fibrinogen fractions. J. Agric. Food. Chem. 2004, 52, 5215–5222. [Google Scholar] [CrossRef] [PubMed]
- Schaefer, A.S.; Bochenek, G.; Jochens, A.; Ellinghaus, D.; Dommisch, H.; Güzeldemir-Akçakanat, E.; Graetz, C.; Harks, I.; Jockel-Schneider, Y.; Weinspach, K.; et al. Genetic evidence for PLASMINOGEN as a shared genetic risk factor of coronary artery disease and periodontitis. Circ. Cardiovasc. Genet. 2015, 8, 159–167. [Google Scholar] [CrossRef] [PubMed]
- Strauss, E.; Oszkinis, G.; Staniszewski, R. SEPP1 gene variants and abdominal aortic aneurysm: Gene association in relation to metabolic risk factors and peripheral arterial disease coexistence. Sci. Rep. 2014, 4, 7061. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.J.; Chen, L.; Bai, Y.P.; Li, L.; Sun, J.; Zhang, G.G.; Yang, T.L.; Xia, J.; Li, Y.J.; Chen, X.P. The ALDH2 Glu504Lys polymorphism is associated with coronary artery disease in Han Chinese: Relation with endothelial ADMA levels. Atherosclerosis 2010, 211, 545–550. [Google Scholar] [CrossRef] [PubMed]
- Malik, R.; Dau, T.; Gonik, M.; Sivakumar, A.; Deredge, D.J.; Edeleva, E.V.; Götzfried, J.; van der Laan, S.W.; Pasterkamp, G.; Beaufort, N.; et al. Common coding variant in SERPINA1 increases the risk for large artery stroke. Proc. Natl. Acad. Sci. USA 2017, 114, 3613–3618. [Google Scholar] [CrossRef]
- Rotroff, D.M.; Pijut, S.S.; Marvel, S.W.; Jack, J.R.; Havener, T.M.; Pujol, A.; Schluter, A.; Graf, G.A.; Ginsberg, H.N.; Shah, H.S.; et al. Genetic Variants in HSD17B3, SMAD3, and IPO11 Impact Circulating Lipids in Response to Fenofibrate in Individuals with Type 2 Diabetes. Clin. Pharmacol. 2018, 103, 712–721. [Google Scholar] [CrossRef]
- Yu, X.H.; Qian, K.; Jiang, N.; Zheng, X.L.; Cayabyab, F.S.; Tang, C.K. ABCG5/ABCG8 in cholesterol excretion and atherosclerosis. Clin. Chim. Acta 2014, 428, 82–88. [Google Scholar] [CrossRef]
- Schiekofer, S.; Bobak, I.; Kleber, M.E.; Maerz, W.; Rudofsky, G.; Dugi, K.A.; Schneider, J.G. Association between a gene variant near ataxia telangiectasia mutated and coronary artery disease in men. Diabetes Vasc. Dis. Res. 2014, 11, 60–63. [Google Scholar] [CrossRef]
- Dazert, P.; Meissner, K.; Vogelgesang, S.; Heydrich, B.; Eckel, L.; Böhm, M.; Warzok, R.; Kerb, R.; Brinkmann, U.; Schaeffeler, E.; et al. Expression and localization of the multidrug resistance protein 5 (MRP5/ABCC5), a cellular export pump for cyclic nucleotides, in human heart. Am. J. Pathol. 2003, 163, 1567–1577. [Google Scholar] [CrossRef]
- Wild, P.S.; Zeller, T.; Schillert, A.; Szymczak, S.; Sinning, C.R.; Deiseroth, A.; Schnabel, R.B.; Lubos, E.; Keller, T.; Eleftheriadis, M.S.; et al. A genome-wide association study identifies LIPA as a susceptibility gene for coronary artery disease. Circ. Cardiovasc. Genet. 2011, 4, 403–412. [Google Scholar] [CrossRef] [PubMed]
- Westerterp, M.; Bochem, A.E.; Yvan-Charvet, L.; Murphy, A.J.; Wang, N.; Tall, A.R. ATP-binding cassette transporters, atherosclerosis, and inflammation. Circ. Res. 2014, 114, 157–170. [Google Scholar] [CrossRef] [PubMed]
- Jacquemin, B.; Antoniades, C.; Nyberg, F.; Plana, E.; Müller, M.; Greven, S.; Salomaa, V.; Sunyer, J.; Bellander, T.; Chalamandaris, A.G.; et al. Common genetic polymorphisms and haplotypes of fibrinogen alpha, beta, and gamma chains affect fibrinogen levels and the response to proinflammatory stimulation in myocardial infarction survivors: The AIRGENE study. J. Am. Coll. Cardiol. 2008, 52, 941–952. [Google Scholar] [CrossRef] [PubMed]
- Cheung, E.Y.; Uitte de Willige, S.; Vos, H.L.; Leebeek, F.W.; Dippel, D.W.; Bertina, R.M.; de Maat, M.P. Fibrinogen gamma’ in ischemic stroke: A case-control study. Stroke 2008, 39, 1033–1035. [Google Scholar] [CrossRef]
- Leenaerts, D.; Bosmans, J.M.; van der Veken, P.; Sim, Y.; Lambeir, A.M.; Hendriks, D. Plasma levels of carboxypeptidase U (CPU, CPB2 or TAFIa) are elevated in patients with acute myocardial infarction. J. Thromb. Haemost 2015, 13, 2227–2232. [Google Scholar] [CrossRef]
- Széplaki, G.; Prohászka, Z.; Duba, J.; Rugonfalvi-Kiss, S.; Karádi, I.; Kókai, M.; Kramer, J.; Füst, G.; Kleiber, M.; Romics, L.; et al. Association of high serum concentration of the third component of complement (C3) with pre-existing severe coronary artery disease and new vascular events in women. Atherosclerosis 2004, 177, 383–389. [Google Scholar] [CrossRef]
- Blaskó, B.; Kolka, R.; Thorbjornsdottir, P.; Sigurdarson, S.T.; Sigurdsson, G.; Rónai, Z.; Sasvári-Székely, M.; Bödvarsson, S.; Thorgeirsson, G.; Prohászka, Z.; et al. Low complement C4B gene copy number predicts short-term mortality after acute myocardial infarction. Int. Immunol. 2008, 20, 31–37. [Google Scholar] [CrossRef]
- Shanker, J.; Perumal, G.; Rao, V.S.; Khadrinarasimhiah, N.B.; John, S.; Hebbagodi, S.; Mukherjee, M.; Kakkar, V.V. Genetic studies on the APOA1-C3-A5 gene cluster in Asian Indians with premature coronary artery disease. Lipids Health Dis. 2008, 7, 33. [Google Scholar] [CrossRef]
- Heald, A.H.; Cruickshank, J.K.; Riste, L.K.; Cade, J.E.; Anderson, S.; Greenhalgh, A.; Sampayo, J.; Taylor, W.; Fraser, W.; White, A.; et al. Close relation of fasting insulin-like growth factor binding protein-1 (IGFBP-1) with glucose tolerance and cardiovascular risk in two populations. Diabetologia 2001, 44, 333–339. [Google Scholar] [CrossRef]
- Miyazaki, A.; Sakashita, N.; Lee, O.; Takahashi, K.; Horiuchi, S.; Hakamata, H.; Morganelli, P.M.; Chang, C.C.; Chang, T.Y. Expression of ACAT-1 protein in human atherosclerotic lesions and cultured human monocytes-macrophages. Arterioscler. Thromb. Vasc. Biol. 1998, 18, 1568–1574. [Google Scholar] [CrossRef]
- Thompson, A.; Danesh, J. Associations between apolipoprotein B, apolipoprotein AI, the apolipoprotein B/AI ratio and coronary heart disease: A literature-based meta-analysis of prospective studies. J. Intern. Med. 2006, 259, 481–492. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.T.; Liao, H.Y.; Chang, C.M.; Chen, C.Y.; Chen, C.H.; Yang, C.Y.; Tsai, F.J.; Chen, C.J. Oxidized ApoC1 on MALDI-TOF and glycated-ApoA1 band on gradient gel as potential diagnostic tools for atherosclerotic vascular disease. Clin. Chim. Acta 2013, 420, 69–75. [Google Scholar] [CrossRef] [PubMed]
- Beale, E.G.; Harvey, B.J.; Forest, C. PCK1 and PCK2 as candidate diabetes and obesity genes. Cell Biochem. Biophys. 2007, 48, 89–95. [Google Scholar] [CrossRef] [PubMed]
- Landrier, J.F.; Kasiri, E.; Karkeni, E.; Mihály, J.; Béke, G.; Weiss, K.; Lucas, R.; Aydemir, G.; Salles, J.; Walrand, S.; et al. Reduced adiponectin expression after high-fat diet is associated with selective up-regulation of ALDH1A1 and further retinoic acid receptor signaling in adipose tissue. FASEB J. 2017, 31, 203–211. [Google Scholar] [CrossRef] [PubMed]
- Giacconi, R.; Bonfigli, A.R.; Testa, R.; Sirolla, C.; Cipriano, C.; Marra, M.; Muti, E.; Malavolta, M.; Costarelli, L.; Piacenza, F.; et al. +647 A/C and +1245 MT1A polymorphisms in the susceptibility of diabetes mellitus and cardiovascular complications. Mol. Genet. Metab. 2008, 94, 98–104. [Google Scholar] [CrossRef]
- Yang, X.Y.; Sun, J.H.; Ke, H.Y.; Chen, Y.J.; Xu, M.; Luo, G.H. Metallothionein 2A genetic polymorphism and its correlation to coronary heart disease. Eur. Rev. Med. Pharmacol. Sci. 2014, 18, 3747–3753. [Google Scholar]
- Ercan, B.; Ayaz, L.; Ciçek, D.; Tamer, L. Role of CYP2C9 and CYP2C19 polymorphisms in patients with atherosclerosis. Cell. Biochem. Funct. 2008, 26, 309–313. [Google Scholar] [CrossRef]
- He, B.X.; Shi, L.; Qiu, J.; Tao, L.; Li, R.; Yang, L.; Zhao, S.J. A functional polymorphism in the CYP3A4 gene is associated with increased risk of coronary heart disease in the Chinese Han population. Basic. Clin. Pharmacol. Toxicol. 2011, 108, 208–213. [Google Scholar] [CrossRef]
- Li, Y.Y.; Wu, X.Y.; Xu, J.; Qian, Y.; Zhou, C.W.; Wang, B. Apo A5 -1131T/C, FgB -455G/A, -148C/T, and CETP TaqIB gene polymorphisms and coronary artery disease in the Chinese population: A meta-analysis of 15,055 subjects. Mol. Biol. Rep. 2013, 40, 1997–2014. [Google Scholar] [CrossRef]
- Ebrahim, S.; Lawlor, D.A.; Shlomo, Y.B.; Timpson, N.; Harbord, R.; Christensen, M.; Baban, J.; Kiessling, M.; Day, I.; Gaunt, T.; et al. Alcohol dehydrogenase type 1C (ADH1C) variants, alcohol consumption traits, HDL-cholesterol and risk of coronary heart disease in women and men: British Women’s Heart and Health Study and Caerphilly cohorts. Atherosclerosis 2008, 196, 871–878. [Google Scholar] [CrossRef]
- Clarke, R.; Peden, J.F.; Hopewell, J.C.; Kyriakou, T.; Goel, A.; Heath, S.C.; Parish, S.; Barlera, S.; Franzosi, M.G.; Rust, S.; et al. Genetic variants associated with Lp(a) lipoprotein level and coronary disease. N. Engl. J. Med. 2009, 361, 2518–2528. [Google Scholar] [CrossRef]
- Russo, G.T.; Meigs, J.B.; Cupples, L.A.; Demissie, S.; Otvos, J.D.; Wilson, P.W.; Lahoz, C.; Cucinotta, D.; Couture, P.; Mallory, T.; et al. Association of the Sst-I polymorphism at the APOC3 gene locus with variations in lipid levels, lipoprotein subclass profiles and coronary heart disease risk: The Framingham offspring study. Atherosclerosis 2001, 158, 173–181. [Google Scholar] [CrossRef]
- Siguel, E.N.; Lerman, R.H. Altered fatty acid metabolism in patients with angiographically documented coronary artery disease. Metabolism 1994, 43, 982–993. [Google Scholar] [CrossRef]
- Surendran, R.P.; Visser, M.E.; Heemelaar, S.; Wang, J.; Peter, J.; Defesche, J.C.; Kuivenhoven, J.A.; Hosseini, M.; Péterfy, M.; Kastelein, J.J.; et al. Mutations in LPL, APOC2, APOA5, GPIHBP1 and LMF1 in patients with severe hypertriglyceridaemia. J. Intern. Med. 2012, 272, 185–196. [Google Scholar] [CrossRef] [PubMed]
- Rienks, M.; Carai, P.; Bitsch, N.; Schellings, M.; Vanhaverbeke, M.; Verjans, J.; Cuijpers, I.; Heymans, S.; Papageorgiou, A. Sema3A promotes the resolution of cardiac inflammation after myocardial infarction. Basic Res. Cardiol. 2017, 112, 42. [Google Scholar] [CrossRef]
- Yu, L.; Li, Z.; Dong, X.; Xue, X.; Liu, Y.; Xu, S.; Zhang, J.; Han, J.; Yang, Y.; Wang, H. Polydatin Protects Diabetic Heart against Ischemia-Reperfusion Injury via Notch1/Hes1-Mediated Activation of Pten/Akt Signaling. Oxid. Med. Cell. Longev. 2018, 2018, 2750695. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, Y.; Yamada, S.; Thirunavukkarasu, M.; Nin, V.; Joshi, M.; Rishi, M.T.; Bhattacharya, S.; Camacho-Pereira, J.; Sharma, A.K.; et al. Cardiomyopathy and Worsened Ischemic Heart Failure in SM22-α Cre-Mediated Neuropilin-1 Null Mice: Dysregulation of PGC1α and Mitochondrial Homeostasis. Arterioscler. Thromb. Vasc. Biol. 2015, 35, 1401–1412. [Google Scholar] [CrossRef]
- Chun, J.L.; O’Brien, R.; Berry, S.E. Cardiac dysfunction and pathology in the dystrophin and utrophin-deficient mouse during development of dilated cardiomyopathy. Neuromuscul. Disord. 2012, 22, 368–379. [Google Scholar] [CrossRef]
- Yan, X.X.; Lu, L.; Peng, W.H.; Wang, L.J.; Zhang, Q.; Zhang, R.Y.; Chen, Q.J.; Shen, W.F. Increased serum HMGB1 level is associated with coronary artery disease in nondiabetic and type 2 diabetic patients. Atherosclerosis 2009, 205, 544–548. [Google Scholar] [CrossRef]
- Takada, D.; Ezura, Y.; Ono, S.; Iino, Y.; Katayama, Y.; Xin, Y.; Wu, L.L.; Larringa-Shum, S.; Stephenson, S.H.; Hunt, S.C.; et al. Apolipoprotein H variant modifies plasma triglyceride phenotype in familial hypercholesterolemia: A molecular study in an eight-generation hyperlipidemic family. J. Atheroscler. Thromb. 2003, 10, 79–84. [Google Scholar] [CrossRef]
- Rodríguez, S.; Gaunt, T.R.; O’Dell, S.D.; Chen, X.H.; Gu, D.; Hawe, E.; Miller, G.J.; Humphries, S.E.; Day, I.N. Haplotypic analyses of the IGF2-INS-TH gene cluster in relation to cardiovascular risk traits. Hum. Mol. Genet. 2004, 13, 715–725. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Xu, H.; Shang, Q.; Chen, H.; Du, J.; Wen, J.; Li, G.; Shi, D.; Chen, K. ITIH4: A New Potential Biomarker of “Toxin Syndrome” in Coronary Heart Disease Patient Identified with Proteomic Method. Evid. Based. Complement. Alternat. Med. 2013, 2013, 360149. [Google Scholar] [CrossRef] [PubMed]
- Cahill, L.E.; Levy, A.P.; Chiuve, S.E.; Jensen, M.K.; Wang, H.; Shara, N.M.; Blum, S.; Howard, B.V.; Pai, J.K.; Mukamal, K.J.; et al. Haptoglobin genotype is a consistent marker of coronary heart disease risk among individuals with elevated glycosylated hemoglobin. J. Am. Coll. Cardiol. 2013, 61, 728–737. [Google Scholar] [CrossRef] [PubMed]
- Hammadah, M.; Fan, Y.; Wu, Y.; Hazen, S.L.; Tang, W.H. Prognostic value of elevated serum ceruloplasmin levels in patients with heart failure. J. Card. Fail. 2014, 20, 946–952. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, M.; Mokhtari, G.K.; Terry, R.D.; Balsam, L.B.; Lee, K.H.; Kofidis, T.; Tsao, P.S.; Robbins, R.C. Overexpression of human copper/zinc superoxide dismutase (SOD1) suppresses ischemia-reperfusion injury and subsequent development of graft coronary artery disease in murine cardiac grafts. Circulation 2004, 110, II200–II206. [Google Scholar] [CrossRef] [PubMed]
- Ebana, Y.; Ozaki, K.; Inoue, K.; Sato, H.; Iida, A.; Lwin, H.; Saito, S.; Mizuno, H.; Takahashi, A.; Nakamura, T.; et al. A functional SNP in ITIH3 is associated with susceptibility to myocardial infarction. J. Hum. Genet. 2007, 52, 220–229. [Google Scholar] [CrossRef][Green Version]
- Altamura, C.; Squitti, R.; Pasqualetti, P.; Gaudino, C.; Palazzo, P.; Tibuzzi, F.; Lupoi, D.; Cortesi, M.; Rossini, P.M.; Vernieri, F. Ceruloplasmin/Transferrin system is related to clinical status in acute stroke. Stroke 2009, 40, 1282–1288. [Google Scholar] [CrossRef]
- Gan, W.; Wu, J.; Lu, L.; Xiao, X.; Huang, H.; Wang, F.; Zhu, J.; Sun, L.; Liu, G.; Pan, Y.; et al. Associations of CFH polymorphisms and CFHR1-CFHR3 deletion with blood pressure and hypertension in Chinese population. PLoS ONE 2012, 7, e42010. [Google Scholar] [CrossRef]
- Renner, W.; Nauck, M.; Winkelmann, B.R.; Hoffmann, M.M.; Scharnagl, H.; Mayer, V.; Boehm, B.O.; März, W. Association of angiotensinogen haplotypes with angiotensinogen levels but not with blood pressure or coronary artery disease: The Ludwigshafen Risk and Cardiovascular Health Study. J. Mol. Med. 2005, 83, 235–239. [Google Scholar] [CrossRef]
- He, M.; Guo, H.; Yang, X.; Zhou, L.; Zhang, X.; Cheng, L.; Zeng, H.; Hu, F.B.; Tanguay, R.M.; Wu, T. Genetic variations in HSPA8 gene associated with coronary heart disease risk in a Chinese population. PLoS ONE 2010, 5, e9684. [Google Scholar] [CrossRef]
- Peppiatt-Wildman, C.M.; Albert, A.P.; Saleh, S.N.; Large, W.A. Endothelin-1 activates a Ca2+-permeable cation channel with TRPC3 and TRPC7 properties in rabbit coronary artery myocytes. J. Physiol. 2007, 580, 755–764. [Google Scholar] [CrossRef] [PubMed]
- Biscetti, F.; Straface, G.; Giovannini, S.; Santoliquido, A.; Angelini, F.; Santoro, L.; Porreca, C.F.; Pecorini, G.; Ghirlanda, G.; Flex, A. Association between TNFRSF11B gene polymorphisms and history of ischemic stroke in Italian diabetic patients. Hum. Genet. 2013, 132, 49–55. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Lei, H. Tripartite Motif Protein 72 Regulates the Proliferation and Migration of Rat Cardiac Fibroblasts via the Transforming Growth Factor-β Signaling Pathway. Cardiology 2016, 134, 340–346. [Google Scholar] [CrossRef] [PubMed]
- Muiya, N.P.; Wakil, S.; Al-Najai, M.; Tahir, A.I.; Baz, B.; Andres, E.; Al-Boudari, O.; Al-Tassan, N.; Al-Shahid, M.; Meyer, B.F.; et al. A study of the role of GATA2 gene polymorphism in coronary artery disease risk traits. Gene 2014, 544, 152–158. [Google Scholar] [CrossRef] [PubMed]
- Murr, C.; Grammer, T.B.; Meinitzer, A.; Kleber, M.E.; März, W.; Fuchs, D. Immune activation and inflammation in patients with cardiovascular disease are associated with higher phenylalanine to tyrosine ratios: The ludwigshafen risk and cardiovascular health study. J. Amino Acids 2014, 2014, 783730. [Google Scholar] [CrossRef]


















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balashanmugam, M.V.; Shivanandappa, T.B.; Nagarethinam, S.; Vastrad, B.; Vastrad, C. Analysis of Differentially Expressed Genes in Coronary Artery Disease by Integrated Microarray Analysis. Biomolecules 2020, 10, 35. https://doi.org/10.3390/biom10010035
Balashanmugam MV, Shivanandappa TB, Nagarethinam S, Vastrad B, Vastrad C. Analysis of Differentially Expressed Genes in Coronary Artery Disease by Integrated Microarray Analysis. Biomolecules. 2020; 10(1):35. https://doi.org/10.3390/biom10010035
Chicago/Turabian StyleBalashanmugam, Meenashi Vanathi, Thippeswamy Boreddy Shivanandappa, Sivagurunathan Nagarethinam, Basavaraj Vastrad, and Chanabasayya Vastrad. 2020. "Analysis of Differentially Expressed Genes in Coronary Artery Disease by Integrated Microarray Analysis" Biomolecules 10, no. 1: 35. https://doi.org/10.3390/biom10010035
APA StyleBalashanmugam, M. V., Shivanandappa, T. B., Nagarethinam, S., Vastrad, B., & Vastrad, C. (2020). Analysis of Differentially Expressed Genes in Coronary Artery Disease by Integrated Microarray Analysis. Biomolecules, 10(1), 35. https://doi.org/10.3390/biom10010035