Mapping Metabolite and ICD-10 Associations


Abstract
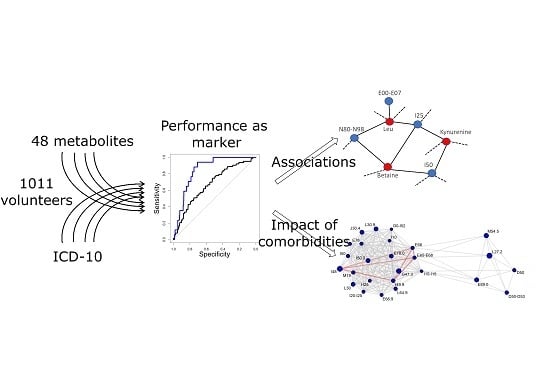
1. Introduction
2. Results
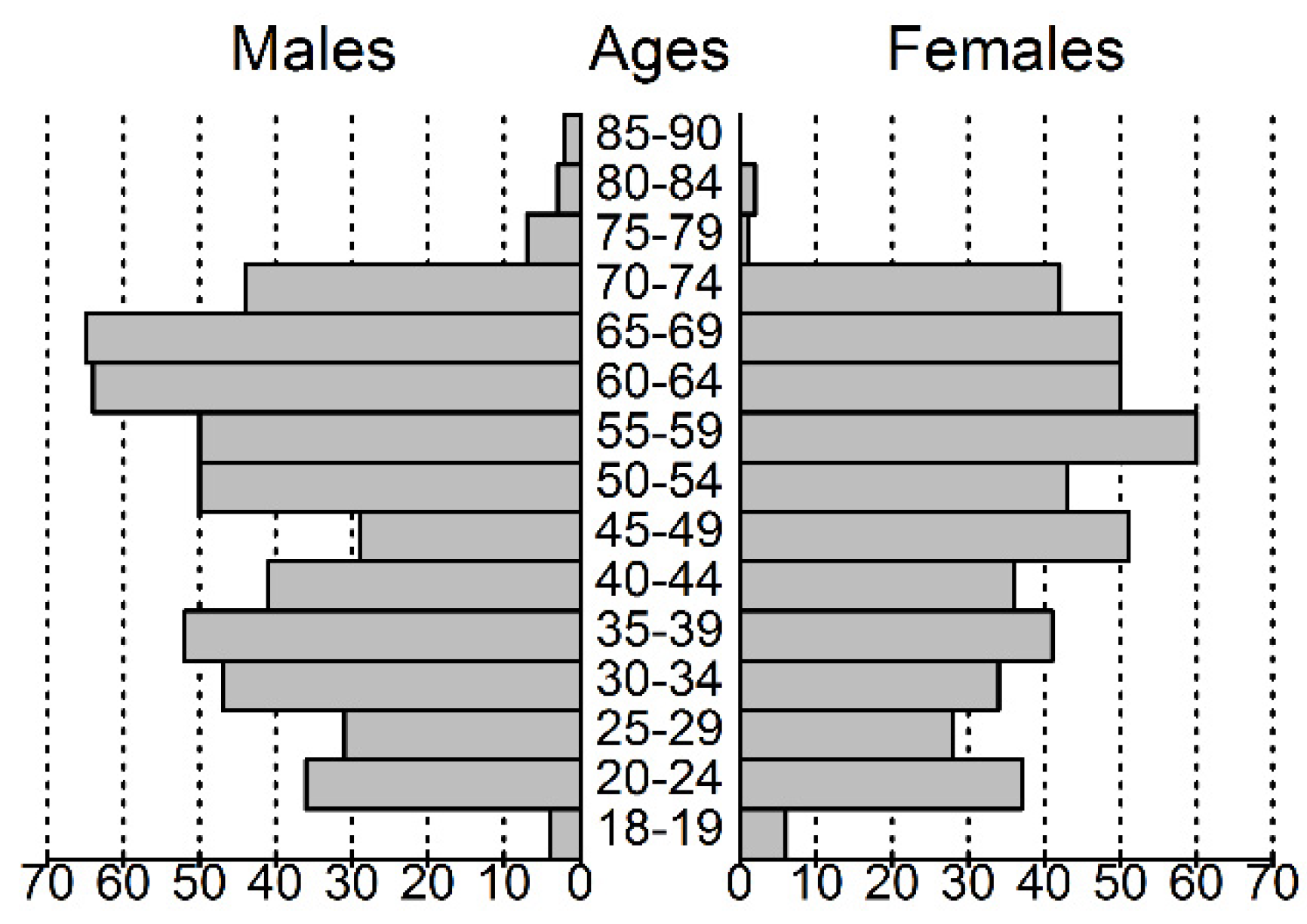
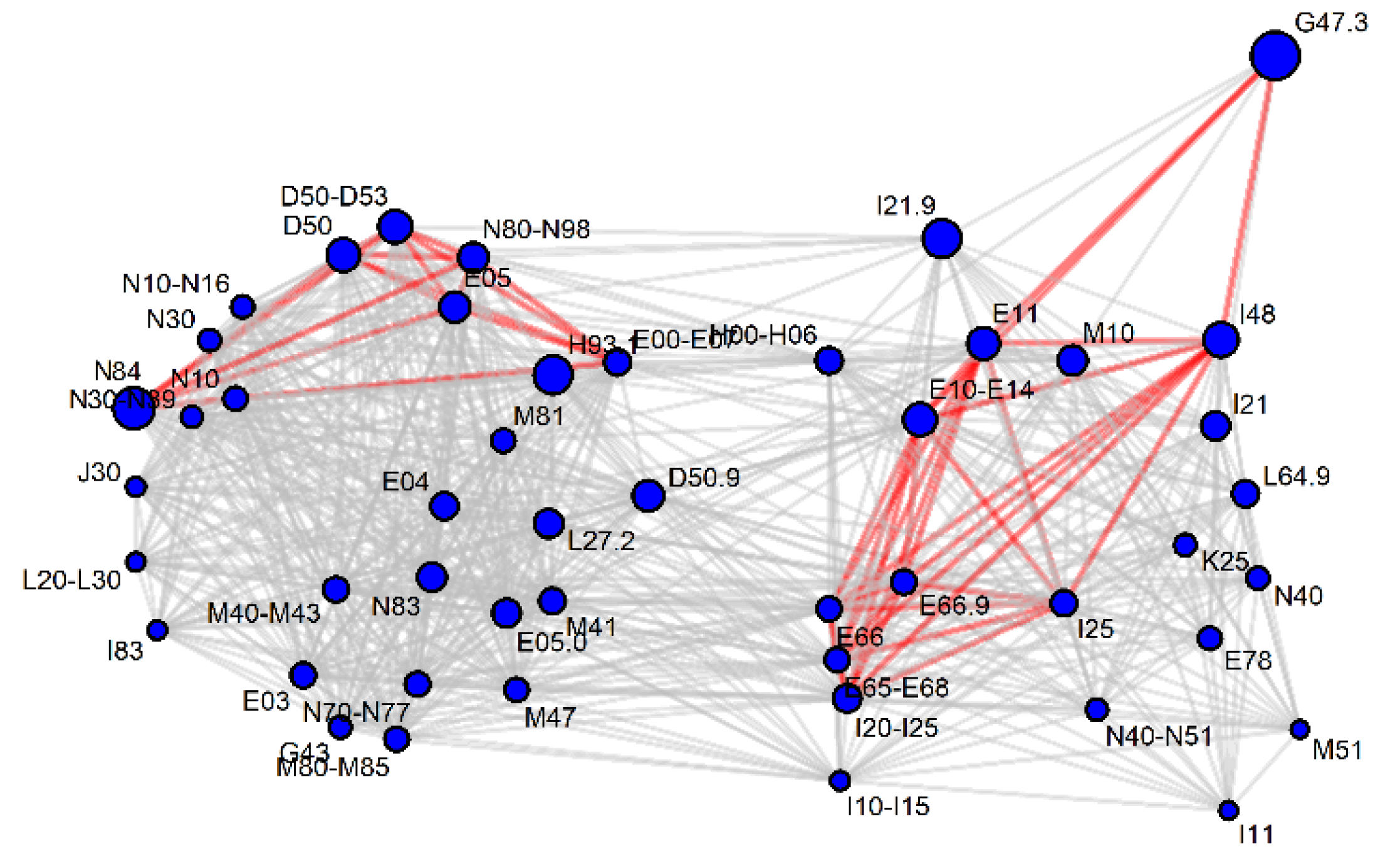
2.1. Characterization of the Study Group
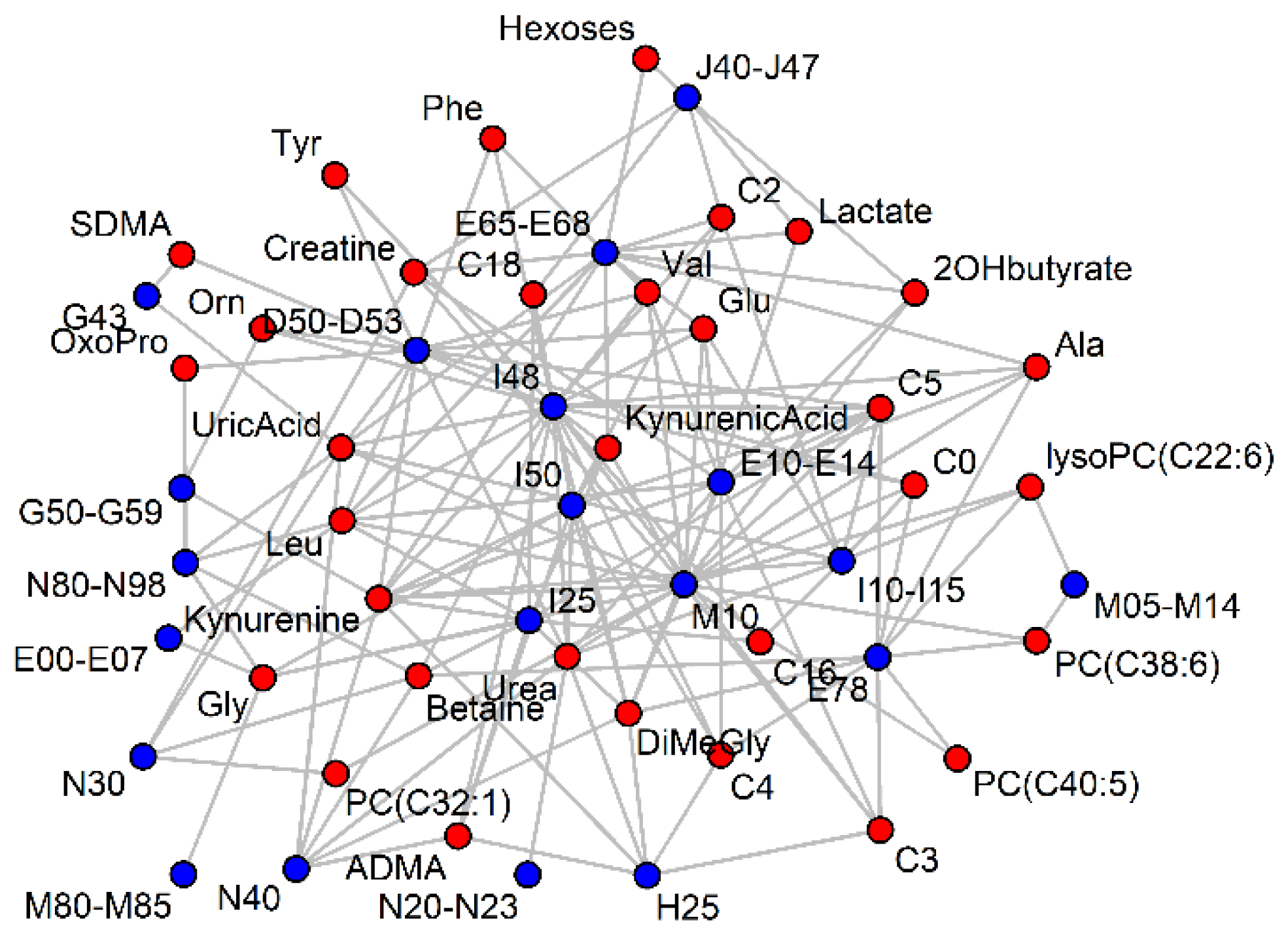
2.2. Selection of Metabolic Biomarker Candidates
2.3. Receiver Operator Curves for Individual Disease Categories
2.4. Importance of Healthy Controls
2.5. The Case of an Underlying Disease
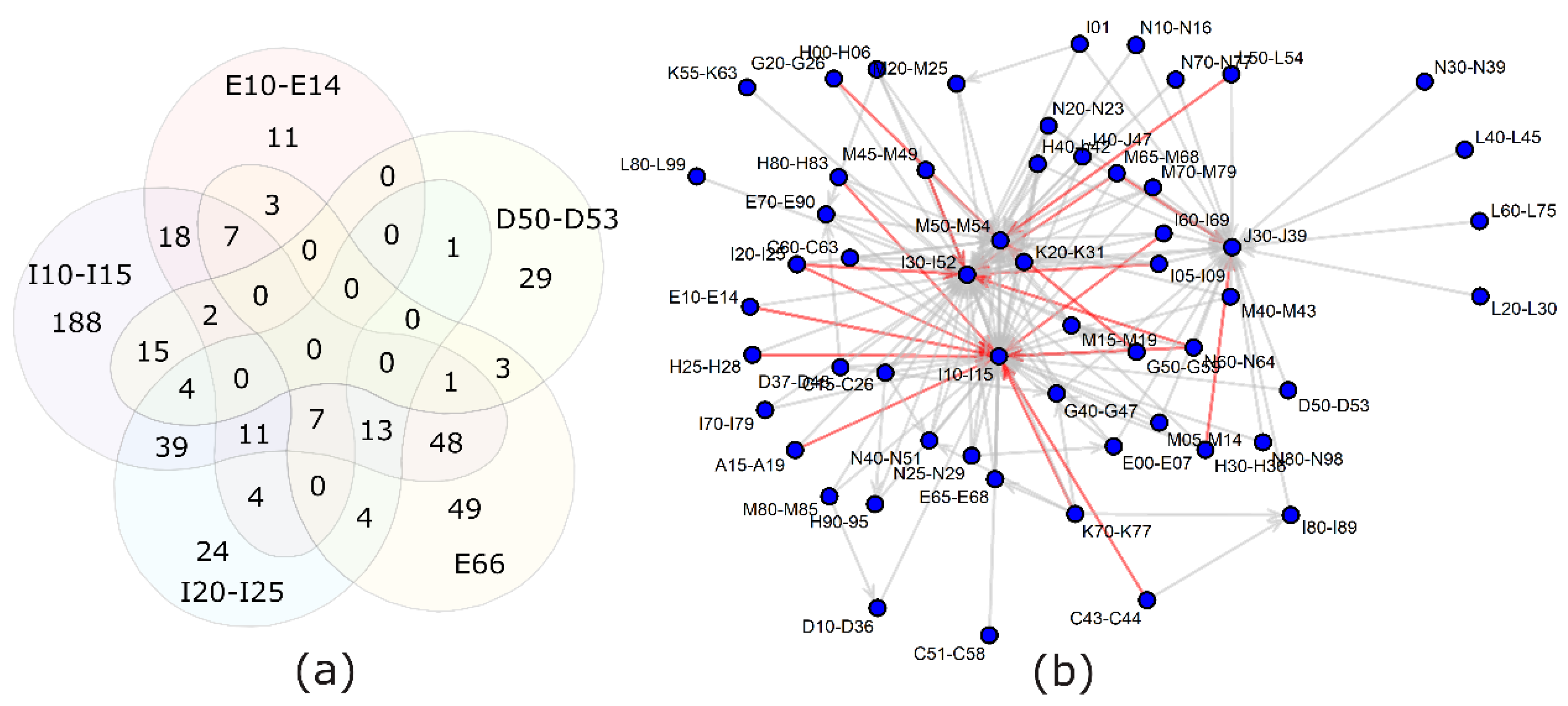
2.6. Combination of Two Diseases
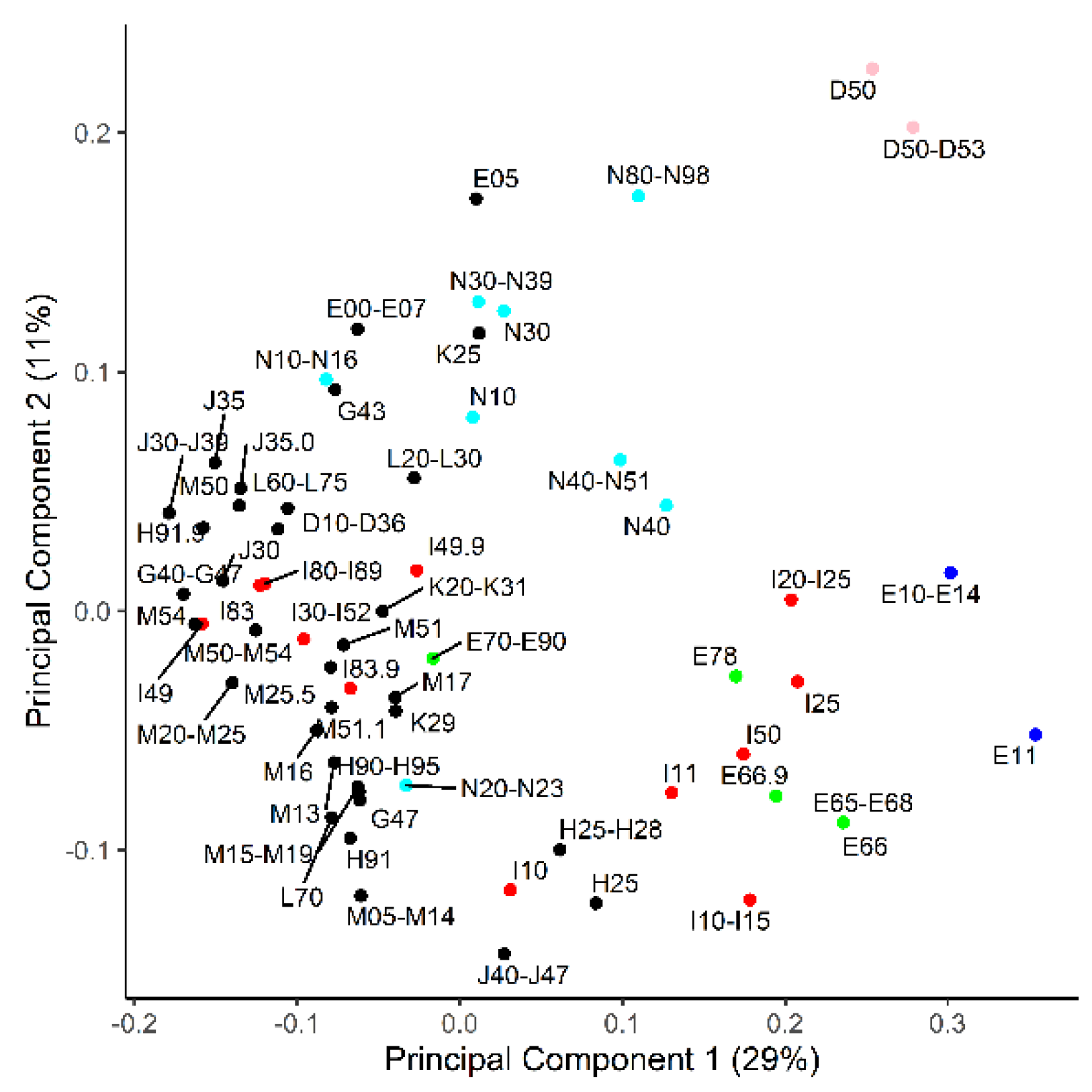
2.7. Pooling of Diagnoses
3. Discussion
4. Materials and Methods
4.1. Subjects Recruitment and Clinical Data Collection
4.2. Sample Preparation and Analysis
4.3. Statistics
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Füzéry, A.K.; Levin, J.; Chan, M.M.; Chan, D.W. Translation of proteomic biomarkers into FDA approved cancer diagnostics: Issues and challenges. Clin. Proteom. 2013, 10, 13. [Google Scholar] [CrossRef] [PubMed]
- Khamis, M.M.; Adamko, D.J.; El-Aneed, A. Strategies and challenges in method development and validation for the absolute quantification of endogenous biomarker metabolites using liquid chromatography-tandem mass spectrometry. Mass Spectrom. Rev. 2019. [Google Scholar] [CrossRef] [PubMed]
- Gowda, G.N.; Raftery, D. Biomarker Discovery and Translation in Metabolomics. Curr. Metabolomics 2013, 1, 227–240. [Google Scholar] [CrossRef] [PubMed]
- Schilsky, R.L. Personalized medicine in oncology: The future is now. Nat. Rev. Drug Discov. 2010, 9, 363–366. [Google Scholar] [CrossRef] [PubMed]
- Ghoochani, B.F.N.M.; Aliannejad, R.; Rezaei-Tavirani, M.; Taheri, S.; Oskouie, A.A. The metabolomics of airway diseases, including COPD, asthma and cystic fibrosis. Biomarkers 2014, 20, 5–16. [Google Scholar] [CrossRef]
- Beebe, K.; Kennedy, A.D. Sharpening Precision Medicine by a Thorough Interrogation of Metabolic Individuality. Comput. Struct. Biotechnol. J. 2016, 14, 97–105. [Google Scholar] [CrossRef]
- Guma, M.; Tiziani, S.; Firestein, G.S. Metabolomics in rheumatic diseases: Desperately seeking biomarkers. Nat. Rev. Rheumatol. 2016, 12, 269–281. [Google Scholar] [CrossRef]
- Pearson, E.R. Personalized medicine in diabetes: The role of ‘omics’ and biomarkers. Diabet. Med. 2016, 33, 712–717. [Google Scholar] [CrossRef]
- Wishart, D.S.; Mandal, R.; Stanislaus, A.; Ramirez-Gaona, M. Cancer Metabolomics and the Human Metabolome Database. Metabolites 2016, 6, 10. [Google Scholar] [CrossRef]
- Ubhi, B.K.; Riley, J.H.; Shaw, P.A.; Lomas, D.A.; Tal-Singer, R.; MacNee, W.; Griffin, J.L.; Connor, S.C. Metabolic profiling detects biomarkers of protein degradation in COPD patients. Eur. Respir. J. 2011, 40, 345–355. [Google Scholar] [CrossRef]
- Floegel, A.; Stefan, N.; Yu, Z.; Mühlenbruch, K.; Drogan, D.; Joost, H.-G.; Fritsche, A.; Häring, H.-U.; De Angelis, M.H.; Peters, A.; et al. Identification of Serum Metabolites Associated with Risk of Type 2 Diabetes Using a Targeted Metabolomic Approach. Diabetes 2013, 62, 639–648. [Google Scholar] [CrossRef] [PubMed]
- Lever, M.; George, P.M.; Slow, S.; Bellamy, D.; Young, J.M.; Ho, M.; McEntyre, C.J.; Elmslie, J.L.; Atkinson, W.; Molyneux, S.; et al. Betaine and Trimethylamine-N-Oxide as Predictors of Cardiovascular Outcomes Show Different Patterns in Diabetes Mellitus: An Observational Study. PLoS ONE 2014, 9, e114969. [Google Scholar] [CrossRef] [PubMed]
- Di Stolfo, G.; Mastroianno, S.; Potenza, D.R.; De Luca, G.; D’Arienzo, C.; Pacilli, M.A.; Fanelli, M.; Russo, A.; Fanelli, R. Serum uric acid as a prognostic marker in the setting of advanced vascular disease: A prospective study in the elderly. J. Geriatr. Cardiol. 2015, 12, 515–520. [Google Scholar] [PubMed]
- Grapov, D.; Fahrmann, J.; Hwang, J.; Poudel, A.; Jo, J.; Periwal, V.; Fiehn, O.; Hara, M. Diabetes associated metabolomic perturbations in NOD mice. Metabolomics 2014, 11, 425–437. [Google Scholar] [CrossRef] [PubMed]
- Shigeta, T.; Kimura, S.; Takahashi, A.; Isobe, M.; Hikita, H. Coronary Artery Disease Severity and Cardiovascular Biomarkers in Patients with Peripheral Artery Disease. Int. J. Angiol. 2015, 24, 278–282. [Google Scholar] [CrossRef] [PubMed]
- Zagura, M.; Kals, J.; Kilk, K.; Serg, M.; Kampus, P.; Eha, J.; Soomets, U.; Zilmer, M. Metabolomic signature of arterial stiffness in male patients with peripheral arterial disease. Hypertens. Res. 2015, 38, 840–846. [Google Scholar] [CrossRef]
- Yokoi, N.; Beppu, M.; Yoshida, E.; Hoshikawa, R.; Hidaka, S.; Matsubara, T.; Shinohara, M.; Irino, Y.; Hatano, N.; Seino, S. Identification of putative biomarkers for prediabetes by metabolome analysis of rat models of type 2 diabetes. Metabolomics 2015, 11, 1277–1286. [Google Scholar] [CrossRef]
- Xia, J.; Broadhurst, D.; Wilson, M.; Wishart, D.S. Translational biomarker discovery in clinical metabolomics: An introductory tutorial. Metabolomics 2012, 9, 280–299. [Google Scholar] [CrossRef]
- International Disease Classification 10 by Ministry of Social Affairs, Republic of Estonia. Available online: https://rhk.sm.ee/ (accessed on 21 March 2020).
- Böger, R.H.; Bode-Böger, S.M.; Szuba, A.; Tsao, P.S.; Chan, J.R.; Tangphao, O.; Blaschke, T.F.; Cooke, J.P. Asymmetric Dimethylarginine (ADMA): A novel risk factor for endothelial dysfunction: Its role in hypercholesterolemia. Circulation 1998, 98, 1842–1847. [Google Scholar] [CrossRef]
- Ouden, H.D.; Pellis, L.; Rutten, G.E.H.M.; Vonderen, I.K.G.-V.; Rubingh, C.M.; Van Ommen, B.; Van Erk, M.J.; Beulens, J.W.J. Metabolomic biomarkers for personalised glucose lowering drugs treatment in type 2 diabetes. Metabolomics 2016, 12, 27. [Google Scholar] [CrossRef]
- Klein, M.; Shearer, J. Metabolomics and Type 2 Diabetes: Translating Basic Research into Clinical Application. J. Diabetes Res. 2015, 2016, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Amrock, S.; Weitzman, M. Multiple biomarkers for mortality prediction in peripheral arterial disease. Vasc. Med. 2016, 21, 105–112. [Google Scholar] [CrossRef] [PubMed]
- Abhishek, A.; Valdes, A.M.; Zhang, W.; Doherty, M. Association of Serum Uric Acid and Disease Duration with Frequent Gout Attacks: A Case-Control Study. Arthritis Care Res. (Hoboken) 2016, 68, 1573–1577. [Google Scholar] [CrossRef] [PubMed]
- Dschietzig, T.B.; Kellner, K.-H.; Sasse, K.; Boschann, F.; Klüsener, R.; Ruppert, J.; Armbruster, F.P.; Bankovic, D.; Meinitzer, A.; Mitrovic, V.; et al. Plasma Kynurenine Predicts Severity and Complications of Heart Failure and Associates with Established Biochemical and Clinical Markers of Disease. Kidney Blood Press. Res. 2019, 44, 765–776. [Google Scholar] [CrossRef]
- Chen, T.; Ni, Y.; Ma, X.; Bao, Y.; Liu, J.; Huang, F.; Hu, C.; Xie, G.; Zhao, A.; Jia, W.; et al. Branched-chain and aromatic amino acid profiles and diabetes risk in Chinese populations. Sci. Rep. 2016, 6, 20594. [Google Scholar] [CrossRef]
- Chrysant, S.G.; Chrysant, G.S. The current status of homocysteine as a risk factor for cardiovascular disease: A mini review. Expert Rev. Cardiovasc. Ther. 2018, 16, 559–565. [Google Scholar] [CrossRef]
- Han, T.S.; Lean, M.E. A clinical perspective of obesity, metabolic syndrome and cardiovascular disease. JRSM Cardiovasc. Dis. 2016, 5, 2048004016633371. [Google Scholar] [CrossRef]
- Yu, X.; Lyu, D.; Dong, X.; He, J.; Yao, K. Hypertension and Risk of Cataract: A Meta-Analysis. PLoS ONE 2014, 9, e114012. [Google Scholar] [CrossRef]
- Forshed, J. Experimental Design in Clinical ‘Omics Biomarker Discovery. J. Proteome Res. 2017, 16, 3954–3960. [Google Scholar] [CrossRef]
- Tayyebi, A.; Poursadeghfard, M.; Nazeri, M.; Pousadeghfard, T. Is There Any Correlation between Migraine Attacks and Iron Deficiency Anemia? ACase-Control Study. Int. J. Hematol. Stem Cell Res. 2019, 13, 164–171. [Google Scholar] [CrossRef]
- Rosen, C.L.; DeBaun, M.R.; Strunk, R.C.; Redline, S.; Seicean, S.; Craven, D.I.; Gavlak, J.C.; Wilkey, O.; Inusa, B.P.D.; Roberts, I.; et al. Obstructive Sleep Apnea and Sickle Cell Anemia. Pediatrics 2014, 134, 273–281. [Google Scholar] [CrossRef] [PubMed]
- Konecny, T.; Kuniyoshi, F.S.; Orban, M.; Pressman, G.S.; Kara, T.; Gami, A.; Caples, S.M.; Lopez-Jimenez, F.; Somers, V.K. Under-diagnosis of sleep apnea in patients after acute myocardial infarction. J. Am. Coll. Cardiol. 2010, 56, 742–743. [Google Scholar] [CrossRef] [PubMed]
- Kotsis, V.; Stabouli, S.; Papakatsika, S.; Rizos, Z.; Parati, G. Mechanisms of obesity-induced hypertension. Hypertens. Res. 2010, 33, 386–393. [Google Scholar] [CrossRef] [PubMed]
- Hall, J.; Carmo, J.M.D.; Da Silva, A.A.; Wang, Z.; Hall, M.E. Obesity-Induced Hypertension: Interaction of neurohumoral and renal mechanisms. Circ. Res. 2015, 116, 991–1006. [Google Scholar] [CrossRef] [PubMed]
- Rangel-Huerta, O.D.; Pastor-Villaescusa, B.; Gil, A. Are we close to defining a metabolomic signature of human obesity? A systematic review of metabolomics studies. Metabolomics 2019, 15, 93. [Google Scholar] [CrossRef]
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.-C.; Müller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef]
- Butts, C.T. network: A Package for Managing Relational Data in R. J. Stat. Softw. 2008, 24, 1548–7660. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ICD-10 Code | Cases | Mean Age (Min–Max) (Years) | Male% |
|---|---|---|---|
| J30–J39; diseases of upper respiratory tract | 395 | 51.5 (23–86) | 50% |
| I10–I15; Hypertension | 353 | 64.1 (28–89) | 58% |
| M50–M54; Other dorsopathies | 347 | 58.5 (22–87) | 57% |
| I30–I52; Other forms of heart disease | 325 | 61.2 (23–89) | 53% |
| J35; Chronic disease of tonsils and adenoids | 272 | 51.0 (23–86) | 43% |
| M51; Other intervertebral disk disorders | 220 | 59.3 (25–87) | 60% |
| I11; Hypertensive heart disease | 197 | 66.6 (36–89) | 57% |
| I49; Atrial fibrillation | 192 | 62.2 (23–89) | 56% |
| K20–K31; Diseases of stomach and duodenum | 192 | 59.7 (25–87) | 60% |
| D10–D36; Benign neoplasms | 191 | 59.1 (24–81) | 31% |
| I80–I89; Disorders of veins and lymph system | 186 | 60.0 (26–87) | 39% |
| G40–G47; Episodic and paroxysmal disorders | 185 | 56.9 (26–86) | 39% |
| I10; Primary hypertension | 164 | 61.3 (28–82) | 59% |
| M15–M19; Arthrosis | 164 | 64.6 (31–87) | 43% |
| E00–E07; Disorders of thyroid gland | 157 | 58.7 (22–89) | 15% |
| I83; Varicose veins of lower extremities | 150 | 61.1 (26–87) | 35% |
| E70–E90; Metabolic disorders | 141 | 59.6 (25–86) | 46% |
| E66; Obesity | 135 | 58.1 (25–83) | 45% |
| E65–E68; Obesity and other hyperalimentation | 135 | 58.1 (25–83) | 45% |
| M20–M25; Other joint disorders | 135 | 57.9 (23–86) | 49% |
| L60–L75; disorders of skin appendages | 129 | 50.0 (23–90) | 68% |
| H90–H95; Other diseases of ear | 128 | 65.2 (31–89) | 63% |
| N40–N51; Diseases of male genitals | 128 | 65.7 (26–90) | 100% |
| ICD-10 Diagnose | Marker | Cases | AUC-ROC (CI 95%) | Regression Beta | Beta p-Value |
|---|---|---|---|---|---|
| E10–E14; Diabetes | Ala | 63 | 0.72 (0.66–0.78) | 2.2 × 10−2 | 1.0 × 10−9 |
| I50; Heart failure | Kyn | 90 | 0.72 (0.66–0.77) | 4.1 × 102 | 8.1 × 10−10 |
| E11; Type II diabetes | Val | 55 | 0.7 (0.63–0.76) | 2.7 × 10−2 | 2.0 × 10−6 |
| E11; Type II diabetes | C3 | 55 | 0.69 (0.62–0.76) | 1.8 | 3.1 × 10−4 |
| M10; Gout | Uric acid | 26 | 0.69 (0.57–0.81) | 4.7 × 102 | 4.9 × 10−5 |
| E10–E14; Diabetes | Leu+Ile | 63 | 0.67 (0.6–0.75) | 1.9 × 10−2 | 8.8 × 10−6 |
| D50–D53; Nutritional anemias | Leu+Ile | 55 | 0.67 (0.61–0.74) | −3.1 × 10−2 | 5.8 × 10−5 |
| I50; Heart failure | Urea | 90 | 0.67 (0.61–0.72) | 4.1 | 1.0 × 10−6 |
| I25; Chronic cardiac ischemia | Kyn | 75 | 0.66 (0.6–0.73) | 3.2 × 102 | 2.9 × 10−6 |
| H25; Senile cataract | ADMA | 85 | 0.66 (0.6–0.72) | 3.1 × 103 | 4.5 × 10−5 |
| E11; Type II diabetes | DiMeGly | 55 | 0.66 (0.59–0.73) | 1.9 × 102 | 1.6 × 10−4 |
| D50–D53; Nutritional anemias | Uric acid | 55 | 0.66 (0.58–0.73) | −3.0 × 102 | 7.2 × 10−5 |
| I25; Chronic cardiac ischemia | Urea | 75 | 0.66 (0.6–0.72) | 4.1 | 4.4 × 10−6 |
| I20–I25; Ischemic heart diseases | DiMeGly | 107 | 0.66 (0.61–0.71) | 1.7 × 102 | 6.4 × 10−6 |
| N80–N98; Noninflammatory disorders of female genital tract | Betaine | 74 | 0.66 (0.59–0.72) | −2.5 × 10 | 1.0 × 10−5 |
| N80–N98; Noninflammatory disorders of female genital tract | Uric acid | 74 | 0.65 (0.59–0.72) | −3.4 × 102 | 6.6 × 10−7 |
| E05; Hyperthyroidism | Leu | 66 | 0.65 (0.58–0.72) | −2.4 × 10−2 | 2.5 × 10−4 |
| E10–E14; Diabetes | Glu | 63 | 0.65 (0.58–0.72) | 4.0 × 10−2 | 9.3 × 10−5 |
| D50–D53; nutritional anemias | Glu | 55 | 0.65 (0.57–0.72) | −5.6 × 10−2 | 4.6 × 10−4 |
| I50; Heart failure | Kyn. acid | 90 | 0.65 (0.59–0.71) | 2.8 × 103 | 1.3 × 10−7 |
| N40; Hyperplasia of prostate | DiMeGly | 105 | 0.65 (0.59–0.7) | 1.8 × 102 | 2.1 × 10−6 |
| N80–N98; Noninflammatory disorders of female genital tract | Leu | 74 | 0.65 (0.59–0.71) | −2.1 × 10−2 | 7.9 × 10−4 |
| I11; Hypertensive heart disease | Urea | 197 | 0.64 (0.6–0.69) | 4.2 | 1.4 × 10−9 |
| E05; Hyperthyroidism | Val | 66 | 0.64 (0.58–0.71) | −2.1 × 10−2 | 2.7 × 10−4 |
| M13; Other inflammatory arthritis | lysoPC (C22:6) | 63 | 0.64 (0.58–0.71) | 1.5 | 4.9 × 10−4 |
| D50–D53; Nutritional anemias | Urea | 55 | 0.64 (0.57–0.72) | −5.4 | 3.5 × 10−4 |
| Metabolite | Disease of Interest | Underlying Disease | Overlap | ||||
|---|---|---|---|---|---|---|---|
| ICD-10 | Cases | AUC-ROC | ICD-10 | AUC-ROC | Cases | AUC-ROC | |
| C5 | I20–I25 | 107 | 0.63 (0.57–0.68) | E00–E07 | 0.59 (0.55–0.64) | 17 | 0.82 (0.73–0.9) |
| C4 | I10–I15 | 353 | 0.59 (0.55–0.62) | H91.9 | 0.48 (0.41–0.56) | 31 | 0.81 (0.7–0.92) |
| Kynurenine | I50 | 22 | 0.81 (0.71–0.92) | I10–I15 | 0.6 (0.56–0.64) | 15 | 0.82 (0.74–0.91) |
| Kyn acid a | I50 | 22 | 0.75 (0.63–0.88) | I10–I15 | 0.59 (0.55–0.63) | 15 | 0.80 (0.7–0.91) |
| Arg | D10–D36 | 191 | 0.56 (0.51–0.6) | I25 | 0.56 (0.5–0.63) | 16 | 0.80 (0.67–0.94) |
| lysoPC(C18:0) | G40–G47 | 185 | 0.53 (0.48–0.58) | I40 | 0.49 (0.41–0.58) | 15 | 0.81 (0.69–0.93) |
| SDMA | G40–G47 | 185 | 0.55 (0.51–0.6) | I40 | 0.57 (0.49–0.65) | 15 | 0.84 (0.72–0.95) |
| Val | E66 | 112 | 0.63 (0.57–0.68) | I49.9 | 0.51 (0.47–0.56) | 25 | 0.80 (0.73–0.87) |
| lysoPC(C16:0) | M05–M14 | 116 | 0.58 (0.52–0.64) | I50 | 0.56 (0.5–0.62) | 16 | 0.83 (0.71–0.95) |
| Hexoses | J40–J47 | 81 | 0.64 (0.57–0.7) | I80–I89 | 0.50 (0.46–0.55) | 17 | 0.81 (0.72–0.89) |
| Kynurenine | I50 | 90 | 0.72 (0.66–0.77) | J30 | 0.53 (0.47–0.59) | 16 | 0.82 (0.74–0.91) |
| Kynurenine | I20–I25 | 107 | 0.65 (0.59–0.7) | J30–J39 | 0.51 (0.47–0.55) | 32 | 0.80 (0.74–0.87) |
| Kynurenine | I50 | 90 | 0.72 (0.66–0.77) | N40 | 0.60 (0.54–0.66) | 16 | 0.84 (0.73–0.96) |
| Gly | G40–G47 | 185 | 0.50 (0.46–0.55) | D50–D53 | 0.51(0.43–0.6) | 17 | 0.81 (0.69–0.93) |
| Metabolite | Disease 1 | Disease 2 | Co-Present | |||
|---|---|---|---|---|---|---|
| ICD-10 | AUC-ROC | ICD-10 | AUC-ROC | Cases | AUC-ROC | |
| Kynurenine | I20–I25 | 0.65 (0.59–0.70) | J30–J39 | 0.51 (0.47–0.55) | 32 | 0.79 (0.73–0.85) |
| Val | E66 | 0.63 (0.58–0.68) | I49 | 0.51 (0.47–0.56) | 29 | 0.75 (0.67–0.83) |
| Kynurenine | E66 | 0.61 (0.56–0.66) | I11 | 0.63 (0.59–0.68) | 39 | 0.75 (0.68–0.83) |
| Uric acid | E66 | 0.61 (0.56–0.66) | I11 | 0.63 (0.58–0.67) | 39 | 0.75 (0.68–0.82) |
| Lactate | J40–J47 | 0.62 (0.55–0.68) | K20–K31 | 0.52 (0.48–0.57) | 29 | 0.73 (0.65–0.82) |
| Val | E66.9 | 0.63 (0.57–0.68) | I10 | 0.55 (0.50–0.60) | 37 | 0.72 (0.64–0.80) |
| Urea | E66 | 0.57 (0.51–0.62) | I49 | 0.55 (0.50–0.59) | 29 | 0.72 (0.63–0.82) |
| Kynurenic acid | E66 | 0.62 (0.56–0.67) | I11 | 0.59 (0.54–0.63) | 39 | 0.72 (0.64–0.81) |
| PC(C40:5) | D10–D36 | 0.56 (0.52–0.61) | E70–E90 | 0.61 (0.55–0.66) | 29 | 0.72 (0.64–0.80) |
| DiMeGly | E66 | 0.58 (0.53–0.63) | I11 | 0.59 (0.55–0.63) | 39 | 0.72 (0.65–0.78) |
| Kynurenine | E66.9 | 0.61 (0.56–0.66) | I80–I89 | 0.53 (0.48–0.58) | 25 | 0.72 (0.63–0.80) |
| Tyr | I49.9 | 0.61 (0.55–0.67) | J30–J39 | 0.52 (0.48–0.55) | 30 | 0.72 (0.64–0.79) |
| Ala | E66 | 0.61 (0.56–0.66) | I10 | 0.59 (0.54–0.64) | 40 | 0.71 (0.63–0.79) |
| Tyr | E66.9 | 0.58 (0.53–0.63) | I49 | 0.53 (0.49–0.58) | 25 | 0.71 (0.62–0.79) |
| Gly | E66.9 | 0.55 (0.49–0.61) | I11 | 0.56 (0.51–0.60) | 30 | 0.71 (0.62–0.80) |
| Gly | M51 | 0.60 (0.56–0.64) | N40 | 0.60 (0.54–0.65) | 37 | 0.71 (0.63–0.78) |
| C3 | E66.9 | 0.59 (0.54–0.65) | I49 | 0.51 (0.46–0.55) | 25 | 0.71 (0.62–0.79) |
| 2-OH butyrate | I11 | 0.57 (0.53–0.62) | M05–M14 | 0.59 (0.53–0.64) | 27 | 0.70 (0.60–0.80) |
| PC(C38:6) | H91 | 0.57 (0.51–0.63) | K20–K31 | 0.55 (0.50–0.59) | 30 | 0.70 (0.60–0.79) |
| lysoPC(C18:0) | D10–D36 | 0.58 (0.54–0.62) | E70–E90 | 0.56 (0.51–0.61) | 29 | 0.70 (0.61–0.78) |
| Leu | E66 | 0.60 (0.55–0.65) | I10 | 0.54 (0.50–0.59) | 40 | 0.70 (0.62–0.77) |
| PC(C32:1) | M15–M19 | 0.51 (0.46–0.56) | N40 | 0.59 (0.53–0.65) | 34 | 0.70 (0.61–0.78) |
| C2 | D10–D36 | 0.54 (0.49–0.58) | I10 | 0.60 (0.55–0.64) | 38 | 0.69 (0.61–0.77) |
| Gly | E66 | 0.53 (0.48–0.59) | K20–K31 | 0.54 (0.49–0.58) | 34 | 0.69 (0.58–0.79) |
| Gly | E10–E14 | 0.56 (0.48–0.64) | I11 | 0.56 (0.51–0.60) | 31 | 0.69 (0.60–0.78) |
| Leu | H90–H95 | 0.53 (0.47–0.58) | I49 | 0.53 (0.48–0.58) | 31 | 0.69 (0.60–0.77) |
| Lactate | I10–I15 | 0.57 (0.53–0.61) | M05–M14 | 0.57 (0.51–0.63) | 52 | 0.68 (0.61–0.76) |
| C0 | J40–J47 | 0.56 (0.5–0.63) | M50–M54 | 0.54 (0.50–0.58) | 37 | 0.67 (0.59–0.75) |
| lysoPC(C22:6) | I11 | 0.57 (0.53–0.62) | K20–K31 | 0.57 (0.52–0.62) | 47 | 0.67 (0.59–0.74) |
| Arg | D10–D36 | 0.56 (0.51–0.60) | M50–M54 | 0.5 (0.47–0.54) | 75 | 0.64 (0.58–0.70) |
| Uric acid | I10–I15 | 0.61 (0.57–0.64) | D10–D36 | 0.56 (0.51–0.60) | 87 | 0.48 (0.41–0.54) |
| C5 | E00–E07 | 0.59 (0.55–0.64) | I10–I15 | 0.60 (0.56–0.64) | 64 | 0.50 (0.44–0.57) |
| C5 | I10–I15 | 0.60 (0.56–0.64) | N10–N16 | 0.59 (0.53–0.65) | 31 | 0.48 (0.38–0.58) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taalberg, E.; Kilk, K. Mapping Metabolite and ICD-10 Associations. Metabolites 2020, 10, 196. https://doi.org/10.3390/metabo10050196
Taalberg E, Kilk K. Mapping Metabolite and ICD-10 Associations. Metabolites. 2020; 10(5):196. https://doi.org/10.3390/metabo10050196
Chicago/Turabian StyleTaalberg, Egon, and Kalle Kilk. 2020. "Mapping Metabolite and ICD-10 Associations" Metabolites 10, no. 5: 196. https://doi.org/10.3390/metabo10050196
APA StyleTaalberg, E., & Kilk, K. (2020). Mapping Metabolite and ICD-10 Associations. Metabolites, 10(5), 196. https://doi.org/10.3390/metabo10050196