



Optimizing the Long-Term Efficiency of Users and Operators in Mobile Edge Computing Using Reinforcement Learning


Abstract
1. Introduction
- (1)
- We designed an SDN-based MEC network framework that integrates NFV technology. By utilizing the virtualized functions of NFV, the functionalities of various hardware devices are centralized in the NFV Infrastructure Nodes (NFVI Node), simplifying the network’s hardware components.
- (2)
- Based on the proposed network framework, we designed utility functions from both the user and operator perspectives. We then employed RL and DRL-based algorithms to optimize the long-term average utility of users and operators in dynamic network environments.
- (3)
- Using the proposed MEC framework and RL/DRL-based algorithms, we designed corresponding experiments. The experimental results show that the RL and DRL-based algorithms we proposed effectively improve the long-term average utility of both users and operators in dynamic network environments.
2. System Model
2.1. SDN-Based MEC Network Framework
2.2. System Model
2.3. Communication Model
2.4. Delay and Energy Consumption Model
3. Problem Formulation
3.1. Maximizing the Operator’s Long-Term Average Utility
3.2. Maximize the Long-Term Average Utility of Users
4. The Proposed Method
4.1. Reinforcement Learning (RL)-Based Learning Algorithm
| Algorithm 1: Long-Term Average Utility Maximization Based on RL (Training Phase) |
|
4.2. DRL-Based Learning Algorithm
| Algorithm 2: Long-Term Average Utility Maximization Based on DRL |
|
4.3. Computational Complexity Analysis of DRL-Based Learning Algorithms
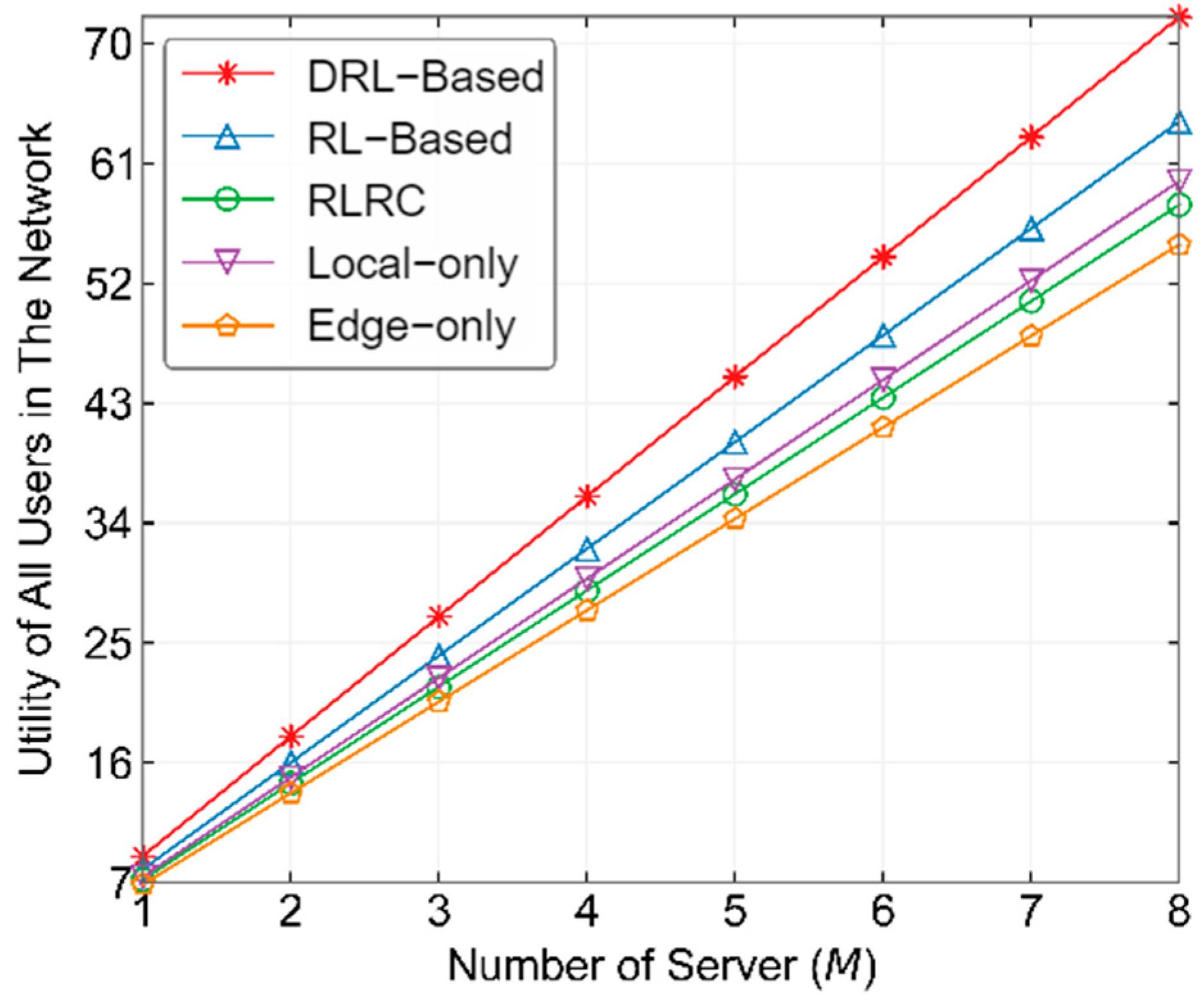
5. Performance Evaluation
5.1. Operator
5.2. User
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Feng, C.; Han, P.; Zhang, X.; Yang, B.; Liu, Y.; Guo, L. Computation Offloading in Mobile Edge Computing Networks: A Survey. J. Netw. Comput. Appl. 2022, 202, 103366. [Google Scholar] [CrossRef]
- Wang, X.; Li, J.; Ning, Z.; Song, Q.; Guo, L.; Guo, S.; Obaidat, M.S. Wireless Powered Mobile Edge Computing Networks: A Survey. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- Dong, S.; Tang, J.; Abbas, K.; Hou, R.; Kamruzzaman, J.; Rutkowski, L.; Buyya, R. Task Offloading Strategies for Mobile Edge Computing: A Survey. Comput. Netw. 2024, 254, 110791. [Google Scholar] [CrossRef]
- Gan, Q.; Li, G.; He, W.; Zhao, Y.; Song, Y.; Xu, C. Delay-Minimization Offloading Scheme in Multi-Server MEC Networks. IEEE Wirel. Commun. Lett. 2023, 12, 1071–1075. [Google Scholar] [CrossRef]
- Zheng, K.; Jiang, G.; Liu, X.; Chi, K.; Yao, X.; Liu, J. DRL-Based Offloading for Computation Delay Minimization in Wireless-Powered Multi-Access Edge Computing. IEEE Trans. Commun. 2023, 71, 1755–1770. [Google Scholar] [CrossRef]
- Yu, L.; Xu, H.; Zeng, Y.; Deng, J. Delay-Aware Resource Allocation for Partial Computation Offloading in Mobile Edge Cloud Computing. Pervasive Mob. Comput. 2024, 105, 101996. [Google Scholar] [CrossRef]
- Yang, J.; Shah, A.A.; Pezaros, D. A Survey of Energy Optimization Approaches for Computational Task Offloading and Resource Allocation in MEC Networks. Electronics 2023, 12, 3548. [Google Scholar] [CrossRef]
- Zhao, J.; Chen, M.; Pan, Y.; Sun, H.; Cang, Y.; Wang, J. Energy Minimization of the Cell-Free MEC Networks with Two-Timescale Resource Allocation. IEEE Trans. Wirel. Commun. 2024, 23, 18623–18636. [Google Scholar] [CrossRef]
- Li, T.; Li, Y.; Hu, P.; Chen, Y.; Yin, Z. Energy Minimization for IRS-and-UAV-Assisted Mobile Edge Computing. Ad Hoc Netw. 2024, 164, 103635. [Google Scholar] [CrossRef]
- Wang, L.; Li, Y.; Chen, Y.; Li, T.; Yin, Z. Air-Ground Coordinated MEC: Joint Task, Time Allocation and Trajectory Design. IEEE Trans. Veh. Technol. 2024, 74, 4728–4743. [Google Scholar] [CrossRef]
- Qin, H.; Du, H.; Wang, H.; Su, L.; Peng, Y. Multi-Objective Optimization for NOMA-Based Mobile Edge Computing Offloading by Maximizing System Utility. China Commun. 2023, 20, 156–165. [Google Scholar] [CrossRef]
- Liu, B.; Peng, M. Online Offloading for Energy-Efficient and Delay-Aware MEC Systems with Cellular-Connected UAVs. IEEE Internet Things J. 2024, 11, 22321–22336. [Google Scholar] [CrossRef]
- An, X.; Li, Y.; Chen, Y.; Li, T. Joint Task Offloading and Resource Allocation for Multi-User Collaborative Mobile Edge Computing. Comput. Netw. 2024, 250, 110604. [Google Scholar] [CrossRef]
- Li, Y.; Li, Y.; Chen, Y.; Tong, J.; Tian, X.; Chi, K. Online Resolution Adaptation and Resource Allocation for Edge-Assisted Video Analytics. Comput. Netw. 2024, 244, 110342. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Y.; Chen, C.S.; Chi, K. Exploring Long-Term Commensalism: Throughput Maximization for Symbiotic Radio Networks. IEEE Trans. Mob. Comput. 2025, 24, 2376–2393. [Google Scholar] [CrossRef]
- Miao, L.; Li, S.; Wu, X.; Liu, B. Mean-Field Stackelberg Game-Based Security Defense and Resource Optimization in Edge Computing. Appl. Sci. 2024, 14, 3538. [Google Scholar] [CrossRef]
- Al-Hammadi, I.; Li, M.; Islam, S.M.; Al-Mosharea, E. Collaborative Computation Offloading for Scheduling Emergency Tasks in SDN-Based Mobile Edge Computing Networks. Comput. Netw. 2024, 238, 110101. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Chen, B.; Li, E.; Zheng, K.; Chi, K.; Zhu, Y.-H. Design of an RFID-Based Self-Jamming Identification and Sensing Platform. IEEE Trans. Mob. Comput. 2024, 23, 3802–3816. [Google Scholar] [CrossRef]
- Du, J.; Jiang, C.; Benslimane, A.; Guo, S.; Ren, Y. SDN-Based Resource Allocation in Edge and Cloud Computing Systems: An Evolutionary Stackelberg Differential Game Approach. IEEE/ACM Trans. Netw. 2022, 30, 1613–1628. [Google Scholar] [CrossRef]
- Chen, G.; Chen, Y.; Mai, Z.; Hao, C.; Yang, M.; Du, L. Incentive-Based Distributed Resource Allocation for Task Offloading and Collaborative Computing in MEC-Enabled Networks. IEEE Internet Things J. 2022, 10, 9077–9091. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Leung, V.C.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef]
- Huang, L.; Bi, S.; Zhang, Y.-J.A. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2020, 19, 2581–2593. [Google Scholar] [CrossRef]
- Zhang, S.; Gu, H.; Chi, K.; Huang, L.; Yu, K.; Mumtaz, S. DRL-Based Partial Offloading for Maximizing Sum Computation Rate of Wireless Powered Mobile Edge Computing Network. IEEE Trans. Wirel. Commun. 2022, 21, 10934–10948. [Google Scholar] [CrossRef]
- Tan, L.; Kuang, Z.; Zhao, L.; Liu, A. Energy-Efficient Joint Task Offloading and Resource Allocation in OFDMA-Based Collaborative Edge Computing. IEEE Trans. Wirel. Commun. 2022, 21, 1960–1972. [Google Scholar] [CrossRef]
- Li, X.; Fan, R.; Hu, H.; Zhang, N.; Chen, X.; Meng, A. Energy-Efficient Resource Allocation for Mobile Edge Computing with Multiple Relays. IEEE Internet Things J. 2021, 9, 10732–10750. [Google Scholar] [CrossRef]
- Xu, D. Device Scheduling and Computation Offloading in Mobile Edge Computing Networks: A Novel NOMA Scheme. IEEE Trans. Veh. Technol. 2024, 73, 9071–9076. [Google Scholar] [CrossRef]
- Li, B.; Si, F.; Zhao, W.; Zhang, H. Wireless Powered Mobile Edge Computing with NOMA and User Cooperation. IEEE Trans. Veh. Technol. 2021, 70, 1957–1961. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Mao, B.; Tang, F.; Fadlullah, Z.M.; Kato, N.; Akashi, O.; Inoue, T.; Mizutani, K. A Novel Non-Supervised Deep-Learning-Based Network Traffic Control Method for Software Defined Wireless Networks. IEEE Wirel. Commun. 2018, 25, 74–81. [Google Scholar] [CrossRef]
- Chiosi, M.; Clarke, D.; Willis, P.; Reid, A. Network Functions Virtualization Introductory White Paper. In Proceedings of the SDN and OpenFlow World Congress, Darmstadt, Germany, 22–24 October 2012; pp. 1–16. [Google Scholar]
- Open Networking Foundation. Software-Defined Networking: The New Norm for Networks. 2012. Available online: https://opennetworking.org (accessed on 10 February 2025).
- Xue, J.; Wang, L.; Yu, Q.; Mao, P. Multi-Agent Deep Reinforcement Learning-Based Partial Offloading and Resource Allocation in Vehicular Edge Computing Networks. Comput. Commun. 2025, 234, 108081. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Y.; Pan, D.; Yuan, D. QoS-Aware Task Offloading and Resource Allocation Optimization in Vehicular Edge Computing Networks via MADDPG. Comput. Netw. 2024, 242, 110282. [Google Scholar] [CrossRef]
- Open Networking Foundation. OpenFlow Switch Specification (Version 1.5.1); ONF TS-025: Menlo Park, CA, USA, 2015; Available online: http://www.opennetworking.org (accessed on 10 February 2025).
- Luo, Q.; Li, C.; Luan, T.H.; Shi, W. Collaborative Data Scheduling for Vehicular Edge Computing via Deep Reinforcement Learning. IEEE Internet Things J. 2020, 7, 9637–9650. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Melo, F.S. Convergence of Q-Learning: A Simple Proof. Institute for Systems and Robotics, USA. [Online]. Available online: https://welcome.isr.tecnico.ulisboa.pt/ (accessed on 10 February 2025).
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Symbol | Meaning | Value |
|---|---|---|---|
| NFVI Node Parameters | Total bandwidth of NFVI Node | 10 MHz | |
| MEC Server computation resource | 18 GHz | ||
| Background noise | −100 dBm | ||
| Number of NFVI Nodes | 1–8 | ||
| MD Parameters | Number of MDs served by each NFVI Node | 5 | |
| CPU frequency of MD | 2 GHz | ||
| Transmission power of MD i | 100 mW | ||
| Computation resources required by MD i | 80–150 Megacycles | ||
| Size of computation task of MD i | 1 MB | ||
| Energy consumption per CPU cycle | 10−10 J/cycle | ||
| d | Distance between MD and NFVI Node | [10 m, 100 m] | |
| Signal attenuation parameter | 2 | ||
| Operator Utility Calculation Parameters | Price per unit data transmission | 10−6 | |
| Price per unit communication resource lease | 10−8 | ||
| Price per unit computation resource | 10−8 | ||
| Price per unit computation resource lease | 10−11 | ||
| User Utility Calculation Parameters | Data amount weight | ||
| Energy consumption weight | 1 | ||
| Delay weight | 100 |
| Meaning | Symbol | Value |
|---|---|---|
| Learning rate | 0.001 | |
| Discount factor | 0.9 | |
| Number of hidden layers | 2 | |
| Number of neurons in hidden layers | 10,100 | |
| Experience pool size | 10,000 | |
| Batch size | 16 | |
| Maximum slot index | 500 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, J.; Li, Y. Optimizing the Long-Term Efficiency of Users and Operators in Mobile Edge Computing Using Reinforcement Learning. Electronics 2025, 14, 1689. https://doi.org/10.3390/electronics14081689
Shao J, Li Y. Optimizing the Long-Term Efficiency of Users and Operators in Mobile Edge Computing Using Reinforcement Learning. Electronics. 2025; 14(8):1689. https://doi.org/10.3390/electronics14081689
Chicago/Turabian StyleShao, Jianji, and Yanjun Li. 2025. "Optimizing the Long-Term Efficiency of Users and Operators in Mobile Edge Computing Using Reinforcement Learning" Electronics 14, no. 8: 1689. https://doi.org/10.3390/electronics14081689
APA StyleShao, J., & Li, Y. (2025). Optimizing the Long-Term Efficiency of Users and Operators in Mobile Edge Computing Using Reinforcement Learning. Electronics, 14(8), 1689. https://doi.org/10.3390/electronics14081689