Abstract
This study proposes a multi-strategy improved Aquila optimizer (MIAO) to address the key limitations of the original Aquila optimizer (AO). First, a phasor operator is introduced to eliminate excessive control parameters in the X2 phase, transforming it into an adaptive parameter-free process. Second, a flow direction operator enhances the X3 phase by improving population diversity and local exploitation. The MIAO algorithm is applied to optimize Long Short-Term Memory (LSTM) hyperparameters, forming the MIAO_LSTM model for monthly railway freight forecasting. Comprehensive evaluations on 15 benchmark functions show MIAO’s superior performance over SOA, PSO, SSA, and AO. Using freight data (2005–2021), MIAO_LSTM achieves lower MAE, MSE, and RMSE compared to traditional LSTM and hybrid models (SSA_LSTM, PSO_LSTM, etc.). Further, Grey Relational Analysis selects high-correlation features (≥0.8) to boost accuracy. The results validate MIAO_LSTM’s effectiveness for practical freight predictions.
1. Introduction
With the continuous advancement of technology and theoretical knowledge in human society, optimization algorithms have evolved from initial derivative-based methods to become derivative-free meta-heuristic intelligent algorithms. This evolution has significantly enhanced the ability of algorithms to handle nonlinear and convex optimization problems. In the current era, where artificial intelligence and big data are prevalent, the demand for optimization algorithms across various industries is increasingly growing. However, the optimization capabilities of different algorithms vary when applied to specific problems. Consequently, a considerable number of scholars are engaged in developing new algorithms or refining existing ones to enhance their accuracy and convergence speed, tailoring them to address distinct challenges. For example, Wu et al. proposed an enhanced AO algorithm improved by PSO to address the UAV path planning problem [1]. Experimental results also demonstrated the practicality of PSAO in UAV path planning. Anirban et al. employed the Aquila optimizer (AO) algorithm to optimize the selection and placement of distributed generators (DG) [2]. This approach demonstrates the effectiveness of AO in addressing complex optimization problems in power system planning. Chiheb et al. enhanced the Aquila optimizer (AO) algorithm by incorporating Cauchy mutation and successfully applied it to the classification of brain tumor data [3]. Furthermore, numerous studies have demonstrated that combining optimization algorithms with neural network models can significantly enhance the overall performance of the algorithms [4,5,6,7,8]. For example, Qiao et al. combined an improved Aquila optimizer with temporal convolutional networks and random forests to form a meta-heuristic deep learning model, demonstrating the effectiveness of the algorithm in rainfall-runoff prediction [9]. Duan et al. proposed a hybrid model integrating a fully convolutional neural network (FCN) and the Aquila optimizer (AO) to predict solar radiation intensity, offering valuable insights for clean energy utilization [10]. These studies represent specific applications of optimization algorithms in various fields. Compared with other deep learning architectures (e.g., CNN), Long Short-Term Memory (LSTM) networks demonstrate superior capability in modeling temporal dependencies within sequential data. Therefore, this study proposes a novel MIAO-LSTM hybrid model that integrates an enhanced Aquila optimizer (improved through phasor and flow direction operators) with an LSTM network for railway freight volume prediction in China.
With the rapid development of the logistics industry, optimization algorithms and deep learning models have demonstrated their significant importance in research related to freight volume prediction. There are also further studies on rail freight volume forecasting. Xu et al. [11] combined the product seasonal model with the LSTM that introduces the attention mechanism, and used the error correction method to improve the poor prediction accuracy of the product seasonal model, which improved the model’s data processing capability compared with the traditional LSTM network. Seock et al. [12] used PCA to complete the screening of input data for the situation of low freight volume data and large data fluctuations. Feng et al. [13] used a capsule neural network algorithm to predict the export demand of the China–Europe liner; the difference with the completely connected neural network is that the capsule neural network adds two coupling coefficients in the stage of input linear weighted summation, which further strengthens the model’s nonlinear fitting ability. Also, to reduce the possible impact of the gradient problem, the capsule neural network optimizes the activation function, which also improves the prediction accuracy. However, these two initiatives reduce the speed of training the model, as well as the adaptability of the model with more input data.
Railway freight is a complex nonlinear system, which is jointly influenced by numerous factors, but the above studies do not consider the influencing factors, and only use the past freight volume data to predict the future freight volume, which is the prediction from the freight volume to the freight volume, with a large uncertainty and a large fluctuation in the prediction results [13,14]. Railway freight, as a large-capacity, long-distance, low-cost mode of transport, has a natural advantage in terms of the transportation of bulk commodities, which leads to the railway being used to transport bulk commodities. National policies have a greater impact, therefore, most scholars will use the production of coal, crude oil, and other types of bulk commodities, and other modes of transport that have a competitive relationship with railway freight, for freight volume forecasting. The influence of these factors has resulted in a large number of studies and has achieved excellent research results. For example, Liu et al. [15] used grey correlation analysis to select the features with higher correlation from the numerous influencing factors. Zhang et al. [16] proposed a multidimensional LSTM prediction model to synchronize data with different attributes of spatial and temporal correlation, considering that railway freight traffic is affected by a variety of factors. The advantage of this model is that it can reflect correlations between data in different dimensions. While these studies have scientifically predicted results for freight traffic, it remains unconvincing that most hyperparameters in algorithmic models are set empirically.
To increase the reliability of the prediction model, numerous experts and scholars in the field of transportation at home and abroad have combined the optimization algorithm with the machine learning model and used the optimization algorithm to optimize the hyperparameters of the model and reduce the influence of subjective factors. For example, in marine ship trajectory prediction, Liu et al. [17] proposed a deep learning-based ship trajectory prediction framework (QSD_LSTM), which incorporated the dynamic QSD algorithm into the LSTM network, and this model improved the prediction accuracy while making it easier to represent the occurrence of trajectory conflicts, which improved the efficiency of intelligent supervision at sea. In terms of passenger flow prediction, Qin et al. [18], based on the passenger flow, which has a nonlinear and seasonal trend, used STL to decompose the data into seasonal, trend component, and residual component, and used the improved grasshopper optimization algorithm to predict the trend and residual, respectively, and, finally, the results of the three parts were added to obtain the monthly passenger flow prediction results. This combination of a decomposition and optimization algorithm reduced the influence of noise information and has great scalability. Similarly, in air cargo prediction, Li et al. [19] used the VMD technique to decompose dynamic and nonlinear air cargo data, extracted the main features of the original data, and eliminated the noise, after which the generated high-frequency components were decomposed twice with an EMD optimized Elman’s network structure using a cuckoo optimization algorithm, and each component was predicted with this model, which technically found the effective data. The critical point of the lag region improves the performance of the prediction method. In terms of traffic flow prediction, Manuel et al. [20] combined a convolutional neural network and a bidirectional LSTM network to form a CNN_BILSTM prediction model, which combined the ability of CNN to extract hidden valuable features from the input and the ability of Bi-LSTM to address the continuity of information in time-series data, which is of some reference value for coping with traffic congestion. In the area of waterborne freight activity prediction, Bhurtyal et al. [21] leveraged near real-time vessel tracking data from the Automatic Identification System (AIS) data set. Long Short-Term Memory (LSTM), Temporal Convolutional Network (TCN), and Temporal Fusion Transformer (TFT) machine learning models are developed using the features extracted from the AIS and the historical WCS data. The output of the model is the prediction of the quarterly volume of commodities (in tons) at the port terminals for four quarters in the future. In terms of railway freight volume prediction, Yang et al. [22] constructed four prediction models based on multivariate statistical methods, which are of some reference value in terms of freight vehicles and labor allocation.
In summary, research on freight volume forecasting has ranged from single-algorithm models, for the use of optimization algorithms to optimize model parameters and reduce human intervention to improve prediction accuracy, to the use of targeted processing and optimization methods based on different data characteristics. All these means are overcoming the limitations of the NFL theorem [23] and expanding the applicability of the models. However, different algorithms differ from each other in the same scenario. Therefore, we employ novel optimization algorithms to solve the freight volume prediction problem.
Based on the above studies, the literature on freight volume prediction is relatively thin and there is a large research space. In this paper, we use the multi-strategy modified Aquila optimizer to optimize LSTM for freight volume prediction research, and the main research contributions are as follows.
(1) The Aquila optimizer (AO) has been improved by incorporating the phasor operator and flow direction operator. The introduction of the phasor operator significantly reduces the impact of parameters on the algorithm’s performance and enhances its optimization capability, as demonstrated by benchmark test functions. The reduction in parameters increases the ability of the Aquila optimizer to handle complex nonlinear systems, such as railway freight volume prediction.
(2) The MIAO_LSTM model was applied to freight volume prediction, and the impact of influencing factors on the prediction results was investigated. Railway freight volume forecasting is jointly affected by numerous factors, and most of its input features are selected by relying on experience, which may have a certain impact on the prediction results, therefore, this paper uses Grey Relational Analysis to calculate the size of the correlation between each input feature and the freight volume, and selects the input features whose correlation is greater than 0.8 to conduct the test again. This result demonstrates that a reasonable choice of input features will also improve the prediction accuracy of freight volume.
The remainder of this paper is structured as follows: Section 2 introduces the LSTM network model; Section 3 presents the multi-strategy improved Aquila optimizer (MIAO) algorithm; and Section 4 applies the constructed MIAO_LSTM model to railway freight volume prediction, further validating the effectiveness of the MIAO model. This section provides a detailed explanation of the model’s inputs and outputs, its construction, and the analysis of prediction results. Section 5 summarizes the contributions of the paper, discusses its limitations, and outlines future research directions.
2. LSTM Neural Network
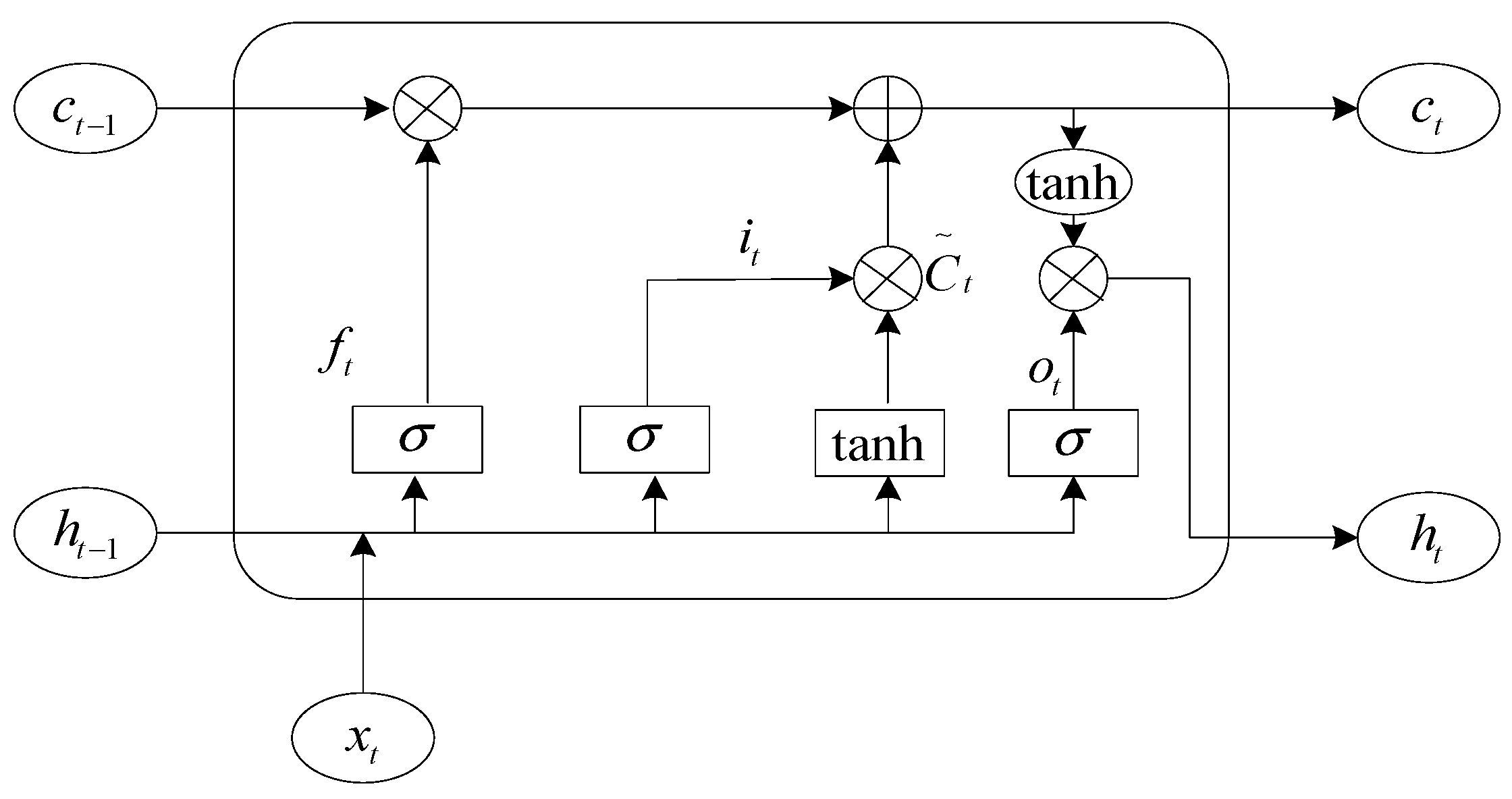
The LSTM (Long Short-Term Memory) neural network is derived from the recurrent neural network, which has achieved great results in the fields of structural modeling [24,25], engineering design [26,27], global optimization [28,29], and energy efficiency [30,31], including three gating units, namely, oblivion gate, input gate, and output gate, and the structure of the LSTM network unit is shown in Figure 1.
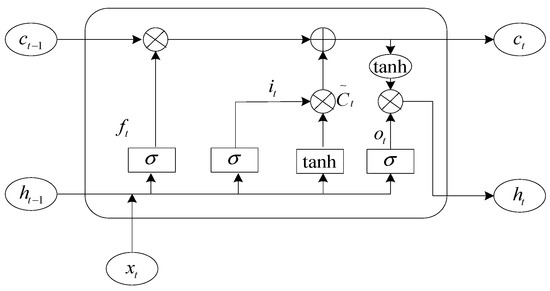
Figure 1.
LSTM network cell structure.
In the Figure, σ denotes the sigmoid activation function, c denotes the information that needs to be stored for a prolonged time, ht−1 denotes the output information at the previous moment, ht is the output information at the current state, and xt denotes the current input.
In the LSTM neural network, the forgetting gate plays the role of screening information. First of all, the last moment of output information ht−1 and the current input information xt are combined into a new input matrix, input to the sigmoid function, and this function will be normalized to the input data between 0 and 1. At this point, the sigmoid function plays the role of a switch, and the data close to 0 “forget” to retain the data close to 1, which is the role of the LSTM forget gate.
In Equation (1), is the weight matrix of the forgetting gate and is the bias of the forgetting gate.
After the tanh function becomes the new candidate vector , the previous part determines the values to be saved and discarded for the original candidate vector, and the saved values are added to the values saved in the previous state. The corresponding formula is as follows.
In the above equation, is the output of the input matrix after the 2nd sigmoid activation function, and are the weight matrix and bias of the sigmoid function in the input gate, and and are the weight and bias of the tanh function.
Finally, the value obtained by summing the input gates is changed to [−1, 1] by the tanh function, and the value retained by the last sigmoid function is the output value at this moment. The following Equations (4) and (5) are shown.
In the above equation, is the output value of the 3rd sigmoid function, is the final output of the network, and and are the weight matrix and bias of the 3rd sigmoid function.
3. Multi-Strategy Improved Aquila Optimizer
The Aquila optimizer is a current meta-heuristic optimization algorithm proposed by Laith Abualigah et al. in 2021 [32]. The algorithm builds a mathematical model by simulating four different predation strategies of Aquila, which has the advantages of quick convergence and strong global search ability, but the traditional Aquila optimizer has extra control parameters, ignores the excellent predation ability of individual Aquila, and lacks the mutual transfer of information between individuals, so the phase quantum operator and the flow direction operator are used to improve the and stages of the Aquila optimizer. The four phases of the Aquila optimizer and their improvements are described below.
where is the solution of the next iteration of the first stage t; is the optimal solution of the t-th iteration; denotes the average of the position of the solution at t iterations; rand denotes the random number between [0 and 1]; t is the number of current iterations; T is the maximum number of iterations; and N denotes the total number of samples. Moreover, Dim is the dimension of the problem.
3.1. Vector Operators to Improve the Aquila Optimizer
The formulas associated with the reduced exploration () phase of the Aquila optimizer are described below.
where is the solution of the next iteration of the second stage t; Levy (D) is the Levy flight distribution function; and is a random number in the range [1, N] at t iterations. Let x and y denote the shape of the helix during the search. The letter s is a constant of 0.01; μ and υ are random numbers between 0 and 1; β has the value of 1.5; δ is computed by Equation (5); is a fixed search for the [1, 20] number of cycles; U is 0.00565; D1 is an integer between [1 and Dim]; and ω is 0.005.
In phase , the Aquila optimizer involves many control parameters. Numerous metaheuristics are highly sensitive to subtle tuning of the control parameters, which may cause the algorithm to converge prematurely or get stuck in a local optimal solution. To overcome this problem, the phase operator is introduced in the stage to remove the influence of the control parameters and transform this stage into a non-parametric adaptive control stage, which improves the performance of the Aquila optimizer.
The phase quantity operator [33] is derived from the theory of phase quantities in mathematics, which reduces or eliminates the control parameters of the optimization algorithm by selecting suitable operator functions through the periodic trigonometric functions sin and cos for the purpose of adaptive, non-parametric optimization. Using the intermittent characteristic of the trigonometric function, all the control parameters of the phase of the Aquila optimizer are represented by the phase angle θ, and the role played by the control parameters is represented by the function containing θ. For this purpose, a one-dimensional phase angle θi is used to represent each individual in the population, so that the i-th individual can be represented by a vector of size and θi, i.e., .
The resulting phase operators are shown in Equations (15) and (16).
Equation (8) is improved by combining Equations (15) and (16), and the improved equation is shown in Equation (17).
3.2. Flow Direction Operator to Improve the Aquila Optimizer
The formula for the development phase of the expansion is described below:
where is the solution generated by at t + 1 iterations; UB and LB are the upper and lower bounds on the solution space, respectively; and the values of α and δ are both 0.1.
Phase of the Aquila optimizer is improved by using the flow direction operator, which enables information transfer between individuals. By improving the utilization of information between individuals, the optimization discovery capability of the proposed algorithm is greatly improved. The flow direction operator [34] is derived from the flow direction algorithm proposed by Hojat, which is a physically based algorithm, and the flow direction algorithm (FDA) simulates the movement state and formation process of runoff. The flow moves towards and around the lowest point, which is the optimal value of the objective function. The flow direction algorithm assumes that φ neighbors exist around each water flow and the mathematical expression of its positional relationship is shown in Equation (19).
where denotes the j-th location adjacent to , randn is a random number following a standard normal distribution, and is the search radius. Equation (19) establishes a search region for each individual in the Aquila optimizer, and the size of the value determines the size of the search range, within which information can be passed to each other, and the formula for is shown below.
In the above equation, rand is a uniformly distributed random number, is a random position generated in the search space, is the optimal solution of the t-th iteration in the Aquila optimizer, and is the current position of the i-th individual at the t-th iteration. The formula for W is as follows.
In the FDA algorithm, the flow rate of runoff to an adjacent region is directly related to its slope, and, therefore, the following relation is used to determine the flow rate vector.
where denotes the slope vector between the current individual and its neighbors, and the slope vector between the i-th individual and the j-th neighbor is determined by the following equation.
where denotes the target value of and denotes the target value of .
The flow operator used in this paper is defined as follows.
The Aquila optimizer suffers from reduced population diversity and tends to get stuck in local optima at later iterations, so the flow direction operator is introduced to improve the phase of the Aquila optimizer. The flow algorithm allows information transfer between individuals and to each other, which improves information utilization. At the same time, the introduction of nonlinear weights W also increases the randomness of the algorithm in the late iteration, which further enhances the algorithm’s ability to search and jump out of the local optimum and improves the stage of the Aquila optimizer, which is also known as Equation (18), as shown in Equation (25).
The formulae for the reduction development stage of the Aquila optimizer are described below.
where is the solution generated by the fourth search method in t + 1 iterations; QF is used to balance the quality function of the search strategy; denotes the various motions of the AO during the hunting period; while is a linear function indicating the flight slope of the AO used to track the prey.
In summary, this paper adopts the phase operator to improve the stage of the Aquila optimizer and the flow operator to improve the stage, forming a multi-strategy improved Aquila optimizer, which has a faster convergence speed and a stronger anti-interference ability, compared with the traditional Aquila optimizer.
3.3. Time Complexity Analysis
According to reference [32], the time complexity of the AO algorithm depends on three aspects: population initialization, fitness calculation, and solution update. Assuming the population size is N, the spatial dimension is D, and the maximum number of iterations is T, the complexity of the population initialization process can be calculated as , where represents the complexity of the solution update process. Therefore, the overall time complexity of the Aquila optimizer (AO) algorithm is .
In the MIAO algorithm, the phasor operator treats each individual in the population as a one-dimensional phasor that varies randomly within the range as the iterations progress. Therefore, the time complexity of the phasor operator is . Compared to the Aquila optimizer (AO) algorithm, the flow direction operator does not involve the population initialization process. The time complexity of the flow direction operator is . Therefore, the inclusion of the phasor operator and the flow direction operator does not increase the overall time complexity. Thus, the time complexity of MIAO remains .
3.4. Algorithm Performance Testing
To verify the effectiveness of the algorithm proposed in this paper, it is tested with the seagull optimization algorithm (SOA), particle swarm optimization (PSO), sparrow search algorithm (SSA), genetic algorithm (GA), whale optimization algorithm (WOA), and the traditional Aquila optimizer (AO) for performance testing with a uniform setting of the number of populations N = 30, the number of iterations T = 500, and the test dimensionality of 10 dimensions, and the selected test functions are shown in Table 1, Table 2 and Table 3.

Table 1.
Test Functions.
Table 2.
CEC2017 Test Functions.
Table 3.
CEC2022 Test Functions.
To ensure that the experimental results are scientifically sound, nine test functions were chosen to test the performance of these algorithms. The algorithms are written in MatlabR2020a and the experimental environment was equipped with an AMD R7 3.2 GHz CPU sourced from the United States, 8.00 GB RAM, and the Windows11 operating system. Each experiment is run independently for 30 epochs, where F1–F3 are 3 unimodal test functions to test the global exploration capability of the algorithm. F4–F6 are 3 multi-peak test functions to test the exploitation capability of the algorithm. F7–F9 are 3 fixed-dimensional multi-peak test functions to check the exploration capability of the algorithm in a low-dimensional search space.
3.5. Optimized Accuracy Analysis
The MIAO algorithm and SOA, PSO, SSA, AO, GA, and WOA are run independently on the above nine test functions for 30 times, the experimental results are recorded, and the optimal value, average value, and standard deviation of each algorithm are taken as the evaluation indexes, and the test results are shown in Table 4 below. The values in bold in the table are the optimal results.
Table 4.
Test function results (Dim = 10).
As can be seen from Table 4, the proposed multi-strategy modified Aquila optimizer shows significant improvement in finding the optimal action for the three unimodal test functions F1–F3, and MIAO is robust. Moreover, MIAO is able to find the theoretical optimal value on the two multi-peak test functions F4 and F6, which indicates that MIAO has excellent evasion performance, does not easily get trapped in the local optimal solution, and has strong anti-stagnation performance. In the last three fixed-dimensional multi-peak test functions, MIAO also has the best optimization search performance and can essentially find its theoretical optimum, indicating the superior global search capability of the multi-strategy modified Aquila optimizer. F10–F15 represent six CEC benchmark test functions, which were used to further validate the optimization capability of MIAO. Experimental results also demonstrate that, compared to AO, MIAO exhibits superior optimization performance.
3.6. Convergence Curve Analysis
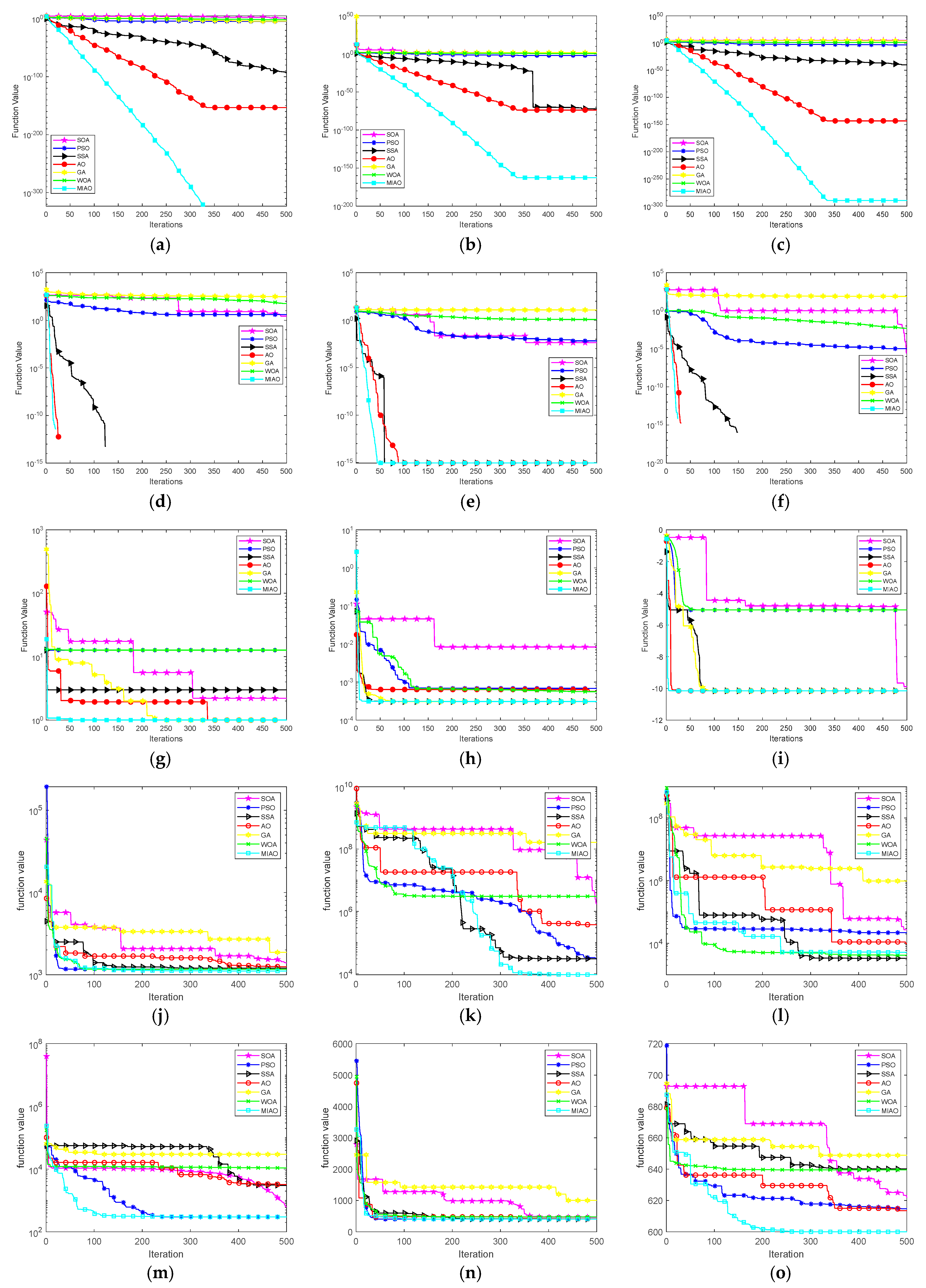
Figure 2 shows the convergence performance analysis of SOA, PSO, SSA, AO, GA, WOA, and MIAO for 10 dimensions and 500 iterations of the pairwise function optimization procedure. It can be visualized from Figure 2 that MIAO has the fastest convergence rate and the highest convergence accuracy among the 15 tested functions. This indicates that MIAO has superior low-dimensional spatial exploration ability to the other six algorithms.
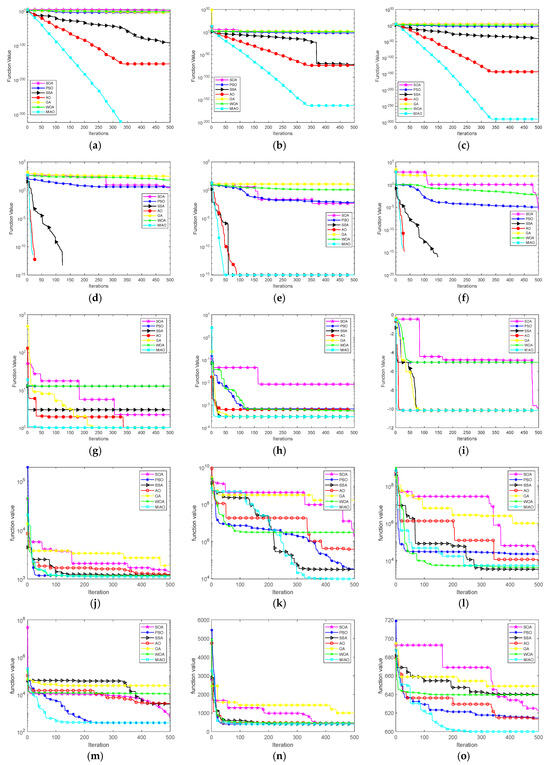
Figure 2.
Algorithm convergence curve. (a) F1 convergence curve, (b) F2 convergence curve, (c) F3 convergence curve, (d) F4 convergence curve, (e) F5 convergence curve, (f) F6 convergence curve, (g) F7 convergence curve, (h) F8 convergence curve, (i) F9 convergence curve, (j) F10 convergence curve, (k) F11 convergence curve, (l) F12 convergence curve, (m) F13 convergence curve, (n) F14 convergence curve, and (o) F15 convergence curve.
3.7. Wilcoxon Rank-Sum Test
The Wilcoxon rank-sum test [35] is a non-parametric statistical method used to determine whether there are significant differences between two samples. In this study, the Wilcoxon rank-sum test was employed on nine classical benchmark functions to assess whether the MIAO algorithm exhibits significant differences compared to the other six algorithms. Here, p represents the test result and h indicates the significance judgment result. When p < 0.05, h = 1 signifies that the MIAO algorithm is significantly stronger than the other algorithms. When p > 0.05, h = 0 indicates that the MIAO algorithm is significantly weaker than the other algorithms. When p is displayed as N/A, it means that the significance test cannot be performed, suggesting that the significance of the MIAO algorithm may be equivalent to that of the other algorithms. The results are shown in Table 5.
Table 5.
The results of the rank-sum test.
3.8. Ablation Experiment
To further validate the effectiveness of the proposed improvements and investigate the impact of each enhancement strategy on the algorithm’s optimization performance, this study conducts comparative experiments on nine classical benchmark functions. The algorithms compared include the original Aquila optimizer (AO), the AO enhanced with the phasor operator (PAO), the AO enhanced with the flow direction operator (FAO), and the AO improved with multiple strategies (MIAO). The experimental results are shown in Table 6.
Table 6.
Optimization Results of Different Strategies.
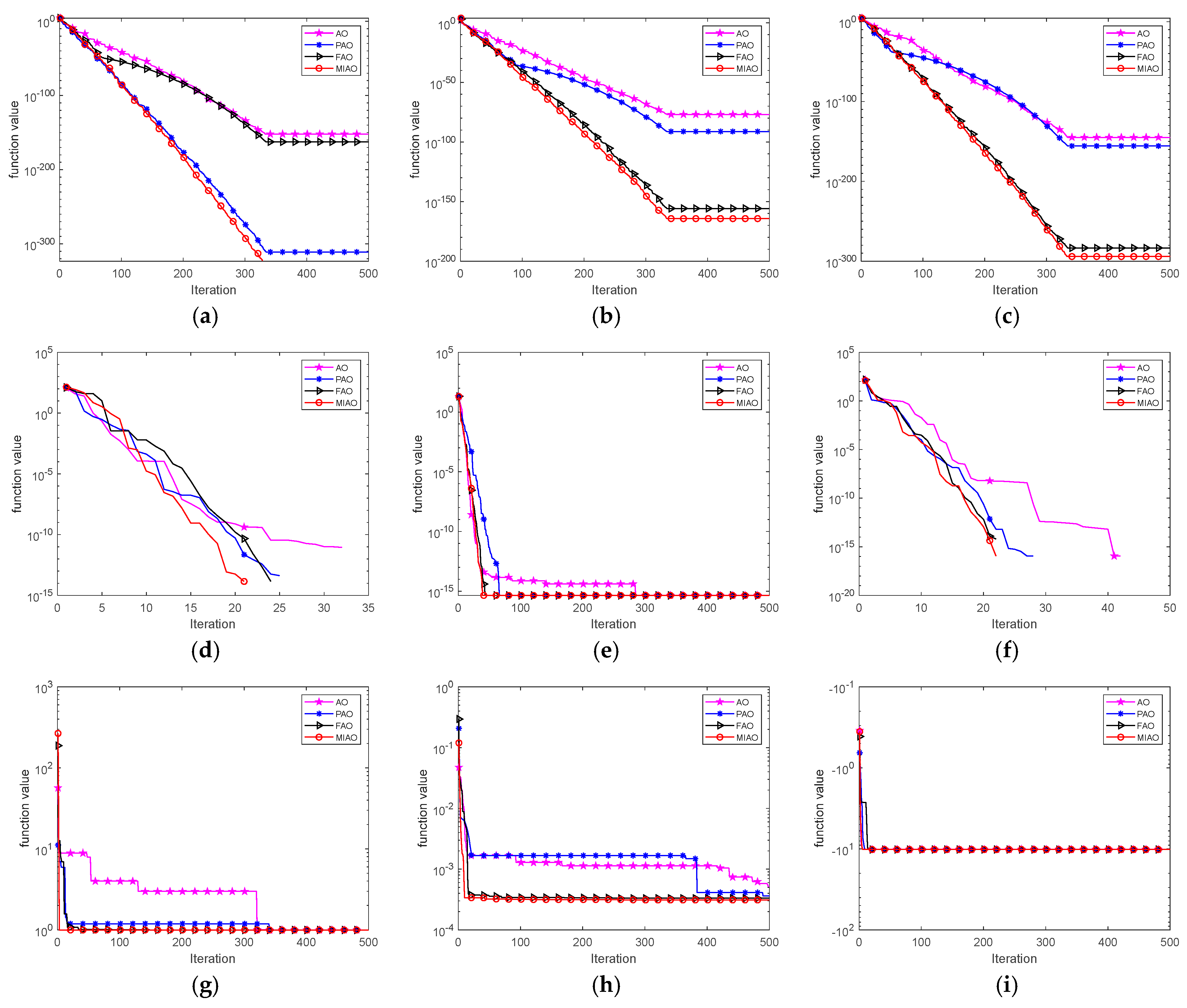
As shown in Table 6, the phasor operator brings a substantial improvement to the optimization capability of the AO. The flow operator enhances the solution diversity of the algorithm in late iterations, also playing a positive role in improving the AO. The convergence curves of these four algorithms AO, PAO, FAO, and MIAO are presented in Figure 3.
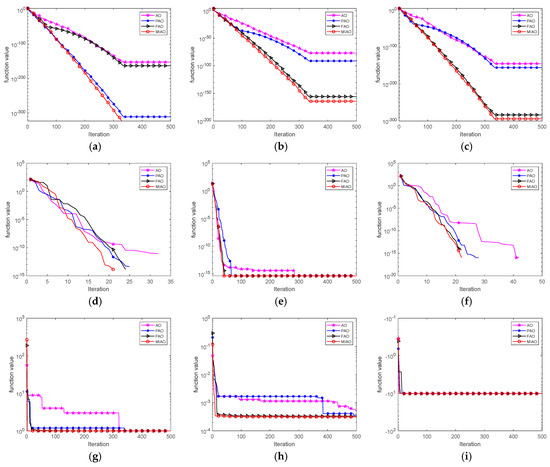
Figure 3.
Convergence curves of AO, PAO, FAO, and MIAO algorithms. (a) F1 convergence curve, (b) F2 convergence curve, (c) F3 convergence curve, (d) F4 convergence curve, (e) F5 convergence curve, (f) F6 convergence curve, (g) F7 convergence curve, (h) F8 convergence curve, and (i) F9 convergence curve.
4. MIAO_LSTM Rail Freight Volume Prediction Model and Analysis of Experimental Results
4.1. MIAO_LSTM Rail Freight Volume Prediction Model
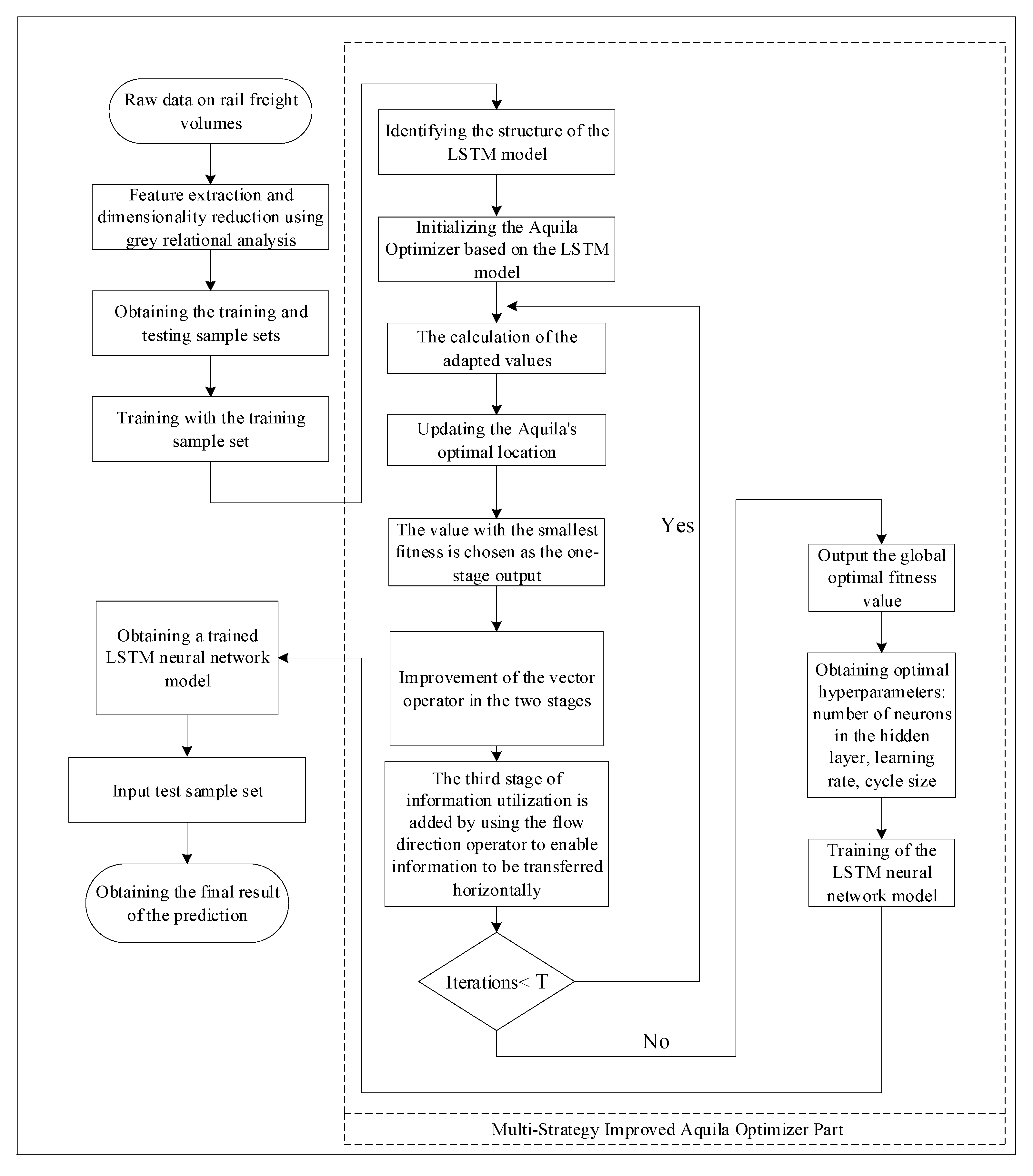
The above experiments demonstrate the effectiveness and stability of MIAO. Next, MIAO is combined with LSTM and used to optimize the relevant parameters of the LSTM network as a means to predict the value of the monthly rail freight traffic. Venkatachalam et al. [36] explored the setting of the relevant hyperparameters of the LSTM. Experimental results show that the learning rate is the most critical hyperparameter of LSTM, followed by the network size, while the momentum gradient has little influence on the final result. To match the LSTM structure with the monthly rail freight volume data, the MIAO_LSTM freight volume prediction model is constructed. Hyperparameters such as the number of neurons in the hidden layer, the number of cycles, and the learning rate are used as optimization objectives for the MIAO optimization algorithm. The flowchart of MIAO_LSTM is shown in Figure 4, and the specific steps of MIAO_LSTM are as follows.
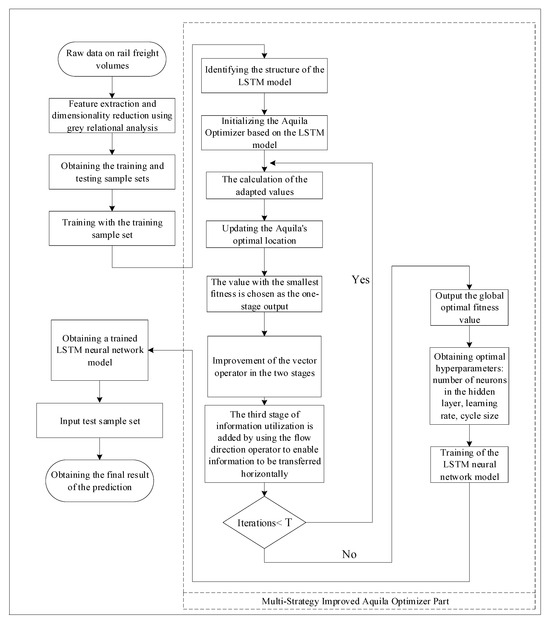
Figure 4.
Flowchart of MIAO_LSTM railway freight volume prediction model.
Step1: data processing clarified the input and output of the MIAO_LSTM rail freight volume prediction model, which takes 16-dimensional influence factors such as rail freight turnover and bulk commodity production as input and freight volume value as output. In addition, to explore the impact of input features on the prediction accuracy of freight volumes, grey correlation analysis was used to quantify these 16-dimensional inputs, and correlations greater than or equal to 0.8 were selected for repeated experiments. Different input data have different dimensions and the difference in values can be large, which can affect the training speed of the model; therefore, the data are normalized and mapped to [−1, 1] in this paper. The training and test sets are split.
Step2: the population size, iteration number, step size, and additional relevant parameters of the MIAO algorithm were set. The training was optimized by using the mean absolute error as the loss function.
Step3: the LSTM hyperparameters were optimized using the MIAO algorithm. A three-layer LSTM network structure with one hidden layer was constructed.
Step4: the optimized model for freight volume prediction was used, and this judged the adaptability and effectiveness of the model by comparing the model prediction results with real data.
4.2. Analysis of Data Sources and Influences
The values of railway freight volume and their influencing factors vary across different countries. We do not have access to freight volume data or related influencing factors for Europe. Therefore, we adopted China’s railway freight volume data for the study, and historical data on monthly rail freight volumes and other 16-dimensional input features were collected from January 2005 to December 2021. All the above data were obtained from the National Bureau of Statistics [37]. The raw freight volume data used in this paper are shown in Figure 5, where the January 2005 to December 2020 freight volume data are used as the training set and the 2021 monthly data are used as the prediction set. The introduction of these 16-dimensional input features is shown in Table 7.
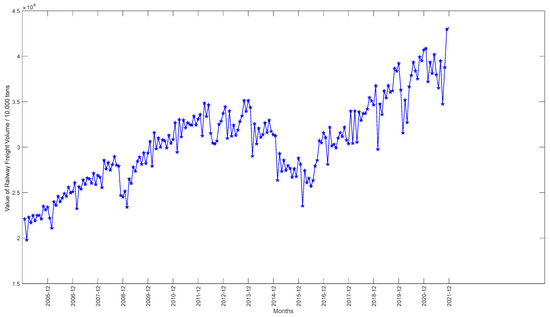
Figure 5.
Raw data of monthly freight volume (unit: 10,000 tons).
Table 7.
Meaning of Input Features.
In the preprocessing of influencing factors, since grey correlation analysis (GRA) can quantitatively analyze the correlation between each input feature and the output freight volume, through experimentation, we have concluded that Grey Relational Analysis (GRA) is more suitable than Principal Component Analysis (PCA) for freight volume prediction, and this paper adopts the GRA method to complete the screening of the input features. The formulation of the GRA method is given below.
In the above equation, is the reference series, and, in this paper, the railway freight volume is chosen as the reference series and ρ is taken as 0.5. The correlation between these impact factors and rail freight volumes is shown in Table 8.
Table 8.
Correlation between the various influencing factors and the volume of freight transported.
Referring to the selection of input features in references [38,39,40], this paper selects 16 influencing factors, and, in Table 8, to denote the railway freight turnover, total retail sales of consumer goods, crude coal production, crude oil production, coke production, highway freight transport, total import and export value, water transport freight transport, national fiscal revenue, power generation, steel production, railway freight vehicles, synthetic rubber production, cement production, volume of goods vehicles, and total postal operations. The correlation data in Table 8 show that the correlation between many of these 16 influencing factors and the freight transport volume is below 0.8 or even 0.7, and some studies have shown that the use of input features with a degree of correlation of 0.8 or more will additionally improve the prediction accuracy. Therefore, in this paper, influence factors with correlations above 0.8 are selected for additional study, based on which the prediction accuracy is improved. The six input features retained with an impact factor higher than 0.8 are rail freight volume, road freight volume, total import and export value, national revenue, electricity generation, and fleet of cargo vehicles.
4.3. Predictive Evaluation Indicators
In this experiment, the LSTM network is used as the base algorithm, and, according to the error back propagation characteristics of the LSTM network [41], the mean absolute error (MAE) is chosen as the fitness function of the hybrid multi-strategy Aquila optimizer. This algorithm and the sparrow search algorithm, particle swarm algorithm, genetic algorithm, seagull optimization algorithm, whale optimization algorithm, and the traditional Aquila optimizer optimization of the LSTM network are chosen to perform comparison experiments. The results show that the MIAO_LSTM algorithm used in this paper is optimal under a number of evaluation indexes such as MAE, MSE, RMSE, MAPE, and SMAPE. The corresponding formulation of the evaluation metric is as follows.
4.4. Comparison of Multiple Algorithms for Optimizing LSTM Prediction Models
In this paper, we optimize the hyperparameters (number of neurons in the hidden layer, maximum training period, and initial learning rate) of the LSTM network using the hybrid multi-strategy Aquila optimizer with multi-strategy improvement and perform comparison experiments with sparrow search algorithm, particle swarm optimization, genetic algorithm, seagull optimization algorithm, whale optimization algorithm, and the traditional Aquila optimizer, and the adaptations of the seven optimization algorithms are shown in Figure 6. The results before and after the hyperparameter optimization described above are shown in Table 9.
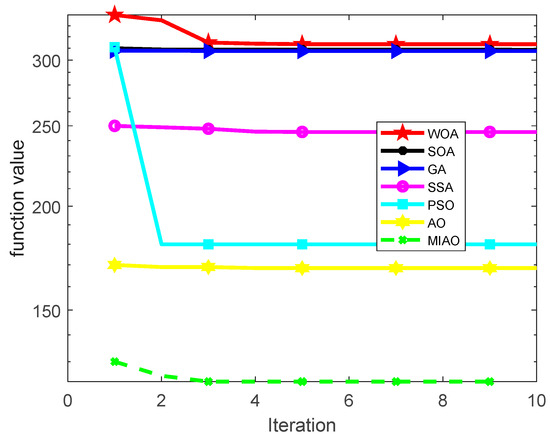
Figure 6.
Seven optimization algorithms for optimizing LSTM fitness curves.
Table 9.
Comparison of results before and after hyperparameter optimization.
From the above Figure 2 and Figure 6, we can see that the hybrid multi-strategy Aquila optimizer adopted in this paper has the fastest convergence rate and the best fitness value compared to alternative optimization algorithms. It effectively addresses the lack of local search in the late stages of traditional Aquila optimizers and further demonstrates the superiority of MIAO.
4.5. Analysis of Experimental Results
Experiment 1: Validation of the effectiveness of the dimensionality reduction operation.
In this paper, we first compare the prediction results using the LSTM network in the case of 16-dimensional input features and 6-dimensional input features after the gray correlation analysis in our experiments, and the results are shown in Table 10.
Table 10.
Comparison of LSTM experimental results.
The results in the above table show that the input features have a larger impact on the prediction accuracy, and a reasonable choice of input features can effectively reduce the impact of other factors containing more noise and improve the prediction accuracy of the freight volume.
Experiment 2: Validation of the effectiveness of the optimization algorithm.
First, 16-dimensional influence factors are used as model inputs and monthly rail freight volume values are used as outputs, and experiments are conducted using the constructed MIAO_LSTM algorithm and compared with the unoptimized LSTM neural networks SSA_LSTM, PSO_LSTM, GA_LSTM, SOA_LSTM, WOA_LSTM, and AO_LSTM models. The experimental results of these seven optimization algorithms are shown in Table 11. The prediction results are shown in Figure 7.
Table 11.
Prediction results for 16-dimensional input features.
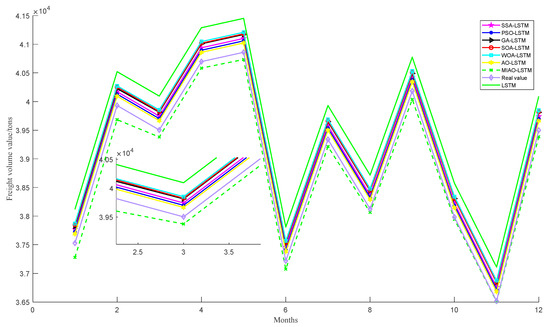
Figure 7.
Line graph of prediction results under 16-dimensional inputs.
The 6-dimensional influence after dimensionality reduction is used as input to the model for additional prediction experiments. The experimental results are shown in Table 12. The experimental results in Table 11 and Table 12 show that the MIAO algorithm used in this paper has the best optimization search performance compared to traditional optimization algorithms, and the prediction accuracy is better than other traditional optimization algorithms for both 16-dimensional and 6-dimensional inputs. In particular, the effect after dimensionality reduction is overall better than the effect before dimensionality reduction. The prediction results for the 6-dimensional input are shown in Figure 8.
Table 12.
Prediction results under 6-dimensional input features.
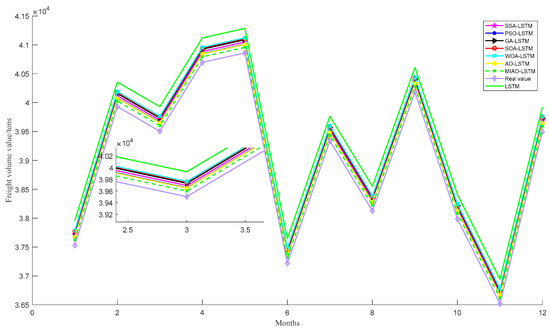
Figure 8.
Line graph of prediction results for 6-dimensional inputs.
4.6. Discussion of the Analysis
In summary, out of all the experiments in this paper, experiment 1 demonstrates that reducing the dimensionality of the input data using gray correlation analysis can improve the prediction accuracy. The reference values of the prediction results are improved. Experiment 2 compares and analyzes the MIAO algorithm with other regularized optimization algorithms and shows that the MIAO algorithm used in this paper has the fastest convergence rate and the MIAO_LSTM model has the optimal prediction for different input dimensions.
5. Conclusions
This paper introduces the phasor operator and flow direction operator to enhance the Aquila optimizer, resulting in a novel MIAO algorithm, and utilizes Chinese railway freight volume data to validate the effectiveness of the MIAO_LSTM model in the field of freight volume prediction. By incorporating the phasor operator, the numerous control parameters in the second phase of the Aquila optimizer have been eliminated. The optimization results from the test functions also demonstrate the effectiveness of our proposed improvements. Additionally, the inclusion of the flow direction operator enables information exchange between adjacent individuals in the Aquila optimizer. It increases the diversity of solutions in the later iterations and reduces the probability of the algorithm falling into local optima. By integrating the LSTM network with MIAO and utilizing freight volume data for further analysis of the optimization capability of the MIAO_LSTM model, the results also indicate that the MIAO_LSTM model exhibits superior performance. The reduction in custom parameters enhances the adaptability of the model. It enables MIAO_LSTM to provide valuable insights for the railway sector in scheduling and planning. In terms of data processing, we employed Grey Relational Analysis (GRA) to discuss the impact of input features on prediction results. The limitations of this study lie in the fact that the effectiveness of the MIAO algorithm in handling low-dimensional real-world problems, such as path planning, remains to be validated. Furthermore, the research on freight volume prediction primarily focuses on static data and does not account for the impact of unexpected events. In the future, we plan to consider the influence of dynamic data on the model. We will delve deeper into the characteristics of optimization algorithms and deep learning models, adopting more diverse hybrid models to address real-world challenges.
Author Contributions
Conceptualization, L.B. and Y.Z.; data curation, Z.P. and J.W.; formal analysis, L.B. and Z.P.; investigation, Z.P. and J.W.; methodology, L.B. and Z.P.; software, Z.P. and Y.Z.; validation, Y.Z.; writing—original draft, L.B. and Z.P.; and writing—review and editing, L.B. and Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (U1504622), Project of Cultivation Programme for Young Backbone Teachers of Higher Education Institutions in Henan Province (2018GGJS079).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author. Data will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wu, S.; He, B.; Zhang, J.; Chen, C.; Yang, J. PSAO: An enhanced Aquila Optimizer with particle swarm mechanism for engineering design and UAV path planning problems. Alex. Eng. J. 2024, 106, 474–504. [Google Scholar] [CrossRef]
- Chowdhury, A.; Roy, R.; Mandal, K.K. Enhancement of technical, economic & environmental benefits in multi-point PV & wind-based DG integrated radial distribution network using Aquila optimizer. Expert Syst. Appl. 2024, 252, 124307. [Google Scholar] [CrossRef]
- Jamazi, C.; Manita, G.; Chhabra, A.; Manita, H.; Korbaa, O. Mutated Aquila Optimizer for assisting brain tumor segmentation. Biomed. Signal Process. Control. 2024, 88, 105589. [Google Scholar] [CrossRef]
- Zhang, H.; Hu, H.; Ding, W. A time-varying image encryption algorithm driven by neural network. Opt. Laser Technol. 2025, 186, 122751. [Google Scholar] [CrossRef]
- Zhou, Y.; Xia, H.; Yu, D.; Cheng, J.; Li, J. Outlier detection method based on high-density iteration. Inf. Sci. 2024, 662, 120286. [Google Scholar] [CrossRef]
- Bounnah, Y.; Mihoubi, M.K.; Larbi, S. Physics informed neural network with Fourier feature for natural convection problems. Eng. Appl. Artif. Intell. 2025, 146, 110327. [Google Scholar] [CrossRef]
- Liu, C.; Guo, H.; Di, J.; Zheng, K. Quantitative method for structural health evaluation under multiple performance metrics via multi-physics guided neural network. Eng. Appl. Artif. Intell. 2025, 147, 110383. [Google Scholar] [CrossRef]
- Wang, T.; Hu, Z.; Kawaguchi, K.; Zhang, Z.; Karniadakis, G.E. Tensor neural networks for high-dimensional Fokker-Planck equations. Neural Netw. 2025, 185, 107165. [Google Scholar] [CrossRef] [PubMed]
- Qiao, X.; Peng, T.; Sun, N.; Zhang, C.; Liu, Q.; Zhang, Y.; Wang, Y.; Nazir, M.S. Metaheuristic evolutionary deep learning model based on temporal convolutional network, improved aquila optimizer and random forest for rainfall-runoff simulation and multi-step runoff prediction. Expert Syst. Appl. 2023, 229, 120616. [Google Scholar] [CrossRef]
- Duan, J.; Zuo, H.; Bai, Y.; Chang, M.; Chen, X.; Wang, W.; Ma, L.; Chen, B. A multistep short-term solar radiation forecasting model using fully convolutional neural networks and chaotic aquila optimization combining WRF-Solar model results. Energy 2023, 271, 126980. [Google Scholar] [CrossRef]
- Yuping, X.; Junxiang, D.; Zehua, J. Railway freight volume forecasting based on a combined model. J. Railw. Sci. Eng. 2021, 18, 243–249. [Google Scholar]
- Hong, S.-J.; Randall, W.; Han, K.; Malhan, A.S. Estimation viability of dedicated freighter aircraft of combination carriers: A data envelopment and principal component analysis. Int. J. Prod. Econ. 2018, 202, 12–20. [Google Scholar] [CrossRef]
- Feng, F.; Li, W.; Jiang, Q. Railway freight volume forecast using an ensemble model with optimised deep belief network. IET Intell. Transp. Syst. 2018, 12, 851–859. [Google Scholar] [CrossRef]
- Wang, D. Analysis of Influencing Factors and Research on Freight Volume Prediction of Railway Freight Transport in Hebei Province. Master’s Thesis, Shijiazhuang Tiedao University, Shijiazhuang, China, 2024. [Google Scholar]
- Liu, X.T. Research on Railway Freight Demand Forecasting Technonlgy under Uncertain Environment. Master’s Thesis, Beijing Jiaotong University, Beijing, China, 2020. [Google Scholar]
- Zhang, G.D.; Yang, C. Freight volume prediction based on multidimensional long and short-term memory networks. Stat. Decision. 2022, 38, 180–183. [Google Scholar]
- Liu, R.W.; Hu, K.; Liang, M.; Li, Y.; Liu, X.; Yang, D. QSD-LSTM: Vessel trajectory prediction using long short-term memory with quaternion ship domain. Appl. Ocean Res. 2023, 136, 103592. [Google Scholar] [CrossRef]
- Qin, L.; Li, W.; Li, S. Effective passenger flow forecasting using STL and ESN based on two improvement strategies. Neurocomputing 2019, 356, 244–256. [Google Scholar] [CrossRef]
- Li, H.; Bai, J.; Cui, X.; Li, Y.; Sun, S. A new secondary decomposition-ensemble approach with cuckoo search optimization for air cargo forecasting. Appl. Soft Comput. 2020, 90, 106161. [Google Scholar] [CrossRef]
- Méndez, M.; Merayo, M.G.; Núñez, M. Long-term traffic flow forecasting using a hybrid CNN-BiLSTM model. Eng. Appl. Artif. Intell. 2023, 121, 106041. [Google Scholar] [CrossRef]
- Bhurtyal, S.; Bui, H.; Hernandez, S.; Eksioglu, S.; Asborno, M.; Mitchell, K.N.; Kress, M. Prediction of waterborne freight activity with Automatic identification System using Machine learning. Comput. Ind. Eng. 2025, 200, 110757. [Google Scholar] [CrossRef]
- Yang, Y.; Yu, C. Prediction models based on multivariate statistical methods and their applications for predicting railway freight volume. Neurocomputing 2015, 158, 210–215. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Kuo, P.-C.; Chou, Y.-T.; Li, K.-Y.; Chang, W.-T.; Huang, Y.-N.; Chen, C.-S. GNN-LSTM-based fusion model for structural dynamic responses prediction. Eng. Struct. 2024, 306, 117733. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, L.; Shi, W. Seismic control of adaptive variable stiffness intelligent structures using fuzzy control strategy combined with LSTM. J. Build. Eng. 2023, 78, 107549. [Google Scholar] [CrossRef]
- Yüksel, N.; Börklü, H.R.; Sezer, H.K.; Canyurt, O.E. Review of artificial intelligence applications in engineering design perspective. Eng. Appl. Artif. Intell. 2023, 118, 105697. [Google Scholar] [CrossRef]
- Qian, C.; Ling, T.; Schiele, G. Exploring energy efficiency of LSTM accelerators: A parameterized architecture design for embedded FPGAs. J. Syst. Arch. 2024, 152, 103181. [Google Scholar] [CrossRef]
- Zhu, D.; Wang, S.; Zhou, C.; Yan, S.; Xue, J. Human memory optimization algorithm: A memory-inspired optimizer for global optimization problems. Expert Syst. Appl. 2023, 237, 121597. [Google Scholar] [CrossRef]
- Ma, Y.; Shan, C.; Gao, J.; Chen, H. A novel method for state of health estimation of lithium-ion batteries based on improved LSTM and health indicators extraction. Energy 2022, 251, 123973. [Google Scholar] [CrossRef]
- Lu, Y.; Jiang, Z.; Chen, C.; Zhuang, Y. Energy efficiency optimization of field-oriented control for PMSM in all electric system. Sustain. Energy Technol. Assess. 2021, 48, 101575. [Google Scholar] [CrossRef]
- Jiang, P.; Wang, Z.; Li, X.; Wang, X.V.; Yang, B.; Zheng, J. Energy consumption prediction and optimization of industrial robots based on LSTM. J. Manuf. Syst. 2023, 70, 137–148. [Google Scholar] [CrossRef]
- Abualigah, L.; Yousri, D.; Abd Elaziz, M.; Ewees, A.A.; Al-Qaness, M.A.; Gandomi, A.H. Aquila optimizer: A novel meta-heuristic optimization algorithm. Comput. Ind. Eng. 2021, 157, 107250. [Google Scholar] [CrossRef]
- Ghasemi, M.; Akbari, E.; Rahimnejad, A.; Razavi, S.E.; Ghavidel, S.; Li, L. Phasor particle swarm optimization: A simple and efficient variant of PSO. Soft Comput. 2019, 23, 9701–9718. [Google Scholar] [CrossRef]
- Karami, H.; Anaraki, M.V.; Farzin, S.; Mirjalili, S. Flow Direction Algorithm (FDA): A Novel Optimization Approach for Solving Optimization Problems. Comput. Ind. Eng. 2021, 156, 107224. [Google Scholar] [CrossRef]
- Li, Y.; Mu, W.; Chu, X.; Fu, Z. K-means clustering algorithm based on improved quantum particle swarm optimization and its application. Control. Decis. 2022, 37, 839–850. (In Chinese) [Google Scholar]
- Venkatachalam, K.; Trojovský, P.; Pamucar, D.; Bacanin, N.; Simic, V. DWFH: An improved data-driven deep weather forecasting hybrid model using Transductive Long Short Term Memory (T-LSTM). Expert Syst. Appl. 2023, 213, 119720. [Google Scholar] [CrossRef]
- National Bureau of Statistics of China. Available online: https://www.stats.gov.cn/english/ (accessed on 6 August 2024).
- Wei, C.; Li, H.; Luo, Z.; Wang, T.; Yu, Y.; Wu, M.; Qi, B.; Yu, M. Quantitative analysis of flame luminance and explosion pressure in liquefied petroleum gas explosion and inerting: Grey relation analysis and kinetic mechanisms. Energy 2024, 304, 132046. [Google Scholar] [CrossRef]
- Liu, S.; Yang, Y.; Forrest, J.Y.L. Grey Systems Analysis: Methods, Models and Applications; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Chang, T.C.; Lin, S.J. Grey relation analysis of carbon dioxide emissions from industrial production and energy uses in Taiwan. J. Environ. Manag. 1999, 56, 247–257. [Google Scholar] [CrossRef]
- Wang, Y.; Bao, D.; Qin, S.J. A novel bidirectional DiPLS based LSTM algorithm and its application in industrial process time series prediction. Chemom. Intell. Lab. Syst. 2023, 240, 104878. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).