
Edge Exemplars Enhanced Incremental Learning Model for Tor-Obfuscated Traffic Identification


Abstract
1. Introduction
- An incremental learning framework is designed for Tor-obfuscated traffic detection. Adding new types of obfuscated traffic requires only incremental updates to existing models. Compared with retraining, it effectively saves data storage space and model training time.
- A method named edge exemplar enhancement is proposed to optimize the increment learning framework. It enhances the memory of incremental learning on the edge of information from previous classes, and it effectively improves the recognition performance of replay-based incremental learning models.
- Based on public datasets and self-capture datasets, we simulated the iterative process of Tor traffic obfuscation technology in an experiment to verify the proposed model in this paper. The experimental results demonstrate the performance of the incremental learning framework for Tor-obfuscated traffic, and they also verify the effectiveness of edge exemplar enhancement.
2. Related Work
3. Method
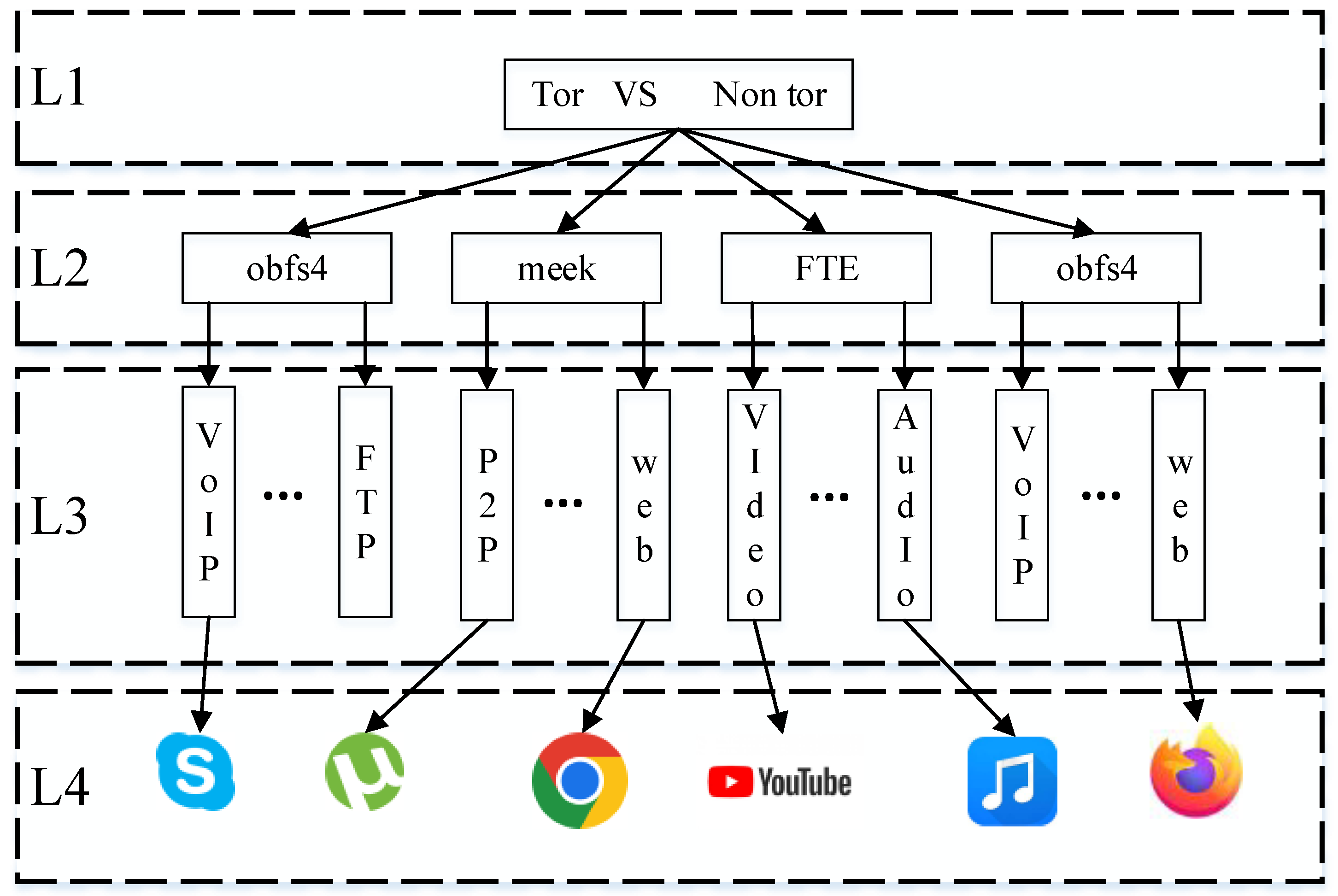
3.1. Tor Pluggable Transports
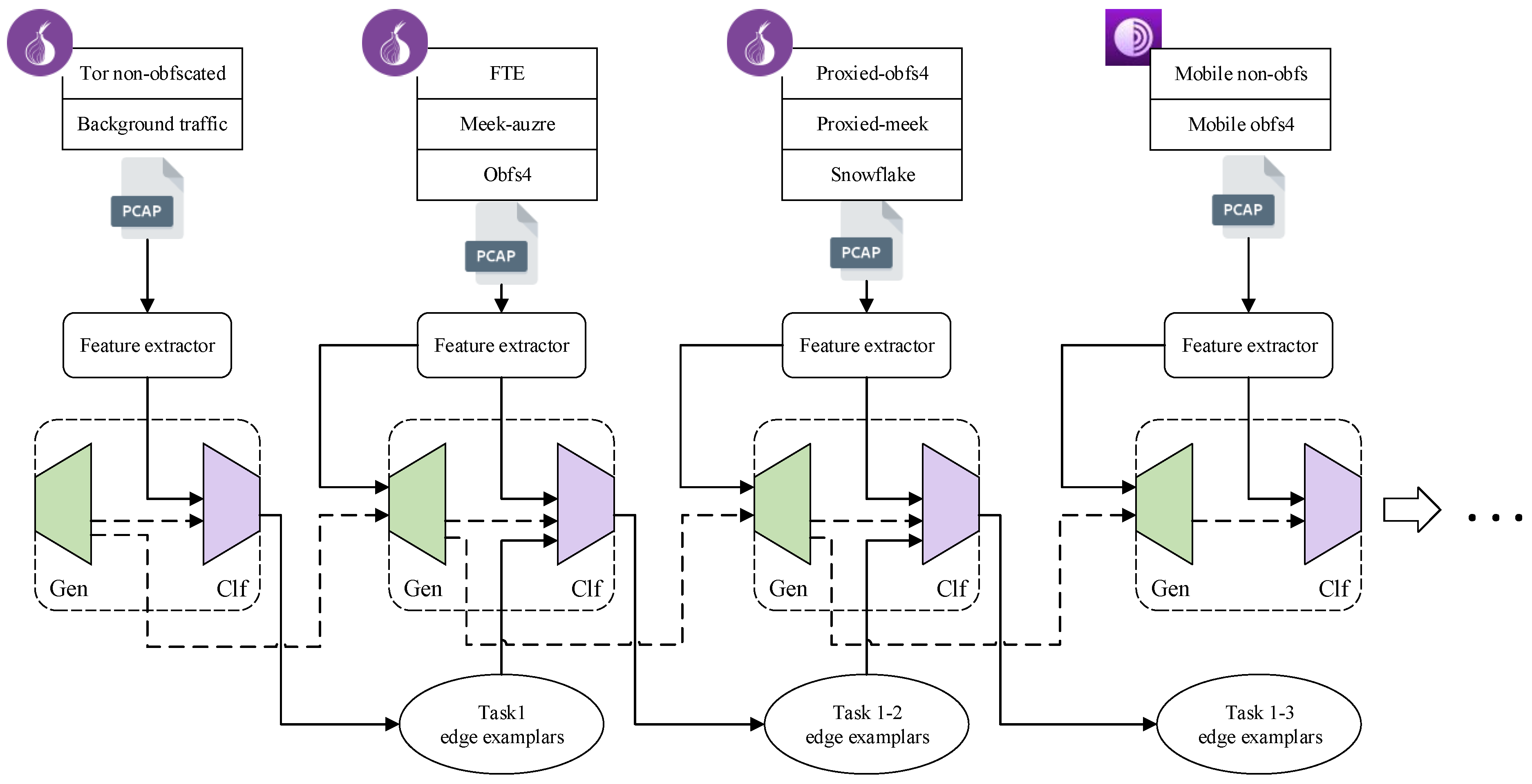
3.2. Increamental Learning
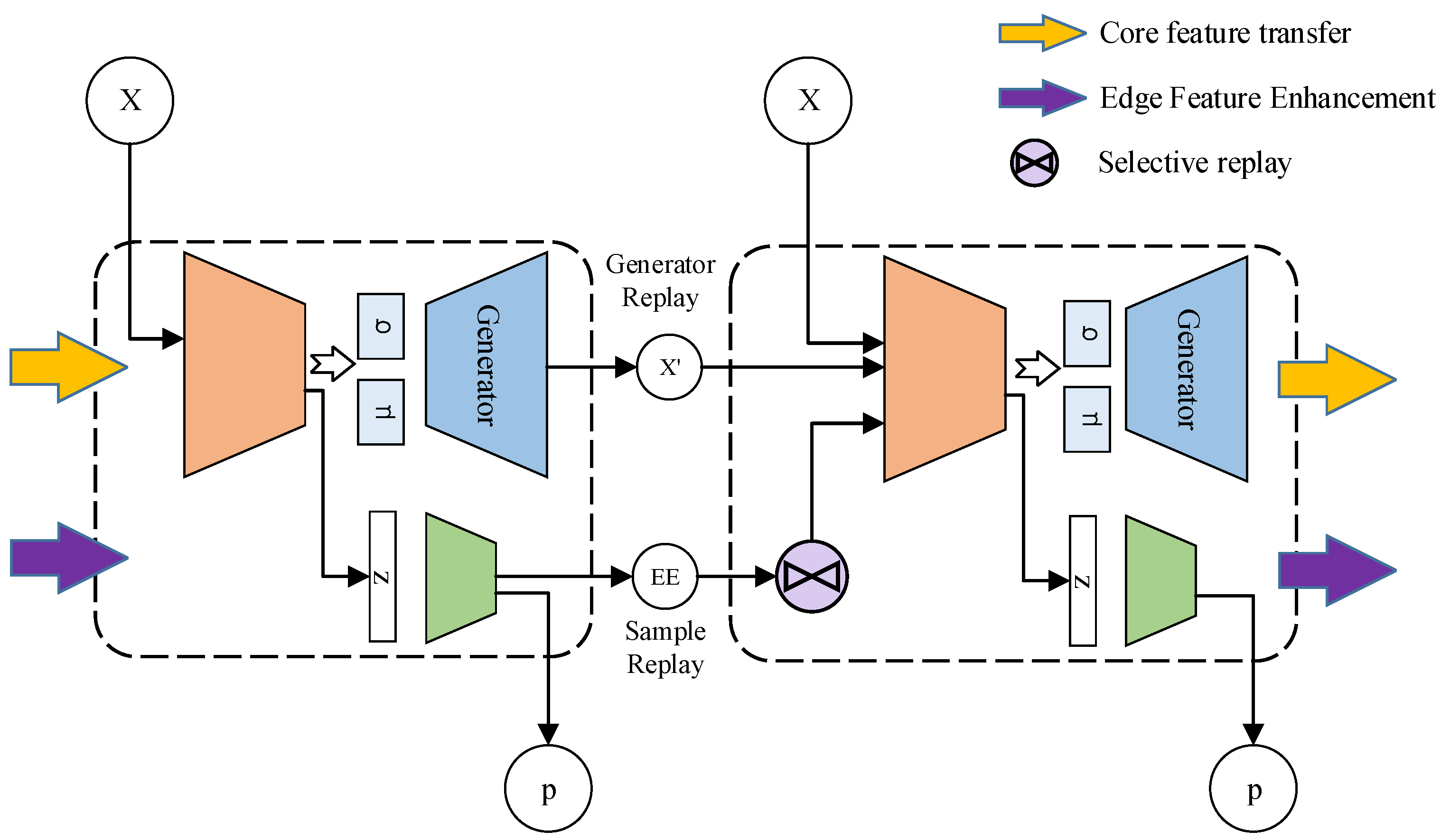
3.3. Edge Exemplars Enhancement
| Algorithm 1 Replay-based incremental learning with edge exemplar enhancement |
Require: The training dataset for the current task: , ; The Generator and classifier of previous task: , ; Edge exemplars extracted by the previous tasks: ; The proportion of EE samples replayed in a batch: ; The size of the EE sampled for each class: m Ensure:
|
4. Experiment
4.1. Data Collection
4.2. Evaluation Metrics
4.3. Network and Parameter Settting
4.4. Evaluation
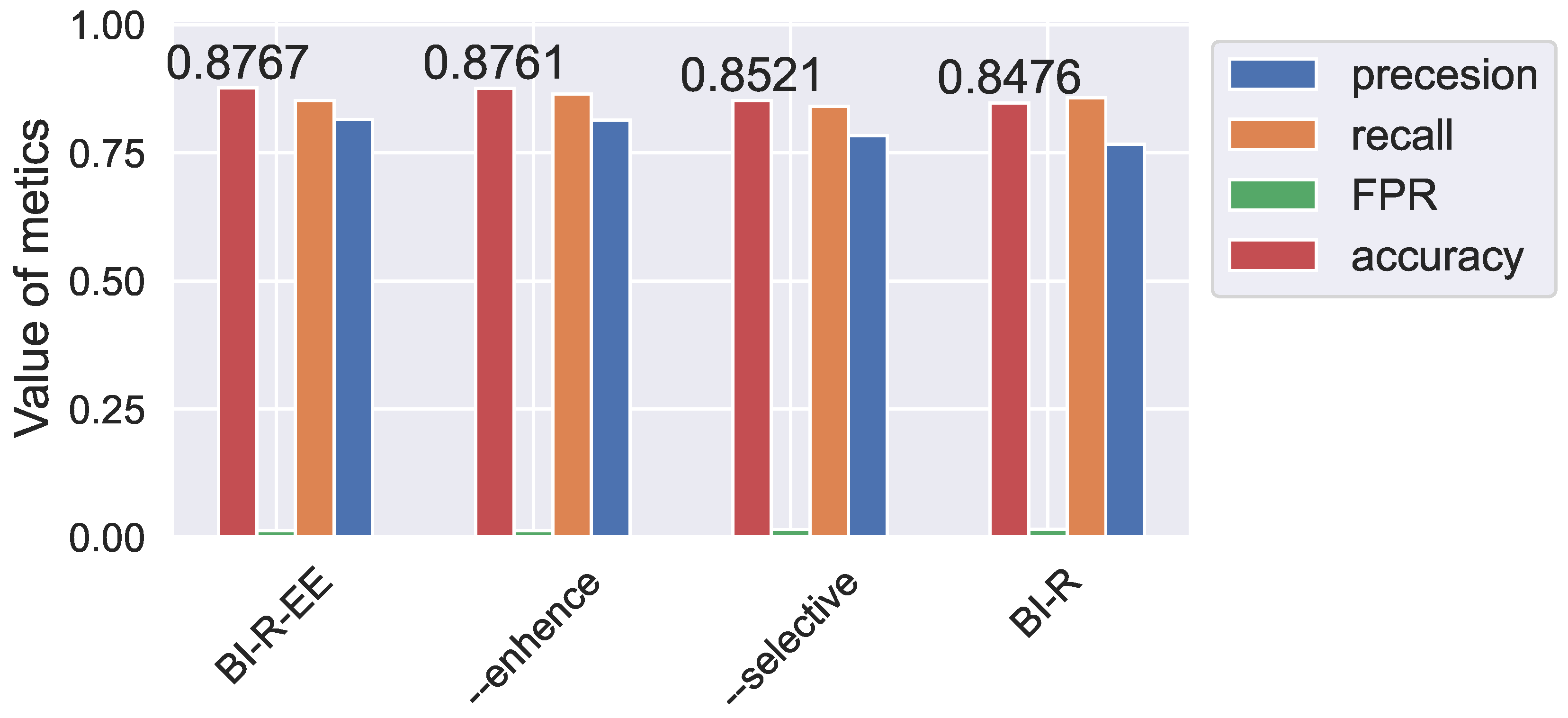
4.5. Ablation Experiment
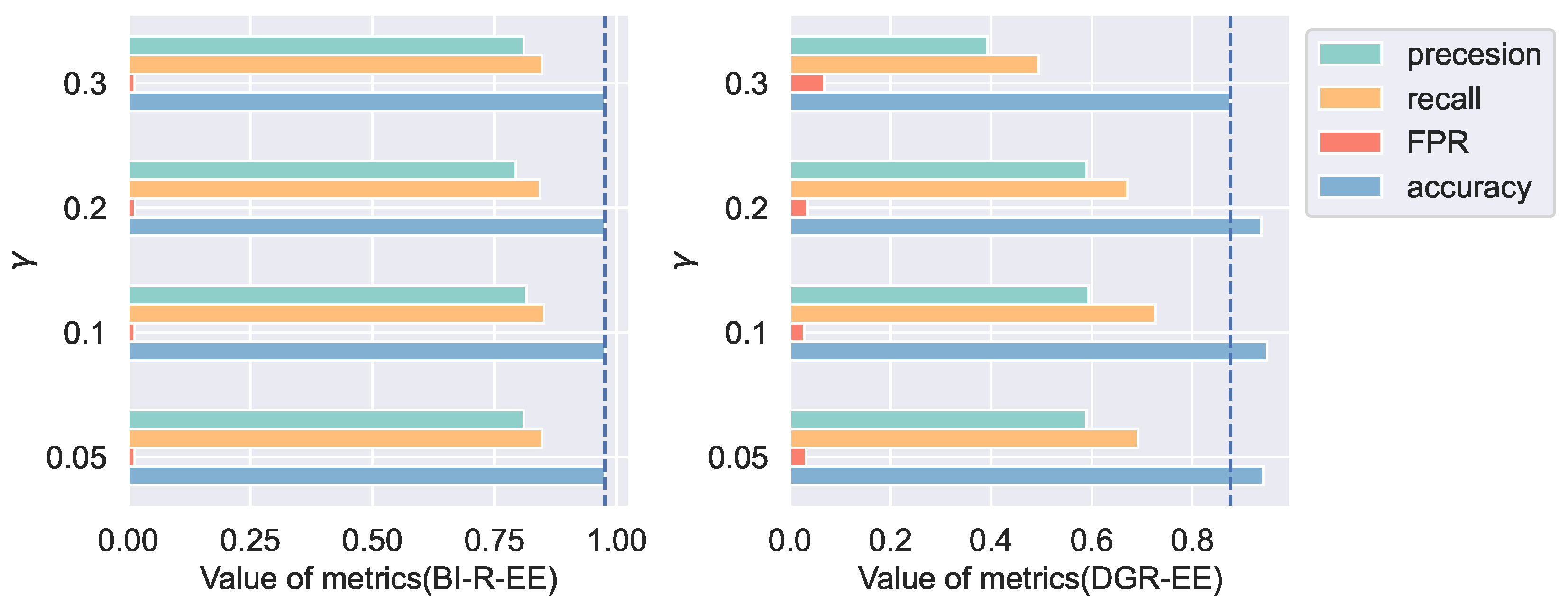
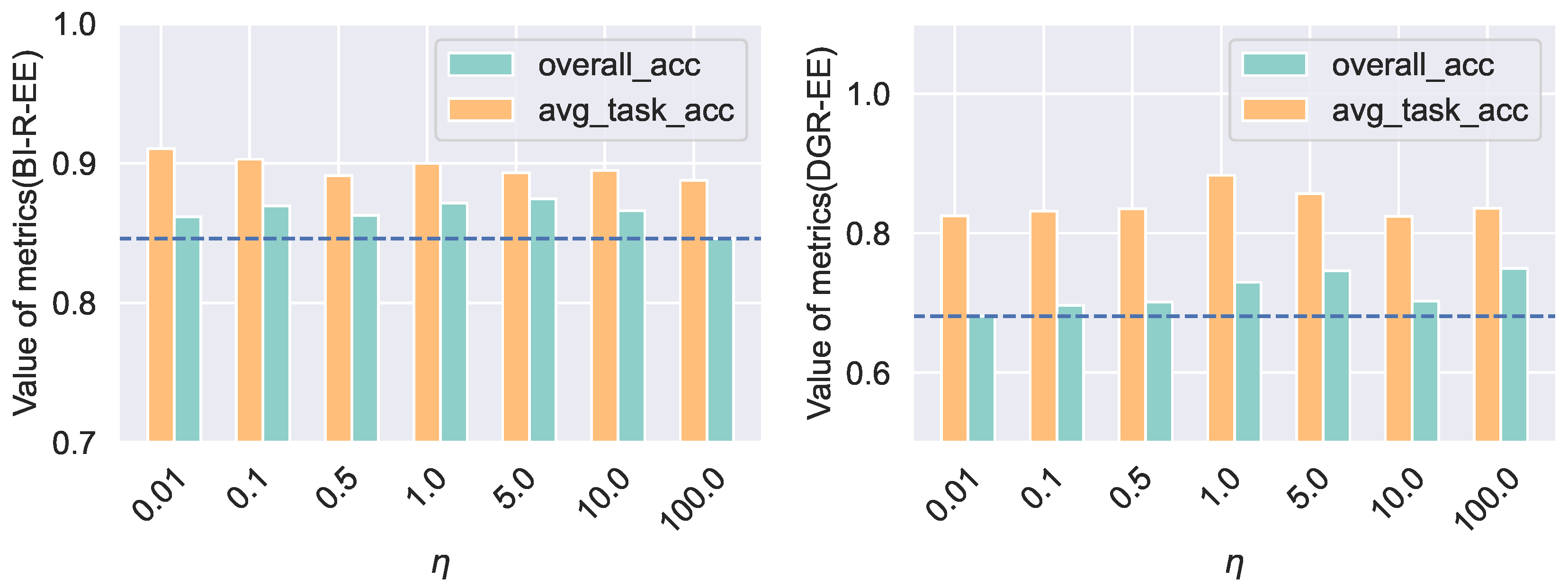
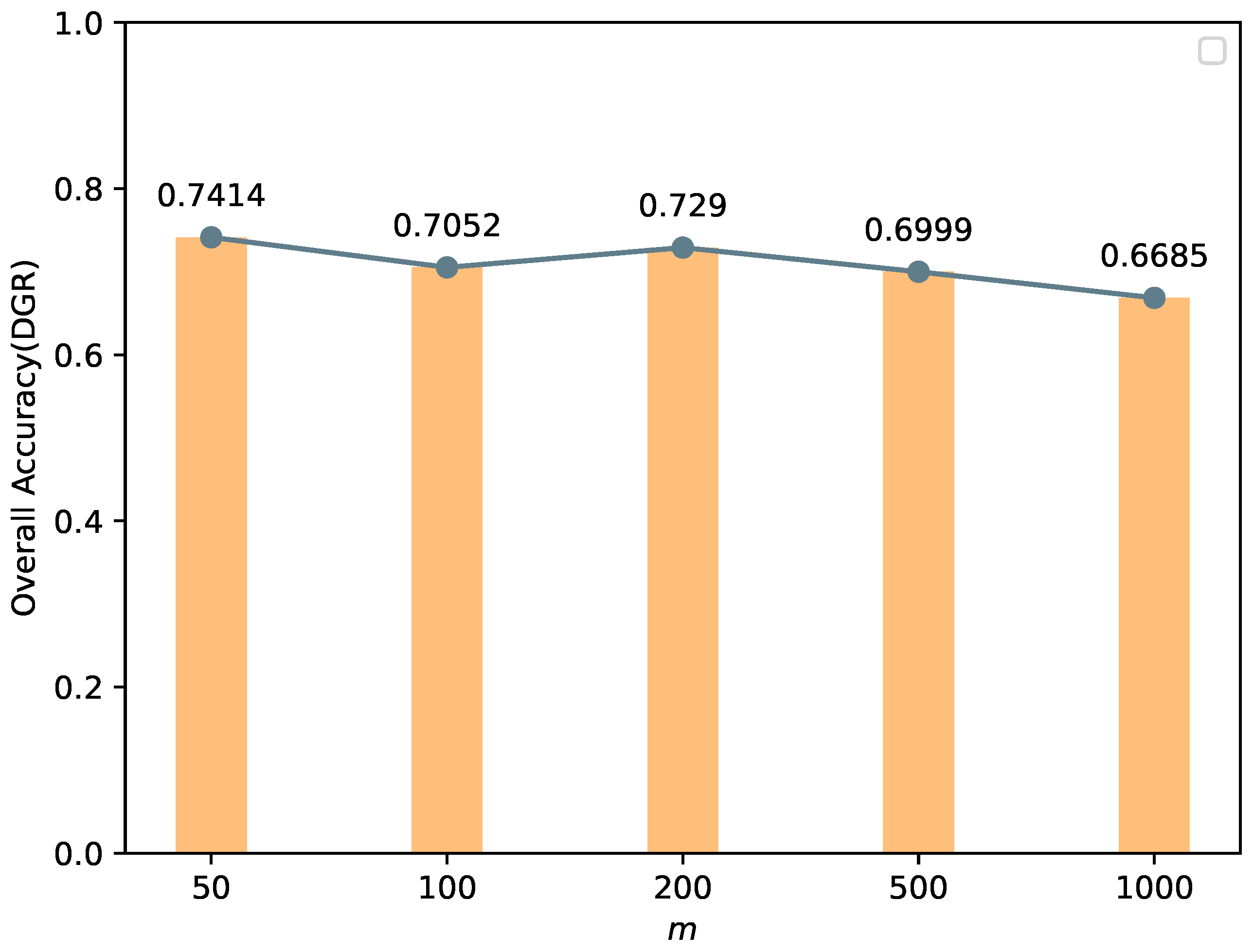
4.6. Sensitivity Analysis
4.7. Time and Space Complexity
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Reed, M.G.; Syverson, P.F.; Goldschlag, D.M. Anonymous connections and onion routing. IEEE J. Sel. Areas Commun. 1998, 16, 482–494. [Google Scholar] [CrossRef]
- Zantout, B.; Haraty, R.A. I2P data communication syste. In Proceedings of the ICN 2011: The Tenth International Conference on Networks, St. Maarten, The Netherlands, 23–28 January 2011; pp. 401–409. [Google Scholar]
- Clarke, I.; Sandberg, O.; Wiley, B.; Hong, T.W. Freenet: A distributed anonymous information storage and retrieval system. In Designing Privacy Enhancing Technologies: International Workshop on Design Issues in Anonymity and Unobservability Berkeley; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Wang, L.; Mei, H.; Sheng, V.S. Multilevel identification and classification analysis of Tor on mobile and PC platforms. IEEE Trans. Ind. Inform. 2021, 17, 1079–1088. [Google Scholar] [CrossRef]
- Gurunarayanan, A.; Agrawal, A.; Bhatia, A.; Vishwakarma, D.K. Improving the performance of Machine Learning Algorithms for TOR detection. In Proceedings of the 2021 International Conference on Information Networking (ICOIN), Jeju Island, Republic of Korea, 13–16 January 2021; pp. 439–444. [Google Scholar]
- Rao, Z.; Niu, W.; Zhang, X.; Li, H. Tor anonymous traffic identification based on gravitational clustering. Peer-Peer Netw. Appl. 2018, 11, 592–601. [Google Scholar] [CrossRef]
- Yao, Z.; Ge, J.; Wu, Y.; Zhang, X.; Li, Q.; Zhang, L.; Zou, Z. Meek-based tor traffic identification with hidden markov model. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Exeter, UK, 28–30 June 2018; pp. 335–340. [Google Scholar]
- Soleimani, M.H.; Mansoorizadeh, M.; Nassiri, M. Real-time identification of three Tor pluggable transports using machine learning techniques. J. Supercomput. 2018, 74, 4910–4927. [Google Scholar] [CrossRef]
- He, Y.; Hu, L.; Gao, R. Detection of tor traffic hiding under obfs4 protocol based on two-level filtering. In Proceedings of the 2019 2nd International Conference on Data Intelligence and Security (ICDIS), South Padre Island, TX, USA, 28–30 June 2019; pp. 195–200. [Google Scholar]
- Hu, Y.; Zou, F.; Li, L.; Yi, P. Traffic classification of user behaviors in tor, i2p, zeronet, freenet. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020–1 January 2021; pp. 418–424. [Google Scholar]
- Salman, O.; Elhajj, I.H.; Kayssi, A.; Chehab, A. Denoising adversarial autoencoder for obfuscated traffic detection and recovery. In Machine Learning for Networking, Proceedings of the Second IFIP TC 6 International Conference, Paris, France, 3–5 December 2019; Springer: Cham, Switzerland, 2020; pp. 99–116. [Google Scholar]
- Xu, W.; Zou, F. Obfuscated Tor Traffic Identification Based on Sliding Window. Secur. Commun. Netw. 2021, 2021, 5587837. [Google Scholar] [CrossRef]
- Lin, K.; Xu, X.; Gao, H. TSCRNN: A novel classification scheme of encrypted traffic based on flow spatiotemporal features for efficient management of IIoT. Comput. Netw. 2021, 190, 107974. [Google Scholar] [CrossRef]
- Chen, J.; Cheng, G.; Mei, H. F-ACCUMUL: A Protocol Fingerprint and Accumulative Payload Length Sample-Based Tor-Snowflake Traffic-Identifying Framework. Appl. Sci. 2023, 13, 622. [Google Scholar] [CrossRef]
- Li, Z.; Wang, M.; Wang, X.; Shi, J.; Zou, K.; Su, M. Identification Domain Fronting Traffic for Revealing Obfuscated C2 Communications. In Proceedings of the 2021 IEEE Sixth International Conference on Data Science in Cyberspace (DSC), Shenzhen, China, 9–11 October 2021; pp. 91–98. [Google Scholar]
- Lashkari, A.H.; Gil, G.D.; Mamun, M.S.; Ghorbani, A.A. Characterization of tor traffic using time based features. In Proceedings of the 3rd International Conference on Information Systems Security and Privacy, Porto, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar]
- Shapira, T.; Shavitt, Y. Flowpic: Encrypted internet traffic classification is as easy as image recognition. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019; pp. 680–687. [Google Scholar]
- Shapira, T.; Shavitt, Y. FlowPic: A generic representation for encrypted traffic classification and applications identification. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1218–1232. [Google Scholar] [CrossRef]
- van de Ven, G.M.; Tuytelaars, T.; Tolias, A.S. Three types of incremental learning. Nat. Mach. Intell. 2022, 4, 1185–1197. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef] [PubMed]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010. [Google Scholar]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Van de Ven, G.M.; Siegelmann, H.T.; Tolias, A.S. Brain-inspired replay for continual learning with artificial neural networks. Nat. Commun. 2020, 11, 4069. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Emanuele, P.; Giuseppe, L.; Claudio, C.; Leonardo, Q. Peel the onion: Recognition of android apps behind the tor network. In Proceedings of the 15th Information Security Practice and Experience, ISPEC 2019, Kuala Lumpur, Malaysia, 26–28 November 2019; pp. 95–112. [Google Scholar]
- Bendale, A.; Boult, T.E. Towards open set deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1563–1572. [Google Scholar]
- Dahanayaka, T.; Ginige, Y.; Huang, Y.; Jourjon, G. Robust open-set classification for encrypted traffic fingerprinting. Comput. Netw. 2016, 236, 109991. [Google Scholar] [CrossRef]
- Yang, F.; Wen, B.; Comaniciu, C.; Subbalakshmi, K.P.; Chandramouli, R. TONet: A Fast and Efficient Method for Traffic Obfuscation Using Adversarial Machine Learning. IEEE Commun. Lett. 2022, 26, 2537–2541. [Google Scholar] [CrossRef]
- Liu, L.; Yu, H.; Yu, S.; Yu, X. Network Traffic Obfuscation against Traffic Classification. Secur. Commun. Netw. 2022. [Google Scholar] [CrossRef]
- Liu, H.; Dani, J.; Yu, H.; Sun, W.; Wang, B. Advtraffic: Obfuscating encrypted traffic with adversarial examples. In Proceedings of the 2022 IEEE/ACM 30th International Symposium on Quality of Service (IWQoS), Oslo, Norway, 10–12 June 2022; pp. 1–10. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Features | Model | Dataset | PTs | Evaluation | Level |
|---|---|---|---|---|---|---|
| 2018 [7] | TR&NTR | Mixture of Gaussian, Hidden Markov Model | self-captured | Meek | acc (99.98%) F1 (99.72%) | L2 |
| 2018 [8] | NTR | SVM, Adaboost, C4.5, Random Forest | self-captured | Obfs3 ScramleSuit Obfs4 | auc (0.99%+) | L2 |
| 2019 [9] | NTR | Two-level filter | self-captured | Obfs4 | pre (98.83%) FPR (00.03%) | L2 |
| 2020 [10] | TR | GBDT, XGboost, LightGBM, et al. | self-captured | – | acc (L1-96.9%, L3-91.6%) | L1, L3 |
| 2020 [11] | TR&NTR | Denoising Adversarial Autoencoder | self-captured | – | recall 83.7% | L2 |
| 2020 [4] | TR&NTR | Naïve Bayes, Bayes networks | self-captured | – | acc (mobile 96%+, PC 98%+) | L1, L3, L4 |
| 2021 [12] | TR&NTR | XGBoost, GBDT, Random Forest, CART | self-captured | Meek Obfs4 FTE | acc (99%+) | L2 |
| 2021 [13] | TR&NTR | TSCRNN | ISCXTor2016 | – | acc (Tor 99.4%, nonTor 95.0%) | L1 |
| 2022 [14] | TR&NTR | XGBoost, SVM, Random Forest, KNN | self-captured | Snowflake | acc (99%+), F1 (98%+) | L2 |
| Features | Description |
|---|---|
| duration | Slide window duration |
| min_iat, max_iat, mean_iat, low_quartile_iat, median_iat, upp_quartile_iat | Statistic Interval time features |
| fb_psec, fp_psec | Flow speed |
| min_pl, max_pl, mean_pl, low_quartile_pl, median_pl, mode_pl | Statistic packet length |
| numPktsSnt, numPktsRcvd, numBytesSnt, numBytesRcvd, maxPktSizeSnt, avePktSizeSnt, minPktSizeSnt | Statistic packet length with direction |
| Conversations | Number of requests and responses |
| PL_entropy | Information entropy of packet length |
| Task ID | Content | Data Size and Type |
|---|---|---|
| T0 | Background traffic flow and non-obfuscated Tor traffic | 9.87 GB background 11.3 GB Tor Non-obfs |
| T1 | Tor obfuscated traffic flow | 12.9 GB FTE 8.43 GB Meek 13.5 GB Obfs4 |
| T2 | Mobile Tor traffic | 1.32 GB orbot_pd 1.30 GB orbot_rpd 0.9 GB Mobile Snowflake |
| T3 | Proxied Tor obfuscated traffic and Snowflake | 0.9 GB proxied-Meek 2.55 GB proxied obfs4 3.86 GB PC Snowflake |
| Class1 | Other Classes | |
|---|---|---|
| Class1 | TP | FN |
| Other classes | FP | TN |
| Layer | Setting |
|---|---|
| Linear | Input_dim = 31, output_dim = 64, active = LeakyReLU |
| Linear | Input_dim = 64, output_dim = 128, active = LeakyReLU |
| Linear | Input_dim = 128, output_dim = 128, active = LeakyReLU |
| Linear | Input_dim = 128, output_dim = 11 |
| Hyperparamter | Describe | Value |
|---|---|---|
| Epochs | Train epochs | 100 |
| lr | Learning rate | 0.001 |
| Batchsize | Batch size | 256 |
| Adam optimizer parameter | 0.9, 0.999 | |
| m | Edge exemplars size per class | 100 |
| The proportion of edge exemplars in the batch | 0.1 | |
| Edge feature enhengcement weight | 2.0 | |
| The weight of each loss function | 1.0, 1.0, 1.0 |
| Task0 | Task1 | Task2 | Task3 | Total | |
|---|---|---|---|---|---|
| Joint | 0.9992 | 0.9354 | 0.8651 | 0.9986 | 0.9437 |
| LwF | - | - | - | 0.998 | 0.1066 |
| iCaRl | 0.9899 | 0.6428 | 0.9311 | 0.9984 | 0.3279 |
| DGR | 0.9826 | 0.8511 | 0.4805 | 0.9988 | 0.5049 |
| DGR-EE | 0.9486 | 0.7261 | 0.7236 | 0.9984 | 0.7187 |
| BI-R | 0.9951 | 0.8651 | 0.8418 | 0.9988 | 0.8476 |
| BI-R-EE | 0.9952 | 0.8245 | 0.7773 | 0.9988 | 0.8767 |
| Model | Train Time (s) | Storage |
|---|---|---|
| LwF | 580 | |
| iCaRL | 2005 | |
| DGR | 2090 | |
| DGR-EE | 2327 | |
| BI-R | 7253 | |
| BI-R-EE | 7579 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, S.; Wang, Z.; Sun, Y.; Wang, C.; Wang, B. Edge Exemplars Enhanced Incremental Learning Model for Tor-Obfuscated Traffic Identification. Electronics 2025, 14, 1589. https://doi.org/10.3390/electronics14081589
Lv S, Wang Z, Sun Y, Wang C, Wang B. Edge Exemplars Enhanced Incremental Learning Model for Tor-Obfuscated Traffic Identification. Electronics. 2025; 14(8):1589. https://doi.org/10.3390/electronics14081589
Chicago/Turabian StyleLv, Sicai, Zibo Wang, Yunxiao Sun, Chao Wang, and Bailing Wang. 2025. "Edge Exemplars Enhanced Incremental Learning Model for Tor-Obfuscated Traffic Identification" Electronics 14, no. 8: 1589. https://doi.org/10.3390/electronics14081589
APA StyleLv, S., Wang, Z., Sun, Y., Wang, C., & Wang, B. (2025). Edge Exemplars Enhanced Incremental Learning Model for Tor-Obfuscated Traffic Identification. Electronics, 14(8), 1589. https://doi.org/10.3390/electronics14081589