1. Introduction
High-resolution remote sensing images are extensively utilized in ecological monitoring, crop assessment, urban planning, military reconnaissance, and disaster response due to their wide coverage, rich information, and enduring records [
1]. However, the undersampling effect of imaging sensors and various degradation factors in the imaging process significantly limit the acquisition of high-resolution remote sensing images. Enhancing resolution through improved hardware performance involves significant costs and risks. Therefore, achieving high-resolution images without hardware modifications is crucial for remote sensor design, improving human visual perception, and advancing subsequent applications.
Single-image super-resolution (SISR) is a fundamental challenging task in computer vision, focusing on reconstructing low-resolution images into high-resolution ones by recovering high-frequency details lost due to imaging system limitations [
2]. The evolution of SISR techniques has gradually transitioned from the initial simple interpolation methods such as neighborhood interpolation, bi-quadratic interpolation, and bi-tertiary interpolation, to the degradation process of considering SISR as a difficult problem to solve and inversely solving it by mathematical modeling of image sampling [
3]. This technology has demonstrated wide application potential in various fields such as remote sensing and medical imaging [
4], and can effectively improve the processing quality and effectiveness of subsequent related tasks [
5]. Numerous variants of Convolutional Neural Networks (CNNs) and Visual Transformers (ViTs) have been developed to model the nonlinear relationship between low-resolution (LR) and high-resolution (HR) image pairs. Early CNN-based models, including SRCNN [
6], SCN [
7], and FSRCNN [
8], prioritized simplicity but struggled to preserve high-frequency details. The development of deep residual networks (e.g., VDSR [
9], LapSRN [
10], EDSR [
11]), and recurrent neural networks (e.g., DRCN [
12], DRRN [
13]) enabled multi-scale super-resolution reconstruction. Additionally, advanced architectures such as densely connected networks (e.g., SRDenseNet [
14], RDN [
15]), generative adversarial networks (e.g., SRGAN [
16], RFB-ESRGAN [
17]), and attention-based networks (e.g., SAN [
18]) have significantly improved super-resolution performance at high magnifications. These innovations enhance reconstruction quality and introduce novel neural network structures, including SRFormer [
19], CROSS-MPI [
20], SRWARP [
21], IMDN [
22], ECBSR [
23], and FMEN [
24]. Recently, Transformer architectures have gained prominence in SISR due to their self-attention mechanisms, which capture global information and leverage image self-similarity. Models like TTSR [
25], ESRT [
26], SwinIR [
27], and TransENet [
28] improve global dependency handling by employing techniques such as feature dimension fusion, cross-token attention, and sliding windows. Despite the progress of CNN- and Transformer-based methods in SISR, their high parameter counts and computational complexity pose significant challenges, particularly for resource-constrained devices. Thus, further research is needed to optimize the balance among performance, parameter count, and computational complexity.
Remote sensing images exhibit diverse feature types and are affected by multiple degradation factors, including sampling errors, shape distortions, sharpness loss, and noise interference during imaging. Additionally, ground artifacts caused by lighting changes, such as cloud cover, terrain variations, and haze, further increase their semantic complexity compared to natural images, complicating remote sensing image super-resolution (RSISR). Researchers have introduced methods such as the characteristic resonance loss function [
29], a two-stage design strategy incorporating spatial and spectral knowledge [
30], and a hybrid higher-order attention mechanism [
31] to address these challenges. However, these approaches still struggle with the complexities inherent in natural image super-resolution networks. Thus, there is an urgent need for lightweight RSISR techniques capable of efficiently processing massive remote-sensing images.
Recently, many lightweight super-resolution models have been developed, employing techniques such as cascading mechanisms [
32], special convolutional layers [
33], context-switching layers [
34], channel-separation strategies [
35], multi-feature distillation [
22], neighborhood filtering [
36], hierarchical feature fusion [
37,
38,
39], novel self-attention mechanisms [
40,
41,
42], large kernel distillation [
43,
44], and N-Gram contextual information [
45]. CNN-based methods reduce model parameters by decreasing convolutional layers or residual blocks [
46] and using dilated or group convolutions instead of traditional operations, often employing recursive structures or parameter-sharing strategies [
12,
13,
38]. Transformer-based methods reduce computational complexity using small windows and sliding mechanisms. However, most of these models are limited to capturing local or regional interdependencies and struggle to explicitly capture long-range global dependencies across the entire image. This limitation is primarily due to the high computational cost of capturing global dependencies. Therefore, existing lightweight RSISR methods require further optimization and breakthroughs to enhance performance.
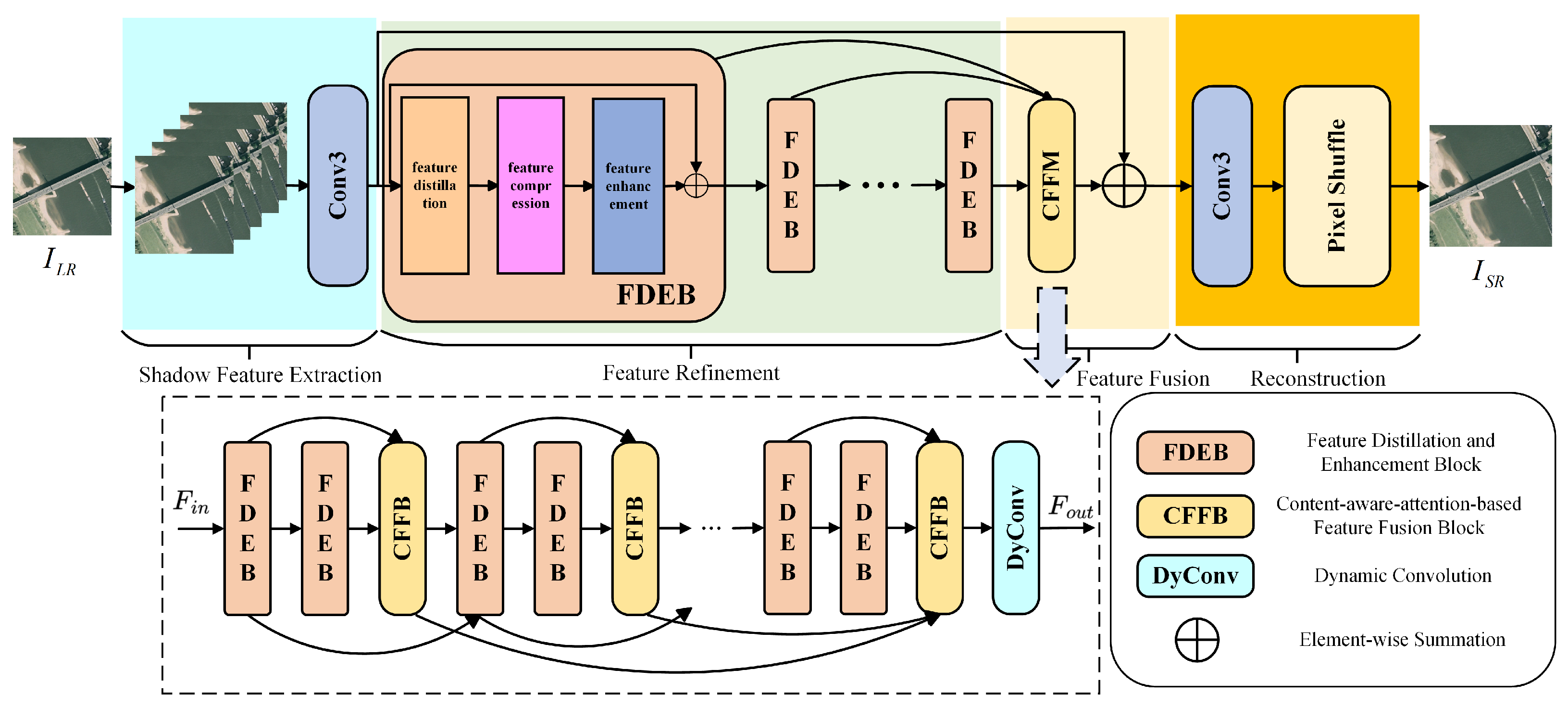
This paper introduces a super-resolution reconstruction method for remote sensing images, employing a dynamic large kernel attention-based feature distillation and fusion network (DyLKANet) to overcome the limitations of existing RSISR methods. The DyLKANet employs a multi-level feature integration strategy to facilitate information exchange between the context-aware attention mechanism and the large kernel attention mechanism. The DyLKANet framework comprises two key modules: the feature distillation and enhancement block (FDEB) for efficient feature extraction, and the context-aware attention-based feature fusion module (CFFM) for capturing global interdependencies. The primary contributions of this study are outlined as follows:
- (1)
DyLKANet introduces a novel lightweight network architecture that employs a multi-level feature integration strategy. This strategy facilitates information exchange between the context-aware attention mechanism and the large kernel attention mechanism, enhancing the overall performance of the network;
- (2)
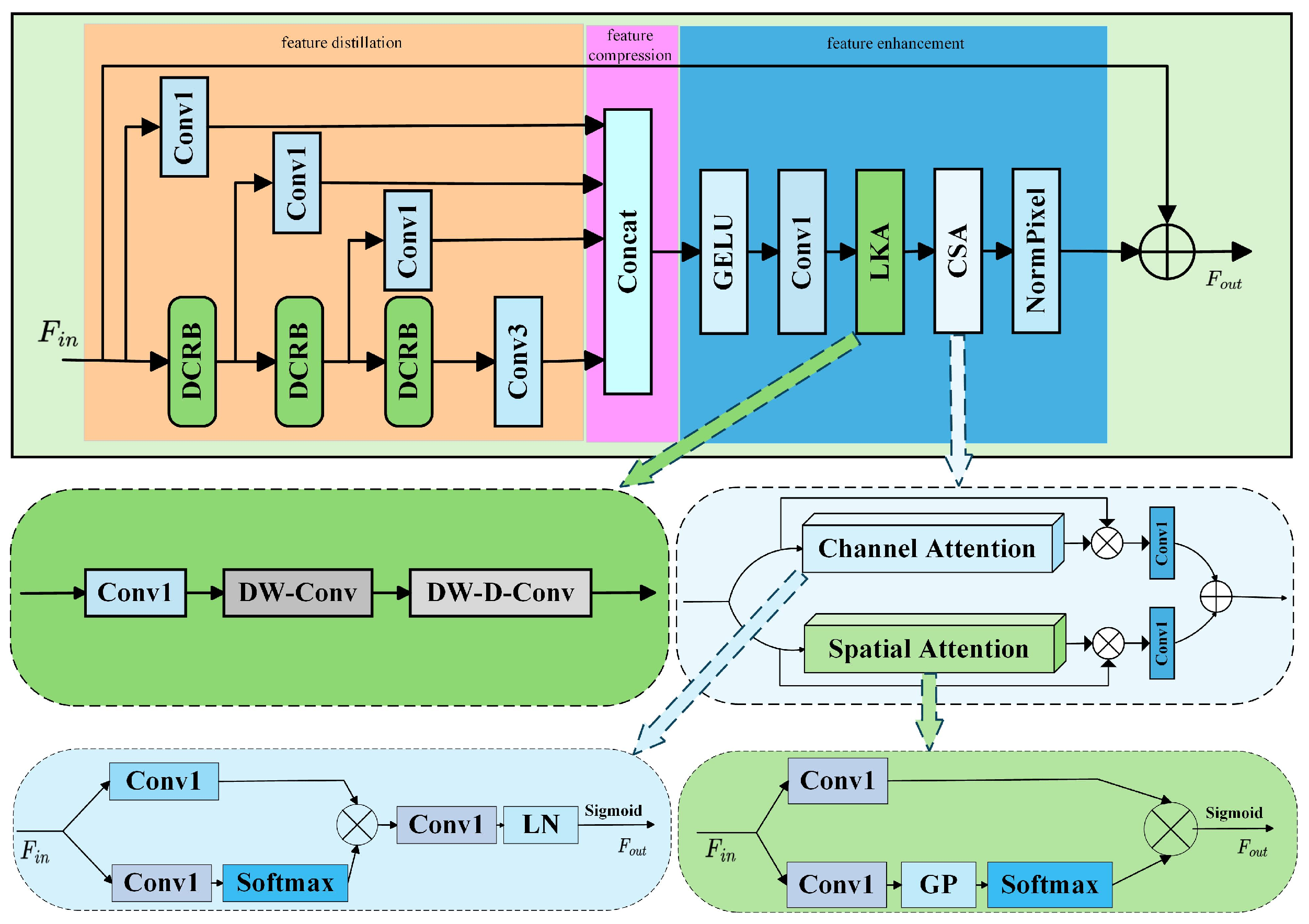
We designed a dynamic convolutional residual block, which utilizes dynamic convolution to adaptively generate convolution kernels for each input sample. This approach not only reduces computational overhead but also preserves the depth of feature extraction;
- (3)
The proposed feature distillation and enhancement block incorporates feature distillation, compression, and enhancement stages. This block is capable of efficiently extracting key features while significantly reducing the number of parameters, contributing to the lightweight nature of DyLKANet.
The rest of the paper is organized as follows.
Section 2 is the description of the methodology proposed in this paper.
Section 3 analyzes the experiments and results.
Section 4 analyzes and discusses the validity of each component of the proposed method and
Section 5 gives a conclusion.
3. Experiments and Results
This section outlines the implementation details, including datasets, evaluation metrics, experimental configurations, and training strategies. Comparative experiments are conducted on the UCMerced [
47] and AID [
48] datasets to analyze quantitative results and visualize them in comparison with state-of-the-art methods. Finally, the efficiency of the baseline model is evaluated against the proposed model using the UCMerced dataset.
3.1. Datasets
Two publicly available remote sensing datasets, UCMerced and AID, are used to validate the proposed model’s effectiveness. The UCMerced dataset contains 2100 images across 21 remote sensing scenes, with each category comprising 100 images of 256 × 256 pixels. The AID dataset consists of 10,000 images from 30 remote sensing scenes, including airports, farmland, beaches, and deserts, with each image of 600 × 600 pixels. Each dataset is divided into training, testing, and validation sets with an 8:1:1 ratio. During experiments, the original HR images from each dataset were used, while LR images were generated using bicubic interpolation to create HR-LR image pairs.
3.2. Metrics
The results were evaluated using the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM).
where
where
and
are the width and height of the image, respectively; the larger the PSNR value, the better the reconstruction effect.
indicates the similarity between the HR image and the reconstructed SR image in terms of brightness, contrast, and structure. Larger SSIM values indicate higher image quality.
3.3. Experimental Settings
To ensure a fair comparison, a unified degradation model was used to generate the experimental dataset, and consistent data enhancement techniques were applied during model training. Six SISR methods—SRCNN, FSRCNN, IMDN, ECBSR FMEN, and OMNISR—and six RSISR methods—CTNet, FENet, HSENET, AMFFN, TransENet, TTST—were selected for this study. The proposed model was developed in this experimental environment using the PyTorch 1.12.0 framework on the Ubuntu 22.04 operating system. An NVIDIA RTX3090, manufactured by ASUS in Taipei, Taiwan, was used to accelerate model training. The GPU was manufactured by ASUS in Santa Clara, California, USA. During model training, the Adam optimizer was employed with momentum parameters = 0.9 and = 0.99. The batch size was set to 16. The initial learning rate was 0.0005, and a linear decay strategy was applied to adjust it progressively during the training cycle. Additionally, the performance of all models was evaluated at scales of ×2, ×3, and ×4. To emphasize details more strongly, we set the , , and to 1, 1 × 10−1, and 1 × 10−2, respectively. The reconstruction loss is the only loss involved in the first three stages of the training process, while the content loss and total variation loss are added in the subsequent stages, up to the final stage.
3.4. Results of Experiments on UCMerced Dataset
Table 1 summarizes the performance of SR models, including SRCNN, FSRCNN, IMDN, ECBSR, OMNISR, FMEN, CTNet, FENet, HSENET, AMFFN, TransENet, TTST and DyLKANet (denoted as “Ours”). The evaluation metrics include the number of parameters (Params [K]), computational complexity (FLops [G]), memory consumption (Memory [MB]), inference time (Time [ms]) PSNR, and SSIM at scales of ×2, ×3, and ×4. Compared to natural image super-resolution models at the scale of ×2, such as IMDN, ECBSR, OMNISR, and FMEN, DyLKANet significantly reduces parameters and computational complexity while enhancing PSNR by 0.44–0.59 dB and SSIM by 0.006–0.010. Compared to remote sensing super-resolution models at the scale of ×2, such as CTNet, FENet, HSENET, and AMFFN, DyLKANet demonstrates superior performance, increasing PSNR by 0.40–0.57 dB, SSIM by 0.005–0.009, and reducing parameters by 18.79–95.42%. At the scale of ×3, DyLKANet improves PSNR by 0.28–3.41 dB and SSIM by 0.008–0.012 compared to IMDN, ECBSR, OMNISR, and FMEN. Compared to remote sensing models such as CTNet, FENet, HSENET, and AMFFN, DyLKANet improves PSNR by 0.21–0.57 dB, SSIM by 0.004–0.012, and reduces parameters by 18.68–95.46%. At the scale of ×4 magnification, DyLKANet enhances PSNR by 0.15–0.65 dB, SSIM by 0.006–0.021, and reduces parameters by 24.63–83.24%. It also reduces computational complexity by 1.81–6.81 times compared to IMDN and ECBSR. Compared to remote sensing models such as CTNet and FENet, DyLKANet achieves PSNR improvements of 0.12–0.60 dB, SSIM improvements of 0.004–0.022, and parameter reductions of 18.15–95.26%. At each super-resolution scale, the FLops operations of DyLKANet are only 12.79–17.36% of those required by ECBSR.
Table 2 presents the performance results of each model across various categories and magnification scales of the UCMerced dataset. At ×2 magnification, the DyLKANet model achieves the highest PSNR values in the chaparral, denseresidential, freeway, parkinglot, and tenniscourt categories, with improvements of 0.031 dB, 0.109 dB, 0.281 dB, 0.143 dB, and 0.018 dB in comparison to TTST. For SSIM values, DyLKANet closely matches the performance of the less optimal model, indicating its strong ability to preserve image structure. At ×3 magnification, the DyLKANet model outperforms the less optimal model in PSNR across all categories, with improvements of 0.093 dB in chaparral, 0.065 dB in freeway, 0.062 dB in parkinglot, 0.045 dB in tenniscourt, and 0.064 dB in denseresidential. Notably, at the scale of ×3, the DyLKANet model is comparable to the AMFFN model in the denseresidential category, being 0.177 dB higher, demonstrating its robust super-resolution reconstruction and generalization capabilities.
Figure 5 compares the reconstruction results of each model on the UCMerced dataset at scale ×4. The visual comparison clearly shows that DyLKANet excels at accurately capturing crucial high-frequency details in remote sensing images. Compared to other models, the image reconstructed by DyLKANet is closer to the real HR, with sharper edge contours and more detailed and accurate texture information. Notably, in the ×4 reconstruction of the parkinglot, only DyLKANet clearly reproduces the front and rear window details of the car.
Figure 6 presents the residual visualization results of different models in the RSISR task. In the figure, yellow and blue regions, indicated by color bars, represent the mean square error (MSE) distribution between the super-resolution and ground truth images. Yellow indicates high MSE values (large error), while blue indicates low MSE values (small error). A comparison of the DyLKANet and AMFFN in
Figure 6 reveals that DyLKANet has a larger blue area in the residual map, indicating superior performance in recovering details with lower MSE values. This comparison highlights the advantages of DyLKANet in the RSISR task, demonstrating that the proposed network structure more effectively captures and recovers high-frequency details.
3.5. Results of Experiments on AID Dataset
Table 3 presents the PSNR and SSIM results for scales ×2, ×3, and ×4 on the AID dataset. DyLKANet demonstrates PSNR gains over suboptimal models across all scale combinations. Specifically, at the scale of ×2, compared to IMDN, ECBSR, OMNISR, and FMEN models, DyLKANet reduces parameters and computational complexity while improving PSNR by 0.16–0.50 dB and SSIM by 0.002–0.024. Compared to remote sensing super-resolution models, such as CTNet, FENet, HSENET, and AMFFN, DyLKANet improves PSNR by 0.19–0.36 dB and SSIM by 0.003–0.004. At the scale of ×3, DyLKANet increases PSNR by 0.168–0.662 dB and SSIM by 0.004–0.074. Compared to advanced remote sensing models like CTNet, it improves PSNR by 0.16–1.50 dB and SSIM by 0.004–0.025. At the scale of ×4 magnification, DyLKANet improves PSNR by 0.10–2.83 dB and SSIM by 0.003–0.089. Compared to CTNet and similar models, it achieves PSNR gains of 0.1–0.658 dB and SSIM gains of 0.003–0.013. While DyLKANet’s SSIM slightly decreases at the scale of ×4, its overall SSIM performance remains stable and comparable to or better than state-of-the-art models. These results indicate that DyLKANet performs well across various scale combinations, balancing parameter count and computational complexity while achieving comparable or superior performance to state-of-the-art models in PSNR and SSIM metrics.
Table 4 presents five typical categories from the AID dataset—bareland, desert, farmland, playground, and bridge—to compare the performance of different SR models. As shown in
Table 4, DyLKANet achieves the best average performance across all evaluation metrics, demonstrating its superior SR performance in remote sensing benchmarks for all categories. At scale ×2, DyLKANet achieves great PSNR values across most of the categories, with gains ranging from 0.033 dB to 0.23 dB. Similarly, the SSIM values range from an increase of 0.001 to 0.004. At scale ×3, DyLKANet achieves great average performance across all categories, with gains ranging from 0.099 dB to 0.243 dB. The SSIM values of DyLKANet range from an increase of 0.001 to 0.005. At scale ×4, DyLKANet achieves the highest PSNR values across all categories, highlighting its superior ability to recover image details. In the desert category, it achieves the highest increase in SSIM value of 0.004 compared to TTST.
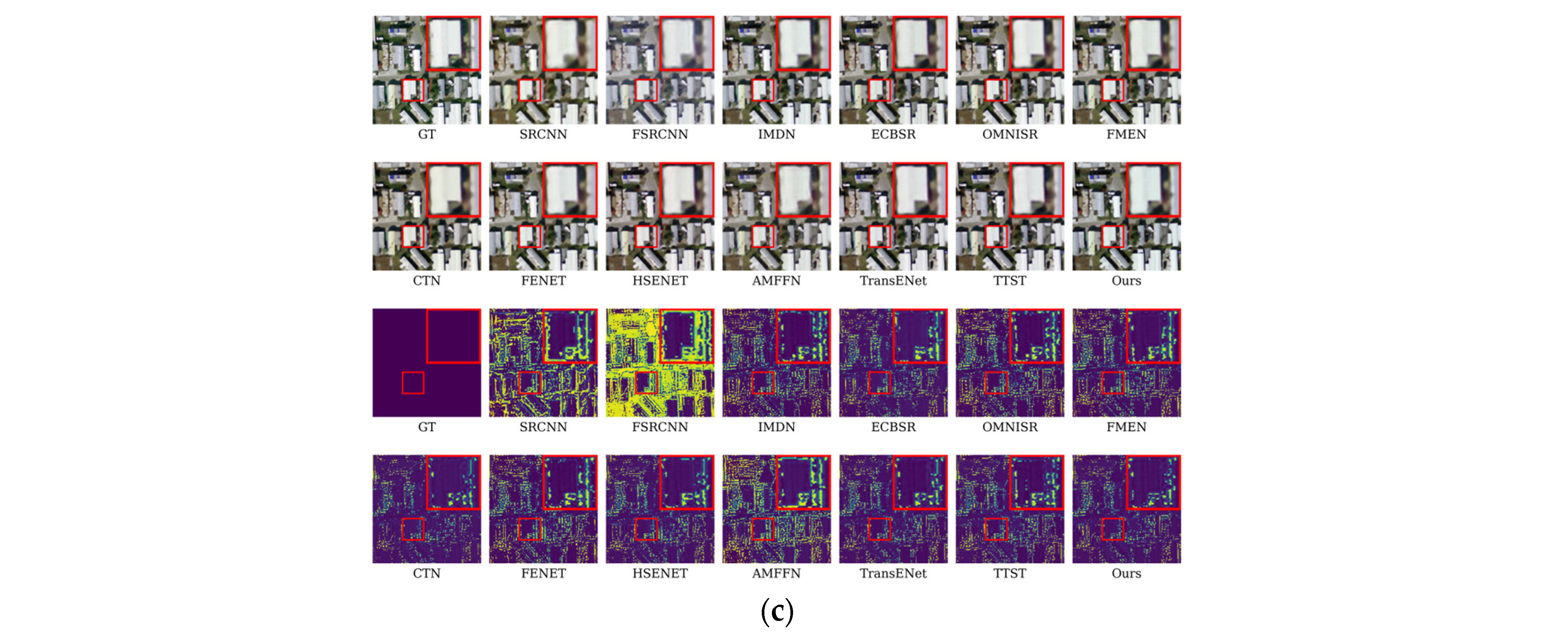
Figure 7 presents visual comparison results for a ×4 magnification factor. The figure illustrates qualitative results from test set samples of remote sensing images to compare different models in the SR task. The figure demonstrates that DyLKANet excels in recovering image edge textures. For instance, in the ×4 reconstruction of the playground, DyLKANet accurately recovers the regular lines, rendering them clear, coherent, and consistent with the real scene. In contrast, other SR models struggle with reconstruction, producing relatively blurred image details. This comparison highlights DyLKANet’s advantage in reconstructing fine details of remote sensing images. The comparison indicates that DyLKANet-reconstructed images exhibit rich edge textures and accurately capture key high-frequency details.
Figure 8 compares residual visualizations generated by various models for the remote sensing image super-resolution task on the AID dataset. The figure shows that compared to the AMFFN model, DyLKANet exhibits a larger blue area in the residual visualization, indicating superior detail reproduction in remote sensing images and a lower MSE value. In contrast, the residual visualization of AMFFN contains more yellow regions and higher MSE values. This suggests that DyLKANet more effectively captures high-frequency details in remote-sensing images.
3.6. Results of Experiments on DIV2K Dataset
To further validate the effectiveness and generalization ability of DyLKANet, experiments were conducted on the widely used DIV2K dataset at a scale of ×4. As illustrated in
Table 5, Compared to HSENET, DyLKANet achieves a 95.26% reduction in parameter count. It also reduces the computational complexity by 66.27% compared to TTST. Although the inference time of DyLKANet has increased slightly compared to the RSISR model HSENET, it remains lower than that of the other five RSISR models. Specifically, DyLKANet achieves a higher PSNR (29.148 dB) and SSIM (0.819). This demonstrates the efficiency and effectiveness of DyLKANet in achieving high-quality super-resolution with a much lighter model architecture.
Figure 9 presents a visual comparison of ×4 super-resolution results on the DIV2K. The image shows a comparison of various image restoration models, highlighting the performance of the proposed model in restoring image details and clarity. Subjectively, the proposed model recovers more precise details of the columns and walls compared to other models, and objectively, it outperforms in metrics such as dB and SSIM values. This indicates the superior performance of the proposed model in image restoration tasks.
5. Limitations and Future Work
DyLKANet, while reducing parameters to meet the demands of lightweight applications, is able to achieve super-resolution results comparable to state-of-the-art models. Although DyLKANet has significantly reduced the number of parameters and computational complexity, there is still room for further optimization. In the future, we will leverage techniques such as pre-training and LoRA to reduce model size, while also decreasing GPU memory usage and maintaining inference efficiency during deployment. Currently, DyLKANet has been tested on visible light remote sensing images, but further optimization and improvements are needed to enhance the network’s ability to handle extremely low-resolution images and remote sensing images of other modalities. Additionally, the degradation model is one of the key issues that need to be addressed in remote sensing super-resolution. In this paper, a fixed degradation model similar to those used in most studies is still adopted, which may not fully capture the diverse degradation patterns encountered in real-world remote sensing images. Future research needs to explore more sophisticated training methods, such as self-supervised or unsupervised learning, to improve the model’s robustness and generalization ability across different degradation scenarios. Lastly, the evaluation of DyLKANet has primarily been conducted on publicly available datasets, which may not fully represent the complexity and diversity of real-world remote sensing data. Future work should include more comprehensive testing on a wider range of datasets, including those with varying levels of noise, blur, and other degradation factors, to better assess the model’s performance in practical applications.
6. Conclusions
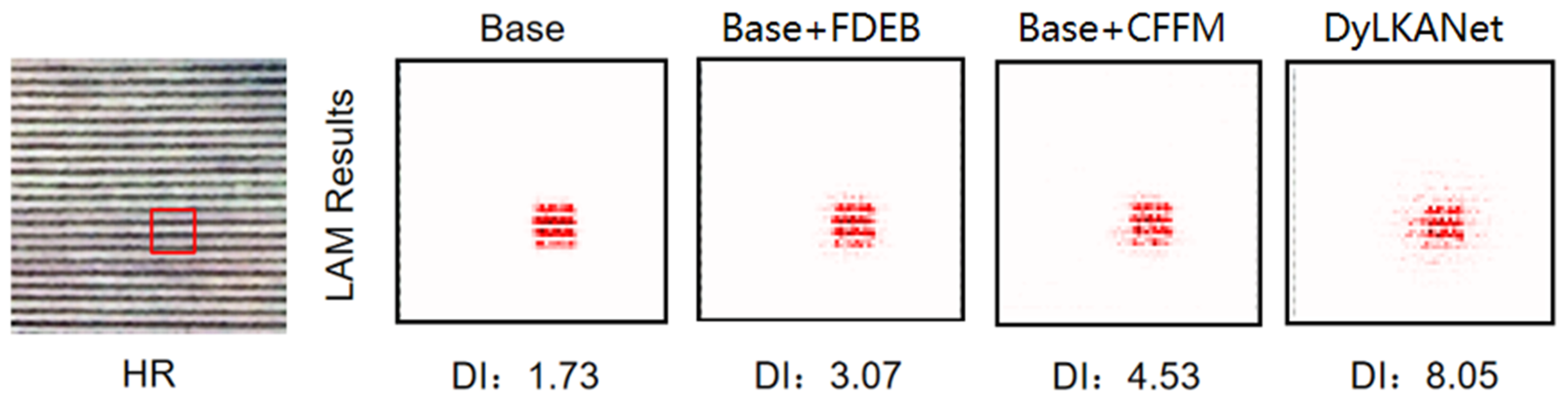
This paper proposes a dynamic distillation network, DyLKANet, to address the challenge of remote sensing image super-resolution. The network leverages a large-kernel attention mechanism to achieve efficient feature extraction and capture global dependencies through a multi-level feature fusion strategy. Experimental results show that DyLKANet performs comparably to state-of-the-art methods on the publicly available UCMerced, AID, and DIV2K datasets, while maintaining low parameter count and computational complexity. Specifically, on the UCMerced dataset, DyLKANet improves the PSNR by 0.212 dB and 0.151 dB over the suboptimal TTST at the scale of ×2 and ×4 scaling factors, respectively. At the scale of ×2, DyLKANet improves PSNR by 0.439–0.589 dB, SSIM by 0.006–0.010, and reduces parameters by 25.54–82.57% compared to natural image super-resolution models. Compared to remote sensing super-resolution models, DyLKANet improves PSNR by 0.212–0.576 dB, SSIM by 0.005–0.009, and reduces parameters by 18.79–95.46%. DyLKANet reduces FLops operations by 7.25–67.30%. Furthermore, ablation experiments validate the effectiveness of key modules, including FDEB, CFFM, and dynamic convolution. Results show that these modules significantly enhance model performance while reducing parameter count and computational complexity. In conclusion, DyLKANet, a lightweight super-resolution network for remote sensing images, demonstrates significant potential in resource-constrained environments.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}