Abstract
In the rapidly evolving field of computer vision and machine learning, 3D skeleton estimation is critical for applications such as motion analysis and human–computer interaction. While stereo cameras are commonly used to acquire 3D skeletal data, monocular RGB systems attract attention due to benefits including cost-effectiveness and simple deployment. However, persistent challenges remain in accurately inferring depth from 2D images and reconstructing 3D structures using monocular approaches. The current 2D to 3D skeleton estimation methods overly rely on deep training of datasets, while neglecting the importance of human intrinsic structure and the principles of camera imaging. To address this, this paper introduces an innovative 2D to 3D gait skeleton estimation method that leverages the Brown camera distortion model and constrained optimization. Utilizing the Azure Kinect depth camera for capturing gait video, the Azure Kinect Body Tracking SDK was employed to effectively extract 2D and 3D joint positions. The camera’s distortion properties were analyzed, using the Brown camera distortion model which is suitable for this scenario, and iterative methods to compensate the distortion of 2D skeleton joints. By integrating the geometric constraints of the human skeleton, an optimization algorithm was analyzed to achieve precise 3D joint estimations. Finally, the framework was validated through comparisons between the estimated 3D joint coordinates and corresponding measurements captured by depth sensors. Experimental evaluations confirmed that this training-free approach achieved superior precision and stability compared to conventional methods.
1. Introduction
Advances in computer vision and machine learning technologies have positioned human pose analysis as an indispensable tool across various domains, including sports biomechanics [1,2], human–computer interaction [3], and surveillance systems [4], among diverse applications. The use of 2D pose estimation algorithms based on a monocular camera and 3D pose estimation algorithms based on a depth camera or binocular camera has made great progress and they are widely used in action recognition, motion analysis, and other fields. The reconstruction of 3D human pose in 2D video sequences is also of concern as a related issue.
Estimating 3D joint positions from monocular RGB inputs (images/video sequences containing human subjects) remains an active focus in computer vision research. By contrast with 2D counterparts, 3D human pose estimation (HPE) delivers enhanced spatial representations and enables more comprehensive use cases across application domains. The method to obtain 3D coordinates of joints is a key supporting technology in many fields, such as human body reconstruction, behavior recognition, virtual reality, game modeling, and has been applied to many products. Estimating 3D poses from 2D video sequences using a monocular camera [5,6] not only enhances the comprehension of the inner principles of human motion but also plays a significant role in evaluating movement ability and assisting rehabilitation training.
Using a single camera to collect data has the advantages of low cost and easy deployment, but it has inherent problems: a single image may correspond to countless scenes in the physical world, so it is difficult to estimate the depth from the image and achieve 3D reconstruction by using a monocular vision method [7]. Traditional pose estimation methods [8] from 2D to 3D mainly rely on deep learning models, which often require a lot of labeled data for training and are sensitive to image noise, such as camera distortion. Moreover, utilizing advanced motion capture systems frequently presents significant hurdles or proves to be impractical for acquiring 3D labels in actual environments.
As a result, unsupervised methods that operate without the need for labeled datasets have attracted significant interest. In the real world, images are inevitably distorted due to camera imaging principles, which creates challenges for pose estimation from 2D to 3D. Therefore, it is essential not only to devise novel algorithms for creating 3D pose estimation models from 2D data but also to enhance their adaptability to image distortion. At the same time, combined with the practical application scenarios, it is necessary to expand the application field of pose estimation, and provide technical support for research in related fields.
The method is inspired by the principle that if a line intersects a sphere, then the line has two points of intersection with the sphere. The human torso is parallel to the imaging plane, and the Z-axis coordinates of the torso can be calculated according to the imaging principle, so all 3D coordinates of the torso part can be obtained. Assuming that the 3D coordinates of a joint i are known and the bone lengths of joint i and joint j are also known, then according to the 2D pixel coordinates of joint j, the projection coordinates of joint j on the plane formed by the torso part can be obtained according to the distortion model and imaging principle, and the actual coordinates of this point are located on the line connected between the projection point of the torso plane and the optical center. Because the bone length is known, the 3D coordinate point of joint j is also located on the sphere with joint i as the center and the length as the radius.
This point is located in both the sphere and the line, so the 3D coordinate is one of the intersection points of the sphere and the line, from which the coordinates of the joint j can be obtained, and the coordinates of other joints connected to the joint j can be derived. It is well known that the sphere intersecting a straight line has two points of intersection, and a series of connections can obtain several 3D possible poses; however, the actual 3D pose is only one of many possibilities.
This principle provides inspiration for 3D estimation from a 2D pose with an optimized model in this paper, which shows that it is feasible to obtain a 3D pose by using bone lengths as constraints when the human torso is parallel to the imaging plane. The process involves the transformation from pixel coordinates to actual coordinates, so the undistorted coordinates should first be acquired. Due to the particularity of the human body structure and the characteristics of gait, this paper also provides some symmetry restrictions, which are helpful to eliminate some wrong poses when estimating a 3D pose with optimization. These constraint conditions are similar to choosing the one that is more consistent with the human body structure and gait law among the two intersection points of a straight line and a sphere.
From the concept of algorithm construction used in this paper, it can be seen that the algorithm in this paper can be easily extended to other scenarios.
A 2D to 3D gait skeleton estimation method based on a camera distortion model and constraint optimization is proposed. In summary, the key contributions of this paper include the following:
- This paper uses Azure Kinect Body Tracking SDK to extract 2D and 3D key points of the human body. First, the Azure Kinect depth sensor captures continuous depth images and color images. These image data are processed by the SDK, which can output the 2D and 3D skeleton of the human body at the same time.
- The camera distortion model is used to eliminate the distortion of 2D skeleton joints: By analyzing the camera imaging principle, the distortion model applicable to Azure Kinect camera is established, and the camera distortion is reduced by an iterative method, thus reducing the impact of distortion on subsequent 3D gait skeleton estimation.
- A constraint optimization algorithm to estimate the 3D skeleton is developed. In the process of 3D skeleton gait estimation, a series of constraints are set to ensure that the estimation results conform to biomechanical principles and actual human gait laws. The objective of the optimization model is to minimize the distance between the estimated 3D skeleton joint projection and the undistorted 2D skeleton joint, and to keep the relationship between the symmetric limb and the torso of the body. The constraints of the optimization model include consistent bone length, bilateral symmetry, linear structure of the specific joint, etc. By solving the optimization problem, the estimated 3D skeleton of a single frame can be obtained.
The structure of the proposed method is shown in Figure 1. Through these steps, the stable 3D skeleton sequence can be obtained, and the 3D skeleton joints estimated in this paper can be compared with those directly obtained by the depth camera to verify the effectiveness of the proposed method. This study provides an efficient and robust solution for the field of skeleton estimation, and promotes the progress and application of related technologies. The algorithm proposed in this paper provides the possibility of calculating human gait parameters from video and evaluating human gait balance. The commonly used 2D estimation algorithm based on monocular RGB cameras obtains pixel coordinates, which are based on the pixel coordinate system. As is well known, the pixel coordinate system of the human skeleton is large when it is close to the camera and small when it is far away from the camera, so the method proposed in this paper provides the possibility of normalization of the skeleton sequence. The normalized skeleton makes it easy to calculate various parameters of human motion, such as speed, acceleration and angle.

Figure 1.
The structure of the proposed method.
2. Related Work
2.1. 3D Human Pose Estimation
With recent advancements in computer vision and machine learning technologies [9], the task of 3D human pose estimation has gained significant attention within motion capture and virtual reality applications. Research paradigms in 3D human pose estimation are typically divided, based on supervision levels, into three principal categories: fully supervised, weakly supervised, and self-supervised approaches.
Fully supervised 3D frameworks [10,11,12,13] utilize precise ground-truth data acquired through labor-intensive annotation processes. In response to these demands, multiple strategies [14,15] have emerged, particularly neural network-based techniques [10,16,17]. These architectures automatically extract discriminative features and establish reconstruction models through large-scale training, demonstrating strong generalizability. Notable implementations incorporating convolutional neural networks [17] and LSTM architectures [16] exhibit enhanced precision in skeletal joint prediction. While achieving state-of-the-art performance, such approaches have two fundamental constraints: substantial dependence on meticulously annotated 3D datasets and intensive computational requirements. Furthermore, their adaptability to complex scenarios involving dynamic motions remains suboptimal compared to traditional methods.
To mitigate the expense of acquiring 3D motion data, weakly supervised frameworks [18,19] have been developed, necessitating minimal or unaligned 3D labels. Self-supervised strategies [20,21,22], differing fundamentally from preceding techniques, eliminate reliance on 3D annotations entirely. These autonomous learning paradigms primarily comprise multi-camera systems and use of a monocular camera.
Multi-camera systems [20,21] implement self-supervisory mechanisms as alternatives to 3D labeling. View-invariant consistency serves as the foundational principle for numerous techniques [21,22], effectively resolving depth uncertainties during model training. This paradigm operates under the core premise that reconstructed 3D poses must maintain invariance across varying viewpoints. Consequently, multi-view 3D reconstruction prioritizes precise camera rotation estimation to achieve view-consistent results.
Unlike multi-view systems, monocular-based 3D reconstruction under self-supervision presents greater complexity. Pioneering works [23,24] have addressed this challenge through cyclic consistency mechanisms, circumventing 3D annotation requirements in monocular settings. The framework [23] develops a 2D-to-3D lifting architecture that deduces skeletal structures from 2D keypoints. Stochastic projections of reconstructed 3D skeletons are evaluated by a 2D pose validator, creating a self-correcting loop through geometric verification. This cyclic process involves reprojecting synthesized 3D poses into multiple 2D planes, enabling autonomous supervision via spatial coherence constraints. Complementing this, [24] introduces stochastic projection modules that map 3D predictions back to 2D space. Their adversarial framework trains discriminators to distinguish between synthesized poses and authentic 2D pose distributions, enhancing reconstruction fidelity through competitive learning.
Numerous studies have explored diverse constraint-based approaches for skeletal estimation and refinement [7,25,26]. Kinematic restrictions are frequently incorporated as supplementary loss functions to guide neural networks in generating anatomically plausible 3D pose predictions. Two predominant constraint formulations involve limb dimension preservation [27] and bilateral symmetry regularization [28]. In particular, the study [25] demonstrates the effectiveness of integrating biological skeletal length preservation principles, bilateral symmetry priors, and temporal continuity constraints to improve anatomical plausibility and motion fluidity in dynamic human pose estimation. Alternative methodologies employ spatial reasoning frameworks [7], where gait analysis systems are developed through parametric geometric representations synchronized with visual data analysis. While these constraint-driven implementations typically achieve computationally lightweight implementations, their predictive accuracy remains contingent upon the fidelity of geometric parameterization.
The constrained optimization model framework proposed in this paper takes into account the characteristics of gait and is highly targeted. In addition to the bone length and symmetry constraints commonly used in previous unsupervised methods, linear constraints on the parts of bones are also added. The construction of objective functions involves the characteristics of gait limb swing, which provides a theoretical basis for research in mathematical modeling.
2.2. Imaging Principle of Pinhole Camera Model
This study considers unsupervised 3D pose estimation for a monocular camera, which uses a constraint optimization model to estimate the 3D pose for a monocular camera in a specific scene. It involves the lens imaging principle. Nowadays, imaging devices, including professional camera systems, mobile imaging units, and surveillance apparatus, predominantly adhere to the optical imaging mechanisms defined by the Pinhole Camera Model [29]. This geometric formulation facilitates the mathematical mapping of three-dimensional spatial coordinates onto two-dimensional pixel matrices through perspective projection and rigid transformation processes. The complete imaging architecture comprises four principal coordinate domains: a World Coordinate System, a Camera Coordinate System, an Image Plane Coordinate System, and a Pixel Coordinate System. Essential to this paradigm is the sequential coordinate transformation pipeline that systematically converts physical world measurements into digital image representations through precisely defined geometrical operations.
Due to lens curvature error, the stacking sequence of the lens group and system error, lens distortion occurs during the imaging process [30]. In particular, the distortion is more obvious in the use of wide-angle lenses and fisheye lenses of non-measuring cameras. Optical distortion affects the geometry and size of the image, thus causing problems in image measurement and analysis. Therefore, in practical use, it is necessary to eliminate the distortion error of the lens, which is of great significance for photogrammetry.
The mathematical characterization of optical aberrations traces its origins to Conrady’s 1919 pioneering work on decenter distortion modeling [31]. Building upon this foundation, Brown’s seminal 1960s framework integrated both radial and decenter distortion components [32]. Radial aberrations originate from lens curvature imperfections, whereas decenter distortions stem from misaligned optical axis configurations. Subsequent investigations [33,34,35,36] proposed incremental refinements to these distortion parameterizations through modified coefficient formulations. Nevertheless, practical implementation of these enhanced models remains constrained by two critical limitations: excessive computational complexity resulting in ill-posed estimation challenges, and insufficient generalizability across diverse imaging hardware configurations.
Researchers have extensively investigated camera distortion models [33,37,38], and proposed a variety of distortion correction methods [39], such as radial distortion, tangential distortion, and use of the thin lens model. These methods are designed to mitigate the adverse effects of camera distortions on image processing. Although the camera distortion model has been continuously developed and refined, their application in 3D skeleton gait estimation remains limited. In this paper, a 2D to 3D gait skeleton estimation method based on the Brown camera distortion model is proposed.
The imaging process of the pinhole camera model involves mapping from three-dimensional space coordinates to the image plane. The 3D coordinate reconstruction process is the process of restoring the geometric structure and topological relationship of three-dimensional objects from a series of two-dimensional images or point cloud data captured under known angles or viewpoints.
To sum up, many researchers have achieved fruitful research results in deep learning in the field of 2D to 3D skeleton estimation. However, there is little research on 2D to 3D gait skeleton estimation based on a camera distortion model and constrained optimization, and there are still some challenges in this field, such as how to fully utilize a camera distortion model to compensate the distortion of skeleton joints and to estimate 3D gait with full consideration of human gait characteristics.
In order to solve this problem, the Brown camera distortion model is fully used in this paper. Then, a constraint optimization algorithm is proposed for 3D gait skeleton reconstruction, which can fully consider the human skeleton structure and gait characteristics, improving the accuracy of the estimation results.
3. Methods
3.1. Skeleton from Azure Kinect
The framework is based on the skeleton captured from the Azure Kinect Body Tracking SDK using the Azure Kinect camera. The joint position is estimated relative to the global depth sensor frame of reference. The position is specified in millimeters. All joint coordinate systems are absolute coordinate systems in the depth camera 3D coordinate system. A skeleton includes 32 joints with the joint hierarchy flowing from the center of the body to the extremities. As demonstrated in Figure 2, this structural mapping accurately replicates the joint locations and connections relative to the human body.
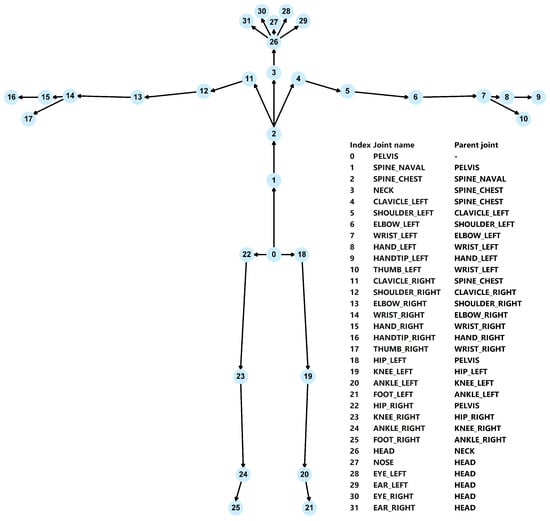
Figure 2.
Joint hierarchy.
The participant was instructed to walk in a straight path, with the depth camera positioned at their front for this study. The user’s 2D and 3D skeleton gaits were obtained by Azure Kinect Body Tracking SDK.
3.2. Camera Transformation Pipeline
The parameters for the Brown distortion model [38] in Azure Kinect can be determined through a camera calibration process or obtained from the recorded file. Several studies [34,38] have indicated that estimating just the initial few parameters of the distortion model is sufficient to achieve high precision in modeling distortion.
A series of transformations for coordinate changes is established through multiple stages [38]. There is a shift from the global (world) coordinate system to the camera coordinate system:
Transition from reference (world) coordinates to camera coordinates:
where R denotes the rotation matrix while t represents the displacement vector defining the geometric mapping between the global reference and camera spatial coordinates. Both the coordinate systems are orthogonal Cartesian coordinate systems.
The mathematical representation of perspective projection involves the coordinate transformation process from the camera’s three-dimensional coordinate system to its two-dimensional projection plane, where the normalized image plane is defined at . This fundamental conversion establishes the relationship between spatial positions observed through the imaging device and their corresponding planar projections within the camera’s optical framework.
Distortion, expressed as the transition from undistorted to distorted coordinates:
where and are the distortion parameters, while are the decentering parameters.
Transition from distorted coordinates to pixel coordinates:
where denote the principal point coordinates in the image plane, corresponding to the intersection position between the optical axis and the imaging projection surface, with their 2D positions referenced to the pixel coordinate framework. The parameter represents the normalized focal length (calculated as the ratio of the lens focal length to the physical width) of individual photosensitive units. Similarly, indicates the vertical normalized focal length (calculated as the ratio of the lens focal length to the physical height) in the vertical dimension.
The Azure Kinect Body Tracking SDK was utilized to obtain both 2D and 3D joints of the human body. The 2D key joints are represented as pixel coordinates that have been distorted, necessitating the correction of these joint positions to achieve undistorted data.
3.3. Obtaining the Undistorted Joints
The process to obtain the undistorted joints [40,41] is actually the process of reprojection, that is, the process going from pixel coordinates to physical coordinates and to pixel coordinates. Compensation for image distortion can be performed in two ways, which are called forward correction and reverse correction. Forward correction involves calculating the standard coordinates from the distortion coordinates, and reverse correction involves calculating the distortion coordinates from the standard coordinates. Either forward correction or reverse correction must first transition to physical coordinates, and then convert to pixel coordinates. The 2D skeleton joint coordinates used in this paper are distorted pixel coordinates, so the joints need to be corrected forward. The UndistortPoints Algorithm 1 used to obtain the undistorted joints in our method refers to the process of UndistortPoints in OpenCV4.7.0. Following OpenCV is an iterative process.
| Algorithm 1 UndistortPoints Algorithm |
| Input: Distorted pixel coordinates: , Camera parameters: Output: Undistort coordinates 1: Iterations initialization: 2: Reprojection error initialization: 3: Calculate distorted coordinates: 4: 5: 6: while do 7: if then 8: break 9: else 10: 11: 12: 13: 14: 15: 16: 17: Calculate the reprojection pixel coordinates according to : 18: 19: 20: 21: 22: , 23: 24: 25: 26: end if 27: end while |
In the iterative calculation, the currently distorted point is taken as the initial value. In step 5, the loop iteration is used to remove the distortion. The iteration error was set to 0.08 and the maximum number of iterations is 5. In steps 17–25, the undistorted point is substituted into the distortion model to obtain the pixel coordinates of reprojection, and the deviation between the pixel coordinates of reprojection and the original pixel coordinates is obtained. The point without distortion is iteratively calculated until the condition of iteration error or maximum number of iterations is met. Through the iteration algorithm, undistorted skeletal joints are obtained.
3.4. Joint Depth Initialization
The model presupposes that the length of bones is known and the length of symmetric bones is consistent. In the subsequent modeling process, if only the length of bones is constrained, the estimated skeleton will show a distorted state due to the absence of a depth benchmark, so a depth value of one of the skeleton joints needs to be assigned. The joint we selected is joint 1, the center of the skeleton. The depth value constraint coupled with the constraint of the bone structure basically determines the position and pose of the skeleton. This section is the depth initialization of joint 1.
As is well known, in the process of walking in front of the camera, the torso part of the body is almost parallel to the imaging plane, and each bone of the torso is also parallel to the imaging plane, so the depth value of the two points connecting the bone is the same. Therefore, the relationship of depth to bone length and the coordinates of these two points can be determined. The process is as follows:
After we obtain the undistorted joints, the coordinates of point i and point j in the imaging plane are , .
If the z coordinates of the 3D skeleton joints are , , respectively, the 3D coordinates can be represented as , .
The bone length is
If the line between points i and j is parallel to the imaging plane, then .
Therefore,
In the process of walking directly towards the camera, the joint combinations (1, 2, 3, 4, 5, 11, 12, 18, 22) in Figure 2 are parallel to the camera and almost in the same plane, so the mean length of these combinations is used as the initial estimate of joint 1.
3.5. 3D Pose Estimated Based on Skeleton Constraints
To obtain the coordinates of the 3D skeleton, the skeleton intrinsic structure and initialization depth of joint 1 are used as constraints. A function is defined that relates the distance squared between the estimated 3D skeleton joint projection and the undistorted 2D skeleton joint and it also relates the relationship between the symmetric limb and the torso of the body, ensuring that the function is minimized.
The generated coordinate positions can reflect the 3D skeleton representation of human gait well. Therefore, accurate reconstruction of the gait skeleton can be obtained.
The physical coordinates of the undistorted joints are , and the estimated 3D coordinates (based on the camera coordinate system) are .
According to Formula (2), .
Therefore, the distance between and is minimized.
For convenience, it was converted into the first term of the objective function. represents the set of points in the gait with symmetric relations, represents the set of all bones, and represents the set of skeleton joins with a linear structure.
The objective function of the model has two terms. The first term minimizes the distance between the estimated 3D skeleton joint projection and the undistorted 2D skeleton joint. The second item ensures a symmetrical position relationship between the limbs and the torso.
There are three constraints. The first constraint guarantees the consistency of the distance between skeleton joints; the second constraint gives the depth information of the skeleton center; and the third constraint ensures the linear characteristics of the spine and hip joints. Through these constraints, a 3D skeleton that is consistent with the human body structure can be obtained.
The bone length obtained by the sensor is inconsistent, but we set the bone length in advance. There will be deviation when the depth information is initialized by the 2D bone length setting. In order to reduce the impact of such error, a second optimization process is used to obtain a more accurate skeleton estimate. The optimization algorithm of this paper is shown in Algorithm 2. In the second optimization process, the depth information of joint 1 with the depth information of other joints of the torso part are compared, and the second constraint is updated to obtain a more accurate 3D skeleton. In the second step, the optimization algorithm dynamically adjusts the constraints according to the estimation results to improve the robustness of the estimation.
| Algorithm 2 2D to 3D human skeleton estimation algorithm |
| Input: Distorted pixel coordinates of skeleton: Bone lengths: Camera parameters: Output: 3D coordinates of skeleton: 1: Get the undistort coordinates from Algorithm 1 (input: ): 2: The Set of child joints of bones in torso: 3: 4: 5: Set the second constraint: 6: Get the 3D coordinates by solving unconstrained optimization model 7: 10,000 8: while do 9: if then 10: break 11: else 12: Update the second constraint 13: Get the 3D coordinates by solving unconstrained optimization model 14: 15: 16: end if 17: end while |
4. Experiments and Results
4.1. Implementation Details
The computational framework presented in this paper was developed using the Python 3.9 programming language combined with Azure Kinect Body Tracking SDK 1.0.1 on the Windows 10 OS. The experiments are performed on real human motions captured by an Azure Kinect camera from Microsoft, a company in Washington, DC, USA. All the experimental tests are run on a PC with an Intel Core i5 CPU i5-12400 at 2.50 GHz and 16.0 GB RAM.
4.2. The Visualization of Estimated 3D Skeleton
The skeleton processed by this approach is shown in Figure 3, where red, green, and blue represent the skeletons of Azure Kinect, and the skeletons of the proposed method in step1 and step2. As shown in the figure, the proposed method is consistent with the generated skeleton of Azure Kinect.
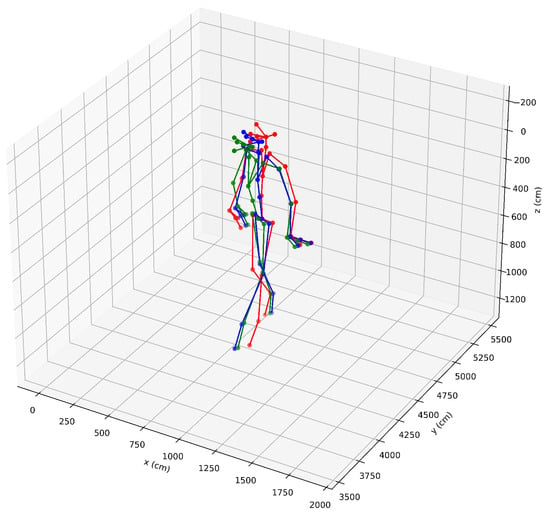
Figure 3.
Comparison of skeletons (red: skeleton from Azure Kinect, green: skeleton of the first step of the proposed method, blue: skeleton of the second step of the proposed method).
The skeletons obtained with or without linear constraints are shown in Figure 4. As shown in the figure, without linear restraint, the bones of the pelvic and spine become distorted and do not conform to the structure of the human body. Therefore, linear constraints are very necessary.
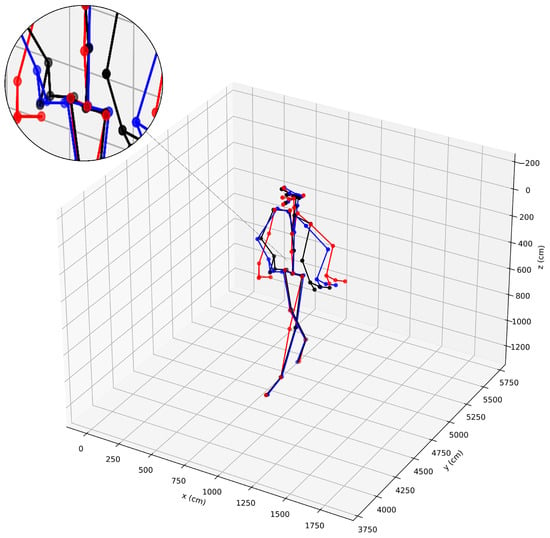
Figure 4.
Comparison of skeletons with and without linear constraints (red: skeleton from Azure Kinect, black: skeleton without linear constraints, blue: skeleton with linear constraints).
4.3. Comparison of the 2D and 3D Skeleton with and Without UndistortPoints Algorithm
The 2D skeleton with and without the UndistortPoints Algorithm is shown in Figure 5, where yellow and blue are the 2D skeleton without and with the UndistortPoints Algorithm.
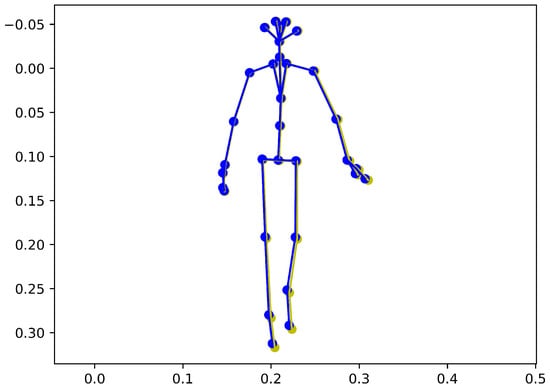
Figure 5.
Comparison of 2D skeletons with and without UndistortPoints Algorithm (yellow: 2D skeleton without UndistortPoints Algorithm, blue: 2D skeleton skeleton with UndistortPoints Algorithm).
The 3D skeleton with and without use of the UndistortPoints Algorithm processed by this approach is shown in Figure 6, where red, blue and yellow represent the 3D skeletons of Azure Kinect, and the estimated 3D skeletons of the proposed method with and without the UndistortPoints Algorithm.
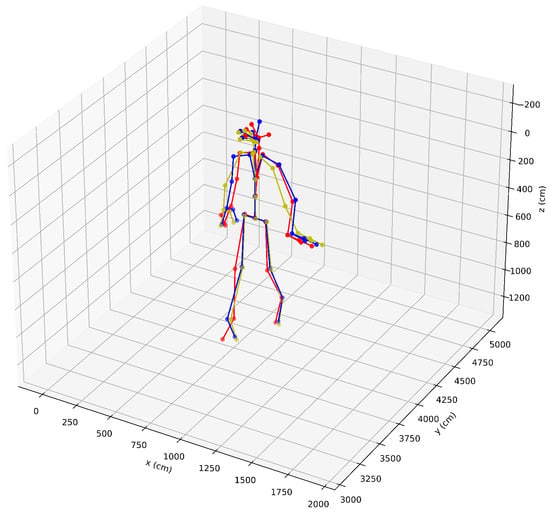
Figure 6.
Comparison of 3D skeletons with and without the UndistortPoints Algorithm (red: 3D skeleton from Azure Kinect, yellow: estimated 3D skeleton without the UndistortPoints Algorithm, blue: estimated 3D skeleton with the UndistortPoints Algorithm).
As shown in Figure 5, the 2D skeletons with and without the UndistortPoints Algorithm are slightly inconsistent, but the 3D skeleton with the UndistortPoints Algorithm is closer to the 3D skeleton of Azure Kinect. This shows that the UndistortPoints Algorithm plays an important role in our estimation algorithm. It is necessary to introduce the Brown camera model into our optimization method.
4.4. The Statistics of Bone Length
This experimental evaluation was designed to quantitatively assess the skeletal dimension accuracy enhancement achieved by the novel algorithm introduced in this research. Figure 7, Figure 8 and Figure 9 demonstrate comparative analyses of bone length fluctuations across distinct anatomical regions during ambulatory motion, where the red, green, and blue curves represent the bone lengths of Azure Kinect, the preliminary phase results from our methodology, and the results of the secondary phase, respectively. Reference values captured during the initialization procedures appear as yellow horizontal baselines.
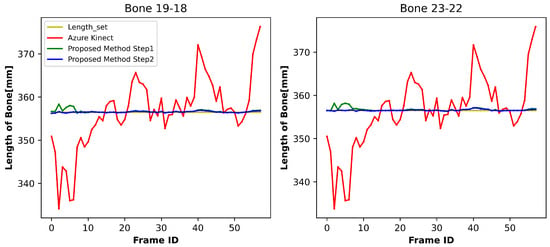
Figure 7.
Variation in bone length at the pelvis.
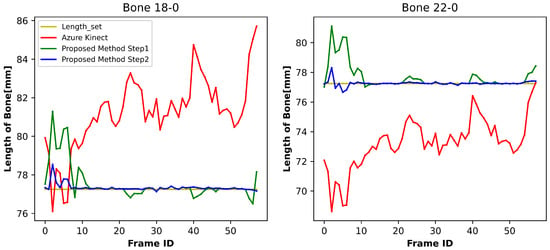
Figure 8.
Variation in bone length at the thigh.
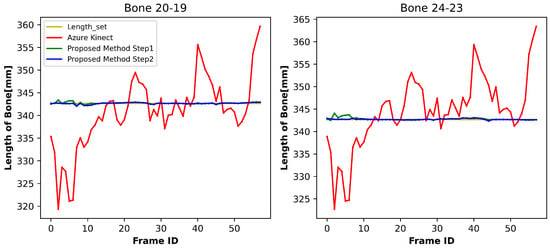
Figure 9.
Variation in bone length at the lower leg.
As can be seen from Figure 7, Figure 8 and Figure 9, the symmetrical bone length changes obtained by Azure Kinect are consistent, but the bone length is not consistent at the time level. Conversely, the developed methodology demonstrates superior performance, achieving both bilateral symmetry and temporal stability in skeletal dimension monitoring across all evaluated motion sequences. Similar results were obtained in experiments with different subjects.
4.5. The Statistics of Joint Position
The coordinates of the three axes of joint 0 are shown in Figure 10. Chromatically differentiated trajectories in the visualization denote distinct data sources: red plots represent Azure Kinect measurements, green plots represent preliminary phase outputs from our methodology, and blue plots indicate refined results from the subsequent processing stage. The graphical data demonstrate spatial congruence between coordinates generated in the optimization phase of our approach and those acquired by Azure Kinect, substantiating the essential role of the refinement procedure. This secondary processing phase effectively mitigates residual errors persisting from the initial estimation phase.
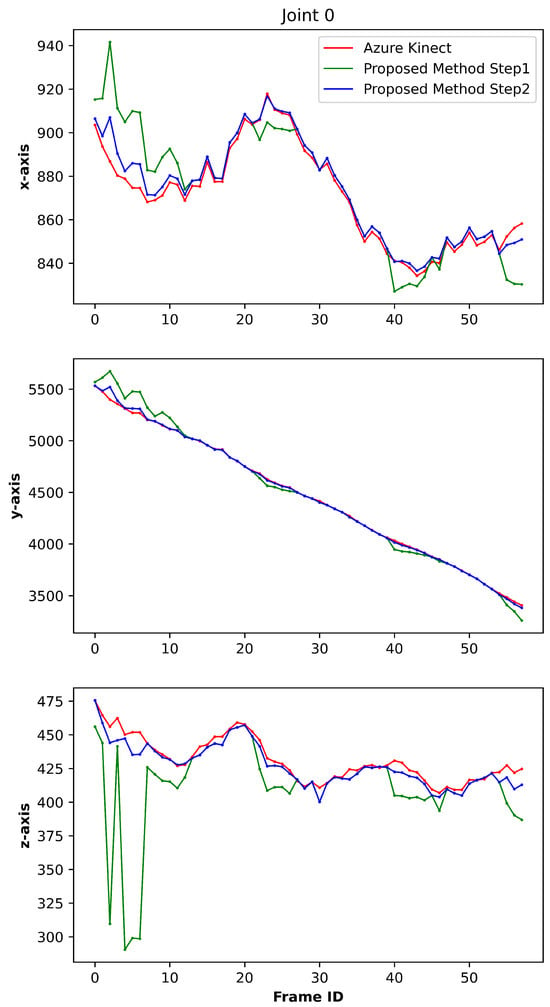
Figure 10.
The coordinates of the three axes of joint 0.
5. Application
From the idea of algorithm construction in this paper, it can be seen that the algorithm in this paper can be easily extended to other scenarios.
The algorithm proposed in this paper provides the possibility of calculating human gait parameters from video and evaluating human gait balance. The commonly used 2D estimation algorithm based on monocular RGB cameras obtains pixel coordinates, which are based on a pixel coordinate system. As is well known, the pixel coordinate system of the human skeleton is large when it is close to the camera and small when it is far away from the camera. The method proposed in this paper provides the possibility of normalization of the skeleton sequence. The normalized skeleton makes it easy to calculate various parameters of human motion, such as speed, acceleration and angle.
In addition, the Azure Kinect camera contains a single RGB sensor and a depth sensor. The RGB image information can be separated from the recorded files. In order to expand the application scenario of this study, this paper uses the human pose estimation algorithm HRnet [42] to estimate the 2D skeleton sequence for the separated RGB video. Because the HRnet skeleton is relatively simple, some unnecessary constraints are removed. Instead of joint 1 in this article, we use the center coordinates of both shoulders from HRnet to initialize the depth.
Analysis of experimental outcomes indicates that the developed method demonstrates robust capabilities in reconstructing 3D skeleton structures. A representative output from a single frame in Figure 11 is illustrated in Figure 12. These findings confirm that the methodology presented in this research possesses broad practical utility across different 2D human pose estimation methods.

Figure 11.
The 2D skeleton from HRnet.
Figure 12.
The 3D skeleton from the proposed method.
6. Discussion
Using a single camera has the advantages of low cost and easy deployment, but there are some problems: a single image may correspond to countless real physical world scenes, so it is difficult to use a monocular vision method to estimate the depth from the image and achieve 3D reconstruction. In this study, a camera distortion model and constraint optimization methods are introduced to reconstruct the 3D skeleton with a single camera.
The application of a camera distortion model can effectively correct the errors caused by camera lens distortion. The distortion model provides a more reliable reference for the subsequent 3D skeleton estimation. The integration of dimensional stability restrictions and bilateral symmetry regulations ensures temporal coherence within the articulated framework. By modeling anatomical joints as dynamic spatial coordinates, their displacement trajectories must obey fundamental principles governing rigid body dynamics in three-dimensional space. Consequently, this dual constraint mechanism maintains invariant interosseous distances throughout motion sequences. Furthermore, depth regularization imposed on the geometric centroid of the human morphological configuration establishes stable positional referents for the skeletal system. In the second step of optimization, this constraint value is updated according to the results obtained in the first step. These constraints not only ensure the stability of the bone structure, but also help eliminate estimation errors caused by data noise and occlusion.
The experimental results show that the 2D to 3D gait skeleton estimation method based on a camera distortion model and constraint optimization achieves remarkable results. Compared to deep learning methods, this method can obtain accurate bone positions while maintaining the stability of the skeleton structure, and does not require prior training.
However, the method proposed in this paper also has some limitations. The gait assessed in this study is based on walking in front of the camera lens, which is mainly based on the consideration that the upper part of the human body is basically parallel to the camera imaging plane, so as to simplify the model solving process. However, this method still has some limitations, which constrain its application in different scenarios. In addition, this research method relies heavily on the preset bone length information, and errors in the preset bone length may significantly affect the estimated results.
In the future, we will further study how to explore more effective constraints and algorithms, enhance the robustness of the model, and further improve the estimation accuracy and real-time performance to meet the needs of more practical application scenarios.
7. Conclusions
In this paper, a method of estimating a human 3D skeleton from 2D is proposed. Optical distortion is a significant problem in many computer vision applications and needs to be compensated. In the 3D gait skeleton estimation technique presented within this paper, the integration of a distortion model markedly enhanced the precision of 2D skeleton joints. This advancement consequently established a robust foundation, which is pivotal for the subsequent 3D skeleton estimation process. Skeleton estimation is based on an optimization framework on frames, which aims to minimize the distance between projection of the estimated 3D skeleton joints and the 2D joints after compensation for optical distortion, as well as the positional relationship between the symmetrical limbs and the body trunk, and takes the human structure characteristics, such as bone length, bilateral symmetry, and linear structures at specific joint points, as constraints. Through comparative experiments, we found that the optimized algorithm proposed in this paper can effectively estimate the positions of 3D skeleton joints while capturing the inherent structure of the human body. The comparison of the 2D and 3D skeleton with and without the UndistortPoints algorithm shows that it is necessary to introduce the Brown camera model into the optimization method. From the application of the algorithm with HRnet, it can be seen that the methodology presented in this research possesses broad practical utility across different 2D human pose estimated methods. Compared with traditional methods, this method does not rely on training on the dataset and provides a new perspective for the estimation of 3D skeleton joints. In summary, the 2D to 3D gait skeleton estimation method based on the camera distortion model and constrained optimization proposed in this paper has significant advantages in terms of accuracy and robustness. In practical applications, this method has broad prospects and is expected to provide support in fields such as gait analysis and human–computer interaction.
Author Contributions
Conceptualization, L.M. and H.H.; methodology, L.M.; software, L.M.; validation, L.M. and H.H.; formal analysis, L.M.; investigation, L.M.; resources, H.H.; data curation, L.M.; writing—original draft preparation, L.M.; visualization, L.M.; project administration, H.H.; funding acquisition, H.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the National Natural Science Foundation of China (61672210), the Major Science and Technology Program of Henan Province (221100210500), and the Central Government Guiding Local Science and Technology Development Fund Program of Henan Province (Z20221343032).
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Ethics Committee of The First Affiliated Hospital of Henan University of Science & Technology (protocol code 2023-469 on 8 June 2023) for studies involving humans.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Arif, A.; Ghadi, Y.Y.; Alarfaj, M.; Jalal, A.; Kamal, S.; Kim, D.S. Human pose estimation and object interaction for sports behaviour. CMC Comput. Mater. Contin. 2022, 72, 1–18. [Google Scholar] [CrossRef]
- Xi, X.; Zhang, C.; Jia, W.; Jiang, R. Enhancing human pose estimation in sports training: Integrating spatiotemporal transformer for improved accuracy and real-time performance. Alex. Eng. J. 2024, 109, 144–156. [Google Scholar] [CrossRef]
- Khean, V.; Kim, C.; Ryu, S.; Khan, A.; Hong, M.K.; Kim, E.Y.; Kim, J.; Nam, Y. Human Interaction Recognition in Surveillance Videos Using Hybrid Deep Learning and Machine Learning Models. CMC Comput. Mater. Contin. 2024, 81, 773. [Google Scholar] [CrossRef]
- Cao, X.; Yan, W.Q. Pose estimation for swimmers in video surveillance. Multimed. Tools. Appl. 2024, 83, 26565–26580. [Google Scholar] [CrossRef]
- Andriluka, M.; Roth, S.; Schiele, B. Monocular 3D pose estimation and tracking by detection. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 623–630. [Google Scholar]
- Wang, C.; Wang, Y.; Lin, Z.; Yuille, A.L. Robust 3D human pose estimation from single images or video sequences. IEEE Trans. Pattern Anal. 2018, 41, 1227–1241. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.J.; Kim, J.H.; Lee, S.W. Geometry-driven self-supervision for 3D human pose estimation. Neural Netw. 2024, 174, 106237. [Google Scholar] [CrossRef] [PubMed]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2D/3D pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5137–5146. [Google Scholar]
- Zhang, Z. Camera calibration. In Computer Vision: A Reference Guide; Springer: Berlin/Heidelberg, Germany, 2021; pp. 130–131. [Google Scholar]
- Chen, C.H.; Ramanan, D. 3D human pose estimation = 2D pose estimation + matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7035–7043. [Google Scholar]
- Hossain, M.R.I.; Little, J. Exploiting Temporal Information for 3D Human Pose Estimation. In Proceedings of the European Conference on Computer Vision 2018, Munich, Germany, 8–14 September 2018; pp. 68–84. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3D human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2640–2649. [Google Scholar]
- Tekin, B.; Márquez-Neila, P.; Salzmann, M.; Fua, P. Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 3941–3950. [Google Scholar]
- Liu, Y.; Qiu, C.; Zhang, Z. Deep learning for 3D human pose estimation and mesh recovery: A survey. Neurocomputing 2024, 596, 128049. [Google Scholar]
- Chochia, P. Transition from 2D-to 3D-images: Modification of two-scale image model and image processing algorithms. J. Commun. Technol. Electron. 2015, 60, 678–687. [Google Scholar] [CrossRef]
- Núñez, J.C.; Cabido, R.; Vélez, J.F.; Montemayor, A.S.; Pantrigo, J.J. Multiview 3D human pose estimation using improved least-squares and LSTM networks. Neurocomputing 2019, 323, 335–343. [Google Scholar] [CrossRef]
- Mehta, D.; Rhodin, H.; Casas, D.; Fua, P.; Sotnychenko, O.; Xu, W.; Theobalt, C. Monocular 3D human pose estimation in the wild using improved cnn supervision. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 506–516. [Google Scholar]
- Iqbal, U.; Molchanov, P.; Kautz, J. Weakly-Supervised 3D Human Pose Learning via Multi-view Images in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 5243–5252. [Google Scholar]
- Rhodin, H.; Sprri, J.; Katircioglu, I.; Constantin, V.; Meyer, F.; Müller, E.; Salzmann, M.; Fua, P. Learning Monocular 3D Human Pose Estimation from Multi-view Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8437–8446. [Google Scholar]
- Gholami, M.; Rezaei, A.; Rhodin, H.; Ward, R.; Wang, Z.J. Self-supervised 3D human pose estimation from video. Neurocomputing 2022, 488, 97–106. [Google Scholar] [CrossRef]
- Kocabas, M.; Karagoz, S.; Akbas, E. Self-Supervised Learning of 3D Human Pose using Multi-view Geometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 1077–1086. [Google Scholar]
- Wandt, B.; Rudolph, M.; Zell, P.; Rhodin, H.; Rosenhahn, B. CanonPose: Self-Supervised Monocular 3D Human Pose Estimation in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 13294–13304. [Google Scholar]
- Chen, C.H.; Tyagi, A.; Agrawal, A.; Drover, D.; Rohith, M.V.; Stojanov, S.; Rehg, J.M. Unsupervised 3D Pose Estimation with Geometric Self-Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 5714–5724. [Google Scholar]
- Drover, D.; Rohith, M.V.; Chen, C.H.; Agrawal, A.; Tyagi, A.; Huynh, C.P. Can 3D Pose Be Learned from 2D Projections Alone? In Proceedings of the European Conference on Computer Vision 2019, Chania, Greece, 10–12 July 2019. [Google Scholar]
- Li, R.; Si, W.; Weinmann, M.; Klein, R. Constraint-Based Optimized Human Skeleton Extraction from Single-Depth Camera. Sensors 2019, 19, 2604. [Google Scholar] [CrossRef]
- Du, S.; Wang, H.; Yuan, Z.; Ikenaga, T. Bi-pose: Bidirectional 2D-3D transformation for human pose estimation from a monocular camera. IEEE Trans. Autom. Sci. Eng. 2024, 21, 3483–3496. [Google Scholar] [CrossRef]
- Li, Z.; Wang, X.; Wang, F.; Jiang, P. On boosting single-frame 3D human pose estimation via monocular videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2192–2201. [Google Scholar]
- Dabral, R.; Mundhada, A.; Kusupati, U.; Afaque, S.; Sharma, A.; Jain, A. Learning 3D human pose from structure and motion. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 668–683. [Google Scholar]
- Juarez-Salazar, R.; Díaz-Ramírez, V. Distorted pinhole camera model for tangential distortion. In Proceedings of the Optics and Photonics for Information Processing XV, San Diego, CA, USA, 1–5 August 2021; pp. 51–54. [Google Scholar]
- Liebold, F.; Mader, D.; Sardemann, H.; Eltner, A.; Maas, H.G. A Bi-Radial Model for Lens Distortion Correction of Low-Cost UAV Cameras. Remote Sens. 2023, 15, 5283. [Google Scholar] [CrossRef]
- Wang, J.; Shi, F.; Zhang, J.; Liu, Y. A new calibration model of camera lens distortion. Pattern Recognit. 2008, 41, 607–615. [Google Scholar] [CrossRef]
- Brown, D.C. Close-Range Camera Calibration. Photogramm. Eng. 1971, 37, 855–866. [Google Scholar]
- Weng, J.; Cohen, P.; Herniou, M. Camera calibration with distortion models and accuracy evaluation. IEEE Trans. Pattern Anal. 1992, 14, 965–980. [Google Scholar] [CrossRef]
- Willson, R.G. Modeling and calibration of automated zoom lenses. In Proceedings of the Videometrics III, Boston, MA, USA, 2–4 November 1994; pp. 170–186. [Google Scholar]
- Yu, W. Image-based lens geometric distortion correction using minimization of average bicoherence index—ScienceDirect. Pattern Recogn. 2004, 37, 1175–1187. [Google Scholar] [CrossRef]
- Heikkila, J. Geometric camera calibration using circular control points. IEEE Trans. Pattern. Anal. Mach. Intell. 2000, 22, 1066–1077. [Google Scholar] [CrossRef]
- Tang, Z.; Von Gioi, R.G.; Monasse, P.; Morel, J.M. A precision analysis of camera distortion models. IEEE Trans. Image Process 2017, 26, 2694–2704. [Google Scholar] [CrossRef]
- Nowakowski, A.; Skarbek, W. Analysis of Brown camera distortion model. In Proceedings of the Photonics Applications in Astronomy, Communications, Industry, and High-Energy Physics Experiments 2013, Wilga, Poland, 27 May–2 June 2013; pp. 248–257. [Google Scholar]
- Benligiray, B.; Topal, C. Lens distortion rectification using triangulation based interpolation. In Proceedings of the Advances in Visual Computing: 11th International Symposium, ISVC 2015, Las Vegas, NV, USA, 14–16 December 2015; pp. 35–44. [Google Scholar]
- Ren, Z.; Su, Y. Self-supervised video distortion correction algorithm based on iterative optimization. Pattern Recognit. 2024, 148, 110114. [Google Scholar] [CrossRef]
- Hong, Y.; Ren, G.; Liu, E. Non-iterative method for camera calibration. Opt. Express 2015, 23, 23992–24003. [Google Scholar] [CrossRef] [PubMed]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).