
ASIGM: An Innovative Adversarial Stego Image Generation Method for Fooling Convolutional Neural Network-Based Image Steganalysis Models



Abstract
1. Introduction
- We propose an innovative adversarial stego image generation method (ASIGM) that combines the two independent processes (adversarial example attack and steganography embedding) into one single process to improve the undetectability and indistinguishability of attack against CNN image steganalysis models.
- We develop and implement the proposed AGISM by using the Jacobian-based Saliency Map Attack (JSMA), one of the representative l0 norm-based adversarial example attack methods, such that AGISM converts a particular cover image to an adversarial stego image that can avoid a target CNN steganalysis model such as YeNet.
- To validate our idea, we conduct extensive experiments to compare ASIGM with two existing steganography methods, Wavelet Obstained Weight (WOW) [15] and Adverse Distinction Steganography [16], on the state-of-the-art steganalysis model YeNet. Our experiment results show that, in terms of the Missed Detection Rate (MDR), ASIGM outperformed WOW and ADS-WOW by up to 97.2%p and 17.7%p, respectively. In addition, ASIGM outperformed WOW and ADS-WOW in terms of Peak-Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) between the cover image and the stego image.
2. Background and Related Works
2.1. Image Steganography
2.2. Steganalysis Using Deep Learning: CNN-Based Steganalysis Model
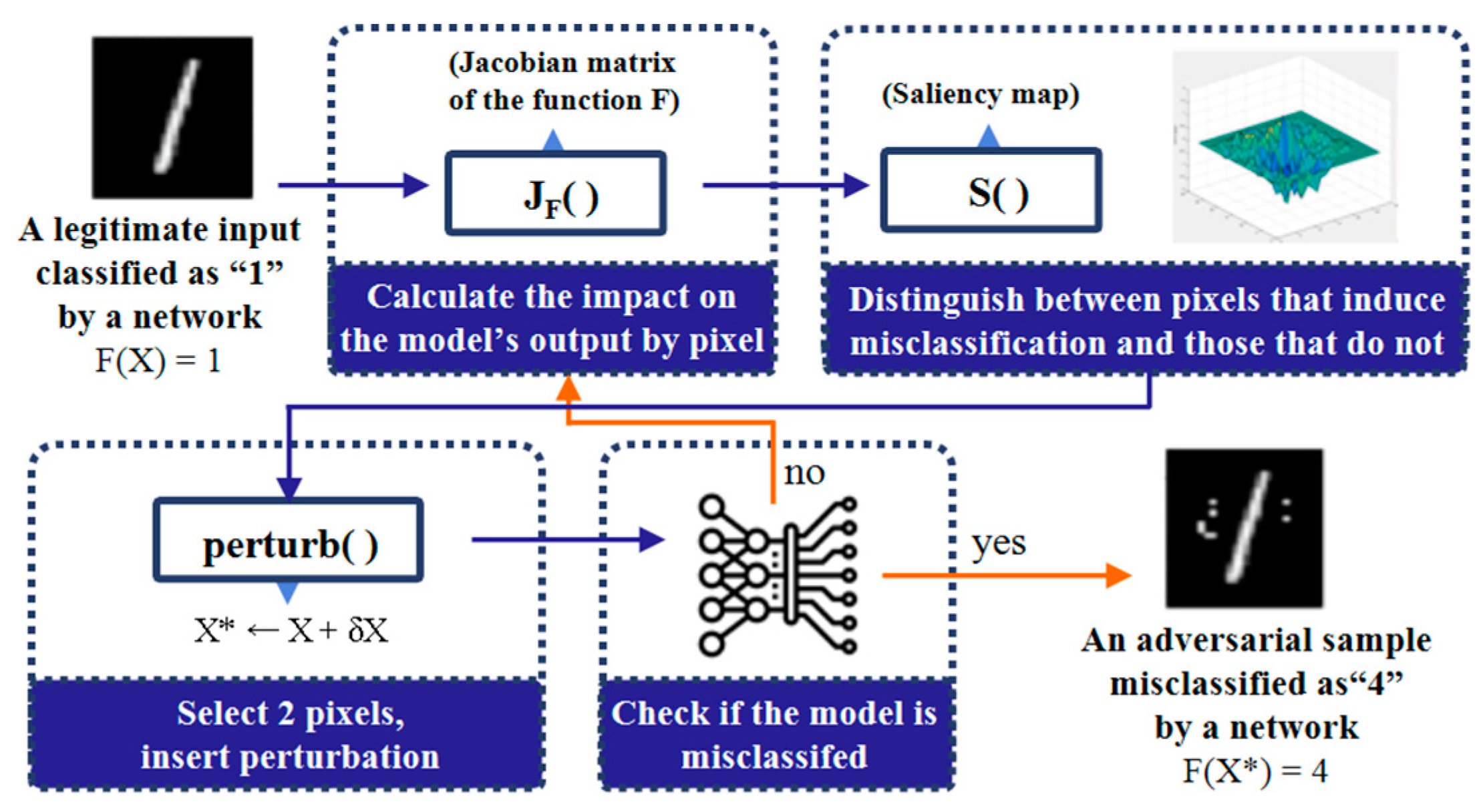
2.3. Adversarial Example Attacks Fooling Deep-Learning Models
2.4. Existing Studies on Steganography Methods with Adversarial Example Attacks
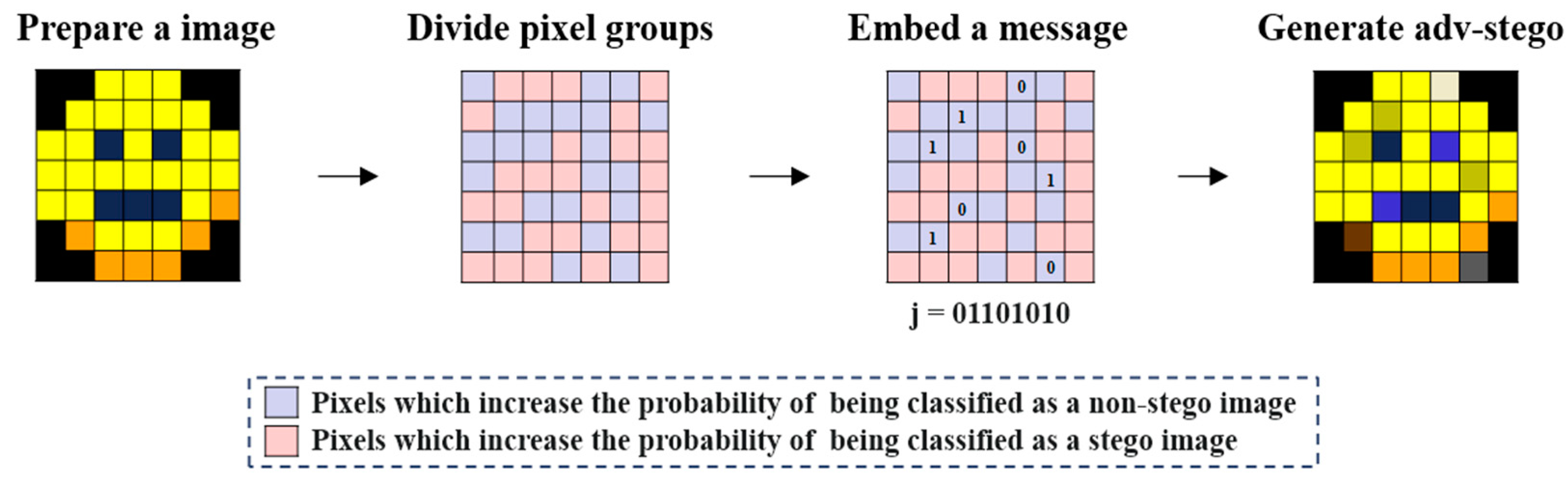
3. ASIGM: Adversarial Stego Image Generation Method Based on JSMA
3.1. Key Idea Behind ASIGM
3.2. Working Steps
- Step 1 (Selecting a set of pixels to hide a secret message): ASIGM calculates a group of pixels desirable for concealing a secret message in a prepared cover image. For this step, we use the modified version of JSMA to effectively find such pixels. Step 1 is implemented by Module 1 in Section 3.3.1.
- Step 2 (Embedding a secret message): ASIGM embeds a secret message into the pixels chosen from the pixel set obtained in Step 1. As a result, an adversarial stego image is generated. Step 2 is implemented by Module 2 in Section 3.3.2.
3.3. Design
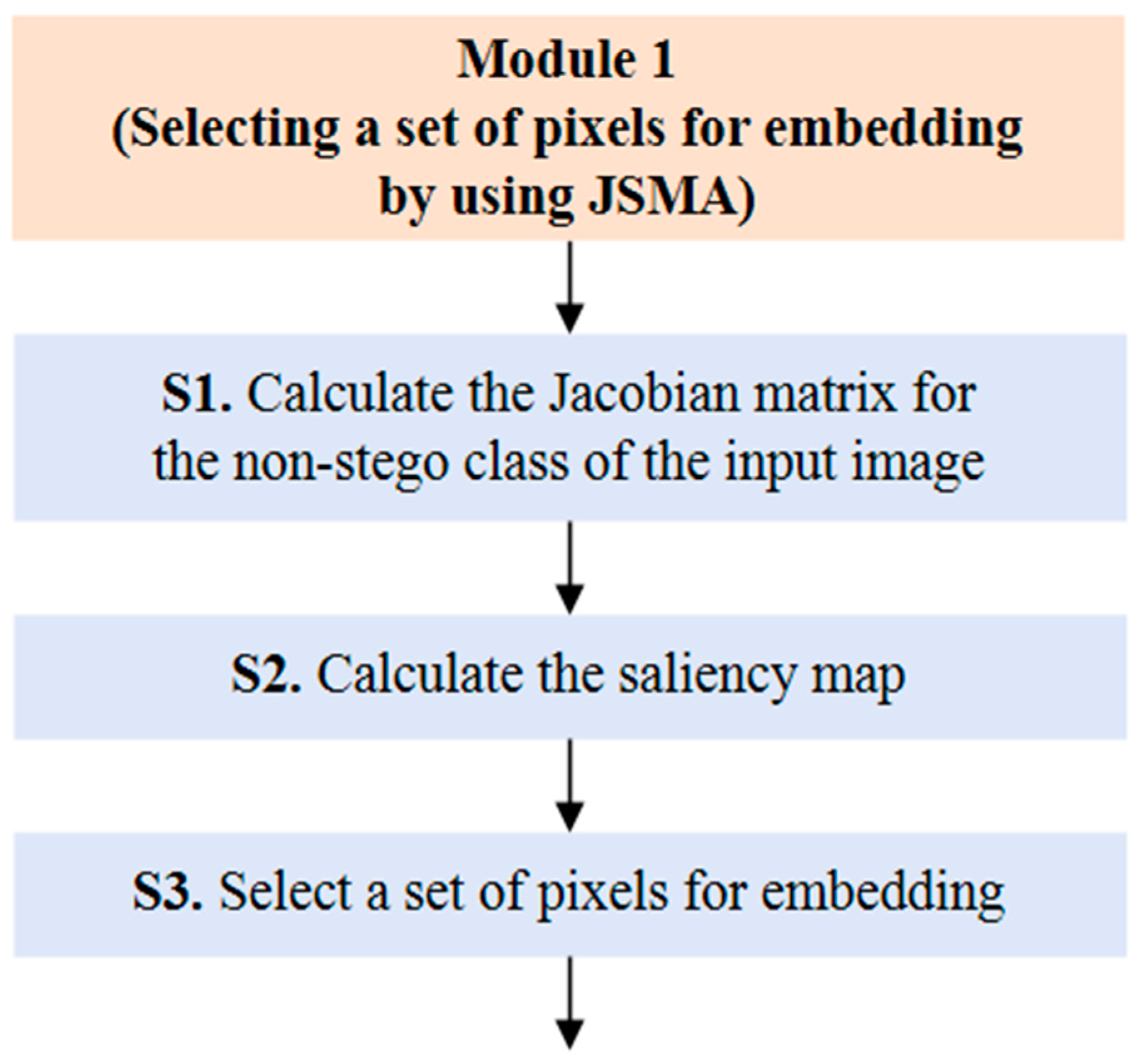
3.3.1. Design of Module 1: Selecting a Set of Pixels for Embedding by Using JSMA
- Sub-step 1 (S1): Calculating the Jacobian matrix for the non-stego class of the input image
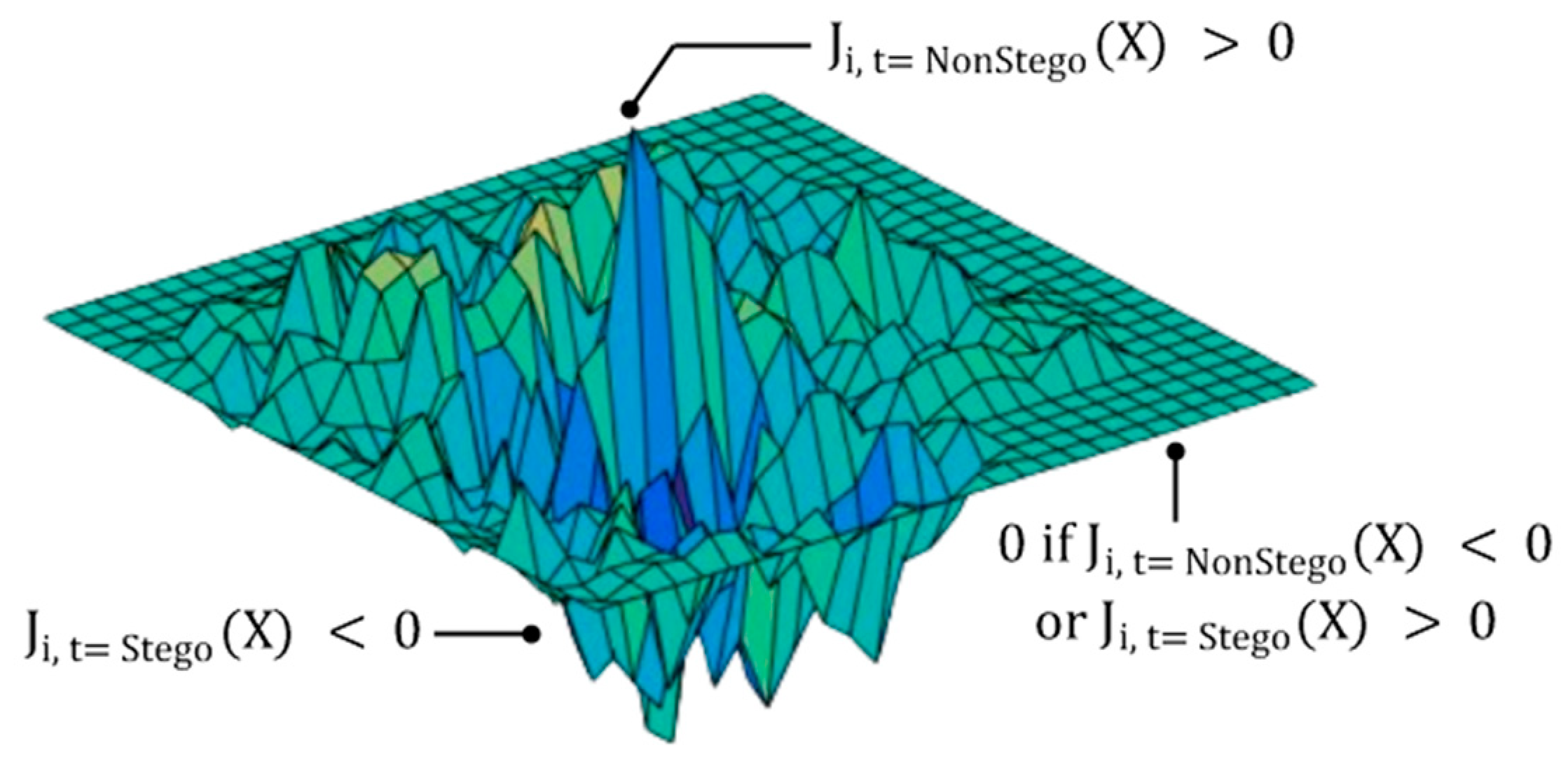
- Sub-step 2 (S2): Calculating the saliency map
- Sub-step 3 (S3): Selecting a set of pixels for embedding a secret message
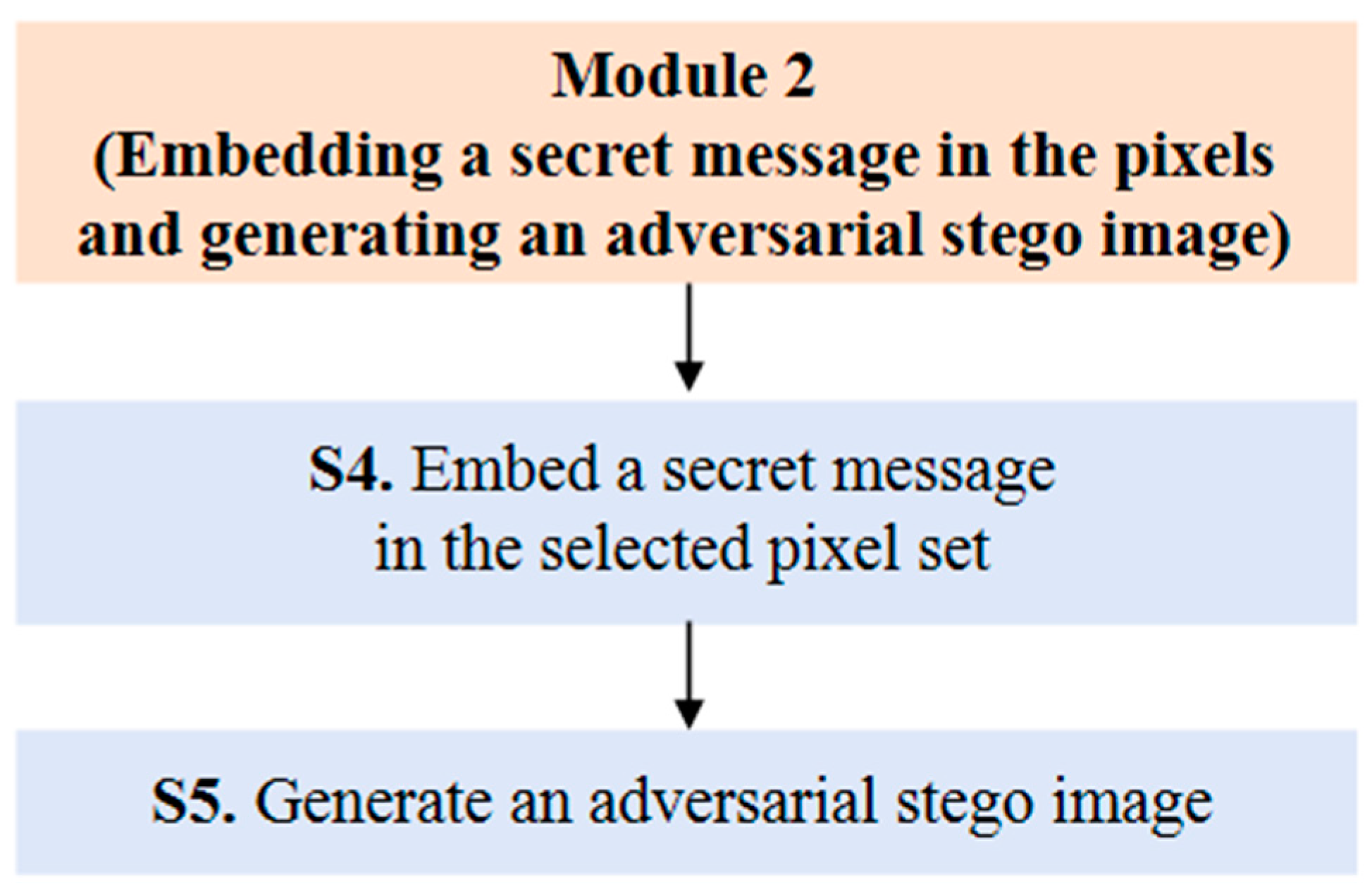
3.3.2. Design of Module 2: Embedding a Secret Message in the Pixels and Generating an Adversarial Stego Image
- Sub-step 4 (S4): Embedding a secret message in the selected pixel set
- Sub-step 5 (S5): Generating an adversarial stego image
3.4. Algorithms
| Algorithm 1: ASIGM (Adversarial Stego Image Generation Method Based on JSMA) |
| Input: X: cover image Y: target class (=non-stego class) F: function learned by target steganalysis during training Γ: full set of pixels in a cover image X M: a secret mesage Output: X*: an adversarial stego image |
| 1: X* ← X 2: SET selected_Γ 3: compute forward derivative JF(X*) 4: selected_Γ ← saliency_map(JF(X*), Γ, Y, len(M)) 5: embed M to selected_Γ 6: return X* |
| Algorithm 2: Saliency map to select a pixel set for embedding |
| Input: JF(X*): forward derivative (Jacobian matrix) of an input image Γ: full set of pixels in a cover image X t: target class len(M): length of a secret message Output: selected_Γ: the set of pixels selected using the saliency_map |
| 1: SET selected_Γ 2: SET N // a unit of pixels to select 3: iteration = len(M)/N // the number of calculations for Saliency Map 4: for i ← 0 to (iteration − 1) do 5: for j ← 0 to (N − 1) do 6: , 7: if α > 0 and β < 0 then 8: add pixel p to selected_Γ 9: return selected_Γ |
4. Experiments
4.1. Purpose and Procedures
- Experimental Platform and Program: For the experimental platform, we used Google Colab Pro (Intel Xeon CPU 2.20 GHz and NVIDIA A100 with Ubuntu 20.04.6 LTS). All programs for experiments were coded by Python program language v.3.10.12.
- Preparing Image Dataset: For the cover image dataset to train the target steganalysis model, we used the BOSSbase v.1.01 [32] and BOWS2 [33] datasets, which are commonly used in steganography and steganalysis studies. Each dataset contains 10,000 grayscale images with a resolution of 512 × 512. For our experiments, these images were resized to 256 × 256 to ensure the optimal performance of the models by making them the same as the dataset configuration used in the referenced studies.
- Generating Adversarial Stego Images: The adversarial stego images using the proposed method were generated by Algorithm 1 and Algorithm 2, as presented in Section 3. N in Algorithm 2 was set to 1000. We also utilized the Adversarial Robustness Toolbox (ART) v1.0.0 [34] as JSMA’s baseline, which is an open source provided by IBM.
- Constructing the Target Steganalysis Model: For the target CNN-based image steganalysis model, we chose YeNet because its performance has been proven in datasets most used in the research field of steganography and steganalysis, such as BOSSBase. Thus, it is the most widely used steganalysis model in existing studies. To train the model, 4000 images were randomly selected from the BOSSBase dataset, and the entire 10,000 images from the BOWS2 datasets were used. In addition, 1000 images of BOSSBase were used for validation, and 5000 images of that were used for testing. This is the same as the setup in the paper [9] that proposed YeNet to ensure the optimal performance of the model. Additionally, we used adversarial stego images generated through each attack method. By setting up the experimental environment for each attack method in the same way, we can easily compare the performance of the proposed method with that of existing method.
- Performance Testing and Experimental Results Analysis: For performance comparison, we compared our proposed method with two existing methods, such as the WOW [15] and the ADS [16]. For intuitive comparison, we used the ADS-WOW because it is the most basic attack method that performs adversarial example attacks and steganography embedding separately without using any other networks. In addition, for the baseline of comparison, we used WOW, which is a basic content-adaptive steganography method without evasion capabilities against the steganalysis model.
4.2. Metrics for Evaluation and Comparison
4.2.1. Attack Performance
4.2.2. Similarity Between Cover Images and Adversarial Stego Images
- Peak Signal-to-Noise Ratio (PSNR)
- SSIM (Structural Similarity Index)
4.2.3. Adversarial Stego Image Generation Time (ASIGT)
4.3. Results and Analysis
4.3.1. Attack Performance: Missed Detection Rate (MDR)
4.3.2. Similarity Between Cover Images and Adversarial Stego Images
4.3.3. Adversarial Stego Image Generation Time (ASIGT)
5. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Provos, N.; Honeyman, P. Hide and seek: An introduction to steganography. IEEE Secur. Priv. 2003, 1, 32–44. [Google Scholar] [CrossRef]
- Martín, A.; Hernández, A.; Alazab, M.; Jung, J.; Camacho, D. Evolving Generative Adversarial Networks to improve image steganography. Expert Syst. Appl. 2023, 222, 119841. [Google Scholar] [CrossRef]
- Johnson, N.F.; Jajodia, S. Exploring Steganography: Seeing the Unseen. Computer 1998, 31, 26–34. [Google Scholar] [CrossRef]
- Chaumont, M. Deep learning in steganography and steganalysis. Digit. Media Steganography 2020, 321–349. [Google Scholar] [CrossRef]
- Li, B.; He, J.; Huang, J.; Shi, Y.-Q. A Survey on Image Steganography and Steganalysis. J. Inf. Hiding Multimed. Signal Process. 2011, 2, 142–172. Available online: https://www.jihmsp.org/2011/vol2/JIH-MSP-2011-03-005.pdf (accessed on 14 January 2025).
- Qian, Y.; Dong, J.; Wang, W.; Tan, T. Deep Learning for Steganalysis via Convolutional Neural Networks. Media Watermarking Secur. Forensics 2015, 9409, 171–180. [Google Scholar] [CrossRef]
- Reinel, T.-S.; Raúl, R.-P.; Gustavo, I. Deep Learning Applied to Steganalysis of Digital Images: A Systematic Review. IEEE Access 2019, 7, 68970–68990. [Google Scholar] [CrossRef]
- Xu, G.; Wu, H.-Z.; Shi, Y.-Q. Structural design of convolutional neural networks for steganalysis. IEEE Signal Process. Lett. 2016, 23, 708–712. [Google Scholar] [CrossRef]
- Ye, J.; Ni, J.; Yi, Y. Deep learning hierarchical representations for image steganalysis. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2545–2557. [Google Scholar] [CrossRef]
- Boroumand, M.; Chen, M.; Fidrich, J. Deep Residual Network for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1181–1193. [Google Scholar] [CrossRef]
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Zhang, L.; Jiang, C.; Chai, Z.; He, Y. Adversarial attack and training for deep neural network based power quality disturbance classification. Eng. Appl. Artif. Intell. 2024, 127, 107245. [Google Scholar] [CrossRef]
- Amini, S.; Heshmati, A.; Ghaemmaghami, S. Fast adversarial attacks to deep neural networks through gradual sparsification. Eng. Appl. Artif. Intell. 2024, 127, 107360. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Jha, S. The limitations of deep learning inadversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbruecken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Designing Steganographic Distortion Using Directional Filters. In Proceedings of the 2012 IEEE International Workshop on Information Forensics and Security (WIFS), Costa Adeje, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, W.; Chen, K.; Liu, J.; Liu, Y.; Yu, N. Adversarial examples against deep neural network based steganalysis. In Proceedings of the 2018 6th ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec ’18), Innsbruck, Austria, 20–22 June 2018; pp. 67–72. [Google Scholar] [CrossRef]
- Hussain, M.; Wahab, A.W.A.; Idris, Y.I.B.; Ho, A.T.; Jung, K.-H. Image steganography in spatial domain: A survey. Signal Process. Image Commun. 2018, 65, 46–66. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion functionfor steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 2014, 1. [Google Scholar] [CrossRef]
- Li, B.; Wang, M.; Huang, J.; Li, X. A new cost function for spatial image steganography. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4206–4210. [Google Scholar] [CrossRef]
- Fridrich, J.; Kodovsky, J. Rich Models for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013. [Google Scholar] [CrossRef]
- Vorobeychik, Y.; Kantarcioglu, M. Adversarial Machine Learning; Morgan & Claypool: San Rafael, CA, USA, 2018. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessingadversarial examples. arXiv 2014. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. Deepfool: A simple andaccurate method to fool deep neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2574–2582. [Google Scholar] [CrossRef]
- Tang, W.; Li, B.; Tan, S.; Barni, M.; Huang, J. CNN-based adversarial embedding for image steganography. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2074–2087. [Google Scholar] [CrossRef]
- Yang, J.; Liao, X. ACGIS: Adversarial Cover Generator for Image Steganography with Noise Residuals Features-Preserving. Signal Process. Image Commun. 2023, 113, 116927. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Shi, H.; Dong, J.; Wang, W.; Qian, Y.; Zhang, X. SSGAN: Secure steganography based on generative adversarial networks. Pac. Rim Conf. Multimed. 2017, 534–544. [Google Scholar] [CrossRef]
- Tan, J.; Liao, X.; Liu, J.; Cao, Y.; Jiang, H. Channel Attention Image Steganography With Generative Adversarial Networks. IEEE Trans. Netw. Sci. Eng. 2021, 9, 888–903. [Google Scholar] [CrossRef]
- Liu, L.; Liu, X.; Wang, D.; Yang, G. Enhancing image steganography security via universal adversarial perturbations. Multimed Tools Appl. 2025, 84, 1303–1315. [Google Scholar] [CrossRef]
- Bas, P.; Filler, T.; Pevný, T. Break our steganographic system: The ins and outs of organizing BOSS. Int. Workshop Inf. Hiding 2011, 59–70. [Google Scholar] [CrossRef]
- Bas, P.; Furon, T. BOWS-2. 2007. Available online: https://data.mendeley.com/datasets/kb3ngxfmjw/1 (accessed on 14 January 2025).
- Nicolae, M.-I.; Mathieu, S.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1.0.0. arXiv 2019. [Google Scholar] [CrossRef]
- Saeed, A.; Islam, M.B.; Islam, M.K. A Novel Approach for Image Steganography Using Dynamic Substitution and Secret Key. Am. J. Eng. Res. 2013, 2, 118–126. Available online: https://www.ajer.org/papers/v2(9)/Q029118126.pdf (accessed on 14 January 2025).
- Ndajah, P.; Kikuchi, H.; Yukawa, M.; Watanabe, H.; Muramatsu, S. SSIM image quality metric for denoised images. In Proceedings of the 3rd WSEAS International Conference on Visualization, Imaging and Simulation, VIS’10, Faro, Portugal, 3–5 November 2010; pp. 53–57. Available online: https://dl.acm.org/doi/abs/10.5555/1950211.1950221 (accessed on 14 January 2025).
- Liao, X.; Yin, J.; Chen, M.; Qin, Z. Adaptive Payload Distribution in Multiple Images Steganography Based on Image Texture Features. IEEE Trans. Dependable Secur. Comput. 2022, 19, 897–911. [Google Scholar] [CrossRef]
- Liao, X.; Yu, Y.; Li, B.; Li, Z.; Qin, Z. A New Payload Partition Strategy in Color Image Steganography. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 685–696. [Google Scholar] [CrossRef]
- Wei, K.; Luo, W.; Tan, S.; Huang, J. Universal Deep Network for Steganalysis of Color Image Based on Channel Representation. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3022–3036. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | bpp (Bit per Pixel) | |
|---|---|---|
| 0.2 bpp | 0.4 bpp | |
| WOW | 9.2 | 0.9 |
| ADS-WOW | 84.5 | 78.4 |
| Our Method (ASIGM) | 97.9 | 96.1 |
| Method | bpp (Bit per Pixel) | |
|---|---|---|
| 0.2 bpp | 0.4 bpp | |
| WOW | 62.93 | 56.99 |
| ADS-WOW | 49.45 | 39.74 |
| Our Method (ASIGM) | 61.18 | 49.12 |
| Method | bpp (Bit per Pixel) | |
|---|---|---|
| 0.2 bpp | 0.4 bpp | |
| WOW | 0.99999 | 0.99999 |
| ADS-WOW | 0.99997 | 0.99573 |
| Our Method (ASIGM) | 0.99999 | 0.99990 |
| Method | bpp (Bit per Pixel) | |
|---|---|---|
| 0.2 bpp | 0.4 bpp | |
| ADS-WOW | 1.04 | 1.05 |
| Our Method (ASIGM) | 0.28 | 0.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Cho, Y.; Park, H.; Qu, G. ASIGM: An Innovative Adversarial Stego Image Generation Method for Fooling Convolutional Neural Network-Based Image Steganalysis Models. Electronics 2025, 14, 764. https://doi.org/10.3390/electronics14040764
Kim M, Cho Y, Park H, Qu G. ASIGM: An Innovative Adversarial Stego Image Generation Method for Fooling Convolutional Neural Network-Based Image Steganalysis Models. Electronics. 2025; 14(4):764. https://doi.org/10.3390/electronics14040764
Chicago/Turabian StyleKim, Minji, Youngho Cho, Hweerang Park, and Gang Qu. 2025. "ASIGM: An Innovative Adversarial Stego Image Generation Method for Fooling Convolutional Neural Network-Based Image Steganalysis Models" Electronics 14, no. 4: 764. https://doi.org/10.3390/electronics14040764
APA StyleKim, M., Cho, Y., Park, H., & Qu, G. (2025). ASIGM: An Innovative Adversarial Stego Image Generation Method for Fooling Convolutional Neural Network-Based Image Steganalysis Models. Electronics, 14(4), 764. https://doi.org/10.3390/electronics14040764