Abstract
Generative Adversarial Networks (GANs) can synthesize images with the same distribution as the training dataset through random vectors. However, there is still no proper way to explain the generation rules in the generator and modify those rules. Although there have been some works on rewriting the rules in generative models in recent years, these works mainly focus on rewriting the rules between the patterns it has already learned. In this paper, we cast the problem of rewriting as rewriting the rule in the generator with out-of-domain patterns. To the best of our knowledge, this is the first time this problem has been investigated. To address this problem, we propose the Re-Generator framework. Specifically, our method projects out-of-domain images into the feature space of a specific layer in the generator and designs a mechanism to enable the generator to decode that feature back to the original image as possible. Besides that, we also suggest viewing multiple layers of the model as nonlinearity associative memory and design a rewriting strategy with better performance based on this. Finally, the results of the experiments on various generative models in multiple datasets show that our method can effectively use the patterns that the model has never seen before as rules for rewriting.
1. Introduction
Image manipulation seeks to edit the whole, or several aspects, of a given image, e.g., changing its rendered style [1,2,3], restoring cropped regions [4,5], or even reconfiguring its coherent semantics [6,7,8], in order to fulfill the practical requirements from diverse users. Catalyzed by the rapid grow of deep generative models, e.g., GANs [9,10] and VAEs [11], synthesizing these visual patterns usually refers to modifying images and frames individually (i.e., one by one). The method aims for the flexibility of conditional image synthesis by sacrificing the scalability of manipulating an entire visual domain. In fact, visual manipulation is being gradually demanded to manipulate large-scale scenarios, e.g., changing the background of a movie, or even configuring a virtual metaverse. It is proficient in transferring similar edits to tons of images or frames at once.
In order to meet the challenge, the generator rewriting method [12] has been proposed. This type of method is not just focused on a single image but also on modifying the model itself. It directly leads to reconfiguration of the internal rules behind the generator with just a limited amount of editing results from the user. The modified rules enable the generative model to generate infinite images with new patterns. The essence of rewriting refers to treating a single convolutional layer in the generator as an associative memory with the input feature as the key and the output feature as the value. Associative memory stores a set of key–value pairs that can be retrieved by neural network operations. Based on that, the rules can be rewritten by modifying the key–value relationship.
Although this method can solve the visual-domain manipulation by rewriting the rule in the generator, as illustrated in Figure 1, the effects are only limited in the patterns that the model has already been trained with. In many practical cases, users would like to rewrite the original-domain image with new patterns that have never been seen during training. This out-of-domain rewriting refers to zero-shot generalization for generative learning, which is a long-standing challenge in artificial extrapolation. However, if we tolerate training with images containing out-of-domain patterns, a lot of relevant data are needed to retrain the original generative model, resulting in a heavy computational burden, and worse, the generation performance can be significantly detrimental in the case of the large gap between the in-domain and out-of-domain data.
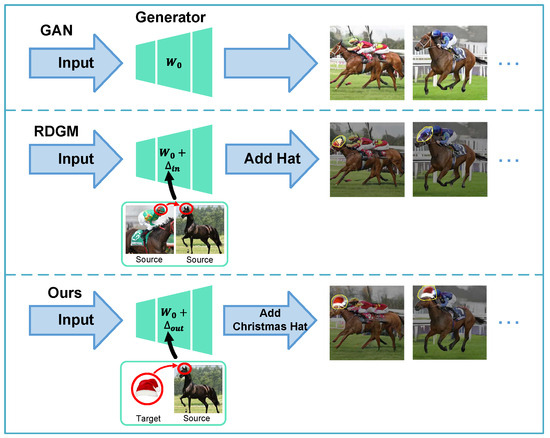
Figure 1.
The proposed problem setting. The original rewriting method (RDGM) can only rewrite rules using patterns that the generator has already learned. And its performance is not satisfactory if there is a large gap between the new patterns and original patterns. Our Re-Generator framework can greatly improve the rewriting performance and the compatibility with new rules. It also can rewrite with out-of-domain patterns that the generator has never seen before.
In this paper, we expand the problem of rewriting as that rewriting the rule in the generator by out-of-domain patterns. The rewriting in our framework is no longer limited to the patterns that the model has already learned. For a given image, even if it contains patterns that the generator has never seen before, we can use it as a new rule to rewrite the generator, such as rewriting the rule that generates human eyes to cat eyes or even gear. Our method just requires only a few or even one edited sample. This will free us from the tedious work of collecting data and expand the scenario to use rewriting.
The proposed Re-Generator framework contains multiple parts. Through the backward projector, the arbitrary image can be projected into the feature space of the value layer. Based on that, we can transfer the rules in any image into the generator. We also add Semi-Cycle-Consistency which is inspired by [13] to prevent the model from over-fitting to the features of the value layer and confirm that the projected feature can be decoded to the original image. We also propose to view the multiple layers in the generator as a nonlinearity associative memory to solve the problem of a single convolutional layer as a linear associative memory that has poor compatibility with new rules which can improve the performance of rewriting.
Overall, our contributions are summarized as follows:
- We cast the problem of rewriting as rewriting the rule in the generator from out-of-domain patterns. In this problem, we need to use out-of-domain patterns and even the patterns that the generator has never seen before as rules to perform a rewrite.
- We propose a new framework to solve this problem, which projects images into feature space of value layer through a backward projector module and cooperate with Semi-Cycle-Consistency. And we design a mechanism to improve the poor compatibility with the new rules of the original rewriting method.
- We conduct extensive experiments on different images to rewrite generators that are trained on different datasets to verify the effectiveness of our method, which achieves putting the generation rules of the patterns in an out-of-domain image into the generator.
2. Related Work
2.1. Deep Generative Models
There are various types of existing generative models. Generative Adversarial Networks (GANs) are widely explored for adversarial learning. With its outstanding generation ability, this method has been applied in many fields such as image synthesis [9,14,15,16,17], image-to-image translation and style transfer [2,6,7,13,18,19], and image inpainting [4,20,21]. Ref. [14] was the first model to apply the GAN on CNN. It can generate a greater variety of images and solve the problem of mode collapse efficiency. But it is not stable during training. Ref. [15] proposes a progressive learning structure, allowing the model to start learning from the simple task of generating low-resolution images and gradually deepen it to achieve better results. But the images generated by this model are still not realistic enough. Ref. [9] draws on the structure of the style transfer method by inputting random vectors into the generator as style and replacing the original input with a learned constant vector to synthesize more realistic images. It can perform style level control over the generated results. In addition, VAE [11] is also popular due to its powerful disentangle ability. It is an autoencoder that can project input to a regularized distribution. WAE [22] introduces the Wasserstein distance into VAE to solve the problem of mode collapse in VAE and improve the quality of the generated results. IntroVAE [23] introduces the adversarial training method into VAE, and makes the encoder behave like a discriminator, which greatly improves the quality of the VAE generated results.
2.2. Image Manipulation
Image editing can provide users with a means to manipulate images, and it usually includes editing the color, texture, shape, and semantics of images. With the rapid development of deep neural networks and Generative Adversarial Networks, they have also produced good results in many image editing scenarios. It mainly includes image colorization [1,21,24], image blending [25], and image deformation [26,27,28]. Such methods are usually only for a single image. Unlike image editing, the generator rewriting method is not only focused on a single image but on modifying the model itself, directly modifying the generation rules of a generator to change all the images generated by the generator.
2.3. Generator Rewriting
The generator rewriting method [12] can rewrite the rules that the generator has already learned. It views a single convolutional layer in the generator as an associative memory, whose input is the key and output is the value. The key–value relationship is called a rule. Modifying this key–value relationship can change the rules of the model and change the feature corresponding to the original value in the generated images to the feature corresponding to the new value. It is also necessary to keep the key–value relationship between the rest features which cannot be rewritten to achieve the rewrite of specific rules.
3. Generator Rewriting
A generator G with the parameter can synthesize an image from an input z, which can be written as . The generator contains multiple layers. If we refer to the input of each layer as and the output as , the relation between the input and output is the rule for the generator. If we want to change the generation rule so that the input produces a new output ,
but due to the large number of parameters in the generator, there will be a substantial over-fitting. Instead of learning the new rules contained in , the model can only learn the simple correspondence between and .
3.1. Linearity Associative Memory and In-Domain Rewriting
To address this problem, [12] propose to view a specific convolutional layer of the generator as a linearity associative memory. Modifying the generation rules by only modifying this part of parameters the over-fitting can be resolved. The input of this layer is the key of the memory represented as k, and the output is the value of the memory represented as v. When we insert a new rule, it just needs to keep the key–value relationship as close as possible, with . So, a new rule can be inserted by the following:
where is all the original rules, is the new rules to be inserted, and represents the distance of . In particular, is the original input feature, and is the target feature which picked from another image in output layer. Based on such a fine-tuning method, the model can translate all selected original patterns into new target patterns and generate images with new rules. Because inserting the new rule into the associative memory requires the value of this pattern, for out-of-domain patterns, it is obvious that the value cannot be obtained directly from generator, so this method can only perform in-domain rewriting.
3.2. Nonlinearity Associative Memory
The original rewriting method views a single convolutional layer as a linearly associative memory which is extremely limited. The compatibility of a single convolutional layer is insufficient to handle the new key–value rules with a large amount. It does not have enough capacity to accommodate as many complex new rules as possible while retaining the old rules well. This limits its ultimate performance. Meanwhile, we need to do rewrite with out-of-domain patterns. There is a large gap between the in-domain and the out-of-domain patterns. This leads to a stronger nonlinear relationship between the values of in-domain and out-of-domain, while the linearly associated memory is unable to describe such a complex relationship.
To solve these problems, we propose to view multiple convolutional layers with the nonlinear activation layers in the generator as a Nonlinearity Associative Memory. In this way, a nonlinear mapping relationship is formed between the input and output of the memory. The generator can be decomposed into
This method enormously increases the capacity of the memory and makes it compatible with rules that are more different from the original rules. So it can improve the performance of rewriting and provide the possibility to use external rules to rewrite a generator.
4. Out-of-Domain Extrapolation
In this section, we first propose the backward projector to project out-of-domain images into the feature space of a specific layer of the generator. Then, we add Semi-Cycle-Consistency on that model to ensure that the projected features will not change in semantic information after being decoded by the generator. After that, we propose to view the multiple layers in the generator as a nonlinearity associative memory and modify the original rewriting method to improve its performance and enhance its compatibility.
4.1. Backward Projector
The original rewriting method can only replace the rules with which the generator has already learned. The rules such as are from the feature maps of generated images. However, not any images can be synthesized by the generator, for which the corresponding feature map cannot be obtained directly from the generator.
To address this problem, we propose the backward projector in Figure 2 to project arbitrary images into the feature space of the value layer of the generator. The backward projector is trained in a self-supervised manner and does not need any additional data during training. The data used for training can be directly obtained from the generator.
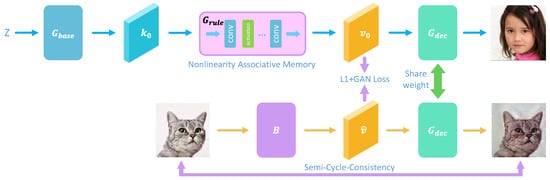
Figure 2.
The overall architecture of the proposed backward projector. The generator is decomposed into three parts with as the associated memory. Backward projector B projects the image to the feature of the value layer and it decodes back to image by . In the training process, B is constrained by the loss on the feature map and Semi-Cycle-Consistency mechanisms.
The generator uses a vector z as input and an image as output. If a convolutional layer is viewed as an associative memory, the generation process can be decomposed into
where is the feature map of the key layer, and is the feature map of the value layer. For an arbitrary image, we use the proposed back projector to project image into the feature space of value as .
The backward projector mainly includes two parts: the down-sampling module and feature alignment module. The down-sampling module is an encoder used for extracting the features of the images . However, the distribution of the feature maps extracted by itself still has a large gap with the value layer. Therefore, a feature alignment module composed of multiple residual blocks [29] needs to be connected in series. This module can change the distribution of the feature map and make it the same as the value layer, which can improve the performance of rule rewriting.
The target of the backward projector is to restore the real image to the feature map of the value layer, and there is an unique correspondence between them. If we use the loss, the feature-level loss can be written as
4.1.1. Adversarial Training
Due to the high dimension of the feature map and the data available for training being limited, simply using loss will not align the two distributions. To make the distribution of better coincide with and quicken the convergence of the model, we add an adversarial loss [30]:
where D is the discriminator for the feature, and represents the distance of . The distribution of the value layer can be better fitted by adding an adversarial loss for the backward projector. Overall the total loss for the feature map is
and are the balance factors.
4.1.2. Semi-Cycle-Consistency
In the model training process, all training samples are synthesized by the generator, which may lead to over-fitting of the backward projector to the training set. In other words, no matter what the original features in the image are, the features extracted by the backward projector will be translated into those features that already exist in the generator shown in Figure 3. If we feed an image containing cat eyes to the model and project it into the feature space, it will also extract features by the human eyes pattern and project cat eyes in the image into the features of human eyes. It is meaningless to use this feature as a new rule to rewrite the generator.
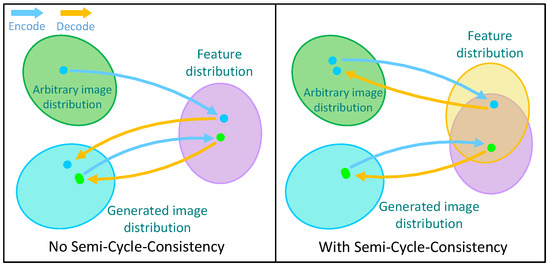
Figure 3.
The model without Semi-Cycle-Consistency will over-fit the feature space of the value layer. And the model with Semi-Cycle-Consistency can convert the image into features that can be better restored to the original image.
To address this problem, we add the Semi-Cycle-Consistency to the original backward projector, which can prevent the change of semantic information when fitting the distribution of the value layer. We force that the features restored by the backward projector can be decoded into the original images:
are the parameters of the backward projector, and are the images decoded by the decoder.
The discrepancy between the decoded image and the original image should be as small as possible not only in the distance of images but also in human perception. To address that, we introduce SSIM [31], and Semi-Cycle-Consistency Loss can be written as
After adding Semi-Cycle-Consistency, the total loss of backward projector is .
4.2. Out-of-Domain Rewriting
In the process of rewriting in Figure 4, we need the generator to protect original rules and only modify the generation rules of the marked patterns to new rules . Therefore, we only need to paste the selected area in the feature extracted by the backward projector into the area to be replaced in the feature generated by the generator:
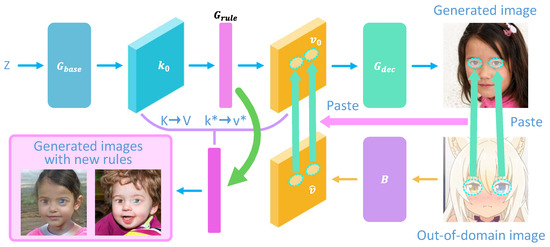
Figure 4.
The overall architecture of the rewrite method. Learn from a few edited samples to replace the original rules in the generator with new ones.
Although this method has the ability to rewrite the rules using the patterns in an out-of-domain image, the performance is not good. This is because the area representing the original rules is much larger than the area representing the new rules, which causes the model to be more inclined to protect the original rules rather than to learn new rules. To address this problem, we assign different weights to the original rule and the new rule . So the rewrite loss becomes
The proposed Re-Generator framework contains two stages. The first stage is training the backward projector, which only needs to be trained once before the rewriting, to learn projecting an arbitrary image into the feature space of the value layer. The second stage is the training of the nonlinear associative memory, which learns new key–value relationships through edited samples. Through these two stages of operation, it is possible to rewrite the generator using the patterns in an out-of-domain image. This creates a new generator that can synthesize images with new rules.
5. Experiments and Analysis
5.1. Experimental Settings
Our framework training is divided into two stages, where the first is the training of the backward projector module. The training data can be obtained directly through the pre-trained generator. The training process of the backward projector is unsupervised and does not need to introduce additional data. The data used for training are completely derived from the generation results of the generator. For the rewriting of a generative model, only one backward projector needs to be trained to project an image into the feature space of the value layer. The second step is training for rewriting. For editing samples that are needed in rewriting, firstly, the image is transformed into a feature map by backward projector. Then, the required features in that image are selected, and some images generated by the generator with the features that need to be replaced are selected. Finally, the selected feature in the image is pasted to the corresponding region of the feature to be replaced in the selected image to form the training data.
In the following experiments, for the hyper-parameter in the training of the backward projector, we choose , and the two hyper-parameters of are and . In the rewrite training, the number of layers in the nonlinear associative memory is 2, and we choose . For rule rewriting, we use the LPIPS [32] distance as an metric to measure the quality of rewriting.
5.2. Rewriting Generative Model
In this section, we evaluate our method under the normal generation task. The modified generator can generate a new image with out-of-domain patterns. We use the current state-of-the-art generative model Styleganv2 [9] as the generator for experiments to verify the effectiveness of our method. We use multiple images from different domains with different patterns to validate our method based on the generator trained on six different datasets, which is the face dataset FFHQ [33], the horse dataset LSUN horse, the car dataset LSUN car, the indoor scene dataset LSUN bedroom [34], the anime face dataset Danbooru [35], and the few-shot panda dataset 100-shot panda [36].
5.2.1. Rewriting High Resolution Human Face Generator
In this section, we first verify the effectiveness of our method based on the generative model trained on FFHQ, which is a high-resolution (1024 × 1024) human face dataset. The generation model trained on this dataset can generate high-resolution face images of different ages and nationalities with different styles. According to the conclusion in [12], we select the 10th convolution layer of the generator as the value layer and use the generation results of the generator to train a backward projector. Selecting this layer as the value layer can make the model learn more general rules, and will not change the semantic information of the new features.
In order to show the wide applicability of our proposed method, we conduct multiple experiments with different difficulty levels, from domains with few discrepancies to domains with a large discrepancy, for example, rewrite based on a generator trained on a face dataset. The images used for rewrite come from multiple different unknown distributions. It is quite a simple task to replace human eyes with anime eyes, while the task of replacing human eyes with sunglasses and putting a mask on a human face is more difficult.
It is shown in Figure 5a,b,g that our method effectively uses some image from unknown distributions to rewrite the rules. We use our method to rewrite the key–value relationship based on edited samples. And then this new patterns can be transformed into the generation rules in the generator and generalized to all generated images with similar original patterns. The rest of the patterns that have not been replaced should remain as they are as much as possible. For example, when we replace the human eye with patterns of an anime eye, we only change the generation rule of eyes, while the rest of the parts are required to remain as close to the original as possible. Our method can effectively protect the rules from being changed when learning new rules. Our method does not need a large number of edited samples. Only a few edited samples are needed for rewriting, and we only use 1–3 samples for learning new rules in the experiment.

Figure 5.
The result of rewriting the generator rules of stylegan using multiple different samples. The upper parts are the original image, and the lower parts are the result of rewriting.
5.2.2. Rewriting Lower Resolution Generator
We also evaluate the performance of our framework on the generative model trained on other lower resolution dataset. The low-resolution image contains less information, and the generator is more difficult to learn some distinctive patterns, which make it more challenging to perform a rewrite.
The generator trained on the Danbooru dataset can synthesize images with various styles of anime face. Compared with the human face, the anime face will be more complex and varied, and the anime face is more colorful and has many kinds of painting styles. Based on the pre-trained generator on this dataset, we try to rewrite the rules of generating animation eyes with the rules of generating sunglasses and real-world glasses. As can be seen from Figure 5d,e, although the animation face is more complex and varied, our method can also effectively rewrite those rules, and the replaced part can also adapt to a variety of painting styles and integrate into the whole image.
We also verify the effectiveness of our method in a more complex dataset of indoor and outdoor scenes such as LSUN horse, LSUN car, and LSUN bedroom. We force the generator to generate a horse with a Christmas hat, a car with football wheels, and a bedroom with a TV instead of a hanging picture. It can be seen from Figure 5c,h,i that even in these more complex scenes, our model can perform well by using patterns with a large domain discrepancy to perform a rewrite. This also proves that our proposed nonlinearity associative memory can effectively accommodate some rules that deviate greatly from the original rules.
5.3. Rewriting Image-to-Image Translation Model
In addition to the conventional generation task, we also verify our method on the image-to-image translation task. We verify our framework based on the MUNIT [6] model, which can transfer images from one domain to another in different styles, for example, translating an image of a dog into an image of a cat. With our method, we can modify the translation rules of the model according to a tiny number of editing samples and let the model translate the dog image into a cat image with a Christmas hat. The modified model will translate an image into a cat with a Christmas hat whenever it sees a dog.
We verify the effectiveness of our method in the image-to-image translation task under the MUNIT model pre-trained with the afhq-dog2cat dataset. We try to make the model translate the dog into a cat with anime eyes and a cat with a Christmas hat. As can be seen from Figure 6, our model can show excellent performance, and the modified patterns can also be well integrated into the original image.

Figure 6.
The result of rewriting MUNIT (image-to-image translation model) generation rules using multiple different samples. The upper parts are the original image and the lower parts are the result of rewriting.
5.4. Rewriting Inpainting Model
Finally, we verify our method on inpainting tasks. We perform the following experiments based on RFR [20] model. For a partially missing image, the inpainting model can generate the missing part of the image according to the rest of the image and fill the blank area. With the help of our method, we can modify the blank-area-filling rules the model has learned. For example, the original model can fill the missing eyes area with normal eyes. With our method, we can make the model fill this area with anime eyes. Only a few editing samples are needed to modify the inpainting rules of the model.
We use the RFR model pre-trained on the CelebA dataset [37] to verify our method under the inpainting task. We try to replace the inpainting rule for human eyes with the inpainting rule for anime eyes, and the inpainting rule for nose with the inpainting rule for clown nose. As can be seen from Figure 7, our method can rewrite these inpainting rules well. The model can also protect other rules when learning new rules.

Figure 7.
The result of rewriting RFR (inpainting model) generator rules using multiple different samples. The upper parts are the original image, and the lower parts are the result of rewriting.
6. Ablation Study
6.1. Evaluation of Backward Projector
In this section, we compare the performance of the backward projector and that without adding adversarial loss and Semi-Cycle-Consistency. Our experiments are all conducted under the generator that is trained on the human face dataset.
It can be seen from Figure 8b that in the model without Semi-Cycle-Consistency, the extracted features cannot be effectively restored. The model has over-fitted the features of the value layer. This image is decoded by the generator, and the features generated by the new rules are also decoded by the same model. So such a feature cannot be used as a rule for rewrites. The model after adding Semi-Cycle-Consistency can learn more refined features. From Figure 8c, it can be seen that although the extracted feature map can be decoded into an image similar to the original image, the distribution of that feature map differs greatly from the original feature map of the value layer. From Figure 8d, it can be seen that the model with adversarial loss can align the features extracted by the backward projector with the features generated by the generator. Using features similar to the feature distribution generated by the generator can significantly reduce the difficulty of rewriting.
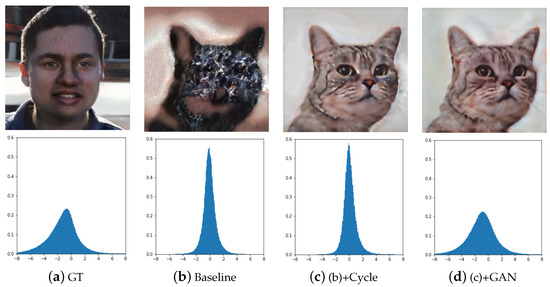
Figure 8.
The results of the backward projector under different training methods and the distribution of extracted features.
We also make a quantitative evaluation in Table 1, using the LPIPS distance to measure the distance between the restored image and the original image, and the Wasserstein distance to measure the distribution similarity between the features extracted by backward projector and the original features. The restored image with the features extracted by the baseline model has a larger LPIPS distance than the original image, which is 0.4747. The model that adds Semi-Cycle-Consistency and continues to add adversarial loss reduces the LPIPS distance to 0.2066 and 0.1970.

Table 1.
Quantitative evaluation of the results of the backward projector under different training methods. (The best performance has been bolded).
The model without adversarial loss has a larger Wasserstein distance with values of 89.29 and 88.13, which also shows that there is a large gap between the distribution of features and the generator. The addition of adversarial loss addresses this problem and greatly shrinks the distance to 20.11.
6.2. Impact of Different Rewrite Strategy
For the rewrite method, we also investigate the impact of using linear associative memory and nonlinear associative memory, and add weight to the new rule and the original rule in the rewriting process. All experiments are finished under the task of replacing the rule of human eyes with cat eyes.
It can be seen from Figure 9 and Table 2 that the effect of using linear associative memory for rewriting is quite poor. The model cannot effectively learn the rules that can generate images with new patterns and has a great impact on the original rules. This also proves that the capacity of the linear associative memory is extremely limited and cannot accommodate widely differing patterns. The nonlinear associative memory can effectively solve this problem. The model can not only generate clearer new patterns but also effectively protect the original rules from being changed.

Figure 9.
Results of using different strategies for rewrite. L is the number of convolutional layer in associative memory. p and q are the hyper-parameters of Equation (11).
Table 2.
Quantitative evaluation of the results of the backward projector under different training methods and comparing with the NBB method. Using the LPIPS distance from the masked original image as the metric. (The best performance has been bolded).
Without adding weights, the model cannot learn new rules well. The area in the generated image that should be synthesized with new patterns can only synthesize patterns similar to the original patterns. This also proves that the imbalance between the original rules and the new rules will indeed affect the learning of the new rules. The model will be more inclined to protect the original rules. So the new rules cannot be effectively learned. Adding weight to balance them allows the model to learn the new rules better without significant changes in the original rules.
7. Conclusions
In this work, we propose the Re-Generator framework. Through this framework, we can rewrite the generator by patterns in an out-of-domain image, even those the generative model has never seen before. The rewritten generator has new rules and can generate images with new patterns. We propose the backward projector to project the image into the feature space of the value layer to obtain new rules that can be used for rewriting. And we add Semi-Cycle-Consistency to it to prevent over-fitting to the feature space. We propose to view the generator multi-layer as a nonlinearity associative memory to solve the problem of the insufficient capacity of the linear associative memory. We also propose a new strategy to improve the performance of rewriting. The experiments demonstrate the effectiveness of our proposed framework. Our method can effectively put the rules in arbitrary images into the generator.
8. Discussion
8.1. Limitations
Our method exhibits limitations when handling out-of-domain patterns with complex textures. Specifically, the rewritten model struggles to sufficiently reconstruct fine texture details as illustrated in the Figure 10.

Figure 10.
Failure case of our rewriting method.
8.2. Future Works
Our method is currently limited to GAN models and is ineffective for diffusion models that require multi-step iterative processes. Future research could focus on extending the rewriting approach to diffusion models for handling out-of-domain patterns. Currently, research on video generation models is gradually becoming a hotspot. Leveraging per-frame annotated data, our rewrite method has the potential to be extended to video generation models in future studies.
Author Contributions
Conceptualization, P.G.; methodology, H.S.; software, G.C.; validation, M.L.; formal analysis, P.G. and H.S.; investigation, G.C.; resources, M.L.; data curation, P.G.; writing—original draft preparation, P.G.; writing—review and editing, P.G.; visualization, G.C.; supervision, M.L.; project administration, G.C.; funding acquisition, H.S. and P.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China grant number 52075046.
Data Availability Statement
Data available in a publicly accessible repository.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Cao, Y.; Zhou, Z.; Zhang, W.; Yu, Y. Unsupervised diverse colorization via generative adversarial networks. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Skopje, Macedonia, 18–22 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 151–166. [Google Scholar]
- Wang, Z.; Zhao, L.; Xing, W. StyleDiffusion: Controllable Disentangled Style Transfer via Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, 1–6 October 2023; pp. 7643–7655. [Google Scholar]
- Hamazaspyan, M.; Navasardyan, S. Diffusion-Enhanced PatchMatch: A Framework for Arbitrary Style Transfer with Diffusion Models. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 797–805. [Google Scholar]
- Zhao, L.; Mo, Q.; Lin, S.; Wang, Z.; Zuo, Z.; Chen, H.; Xing, W.; Lu, D. UCTGAN: Diverse Image Inpainting Based on Unsupervised Cross-Space Translation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5740–5749. [Google Scholar]
- Corneanu, C.A.; Gadde, R.; Martínez, A.M. LatentPaint: Image Inpainting in Latent Space with Diffusion Models. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2024, Waikoloa, HI, USA, 3–8 January 2024; pp. 4322–4331. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Zhou, L.; Lou, A.; Khanna, S.; Ermon, S. Denoising Diffusion Bridge Models. In Proceedings of the Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Brooks, T.; Holynski, A.; Efros, A.A. InstructPix2Pix: Learning to Follow Image Editing Instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 18392–18402. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming Transformers for High-Resolution Image Synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 12873–12883. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Bau, D.; Liu, S.; Wang, T.; Zhu, J.Y.; Torralba, A. Rewriting a deep generative model. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 351–369. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 10674–10685. [Google Scholar]
- Podell, D.; English, Z.; Lacey, K.; Blattmann, A.; Dockhorn, T.; Müller, J.; Penna, J.; Rombach, R. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. In Proceedings of the Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Li, J.; Wang, N.; Zhang, L.; Du, B.; Tao, D. Recurrent feature reasoning for image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7760–7768. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding Conditional Control to Text-to-Image Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, 1–6 October 2023; pp. 3813–3824. [Google Scholar]
- Tolstikhin, I.; Bousquet, O.; Gelly, S.; Schoelkopf, B. Wasserstein auto-encoders. arXiv 2017, arXiv:1711.01558. [Google Scholar]
- Huang, H.; Li, Z.; He, R.; Sun, Z.; Tan, T. IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis. In Proceedings of the NeurIPS, Montréal, ON, Canada, 3–8 December 2018. [Google Scholar]
- Ci, Y.; Ma, X.; Wang, Z.; Li, H.; Luo, Z. User-guided deep anime line art colorization with conditional adversarial networks. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1536–1544. [Google Scholar]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Gp-gan: Towards realistic high-resolution image blending. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21 October 2019; pp. 2487–2495. [Google Scholar]
- Chen, Z.; Fu, Y.; Wang, Y.X.; Ma, L.; Liu, W.; Hebert, M. Image deformation meta-networks for one-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8680–8689. [Google Scholar]
- Schaefer, S.; McPhail, T.; Warren, J. Image deformation using moving least squares. In ACM SIGGRAPH 2006 Papers; ACM Digital Library: New York, NY, USA, 2006; pp. 533–540. [Google Scholar]
- Pan, X.; Tewari, A.; Leimkühler, T.; Liu, L.; Meka, A.; Theobalt, C. Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold. arXiv 2023, arXiv:2305.10973. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Anonymous; The Danbooru Community; Gwern Branwen. Danbooru2020: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset. 2021. Available online: https://www.gwern.net/Danbooru2020 (accessed on 2 March 2023).
- Zhao, S.; Liu, Z.; Lin, J.; Zhu, J.Y.; Han, S. Differentiable Augmentation for Data-Efficient GAN Training. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).