Abstract
To address the edge blurring issue of drone inspection images of mountainous transmission lines caused by non-uniform haze interference, as well as the low operational efficiency of traditional dehazing algorithms due to increased network complexity, this paper proposes a high-frequency guided dual-branch attention multi-scale hierarchical dehazing network for transmission line scenarios. The network adopts a core architecture of multi-block hierarchical processing combined with a multi-scale integration scheme, with each layer based on an asymmetric encoder–decoder with residual channels as the basic framework. A Mix structure module is embedded in the encoder to construct a dual-branch attention mechanism: the low-frequency global perception branch cascades channel attention and pixel attention to model global features; the high-frequency local enhancement branch adopts a multi-directional edge feature extraction method to capture edge information, which is well-adapted to the structural characteristics of transmission line conductors and towers. Additionally, a fog density estimation branch based on the dark channel mean is added to dynamically adjust the weights of the dual branches according to haze concentration, solving the problem of attention failure caused by attenuation of high-frequency signals in dense haze regions. At the decoder end, depthwise separable convolution is used to construct lightweight residual modules, which reduce running time while maintaining feature expression capability. At the output stage, an inter-block feature fusion module is introduced to eliminate cross-block artifacts caused by multi-block processing through multi-strategy collaborative optimization. Experimental results on the public datasets NH-HAZE20, NH-HAZE21, O-HAZE, and the self-built foggy transmission line dataset show that, compared with classic and cutting-edge algorithms, the proposed algorithm significantly outperforms others in terms of Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM); its running time is 19% shorter than that of DMPHN. Subjectively, the restored images have continuous and complete edges and high color fidelity, which can meet the practical needs of subsequent fault detection in transmission line inspection.
1. Introduction
The employment of Unmanned Aerial Vehicles (UAVs) for transmission line inspection, fault detection, and timely mitigation of potential risks has evolved into an essential auxiliary approach in the operation and maintenance of modern power systems [,]. However, images acquired by UAVs are susceptible to degradation in quality due to factors such as haze, consequently impairing the accuracy of subsequent visual tasks.
Currently, numerous methods exist in the field of image dehazing, which can generally be categorized into three major types: image enhancement, physics model-based methods, and deep learning-based approaches. The objective of image dehazing is to restore haze-free images from hazy inputs. Traditional image enhancement techniques improve visual quality by accentuating image details or enhancing contrast. Specific algorithms include the Retinex algorithm, histogram equalization, and partial differential equation-based methods [,,]. Although these approaches amplify image detail features through certain statistical and transformational means, they often result in incomplete haze removal to a significant extent.
The Atmospheric Scattering Model (ASM) [] is commonly employed to explain the process of image dehazing, as represented by Equation (1):
where represents the hazy image; denotes the restored image; signifies the transmission map; indicates the scene depth; stands for the global atmospheric light.
The principle of image dehazing based on physical models simulates the scattering and absorption processes of light in the atmosphere to estimate the scene depth, subsequently derive the transmission map, and ultimately restore a clear image. The Dark Channel Prior (DCP) [] is a representative algorithm. While it improves dehazing performance in the atmospheric scattering model by providing more accurate scene depth estimation and atmospheric light estimation, it tends to over-enhance sky regions and is susceptible to image noise. For instance, in reference [], the gradient features of directly transmitted light intensity estimated by the DCP algorithm were used as guidance to solve and optimize the target degree of polarization for image dehazing. Although the resulting images are relatively clear to some extent, the high dependency on parameter accuracy leads to noise and color artifacts in the images. In reference [], bilateral filtering was employed as the transfer function for homomorphic filtering to estimate atmospheric light and scene reflectance. This approach maintains edge clarity from the perspective of color components, but the independent dehazing operations on each color channel result in inconsistent dehazing effects across channels, thereby weakening edge and texture information. To preserve edge information in clearly dehazed images, edge-preserving filters have been introduced. For example, reference [] proposed a weighted guided image filter. The method decomposes multiple underexposed images generated with different gamma values, refines the weights of each decomposed image block using this filter, and finally performs image fusion. However, due to the decomposition and fusion processes, the algorithm requires longer computational time, making it unsuitable for real-time image processing.
In addition to visual sensors such as cameras, other sensing technologies, including LiDAR, have also been applied in image dehazing. For instance, in reference [], single-photon counting was utilized to enhance the GM-APD LiDAR system. By performing maximum likelihood estimation on echo photons, the backscattering distribution was obtained, and target echo positions were extracted to achieve image dehazing. However, this method exhibits limited echo signal extraction capability under dense fog conditions. In reference [], a fusion strategy combining images and LiDAR data was adopted for dehazing. Nevertheless, relying solely on the mean pixel value to estimate the dark channel mean deviates from the scattering coefficient estimation model, leading to suboptimal dehazing performance. Moreover, LiDAR noise points increase significantly in heavy fog. Reference [] proposed a fusion approach integrating radar and LiDAR data through a bird’s-eye view representation to enhance edge clarity. However, this method requires substantial computational resources for dense bird’s-eye view queries and assigns uniform attention to all features, lacking adaptive emphasis. Although the aforementioned dehazing methods can produce relatively clear images to some extent, they struggle to achieve satisfactory performance in complex scenarios such as non-uniform fog.
Deep learning methods are capable of learning haze patterns and image priors from large-scale data, without imposing stringent requirements on the accuracy of model parameters, and demonstrate strong adaptability to non-uniform haze or complex scenes. Consequently, convolutional neural network (CNN)-based image dehazing algorithms have been extensively studied in recent years. In reference [], an edge extraction branch was incorporated as an additional edge prior, supplemented by an edge loss to impose secondary constraints on the network. Reference [] introduced a depth-refinement branch to recover structural information in the form of a depth map, which guided a dehazing branch to enhance contour restoration. However, this method performs poorly at depth discontinuities and tends to lose information in low-light regions. In reference [], multi-scale parallel large convolutional kernels and an enhanced parallel attention module were employed for feature extraction and reconstruction. Reference [] proposed a dynamic convolution mechanism that adaptively adjusts the weights of output channels and spatial dimensions based on input characteristics. This was combined with depthwise separable convolution to leverage multi-dimensional features for haze-free image recovery. Although these approaches improve dehazing performance by expanding multi-scale receptive fields to capture both global and local features, they often increase model complexity, making it difficult to meet practical requirements for real-time inspection. In reference [], a lightweight encoder–decoder dehazing architecture was used as a teacher network, while a student network constructed via channel multipliers distilled knowledge encoded from hazy images; the teacher-student collaboration aimed to reduce computational complexity. Reference [] adopted a parallel combination of standard and dilated convolutions to enlarge the receptive field, along with downsampling operations prior to haze extraction and removal modules to reduce computational load in subsequent layers. Nevertheless, this approach inherently increases the number of convolutional layers and kernels. Reference [] employed atrous convolutions to construct a multi-scale adaptive module for balancing dehazing performance and computational cost. It introduced a lightweight channel attention-guided fusion module to improve feature extraction. However, the conventional serial attention structure fails to adequately account for the non-uniform distribution of haze, leading to insufficient dehazing in dense haze regions.
Generative Adversarial Networks (GANs) have also been introduced into dehazing algorithms. Reference [] proposed an enhanced cycle-consistent GAN model that employs local-global discriminators to address non-uniformly distributed haze, thereby reducing residual haze in the restored images. Nevertheless, due to the lack of paired training data in image dehazing tasks, GAN-based methods often struggle to generate high-quality dehazed images with satisfactory perceptual and quantitative performance. Furthermore, With the remarkable performance of Transformer models in image-related tasks, numerous studies have begun to employ Transformer architectures for image dehazing. In reference [], a dual-branch collaborative dehazing network integrating both Transformer and CNN components was proposed. This network utilizes residual modules to extract features and incorporates a non-autoregressive mechanism with lateral connections in the Transformer blocks to preserve features at different depths. However, Transformer-based models generally involve a large number of parameters and high computational latency, making them difficult to deploy in practical scenarios.
In the field of engineering inspection, machine learning technologies have demonstrated the value of scenario-specific model optimization, which can significantly enhance their detection performance in complex engineering environments. For instance, in Reference [], researchers leveraged Bayesian optimization to automatically tune the hyperparameters of the LSTM model, addressing the inherent parameter tuning challenges of traditional machine learning methods and achieving high classification accuracy for Concrete-Filled Steel Tube (CFST) debonding defects of different levels.
Therefore, to address the core requirement of balancing dehazing performance and computational efficiency in the scenario of UAV-based transmission line inspection, this paper proposes a fast multi-patch hierarchical algorithm based on machine learning. This approach enhances defogging effects in drone inspection photos of power transmission lines by incorporating high-frequency guidance to improve the attention mechanism and utilizing an asymmetric encoder–decoder architecture. A Mix structure module is embedded in the encoder to establish a dual-branch attention coordination mechanism. Multi-source high-frequency features guide attention allocation, integrating Laplace, Sobel-X/Y, and Prewitt operators to extract multi-directional edge features. This enhances edge capture capabilities for critical targets such as horizontal conductors and vertical towers. Simultaneously, a new fog density estimation branch based on the dark channel mean is introduced. This dynamically adjusts the weights of the dual branches according to fog concentration, resolving attention failure caused by high-frequency signal attenuation in dense fog areas. At the decoder stage, depthwise separable convolutions (DSCs) are employed to build lightweight residual modules, significantly reducing computational load while preserving feature combination capabilities. An inter-block feature fusion module is introduced at the decoder output, utilizing a multi-scale weighted fusion strategy to eliminate edge artifacts accumulated through multi-level segmentation. This further enhances edge continuity and overall image quality in the defogged output.
2. Dehazing Treatment in Non-Uniform Haze Areas
Multi-scale segmentation is a common strategy in fog removal, but existing methods suffer from issues such as fragmented inter-block features or poor scale adaptability. The algorithm proposed in this paper adopts a multi-layer architecture that progresses from coarse to fine, fully integrating features from different levels, as shown in Figure 1a. Each layer employs an asymmetric encoder–decoder structure, with asymmetry primarily manifested in the distinct modules they comprise. For each pair of encoder–decoder modules at different levels, the algorithm processes image blocks at distinct scales, reconstructing corresponding clear images at each scale. Processing at multiple scales enables richer spatial feature information and defogged downsampled images. The input raw image is segmented into multiple non-overlapping blocks as inputs for each scale. This approach alters the receptive field by varying the image size, thereby capturing more feature information and enhancing image clarity.
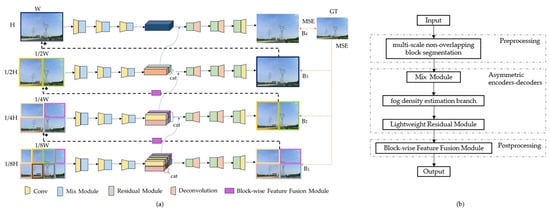
Figure 1.
The algorithmic framework proposed in this paper is illustrated in Figure (a), and the algorithm flow is shown in Figure (b).
This structure comprises four distinct scales (, ), each of which segments the input image into number of non-overlapping image blocks. Let denote the input image, represent the scale, and the block. Here, indicates the number of image blocks at each scale, and denotes the final defogged output image. Through the aforementioned multi-scale process, richer spatial guided features can be obtained, which can be expressed as Equation (2):
where denotes the non-uniform dehazing algorithm proposed in this paper, and represents the training parameters. Since the algorithm is recurrent, serves as the intermediate state features to enable cross-scale flow from to . Each encoder branch consists of 3 convolutions, with a Mix structure module following each convolutional layer. Furthermore, in each decoder branch, a residual module is placed prior to each deconvolutional layer. The blue arrow denotes the intermediate feature map , which is obtained by performing dual upsampling on and the input original image.
The workflow of the algorithm proposed in this paper is illustrated in Figure 1b. First, the input hazy image is divided into non-overlapping blocks according to the aforementioned 4 scales, and then each block under different scales is separately fed into the asymmetric encoder–decoder at the corresponding level. Blocks and scales interact through cross-scale feature flow—after bilinear upsampling, the block features of the previous scale serve as the initialization features of the corresponding block in the next scale, ensuring the coherence of block features across different scales. Specifically, the encoder embeds a Mix structure module to construct the dual-branch attention mechanism, and at the same time, the fog density estimation branch calculates the haze concentration based on the dark channel mean to dynamically adjust the weight allocation between the low-frequency global perception branch and the high-frequency local enhancement branch in the Mix module; the decoder adopts DSC to construct lightweight residual modules for feature reconstruction. Then, the inter-block feature fusion module performs weighted fusion processing on the reconstructed features of each block at layers B1 (1/2) and B2 (1/4), eliminating inter-block artifacts caused by multi-block division. Finally, the fused features are output as haze-free images.
2.1. Asymmetric Encoders-Decoders
Current mainstream lightweight networks, such as MobileNet and EfficientNet, are designed to optimize end-to-end computational efficiency. They adopt strategies like depthwise separable convolution to reduce the parameter count and computational complexity; however, they focus on balanced efficiency improvement across all modules, leading to inadequate performance in complex scenarios. To address the problems of increased computational complexity and blurred edge feature regions in dehazing algorithms, this paper employs an asymmetric encoder–decoder structure.
Within the architecture proposed in this paper, asymmetry is primarily achieved through the differentiation of modules in the encoder and decoder branches. The decoder module is composed of 2 deconvolutional layers, 3 lightweight residual modules, and 1 convolutional layer. Each of these 3 lightweight residual modules contains two DSC, with a ReLU activation function placed in the middle, as illustrated in Figure 2. The encoder module consists of 3 convolutional layers and 3 hybrid modules. Specifically, each module within the residual modules comprises two standard convolutions, with a ReLU activation function inserted in between, as illustrated in Figure 3.
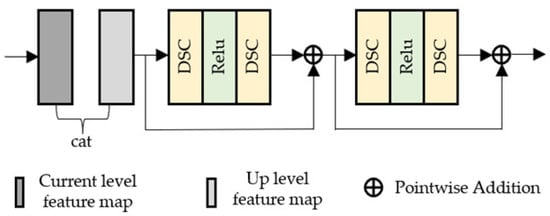
Figure 2.
Lightweight Residual Module.
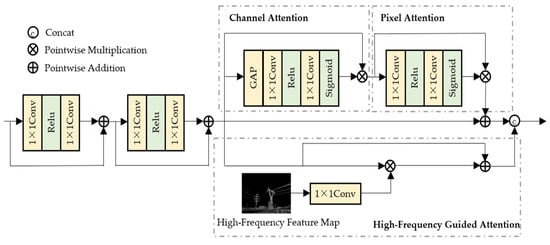
Figure 3.
Mix Structure Module.
In contrast, standard convolutions are employed in the hybrid structure modules of the encoder branches to avoid the inter-channel information disconnection caused by DSC. Additionally, an attention mechanism guided by high-frequency feature maps is introduced into these branches to ensure the complete extraction of density differences and edge details in non-uniform hazy regions. Meanwhile, the decoder adopts DSC to reconstruct the features extracted by the encoder into haze-free images, which can reduce computational complexity while maintaining the feature combination capability.
To eliminate the inter-block edge artifacts accumulated across multiple levels, such as the inter-block discontinuity of transmission lines, an inter-block feature fusion module is introduced at the output of the decoder. Input images of different scales are processed through a pair of encoders-decoders, denoted as and (), yielding the global feature , as formulated in Equation (3):
where
denotes the intermediate feature of the previous level, which enables cross-scale feature flow and avoids inter-block discontinuity. The inter-block weights are calculated via cosine similarity to achieve smooth fusion, as shown in Equation (4):
Scale requires no fusion and directly outputs the global feature map for generating the final haze-free image , as shown in Equation (5):
2.2. Mix Structure Module
The Mix structure module is embedded in the encoder and comprises a residual module and an attention module guided by high-frequency feature maps. The overall structure of the module is illustrated in Figure 3.
Existing high-frequency guided methods mostly suffer from problems such as a single branch, poor noise resistance, or low adaptability. To address these issues, this paper achieves differentiated advantages through a dual-branch collaboration and noise-resistant optimization approach. The core structure of the dual-branch attention collaboration module consists of two complementary branches: a low-frequency global perception branch and a high-frequency local enhancement branch. A frequency domain decomposition strategy is adopted to realize the collaborative optimization of global context modeling and local detail preservation, thereby improving the network’s adaptability to the non-uniform distribution of haze. This hierarchical attention mechanism can dynamically adjust the feature weights of different channels and spatial positions, effectively overcoming the limitations of traditional methods.
The low-frequency global perception branch cascades Channel Attention (CA) and Pixel Attention (PA) to model cross-channel dependencies and spatial local features, respectively. Feature extraction is performed on the input image via a residual module to obtain a shallow feature map, which is then fed into the attention module guided by high-frequency features.
CA primarily focuses on the importance of different channels in the feature map, enabling effective extraction of global information and adjustment of the channel dimension of features. It aggregates spatial information through a global average pooling operation and then employs convolutional layers to learn the weight of each channel, assisting the model in enhancing the feature channels most useful for the current task. Assuming the feature map is , CA can be expressed as Equation (6):
where denotes pointwise convolution; represents the assignment of different weights to each channel; and stands for global average pooling.
PA, by contrast, focuses more on the importance of each pixel in the feature map, enhancing the representational capability of the feature map and the detailed features of the image. The pixel attention module enables the model to better focus on high-frequency regions in the image, assigning higher weights to regions with significant variations in fog density, thereby improving the dehazing effect. Pixel attention can be expressed as Equation (7):
where denotes the feature map after pixel attention.
In the high-frequency local enhancement branch, the given hazy image is denoised using a Gaussian function to pre-smooth the image. Subsequently, the Laplacian operator is employed to separate the texture edge information in the image, and information interaction is performed through convolution operations to obtain high-frequency features of the image. To compensate for the directional limitation of a single operator, multi-directional edge features—including Sobel-X (horizontal), Sobel-Y (vertical), and Prewitt (diagonal)—are fused to fully capture the edges of horizontal conductors and vertical towers of transmission lines. Finally, the two types of high-frequency edge features are fused and used as weight information to guide the model in learning the edge information of the image from the image features. Detailed explanations of each operator are provided in Appendix A.
To address the issue of attention mechanism failure caused by high-frequency signal attenuation in dense haze regions, an additional fog density estimation branch is introduced, which adjusts the weights of the dual branches based on an adaptive fog density-guided mechanism. Firstly, the fog density is estimated via the dark channel mean value, as shown in Equation (8):
where denotes the RGB channels; represents the local window of the image; stands for the pixel value of channel at coordinates .
Subsequently, the weights of the dual branches are adjusted according to : global guidance is enhanced in dense haze, while local guidance is strengthened in light haze, as shown in Equation (9):
where denotes the finally output feature map; is the fused multi-directional high-frequency edge feature map.
This feature attention mechanism adopts a differentiated weight allocation strategy to dynamically adjust inter-channel dependencies and spatial features, assigning adaptive attention weights to different channels and pixels. Furthermore, high-frequency features, which provide abundant multi-scale edge prior information, are introduced as attention modulation factors to guide the network in strengthening edge regions during feature learning. This mechanism allocates more weights to image edge regions, thereby improving the dehazing effect in dense haze regions.
2.3. Block-Wise Feature Fusion Module
Although the block-wise features output by the decoder can effectively preserve local image details, the non-overlapping block processing method is prone to causing the problem of inter-block edge discontinuity. To address this issue, this paper proposes an inter-block attention fusion module at the output end of the decoder, as illustrated in Figure 4. Through the core strategies of cross-scale feature alignment, cosine similarity-based edge continuity quantification, and region-wise weighted fusion, this module effectively resolves the inter-block edge discontinuity problem.

Figure 4.
Block-wise Feature Fusion Module.
Feature alignment is guided by the global feature after fusion at the previous scale, which calibrates the spatial deviation of adjacent blocks at the current scale and avoids edge misalignment caused by block cropping. is enlarged to the resolution of the current scale via bilinear upsampling to obtain the guiding feature map , as shown in Equation (10):
For adjacent blocks at the current scale, with as the reference, extract the right pixel region of the edge region of one adjacent block and the left pixel region of the edge region of the other adjacent block. Then, find the regions with the maximum grayscale correlation to them in , respectively, and calculate the spatial offsets and . We define the edge offset threshold . If condition or is satisfied, spatial translation calibration is performed on to ensure edge alignment.
Perform global average pooling only on the calibrated edge regions to compress the spatial dimensions and obtain edge feature vectors, as shown in Equation (11):
Calculate the cosine similarity of the feature vectors of adjacent blocks to quantify edge continuity. If the edges of the two blocks are continuous, sim approaches 1; if the edges are discontinuous, sim approaches below 0.3, as shown in Equation (12):
Weighted fusion only weights the edge connection region , while retaining the original features in non-overlapping regions to avoid distortion in non-edge regions. For each pixel in the connection region, weighting is performed according to similarity to highlight continuous edge features; original features are retained in non-connection regions, as shown in Equation (13):
2.4. Loss Function
The loss function serves as a performance evaluation metric that dynamically quantifies the prediction deviation of the model during training. Through gradient-based optimization strategies, it continuously drives parameter updates, guiding the model toward convergence to an optimal or sub-optimal solution. This process enhances the model’s representational learning capability and task-specific adaptability.
This paper adopts a multi-scale progressive optimization approach, where, within a coarse-to-fine hierarchical structure, the output images at each scale are constrained to restore the true haze-free scene. Accordingly, the training loss is defined as the Mean Square Error (MSE) between the dehazed result at each scale and the corresponding ground-truth image. This ensures consistent dehazing performance and detail fidelity across different resolution levels, as formalized in Equation (14):
where denotes the , and represent the dehazed image and the ground-truth image at the scale, respectively, indicates the weight assigned to each scale, and , , specify the dimensions of the multi-scale images.
Furthermore, to mitigate stripe artifacts in the dehazed images, a Laplacian loss is introduced, as defined in Equation (15):
where denotes the pixel coordinates in the image, and represents the Laplacian operator.
Furthermore, to constrain the edge consistency after inter-block fusion, an additional edge consistency loss is introduced to ensure the matching degree between the edges of the dehazed image and the real edges, as defined in Equation (16):
Therefore, the total loss is defined as follows in Equation (17):
where is used to control the influence of the Laplacian loss and the gradient consistency loss.
3. Analyze the Performance and Runtime Consumption of the Algorithm
3.1. Processing of Detection Algorithm Datasets
The experimental validation was conducted on multiple datasets: the NH-HAZE20 [] and NH-HAZE21 [] datasets for non-uniform haze removal, the O-HAZE [] dataset for homogeneous haze removal, the NTIRE2021 test set with NH-Haze20 as additional evaluation data, and a self-built transmission line haze dataset. The NH-HAZE20 dataset contains 55 hazy-clear image pairs with a resolution of 1600 × 1200, featuring diverse outdoor scenes with non-uniform haze distribution. The NH-HAZE21 dataset includes 25 hazy-clear image pairs. The O-HAZE dataset, originally proposed for the NTIRE-2018 dehazing challenge, consists of 45 hazy-clear image pairs. The self-built transmission line haze dataset comprises 54 hazy-clear image pairs captured in real-world transmission line scenarios. To address the issue of limited data volume in the dataset, this experiment implements sample expansion through data augmentation strategies to ensure the model training effect. The specific experimental training settings of the proposed algorithm are shown in Table 1.

Table 1.
Training Details of the Proposed Algorithm.
In accordance with the evaluation standards of the NTIRE Non-Homogeneous Image Dehazing Challenge, this experiment adopted three metrics to comprehensively evaluate the algorithm’s performance. The peak signal-to-noise ratio (PSNR) was used to quantify the reconstruction quality of images affected by lossy compression, while the structural similarity index (SSIM) assessed the structural similarity between image pairs. Additionally, runtime was measured to evaluate the computational efficiency of the algorithm.
3.2. Performance and Time Consumption Analysis
To evaluate the performance of the proposed algorithm, this study selected four representative and advanced dehazing algorithms for comparison: DCP [], AOD-Net [], GridDehaze [], DMPHN [], MSBDN [] and Dehamer []. To ensure the reliability of the comparative results, all compared methods were trained and tested under a unified experimental environment, including consistent hardware configurations, training data, and test sets, thereby eliminating the influence of environmental factors on the performance evaluation.
For the objective analysis of the detection algorithm’s performance and time consumption, the results are shown in Table 2. The experimental results on NH-HAZE20, NH-HAZE21, O-HAZE, and the self-built foggy transmission line inspection dataset indicate that the proposed algorithm significantly outperforms the comparative algorithms in terms of image quality evaluation metrics, namely PSNR and SSIM. Meanwhile, to verify the computational efficiency of the proposed algorithm, the average processing time per image was calculated. Experiments show that the proposed algorithm reduces the processing time by approximately 19% compared with the DMPHN algorithm. The advantages exhibited by the proposed algorithm stem from its in-depth optimized design tailored to the particularities of dense haze regions and the comprehensiveness of its feature modeling for complex foggy scenarios. Specifically, in the dual-branch attention mechanism guided by high-frequency information, an additional fog density estimation branch is introduced. This branch quantifies the haze concentration of each pixel via a formula, dynamically adjusts the weights of the dual branches, and thereby avoids the high-frequency feature failure problem that is prone to occur in dense haze regions. Furthermore, through the cross-scale feature flow mechanism combined with the inter-block feature fusion module at the output end, the problems of long-distance feature separation and color inconsistency caused by local processing are effectively avoided.
Table 2.
Quantitative comparison with different algorithms across multiple datasets.
For the subjective performance analysis of the detection algorithms, Figure 5, Figure 6, Figure 7 and Figure 8 present the visual comparisons of different algorithms on various datasets, respectively. Experimental analysis indicates that the traditional DCP algorithm has obvious limitations in dehazing performance, exhibiting insufficient brightness, severe color distortion, and detail loss across different datasets. Mainstream deep learning-based image dehazing methods, namely AOD-Net and GridDehaze, suffer from more severe haze residue issues on non-uniform haze datasets, as shown in Figure 5 and Figure 6. On the uniform haze dataset in Figure 7, they have less haze residue but generate dehazed images with an overall dark color. Moreover, while improving the dehazing effect, GridDehaze distorts the original colors of the scene, leading to significant color deviation in the dehazed images—for instance, the unnatural colors in the sky area in Figure 7 and the grass area in Figure 6. The DMPHN algorithm achieves remarkable improvements in color recovery and dense haze area restoration through multi-scale feature fusion based on a multi-block hierarchical architecture. However, it has more prominent problems of local artifacts in Figure 8 and color irregularities in the sky area in Figure 7. MSBDN realizes effective cross-scale feature fusion via dense connections and feature feedback, which considerably enhances dehazing performance, with results close to real images. Nevertheless, it exhibits color distortion in large sky areas in Figure 7 and Figure 8, as well as black artifacts in dense haze regions on the ground in Figure 6. Dehamer dynamically fuses the global features of Transformer and the local features of CNN, also improving dehazing performance, but it still produces a large number of black artifacts in the sky area in Figure 7 and obvious edge blurring in Figure 5.

Figure 5.
Comparative Evaluation with State-of-the-Art Algorithms on the NH-HAZE20 Dataset.

Figure 6.
Comparative Evaluation with Competing Algorithms on the NH-HAZE21 Dataset.

Figure 7.
Comparative Evaluation with State-of-the-Art Algorithms on the O-HAZE Dataset.

Figure 8.
Comparative Evaluation with State-of-the-Art Algorithms on Self-Built Foggy Transmission Line Dataset.
In contrast, the proposed algorithm demonstrates excellent color restoration capability and edge preservation performance on dehazing datasets. Leveraging the high-frequency guided dual-branch attention mechanism in the encoder, the low-frequency branch models the global color distribution, while the high-frequency branch captures image edge textures, effectively avoiding color distortion issues—for example, preserving the natural color transition in sky areas. Meanwhile, the decoder adopts a lightweight residual module constructed with depthwise separable convolution, which reduces computational redundancy while ensuring feature expression capability. Coordinated with the inter-block feature fusion module at the output end, it avoids artifacts caused by multi-block processing and further enhances edge information. However, when handling certain extreme dense haze scenarios—such as the dense haze area around the wooden stake in Figure 5—the algorithm still has the shortcoming of a small amount of residual haze, limited by the objective condition of severe attenuation of high-frequency signals. Overall, its dehazing performance in most practical scenarios, such as non-uniform haze and uniform haze, significantly outperforms that of comparative methods. It better enables the complete restoration of target contour boundaries, providing image data support for subsequent downstream tasks such as fault detection.
3.3. Ablation Experiments of Algorithms
To validate the necessity of each module in the proposed algorithm, ablation studies were conducted with the following four experimental configurations:
- Model 1: A model using standard residual modules in both the encoder and decoder;
- Model 2: Based on Model 1, an attention module is incorporated into the encoder;
- Model 3: Based on Model 2, an inter-block feature fusion module is incorporated into the decoder part;
- Model 4: To further improve Model 3, an asymmetric network model is proposed, where the decoder is replaced with lightweight residual modules.
The same NH-HAZE20/21 and O-HAZE training datasets are used in this paper to train each algorithm, and performance evaluation is conducted, with the experimental results shown in Table 3. The results indicate that Model 1 has poor dehazing performance. With the assistance of the multi-directional edge feature-guided attention mechanism, Model 2 provides more natural results in dense haze regions. However, due to the block-wise strategy of the overall structure, the dehazed images suffer from inter-block artifacts. Model 3’s inter-block fusion effectively restores the overall texture of the image and avoids inter-block artifacts; nevertheless, its processing speed slows down due to improved performance and increased parameters. In contrast, the complete model proposed by us—Model 4—achieves a better balance among performance, complexity, and speed. This verifies that the proposed lightweight design effectively reduces redundant parameters and computational costs while shortening the algorithm’s running time.
Table 3.
Quantitative Comparison of Ablation Studies Across Different Datasets.
4. Conclusions
To address the problem of edge blurring in mountainous transmission line inspection images caused by non-uniform haze, as well as the drawback of low operational efficiency in traditional dehazing algorithms due to high network complexity, this paper proposes a multi-block hierarchical dehazing network based on high-frequency guided feature fusion. The network adopts an asymmetric encoder–decoder with residual channels as its core framework: at the encoder end, a Mix structure module is embedded to construct a dual-branch attention mechanism—the low-frequency branch cascades channel attention and pixel attention to model global features, while the high-frequency branch fuses Laplacian, Sobel-X/Y, and Prewitt operators to extract multi-directional edge features, adapting to the structural characteristics of transmission lines; an additional fog density estimation branch based on the dark channel mean dynamically adjusts the weights of the dual branches, solving the problem of attention failure in dense haze regions. At the decoder end, lightweight residual modules constructed with depthwise separable convolution reduce computational overhead while maintaining feature expression capability; the inter-block feature fusion module at the output stage eliminates cross-block artifacts through cross-scale feature alignment, cosine similarity-based edge continuity quantification, and region-wise weighted fusion. Experimental results demonstrate that the proposed algorithm outperforms other comparative algorithms on various datasets.
Despite these advantages, the algorithm still has limitations in extremely dense haze scenarios: when the haze concentration is excessively high (e.g., the area around the wooden stake in Figure 5), the restored images will have a small amount of residual haze and slightly blurred edges. This is because high-frequency signals are severely attenuated in extremely dense haze environments, leading to insufficient feature extraction by the high-frequency branch in the Mix module. Two improvement directions will be adopted in the future: (1) Fuse infrared and visible images to supplement high-frequency information. (2) Design an adaptive weight adjustment strategy based on fog density and add a residual connection to the high-frequency branch.
In addition, the proposed algorithm can be migrated to other vision tasks requiring visibility enhancement. In the field of autonomous driving, by adjusting edge extraction operators to focus on road markings, vehicles, and pedestrians, the framework can be adapted to visibility enhancement tasks under adverse weather conditions; in the field of infrared image restoration, the high-frequency branch can be modified to extract thermal edge features, improving the clarity of thermal imaging targets under low-visibility conditions. This generalization potential is not limited to the scenario of transmission line inspection but also provides insights into visibility enhancement in various complex environments.
Author Contributions
Conceptualization, L.G.; methodology, J.S.; software, L.G.; validation, L.G. and R.H.; formal analysis, L.G.; investigation, L.G.; resources, J.S.; data curation, L.G.; writing—original draft preparation, L.G.; writing—review and editing, L.G.; visualization, J.S.; supervision, J.S.; project administration, R.H.; funding acquisition, J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (NSFC), grant number 52277012.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
We present three classic edge extraction operators relied on by the high-frequency local enhancement branch in the Mix module, namely Sobel-X, Sobel-Y, and Prewitt.
Appendix A.1. Laplacian Operator
The Laplacian operator is a second-order differential operator that quantifies the gray-level change rate of image pixels. It is highly sensitive to edge regions (where gray levels change sharply) and can effectively separate texture edge information from the background, laying the foundation for subsequent multi-directional edge fusion.
For a given image pixel , the discrete form of the Laplacian operator is:
where denotes the pixel coordinates; , , , are the gray values of the four adjacent pixels (up, down, left, right) of ; and represent the input image and the sharpened image, respectively.
Appendix A.2. Sobel Operator
The Sobel operator is a first-order differential operator that extracts edge features in specific directions (horizontal and vertical) through convolution with directional kernels. It balances edge detection and noise suppression by assigning different weights to adjacent pixels, making it suitable for extracting structured edges of transmission lines.
The Sobel operator consists of two orthogonal convolution kernels, corresponding to horizontal and vertical edge detection:
Appendix A.3. Prewitt Operator
The Prewitt operator is a first-order differential operator similar to the Sobel operator, but with equal weights for adjacent pixels. It has stronger noise resistance and is mainly used to extract diagonal edge features, supplementing the horizontal/vertical edge extraction capabilities of the Sobel operator.
The Prewitt operator includes two diagonal convolution kernels, corresponding to two diagonal directions:
Appendix A.4. Fusion Logic of Operators
In the high-frequency local enhancement branch, the outputs of the three operators are fused through element-wise addition, as expressed in the following formula:
where denotes convolution operation; is the fused multi-directional high-frequency edge feature map.
References
- Gao, Y.; Hu, Y.; Liu, M.; Huang, Y.; Sun, P. Multi-UAV Transmission Line Inspection Joint Trajectory Design Method. J. Electron. Inf. Technol. 2024, 46, 1958–1967. [Google Scholar] [CrossRef]
- Xiao, Z.; Wang, H. Fault Detection of Typical Small Targets on High-Voltage Transmission Lines via Image Dual-Segmentation and Multi-Feature Fusion in Wavelet Domain. Power Syst. Technol. 2021, 45, 4461–4470. [Google Scholar] [CrossRef]
- Wu, X.; Gao, Q.; Huang, S.; Wang, K. Adaptive Retinex Image Defogging Algorithm Based on Depth-of-Field Information. Laser Optoelectron. Prog. 2023, 60, 1210013. [Google Scholar] [CrossRef]
- Wen, Y. Research on Infrared Image Enhancement Algorithm Based on Improved Adaptive Histogram Equalization. Chang. Inf. Commun. 2025, 38, 87–90. [Google Scholar] [CrossRef]
- Zhao, P.; Li, Z. Solution Method for Dynamic PDE Models of Gas Pipeline Networks Based on Discretization and Linearization. Adv. Eng. Sci. 2025, 57, 277–288. [Google Scholar] [CrossRef]
- Cantor, A. Optics of the Atmosphere—Scattering by Molecules and Particles. IEEE J. Quantum Electron. 1978, 14, 698–699. [Google Scholar] [CrossRef]
- Zhang, Q.; Chi, J.; Chen, Y.; Zhang, C. Multi-Branch Dehazing Network Based on Haze Density Classification and Dark-Bright Channel Priors. Comput. Res. Dev. 2024, 61, 762–779. [Google Scholar]
- Xu, W.; Zhang, Y.; Zhang, J.; Ling, F.; Li, S. Gradient-Guided Polarization Estimation for Image Dehazing. Acta Electron. Sin. 2024, 52, 2011–2024. [Google Scholar] [CrossRef]
- Song, C.; Tang, Y.; Qiao, M.; Liu, S.; Liu, D. Image Dehazing Algorithm for Mitigating Halo Artifacts and Color Distortion in Smooth Regions. Comput. Aided Des. Comput. Graph. 2022, 34, 953–969. [Google Scholar] [CrossRef]
- Yadav, S.K.; Sarawadekar, K. Effective Edge-Aware Weighting Filter-Based Structural Patch Decomposition Multi-Exposure Image Fusion for Single Image Dehazing. Multidimens. Syst. Signal Process. 2023, 34, 543–574. [Google Scholar] [CrossRef]
- Guo, S.; Lu, W.; Sun, J.; Liu, D.; Zhou, X.; Jiang, P. Single-Photon Laser Imaging Through Fog Based on Single-Quantity Estimation Method. Opt. Precis. Eng. 2021, 29, 1234–1241. [Google Scholar] [CrossRef]
- Chung, W.Y.; Kim, S.Y.; Kang, C.H. Image Dehazing Using LiDAR Generated Grayscale Depth Prior. Sensors 2022, 22, 1199. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, J.; Huang, T.; Han, Q.-L.; Ma, G.; Zhu, B. RaLiBEV: Radar and LiDAR BEV Fusion Learning for Anchor Box Free Object Detection Systems. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 4130–4143. [Google Scholar] [CrossRef]
- Chen, Y.; Tai, Y.; Meng, F.; Zhang, Z. EGAD: An Edge-Guided Attention Dehazing Network for Aircraft Landing Views. J. Electron. Imaging 2025, 34, 013051. [Google Scholar] [CrossRef]
- Ma, W.; Zhang, Y.; Guo, J. Image Dehazing via Depth Prior Guidance and Ambient Light Optimization. Acta Electron. Sin. 2022, 50, 1708–1721. [Google Scholar]
- Lu, L.; Xiong, Q.; Xu, B.; Chu, D. MixDehazeNet: Mix Structure Block for Image Dehazing Network. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–10. [Google Scholar] [CrossRef]
- Shi, Z. Dynamic Convolution-Based Image Dehazing Network. Multimed. Tools Appl. 2023, 83, 49039–49056. [Google Scholar] [CrossRef]
- Tran, L.; Park, D. Lightweight Image Dehazing Networks Based on Soft Knowledge Distillation. Vis. Comput. 2024, 41, 4047–4066. [Google Scholar] [CrossRef]
- Tao, F.; Chen, Q.; Fu, Z.; Zhu, L.; Ji, B. LID-Net: A Lightweight Image Dehazing Network for Automatic Driving Vision Systems. Digit. Signal Process. 2024, 154, 104673. [Google Scholar] [CrossRef]
- Wei, Y.; Li, J.; Wei, R.; Lin, Z. A Lightweight Attention—Based Network for Image Dehazing. Signal Image Video Process. 2024, 18, 7271–7284. [Google Scholar] [CrossRef]
- Wang, S.; Mei, X.; Kang, P.; Li, Y.; Liu, D. DFC-Dehaze: An Improved Cycle-Consistent Generative Adversarial Network for Unpaired Image Dehazing. Vis. Comput. 2024, 40, 2807–2818. [Google Scholar] [CrossRef]
- Zhao, X.; Xu, F.; Liu, Z. TransDehaze: Transformer-Enhanced Texture Attention for End-to-End Single Image Dehaze. Vis. Comput. 2025, 41, 1621–1635. [Google Scholar] [CrossRef]
- Yao, M.; Chen, Z.; Li, J.; Guan, S.; Tang, Y. Ultrasonic identification of CFST debonding via a novel Bayesian Optimized-LSTM network. Mech. Syst. Signal Process. 2025, 238, 113175. [Google Scholar] [CrossRef]
- Ancuti, C.-O.; Ancuti, C.; Vasluianu, F.A.; Timofte, R. NTIRE 2020 Challenge on Nonhomogeneous Dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2029–2044. [Google Scholar] [CrossRef]
- Ancuti, C.-O.; Ancuti, C.; Vasluianu, F.A.; Timofte, R. NTIRE 2021 Nonhomogeneous Dehazing Challenge Report. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 627–646. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.-O.; Timofte, R. NTIRE 2018 Challenge on Image Dehazing: Methods and Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 891–901. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [CrossRef]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-Net: All-in-one dehazing network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4780–4788. [Google Scholar] [CrossRef]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar] [CrossRef]
- Das, S.D.; Dutta, S. Fast Deep Multi-patch Hierarchical Network for Nonhomogeneous Image Dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1994–2001. [Google Scholar] [CrossRef]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Guo, C.L.; Yan, Q.; Anwar, S.; Cong, R.; Ren, W.; Li, C. Image dehazing transformer with transmission-aware 3D position embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5812–5820. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).