Abstract
Online advertising is vital for reaching target audiences and promoting products. In 2020, US online advertising revenue increased by 12.2% to $139.8 billion. The industry is projected to reach $487.32 billion by 2030. Artificial intelligence has improved click-through rates (CTR), enabling personalized advertising content by analyzing user behavior and providing real-time predictions. This review examines the latest CTR prediction solutions, particularly those based on deep learning, over the past three years. This timeframe was chosen because CTR prediction has rapidly advanced in recent years, particularly with transformer architectures, multimodal fusion techniques, and industrial applications. By focusing on the last three years, the review highlights the most relevant developments not covered in earlier surveys. This review classifies CTR prediction methods into two main categories: CTR prediction techniques employing text and CTR prediction approaches utilizing multivariate data. The methods that use multivariate data to predict CTR are further categorized into four classes: graph-based methods, feature-interaction-based techniques, customer-behavior approaches, and cross-domain methods. The review also outlines current challenges and future research opportunities. The review highlights that graph-based and multimodal methods currently dominate state-of-the-art CTR prediction, while feature-interaction and cross-domain approaches provide complementary strengths. These key takeaways frame open challenges and emerging research directions.
1. Introduction
Over the past decade, rapid advancements in information technology have considerably changed the advertising and marketing industry [1]. Advertisers increasingly use various technological methods to promote their products and services more effectively and in a timely manner. This shift has resulted in the widespread use of online advertising as a crucial modern marketing communication tool [2]. Due to the increased amount of time that people of various socioeconomic levels spend on the internet, online advertising is used in e-commerce advertising and as a means of distribution. There are several key reasons why the internet has become an important advertising medium. These include the shift of television viewers to the internet, the increased time people spend on mobile devices and tablets, and the widespread availability of advanced technology and communication networks. Consequently, advertisers increasingly use social networking sites such as Facebook, Twitter, and YouTube to promote their products, as they recognize the value of online advertising as an essential tool for reaching potential customers [3]. Figure 1 shows the effect of online advertisements distributed via the internet to GetResponse customers from January to December 2023 [4], specifically through email, and the click-through rate (CTR) for these ads in various European countries.

Figure 1.
The email CTR in various European countries.
Online advertising is currently regarded as the most effective method of reaching a target audience personally. By leveraging users’ pages on various platforms, online advertising has become crucial for promoting products, raising awareness, and influencing purchase decisions. While direct sales may not occur through these platforms, marketers recognize their importance in building customer relationships and maximizing ad visibility and exposure. Hence, online advertising has emerged as a dominant force within the industry. Online advertising revenue in the US rose from $124.6 billion to $139.8 billion in 2020, a 12.2 percent increase from 2019 [5]. The online advertising industry is projected to reach 487.32 billion by 2030 [6].
The rise of artificial intelligence (AI) in advertising presents tremendous potential and opportunities. It allows for more targeted, efficient, and effective advertising. AI has improved the CTR, which measures the ratio of users clicking on an ad to the total number of users viewing the ad [7]. This metric is crucial in evaluating the effectiveness of online advertising [8]. The CTR directly impacts the success of online businesses, making it a fundamental measure of online advertising quality for these companies [9]. AI creates personalized and pertinent advertising content by analyzing extensive data, comprehending user behavior, and providing real-time predictions. This AI capability eliminates the need for traditional advertising methods, thereby enhancing the effectiveness, efficiency, and appeal of online advertising [10,11].
Despite this rapid progress, existing surveys on CTR prediction remain fragmented and limited in scope. Some prior works provide broad overviews of recommendation systems or advertising technologies. Still, they do not specifically synthesize the advances in CTR prediction driven by deep learning across multiple data modalities. Some surveys focus on specific aspects of CTR prediction, such as feature interactions or graph models, which creates gaps in understanding the connections between methods. Without a comprehensive review, researchers may duplicate efforts, miss opportunities, and struggle to identify challenges. Therefore, this review is necessary to make more contributions, highlight the state-of-the-art, and provide a forward-looking perspective that can guide both academic research and industrial practice in CTR prediction. This survey focuses on CTR prediction research from the last three years. As deep learning advances—especially in transformer architectures, multimodal data integration, and distributed training—traditional methods are becoming outdated. Earlier surveys do not cover the recent innovations in the field. By highlighting trends from the most recent three years, this review offers an updated perspective that complements existing surveys.
The contributions of this survey can be summarized as follows:
- This paper addresses gaps in previous surveys, emphasizes the need for an updated perspective and reviews state-of-the-art CTR prediction methods (those that demonstrate competitive or superior performance on widely used public datasets using standard metrics and/or those validated in industrial-scale deployments) published in the last three years as well as those that were not covered by previous surveys (e.g., [5,12,13,14]). By focusing on developments from the last three years, it highlights key advancements that provide valuable insights for researchers and practitioners.
- We expand existing knowledge by outlining a taxonomy of CTR prediction methods, which are divided into two main categories: text-based methods and multivariate data-based methods. The multivariate data-based methods are further classified into four groups: graph-based approaches, feature interaction methods, customer behavior techniques, and cross-domain methods. This layered classification highlights methodological complementarities and clarifies how different techniques address distinct challenges in CTR prediction.
- We provide a synthesized state-of-the-art summary that identifies graph-based and multimodal methods as the leading approaches, highlights complementary strengths of feature-interaction and cross-domain techniques, and distills key takeaways to guide future CTR research. For instance, graph-based models consistently demonstrate superior scalability on industrial-scale datasets. At the same time, multimodal methods show clear benefits from combining text, image, and behavioral signals.
- Finally, we identify open challenges and forward-looking research directions, including multimodal integration, transfer learning for cold-start and generalization challenges, meta-learning, and distributed edge computing, thereby providing a roadmap for future work that builds upon and extends the current CTR prediction methods.
The paper is organized as follows. Section 3 introduces the background of digital marketing and the CTR. Section 2 describes the methodology used to identify the works covered in this review. Section 4 presents the background of click-through prediction. Section 5 explores and analyzes state-of-the-art CTR prediction methods. Section 6 introduces the challenges facing current CTR prediction methods and recommends future research directions for overcoming these challenges. Section 7 concludes the paper.
2. Research Methodology
We outline the methodology for identifying works in this review to ensure transparency and reproducibility. We searched multiple academic databases, including IEEE Xplore, ACM Digital Library, SpringerLink, ScienceDirect, and Google Scholar. The searches were restricted to peer-reviewed journal articles and conference proceedings published between January 2021 and July 2024, aligning with our focus on the last three years. We employed combinations of the following keywords and Boolean strings: “click-through rate prediction” or “CTR prediction” and (“deep learning” or “neural network” or “transformer” or “graph neural network” or “multimodal” or “recommendation systems”). To capture domain-specific contributions, we also used refinements such as “CTR and advertising,” “CTR and feature interaction,” and “CTR and cross-domain.”
Inclusion criteria required that studies: proposed or evaluated a CTR prediction method, used deep learning or graph-based models, provided empirical validation using public datasets (e.g., Criteo, Avazu, MovieLens, Frappe) or industrial-scale data, and were written in English. We excluded purely theoretical works without experimental validation, non-peer-reviewed preprints, and studies focused only on traditional machine learning that were not relevant to current state-of-the-art methods. This search strategy yielded an initial set of over 300 papers. After removing duplicates and applying inclusion/exclusion criteria, we selected approximately 110 studies that form the basis of this review.
3. Background on Digital Marketing and the Click-Through Rate
A business’s ultimate ad and marketing goal is to accurately deliver information to potential consumers. In the mass marketing era, ads were designed to target the entire market without any differentiation because manufacturers needed more means to obtain multidimensional consumer information and the computational ability to analyze such data. This behavior has resulted in problems associated with high investment waste and low accuracy [15]. Thus, identifying potential customers and delivering tailored ads to those consumers has become essential in marketing. Over the past century, marketing professionals have continuously pursued precision in marketing and advertising strategies, including corner shopkeepers, direct response, and database-driven marketing.
With the internet rapidly expanding and e-commerce becoming more prevalent, companies have implemented numerous methods to gather multidimensional consumer information. The rapid advancement of data analysis techniques, such as big data, machine learning, and cognitive computing, has enabled companies to categorize various customer types and profile users accurately [16]. Consequently, companies can deliver product information directly to potential customers through targeted marketing, leading to increased effectiveness and precision [17]. Various ads exist, including images, basic cards, videos, basic and optional cards, and advertiser mentions in interactive ads. Users typically are shown one or more ads and may click on an ad if a product interests them. The ad generally shows only partial information about the product, such as an image, price, and brand. Detailed information is revealed only when the customer clicks on the ad. Therefore, the CTR is a vital metric for assessing ad effectiveness. Figure 2 shows the CTR for each quarter over the past five years, which is a series compiled by Statista from underlying industry sources from the first quarter of 2018 to the second quarter of 2024 [18]. The CTR is decreasing over time, indicating that focusing on targeted customers is essential for improvement.
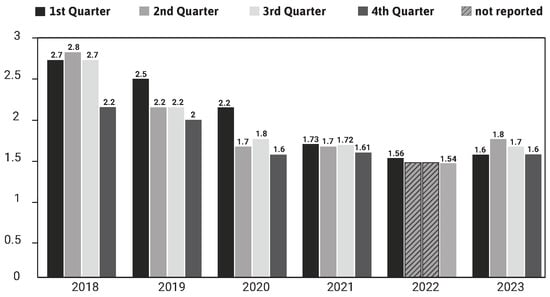
Figure 2.
The CTR for every quarter from 2018 to 2023.
The CTR is crucial in business valuation across various applications, including online advertising, recommender systems, and product search. Generally, CTR prediction is vital for accurately estimating the likelihood of a user clicking or interacting with a suggested item. A slight increase in prediction accuracy for large user base applications will undoubtedly lead to a considerable increase in overall revenue. For example, researchers from Microsoft and Google have indicated that even a slight improvement of 1% in logloss or area under the curve is considered significant in real CTR prediction problems [19]. When solving CTR prediction problems, the data are usually large scale and highly sparse. They include numerous categorical features of different characteristics. For example, app recommendations on Google Play consist of billions of samples and millions of features [20]. Constructing a model that significantly enhances CTR prediction accuracy is a formidable task. The significance of CTR and its distinctive challenges have attracted the attention of numerous researchers from both industry and academia. CTR models have evolved from simple conventional machine learning models to more complex deep learning models.
4. Click-Through Prediction
Figure 3 illustrates the typical CTR framework. It begins when a customer visits a website or app. The customer’s behavior, including their navigation of the interface and clicks on specific items, is monitored and recorded for further analysis. This behavior is then preprocessed to highlight meaningful features, making it suitable for machine learning training. Once the training is complete, a customer profile is created for the target user and integrated into the CTR prediction model. The suggested ads are subsequently presented to the target customer. This section presents an overview of CTR prediction, which can be classified into models that utilize multivariate data and models that employ text to predict click-through.
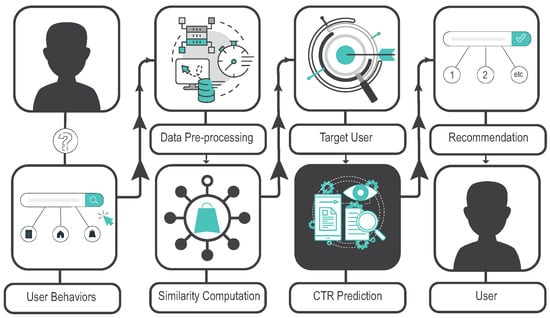
Figure 3.
The typical framework for predicting the click-through rate.
4.1. CTR Prediction Utilizing Multivariate Data
CTR prediction aims to predict the probability of a customer clicking on a given ad. Improving the accuracy of CTR prediction is undeniably a formidable research challenge. Compared with research problems that involve only one data type (e.g., texts or images), data in CTR prediction are multivariate and generally tabular. They consist of categorical, numerical, and other multivalued features. Furthermore, CTR prediction problems involve many samples, and the feature space is highly sparse. A CTR prediction model typically includes the following main components [19].
4.1.1. Embedding Features
Generally, CTR prediction input samples consist of three feature groups: item profile, user profile, and context information. Each feature group contains several fields. Item profile consists of various features, such as category, brand, tags, item ID, seller, and price. User profile comprises personal features such as gender, age, occupation, city, and interests. Context information includes other details such as position, weekday, hour, and slot ID.
Each field in these feature groups contains a different type of data, such as numeric, categorical, or multivalued data (e.g., a single item might have more than one tag). Features are very sparse and require preprocessing via one-hot or multihot encoding, which leads to a high-dimensional feature space. Thus, applying feature embedding is a common practice for mapping high-dimensional features to low-dimensional dense vectors. The embedding strategy utilizing three groups of features can be summarized as follows.
- Numeric Features: A numeric feature field i has various alternatives for feature embedding, such as the following:
- 1.
- Numeric values can be contained in discrete features by manually creating numeric values, such as grouping the age of users by age categories (e.g., grouping users aged between 40 and 59 as middle adulthood) or training them using tree-based algorithms such as decision trees. These features can then be embedded and represented as categorical features.
- 2.
- The embedding of the normalized scalar value is set, where is the intercommunicated embedding vector of the field i features and e is the embedding dimension.
- 3.
- Rather than retaining each value in one vector or allocating a given vector to each numeric field, there are other solutions, such as applying a numeric feature embedding technique to automatically incorporate the numeric feature and calculate the embedding via a meta embedding matrix [21].
- Categorical Features: A categorical feature j is assigned a one-hot feature vector and possesses an embedding , where is the embedding matrix, which is represented as , where e is the embedding dimension and w is the vocabulary size.
- Multivalued Features: A multivalued feature u has several features, each representing a sequence. Each feature embedding can be represented as , and the sequence element’s one-hot encoded vector can be denoted as , where x represents the maximal length of the sequence. The mean pooling or sum pooling can aggregate the embedding to an e-dimensional vector. Other enhancements can be applied through sequential models, such as target attention, which aggregate multivalued behavior sequence features [22,23].
4.1.2. Feature Interaction
Applying a prediction model in CTR after embedding features is straightforward; however, feature interactions (i.e., conjunctions between features) are crucial for improving prediction performance. Pairwise feature conjunctions can be captured utilizing inner products through factorization machines (FMs) [24]. Due to the success of FMs, many researchers have concentrated on capturing the conjunctions among features from various perspectives, including inner and outer products [25,26], cross-networks [27], bi-interactions [28], explicit and implicit feature interactions [29], graph neural networks [30], convolutions [31] and circular convolutions [32], bilinear interactions [33], self-attention [34], and hierarchical attention [35,36]. Several researchers have recently explored ways to merge inner and outer feature interactions with fully connected layers.
4.1.3. Evaluation Metrics
CTR prediction is a binary classification task (i.e., there are two classes: click or not); therefore, the common performance metric used is cross-entropy loss, which is denoted as:
where the training set consists of S samples and has the ground truth labels l and an estimated click probability . The estimated click probability can be represented as , where denotes the function of the model and i represents the input features. The sigmoid function that maps to can be denoted as . The core concept of predicting CTR relies on creating the model function and optimizing the parameters from the training data .
Another standard metric utilized to assess the likelihood of a randomly selected positive instance being classified as larger than a randomly chosen negative instance is the area under the ROC curve (AUC). A higher AUC is directly correlated with superior CTR prediction performance. This metric serves as a strong indicator of the predictive model’s accuracy and effectiveness. Importantly, as the user base increases, an increase in the AUC of 0.001 is significant for the CTR prediction task when deployed in industries [37].
4.1.4. Statistical Information on Datasets
Most of the surveyed research papers evaluate their methods using two publicly available datasets: Criteo, Avazu, MovieLens-1M [38], and Frappe. These datasets include real click logs in production and comprise tens of millions of instances, enabling CTR prediction models to be trained and efficiently deployed in industrial settings. Table 1 lists the statistical information of these datasets.

Table 1.
Statistics of three well-known CTR prediction datasets.
The Criteo dataset captures data on advertisement clicks gathered over a period spanning more than a week. The dataset contains 13 numerical and 26 categorical feature fields. The number of samples is approximately 49 million. The Avazu dataset consists of advertisement clicks obtained over a period of approximately ten days. The dataset contains 23 categorical feature fields and approximately 40 million samples. The MovieLens-1M dataset consists of seven feature fields and approximately 740,000 instances. The frappe dataset consists of 288,609 and 10 feature fields.
4.1.5. Prediction Models
The CTR prediction task is known to involve large-scale data. Thus, logistic regression (LR) [39] is commonly applied or utilized as a baseline model because of its simplicity and computational efficiency. Other enhanced conventional machine learning models, such as FM, field-aware FM, and gradient boosting, are adopted for CTR prediction tasks to improve computational efficiency and nonlinear expressiveness [40]. Recently, deep learning has been integrated into CTR prediction to enhance performance. Methods using recurrent neural networks (RNNs) can capture user behavior and directly extract user interests from time sequence data instead of aggregating interest vectors. For example, a model based on an RNN [41] predicts user preferences from their past click-through behavior. Additionally, an attentive capsule network (ACN) technique [42] was developed to address users’ diverse interests. To enhance performance, targeting advertisement segment groups is a highly effective technique for efficiently delivering customized ads to specific segments [43].
4.1.6. Imbalanced Data Issue
In machine learning, class imbalance is a common issue [44]. When there is an imbalanced distribution of classes in the dataset, the machine-learning model tends to favor the majority class samples over the minority class samples. Therefore, this behavior can lead to a biased output favoring the dominant class. Due to the model’s disregard for the class with fewer samples, the reliability of its performance is questionable. Thus, considerable research proposals have recently concentrated on class imbalance because of the negative effect that class imbalance might have on learning and prediction processes.
In the CTR prediction task, class imbalance techniques are mature enough and can be categorized into three categories: algorithm-level techniques, sampling methods, and ensemble methods.
Algorithm-level techniques are methods that isolate the classifier from the skewed distribution or when traditional machine learning models are adjusted and bound to a cost variable or weight [45]. Other studies have focused on addressing the issue of class imbalance at the algorithm level [46].
Sampling methods employ several steps during training to scale the class distribution by tightening samples from the majority class or appending more samples to the minority class [47]. The sampling methods are typically applied during the data preprocessing phase. These techniques involve redistributing training data from multiple classes through resampling [48]. To balance the imbalanced class, it is necessary to alter the data layout; hence, some studies resample the data to modify the instances of the analog distribution to enhance the model’s performance [49]. Resampling methods can be categorized into three classes:
- 1.
- Undersampling strategies maintain meaningful data for the learning process while ignoring instances from the majority class until each class number of instances is approximately equal. Nevertheless, when undersampling is applied to a dataset, it is expected that certain meaningful instances for the training model may be overlooked. Various undersampling methods utilize several filtering fundamentals, including the following:
- (a)
- Random undersampling is a straightforward technique that randomly discards samples from the majority class, effectively balancing the dataset [50].
- (b)
- The edited nearest neighbor (ENN) technique checks each sample against the others via k-nearest neighbors (KNN), discarding improperly identified instances and updating the dataset with the remaining samples [51].
- (c)
- The neighborhood cleaning rule (NCR) is a technique that considers the three nearest neighbors for each sample. It removes the sample that belongs to the majority class and is misclassified by its three nearest neighbors. Furthermore, the samples of the majority class that are close to an instance of the minority class and are misclassified by their three nearest neighbors are eliminated [52].
- (d)
- Near miss is a technique that selects majority instances based on their proximity to minority instances, specifically those with the least average distances from the three nearest minority samples [53].
- (e)
- The instance hardness threshold (IHT) identifies which samples from the majority class are most likely to be misclassified or redundant during training and excludes them to balance the dataset [54].
- (f)
- The Tomek links method relies on a pair of instances that belong to distinct classes and that are neighbors. These are the links for which the method considers noisy or boundary samples; thus, the boundary sample that belongs to the majority class is removed [55].
- (g)
- One-sided selection (OSS) uses the one-nearest neighbor (1-NN) technique to identify misclassified samples from both distributions (i.e., the minority class and the majority class). The Tomek links method eliminates noisy and borderline majority class samples [56]. The condensed nearest neighbor rule is then employed to remove instances that belong to the majority class, are redundant, and are distant from the decision board to form a constituent subset of the dataset.
- 2.
- Oversampling techniques provide an equal class distribution while preserving class borders; these techniques are responsible for constructing new instances from the minority class to balance the dataset. Due to the replication or synthesis of samples, these techniques are susceptible to overfitting [57]. Oversampling techniques include the following:
- (a)
- Random oversampling is the oldest oversampling technique. It replicates random instances from the minority class to equalize or approximates the majority class [58].
- (b)
- The synthetic minority oversampling technique (SMOTE) is a well-known oversampling approach. It is based on the hypothesis that the feature space of minority class samples is similar. For each minority class sample , SMOTE identifies its k nearest neighbors, and then one of the searched neighbors is randomly chosen as ; these two types of samples and are called seed instances. The method then generates a random number between . A newly synthesized instance is artificially assembled as:In contrast to the random oversampling method, SMOTE can effectively prevent overfitting.
- (c)
- Borderline SMOTE is a technique that identifies the borderline instances repeatedly misclassified by their nearest neighbors and then applies the SMOTE technique to them [59].
- (d)
- Adaptive synthetic sampling is another oversampling method that distributes the minority class samples based on their learning difficulty, constructing more synthetic instances for the minority samples that are harder to learn. Thus, the method enhances the learning concerning the data distributions in two ways:
- Decreasing the bias created by the imbalanced class is crucial for ensuring accurate results.
- The classification decision boundary is adaptively shifted toward difficult-to-learn instances, thus enhancing the learning performance.
- 3.
- Hybrid sampling methods merge oversampling and undersampling techniques to extrapolate a balanced dataset. Although these approaches demonstrate their effectiveness in a way that surpasses individual oversampling/undersampling techniques, they may still exhibit the drawbacks of these methods, such as the loss of significant information in undersampling and overfitting in oversampling. To address these drawbacks, two effective approaches have been introduced:
- (a)
- SMOTE-ENN method is introduced to perform linear interpolation between neighboring minority class instances to produce new minority class instances, effectively resolving the issue of substantial data overlap compared with random oversampling [60]. The k nearest neighboring instance of the same class C is found for each sample that belongs to the minority class and can be represented as . Then, i samples can be selected from class C and represented as . Random linear interpolation is achieved on the lines between and . Thus, the synthetic instance can be represented as:where is the synthetic sample, o is a random coefficient between 0 and 1, and is a vector that contains the synthetic samples.
- (b)
- SMOTE-Tomek is a hybrid approach that combines an oversampling method (SMOTE) and an undersampling method (Tomek links) to avoid the drawbacks of both methods [61]. The approach uses SMOTE to address overfitting issues when increasing the minority class instances. It applies Tomek links to reduce noise by removing samples that consist of pairs of data points from different classes [62].
Ensemble methods are employed to address data internally and adjust the category distribution of the instance. These techniques utilize data-level methods to change the learning process internally via well-known classifiers. This behavior prevents the model from disproportionately favoring the majority class during prediction. The notable resampling ensemble methods can be categorized as follows:
- 1.
- Balanced random forest constructs a balanced dataset from which each tree is assembled. In particular, a bootstrap instance is drawn from the minority class in each iteration. The same number of cases is randomly drawn with replacements from the majority class. A classification tree is generated from the data without pruning (i.e., to the maximum size). Finally, the final prediction is made by aggregating the ensemble (i.e., a certain number of trees) predictions [63].
- 2.
- Balanced bagging uses random undersampling and bagging to address imbalanced data. After resampling each data subgroup, balanced bagging employs integrated estimators.
- 3.
- Easy ensemble uses the AdaBoost algorithm to train multiple classifiers on a proportional subset of the data. The outputs from each classifier are then combined to create an ensemble method [64]. For the majority class samples and the minority class samples , the undersampling technique randomly selects a portion from . The selected subset of samples is usually equal to the minority samples (i.e., ). Thus, various subsets are independently sampled from the majority training set . A classifier constructed by AdaBoost is trained utilizing each subset and the complete set of the minority class . The constructed classifiers are combined to make the final decision. The learning process is as follows:where is the number of iterations, are the weak classifiers, are the corresponding weights, and is the ensemble threshold. This learning process continues until and then outputs the ensemble, which is denoted as follows:An easy ensemble trains the data in an unsupervised manner.
- 4.
- The balance cascade is similar to the easy ensemble. However, it investigates in a supervised fashion. Once the first classifier completes the training process, if a given instance is correctly classified by as part of , then it is likely that is redundant in the majority class. Therefore, some majority class instances would be removed to balance the dataset.
- 5.
- Random undersampling boost utilizes both boosting and sampling to balance the data. This method uses the random undersampling technique in each round of boosting [65]. The algorithm is given a set of samples S, represented as , which includes a minority class . Initially, the algorithm initializes each instance weight as , where z is the number of instances in the training. The H weak learners are trained in an iterative manner as follows. During training, the algorithm applies random undersampling in each iteration to the majority class samples until a specific percentage of the new subset of data , which belongs to the minority class, is obtained. The new subset of data has a new weight distribution . The base learner then receives and to construct the weak hypotheses . The pseudo-loss is then calculated for the original data and weight distribution as follows:The update parameter for the weight is then calculated as:Then, the upcoming iteration weight distribution is revised as follows:The upcoming iteration weight distribution is normalized as follows:Once the iterations are completed, the final hypothesis is acquired as a weighted vote of the weak hypotheses as follows:
4.2. CTR Prediction Utilizing Text
A commercial search engine entices user clicks by pairing search queries with multiple ads (a.k.a. sponsored search). Recent studies have suggested the use of deep learning models to detect similarities between texts and explore the application of deep learning in web searches. Additionally, many studies have suggested implementing the learning process at the word or character level to predict customers’ click-through behaviors [66].
4.2.1. Sponsored Search
Sponsored search is a feature that displays advertisements next to organic search results. The sponsored search ecosystem comprises three crucial components: the user, the search platform, and the advertiser. The search platform aims to display the advertisement that best matches the user’s intent [67]. The key concepts of the ecosystem can be interpreted in the following way:
- Query: the text entered by the user into the search engine website’s search textbox.
- Keyword: the text provided by the advertiser to match a user’s query that includes relevant product-related words.
- Title: the sponsored advertisement label chosen by the advertiser to capture the user’s attention.
- Landing page: the web page the user reaches after clicking on the corresponding advertisement, where the product is featured [68].
- Match type: an option provided to advertisers to specify how closely a user’s query should match the keyword. There are typically four match types: broad, exact, phrase, and contextual [69].
- Campaign: a set of ads with similar settings, including location targeting and budgets, that are often employed to classify products.
- Impression: an instance of a displayed advertisement by a given user that is usually saved in a log file along with other information and is available at runtime.
- Click: indicates whether a user clicks an impression. It is saved in the same log file as the impression and is available at runtime.
- Click-through rate: the total number of clicks divided by the total number of impressions.
- Click prediction: a crucial capability of the search platform. It forecasts the likelihood of a user clicking on an advertisement for a specific query.
Sponsored search is one of many web-scale applications. This approach remains challenging to implement due to the richness of the problem space, the various feature types, and the small data volume. However, features play an integral role in designating sponsored searches.
- 1.
- Sponsored search features: is available at runtime once an impression is clicked (i.e., an advertisement is displayed) and is provided offline to train the model. Features comprise two types:
- (a)
- Individual features: Each feature in the dataset is represented as a vector. Text features such as they query, keyword, and title should be converted into a suitable format for the model, such as a tri-letter gram with a given number of dimensions. Categorical features such as match type could be represented using a one-hot encoder, where, for example, the exact match could be represented as , the phrase match represented as , the broad match represented as , and the contextual match represented as . The sponsored search paradigm contains millions of campaigns, and each campaign usually has a unique ID, so converting the campaigns’ IDs into a one-hot vector (e.g., named campaign ID) would significantly increase the model’s size. Thus, using a pair of companion features to solve this issue is better. One feature consists of campaign IDs; the other represents only the top (e.g., 20,000 campaigns) with the highest number of clicks (the 20,000th cell starts with the remaining campaigns starting from an index of 0); the second feature should be a one-hot vector. Different campaigns can be represented by different numerical features that reflect the corresponding campaign’s data, such as the CTR. In some contexts, such features are called counting features in CTR prediction research. The features explained here are sparse features except for the counting features.
- (b)
- Combinatorial features: Given features and , a combinatorial feature can be represented as . Both sparse representation and dense representation are common in combinatorial features. For example, the product of the campaign ID and match type feature (campaign ID × match type) could be represented as sparse and placed into a one-hot vector of 80,004 (i.e., 20,001 × 4). An instance of a dense representation is the total number of advertisement clicks for a combination of campaign and match types. The dense representation dimension in this situation is identical to its sparse counterpart.
- 2.
- Semantic features: The raw text features (e.g., query) are mapped into semantic space features using a machine learning architecture (e.g., the DNN model) [70]. The raw text features are fed into the model as a high-dimensional term vector, such as a document, before the normalization step or counts of terms found in the query are applied. The model produces a vector in a semantic feature space with low dimensions. A web document is ranked by the model as follows:
- (a)
- It is utilized to map term vectors to their semantic vector counterparts.
- (b)
- It calculates the relevance score between a document and a query using the cosine similarity of their semantic vectors.
Let us denote v as the input (i.e., term vector), o as the output (i.e., semantic vector), as the hidden layers (i.e., usually located between the input and output layers in a neural network), as the n-th weight matrix, and as the n-th bias. Therefore, the web document ranking would be performed through the model as follows:where the function is used at the output layer as an activation function, and the hidden layers are represented as:The score of semantic relevance between a given query q and a specific document d can be estimated as follows:where is the query term vector and is the document vector. Therefore, when a user enters a query into the search engine text box, the documents are saved by their semantic relevance scores.The term vector size can be visualized as bag-of-word features. It is identical to the vocabulary employed to index the web document collection. In real-world web search tasks, the vocabulary size is significantly high. Thus, when the term vector is used as input, the input layer size of the neural network becomes uncontrollable, making it inefficient to train the model and deduce a meaningful interpretation of the input. Thus, various methods have been implemented at the word and character levels to address this issue, as discussed in the following subsection.
4.2.2. Word-Level and Character Level CTR
The research community has investigated the following two alternatives to address the issues that face text-level models.
- 1.
- Some research conveys the learning process from the text level to the word level to address the issues encountered by text-level models. The task is similar to that of text-level models (i.e., word-level models (e.g., convolutional neural networks (CNNs)) trained to learn the clicked and nonclicked sponsored impressions and output the prediction of the thought query) [66].These models process word vectors and are pretrained via external sources such as Wikipedia [71] or search logs. The search for the best way to train word vectors is still an intriguing open issue. Successful proposals with similarities in the processing phase have been introduced. Let us denote a given word as w, the word vector dimension as , the length of the fixed query as , and the length of the fixed advertisement as . Therefore, the query matrix dimension is , and the advertisement matrix dimension is .
- 2.
- The character-level prediction models process characters instead of texts or words. More formally, the input character is denoted as c, and the length of the fixed query is represented as ; thus, queries can be defined as a binary of size , which is considered a matrix of one-hot encodings. The query sequence is composed of characters. Each character in the input matrix corresponds to a tuple of size . A particular tuple consists of only one unique entry. The objective is to set the entry to 1 at the position corresponding to the dimension implied by the supposed character at the query while setting all other entries of the same tuple to 0. Therefore, the query matrix includes a value of 1, which denotes the query length ; hence, it also indicates the number of tuples in the matrix. Thus, the character in the query is encoded by the tuple in the matrix. On the one hand, if the length of the query is less than , the zero-padding mechanism is employed to fill the remaining tuples with zeroes.On the other hand, if the length of the query is more significant than , the characters that appear after the character of the query are eliminated. An identical concept is applied to represent advertisements. The textual advertisement encapsulates three essential elements: the advertisement’s display uniform resource locator (URL), description, and title. These elements are initially combined into a unique sequence and then encoded into a matrix containing one-hot encodings of size .
5. CTR Prediction Methods
CTR prediction methods can be categorized into two main categories: CTR prediction that utilizes text and CTR prediction that uses multivariate data. A comparison of these two categories reveals their respective strengths and weaknesses. Text-based models effectively leverage semantic relationships present in user queries and behavioral data, rendering them particularly advantageous in personalized contexts and cold-start situations. Nevertheless, these models encounter challenges such as out-of-vocabulary issues, data sparsity, and increased latency during inference, especially when handling large and evolving text corpora. In contrast, multivariate data-driven models—especially graph-based and feature-interaction-based methods—are highly scalable, can efficiently process large-scale categorical and numeric features, and typically deliver lower inference times due to the structured nature of their inputs. These models demonstrate superior performance in large-scale industrial applications that require both efficiency and speed, particularly when managing substantial volumes of data. However, their effectiveness may be compromised in situations that necessitate thorough feature engineering or precise relationship modeling. Furthermore, they may exhibit reduced efficacy in contexts where structured data is either minimal or noisy.
5.1. Retrieval of Items for Search Engine Methods That Utilize Text
This subsection reviews the approaches that predict CTR that utilizes text. Table 2 compares these approaches with various metrics. Grbovic et al. [72] investigate the semantic embedding for ads and queries by mining a search session that consists of clicks on advertisements, queries, search links, skipped ads, and dwell times and proposes an approach called the search embedding model (search2vec). They leveraged cosine similarity between the acquired embeddings to assess the similarity between a query and an advertisement. The main issue of the proposed method is its reliance on the whole query level and advertisement identifier level, which means that the technique cannot differentiate two queries with similar content if they appear in the same context in search sessions. The method also suffers from the out-of-vocabulary issue, as many search queries are new, and advertisers continually update their advertisements. Other approaches, such as DeepIntent [73], a method that combines attention and RNNs to bind queries and ads to real-valued vectors, have tried to solve these issues. The authors utilize the cosine similarity mechanism to investigate the query and ad vector likenesses. The authors apply their method at the word level, making their approach less sensitive to the issue of out-of-vocabulary words.
Table 2.
Comparison of the approaches that utilize NLP models to predict the CTR using texts.
Regarding the sponsored search task, Huang et al. [70] propose n-gram-based word hashing letter trigram-based word hashing with DNN (L-WH DNN), which differs from traditional one-hot vector encoding, as it represents a query or document using a vector with reduced dimensionality. Compared with character-level one-hot encodings, this method has much higher dimensionality. The dimension of the character-level encodings corresponds to the input (i.e., the number of characters) multiplied by the alphabet size. Therefore, it is much lower than the vector dimension that utilizes letter trigrams. Additionally, unlike character-level encoding, word hashing encoding sacrifices sequence information. Shen et al. [74] utilize queries of word-n-gram representations to learn the query-document similarity using a convolutional latent semantic model (CLSM). The authors convert individual words or word sequences into low-dimensional vectors. They then use a max pooling operation to select the highest neuron activation value across all word and word sequence features. The authors also make effective use of negative sampling on search click logs. This approach enhances the quality and relevance of the data, leading to more accurate results.
Alves Gomes et al. [75] introduce a two-stage method that includes a customer behavior embedding representation and an RNN. The authors first utilize customer activity data to train a self-supervised skip-gram embedding; the output of this phase is employed to encode the consumer sequences in the second phase. The production of the second phase is utilized to train the model. This method differs from traditional methods, which use comprehensive end-to-end models to train and predict click-through. The authors evaluate their method via an industrial use case and a publicly available benchmark, i.e., the Amazon review 2018 (can be found at https://nijianmo.github.io/amazon/index.html, accessed on 18 September 2025) dataset [78]. The experimental results demonstrate the effectiveness of their approach compared with state-of-the-art methods such as the multimodal adversarial representation network (MARN) [79] and TIEN [80] in terms of the F1 score. The proposed method yields an F1 score of 79% on the public dataset, outperforming the baseline models by more than 7%. This result indicates that applying an extensive end-to-end model to present an accurate method is not always necessary; some light and well-developed models outperform complicated and computationally intensive models. The exceptional performance of this approach is attributed to the representation of the customer, which is derived from self-supervised pretrained behavior embeddings. However, this method relies on obtaining personal information that is difficult to acquire due to legal and government restrictions. Moreover, traditional approaches that use manually designed features can be easily understood by experts in the field. Therefore, end-to-end methods and decoupled models such as this approach are difficult to explain because of the black-box nature of deep learning architectures. Thus, there is a need to incorporate eXplainable AI (XAI) with such approaches to increase explainability and interoperability. Cui et al. [76] introduce a recommendation system that uses the sentiment knowledge graph attention network (ASKAT). The authors obtain aspectual sentiment features from reviews via an enhanced aspect-based sentiment analysis technique. They develop a collaborative knowledge mapping method that enhances sentiment to make the most of the information gathered from reviews. They generate an innovative graph attention network equipped with sentiment-aware attention capabilities, enabling the effective collection of neighbor information. The authors evaluated their method with three publicly available datasets: Amazon book (can be found at: http://jmcauley.ucsd.edu/data/amazon, accessed on 31 July 2025), Movie (can be found at: https://developer.imdb.com/non-commercial-datasets/, accessed on 31 July 2025), and Yelp (can be found at https://www.yelp.com/dataset, accessed on 31 July 2025). The experimental evaluation demonstrates the superiority in terms of accuracy and personalized recommendation of the proposed method over the baseline state-of-the-art methods, such as the knowledge graph attention (KGAT) network [81], knowledge-based embeddings for explainable recommendation [82], knowledge graph convolutional networks (KGCNs) [83], and the LightGCN [84], on two recommendation tasks (i.e., CTR prediction and top-k recommendation).
Edizel et al. [66] introduce two methods (i.e., at the word and character levels named deep word match (DWM) and deep character match (DCM), respectively) based on a CNN and use text content to forecast the CTR of a query-ad pair. The proposed method utilizes texts represented in the query-ad pair, feeds them into the architecture as input, and outputs the CTR prediction. The authors conclude that the character-level method is more effective than the word-level method because it learns the language representation when trained on sufficient data. The authors evaluate their two methods via a commercial search engine’s real-world data of 1.5 billion query ad pairs. The proposed methods are compared with baseline methods such as feature-engineered logistic regression (FELR) [85] and Search2Vec [72] and outperform them in terms of AUC. Geng et al. [77] present an approach named behavior aggregated hierarchical encoding (BAHE) to improve the efficiency of LLM-based CTR prediction. The proposed approach dismantles the customer behavior encoding from the interactions of interbehavior. The authors use pretrained shallow layers to avoid duplicating the encoding of the same user behaviors. These layers extract detailed user behaviors from long sequences and store them in a database for later use. Hence, deeper trainable layers in large language models facilitate complex behavior interactions, thus creating comprehensive user embeddings. This difference permits the independent training of high-level customer representations from low-level behavior encoding, thus significantly lowering computational complexity. Then, the authors combine the refined customer and processed item embeddings in the CTR model to calculate the CTR scores. The experimental results show a significant improvement (i.e., five times) over similar approaches, including the unified framework for CTR prediction (Uni-CTR) [86], fine-grained feature-level alignment between ID-based models and pretrained language models (FLIP) [87], and the knowledge augmented recommendation (KAR) framework [88], particularly when using longer customer sequences for training time and memory usage compared with CTR models based on LLMs. The authors successfully implemented this approach in a real-world operational environment. This implementation has enabled them to achieve daily updates of 50 million CTR data points on 8 A100 GPUs. Consequently, this advancement has made large language models (LLMs) a viable and practical option for industrial CTR prediction.
Text-based approaches (e.g., Search2Vec [72], DeepIntent [73], BAHE [77]) highlight the importance of leveraging semantic embeddings of queries, ads, and reviews. These approaches are efficient in resolving the cold-start concerns of sparse settings. However, they encounter issues regarding scalability when dealing with rapidly changing ad corpora and out-of-vocabulary problems. The key takeaway is that text-only solutions remain valuable for semantic personalization but must often be combined with other modalities or structural data for robust industrial performance.
5.2. Showing Ads or Product Solutions Using Multivariate Data
This section surveys solutions that utilize various data types to predict the CTR. These solutions can be classified into graph-based approaches, feature-interaction-based methods, customer behavior techniques, and cross-domain approaches.
5.2.1. CTR Prediction Utilizing Graph Models
This subsection presents solutions that utilize graph models to predict the CTR. A comparison of these approaches using different criteria is shown in Table 3. Liu et al. [89] introduce an approach based on graph convolutional neural networks named graph convolutional network interaction (GCN-int). This approach facilitates the learning of the hard-to-comprehend interaction between various features, offers a decent interaction representation across high-order features, and enhances the explainability of feature interaction. The method is evaluated on two public datasets (i.e., Criteo and Avazu) and a customized dataset comprising internet protocol television (IPTV) movie recommendation records. The experimental results demonstrate the effectiveness of the proposed method in terms of accuracy and efficiency compared with existing methods, such as the attentional factorization machine (AFM) [90] and DeepCrossing [67]. However, the proposed method omits the weights of interactions between features and instead performs feature interactions with identical weight values. Zhang et al. [91] propose a graph fusion reciprocal recommender (GFRR) approach, which can learn reciprocal information circulation across customers to predict pair matching. This approach can also learn structural information about customers’ historical behaviors and is based on a graph neural network (GNN). Compared with previous reciprocal recommender systems (RSSs) that concentrate only on reply prediction, this approach focuses on both transmit and response signals. Additionally, the authors present negative instance mining to investigate the impact of various kinds of instances on recommendation precision in real-world settings. The authors validate their approach on a real-world dataset, which yielded decent results compared with those of other previous works, such as latent factor for reciprocal recommender (LFRR) systems [92] and deep feature interaction embedding (DFIE) [93], with prediction results of 73.15% for the AUC and 26.01% for the average precision, good response prediction results of 68.95% for the AUC and 23.02% for the average precision, and proper fusion reciprocal prediction results of 71.26% for the AUC and 23.95% for the average precision. However, the only information utilized is the user’s profile and historical behavior; hence, user embeddings could be enriched with more information, such as social networks and interest features, to improve the recommender system.
Table 3.
Comparison of the approaches that utilize graph models to predict the CTR using multivariate data.
Existing methods usually overcome the cold start and sparsity issues in collaborative filtering using side information such as knowledge graphs and social networks. Yang et al. [94] address these limitations similarly: they introduce a knowledge-enhanced user multi-interest modeling (KEMIM) approach to act as a recommender system. The authors initially use a historical interaction between customers and items, which serves as the main component of the knowledge graph. They then create a customer’s specific interests and use the connection path to broaden their potential interests by leveraging the relationships within the knowledge graph. They analyze changes in customer interest and use a capability to understand the customer’s attention to each past interaction and potential interest. The authors subsequently concatenate the customer’s interests with the attribute features to address the cold start issue in an effective manner. The framework consists of structured data from a knowledge graph, which can describe the user’s characteristics in detail and provide understandable recommendation results to users. The framework is evaluated extensively on three publicly available datasets for two distinctive research problems: top-k recommendation and CTR prediction. The experimental results show that the method outperforms the state-of-the-art models on two datasets (i.e., Book-crossing [102] and Last.FM), including knowledge-enhanced recommendation with feature interaction and intent-aware attention networks (FIRE) [103], hierarchical knowledge and interest propagation networks (HKIPNs) [104], and collaborative guidance for personalized recommendation (CG-KGR) [105]. However, the performance of this method could be improved, particularly knowledge extraction in the knowledge graph-based recommender system, and an explainable recommendation model could be introduced. Li et al. [95] introduce a graph factorization machine (GraphFM) to illustrate features in the graph configuration. Specifically, the authors create a capability that chooses meaningful feature interactions and designates these interactions as edges between features. The framework then incorporates the FM’s interaction function into the GNN, represented by the feature aggregation mechanism. The feature aggregation mechanism uses stacking layers to model the arbitrary-order feature interactions on the graph-structured features. The authors validate their method with three public datasets (i.e., Criteo, Avazu, and MovieLens-1M) and compare it with several previous methods, such as higher-order FMs (HOFMs) [106], adaptive factorization networks (AFNs) [107] and FM2 [108]. The proposed method outperforms the other techniques in terms of logloss and AUC.
The surge in multimodel sharing platforms such as TikTok has ignited heightened fascination with online microvideos. These concise videos contain diverse multimedia elements, including visual, textual, and auditory components. Thus, merchants can enhance the user experience by incorporating microvideos into their advertising strategies to their advantage. In many CTR prediction studies, item representations rely on unimodal content. A few studies concentrate on feature representations in a multimodal fashion; one of these approaches is hypergraph CTR (HyperCTR), which was proposed by [96]. The hypergraph neural network inspired the hypergraph CTR approach. A hypergraph is an extension of an edge in graph theory [109,110] that can link more than two edges. It guides feature representation learning in a multimodal manner (i.e., textual, acoustic, and frames) by leveraging temporal user-item interactions to comprehend user preferences. Figure 4 depicts an example of applying the proposed method, where users and have interacted with various microvideos, for example, videos and . A microvideo (e.g., ) might be watched by more than one user (e.g., , , ) because of the exciting soundtracks. A group-aware hypergraph can be created using these signals, consisting of various users interested in the same item. This interaction enables the proposed framework to connect multiple item nodes on a single edge via hyperedges. The hypergraph’s unique ability to utilize degree-free hyperedges allows it to capture pairwise connections and high-order data correlations effectively. This ability facilitates CTR prediction for microvideo items, as it can generate model-specific representations of users and microvideos to capture user preferences efficiently. The authors also develop a mutual network for time-aware user-item pairs to learn the correlation of intrinsic data [111] (this approach is inspired by the success of self-supervised learning (SSL) [112]), which addresses multimodal information. This enrichment process aims to enrich each user-item representation with the generated interest-based user and item hypergraphs. The authors validate their proposed technique with three publicly available datasets: Kuaishou [113], Micro-Video 1.7 [114], and MovieLens-20M. The proposed method is compared with several state-of-the-art techniques, such as user behavior retrieval for CTR prediction (UBR4CTR) [115] and automatic feature interaction selection (AutoFIS) [116]. The results demonstrate its superiority over these methods.
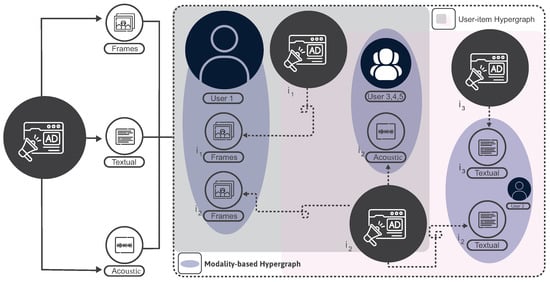
Figure 4.
The constructed hypergraphs for user preferences.
As shown in Figure 5a, Ariza-Casabona et al. [97] propose a multidomain graph-based recommender (MAGRec), which uses graph neural networks to learn a multidomain representation of sequential customers’ interplays. Specifically, the customer c, the chosen user history representation , the target item domain , and the target item itself are fed as inputs into the model. The graph comprises edge features, denoted by target and source domains, and node features, denoted by item embeddings. The authors employ temporal intradomain and interdomain interaction capabilities that act as contextual information and are equipped with their method. In a specific multidomain environment, the relationships are efficiently captured via two graph-based sequential representations that work simultaneously: a general sequence representation for long-term interest and a domain-guided representation for recent user interest. The proposed method effectively addresses the negative knowledge transfer issue and improves the sequential representation. The method is evaluated on the Amazon review dataset [78], which outperforms baseline approaches such as the full graph neural network (FGNN) [117] and multigate mixture-of-experts (MMoE) [118].
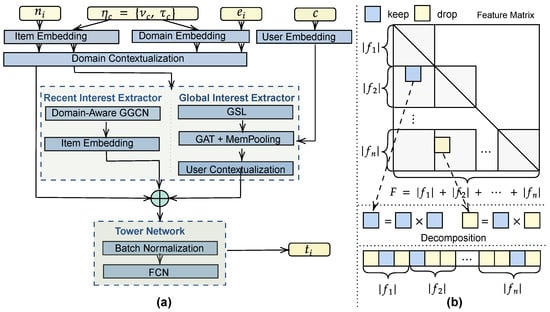
Figure 5.
(a) The mechanism used to capture global and local customer preferences utilizing a multidomain customer history graph representation. (b) The technique utilized to unify feature selection and its corresponding interaction to either include or exclude the feature from the feature set.
Sang et al. [98] introduce a framework named the adaptive graph interaction network (AdaGIN), which consists of three mechanisms: a multisemantic feature interaction module (MFIM), a graph neural network-based feature interaction module (GFIM), and a negative feedback-based search (NFS). The purpose of the MFIM is to obtain information from various semantic domains, while the purpose of integrating the GFIM is to combine information across features and evaluate their significance explicitly. The framework uses the NFS capability to employ negative feedback to increase model complexity. The proposed method is validated on four publicly available datasets: Avazu, Frappe (which can be found at http://baltrunas.info/research-menu/frappe, accessed on 31 July 2025), Criteo, and MovieLens-1M (can be found at https://grouplens.org/datasets/movielens, accessed on 31 July 2025). The extensive evaluation proves that the proposed approach is more effective than previous methods in terms of logloss and AUC.
Shih et al. [99] introduce a new evaluation metric called the cluster-aware ranking-based bidding strategy (CARBS). This metric evaluates the worth of each bid request by comparing it to a cluster of similar bid requests via a measure called the cluster expected win rate (CEWR). Bid requests with similar predicted CTRs are grouped into clusters using a two-step clustering mechanism to consolidate matching information. The CARBS sets a clear affordability threshold and prioritizes spending to ensure optimal efficiency and cluster ranking to spend the budget wisely and efficiently. The results of the CARBS are evaluated with CEWR, which proves that it can correlate and that its performance is better than that of inaccurate individual CTR predictions. The authors also introduce a bidding strategy based on reinforcement learning to modify the bid request expected win rate (BEWR). It is a hybrid mechanism that combines CEWR and the dynamic market to derive the final bid prices. As shown in the figure, the authors evaluate their method with three real advertising campaigns, confirming its effectiveness. In Figure 6a, the correlations between the average predicted CTR after utilizing the clustering techniques proposed by [119,120] are depicted alongside their empirical CTR counterparts for three advertising campaigns (1458, 3386, and 215). Ideally, if the average predicted CTR equals its empirical counterpart, the data points indicating clusters will lie on the diagonal dashed line. However, it is evident that in most cases, the predicted CTRs differ significantly from their empirical counterparts, suggesting that the CTR predictions are not correlated with the actual environments. In Figure 6b, the correlations between the average predicted CTR after applying the proposed clustering method are shown alongside their empirical CTR counterparts on the same advertisement campaigns, which proves the effectiveness of the method, as most data points lie on the ideal line. Even in a hard-to-predict campaign with an exceptionally tight budget, the AUC is 0.73, representing an improvement of approximately 33% and indicating the effectiveness of this approach.
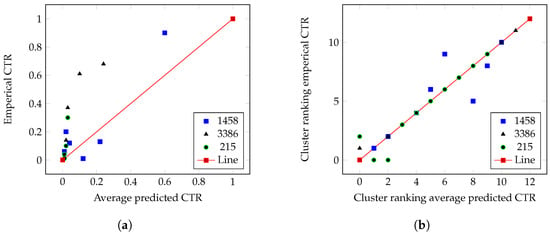
Figure 6.
Cluster rankings using the average predicted CTR shown on the x-axis against cluster rankings using the empirical CTR shown on the y-axis. (a) The correlations between the average predicted CTR after utilizing the clustering techniques proposed by [119,120] are depicted alongside their empirical CTR counterparts for three ad campaigns. (b) The correlations between the average predicted CTR after applying the clustering method proposed by [99] are depicted alongside their empirical CTR counterparts for the three advertisement campaigns.
Conventional CTR models utilize deep learning to train the model statically, and the network architecture parameters are identical across all the samples. Hence, these models face challenges in characterizing each sample, as they may stem from diverse underlying distributions. This limitation significantly impacts the CTR model’s representation capability, resulting in suboptimal outcomes. Yan et al. [101] developed a new universal module known as adaptive parameter generation (APG), which aims to address this issue by dynamically generating parameters for CTR models based on different samples. As shown in Figure 7a, when the authors add certain parameters, the model captures specific patterns for distinctive samples, particularly long-tailed samples. This figure analyzes the effects of different samples when these parameters are used. The participants were divided into ten groups based on frequency. The number of participants in each group is the same, and the frequency increases from the first group to the tenth group. More formally, the basic version of the method dynamically generates parameters via the distinct condition ; hence, , where G denotes the adaptive parameter generation network. The produced parameters are subsequently fed into the deep CTR models, which are represented as , where is the neural network and represents the input features. The authors introduce three types of techniques to design different conditions (i.e., groupwise, mixedwise, and selfwise). Once the conditions are obtained, the framework utilizes an MLP as to produce parameters that rely on the three conditions, where are the adaptive parameters, is the input-aware condition, and e is the reshape operation responsible for reshaping the vectors generated by the multilayer perceptron (MLP) into a matrix form. Consequently, the CTR model that utilizes APG can be represented as , where denotes the activation function. This basic version is time and memory inefficient and not particularly effective in pattern recognition. Thus, the authors present three versions to solve these issues: low-rank parameterization, shared parameters, and overparameterization. Low-rank parameterization uses the low-rank subspace to optimize the task. The authors suggest that the adaptive parameters contain a low intrinsic rank; thus, they suggest representing the parameters of the weight matrix as a low-rank matrix. This matrix is generated by three different matrices (i.e., ), and the low rank can be represented as . In the shared parameters version, the framework decomposes the weight matrix into three submatrices (i.e., , , and ). The authors introduce the overparameterized version, which enlarges the capacity of the model by increasing the number of shared parameters. Two matrices are introduced in this version to replace the shared parameters proposed in the previous version, i.e., , where i is the i-th hidden layer, and . Figure 7b depicts the final APG framework without the decomposed feed-forwarding mechanism. The authors then evaluate the performance via AUC and CTR gains for distinctive groups. As shown in Figure 8a,b, the authors conclude that because group nine represents the participants that have the highest frequency, even though they represent only 10% of all participants, this group generates more than half of the total samples. The parameters contribute more to the performance of low-frequency participants (for example, participants in group zero), as they result in higher CTR and AUC gains. Therefore, these parameters allow low-frequency samples to adequately represent their features, leading to improved performance. This approach allows for adapting model parameters to better fit the characteristics of diverse data samples, potentially improving the model’s performance across various scenarios. The authors conducted multiple experiments to evaluate their proposed technique and incorporated the technique as a capability in several deep learning models to enhance performance. The evaluation demonstrated the effectiveness of the proposed technique in significantly improving the CTR of the deep models. Additionally, the proposed method reduced time costs by 38.7% and memory usage by 96.6% compared with a deep CTR model. Furthermore, the model was deployed in a real environment, resulting in a 3% increase in CTR and a 1% gain in revenue per mile (RPM).
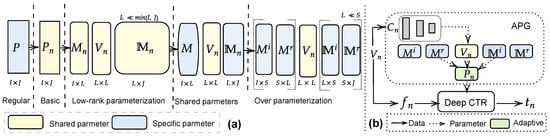
Figure 7.
Different versions of APG are shown in (a), and a simplified version of the final APG framework is shown in (b).
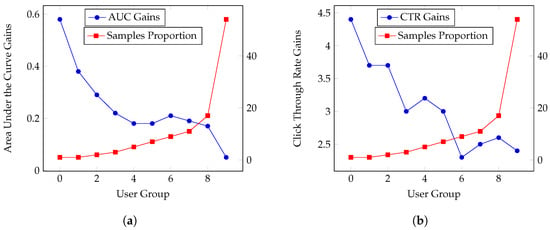
Figure 8.
The area under the curve and the CTR gains for sample proportions in different user groups. (a) The area under the curve gains for sample proportions in different user groups. (b) The CTR gains for sample proportions in different user groups.
Graph-based approaches (e.g., GCN-int [89], GraphFM [95], HyperCTR [96]) represent the current state-of-the-art in handling large-scale structured data. They are highly effective in capturing high-order feature interactions, modeling user-item relations in non-Euclidean spaces, and delivering strong performance on industrial datasets such as Criteo and Avazu. Their scalability and predictive accuracy make them highly deployable, though preprocessing pipelines and graph construction can be complex. A clear trend is the integration of multimodal signals into graph frameworks, enabling richer representations of users and items.
Table 4 illustrates representative graph-based CTR methods. Graph-based CTR models are effective for large, structured datasets, such as Criteo and Avazu, where feature interactions significantly impact prediction accuracy. They are ideal for industrial applications that require high AUC and the handling of sparse features. However, practitioners must weigh their computational cost and engineering complexity against simpler baselines. Graph-based models have some limitations. They require extensive preprocessing and graph construction, with some models, such as HyperCTR, necessitating a substantial amount of GPU hours, which limits their scalability for real-time use. Additionally, many of these models assume uniform or static weights for feature interactions. This assumption may not be valid in the context of dynamic industrial environments, where conditions can change rapidly.
Table 4.
Summary of representative graph-based CTR methods.
The rise of multimodal data—such as text, images, and behavioral signals—is transforming CTR prediction. Traditional text-only approaches struggle to fully capture user intent. Recent studies demonstrate that integrating different data types enables models to learn more effective representations by communicating sentiment through text, showcasing product attractiveness with images, and representing interaction dynamics through behavioral logs. For example, ASKAT [76] leverages graph attention networks to combine textual sentiment features with user interaction data, whereas BAHE [77] aggregates multimodal behavioral patterns (e.g., search logs, mini-program visits, and item titles) at an industrial scale, significantly reducing redundancy in representation learning. Similarly, HyperCTR [96] uses hypergraph neural networks to merge textual, acoustic, and visual frame-level features for microvideo CTR prediction, attaining considerable improvements in AUC and log loss on datasets like Kuaishou and MovieLens.
Multimodal frameworks show that combining different modalities offers complementary benefits. They enhance content understanding by merging visual and textual embeddings, while sequential behavior models effectively manage temporal dependencies.This holistic approach strengthens CTR models, making them more robust against data sparsity, addressing cold-start challenges, and enhancing personalization in recommendations. However, the integration of these modalities also introduces computational complexities, which require extensive parallel training and sophisticated fusion techniques, such as attention-based late fusion and cross-modal transformers. Future directions point toward end-to-end multimodal representation learning with eXplainable AI (XAI) components to enhance interpretability, scalability, and industrial deployability.
5.2.2. Cross-Domain CTR Prediction Methods
This subsection introduces the approaches that transfer knowledge across domains to predict the CTR. Table 5 compares these approaches via different assessment measures. Liu et al. [121] introduced a groundbreaking approach to continual transfer learning (CTL), a field that has received relatively limited attention from researchers. CTL focuses on transferring knowledge from a source domain that evolves over time to a target domain that also changes dynamically. By addressing this underexplored aspect of transfer learning, this work (i.e., CTNet) has the potential to significantly advance how knowledge can be effectively conveyed and utilized in evolving environments. The main idea of this approach is to process the representations of the source domain as transferred knowledge for target domain CTR prediction. Thus, the target and source domain parameters are continuously reused and retained during knowledge transfer. This approach outperforms other methods, such as the knowledge extraction and plugging (KEEP) [122] method and progressive layered extraction (PLE) [123]. It has been evaluated via extensive offline experiments, where it yielded significant enhancements. It is now utilized online at Taobao (a Chinese e-commerce platform).
An et al. [124] introduce the disentangle-based distillation framework for cross-domain recommendation (DDCDR), a cutting-edge approach operating at the representational level. This approach is based on the teacher-student knowledge distillation theory. The proposed method first creates a teacher model that operates across different domains. This model undergoes adversarial training side by side with a domain discriminator. Then, a student model is constructed for the target domain. The trained domain discriminator detaches the domain-shared representations from the domain-specific representations. The teacher model effectively directs the domain-shared feature learning process, whereas contrastive learning approaches significantly enrich the domain-specific features. The method is evaluated thoroughly on two publicly available datasets (i.e., Douban and Amazon) and a real-world dataset (i.e., Ant Marketing). The evaluation phase demonstrates the method’s effectiveness, which achieved a new state-of-the-art performance compared with previous methods such as the collaborative cross-domain transfer learning (CCTL) framework [125] and disentangled representations for cross-domain recommendation (DisenCDR) [126]. The deployment of the technique on an e-commerce platform proves the efficiency of the method, which yields improvements of 0.33% and 0.45% compared with the baseline models in terms of unique visitor CTRs in two different recommendation scenarios.
Table 5.
Comparison of the cross-domain approaches to CTR prediction using multivariate data.
Table 5.
Comparison of the cross-domain approaches to CTR prediction using multivariate data.
| Model | Key Idea | Dataset | Performance | Limitations (+)/Advantages (−) |
|---|---|---|---|---|
| CTNet [121] | Processed the source domain | Taobao production: three | 0.7474 AUC and | − The homogeneous features |
| representations as transferred | domains (A, B, and C); | 0.6888 GAUC from | might affect this method’s | |
| knowledge for the target | the aim is to validate | domain A to B; 0.7451 | performance in practice (e.g., | |
| domain; thus, the source and | the framework’s transfer | AUC and 0.7040 GAUC | heterogeneous input features | |
| target domain parameters are | effectiveness from A to B | from domain A to C | which indicate two domain have | |
| continuously reused and retained | and A to C. A dataset size | different feature fields, e.g., | ||
| during knowledge transfer | is 150B, B dataset | image retrieval technique relies | ||
| size is 2B, and C | on image features while | |||
| dataset size is 1B. | text retrieval method relies on | |||
| features preprocessed from text) | ||||
| DDCDR [124] | Based on the teacher-student | Douban (consists of 1.5 M | 0.6350, 0.6602, and | + The approach filters useful |
| knowledge distillation, it constructs | samples), Amazon (consists | 0.8096 AUC on | information for transfer, | |
| a teacher model to execute across | of 1.9 M samples), and | Douban, Amazon, | strengthens domain-specific | |
| different domains. The model goes | Ant Marketing (consists | and Ant Marketing, | representation and sampling, | |
| through adversarial training with | of 40 M samples) | respectively | leading to superior | |
| a domain discriminator and a student | performance in practice | |||
| model is created for the target domain | ||||
| DASL [127] | Proposed an approach that | Imhonet (consists of | 0.8375 and 0.8380 AUC | − The method can be applied |
| transfers information between | 223 M book records | on Imhonet (books and | only in domain pairs; | |
| two relevant domains iteratively | and 51 M movie records), | movies, respectively); 0.8520 | thus it can be extended to | |
| until the learning process | Amazon (consists of 2.3 M | and 0.8511 AUC on Amazon | supply recommendations | |
| stabilizes utilizing dual | toys records and 1.3 M | (toys and video games, | through various domains | |
| attention and dual | video games records), and | respectively); 0.8825 and | ||
| embedding mechanisms | Youku (consists of 11.6 M | 0.8635 AUC on Youku | ||
| TV shows records and | (TV shows and short | |||
| 19.2 M short videos records) | videos, respectively) | |||
| MAN [128] | Utilized global and local encoding | Micro Video (A and | 0.8285 and 0.8094 AUC; | − The approach needs to be |
| layers to capture the cross-domain | B) and Amazon (video | 0.6167 and 0.5756 MRR on | further evaluated using | |
| and specific-domain sequential | games and toys) | Micro Video A and B | an online A/B tests to | |
| patterns. Applied a mixed attention | respectively; 0.6559 and | prove its effectiveness | ||
| layer to obtain local/global item | 0.6712 AUC; 0.4755 and | |||
| similarity, integrate item sequence, | 0.6385 MRR on Amazon | |||
| and capture customer groups in | video games and toys, | |||
| different domains | respectively | |||
| Park et al. [129] | To maintain gradient flows | Amazon [130] | 0.3398 MRR @10 and | + Deployed in a personal |
| across domains with significant | (contains 105,364 users) and | 0.3838 NDCG @10 on | assistant app service and | |
| negative transfer, they | Telco (contains | Amazon dataset and 0.7366 | outperformed previous works | |
| dynamically assign it as | 99,936 users) | MRR @10 and 0.7802 | by 21.4% CTR prediction | |
| a weight factor to the | NDCG @10 on Telco | increase | ||
| prediction loss | dataset | |||
| MACD [131] | Developed an architecture that | Amazon dataset and | The average exposure is | + The model is tested on a |
| considers users’ varying interests, | A/B test | enhanced by about 10%, the | financial platform for | |
| including a capability that | CVR by about 1.5% and | fourteen days and proved | ||
| investigates potential customers’ | the conversion rate by | its effectiveness | ||
| interests and used a contrastive | about 6% | |||
| information regularizer to | ||||
| filter out background noise | ||||
| DCN [132] | Utilize DNN with FTRL | Four iPinyou sub-datasets, | 0.8338, 0.8969, 0.8040, | − The method could be enhanced |
| augmentation to predict CTR. | which consists of 10M | 0.8574 AUC and 0.448, | by adding sequential features at | |
| They use SMOTE oversampling | training samples and | 0.4697, 0.5891, 0.4564 | the feature engineering phase | |
| to balance the dataset and | 2 M testing samples | Logloss from 1st to 4th | and utilizing advanced network | |
| improve performance | sub-dataset, respectively | such as transformer to extract | ||
| high-order feature combinations |
GAUC stands for group area under the curve. MRR stands for mean reciprocal rank.
Li et al. [127] introduce a cross-domain sequential recommendation approach that conveys information between two relevant domains iteratively until the learning process stabilizes. This approach uses a dual-learning capability called dual attentive sequential learning (DASL), which comprises two elements: dual attention and dual embedding. These two components work together to create a two-phase learning process. First, they create dual latent embeddings that capture customer preferences from both domains. Then, they utilize these embeddings to provide cross-domain recommendations by matching them with suggested items. To evaluate their method, the authors conducted extensive experiments utilizing three datasets (i.e., Imhonet [133], Amazon [78], and Alibaba-Youku datasets). The proposed method is demonstrated to be superior to baseline models such as the mixed interest network (MiNet) [134] and collaborative cross network (CoNet) [135] on the three datasets.
Well-known cross-domain sequential recommendation solutions such as DASL [127] and -Net [136] have identical limitations and rely intensively on overlapped customers in distinct domains, which makes them difficult to deploy in practical recommender systems. Therefore, Lin et al. [128] introduce a mixed attention network (MAN) with global and local attention capabilities that obtains cross-domain and domain-specific information. The authors employ a global/local encoding layer to extract the cross-domain and specific-domain sequential patterns. Additionally, to obtain the local/global item similarity, integrate the item sequence, and capture the customer groups in distinct domains, the authors leverage a mixed attention layer that consists of sequence-fusion attention, item similarity attention, and group-prototype attention. Cross-domain and specific-domain interests are incorporated via a global/local prediction layer. Two datasets are used to validate the proposed method; each dataset contains information from the two domains. The experimental results demonstrate the effectiveness of the proposed method compared with other similar methods.
Park et al. [129] introduce a cross-domain sequential recommendation approach to address the negative transfer issue. The newly introduced technique involves estimating the level of negative transfer to preserve gradient flows across domains characterized by significant negative transfer. This estimation is achieved by dynamically assigning the negative transfer as a weight factor in the prediction loss. The authors assess the performance of a model trained on cross-domains to investigate the negative transfer of two distinct domain settings to demonstrate the effectiveness of the proposed asymmetric cooperative network. They then compare its performance with that of a different model trained on a specific domain. The authors also present an auxiliary loss capability to maximize the collective information between the representation entities in a per-domain setting; in this way, the transfer of meaningful signals between cross-domain and specific-domain sequential recommendations is facilitated. This process of collective learning, involving specific domains and cross-domains, is similar to the cooperative dynamics between pacers and runners in long-distance races. Thorough experiments with two real-world datasets across multiple service domains indicate that the proposed model outperforms other methods, highlighting its superiority and efficacy. The proposed method has been deployed in a personal assistant app service to demonstrate its effectiveness for recommendation systems and showed a 21.4% CTR increase over other methods such as the context and attribute-aware recommender (CARCA) model [137] and mixed information flow network (MIFN) [138].
Xu et al. [131] introduce model-agnostic contrastive denoising (MACD) to efficiently predict the CTR. This approach implements an auxiliary behavior sequence information capability to investigate conceivable customers’ interests. Researchers have created a specialized architecture that considers users’ varying interests, combined with a contrastive information regularizer, to effectively filter out background noise from secondary behaviors and gain insights into customers’ diverse interests. The authors rigorously conduct experiments on real-world datasets to affirm their method’s effectiveness unequivocally. The proposed method outperforms state-of-the-art methods such as the self-attention-based sequential model (SASRec) [139] and Bert4rec [140] on more than one performance metric.
Huang et al. [132] introduce a DNN-based approach to enhance CTR prediction performance. The authors specifically utilize the deep and cross-network (DCN), supplemented with an augmentation technique known as the regularized leader (FTRL). To balance the dataset and address noise, the authors use an oversampling technique known as SMOTE to increase the number of samples of one of the classes to improve the performance. The authors conduct extensive experiments using five subsets of the iPinYou (can be found at https://contest.ipinyou.com/ accessed on 31 July 2025) dataset. The results demonstrate the effectiveness of the proposed method compared with other methods. Figure 9 compares the performance of the proposed method on one of the subsets with that of the deep and cross-network (DCN) [27] model, DCN with the FTRL mechanism, and the complete framework (i.e., FO-FTRL-DCN), including feature optimization (FO). Figure 9a compares the effectiveness of the proposed framework with that of the other methods for 40 iterations in terms of logloss. In contrast, Figure 9b compares the performance of the proposed framework with that of the other methods for 40 iterations in terms of the AUC. This figure demonstrates that the proposed framework converged more quickly than the other methods due to the optimization mechanism and the oversampling technique. One of the most challenging issues in the CTR prediction task is data sparsity (the nonclicked samples are significantly more numerous than the click samples are).
Figure 9.
The performance of FO-FTRL-DCN [132] compared with that of Base-DCN [27] and DCN follows that of the regularized leader (FTRL-DCN) mechanism in terms of logloss and AUC. (a) The performance of the methods for 40 iterations in terms of the logloss value. (b) The performance of the methods for 40 iterations in terms of AUC.
Cross-domain approaches (e.g., CTNet [121], DDCDR [124]) emphasize the need for continual learning and knowledge transfer to address sparsity and dynamic environments. Multimodal frameworks such as HyperCTR [96] and ASKAT [76] demonstrate the benefits of fusing text, images, and behavior logs, which not only improve accuracy but also enhance robustness against cold-start scenarios. A major direction emerging from these studies is the integration of multimodal and cross-domain approaches as the foundation for next-generation CTR prediction.
Table 6 shows representative cross-domain CTR methods. These methods are most valuable for multi-service platforms (e.g., Taobao, Amazon) where sparsity in one domain can be mitigated by knowledge transfer. They are less suitable when domains are highly heterogeneous or user overlap is minimal. However, cross-domain models often rely heavily on overlapping users across domains (DASL, MAN), face negative transfer (CTNet), and require large labeled datasets (DDCDR).
Table 6.
Summary of representative cross-domain CTR methods.
5.2.3. Customer Behavior-Based Approaches
This subsection presents the methods used to study user behavior to predict CTR via multivariate data. A comparison of these approaches using different evaluation metrics is shown in Table 7. Guo et al. [141] present a multi-interest self-supervised learning (MISS) technique to improve feature embedding via designated signals called interest-level self-supervision. The authors employ two extractors based on a convolutional neural network to explore self-supervision signals, considering various interest representations either unionwise or pointwise, long- and short-range interest dependencies, and inter- and intraitem interest correlations. Then, the authors use contrastive learning losses to enhance feature representation learning by augmenting the views of interest representations. The proposed method can also be added to existing methods as a plug-in capability to improve their effectiveness. The authors evaluate the framework via three publicly available datasets, which demonstrates its superiority over state-of-the-art techniques such as the search-based interest model (SIM) [142] and the deep match-to-rank (DMR) model [143] (i.e., it improves the AUC by 13.55%).
Table 7.
Comparison of the user behavior-based approaches that predict CTR using multivariate data.
Lin et al. [144] introduce the sparse attentive memory (SAM) approach to address the complexity of lengthy sequential customer behavior modeling. The method has been proposed to be highly efficient for training models and conducting real-time inference on user behavior sequences with lengths on the order of thousands. This claim implies that the method is suitable for handling large-scale user behavior data without experiencing significant computational bottlenecks. The proposed method adopts a strategy where the specific item of interest is regarded as the query, and the lengthy sequence is utilized as the knowledge database. This design enables the item of interest to consistently trigger the extraction of valuable and relevant information from the lengthy sequence. The authors conduct comprehensive experiments to evaluate their method. The results demonstrate their method’s effectiveness on both long and short user behavior sequences. The proposed method is applied to an international e-commerce platform that uses sequences of length 1000. The efficiency of the proposed method is high, with an inference time within 30 ms when deployed on GPU clusters, and the prediction rate is decent, with a significant improvement of 7.30%.
Previous works that utilize customers’ interests, such as the DIN [23], deep session interest network (DSIN) [150], and deep interest evolution network (DIEN) [22], have accomplished decent results in practice. Nevertheless, these approaches rely excessively on filtering customers’ historical behavior sequences while omitting context features, leading to decreased recommendation effectiveness. Yu et al. [145] introduce a deep filter context network (DFCN) approach to address this challenge. This approach employs an attention capability to integrate a filter that refines data related to the customer’s historical sequence that varies significantly from the target ad. The proposed framework is attentive to the context features that alternate across two local activation units. The authors validated their work by utilizing Taobao user and Amazon user datasets. The experimental results demonstrate the approach’s effectiveness compared with the authors’ previously proposed technique (i.e., deep interest context network (DICN) [151]) in terms of the AUC. Wei et al. [146] present a deep adaptive interest network (DAIN) to predict CTR in the global view and local view. The authors first create a local attention capability to adaptively compute customer interest representations and obtain customer interest from candidate advertisements and customer behaviors. Then, they design a feature interaction extractor, including FM and multilayer perceptron (MLP) mechanisms, which are responsible for obtaining low- and high-order feature interactions. The authors subsequently utilize a linear-based global attention capability attached to the feature interaction extractor to adaptively learn the effect of low- and high-order feature interactions concerning the target item. The proposed framework is evaluated with three subsets of the Amazon dataset, namely, electronics, beauty, and office_products. The results demonstrate its effectiveness compared with various baseline models, such as the graph intention network (GIN) approach [152].
Xue et al. [147] introduce an interactive attention-based capsule (IACaps) architecture to explore complex and varying click information for customer behavior representation. The model’s core is an interactive attention dynamic routing capability utilized to mine the conceivable linkages across various browsing behaviors. Thus, this capability enables the extraction and interpretability of apparently irrelevant information invisible in enormous amounts of click data. To ensure the method’s deployability in real applications, the authors evaluate it with three subdatasets from the Amazon dataset. The proposed method is compared with various techniques, such as the deep user match network (DUMN) [153], deep multi-interest network (DMIN) [154], and DRINK [148]. The results demonstrate its superiority over these methods on four performance metrics: accuracy, F1 score, logloss, and AUC.
Advertising data comprise many features, and the volume of data is expanding at a remarkable pace. This issue can be addressed by implementing customer segmentation according to shared interests. Kim et al. [43] suggest that it is possible to forecast a customer’s changing interests based on the changing interests of other customers. Customers with shared interests are likely to change their interests in a similar direction. Based on this assumption, the authors present a deep user segment interest network (DUSIN) approach to enhance CTR prediction. The proposed framework consists of three layers: customer and segment interest extractors and segment interest activation. The purpose of these layers is to capture each customer’s hidden interests and create a comprehensive interest profile for the segment by combining the interests of each customer. The authors perform a random undersampling technique because the dataset is imbalanced (i.e., the number of nonclicked instances is greater than the number of click instances). The authors evaluated their framework via the TaoBao dataset (i.e., real industrial data). The experiments demonstrate the effectiveness of the framework, which improved CTR prediction compared with two baseline models (i.e., the deep interest network (DIN) [23] and DIN with dynamic time warping (DTW) [155]). As shown in Figure 10, as the behavior sequence length increases above 30, the proposed framework outperforms the baseline models in terms of the area under the curve (AUC), achieving an AUC of 0.0029 with a 100-sequence behavior length. Compared with other baseline approaches, the framework’s performance demonstrates its effectiveness, making it potentially useful for business deployment. Zhang et al. [148] introduce a deep multirepresentational item network (DRINK) to predict the CTR. To address the sparse customer behavior issue, the authors represent the target item as a sequence of interacting customers and timestamps. Additionally, the authors present a transformer-based item architecture comprising multiclass and global item representation minimodules. The authors also introduce a mechanism to disassemble the item behavior and the time information to avert overwhelming the information. The mechanism outputs are combined and input into an MLP layer to train the CTR model. The proposed method is evaluated through extensive experiments using the Amazon subdatasets (i.e., grocery, beauty, and sports) and outperforms other methods, such as the deep time-aware item evolution network (TIEN) [80].
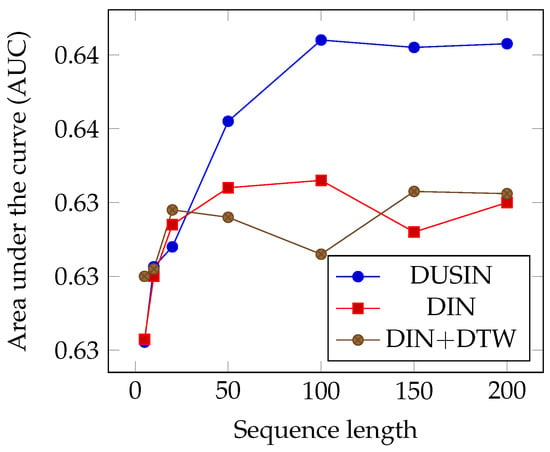
Figure 10.
The performance of the proposed framework is compared with that of the baseline models (i.e., DUSIN [43] and DIN [23]) in terms of the historical behavior sequence length and AUC.
An innovative research method known as automatic feature interaction learning (AutoInt) [34] creates a mechanism based on multihead attention that merges features. However, this method does not fully capture meaningful high-order features and neglects customer privacy preservation. To address these challenges, Tian et al. [149] introduce a differential privacy bidirectional long short-term memory (DP-Bi-LSTM) approach to enhance AutoInt. The proposed framework comprises an embedded layer and the Bi-LSTM. The Bi-LSTM captures the nonlinear connection across customer click behaviors and creates high-order features. Additionally, the authors utilize a differential privacy mechanism to preserve customer privacy. The authors also adopt a Gaussian capability to randomly perturb the gradient descent model used in the framework. The authors evaluated their framework via a publicly available dataset called Criteo. The proposed method showed higher effectiveness compared with AutoInt, improving the performance by 0.65%. The proposed method is also highly secure and reliable compared with the AutoInt approach.
Table 8 consists of representative snippets of behavior-based methods. There are common limitations with behavior-based methods, including struggles with very sparse users, evolving interests, and high memory costs when sequences are long. They often omit multimodal context beyond clicks. The key ideas can be summarized as follows: behavior-based methods can be useful on platforms with rich sequential logs (e.g., Amazon, Taobao). They are best applied to personalization tasks where modeling user history is key, but require scalable architectures (e.g., transformer or capsule-based) to manage long sequences.
Table 8.
Summary of representative customer behavior CTR methods.
5.2.4. Feature Interaction-Based Methods
This subsection surveys the approaches that take advantage of feature interactions to improve the effectiveness of CTR prediction methods. Table 9 compares these approaches on various criteria. Li et al. [156] introduce an innovative approach to address a challenge encountered in previous research. Their method focuses on overcoming the performance bottleneck of implicit feature interactions without relying on explicit feature interactions. Well-known deep CTR models that present parallel architectures obtain information from various semantic spaces. The subcomponents of parallel architecture-based models encounter difficulties because they lack supervision and communication signals. This limitation makes it challenging to capture meaningful multiview feature interaction information effectively across various semantic spaces. To solve this issue, the authors present a contrast-enhanced model through the network (CETN) that captures valuable multiview feature interaction information across multiple semantic spaces. The approach is rooted in a sociological concept that harnesses the synergy between diversity and homogeneity to enhance the model’s ability to acquire more refined and high-quality feature interaction information. The illustration on the left-hand side of Figure 11 shows that if the method identifies that feature interaction information varies across different semantic spaces, excessive diversity results. Thus, distinct subspaces have significantly different structures, resulting in excessively large angles between and . The CETN leverages feature interactions connected to the product and the concept of augmentation from contrastive learning. This process is performed to segment various semantic spaces, each with its own distinct activation functions. Specifically, this approach enhances the diversity of feature interaction information obtained by the model. Furthermore, each semantic space is equipped with self-supervised signals and connections to guarantee the uniformity of the captured feature interaction information. The authors validated their model via four datasets, demonstrating its superiority over baseline methods such as MaskNet [157] and the model-agnostic contrastive learning for CTR (CL4CTR) method [158] in terms of the logloss and AUC.
Table 9.
Comparison of the feature interactions-based approaches that improve CTR prediction models.
Figure 11.
Self-supervisory signals are integrated into the fusion layer to balance homogeneity and diversity in different semantic spaces.
Lyu et al. [159] present a new approach named optimizing feature set (OptFS), which unifies feature selection and its corresponding interaction. As shown in Figure 5b, the authors separate each feature selection interaction into two correlated feature selections to analyze the relationships between different features comprehensively. This separation enables the model to be trained from end to end via several feature interaction procedures. The authors use a feature-level search space to allow a learnable gate to determine whether a given feature f should be included in the feature set F. The experimental results demonstrate the ability of the proposed model to create a feature set that consists of features that enhance the prediction performance. The authors evaluated their approach on three public datasets (i.e., Criteo (can be downloaded from https://ailab.criteo.com/download-criteo-1tb-click-logs-dataset/, accessed on 1 August 2025), Avazu (can be downloaded from https://www.kaggle.com/c/avazu-ctr-prediction/data, accessed on 1 August 2025), and KDD12 (can be found at https://www.kdd.org/kdd-cup/view/kdd-cup-2012-track-2, accessed on 1 August 2025)), demonstrating its high performance in terms of prediction, computational cost, and storage.
Conventional CTR techniques attempt to enhance prediction via extensive feature engineering. Although these methods have shown some success, they are time-consuming, and it is difficult to deploy them in industrial environments. It is vital to take full advantage of minimal features and extract efficient feature interactions to overcome the drawback of the learning process of either sparse or high-dimensional features. Wang et al. [160] present a method called mutual information and feature interaction (MiFiNN) to solve these issues. Each sparse feature weight is computed from the mutual information of that feature and the click result. Then, the authors utilize an interactive mechanism that merges the inner and outer products to extract the feature interaction. The extracted feature interactions and the original input-dense features are subsequently fed into the DNN as inputs. The authors compared their model with well-known models such as FiBiNET [33] using four datasets. The results show that their method outperforms the other approaches.
Wang and Dong [161] introduce a framework to quantify the proposed model uncertainty that generates reliable and precise results. The framework merges feature interaction and selection capabilities based on Bayesian deep learning, which is named FiBDL. The authors utilize the DNN parallel mechanism and squeeze network for prediction, and the Monte Carlo dropout capability is employed to extract the approximate posterior parameter distribution of the model. Two types of uncertainties, aleatoric and epistemic, are identified, and information entropy is adopted to compute the aggregate of these types. Mutual information can be utilized to estimate epistemic uncertainty. The proposed framework is evaluated via three publicly available datasets (i.e., Taobao (can be found at http://www.comp.hkbu.edu.hk/~lichen/download/TaoBao_Serendipity_Dataset.html, accessed on 1 August 2025), Avazu, and ICME). Its superiority compared with previous methods, such as deep field-embedded factorization machine (DeepFEFM) [168] and extreme cross network (XCrossNet) [169], is demonstrated in terms of the prediction performance and efficient uncertainty quantification. Lin et al. [162] introduce a model-agnostic framework (MAP) that consists of two feature detection algorithms, namely, replaced feature detection (RFD) and masked feature prediction (MFP), to recover and break down multifield categorical data. On the one hand, MFP explores feature interactions within each sample by masking and identifying input features and presents noise contrastive estimation (NCE) to address large feature spaces. On the other hand, RFD transforms MFP into a binary classification task utilizing input features to apply replacement and detection transformations, making it more straightforward and more adequate for CTR pretraining. The proposed method is evaluated via two widely used public datasets (Criteo and Avazu). The results demonstrate its efficiency and effectiveness in predicting CTR via backbone approaches such as DeepFM [170] and DCNv2 [171].
Sahllal and Souidi [40] compare the performance of 19 resampling techniques, including four ensemble techniques, four oversampling methods, seven undersampling methods, and four hybrid methods, to identify the most effective method for CTR prediction. The new data constructed by these methods are fed into four well-known machine learning algorithms to investigate the effects of these resampling techniques on the CTR prediction performance. The authors evaluate these techniques extensively using a public dataset; the experiments show that resampling methods can improve the model’s performance by approximately 20%. Their research findings indicate that oversampling is more effective than other resampling techniques are and that undersampling techniques perform precisely with ensemble methods such as random forest.
Yuan et al. [163] introduce a feature-interaction-enhanced sequence (FESeq) approach that combines the sequential recommendation mechanism and feature interaction capability. The framework consists of an interacting layer, a feature engineering mechanism required by the transformer architecture. The framework uses a linear time interval embedding layer to retain the time intervals and a positional embedding layer to obtain the position information from the customer’s sequence behaviors. The authors also create an attention-based sequence pooling layer capable of reshaping the connection between the target ad representation and the customer’s historical behaviors, leveraging bilinear attention. The authors evaluate the proposed method via public (i.e., Alibaba (a.k.a., Ele.me) (can be found at https://tianchi.aliyun.com/dataset/131047, accessed on 1 August 2025)) and real-world (i.e., Bundle) datasets. The proposed framework outperforms the baseline models, such as a joint CTR prediction (JointCTR) framework [172] and time interval aware self-attention-based sequential recommendation (TiSASRec) [173], on both datasets in terms of the logloss and AUC.
Yang et al. [164] introduce a learning adaptively sparse structure (AdaSparse) framework, as shown in Figure 12, to train the model adaptively on each domain sparse structure and hence accomplish decent generalization across domains while maintaining low computational complexity. The framework measures the neurons’ significance through domain-aware neuron-level weighting factors. Thus, the proposed framework can prune redundant neurons in each domain to promote generalization. Moreover, the framework incorporates adaptable sparsity regularization to control the sparsity ratio of acquired structures effectively. The most important part of the framework is the domain-aware pruner, which generates neuron-level weighting factors capable of trimming redundant neurons. The framework uses an n-layered fully connected neural network as the core of the proposed framework to present AdaSparse. Once the framework transforms the features into embeddings, it combines the domain-aware embeddings and domain-agnostic embeddings , which form the input of the models (i.e., ). The learnable matrix of the n-th fully connected layer can be represented as , and the neuron of the n-th layer that acts as the input is denoted as . To train the model on the CTR task, the authors use the cross-entropy evaluation metric via the CTR instances . For each domain o, the model uses the pruner to eliminate the neurons of each layer and generates a weighting factor vector (the authors propose three weighting factors: binarization, scaling, and fusion) capable of trimming the neuron l. This procedure continues for each layer, and the sparse structure is eventually acquired. The framework is evaluated via two datasets (i.e., a public dataset called IAAC [101] and a customized dataset named Production). Its superiority to multi-domain CTR state-of-the-art models such as the star topology adaptive recommender (STAR) [174] and gradient-based meta-learning method (MAML) [175] is demonstrated.
Figure 12.
The across-domains CTR prediction using AdaSparse.
Several two-stream interaction approaches incorporate MLP with a customized architecture to improve CTR prediction. The MLP mechanism implicitly learns feature interactions, and the customized architecture is used to learn feature interactions explicitly. Mao et al. [166] propose an approach named FinalMLP that compensates for the customized architecture with another well-tuned MLP mechanism. Thus, the authors merge two streams of the MLP architecture to learn the implicit and explicit feature interactions. The authors also introduce a feature selection mechanism and an interaction aggregation layer to facilitate the feed of differentiated features and integrate stream-level interactions through two streams. The authors evaluate their method via four publicly available datasets: Criteo, Avazu, MovieLens, and Frappe; the evaluation metrics demonstrate the method’s effectiveness in terms of AUC.
Tian et al. [167] introduce an adaptive feature interaction learning approach called EulerNet. The framework facilitates learning feature interactions via a complex vector space (i.e., consisting of an imaginary part b and a real part a) on a given embedding dimension e and performs space mapping via Euler’s formula. Specifically, the model transforms the exponential growth of feature interactions into simple linear aggregations of complex feature phases and a modulus , enabling the model to adaptively and efficiently learn high-order feature interactions. Additionally, as shown in Figure 13, the proposed framework combines the feature interactions explicitly and implicitly utilizing feature embeddings in the complex feature space f in a harmonious architecture , which accomplishes the required reciprocal improvement and significantly increases the model performance on three datasets compared with various baseline models such as the deep interaction machine (DeepIM) [176].
Figure 13.
EulerNet implicit and explicit feature interactions.
Feature-interaction-based methods (e.g., CETN [156], OptFS [159]) improve CTR prediction performance by automatically identifying meaningful feature interactions, often outperforming manually engineered baselines. Meanwhile, customer behavior models demonstrate that long sequential dependencies and evolving interests are essential for personalization. However, issues remain regarding sequence length and memory efficiency. The key insight is that combining feature-level interactions with temporal behavior modeling yields superior personalization capabilities.
Table 10 demonstrates representative feature-interaction CTR methods. These models perform well with structured datasets that have complex features, like those in Criteo and Avazu, and are useful for capturing higher-order interactions. However, they require careful management of accuracy and computational costs. Key issues include parameter explosion (e.g., CETN), overfitting in high-dimensional spaces, and limited interpretability, with some approaches requiring manual filtering of irrelevant features.
Table 10.
Summary of representative feature-interaction CTR methods.
We find that graph-based and multimodal methods are the top approaches for predicting CTR. These methods consistently perform better than older deep learning models on large benchmarks. However, challenges still exist in modeling user behavior over time and learning how different features interact with each other. Models like CETN offer potential solutions to these challenges. Cross-domain and transfer learning improve prediction accuracy and address cold-start issues when new users or items have limited data. In industrial settings, there is a growing emphasis on distributed architectures that use edge computing. These architectures aim to strike a balance between strong predictions and efficient computation. These findings summarize current literature and outline a roadmap for future CTR research, linking existing methods to broader challenges discussed in the next section.
6. Challenges and Future Directions
This section presents the challenges facing current CTR prediction solutions and suggests future directions to help overcome these challenges.
6.1. Feature Interaction Methods: Challenges and Future Directions
Conventional CTR techniques aim to improve predictions through extensive feature engineering. While these methods can be effective, they are time-consuming and challenging to implement in industrial settings. To address the limitations of working with either sparse or high-dimensional features, maximizing the use of minimal features and identifying efficient interactions between them is crucial. Learning high-order feature interactions is critical in the CTR prediction task. Nevertheless, calculating these interactions via numerous features in e-commerce platforms is complicated and time-consuming. Various approaches develop a maximal order manually and remove the worthless interactions. The increase in high-order feature aggregations provided by these approaches can decrease the computational complexity; however, the model’s capability becomes a significant issue because of the suboptimal learning of the restricted feature orders. Thus, sustaining the model’s high performance while maintaining its computational efficiency is a challenging issue that has not been effectively addressed. Some techniques utilize the transformer, which relies on the self-attention capability to extract the global dependencies of customers’ historical interactions and forecast the target item. These approaches are practical for capturing user behavior sequences; however, most of them are highly limited in their application of feature interaction methods to obtain high-order feature interactions.
Most CTR approaches convert features into inherent vectors and then itemize potential feature interactions to enhance prediction by relying on the input features. Thus, considering the impact of features and their interaction is necessary when choosing the optimal feature set. However, many methods concentrate on feature field selection or identifying feature interactions from all the features to construct a conclusive feature set. Relying on feature field extraction limits the search space to the feature field, which is too coarse to identify subtle features. Additionally, some CTR methods do not apply filtering mechanisms to eliminate useless features, leading to higher feature dimensions and computational costs and ultimately decreasing model performance. The use of all the features to identify applicable feature interactions results in various redundant features in the dataset.
Previous CTR prediction solutions encounter various challenges. The first challenge is that many models utilize a primary method for feature integration, which causes noise and decreases precision. The second challenge is that previous research neglects the significance of varying features in various interaction orders, which degrades the model performance. The third challenge is that existing architectures lack the ability to obtain various interaction signals from different semantic spaces, resulting in suboptimal performance. FM is one of the earliest methods utilized in the CTR prediction task because it is a decent approach for modeling pairwise feature interactions and high-dimensional sparse data. However, FM-based approaches encounter two challenges. The first challenge is their inability to capture high-order feature interactions that exhibit combinatorial expansion. The second challenge is that noise is introduced when considering the interaction between each pair of features, and the model’s performance decreases.
Integrating resampling techniques with machine learning algorithms significantly impacts CTR prediction. Advertisers and marketers often need help with imbalanced datasets in the CTR prediction task, where a small percentage of customers click the ad while the majority ignore the ad. In these situations, accurately identifying and targeting potential customers is essential for ensuring the success of an advertising campaign. Using the most suitable sampling technique can enhance the performance of machine learning models in predicting imbalanced CTR data, resulting in more effective targeting and a better return on investment for advertisers. Moreover, by considering real-world scenarios and testing models on future data, advertisers can ensure that their models will remain effective over time.
Advancements in some CTR models, such as CETN [156] and OptFS [159], show that automatically learning feature interactions may outperform traditional methods. However, these methods often have problems with too many parameters and complex training processes. Models such as MiFiNN [160] benefit from using mutual-information weighting for predictions, but it has difficulty scaling with large feature spaces. Future research should aim to develop hybrid models that effectively combine interpretability with efficiency. Among the promising approaches are the use of meta-learning for feature selection and the application of contrastive learning to reduce unnecessary interactions. These methods hold the potential to enhance model performance and understanding. Practitioners should focus on designing feature-interaction models for high-dimensional categorical data and use pruning and regularization techniques to improve efficiency.
6.2. Graph-Based Approaches: Challenges and Future Directions
The vast capacity of deep learning models enables them to process large amounts of data via supervised machine learning and graph neural networks. However, they struggle to leverage these abundant data fully because the one-bit click signal is inadequate for guiding the model to learn effective representations of features and samples. The self-supervised learning ecosystem offers a more promising approach for pretraining and fine-tuning, allowing for better utilization of the extensive user click logs and the development of more generalized and effective representations. Nevertheless, the effectiveness of CTR prediction solutions that employ self-supervised learning is still an open research problem because previous work in this area is in its infancy.
Previous CTR research has demonstrated the effectiveness of deep learning in predicting customer clicks; however, it uses deterministic models. Thus, there is an issue related to capturing uncertainty. Model uncertainty, including CTR prediction, remains one of the greatest challenges when machine learning is applied to real-world problems. Some CTR prediction methods have two main issues. The first issue is that these models are not efficient at extracting the interaction of nonEuclidean features. The second issue is the lack of explanation regarding the feature interaction’s implicit meaning.
Graph-based models such as GCN-int [89] and GraphFM [95] achieve robust performance on public datasets but remain limited by graph construction overhead and the assumption of uniform interaction weights. HyperCTR [96] demonstrates the potential of multimodal hypergraph structures, but it also requires significant model training. Similarly, MAGRec [97] effectively models multi-domain interactions but struggles with high-order sparsity. Future work could focus on improving graph sampling efficiency and incorporating noise-robust learning, as suggested in multi-view contrastive frameworks [101]. Additionally, heterogeneous hypergraph networks that integrate both short-term and long-term user preferences [96] and contrastive learning with noise enhancement [101] are promising for handling large-scale, real-world CTR data. Practitioners should consider mini-batch or hierarchical sampling to reduce memory overhead during training. In real-time systems, precomputing static graph embeddings and updating dynamic edges asynchronously can help strike a balance between accuracy and latency. For researchers, integrating noise-robust contrastive learning and heterogeneous hypergraph modeling should be a focus for next-generation CTR systems.
6.3. Customer Behavior-Based Methods: Challenges and Future Directions
Existing works focus primarily on customer behavior modeling, and some focus on target item representations. Thus, these approaches rely mainly on customer representations, which makes them ineffective when customer behavior is sparse. Additionally, many current approaches identify the target item as a fixed embedding and omit the item’s multirepresentational attributes. Previous works utilizing customer interests have achieved decent results. However, these approaches depend heavily on filtering customers’ historical behavior sequences and neglect context features, which reduces the effectiveness of recommendations.
Sequential recommendation systems are based on predicting future customer behavior based on past interactions. This valuable insight allows businesses to tailor their strategies and offerings to better meet customer needs. Leveraging longer sequences significantly increases the precision of recommendations and increases personalization. As the sequence becomes longer, the previous methods face two main challenges. First, it becomes difficult to model long-range dependencies within the sequence. Second, there is a need to develop memory-efficient and computationally fast models.
In recent decades, CTR approaches have focused on extracting valuable feature interactions or mining essential behavior patterns via deep learning. Despite their success in predicting CTR, these approaches need to improve the efficiency of label sparsity, in which user-item interactions are relatively sparse with respect to the feature space. Additionally, the captured user-item interactions are often noisy, and the lack of utilization of domain knowledge is linked to the pairwise correlations between samples.
For example, SAM [144] demonstrates efficiency in modeling sequences of length up to 1000 but requires GPU clusters for real-time prediction. MISS [141] improves interest-level embeddings but assumes uniform distribution of dependencies, which may not hold in practice. Similarly, DUSIN [43] highlights the potential of segment-level interest modeling but struggles with evolving segment preferences. Future research should therefore target models that balance memory efficiency and long-sequence modeling, potentially via transformer-based architectures (e.g., DRINK [148]) or by integrating federated/distributed training for industrial scalability. Platforms with long interaction logs should implement transformer-based or capsule-based architectures for sequence modeling, but limit sequence length via summarization techniques (e.g., session-level pooling) to avoid inefficiency. Practitioners should also incorporate contextual features (such as time, device, and location) alongside click histories. Researchers could explore federated sequence modeling to address data privacy concerns in behavior-driven CTR tasks.
6.4. Cross-Domain Methods: Challenges and Future Directions
A cross-domain recommender system is an advanced mechanism that effectively addresses the sparsity issue by consolidating and modifying customer preferences across different categories and domains. This approach significantly enhances the CTR prediction performance of e-commerce platforms with multiple product domains. Many cross-domain sequential recommendation methods have attempted to use information from one domain to improve CTR predictions in another domain. However, these approaches often fail to integrate the bidirectional latent relationships of user preferences between the two domains. Therefore, they cannot yield improved simultaneous cross-domain CTR predictions for both domains.
Recent research has demonstrated that training a consolidated model to cover various domains can enhance CTR prediction. Nevertheless, owing to the limited training data, it is not easy to promote generalization across domains. Additionally, deploying current approaches in real CTR prediction applications is challenging because of their high computational complexity. Implementing current recommender system solutions in real environments that utilize cross-domain recommendation practices presents various challenges, including the involvement of long-tailed customers revealing sparse behaviors and cold-start customers who appear solely within one domain. Additionally, the lack of investigation into customers’ interests in these approaches leads to poor performance in real environments. Thus, it is essential to analyze information on complementary interests to enhance the recommendation system’s performance. Current sequential recommendation methods rely on supplementary behaviors to support long-tailed customers effectively. However, the performance of these approaches is limited by their failure to address the semantic gap between the intended target and the additional behaviors, as well as the variation in customer interest across different domains.
In recent recommender system solutions, sequential recommendation uses chronological customer behaviors to suggest a suitable next-time recommendation. However, this approach faces data sparsity challenges, especially for new customers. The use of cross-domain data from various domains to enhance data-scarce domain performance is a promising alternative for addressing such issues. Existing cross-domain sequential recommendation solutions face significant limitations, as they depend heavily on overlapping customers across different domains, making practical deployment in recommender systems challenging.
Some cross-domain recommendation systems have drawbacks regarding the mitigation of negative transfer. In knowledge transfer, these methods carefully select and transfer knowledge from the source domain, known as domain-shared knowledge. Simultaneously, they maintain the dependability of domain-unique insights within the target domain, recognized as domain-specific knowledge. Therefore, cross-domain CTR prediction models designed for industrial recommender systems need to consider the continual learning context.
Cross-domain representation learning and positive knowledge transfer empower multidomain recommender systems to achieve their burdens efficiently. These capabilities can be unlocked through specialized data modeling techniques such as disjoint history or by implementing tailored training processes. In the meantime, treating domains as separate input streams is a limitation because it fails to capture the interaction between domains. Some real-time bidding (RTB) strategies offer a bidding price for every incoming request based on its single predicted CTR. This approach ensures efficient resource utilization and maximizes the impact of individual bid requests if the feature space is not sparse. However, with a large and sparse feature space, such approaches suffer from inaccurate individual CTR predictions. Additionally, when similar CTR prediction models are deployed in real-world environments, their performance decreases significantly compared with that in the environment (i.e., public dataset) on which they were trained because of the outliers and noise that might appear in real-world environments.
For instance, CTNet [121] shows robust results with continual transfer learning but remains limited when domains are heterogeneous. DDCDR [124] demonstrates the use of distillation to transfer domain knowledge but still requires large-scale labeled datasets. DASL [127] illustrates potential for iterative cross-domain transfer but is restricted to pairs of related domains. Future work should therefore explore meta-learning frameworks for low-resource domains, as suggested in MAN [128], and investigate federated cross-domain recommendation [129] to address data privacy and scalability issues. Practitioners should use cross-domain transfer when operating multiple related services (e.g., video and e-commerce) but carefully monitor for negative transfer by validating per-domain metrics. Researchers should test meta-learning and federated cross-domain setups to improve generalization in data-scarce domains. Operationally, domain-specific embeddings should be kept lightweight and updatable to reflect changing preferences.
6.5. Text-Based Methods: Challenges and Future Directions
With the widespread development of large language models (LLMs), previous works have utilized these models to enhance CTR prediction; however, deploying these models in environments remains an issue because of the long history of textual user behavior. When user sequences become longer, the efficiency of such models still needs to be improved, especially when dealing with billions of items and users. Existing CTR prediction methods often overlook valuable textual information such as reviews, relying solely on rating data to understand customer preferences. Harnessing the power of rich textual data to gain deeper insights into customer interests and drive more effective predictions is indispensable. Numerous studies integrate reviews and ratings to enhance recommendations; nevertheless, certain challenges persist regarding these methodologies. Some methods hinge entirely on the precision of external sentiment analysis tools. In addition, some methods need to pay more attention to the meaningful features obtained from customer reviews. Other methods focus on positive reviews while neglecting negative reviews; thus, they need to learn customers’ genuine preferences.
Experts in the field easily understand traditional approaches that use manually designed features. However, end-to-end CTR prediction methods and decoupled models are difficult to explain because of the black-box nature of deep learning architectures. Thus, eXplainable AI (XAI) is needed to improve their explainability and interoperability.
For instance, ASKAT [76] demonstrates the power of aspect-based sentiment integration but cannot personalize well with sparse reviews. BAHE [77] shows efficiency in handling more than 50 million text samples but only modest improvements in AUC. L-WH DNN [70] and CLSM [74] highlight fundamental sequence encoding issues that remain unresolved. Future research should therefore focus on multimodal fusion of textual, behavioral, and visual modalities (e.g., HyperCTR [96]), as well as integrating explainable AI techniques to improve interpretability of text-driven CTR predictions. Large language models also present opportunities for contextual CTR modeling, but their deployment requires research into compression and efficient inference strategies. For practitioners, text-driven CTR models should be deployed with real-time embedding updates to handle evolving queries and ads. Hybrid pipelines (text and behavioral signals) offer stronger robustness in production. Researchers should prioritize explainability (e.g., attention heatmaps over reviews) to make text-based models more transparent and actionable for advertisers.
6.6. Emerging Technologies: Forward-Looking Directions
The previous subsections discuss the current challenges, but new technologies offer good opportunities for future research in CTR prediction. One effective method is transfer learning. This approach helps solve the cold-start problem by applying knowledge from well-established areas to new items or users that have little data. This method allows for fine-tuning of pretrained models from large-scale CTR prediction tasks, speeding up convergence and improving prediction accuracy. Additionally, meta-learning can enhance the generalization of CTR models. Unlike traditional methods that use fixed datasets, approaches like model-agnostic meta-learning (MAML) enable quick adaptation to new features and shifting user behaviors. This is particularly beneficial in online advertising, where user preferences and product inventories shift rapidly, allowing models to generalize to new tasks with minimal retraining. Also, for large-scale and real-time CTR prediction problems, edge computing and distributed learning offer important opportunities. Edge computing can reduce latency by performing CTR inference close to the user, enabling time-sensitive applications such as personalized mobile advertising. On the other hand, federated learning, allow model training using many servers and user devices while keeping data private. They make it easier to scale and respond quickly, reducing the need for centralized systems. This leads to more efficient and secure data processing. Together, these forward-looking directions—transfer learning, meta-learning, and edge/distributed computing—highlight the next stage of CTR prediction research. They aim to improve adaptability, generalization, and efficiency in real-world environments where data are multimodal, large-scale, and highly dynamic.
7. Conclusions
This review highlights recent advancements in CTR prediction, concentrating on deep learning methods from the past three years. It surveys contributions from text-based and multivariate approaches, presenting a taxonomy of current techniques and highlighting key lessons for researchers and practitioners. Graph-based and multimodal approaches are pioneering in enhancing scalability and predictive performance in industrial datasets. Feature interaction learning and customer behavior models enhance personalization and sequence modeling, leading to a more effective customer experience. Cross-domain methods address data sparsity and cold-start issues through transfer and continual learning. Future CTR prediction systems are likely to use hybrid frameworks that combine graph learning, multimodal fusion, and cross-domain generalization. This work has the following limitations. It only reviews studies from the last three years on deep learning-based CTR prediction, excluding earlier research, traditional machine learning-based methods, and non-English studies. Consequently, it may miss some relevant insights. In addition, while the review highlights methodological strengths and weaknesses, it does not include a quantitative meta-analysis, which could provide further comparative evidence. Despite these limitations, the review successfully integrates fragmented knowledge, identifies leading methodologies, and outlines promising opportunities for future research. It illustrates the challenges of feature interaction, sequence modeling, multimodal integration, and scalability by reviewing relevant studies. It provides an updated overview of the field and presents a roadmap for future research. In doing so, it emphasizes the importance of CTR prediction in online advertising. It highlights the methodological approaches that are likely to influence the development of the next generation of intelligent recommender and advertising systems.
Author Contributions
S.A. and B.A. wrote and reviewed the manuscript, and S.A. performed the visualization. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Acknowledgments
We acknowledge that the charts and some figures presented in this paper have been reproduced from the original sources, and every effort has been made to ensure their precise representation.
Conflicts of Interest
The authors declare that there are no competing interests.
References
- Graesch, J.P.; Hensel-Börner, S.; Henseler, J. Information technology and marketing: An important partnership for decades. Ind. Manag. Data Syst. 2021, 121, 123–157. [Google Scholar] [CrossRef]
- Bílková, R. Digital marketing communication in the age of globalization. In Proceedings of the SHS Web of Conferences, EDP Sciences, Zilina, Slovakia, 13–14 October 2021; Volume 129, p. 06002. [Google Scholar] [CrossRef]
- Gharibshah, Z.; Zhu, X.; Hainline, A.; Conway, M. Deep learning for online display advertising user clicks and interests prediction. In Proceedings of the Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data, Chengdu, China, 1–3 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 196–204. [Google Scholar] [CrossRef]
- GetResponse. Email Marketing Benchmarks Report. Available online: https://www.getresponse.com/resources/reports/email-marketing-benchmarks (accessed on 13 September 2025).
- Yang, Y.; Zhai, P. Click-through rate prediction in online advertising: A literature review. Inf. Process. Manag. 2022, 59, 102853. [Google Scholar] [CrossRef]
- Mordor Intelligence. Available online: https://www.mordorintelligence.com/industry-reports/online-advertising-market (accessed on 12 September 2025).
- Jain, A.; Khan, S. Optimizing Cost per Click for Digital Advertising Campaigns. arXiv 2021, arXiv:2108.00747. [Google Scholar] [CrossRef]
- Dumitriu, D.; Popescu, M.A.M. Artificial intelligence solutions for digital marketing. Procedia Manuf. 2020, 46, 630–636. [Google Scholar] [CrossRef]
- Kumar, V.; Raman, R.; Meenakshi, R. Online Advertising Strategies to Effectivly Market a Business School. Int. J. High. Educ. 2021, 10, 1–61. [Google Scholar] [CrossRef]
- Davenport, T.; Guha, A.; Grewal, D.; Bressgott, T. How artificial intelligence will change the future of marketing. J. Acad. Mark. Sci. 2020, 48, 24–42. [Google Scholar] [CrossRef]
- Yu, Y. The role and influence of artificial intelligence on advertising industry. In Proceedings of the 2021 International Conference on Social Development and Media Communication (SDMC 2021), Sanya, China, 26–28 November 2021; Atlantis Press: Dordrecht, The Netherlands, 2022; pp. 190–194. [Google Scholar] [CrossRef]
- Leszczełowska, P.; Bollin, M.; Grabski, M. Systematic literature review on click through rate prediction. In Proceedings of the European Conference on Advances in Databases and Information Systems, Barcelona, Spain, 4–7 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 583–590. [Google Scholar]
- Zhang, W.; Qin, J.; Guo, W.; Tang, R.; He, X. Deep learning for click-through rate estimation. arXiv 2021, arXiv:2104.10584. [Google Scholar] [CrossRef]
- Gu, L. Ad click-through rate prediction: A survey. In Proceedings of the Database Systems for Advanced Applications. DASFAA 2021 International Workshops: BDQM, GDMA, MLDLDSA, MobiSocial, and MUST, Taipei, Taiwan, 11–14 April 2021; Proceedings 26. Springer: Berlin/Heidelberg, Germany, 2021; pp. 140–153. [Google Scholar] [CrossRef]
- Yu, C.; Zhang, Z.; Lin, C.; Wu, Y.J. Can data-driven precision marketing promote user AD clicks? Evidence from advertising in WeChat moments. Ind. Mark. Manag. 2020, 90, 481–492. [Google Scholar] [CrossRef]
- Liu, C.; Wang, S.; Jia, G. Exploring e-commerce big data and customer-perceived value: An empirical study on Chinese online customers. Sustainability 2020, 12, 8649. [Google Scholar] [CrossRef]
- Haleem, A.; Javaid, M.; Qadri, M.A.; Singh, R.P.; Suman, R. Artificial intelligence (AI) applications for marketing: A literature-based study. Int. J. Intell. Netw. 2022, 3, 119–132. [Google Scholar] [CrossRef]
- Statista. Search Advertising Click-Through Rate (CTR). Available online: https://www.statista.com/statistics/873637/search-advertising-ctr/ (accessed on 13 September 2025).
- Zhu, J.; Liu, J.; Yang, S.; Zhang, Q.; He, X. Open benchmarking for click-through rate prediction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 2759–2769. [Google Scholar] [CrossRef]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar] [CrossRef]
- Guo, H.; Chen, B.; Tang, R.; Zhang, W.; Li, Z.; He, X. An embedding learning framework for numerical features in ctr prediction. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 2910–2918. [Google Scholar] [CrossRef]
- Zhou, G.; Mou, N.; Fan, Y.; Pi, Q.; Bian, W.; Zhou, C.; Zhu, X.; Gai, K. Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5941–5948. [Google Scholar] [CrossRef]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1059–1068. [Google Scholar] [CrossRef]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 995–1000. [Google Scholar] [CrossRef]
- Qu, Y.; Cai, H.; Ren, K.; Zhang, W.; Yu, Y.; Wen, Y.; Wang, J. Product-based neural networks for user response prediction. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1149–1154. [Google Scholar] [CrossRef]
- Qu, Y.; Fang, B.; Zhang, W.; Tang, R.; Niu, M.; Guo, H.; Yu, Y.; He, X. Product-based neural networks for user response prediction over multi-field categorical data. ACM Trans. Inf. Syst. (TOIS) 2018, 37, 1–35. [Google Scholar] [CrossRef]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17; ACM: New York, NY, USA, 2017; pp. 1–7. [Google Scholar] [CrossRef]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; ACM: New York, NY, USA, 2017; pp. 355–364. [Google Scholar] [CrossRef]
- Lian, J.; Zhou, X.; Zhang, F.; Chen, Z.; Xie, X.; Sun, G. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; ACM: New York, NY, USA, 2018; pp. 1754–1763. [Google Scholar] [CrossRef]
- Li, Z.; Cui, Z.; Wu, S.; Zhang, X.; Wang, L. Fi-gnn: Modeling feature interactions via graph neural networks for ctr prediction. In Proceedings of the 28th ACM international Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; ACM: New York, NY, USA, 2019; pp. 539–548. [Google Scholar] [CrossRef]
- Liu, B.; Tang, R.; Chen, Y.; Yu, J.; Guo, H.; Zhang, Y. Feature generation by convolutional neural network for click-through rate prediction. In Proceedings of the The World Wide Web Conference, Francisco, CA, USA, 13–17 May 2019; ACM: New York, NY, USA, 2019; pp. 1119–1129. [Google Scholar] [CrossRef]
- Tay, Y.; Zhang, S.; Luu, A.T.; Hui, S.C.; Yao, L.; Vinh, T.D.Q. Holographic factorization machines for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5143–5150. [Google Scholar] [CrossRef]
- Huang, T.; Zhang, Z.; Zhang, J. FiBiNET: Combining feature importance and bilinear feature interaction for click-through rate prediction. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; ACM: New York, NY, USA, 2019; pp. 169–177. [Google Scholar] [CrossRef]
- Song, W.; Shi, C.; Xiao, Z.; Duan, Z.; Xu, Y.; Zhang, M.; Tang, J. Autoint: Automatic feature interaction learning via self-attentive neural networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; ACM: New York, NY, USA, 2019; pp. 1161–1170. [Google Scholar] [CrossRef]
- Li, Z.; Cheng, W.; Chen, Y.; Chen, H.; Wang, W. Interpretable click-through rate prediction through hierarchical attention. In Proceedings of the 13th International Conference on Web Search and Data Mining, Virtual, 10–13 July 2020; ACM: New York, NY, USA, 2020; pp. 313–321. [Google Scholar] [CrossRef]
- Cheng, W.; Chen, H. Interpretable Click-Through Rate Prediction Through Hierarchical Attention. U.S. Patent 11,423,436, 23 August 2022. [Google Scholar]
- Ling, X.; Deng, W.; Gu, C.; Zhou, H.; Li, C.; Sun, F. Model ensemble for click prediction in bing search ads. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 689–698. [Google Scholar] [CrossRef]
- Harper, F.M.; Konstan, J.A. The movielens datasets: History and context. Acm Trans. Interact. Intell. Syst. (TiiS) 2015, 5, 1–19. [Google Scholar] [CrossRef]
- Richardson, M.; Dominowska, E.; Ragno, R. Predicting clicks: Estimating the click-through rate for new ads. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 521–530. [Google Scholar] [CrossRef]
- Sahllal, N.; Souidi, E.M. A Comparative Analysis of Sampling Techniques for Click-Through Rate Prediction in Native Advertising. IEEE Access 2023, 11, 24511–24526. [Google Scholar] [CrossRef]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. arXiv 2015, arXiv:1511.06939. [Google Scholar]
- Li, D.; Hu, B.; Chen, Q.; Wang, X.; Qi, Q.; Wang, L.; Liu, H. Attentive capsule network for click-through rate and conversion rate prediction in online advertising. Knowl.-Based Syst. 2021, 211, 106522. [Google Scholar] [CrossRef]
- Kim, K.; Kwon, E.; Park, J. Deep user segment interest network modeling for click-through rate prediction of online advertising. IEEE Access 2021, 9, 9812–9821. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man, Cybern. Part C Appl. Rev. 2011, 42, 463–484. [Google Scholar] [CrossRef]
- Elkan, C. The foundations of cost-sensitive learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; Lawrence Erlbaum Associates Ltd.: Mahwah, NJ, USA, 2001; Volume 17, pp. 973–978. [Google Scholar]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- García, V.; Sánchez, J.S.; Mollineda, R.A. Exploring the performance of resampling strategies for the class imbalance problem. In Proceedings of the Trends in Applied Intelligent Systems: 23rd International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems, IEA/AIE 2010, Cordoba, Spain, 1–4 June 2010; Proceedings, Part I 23. Springer: Berlin/Heidelberg, Germany, 2010; pp. 541–549. [Google Scholar] [CrossRef]
- Khushi, M.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Uddin, S.; Luo, S.; Yang, X.; Reyes, M.C. A comparative performance analysis of data resampling methods on imbalance medical data. IEEE Access 2021, 9, 109960–109975. [Google Scholar] [CrossRef]
- Pereira, R.M.; Costa, Y.M.; Silla, C.N., Jr. Toward hierarchical classification of imbalanced data using random resampling algorithms. Inf. Sci. 2021, 578, 344–363. [Google Scholar] [CrossRef]
- Sowah, R.A.; Kuditchar, B.; Mills, G.A.; Acakpovi, A.; Twum, R.A.; Buah, G.; Agboyi, R. HCBST: An efficient hybrid sampling technique for class imbalance problems. ACM Trans. Knowl. Discov. Data (TKDD) 2021, 16, 1–37. [Google Scholar] [CrossRef]
- Goyal, S. Handling class-imbalance with KNN (neighbourhood) under-sampling for software defect prediction. Artif. Intell. Rev. 2022, 55, 2023–2064. [Google Scholar] [CrossRef]
- Laurikkala, J. Improving identification of difficult small classes by balancing class distribution. In Proceedings of the Artificial Intelligence in Medicine: 8th Conference on Artificial Intelligence in Medicine in Europe, AIME 2001 Cascais, Portugal, 1–4 July 2001; Proceedings 8. Springer: Warsaw, Poland, 2001; pp. 63–66. [Google Scholar] [CrossRef]
- Mqadi, N.M.; Naicker, N.; Adeliyi, T. Solving misclassification of the credit card imbalance problem using near miss. Math. Probl. Eng. 2021, 2021, 7194728. [Google Scholar] [CrossRef]
- Ahmed, S.; Rahman, A.; Hasan, M.A.M.; Ahmad, S.; Shovan, S. Computational identification of multiple lysine PTM sites by analyzing the instance hardness and feature importance. Sci. Rep. 2021, 11, 18882. [Google Scholar] [CrossRef]
- Pereira, R.M.; Costa, Y.M.; Silla, C.N., Jr. MLTL: A multi-label approach for the Tomek Link undersampling algorithm. Neurocomputing 2020, 383, 95–105. [Google Scholar] [CrossRef]
- FOLORUNSO, S.O. Development of Advanced Data Sampling Schemes to Alleviate Class Imbalance Problem in Data Mining Classification Algorithms. Ph.D. Thesis, University of Ibadan, Oyo, Nigeria, 2015. [Google Scholar]
- Zheng, Z.; Cai, Y.; Li, Y. Oversampling method for imbalanced classification. Comput. Inform. 2015, 34, 1017–1037. [Google Scholar]
- Mohammed, R.; Rawashdeh, J.; Abdullah, M. Machine learning with oversampling and undersampling techniques: Overview study and experimental results. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 243–248. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the 2005 International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar] [CrossRef]
- Lin, M.; Zhu, X.; Hua, T.; Tang, X.; Tu, G.; Chen, X. Detection of ionospheric scintillation based on xgboost model improved by smote-enn technique. Remote Sens. 2021, 13, 2577. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, C.; Zheng, K.; Niu, X.; Wang, X. SMOTETomek-based resampling for personality recognition. IEEE Access 2019, 7, 129678–129689. [Google Scholar] [CrossRef]
- Talukder, M.A.; Sharmin, S.; Uddin, M.A.; Islam, M.M.; Aryal, S. MLSTL-WSN: Machine learning-based intrusion detection using SMOTETomek in WSNs. Int. J. Inf. Secur. 2024, 23, 2139–2158. [Google Scholar] [CrossRef]
- Chen, C.; Liaw, A.; Breiman, L. Using Random Forest to Learn Imbalanced Data; University of California: Berkeley, CA, USA, 2004; Volume 110, p. 24. [Google Scholar]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 39, 539–550. [Google Scholar] [CrossRef]
- Seiffert, C.; Khoshgoftaar, T.M.; Van Hulse, J.; Napolitano, A. RUSBoost: Improving classification performance when training data is skewed. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Edizel, B.; Mantrach, A.; Bai, X. Deep character-level click-through rate prediction for sponsored search. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 305–314. [Google Scholar] [CrossRef]
- Shan, Y.; Hoens, T.R.; Jiao, J.; Wang, H.; Yu, D.; Mao, J. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 255–262. [Google Scholar] [CrossRef]
- Gharibshah, Z.; Zhu, X.; Hainline, A.; Conway, M. Deep learning for user interest and response prediction in online display advertising. Data Sci. Eng. 2020, 5, 12–26. [Google Scholar] [CrossRef]
- Du, X.; Su, M.; Zhang, X.; Zheng, X. Bidding for multiple keywords in sponsored search advertising: Keyword categories and match types. Inf. Syst. Res. 2017, 28, 711–722. [Google Scholar] [CrossRef]
- Huang, P.S.; He, X.; Gao, J.; Deng, L.; Acero, A.; Heck, L. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2333–2338. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Grbovic, M.; Djuric, N.; Radosavljevic, V.; Silvestri, F.; Baeza-Yates, R.; Feng, A.; Ordentlich, E.; Yang, L.; Owens, G. Scalable semantic matching of queries to ads in sponsored search advertising. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 375–384. [Google Scholar] [CrossRef]
- Zhai, S.; Chang, K.H.; Zhang, R.; Zhang, Z.M. Deepintent: Learning attentions for online advertising with recurrent neural networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1295–1304. [Google Scholar] [CrossRef]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. A latent semantic model with convolutional-pooling structure for information retrieval. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 101–110. [Google Scholar] [CrossRef]
- Alves Gomes, M.; Meyes, R.; Meisen, P.; Meisen, T. It’s Not Always about Wide and Deep Models: Click-Through Rate Prediction with a Customer Behavior-Embedding Representation. J. Theor. Appl. Electron. Commer. Res. 2024, 19, 135–151. [Google Scholar] [CrossRef]
- Cui, Y.; Zhou, P.; Yu, H.; Sun, P.; Cao, H.; Yang, P. ASKAT: Aspect Sentiment Knowledge Graph Attention Network for Recommendation. Electronics 2024, 13, 216. [Google Scholar] [CrossRef]
- Geng, B.; Huan, Z.; Zhang, X.; He, Y.; Zhang, L.; Yuan, F.; Zhou, J.; Mo, L. Breaking the length barrier: Llm-enhanced CTR prediction in long textual user behaviors. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; pp. 2311–2315. [Google Scholar] [CrossRef]
- Ni, J.; Li, J.; McAuley, J. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 188–197. [Google Scholar] [CrossRef]
- Li, X.; Wang, C.; Tan, J.; Zeng, X.; Ou, D.; Ou, D.; Zheng, B. Adversarial multimodal representation learning for click-through rate prediction. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 827–836. [Google Scholar] [CrossRef]
- Li, X.; Wang, C.; Tong, B.; Tan, J.; Zeng, X.; Zhuang, T. Deep time-aware item evolution network for click-through rate prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 785–794. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar] [CrossRef]
- Ai, Q.; Azizi, V.; Chen, X.; Zhang, Y. Learning heterogeneous knowledge base embeddings for explainable recommendation. Algorithms 2018, 11, 137. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar] [CrossRef]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25 July 2020; pp. 639–648. [Google Scholar] [CrossRef]
- McMahan, H.B.; Holt, G.; Sculley, D.; Young, M.; Ebner, D.; Grady, J.; Nie, L.; Phillips, T.; Davydov, E.; Golovin, D.; et al. Ad click prediction: A view from the trenches. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1222–1230. [Google Scholar] [CrossRef]
- Fu, Z.; Li, X.; Wu, C.; Wang, Y.; Dong, K.; Zhao, X.; Zhao, M.; Guo, H.; Tang, R. A unified framework for multi-domain ctr prediction via large language models. arXiv 2023, arXiv:2312.10743. [Google Scholar] [CrossRef]
- Wang, H.; Lin, J.; Li, X.; Chen, B.; Zhu, C.; Tang, R.; Zhang, W.; Yu, Y. FLIP: Fine-Grained Alignment Between ID-Based Models and Pretrained Language Models for CTR Prediction. In Proceedings of the 18th ACM Conference on Recommender Systems, Bari, Italy, 14–18 October 2024; pp. 94–104. [Google Scholar] [CrossRef]
- Xi, Y.; Liu, W.; Lin, J.; Cai, X.; Zhu, H.; Zhu, J.; Chen, B.; Tang, R.; Zhang, W.; Yu, Y. Towards open-world recommendation with knowledge augmentation from large language models. In Proceedings of the 18th ACM Conference on Recommender Systems, Bari, Italy, 14–18 October 2024; pp. 12–22. [Google Scholar] [CrossRef]
- Liu, Y.; Li, C.; Xiao, H.; Cai, J. Gcn-int: A click-through rate prediction model based on graph convolutional network interaction. IEEE Access 2021, 9, 140022–140030. [Google Scholar] [CrossRef]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.S. Attentional factorization machines: Learning the weight of feature interactions via attention networks. arXiv 2017, arXiv:1708.04617. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, X.; Yamasaki, T. Graph Fusion in Reciprocal Recommender Systems. IEEE Access 2023, 11, 8860–8869. [Google Scholar] [CrossRef]
- Neve, J.; Palomares, I. Latent factor models and aggregation operators for collaborative filtering in reciprocal recommender systems. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 219–227. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, X.; Yamasaki, T. Deep feature interaction embedding for pair matching prediction. In Proceedings of the 1st ACM International Conference on Multimedia in Asia, Beijing, China, 15–18 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, F.; Yue, Y.; Li, G.; Payne, T.R.; Man, K.L. KEMIM: Knowledge-Enhanced User Multi-Interest Modeling for Recommender Systems. IEEE Access 2023, 11, 55425–55434. [Google Scholar] [CrossRef]
- Li, Z.; Wu, S.; Cui, Z.; Zhang, X. GraphFM: Graph factorization machines for feature interaction modeling. arXiv 2021, arXiv:2105.11866. [Google Scholar]
- He, L.; Chen, H.; Wang, D.; Jameel, S.; Yu, P.; Xu, G. Click-through rate prediction with multi-modal hypergraphs. In Proceedings of the 30th ACM international Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 690–699. [Google Scholar] [CrossRef]
- Ariza-Casabona, A.; Twardowski, B.; Wijaya, T.K. Exploiting graph structured cross-domain representation for multi-domain recommendation. In Proceedings of the European Conference on Information Retrieval, Dublin, Ireland, 2–6 April 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 49–65. [Google Scholar] [CrossRef]
- Sang, L.; Li, H.; Zhang, Y.; Zhang, Y.; Yang, Y. AdaGIN: Adaptive Graph Interaction Network for Click-Through Rate Prediction. ACM Trans. Inf. Syst. 2024, 43, 1–31. [Google Scholar] [CrossRef]
- Shih, W.Y.; Lai, H.C.; Huang, J.L. A Robust Real Time Bidding Strategy Against Inaccurate CTR Predictions by Using Cluster Expected Win Rate. IEEE Access 2023, 11, 126917–126926. [Google Scholar] [CrossRef]
- Zhang, W.; Yuan, S.; Wang, J.; Shen, X. Real-time bidding benchmarking with ipinyou dataset. arXiv 2014, arXiv:1407.7073. [Google Scholar]
- Yan, B.; Wang, P.; Zhang, K.; Li, F.; Deng, H.; Xu, J.; Zheng, B. Apg: Adaptive parameter generation network for click-through rate prediction. Adv. Neural Inf. Process. Syst. 2022, 35, 24740–24752. [Google Scholar]
- Ziegler, C.N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving recommendation lists through topic diversification. In Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 22–32. [Google Scholar] [CrossRef]
- Zhang, R.; Ma, H.; Li, Q.; Wang, Y.; Li, Z. Fire: Knowledge-enhanced recommendation with feature interaction and intent-aware attention networks. Appl. Intell. 2023, 53, 16424–16444. [Google Scholar] [CrossRef]
- Chen, Q.; Tan, H.; Lin, G.; Wang, Z. A hierarchical knowledge and interest propagation network for recommender systems. In Proceedings of the 2020 International Conference on Data Mining Workshops (ICDMW), Sorrento, Italy, 17–20 November 2020; pp. 119–126. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, Y.; Wang, Y.; Bai, J.; Song, X.; King, I. Attentive knowledge-aware graph convolutional networks with collaborative guidance for personalized recommendation. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 299–311. [Google Scholar] [CrossRef]
- Blondel, M.; Fujino, A.; Ueda, N.; Ishihata, M. Higher-order factorization machines. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3359–3367. [Google Scholar]
- Cheng, W.; Shen, Y.; Huang, L. Adaptive factorization network: Learning adaptive-order feature interactions. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3609–3616. [Google Scholar] [CrossRef]
- Sun, Y.; Pan, J.; Zhang, A.; Flores, A. FM2: Field-matrixed factorization machines for recommender systems. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 12–23 April 2021; pp. 2828–2837. [Google Scholar] [CrossRef]
- Bretto, A. Hypergraph theory. In Hypergraph Theory: An Introduction; Mathematical Engineering; Springer: Cham, Switzerland, 2013; Volume 1, pp. 209–216. [Google Scholar] [CrossRef]
- Sun, X.; Yin, H.; Liu, B.; Chen, H.; Meng, Q.; Han, W.; Cao, J. Multi-level hyperedge distillation for social linking prediction on sparsely observed networks. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 12–23 April 2021; pp. 2934–2945. [Google Scholar] [CrossRef]
- Zhou, K.; Wang, H.; Zhao, W.X.; Zhu, Y.; Wang, S.; Zhang, F.; Wang, Z.; Wen, J.R. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 1893–1902. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Li, Y.; Liu, M.; Yin, J.; Cui, C.; Xu, X.S.; Nie, L. Routing micro-videos via a temporal graph-guided recommendation system. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1464–1472. [Google Scholar] [CrossRef]
- Chen, X.; Liu, D.; Zha, Z.J.; Zhou, W.; Xiong, Z.; Li, Y. Temporal hierarchical attention at category-and item-level for micro-video click-through prediction. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1146–1153. [Google Scholar] [CrossRef]
- Qin, J.; Zhang, W.; Wu, X.; Jin, J.; Fang, Y.; Yu, Y. User behavior retrieval for click-through rate prediction. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25 July 2020; pp. 2347–2356. [Google Scholar] [CrossRef]
- Liu, B.; Zhu, C.; Li, G.; Zhang, W.; Lai, J.; Tang, R.; He, X.; Li, Z.; Yu, Y. Autofis: Automatic feature interaction selection in factorization models for click-through rate prediction. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 2636–2645. [Google Scholar] [CrossRef]
- Qiu, R.; Li, J.; Huang, Z.; Yin, H. Rethinking the item order in session-based recommendation with graph neural networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 579–588. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, Z.; Yi, X.; Chen, J.; Hong, L.; Chi, E.H. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1930–1939. [Google Scholar] [CrossRef]
- Zhang, W.; Yuan, S.; Wang, J. Optimal real-time bidding for display advertising. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1077–1086. [Google Scholar] [CrossRef]
- Cai, H.; Ren, K.; Zhang, W.; Malialis, K.; Wang, J.; Yu, Y.; Guo, D. Real-time bidding by reinforcement learning in display advertising. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 661–670. [Google Scholar] [CrossRef]
- Liu, L.; Wang, Y.; Wang, T.; Guan, D.; Wu, J.; Chen, J.; Xiao, R.; Zhu, W.; Fang, F. Continual Transfer Learning for Cross-Domain Click-Through Rate Prediction at Taobao. In Proceedings of the Companion Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April 2023–4 May 2023; pp. 346–350. [Google Scholar] [CrossRef]
- Zhang, Y.; Chan, Z.; Xu, S.; Bian, W.; Han, S.; Deng, H.; Zheng, B. KEEP: An industrial pre-training framework for online recommendation via knowledge extraction and plugging. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 3684–3693. [Google Scholar] [CrossRef]
- Tang, H.; Liu, J.; Zhao, M.; Gong, X. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. In Proceedings of the 14th ACM Conference on Recommender Systems, Virtual, 22–26 September 2020; pp. 269–278. [Google Scholar] [CrossRef]
- An, Z.; Gu, Z.; Yu, L.; Tu, K.; Wu, Z.; Hu, B.; Zhang, Z.; Gu, L.; Gu, J. DDCDR: A Disentangle-based Distillation Framework for Cross-Domain Recommendation. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 4764–4773. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, P.; Zhang, B.; Wang, X.; Wang, D. A collaborative transfer learning framework for cross-domain recommendation. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 5576–5585. [Google Scholar] [CrossRef]
- Cao, J.; Lin, X.; Cong, X.; Ya, J.; Liu, T.; Wang, B. Disencdr: Learning disentangled representations for cross-domain recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 267–277. [Google Scholar] [CrossRef]
- Li, P.; Jiang, Z.; Que, M.; Hu, Y.; Tuzhilin, A. Dual attentive sequential learning for cross-domain click-through rate prediction. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 3172–3180. [Google Scholar] [CrossRef]
- Lin, G.; Gao, C.; Zheng, Y.; Chang, J.; Niu, Y.; Song, Y.; Gai, K.; Li, Z.; Jin, D.; Li, Y.; et al. Mixed Attention Network for Cross-domain Sequential Recommendation. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Merida, Mexico, 4–8 March 2024; pp. 405–413. [Google Scholar] [CrossRef]
- Park, C.; Kim, T.; Yoon, H.; Hong, J.; Yu, Y.; Cho, M.; Choi, M.; Choo, J. Pacer and Runner: Cooperative Learning Framework between Single-and Cross-Domain Sequential Recommendation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; pp. 2071–2080. [Google Scholar] [CrossRef]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar] [CrossRef]
- Xu, W.; Ning, X.; Lin, W.; Ha, M.; Ma, Q.; Liang, Q.; Tao, X.; Chen, L.; Han, B.; Luo, M. Towards open-world cross-domain sequential recommendation: A model-agnostic contrastive denoising approach. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Vilnius, Lithuania, 9–13 September 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 161–179. [Google Scholar] [CrossRef]
- Huang, G.; Chen, Q.; Deng, C. A new click-through rates prediction model based on Deep&Cross network. Algorithms 2020, 13, 342. [Google Scholar] [CrossRef]
- Bobrikov, V.; Nenova, E.; Ignatov, D.I. What is a fair value of your recommendation list? In Proceedings of the Third Workshop on Experimental Economics and Machine Learning, Moscow, Russia, 18 July 2016; pp. 1–12. [Google Scholar]
- Ouyang, W.; Zhang, X.; Zhao, L.; Luo, J.; Zhang, Y.; Zou, H.; Liu, Z.; Du, Y. Minet: Mixed interest network for cross-domain click-through rate prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 2669–2676. [Google Scholar] [CrossRef]
- Hu, G.; Zhang, Y.; Yang, Q. Conet: Collaborative cross networks for cross-domain recommendation. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 667–676. [Google Scholar] [CrossRef]
- Ma, M.; Ren, P.; Lin, Y.; Chen, Z.; Ma, J.; Rijke, M.D. π-net: A parallel information-sharing network for shared-account cross-domain sequential recommendations. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 685–694. [Google Scholar] [CrossRef]
- Rashed, A.; Elsayed, S.; Schmidt-Thieme, L. Context and attribute-aware sequential recommendation via cross-attention. In Proceedings of the 16th ACM Conference on Recommender Systems, Seattle, WA, USA, 18–3 September 2022; pp. 71–80. [Google Scholar] [CrossRef]
- Ma, M.; Ren, P.; Chen, Z.; Ren, Z.; Zhao, L.; Liu, P.; Ma, J.; de Rijke, M. Mixed information flow for cross-domain sequential recommendations. ACM Trans. Knowl. Discov. Data (TKDD) 2022, 16, 1–32. [Google Scholar] [CrossRef]
- Kang, W.C.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar] [CrossRef]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar] [CrossRef]
- Guo, W.; Zhang, C.; He, Z.; Qin, J.; Guo, H.; Chen, B.; Tang, R.; He, X.; Zhang, R. Miss: Multi-interest self-supervised learning framework for click-through rate prediction. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 727–740. [Google Scholar] [CrossRef]
- Pi, Q.; Zhou, G.; Zhang, Y.; Wang, Z.; Ren, L.; Fan, Y.; Zhu, X.; Gai, K. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 2685–2692. [Google Scholar] [CrossRef]
- Lyu, Z.; Dong, Y.; Huo, C.; Ren, W. Deep match to rank model for personalized click-through rate prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 156–163. [Google Scholar] [CrossRef]
- Lin, Q.; Zhou, W.J.; Wang, Y.; Da, Q.; Chen, Q.G.; Wang, B. Sparse attentive memory network for click-through rate prediction with long sequences. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 3312–3321. [Google Scholar] [CrossRef]
- Yu, M.; Liu, T.; Yin, J. Deep Filter Context Network for Click-Through Rate Prediction. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 1446–1462. [Google Scholar] [CrossRef]
- Wei, J.; Wang, L.; Ge, M. Deep Adaptive Interest Network for CTR Prediction. IEEE Access 2023, 11, 109397–109407. [Google Scholar] [CrossRef]
- Xue, S.; He, C.; Hua, Z.; Li, S.; Wang, G.; Cao, L. Interactive attention-based capsule network for click-through rate prediction. IEEE Access 2024, 12, 170335–170345. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, F.; Yang, C.; Wang, W. Deep multi-representational item network for CTR prediction. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 2277–2281. [Google Scholar] [CrossRef]
- Tian, L.; Ge, L.; Wang, Z.; Zhang, G.; Xu, C.; Qin, X. Research on Improvement of the Click-Through Rate Prediction Model Based on Differential Privacy. IEEE Access 2022, 10, 110960–110969. [Google Scholar] [CrossRef]
- Feng, Y.; Lv, F.; Shen, W.; Wang, M.; Sun, F.; Zhu, Y.; Yang, K. Deep session interest network for click-through rate prediction. arXiv 2019, arXiv:1905.06482. [Google Scholar]
- Yu, M.; Liu, T.; Yin, J.; Chai, P. Deep interest context network for click-through rate. Appl. Sci. 2022, 12, 9531. [Google Scholar] [CrossRef]
- Li, F.; Chen, Z.; Wang, P.; Ren, Y.; Zhang, D.; Zhu, X. Graph intention network for click-through rate prediction in sponsored search. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 961–964. [Google Scholar] [CrossRef]
- Huang, Z.; Tao, M.; Zhang, B. Deep user match network for click-through rate prediction. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 1890–1894. [Google Scholar] [CrossRef]
- Xiao, Z.; Yang, L.; Jiang, W.; Wei, Y.; Hu, Y.; Wang, H. Deep multi-interest network for click-through rate prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 2265–2268. [Google Scholar] [CrossRef]
- Berndt, D.J.; Clifford, J. Using dynamic time warping to find patterns in time series. In Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 31 July–1 August 1994; pp. 359–370. [Google Scholar]
- Li, H.; Sang, L.; Zhang, Y.; Zhang, X.; Zhang, Y. CETN: Contrast-enhanced Through Network for Click-Through Rate Prediction. ACM Trans. Inf. Syst. 2024, 43, 1–34. [Google Scholar] [CrossRef]
- Wang, Z.; She, Q.; Zhang, J. Masknet: Introducing feature-wise multiplication to CTR ranking models by instance-guided mask. arXiv 2021, arXiv:2102.07619. [Google Scholar]
- Wang, F.; Wang, Y.; Li, D.; Gu, H.; Lu, T.; Zhang, P.; Gu, N. Cl4ctr: A contrastive learning framework for ctr prediction. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, Singapore, 27 February–3 March 2023; pp. 805–813. [Google Scholar] [CrossRef]
- Lyu, F.; Tang, X.; Liu, D.; Chen, L.; He, X.; Liu, X. Optimizing feature set for click-through rate prediction. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 3386–3395. [Google Scholar] [CrossRef]
- Wang, X.; Dong, H.; Han, S. Click-through rate prediction combining mutual information feature weighting and feature interaction. IEEE Access 2020, 8, 207216–207225. [Google Scholar] [CrossRef]
- Wang, X.; Dong, H. Click-through Rate Prediction and Uncertainty Quantification Based on Bayesian Deep Learning. Entropy 2023, 25, 406. [Google Scholar] [CrossRef]
- Lin, J.; Qu, Y.; Guo, W.; Dai, X.; Tang, R.; Yu, Y.; Zhang, W. Map: A model-agnostic pretraining framework for click-through rate prediction. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 1384–1395. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhu, M.; Li, Y.; Liu, H.; Guo, S. Feature-Interaction-Enhanced Sequential Transformer for Click-Through Rate Prediction. Appl. Sci. 2024, 14, 2760. [Google Scholar] [CrossRef]
- Yang, X.; Peng, X.; Wei, P.; Liu, S.; Wang, L.; Zheng, B. Adasparse: Learning adaptively sparse structures for multi-domain click-through rate prediction. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 4635–4639. [Google Scholar] [CrossRef]
- Wei, P.; Zhang, W.; Xu, Z.; Liu, S.; Lee, K.c.; Zheng, B. Autoheri: Automated hierarchical representation integration for post-click conversion rate estimation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 3528–3532. [Google Scholar] [CrossRef]
- Mao, K.; Zhu, J.; Su, L.; Cai, G.; Li, Y.; Dong, Z. FinalMLP: An enhanced two-stream MLP model for CTR prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 4552–4560. [Google Scholar] [CrossRef]
- Tian, Z.; Bai, T.; Zhao, W.X.; Wen, J.R.; Cao, Z. EulerNet: Adaptive Feature Interaction Learning via Euler’s Formula for CTR Prediction. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 1376–1385. [Google Scholar] [CrossRef]
- Pande, H. Field-embedded factorization machines for click-through rate prediction. arXiv 2020, arXiv:2009.09931. [Google Scholar]
- Yu, R.; Ye, Y.; Liu, Q.; Wang, Z.; Yang, C.; Hu, Y.; Chen, E. Xcrossnet: Feature structure-oriented learning for click-through rate prediction. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Virtual, 11–14 May 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 436–447. [Google Scholar] [CrossRef]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Wang, R.; Shivanna, R.; Cheng, D.; Jain, S.; Lin, D.; Hong, L.; Chi, E. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 12–23 April 2021; pp. 1785–1797. [Google Scholar] [CrossRef]
- Yan, C.; Li, X.; Chen, Y.; Zhang, Y. JointCTR: A joint CTR prediction framework combining feature interaction and sequential behavior learning. Appl. Intell. 2022, 52, 4701–4714. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; McAuley, J. Time interval aware self-attention for sequential recommendation. In Proceedings of the 13th International Conference on Web Search and Data Mining, Virtual, 10–13 July 2020; pp. 322–330. [Google Scholar] [CrossRef]
- Sheng, X.R.; Zhao, L.; Zhou, G.; Ding, X.; Dai, B.; Luo, Q.; Yang, S.; Lv, J.; Zhang, C.; Deng, H.; et al. One model to serve all: Star topology adaptive recommender for multi-domain ctr prediction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 4104–4113. [Google Scholar] [CrossRef]
- Yu, R.; Gong, Y.; He, X.; Zhu, Y.; Liu, Q.; Ou, W.; An, B. Personalized adaptive meta learning for cold-start user preference prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021; Volume 35, pp. 10772–10780. [Google Scholar] [CrossRef]
- Yu, F.; Liu, Z.; Liu, Q.; Zhang, H.; Wu, S.; Wang, L. Deep interaction machine: A simple but effective model for high-order feature interactions. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 2285–2288. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).