Abstract
Unmanned Surface Vehicles (USVs) play a critical role in maritime monitoring, environmental protection, and emergency response, necessitating accurate scene understanding in complex aquatic environments. Conventional semantic segmentation methods often fail to capture global context and lack physical boundary consistency, limiting real-world performance. This paper proposes USV-Seg, a unified segmentation framework integrating a vision-language model, the Segment Anything Model (SAM), DINOv2-based visual features, and a physically constrained refinement module. We design a task-specific <Describe> Token to enable fine-grained semantic reasoning of navigation scenes, considering USV-to-shore distance, landform complexity, and water surface texture. A mask selection algorithm based on multi-layer Intersection-over-Prediction (IoP) heads improves segmentation precision across sky, water, and obstacle regions. A boundary-aware correction module refines outputs using estimated sky-water and land-water boundaries, enhancing robustness and realism. Unlike prior works that simply apply vision-language or geometric post-processing in isolation, USV-Seg integrates structured scene reasoning and scene-aware boundary constraints into a unified and physically consistent framework. Experiments on a real-world USV dataset demonstrate that USV-Seg outperforms state-of-the-art methods, achieving 96.30% mIoU in challenging near-shore scenarios.
1. Introduction
Unmanned Surface Vehicles (USVs) are gaining increasing prominence across a wide range of applications, including maritime monitoring, environmental surveillance, emergency response, and autonomous navigation [1,2,3]. Their expanding role in marine scenarios has spurred the development of advanced perception technologies, with image segmentation emerging as a critical task for scene understanding and navigation decision-making [4,5,6]. Accurate segmentation of semantic regions—such as sky, water surfaces, shoreline, and obstacles—is essential for ensuring the robustness and safety of USV operations, particularly in dynamic and visually complex environments.
Over the past decade, significant progress has been made in USV image segmentation. Traditional approaches based on edge detection, thresholding, or region-growing techniques [7] provided simple solutions but were highly sensitive to illumination changes, water reflections, and wave-induced patterns, limiting their effectiveness in real-world maritime scenes. The advent of deep learning revolutionized this field: fully convolutional networks (FCNs) [8] and U-Net [9] architectures significantly improved segmentation accuracy by learning rich hierarchical features and capturing fine details. Later studies introduced post-processing with conditional random fields (CRFs) [10] or superpixel enhancements [11] to further improve boundary delineation and robustness.
Recent trends have explored multimodal and promptable segmentation models that leverage vision-language learning [12,13] and self-supervised representation learning [14,15] to enable zero-shot generalization, few-shot learning, and reduced annotation burdens. In parallel, researchers have begun incorporating domain-specific physical constraints into the segmentation process [16,17], using LiDAR, multibeam sonar, and epipolar geometry to enforce geometric plausibility and improve shoreline detection. These advances have led to improved performance in specific aspects of the segmentation task.
Nevertheless, current methods remain inadequate in several respects when deployed in realistic maritime environments. Many vision-only models lack scene-level reasoning, treating each pixel independently without considering the broader navigational context. Geometric constraints are often applied only as post-processing steps, rather than being integrated into the model’s core reasoning pipeline. Furthermore, the computational demands of large deep networks frequently exceed the processing capacity of embedded USV hardware, making them unsuitable for real-time deployment. Finally, generalization to diverse and visually ambiguous maritime scenes—such as those with adverse weather, dynamic waves, or complex shorelines—remains an unresolved challenge.
To summarize, existing segmentation methods for USV navigation face the following key limitations:
- Poor generalization to diverse maritime scenes: Current models trained on limited datasets often fail when applied to unseen conditions, such as varying illumination, sea states, or shoreline geometries.
- Lack of physically plausible boundaries: Many approaches produce inconsistent or implausible boundaries, misclassifying water, sky, and land in visually ambiguous regions.
- Insufficient semantic reasoning: Existing models rarely incorporate structured scene-level knowledge, such as the expected spatial relationship between shoreline, water surface, and sky.
- computational complexity: State-of-the-art deep models are often too resource-intensive for real-time inference on USV platforms.
To address these challenges, we propose USV-Seg, a novel semantic segmentation framework tailored to the unique demands of USV navigation. USV-Seg integrates vision-language understanding, multimodal promptable segmentation, and domain-specific physical constraints into a unified and lightweight model that is both accurate and real-time capable. Our framework bridges the gap between semantic reasoning and physical plausibility, producing scene-consistent and robust segmentations suitable for real-world deployment.
2. Related Work
2.1. Traditional Image Segmentation for USVs
Early image segmentation approaches for USVs primarily relied on conventional image processing techniques, such as edge detection and threshold-based segmentation. As reviewed by Albukhnefis [7], these included edge detection algorithms, threshold-based segmentation, and region-growing methods. While effective in controlled environments, these techniques demonstrated limited performance in complex maritime scenarios due to their susceptibility to illumination variations, water surface reflections, and dynamic wave patterns. Other notable approaches included histogram-based water detection [18], line-segment-based detection with temporal stability filtering [19], and gradient-based sky-water separation [20]. These early methods laid the groundwork for later developments but were often brittle and lacked robustness under dynamic sea states and non-uniform lighting conditions [21,22,23].
2.2. Deep Learning-Based Segmentation
The advent of deep learning revolutionized image segmentation for USVs, with Fully Convolutional Networks (FCN) [8] establishing the foundation for modern approaches. Ronneberger [24] demonstrated that FCN-based architectures could achieve over 95% accuracy in water/non-water classification tasks, a significant improvement over traditional methods. The introduction of U-Net [9] with its distinctive encoder-decoder structure and skip connections further enhanced performance, particularly in capturing fine details of water edges and small obstacles.
Subsequent work adapted other mainstream architectures to maritime scenes, such as DeepLabv3+ [25,26], PSPNet [27], and HRNet [28], which leveraged atrous convolutions and pyramid pooling to better model multi-scale context. GAN-based methods were also introduced for improving segmentation quality under adverse weather and low-light conditions [29]. Transformer-based architectures like SegFormer [30] and Swin-UNet [31] were recently explored for their ability to capture long-range dependencies and improve boundary sharpness. Recent domain adaptation techniques [32] addressed dataset bias by aligning feature distributions across different maritime datasets. Xue [11] proposed a SLIC algorithm-enhanced deep semantic segmentation model that improved obstacle edge detection accuracy by 12% compared to standard U-Net. Zhan [10] developed an adaptive semantic segmentation method incorporating Conditional Random Fields (CRF) for post-processing, achieving excellent performance with limited training data through self-training with refined pseudo-labels.
2.3. Physical Constraints in Segmentation
Recognizing that pure vision-based approaches sometimes produce physically implausible results, researchers have increasingly incorporated domain-specific physical constraints into segmentation frameworks. Jaszcz [16] developed a comprehensive system combining USV-mounted LiDAR and multibeam echosounder (MBES) data with satellite imagery to generate accurate shoreline segmentation masks. Several studies [33,34] have focused specifically on water-shoreline (WSL) detection, a critical task for USV navigation. Zou [19] proposed a three-stage method using line segment detection, water region instability analysis, and epipolar constraints that demonstrated robust performance for both straight and curved shorelines. Halicki [17] further improved precision by incorporating LiDAR point cloud data from USV-mounted sensors, enabling sub-meter accuracy in shoreline extraction. Additional approaches integrated elevation models [16], polarimetric imaging [35], and bathymetric priors [36] to enforce geometric plausibility. Recent probabilistic graphical models [37,38] have also been employed to enforce higher-order spatial consistency across segmentation boundaries.
2.4. Multimodal and Prompt-Based Segmentation
Recent advances in multimodal learning have opened new possibilities for maritime image segmentation. The Segment Anything Model (SAM) [12] introduced a promptable segmentation framework that enables zero-shot generalization to new maritime environments. Wang [13] extended this approach to multimodal image segmentation through latent space token generation and fused mask prompting mechanisms. Self-supervised learning methods like DINOv2 [14] have demonstrated remarkable feature learning capabilities without extensive labeled data. Ayzenberg [15] successfully adapted these techniques for few-shot image segmentation, significantly reducing annotation requirements while maintaining high accuracy. Other prompt-based approaches such as CLIPSeg [39], LSeg [40], and DenseCLIP [41] have demonstrated impressive flexibility in transferring semantic knowledge to novel maritime domains. Multimodal sensor fusion combining RGB, LiDAR, SAR, and hyperspectral imagery has been explored to enhance segmentation reliability under extreme conditions [42,43,44]. Recent work has also proposed integrating temporal cues for video-based segmentation of USV navigation scenes [45,46].
2.5. Remaining Challenges
While USV image segmentation has made notable progress, current methods still face key limitations in complex maritime environments. Despite high accuracy in controlled settings, they struggle with illumination changes, wave dynamics, and adverse weather. Generalization across diverse water bodies is poor due to limited training datasets. Moreover, balancing accuracy and real-time performance remains a challenge for resource-constrained USV platforms, especially when handling high-resolution or multi-sensor data. A more fundamental issue lies in the limited incorporation of domain-specific physical constraints—such as water-sky and water-shoreline relationships—into segmentation models. This often leads to boundary misclassification in visually ambiguous scenes. While some approaches incorporate LiDAR or radar, they typically require costly sensor setups and lack the flexibility of vision-only solutions. Developing lightweight, physically consistent, and semantically aware segmentation methods remains an open research direction.
3. Algorithm
3.1. Algorithm Structure
The proposed USV-Seg system consists of five main modules: a pre-trained MiniCPM vision-language model, the Segment Anything Model (SAM), the DINOv2 model, a mask selection module, and a physical constraint-enhanced segmentation module. The vision-language model (MiniCPM-o 2.6) [47] is responsible for interpreting both the input image and user queries. We introduce a special segmentation control token, <Describe>, into the MiniCPM-o 2.6 vocabulary to indicate segmentation. During forward propagation, the <Describe> token is dynamically updated to store specific information related to USV segmentation targets.
In our implementation, the MiniCPM visual encoder is kept frozen during both training and inference to reduce computational cost and prevent catastrophic forgetting of pre-trained knowledge. The structured prompt template (see Section 3.2) is automatically constructed in JSON-like format with placeholders filled by scene recognition modules to enable reproducible and consistent input to MiniCPM.
The mask proposal generator processes the input image and outputs multiple binary masks representing candidate regions. The mask selection module, guided by the <Describe> token, selects the optimal combination of masks to form an initial segmentation result. Finally, the physical constraint-enhanced segmentation module further refines the result to ensure consistency with real-world physical structures. The boundary-aware module is implemented as a non-differentiable, modular post-processing stage applied only during inference and does not participate in backpropagation.
As shown in Figure 1, only the mask selection module contains trainable parameters. The Segment Anything Model (SAM), CLIP model, and MiniCPM visual encoder are all frozen during training. This parameter control strategy enables the entire system to run efficiently on a single RTX 3090 GPU. To facilitate downstream navigation decisions, we treat both land regions (e.g., shoreline, buildings) and water surface obstacles (e.g., floating debris, ships) as non-navigable areas. These regions are grouped into a unified "obstacle" category in the final segmentation mask to ensure the safe path planning of the USV system.
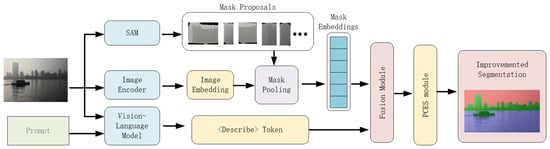
Figure 1.
Architecture of the USV-Seg model. The input image is processed through five modules: the SAM model generates binary mask proposals using the “Everything” mode; the CLIP image encoder extracts global visual features; the vision-language model combines image features with user queries and generates semantic representation using the <Describe> token; the mask selection module scores each candidate mask based on its embedding and the <Describe> token; finally, the physical constraint-enhanced module refines the segmentation results using sky-waterline and land-waterline constraints.
3.2. <Describe> Token Generation
A vision-language model-based scene understanding framework is employed to perform fine-grained reasoning on the geographic features and physical properties present in complex USV environments. Specifically, the system uses a visual encoder to extract high-level semantic features from images, and a text generation model to produce structured scene descriptions. These outputs are transformed into <Describe> Tokens, which serve as control inputs to guide the segmentation network.
USV navigation scene localization is determined based on the spatial distribution of land and water within the image. The model infers the relative distance between the USV and the shoreline by identifying nearshore objects (e.g., docks, vegetation), medium-range landmarks (e.g., lighthouses, buoys), and far-background features (e.g., horizon lines, mountain silhouettes). The scene is then categorized into one of three types: “close to shore,” “moderate distance,” or “far from shore.”
To support reproducibility and systematic generation of the <Describe> token, the prompt template is implemented as a structured JSON-like string with predefined keys for each semantic dimension. The placeholders in the template are automatically filled based on the scene analysis module’s predictions, then serialized and fed to MiniCPM for token embedding. Compared to conventional free-text prompts, this structured format ensures explicit encoding of multi-dimensional scene semantics, reduces ambiguity, and facilitates consistent interaction with the vision-language model.

3.3. Mask Selection
The mask selection process is based on a multi-class recognition algorithm that incorporates multi-layer IoP (Intersection over Prediction) heads. It comprises two key components: a Fusion Module and a 3-layer IoP Head. In the Fusion Module, each mask embedding interacts with a special segmentation control <Describe> token, through multiple layers of self-attention and cross-attention, resulting in a set of fused mask features. These features are then passed to the IoP Head, where each mask is assigned a prediction score across three target categories: sky, water, and obstacle. These scores are used to determine the final multi-class masks during inference.
3.3.1. Model Overview
As shown in Figure 2, the input to the module consists of candidate mask embeddings , where each is a high-dimensional vector (e.g., 256 or 512 dimensions) representing the k-th candidate mask. The <Describe> token serves as a task-specific control token that steers the network toward segmentation-relevant information. The goal of the Fusion Module is to integrate contextual information between the candidate mask embeddings and the <Describe> token to produce a set of fused mask features, denoted as .
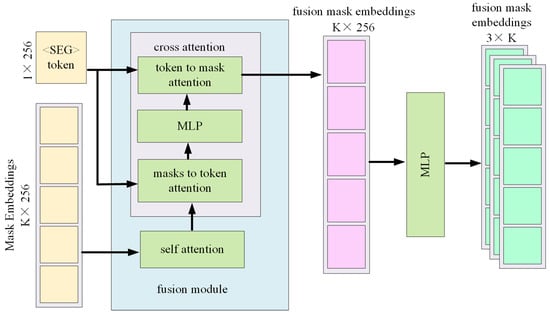
Figure 2.
Overview of the Mask Selection Module.
Self-attention enables mutual information exchange among the mask embeddings, capturing complementary or competitive relations to avoid redundancy or conflicts. Cross-attention allows the <Describe> token to modulate each mask embedding with task-relevant semantic cues. If the model also contains learnable category tokens (e.g., "sky", "water", "obstacle"), the cross-attention mechanism guides these semantic flows to corresponding masks.
The attention outputs are passed through one or more multilayer perceptrons (MLPs) to generate unified feature vectors of fixed size (e.g., ). The final output of the Fusion Module is denoted as , a matrix consisting of K fused feature vectors: see Equation (1).
These fused features serve as general-purpose representations of the candidate masks. To perform multi-class, multi-instance segmentation (i.e., multiple masks per category), the model must estimate the purity or accuracy of each mask for each target class. This is done through the 3-layer IoP Head, which maps the feature matrix to a prediction matrix.
First, all vectors are passed through a shared-parameter MLP to extract features suitable for IoP prediction. These are then split into three parallel branches, each corresponding to one of the target categories: Sky, Water, and Obstacle. Each branch outputs a scalar , where denotes the class index. In our implementation, the Obstacle category encompasses both land regions (shoreline, buildings) and waterborne obstacles (floating objects, vessels). This unified category design reflects their shared semantic role as non-navigable zones in USV navigation. The result is a score matrix P, where:
indicating the predicted IoP value of the k-th mask with respect to class c.
3.3.2. Training
During training, each image is annotated with pixel-level or mask-level labels across the three classes: sky, water, and obstacle. Once the network predicts IoP scores , these are regressed against ground-truth IoP values using a weighted mean squared error (MSE) loss:
where denotes the class-specific weight used to balance class imbalance (e.g., obstacle regions are typically underrepresented).
Through backpropagation, the network gradually learns to predict accurate IoP scores for each mask across all classes, enabling robust multi-category segmentation.
3.4. Physical Constraint Enhanced Segmentation
To improve the accuracy and real-world applicability of semantic segmentation for USV images, we propose a boundary-aware physical constraint framework. Unlike traditional CRF-based post-processing that applies general smoothness priors, our method explicitly models sky-water and land-water boundaries, adapts dynamically to the inferred scene type, and provides physically interpretable correction rules at both local and global levels.
3.4.1. Boundary Line Definition and Extraction
Let denote the predicted binary masks for sky, water, and land, respectively. Let and denote the sky and water boundaries, respectively, which partition the image into three regions: sky, water, and land.
Sky boundary line is the lowest edge of each connected sky region which is extracted to form a boundary line. To estimate the lower edge of the sky region, we compute the bottom-most pixel of each sky-connected component along the horizontal axis. For each column x, the vertical position corresponds to the largest y such that the pixel belongs to the sky mask . The sky boundary line is thus defined as:
The water boundary line serves as an important physical constraint that separates the water surface from the sky or adjacent land regions. To delineate the upper edge of the water surface, we extract the topmost water pixels across the image. Specifically, for each column x, we identify the first pixel y from top to bottom such that and all pixels above are non-water. The set of these edge pixels is:
To ensure robustness against noise and local irregularities, we apply the RANSAC algorithm to fit a straight line to the points in . The resulting line is modeled as:
The fitted waterline is accepted if the majority of the candidate points satisfy the residual condition:
where is a predefined tolerance threshold.
3.4.2. Scene-Aware Geometric Constraints on Water Boundary
Based on the relative distance between the USV and the shoreline—determined by the vision-language model through semantic classification (e.g., <Near Shore>, <Moderate Distance>, <Far from Shore>)—we impose different geometric constraints on the fitted water boundary line . This scene-aware modeling approach enables the segmentation framework to adapt to diverse spatial configurations, thereby improving accuracy and robustness in complex maritime environments.
In nearshore scenarios (Type C), where the USV is close to the shoreline, the visible shoreline may exhibit significant curvature due to landform irregularities and perspective distortion. To accommodate such cases, we apply a point-wise deviation constraint, which ensures that each detected water boundary point remains close to the fitted line within a small tolerance:
This constraint preserves local variations while maintaining overall boundary coherence.
For moderate-distance scenes (Type M), where the shoreline appears approximately linear, we employ a relaxed global constraint based on the average deviation of boundary points from the fitted line. This approach provides a balance between local tolerance and global shape consistency:
Such a formulation is effective in scenes where small disturbances (e.g., ripples or uneven terrain) may affect boundary detection.
In farshore conditions (Type F), where the USV is located far from the landmass, the visible water horizon typically appears as a straight line. Under this assumption, we impose a strict linearity constraint by minimizing the root mean square error (RMSE) between the fitted line and the actual water boundary points:
This ensures that the segmentation output reflects the expected geometric simplicity of the distant horizon.
By dynamically adapting the geometric constraints according to the inferred scene type, our method enhances the reliability of water boundary estimation, particularly in visually ambiguous or geometrically challenging regions.
3.4.3. Boundary-Guided Mask Correction Rules
To further enhance segmentation reliability and eliminate physically implausible outputs, we introduce a set of boundary-guided post-processing rules that leverage the estimated sky and water boundaries. These rules correct potential inconsistencies arising from visual ambiguities or imperfect mask selection, ensuring that final segmentation results conform to real-world scene geometry.
Rule 1: Remove Non-Sky Labels Above the Sky Boundary
Due to over-segmentation or misclassification, land or water labels may occasionally appear above the estimated sky boundary. Such labels are physically invalid, as the sky region is expected to occupy the uppermost portion of the image. Therefore, for any pixel located above the sky boundary , if it is mistakenly labeled as land or water, its label is reassigned as sky:
This rule eliminates upward label contamination and enforces vertical consistency in the spatial layout of sky-related regions.
Rule 2: Reject Water Labels Above the Water Boundary
Water regions are physically constrained to lie below the water surface boundary. However, due to reflection artifacts or texture confusion (e.g., with clouds), water may be incorrectly labeled above the horizon. To address this, we remove all water labels that are located significantly above the fitted water boundary line, with a tolerance margin :
This constraint suppresses implausible high-position water predictions and helps disambiguate water-sky confusion, especially in bright scenes.
Rule 3: Reject Sky Labels Below the Water Boundary
Similarly, sky labels that appear below the water boundary are also considered physically incorrect, as they often arise from misclassified bright water patches or occluded reflections. Therefore, we enforce a rule that removes sky labels below the water boundary, allowing a small tolerance to accommodate fitting noise:
This rule sharpens the vertical separation between sky and non-sky regions and improves robustness in horizon detection scenarios.
These boundary-aware correction rules collectively reinforce semantic consistency across vertical image structures and ensure that segmentation outcomes respect scene physics and horizon geometry. They are particularly effective in refining predictions near ambiguous regions such as horizon lines, cloud edges, or reflective water surfaces.
3.4.4. Global Scene Consistency via Area Proportions
While local boundary constraints help ensure pixel-level plausibility, a global understanding of scene composition is also crucial for achieving semantically coherent segmentation. To this end, we introduce a global consistency check based on the pixel-level area proportions of each semantic class (i.e., sky, water, and land). This check ensures that the overall segmentation result aligns with expected spatial distributions under different navigation scenarios.
Let the normalized area proportion of each semantic class be defined as:
where H and W denote the height and width of the input image, respectively, and is the indicator function that counts whether a pixel belongs to the target class.
To evaluate scene-level plausibility, we predefine the expected class area distribution vector for each scene type . For example, in farshore scenes, we expect a large portion of the image to be sky and water, with minimal land presence; conversely, nearshore scenes may contain more land pixels.
We then compute an L2-based consistency score between the observed class distribution and the scene-specific expectation as follows:
This score lies in the range , where higher values indicate better alignment with the expected scene composition. A low score reveals global inconsistency in the segmentation, which may result from misclassification or poor mask fusion in ambiguous regions.
In such cases, the system can trigger fallback mechanisms, such as uncertainty-aware refinement modules, confidence thresholding, or secondary prompt-based verification using the vision-language model. This global validation step complements local correction rules and reinforces holistic scene understanding, particularly in visually complex or transitional areas.
3.4.5. Integration and Deployment
This framework is implemented as a modular post-processing component that operates on the output of existing segmentation networks. Specifically, it takes as input the raw segmentation masks produced by models such as Segment Anything Model (SAM), DeepLabV3+, or SegFormer, and applies physically-informed corrections based on geometric boundaries and global scene consistency.
4. Experiments
4.1. Dataset Preparation and Training Details
To comprehensively evaluate the effectiveness and robustness of the proposed method in supporting multi-class semantic segmentation for Unmanned Surface Vehicles (USVs) under complex water environments, we constructed a diverse image dataset captured using real-world USV platforms. The dataset covers a wide range of aquatic scenarios, including far-from-shore scenes, medium-distance scenes, and near-shore complex scenes.
In far-from-shore scenarios, the images primarily consist of expansive water surfaces with clearly defined boundaries between sky and water. Medium-distance scenarios contain a balanced proportion of water and land with moderately complex backgrounds. Near-shore complex scenarios feature intricate shoreline contours with various interfering elements such as vegetation, buildings, and reflections. Each image is annotated at the pixel level, dividing pixels into three categories: sky, water, and non-navigable regions (including land and waterborne obstacles). A total of approximately 30,000 images were collected, with the distribution of scene categories summarized in Table 1.

Table 1.
Scene Category Statistics.
To facilitate model training and evaluation, the dataset is split into training, validation, and testing sets, with approximately 20,000, 5000, and 5000 images respectively. Each scene category is proportionally represented across the three subsets. For example, the 9000 images in the “far-from-shore” scene category are divided according to the specified ratio into 6000 training images, 1500 validation images, and 1500 test images. The other scene categories are similarly partitioned following the same ratio.
The proposed USV-Seg framework is implemented using PyTorch v2.6.0 and trained on a single NVIDIA RTX 3090 GPU. We use a batch size of 16, an initial learning rate of with a cosine annealing schedule, and the AdamW optimizer with weight decay set to . The model is trained for 100 epochs.
4.2. Describe Token Generation
We conducted experiments to evaluate the generation of Describe Tokens using the proposed vision-language model across different scene types. The model processes input images through a visual encoder to extract high-level semantic features, which are then used by a text generation module to construct structured scene descriptions. Each Describe Token contains three semantic dimensions: USV scene localization, landform complexity analysis, and water surface texture evaluation.
For each dimension, human-annotated ground truth labels were created to serve as references for accuracy evaluation. The classification accuracy of the generated Describe Tokens under each scene type is shown in Table 2.
Table 2.
Describe Token Classification Accuracy(%) Across Scene Types.
As shown in Table 2, the proposed Describe Token generation method based on the vision-language model demonstrates stable and high classification accuracy across all three semantic dimensions, validating its effectiveness and robustness under various complex water scenes.
4.3. Quantitative Evaluation
To evaluate the performance of the proposed segmentation method under diverse maritime conditions, we conducted experiments across three scene types categorized by the distance between the USV and the shoreline. These include simple far-from-shore environments, moderately complex medium-distance scenes, and near-shore cases characterized by irregular shorelines and reflection-induced interference. We compare our method with six state-of-the-art segmentation models: GRES [48], OV-Seg [49], X-Decoder [50], SEEM [51], SC-CLIP [52], and LISA [53]. Table 3 presents the mean Intersection over Union (mIoU) results across all scene types.
Table 3.
mIoU Results (%) of Different Algorithms on USV Water Segmentation Tasks.
As shown in Table 3, our method consistently outperforms the baselines across all scene types. In particular, it achieves outstanding performance in complex near-shore scenarios where elevated landforms and strong reflections often challenge conventional methods. The proposed method USV-Seg maintains mIoU scores above 95% even in the most difficult scenes, demonstrating its robustness and superior accuracy.
4.4. Ablation Study
We conducted ablation studies to assess the contribution of each component in the proposed USV-Seg framework. In particular, we examined the impact of removing the Describe Token, the boundary-aware correction module, and the three individual semantic dimensions of the Describe Token. Table 4 summarizes the results on the near-shore complex scene subset.
Table 4.
Ablation Study on Near-shore Complex Scenes (mIoU, %).
As shown in Table 4, removing the Describe Token or the boundary-aware correction results in a notable mIoU drop of over 4%, confirming that both modules are critical and complementary. The Describe Token provides semantic priors to resolve ambiguities in reflective and irregular scenes, while the boundary-aware correction enforces geometric consistency to suppress leakage and over-segmentation.
We also evaluated each semantic dimension of the Describe Token in isolation. Scene localization contributes the most (93.21%), as it provides coarse positional awareness. Landform complexity (93.05%) helps distinguish irregular shorelines, and water texture (92.89%) aids in handling reflective or cluttered surfaces. None of the dimensions alone match the full token, confirming the advantage of integrating all three.
These results highlight the necessity of combining high-level semantic priors with low-level geometric constraints, as well as the complementary nature of the three semantic dimensions, for robust segmentation in challenging maritime environments.
4.5. Qualitative Evaluation
Figure 3 presents a visual comparison of segmentation results under different scene types, including far-from-shore, medium-distance, and near-shore complex conditions. The figure includes the original image, results from SEEM [51], SC-CLIP [52], LISA [53], the proposed USV-Seg, and ground truth annotations.
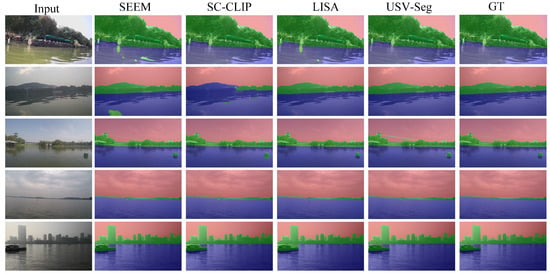
Figure 3.
Segmentation comparison across different water scenes. Left: original image; middle: results from baseline methods (e.g., SEEM, LISA); right: results from the proposed USV-Seg method and ground truth.
As visually evident, most methods perform reasonably well under simple and moderately complex scenes. However, our method delivers superior boundary precision and mask quality, producing tighter adherence to object contours. In more challenging scenes with strong reflections and intricate shoreline structures, our approach remains highly robust and accurately distinguishes between navigable and non-navigable regions. In contrast, other methods tend to exhibit segmentation gaps or boundary misclassification.
5. Conclusions
This paper presents a unified semantic segmentation framework for Unmanned Surface Vehicles (USVs) navigating in complex aquatic environments. To address key challenges such as segmentation inaccuracy, boundary ambiguity, and lack of physical consistency, we integrate a vision-language model with a physically constrained refinement strategy. A core contribution of this work is the design of a structured Describe Token mechanism, which leverages prompt-guided reasoning to infer scene semantics—such as shoreline distance, landform complexity, and water surface texture—without requiring large-scale annotations. Experimental results demonstrate high accuracy in Describe Token classification across diverse water scenarios, confirming the model’s capability for semantic scene understanding.
In addition, a boundary-aware correction module is introduced to refine segmentation results using sky-water and land-water constraints, enhancing geometric plausibility. Extensive evaluations show that the proposed framework significantly outperforms state-of-the-art methods, achieving up to 96.30% mIoU in near-shore complex scenes. Ablation studies further confirm the effectiveness and complementary nature of the key modules.
We note that the proposed method may exhibit reduced performance in highly challenging scenarios, such as under complex illumination, very close proximity to irregular shorelines, severe reflections, large waves, camera tilt, or nighttime conditions—where even human observers struggle to delineate clear boundaries. Addressing these limitations will be part of our future work, through the exploration of temporal modeling, multi-sensor fusion, uncertainty-aware reasoning, and robust adaptation to embedded hardware platforms.
Overall, our approach offers a robust, interpretable, and extensible solution for maritime segmentation tasks, with promising potential for real-world USV navigation and monitoring applications.
Author Contributions
Conceptualization, W.Z., R.Z. and Y.W.; Methodology, W.Z., R.Z., Q.C. and G.L.; Software, W.Z., L.M. and X.Z.; Validation, S.C., X.Z., L.M. and Y.W.; Formal analysis, W.Z., S.C. and G.L.; Investigation, W.Z., Y.W. and G.L.; Resources, R.Z., Q.C. and Y.W.; Data curation, L.M. and X.Z.; Writing—original draft preparation, W.Z.; Writing—review and editing, W.Z., R.Z., S.C., L.M., Y.W., Q.C. and G.L.; Visualization, S.C. and W.Z.; Supervision, R.Z. and Q.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported internally by the affiliated organization. No external funding was received.
Data Availability Statement
The data and code supporting the findings of this study are subject to commercial confidentiality and cannot be publicly disclosed. Requests for declassified data and code can be considered upon reasonable request and organizational approval.
Conflicts of Interest
Authors were employed by the company of China Nanhu Academy of Electronics and Information Technology. The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest. The authors declare that this study received funding from Labor Union Committee of China Electronics Hikvision Group Co., Ltd. The funder was not involved in the study design, collection, analysis, interpretation of data, the writing of this article or the decision to submit it for publication.
References
- Wu, G.; Li, D.; Ding, H.; Shi, D.; Han, B. An overview of developments and challenges for unmanned surface vehicle autonomous berthing. Complex Intell. Syst. 2024, 10, 981–1003. [Google Scholar] [CrossRef]
- Hashali, S.D.; Yang, S.; Xiang, X. Route planning algorithms for unmanned surface vehicles (usvs): A comprehensive analysis. J. Mar. Sci. Eng. 2024, 12, 382. [Google Scholar] [CrossRef]
- Katsouras, G.; Dimitriou, E.; Karavoltsos, S.; Samios, S.; Sakellari, A.; Mentzafou, A.; Tsalas, N.; Scoullos, M. Use of unmanned surface vehicles (USVs) in water chemistry studies. Sensors 2024, 24, 2809. [Google Scholar] [CrossRef]
- Ding, Y.; Xu, Y.; Liu, Q.; Sun, H.; Chen, F. Research on boundary-aware waters segmentation network for unmanned surface vehicles in complex inland waters. Int. J. Mach. Learn. Cybern. 2024, 15, 2297–2308. [Google Scholar] [CrossRef]
- Yao, L.; Kanoulas, D.; Ji, Z.; Liu, Y. ShorelineNet: An efficient deep learning approach for shoreline semantic segmentation for unmanned surface vehicles. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: New York, NY, USA, 2021; pp. 5403–5409. [Google Scholar]
- Chen, X.; Liu, Y.; Achuthan, K. WODIS: Water obstacle detection network based on image segmentation for autonomous surface vehicles in maritime environments. IEEE Trans. Instrum. Meas. 2021, 70, 7503213. [Google Scholar] [CrossRef]
- Albukhnefis, A.L.; Al-Fatlawi, T.T.; Alsaeedi, A.H. Image Segmentation Techniques: An In-Depth Review and Analysis. J. Al-Qadisiyah Comput. Sci. Math. 2024, 16, 195–215. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhan, W.; Xiao, C.; Wen, Y.; Zhou, C.; Yuan, H.; Xiu, S.; Zou, X.; Xie, C.; Li, Q. Adaptive semantic segmentation for unmanned surface vehicle navigation. Electronics 2020, 9, 213. [Google Scholar] [CrossRef]
- Xue, H.; Chen, X.; Zhang, R.; Wu, P.; Li, X.; Liu, Y. Deep learning-based maritime environment segmentation for unmanned surface vehicles using superpixel algorithms. J. Mar. Sci. Eng. 2021, 9, 1329. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar]
- Li, D.; Xie, W.; Cao, M.; Wang, Y.; Zhang, J.; Li, Y.; Fang, L.; Xu, C. FusionSAM: Visual multimodal learning with segment anything model. In KDD ’25: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2; Association for Computing Machinery: New York, NY, USA, 2025. [Google Scholar] [CrossRef]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. Dinov2: Learning robust visual features without supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Ayzenberg, L.; Giryes, R.; Greenspan, H. DINOv2 based self supervised learning for few shot medical image segmentation. In Proceedings of the 2024 IEEE International Symposium on Biomedical Imaging (ISBI), Athens, Greece, 27–30 May 2024; IEEE: New York, NY, USA, 2024; pp. 1–5. [Google Scholar]
- Jaszcz, A.; Włodarczyk-Sielicka, M.; Stateczny, A.; Połap, D.; Garczyńska, I. Automated shoreline segmentation in satellite imagery using USV measurements. Remote Sens. 2024, 16, 4457. [Google Scholar] [CrossRef]
- Halicki, A.; Specht, M.; Stateczny, A.; Specht, C.; Specht, O. Shoreline extraction based on LiDAR data obtained using an USV. TransNav Int. J. Mar. Navig. Saf. Sea Transp. 2023, 17, 445–453. [Google Scholar] [CrossRef]
- Walusiak, G.; Witek, M.; Niedzielski, T. Histogram-Based Edge Detection for River Coastline Mapping Using UAV-Acquired RGB Imagery. Remote Sens. 2024, 16, 2565. [Google Scholar] [CrossRef]
- Zou, X.; Xiao, C.; Zhan, W.; Zhou, C.; Xiu, S.; Yuan, H. A Novel Water-Shore-Line Detection Method for USV Autonomous Navigation. Sensors 2020, 20, 1682. [Google Scholar] [CrossRef] [PubMed]
- Tan, C.S.; Arshad, M.R.; Mohd-Mokhtar, R. River navigation system using Autonomous Surface Vessel. In Proceedings of the 2016 IEEE International Conference on Underwater System Technology: Theory and Applications (USYS), Penang, Malaysia, 13–14 December 2016; IEEE: New York, NY, USA, 2016; pp. 13–18. [Google Scholar]
- Qiao, D.; Liu, G.; Lv, T.; Li, W.; Zhang, J. Marine vision-based situational awareness using discriminative deep learning: A survey. J. Mar. Sci. Eng. 2021, 9, 397. [Google Scholar] [CrossRef]
- Dong, K.; Liu, T.; Zheng, Y.; Shi, Z.; Du, H.; Wang, X. Visual detection algorithm for enhanced environmental perception of unmanned surface vehicles in complex marine environments. J. Intell. Robot. Syst. 2024, 110, 1. [Google Scholar] [CrossRef]
- Zeng, W.; Zou, X.; Zhan, H. Water-shore-line detection for complex inland river background. J. Phys. Conf. Ser. 2020, 1486, 052017. [Google Scholar]
- Adam, M.A.M.; Ibrahim, A.I.; Abidin, Z.Z.; Zaki, H.F.M. Deep learning-based water segmentation for autonomous surface vessel. J. Phys. Conf. Ser. 2020, 540, 012055. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar]
- Choi, J.; Kim, T.; Kim, C. Self-ensembling with gan-based data augmentation for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6830–6840. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]
- Li, Y.; Yuan, L.; Vasconcelos, N. Bidirectional learning for domain adaptation of semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6936–6945. [Google Scholar]
- Zhan, W.; Xiao, C.; Yuan, H.; Wen, Y. Effective waterline detection for unmanned surface vehicles in inland water. In Proceedings of the 2017 Seventh International Conference on Image Processing Theory, Tools and Applications (IPTA), Montreal, QC, Canada, 28 November–1 December 2017; IEEE: New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Yin, Y.; Guo, Y.; Deng, L.; Chai, B. Improved PSPNet-based water shoreline detection in complex inland river scenarios. Complex Intell. Syst. 2023, 9, 233–245. [Google Scholar] [CrossRef]
- Baltaxe, M.; Pe’er, T.; Levi, D. Polarimetric imaging for perception. arXiv 2023, arXiv:2305.14787. [Google Scholar] [CrossRef]
- Specht, M.; Stateczny, A.; Specht, C.; Widźgowski, S.; Lewicka, O.; Wiśniewska, M. Concept of an innovative autonomous unmanned system for bathymetric monitoring of shallow waterbodies (INNOBAT system). Energies 2021, 14, 5370. [Google Scholar] [CrossRef]
- Pastorino, M.; Moser, G.; Serpico, S.B.; Zerubia, J. Semantic segmentation of remote-sensing images through fully convolutional neural networks and hierarchical probabilistic graphical models. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5407116. [Google Scholar] [CrossRef]
- del Pino, I.; Santamaria-Navarro, A.; Zulueta, A.G.; Torres, F.; Andrade-Cetto, J. Probabilistic graph-based real-time ground segmentation for urban robotics. IEEE Trans. Intell. Veh. 2024, 9, 4989–5002. [Google Scholar] [CrossRef]
- Lüddecke, T.; Ecker, A. Image segmentation using text and image prompts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7086–7096. [Google Scholar]
- Li, B.; Weinberger, K.Q.; Belongie, S.; Koltun, V.; Ranftl, R. Language-driven semantic segmentation. arXiv 2022, arXiv:2201.03546. [Google Scholar] [CrossRef]
- Rao, Y.; Zhao, W.; Chen, G.; Tang, Y.; Zhu, Z.; Huang, G.; Zhou, J.; Lu, J. Denseclip: Language-guided dense prediction with context-aware prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18082–18091. [Google Scholar]
- Yang, L.; Cai, H. Cost-efficient image semantic segmentation for indoor scene understanding using weakly supervised learning and BIM. J. Comput. Civ. Eng. 2023, 37, 04022062. [Google Scholar] [CrossRef]
- Biswas, B. Deep Learning-Based Multimodal Fusion of Sentinel-1 and Sentinel-2 Data for Mapping Deforested Areas in the Amazon Rainforest. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2022. [Google Scholar]
- Wang, Q.; Chen, W.; Huang, Z.; Tang, H.; Yang, L. MultiSenseSeg: A cost-effective unified multimodal semantic segmentation model for remote sensing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4703724. [Google Scholar] [CrossRef]
- Khoreva, A.; Benenson, R.; Ilg, E.; Brox, T.; Schiele, B. Lucid data dreaming for object tracking. In Proceedings of the The DAVIS Challenge on Video Object Segmentation, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dutt Jain, S.; Xiong, B.; Grauman, K. Fusionseg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3664–3673. [Google Scholar]
- Yao, Y.; Yu, T.; Zhang, A.; Wang, C.; Cui, J.; Zhu, H.; Cai, T.; Li, H.; Zhao, W.; He, Z.; et al. MiniCPM-V: A GPT-4V Level MLLM on Your Phone. arXiv 2024, arXiv:2408.01800. [Google Scholar]
- Liu, C.; Ding, H.; Jiang, X. GRES: Generalized Referring Expression Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23592–23601. [Google Scholar]
- Liang, F.; Wu, B.; Dai, X.; Li, K.; Zhao, Y.; Zhang, H.; Zhang, P.; Vajda, P.; Marculescu, D. Open-Vocabulary Semantic Segmentation with Mask-Adapted CLIP. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7061–7070. [Google Scholar]
- Zou, X.; Dou, Z.Y.; Yang, J.; Gan, Z.; Li, L.; Li, C.; Dai, X.; Behl, H.; Wang, J.; Yuan, L.; et al. Generalized Decoding for Pixel, Image, and Language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15116–15127. [Google Scholar]
- Zou, X.; Yang, J.; Zhang, H.; Li, F.; Li, L.; Wang, J.; Wang, L.; Gao, J.; Lee, Y.J. Segment Everything Everywhere All at Once. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Volume 36, pp. 19769–19782. [Google Scholar]
- Bai, S.; Liu, Y.; Han, Y.; Zhang, H.; Tang, Y. Self-Calibrated CLIP for Training-Free Open-Vocabulary Segmentation. arXiv 2024, arXiv:2411.15869. [Google Scholar]
- Lai, X.; Tian, Z.; Chen, Y.; Li, Y.; Yuan, Y.; Liu, S.; Jia, J. LISA: Reasoning Segmentation via Large Language Model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 9579–9589. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).