Abstract
Mobile edge computing (MEC) has emerged as a promising solution for enabling resource-constrained user devices to run large-scale and complex applications by offloading their computational tasks to the edge servers. One of the most critical challenges in MEC is designing efficient task offloading strategies. Traditional approaches either rely on non-intelligent algorithms that lack adaptability to the dynamic edge environment, or utilize learning-based methods that often ignore task dependencies within applications. To address this issue, this study investigates task offloading for mobile applications with interdependent tasks in an MEC system, employing a deep reinforcement learning framework. Specifically, we model task dependencies using a Directed Acyclic Graph (DAG), where nodes represent subtasks and directed edges indicate their dependency relationships. Based on task priorities, the DAG is transformed into a topological sequence of task vectors. We propose a novel graph-based offloading model, which combines an attention-based network and a Proximal Policy Optimization (PPO) algorithm to learn optimal offloading decisions. Our method leverages offline reinforcement learning through the attention network to capture intrinsic task dependencies within applications. Experimental results show that our proposed model exhibits strong decision-making capabilities and outperforms existing baseline algorithms.
1. Introduction
With the rapid growth of modern computing and networking technologies in recent times, there has been a steady rise in novel mobile applications [1], including facial recognition systems, augmented/virtual reality (AR/VR), and smart healthcare services. These applications typically require intensive computational resources, and user devices (UDs) face significant challenges such as high energy consumption and long processing times due to their limited processing capabilities and resources [2]. To address this challenge, task offloading strategies have been proposed to migrate computationally intensive tasks from UDs to more powerful platforms. Although centralized cloud facilities provide substantial processing power, the considerable transmission delay between these centers and edge-side devices may degrade user experience [3]. In contrast, mobile edge computing (MEC) mitigates such delays by providing computing services at the network edge [4,5], thereby enabling faster and more energy-efficient task execution. However, given the limited and dynamically changing nature of MEC resources, it is crucial to design efficient offloading strategies that balance performance and resource constraints.
One of the primary challenges in task offloading lies in effectively coordinating the interaction between end-user devices and edge nodes, while adaptively distributing constrained computational resources to the incoming offloaded workloads [6]. In particular, offloading policies are designed to decide if a task should be executed on the user device or partially or entirely transferred to a nearby MEC server for processing. These strategies must also decide how to allocate edge server resources to offloaded tasks while meeting task completion time and energy consumption requirements. However, selecting the appropriate edge server (ES) for a given offloading task is often challenging due to the need to account for various factors, including task characteristics, user device profiles, edge server capabilities, and communication conditions. Moreover, considering the rapidly changing characteristics of edge environments, an effective offloading approach must possess the flexibility to respond to real-time system variations [7].
Earlier studies primarily employed non-intelligent offloading methods, which are relatively simple but often inefficient due to their static nature and lack of adaptability. For example, many existing studies [8,9,10,11] have introduced heuristic and approximate techniques, yet such approaches often depend on domain expertise or accurate mathematical modeling, requiring significant manual effort and domain expertise to fine-tune the models for different application scenarios [2]. Deep reinforcement learning (DRL), which integrates reinforcement learning with deep neural networks (DNNs), provides a promising solution to the challenges mentioned above. DRL enables agents to learn optimal strategies for solving intricate problems such as gaming [12], robotics [13], and traffic scheduling [14] through trial-and-error interactions, without requiring an accurate model of the environment. In recent years, researchers have explored the application of DRL to various task offloading problems in MEC systems [15,16,17,18,19,20]. An MEC system, consisting of wireless access devices, channels, and MEC servers, can be modeled as a reinforcement learning environment. Leveraging the strong representational power of deep neural networks, DRL-based approaches continuously interact with the environment to learn task offloading policies that map states to actions [21], with the goal of maximizing cumulative rewards.
However, most existing DRL-based methods assume tasks are independent, failing to take into account the inherent dependencies that exist between tasks in practical applications. With the rapid advancement of intelligent technologies, many applications on user devices consist of multiple interdependent computational tasks [21,22]. Recently, a few studies have attempted to introduce DRL methods to support task offloading for Directed Acyclic Graph (DAG)-structured tasks. However, these studies often exhibit limited capability in representing the task graph structure [21,23,24], as they do not explicitly incorporate graph-based representation learning mechanisms. As a result, they lack effective modeling of the global structure of the DAG and its long-term dependencies. Moreover, some of these works adopt the Double Deep Q-Network (DDQN) algorithm for task offloading [24], which may suffer from issues such as policy instability and susceptibility to local optima. In contrast, other researchers have explored the use of encoder–decoder architectures to better capture long-term dependencies in task offloading [2,25]. While such models offer improved handling of sequential dependencies, they significantly increase the complexity of training. Furthermore, as the state space expands, the computational cost required for training escalates substantially.
To address the aforementioned challenges, this paper proposes a DRL-based dependent task graph offloading model, named APPGM (Attention-based Proximal Policy Optimization (PPO) with Task Graph Model), which is designed to efficiently handle mobile application offloading tasks with inter-task dependencies. The dependencies among tasks are modeled as a DAG, enabling a more accurate representation of the sequential execution logic among subtasks in real-world applications. Unlike existing approaches that simplify DAGs into linear sequences, APPGM leverages an attention mechanism to effectively capture the global structural features of the tasks. It integrates the PPO algorithm within a reinforcement learning framework to learn an optimal offloading policy that maximizes the overall system profits. This model not only effectively captures long-term dependencies among tasks but also demonstrates strong generalization capabilities, making it well-suited for dynamically changing edge environments. In a nutshell, the main contributions of this article are summarized as follows.
- Unlike most existing MEC works, which focus on isolated task offloading assignments, we propose a low-complexity dynamic multi-task offloading framework. In order to adjust to dynamic offloading circumstances, this framework dynamically allocates computing resources according to the number of tasks and their dependencies.
- We formulate the offloading decision-making problem for DAG-based tasks as a Markov Decision Process (MDP), incorporating a carefully designed state–action space and reward function. To solve this, we develop a dependent task graph offloading model—APPGM. This model leverages an attention-based network to model extended dependencies among task inputs and translate task representations into offloading decisions. Notably, the model can learn near-optimal offloading strategies without relying on expert knowledge.
- In order to enhance the effectiveness of the attention module, we employ a GRU (Gated Recurrent Unit)-driven RNN (Recurrent Neural Network) model trained with clipped surrogate loss functions combined with first-order approximation techniques. This training approach leads to enhanced comprehensive profits () of the offloading system.
- We conduct extensive simulation experiments using synthetic DAGs to evaluate the performance of our proposed method. The results are compared against advanced heuristic baselines, demonstrating the superior effectiveness of our approach.
The remainder of this paper is organized as follows. Related work is discussed in Section 2. Section 3 presents the system model and problem formulation. Section 4 provides a detailed description of our proposed APPGM model. In Section 5, we analyze the experimental results. Finally, Section 6 summarizes our work.
2. Related Works
At its essence, MEC aims to boost edge-level processing power by delegating demanding computational workloads to proximate, resource-rich servers. However, the constrained computational and network resources at edge nodes can result in service degradation if task offloading is conducted without proper coordination. Thus, offloading decisions and resource allocation are crucial for ensuring Quality of Service (QoS) in MEC environments [3]. Task offloading has become a prominent research topic across various edge computing paradigms.
2.1. Heuristic Algorithm-Based Task Offloading
Mach et al. [9] presented an extensive survey on offloading frameworks and techniques utilized in mobile edge computing environments. A significant portion of existing research treats tasks as isolated entities and depends on non-adaptive algorithms. Meng et al. [10] introduced a scheduling method guided by deadlines, employing a greedy heuristic that accounts for both bandwidth availability and computing capability. Tran and Pompili [11] formulated the task offloading challenge across multiple MEC nodes using a mixed-integer nonlinear programming (MINLP) framework and developed an iterative heuristic-based optimization method. Likewise, Ref. [26] described the problem through a nonlinear integer programming formulation and leveraged a genetic-based optimization technique. In [27], the researchers designed a heuristic method for co-scheduling wireless sensing and computational tasks in complex multi-component scenarios to reduce latency. Other studies have applied heuristic approaches to solve offloading problems for independent tasks using methods such as game theory [28,29], value iteration algorithms [30], and Lyapunov optimization [31].
However, some studies have also considered task dependencies, though they mostly rely on non-intelligent offloading algorithms. For instance, Ref. [32] modeled real-world applications as general DAG task structures and formulated the offloading problem as a binary (0–1) programming model, addressed through particle swarm optimization techniques. Lin et al. [8] developed a heuristic-based algorithm (HEFT) for DAG-based mobile applications in MEC environments. Liu et al. [33] formulated the dependency-aware task scheduling issue as an average completion time minimization problem and introduced a heuristic solution based on task prioritization. These solutions often depend on manually designed heuristics, which incur high computational overhead and hinder real-time decision-making in MEC systems. Furthermore, heuristic methods typically require domain-specific expert knowledge, reducing their flexibility and general applicability.
2.2. DRL-Based Task Offloading
To address these limitations, DRL approaches have been widely adopted for offloading decision-making in MEC systems [15,18,19,34,35,36]. Zhan et al. [15] tackled the issue by modeling it through a partially observable Markov Decision Process (POMDP) framework and adopting a DRL approach based on policy gradients. Min et al. [18] proposed a task offloading strategy based on an improved Double Deep Q-Network (DDQN), which integrates task priority and a multi-agent coordination mechanism to effectively optimize MEC resource allocation in highly dynamic vehicular networks. Moghaddasi et al. [19] constructed an offloading model under a three-tier D2D-edge-cloud architecture, utilizing the Rainbow Deep Q-Network (DQN) algorithm to dynamically optimize offloading decisions across different computing layers, thereby reducing latency and energy consumption. Zou et al. [34] introduced an offloading strategy leveraging the asynchronous advantage actor–critic (A3C) framework, with the objective of reducing delay and energy consumption. Additionally, Xiao et al. [35] developed a DRL-based mobile offloading method using an actor–critic framework to select offloading strategies and improve computational performance. Rahmani et al. [36] addressed energy efficiency issues in IoT-MEC systems by introducing the Soft Actor–Critic (SAC) algorithm, which enables localized offloading and adaptive power management, significantly improving energy efficiency in task execution.
Although these studies have made significant contributions, they often assume tasks are independent, overlooking inter-task dependencies that are common in real-world applications. Currently, A few recent studies have begun to consider task dependencies [2,21,23,24,25]; however, they have the following major limitations. For example, the TBDTOA algorithm proposed by Zhu et al. [24] simplifies task dependency structures into temporal sequences, which fails to explicitly model the complex structures within a DAG. Moreover, the algorithm is implemented based on DDQN, which is prone to policy instability and local optima. Mao et al. [21] introduced the DRL-GMOM model, which uses a custom PTRE sorting mechanism to convert DAG tasks into linear vector sequences and employs the A3C framework to train an actor–critic network for offloading decisions. However, this method primarily relies on local task features and fixed-dimension vector representations, lacking effective modeling of the DAG’s global structure and long-term dependencies. Additionally, its generalization ability in dynamic offloading scenarios is limited. Yan et al. [23] proposed a DRL algorithm based on the actor–critic structure, which achieved a low-complexity offloading policy in general task graph settings. Nevertheless, the method has limited capacity to represent task graph structures, as it does not incorporate explicit graph representation learning mechanisms, making it difficult to model concurrency and multi-level dependencies in complex DAGs. Wang et al. [2,25] proposed a sequence-to-sequence offloading framework to study dependency-aware task offloading in MEC scenarios. However, this approach is impractical in real-world settings, as encoder–decoder models significantly increase training complexity and lead to substantial computational overhead as the state space grows.
To address this issue, we propose a DRL-based approach that models user applications as DAGs, explicitly capturing task dependencies. Our method incorporates an attention mechanism to model long-term dependencies among tasks and maps task representations to optimal offloading decisions. This model can generate near-optimal decisions without requiring expert knowledge. Additionally, we conduct extensive simulation experiments to demonstrate the effectiveness and superiority of our model in dynamic MEC environments.
3. System Model and Problem Formulation
To tackle the task offloading challenge for applications with interdependent subtasks, we first construct a detailed system model for MEC and formulate the optimization problem. In this section, we introduce the system architecture, latency and energy models, task topological sorting model, and the mathematical problem definition.
3.1. System Architecture Overview
In our architecture, MEC servers provision computing capabilities through virtual machine (VM) instances [25]. Communication between end-user devices and edge nodes primarily takes place via these associated VMs. To focus on the modeling of dependency relationships and the design of scheduling strategies for DAG tasks, our work adopts a simplified assumption of “each user device is bound to an exclusive VM instance”, which provides personalized resources for computing, data transmission, and storage services for the device [2].
On the user side, the Local Processing Unit (LPU) handles local computation, while a Local Transmission Unit (LTU) manages uplink and downlink communication. On the edge side, the Virtual CPU (VCPU) within the VM executes offloaded tasks, and the Virtual Transmission Unit (VTU) receives and returns application data, as can be seen in Figure 1.
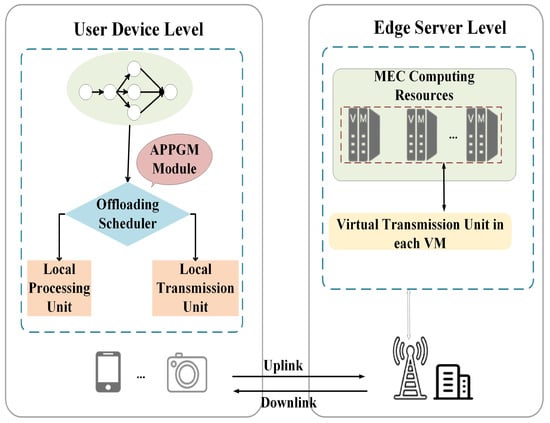
Figure 1.
The execution workflow of the entire system begins at the user device layer, where it is decided whether a task will be processed locally or uplinked to the corresponding VM at the edge server layer via the Local Transmission Unit (LTU). If processed at the edge server layer, the task is transmitted to the VM through the VTU, and once execution is complete, the results are downlinked back to the UD device.
In real-world scenarios, resource-constrained user devices frequently execute computation-intensive applications such as augmented reality (AR), image and facial recognition, and smart sensing. These applications often consist of multiple interdependent subtasks, which must be executed in specific logical orders. Figure 2 illustrates two examples—face recognition and gesture recognition applications—where each is decomposed into several subtasks [37]. To model these dependencies, we represent each application as a DAG, where nodes denote subtasks and edges represent dependency constraints. Let a DAG be defined as , where T represents the set of task nodes and E is set of edges. Each task node is denoted by , where , and is the total number of task nodes [21]. An edge indicates that task node is a predecessor of task node and is a successor of . Entry task nodes have no predecessors, and exit task nodes have no successors. The key notations used in this paper are summarized in Table 1.
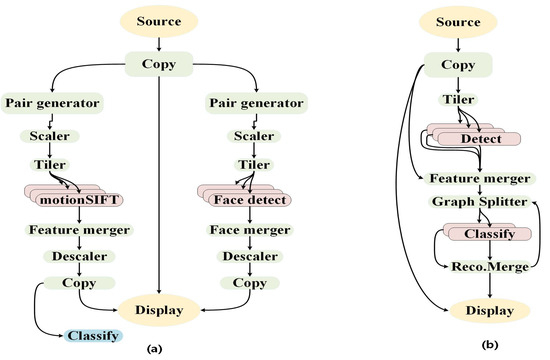
Figure 2.
Examples of tasks that are split into multiple subtasks. (a) Face recognition. (b) Gesture recognition.

Table 1.
Summary of key notations.
In general, in a complete DAG, the consists of two key factors: latency and energy consumption, and our goal is to maximize the system’s . Each task node must be assigned either to a local LPU or to a VCPU on the edge server [21]. The choice of processing node for data computation may have an impact on each task’s . Table 1 illustrates the execution flow of the entire system. Application data is transmitted through a wireless uplink and downlink, and each subtask is treated as an indivisible atomic unit due to interdependencies.
3.2. Latency Model
Latency during task execution may be classified as propagation latency and processing latency. If a task is executed locally, only processing latency is involved. However, if the task is offloaded to an edge server, the total latency includes the upload latency, execution latency on the virtual machine, and the download latency. Let , , and denote the upload, execution, and download latencies for task , respectively. Let represent the local execution latency for task . The CPU clock frequency of the Local Processing Unit on the UD is denoted as , while denotes the clock frequency of the Virtual CPU (VCPU) on the edge server. The uplink and downlink data rates are and , respectively. The size of data uploaded and downloaded for task are represented by and , respectively. The number of CPU cycles required to execute task is denoted by .
The local execution latency is expressed as
For offloaded execution, the latencies are
We define the available times for each resource as follows: for the uplink channel, for the edge server, for downlink transmission, and for the Local Processing Unit. Based on a given scheduling sequence , a resource’s availability is determined by the finish time (FT) of the most recent task allocated to it before . If no such task exists, the finish time on that resource is set to zero. Let , , , and represent the completion times for local execution, data upload, edge execution, and result download of task , respectively. Due to task dependencies, all predecessor tasks of must be completed before can begin execution.
3.2.1. Local Execution
When task is executed locally, , and the final completion time is the sum of the local execution start time and the local execution delay,
where denotes the set of all predecessor tasks of . This ensures that the local CPU is available and all dependencies are resolved before execution begins.
3.2.2. Offloaded Execution
If task is offloaded, then , and the total completion time consists of three parts: upload, execution, and download. The completion time is calculated as
The overall finish time for offloaded execution is determined by the final download completion time:
Accordingly, the total latency for a given offloading schedule is the sum of all individual task completion times:
To enhance the clarity and intuitiveness of the model description, a simple example of a DAG task graph (Figure 3) is presented to illustrate the costs involved in the task offloading process, including execution cost, communication cost, and the overall finish time of the DAG. The figure shows three nodes, , , and , which represent three distinct subtasks. Among them, serves as the entry task and as the exit task. To clearly demonstrate the construction of the system model and simplify the analysis, it is assumed that when a task is offloaded to the edge for execution, the communication channels and computational resources of each node are always sufficient and readily available, without any waiting time. In the example shown in Figure 3, tasks and are assumed to be executed locally, while task is offloaded to the edge. Specifically, node has no predecessor and can begin execution immediately; node must wait until is finished; and node depends on both and , and can only start after both have finished. The figure indicates the execution costs of each task as well as the communication costs associated with data transmission. To make the offloading process and the resulting delays more intuitive, specific numerical values are assigned to the variables shown in the figure. It should be noted that the variables and formulas illustrated in the figure do not cover all aspects of the system model. For instance, if node is executed locally, the variables related to offloading do not apply. Additionally, each node incurs energy consumption during execution, whether locally or at the edge, which can be calculated using Equation (9) and Equation (10), respectively.
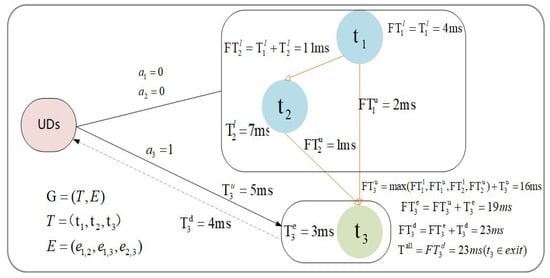
Figure 3.
An illustrative example of DAG task dependencies in the system model.
3.3. Energy Consumption Model
Energy consumption on the UD is another critical factor in mobile edge computing [2]. It primarily consists of computation and communication costs, depending on whether a task is executed locally or offloaded.
3.3.1. Local Execution
When task is executed locally, no transmission occurs, and the energy consumption is solely due to computation. It can be modeled as
where and are constants representing the power model of the local processor.
3.3.2. Offloaded Execution
When task is offloaded, the energy cost arises from wireless transmission, as no local computation occurs. The energy consumption can be expressed as
where and are the transmission and reception power of the user device, respectively. Thus, the total energy consumption for an offloading schedule is the sum of energy consumed across all tasks:
3.4. Optimization Objective
Compared with executing all tasks locally, an offloading schedule can lead to savings in both latency and energy. These savings are quantified as the latency gain and the energy gain , defined as
where and denote the total latency and energy consumption under full local execution, while and represent the values under a specific offloading strategy. The smaller the values of and , the higher the gain.
In this work, we define comprehensive profit () as a unified metric to evaluate the trade-off between latency and energy consumption during task offloading. quantifies the overall system efficiency from the user’s perspective by balancing delay-sensitive responsiveness with energy efficiency. This metric plays a critical role in guiding the reinforcement learning agent to make balanced decisions, rather than focusing solely on latency or energy optimization. The objective is to maximize the function:
where and are the weights representing the relative importance of latency and energy in the offloading decision, and . The represents a penalty weight used to regulate the impact of resource imbalance or highly skewed task offloading distributions. Furthermore, is a penalty function that quantifies the deviation of the task offloading decision sequence from an optimal or balanced strategy.
3.5. Task Topological Sorting Model
It is essential to convert the DAG into a linear sequence while maintaining task dependencies in order to enable optimization through the use of attention mechanisms and the PPO algorithm. This transformation is achieved through rank-based topological sorting. Dependency constraints require that a subtask be deferred from offloading until the completion of all its parent tasks. The rank-based method computes task priorities recursively from the exit nodes and ensures that offloading respects the execution order. Let denote the set of immediate successors of task , and [2]. The rank of each task is determined accordingly, enabling the construction of a valid linear sequence for scheduling:
4. Attention-Based Proximal Policy Optimization for Task Graph Offloading Model (APPGM)
The APPGM is a decision-making framework that maps a sequence of task vectors to a corresponding sequence of offloading decisions using an attention mechanism. Within this framework, the PPO algorithm is employed to train the parameters of the attention network. By leveraging the interaction between the PPO algorithm [25], the attention mechanism, and the environment, APPGM aims to maximize the comprehensive profit in the task offloading scenario. This section presents a detailed explanation of the proposed APPGM model. We begin by introducing the necessary background knowledge on DRL and attention mechanisms. Next, we describe how the PPO algorithm is utilized to train the attention-based network. Figure 4 illustrates the proposed method for task offloading and resource allocation [38], which comprises four main steps: Step 1: Topological Sorting: As a preprocessing stage, the DAG tasks generated by the UD applications are first topologically sorted according to Equation (14), transforming the DAG into a linear task sequence that preserves task dependencies. Step 2: Attention Network: Task offloading is guided by an attention-driven model. Prior to embedding, the sequential task flow is first organized using topological sorting. These embeddings are then processed by the encoder component of the attention network. The encoder aggregates the input representations into a semantic vector C [38], which is subsequently interpreted by the decoder to produce offloading strategies executed in the target environment. Step 3: Action Execution: The generated offloading decisions are executed, and the resulting system benefit is evaluated. The comprehensive system profit is calculated using Equation (13), which then defines the MDP for the environment. Step 4: PPO Algorithm: A pair of structurally identical attention networks is instantiated, where one functions in the sampling phase and the other handles the update stage. Both models operate under a shared parameter set denoted as . The PPO algorithm is then used to train the attention network, optimizing to achieve the best policy performance.
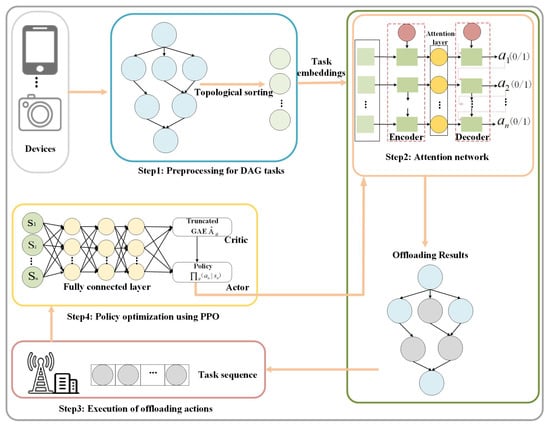
Figure 4.
Structure of the APPGM offloading model based on Attention Mechanism and PPO, comprising four steps: Topological Sorting, Attention Network, Action Execution, and PPO Algorithm.
4.1. Construction of MDP
The MDP serves as a fundamental framework in reinforcement learning for modeling the interaction between agents and their environment. An MDP is defined by a quintuple [2], where S denotes the state space, A represents the action space, P is the state transition probability matrix, R is the reward function, and serves as the discount coefficient, typically bounded between 0 and 1. Under the MDP framework, given a current state , an agent selects an action according to a policy , which specifies the conditional probability of opting for action when in state . Upon executing action , the environment transitions to a new state according to the transition probability , and returns a reward R that evaluates the quality of the action taken.
The goal of the agent is to optimize its behavior so as to achieve the highest possible expected total reward over time, formally expressed as During training, the agent engages in ongoing interaction with its environment to gather experience, refining its policy to gradually acquire the optimal decision strategy for each state, thereby enhancing adaptability and decision-making effectiveness. Within task offloading scenarios, the result of an earlier task has a notable impact on the system’s current status and subsequent decision-making. Therefore, task offloading decisions are executed following the topological order in a DAG.
Based on observations of the current system state and calculated decision values, the agent schedules each task sequentially according to the topological order, thereby generating a task offloading sequence , where n refers to the number of tasks in the application and represents the offloading decision for task . Specifically, signifies local execution, and denotes offloading to an edge node.
- (1)
- State Space
The offloading decisions of prior tasks impact the state of MEC resources at the time of scheduling task . Thus, the state space is characterized by integrating the DAG structure with the historical sequence of offloading decisions:
where represents the task embedding sequence, and denotes the historical sequence of offloading actions for completed tasks.
- (2)
- Action Space
The attention mechanism selects actions for the task set based on the topological order. Each task has two choices: it can either be executed locally on the user device () or offloaded to the edge host (). Consequently, the action space is determined to be
- (3)
- Reward Function
The reward function quantifies the expected incremental profit, aiming to maximize the comprehensive system profit. The reward at each step consists of the increments in total delay and energy consumption, denoted as and , respectively. Specifically, the reward function is formulated as
where and represent the incremental increases in delay and energy consumption. Here, . The cumulative reward across the MDP process can thus be expressed as
By maximizing the cumulative reward R, the of the task offloading process is also maximized, ensuring optimal overall system profit.
4.2. The APPGM Module Design
- (1)
- The Attention Mechanism Network for APPGM
The attention network block in Figure 4 is a schematic representation of the offloading decision generation process. The Seq2Seq [2] model, based on an encoder–decoder structure, is employed. After performing topological sorting, the ordered task sequence is input into the Seq2Seq network for processing. RNNs are employed to construct both the encoder and decoder components within our proposed framework. The encoder receives a sequence of task embeddings , and corresponding offloading actions () are inferred from the policy function outputted by the decoder.
All input vectors are compressed by the encoder into a unified semantic embedding C, which the decoder module subsequently decodes [38]. In traditional designs, C assigns equal weights to all input vectors, which we improve by incorporating an attention mechanism to extend the semantic representation of C [25]. In particular, C is redefined as a set , where each gives the input vectors a distinct weight. The number of hidden states in the encoder and decoder is indicated by L in this case. The attention mechanism emphasizes crucial details while attenuating the influence of less relevant features.
To effectively capture shared representations across tasks, two attention networks that are structurally identical are initialized for sampling and updating [2]. Most of their parameters are shared via a parameter-sharing mechanism. The shared parameters of the attention networks are represented by , and the training objective under the PPO algorithm is to optimize for the best attention network performance.
The encoder component of the attention network takes as input a task sequence that has been topologically sorted and transformed via embedding. After embedding, the vector dimension, hidden state size, and semantic vector size are uniformly defined with dimensionality L. The encoder transforms the input task sequence into a semantic vector [21] set , which is subsequently processed by the decoder. The encoder and decoder functions are denoted by and , respectively.
In this work, a GRU is used for both and . In the encoder, each state is computed based on the prior hidden state along with the current input embedding [2], as follows:
where is the i-th embedded vector derived from the task sequence. This sequence of embedded vectors is fed into the encoder of the attention sampling network.
For the decoder, every input corresponds to a semantic vector denoted by [38], and the output from the preceding step serves as the input for the subsequent one [2]. The hidden state in the decoder is generated by a nonlinear function , as expressed in the following formulation:
where and are the hidden state and output from the previous decoding step.
The semantic vector is defined as the weighted sum of the encoder’s hidden states:
The weight for each hidden state is determined by
Here, , , and are learnable parameters. Due to variations in the size and complexity of DAGs, the length of the task sequences after topological sorting may vary. As a result, the attention mechanism produces an action sequence that is adaptively aligned with the task count, where the output state of task t depends on the state of task . The policy function denoted as is output by the decoder [38]. Once the attention network has been trained, offloading decisions can be determined by applying this policy:
- (2)
- The Training Process of the APPGM
To enhance traditional reinforcement learning (RL) approaches, we employ a DNN architecture as a function and state approximator. Here, represents the set of parameters of the DNN. This architecture shares the same parameters between the policy (actor) and the value function (critic) networks. In the value-based PPO method, a DNN is used to approximate the value function through a critic network [33]. Let denote the value function that approximates the negative cost function . The critic network aims to minimize the difference between and , with the widely used loss function defined in [35] as
where represents the optimal negative cost function, and corresponds to the mean estimation computed from mini-batch data acquired throughout the training process.
Traditional policy-based DRL methods estimate policy gradients, useful in stochastic gradient ascent algorithms. The estimated policy gradient is given by
where is the stochastic policy and is the estimated advantage function.
To address the shortcomings of classical DRL methods, we first adopt a truncated version of the Generalized Advantage Estimator (GAE) [25,36] for lower variance estimation of the advantage function at time t:
where balances bias and variance. The Temporal Difference (TD) error term is defined as
Furthermore, to avoid local optima during training and sampling, we utilize an off-policy learning approach, specifically Proximal PPO [25]. Instead of directly optimizing as in (24), PPO optimizes the clipped surrogate objective:
where denotes the advantage estimate corresponding to time step t, and serves as a hyperparameter controlling the clipping range, and represents the parameters of the old sampling policy. The probability ratio is defined as
The clipping function [21] constrains within a fixed range, discouraging updates that push it beyond the interval . Since takes the minimum of the unclipped and clipped objectives, it provides a lower bound, ensuring stable updates. Following [38], we consider a parameter-sharing DNN architecture that combines the clipped surrogate loss and value loss as the final optimization target:
where q is a loss coefficient.
5. Simulation Results and Discussion
5.1. Simulation Settings and Hyperparameter Details
During the simulation phase, the transmission rate set is configured as {3 Mbps, 5 Mbps, 7 Mbps, 9 Mbps, 11 Mbps, 13 Mbps, 15 Mbps, 17 Mbps}. A Python-based simulator is used to generate various DAG datasets, simulating different task dependency structures [8]. The datasets are divided into a training set and a testing set. Each set is further categorized into six classes based on the number of task nodes: 10, 18, 26, 34, 42, and 50 nodes. Each category in the training set contains 500 DAG tasks, while the testing set contains 100 DAG tasks per category. In total, there are 3000 DAG tasks for training and 600 for testing. The objective is to simulate computation-intensive tasks with varying numbers of nodes. The DAGs’ structural width and connection density are produced in a stochastic manner, and for each task node, the uplink and downlink data sizes are randomly drawn from the range [25 KB, 150 KB]. The local user device’s processing unit operates at a clock frequency GHz, while the edge server’s virtual machine operates at GHz. The uplink and downlink power consumptions for user devices are set to W and W, respectively [10]. We assign equal weights to delay and energy consumption, setting and , with balance factors and . For the attention mechanism, we adopt a GRU-based RNN with two layers, each comprising 256 hidden units. In the PPO design, the identical architecture of Multilayer Perceptron (MLP) is employed, consisting of three fully connected layers with 128 units each and employing the tanh activation function. The discount factor is set as [25], the advantage discount factor is set to 0.95, the clipping parameter is 0.2, and the learning rate is chosen as . It is worth noting that hyperparameters can significantly influence the training performance of APPGM. In our experiments, we initially set the hyperparameters based on the configurations reported in [39]. Subsequently, a grid search strategy was employed to identify the optimal values for key hyperparameters, including the learning rate, batch size, and discount factor. These optimized settings were consistently applied across all experimental scenarios to ensure fairness and comparability.
All experiments were conducted using Python 3.10 on a computer equipped with an AMD Ryzen 7 8745H CPU and 16 GB of RAM (Advanced Micro Devices, Inc., Santa Clara, CA, USA). Additional hyperparameters are summarized in Table 2. To highlight the effectiveness of the APPGM method, we compare it against the following benchmark algorithms:
Table 2.
Simulation parameters.
- Greedy Algorithm: Offloads the task to the location (local or edge) that yields a better combined benefit based on immediate comparison.
- HEFT Algorithm: A heuristic static DAG scheduling algorithm based on the earliest finish time strategy.
- Round Robin (RR): Tasks in the DAG are alternately assigned between local processing and edge computing.
- Random Strategy: Each task node is randomly allocated to either local execution or edge computing, while ensuring dependency constraints are respected.
5.2. Results Analysis
After training APPGM under the specified experimental settings described above, we evaluate the performance of all five algorithms using the test datasets. To comprehensively assess the performance of the APPGM algorithm in dependent task offloading scenarios, we conducted experiments from three perspectives: task node scale, objective preference weights, and transmission rate. Benchmark comparisons include Greedy, HEFT, RR, and Random strategies.
Note that the average profit (or average ) presented in these results is directly derived from the function defined in Equation (13) and is calculated over all test DAGs. This ensures consistency between theoretical formulation and performance evaluation.
5.2.1. Impact of Weight Preference
Figure 5 shows the relationship between average profits and different weight settings for delay and energy ( and ). We select the test set containing 18 task nodes and evaluate five different weight configurations: (0.1, 0.9), (0.3, 0.7), (0.5, 0.5), (0.7, 0.3), and (0.9, 0.1). From the figure, it is evident that APPGM achieves the highest average profits across all five configurations. Notably, under a delay-prioritized setting (0.9, 0.1), it achieves an average of 0.78, compared to HEFT (0.43), Greedy (0.40), and Random (0.41), corresponding to a relative improvement of over 77%. While RR and Random temporarily approach APPGM in the (0.7, 0.3) setting, their performance remains unstable across configurations. In contrast, APPGM demonstrates strong adaptability to varying optimization objectives, dynamically adjusting offloading policies to maintain high average profits regardless of user preferences between latency and energy efficiency.
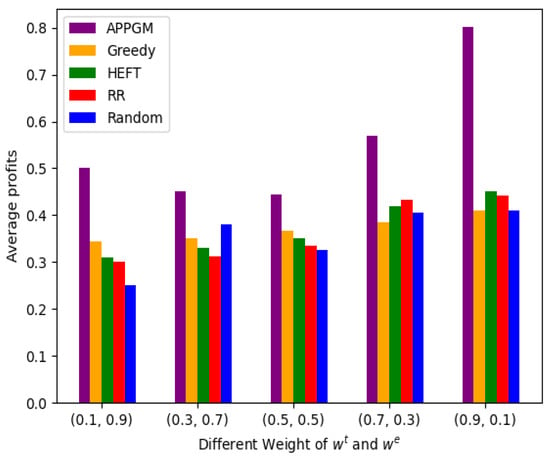
Figure 5.
Different weight between latency and energy.
5.2.2. Impact of Transmission Rate
In MEC environments, the efficiency of offloading algorithms is highly influenced by the data transmission rate, which serves as a key performance factor. To assess how APPGM’s performance scales with increasing transmission rates, we selected a training dataset with 10 task nodes. The model undergoes retraining with varying transmission rates and is evaluated using a test set that includes 10 task nodes as well. We evaluated the average comprehensive profit, average latency, and average energy consumption across transmission rates ranging from 3 Mbps to 17 Mbps, as shown in Figure 6a–c.
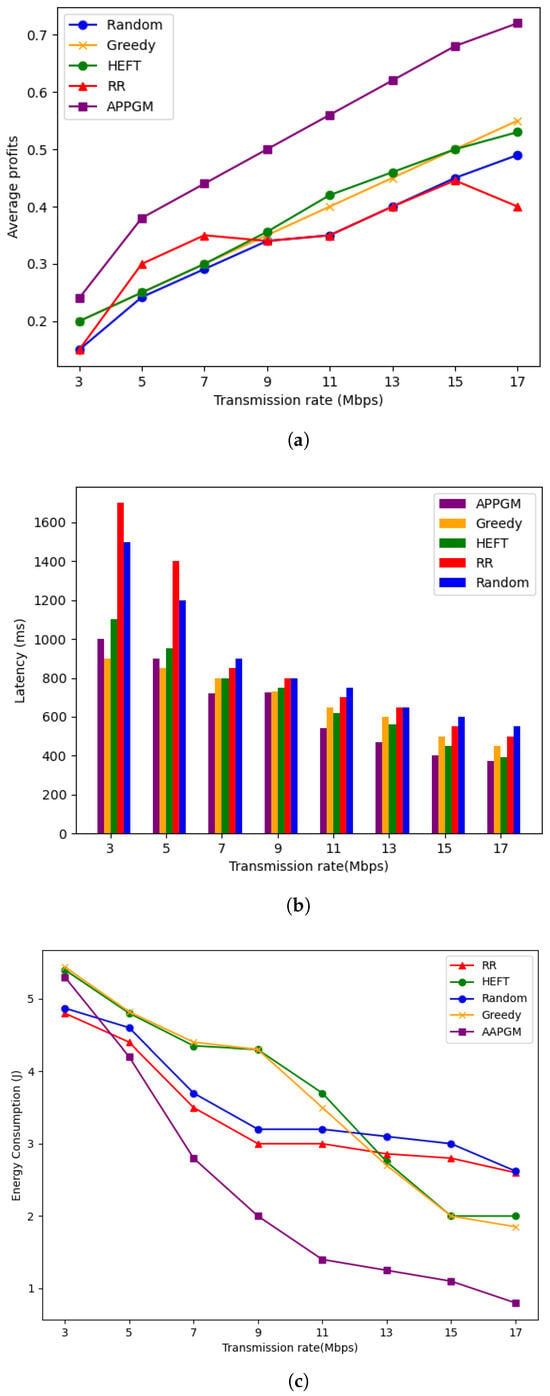
Figure 6.
The comparison of the APPGM and existing algorithms in terms of (a) average profits, (b) average latency, and (c) average energy consumption with transmission rate increasing.
As shown in Figure 6a, APPGM consistently delivers the highest comprehensive profit compared to the other four algorithms as transmission rates increase. Beyond 9 Mbps, HEFT and Greedy algorithms begin to outperform RR and Random strategies, suggesting that heuristic strategies can partially benefit from higher transmission rate. Nonetheless, APPGM still maintains a clear lead, demonstrating superior adaptability. Conversely, RR and Random plateau around a of 0.32, underscoring their inability to utilize higher transmission rates due to a lack of task-awareness and dynamic scheduling. In low-transmission-rate conditions (3–5 Mbps), the performance gap among all algorithms narrows, yet APPGM still retains a consistent advantage, highlighting its robustness and ability to learn effective policies even under constrained resources.
Figure 6b presents the average latency performance under different transmission rates. All algorithms exhibit a downward trend in latency as transmission rate increases. Due to their lack of consideration for task dependencies and system states, RR and Random consistently suffer from high latency, with values exceeding 1500 ms at 3 Mbps. In contrast, APPGM maintains the lowest latency across all transmission rates, with a reduction to approximately 1000 ms at 3 Mbps. This indicates a latency reduction of about 33.3%. As the rate increases to 17 Mbps, APPGM further reduces latency to around 400 ms.
Figure 6c shows the average energy consumption of each algorithm. With increasing transmission rate, energy consumption generally declines due to reduced communication time and faster task execution. Notably, APPGM achieves significantly lower energy consumption than all baselines across the board, dropping from approximately 5.3 J at 3 Mbps to just 0.8 J at 17 Mbps—an 85% reduction. In contrast, HEFT and Greedy still consume more than 2 J under optimal conditions, while RR and Random exhibit limited improvement due to inefficient scheduling policies.
In summary, APPGM exhibits excellent adaptability and robustness under varying transmission rates. It consistently delivers the highest comprehensive profits while maintaining low latency and energy consumption. By leveraging attention mechanisms to capture task dependencies and optimizing policies via PPO, APPGM offers a highly effective and scalable solution for dynamic MEC scenarios.
5.2.3. Impact of Task Node Scale
Figure 7 further illustrates the trend in average energy consumption as the number of task nodes increases. While all algorithms exhibit an approximately linear increase in energy usage with growing task complexity, APPGM consistently achieves the lowest energy consumption across all task scales. For instance, its energy usage rises moderately from approximately 2.0 J with 10 nodes to about 5.1 J with 50 nodes, reflecting effective energy efficiency. In contrast, both Greedy and HEFT consume more than 7.5 J at 50 nodes, which is nearly 47% higher than that of APPGM. This clearly demonstrates their limitations in effectively balancing the trade-off between latency and energy consumption during the scheduling process.
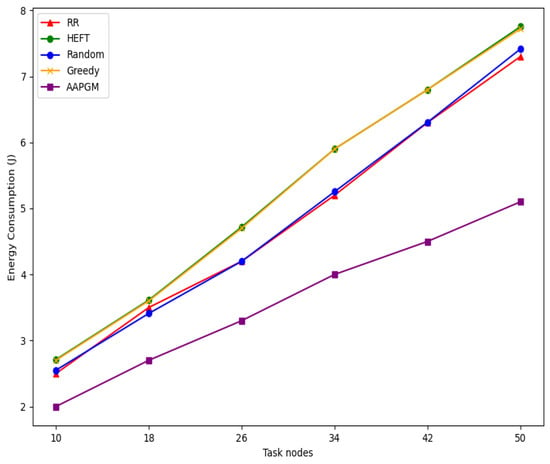
Figure 7.
The comparison of the APPGM and existing algorithms in terms of average energy consumption with different numbers of task nodes.
As shown in Table 3, while all algorithms demonstrated increasing average with the number of task nodes, APPGM consistently outperformed the others across all scales. Notably, to evaluate the statistical significance of performance differences in average among five algorithms, we conducted six independent experiments, each under a different task node setting. The mean and standard deviation for each algorithm are summarized in Table 3. A one-way analysis of variance (ANOVA), performed using SPSS Version 27, revealed statistically significant differences among the algorithms (, ), which is well below the significance threshold of 0.05. This indicates that there are significant overall differences in the average of the five algorithms. Further analysis using Tukey’s Honest Significant Difference (HSD) post hoc test confirmed that APPGM significantly outperforms each of the other four algorithms across all task node settings (), with some comparisons yielding p-values below 0.01.
Table 3.
Comparison of average (with standard deviation) and significance testing between APPGM and other algorithms under varying task node settings.
To strengthen the robustness of the statistical inference, we also computed the 95% confidence intervals for each group. For instance, under the task node setting of 10, the confidence interval for APPGM was [0.499, 0.511], while those for Greedy, HEFT, RR, and Random were [0.273, 0.301], [0.265, 0.293], [0.322, 0.388], and [0.296, 0.322], respectively. The lack of overlap among these intervals provides further statistical evidence for APPGM’s superior performance under this configuration. Similar trends were observed across other task node settings, highlighting the consistent and statistically significant advantage of APPGM in task offloading scenarios.
Therefore, the above experiments preliminarily validate the stability of the proposed method in terms of communication and computation performance as the task scale increases, demonstrating good scalability.
5.3. Discussion
Firstly, convergence plays a critical role in evaluating the performance of the APPGM algorithm. To assess the effectiveness of the attention mechanism, we compared the convergence performance of Seq2Seq networks with and without attention. As shown in Figure 8, the attention-based network demonstrates a significantly faster convergence rate than its counterpart without attention. Furthermore, after convergence, the attention-equipped Seq2Seq network achieves a higher average return compared to the non-attention model. In summary, the incorporation of the attention mechanism into the Seq2Seq architecture leads to both faster convergence and improved performance.
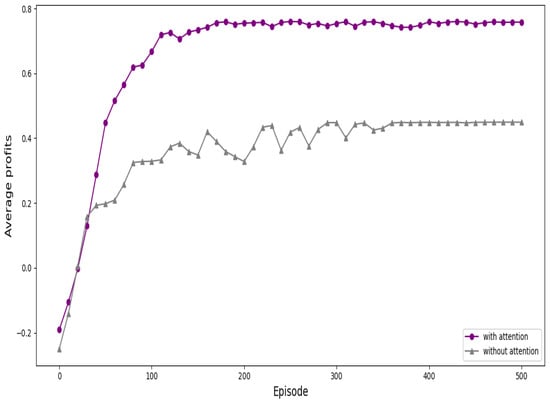
Figure 8.
The convergence for APPGM with/without attention mechanism.
Secondly, to evaluate inference time, we conducted experiments on a laptop equipped with an AMD Ryzen 7 8745H CPU and 16 GB of RAM. We performed inference using the model on 10 DAGs, each consisting of 10 task nodes. The results show a total inference time of 16.4 ms, corresponding to an average of 1.64 ms per DAG. As presented in Table 4, although the inference efficiency of our algorithm is not the highest among all methods, it remains within the millisecond range, thereby fully satisfying the real-time requirements of edge computing scenarios. Compared to the task offloading latency shown in Figure 6, the inference time is negligible. While APPGM demonstrates relatively high efficiency during the inference stage, it incurs considerable resource and time costs during training, primarily due to its use of a deep reinforcement learning framework and an attention-based sequence model. For instance, training on a dataset comprising 3000 DAGs with 50 task nodes each takes approximately 4.2 h in a single-CPU environment. Although training is performed offline, in dynamic MEC environments, where frequent model retraining may be necessary, this could pose certain challenges. Nevertheless, since retraining is not required frequently, the associated offline training overhead is generally acceptable. Moreover, the integration of the attention mechanism with the PPO algorithm increases the model’s convergence time. To mitigate the training burden, we have employed various optimization strategies in our experiments, such as parameter sharing and replacing LSTM units with GRU units, thereby enhancing training efficiency.
Table 4.
Evaluation of inference time.
Finally, we briefly discuss the computational complexity of the proposed algorithm. In terms of time complexity, the algorithm incorporates an attention mechanism designed to focus on the most critical feature dimensions within the system state. The attention computation involves a dot-product similarity matrix of size , resulting in a time complexity of . The policy learning process in the PPO algorithm—comprising both actor and critic networks—is performed on the aggregated context vector c produced by the attention module. This process has a constant time complexity of , independent of the number of tasks. Therefore, the overall time complexity of the proposed algorithm is .
Regarding space complexity, the system state is represented by the features of n tasks or devices, forming a state vector of dimension n. This leads to a storage complexity of . Although the attention module temporarily stores an attention weight matrix during computation, this matrix is released immediately after the forward pass and does not contribute significantly to the overall memory usage. The PPO network architecture and sampling buffer are of fixed size, contributing a constant space complexity of . Thus, the total space complexity of the algorithm is .
In practical Internet of Things (IoT) scenarios, the number of tasks or devices rarely exceeds 100. Therefore, the proposed algorithm demonstrates favorable computational feasibility for real-world applications.
6. Conclusions
In this paper, we propose a novel dependent task graph offloading model, named APPGM, based on deep reinforcement learning. The proposed approach combines an attention mechanism and a PPO-based cooperative algorithm, aiming to maximize comprehensive profit by jointly optimizing latency and energy efficiency. Experimental results demonstrate that APPGM significantly outperforms existing baseline algorithms in terms of user-perceived comprehensive profit, confirming its effectiveness and feasibility.
However, several limitations should be acknowledged. First, the proposed model focuses on single-user scenario and does not consider resource contention among multiple users during task offloading and scheduling. This may limit its applicability in real-world MEC systems, where multi-user resource competition is a common and critical factor. Second, the complexity of the DAG structure employed by the model increases significantly with the number of tasks, which may lead to computational challenges, especially when scaling to large or ultra-large networks. Additionally, while APPGM performs well in simulation scenarios, real-world deployments may introduce additional factors such as network congestion, hardware variability, and interference, which are not fully accounted for in the current model. Despite these limitations, APPGM holds significant practical value. It can be applied in latency- and energy-sensitive edge applications such as real-time video analytics, AR/VR rendering, and intelligent surveillance. By supporting adaptive offloading decisions under task dependencies, it contributes to the development of responsive and efficient edge intelligence frameworks.
Author Contributions
Conceptualization, R.G. and X.X.; methodology, L.Z.; software, L.L.; validation, Y.S. and X.X.; formal analysis, Y.S.; investigation, X.X.; resources, R.G.; data curation, X.X.; writing—original draft preparation, R.G.; writing—review and editing, R.G.; visualization, X.X.; supervision, Y.S.; project administration, Y.S.; funding acquisition, X.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the National Natural Science Foundation of China under Grant 62262011, in part by the Guangxi Science and Technology Base and Talent Special Project under Grant GuiKe AD24010012, in part by the Guangxi Science and Technology Major Project under Grant GuiKeAA23062001, in part by the Guangxi Science and Technology Base and Talent Special Project under Grant GuiKeAD24010060, and in part by the Guangxi Key Research and Development Program under Grant GuiKeAB23049001.
Data Availability Statement
Data is contained within the article.
Acknowledgments
We thank the anonymous reviewers for their comments and suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bai, T.; Pan, C.; Deng, Y.; Elkashlan, M.; Nallanathan, A.; Hanzo, L. Latency Minimization for Intelligent Reflecting Surface Aided Mobile Edge Computing. IEEE J. Sel. Areas Commun. 2020, 38, 2666–2682. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Min, G.; Zhan, W.; Zomaya, A.Y.; Georgalas, N. Dependent Task Offloading for Edge Computing Based on Deep Reinforcement Learning. IEEE Trans. Comput. 2022, 71, 2449–2461. [Google Scholar] [CrossRef]
- Sun, Z.; Mo, Y.; Yu, C. Graph-Reinforcement-Learning-Based Task Offloading for Multiaccess Edge Computing. IEEE Internet Things J. 2023, 10, 3138–3150. [Google Scholar] [CrossRef]
- Sabella, D.; Sukhomlinov, V.; Trang, L.; Kekki, S.; Paglierani, P.; Rossbach, R. Developing Software for Multi-Access Edge Computing; ETSI White Paper No. 20; ETSI: Sophia Antipolis, France, 2019. [Google Scholar]
- Masoud, A.; Haider, A.; Khoshvaght, P.; Soleimanian, F.; Moghaddasi, K.; Rajabi, S. Optimizing Task Offloading with Metaheuristic Algorithms Across Cloud, Fog, and Edge Computing Networks: A Comprehensive Survey and State-of-the-Art Schemes. Sustain. Comput. Inf. Syst. 2025, 45, 101080. [Google Scholar]
- Shi, Y.; Yang, K.; Jiang, T.; Zhang, J.; Letaief, K.B. Communication-Efficient Edge AI: Algorithms and Systems. IEEE Commun. Surv. Tutor. 2020, 22, 2167–2191. [Google Scholar] [CrossRef]
- Saeik, F.; Avgeris, M.; Spatharakis, D.; Santi, N.; Dechouniotis, D.; Violos, J. Task Offloading in Edge and Cloud Computing: A Survey on Mathematical, Artificial Intelligence and Control Theory Solutions. Comput. Netw. 2021, 195, 108177. [Google Scholar] [CrossRef]
- Lin, X.; Wang, Y.; Xie, Q.; Pedram, M. Task scheduling with dynamic voltage and frequency scaling for energy minimization in the mobile cloud computing environment. IEEE Trans. Services Comput. 2015, 8, 175–186. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surveys Tuts. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Meng, J.; Tan, H.; Xu, C.; Cao, W.; Liu, L.; Li, B. Dedas: Online task dispatching and scheduling with bandwidth constraint in edge computing. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2287–2295. Available online: https://ieeexplore.ieee.org/document/8737577 (accessed on 24 June 2024).
- Tran, T.X.; Pompili, D. Joint task offloading and resource allocation for multi-server mobile-edge computing networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S. Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef]
- Satheeshbabu, S.; Uppalapati, N.K.; Fu, T.; Krishnan, G. Continuous Control of a Soft Continuum Arm Using Deep Reinforcement Learning. In Proceedings of the 3rd IEEE International Conference on Soft Robotics (RoboSoft), New Haven, CT, USA, 15 May–15 July 2020; pp. 497–503. Available online: https://ieeexplore.ieee.org/document/9116003 (accessed on 2 June 2025).
- Zhang, T.; Shen, S.; Mao, S.; Chang, G.-K. Delay-Aware Cellular Traffic Scheduling with Deep Reinforcement Learning. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. Available online: https://ieeexplore.ieee.org/document/9322560 (accessed on 29 July 2024).
- Zhan, Y.; Guo, S.; Li, P.; Zhang, J. A Deep Reinforcement Learning Based Offloading Game in Edge Computing. IEEE Trans. Comput. 2020, 69, 883–893. [Google Scholar] [CrossRef]
- Moghaddasi, K.; Rajabi, S.; Gharehchopogh, F.S. Multi-Objective Secure Task Offloading Strategy for Blockchain-Enabled IoV-MEC Systems: A Double Deep Q-Network Approach. IEEE Access 2024, 12, 3437–3463. [Google Scholar] [CrossRef]
- Tang, M.; Wong, V.W.S. Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing Systems. IEEE Trans. Mob. Comput. 2022, 21, 1985–1997. [Google Scholar] [CrossRef]
- Min, H.; Rahmani, A.M.; Ghaderkourehpaz, P.; Moghaddasi, K.; Hosseinzadeh, M. A Joint Optimization of Resource Allocation Management and Multi-Task Offloading in High-Mobility Vehicular Multi-Access Edge Computing Networks. Ad Hoc Netw. 2025, 166, 103656. [Google Scholar] [CrossRef]
- Moghaddasi, K.; Rajabi, S.; Gharehchopogh, F.S.; Ghaffari, A. An Advanced Deep Reinforcement Learning Algorithm for Three-Layer D2D-Edge-Cloud Computing Architecture for Efficient Task Offloading in the Internet of Things. Sustain. Comput. Inf. Syst. 2024, 43, 100992. [Google Scholar] [CrossRef]
- Huang, L.; Bi, S.; Zhang, Y.-J.A. Deep reinforcement learning for online computation offloading in wireless powered mobile-edge computing networks. IEEE Trans. Mobile Comput. 2020, 19, 2581–2593. [Google Scholar] [CrossRef]
- Mao, N.; Chen, Y.; Guizani, M.; Lee, G.M. Graph mapping offloading model based on deep reinforcement learning with dependent task. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin, China, 28 June–2 July 2021; pp. 21–28. [Google Scholar]
- Liu, S.; Yu, Y.; Lian, X.; Feng, Y.; She, C.; Yeoh, P.L. Dependent Task Scheduling and Offloading for Minimizing Deadline Violation Ratio in Mobile Edge Computing Networks. IEEE J. Sel. Areas Commun. 2023, 41, 538–554. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.J.A. Offloading and Resource Allocation with General Task Graph in Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Wireless Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, J. Research on Dependent Task Offloading Based on Deep Reinforcement Learning. In Proceedings of the 6th International Conference on Natural Language Processing (ICNLP), Xi’an, China, 22–24 March 2024; pp. 705–709. Available online: https://ieeexplore.ieee.org/document/10692374 (accessed on 3 March 2025).
- Wang, J.; Hu, J.; Min, G.; Zomaya, A.Y.; Georgalas, N. Fast adaptive task offloading in edge computing based on meta reinforcement learning. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 242–253. [Google Scholar] [CrossRef]
- Cheng, Z.; Li, P.; Wang, J.; Guo, S. Just-in-time code offloading for wearable computing. IEEE Trans. Emerg. Topics Comput. 2015, 3, 74–83. [Google Scholar] [CrossRef]
- Mahmoodi, S.E.; Uma, R.N.; Subbalakshmi, K.P. Optimal joint scheduling and cloud offloading for mobile applications. IEEE Trans. Cloud Comput. 2019, 7, 301–313. [Google Scholar] [CrossRef]
- Zhao, J.; Li, Q.; Gong, Y.; Zhang, K. Computation offloading and resource allocation for cloud assisted mobile edge computing in vehicular networks. IEEE Trans. Veh. Technol. 2019, 68, 7944–7956. [Google Scholar] [CrossRef]
- Hong, Z.; Chen, W.; Huang, H.; Guo, S.; Zheng, Z. Multi-hop cooperative computation offloading for industrial IoT–edge–cloud computing environments. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2759–2774. [Google Scholar] [CrossRef]
- Wu, H.; Wolter, K.; Jiao, P.; Deng, Y.; Zhao, Y.; Xu, M. EEDTO: An energy-efficient dynamic task offloading algorithm for blockchain-enabled IoT-edge-cloud orchestrated computing. IEEE Internet Things J. 2021, 8, 2163–2176. [Google Scholar] [CrossRef]
- Yang, G.; Hou, L.; He, X.; He, D.; Chan, S.; Guizani, M. Offloading time optimization via Markov decision process in mobile-edge computing. IEEE Internet Things J. 2021, 8, 2483–2493. [Google Scholar] [CrossRef]
- Deng, M.; Tian, H.; Fan, B. Fine-granularity based application offloading policy in cloud-enhanced small cell networks. In Proceedings of the 2016 IEEE International Conference on Communications Workshops (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; pp. 638–643. Available online: https://ieeexplore.ieee.org/document/7503859 (accessed on 4 February 2023).
- Liu, J.; Ren, J.; Zhang, Y.; Peng, X.; Zhang, Y.; Yang, Y. Efficient dependent task offloading for multiple applications in MEC-cloud system. IEEE Trans. Mobile Comput. 2021; early access. [Google Scholar]
- Zou, J.; Hao, T.; Yu, C.; Jin, H. A3C-DO: A Regional Resource Scheduling Framework Based on Deep Reinforcement Learning in Edge Scenario. IEEE Trans. Comput. 2021, 70, 228–239. [Google Scholar] [CrossRef]
- Xiao, L.; Lu, X.; Xu, T.; Wan, X.; Ji, W.; Zhang, Y. Reinforcement learning-based mobile offloading for edge computing against jamming and interference. IEEE Trans. Commun. 2020, 68, 6114–6126. [Google Scholar] [CrossRef]
- Rahmani, A.M.; Haider, A.; Moghaddasi, K.; Gharehchopogh, F.S.; Aurangzeb, K.; Liu, Z. Self-learning adaptive power management scheme for energy-efficient IoT-MEC systems using soft actor-critic algorithm. Internet Things 2025, 31, 101587. [Google Scholar] [CrossRef]
- Ra, M.-R.; Sheth, A.; Mummert, L.; Pillai, P.; Wetherall, D.; Govindan, R. Odessa: Enabling Interactive Perception Applications on Mobile Devices. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services (MobiSys), Bethesda, MD, USA, 28 June–1 July 2011; pp. 43–56. [Google Scholar]
- Chai, F.; Zhang, Q.; Yao, H.; Xin, X.; Gao, R.; Guizani, M. Joint multi-task offloading and resource allocation for mobile edge computing systems in satellite IoT. IEEE Trans. Veh. Technol. 2023, 72, 7783–7795. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).