Abstract
The widespread adoption of heartbeat monitoring sensors has increased the demand for secure and trustworthy multimodal cardiac monitoring systems capable of accurate heartbeat pattern recognition. While existing systems offer convenience, they often suffer from critical limitations, such as variability in the number of available modalities and missing or noisy data during multimodal fusion, which may compromise both performance and data security. To address these challenges, we propose MultiHeart, which is a robust and secure multimodal interactive cardiac monitoring system designed to provide reliable heartbeat pattern recognition through the integration of diverse and trustworthy cardiac signals. MultiHeart features a novel multi-task learning architecture that includes a reconstruction module to handle missing or noisy modalities and a classification module dedicated to heartbeat pattern recognition. At its core, the system employs a multimodal autoencoder for feature extraction with shared latent representations used by lightweight decoders in the reconstruction module and by a classifier in the classification module. This design enables resilient multimodal fusion while supporting both data reconstruction and heartbeat pattern classification tasks. We implement MultiHeart and conduct comprehensive experiments to evaluate its performance. The system achieves 99.80% accuracy in heartbeat recognition, surpassing single-modal methods by 10% and outperforming existing multimodal approaches by 4%. Even under conditions of partial data input, MultiHeart maintains 94.64% accuracy, demonstrating strong robustness, high reliability, and its effectiveness as a secure solution for next-generation health-monitoring applications.
1. Introduction
The growing popularity of heartbeat monitoring sensors, such as the Apple Watch’s ECG feature and Fitbit’s heart rate tracking, has driven an increasing demand for more advanced interactive cardiac monitoring systems [1,2,3]. For instance, hospitals now integrate remote patient monitoring (RPM) platforms like Biofourmis [4] or iRhythm [5] to analyze real-time cardiac data from wearables, enabling early detection of arrhythmias. For an interactive cardiac monitoring system, accurately recognizing heartbeat patterns is essential for early disease detection and personalized care. Recent research [6,7,8] has leveraged advanced AI techniques, such as deep convolutional neural networks (DCNNs) and attention-based transformers, to classify arrhythmias with high precision. For instance, studies using the MIT-BIH Arrhythmia Database have demonstrated AI models achieving high accuracy in distinguishing ventricular tachycardia (VT) from normal sinus rhythm.
While conventional single-modal monitoring systems frequently suffer from performance biases across varying clinical scenarios, multimodal learning approaches [9,10,11,12] offer a transformative solution by simultaneously processing diverse physiological signals. This paradigm shift enables models to compensate for the limitations of individual modalities, for instance, combining ECG’s electrical precision with PPG’s continuous monitoring capability and SCG’s mechanical motion data. Contemporary smart healthcare systems are increasingly adopting this approach, integrating multiple biosensors [10,13] to create comprehensive cardiac profiles that enhance both diagnostic accuracy and patient-clinician interaction. The true potential of multimodal systems lies in their ability to transform data heterogeneity from a challenge into an advantage, where the complementary nature of different signals yields more robust and generalizable cardiac assessments.
Despite the progress in multimodal approaches, several key challenges remain in achieving optimal performance for such systems, including varying number of modalities and interpretability of DL based heartbeat identification. Firstly, in real-world environments, the availability of sensor modalities can be inconsistent due to factors such as user behavior, environmental conditions, and hardware limitations. For example, optical sensors in consumer wearables often struggle with accuracy during high-motion activities, leading to false alarms. These variations often result in missing or incomplete data from certain sensors during data collection. Additionally, concerns about data reliability persist, as seen in cases where FDA-cleared devices like the AliveCor KardiaBand [14] were discontinued due to inconsistent readings. This variability poses a challenge in ensuring continuous and reliable system performance, as the system must be capable of handling incomplete sensor data while maintaining both accuracy and robustness in its predictions.
While advanced AI architectures [15,16,17,18] have demonstrated remarkable accuracy in diagnosing heartbeat-related diseases, including arrhythmias, myocardial infarction, and cardiomyopathy, their clinical adoption hinges on overcoming critical challenges in real-time processing, interpretability, and scalability. As illustrated in Figure 1, edge AI solutions enable on-device heartbeat classification to mitigate latency and privacy concerns, yet persistent gaps in explainability hinder trust among clinicians, particularly when FDA-approved algorithms produce false positives. Current state-of-the-art AI models predominantly rely on either feature fusion [9,10,11] or classification fusion [12] to enhance the robustness and confidence of classification outcomes. Feature fusion combines individual features extracted from each modality, while classification fusion aggregates predictions from multiple classifiers. However, these methods often fail to account for the complex, inherent correlations between modalities, such as the interactions and complementary nature of physiological signals from different sensors. As a result, the fusion process can be less effective, leading to suboptimal classification performance. A more effective approach would explicitly capture these correlations, ensuring that the multimodal data is integrated in a way that maximizes the complementary information from each modality.

Figure 1.
Multimodal health monitoring system.
To address these critical limitations, we introduce MultiHeart, an innovative multimodal cardiac monitoring system designed to achieve clinically reliable heartbeat pattern recognition through three key advances: (1) synchronized analysis of complementary physiological signals (ECG, PPG, and seismocardiography) to overcome single-modality artifacts, (2) an interpretable hybrid architecture combining temporal convolutional networks with attention mechanisms for clinically transparent decisions, and (3) edge-cloud collaborative processing that balances real-time performance with comprehensive analytics. By fusing multimodal physiological data with explainable AI, MultiHeart enables robust arrhythmia detection while addressing the trust gap in current clinical implementations.
Our contributions are summarized as follows:
- We propose MultiHeart, a framework that combines two key modules, reconstruction and classification, designed for multimodal heartbeat pattern recognition. To the best of our knowledge, MultiHeart is the first interactive multimodal heartbeat monitoring system that accommodates a dynamic number of cardiac sensors, enabling users or patients to interact with different sensors during each data collection session. Additionally, MultiHeart introduces a multi-task learning framework that simultaneously reconstructs the missing sensor data and recognizes the heartbeat pattern using a unified deep learning model. Compared to existing multimodal solutions, our system delivers superior performance, enhanced robustness, and greater flexibility.
- MultiHeart utilizes an autoencoder architecture for its ability to extract environment-independent representative features and serve as a scalable representation learner, providing strong transfer learning capabilities for downstream classification tasks. The system operates as follows: During training, we randomly mask certain patches of the multimodal data (including full modality masking scenarios). The remaining unmasked patches are processed by a transformer encoder, which captures both global classification features and local patch-specific features. This encoder is shared by two modules, reconstruction and classification modules, with its output being used by each module for their respective tasks. With patch embeddings, the reconstruction module reconstructs the masked patches through modality-specific decoders, leveraging cross-modality information. This process aligns features across modalities and improves reconstruction accuracy. Simultaneously, the classification module utilizes the learned global classification embeddings for heartbeat pattern recognition. During the inference phase, the pre-trained model processes the observed multimodal input, performs reconstruction, and predicts the heartbeat pattern.
- We implemented a prototype of MultiHeart and conduct extensive experiments to evaluate its effectiveness. MultiHeart achieves 99.80% accuracy in heartbeat recognition across 100 patients and 20,000 samples, delivering a 10% average improvement over single-modal methods. It also outperforms existing multimodal approaches, with a 4% improvement in heartbeat pattern recognition. With the masking mechanism, MultiHeart maintains 94.64% accuracy for heartbeat recognition. Overall, MultiHeart demonstrates enhanced performance, robustness, and versatility compared to state-of-the-art methods.
2. Related Work
2.1. Single-Modal Heartbeat Identification
Single-modal heartbeat identification leverage various sensing approaches, each with unique strengths and challenges. Electrophysiological-based approach such as Electrocardiography (ECG) [19] measures electrical heart activity, offering strong biometric reliability tied to individual physiology but requiring stable conditions or frequent retraining. Acoustic-based approach such as Phonocardiography (PCG) records heart sounds, capturing distinct cardiovascular features, making it a viable biometric. Mechanical-based approach such as Seismocardiography (SCG) [20] tracks chest vibrations from heart contractions using accelerometers, providing non-invasive monitoring but struggling with noise and motion artifacts. Optical-based approach such as Photoplethysmography (PPG) [19] uses light sensors to measure blood flow changes, offering cost-effective and passive monitoring, though its signals fluctuate due to autonomic nervous system influences, making it ideal for mobile applications.
2.2. Multimodal Fusion Sensing
Current state-of-the-art research in multimodal learning relies on either feature fusion [9,10,11] or classification fusion [12] to enhance classification robustness and confidence. For instance, [19] combines ECG, PPG, and accelerometer signals for heartbeat monitoring, while [9] fuses physiological signals (ECG, ABP, SpO2) with electronic health record (EHR) data. Reflectance oximeters can sense reflected light, allowing PPG to collaborate with other biometrics, such as face recognition. In contrast, [12] used features from multiple ECG signals, exemplifying classification fusion. Feature fusion is more commonly used in multimodal learning [11,21]. Feature-level fusion integrates independent feature vectors from various biometric signals into a single vector for matching. These methods include concatenation [22], pooling [23], traditional attention mechanism-based methods [24], multihead self-attention (MHSA) mechanism, and cross-attention mechanism [25].
Since the number of abnormal heartbeat instances is relatively small, compared to attention mechanism-based methods, fusing instance features by pooling or concatenation does not adequately highlight the importance of abnormal heartbeat instance features. In the cross attention-based fusion method, the instance-attention weights are calculated by stacking the multimodal instance feature vectors, and the resulting weights are used to aggregate the feature vectors, thereby deriving the fused feature vector. Instance feature vectors from one modality serve as the queries whereas instance feature vectors from another modality are usesd as keys and values. The attention mechanism allows instances of several modalities to interact with one another.
2.3. Deep Learning Based Heartbeat Recognition
Popular AI models include convolutional neural networks (CNNs) [8], long short-term memory (LSTM) networks, multilayer perceptrons (MLPs), transformers, recurrent neural networks (RNNs) [26], gated recurrent units (GRUs) [27], residual neural networks (ResNet) [28], and autoencoders (AEs). These techniques develop robust models by uncovering complex patterns in ECG and PPG datasets [18], suitable for high-level data abstraction, such as identifying arrhythmias. Notably, RNNs, CNNs, and transformers can capture both short-term patterns in individual heartbeats and long-term irregularities across multiple heartbeats, enabling the detection of conditions like premature ventricular contractions (PVCs) and atrial fibrillation (AF). In cases requiring specific beat observations, dynamic classifiers like SGD, RNNs, and streaming Bayesian networks maintain long-term memory, essential for classification. They can also retain short-term memory, addressing conditions like ectopic beats, characterized by deviations in P-wave shape.
Autoencoder [7] arise as an efficient DL method by transforming the input vector into a lower-dimensional representation. Autoencoder architecture contains an encoder and decoder, and coding process involves conversing the input vector to a hidden representation and then returning it to its original form in the decoding process. It consists of stacks of layers where the hidden variables of each layer serve as the visible variables for the following layer.Autoencoders may help develop robust, discriminative models by discovering complex patterns inside datasets, which enables them to generate top-down models. They are, therefore, appropriate for applications requiring high-level data abstraction, such as identifying arrhythmia-indicating hidden patterns in ECG signals.
3. Problem Formulation
3.1. System Model
MultiHeart is a multimodal health monitoring system that continuously collects and analyzes physiological signals from multiple sensing modalities to assess a user’s health status, As illustrated in Figure 2. The system integrates data from commonly used biosensors, such as electrocardiogram (ECG) sensors for heart activity, photoplethysmogram (PPG) sensors for blood volume changes, and seismocardiogram (SCG) sensors for chest vibrations associated with cardiac cycles. These sensors are embedded in wearable or ambient devices and are deployed in clinical settings, home environments, or mobile health applications.

Figure 2.
Overview of MultiHeart.
The collected signals are transmitted either locally or through secure communication channels to a central processing unit, which may reside on a personal device, an edge server, or a cloud-based health monitoring platform. The system performs signal synchronization, quality assessment, and feature extraction to prepare the data for further health status evaluation. MultiHeart operates in real time, enabling prompt detection of abnormal conditions and supporting continuous health tracking. It is designed to function reliably under varying sensor conditions and data availability, providing robust monitoring even when some modalities are temporarily missing or degraded.
3.2. Threat Model
The development of multimodal cardiac monitoring systems, such as MultiHeart, has improved heartbeat pattern recognition by integrating signals from various sources, including ECG and PPG. While this multimodal fusion enhances diagnostic accuracy and robustness, it also introduces new vulnerabilities, particularly to digital signal manipulation attacks, where adversaries manipulate or inject falsified sensor data into the system through digital interfaces.
Digital signal manipulation attacks can occur at multiple stages of the cardiac data pipeline, beginning with compromised device firmware or signal processing algorithms that deliberately distort waveforms in memory (e.g., selectively modifying ECG samples to mask arrhythmias), and extending to post-acquisition tampering where attackers with access to stored or transmitted data (e.g., via breached cloud servers or unsecured USB interfaces) surgically alter signal files, such as editing PPG peak intervals in CSV-formatted records, to undermine diagnostic integrity without leaving visible artifacts.
Adversarial Capabilities and Clinical Impact: A sophisticated adversary in this context can leverage clinical datasets (e.g., PTBDB or MIT-BIH) and generative models (e.g., GANs or VAEs) to synthesize high-fidelity pathological waveforms or subtly modify authentic signals to evade detection. Key threats include (1) evasion attacks, where adversarial perturbations cause AI classifiers to misdiagnose critical conditions (e.g., masking ventricular fibrillation as normal sinus rhythm), and (2) fusion system exploitation, where attackers target the most influential modality in multimodal setups (e.g., corrupting PPG data while ECG remains intact) to skew diagnostic outcomes. Such manipulations could lead to harmful clinical decisions, including delayed interventions or unnecessary treatments, highlighting the urgent need for robust detection mechanisms tailored to digital-domain threats. Future iterations of MultiHeart will incorporate adversarial training, anomaly detection, and fusion-layer robustness techniques to actively defend against digital threats outlined in this section, particularly GAN-based perturbations targeting the multimodal embeddings.
4. MultiHeart System Design
4.1. System Overview
At the core of MultiHeart is a multimodal autoencoder that extracts shared latent representations across modalities. These embeddings are fed into two parallel modules: a lightweight reconstruction module that regenerates missing or corrupted modalities to ensure signal completeness, and a classification module that predicts heartbeat categories based on the fused latent features. The design supports both complete and partially missing modality scenarios, allowing the system to maintain performance even when certain sensor inputs are unavailable.
To ensure reliability and adaptability, MultiHeart uses a multi-task learning architecture that jointly optimizes both reconstruction and classification objectives. This dual-task design not only enhances robustness to input variability but also enforces consistency across modalities during training. The system assumes that sensors may occasionally fail or transmit incomplete data due to noise, device limitations, or user behavior. Therefore, the reconstruction module plays a critical role in preserving multimodal integrity and enabling accurate classification, even under partial observability. As illustrated in Figure 2, our system comprises two main components:
Real-world conditions often lead to inconsistent availability of sensor modalities, as variations in individual interactions and environmental factors can affect the sensing data. Additionally, sensor malfunctions may result in data loss. To enhance robustness, we propose randomly masking multimodal data and reconstructing the masked (or missing) modality during the training phase. This approach ensures comprehensive input from all available sensors. It enables real-time, fine-grained heartbeat pattern recognition, even in the presence of missing modalities. Using the complete dataset, we perform multimodal heartbeat pattern recognition by leveraging complementary information across different modalities.
4.2. Our Basic Approach
Figure 3 presents an overview of the MultiHeart framework, highlighting its training (pre-training and fine-tuning) and inference phases for multimodal heartbeat pattern recognition. The framework integrates multiple physiological signal modalities, such as ECG, PPG, and SCG waveforms, which capture distinct characteristics of the cardiac activity. These signals are divided into sequential patches for efficient processing and analysis.
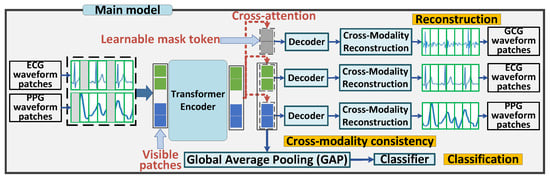
Figure 3.
MultiHeart via Multi-modal Fusion.
During the training phase, we randomly mask a subset of waveform patches across the multimodal data. The remaining unmasked patches are processed by a transformer encoder. The transformer encoder integrates the multimodal waveform patches, extracting individual patch-specific features while simultaneously obtaining one global classification features tailored for the classification task. This design enables the encoder to effectively capture both localized and global representations required for robust reconstruction and classification.
In the reconstruction module, learnable mask tokens are embedded into the input of the decoders along with the encoded embeddings. Using cross-attention mechanisms, the decoders perform cross-modality reconstruction, where information from one modality is utilized to reconstruct another. This approach aligns features across modalities, facilitating robust feature learning and allowing the model to leverage complementary information from multimodal signals. Both the encoded embeddings and mask tokens are reconstructed during this process. In the meanwhile, the classification module includes a task-specific head to perform heartbeat pattern recognition. It utilizes the global class embedding learned by the transformer encoder to provide accurate predictions.
During the inference phase, the pre-trained and fine-tuned model is deployed for real-world applications. The trained encoder processes real-time multimodal input waveforms, extracting meaningful features without requiring further training. The decoders perform cross-modality reconstruction to preserve robust multimodal feature representations. Simultaneously, the task-specific head utilizes these features to accurately predict the heartbeat pattern, ensuring reliable and efficient performance in real-world scenarios.
4.2.1. Encoder
Our approach involves the initial training of a multimodal masked autoencoder (MultiMAE) [29], as illustrated in Figure 4. The framework adopts the Vision Transformer (ViT) as the encoder, which generates the patch embeddings that capture characteristics of multimodal sensor readings.
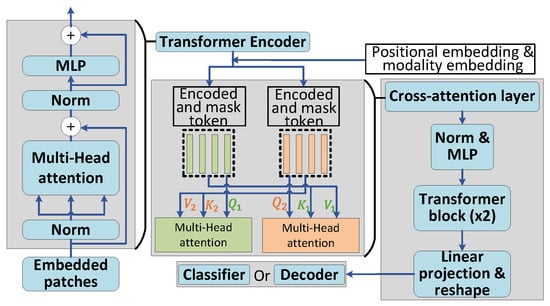
Figure 4.
Overview of ViT encoder and decoder.
4.2.2. Decoder
As illustrated in Figure 4, the decoder architecture in MultiHeart is designed to integrate cross-modal information effectively. This integration is achieved using a cross-attention mechanism, followed by one layer of Multilayer Perceptron (MLP) and two Transformer blocks. The final step involves projecting and reshaping each token to reconstruct a complete sample. A critical component of this architecture is the cross-attention layer, which aligns and integrates information across modalities. The process begins with input tokens derived from the transformer encoder, encompassing both masked and encoded patches. To enrich these tokens, two types of embeddings are added: positional embeddings, which encode the spatial or temporal positions of the tokens, and modality embeddings, which differentiate data sources from various modalities. These embeddings are essential for ensuring that the cross-attention mechanism can accurately capture modality-specific and positional relationships, thereby facilitating robust multimodal data alignment and reconstruction.
4.2.3. Classifier
For classification, the encoder-generated patch embeddings are processed by a global average pooling (GAP) layer followed by a task-specific classifier, implemented as MLPs in this work. The classifier is paired with a softmax layer to produce label predictions for heartbeat pattern classification. This design enables the framework to effectively leverage the learned patch embeddings, ensuring accurate and task-specific predictions.
4.3. Noisy (or Missing) Modality Reconstruction
In this section, we focus on addressing the challenge of reconstructing missing modality information. While many prior approaches assume that all modalities are consistently available for each training data point, we recognize that this assumption does not hold in real-world scenarios. To tackle these issues, we employ MultiMAE to reconstruct the missing modalities.
The basic training process for reconstruction is illustrated in Figure 3. A small subset of visible patches (with masked patches removed) from various modalities is linearly projected into tokens and encoded using a Transformer. Importantly, we account for entire modality masking scenarios, as this is critical for reconstructing missing modalities during the inference phase. Modality-specific decoders then perform reconstruction on both the visible and masked patches. The reconstruction loss function is defined as follows:
Here, B, M, and N represent the number of samples in the training dataset , the number of patches per sample, and the number of pixels per patch, respectively. and denote the original and reconstructed patches for the b-th sample and m-th patch, respectively. denotes the norm. The reconstruction loss, , is computed as the Mean Squared Error (MSE) between s and s across all patches.
4.4. Feature and Prediction Consistency
4.4.1. Cross Attention Mechanism
The cross-attention layer [29] facilitates the integration of multimodal information by computing the relationships between queries (Q), keys (K), and values (V). As is shown in Equation (2), the query, Q, is derived from the encoded tokens of the current modality, where , , and are learnable weight matrices. It represents the information that needs alignment with other modalities. The keys K and values V are obtained from the encoded tokens of other modalities, providing cross-modality contexts for this alignment. Using scaled dot-product attention, , the mechanism calculates similarity scores between the query and the keys, quantifying the relevance of tokens across modalities. These scores are then normalized through a softmax function to create a probability distribution, A, emphasizing the most relevant keys (i.e., tokens from other modalities) while diminishing the influence of less pertinent ones. Subsequently, the values are weighted based on the normalized attention scores, generating the final attention output . This process aggregates the most critical information from the tokens of other modalities, ensuring that the system aligns and integrates cross-modal features effectively. The results enhance the robustness and consistency of the feature representation, thereby facilitating more accurate reconstruction of the input patches.
Here, denotes the modality-specific latent representation, while represents the fused latent token for modality i, obtained by aggregating contributions from other modalities.
4.4.2. Fusion of Multi-Modal Information
In our multi-modal classification framework based on the MultiMAE architecture [29], the teacher model can be entirely omitted, with clustering instead guiding semantic learning. The model processes multiple signal modalities, such as I/Q samples, spectrograms, and RSS time series, through a unified transformer backbone architecture. This shared transformer enables cross-modal feature fusion by learning a joint latent embedding space that captures complementary information across different signal representations. The training paradigm implements a novel cross-modal masked reconstruction objective. During each training iteration, we randomly select and completely mask all input tokens from one modality, challenging the model to reconstruct the original signals across all modalities based on the remaining available information. This approach forces the network to develop robust cross-modal associations and learn modality-invariant features, while maintaining the discriminative information needed for effective signal classification.
Feature divergence. To introduce semantic structure, we cluster the encoded tokens from multiple modalities, , producing pseudo-labels for each i-modality-masked instance of sample b, where C denotes the number of clusters. These cluster assignments serve as supervisory signals. The KL divergence is used to define the consistency loss , as shown in Equation (4), which encourages alignment between the output distributions of the i- and -modality-masked versions.
Here B is the batch size, and denotes the defined clustering algorithm. We specifically adopt the K-means algorithm as our clustering approach. This formulation enables the model to learn robust and discriminative representations from unlabeled multi-modal signal data, with clustering serving as a form of self-supervision.
Prediction divergence. To enhance robust alignment across modalities, we introduce a classification loss, (see Equation (5)), which minimizes the divergence between predictions from the fully fused representation, , and those from each modality-masked variant, . Note that predictions are made with the averaged fused token embedding serving as the classification head, and the classifier is trained using the cross-entropy loss to align with . This approach enforces prediction stability under noisy or missing modalities and encourages balanced multi-modal fusion.
Here, denotes the classification function based on the cross-attention results. This formulation enables the model to capture cross-modality relationships and leverage them for final multi-modal classification.
4.5. Multimodal Heartbeat Pattern Recognition
After reconstruction of the modality data, we train MultiHeart to aggregate and enhance multimodal data for classification. As shown in Figure 3, we utilize a MLP classifier specifically designed for multimodal heartbeat pattern recognition. This classifier performs the classification task through feature fusion, enabling the identification of potential cardiac conditions in users or patients. The system’s classification loss function is outlined in the following formulation,
Here, represent the classifier for heartbeat pattern recognition, while y denotes the real labels. The classification loss, , is defined using the cross-entropy loss, , which measures the discrepancy between the predicted labels and the true labels y.
We evaluated our model using the dataset from [20], which includes 32 unique heartbeat patterns. Figure 5 illustrates both the reconstruction and heartbeat classification losses during training. The loss values decrease sharply in the initial stages, eventually converging to near zero after around 100 epochs, demonstrating the effectiveness of MultiHeart in learning robust representations.
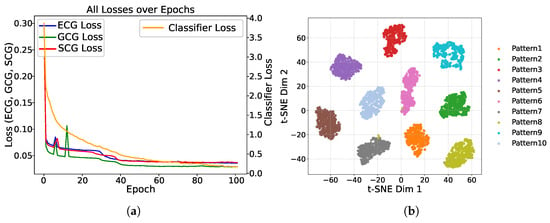
Figure 5.
Performance illustration of MultiHeart. (a) Reconstruction (MSE) and classification (Cross-Entropy) losses vs. training epochs for ECG, GCG, and SCG. (b) 2D feature space of heartbeat pattern recognition using t-SNE on approximately 5000 samples across 10 pattern classes.
4.6. Trustworthy Multi-Modal Heartbeat Pattern Recognition
This section details the training process of the unified The MultiHeart model performs two crucial tasks: multimodal data reconstruction and heartbeat pattern recognition. Our approach is based on three key insights. First, autoencoders are highly effective in learning environment-independent representations, enabling transfer learning for downstream classification tasks, delivering performance comparable to traditional supervised pre-training [29,30,31]. Second, masked autoencoders (MAE) have proven successful in reconstructing missing or low-quality time-series data [29,30,31]. Third, state-of-the-art multimodal MAE frameworks demonstrate scalability, handling varying numbers of input modalities and output decoders [29]. Leveraging these principles, our method utilizes multimodal masked autoencoders to simultaneously reconstruct missing modality data and perform multimodal classification.
Finally, we integrate the trustworthiness assessment into our MultiHeart framework to improve the robustness of our classification model. We define two key criteria for the reconstruction and classification modules during model training. First, we define a reconstruction trustworthiness threshold based on reconstruction errors, calculated as . Only samples with errors below this threshold, , are included in the next training iteration. This trustworthiness threshold helps filter out trigger-embedded samples that cause significant reconstruction errors. Second, for trustworthy classification, we only utilize the samples with a maximum prediction score above a classification trustworthiness threshold , indicated by . These two thresholds ensure that only trustworthy samples contribute to accurate reconstruction and classification. Based on this, we adjust the objectives in Equation (7) to incorporate these trustworthiness criteria. Once trained, the model can reliably identify and classify samples, achieving our final goal.
We seamlessly integrate the reconstruction and classification modules into a unified model, as shown in Figure 3. The model’s loss function consists of four components: reconstruction loss, classification loss, feature consistency loss and prediction consistency loss, as illustrated in Equation (7). Here, the hyperparameters, , , and , control the trade-off between reconstruction accuracy, prediction consistency, and classification accuracy. To summarize, the loss function for MultiHeart captures deviations in both feature and label spaces.
5. Evaluation and Results
In this section, we experimentally evaluate the performance of MultiHeart in comparison to other cardiac disease diagnosis techniques.
5.1. Dataset and Methodology
To evaluate the effectiveness of MultiHeart, we conducted extensive experiments using real-world multimodal cardiac datasets [20]. The dataset comprises recordings from 100 subjects, each contributing multiple synchronized ECG, GCG, and SCG signals. Among these, 40 participants are clinically healthy, while 60 are diagnosed with valvular heart disorders. After quality control, we retained 6418 valid multichannel segments, each approximately 8 s long, spanning 32 distinct heartbeat patterns. These patterns correspond to five primary cardiac conditions: mitral stenosis (MS), mitral regurgitation (MR), aortic regurgitation (AR), aortic stenosis (AS), and tricuspid regurgitation (TR).
Due to moderate class imbalance (e.g., MR: 18%, TR: 9%) and limited sample size, we applied data augmentation using the TSaug library in Python 3.7. Techniques included Gaussian jitter (), magnitude scaling (±12%), time warping (window size = 32, ), permutation, and 10% patch-level random masking. These augmentations increased physiological diversity and balanced the number of samples across classes. The final dataset consisted of approximately 20,000 segments with a near-uniform class distribution and an overall 1:1 ratio of healthy to pathological cases.
We employed a subject-level stratified split of 50% training, 20% validation, and 30% testing—yielding 10,000 training, 4000 validation, and 6000 test samples. This ensures no subject overlap between splits, effectively preventing patient-level data leakage and preserving the integrity of model evaluation. All of the reported classification accuracy and mean squared error (MSE) results in Section 5.3 and Section 5.4 are derived from the 30% hold-out test set.
We assessed heartbeat pattern recognition using classification accuracy across the 32 categories, while the reconstruction performance was measured using MSE to quantify the signal recovery from masked or missing modalities.
5.2. Experiment Setup
5.2.1. Random Masking Schemes
For each modality, we set the patch size to , corresponding to signal lengths of 300 for ECG, GCG, and SCG. This results in 30 tokens per modality. We apply the Dirichlet method for masking and train our model with varying numbers of masked tokens: 50, 30, and 20 out of a total of 90 tokens. Consequently, the number of tokens that pass to the encoder in each case is 40, 60, and 70, respectively.
5.2.2. Conventional Deep Learning Models for Comparison
We compare our model with three classic deep learning models—CNN, ResNet, and ViT—using both single-modal and multimodal classification approaches.
The CNN model begins with three convolutional layers, which are each followed by ReLU activation, max-pooling, and dropout for regularization. These convolutional layers use varying kernel sizes and strides to capture multi-scale features with the number of filters progressively increasing from 16 to 64 to enhance feature representation. The extracted features are then flattened and passed through two fully connected layers, leading to a final classification layer.
The ResNet Stack model consists of six residual units, leveraging skip connections to enhance gradient flow and mitigate vanishing gradient issues during training. The first residual unit processes the input while expanding the feature dimensionality to 32 channels. This is followed by five additional residual units maintaining consistent channel dimensions. Each unit incorporates convolutional layers with ReLU activation and optional max-pooling for downsampling. The extracted features are subsequently reduced using a max-pooling layer; then, they are flattened and passed through three fully connected layers with SELU activation. To enhance robustness, AlphaDropout is employed for regularization.
The ViT model is a Vision Transformer architecture specifically adapted for input data with a resolution of 3. The input is divided into 30 non-overlapping patches of size , and each patch is transformed into a 32-dimensional vector using a patch embedding layer. The architecture incorporates a transformer stack with eight layers, each featuring eight attention heads to perform multi-head self-attention, effectively capturing global dependencies across the input. To preserve spatial information, positional embeddings are added to the patch embeddings. The eight-layer transformer processes this enriched representation, and the resulting patch features are aggregated via an average pooling operation. The aggregated features are then passed through a fully connected layer for classification. Additionally, the model includes a pruning mechanism for convolutional layers, providing adaptability for deployment in resource-constrained environments.
For single-modal classification, individual modal data are directly input into each DL model for training. For multimodal classification, we explore various fusion strategies, including input-level fusion, feature-based fusion, majority voting for classification fusion, and weighted voting for classification fusion.
To evaluate early fusion, we concatenate the input data from all modalities into a single tensor and train the DL models directly on this combined input. For feature fusion, we utilize a DL model to independently extract features from each modality. The extracted features are flattened, concatenated into a unified representation, and passed through a single linear layer for classification across all modalities. In this approach, the feature extraction layers are frozen after their initial training. Additionally, we implement classification fusion using both weighted voting and majority voting strategies. For this, a separate DL model is trained for each individual modality. The classification results from all modalities are then fused to make the final decision, leveraging the complementary strengths of the modalities to improve the overall performance.
5.2.3. MultiHeart
The MultiHeart model is a flexible architecture designed for multi-task learning across diverse input modalities. It incorporates modular input and output adapters to effectively handle varying amounts of input data and produce task-specific outputs. The input adapters tokenize the data into patches of size . At the heart of the model is a transformer-based encoder with 12 layers, each featuring 12 attention heads, which processes the tokenized inputs. Classification tasks are managed through specialized linear output adapters, utilizing decoder settings with two convolutional layers and eight attention heads.
For model training, we configure a batch size of 64, a learning rate of 0.001, and enable GPU acceleration to optimize performance. The model supports advanced configurations, including cross-attention in the decoders, loss calculation on unmasked tokens, and task balancing to enhance performance across modalities and tasks. This modular and scalable design optimizes multi-task learning, making it well suited for complex multimodal datasets and varied experimental scenarios.
5.3. Results
5.3.1. Reconstruction Results
To assess the performance of missing modality reconstruction, we randomly mask one full modality during the testing (inference) phase and reconstruct it using information from the other modalities. The reconstruction performance of the MultiMAE model, as shown in Table 1, Table 2 and Table 3, demonstrates its effectiveness in recovering missing data across various modalities.

Table 1.
Performance evaluation of MultiHeart under various input configurations (trained with 50 masked patches). Input signal availability is shown per modality. MSE values are unitless, computed over normalized signals. Best results per column are bolded.
Table 2.
Performance evaluation of MultiHeart under various input configurations (trained with 30 masked patches). MSE values are unitless and computed over normalized signals. Best results in each column are bolded.
Table 3.
Performance evaluation of MultiHeart under various input configurations (trained with 20 masked patches). MSE values are unitless and computed over normalized signals. Best results in each column are bolded.
When the model is trained with 50 masked tokens, it achieves low reconstruction errors during testing with mean squared error (MSE) values consistently below 0.002 for all modalities when all signals are available. As the number of masked tokens decreases to 30 and 20, reconstruction accuracy improves slightly when all modalities are present, further enhancing the model’s ability to recover missing data. In scenarios where one modality is missing, the reconstruction errors remain low (around 0.0015), except when the ECG modality is absent, where the MSE increases to approximately 0.02. This higher error may be due to the ECG modality carrying more critical features for reconstruction.
The elevated reconstruction error observed when ECG is absent (MSE ≈ 0.02), relative to GCG and SCG, underscores the critical role ECG plays in reconstruction task. This finding aligns with the physiological significance of ECG signals, which directly reflect the heart’s electrical activity, capturing key phases such as depolarization and repolarization. Components like the P-wave and QRS complex are indispensable for identifying arrhythmias and other cardiac abnormalities. In contrast, GCG and SCG record mechanical vibrations resulting from cardiac motion, which are influenced by external factors such as body posture or noise, and often lag behind the electrical events temporally. Therefore, the consistently superior performance when ECG is included highlights its diagnostic importance and central role in multimodal cardiac signal processing.
These results indicate that while a higher number of masked tokens improves performance in fully available data scenarios, the masking mechanism used during training ensures the model remains robust when dealing with missing modalities. The shared encoder–decoder architecture allows the MultiMAE model to maintain reasonable reconstruction accuracy even in challenging conditions where one or more modalities are missing.
5.3.2. Classification Results
In Table 1, we present the classification results for the model trained with 50 masked tokens. When all modalities are available, the average classification accuracy exceeds 96%. Even when one modality is missing, the classification accuracy remains around 95%. When the number of masked tokens is reduced to 30 during training, as shown in Table 2, the classification accuracy for disease recognition improves to approximately 99% when all modalities are present. However, when one modality, particularly ECG, is missing, the accuracy drops to around 90%, highlighting the critical role of ECG data. Unlike mechanical modalities like GCG and SCG, ECG directly captures the heart’s electrical activity, thus playing a central role in classification. For the model trained with 20 masked tokens, as shown in Table 3, classification accuracy continues to improve when all modalities are present, but it drops to approximately 85% when one modality is missing.
This illustrates an important trade-off: while using a higher number of masked tokens improves classification accuracy when all modalities are available, it results in decreased accuracy when a modality is missing. Conversely, training with more masked tokens (e.g., 50) during the training phase slightly reduces accuracy with all modalities present, but the increased masking mechanism enhances robustness, allowing the model to maintain better accuracy even when one modality is missing.
These observations suggest that masking strategies should be tailored to user behavior in interactive systems. For example, if a user is likely to wear all the sensors for cardiac monitoring, training with fewer masked tokens may be optimal. On the other hand, if all modalities are not consistently available, training with more masked tokens could improve robustness. Thus, it is crucial to balance the trade-off between accuracy in complete and incomplete modality scenarios.
Table 4 compare the classification performance of MultiHeart with other DL models. To ensure fairness, we removed the masking mechanism for MultiHeart, as other models do not incorporate data reconstruction. These experiments assess whether MultiHeart, with its additional reconstruction functionality, can maintain competitive classification performance compared to other DL models. The results show that our MultiMAE model achieves over 99% accuracy, slightly surpassing the highest accuracies achieved by ResNet (95.40%) and ViT (95.45%) when feature fusion is used for multimodal classification.
Table 4.
Accuracy of heartbeat pattern recognition.
In heartbeat pattern recognition (Table 4), we observe similar results. While ResNet and ViT achieve the highest accuracy with feature fusion, the MultiMAE model consistently outperforms all configurations, demonstrating its robustness and effectiveness even with the added reconstruction module.
5.4. Model Complexity and Deployment Considerations
This comparison highlights the higher computational cost of MultiHeart, which is expected due to its multimodal architecture and the dual-task nature—performing both classification and modality reconstruction. Unlike baseline models that perform classification only, MultiHeart is designed to jointly reason across ECG, GCG, and SCG signals while also reconstructing the missing modalities. This increases its parameter count and inference latency, but also makes it more versatile and informative, especially for clinical use cases where signal degradation or loss may occur.
While MultiHeart achieves high accuracy through its transformer-based and autoencoder-driven architecture, this comes at the cost of increased computational complexity and power consumption. As illustrated in Table 5, MultiHeart exhibits the highest computational complexity, featuring the most parameters and the longest training time among the models evaluated. Furthermore, the inference time for MultiHeart is approximately five times higher than that of Vision Transformers (ViT) and over 45 times greater than that of convolutional neural networks (CNNs). All experiments were conducted on an NVIDIA GeForce GTX TITAN X GPU with 12,212 MiB of memory.
Table 5.
Model comparison table (batch size = 64, 5 epochs).
The significant demands placed by transformers, particularly those utilizing multi-head self-attention and processing long token sequences, result in substantial memory and computation requirements. In contrast, CNNs and ResNets exhibit linear complexity with respect to their depth and parameter count, whereas ViTs introduce quadratic complexity due to self-attention. MultiHeart, with its eight-layer, eight-head transformer stack and two-head decoder, reflects a hybrid computational profile that amplifies both the memory footprint and runtime cost.
Given the added complexity of the autoencoder design and transformer-based decoder, deploying MultiHeart in real-time applications remains challenging—particularly for wearable or embedded systems with constrained resources. To address this, future work will explore model compression strategies such as pruning, quantization, and knowledge distillation. These approaches aim to reduce latency and model size while preserving performance, thereby enabling practical, energy-efficient deployment for continuous cardiac monitoring.
5.5. Ablation Study
During training, random patches across the multimodal inputs are masked, compelling the model to learn contextual representations capable of reconstructing missing segments. This approach not only enhances the model’s ability to understand the relationships between different modalities but also prepares it for real-world scenarios where certain data streams may be degraded or unavailable. To assess the robustness of MultiHeart in handling missing or incomplete inputs, we conduct an ablation study that specifically evaluates the effectiveness of its patch-masking strategy. This study provides critical insights into how well the model adapts to variations in input quality, ensuring its reliability in diverse clinical settings.
As shown in Figure 6a, the reconstruction accuracy for ECG, GCG, and SCG remains relatively high when the number of masked patches ranges from 15 to 40. However, a significant decline in performance is observed, particularly for SCG and ECG, when more than 55 patches are masked. This drop indicates that excessive masking can impede the model’s ability to recover essential signal structures. Similarly, Figure 6b reveals that classification accuracy continues to rise until approximately 50 masked patches, after which there is a notable decline. This suggests that a practical masking ratio of 15 to 40 strikes an effective balance between the challenges of pretraining and the fidelity of reconstruction and classification, depending on the dataset size and training objectives. Although performance does experience some degradation with incomplete inputs, the system consistently achieves high classification accuracy and low reconstruction error, demonstrating its resilience to modality dropout.
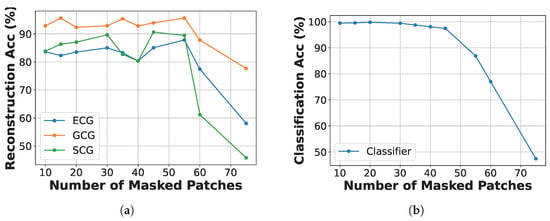
Figure 6.
Reconstruction and classification accuracy of ECG, GCG, and SCG under different numbers of masked patches. (a) Reconstruction accuracy vs. number of masked patches. (b) Classification accuracy vs. number of masked patches.
6. Limitations
The study utilizes a dataset comprising 100 patients and 20,000 samples; While 20,000 samples may seem substantial, the relatively small number of patients (e.g., 100) raises concerns about the diversity and representativeness of the cohort. A limited patient population can lead to biases in the model’s performance, as it may not adequately capture the physiological variations seen across different demographics, including age, gender, and comorbidities. Moreover, the findings may not be easily generalizable to broader clinical settings. Since the dataset primarily includes patients with specific types of cardiac conditions from particular geographical locations, the model’s applicability to diverse patient populations, including those with varying health backgrounds, remains uncertain. This lack of diversity can hinder the model’s effectiveness in real-world scenarios where patient characteristics greatly vary.
To enhance generalizability, future studies should aim to incorporate larger and more diverse datasets that encompass a wide range of cardiovascular pathologies and demographics. Such efforts would help validate the model’s performance across different patient groups and settings, ultimately improving its clinical utility and ensuring that it can be reliably used in a variety of healthcare environments.
Another limitation is the real-world testing of the MultiHeart system. While the model may perform well under controlled conditions, its effectiveness in everyday clinical practice remains uncertain. Factors such as variability in patient adherence to monitoring protocols, differences in healthcare provider training, and the integration of the system into existing workflows can significantly impact its usability and effectiveness. Additionally, the system must be adaptable to various healthcare environments, from urban hospitals to rural clinics, which may have differing levels of technological infrastructure and resources. Issues related to data privacy and security also need to be addressed, as sensitive health information will be processed and transmitted. Furthermore, the system’s performance may be affected by external variables, such as patient mobility, environmental conditions, and the presence of comorbidities that were not fully represented in the original study cohort. To overcome these challenges, a comprehensive implementation strategy that includes pilot testing in diverse settings, robust training programs for healthcare providers, and ongoing support for patients will be essential to ensure the successful integration and utilization of the MultiHeart system in real-world scenarios.
7. Conclusions
This paper proposes the MultiHeart model, which is an autoencoder-based framework for simultaneously performing user identification and heartbeat pattern recognition using multimodal data (e.g., ECG, GCG, and SCG). During training, one modality is randomly masked, and cross-modality reconstruction is achieved using a transformer encoder and decoders. This process aligns features across modalities, enabling robust feature learning. The encoder captures both local patch features and global classification features for modality reconstruction and downstream classification tasks. A reconstruction module with lightweight decoders handles the recovery of masked or missing modality data, while a classification module with task-specific heads enables user identification and heartbeat pattern recognition. During inference, the pre-trained encoder processes multimodal input, while the task-specific head predicts user identity or heartbeat patterns without further training.
8. Discussion and Future Directions
While MultiHeart demonstrates strong performance in both classification and cross-modal reconstruction across ECG, GCG, and SCG signals, several promising avenues exist to further enhance its real-world impact.
Real-Time On-Device Deployment: A critical direction involves optimizing MultiHeart for real-time inference on wearable or embedded devices. Given its current computational complexity, deploying the full model on resource-constrained platforms may pose challenges. However, techniques such as model pruning, quantization, and knowledge distillation can reduce both parameter count and inference latency. Future work may explore lightweight variants of MultiHeart with fewer tokens or simplified transformer components to balance accuracy and efficiency. The real-world adoption of MultiHeart must also account for the variability in sensor hardware, data acquisition quality, and data transmission issues. Sensor placement inconsistencies, sampling differences, and communication latency may impair the system’s performance. As such, future directions will explore robust preprocessing pipelines, adaptive fusion strategies, and error-resilient transmission mechanisms. Furthermore, ensuring compatibility across different wearable systems is critical for widespread deployment.
Integration of Additional Modalities: The current architecture is modality-agnostic and can be naturally extended to include phonocardiograms (PCG) or respiratory signals such as electromyography (EMG) of respiratory muscles. PCG is a technique that records the sounds produced by the heart during the cardiac cycle. It captures heart sounds using a microphone or sensor placed on the chest. EMG measures the electrical signals generated by respiratory muscles during inhalation and exhalation, helping identify issues related to cardiac diseases. These modalities offer complementary acoustic and respiratory cycle data, enhancing robustness in signal-deficient or noisy scenarios. Future research will investigate aligning asynchronous inputs and integrating them within the masked reconstruction framework.
Adversarial Robustness: Although MultiHeart incorporates a trust threshold to filter noisy and low-confidence samples, it has not yet been empirically evaluated against adversarial attacks. In real-world settings, signal manipulation through adversarial perturbations, such as those generated by GANs or gradient-based methods, could affect classification or reconstruction reliability. As part of future work, we plan to simulate adversarial conditions and evaluate the system’s resilience, ensuring that MultiHeart maintains robust performance in security-sensitive deployments.
Clinical Validation: In our future work, we will focus on the clinical validation of our proposed model to ensure its accuracy and reliability in real-world healthcare settings. This process will involve conducting rigorous testing and evaluation across diverse patient populations to assess the model’s performance in diagnosing and monitoring cardiovascular conditions. By employing a structured validation framework, we aim to confirm that our system not only meets regulatory standards but also provides meaningful insights that can enhance patient care. This will include collaboration with healthcare professionals to gather feedback and refine the model based on clinical needs and practical applications.
Furthermore, we plan to integrate real-world evidence into our validation process by conducting longitudinal studies that track patient outcomes over time. This approach will help us understand the model’s effectiveness in various clinical scenarios and its impact on treatment decisions. By analyzing data from actual implementations, we can identify potential areas for improvement and ensure that our system is both robust and adaptable to the dynamic nature of healthcare. Ultimately, clinical validation will be a critical step in translating our research into a practical tool that enhances cardiac monitoring and supports healthcare providers in delivering optimal patient care.
Ethical considerations: For cloud-based systems, especially in the healthcare sector, the focus is primarily on the crucial challenges of data privacy and security. As sensitive patient information, including medical histories and biometric data, is often stored and processed in the cloud, the risk of unauthorized access and data breaches becomes a significant concern. It is essential to ensure that users are fully informed about how their data are collected, shared, and utilized, promoting transparency and informed consent. Moreover, the potential for data misuse by third parties necessitates robust security measures and strict adherence to regulatory frameworks. Ethical practices must prioritize the protection of individual privacy, advocating for user-centric designs that empower patients to control their own data. Ultimately, fostering trust and accountability in cloud-based systems is imperative to safeguard personal information and uphold ethical standards in technology.
Author Contributions
Author Y.Z. led the conceptualization, methodology development, and original draft preparation; Author H.A. conducted data curation and formal analysis; Author N.H.T. provided supervision and secured funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
The work by Nghi Tran was supported in part by the National Science Foundation (NSF) under award SaTC-1956110.
Data Availability Statement
The datasets generated and analyzed during this study are available from the corresponding author on reasonable request.
Acknowledgments
The authors thank the Internet and Server Systems (ISS) at The University of Akron for providing computing resources.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Georgieva-Tsaneva, G. Interactive Cardio System for Healthcare Improvement. Sensors 2023, 23, 1186. [Google Scholar] [CrossRef]
- Ha, M.; Lim, S.; Ko, H. Wearable and flexible sensors for user-interactive health-monitoring devices. J. Mater. Chem. B 2018, 6, 4043–4064. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y. TrustHeartbeat: A Trustworthy Multimodal Interactive System with Heartbeat Recognition and User Identification. In Proceedings of the 2024 IEEE Conference on Communications and Network Security (CNS), Taipei, Taiwan, 30 September–3 October 2024; pp. 1–9. [Google Scholar]
- Biofourmis. A Platform for AI-Driven In-Home Care. 2025. Available online: https://biofourmis.com/ (accessed on 1 January 2025).
- Irhythmtech. A Platform for AI-Driven In-Home Care. 2025. Available online: https://www.irhythmtech.com/us/en (accessed on 1 January 2025).
- Ebrahimi, Z.; Loni, M.; Daneshtalab, M.; Gharehbaghi, A. A review on deep learning methods for ECG arrhythmia classification. Expert Syst. Appl. 2020, 7, 100033. [Google Scholar] [CrossRef]
- Nurmaini, S.; Darmawahyuni, A.; Mukti, A.; Rachmatullahf, M.; Firdaus, F.; Tutuko, B. Deep learning-based stacked denoising and autoencoder for ECG heartbeat classification. Electronics 2020, 9, 135. [Google Scholar] [CrossRef]
- Petmezas, G.; Haris, K.; Stefanopoulos, L.; Kilintzis, V.; Tzavelis, A.; Rogers, J.; Katsaggelos, A.; Maglaveras, N. Automated atrial fibrillation detection using a hybrid CNN-LSTM network on imbalanced ECG datasets. Biomed. Signal Process. Control 2021, 63, 102194. [Google Scholar] [CrossRef]
- Hernandez, L.; Kim, R.; Tokcan, N.; Derksen, H.; Biesterveld, B.; Croteau, A.; Williams, A.; Mathis, M.; Najarian, K.; Gryak, J. Multimodal tensor-based method for integrative and continuous patient monitoring during postoperative cardiac care. Artif. Intell. Med. 2021, 113, 102032. [Google Scholar] [CrossRef]
- John, A.; Redmond, S.; Cardiff, B.; John, D. A multimodal data fusion technique for heartbeat detection in wearable IoT sensors. IEEE Internet Things J. 2021, 9, 2071–2082. [Google Scholar] [CrossRef]
- Han, H.; Lian, C.; Zeng, Z.; Xu, B.; Zang, J.; Xue, C. Multimodal multi-instance learning for long-term ECG classification. Knowl.-Based Syst. 2023, 270, 110555. [Google Scholar] [CrossRef]
- Saranya, A.K.S.; Jaya, T. Early Detection of Heartbeat from Multimodal Data Using RPA Learning with KDNN-SAE. Comput. Syst. Sci. Eng. 2023, 45, 545–562. [Google Scholar] [CrossRef]
- Muhammad, G.; Alshehri, F.; Karray, F.; Saddik, A.E.; Alsulaiman, M.; Falk, T.H. A comprehensive survey on multimodal medical signals fusion for smart healthcare systems. Inf. Fusion 2021, 76, 355–375. [Google Scholar] [CrossRef]
- Kardiaband, A. ECG Wristband. 2025. Available online: https://www.mobihealthnews.com/news/north-america/alivecor-ends-sales-kardiaband-its-ecg-accessory-apple-watches (accessed on 1 January 2025).
- Siontis, K.; Noseworthy, P.; Attia, Z.; Friedman, P. Artificial intelligence-enhanced electrocardiography in cardiovascular disease management. Nat. Rev. Cardiol. 2021, 18, 465–478. [Google Scholar] [CrossRef]
- Musa, N.; Gital, A.Y.; Aljojo, N.; Chiroma, H.; Adewole, K.S.; Mojeed, H.A.; Faruk, N.; Abdulkarim, A.; Emmanuel, I.; Folawiyo, Y.Y.; et al. A systematic review and Meta-data analysis on the applications of Deep Learning in Electrocardiogram. J. Ambient Intell. Humaniz. Comput. 2023, 14, 9677–9750. [Google Scholar] [CrossRef] [PubMed]
- Attia, Z.; Harmon, D.; Behr, E.; Friedman, P. Application of artificial intelligence to the electrocardiogram. Eur. Heart J. 2021, 42, 4717–4730. [Google Scholar] [CrossRef] [PubMed]
- Ansari, Y.; Mourad, O.; Qaraqe, K.; Serpedin, E. Deep learning for ECG Arrhythmia detection and classification: An overview of progress for period 2017–2023. Front. Physiol. 2023, 14, 1246746. [Google Scholar] [CrossRef]
- Nathan, V.; Jafari, R. Particle filtering and sensor fusion for robust heart rate monitoring using wearable sensors. IEEE J. Biomed. Health Inform. 2017, 22, 1834–1846. [Google Scholar] [CrossRef]
- Yang, C.; Fan, F.; Aranoff, N.; Green, P.; Li, Y.; Liu, C.; Tavassolian, N. An open-access database for the evaluation of cardio-mechanical signals from patients with valvular heart diseases. Front. Physiol. 2021, 12, 750221. [Google Scholar] [CrossRef]
- John, A.; Nundy, K.K.; Cardiff, B.; John, D. Multimodal multiresolution data fusion using convolutional neural networks for IoT wearable sensing. IEEE Trans. Biomed. Circuits Syst. 2021, 15, 1161–1173. [Google Scholar] [CrossRef]
- Nojavanasghari, B.; Gopinath, D.; Koushik, J.; Baltrušaitis, T.; Morency, L.P. Deep multimodal fusion for persuasiveness prediction. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 284–288. [Google Scholar]
- Ilse, M.; Tomczak, J.; Welling, M. Attention-based deep multiple instance learning. In Proceedings of the International Conference on Machine Learning. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2127–2136. [Google Scholar]
- Hashimoto, N.; Fukushima, D.; Koga, R.; Takagi, Y.; Ko, K.; Kohno, K.; Nakaguro, M.; Nakamura, S.; Hontani, H.; Takeuchi, I. Multi-scale domain-adversarial multiple-instance CNN for cancer subtype classification with unannotated histopathological images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3852–3861. [Google Scholar]
- Hendricks, L.A.; Mellor, J.; Schneider, R.; Alayrac, J.B.; Nematzadeh, A. Decoupling the role of data, attention, and losses in multimodal transformers. Trans. Assoc. Comput. Linguist. 2021, 9, 570–585. [Google Scholar] [CrossRef]
- Sun, L.; Wang, Y.; Qu, Z.; Xiong, N. BeatClass: A sustainable ECG classification system in IoT-based eHealth. IEEE Internet Things J. 2021, 9, 7178–7195. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, A.; Gao, M.; Chen, X.; Zhang, X.; Chen, X. ECG-based multi-class arrhythmia detection using spatio-temporal attention-based convolutional recurrent neural network. Artif. Intell. Med. 2020, 106, 101856. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Murphy, D.; Gifford, H.; Williams, S.; Darlington, A.; Relton, S.; Fang, H.; Wong, D. Analysis of an adaptive lead weighted ResNet for multiclass classification of 12-lead ECGs. Physiol. Meas. 2022, 43, 034001. [Google Scholar] [CrossRef] [PubMed]
- Bachmann, R.; Mizrahi, D.; Atanov, A.; Zamir, A. Multimae: Multi-modal multi-task masked autoencoders. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the ACM CVPR, New Orleans, LO, USA, 19–24 June 2022. [Google Scholar]
- Li, J.; Savarese, S.; Hoi, S. Masked Unsupervised Self-training for Label-free Image Classification. In Proceedings of the ICLR, Virtual, 25–29 April 2022. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).