
Blockchain-Based Secure and Reliable High-Quality Data Risk Management Method


Abstract
1. Introduction
1.1. Overview
1.2. Key Challenges
- (1)
- Data Security and Privacy: While certain data can be made publicly available, other types must remain confidential. For instance, the disclosure of enterprise order information along with customers’ addresses, contact details, and other private data could significantly damage a company’s reputation. The existing centralized approach to data management fails to instill sufficient confidence in data owners regarding security levels. Due to its reliance on a centralized entity, the presence of a single point of failure becomes challenging to circumvent [8]. Additionally, when data are stored on conventional cloud servers, the absence of technical measures to ensure security (e.g., data identification and traceability) can give rise to issues such as ambiguous copyrights and potential information leakage.
- (2)
- No Generic or Fair Incentives: Data collection is a costly endeavor and often holds significant commercial value. In the absence of a shared business need, there is little incentive for participants to contribute their datasets unconditionally. Furthermore, if an incentivization mechanism is implemented, it becomes imperative to ensure complete openness, transparency, and traceability of all economic rewards to prevent any crisis of confidence arising from potential fraudulent practices [9].
- (3)
- Lack of Reliable Dataset Quality Assessment Methods: The utilization of low-quality datasets often exerts a detrimental impact on the performance of machine learning models [9,10]. Blindly incorporating such datasets without thoroughly assessing their quality is highly likely to result in model failure, leading to wastage of valuable resources, including time and money. Most conventional approaches for evaluating dataset quality are confined to theoretical frameworks, providing a superficial assessment based on a limited set of dimensions such as accuracy, completeness, and timeliness, which can compromise reliability.
1.3. Solution
- (1)
- Addressing Challenge 1: Blockchain technology inherently resolves the trust and security issues of centralized systems [10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26]. As a distributed ledger, it eliminates the risk of a single point of failure [10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26]. We have established trustworthiness among participants through cryptographic techniques and consensus protocols, which guarantee the immutability and traceability of all data transactions recorded on the chain. Furthermore, by utilizing smart contracts, all data operations—from invocation to storage—are executed securely on the blockchain, directly mitigating risks such as ambiguous copyrights and potential information leakage that are prevalent in conventional cloud storage.
- (2)
- Addressing Challenge 2: Our framework has incorporated a token-based incentive mechanism built upon smart contracts to encourage participation. This system has provided fair and transparent economic rewards to data contributors. The issuance of token rewards generates corresponding transaction credentials on the blockchain that can be audited at any time. This has ensured the entire process is open and traceable, thereby building confidence and preventing disputes over rewards.
- (3)
- Addressing Challenge 3: To combat the risk of “garbage in, garbage out” and the resulting model underperformance, we have moved beyond superficial, theoretical quality metrics. We have introduced an innovative and practical method for assessing the quality of categorical datasets based on label reordering. This approach evaluates the intrinsic strength of the association between a dataset’s features and its labels. It provides a robust tool to scrutinize participant-provided datasets, ensuring that only high-quality data are accepted and rewarded, thus preventing the wastage of valuable resources.
1.4. Our Contributions
- (1)
- To address the challenges of data security, privacy, and the lack of fair incentives [27,28,29,30], we propose a blockchain-based decentralized trust management and secure use control scheme in response to concerns raised by data providers regarding the security and privacy of datasets. This scheme effectively handled all data operations and management through smart contracts, while also designing a fair and equitable incentive system based on credit value for participating parties, thereby encouraging the provision of high-quality datasets.
- (2)
- To overcome the lack of reliable dataset quality assessment methods [31,32,33,34,35,36], a two-part quality evaluation method for categorized datasets based on label rearrangement is proposed: a correlation coefficient test and a performance evaluation test. The abstract problem of the strength of correlation between features and labels is concretized into observing the trends of correlation coefficients, model performance, and feature contribution. A comprehensive evaluation of the categorized dataset is conducted to ensure that each participant provides high-quality data.
- (3)
- To validate the feasibility and effectiveness of our proposed solutions, we conducted extensive experiments. Simultaneously, we simulated a complete evaluation process through the UCI Dry Bean Dataset as a high-quality dataset sample and the self-constructed dataset Toy Dataset as a low-quality dataset sample, which proved that the proposed categorized dataset quality evaluation method can make correct judgments on the quality of datasets. Furthermore, we developed a complete dataset management scheme on the consortium blockchain platform FISCO BCOS and evaluated its performance against existing schemes, confirming the feasibility of our proposed approach.
2. Related Work
2.1. Blockchain-Based Secure Data Sharing
2.2. Most Conventional
3. Scheme Overview
- Key distribution center (KDC): usually a trusted third party that distributes corresponding certificates and keys for registered users after they complete the corresponding registration.
- Data owner (DO): an individual or company that owns the dataset required by the RA and may be an honest participant who provides a high-quality dataset or a malicious participant who provides a poor dataset.
- Researcher (RA): usually the leader of a machine learning project that needs many high-quality datasets for model training and is willing to pay a fee to the DO for access to the datasets.
- Blockchain: Blockchain is an entity that protects the privacy and security of datasets. By deploying well-designed smart contracts, DOs can set up access policies for datasets on the blockchain, and RAs can obtain the desired datasets by paying a certain number of tokens, both of which remain anonymous throughout the entire data-sharing transaction. We use consortium blockchain to ensure better privacy and scalability of the proposed scheme.
- Decentralized storage: The InterPlanetary File System (IPFS) is a decentralized storage system based on content addressing, which ensures the security of dataset storage while relieving the storage pressure on the blockchain.
- Dataset evaluation platform: provides a feasible quality evaluation method for categorized datasets. Through this platform, the RA can conduct quality checks on datasets provided by DOs and determine whether to reward them with corresponding tokens based on the results of the evaluation.
4. Trustworthy Dataset Management System
4.1. Design Goals
4.2. Reliable Identity Information
- (1)
- Bilinear: For all and for all is bilinear if there exists:
- (2)
- Nondegenerate: The map does not convert all pairs of to the identity in , and there exists the fact that if P is a generator of , then is a generator of .
- (3)
- Computable: For any , there exists an efficient algorithm to compute .
| Algorithm 1. User setup and registration | |
| Require: List of RegisteredUsers, List of AppliedUsers Ensure: Blockchain Address Addru.ID for valid users 1: for each user in RegisteredUsers do 2: userInfo ← user.UploadInfo(username, pswd, CI, S) 3: if Verify(userInfo) is false then 4: return Registration Failed 5: else 6: x, y ← RandomlyChooseFrom(Z*q); 7: PKu ← (Px, hy, Z = Pxhy); 8: SKu ← (x, y); 9: SendToUser(user, SKu, PKu, GenerateUniqueID()); 10: end if 11: end for 12: 13: for each user in AppliedUsers do; 14: if user.ID not in ID.list then 15: return Join Network Failed 16: else//User ID is in ID.list, proceed to generate address 17: Addru.ID ← GenerateAddress(PKu, SID); 18: return Addru.ID; 19: end if 20: end for |
4.3. Secure Dataset Storage
4.4. Access Control
| Algorithm 2. Access verification process |
| Require: Requester’s Address requesterAddr, Data Owner’s Address ownerAddr, Requester’s Attribute ID SID, datasetID Ensure: IPFSStorageAddress or an error message 1: if IsOnAllowedList(SID) is false then 2: return Error: No Access Privileges 3: else 4: GenerateAccessAuthorization(requesterAddr, ownerAddr); 5: if IsAuthorized(requesterAddr) and HasCompletedPrepayment(requesterAddr) is true then 6: GenerateAcceptAuthorization(ownerAddr); 7: IPFSAddress, CT2 ← RetrieveDatasetInfo(datasetID); 8: SendToUser(requesterAddr, IPFSAddress, CT2); 9: GenerateSendAuthorization(ownerAddr); 10: φ ← e(C, gβ D01/d)); 11: if VerifyDecryptionKey(CT, H2(φ)) is true then 12: return IPFSAddress 13: else 14: return Error: Decryption Failed 15: end if 16: else 17: return Error: Address not Authorized or Prepayment Incomplete 18: end if 19: end if |
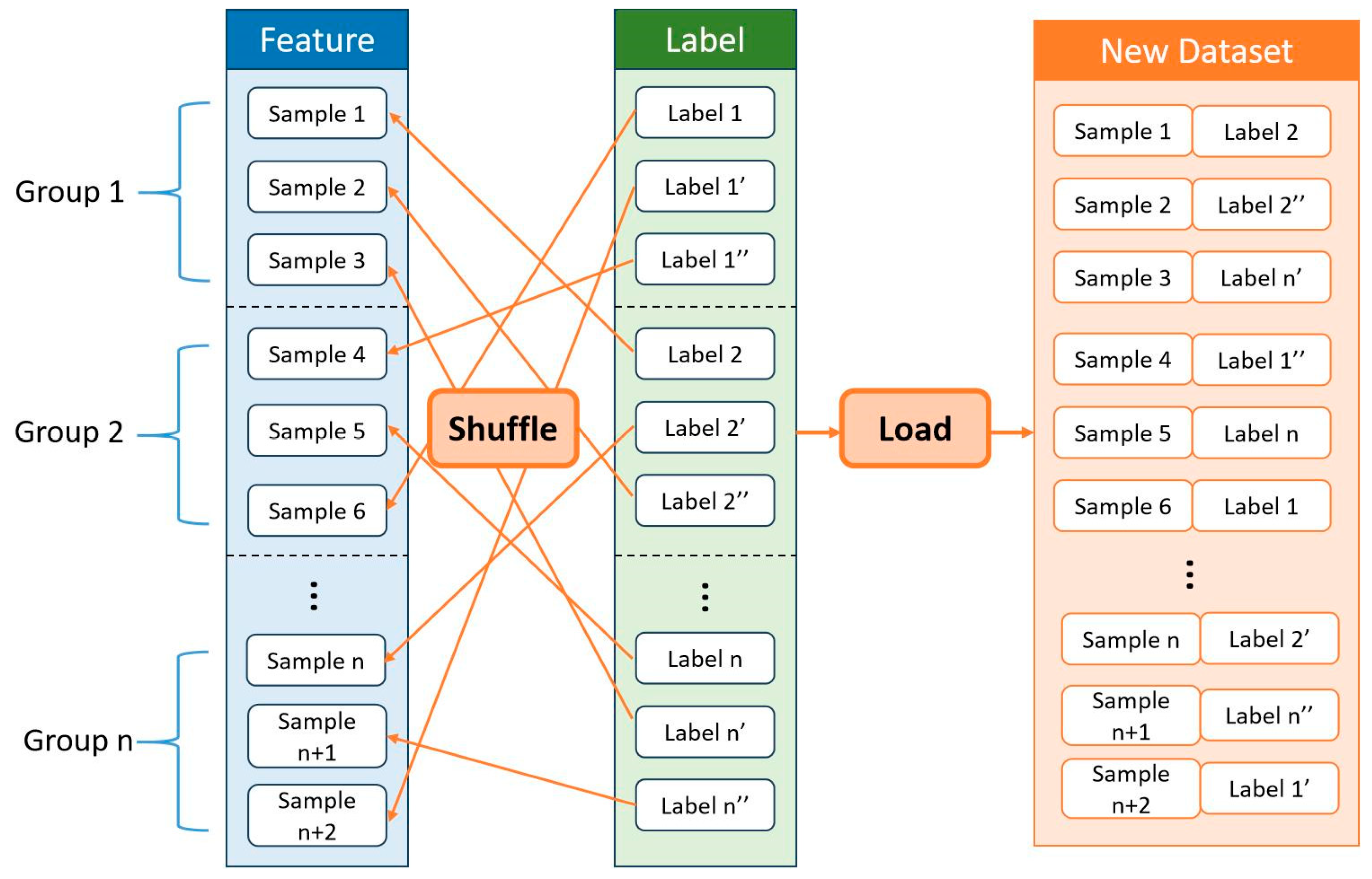
5. Reliable Method for Quality Evaluation of Categorized Dataset
| Algorithm 3. Correlation coefficient test |
| Require: originalDataset, List of rearrangement percentages Ensure: “Proceed to Performance Test” or “Dataset is Low Quality” 1: initialCoefficients ← CalculateSpearmanCoefficients(originalDataset)//A map of feature to coefficient, e.g., {feature_j: p_j} 2: rearrangedCoefficients ← an empty map; 3: for each percentage in percentages do 4: tempCoefficients ← an empty list 5: for i from 1 to T do//Perform T trials for statistical stability 6: rearrangedDataset ← RearrangeLabels(originalDataset, percentage) 7: trialCoeffs ← CalculateSpearmanCoefficients(rearrangedDataset) 8: Add(trialCoeffs) to tempCoefficients 9: end for 10: meanCoefficients ← CalculateMean(tempCoefficients); 11: rearrangedCoefficients[percentage] ← meanCoefficients 12: end for 13: 14: // Compare coefficients for each feature j 15: for each feature_j in initialCoefficients do 16: pj ← initialCoefficients[feature_j] 17: p1% ← rearrangedCoefficients[1%] [feature_j] 18: p5% ← rearrangedCoefficients[5%] [feature_j] 19: … // and so on for other percentages 20: if not (pj > p1% > p5% > …) then 21: return Dataset is Low Quality 22: end if 23: end for 24: return Proceed to Performance Test |
| Algorithm 4. Performance testing |
| Require: originalDataset, a classifierPool, List of rearrangement percentages Ensure: “High-Quality Dataset” or “Low-Quality Dataset” 1: for all perc ∈ Percentages do 2: //Phase 1: Establish Baseline 3: Minitial ← CalculateMeanPerformance(originalDataset, classifierPool) 4: W ← CalculateFeatureWeights(originalDataset, classifierPool)//A map {feature_j: weight W_j} 5: pinitial ← CalculateSpearmanCoefficients(originalDataset)//From Algorithm 3 6: 7: //Phase 2: Evaluate Performance on Rearranged Datasets 8: Mrearranged ← an empty map 9: prearranged ← an empty map//To store mean coefficients from Algorithm 3 10: for each percentage in percentages do 11. meanPerf ← CalculateMeanPerformance(RearrangedDatasets(percentage), classifierPool) 12: Mrearranged[percentage] ← meanPerf 13: //Assume mean Spearman’s coeffs for each percentage are available from Algorithm 3 14: prearranged[percentage] ← GetMeanSpearmanCoefficients(percentage) 15: end for 16: 17: //Phase 3: Final Verification 18: if the performance trend isDecreasing(Minitial, Mrearranged) is false then 19: return Low-Quality Dataset//Performance should decrease as data quality degrades 20: end if 21: 22: //Calculate performance degradation contribution for each feature 23: for each feature_j in W do 24: //Degradation in correlation for feature j (using 50% rearrangement as example) 25: corrDegradationj ← pinitial[feature_j] − prearranged[50%][feature_j] 26: //Contribution to performance drop 27: Dj ← corrDegradationj × W[feature_j] 28: end for 29: 30: //Check if features with higher weights contribute more to the performance drop 31: if IsProportional(D, W) is true then 32: return High-Quality Dataset 33: else 34: return Low-Quality Dataset 35: end if 36: end for |
6. Fair Incentive System
6.1. Incentive Principles
| Algorithm 5. Reward method |
| Input: Addr_r, Addr_d, S_ID, PA_Pre, Dataset_ID Output: Payment Result 1: RA pays corresponding advance to DO; 2: if RAPayment < SpecifiedAmount then 3: return Please Pay Advance Payment; 4: else 5: Generate Prepay—Autr; 6: Checking Addr_r for Authorization; 7: if Addr_r ∉ Addr.List then 8: return Address not Authorized; 9: else // Addr_r is in Addr_List(User is authorized) 10: Sending IPFS Address to User; 11: Generate Send—Autd; 12: if IsHighQualityDataset(Dataset_Id) then // Inferred condition for dataset quality 13: Calculate US_cv; 14: Generate Fullpay—Autr; 15: else // Dataset is not high quality 16: Generate Refund—Autr; 17: return Dataset is not a High Quality Dataset; 18: end if 19: end if 20: end if |
6.2. Credit Value Evaluation
- (1)
- Increase credit value: If the DO provides whose quality is greater than the dataset quality standard set by the system, the dataset provider will receive a higher reputation value as the number of high-quality dataset submissions increases.
- (2)
- Reduce credit value: (1) If the DO accepts a task sent by the system, but uploads a dataset that is unrelated to the task or if the content of the dataset is suspected to be in violation of the law, appropriate actions will be taken. (2) In cases where a DO repeatedly provides datasets below the quality standard despite being required to provide relevant datasets, necessary measures will be implemented. (3) If a DO engages in multiple instances of malicious pricing by offering prices significantly higher than , their account will be terminated after committing this misdeed more than three times.
6.3. Reward Acquisition
- (1)
- Verify the amount paid by the RA and if the specified amount is reached, proceed to the next step; otherwise, terminate the transaction.
- (2)
- Generate the permit (Pmt) for RA:where is the unique identifier of the , includes the usage rights (e.g., download, browse, etc.) and the expiration time of the license, and Timestampp is the timestamp of the . At the same time, credible deposit information is generated, where is the specific amount of advance payment made by the RA.
7. Security Analysis of Our Scheme
7.1. Validation and Consensus
- (1)
- Calculate .
- (2)
- Calculate .
7.2. Dataset Interaction Security
7.3. Privacy Protection
- (1)
- In the anonymous purchase phase, the payment address associated with the RA’s public key is a random point on .
- (2)
- In the anonymous license implementation, the RA generates a signature . T is a random point on . are n-1 randomly selected points on , and is calculated:since is randomly selected by the RA, the signature does not reveal any information about the RA’s identity.
- (3)
- In the anonymized data acquisition phase, the RA acquires data through a private address on the blockchain. The private address is independent of the RA’s identity.
8. Experimental Evaluations
8.1. Dataset Introduction
8.2. Validation of Quality Assessment Methods for Categorized Dataset
8.3. Blockchain Network Performance
8.4. Performance Comparison
8.4.1. Comparison Dimensions and Strategy
- (1)
- End-to-end latency of open (write + read) and transfer operations.
- (2)
- Stable throughput under a constant load of 100 tps.
- (3)
- Storage-integrity guarantees—hash-based vs. PDP-based mechanisms.
- (4)
- Privacy-preservation techniques—ABAC, ring-signature, and public-chain pseudonymity [57].
8.4.2. Experimental Setup and Metric Collection
8.4.3. Results and Analysis
8.5. Summary of Results
- (1)
- Effectiveness of quality assessment: Our label rearrangement method successfully distinguished between high-quality and low-quality datasets. The high-quality Dry Bean Dataset showed a clear, predictable decline in feature correlation and model performance as label randomness increased, while the low-quality Toy Dataset exhibited irregular and weak correlations, confirming the method’s reliability.
- (2)
- System performance and scalability: The performance benchmarks were conducted on the FISCO BCOS platform and demonstrated the system’s robustness. For key operations like user addition, data write/read, and transfers, the network achieved stable throughput rates (e.g., up to ~301 tps for transfers) and acceptable latency within a load of 2000 transactions. The data-read operation was exceptionally efficient, and the IPFS proved capable of handling large-file storage within reasonable timeframes.
- (3)
- Comparative advantage: In a direct performance comparison with schemes based on the Hyperledger Fabric and Ethereum platforms, our proposed solution showed a clear advantage. While maintaining low latency comparable to the Fabric-based scheme, our method achieved significantly higher throughput for both open and transfer operations, confirming its superior efficiency and scalability.
9. Conclusions
- (1)
- Overcoming data security, privacy, and incentive challenges: To address the lack of trust in centralized systems and the absence of fair incentives, our solution provides a secure and reliable data management system. By leveraging a consortium blockchain, the IPFS, and smart contracts, we guarantee the traceability and immutability of all data transactions, alleviating provider concerns. Furthermore, our reputation-based incentive mechanism ensures that honest participants who provide high-quality datasets are rewarded, promoting sustainable collaboration.
- (2)
- Establishing a reliable dataset quality assessment method: To counter the risk of “garbage in, garbage out” stemming from unreliable quality assessment, we introduced and validated a novel method based on label rearrangement. This practical approach allowed us to robustly evaluate the intrinsic quality of categorized datasets, ensuring that only high-quality data were used for model training. Our experiments confirmed its effectiveness in distinguishing between high- and low-quality data samples.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Buterin, V. A next-generation smart contract and decentralized application platform. White Pap. 2014, 37, 2-1. [Google Scholar]
- Camacho, J.; Wasielewska, K. Dataset quality assessment in autonomous networks with permutation testing. In Proceedings of the NOMS 2022—IEEE/IFIP Network Operations and Management Symposium (2022), Budapest, Hungary, 25–29 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Camacho, J.; Wasielewska, K.; Fuentes-García, M.; Rodríguez-Gómez, R. Quality in/quality out: Assessing data quality in an anomaly detection benchmark. arXiv 2023, arXiv:2305.19770. [Google Scholar]
- Chen, H.; Pipeta, L.F.; Ding, J. Construction and evaluation of a high-quality corpus for legal intelligence using semiautomated approaches. IEEE Trans. Reliab. 2022, 71, 657–673. [Google Scholar] [CrossRef]
- Ding, J.; Li, X.; Kang, X.; Gudivada, V.N. A case study of the augmentation and evaluation of training data for deep learning. J. Data Inf. Qual. (JDIQ) 2019, 11, 1–22. [Google Scholar] [CrossRef]
- Gong, Y.; Xue, Y.; Dong, Q.; Yang, G.; Wang, P.; Shi, Y.; Meng, L. Quality evaluation of image dataset based on label file. In Proceedings of the 2021 8th International Conference on Dependable Systems and Their Applications (DSA), Yinchuan, China, 11–12 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 639–646. [Google Scholar]
- Guerra, J.L.; Catania, C.; Veas, E. Datasets are not enough: Challenges in labeling network traffic. Comput. Secur. 2022, 120, 102810. [Google Scholar] [CrossRef]
- Restuccia, F.; Das, S.K.; Payton, J. Incentive Mechanisms for Participatory Sensing: Survey and Research Challenges. ACM Trans. Sen. Netw. 2016, 12, 13. [Google Scholar] [CrossRef]
- Bhattacharjya, A.; Xiaofeng, Z.; Jing, W. An end-to-end user two-way authenticated double encrypted messaging scheme based on hybrid RSA for the future internet architectures. Int. J. Inf. Comput. Secur. 2018, 10, 63–79. [Google Scholar] [CrossRef]
- Bhattacharjya, A.; Xiaofeng, Z.; Jing, W.; Xing, L. Hybrid RSA-based highly efficient, reliable and strong personal full mesh networked messaging scheme. Int. J. Inf. Comput. Secur. 2018, 10, 418–436. [Google Scholar] [CrossRef]
- Bhattacharjya, A.; Xiaofeng, Z.; Jing, W.; Xing, L. On mapping of address and port using translation. Int. J. Inf. Comput. Secur. 2019, 11, 214–232. [Google Scholar] [CrossRef]
- Bhattacharjya, A.; Zhong, X.; Wang, J.; Li, X. Security challenges and concerns of Internet of Things (IoT). In Cyber-Physical Systems: Architecture, Security and Application; Springer: Berlin/Heidelberg, Germany, 2019; pp. 153–185. [Google Scholar]
- Bhattacharjya, A.; Zhong, X.; Wang, J.; Li, X. Secure IoT structural design for smart homes. In Smart Cities Cybersecurity and Privacy; Elsevier: Amsterdam, The Netherlands, 2019; pp. 187–201. [Google Scholar]
- Bhattacharjya, A.; Zhong, X.; Wang, J.; Li, X. Present scenarios of IoT projects with security aspects focused. In Digital Twin Technologies and Smart Cities; Springer: Berlin/Heidelberg, Germany, 2020; pp. 95–122. [Google Scholar]
- Bhattacharjya, A.; Zhong, X.; Wang, J.; Li, X. CoAP—Application layer connection-less lightweight protocol for the Internet of Things (IoT) and CoAP-IPSEC Security with DTLS Supporting CoAP. In Digital Twin Technologies and Smart Cities; Springer: Berlin/Heidelberg, Germany, 2020; pp. 151–175. [Google Scholar]
- Bhattacharjya, A.; Zhong, X.; Xing, L. Secure Hybrid RSA (SHRSA) based multilayered authenticated, efficient and End to End secure 6-layered personal messaging communication protocol. In Digital Twin Technologies and Smart Cities; Springer Series Title: Internet of Things (IoT); Springer: Berlin/Heidelberg, Germany, 2020; Available online: https://www.springer.com/gb/book/9783030187316#aboutBook (accessed on 23 July 2019).
- Bhattacharjya, A.; Kozdroj, K.; Bazydlo, G.; Wisniewski, R. Trusted and Secure Blockchain-Based Architecture for Internet-of-Medical-Things. Electronics 2022, 11, 2560. [Google Scholar] [CrossRef]
- Bhattacharjya, A. A Holistic Study on the Use of Blockchain Technology in CPS and IoT Architectures Maintaining the CIA Triad in Data Communication. Int. J. Appl. Math. Comput. Sci. 2022, 32, 403–413. [Google Scholar] [CrossRef]
- Bhattacharjya, A.; Wisniewski, R.; Nidumolu, V. Holistic Research on Blockchain’s Consensus Protocol Mechanisms with Security and Concurrency Analysis Aspects of CPS. Electronics 2022, 11, 2760. [Google Scholar] [CrossRef]
- Bhattacharjya, A.; Zhong, X.; Li, X. A Lightweight and Efficient Secure Hybrid RSA (SHRSA) Messaging Scheme With Four-Layered Authentication Stack. IEEE Access 2019, 7, 30487–30506. [Google Scholar] [CrossRef]
- Bazydlo, G.; Kozdroj, K.; Wisniewski, R.; Bhattacharjya, A. Trusted Third Party Application in Durable Medium e-Service. Appl. Sci. 2024, 14, 191. [Google Scholar] [CrossRef]
- Gu, H.; Shang, J.; Wang, P.; Mi, J.; Bhattacharjya, A. A Secure Protocol Authentication Method Based on the Strand Space Model for Blockchain-Based Industrial Internet of Things. Symmetry 2024, 16, 851. [Google Scholar] [CrossRef]
- Bachani, V.; Wan, Y.; Bhattacharjya, A. Preferential DPoS: A Scalable Blockchain Schema for High-Frequency Transaction. In Proceedings of the Americas Conference on Information Systems (AMCIS 2022); Paper 36; Association for Information Systems: Atlanta, GA, USA, 2022; Available online: https://aisel.aisnet.org/treos_amcis2022/36 (accessed on 22 July 2022).
- Bachani, V.; Bhattacharjya, A. Preferential Delegated Proof of Stake (PDPoS)-Modified DPoS with Two Layers towards Scalability and Higher TPS. Symmetry 2023, 15, 4. [Google Scholar] [CrossRef]
- Kumar, J.R.H.; Bhargavramu, N.; Durga, L.S.N.; Nimmagadda, D.; Bhattacharjya, A. Blockchain Based Traceability in Computer Peripherals in Universities Scenarios; Conference Paper. In Proceedings of the 2023 3rd International Conference on Electronic and Electrical Engineering and Intelligent System (ICE3IS), Yogyakarta, Indonesia, 9–10 August 2023. [Google Scholar]
- Guidi, B.; Michienzi, A.; Ricci, L. Assessment of wealth distribution in blockchain online social media. IEEE Trans. Comput. Soc. Syst. 2024, 11, 671–682. [Google Scholar] [CrossRef]
- Jiang, S.; Cao, J.; Wu, H.; Chen, K.; Liu, X. Privacy-preserving and efficient data sharing for blockchain-based intelligent transportation systems. Inf. Sci. 2023, 635, 72–85. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Z.; Fu, M.; Su, W.; Chang, T.; Chen, X.; Zhou, X. Multi-ARCL: Multimodal Adaptive Relay-Based Distributed Continual Learning for Encrypted Traffic Classification. J. Parallel Distrib. Comput. 2025, 201, 105083. [Google Scholar] [CrossRef]
- Li, Z.; Wang, P.; Wang, Z. FlowGANanomaly: Flow-Based Anomaly Network Intrusion Detection with Adversarial Learning. Chin. J. Electron. 2024, 33, 58–71. [Google Scholar] [CrossRef]
- Kenyon, A.; Deka, L.; Elizondo, D. Are public intrusion datasets fit for purpose characterising the state of the art in intrusion event datasets. Comput. Secur. 2020, 99, 102022. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Z.; Fu, M.; Wang, P. A Novel Network Flow Feature Scaling Method Based on Cloud-Edge Collaboration. In Proceedings of the 2023 IEEE 22nd International Conference on Trust, Security and Privacy in Computing and Communications, Exeter, UK, 1–3 November 2023. [Google Scholar]
- Li, T.; Wang, H.; He, D.; Yu, J. Blockchain-based privacy-preserving and rewarding private data sharing for IoT. IEEE Internet Things J. 2022, 9, 15138–15149. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS 2017), Fort Lauderdale, FL, USA, 20–22 April 2017; PMLR: Fort Lauderdale, FL, USA, 2017; pp. 1273–1282. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 31 October 2008).
- Nguyen, D.C.; Ding, M.; Pham, Q.-V.; Pathirana, P.N.; Le, L.B.; Seneviratne, A.; Li, J.; Niyato, D.; Poor, H.V. Federated learning meets blockchain in edge computing: Opportunities and challenges. IEEE Internet Things J. 2021, 8, 12806–12825. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Pham, Q.-V.; Pathirana, P.N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; Hwang, W.-J. Federated learning for smart healthcare: A survey. ACM Comput. Surv. (CSUR) 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Leyva-Mayorga, I.; Lewis, A.N.; Popovski, P. Modeling and analysis of data trading on blockchain-based market in IoT networks. IEEE Internet Things J. 2021, 8, 6487–6497. [Google Scholar] [CrossRef]
- Picard, S.; Chapdelaine, C.; Cappi, C.; Gardes, L.; Jenn, E.; Lefèvre, B.; Soumarmon, T. Ensuring dataset quality for machine learning certification. In Proceedings of the 2020 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Coimbra, Portugal, 12–15 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 275–282. [Google Scholar]
- Rahman, M.U.; Guidi, B.; Bialrdi, F. Blockchain-based access control management for decentralized online social networks. J. Parallel Distrib. Comput. 2020, 144, 41–54. [Google Scholar] [CrossRef]
- Sidi, F.; Panahy, P.H.S.; Arpendev, L.S.; Jabar, M.A.; Ibrahim, H.; Mustapha, A. Data quality: A survey of data quality dimensions. In Proceedings of the 2012 International Conference on Information Retrieval & Knowledge Management, Kuala Lumpur, Malaysia, 13–15 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 300–304. [Google Scholar]
- Silva, R.M.; Gomes, G.C.; Alvim, M.S.; Gonçalves, M.A. How to build high quality L2R training data: Unsupervised compression-based selective sampling for learning to rank. Inf. Sci. 2022, 601, 90–113. [Google Scholar] [CrossRef]
- Sim, R.H.L.; Zhang, Y.; Chan, M.C.; Low, B.K.H. Collaborative Machine Learning with Incentive-Aware Model Rewards. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Virtual Event, 13–18 July 2020; PMLR: Vienna, Austria, 2020; pp. 8927–8936. [Google Scholar]
- Spanaki, K.; Karafili, E.; Despoudi, S. AI applications of data sharing in agriculture 4.0: A framework for role-based data access control. Int. J. Inf. Manag. 2021, 59, 102350. [Google Scholar] [CrossRef]
- Wang, H.; He, D.; Fu, A.; Li, Q.; Wang, Q. Provable data possession with outsourced data transfer. IEEE Trans. Serv. Comput. 2019, 14, 1929–1939. [Google Scholar] [CrossRef]
- Wang, R.Y.; Strong, D.M. Beyond accuracy: What data quality means to data consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, A.; Zhang, P.; Qu, Y.; Yu, S. Security-aware and privacy-preserving personal health record sharing using consortium blockchain. IEEE Internet Things J. 2021, 9, 12014–12028. [Google Scholar] [CrossRef]
- Wen, B.; Wang, Y.; Ding, Y.; Zheng, H.; Qin, B.; Yang, C. Security and privacy protection technologies in securing blockchain applications. Inf. Sci. 2023, 645, 119322. [Google Scholar] [CrossRef]
- Wu, C. Effect of inconsistency rate of granulated datasets on classification performance: An experimental approach. Inf. Sci. 2023, 622, 357–373. [Google Scholar] [CrossRef]
- Xuan, S.; Wang, M.; Zhang, J.; Wang, W.; Man, D.; Yang, W. An incentive mechanism design for federated learning with multiple task publishers by contract theory approach. Inf. Sci. 2024, 664, 120330. [Google Scholar] [CrossRef]
- Xue, K.; Xue, Y.; Hong, J.; Li, W.; Yue, H.; Wei, D.S.; Hong, P. RAAC: Robust and auditable access control with multiple attribute authorities for public cloud storage. IEEE Trans. Inf. Forensics Secur. 2017, 12, 953–967. [Google Scholar] [CrossRef]
- Yang, W.; Guan, Z.; Wu, L.; Du, X.; Guizani, M. Secure data access control with fair accountability in smart grid data sharing: An edge blockchain approach. IEEE Internet Things J. 2020, 8, 8632–8643. [Google Scholar] [CrossRef]
- You, Q.; Pang, R.; Cao, L.; Luo, J. Image-based appraisal of real estate properties. IEEE Trans. Multimed. 2017, 19, 2751–2759. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, M.; Zhu, L.; Zhang, W.; Wu, T.; Ni, J. Fruit: A blockchain-based efficient and privacy-preserving quality-aware incentive scheme. IEEE J. Sel. Areas Commun. 2022, 40, 3343–3357. [Google Scholar] [CrossRef]
- NIST. *Security and Privacy Controls for Information Systems and Organizations* (SP 800-53 Rev. 5); NIST Special Publication: Gaithersburg, MD, USA, 2020.
- ISO/IEC 27001:2022; Information Security, Cybersecurity and Privacy Protection—Information Security Management Systems —Requirements. International Organization for Standardization: Geneva, Switzerland, 2022.
- Zhang, J.; Yang, Y.; Liu, X.; Ma, J. An efficient blockchain-based hierarchical data sharing for healthcare internet of things. IEEE Trans. Ind. Inform. 2022, 18, 7139–7150. [Google Scholar] [CrossRef]
- Koklu, M.; Ozkan, I.A. Multiclass classification of dry beans using computer vision and machine learning techniques. Comput. Electron. Agriculture. 2020, 174, 105507. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugenics. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, X.; Liu, A.; Lu, Q.; Xu, L.; Tao, F. Blockchain-based trust mechanism for IoT-based smart manufacturing system. IEEE Trans. Comput. Soc. Syst. 2019, 6, 1386–1394. [Google Scholar] [CrossRef]
- Zhaofeng, M.; Lingyun, W.; Xiaochang, W.; Zhen, W.; Weizhe, Z. Blockchain-enabled decentralized trust management and secure usage control of IoT big data. IEEE Internet Things J. 2019, 5, 4000–4015. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Key Technical Features | Application Domain | Key Advantages | Limitations |
|---|---|---|---|---|
| [37] | Distributed ledger technology | Cryptocurrency (foundation) | Decentralization, immutability | Not specified |
| [39] | Multi-keyword search protocol | Intelligent transportation systems (ITSs) | Improved search efficiency, privacy protection for ITS devices | Not specified |
| [40] | Module chaining, zero-knowledge proofs (ZKPs) | Personal health records (PHRs) | Secure PHR management/sharing, verifiable information indexes | Not specified |
| [41] | Provable data possession (PDP), blockchain data structure | Enterprise asset transfer | Ensures data integrity during transfer | Not specified |
| [42] | Hierarchical data sharing framework (BHDSF) | IoT data sharing | Fine-grained access control, efficient encrypted retrieval | Not specified |
| [43] | Edge-chained authorization | Smart grid | Enhanced privacy protection, fair accountability | Not specified |
| [44] | Incentives based on Shapley values and information gain | Collaborative machine learning | Incentivizes user participation | No privacy protection for participants |
| [45] | Deniable ring signatures, Monroe coins, blockchain | IoT private data sharing | Privacy preservation, reward mechanism, dispute resolution under anonymity | Not specified |
| [46] | Lightweight encryption, task allocation strategies, blockchain | Privacy-preserving knowledge discovery | Efficient and privacy-preserving incentives, rewards for computing nodes | Ignores historical contribution and reputation |
| Ref. | Key Technical Features | Application Domain | Key Advantages | Limitations |
|---|---|---|---|---|
| [47] | Dimensions: accuracy, completeness, validity, consistency, reliability | General data quality | Standard theoretical framework | Hard to measure practically |
| [48] | Scenario-specific evaluation | General data quality | Considers real-world usage context, domain-specific needs | Not specified |
| [49] | Dimensions: data adequacy, category balance, labeling accuracy | Categorized datasets | Focuses on improvement strategies | No in-depth assessment discussion |
| [50] | Dimensions: labeling completeness, category validity, category uniqueness + thresholds | Image datasets | Quantitative analysis, automated evaluation reports | Not specified |
| [51] | Noise removal, dataset volume increase | Biological cell image classification | Improves deep learning model performance | Focuses on improvement, not direct assessment |
| [52] | Replacement test (observation/labeling split, p-value model performance) | Autonomous network datasets | Evaluates quality based on intrinsic data-label relationship | Only validated for binary datasets |
| [53,54] | Intrinsic link between data quality & label quality | Network traffic datasets | Focuses on critical connection between data and labels | Not specified |
| Notations | Description |
|---|---|
| CI | Registered user’s trusted contact information |
| S, CT | User’s attributes, user’s corresponding key cipher text |
| Hash key | |
| Users’ private and public keys | |
| Two large prime numbers | |
| The multiplicative group | |
| Ordinal groups corresponding to the prime numbers | |
| Access tree, access tree nodes | |
| Set of brother nodes of tree node x | |
| Access policy, access interference policy | |
| Final access policy | |
| Access structure, access paths | |
| Key decryption, attribute verification | |
| Dataset transfer proof parameters | |
| Dataset access credentials | |
| Dataset value, dataset quality standard | |
| DO historical credit value, DO current credit value | |
| Dataset prepayment, dataset complete payment | |
| y | Node in the access tree γ |
| i | Range from 1 to n as an index |
| Feature | 0% | 1% | 5% | 10% | 25% | 50% |
|---|---|---|---|---|---|---|
| SepalLength | 0.0898 | 0.0323 | 0.0072 | 0.0125 | 0.0091 | 0.0209 |
| SepalWidth | 0.0122 | 0.0063 | 0.0133 | 0.0156 | 0.0095 | 0.0090 |
| PetalLength | 0.0247 | 0.0309 | 0.0207 | 0.0475 | 0.0817 | 0.0521 |
| PetalWidth | 0.0546 | 0.0421 | 0.0338 | 0.0731 | 0.0836 | 0.0583 |
| ConvexArea | 0.586 | 0.575 | 0.571 | 0.566 | 0.367 | 0.172 |
| ShapeFactor1 | 0.552 | 0.541 | 0.536 | 0.528 | 0.329 | 0.189 |
| Feature | 0% | 1% | 5% | 10% | 25% | 50% |
|---|---|---|---|---|---|---|
| Area | 0.813 | 0.792 | 0.785 | 0.743 | 0.541 | 0.214 |
| MinorAxisLength | 0.802 | 0.786 | 0.781 | 0.736 | 0.526 | 0.176 |
| Perimeter | 0.649 | 0.633 | 0.630 | 0.623 | 0.414 | 0.248 |
| EquivDiameter | 0.649 | 0.624 | 0.622 | 0.617 | 0.408 | 0.253 |
| ConvexArea | 0.586 | 0.575 | 0.571 | 0.566 | 0.367 | 0.172 |
| ShapeFactor1 | 0.552 | 0.541 | 0.536 | 0.528 | 0.329 | 0.189 |
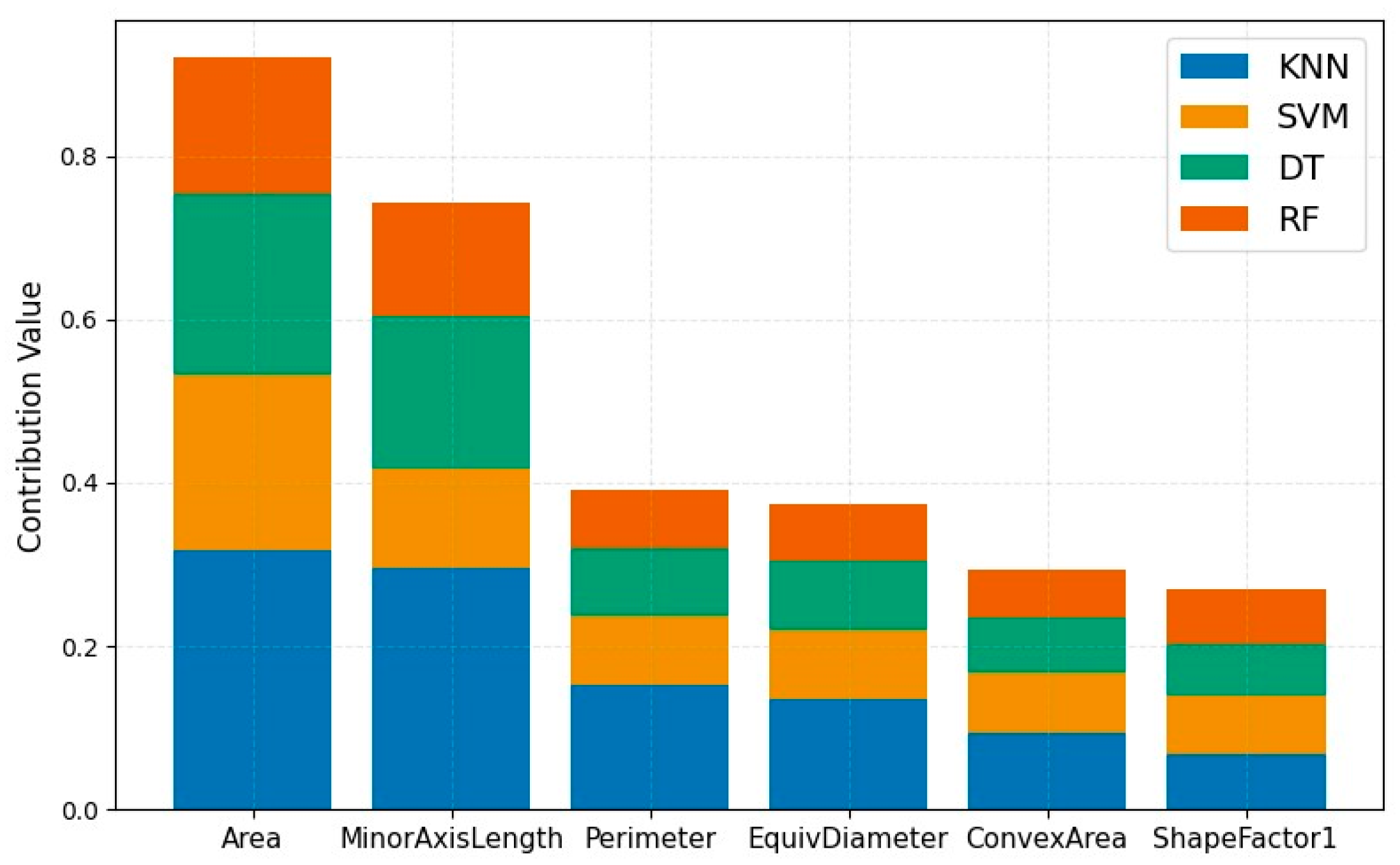
| Features | KNN | SVM | DT | RF |
|---|---|---|---|---|
| Area | 0.533 | 3.59 | 0.376 | 0.282 |
| MinorAxisLength | 0.492 | 2.01 | 0.314 | 0.235 |
| Perimeter | 0.381 | 2.12 | 0.206 | 0.184 |
| EquivDiameter | 0.379 | 2.07 | 0.205 | 0.171 |
| ConvexArea | 0.208 | 2.02 | 0.177 | 0.167 |
| ShapeFactor1 | 0.187 | 1.98 | 0.174 | 0.203 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, C.; Wang, Y.; Zhang, T.; Hao, F.; Ma, Y. Blockchain-Based Secure and Reliable High-Quality Data Risk Management Method. Electronics 2025, 14, 3058. https://doi.org/10.3390/electronics14153058
He C, Wang Y, Zhang T, Hao F, Ma Y. Blockchain-Based Secure and Reliable High-Quality Data Risk Management Method. Electronics. 2025; 14(15):3058. https://doi.org/10.3390/electronics14153058
Chicago/Turabian StyleHe, Chuan, Yunfan Wang, Tao Zhang, Fuzhong Hao, and Yuanyuan Ma. 2025. "Blockchain-Based Secure and Reliable High-Quality Data Risk Management Method" Electronics 14, no. 15: 3058. https://doi.org/10.3390/electronics14153058
APA StyleHe, C., Wang, Y., Zhang, T., Hao, F., & Ma, Y. (2025). Blockchain-Based Secure and Reliable High-Quality Data Risk Management Method. Electronics, 14(15), 3058. https://doi.org/10.3390/electronics14153058