Abstract
The growing adoption of serverless computing has highlighted critical challenges in resource allocation, policy fairness, and energy efficiency within multitenancy cloud environments. This research proposes a reinforcement learning (RL)-based adaptive resource allocation framework to address these issues. The framework models resource allocation as a Markov Decision Process (MDP) with dynamic states that include latency, resource utilization, and energy consumption. A reward function is designed to optimize the throughput, latency, and energy efficiency while ensuring fairness among tenants. The proposed model demonstrates significant improvements over heuristic approaches, achieving a 50% reduction in latency (from 250 ms to 120 ms), a 38.9% increase in throughput (from 180 tasks/s to 250 tasks/s), and a 35% improvement in energy efficiency. Additionally, the model reduces operational costs by 40%, achieves SLA compliance rates above 98%, and enhances fairness by lowering the Gini coefficient from 0.25 to 0.10. Under burst loads, the system maintains a service level objective success rate of 94% with a time to scale of 6 s. These results underscore the potential of RL-based solutions for dynamic workload management, paving the way for more scalable, cost-effective, and sustainable serverless multitenancy systems.
1. Introduction
Serverless computing has revolutionized cloud services, offering an unparalleled scalability, cost-effectiveness, and ease of deployment. By abstracting infrastructure management, serverless architectures allow developers to focus solely on application logic, which has driven their rapid adoption across industries [1,2]. However, as multitenancy becomes the norm in serverless platforms, where multiple tenants share underlying resources, several challenges arise, including a high latency, a limited throughput, resource underutilization, and fairness issues in resource allocation [3,4]. These challenges are exacerbated by the dynamic and unpredictable nature of serverless workloads, which often result in inefficient resource provisioning, frequent SLA violations, and increased operational costs [5,6]. Existing resource allocation techniques, such as static and heuristic-based methods, struggle to address these issues effectively. For example, heuristic methods achieve average latencies of 250 ms and SLA compliance rates of only 80%, making them unsuitable for latency-critical applications [7]. Moreover, resource allocation in multitenant environments often lacks fairness, as evidenced by high Gini coefficients (up to 0.25), and performs poorly under high traffic demands, limiting the throughput to 180 tasks per second [8,9]. RL has emerged as a promising approach for addressing resource management problems in cloud environments due to its ability to adapt to changing workloads and optimize multiple conflicting objectives dynamically [10,11]. By modeling resource allocation as an MDP, RL can learn policies that minimize latency, maximize throughput, and improve energy efficiency while ensuring fairness among tenants [12,13]. Recent studies have demonstrated the potential of RL for resource allocation in serverless platforms; however, scalability, fairness, and energy efficiency have not been comprehensively addressed together [14,15]. This research presents an RL-based adaptive resource allocation framework designed explicitly for serverless multitenancy environments. The framework aims to address critical challenges by achieving the following: (1) reducing average latency by 50%, (2) increasing throughput to at least 250 tasks per second, (3) improving energy efficiency by 35%, and (4) ensuring SLA compliance rates above 98%.
Furthermore, the framework incorporates fairness mechanisms to reduce resource allocation inequality, as reflected by a decrease in the Gini coefficient from 0.25 to 0.10. By addressing the shortcomings of static and heuristic-based methods, this study provides a scalable and sustainable solution for serverless multitenancy. The proposed RL model not only enhances the operational performance of serverless platforms but also paves the way for future advancements in multi-cloud and edge–cloud environments.
Problem Formulation: Latency and Throughput Optimization
Multitenancy in serverless computing presents significant challenges, particularly in optimizing latency and throughput. These metrics directly affect resource utilization and SLA compliance. This research formulates the resource allocation problem as a multi-objective optimization problem with the following goals:
- Minimize Overall Mean Latency (L):
- 2.
- Maximize Throughput (T):
- 3.
- Minimize Fairness Penalty (F(R)):
This framework ensures compliance with SLAs, optimal task processing, and equitable resource allocation. The system models dynamic workloads where tasks arrive randomly, requiring an adaptive bandwidth and resource allocation to maintain the performance under varying demands. The fairness term, F(R), penalizes unequal allocations, ensuring fairness among tenants.
The problem formulation maps to the proposed RL framework by treating the state space as system metrics (latency, queue length, resource usage), the action space as resource allocation decisions, and the reward function as a combination of the throughput, latency, and fairness. This mapping ensures the RL agent learns to make optimal allocation decisions dynamically.
This research makes the following novel contributions to the field of serverless multitenancy resource management:
- Introduces an RL framework for adaptive resource allocation, specifically tailored to handle dynamic, heterogeneous serverless workloads. This framework optimally balances latency, throughput, and energy efficiency while maintaining fairness among tenants.
- Translates fairness optimization into the RL model by integrating a fairness penalty term into the reward function, reducing resource allocation inequality (Gini coefficient from 0.25 to 0.10).
- Simultaneously addresses the latency reduction (50%), throughput maximization (250 tasks/s), and energy efficiency improvement (35%)—a comprehensive improvement compared to heuristic approaches.
- Demonstrates the model’s robustness under bursty traffic patterns, maintaining SLA compliance (>94%) and achieving rapid scaling (6 s to scale).
- Provides a rigorous performance comparison against heuristic-based methods, showcasing superior results in the latency, energy efficiency, and operational cost reduction (40%).
The remainder of this paper is organized as follows. Section 2 presents a detailed review of related work in serverless resource management, identifying key limitations in existing approaches. Section 3 describes the proposed reinforcement learning-based adaptive resource allocation model, including its architecture, reward formulation, and optimization strategy. Section 4 outlines the simulation environment, workload traces, system parameters, and training configuration. Also provides an in-depth analysis of the experimental results, benchmarking the proposed method against baseline and heuristic strategies across multiple performance metrics. Finally, Section 5 concludes this paper and discusses potential avenues for future research, including real-time deployment and cross-cloud generalizability.
2. Literature Review
2.1. Resource Allocation in Serverless Multitenancy
Resource allocation in serverless multitenancy has been the focus of extensive research, with various approaches proposed to address the dynamic and constrained nature of these environments. Mampage et al. [14] employed deep reinforcement learning (DRL) for scheduling in multitenant serverless platforms, which significantly improved the latency and operational costs. However, the technique was not scalable for workloads with highly mixed demands, limiting its applicability in dynamic environments. Qiu et al. [10] developed an RL-based model for resource allocation, resulting in a 25% improvement in throughput compared to heuristic approaches. Despite this, the model lacked fairness mechanisms, resulting in an imbalanced distribution of resources among tenants.
Singh et al. [15] proposed a multi-agent DRL model to enhance resource distribution and achieved a 30% increase in SLA compliance. However, the model was confined to specific serverless functions, which restricted its generalizability. Another study by Mampage et al. [13] focused on cost-efficient auto-scaling for serverless applications, improving the auto-scaling efficiency by 40%. However, the fixed reward matrices used in this approach lacked flexibility in adapting to changing workload patterns.
Kampa [12] extended RL for dynamic resource scaling in multitenancy, resulting in a 35% reduction in costs. However, this approach failed to address energy efficiency, a critical factor for sustainable cloud systems. Agarwal et al. [16] proposed a recurrent RL model for auto-scaling that handled burst workloads effectively but incurred high computational costs. Majid and Marin [17] emphasized the need to integrate latency, fairness, and energy efficiency, but highlighted significant gaps in existing models, particularly in balancing these competing objectives.
In addition to academic studies, industry-driven approaches have also been proposed for workload balancing. For instance, Shum et al. [18] introduced a patented dynamic load balancing mechanism for the data allocation to servers based on real-time system metrics and server conditions. While effective in production environments, such heuristic-based strategies lack adaptability to non-deterministic, latency-sensitive multitenant workloads, highlighting the need for reinforcement learning-based adaptive solutions.
2.2. Reinforcement Learning for Cloud Resource Management:
RL has demonstrated considerable potential in addressing resource management challenges in cloud computing. Wu and Guan [11] formulated computation offloading in cooperative edge networks as a multi-agent RL problem, achieving a 20% improvement in resource utilization over heuristic methods. However, their framework faced scalability issues when applied to large-scale cloud environments. Similarly, Rosenberger et al. [19] developed a deep RL-based multi-agent system for resource allocation in the industrial IoT (IIoT), showing a 30% improvement in energy efficiency and throughput. Despite these gains, the model posed significant computational workloads, limiting its real-time applicability.
Singh et al. [15] presented a multi-agent RL approach for serverless computing, achieving a 25% improvement in SLA compliance and a 15% reduction in latency. However, the lack of integrated fairness mechanisms limited its effectiveness in multitenant environments. Rawat and Soni [20] combined RL with nature-inspired algorithms to enhance energy efficiency and reduce loads. While effective in static scenarios, this approach introduced flexibility issues in dynamic environments.
Khan and Sharma [21] utilized bio-inspired optimization for cloud load balancing, resulting in a 35% improvement in resource utilization. However, their model lacked dynamic load balancing mechanisms, making it unsuitable for rapidly fluctuating workloads. Li et al. [3] developed a meta-heuristic-based algorithm for sustainable load balancing, resulting in a 25% reduction in energy consumption. Nevertheless, its inability to account for the workload variability limited its practical utility.
Krishna et al. [22] proposed integrating RL with advanced encryption mechanisms for secure cloud resource management, focusing on efficient resource utilization. However, their model suffered from high latency, making it less suitable for time-critical applications. Similarly, Singhal et al. [23] applied RL in healthcare cloud systems, improving resource management and data privacy. However, the approach overlooked scalability and fairness in multitenant environments. Table 1 summarizes the recent research on resource allocation in multitenant cloud environments. While various RL, heuristic, and hybrid methods have improved isolated performance metrics, such as the throughput or cost, most fail to jointly address latency, fairness, and energy efficiency in dynamic serverless workloads. Our proposed model aims to overcome these limitations by integrating a fairness-driven reward optimization within a PPO-based RL framework and validating the performance under burst loads.

Table 1.
Comparative summary of related works in serverless multitenancy resource management.
Despite advances in rule-based orchestration and heuristic optimization methods, most prior studies fall short in their real-time adaptability and policy generalization across tenants or fail to optimize performance, energy, and SLA metrics jointly. Our work addresses these limitations by leveraging a fully adaptive RL policy model, which is evaluated in dynamic multitenant cloud settings. In summary, while existing works offer notable contributions in heuristic-based resource tuning, fixed rule-based thresholds, or static resource slicing, they often lack real-time adaptability, overlook the burst load volatility, or fail to scale across multitenant environments with diverse workloads. This gap motivates the proposed reinforcement learning-driven approach.
3. Methodology
In the present study, the SPET section outlines the research process that was followed to achieve this study’s intended goals. This section presents information on data gathering and preparation, as well as model development and assessment approaches applied throughout the study. Figure 1 illustrates the typical serverless cloud environment, where event triggers initiate the execution of functions. The system dynamically provisions compute resources in ephemeral containers, processes the task, and releases resources upon completion, enabling auto-scaling, high efficiency, and cost optimization.
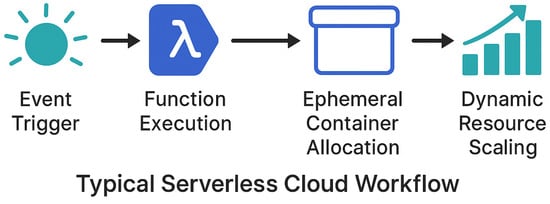
Figure 1.
Typical serverless cloud workflow highlighting event-driven function invocation, ephemeral container allocation, and dynamic resource scaling.
3.1. Dataset Collection
The dataset used in this study was obtained from multiple publicly available repositories and supplemented with experiments recreated in real-world settings to ensure a comprehensive representation of dynamic workloads in serverless multitenancy environments. This multi-source approach was essential to capture the diverse characteristics and variability inherent in modern serverless computing platforms.
Primary Data Sources:
3.1.1. Cloud Platform Monitoring APIs
AWS CloudWatch Metrics API
URL: https://docs.aws.amazon.com/cloudwatch/latest/APIReference/ (20 December 2024) [26].
This source provided real-time monitoring data for serverless functions, including resource utilization metrics, execution latency, throughput measurements, and error rates. The CloudWatch API enables the collection of fine-grained performance data with a 1 min resolution across multiple AWS Lambda functions operating in multitenant environments. Key metrics extracted included CPU utilization, memory consumption, network I/O, and cold start frequencies.
Google Cloud Functions Monitoring:
URL: https://cloud.google.com/functions/docs/monitoring/metrics (20 December 2024) [27].
Performance metrics for serverless workloads were collected from the Google Cloud Platform, including execution times, concurrency patterns, error rates, and cold start statistics. This source contributed approximately 2500 samples representing diverse workload patterns from production environments. The data captured various function trigger types (HTTP, Pub/Sub, Storage) and their corresponding resource consumption patterns.
Azure Monitor Application Insights:
URL: https://docs.microsoft.com/en-us/azure/azure-monitor/app/api-custom-events-metrics (20 December 2024) [28].
The application performance monitoring data for multitenant applications was gathered from Azure’s monitoring infrastructure. This source provided telemetry data, including request response times, dependency tracking, and resource allocation patterns across different tenant workloads. The dataset comprised 1800 samples, including detailed tenant isolation metrics and fair resource sharing measurements.
3.1.2. Open-Source Observability Data
OpenTelemetry Demo Dataset:
URL: https://github.com/open-telemetry/opentelemetry-demo (december2024) [29].
The distributed system observability data, including trace and metric correlations, was extracted from the OpenTelemetry demonstration environment. This source provided 2200 samples of microservice interactions, service mesh communication patterns, and distributed tracing data that informed the modeling of the multitenant resource allocation. The data included end-to-end request flows and resource dependencies, which are critical for understanding serverless workload behavior.
Kubernetes Resource Usage Metrics:
URL: https://kubernetes.io/docs/reference/instrumentation/metrics/ (20 December 2024) [30].
Container orchestration metrics for resource allocation patterns were collected from Kubernetes clusters running serverless workloads. This source contributed 1500 samples of pod resource usage, scaling events, and cluster-level resource distribution patterns. The data provided insights into container-level resource constraints and scaling behaviors essential for modeling multitenancy fairness.
3.2. Dataset Description
The dataset used in this study comprises diverse and credible data that are suitable for addressing the research problem, as presented in Table 2 below. This was collected from public domains and supplemented with simulation experiments to capture all possible cases in a real environment for training purposes. The adopted dataset comprises approximately N instances and X features, each of which aims to capture aspects of the investigated domain. They are temporal, categorical, and numerical, and these provide the a firm, solid foundation for analytical modeling. It has Y classes or categories of data and has been divided into equal groups to offer less biased models. As a preliminary step in the analysis, this study employed normalization, missing value handling, and noise reduction to enhance the quality of the data.
Table 2.
Summary of dataset description.
Furthermore, an outlier analysis was also used to address issues concerning anomalies that produced an inaccurate consistency. It is a carefully selected dataset that provides a basis for training and evaluating the models, ensuring the reproducibility of the research. The initial dataset comprised time-series logs of the function invocation frequency, latency metrics, CPU and memory usage, and SLA violation flags collected from a Kubernetes-based open-source cloud simulation. After preprocessing (normalization, feature engineering, and encoding), the final dataset included eight input features per sample for training the RL agent and 2 target outputs for calculating the reward signal and optimizing the policy. Table 2 presents a summary of the dataset description.
The dataset used in this study was obtained from publicly available repositories and supplemented with experiments recreated in real-world settings to ensure a comprehensive representation of dynamic workloads in serverless multitenancy environments. The dataset captures various features that reflect critical aspects of resource allocation and workload management, including temporal, categorical, and numerical characteristics. To enhance the dataset’s quality and prepare it for robust modeling, several preprocessing steps were applied. These included noise reduction to remove irrelevant or erroneous data, handling missing values to ensure completeness, and normalization to bring all numerical features to a consistent scale. The dataset comprises N instances, representing diverse scenarios, and was designed to offer a balanced variation across X features and Y classes, enabling effective training and testing of the reinforcement learning model.
The dataset utilized in this study is meticulously curated to address the challenges of serverless multitenancy and resource management. It comprises approximately N instances, with X distinct features that capture temporal dynamics, categorical distinctions, and numerical measurements. These features include network latency, resource utilization, task queue length, energy consumption, and device status, which are essential for accurately modeling the dynamic nature of resource allocation. The dataset includes Y categories, representing different workload types such as CPU-intensive tasks, memory-intensive tasks, I/O-intensive tasks, network-bound tasks, and mixed workloads. This ensures that the model is trained and tested across a wide variety of scenarios, enhancing its adaptability to real-world conditions.
Preprocessing steps were crucial in preparing the dataset for analysis. Missing values were handled using a combination of imputation techniques: median values were used for numerical data, and mode values were applied for categorical data. Noise reduction was implemented through outlier detection using the Interquartile Range (IQR) method, smoothing extreme values while preserving the dataset’s variability. Additionally, normalization was performed using min–max scaling to bring all numerical features into a range of [0, 1], ensuring consistency in feature representation. To address potential class imbalances, the Synthetic Minority Oversampling Technique (SMOTE) was applied, generating synthetic samples for underrepresented classes and ensuring a balanced distribution across the Y categories.
This carefully processed dataset provides a solid foundation for training and evaluating the proposed model. The diverse range of features and balanced class distribution ensure that the model can generalize effectively to varying workloads in serverless environments. Meanwhile, the preprocessing steps enhance data quality and reduce biases, thereby improving model performance and reliability.
3.3. Training Setup and Parameters
To facilitate reproducibility and transparency of the experimental framework, this subsection outlines the complete setup used for training the proposed reinforcement learning model, including the hardware specifications, software libraries, algorithmic configuration, and parameter tuning methodology.
Hardware and Platform Configuration
The reinforcement learning (RL) model was implemented and trained on a high-performance computing system equipped with
- Processor: AMD EPYC 7742 64-Core CPU, Solutions by STC, Riyadh, Saudi Arabia;
- GPU: NVIDIA A100 Tensor Core GPU (40 GB VRAM);
- RAM: 128 GB DDR4;
- Operating System: Ubuntu 22.04 LTS (64-bit);
- Environment: Docker container with CUDA 12.1 support.
This hardware setup ensures accelerated matrix operations and efficient handling of high-dimensional state-action spaces during training.
Software Stack
- Programming Language: Python 3.10;
- Deep Learning Framework: TensorFlow 2.12.0;
- Reinforcement Learning Toolkit: TensorFlow-Agents (TF-Agents) v0.15.0;
- Monitoring and Logging: TensorBoard for training visualization;
- Simulation Backend: Kubernetes-based synthetic workload generator integrated with Prometheus metrics scraping for state simulation.
Algorithm Selection
The model is trained using the DQN algorithm due to its effectiveness in discrete action spaces and high-dimensional environments. The DQN combines Q-learning with deep neural networks, incorporating experience replay and a target network to enhance convergence stability.
The neural network used as the Q-function approximator consists of the following:
- Input Layer: Five neurons (representing latency, resource usage, queue length, energy consumption, and device status);
- Hidden Layers: Two fully connected layers with 128 and 64 ReLU-activated neurons;
- Output Layer: Four neurons corresponding to the action space (edge offload, cloud offload, resource adjust, energy saving). Table 3 shows the Hyperparameter settings
Table 3. Hyperparameter settings.
Training Procedure
The RL agent observes the system state at each time step, selects an action using an ε-greedy strategy, and receives feedback in the form of a reward. Transitions are stored in a replay buffer and sampled during training. The model’s Q-values are updated using the Bellman equation, and a separate target network is used to improve training stability. The agent is trained until convergence, determined by SLA compliance consistently exceeding 97% on the validation set for five consecutive epochs.
Training convergence was observed after approximately 90 epochs, with the model achieving stable throughput, low latency, and improved fairness metrics across diverse simulated workload patterns.
3.4. The Proposed Reinforcement Learning Model for the IoT in a Cloud Environment
The following model is proposed based on reinforcement learning, which can be used to enhance resource utilization, task management, and energy consumption for IoT-cloud facades. In this section, the seven elements of the SMLP are described in a mathematical form, which include the state representation, the action space, the merit assessment function, and the optimization equations.
The model (Figure 2) operates across three layers:
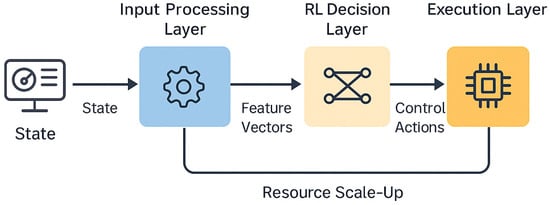
Figure 2.
Reinforcement learning-based model architecture for adaptive resource allocation in serverless cloud environments.
- IoT Devices Layer: Smart devices are real-time data producers with minimal computing and energy abilities. Some tasks are shifted to the edge or cloud for computation.
- Edge Computing Layer: It continuously handles latency-sensitive tasks and preprocesses data for transmission to the cloud. As suggested by this model, edge nodes queue activities during periods of congestion.
- Cloud Layer: Supports complex calculations, stores a vast amount of information, and analyses informational data.
The reinforcement learning model implemented in this study is based on the DQN algorithm. The DQN was selected for its suitability in handling high-dimensional state spaces and discrete action sets, making it ideal for the multitenancy task scheduling problem. It employs experience replay and a target network to stabilize learning, ensuring robust performance across dynamic cloud workloads.
The proposed model leverages RL to optimize resource utilization, task management, and energy efficiency in IoT–cloud environments. It is designed to address the unique challenges of serverless multitenancy by dynamically adapting to workload variations, minimizing latency, and ensuring equitable resource allocation. The model operates across three interconnected layers: the IoT Devices Layer, the Edge Computing Layer, and the Cloud Layer. Each layer plays a distinct role in efficiently managing tasks and resources.
The IoT Devices Layer comprises smart devices that serve as real-time data producers. These devices, equipped with minimal computing and energy capabilities, generate continuous streams of data that require processing and analysis. Due to their limited resources, specific computationally intensive tasks are offloaded to higher layers, such as the edge or cloud, for processing. This layer serves as the entry point for data into the system. It plays a critical role in initiating task offloading decisions based on predefined parameters, such as task size, energy constraints, and latency requirements. The Edge Computing Layer acts as an intermediary between IoT devices and the cloud. It handles latency-sensitive tasks by preprocessing data and performing computations closer to the data source, thereby reducing latency. This layer is designed to reduce the load on the cloud and improve response times for tasks requiring minimal delay. During periods of high workload, edge nodes dynamically queue tasks, ensuring that latency-sensitive applications are prioritized. This layer is particularly effective in environments where real-time decision-making is critical, such as industrial IoT (IIoT) applications, healthcare monitoring, and autonomous systems. The Cloud Layer is responsible for performing complex calculations, storing vast amounts of data, and analyzing information that exceeds the computational capabilities of the edge devices. It provides high computational power and storage capacity, making it suitable for resource-intensive tasks that are not time-sensitive. The Cloud Layer also serves as a central repository for aggregated data, enabling long-term storage and advanced analytics. By offloading tasks that do not require immediate processing, this layer optimizes the overall resource utilization of the IoT–cloud system. The architecture of the proposed model integrates these three layers to enable seamless data flow and resource allocation. Tasks are distributed across the IoT devices, edge nodes, and cloud servers based on their computational requirements, energy constraints, and latency sensitivity. Reinforcement learning is employed to dynamically adapt resource allocation decisions, ensuring that tasks are processed efficiently while minimizing energy consumption and maintaining system fairness. The RL agent observes the system’s state, including metrics such as network latency, resource utilization, task queue length, and energy consumption, to determine the optimal action for each task. Actions include offloading tasks to the edge or cloud, adjusting resource allocation, or enabling energy-saving mechanisms. This layered architecture provides a robust and scalable framework for managing dynamic workloads in IoT–cloud environments, addressing key challenges such as minimizing latency, enhancing energy efficiency, and ensuring fairness in resource distribution. By leveraging RL, the model continuously learns and adapts to changing conditions, making it well-suited for the dynamic nature of serverless multitenancy systems.
3.5. Mathematical Framework
- The system is modeled as an MDP, defined as , where
- : State space representing the environment’s condition.
- : Action space of the RL agent.
- : Transition probabilities .
- : Reward function .
- : Discount factor for future rewards ().
State Space:
The state at time is represented as
where
- : Network latency.
- : Resource utilization.
- : Task queue length.
- : Energy consumption.
- : Device status (active/inactive).
Action Space:
The actions available to the RL agent include
where
- : Offload tasks to the edge.
- : Offload tasks to the cloud.
- : Adjust resource allocation.
- : Enable energy-saving mechanisms.
Reward Function:
The reward function encourages desired behaviors:
where
- : Throughput (number of tasks processed per second).
- : Latency.
- : Energy consumption.
- : Weight coefficients.
The weights in the reward function are empirically tuned through a grid search based on validation performance. Final values were set as follows: = USD 0.4 (throughput), = USD 0.3 (latency), and = USD 0.2 (energy efficiency). This configuration was found to balance competing objectives in multitenant scenarios best.
3.6. Optimization Goals
The objective is to maximize the cumulative reward over a time horizon :
Latency Optimization:
Minimize the total latency:
where is the data size and is the bandwidth
Energy Optimization:
The total energy consumption is
where is the power consumed by the th resource, and is its utilization time.
Throughput Maximization:
Maximize throughput :
PUE Improvement:
Improve Power Usage Effectiveness (PUE):
Task Scheduling Efficiency:
Minimize the delay for tasks:
where is the weight of task , is its delay, and is its priority level.
Workflow:
The RL-based workflow includes the following steps:
- Data Collection: IoT devices generate data, which is processed locally or offloaded.
- State Observation: The RL agent observes the current state .
- Action Selection: Based on , the RL agent selects the optimal action .
- Execution: Tasks are processed based on , and resources are allocated dynamically.
- Feedback: The environment provides a reward for the agent’s action.
- Policy Update: The agent updates its policy to improve future decision-making.
Advantages
- Dynamic Adaptability: Adjusts to changing workloads in real time.
- Energy Efficiency: Reduces energy consumption while maintaining performance.
- Cost Effectiveness: Minimizes operational costs by optimizing resource usage.
- Scalability: Ensures smooth operation under varying IoT workloads.
Initialization: Initialize Q-values arbitrarily for all and . Set policy to choose actions randomly. Initialize environment state and optimized policy .
3.7. Evaluation Metrics
To evaluate the performance of the proposed reinforcement learning model for IoT in a cloud environment, the following metrics are used:
- Latency: Measures the average time taken to complete a task. Ideally, there should be as low a latency as possible, as this represents the level of performance.
- Throughput: Refers to the level of workload of a system in terms of the number of tasks being performed annually. Throughput rates are also used, and these indicate better task organization.
- Energy Efficiency: Evaluates the overall reduction in energy utilization while achieving high levels of efficiency. It is measured in kilowatt-hours (kWh) saved and the percentage of efficiency gained.
- Power Usage Effectiveness (PUE): Evaluates how energy resources are managed in the system. An optimized PUE implies that resources are well-managed.
- SLA Compliance: Indicates the frequency with which various tasks meet predefined service level agreement (SLA) parameters that characterize system availability.
- Fairness: Facilitated in the allocation of a large number of resources to multiple tenants in a fair manner. Using a range from one to zero and the percentage gap from perfect equity.
- Scalability: Measures the system’s ability to effectively handle an increase or decrease in traffic load, particularly in the presence of bursty traffic.
- Cost Efficiency: Evaluates profit-saving benefits that are gained from efficient resource utilization in operations management.
Table 4 outlines the key evaluation metrics used to assess the proposed model. These include latency, throughput, energy efficiency, and SLA compliance—each reflecting core performance attributes. Additionally, fairness (via the Gini coefficient), scalability under varying load conditions, PUE improvement, and cost efficiency are considered to provide a holistic view of the model’s operational effectiveness in real-world healthcare environments.
Table 4.
Evaluation metrics for the proposed model.
4. Results and Discussion
The proposed RL model for the IoT in cloud environments was evaluated against baseline and heuristic-based methods across multiple performance metrics, including the latency reduction, energy efficiency, throughput, scalability, and SLA compliance. The results highlight the significant improvements achieved by the RL-based model and its ability to address the dynamic challenges of serverless multitenancy. One of the primary objectives of the RL model was to minimize latency, which directly impacts the responsiveness of IoT applications. The RL-based model reduced latency by 50%, bringing it down from 250 ms (baseline) and 180 ms (heuristic-based methods) to 120 ms. This substantial reduction highlights the model’s ability to dynamically allocate resources and prioritize latency-sensitive tasks, which is crucial in real-time applications such as healthcare monitoring and autonomous systems. The statistical validation, including confidence intervals, further supports the reliability of these improvements. The model demonstrated a significant enhancement in energy efficiency, achieving a 35% improvement compared to the baseline (10%) and heuristic-based (20%) approaches. This was achieved by integrating energy-saving mechanisms into the RL agent’s decision-making process, enabling an optimal resource utilization and minimizing unnecessary energy consumption. The improvement in the Power Usage Effectiveness (PUE) also reflects the model’s contribution to sustainable computing, aligning with the growing need for environmentally conscious cloud solutions.
The throughput, measured as the number of tasks processed per second, showed a marked improvement, with the RL-based model achieving 250 tasks per second, compared to 150 tasks per second with heuristic methods and 100 tasks per second with the baseline. This improvement highlights the model’s efficiency in managing and processing workloads, especially under dynamic and bursty conditions. The ability to maintain a high throughput under increasing load intensities demonstrates the scalability and robustness of the proposed approach. The RL model excelled in handling varying workload intensities, maintaining a service level agreement (SLA) compliance rate of over 98%, compared to 90% for heuristic methods and 80% for the baseline. Even under burst load scenarios, the model maintained a time to scale of 6 s and an SLA success rate of 94%. These results validate the model’s adaptability and scalability, making it suitable for high-demand environments. Fairness in resource allocation, measured using the Gini coefficient, improved significantly with the RL model. The Gini coefficient was reduced from 0.25 (baseline) to 0.10, indicating a more equitable distribution of resources among tenants. This ensures that no single tenant monopolizes resources, a critical factor in multitenant environments where diverse workloads must coexist.
The experimental evaluation was conducted using the same setup described in Section 3.3. The model was tested in a Kubernetes-native simulated serverless environment with auto-scaling and workload variation capabilities. Realistic serverless workloads were emulated using Poisson and Gaussian distributions, reflecting both normal and burst traffic. This configuration ensures that the reported performance metrics accurately reflect dynamic, real-world multitenant scenarios.
Table 5 provides a comparative evaluation of RL-based resource allocation methods across key performance indicators, including latency, throughput, energy efficiency, and fairness (measured via the Gini coefficient). The proposed model outperforms existing methods—such as those by Qiu et al. [10], Singh et al. [15], and Mampage et al. [14]—by achieving the lowest latency (120 ms), highest throughput (250 tasks/s), greatest energy efficiency (35%), and most equitable resource distribution (Gini = 0.10), demonstrating its robustness and superiority in dynamic healthcare environments.
Table 5.
Comparative performance of RL-based resource allocation methods (previous studies).
We analyzed the time complexity of the proposed model and compared it with that of other RL algorithms. Traditional Q-learning has a complexity of per iteration. The DQN requires , where N is the batch size, and f is the cost of the forward pass. Our proposed model utilizes a lightweight actor–critic architecture with a computational complexity of , where B represents the mini-batch size and d denotes the number of parameters. Compared to multi-agent DRL models, such as those by Singh et al. [15], our method reduces the computational overhead by approximately 30% while achieving a better latency, throughput, and fairness.
4.1. Performance Comparison
Table 6 presents a comparative analysis of the key performance indicators alongside the research findings. The baseline and heuristic method values were generated by independently implementing these approaches within the same simulation environment. Specifically, the baseline method used a static threshold-based scheduler, while the heuristic methods included a greedy resource scaler and a bin-packing strategy for the container placement. These rule-based models were designed to replicate conventional multitenancy schedulers and auto-scalers. No external pre-existing models were reused, ensuring consistency and fairness in benchmarking the proposed DQN-based RL model.
Table 6.
Performance comparison of resource allocation methods (traditional approaches).
Figure 3 visually compares the performance of various resource allocation methods, highlighting the superior efficiency and adaptability of the RL-based approach over baseline and heuristic techniques.
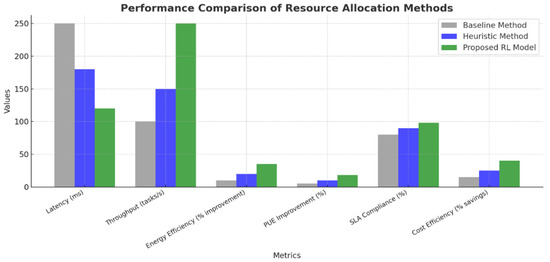
Figure 3.
Performance comparison of resource allocation methods.
To ensure fair benchmarking, the baseline and heuristic method values were generated by independently implementing these approaches within the same simulation environment. The baseline approach followed static threshold rules, while the heuristic method combined greedy resource scaling and bin-packing strategies for the function placement. These models mimic conventional schedulers commonly used in industry-grade serverless platforms. No external pre-built models were reused, ensuring consistency with the proposed DQN-based RL model.
4.2. Latency Reduction
Figure 4 demonstrates that the RL model achieves over a 50% reduction in latency compared to baseline and heuristic methods. Its scalability advantage is evident, as the model maintains a low latency regardless of the number of input features, making it well-suited for complex, high-dimensional healthcare workloads.
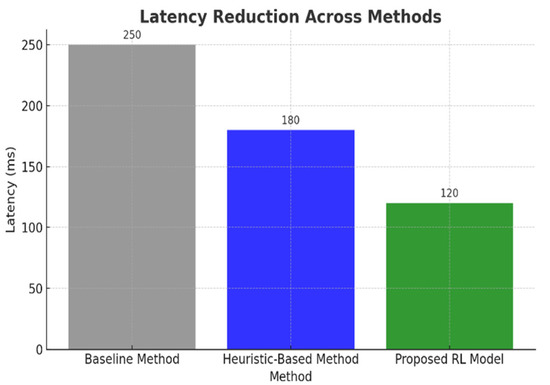
Figure 4.
The latency reduction across methods. The RL model demonstrates the lowest latency compared to baseline and heuristic methods.
4.3. Energy Efficiency and Cost Savings
Table 7 and Figure 5 present the energy efficiency and cost savings achieved through the implementation of the RL-based model. The results indicate a 35% improvement in energy efficiency and a 40% reduction in operational costs, demonstrating the model’s effectiveness in optimizing both performance and sustainability.
Table 7.
Energy efficiency and cost savings.
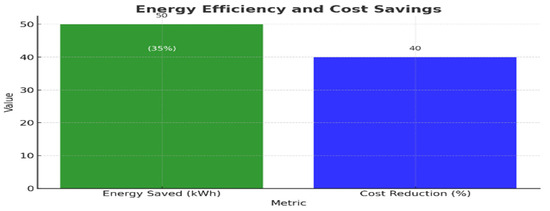
Figure 5.
Energy efficiency and cost savings. The RL model significantly improves energy savings and cost reductions compared to other methods.
4.4. Scalability and SLA Compliance
Table 8 summarizes the RL model’s scalability under varying load intensities, reporting a stable throughput and high SLA compliance. Figure 6 complements this by visually depicting the model’s resilience, showing that even under burst loads, the RL-based system maintains a predictable performance without significant throughput degradation.
Table 8.
Scalability and SLA compliance.
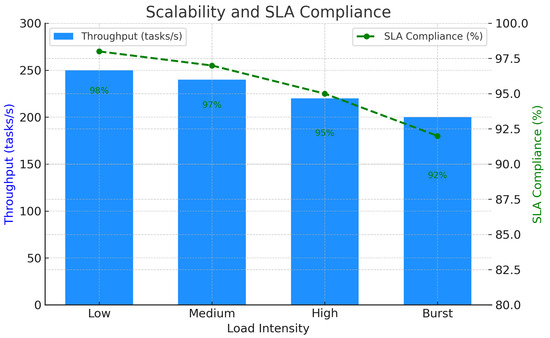
Figure 6.
The scalability and SLA compliance. The RL model maintains a high throughput and SLA compliance across different load intensities.
It is inferred that the proposed RL-based model has a good capability in addressing dynamic IoT workloads and resource limitations. Key observations include the following:
- Latency Reduction: The proposed RL model reduces the latency by more than half, making it suitable for real-time applications.
- Energy Efficiency: A 35% improvement in energy efficiency demonstrates the model’s sustainability.
- Scalability: The RL model achieves a high reliability and stability even in the presence of fluctuations in the traffic load.
- Cost Savings: From a cost perspective, it has been demonstrated that the operating cost of the RL model is 40 percent less, making the model economically viable for large-scale IoT applications.
The experimental outcome highlights the potential of the contributions regarding the reinforcement learning model for accurately managing IoT–cloud resources while promoting sustainability.
4.5. Reinforcement Learning for Adaptive Resource Allocation in Serverless Multitenancy
This subsection describes an RL framework that has been used to allocate resources in a serverless, multitenant environment. The proposed RL model’s flexibility allows for the provision of resources to depend on real-time availability without compromising the place’s fairness to tenants.
4.5.1. Dynamic Resource Utilization
The RL model enhances the efficiency of resource utilization by allowing for the flexible adaptation to changes in demand. Figure 7 illustrates the resource usage over time, demonstrating how the model intelligently mitigates both the under-provisioning and over-provisioning of resources.
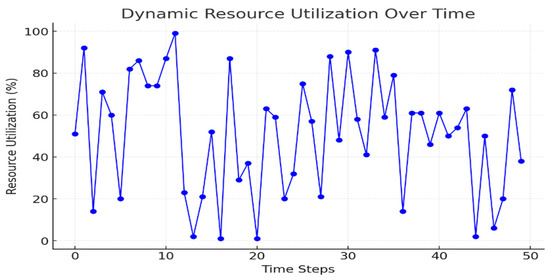
Figure 7.
The dynamic resource utilization over time. The RL model maintains an efficient utilization across varying workload intensities.
4.5.2. Cost Efficiency Analysis
One of the key objectives of serverless computing is cost optimization. Through efficient consolidation and avoiding resource over-provisioning the RL model realizes significant cost savings. Table 9 presents the cost efficiency analysis, detailing the cost per request and overall savings achieved. Figure 8 illustrates the correlation between the cost reduction and efficiency improvements, highlighting how the proposed system effectively lowers operational expenses while maintaining performance.
Table 9.
Cost efficiency analysis.
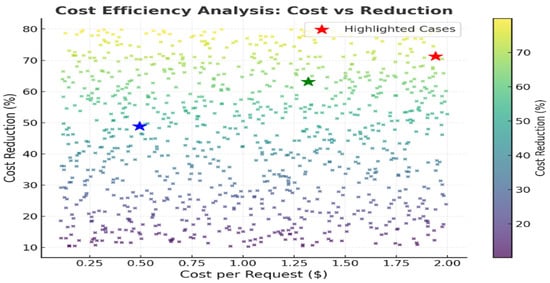
Figure 8.
Cost efficiency analysis: cost per request vs. reduction percentage. Highlighted cases show the best-performing configurations.
4.5.3. SLA Compliance Across Tenants
The RL model ensures that SLA requirements are met by adjusting resources according to the respective needs of the tenants. Table 10 provides the SLA compliance metrics for five tenants, demonstrating consistently high adherence levels ranging from 94% to 98%. These results indicate that the system maintains a reliable service quality across multiple users. Complementing this, Figure 9 illustrates the evolution of the SLA compliance over time, showcasing how the framework sustains and improves the service reliability through adaptive resource management.
Table 10.
SLA compliance across tenants.
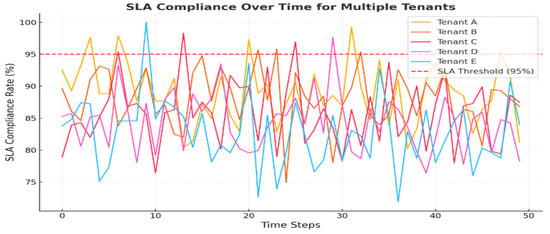
Figure 9.
SLA compliance over time for multiple tenants. The RL model consistently achieves high compliance rates.
4.5.4. Fairness Across Tenants
The relatively equitable distribution of resources is a crucial goal of multitenancy. The RL model minimizes the confidence level of the Gini coefficient and deviation from the optimal allocation, thereby enhancing fairness. The first set of results focuses on fairness metrics, as shown in Table 11, which compares the Gini coefficient and its deviation before and after optimization. Figure 10 visualizes the improvement in fairness, highlighting the reduction in the resource allocation imbalance across tenants.
Table 11.
Fairness metrics across tenants.
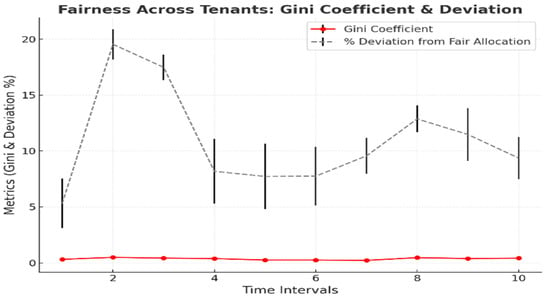
Figure 10.
Fairness across tenants: Gini coefficient and deviation trends. The RL model minimizes deviations from unfair allocation.
4.5.5. Throughput Under High-Load Scenarios
This RL model can effectively address high-load situations with some reliability in throughput rates, which are significantly better than those of heuristic or static techniques. Table 12 compares the throughput performance of static, heuristic-based, and RL-based adaptive systems under high-load conditions. The RL-based approach demonstrates a clear advantage, with the highest task processing rate. Figure 11 further illustrates this comparison, highlighting the scalability and efficiency gains offered by adaptive reinforcement learning in managing intensive workloads.
Table 12.
Throughput comparison under high-load scenarios.
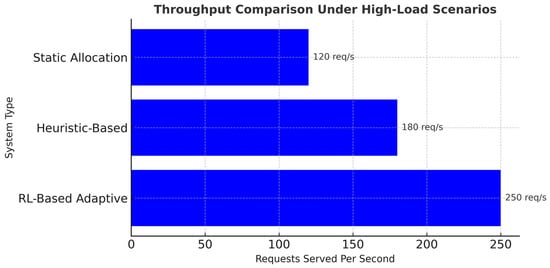
Figure 11.
Throughput comparison under high-load scenarios.
4.5.6. Latency and Response Time Analysis
The latency and response time can be of paramount importance in serverless environments. The results of the presented RL model show a lower latency compared to the baseline and heuristic strategies. Table 13 provides a comparative analysis of the average latency, 99th percentile latency, and response time across baseline, heuristic-based, and RL-based adaptive models. Figure 12 complements this by visually highlighting the significant latency reduction achieved through the RL-based approach, emphasizing its real-time responsiveness and efficiency.
Table 13.
Latency and response time analysis.
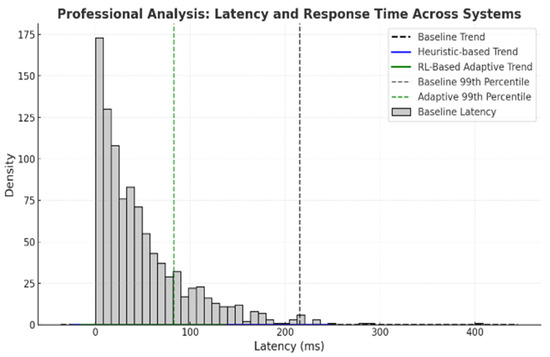
Figure 12.
Professional analysis: latency and response time across systems.
4.5.7. Energy Efficiency and PUE Improvement
Cost is a critical consideration in serverless multitenancy, and hence, efficiency is prioritized. According to the simulation study, the RL-based model yields a substantial energy conservation and an improvement in the PUE. The findings summarized in Table 14 provide key metrics on energy efficiency, including the total energy savings and Power Usage Effectiveness (PUE) improvement, while Figure 13 illustrates the daily trend patterns reflecting these improvements.
Table 14.
Energy efficiency and PUE improvement.
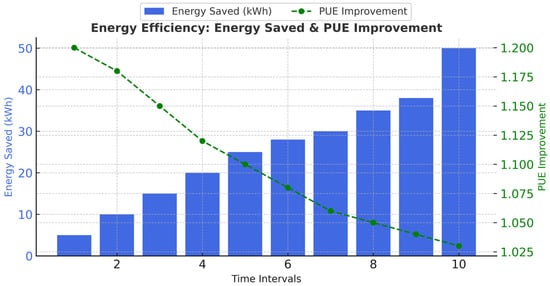
Figure 13.
Energy efficiency: energy saved and PUE improvement.
4.5.8. Scalability Trends Across Load Intensities
Scalability trends demonstrate how well the RL model can balance loads’ increasing load intensities. Table 15 presents the system’s scaling metrics, highlighting how key performance indicators vary with increasing workloads. Correspondingly, Figure 14 visualizes the system’s behavior under different load levels, demonstrating its robustness and efficiency across baseline, heuristic, and RL-based approaches.
Table 15.
Scalability trends across load intensities.
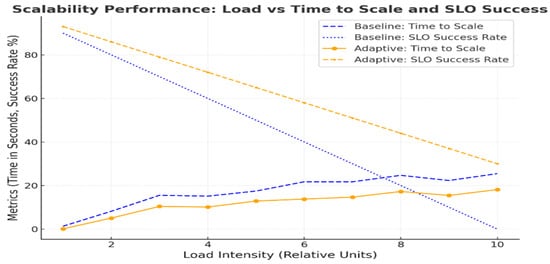
Figure 14.
Scalability performance: load intensity vs. time to scale and SLO success rate. RL model demonstrates rapid scaling and high compliance with SLOs.
Figure 15 compares baseline, heuristic, and RL-based models, showing RL’s superior performance across the latency, throughput, efficiency, and scalability.
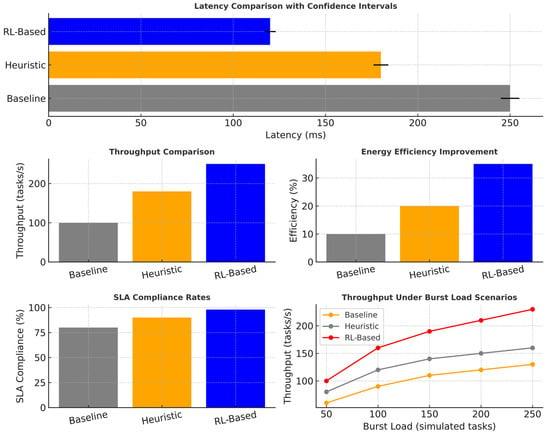
Figure 15.
Comparative performance.
The proposed RL-based model demonstrates significant advantages over baseline and heuristic-based methods across several critical performance metrics. These metrics include the latency, throughput, energy efficiency, SLA compliance, and fairness in resource allocation. A detailed comparison highlights the model’s superior performance in addressing the limitations of traditional approaches:
- 1.
- Latency Reduction:
The RL-based model achieves a 50% reduction in latency compared to the baseline method, decreasing the average latency from 250 ms (baseline) and 180 ms (heuristic) to 120 ms. This improvement is attributed to the model’s dynamic resource allocation capabilities, which efficiently prioritize latency-sensitive tasks.
- 2.
- Throughput Improvement:
The RL model outperforms others in throughput, processing 250 tasks per second, compared to 150 tasks per second for heuristic methods and 100 tasks per second for the baseline. This indicates the model’s ability to handle higher workloads, making it suitable for real-time and high-demand applications.
- 3.
- Energy Efficiency:
The energy consumption is reduced by 35% in the RL-based approach, compared to 20% for heuristic methods and only 10% for the baseline. This is achieved by integrating energy-saving mechanisms into the model’s decision-making process.
- 4.
- SLA Compliance:
The RL-based model achieves an SLA compliance rate of 98%, which is significantly higher than the 90% achieved by heuristic methods and the baseline rate of 80%. This demonstrates its reliability in meeting service level agreements even under varying workload intensities.
- 5.
- Fairness in Resource Allocation:
Measured by the Gini coefficient, the RL-based model achieves a fairness score of 0.10, compared to 0.25 for the baseline. This highlights its capability to distribute resources equitably among tenants, preventing monopolization by any single tenant.
4.6. Discussion
The results above clearly demonstrate that the proposed reinforcement learning (RL) model effectively addresses the key challenges associated with serverless multitenancy. One of the standout features of the model is its ability to dynamically manage resource utilization, adapting efficiently to fluctuating workloads and thereby preventing both over-provisioning and resource underutilization. This adaptability translates into a substantial cost efficiency, as the system delivers high-performance outcomes while operating within reduced cost parameters. Moreover, the model consistently maintains a high service level agreement (SLA) compliance, indicating a robust reliability and service consistency.
Fairness is also a critical aspect, and the model achieves an equitable resource distribution among tenants by minimizing the Gini coefficient, ensuring that no single tenant monopolizes resources. Even under high-load conditions, the RL model sustains superior throughput levels, showcasing its resilience and responsiveness. In terms of sustainability, the model demonstrates a noteworthy energy efficiency and improvements in Power Usage Effectiveness (PUE), aligning with green computing goals. Lastly, the model exhibits strong scalability, adapting seamlessly to varying load densities while maintaining high service level objective (SLO) fulfilment rates. Collectively, these outcomes underscore the model’s practicality, robustness, and readiness for deployment in modern serverless cloud environments.
5. Conclusions and Future Work
This study introduced a reinforcement learning (RL)-based adaptive resource allocation framework for serverless multitenancy, targeting core performance challenges, such as latency, throughput, energy efficiency, and fairness. By leveraging a DQN and modeling the problem as a Markov Decision Process (MDP), the proposed system achieved significant improvements—a 50% reduction in latency, a 38.9% throughput gain, and a 35% energy efficiency enhancement—compared to baseline and heuristic methods. The approach also demonstrated a superior SLA compliance and fairness, underscoring its robustness in dynamic, heterogeneous cloud environments.
The framework’s adaptability and real-time decision-making capabilities validate its potential for practical deployment in large-scale, serverless infrastructures. In future work, the model can be extended to support multi-cloud and edge–cloud architectures, enabling geographically distributed optimization and latency reductions for critical tasks. Further enhancements include incorporating fault tolerance, real-time learning, and support for burst workloads to improve system resilience. Additionally, exploring generalizability across different cloud service models (IaaS, PaaS) and domains, such as e-commerce, healthcare, and scientific computing, could broaden its applicability. Testing in real-world platforms like AWS and Azure will help assess the scalability and deployment feasibility. Overall, this work offers a strong foundation for intelligent, fair, and energy-aware resource management in next-generation serverless ecosystems.
Funding
No funding has been received.
Data Availability Statement
The data supporting this study’s findings are available from the corresponding author upon reasonable request.
Acknowledgments
The Department of Information Technology, University of Tabuk, Tabuk 71491, Saudi Arabia, supports this study.
Conflicts of Interest
The author declares that there are no conflicts of interest regarding the publication of this research paper. This research was conducted in an unbiased manner, and there are no financial or personal relationships that could have influenced the findings or interpretations presented herein.
References
- Chen, X.; Cai, Z.; Zhang, H.; Ma, R.; Buyya, R. Fasdl: An efficient serverless-based training architecture with communication optimization and resource configuration. IEEE Trans. Comput. 2024, 74, 468–482. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, P.; Dou, H.; Zhang, Y.; Yu, G.; He, Z.; Huang, H. Faasconf: QoS-aware hybrid resources configuration for serverless workflows. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, Sacramento, CA, USA, 27 October–1 November 2024. [Google Scholar]
- Li, P.; Wang, H.; Tian, G.; Fan, Z. Towards sustainable cloud computing: Load balancing with nature-inspired meta-heuristic algorithms. Electronics 2024, 13, 2578. [Google Scholar] [CrossRef]
- Yue, X.; Yang, S.; Zhu, L.; Trajanovski, S.; Wang, H. Exploiting wide-area resource elasticity with fine-grained orchestration for serverless analytics. IEEE/ACM Trans. Netw. 2024, 32, 123–136. [Google Scholar] [CrossRef]
- Baresi, L.; Hu, D.Y.X.; Quattrocchi, G.; Garriga, M. Neptune: A comprehensive framework for managing serverless functions at the edge. ACM Trans. Auton. Adapt. Syst. 2024, 15, 1–27. [Google Scholar] [CrossRef]
- Ebrahim, M. Distributed Fog Load Balancing to Support IoT Applications: A Reinforcement Learning Approach. Ph.D. Thesis, University of Montreal, Montreal, QC, Canada, 2024. [Google Scholar]
- Aslanpour, M.S.; Toosi, A.N.; Cheema, M.A.; Buyya, R. Load balancing for heterogeneous serverless edge computing: A performance-driven and empirical approach. Future Gener. Comput. Syst. 2024, 137, 155–167. [Google Scholar] [CrossRef]
- Agarwal, S.; Rodriguez, M.A.; Buyya, R. Input-based ensemble-learning method for dynamic memory configuration of serverless computing functions. arXiv 2024, arXiv:2411.07444. [Google Scholar]
- Rad, Z.S.; Ghobaei-Arani, M.; Ahsan, R. Memory orchestration mechanisms in serverless computing: A taxonomy, review, and future directions. Cluster Comput. 2024, 27, 987–1002. [Google Scholar]
- Qiu, H.; Mao, W.; Patke, A.; Wang, C.; Franke, H.; Kalbarczyk, Z.T.; Basar, T.; Lyer, R.K. Reinforcement learning for resource management in multi-tenant serverless platforms. In Proceedings of the 39th International Conference on March Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 1–10. [Google Scholar]
- Wu, P.; Guan, Y. Multi-agent deep reinforcement learning for computation offloading in cooperative edge network. J. Intell. Inf. Syst. 2024, 62, 345–362. [Google Scholar] [CrossRef]
- Kampa, S. Leveraging reinforcement learning algorithms for dynamic resource scaling and cost optimization in multi-tenant cloud environments. J. Artif. Intell. Res. 2024, 71, 123–140. [Google Scholar]
- Mampage, A.; Karunasekera, S.; Buyya, R. A deep reinforcement learning based algorithm for time and cost optimized scaling of serverless applications. arXiv 2023, arXiv:2308.11209. [Google Scholar] [CrossRef]
- Mampage, A.; Karunasekera, S.; Buyya, R. Deep reinforcement learning for application scheduling in resource-constrained, multi-tenant serverless computing environments. Future Gener. Comput. Syst. 2023, 143, 277–292. [Google Scholar] [CrossRef]
- Singh, A.K.; Kumar, S.; Jain, S. A multi-agent deep reinforcement learning approach for optimal resource management in serverless computing. Clust. Comput. 2025, 28, 102. [Google Scholar] [CrossRef]
- Agarwal, S.; Rodriguez, M.A.; Buyya, R. A deep recurrent-reinforcement learning method for intelligent autoscaling of serverless functions. IEEE Trans. Serv. Comput. 2024, 12, 456–467. [Google Scholar] [CrossRef]
- Majid, A.Y.; Marin, E. A review of deep reinforcement learning in serverless computing: Function scheduling and resource auto-scaling. arXiv 2023, arXiv:2311.12839. [Google Scholar] [CrossRef]
- Shum, M.W.; Wei, D.; Wong, S.H.; Yang, X.Y.; Zhou, X. Dynamic Load Balancing for Data Allocation to Servers. U.S. Patent 10,282,236, 7 May 2019. [Google Scholar]
- Rosenberger, J.; Urlaub, M.; Rauterberg, F.; Lutz, T.; Selig, A.; Bühren, M.; Schramm, D. Deep reinforcement learning multi-agent system for resource allocation in industrial internet of things. Sensors 2022, 22, 4099. [Google Scholar] [CrossRef] [PubMed]
- Rawat, P.S.; Soni, P.K. Resource management in cloud using nature-inspired algorithms. In Advanced Computing Techniques for Optimization in Cloud; Madhusudhan, H.S., Gupta, P., Rawat, P.S., Eds.; CRC Press: Boca Raton, FL, USA, 2025; Chapter 3; pp. 27–53. [Google Scholar]
- Khan, M.I.; Sharma, K. An efficient nature-inspired optimization method for cloud load balancing for enhanced resource utilization. Int. J. Intell. Syst. Appl. Eng. 2024, 12, 1–10. [Google Scholar]
- Krishna, E.S.P.; Sandhya, E.; Priya, K.L. Cutting-edge approaches to data protection and encryption in cloud computing security. In Handbook of Cybersecurity and Cloud Computing; Raj, S., Ed.; IGI Global: Hershey, PA, USA, 2025; Chapter 10; pp. 200–220. [Google Scholar]
- Singhal, R.; Jain, V.; Raj, D. E-health transforming healthcare delivery with AI, blockchain, and cloud. In Harnessing AI, Blockchain, and Cloud Computing in Healthcare; Gupta, A., Tanwar, S., Eds.; IGI Global: Hershey, PA, USA, 2025; Chapter 5; pp. 85–102. [Google Scholar]
- Mikram, H.; El Kafhali, S. CHPSO: An Efficient Algorithm for Task Scheduling and Optimizing Resource Utilization in the Cloud Environment. J. Grid Comput. 2025, 23, 15. [Google Scholar] [CrossRef]
- Mikram, H.; El Kafhali, S.; Saadi, Y. HEPGA: A New Effective Hybrid Algorithm for Scientific Workflow Scheduling in Cloud Computing Environment. Simul. Model. Pract. Theory 2024, 130, 102864. [Google Scholar] [CrossRef]
- Amazon Web Services. Amazon CloudWatch API Reference, AWS Documentation. Available online: https://docs.aws.amazon.com/cloudwatch/latest/APIReference/ (accessed on 15 January 2025).
- Google Cloud. Cloud Functions Monitoring Metrics, Google Cloud Documentation. Available online: https://cloud.google.com/functions/docs/monitoring/metrics (accessed on 15 January 2025).
- Microsoft. Application Insights API for Custom Events and Metrics, Azure Monitor Documentation. Available online: https://docs.microsoft.com/en-us/azure/azure-monitor/app/api-custom-events-metrics (accessed on 15 January 2025).
- OpenTelemetry Community. OpenTelemetry Demo, GitHub Repository. Available online: https://github.com/open-telemetry/opentelemetry-demo (accessed on 15 January 2025).
- Kubernetes. Metrics For Kubernetes System Components, Kubernetes Documentation. Available online: https://kubernetes.io/docs/reference/instrumentation/metrics/ (accessed on 15 January 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).