Abstract
Steel surface defect detection is a crucial step in ensuring industrial production quality. However, due to significant variations in scale and irregular geometric morphology of steel surface defects, existing detection algorithms show notable deficiencies in multi-scale feature representation and cross-layer multi-scale feature fusion efficiency. To address these challenges, this paper proposes an improved real-time steel surface defect detection model, NGD-YOLO, based on YOLOv5s, which achieves fast and high-precision defect detection under relatively low hardware conditions. Firstly, a lightweight and efficient Normalization-based Attention Module (NAM) is integrated into the C3 module to construct the C3NAM, enhancing multi-scale feature representation capabilities. Secondly, an efficient Gather–Distribute (GD) mechanism is introduced into the feature fusion component to build the GD-NAM network, thereby effectively reducing information loss during cross-layer multi-scale information fusion and adding a small target detection layer to enhance the detection performance of small defects. Finally, to mitigate the parameter increase caused by the GD-NAM network, a lightweight convolution module, DCConv, that integrates Efficient Channel Attention (ECA), is proposed and combined with the C3 module to construct the lightweight C3DC module. This approach improves detection speed and accuracy while reducing model parameters. Experimental results on the public NEU-DET dataset show that the proposed NGD-YOLO model achieves a detection accuracy of 79.2%, representing a 4.6% mAP improvement over the baseline YOLOv5s network with less than a quarter increase in parameters, and reaches 108.6 FPS, meeting the real-time monitoring requirements in industrial production environments.
1. Introduction
Steel, as an indispensable basic material in industrial production, has a surface quality that directly affects product performance and safety []. During the production process, influenced by environmental and technological factors, steel surfaces are prone to defects such as cracks, scratches, and pits, which not only reduce steel performance but may also lead to serious safety accidents []. Therefore, it is crucial to accurately detect the health of steel structures at an early stage []. For this reason, developing high-precision, real-time defect detection technology is a crucial step in ensuring steel quality []. Traditional detection methods, primarily based on the physical characteristics of defects, include manual visual inspection, infrared detection, and eddy current detection. While these methods can identify some defects, they have obvious limitations []. Manual inspection relies on experience, has low efficiency, and has high miss rates. At the same time, physical detection equipment faces issues such as strong dependencies and insufficient adaptability to complex defects. With the development of computer vision technology, traditional machine learning algorithms, such as support vector machines and decision trees, have been applied to defect detection. These algorithms mainly distinguish defects based on shallow pixel differences between targets and backgrounds []. However, these methods require manually designed feature extractors and classifiers, and the extracted shallow features are only effective for specific defects, resulting in poor generalization performance and high computational resource requirements, making it difficult to meet the reliability requirements of industrial scenarios.
In recent years, the rapid development of deep learning technology, particularly convolutional neural networks, has led to significant progress in defect detection. Among them, the single-stage detection model YOLO [] has become the mainstream solution for industrial inspection due to its end-to-end architecture, which achieves an excellent balance between speed and accuracy. Zhou et al. [] proposed the CABF-YOLO model based on YOLO, which introduced a Triple Convolutional Coordinate Attention (TCCA) mechanism in the feature extraction module and designed a Bidirectional Fusion (BF) strategy in the feature fusion module, effectively improving detection performance. Song et al. [] optimized YOLOv8 by adding a Deformable Convolution Network (DCN) and a BiFormer attention mechanism to the backbone network, enabling the model to allocate attention adaptively, and applied Bidirectional Feature Pyramid Network (BiFPN) in the feature fusion network to effectively capture multi-scale feature information, improving detection accuracy by 6.9%. However, due to significant scale differences and irregular geometric shapes of steel defects, YOLO variant models still face many challenges.
Firstly, multi-scale feature representation is insufficient. These defects vary significantly in scale, with textures that resemble the background. Existing algorithms typically enhance salient features through attention mechanisms but often ignore non-salient features. At the same time, industrial environments require lightweight real-time detection models, but current attention mechanisms primarily rely on computation-heavy convolution and fully connected operations. Secondly, cross-layer multi-scale feature fusion is inefficient. Existing feature fusion methods mainly employ adjacent layer recursion to pass features, thereby preventing direct interaction between non-adjacent layers and resulting in information loss. In addition, small targets, which constitute a high proportion of steel defects, are often overlooked by current fusion methods, leading to high miss rates. Thirdly, it is difficult to strike a balance between model accuracy, the number of parameters, and detection speed. Real industrial environments have limited hardware capabilities, requiring compact models for high-precision real-time detection. However, most variant models dramatically increase computational complexity while improving accuracy, whereas excessive lightweighting compromises accuracy, creating a difficult balance to achieve in practical applications.
In response to these issues, this paper proposes a novel object detection algorithm, NGD-YOLO, which maintains high detection speed while improving model accuracy. Experiments on the NEU-DET dataset demonstrate that this algorithm can effectively enhance the accuracy of steel surface defect detection, achieving a smaller parameter count and real-time detection capability, thereby providing a reliable solution for industrial real-time inspection. The study’s main contributions can be summarized as follows:
- (1)
- Embedding the lightweight and efficient Normalization-based Attention Module (NAM) into the C3 module to construct a new C3NAM to enhance the multi-scale feature representation capability.
- (2)
- Proposing the GD-NAM feature fusion mechanism with four detection heads, which fuses features using a Gather–Distribute (GD) approach and embeds the C3NAM to enhance representation capability, while adding a dedicated small target detection layer.
- (3)
- Proposing an efficient lightweight convolution module, DCConv, and combining it with the C3 module to construct the C3DC module, addressing the problem of ignoring channel information interaction in Depthwise Convolution (DWConv) by introducing the Efficient Channel Attention (ECA) mechanism, improving detection speed and accuracy while reducing model parameters.
2. Related Work
2.1. Deep Learning-Based Defect Detection
Object detection algorithms demonstrate significant advantages in steel defect detection tasks. Existing methods can be categorized into two-stage and single-stage object detection models. Two-stage object detection models achieve high-precision detection through two steps: bounding box generation and classification regression. The most representative is Faster R-CNN [], which has been improved upon by numerous researchers. For instance, He et al. [] introduced deformable convolution into Faster R-CNN and adopted ResNet as the backbone network, improving mAP by 4.3% on the NEU-DET dataset. Ye et al. [] incorporated the adaptive feature recognition convolution (AFRC) and path-balanced feature pyramid fusion networks into Faster R-CNN, enhancing model robustness. In addition, Ref. [] proposes a new two-stage cascade model, CNN-SegFormer, which employs CNN to perform image block-level classification and thus select image regions containing cracks, and then uses SegFormer to perform pixel-level segmentation to obtain the crack target, which significantly improves the extraction accuracy of the defects on the field-collected steel bridge dataset. Although two-stage models can achieve higher accuracy, their complex structure and computational redundancy result in lower detection speeds, making it difficult to meet industrial real-time requirements.
Single-stage object detection models employ an end-to-end design, simultaneously performing bounding box extraction and classification, providing faster detection speeds. The most representative are SSD [] and YOLO. SSD typically utilizes pre-trained models, such as VGG19 and ResNet, for feature extraction, employing multiple convolutional layers for object localization and prediction. However, the stacking of convolutional layers reduces spatial dimensions and resolution, making the model sensitive to large objects while limiting its ability to detect small objects. Chen et al. [] introduced a feature cross-fusion strategy in the SSD algorithm, enhancing semantic information in lower layers and improving small object detection capability. In comparison, the YOLO series has become the primary research direction for steel surface defect detection [] due to its efficient end-to-end architecture, dynamic multi-scale fusion, and lightweight deployment capabilities. Various variant models have been developed based on the YOLO framework, primarily focusing on two aspects: the synergistic optimization of dynamic attention mechanisms and lightweight design, and cross-layer multi-scale feature fusion strategies, which are described in detail in Section 2.2 and Section 2.3, respectively.
Additionally, some classic networks have demonstrated outstanding performance in object detection tasks. For example, Cheng et al. [] incorporated channel attention mechanisms and adaptive spatial feature modules into RetinaNet, effectively improving detection performance. However, these network models have complex structures and high computational costs, making it difficult to meet real-time detection requirements in industrial environments. The YOLO series, with its balanced advantage in speed and accuracy, has become the mainstream choice in the field of steel defect detection.
2.2. Synergistic Optimization Strategy of Dynamic Attention Mechanisms and Lightweight Design
In recent years, research on YOLO variant models in the industrial defect detection field has focused on the synergistic optimization of dynamic attention mechanisms and lightweight design []. Traditional attention mechanisms such as Convolutional Block Attention Module (CBAM), Squeeze-and-Excitation (SE), and Coordinate Attention (CA) have improved detection accuracy in complex industrial scenarios by adjusting feature channel or spatial weights. Shi et al. [] embedded CBAM into YOLOv5, increasing accuracy by 4.57% on the NEU-DET dataset. Tang et al. [] introduced SE and CA modules to improve model performance, but accuracy gains were only 1.7% and 0.13%, accompanied by significant increases in parameter count. While these attention mechanisms improved detection performance, they have limitations, such as insufficient local fine-grained feature extraction leading to the loss of edge information in micro-cracks and limited global feature long-distance modeling capability, resulting in a loss of contextual information across defect scales. To address these limitations, researchers have introduced dynamic weight allocation mechanisms. Liu et al. [] incorporated Dual Attention Blocks (DAB) into YOLOv5 to enhance long-distance feature dependencies in global contextual features, effectively improving detection performance but increasing model complexity. Luo et al. [] introduced the Global Attention Module (GAM), enhancing shallow feature reusability and expanding the model’s receptive field, increasing mAP by 5.2% on the NEU-DET dataset. However, these attention mechanisms primarily improve feature extraction capabilities through complex convolution and fully connected operations, significantly increasing the computational burden of the model.
A lightweight design is a core requirement for the industrial deployment of object detection systems, especially in resource-constrained real-time detection scenarios. Lightweight design is typically achieved by replacing standard convolutions with lightweight convolutions or applying model pruning techniques, but often at the expense of detection accuracy. For example, Chu et al. [] replaced the backbone network of YOLOv8 with StartNet and introduced a lightweight DWR module in the neck. The experimental results showed a 34.4% reduction in the number of parameters, but the accuracy was only improved by 1.8%. Zhang et al. [] replaced YOLOv5’s backbone network with MobileNet v2 and combined pruning techniques, reducing parameters by 25.6% but decreasing mAP by 3.2%. Existing lightweight networks mainly rely on DWConv to reduce channel parameters, but such convolutions use linear channel fusion mechanisms that struggle to capture cross-channel non-linear correlation features, such as joint features of crack edge gradients and scale texture. Additionally, their fixed weight mechanisms cannot adaptively respond to input content, leading to insufficient detection stability in complex scenarios.
To address these issues, current research is dedicated to the synergistic optimization of dynamic attention and lightweight design. Liang et al. [] proposed the GBS-YOLOv7t algorithm, which employs progressive feature pyramids and cross-layer connections without increasing model complexity, while utilizing a Bilateral Routing Attention (BRA) module to enhance small object perception capability, improving mAP by 4.2% with only a 0.81 M increase in parameters. Liu et al. [] adopted BiFPN and GhostConv structures to reduce model computation by 41%, while introducing the ECA channel attention mechanism to improve mAP by 1.8%. Ma et al. [] improved upon YOLOv8s by replacing the backbone network with GhostNet to reduce model computation by 37% and introducing the Multi-Path Coordinate Attention (MPCA) mechanism to enhance feature extraction capability, improving accuracy by 1.2%. Although these methods achieve a certain balance between computational efficiency and accuracy, they still exhibit insufficient dynamic feature modeling capabilities, which limits their detection performance in complex steel defect scenarios. At the same time, steel defect detection requires both real-time performance and high accuracy; however, improving model detection accuracy while maintaining low computational cost remains a key technical challenge.
2.3. Design Cross-Layer Multi-Scale Feature Fusion Networks
In early deep learning-based defect detection models, feature fusion utilized only shallow, deep, or simple combinations of both layers to distinguish defects from background textures []. However, steel defects typically exhibit significant scale variations and irregular morphologies, making it impossible for these methods to obtain comprehensive features that capture scale variations and texture characteristics. To address this issue, many scholars have proposed new feature fusion modules that significantly enhance detection performance. Examples include the Dense Attention-guided Cascaded Network (DACNet) [], multi-scale depth-point convolution interaction fusion network [], and cross-scale local-global dense fusion network []. These networks effectively alleviate small object detection challenges and achieve stable defect recognition in complex textured backgrounds through optimized multi-scale feature interaction mechanisms.
The three most classic cross-layer multi-scale feature fusion methods in YOLO are as follows: Firstly, the Feature Pyramid Network (FPN) [], which employs a unidirectional top-down structure to transmit high-level information to lower-level layers, thereby improving the localization capability of small objects. Secondly, the Path Aggregation Network (PAN) [], which introduces a unidirectional, bottom-up network based on FPN to transmit low-level information to high-level layers, incorporates more scale information. Thirdly, the Bidirectional Feature Pyramid Network (BiFPN) [], which introduces bidirectional cross-level connections and learnable weighted feature fusion mechanisms, significantly enhances the multi-scale feature representation capabilities and computational efficiency of FPN through multiple cross-scale interactions and adaptive weight allocation. Many variants have been developed based on these cross-layer multi-scale feature fusion networks. For example, Lu et al. [] constructed a Scale-Aware Feature Pyramid Network (SA-FPN), enhancing small defect detection performance. Ni et al. [] adopted a Generalized Dynamic Feature Pyramid Network (GD-FPN) to enhance multi-scale feature fusion. Zhang et al. [] proposed a weighted bidirectional feature pyramid network with embedded residual modules to fuse multi-scale feature information, improving mAP by 1.8% on the NEU-DET dataset and enhancing the robustness of defect features.
Although FPN and its variants provide effective frameworks for multi-scale feature fusion, they generally share a critical limitation: cross-layer feature information cannot interact directly with each other. These networks fundamentally follow architectures that gradually fuse adjacent layers in both top-down and bottom-up manners, as shown in Figure 1. For cross-layer features such as B3 and B5, they cannot be directly fused but instead require recursive calls to B4 to obtain feature information, resulting in information loss []. Consequently, lower layers cannot fully utilize the rich semantic features from higher layers, and higher layers cannot directly use the localization information from lower layers to assist with object localization. This is particularly problematic for steel defects with large-scale variations, where models struggle to account for both texture features and multi-scale characteristics simultaneously, thus hindering YOLO from achieving better information fusion from a global information perspective.
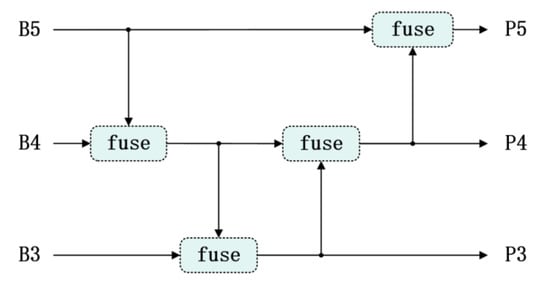
Figure 1.
The fusion mechanism of FPN.
Additionally, many scholars have proposed new feature fusion strategies. For instance, Huang et al. [] proposed a cross-layer multi-scale fusion network consisting of a Multi-level Alignment Module (MAM) and a Fusion Redistribution Module (FRM). This network fuses multi-scale feature information into global features through MAM. Then, it applies the resulting global features back to the multi-level features through FRM, thereby reducing the loss of feature information. Chen et al. [] proposed a feature fusion network based on Multi-scale Dynamic Snake Convolution (MDSC), which integrates the Locally enhanced Positional Encoding (LePE) attention module and the upsampling module, enhancing small object features and improving accuracy by 3.5% on the NEU-DET dataset. Zhang et al. [] proposed a cross-layer multi-scale feature fusion network, MSF, which fuses shallow layer features with detection heads at other layers, effectively utilizing shallow layer features and enhancing small object detection performance. These methods provide an effective solution for multi-scale feature fusion, significantly improving the model’s adaptability to defects of various morphologies. In addition, Wang et al. [] proposed the feature fusion strategy of Gather–Distribute based on YOLO, which is mainly realized by two branches of low-level and high-level GD mechanisms, effectively realizing the transmission and interaction of information. The Gather–Distribute idea has given us great inspiration, but the redundancy of the network and the large amount of computation are unable to satisfy the real-time requirements of actual industrial production. Therefore, achieving high-precision inspection and real-time measurement of small objects and those with large-scale differences in complex industrial environments remains a direction worthy of in-depth research.
2.4. YOLOv5 Model and Its Limitations
The YOLO series algorithms have become research hotspots in the field of single-stage object detection due to their excellent real-time performance and detection accuracy. Among them, the YOLOv5 algorithm features a simple model structure, fast inference speed, and high accuracy, making it one of the most representative single-stage object detection models currently. According to the depth and width of the algorithm, YOLOv5 can be divided into YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. This paper uses the smallest variant, YOLOv5s, as the baseline model for metal surface defect detection research. The overall structure of the YOLOv5s model is shown in Figure 2.
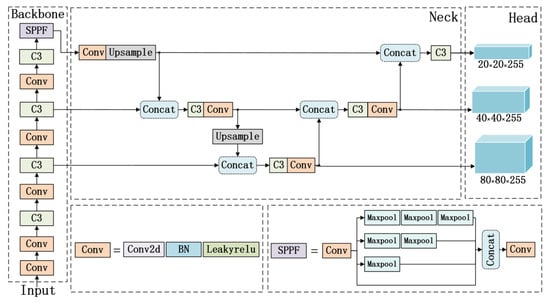
Figure 2.
The structure of YOLOv5.
YOLOv5s mainly consists of four parts: input, backbone, neck, and head. Input employs Mosaic data augmentation, adaptive random scaling, cropping, layout, and adaptive anchor box strategies, primarily responsible for input image data augmentation and preprocessing. The backbone comprises multiple Conv, C3, and SPPF components, mainly responsible for image feature extraction. The neck consists of a feature pyramid structure PAN formed by multiple Conv, C3, Upsample, and Concat components, which are mainly responsible for extracting and fusing feature information. The head consists of three detection heads of different sizes, mainly responsible for target prediction.
Despite subsequent iterations of the YOLO series, such as YOLOv7, YOLOv8, and YOLOv11, research in this field confirms that YOLOv5 still maintains unique advantages in steel surface defect detection tasks []. This is because subsequent versions primarily focus on continuous optimization for general object detection scenarios, with core improvements concentrated on enhancing detection efficiency for objects of conventional scales and morphologies. However, steel surface defects possess significant scale differences, such as the coexistence of micron-level cracks and centimeter-level scale, and irregular geometric morphologies, such as crack bifurcation and inclusion divergent distribution, making subsequent versions unsuitable for steel surface defect detection research []. Furthermore, subsequent versions have further increased model complexity by introducing complex operators, such as dynamic convolution and large kernel attention, which face real-time bottlenecks in industrial embedded device deployment.
Based on the above analysis, this paper chooses to improve upon YOLOv5s as the baseline model. YOLOv5s, with its lightweight network architecture and balanced multi-scale detection capability, has already achieved 74.6% mAP on steel defect datasets such as NEU-DET, but it still has limitations. Firstly, the Backbone has an insufficient multi-scale feature representation, where the C3 module utilizes static residual connections for inter-channel information interaction, lacking dynamic attention guidance, which leads to confusion between target texture features and background features. Secondly, the Neck has low efficiency in cross-layer information fusion because PAN depends on recursive stacking to transmit features, which only allows interactions between adjacent levels. This prevents direct fusion of deep semantic features with shallow location features, resulting in a loss of contextual information across defect scales. Thirdly, the Head has a limited multi-scale perception capability, as the default three detection heads’ preset anchors cannot adapt to the extreme scale spans and minute scales of steel defects, resulting in serious missed detections. This paper addresses these limitations to overcome YOLOv5’s performance bottlenecks in complex industrial scenarios, providing new solutions for high-precision, real-time defect detection.
3. NGD-YOLO Model
This paper introduces the NGD-YOLO object detection model, an improved version of YOLOv5s, as illustrated in Figure 3. To address the limitations of weak multi-scale feature extraction in the backbone, insufficient cross-layer multi-scale feature fusion in the neck, and poor small object detection performance, we have developed three key modules: an efficient C3NAM, a four-headed GD-NAM feature fusion network, and a lightweight C3DC module.
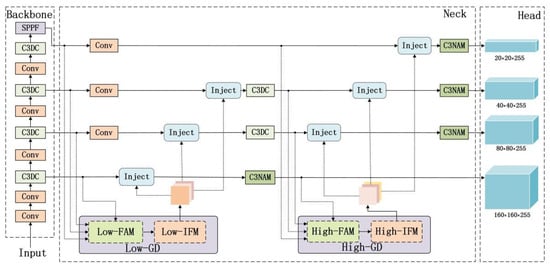
Figure 3.
The structure of NGD-YOLO.
We have implemented four significant improvements to the YOLOv5s architecture using these modules. Firstly, we replaced the last C3 module in both the backbone and neck with our C3NAM to enhance the multi-scale feature extraction capability in the backbone and the feature representation capability after fusion in the neck. Secondly, we substituted the PAN feature fusion method in the neck with our GD-NAM to improve feature information interaction during cross-layer multi-scale feature fusion and enhance small object detection performance. Thirdly, we increased the number of detection heads in the head from three to four and the number of predicted bounding boxes from nine to twelve, further expanding the model’s perceptual range and detection capability. Finally, we replaced the remaining C3 modules with our C3DC modules, reducing parameters while improving detection performance.
3.1. Convolutional Attention Module Based on C3NAM
The NAM [] enhances prominent features while suppressing less significant ones. In this paper, we integrate the NAM attention mechanism into the C3 module to construct the C3NAM. The NAM utilizes channel and pixel weights as metrics for feature significance. It employs a set of normalized scaling factors to represent the importance of weights, effectively suppressing non-salient channel and pixel information while significantly reducing computational complexity. The NAM consists of two components: the Channel Attention Module (CAM) and the Spatial Attention Module (SAM). The structure of NAM is illustrated in Figure 4.
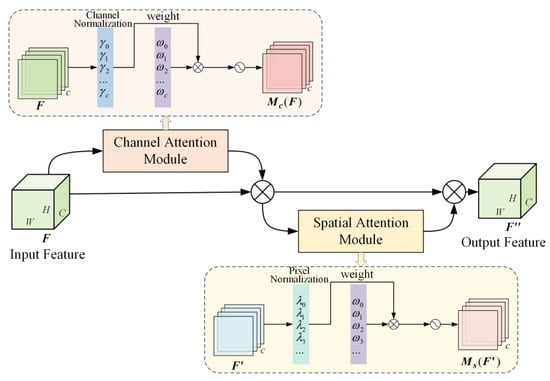
Figure 4.
The structure of NAM.
The computational procedure for NAM is as follows: First, the input feature F passes through the CAM to obtain a channel weight vector . This vector is then multiplied by F to produce weighted features . These weighted features are subsequently input to the SAM to generate a pixel weight vector . Finally, multiplying these components yields the output feature .
The CAM utilizes channel batch normalization scaling factors to assess channel importance: it first performs channel batch normalization on the input features to obtain scaling factors for each channel, then multiplies these by the channel scaling factor weights , and finally applies a sigmoid activation function to produce the CAM output. The equation for CAM is as shown in (4).
The SAM employs pixel batch normalization scaling factors to evaluate pixel importance: it first performs pixel batch normalization on the input features to obtain scaling factors for each pixel, then multiply these by pixel scaling factor weights , and finally applies a sigmoid activation function to produce the SAM output. The equation for CAM is as shown in (6).
To further suppress non-salient features, a regularization term is added to the loss function, as shown in Equation (7), where x denotes the input; y denotes the target; (·) denotes the predicted output; W denotes the trainable weights; l(·) denotes main loss function to measure the difference between (·) and y; g(·) denotes l1-norm loss function; and γ denotes the channel batch normalization scaling factors, which is used to assess the importance of channels. λ represents the pixel batch normalization scaling factors, which are used to assess the importance of pixels, and p is a penalty factor, which is used to balance the contribution of the regularization terms g(γ) and g(λ) to the total loss.
The NAM attention mechanism reduces the weights of non-salient channels and pixels during the model’s training process by imposing sparsity penalties on the scaling factors, effectively suppressing non-salient feature information, reducing background noise interference, and improving object detection accuracy and speed without increasing model parameters and computational complexity.
3.2. Cross-Layer Multi-Scale Feature Fusion Module Based on GD-NAM
The GD mechanism [] achieves efficient information interaction and fusion by globally integrating multi-layer features to obtain global information and injecting this global information into higher layers, thereby significantly enhancing information fusion capabilities. This study extends the GD framework by incorporating the NAM attention mechanism and adding a small object detection layer to form the GD-NAM, as illustrated in Figure 5. This module not only improves information fusion capability and enhances small object detection performance but also selectively filters different channels and positional information based on feature importance.
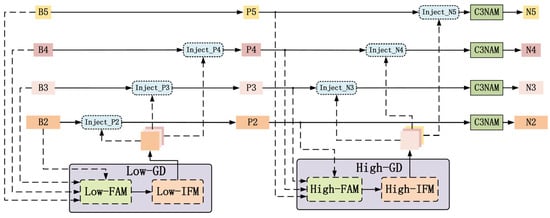
Figure 5.
The structure of GD-NAM.
The GD-NAM primarily consists of a low-GD branch and a high-GD branch. As shown in Figure 6 and Figure 7, these two branches extract and fuse features using convolution and transformation operators, respectively. The low-GD branch is responsible for injecting fused information into lower layers, while the high-GD branch injects fused information into higher layers. Each branch mainly comprises a Feature Alignment Module (FAM), an Information Fusion Module (IFM), and an Information Injection Module (Inject). The FAM collects feature information from different layers and aligns them to ensure they have the same dimensions and semantics. The IFM fuses the aligned features to generate global feature information. The inject module is responsible for injecting global features into different layers. Compared to traditional neck fusion methods, the proposed GD-NAM demonstrates superior detection capability when addressing datasets with challenges such as small target objects, similarity between background and targets, and densely clustered objects.
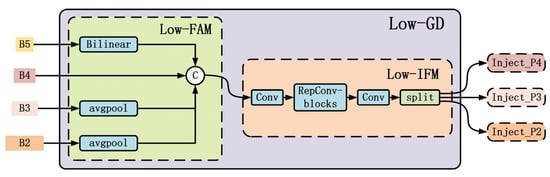
Figure 6.
The structure of low-GD.
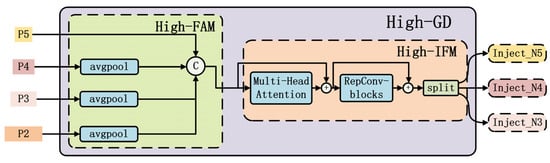
Figure 7.
The structure of high-GD.
3.3. Lightweight Convolutional Attention Module Based on C3DC
This study proposes a lightweight convolution operation called DCConv, which replaces the standard convolution operations in the C3 module to construct a lightweight and efficient C3DC module. The structure is shown in Figure 8.

Figure 8.
The structure of C3DC.
DCConv primarily consists of DWConv [] and ECA [] components, where DWConv reduces the number of channels in the model, and ECA captures correlation information between channels. DCConv is completed in three steps: First, the input feature passes through a 1 × 1 Conv layer, producing with half the number of channels. Then, is processed through a 3 × 3 DWConv layer to implement linear transformation and combination of features, and the resulting output passes through the ECA module to enhance information transfer between separated channels, generating . Finally, the two parts are concatenated to fuse the feature information further. The equations are as follows:
DWConv consists of two parts: Depthwise Convolution and Pointwise Convolution. Depthwise Convolution performs channel-wise convolution operations on the feature map, and Pointwise Convolution is used for linear fusion of channel information.
Assuming the input feature map size is H × W × C, the convolution kernel size is K × K, and the number of output feature channels is C′. The computational cost of standard convolution is as follows:
Since DWConv consists of depthwise convolution and pointwise convolution, where depthwise convolution calculates each channel separately and pointwise convolution uses 1 × 1 convolution for cross-channel linear fusion, the computational cost of DWConv is as follows:
The ratio of the computational cost of depthwise separable convolution to standard convolution is as follows:
where denotes the number of output channels, and denotes the convolutional kernel size. Therefore, compared to standard convolution, the introduction of depthwise separable convolution significantly reduces computational cost and model parameters.
Figure 9 shows the ECA network. ECA emphasizes the importance of different channels in detection tasks with different weights while suppressing irrelevant and redundant channels. This network is completed in three steps: first, a global average pooling operation is performed on the input feature, then a one-dimensional convolution with k = 5 is applied to achieve local interaction between channels, and finally, a sigmoid activation function is used to obtain channel weights, which are multiplied with the original input features to obtain enhanced feature information.
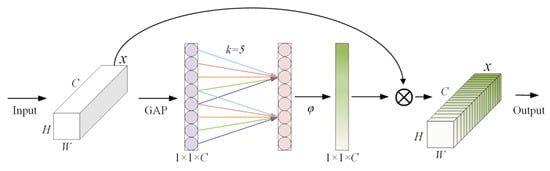
Figure 9.
The structure of ECA.
Compared to current mainstream attention mechanisms, the ECA mechanism diverges from the traditional approach of enhancing performance through stacked fully connected layers or spatial attention modules. It achieves performance breakthroughs with almost no increase in model complexity, providing an innovative solution for real-time detection under equipment constraints in industrial defect detection scenarios.
4. Experiments and Results
4.1. Experimental Set
International standards classify steel surface defects into 33 categories in total. This study utilizes the NEU-DET steel surface defect dataset [] released by Northeastern University. This dataset is widely representative and universal, including six common steel surface defects: Crazing (Cr), Inclusion (In), Patches (Pa), Pitted surface (Ps), Rolled-in scale (Rs), and Scratches (Sc). Its image quality and defect features reflect the main challenges in real industrial scenarios and are widely used in steel surface defect detection tasks. Each defect type contains 300 grayscale images, totaling 1800 images. The dataset was randomly divided in an 8:1:1 ratio, resulting in 1440 images for training, 180 for validation, and 180 for testing. To address the restricted grayscale dynamic range observed in the dataset, we implement gamma correction (γ = 1.5) as a data augmentation strategy, effectively expanding the intensity distribution while preserving semantic consistency. Sample images before and after augmentation are shown in Figure 10.

Figure 10.
Comparison of data augmentation.
The experiments were conducted on a Windows 10 64-bit operating system using the PyTorch 1.13.1 framework and PyCharm 2023.2.7 integrated development environment. Python version 3.8 was used, with hardware specifications including an Intel(R) Xeon(R) W-2133 CPU and an NVIDIA GeForce RTX 3070 GPU(24GB VRAM). During training, we employed the Stochastic Gradient Descent (SGD) optimizer, the initial learning rate was set to 0.01, the early stopping mechanism patience was set to 50, momentum to 0.937, and weight_decay to 0.0005, input image size were configured at 640 px × 640 px, with 200 epochs and a batch size of 16. During testing, the batch sizes were kept consistent at 1.
4.2. Evaluation Indicators
In object detection tasks, commonly used model evaluation metrics include mean Average Precision (mAP), Average Precision (AP), Recall (R), F1-score (F1), Parameters (Params), Floating Point Operations Per Second (FLOPs), and Frames Per Second (FPS). To validate model effectiveness, this study primarily uses mAP, Params, FLOPS, and FPS as evaluation methods for steel defect detection.
Among these metrics, mAP represents the mean of AP values across all categories, while AP serves as an evaluation metric for detection precision of each category and is closely related to the Precision (P) and Recall (R) metrics. mAP evaluates the overall performance of the model, with numbers closer to 1 indicating better detection performance. The equations are as follows:
where TP, FP, and FN represent the number of correctly classified positive samples, negative samples incorrectly marked as positive, and positive samples incorrectly marked as negative, respectively. k denotes the number of detection categories.
Params and FLOPs are used to evaluate the model’s parameter count and computational complexity, respectively.
Additionally, FPS is used to assess the model’s detection speed, representing the number of images processed per second.
4.3. Comparative Experiment
Table 1 presents a comparison between NGD-YOLO and mainstream object detection algorithms. NGD-YOLO was compared with SSD, YOLOv3-tiny, YOLOv3s, YOLOv4s, YOLOv5s, YOLOv7, YOLOv8s, YOLOV9s, YOLOv10s, YOLOv11n, YOLOv12s, RT-DETR, and Faster R-CNN under identical experimental conditions.

Table 1.
Comparison of NGD-YOLO with other mainstream detector performance.
The experimental results demonstrate that the NGD-YOLO model exhibits excellent overall performance on the NEU-DET dataset, achieving an mAP of 79.2%. Examining the detection results across categories, the algorithm demonstrates significant advantages in detecting Cr, Pa, Rs, and Sc, with AP values higher than those of other detection algorithms. For Cr detection in particular, it achieves an AP of 54.6%, which is 4.8% higher than YOLOv10s (the second-best performer in this category), representing a qualitative improvement compared to other detection methods. Although the algorithm did not outperform other comparative algorithms in detecting In and Ps, it still achieved satisfactory AP values of 79.6% and 80.8%, which are only 1.6% and 3.4% lower than the highest AP values of 81.2% and 84.2% for these categories, comparable to the second-best AP values of 80.8% and 83.5%, and consistently higher than the baseline model. Analysis indicates that the algorithm has certain detection advantages for various defects in complex scenarios.
From an overall detection perspective, NGD-YOLO achieves an mAP of 79.2%, which is significantly higher than that of other one-stage detection models in the YOLO series. This represents an improvement of 4.5% compared to the highest mAP of 74.7% among YOLO series models and a 4.6% improvement over the baseline model’s 74.6%. Compared to the classic two-stage object detection model, Faster R-CNN, and the single-stage object detection algorithm SSD, the mAP increases by 3.7% and 8.2%, respectively. Compared to the current mainstream real-time detector RT-DETR, the mAP was increased by 7.7%. In terms of Params and GFLOPs, NGD-YOLO has 8.752M Params and 18.3 GFLOPs, substantially lower than SSD and Faster R-CNN. Compared to the baseline model YOLOv5s, Params and GFLOPs increase by 24.6% and 15.8%, respectively, but mAP improves by 4.6%. Compared to YOLOv3-tiny, which has similar parameters, GFLOPs increases by 41.9%, but mAP improves by 10.8%. Compared to YOLOv11n, which has the lowest parameters and GFLOPs, approximately triple, mAP is improved by 5%. In comparison, although our model’s Params and GFLOPs are higher than those of some lightweight networks, it remains a small-volume model at the sub-10M level, with accuracy far exceeding that of other models. In terms of FPS, the algorithm achieves 108.6, second only to YOLOv3-tiny’s 370.3 FPS and YOLOv5s’ 121.9 FPS. In summary, NGD-YOLO achieves breakthrough improvements in accuracy while remaining edge-device friendly, providing a reliable solution for high-precision real-time defect detection.
Figure 11 presents the recognition results of the NGD-YOLO model compared with other models, further validating the advantages of NGD-YOLO in defect detection tasks. NGD-YOLO demonstrates significant advantages in detecting small defects within the same category, defects with severe background interference, variable morphologies, and inconsistent sizes, while effectively reducing false detections. Comparing detection results across categories, as shown in Figure 11b,e,f, our model can detect smaller target defects while effectively mitigating false detections caused by similarities between targets and backgrounds. As shown in Figure 11a,c,d, our model accurately detects targets of varying sizes and morphologies, with more precise bounding box localization. Overall, the NGD-YOLO model performs well in defect detection tasks.


Figure 11.
Comparison of detection results across different models.
Figure 12 illustrates the overall performance of NGD-YOLO on the NEU-DET dataset, reflecting the relationship between Params, mAP, and FPS. Figure 12a shows the relationship between Params and mAP for various algorithms. Models that achieve higher mAP with fewer Params are considered superior, i.e., those positioned closer to the upper-left corner indicate a better balance between Params and mAP. Notably, NGD-YOLO is positioned closest to the upper-left corner, achieving the highest mAP with relatively low Params, thus establishing a favorable balance between Params and mAP. Figure 12b depicts the relationship between FPS and mAP for NGD-YOLO. Models with higher mAP at higher FPS are considered superior, i.e., those positioned closer to the upper-right corner indicate a better balance between FPS and mAP. The models closest to the upper-right corner are NGD-YOLO. In Figure 12, YOLOv3-tiny provides the fastest FPS, but it has the lowest mAP, failing to meet the high-precision detection requirements in industrial production. In contrast, NGD-YOLO achieves the highest mAP while maintaining relatively fast FPS, establishing a favorable balance between FPS and mAP compared to other models. In summary, NGD-YOLO achieves an excellent balance among Params, mAP, and FPS, demonstrating considerable industrial practical value.
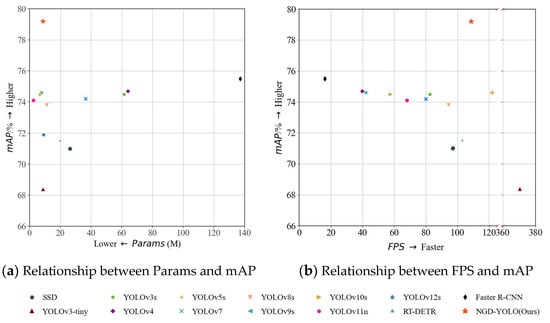
Figure 12.
Comparison of detection performance across different models.
Furthermore, we compare the NGD-YOLO method presented in this paper with current algorithms in the field that have achieved better results based on YOLO improvements on the NEU-DET dataset and investigate the effectiveness of this method in real industrial production. Since none of these algorithms are open-source, this paper directly quotes the experimental results from the article. To ensure the fairness of the evaluation, GFLOPs, which are not affected by the experimental environment, are selected as the evaluation index, along with mAP.
As shown in Table 2, among them, the authors of [,] innovated their research by striking a balance between model lightweight and detection accuracy. The authors of [,] innovated their research by efficiently fusing model multi-scales across layers. We can see that all models achieve satisfactory results with mAP above 78.1%. Our method is second only to that found in [], which showed 80.7%; however, its GFLOPs are 2.8 times higher than ours, and its real-time performance is extremely poor, which makes it suitable for scenarios where resource environments are not restricted. In particular, for crack detection, all of the methods except Ref. []. achieve high detection results, which are almost all greater than the results in Table 2, and the best found in this paper. Compared with [,], although the GFLOPs are improved, they still belong to the lower GFLOPs, while the mAP is significantly higher than both of them, which verifies the effectiveness of the C3NAM model in this paper in suppressing the background noise and enhancing the ability of small target feature characterization and the C3DC model in reducing the model burden to enhance the channel interaction. Compared with [,], although the results are slightly lower than in [], the computational efficiency is improved by 65% and significantly exceeds that found in [], which verifies that the GD-NAM proposed in this paper can effectively enhance the fusion ability of cross-layer multi-scale features. Overall, NGD-YOLO demonstrates the best comprehensive performance in defect detection, providing a feasible solution for industrial defect detection.
Table 2.
Comparison of detection performance between NGD-YOLO and other models.
4.4. Ablation Experiments
To verify the effectiveness of the GD-NAM and C3DC modules proposed in this paper, ablation experiments were conducted on the internal components of these modules using the NEU-DET dataset. In the table below, “-” indicates the module was not added, and “√” indicates the module was included.
Table 3 shows the internal component ablation experiment of the GD-NAM based on the baseline model. The experiments demonstrate that introducing the GD mechanism improves mAP by 1.3%, which indicates that it enhances the ability to interact with multi-scale features. This is particularly beneficial for targets with significant scale differences in the defect dataset. However, performance improvement is accompanied by an increase in Params and GFLOPs. The addition of NAM increases mAP by a further 0.3%, making it 1.6% higher than the baseline model, without increasing Params or GFLOPs. This indicates that NAM effectively suppresses background features that resemble defect textures while enhancing the characterization of multi-scale information during feature fusion. Finally, to address the prevalence of small targets in the defective dataset, we added a small target detection head. This improved the mAP by a further 0.6% compared to the baseline model and by 2.2% overall, while Params only increased by 0.084M. Therefore, the GD-NAM significantly enhances the model’s detection performance by synergistically integrating the GD mechanism, the NAM, and the small target detector head.
Table 3.
GD-NAM internal ablation experiment.
While the GD-NAM improved mAP by 2.2%, it simultaneously increased the model’s Params and GFLOPs. To address this issue, we propose the C3DC module, designed to reduce the number of model parameters while enhancing its detection performance further. Building upon the integrated C3NAM and GD-NAM, we conducted an ablation study on the internal components of the C3DC module, with experimental results presented in Table 4. Experiments demonstrate that replacing standard convolutions with DWConv led to a decrease in Params and GFLOPs. However, the model’s key performance indicator, mAP, also dropped from 78.2% to 77.3%, accompanied by reductions in both P and R metrics. This indicates that while DWConv effectively reduces Params, it causes a certain degree of accuracy loss because it ignores the information interaction between channels. Nevertheless, upon further integrating the ECA module with DWConv, mAP significantly improved from 77.3% to 79.2%. This not only fully compensated for the accuracy loss caused by using DWConv but also surpassed the performance of the original baseline model. Concurrently, P and R metrics also showed comprehensive improvements. Notably, compared to the model employing only DWConv, the increases in Params and GFLOPs were marginal. Therefore, the C3DC module is capable of significantly boosting the model’s mAP while simultaneously reducing its Params.
Table 4.
C3DC module internal ablation experiment.
To further validate the effectiveness of the three improved modules in C3NAM, GD-NAM, and C3DC, for steel surface defect detection using NGD-YOLO, we conducted multicomponent ablation experiments on the NEU-DET dataset. As shown in Table 5, the proposed NGD-YOLO achieves significant improvements in P, R, and mAP metrics without substantial increases in Params and GFLOPs. Compared to the baseline YOLOv5s model, the mAP increased from 74.6% to 79.2%, a relative improvement of 4.6%.
Table 5.
Comparison of detection performance in ablation experiments for NGD-YOLO.
The ablation experiments confirm that the introduction of all three modules in NGD-YOLO enables more accurate and rapid recognition of steel surface defects. When each of the above three modules was individually integrated, the model’s mAP consistently improved. Notably, the incorporation of the C3DC module alone resulted in a relative mAP increase of 2.4%, while simultaneously reducing the model’s Params and GFLOPs by 0.42 M and 2.2, respectively. This demonstrates the C3DC module’s efficacy in enhancing accuracy while lowering computational overhead. Further analysis of the synergistic effects of module combinations indicated that all pairs of mAP were superior to the addition of modules individually. In particular, the combination of the C3NAM and GD-NAM improved the model’s mAP by 3.6% relative to the baseline model. Combined with the experimental analysis of C3NAM added individually, the C3NAM effectively suppresses non-tilted features and enhances the ability to represent multi-scale features. On the other hand, the GD-NAM enhances information interaction during feature fusion and improves sensitivity to small object features but increases Params and GFLOPs. To further optimize the model’s efficiency and accuracy, the C3DC module was subsequently integrated, which increased the mAP from 78.2% to 79.2%, representing a relative improvement of 1%. This integration also reduced the number of parameters and GFLOPs from 9.212 M and 21 to 8.752 M and 18.3, respectively. This indicates that the module effectively captures correlations between channels, enhances feature expression capability, and further improves accuracy while reducing Params. Based on the ablation experiment results, the addition of each module improves the model’s detection performance. Through the combined effect of these modules, the NGD-YOLO model can more accurately and rapidly identify steel surface defects, providing potential for deployment on an edge device.
Figure 13 shows a comparison of mAP curves before and after improvements in the mAP curves during the training process for the baseline YOLOv5s model and the NGD-YOLO model. As observed, the trends in mAP changes are broadly similar. In the early stages of training, the mAP increases rapidly for both models, although NGD-YOLO initially shows a lower value than YOLOv5s. This is due to the introduction of new modules, increased network depth and width, and changes in feature fusion methods, which make the network more difficult to converge initially and require more time to learn appropriate weights. At around 50 epochs, both models’ mAP fluctuates consistently; by 80 epochs, NGD-YOLO’s mAP exceeds that of YOLOv5s and gradually stabilizes. After 200 epochs of training, the mAP converges, with the proposed NGD-YOLO significantly outperforming the baseline YOLOv5s model.
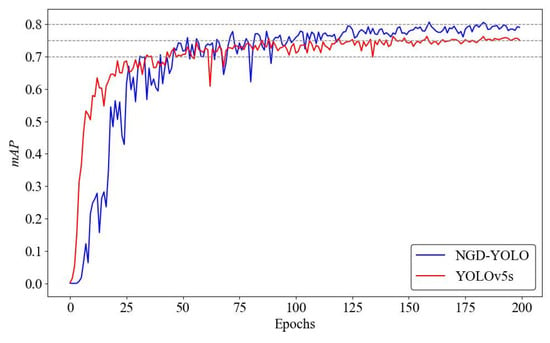
Figure 13.
Comparison of mAP curves before and after improvement.
Figure 14 displays the recognition results of the baseline YOLOv5s model and the NGD-YOLO model. As shown, NGD-YOLO outperforms the baseline YOLOv5s model across all categories. In Figure 14a,b,e, defects such as Cr, In, and Rs are small, irregular, overlapping, and similar to the background, making feature extraction challenging and resulting in significant missed detections by YOLOv5s. In contrast, NGD-YOLO detects more defect targets, especially in cases with multiple small defects, where it can detect most small defect targets. As shown in Figure 14c,d,f, Pa, Ps, and Sc targets vary in scale with large edge coverage areas, leading to inaccurate bounding box localization by YOLOv5s, while NGD-YOLO can more accurately locate defect positions. In comparison, the NGD-YOLO model can more accurately identify the location and type of various defects, improving upon the baseline model’s missed and false detections, and accurately recognizing small targets.

Figure 14.
Comparison of prediction results between YOLOv5s and NGD-YOLO.
5. Conclusions
This paper proposes a novel defect detection model, NGD-YOLO. Firstly, to enhance multi-scale feature representation capability, the algorithm constructs the C3NAM to replace the traditional C3 module. Secondly, by introducing the GD mechanism, a GD-NAM cross-layer feature fusion module with four detection heads is constructed, thereby enhancing the cross-layer fusion ability of multi-scale feature information, effectively reducing information loss during feature fusion, and improving the performance of small object detection. Finally, a new efficient lightweight convolution module, DCConv, is proposed, and the C3DC module is developed to replace some traditional C3 modules, further improving detection performance while reducing model parameter count. Additionally, the three modules proposed in this paper are independent, with plug-and-play characteristics, and could be flexibly integrated into other YOLO series networks or other deep learning frameworks, which lays a solid foundation for the generalized application of industrial vision defect detection technology. Experimental results demonstrate that the model achieves a 79.2% mAP on the public NEU-DET dataset, representing an improvement of 4.6% over the baseline model. Compared to other algorithms, the model achieves the highest mAP while maintaining relatively low Params, with an FPS of up to 108.6.
In the future, we will focus on continuously optimizing defective feature representations and exploring strategies for making models lighter. This will not only improve model performance but also lay the foundation for efficient deployment on edge or embedded systems. Additionally, we will actively construct high-quality industrial defect datasets and apply transfer learning techniques to enhance the models’ generalization capability and robustness in diverse and complex industrial scenarios, thereby better meeting the needs of real production environments.
Author Contributions
Conceptualization, B.L.; Methodology, B.L. and K.Q.; Validation, A.X.; Investigation, X.H. and S.Z.; Resources, G.W., K.Q. and P.S.; Data curation, B.L. and A.X.; Writing—original draft, B.L. and A.X.; Writing—review & editing, G.W., K.Q. and P.S.; Funding acquisition, P.S. All authors have read and agreed to the published version of the manuscript.
Funding
The Jiangsu Province Natural Science Foundation (BK20231186), the Changzhou Sci&Tech Program (CE20235053), and the Open Research Fund of Hubei Technology Innovation Center for Smart Hydropower (1523020038).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this study, NEU-DET, is publicly accessible. You can obtain this dataset from the following links: https://drive.google.com/drive/home (accessed on 1 December 2024).
Conflicts of Interest
Authors Bingyi Li, Andong Xiao, Xing Hu, Sisi Zhu and Gang Wan were employed by the company China Yangtze Power Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Luo, Q.; Fang, X.; Liu, L.; Yang, C.; Sun, Y. Automated Visual Defect Detection for Flat Steel Surface: A Survey. IEEE Trans. Instrum. Meas. 2020, 69, 626–644. [Google Scholar] [CrossRef]
- Saberironaghi, A.; Ren, J.; El-Gindy, M. Defect Detection Methods for Industrial Products Using Deep Learning Techniques: A Review. Algorithms 2023, 16, 95. [Google Scholar] [CrossRef]
- Nick, H.; Ashrafpoor, A.; Aziminejad, A. Damage Identification in Steel Frames Using Dual-Criteria Vibration-Based Damage Detection Method and Artificial Neural Network. Structures 2023, 51, 1833–1851. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, J.; Yu, H.; Li, F.; Yu, L.; Zhang, C. Surface Defect Detection of Steel Products Based on Improved YOLOv5. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; School of Electrical and Information Engineering: Singapore; Tianjin University: Tianjin, China; Hebei Jinxi Iron and Steel Group: Tangshan, China, 2022; pp. 5794–5799. [Google Scholar]
- Su, Y.; Deng, Y.; Zhou, N.; Si, H.; Peng, J. Steel Surface Defect Detection Algorithm Based on Improved YOLOv5s. In Proceedings of the 2024 IEEE 6th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 24–26 May 2024; Volume 6, pp. 865–869. [Google Scholar]
- Zhang, J.; Wang, H.; Tian, Y.; Liu, K. An Accurate Fuzzy Measure-Based Detection Method for Various Types of Defects on Strip Steel Surfaces. Comput. Ind. 2020, 122, 103231. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhou, Q.; Wang, H. CABF-YOLO: A Precise and Efficient Deep Learning Method for Defect Detection on Strip Steel Surface. Pattern Anal. Appl. 2024, 27, 36. [Google Scholar] [CrossRef]
- Song, X.; Cao, S.; Zhang, J.; Hou, Z. Steel Surface Defect Detection Algorithm Based on YOLOv8. Electronics 2024, 13, 988. [Google Scholar] [CrossRef]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An End-to-End Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features. IEEE Trans. Instrum. Meas. 2020, 69, 1493–1504. [Google Scholar] [CrossRef]
- Ye, Q.; Dong, Y.; Zhang, X.; Zhang, D.; Wang, S. Robustness Defect Detection: Improving the Performance of Surface Defect Detection in Interference Environment. Opt. Lasers Eng. 2024, 175, 108035. [Google Scholar] [CrossRef]
- Zhang, C.; Yu, J.; Zhao, Y.; Wu, H.; Wu, G. Cracks Segmentation of Engineering Structures in Complex Backgrounds Using a Concatenation of Transformer and CNN Models Driven by Scene Understanding Information. Structures 2024, 65, 106685. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Chen, J.; Liu, M.; Fu, Q.; Yao, Z. Hot Rolled Steel Strip Surface Defect Detection Method Based on Deep Learning. Autom. Inf. Eng. 2019, 40, 11–16, 19. [Google Scholar] [CrossRef]
- Xia, Y.; Lu, Y.; Jiang, X.; Xu, M. Enhanced Multiscale Attentional Feature Fusion Model for Defect Detection on Steel Surfaces. Pattern Recognit. Lett. 2025, 188, 15–21. [Google Scholar] [CrossRef]
- Cheng, X.; Yu, J. RetinaNet with Difference Channel Attention and Adaptively Spatial Feature Fusion for Steel Surface Defect Detection. IEEE Trans. Instrum. Meas. 2021, 70, 2503911. [Google Scholar] [CrossRef]
- Sun, G.; Wang, S.; Xie, J. An Image Object Detection Model Based on Mixed Attention Mechanism Optimized YOLOv5. Electronics 2023, 12, 1515. [Google Scholar] [CrossRef]
- Shi, J.; Yang, J.; Zhang, Y. Research on Steel Surface Defect Detection Based on YOLOv5 with Attention Mechanism. Electronics 2022, 11, 3735. [Google Scholar] [CrossRef]
- Tang, J.; Liu, S.; Zhao, D.; Tang, L.; Zou, W.; Zheng, B. PCB-YOLO: An Improved Detection Algorithm of PCB Surface Defects Based on YOLOv5. Sustainability 2023, 15, 5963. [Google Scholar] [CrossRef]
- Luo, T.; Wang, X.; Li, Z.; Zeng, T.; Chen, W. Steel Surface Defect Detection Based on Multi-Scale Feature Fusion. Intell. Comput. Appl. 2024, 14, 197–200. [Google Scholar]
- Chu, Y.; Yu, X.; Rong, X. A Lightweight Strip Steel Surface Defect Detection Network Based on Improved YOLOv8. Sensors 2024, 24, 6495. [Google Scholar] [CrossRef]
- Zhang, L.; Cai, J. Target Detection System Based on Lightweight Yolov5 Algorithm. Comput. Technol. Dev. 2022, 32, 134–139. [Google Scholar] [CrossRef]
- Liang, L.; Long, P.; Lu, B.; Li, R. Improvement of GBS-YOLOv7t for Steel Surfacedefect Detection. Opto-Electron. Eng. 2024, 51, 61–73. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, D. Lightweight Steel Surface Defect Detection Model Based on Machine Vision. Comput. Technol. Autom. 2024, 43, 43–49. [Google Scholar] [CrossRef]
- Ma, S.; Zhao, X.; Wan, L.; Zhang, Y.; Gao, H. A Lightweight Algorithm for Steel Surface Defect Detection Using Improved YOLOv8. Sci. Rep. 2025, 15, 8966. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Fang, H.; Liu, Z.; Zheng, B.; Sun, Y.; Zhang, J.; Yan, C. Dense Attention-Guided Cascaded Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2022, 71, 5004914. [Google Scholar] [CrossRef]
- Shen, K.; Zhou, X.; Liu, Z. MINet: Multiscale Interactive Network for Real-Time Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Ind. Inform. 2024, 20, 7842–7852. [Google Scholar] [CrossRef]
- Han, B.; He, L.; Ke, J.; Tang, C.; Gao, X. Weighted Parallel Decoupled Feature Pyramid Network for Object Detection. Neurocomputing 2024, 593, 127809. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Han, L.; Li, N.; Li, J.; Gao, B.; Niu, D. SA-FPN: Scale-Aware Attention-Guided Feature Pyramid Network for Small Object Detection on Surface Defect Detection of Steel Strips. Measurement 2025, 249, 117019. [Google Scholar] [CrossRef]
- Ni, Y.; Zi, D.; Chen, W.; Wang, S.; Xue, X. Egc-Yolo: Strip Steel Surface Defect Detection Method Based on Edge Detail Enhancement and Multiscale Feature Fusion. J. Real-Time Image Process. 2025, 22, 65. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, W.; Li, Z.; Shu, S.; Lang, X.; Zhang, T.; Dong, J. Development of a Cross-Scale Weighted Feature Fusion Network for Hot-Rolled Steel Surface Defect Detection. Eng. Appl. Artif. Intell. 2023, 117, 105628. [Google Scholar] [CrossRef]
- Yu, X.; Lyu, W.; Wang, C.; Guo, Q.; Zhou, D.; Xu, W. Progressive Refined Redistribution Pyramid Network for Defect Detection in Complex Scenarios. Knowl.-Based Syst. 2023, 260, 110176. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Jia, L.; Zhou, Y. An Improved You Only Look Once Model for the Multi-Scale Steel Surface Defect Detection with Multi-Level Alignment and Cross-Layer Redistribution Features. Eng. Appl. Artif. Intell. 2025, 145, 110214. [Google Scholar] [CrossRef]
- Chen, J.; Jin, W.; Liu, Y.; Huang, X.; Zhang, Y. Multi-Scale and Dynamic Snake Convolution-Based YOLOv9 for Steel Surface Defect Detection. J. Supercomput. 2025, 81, 541. [Google Scholar] [CrossRef]
- Zhang, H.; Li, S.; Miao, Q.; Fang, R.; Xue, S.; Hu, Q.; Hu, J.; Chan, S. Surface Defect Detection of Hot Rolled Steel Based on Multi-Scale Feature Fusion and Attention Mechanism Residual Block. Sci. Rep. 2024, 14, 7671. [Google Scholar] [CrossRef]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Han, K.; Wang, Y. Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism. arXiv 2023, arXiv:2309.11331. [Google Scholar] [CrossRef]
- Yan, R.; Zhang, R.; Bai, J.; Hao, H.; Guo, W.; Gu, X.; Liu, Q. STMS-YOLOv5: A Lightweight Algorithm for Gear Surface Defect Detection. Sensors 2023, 23, 5992. [Google Scholar] [CrossRef]
- Yang, J.; Liu, Z. A Novel Real-Time Steel Surface Defect Detection Method with Enhanced Feature Extraction and Adaptive Fusion. Eng. Appl. Artif. Intell. 2024, 138, 109289. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-Based Attention Module. arXiv 2021, arXiv:2111.124190. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).