Abstract
Although recent multi-object tracking (MOT) methods have shown impressive performance, MOT remains challenging due to two key issues: the poor generalization of ReID in MOT tasks and motion estimation errors caused by camera movement. To address these, we propose DCTrack, a novel tracker with two core modules: Domain Adaptation-based Batch Instance Normalization (DA-BIN) and camera motion compensation mapped to the Ground Plane (CMC-GP). DA-BIN enhances appearance modeling through domain adaptation using a combination of batch and instance normalization layers, allowing DCTrack to simulate unsuccessful generalization scenarios and improving ReID performance in MOT. CMC-GP uses a Kalman Filter-based method to map object motion estimation to the ground plane and applies the same compensation parameters across the video sequence, enhancing robustness to camera motion. Experimental results show that DCTrack effectively improves ReID generalization in MOT and performs well in scenes with camera motion, achieving a HOTA of 67.3% and an IDF1 of 65.8% on DanceTrack.
1. Introduction
Multi-Object Tracking (MOT) has emerged as a cornerstone technology in computer vision, enabling critical applications from autonomous driving and surveillance systems to sports analytics and human–computer interaction [,,,]. As the demand for real-time, robust tracking in diverse and challenging environments continues to grow, the field faces fundamental challenges that existing solutions struggle to address effectively.
The predominant Tracking-by-Detection (TBD) paradigm [] decomposes MOT into object detection and cross-frame association, relying heavily on appearance features from re-identification (ReID) models [,] and motion features from prediction models []. While conceptually elegant, this approach encounters two critical bottlenecks in real-world deployment: domain adaptation failures and camera motion interference.
The Domain Gap Challenge: ReID models, trained on specific datasets with controlled conditions, exhibit significant performance degradation when deployed in diverse MOT scenarios. This degradation stems from the fundamental mismatch between ReID’s assumption of consistent cross-camera statistics and MOT’s reality of dynamic, multi-sequence environments with varying illumination, viewpoints, and scene characteristics. Consequently, even state-of-the-art (SOTA) ReID performance fails to translate into effective MOT performance, particularly in crowded scenes with frequent occlusions.
The Camera Motion Problem: Traditional motion models operate in 2D image coordinates, where camera movement introduces pseudo-motion artifacts that severely compromise tracking accuracy. Existing camera motion compensation (CMC) methods [] attempt post hoc corrections through expensive frame-by-frame processing, creating computational bottlenecks that conflict with real-time requirements. This fundamental mismatch between 2D image plane modeling and 3D ground plane reality represents a persistent challenge in the field.
Current solutions typically address these challenges independently through additional datasets, complex training strategies, or computationally intensive compensation methods. However, these approaches often sacrifice either accuracy for efficiency or vice versa, failing to provide the robust, real-time performance required for practical deployment.
In this work, we introduce DCTrack (domain adaptation and camera motion compensation track), a novel MOT framework that fundamentally addresses both challenges through principled domain adaptation and geometric motion modeling. Our approach makes two key contributions.
First, we propose the Domain Adaptation-based Batch Instance Normalization (DA-BIN) module, which transcends traditional normalization approaches by actively simulating failure scenarios during training. Unlike existing methods that passively adapt to domain shifts, DA-BIN employs a learnable balancing mechanism between batch normalization (BN) and instance normalization (IN), coupled with multi-objective optimization that deliberately explores overfitting and underfitting boundaries. This approach enhances ReID generalization without requiring additional datasets or complex training strategies.
Second, we introduce the camera motion compensation on ground plane (CMC-GP) module, which revolutionizes motion modeling by projecting Kalman Filter (KF) from image coordinates to ground plane coordinates. This paradigm shift eliminates camera-induced pseudo-motion at its source while modeling spatial motion correlations through non-diagonal noise covariance matrices. Unlike traditional frame-by-frame compensation methods, CMC-GP achieves superior accuracy with minimal computational overhead.
As demonstrated in Figure 1, DCTrack achieves exceptional performance on the challenging DanceTrack benchmark [], reaching 67.3 HOTA and 65.8 IDF1 while using only ReID training data without additional MOT dataset augmentation. This performance represents a significant advancement in balancing accuracy and efficiency for real-world MOT applications.
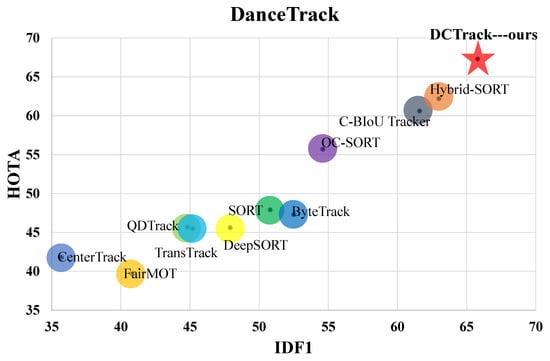
Figure 1.
HOTA-IDF1 comparison of different trackers on DanceTrack. With IDF1 on the horizontal axis and HOTA on the vertical axis, our DCTrack with an star symbol achieves 67.3 HOTA and 65.8 IDF1, which is significantly competitive compared with SOTA trackers with circle symbols.
Our main contributions are as follows:
- We propose the DA-BIN module, a novel domain adaptation framework that dynamically balances BN and IN through learnable parameters. By actively simulating failure scenarios during training, DA-BIN prevents source domain overfitting and significantly enhances ReID generalization in MOT tasks without requiring additional training data.
- We introduce the CMC-GP module, a ground plane-based camera motion compensation approach that projects KF from image coordinates to ground coordinates. This paradigm shift fundamentally eliminates camera-induced pseudo-motion while modeling spatial correlations through non-diagonal noise covariance matrices, achieving superior accuracy with minimal computational overhead.
- We present DCTrack, integrating DA-BIN and CMC-GP modules within the TBD framework, which achieves SOTA performance across DanceTrack, MOT20 [], and MOT17 [] benchmarks, demonstrating significant improvements in both accuracy and efficiency for real-world MOT applications.
The rest of this paper is arranged as follows: Section 2 examines the relevant studies on appearance modeling and motion estimation for MOT. Section 3 presents the detailed methodology of DCTrack, including the DA-BIN and CMC-GP modules. Section 4 provides comprehensive experimental evaluation and analysis. Section 5 concludes this paper with a discussion of limitations and future directions.
2. Related Works
2.1. Appearance Models and Domain Adaptation in MOT
To improve long-term association, current MOT methods can be divided into two major categories depending on their use of appearance features. Traditional two-stage methods [,] employ independent ReID models to extract deep appearance features, which effectively reduce identity switches (IDSWs) in occlusion scenarios but suffer from high computational overhead. Joint Detection and Tracking (JDT) methods [,,,,,] address this efficiency issue by optimizing detection and embedding through shared backbone networks, yet require complex association strategies and large-scale joint training on both detection and ReID datasets.
However, both paradigms face a fundamental challenge: domain shift in appearance models. ReID models, designed for cross-camera person retrieval, exhibit significant performance degradation when applied to MOT tasks due to statistical distribution differences between training (source) and testing (target) domains. This problem is exacerbated in MOT scenarios where datasets consist of multiple sub-sequences with varying statistical properties, creating not only source-target domain gaps but also intra-target domain variations.
Current domain adaptation approaches in ReID primarily rely on BN-based strategies [] that adjust batch statistics to align with cross-domain distributions. These methods fall into two categories: (1) online statistical estimation for unlabeled target data [], and (2) progressive feature transfer via pseudo-labeling or combined statistics calculation []. While effective in traditional ReID settings, these approaches have critical limitations when applied to MOT:
- Data dependency: Require substantial additional datasets and complex training strategies with limited performance gains;
- Single normalization bias: Using BN or IN alone leads to overfitting or underfitting in diverse MOT scenarios;
- Passive adaptation: Cannot actively explore domain boundaries or simulate failure scenarios.
To address these limitations, our DA-BIN module introduces a novel domain adaptation framework specifically designed for MOT. Unlike existing methods that passively adapt to domain shifts, DA-BIN actively simulates failure scenarios during training to enhance generalization. By dynamically balancing BN and IN through learnable parameters and employing three complementary loss functions, DA-BIN achieves superior cross-domain adaptation without requiring additional data or complex network architectures. This approach significantly improves cross-domain ID matching accuracy while maintaining model efficiency, making it particularly suitable for the TBD paradigm where lightweight and effective appearance models are crucial.
2.2. Motion Models and Camera Motion Compensation in MOT
Motion prediction is fundamental to MOT, where objects’ future positions are estimated based on previous states through Bayesian estimation frameworks. Despite rapid advances in object detection, many SOTA end-to-end MOT models still underperform compared to classical motion model-based approaches, highlighting the continued importance of effective motion modeling.
Current Motion Models and Their Limitations: The KF remains the dominant motion model due to its recursive predict–update cycle and computational efficiency. Representative methods include SORT [] with linear motion assumptions, ByteTrack [] that balances detection quality and tracking confidence, and OC-SORT [] that enhances robustness in nonlinear scenarios. Alternative approaches include optical flow-based models [], LSTM-based sequential models [], transformer-based long-term dependency models [], and graph-based implicit motion estimation []. However, these methods share critical limitations:
- Image plane constraint: Traditional motion models operate in 2D image coordinates, failing to capture true 3D object motion on the ground plane;
- Camera motion interference: Camera movement introduces pseudo-motion artifacts that severely degrade motion prediction accuracy;
- Computational complexity: Advanced models (LSTM, Transformer, graph-based) require extensive computational resources and labeled data, compromising real-time performance.
Camera Motion Compensation Challenges: To address camera-induced motion artifacts, existing camera motion compensation (CMC) methods [,,] employ techniques such as ORB feature matching [] or Enhanced Correlation Coefficient (ECC) maximization []. These approaches fall into two categories: (1) offline methods that pre-compute affine transformations but lack adaptability, and (2) online methods that provide better adaptation but impose significant computational overhead. Recent CMC frameworks [] leverage temporal–spatial structures but require pre-provided background models, limiting generalization to new scenes. Critically, current CMC techniques struggle with high-frame-rate, high-resolution videos due to computational constraints, hindering real-time MOT applications.
Fundamental Problem: Existing motion models suffer from a fundamental mismatch between the 2D image plane representation and the 3D ground plane reality of object motion. This discrepancy is exacerbated by camera motion, which introduces complex nonlinear distortions that cannot be effectively handled by traditional image-based KF or computationally expensive compensation methods.
Our proposed CMC-GP module addresses these limitations through a paradigm shift: projecting motion estimation from image plane to ground plane. This approach offers several key advantages: (1) Ground-truth motion modeling: Eliminates camera-induced pseudo-motion by operating in the actual motion space. (2) Efficient compensation: Achieves camera motion compensation through geometric projection rather than expensive feature matching. (3) Correlation modeling: Captures inherent spatial correlations in ground plane motion through non-diagonal noise covariance matrices. And (4) real-time performance: Maintains computational efficiency suitable for real-time applications. Unlike existing methods that treat camera motion as a post-processing correction, CMC-GP fundamentally reformulates the motion estimation problem in the appropriate coordinate system, providing both theoretical elegance and practical effectiveness.
3. Method
In this section, we introduce two key improvements of DCTrack that address fundamental challenges in multi-object tracking: the DA-BIN module for cross-domain generalization and the CMC-GP module for camera motion compensation.
The DA-BIN module tackles the domain shift problem in ReID models by dynamically balancing BN and IN through a learnable parameter . By simulating failure scenarios during training with three complementary loss functions, DA-BIN enhances model generalization to unknown target domains without requiring additional data.
The CMC-GP module addresses camera motion interference by projecting traditional image plane KF to the ground plane. This approach eliminates pseudo-motion artifacts caused by camera movement and models spatial motion correlations through a non-diagonal noise covariance matrix, significantly improving tracking accuracy in dynamic camera scenarios.
DCTrack follows the TBD paradigm. The complete pipeline of DCTrack is shown in Figure 2 and Algorithm 1. The tracking process operates as follows: For each frame, detections are first separated by confidence scores, then DA-BIN extracts appearance features for high-confidence detections while CMC-GP predicts track locations on the ground plane. Two-stage association is performed using IoU and embedding distances, followed by track updates with non-diagonal noise modeling and initialization of new tracks with ground plane KF.
| Algorithm 1 Pseudo-code of DCTrack | |
| 1: Input: A video sequence V; object detector ; appearance feature extractor ; high detection score threshold ; new track score threshold ; camera parameters A | |
| 2: Output: Tracks of the video | |
| 3: Initialization: | |
| 4: for frame in V do | |
| 5: | ▹ Handle new detections |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
| 10: for d in do | |
| 11: if then | |
| 12: | ▹ Store high scores detections |
| 13: | |
| 14: | ▹ Extract appearance features using DA-BIN |
| 15: | ▹ Equation (1): hybrid BN-IN |
| 16: else | |
| 17: | ▹ Store low scores detections |
| 18: | |
| 19: end if | |
| 20: end for | |
| 21: | ▹ Find warp matrix from k-1 to k |
| 22: | |
| 23: | ▹ Predict new locations of tracks using CMC-GP |
| 24: for t in do | |
| 25: | ▹ Standard prediction |
| 26: | ▹ CMC-GP Equations (11)–(15) |
| 27: end for | |
| 28: | ▹ First association |
| 29: | |
| 30: | |
| 31: | |
| 32: Linear assignment by Hungarian’s alg. with | |
| 33: remaining object boxes from | |
| 34: remaining tracks from | |
| 35: | ▹ Second association |
| 36: | |
| 37: Linear assignment by Hungarian’s alg. with | |
| 38: remaining tracks from | |
| 39: | ▹ Update matched tracks using CMC-GP |
| 40: Update matched tracklets Kalman filter | ▹ with non-diagonal Equation (14) |
| 41: Update tracklets appearance features | ▹ using DA-BIN features Equation (1) |
| 42: | ▹ Delete unmatched tracks |
| 43: | |
| 44: | ▹ Initialize new tracks with CMC-GP |
| 45: for d in do | |
| 46: if then | |
| 47: | ▹ Initialize on ground plane Equation (11) |
| 48: end if | |
| 49: end for | |
| 50: | ▹ Cascaded offline post-processing |
| 51: | |
| 52: end for | |
| 53: Return: | |
| In red are the key modules of our method. | |
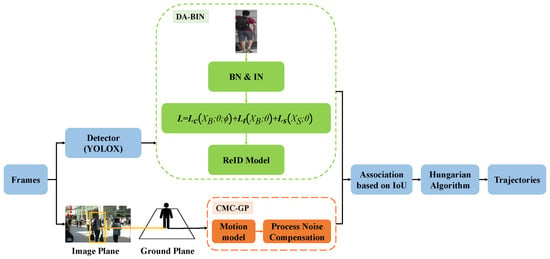
Figure 2.
The pipeline of our DCTrack.
3.1. DA-BIN:Appearance Enhancement Model Based on Domain Adaptation
The core problem faced by ReID models in MOT tasks is domain shift: statistical distribution differences exist between source domain and target domain. The multi-subsequence nature of MOT datasets exacerbates this issue, as not only do source and target domains have inconsistent distributions, but different subsequences within the target domain also exhibit varying statistical properties.
To tackle this core problem, this paper proposes the DA-BIN module with three key contributions: (1) designing a BN-IN hybrid module with learnable balancing parameters that dynamically balances batch statistics and instance statistics; (2) innovatively introducing failure scenario simulation training to actively explore overfitting/underfitting boundaries; and (3) proposing intra-domain scattering loss to enhance source domain distribution coverage through feature dispersion. This method significantly improves cross-domain generalization without requiring additional data.
The DA-BIN module is formulated as follows:
where y represents the BN-and-IN hybrid module output, is the learnable balance parameter, are the affine parameters for the BN layer, and serve the same purpose for the IN layer. is the batch-normalized features, and is the instance-normalized features.
Dynamic Adjustment of Balance Parameter : The balance parameter is updated through standard backpropagation with specific gradient flow designed to explore domain adaptation boundaries. The gradient of concerning the total loss is determined by calculating
The parameter update follows the following:
where is the learning rate. The key insight is that different loss components drive in different directions:
- encourages toward values that maximize classification accuracy;
- with hard negatives pushes toward IN () to simulate overfitting scenarios;
- promotes toward BN () when domain diversity is needed.
To ensure remains in , we apply sigmoid activation: , where is the unconstrained parameter.
However, balancing BN and IN through learnable parameters can lead to over-adaptation to the source domain style. To solve this, we use three loss functions to update the model while simulating unsuccessful scenarios during training.
First, we use cross-entropy loss for target identity learning:
where represents the mini-batch samples, represents the balance parameter, represents the classifier parameters, is the batch size, is the i-th sample, is its label, is the feature extractor, is the classifier, and is the cross-entropy function.
Second, we employ triplet loss to simulate generalization failures by inducing the balancing parameter towards IN (examining overfitting) and towards BN (exploring underfitting):
Failure Scenario Simulation Mechanism: The triplet loss is designed to deliberately create challenging scenarios:
- When hard negative mining selects very similar inter-class samples, the gradient tends to be positive, pushing toward 0 (more IN), simulating overfitting to instance-specific features;
- When positive samples are diverse within the same identity, the gradient tends to be negative, pushing toward 1 (more BN), exploring potential underfitting to batch statistics;
- This creates a dynamic exploration of the space, preventing the model from settling into suboptimal local minima.
Where is the triplet loss function, is the anchor feature vector, and are the hardest positive and negative features in the mini-batch, is the Euclidean distance, m is the margin parameter, and .
Third, to enhance intra-domain diversity and extend the source domain feature distribution, we introduce the intra-domain scattering loss:
where is the mean feature vector of domain p in the mini-batch, is the number of source domains, is the number of samples in domain p, is the total number of samples, and represents cosine similarity.
The total loss function combines all three components:
where and are weighting coefficients to balance the three loss functions.
Training Dynamics and Convergence: During training, exhibits the following behavior patterns:
- Early stage: oscillates significantly as the model explores different BN-IN combinations;
- Middle stage: gradually stabilizes but maintains sensitivity to hard samples;
- Late stage: converges to domain-specific optimal values while retaining adaptability.
The convergence pattern indicates successful boundary exploration without overfitting to any single normalization strategy.
Through this multi-objective optimization, we induce parameter bias via three loss functions. By simulating unsuccessful target ReID scenarios during parameter updates, we extend the source domain’s feature distribution and enhance the model’s generalization to unknown target domains.
3.2. CMC-GP: Camera Motion Compensation Model on Ground Plane
Traditional KF-based tracking operates in the image plane, where camera motion introduces pseudo-motion that degrades tracking accuracy. To address this fundamental limitation, this paper proposes the CMC-GP module with key innovations: (1) projecting KF from image plane to ground plane to eliminate camera-induced pseudo-motion interference; (2) designing non-diagonal measurement noise covariance matrix to model spatial correlations in ground motion; (3) integrating camera parameters through Jacobian transformation for accurate noise propagation. This method significantly improves tracking precision in moving camera scenarios.
In traditional image plane tracking, the KF uses the following formulation:
where are the horizontal and vertical coordinates of the BBox in the image plane, is the aspect ratio (width-to-height) of the BBox, is the height of the BBox, and and represent the corresponding rate of change. are the process noise factors, and is the measurement noise factor.
To minimize motion estimation deviations, we estimate object motion directly on the ground plane. Based on the linear camera model [], the mapping relationship between the ground-truth coordinates and the image plane coordinates can be expressed as
where denotes the projection matrix, which is the product of the camera’s internal and external parameters:
where is the camera intrinsic matrix, is the rotation matrix, and is the translation vector.
Ground Plane Projection: Our method transforms the traditional 8-dimensional image state into a simplified 4-dimensional ground state by mapping from the image plane to the ground plane. This projection eliminates camera motion artifacts while preserving essential motion dynamics.
The transformed state vector, measurement vector, and covariance matrices for ground plane tracking are
Non-diagonal Noise Modeling: The key innovation lies in the non-diagonal measurement noise covariance matrix , which captures the inherent correlations between lateral and longitudinal movements on the ground plane:
where is the Jacobian matrix describing the sensitivity of image coordinates to ground plane coordinates:
where and are the ground plane coordinates, and are their velocities.
Correlation Modeling Significance: The non-diagonal matrix shows that measurement noise in different dimensions is correlated. Object motion patterns on the ground plane are often intrinsically linked, as lateral and longitudinal movements can be affected by common disturbances like camera rotation or translation. By reflecting this correlation in , the KF can more accurately represent the statistical properties of measurement noise. This allows for a better handling of uncertainties during data association. Our CMC-GP module leverages the non-diagonal properties of for more precise object association. Specifically, by considering the correlation of measurement noise, the KF can more accurately estimate an object’s position and velocity on the ground plane, improving trajectory prediction. This is crucial when the camera is in motion, as it can introduce extra noise and uncertainties.
4. Experiments
4.1. Implementation Details
Our ReID model employed ResNet50 [] backbone with an additional fully connected layer, trained exclusively on Market1501 [] for 60 epochs without MOT dataset enhancement. We used SGD optimizer (momentum = 0.9) with learning rate reduction at epochs 20 and 40, achieving 86.3% rank-1 accuracy on Market1501. All experiments used a YOLOX [] detector with identical configurations across all datasets. Lost tracks were retained for 30 frames for potential re-association. Experiments were run on Intel i9-10900X CPU and NVIDIA RTX3090 GPU with Ubuntu 20.04, CUDA 11.6, and PyTorch 1.13.1.
4.2. Datasets
We evaluated on three challenging MOT benchmarks:
DanceTrack: Features similar appearances and irregular movements in dance scenarios, emphasizing data association over detection. Contains 100 videos (40 train, 25 validation, 35 test) with 105,834 total frames.
MOT20: Focuses on extremely dense crowds (up to 246 people per frame), testing tracking robustness in frequent occlusion scenarios. Contains 8 videos with 13,410 frames total (4 train, 4 test). Training follows the same split strategy as DanceTrack.
MOT17: A standard MOT benchmark with 28 sequences (14 train, 14 test) containing 11,235 frames. Each sequence provides three detector variants (DPM, FRCNN, SDP). We apply consistent training/validation splits across all variants.
4.3. Evaluation Metrics
We employed three standard MOT metrics:
HOTA []: Higher-Order Tracking Accuracy balancing detection accuracy (DetA), association accuracy (AssA), and localization precision. Primary evaluation metric.
MOTA []: Multiple-Object Tracking Accuracy measuring detection errors (FP, FN) and IDSW. Higher values indicate better performance.
IDF1 []: Identity F-Score evaluating the proportion of correctly identified detections, emphasizing tracking continuity and ReID accuracy.
4.4. Benchmark Results
DCTrack achieves SOTA performance across all three datasets, demonstrating superior accuracy while maintaining real-time efficiency. Despite incorporating ReID computation, our method remains practical for real-world MOT applications. The best results are highlighted in bold, with ↑/↓ indicating performance direction.
The DanceTrack is characterized by irregular object motions and similar appearances, which can cause identity confusion errors in appearance-based tracking methods and challenge motion-based methods to handle motion changes. As shown in Table 1 with DanceTrack, DCTrack achieves a 5.1% improvement in the HOTA metric over Hybrid-SORT, mainly due to the synergy of the DA-BIN and CMC-GP modules. The DA-BIN module enhances the generalization of ReID models across domains by simulating domain shift scenarios. On DanceTrack, where objects have similar appearances and complex motion patterns, models are prone to domain differences. DA-BIN combines BN and IN with a learnable balance parameter, enabling models to better adapt to varying appearance distributions and reducing misassociation due to similar object appearances. This improves identity association accuracy. The CMC-GP module addresses motion estimation deviations from camera movements by performing camera motion compensation on the ground plane. On DanceTrack, camera movements can significantly change object projection positions on the image plane, increasing motion estimation difficulty. CMC-GP uses a KF to simulate object motion on the ground plane and employs unified compensation parameters for more accurate object position prediction. This reduces trajectory prediction errors caused by camera movements and boosts the model’s robustness in handling irregularly moving objects.

Table 1.
Comparison of our method with other SOTA algorithms on DanceTrack. The best results are shown in bold.
As shown in Table 2 with the MOT20 dataset, DCTrack achieves a 2.5% increase in HOTA metric compared to SMILEtrack. MOT20 is known for its extremely high target density and frequent occlusions. The DA-BIN module enhances to distinguish different targets in high-density scenarios by improving its adaptation to varying appearance features across domains. The CMC-GP module reduces trajectory crossing and identity confusion errors caused by dense target motion through more accurate motion estimation. Consequently, the tracking performance is enhanced.
Table 2.
Comparison of our method with other SOTA algorithms on MOT20. The best results are shown in bold.
For MOT17, DCTrack also surpasses SMILEtrack in key metrics. As shown in Table 3 with MOT17, object motion patterns are highly linear, yet occlusions and interactions between objects still occur. The DA-BIN module enhances the model’s generalization ability, enabling it to better handle appearance changes across different scenarios. The CMC-GP module ensures trajectory continuity and stability in long-sequence tracking through effective camera motion compensation, reducing ID switches and fragmented trajectories.
Table 3.
Comparison of our method with other SOTA algorithms on MOT17. The best results are shown in bold.
4.5. Ablation Studies
To validate the impact of the DA-BIN module and the CMC-GP module on tracking performance and quantify the contributions of each module, we conducted comprehensive ablation experiments on DanceTrack, MOT20, and MOT17, as shown in Table 4.
Table 4.
Each component of our method is ablated and compared on DanceTrack, MOT20, and MOT17. DA-BIN = Domain Adaptation-based Batch Instance Normalization. CMC-GP = camera motion compensation on ground plane. The best results are shown in bold.
We designed four experimental configurations:
- Method A: Baseline method without proposed modules;
- Method B: Baseline + CMC-GP module only;
- Method C: Baseline + DA-BIN module only;
- Method D: Baseline + both DA-BIN and CMC-GP modules (DCTrack).
DA-BIN Module Analysis: Comparing Method A with Method C reveals significant performance improvements: on DanceTrack, there is a +5.7 HOTA, +1.3 MOTA, and +3.7 IDF1 boost; on MOT20, a +2.9 HOTA, +1.1 MOTA, and +2.2 IDF1 improvement; and on MOT17, a +3.1 HOTA, +0.9 MOTA, and +4.3 IDF1 gain. The results highlight the module’s positive impact on tracking performance. Notably, on DanceTrack, irregular motion and dense occlusions create many low-scoring boxes in crowded scenes, making the use of limited appearance features critical. Our method achieves a remarkable +5.7 boost in HOTA. The experimental results demonstrate that the DA-BIN module enhances the appearance model’s generalization ability on MOT datasets, thereby improving the tracker’s overall performance.
CMC-GP Module Analysis: Comparing Method A with Method B reveals the following performance improvements: on DanceTrack, there are gains of +0.9 HOTA, +0.8 MOTA, and +1.1 IDF1; on MOT20, improvements of +2.2 HOTA, +0.5 MOTA, and +1.6 IDF1 are seen; and on MOT17, enhancements of +2.4 HOTA, +0.4 MOTA, and +2.1 IDF1 are observed. These results demonstrate our CMC-GP module’s positive impact on tracking performance. In particular, on MOT17, sequences 05, 10, 11, and 13 involve significant camera motion. Our proposed method achieves a +2.4 boost in HOTA, indicating that the CMC-GP module effectively addresses motion estimation deviations, thereby improving tracker accuracy and stability. Although DanceTrack sequences do not exhibit significant viewpoint changes, our CMC-GP module still leads to performance improvements, showing its effectiveness even with minor camera jitter.
Combined Module Analysis: Finally, we analyzed the joint impact of the DA-BIN and CMC-GP. By comparing Method A with Method D, we observe improvements across all three metrics on the three validation datasets. Specifically, the HOTA metric shows significant improvements of +7.1 on DanceTrack, +5.6 on MOT20, and +4.7 on MOT17. The ablation studies demonstrate that DCTrack can significantly enhance MOT results through the complementary effects of both modules.
As shown in Table 5, we explored the impact of CMC on DCTrack across three datasets. Our CMC-GP outperforms traditional CMC in all cases, with better efficiency due to using unified compensation parameters instead of per-frame compensation, which reduces computational overhead. When applied to DCTrack, CMC-GP consistently boosted performance on MOT20 and MOT17. However, on DanceTrack, traditional CMC caused a performance drop due to minimal viewpoint changes between frames, leading to incorrect trajectory matches from slight object movements. In contrast, CMC-GP showed greater robustness to minor object movements, demonstrating the effectiveness of our ground plane-based approach over conventional frame-by-frame compensation methods.
Table 5.
Comparison between our method and CMC method on DanceTrack, MOT20, and MOT17. The best results are shown in bold.
Analysis of the Balancing Parameter : A key parameter in the DA-BIN module for balancing BN and IN weights, is dynamically adjusted via a loss function with three components: cross-entropy loss for target identity learning, triplet loss for similarity learning, and intra-domain scattering loss for enhancing domain diversity. Early in training, is driven by due to the model’s poor adaptation to the source domain, gradually shifting toward IN. As training progresses and the model adapts to the source style, and become more influential. improves feature discrimination by similarity learning, pushing toward BN. increases intra-domain diversity, preventing overfitting to the source style and dynamically adjusting between BN and IN.
4.6. Visualization Results
We conducted a qualitative analysis to demonstrate the effectiveness of our proposed modules. Figure 3 shows frames 189–192 from the dancetrack0008 dataset under severe occlusion conditions, and Figure 4 shows frames 287–290 from the same dataset under dense occlusion conditions. In both figures, group (a) represents the baseline algorithm and group (b) represents our DCTrack algorithm.

Figure 3.
Comparison between our algorithm and the baseline algorithm under severe occlusion conditions. (a) Baseline algorithm (ByteTrack) on the left; (b) our DCTrack algorithm on the right.

Figure 4.
Comparison between our algorithm and the baseline algorithm under dense occlusion conditions. (a) Baseline algorithm (ByteTrack) on the left; (b) our DCTrack algorithm on the right.
Severe Occlusion Analysis: As shown in the 190th frame of Figure 3, severe occlusion occurs between tracking targets ID 1 and 8, as well as ID 2 and 3, with targets 3 and 8 having visibility of less than 0.2. Our method, utilizing the DA-BIN module, fully exploits appearance features for severely occluded targets, allowing the tracker to continue matching trajectories accurately. In contrast, the baseline algorithm fails to handle severe occlusion effectively, causing targets 3 and 8 to lose matching opportunities. The results show that our DCTrack greatly boosts the tracker’s capacity to manage severe occlusion by optimally utilizing limited appearance features.
These visualization results validate the complementary effects of DA-BIN and CMC-GP modules: DA-BIN enhances appearance-based matching under severe occlusion through improved cross-domain generalization, while CMC-GP maintains accurate motion prediction in camera motion scenarios, together providing robust tracking performance in challenging conditions.
Dense Occlusion Analysis: In the densely occluded scenario shown in the 288th frame of Figure 4, frequent object movement, interaction, and occlusion generate numerous low-confidence detections. The CMC-GP module reduces motion estimation errors caused by camera movement, while the DA-BIN module recovers the correct IDs of targets, boosting accurate tracking of low-confidence detections affected by camera motion. The baseline algorithm, which matches all trajectories simultaneously without properly handling dense occlusion, causes incorrect tracking of targets 4 and 6 and loses target 7. The results show that our proposed MOT method, combining domain adaptation and camera motion compensation, increases target matching likelihood in dense occlusion scenarios and reduces identity switches caused by occlusion.
In Figure 5, we analyze the distribution ratio of the balancing parameter, based on experiments conducted on DanceTrack. All balancing parameters are initialized to 1, favoring BN. It can be observed that retains BN characteristics, with only a few shifting toward IN. This shift improves performance, proving that eliminating irrelevant information on source domain style enhances generalization. Specifically, DA-BIN shows that in middle and shallow layers, shifting slightly toward IN effectively reduces overfitting and boosts generalization.
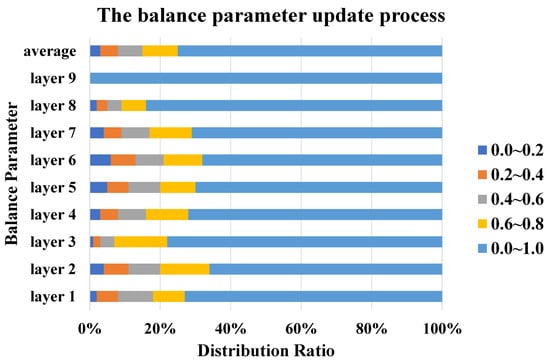
Figure 5.
Analysis of the distribution ratio of balancing parameters in each layer.
In Figure 6, the cross-entropy loss function creates a positive gradient, pushing toward IN. The triplet loss function generates a negative gradient, pulling toward BN. The intra-domain scattering loss function enables dynamic adjustment of between BN and IN. We demonstrate that training via the total loss function guides movement in specific directions. This means that simulating unsuccessful generalization scenarios in advance can enhance the tracker’s overall performance, as shown in Table 4.
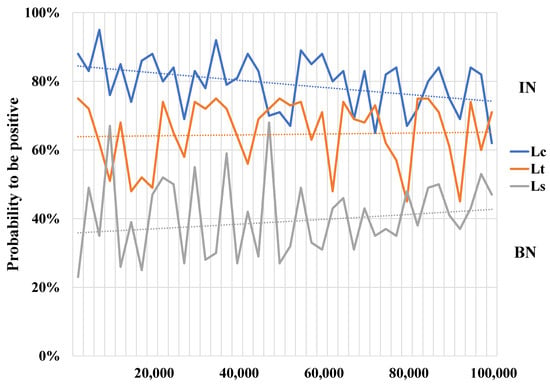
Figure 6.
Analysis of the gradient change in loss function during training.
Limitations and Applicability: While CMC-GP significantly improves tracking accuracy for ground-based scenarios, it relies on the ground plane assumption. The method is designed for typical MOT applications where objects move on relatively flat surfaces, such as pedestrian and vehicle tracking in urban environments. For scenarios involving aerial targets (e.g., UAVs) or significant height changes (e.g., staircases), traditional image plane tracking would be more appropriate. Current MOT benchmarks (MOT17, MOT20, DanceTrack) inherently satisfy this assumption, validating our approach for mainstream tracking applications.
5. Conclusions
This work addresses two fundamental challenges in multi-object tracking: domain adaptation failures in appearance models and camera motion interference in motion estimation. Our DCTrack framework introduces paradigmatic solutions through two key innovations. First, the DA-BIN module revolutionizes domain adaptation by actively simulating failure scenarios during training. Through dynamic balancing of BN and IN with multi-objective optimization, DA-BIN achieves superior cross-domain generalization without additional training data. And second, the CMC-GP module transforms motion estimation by projecting KF from image coordinates to ground plane coordinates. This geometric reformulation eliminates camera-induced pseudo-motion while modeling spatial correlations through non-diagonal noise covariance matrices. Results show SOTA performance across three benchmarks (DanceTrack: 67.3% HOTA, MOT20: 66.9% HOTA, MOT17: 67.8% HOTA) while maintaining real-time capability using only standard ReID training data. Our approach establishes new paradigms for domain adaptation and motion compensation with broader implications for computer vision applications involving cross-domain deployment and camera motion.
Author Contributions
Conceptualization, Y.Z.; Methodology, Y.Z.; Software, Y.Z.; Validation, Y.Z.; Formal analysis, Y.Z. and H.Z.; Investigation, H.Z.; Resources, H.Z.; Data curation, H.Z.; Writing—original draft, Y.Z.; Writing—review and editing, Y.Z. and F.D.; Supervision, F.D.; Project administration, F.D.; Funding acquisition, F.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China under Grant 51475092. And supported by the Jiangsu province frontier leading technology basic research project under Grant BK20192004C.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflict of interest. Although one of the affiliations includes a company, the authors confirm that the company had no role in the design, execution, interpretation, or writing of the study.
References
- Yi, K.; Luo, K.; Luo, X.; Huang, J.; Wu, H.; Hu, R.; Hao, W. Ucmctrack: Multi-object tracking with uniform camera motion compensation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 6702–6710. [Google Scholar]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-centric sort: Rethinking sort for robust multi-object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9686–9696. [Google Scholar]
- Zeng, F.; Dong, B.; Zhang, Y.; Wang, T.; Zhang, X.; Wei, Y. Motr: End-to-end multiple-object tracking with transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 659–675. [Google Scholar]
- Bai, H.; Cheng, W.; Chu, P.; Liu, J.; Zhang, K.; Ling, H. Gmot-40: A benchmark for generic multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6719–6728. [Google Scholar]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. Poi: Multiple object tracking with high performance detection and appearance feature. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part II 14. Springer: Cham, Switzerland, 2016; pp. 36–42. [Google Scholar]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.Z. Bot-sort: Robust associations multi-pedestrian tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Zhao, Y.; Zhong, Z.; Yang, F.; Luo, Z.; Lin, Y.; Li, S.; Sebe, N. Learning to generalize unseen domains via memory-based multi-source meta-learning for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6277–6286. [Google Scholar]
- Guo, X.; Zheng, Y.; Wang, D. PMTrack: Multi-object Tracking with Motion-Aware. In Proceedings of the Asian Conference on Computer Vision, Hanoi, Vietnam, 8–12 December 2024; pp. 3091–3106. [Google Scholar]
- Han, S.; Huang, P.; Wang, H.; Yu, E.; Liu, D.; Pan, X. Mat: Motion-aware multi-object tracking. Neurocomputing 2022, 476, 75–86. [Google Scholar] [CrossRef]
- Sun, P.; Cao, J.; Jiang, Y.; Yuan, Z.; Bai, S.; Kitani, K.; Luo, P. Dancetrack: Multi-object tracking in uniform appearance and diverse motion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20993–21002. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. Mot20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning discriminative features with multiple granularities for person re-identification. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 274–282. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards real-time multi-object tracking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 107–122. [Google Scholar]
- Xu, Y.; Osep, A.; Ban, Y.; Horaud, R.; Leal-Taixé, L.; Alameda-Pineda, X. How to train your deep multi-object tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision And pattern Recognition, Seattlw, WA, USA, 13–19 June 2020; pp. 6787–6796. [Google Scholar]
- Lu, Z.; Rathod, V.; Votel, R.; Huang, J. Retinatrack: Online single stage joint detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14668–14678. [Google Scholar]
- Yu, E.; Li, Z.; Han, S.; Wang, H. Relationtrack: Relation-aware multiple object tracking with decoupled representation. IEEE Trans. Multimed. 2022, 25, 2686–2697. [Google Scholar] [CrossRef]
- Peng, J.; Wang, C.; Wan, F.; Wu, Y.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Fu, Y. Chained-tracker: Chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer: Cham, Switzerland, 2020; pp. 145–161. [Google Scholar]
- Wang, Q.; Zheng, Y.; Pan, P.; Xu, Y. Multiple object tracking with correlation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3876–3886. [Google Scholar]
- Zhuang, Z.; Wei, L.; Xie, L.; Zhang, T.; Zhang, H.; Wu, H.; Ai, H.; Tian, Q. Rethinking the distribution gap of person re-identification with camera-based batch normalization. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII 16. Springer: Cham, Switzerland, 2020; pp. 140–157. [Google Scholar]
- Schneider, S.; Rusak, E.; Eck, L.; Bringmann, O.; Brendel, W.; Bethge, M. Improving robustness against common corruptions by covariate shift adaptation. Adv. Neural Inf. Process. Syst. 2020, 33, 11539–11551. [Google Scholar]
- Chang, W.G.; You, T.; Seo, S.; Kwak, S.; Han, B. Domain-specific batch normalization for unsupervised domain adaptation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7354–7362. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: New York, NY, USA, 2016; pp. 3464–3468. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Zhang, J.; Zhou, S.; Chang, X.; Wan, F.; Wang, J.; Wu, Y.; Huang, D. Multiple object tracking by flowing and fusing. arXiv 2020, arXiv:2001.11180. [Google Scholar]
- Chaabane, M.; Zhang, P.; Beveridge, J.R.; O’Hara, S. Deft: Detection embeddings for tracking. arXiv 2021, arXiv:2102.02267. [Google Scholar]
- Qin, Z.; Zhou, S.; Wang, L.; Duan, J.; Hua, G.; Tang, W. Motiontrack: Learning robust short-term and long-term motions for multi-object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17939–17948. [Google Scholar]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 941–951. [Google Scholar]
- Stadler, D.; Beyerer, J. Modelling ambiguous assignments for multi-person tracking in crowds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 133–142. [Google Scholar]
- Du, Y.; Wan, J.; Zhao, Y.; Zhang, B.; Tong, Z.; Dong, J. Giaotracker: A comprehensive framework for mcmot with global information and optimizing strategies in visdrone 2021. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, USA, 11–17 October 2021; pp. 2809–2819. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: New York, NY, USA, 2011; pp. 2564–2571. [Google Scholar]
- Evangelidis, G.D.; Psarakis, E.Z. Parametric image alignment using enhanced correlation coefficient maximization. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1858–1865. [Google Scholar] [CrossRef] [PubMed]
- Yeh, C.H.; Lin, C.Y.; Muchtar, K.; Lai, H.E.; Sun, M.T. Three-pronged compensation and hysteresis thresholding for moving object detection in real-time video surveillance. IEEE Trans. Ind. Electron. 2017, 64, 4945–4955. [Google Scholar] [CrossRef]
- Yu, J.; McMillan, L. General linear cameras. In Proceedings of the Computer Vision-ECCV 2004: 8th European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; Proceedings, Part II 8. Springer: Berlin/Heidelberg, Germany, 2004; pp. 14–27. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Wang, Y.H.; Hsieh, J.W.; Chen, P.Y.; Chang, M.C.; So, H.H.; Li, X. Smiletrack: Similarity learning for occlusion-aware multiple object tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 5740–5748. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2016; pp. 17–35. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 474–490. [Google Scholar]
- Sun, P.; Cao, J.; Jiang, Y.; Zhang, R.; Xie, E.; Yuan, Z.; Wang, C.; Luo, P. Transtrack: Multiple object tracking with transformer. arXiv 2020, arXiv:2012.15460. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: New York, NY, USA, 2017; pp. 3645–3649. [Google Scholar]
- Pang, J.; Qiu, L.; Li, X.; Chen, H.; Li, Q.; Darrell, T.; Yu, F. Quasi-dense similarity learning for multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 164–173. [Google Scholar]
- Yang, F.; Odashima, S.; Masui, S.; Jiang, S. Hard to track objects with irregular motions and similar appearances? Make it easier by buffering the matching space. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 4799–4808. [Google Scholar]
- Yang, M.; Han, G.; Yan, B.; Zhang, W.; Qi, J.; Lu, H.; Wang, D. Hybrid-sort: Weak cues matter for online multi-object tracking. Proc. AAAI Conf. Artif. Intell. 2024, 38, 6504–6512. [Google Scholar] [CrossRef]
- Wang, Y.; Kitani, K.; Weng, X. Joint object detection and multi-object tracking with graph neural networks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: New York, NY, USA, 2021; pp. 13708–13715. [Google Scholar]
- Zhang, Y.; Wang, T.; Zhang, X. Motrv2: Bootstrapping end-to-end multi-object tracking by pretrained object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22056–22065. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).