
MRNet: A Deep Learning Framework for Drivable Area Detection in Multi-Scenario Unstructured Roads

 , ,
, ,
Abstract
1. Introduction
- A deep learning framework based on the MRNet model is proposed for drivable area detection in a variety of unstructured road scenes, which enhances the understanding of complex road scenes.
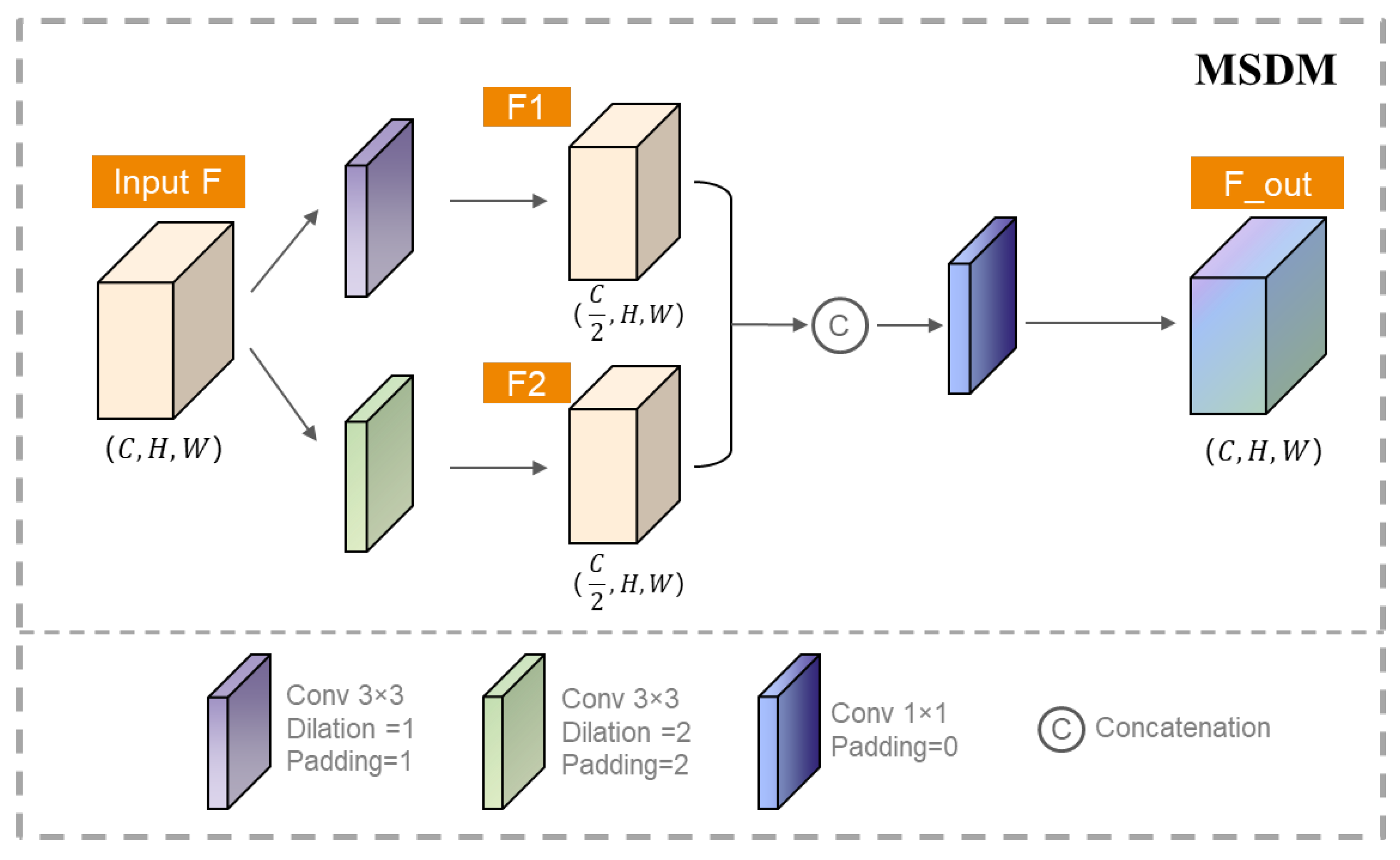
- The multi-scale dilated convolution module enables the model to capture features of different scales, so as to better adapt to complex scenes such as edge blur and rutting interference. This module significantly improves the adaptability of the model to complex scenes.
- The residual upsampling module effectively solves the gradient vanishing problem in feature fusion and further improves the segmentation accuracy. The residual upsampling mechanism learns the residual between input and output, enabling the network to propagate gradients more effectively and thereby improving training efficiency and model performance.
2. Related Work
2.1. Traditional Image Segmentation Methods
2.2. Deep Learning-Based Image Segmentation Methods
2.3. Multimodal Data Fusion Methods
3. Methods
3.1. Formulation of Drivable Area Detection Task
3.2. Methodology Overview
3.3. Surface Normal Map Generation
| Algorithm 1: Surface normal map generation. |
 |
3.4. Encoder and Decoder Design
3.5. Multi-Scale Dilated Convolution Module
3.6. Residual Upsampling Block
3.7. Loss Function
4. Experiments
4.1. Implementation Details
4.2. Datasets and Evaluation Metrics
4.3. Quantitative Evaluation
4.4. Ablation Studies
4.5. Qualitative Evaluation
5. Discussion and Conclusions
5.1. Summary of Research Contributions
5.2. Future Work Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Lyu, C.; Li, Y. A Method for All-Weather Unstructured Road Drivable Area Detection Based on Improved Lite-Mobilenetv2. Appl. Sci. 2024, 14, 8019. [Google Scholar] [CrossRef]
- Shang, E.; An, X.J.; Li, J.; Ye, L.; He, H.G. Robust Unstructured Road Detection: The Importance of Contextual Information. Int. J. Adv. Robot. Syst. 2013, 10, 179. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zhang, Y.; Sidibé, D.; Morel, O.; Mériaudeau, F. Deep multimodal fusion for semantic image segmentation: A survey. Image Vis. Comput. 2021, 105, 104042. [Google Scholar] [CrossRef]
- Alvarez, J.M.; Lopez, A.M. Road Detection Based on Illuminant Invariance. IEEE Trans. Intell. Transp. Syst. 2011, 12, 184–193. [Google Scholar] [CrossRef]
- Chen, C.C.; Lu, W.Y.; Chou, C.H. Rotational copy-move forgery detection using SIFT and region growing strategies. Multimed. Tools Appl. 2019, 78, 18293–18308. [Google Scholar] [CrossRef]
- Slavkovic, N.; Bjelica, M. Risk prediction algorithm based on image texture extraction using mobile vehicle road scanning system as support for autonomous driving. J. Electron. Imaging 2019, 28, 033034. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Wang, B.; Zhang, Y.F.; Li, J.; Yu, Y.; Sun, Z.P.; Liu, L.; Hu, D.W. SplatFlow: Learning Multi-frame Optical Flow via Splatting. Int. J. Comput. Vis. 2024, 132, 3023–3045. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.E.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.J.; Li, Y.; Bao, Y.J.; Fang, Z.W.; Lu, H.Q.; Soc, I.C. Dual Attention Network for Scene Segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar]
- Xie, E.Z.; Wang, W.H.; Yu, Z.D.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the 35th Annual Conference on Neural Information Processing Systems (NeurIPS), Electr Network, 6–14 December 2021. [Google Scholar]
- Wang, J.D.; Sun, K.; Cheng, T.H.; Jiang, B.R.; Deng, C.R.; Zhao, Y.; Liu, D.; Mu, Y.D.; Tan, M.K.; Wang, X.G.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Tian, Y.; Yao, Z.; Zhao, Y.; Zhang, T. Semantic Segmentation Network for Unstructured Rural Roads Based on Improved SPPM and Fused Multiscale Features. Appl. Sci. 2024, 14, 8739. [Google Scholar] [CrossRef]
- Min, C.; Jiang, W.Z.; Zhao, D.W.; Xu, J.L.; Xiao, L.; Nie, Y.M.; Dai, B. ORFD: A Dataset and Benchmark for Off-Road Freespace Detection. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2532–2538. [Google Scholar]
- Maiti, A.; Elberink, S.O.; Vosselman, G. TransFusion: Multi-modal fusion network for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6537–6547. [Google Scholar]
- Li, H.R.; Chen, Y.R.; Zhang, Q.C.; Zhao, D.B. BiFNet: Bidirectional Fusion Network for Road Segmentation. IEEE Trans. Cybern. 2022, 52, 8617–8628. [Google Scholar] [CrossRef]
- Fan, R.; Wang, H.; Cai, P.; Liu, M. SNE-RoadSeg: Incorporating Surface Normal Information into Semantic Segmentation for Accurate Freespace Detection. In Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Feng, Z.; Feng, Y.C.; Guo, Y.N.; Sun, Y.X. Adaptive-Mask Fusion Network for Segmentation of Drivable Road and Negative Obstacle With Untrustworthy Features. In Proceedings of the 34th IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023. [Google Scholar]
- Ni, T.; Zhan, X.; Luo, T.; Liu, W.; Shi, Z.; Chen, J. UdeerLID+: Integrating LiDAR, Image, and Relative Depth with Semi-Supervised. arXiv 2024, arXiv:2409.06197. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, Y.F.; Zhang, G.; Wang, S.Q.; Li, B.; Liu, Q.; Hui, L.; Dai, Y.C. Improving Depth Completion via Depth Feature Upsampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 21104–21113. [Google Scholar]
- Meijering, E. A chronology of interpolation: From ancient astronomy to modern signal and image processing. Proc. IEEE 2002, 90, 319–342. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Pantofaru, C.; Hebert, M. A Comparison of Image Segmentation Algorithms; Carnegie Mellon University: Pittsburgh, PA, USA, 2005. [Google Scholar]
- Powers, D.M.W. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation. arXiv 2008, arXiv:2010.16061. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-Based CNN Architecture. In Proceedings of the 13th Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, 20–24 November 2016; pp. 213–228. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title 1 | Accuracy | Precision | Recall | F1-Score | IoU | Params | Inference Time |
|---|---|---|---|---|---|---|---|
| FuseNet [35] | 0.874 | 0.745 | 0.852 | 0.795 | 0.660 | 50 M | 20.4 ms |
| SNE-RoadSeg [25] | 0.938 | 0.867 | 0.927 | 0.896 | 0.812 | 201.3 M | 80 ms |
| AMFNet [26] | 0.943 | 0.907 | 0.920 | 0.905 | 0.836 | 183.9 M | 55.6 ms |
| OFF-Net [22] | 0.946 | 0.892 | 0.942 | 0.916 | 0.845 | 25.2 M | 29.5 ms |
| MRNet | 0.957 | 0.918 | 0.923 | 0.921 | 0.853 | 29 M | 31.2 ms |
| Dataset | Weather Condition | Light Condition | ||||||
|---|---|---|---|---|---|---|---|---|
| Sunny | Rainy | Foggy | Snowy | Bright Light | Daylight | Twilight | Darkness | |
| Train | 3803 | 2434 | 1136 | 1025 | 1019 | 4254 | 927 | 2198 |
| Val | 356 | 302 | 0 | 587 | 0 | 356 | 302 | 587 |
| Test | 1071 | 405 | 720 | 359 | 362 | 709 | 359 | 1125 |
| Condition | Accuracy | Precision | Recall | F1-Score | IoU | |
|---|---|---|---|---|---|---|
| Weather | Sunny | 0.976 | 0.98 | 0.924 | 0.961 | 0.924 |
| Rainy | 0.954 | 0.871 | 0.896 | 0.879 | 0.778 | |
| Foggy | 0.946 | 0.875 | 0.942 | 0.924 | 0.861 | |
| Snowy | 0.932 | 0.869 | 0.958 | 0.883 | 0.793 | |
| Light | Bright light | 0.955 | 0.966 | 0.88 | 0.944 | 0.853 |
| Daylight | 0.977 | 0.987 | 0.914 | 0.972 | 0.936 | |
| Twilight | 0.941 | 0.869 | 0.942 | 0.884 | 0.785 | |
| Darkness | 0.955 | 0.911 | 0.927 | 0.92 | 0.857 | |
| MSDM | ResUp Block | Accuracy | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|---|---|
| - | - | 0.946 | 0.892 | 0.942 | 0.916 | 0.845 |
| √ | - | 0.952 | 0.909 | 0.915 | 0.916 | 0.852 |
| - | √ | 0.954 | 0.910 | 0.923 | 0.923 | 0.847 |
| √ | √ | 0.957 | 0.918 | 0.923 | 0.921 | 0.853 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Chen, J.; Wang, Y.; Sun, S.; Xie, H.; Wu, J.; Wang, W. MRNet: A Deep Learning Framework for Drivable Area Detection in Multi-Scenario Unstructured Roads. Electronics 2025, 14, 2242. https://doi.org/10.3390/electronics14112242
Yang J, Chen J, Wang Y, Sun S, Xie H, Wu J, Wang W. MRNet: A Deep Learning Framework for Drivable Area Detection in Multi-Scenario Unstructured Roads. Electronics. 2025; 14(11):2242. https://doi.org/10.3390/electronics14112242
Chicago/Turabian StyleYang, Jun, Jiayue Chen, Yan Wang, Shulong Sun, Haizhen Xie, Jianguo Wu, and Wei Wang. 2025. "MRNet: A Deep Learning Framework for Drivable Area Detection in Multi-Scenario Unstructured Roads" Electronics 14, no. 11: 2242. https://doi.org/10.3390/electronics14112242
APA StyleYang, J., Chen, J., Wang, Y., Sun, S., Xie, H., Wu, J., & Wang, W. (2025). MRNet: A Deep Learning Framework for Drivable Area Detection in Multi-Scenario Unstructured Roads. Electronics, 14(11), 2242. https://doi.org/10.3390/electronics14112242