Energy-Efficient Partial LDPC Decoding for NAND Flash-Based Storage Systems


Abstract
1. Introduction
2. Backgrounds
2.1. LDPC Decoding Algorithms
2.2. Quasi-Cyclic LDPC Codes
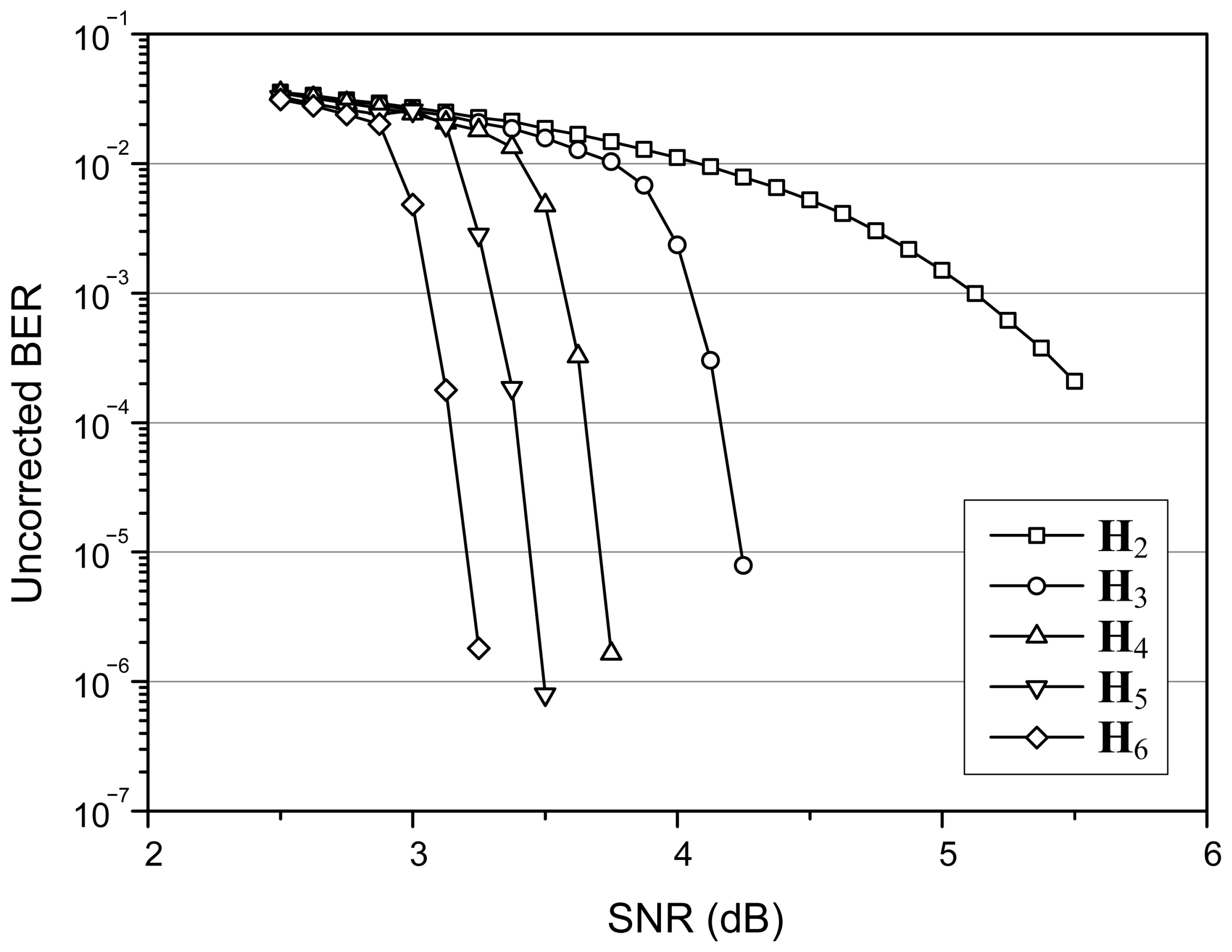
3. Proposed Partial Decoding of LDPC Codes
3.1. Construction of a Partial H-Matrix
3.2. Decoding of a Partial H-Matrix
| Algorithm 1 Partial LDPC decoding. | |
| 1: Initialization: load the initial LLR values to each variable node. | |
| 2: Iterative Decoding: Perform the following steps in accordance with the SPA or MSA. | |
| 3: for to do | ▹ Iterative decoding |
| 4: for all check nodes included in the full H, do | ▹ Syndrome check |
| 5: compute syndrome | |
| 6: end for | |
| 7: if syndromes are all zeros then | ▹ Decoding success |
| 8: report a decoding success do terminate the decoding | |
| 9: end if | |
| 10: for check nodes included in the partial H, do | ▹ Check node update |
| 11: update check nodes and generate check-to-variable node (C2V) messages | |
| 12: end for | |
| 13: for all variable nodes do H, do | ▹ Variable node update |
| 14: update LLR values and generate variable-to-check node (V2C) messages | |
| 15: end for | |
| 16: end for | |
| 17: report a decoding failure | ▹Decoding failure |
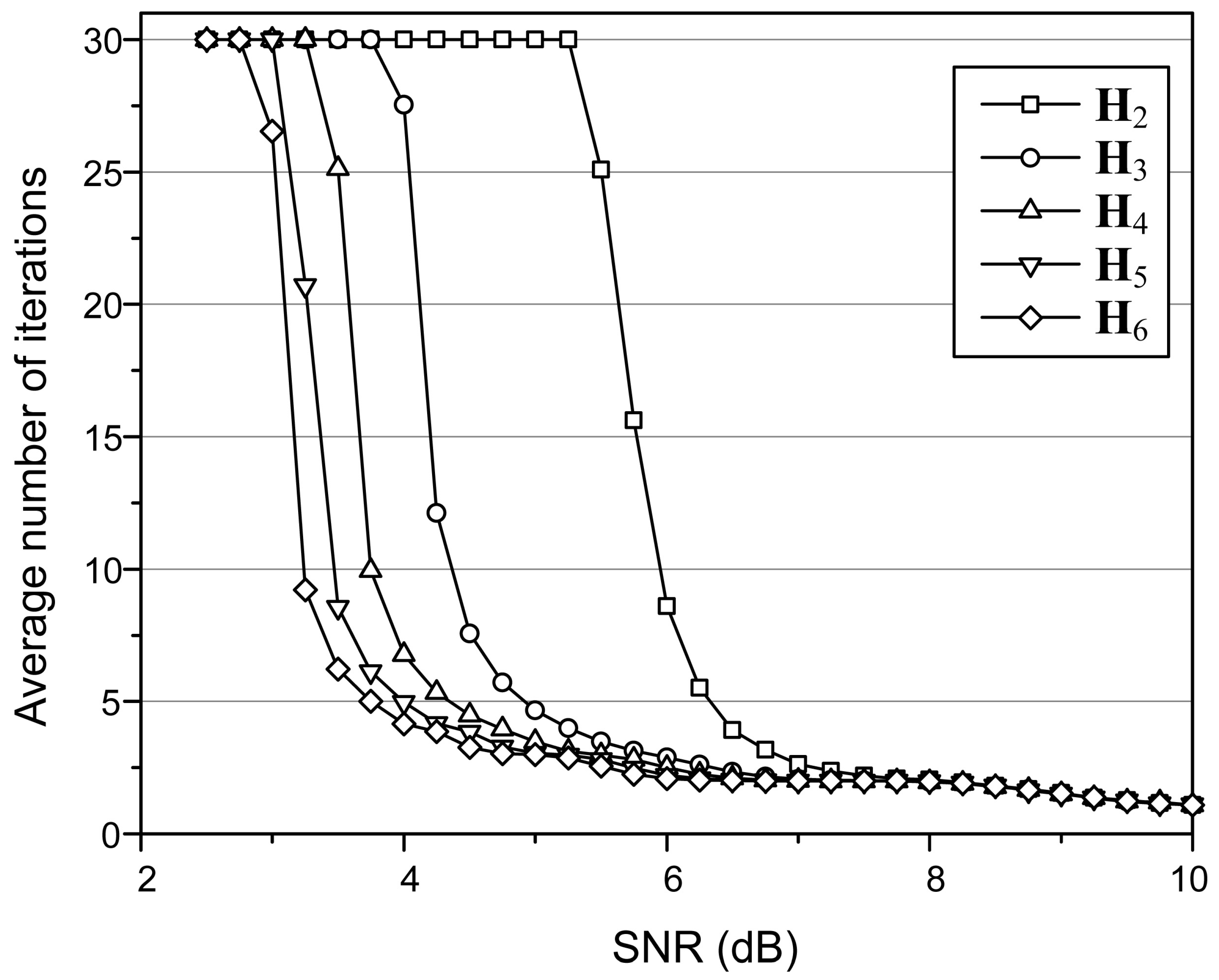
3.3. Proposed Energy-Efficient Decoding of a Partial H-Matrix
| Algorithm 2: Energy-efficient LDPC decoding. |
|
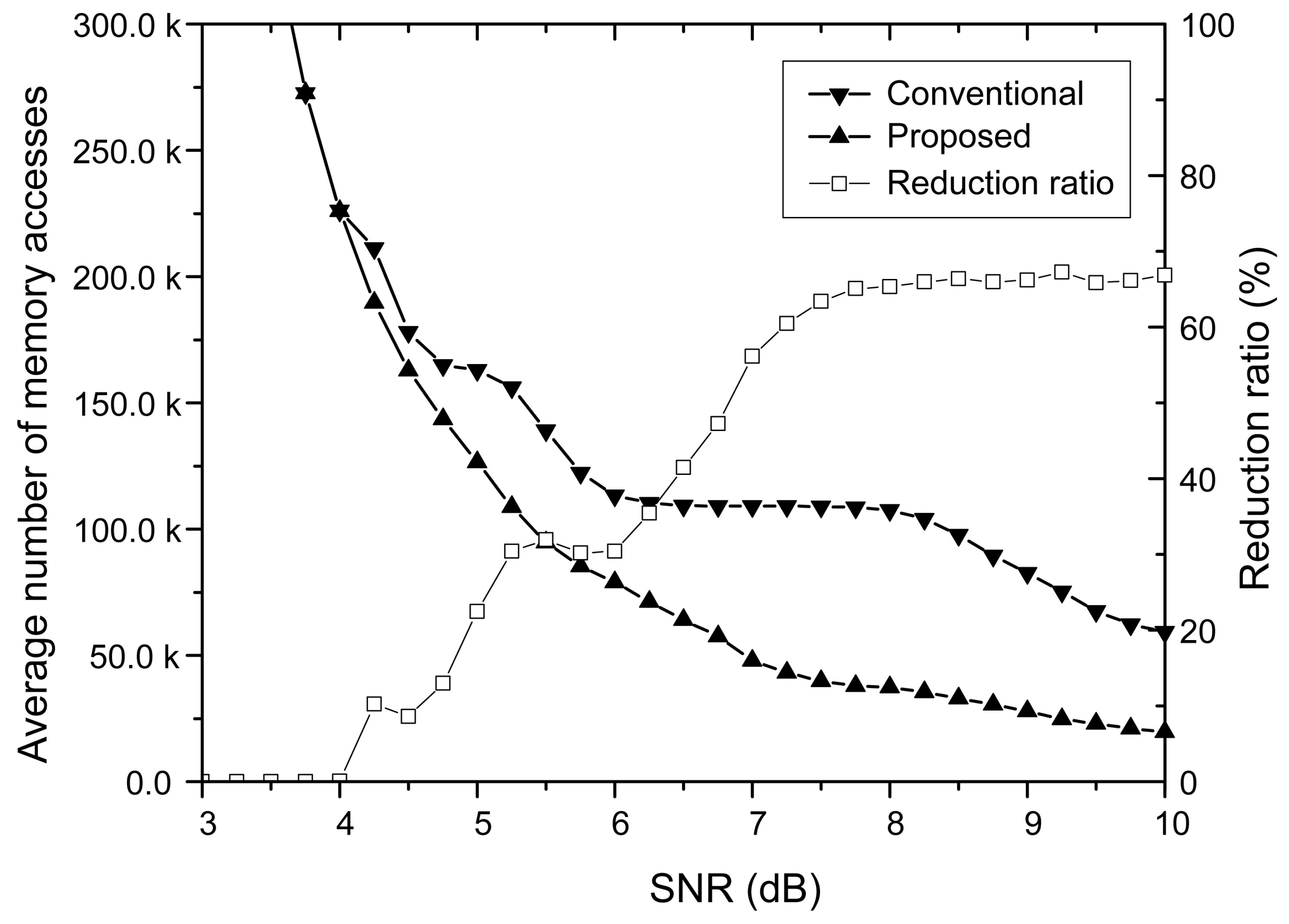
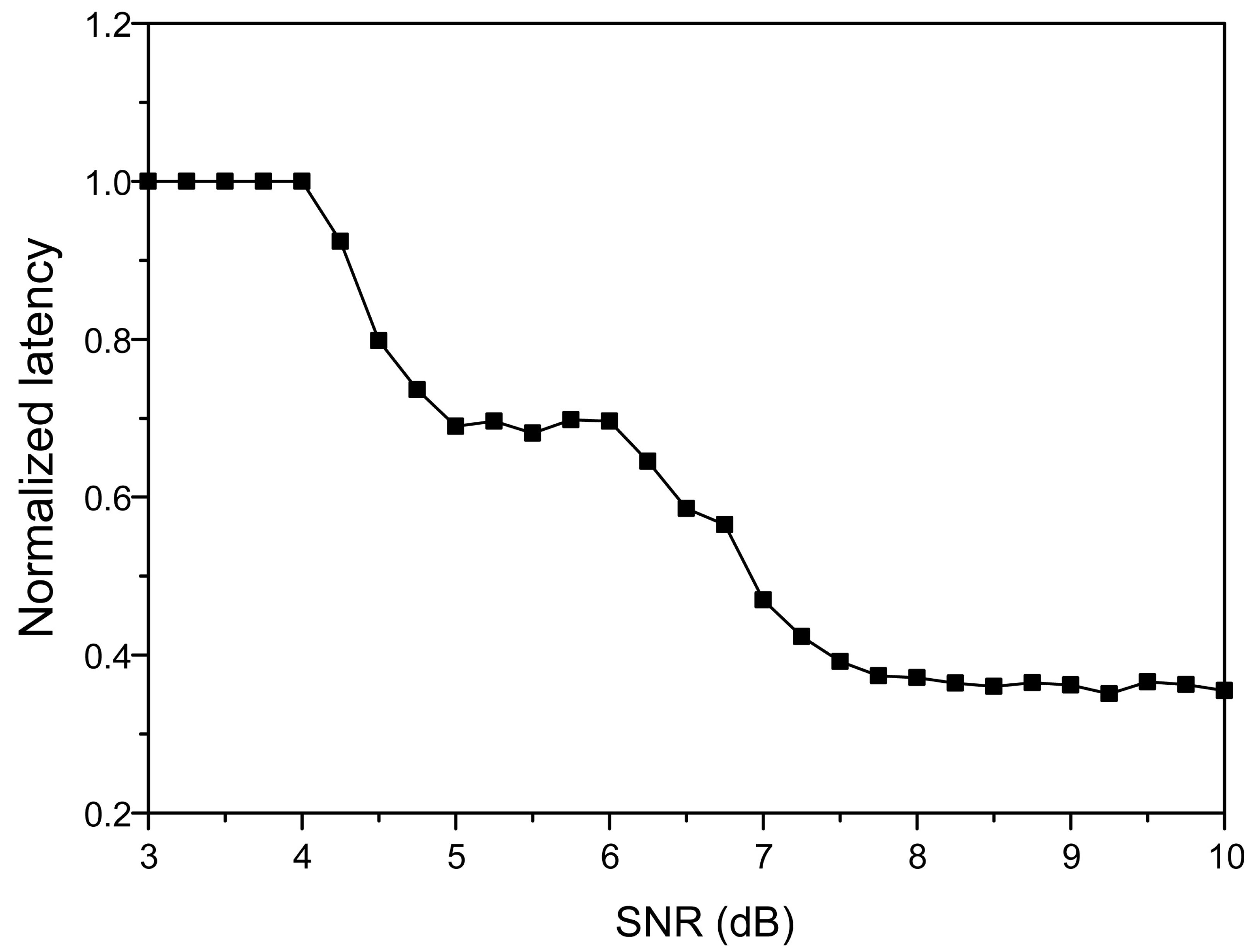
4. Simulation Results
5. Theoretical Analysis
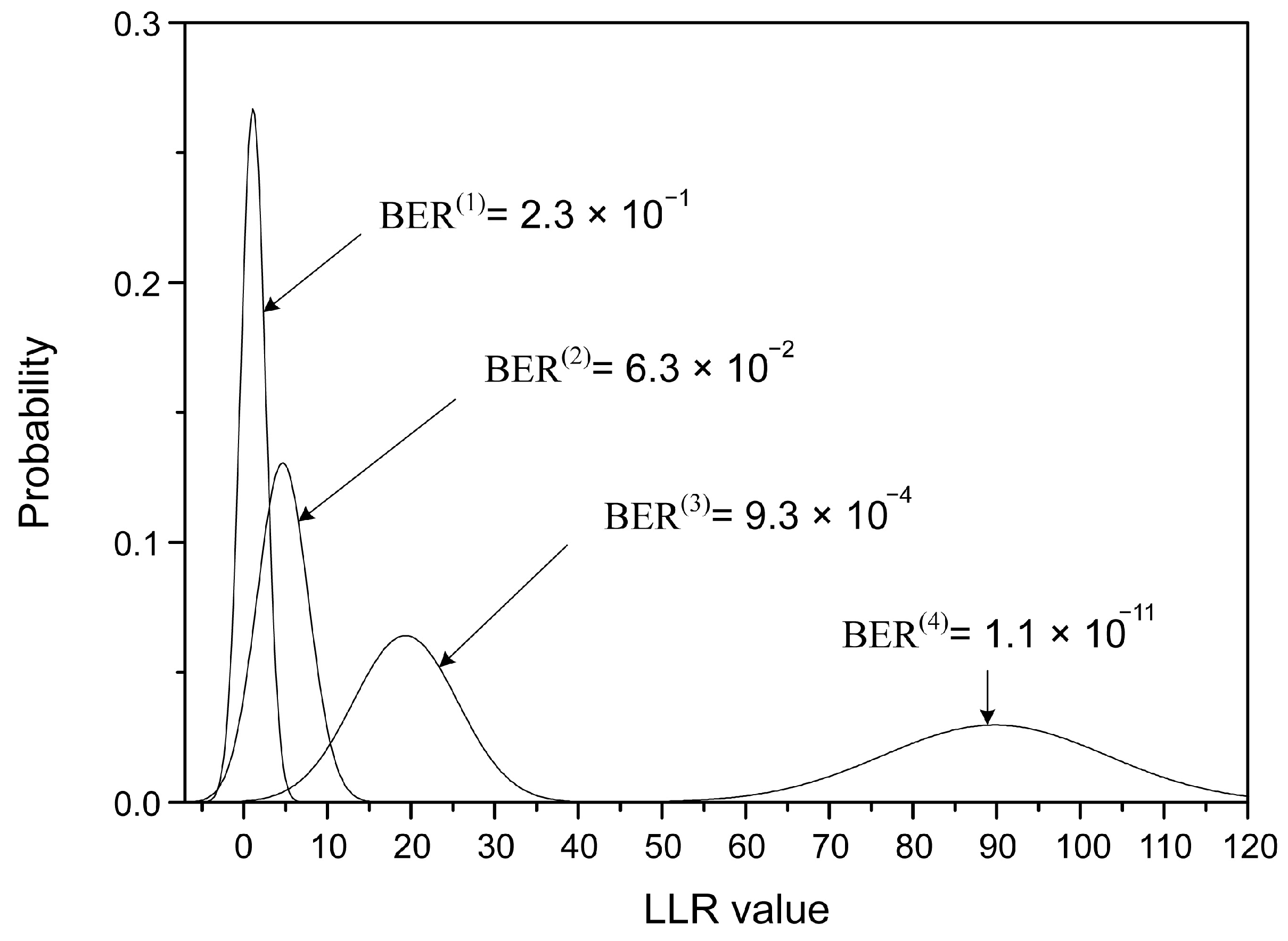
5.1. Calculation of the LLR Distribution
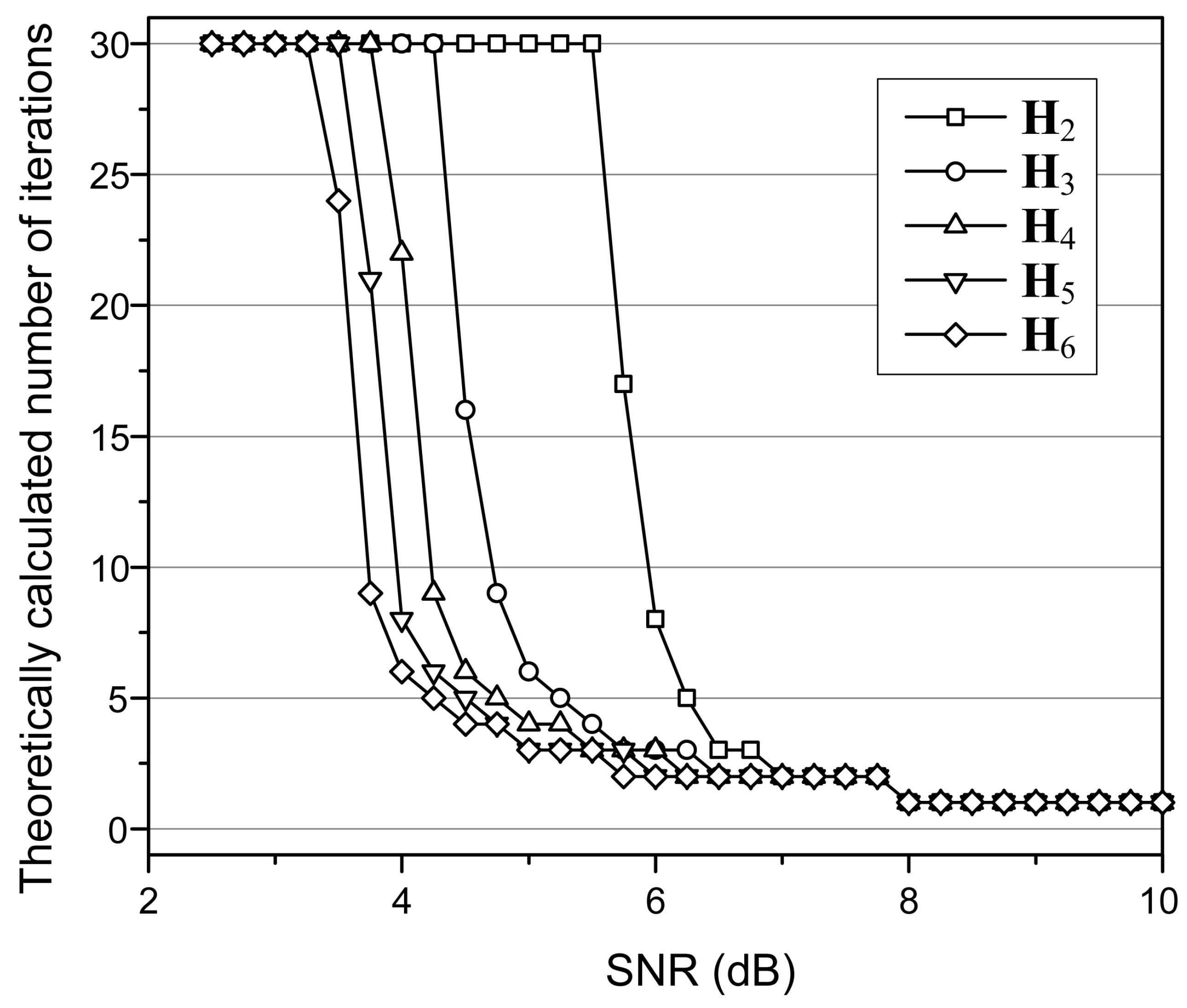
5.2. Calculation of the Number of Iterations
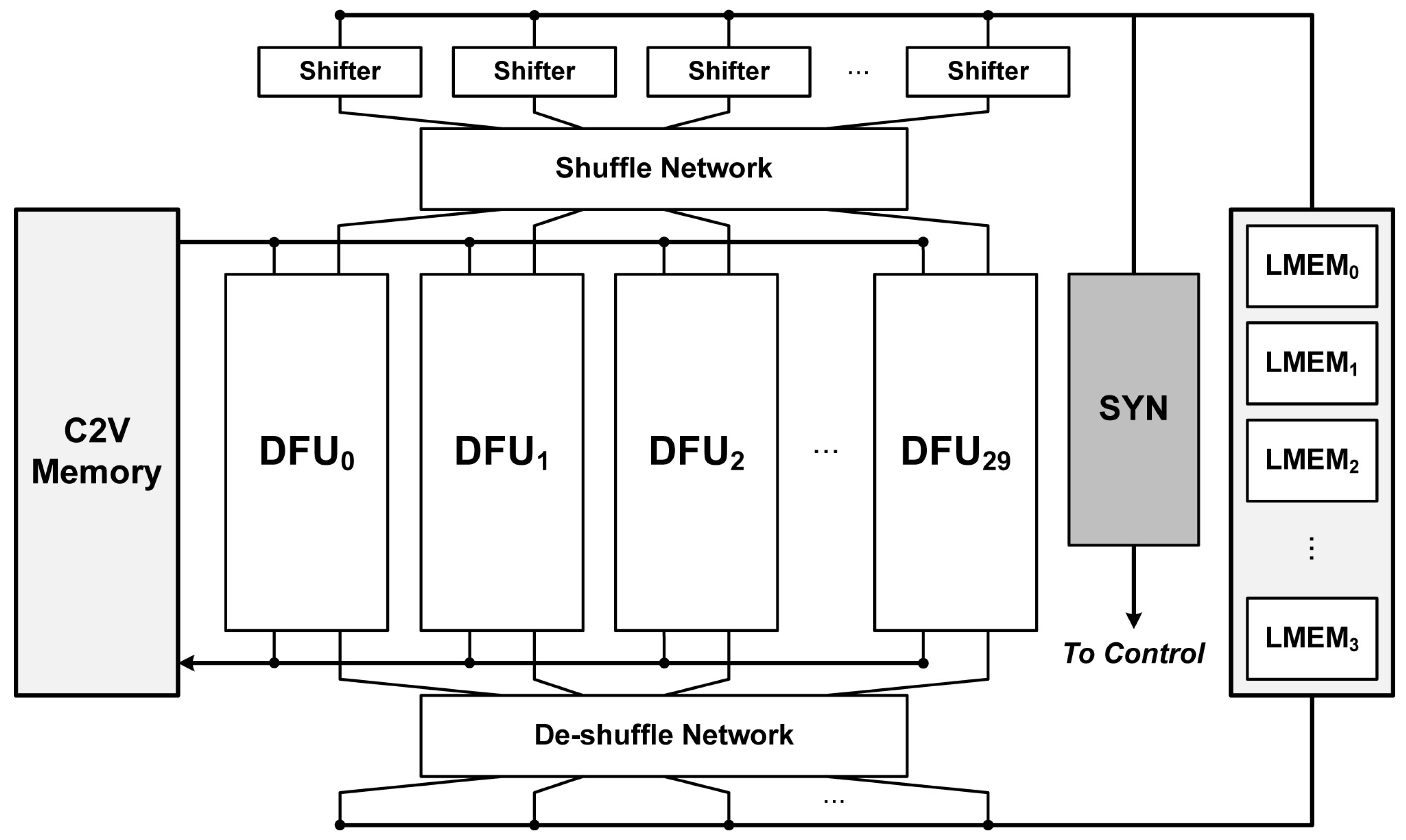
6. Hardware Architecture
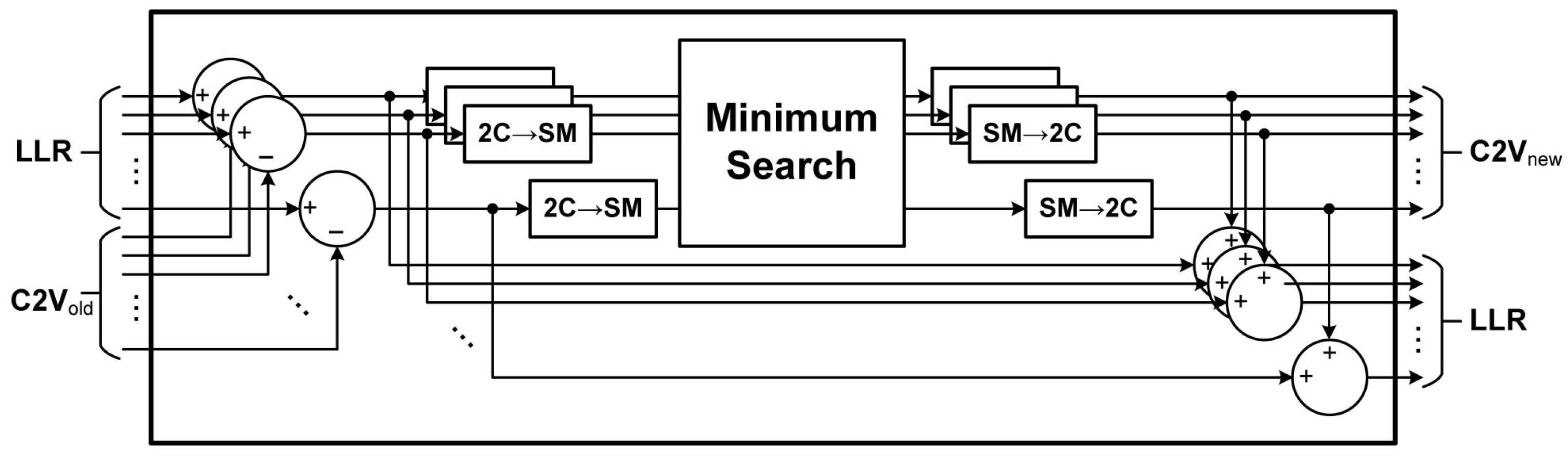
6.1. Dedicated Syndrome Check Module

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code 1 [12] | Code 2 [18] | Code 3 | |
|---|---|---|---|
| Target system | SSD | SSD | IEEE 802.11ac |
| Code type | Array | EG-LDPC | PEG |
| Cyclic | QC | Cyclic or QC | QC |
| User-message size | 4 KB | 8 KB | 1944 bits |
| Code rate | 0.9 | 0.96 | 0.5 |
| Target frequency (MHz) | 250 | 250 | 500 |
| Area (Equation gate count) | 22.1 k | 38.4 k | 6.6 k |
6.2. Decoding Architecture
7. Implementation Results
| This Work | DASIP [22] | TVLSI [18] | ISCAS [23] | JSSC [24] | ISCAS [21] | |
|---|---|---|---|---|---|---|
| ECC type | LDPC | LDPC | LDPC | LDPC | CBCH | BCH |
| Technology | 65 nm | 45 nm | 130 nm | 45 nm | 65 nm | 45 nm |
| Code rate | 0.96 | 0.96 | 0.96 | 0.9 | 0.93 | 0.9 |
| User-message size | 4 KB | 8 KB | 8 KB | 1 KB | 8 KB | 1KB |
| Quantization level | 4 bits | 7 bits | 4 bits | 1 bit | 1 bit | 1 bit |
| Internal precision | 8 bits | 7 bits | 4 bits | N. A. a | N. A. | N. A. |
| Operating voltage (V) | 1.0 | N. A. | 1.2 | N. A. | 1.2 | 1.05 |
| Operating frequency (MHz) | 200 | 179 | 131 | 200 | 250 | 400 |
| Decoding throughput (Gb/s) | 2.96–29.6 | 0.9 | 5.4 | 3.2 | 17.7 | 6.4 |
| Area (Equation gate count) | 1018 k | N. A. | N. A. | 700 k | 335 k | 230k |
| Power consumption (mW) | 279 | N. A. | 2090 | N. A. | 48.5 b | 88.4 |
| Energy efficiency (pJ/bit) | 9.43–94.26 | N. A. | 387 | N. A. | 2.74 b | 13.8 |
| Normalized energy efficiency c (pJ/bit) | 9.43–94.26 | N. A. | 134 | N. A. | 1.9 b | 12.5 |
8. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LDPC | Low-density parity-check |
| SSD | Solid-state drive |
| SD | Secure digital |
| ECC | Error correcting code |
| BCH | Bose–Chaudhuri–Hocquenghem |
| RS | Reed–Solomon |
| BP | Belief Propagation |
| QC | Quasi-cyclic |
| LLR | Log-likelihood ratio |
| SPA | Sum-product algorithm |
| MSA | Min-sum algorithm |
| MAI | Maximally allowed iterations |
| SNR | Signal-to-noise ratio |
| BER | Bit-error rate |
| AWGN | Additive white Gaussian noise |
| V2C | Variable-to-check |
| C2V | Check-to-variable |
| 2C | 2’s complement |
| SM | Signed magnitude |
| CBCH | Concatenated BCH |
| CMOS | Complementary Metal-Oxide-Semiconductor |
References
- Lee, D.; Chang, I.J.; Yoon, S.Y.; Jang, J.; Jang, D.S.; Hahn, W.G.; Park, J.Y.; Kim, D.G.; Yoon, C.; Lim, B.S.; et al. A 64Gb 533Mb/s DDR interface MLC NAND Flash in sub-20 nm technology. In Proceedings of the 2012 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 19–23 February 2012; pp. 430–432. [Google Scholar] [CrossRef]
- Li, Y.; Lee, S.; Oowada, K.; Nguyen, H.; Nguyen, Q.; Mokhlesi, N.; Hsu, C.; Li, J.; Ramachandra, V.; Kamei, T.; et al. 128Gb 3b/cell NAND flash memory in 19 nm technology with 18 MB/s write rate and 400 Mb/s toggle mode. In Proceedings of the 2012 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 19–23 February 2012; pp. 436–437. [Google Scholar] [CrossRef]
- Cai, Y.; Haratsch, E.F.; Mutlu, O.; Mai, K. Error patterns in MLC NAND flash memory: Measurement, characterization, and analysis. In Proceedings of the 2012 Design, Automation & Test in Europe Conference & Exhibition, Dresden, Germany, 12–16 March 2012; pp. 521–526. [Google Scholar] [CrossRef]
- Cai, Y.; Yalcin, G.; Mutlu, O.; Haratsch, E.F.; Cristal, A.; Unsal, O.S.; Mai, K. Flash correct-and-refresh: Retention-aware error management for increased flash memory lifetime. In Proceedings of the 2012 IEEE 30th International Conference on Computer Design (ICCD), Montreal, QC, Canada, 30 September–3 October 2012; pp. 94–101. [Google Scholar] [CrossRef]
- Yaakobi, E.; Ma, J.; Grupp, L.; Siegel, P.H.; Swanson, S.; Wolf, J.K. Error characterization and coding schemes for flash memories. In Proceedings of the 2010 IEEE Globecom Workshops, Miami, FL, USA, 6–10 December 2010; pp. 1856–1860. [Google Scholar] [CrossRef]
- Hwang, S.; Jung, J.; Kim, D.; Ha, J.; Park, I.C.; Lee, Y. An energy-optimized (37840, 34320) symmetric BC-BCH decoder for healthy mobile storages. In Proceedings of the 2017 IEEE Asian Solid-State Circuits Conference (A-SSCC), Seoul, Republic of Korea, 6–8 November 2017; pp. 169–172. [Google Scholar] [CrossRef]
- Hwang, S.; Moon, S.; Jung, J.; Kim, D.; Park, I.C.; Ha, J.; Lee, Y. Energy-Efficient Symmetric BC-BCH Decoder Architecture for Mobile Storages. IEEE Trans. Circuits Syst. Regul. Pap. 2019, 66, 4462–4475. [Google Scholar] [CrossRef]
- Gunnam, K.; Choi, G.; Wang, W.; Yeary, M. Multi-Rate Layered Decoder Architecture for Block LDPC Codes of the IEEE 802.11n Wireless Standard. In Proceedings of the 2007 IEEE International Symposium on Circuits and Systems (ISCAS), New Orleans, LA, USA, 27–30 May 2007; pp. 1645–1648. [Google Scholar] [CrossRef]
- Kienle, F.; Brack, T.; Wehn, N. A synthesizable IP core for DVB-S2 LDPC code decoding. In Proceedings of the Design, Automation and Test in Europe, Munich, Germany, 7–11 March 2005; Volume 3, pp. 100–105. [Google Scholar] [CrossRef]
- Chen, J.; Dholakia, A.; Eleftheriou, E.; Fossorier, M.; Hu, X.Y. Near optimal reduced-complexity decoding algorithms for LDPC codes. In Proceedings of the Proceedings IEEE International Symposium on Information Theory, Lausanne, Switzerland, 30 June–5 July 2002; p. 455. [Google Scholar] [CrossRef]
- Mohsenin, T.; Truong, D.N.; Baas, B.M. A Low-Complexity Message-Passing Algorithm for Reduced Routing Congestion in LDPC Decoders. IEEE Trans. Circuits Syst. Regul. Pap. 2010, 57, 1048–1061. [Google Scholar] [CrossRef]
- Olcer, S. Decoder architecture for array-code-based LDPC codes. In Proceedings of the GLOBECOM ’03. IEEE Global Telecommunications Conference (IEEE Cat. No.03CH37489), San Francisco, CA, USA, 1–5 December 2003; Volume 4, pp. 2046–2050. [Google Scholar] [CrossRef]
- Studer, C.; Preyss, N.; Roth, C.; Burg, A. Configurable high-throughput decoder architecture for quasi-cyclic LDPC codes. In Proceedings of the 2008 42nd Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 26–29 October 2008; pp. 1137–1142. [Google Scholar] [CrossRef]
- Kienle, F.; Wehn, N. Low complexity stopping criterion for LDPC code decoders. In Proceedings of the 2005 IEEE 61st Vehicular Technology Conference, Stockholm, Sweden, 30 May–1 June 2005; Volume 1, pp. 606–609. [Google Scholar] [CrossRef]
- Chen, Y.; Hocevar, D. A FPGA and ASIC implementation of rate 1/2, 8088-b irregular low density parity check decoder. In Proceedings of the GLOBECOM ’03. IEEE Global Telecommunications Conference (IEEE Cat. No.03CH37489), San Francisco, CA, USA, 1–5 December 2003; Volume 1, pp. 113–117. [Google Scholar] [CrossRef]
- Moon, T.K. Error Correction Coding: Mathematical Methods and Algorithms, 1st ed.; Wiley-Interscience: Hoboken, NJ, USA, 2005. [Google Scholar]
- Chung, S.Y.; Richardson, T.; Urbanke, R. Analysis of sum-product decoding of low-density parity-check codes using a Gaussian approximation. IEEE Trans. Inf. Theory 2001, 47, 657–670. [Google Scholar] [CrossRef]
- Kim, J.; Sung, W. Rate-0.96 LDPC Decoding VLSI for Soft-Decision Error Correction of NAND Flash Memory. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2014, 22, 1004–1015. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, B.; Jung, J.; Park, I.C. Low-Complexity Tree Architecture for Finding the First Two Minima. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 61–64. [Google Scholar] [CrossRef]
- Jung, J.; Lee, Y.; Park, I.C. Area-efficient method to approximate two minima for LDPC decoders. Electron. Lett. 2014, 50, 1701–1702. [Google Scholar] [CrossRef]
- Lee, K.; Lim, S.; Kim, J. Low-cost, low-power and high-throughput BCH decoder for NAND Flash Memory. In Proceedings of the 2012 IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Republic of Korea, 20–23 May 2012; pp. 413–415. [Google Scholar] [CrossRef]
- Zaidi, S.A.A.; Awais, M.; Condo, C.; Martina, M.; Masera, G. FPGA accelerator of Quasi cyclic EG-LDPC codes decoder for NAND flash memories. In Proceedings of the 2013 Conference on Design and Architectures for Signal and Image Processing, Cagliari, Italy, 8–10 October 2013; pp. 190–195. [Google Scholar]
- Kim, D.; Chung, B.; Kim, R.E. Improved hard-decision decoding LDPC Codec IP design. In Proceedings of the 2012 IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Republic of Korea, 20–23 May 2012; pp. 416–419. [Google Scholar] [CrossRef]
- Lee, Y.; Yoo, H.; Jung, J.; Jo, J.; Park, I.C. A 2.74-pJ/bit, 17.7-Gb/s Iterative Concatenated-BCH Decoder in 65-nm CMOS for NAND Flash Memory. IEEE J. Solid State Circuits 2013, 48, 2531–2540. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, J. Energy-Efficient Partial LDPC Decoding for NAND Flash-Based Storage Systems. Electronics 2024, 13, 1392. https://doi.org/10.3390/electronics13071392
Jung J. Energy-Efficient Partial LDPC Decoding for NAND Flash-Based Storage Systems. Electronics. 2024; 13(7):1392. https://doi.org/10.3390/electronics13071392
Chicago/Turabian StyleJung, Jaehwan. 2024. "Energy-Efficient Partial LDPC Decoding for NAND Flash-Based Storage Systems" Electronics 13, no. 7: 1392. https://doi.org/10.3390/electronics13071392
APA StyleJung, J. (2024). Energy-Efficient Partial LDPC Decoding for NAND Flash-Based Storage Systems. Electronics, 13(7), 1392. https://doi.org/10.3390/electronics13071392