
Hierarchical Text Classification and Its Foundations: A Review of Current Research

 ,
,  , , , and
, , , and
Abstract
1. Introduction
1.1. What Is Hierarchical Text Classification?
1.2. Related Work
1.3. Contributions
- We provide an extensive review of the state of current research regarding HTC;
- We explore the NLP background of text representation and the various neural architectures being utilized in recent research;
- We analyze HTC specifically, providing an analysis of common approaches to this paradigm and its evaluation measures;
- We summarize a considerable number of recent proposals for HTC, spanning between 2019 and 2023. Among these, we dive deeper into the discussion of several methods and how they approach the task;
- We test a set of baselines and recent proposals on five benchmark HTC datasets that are representative of five different domains of applications;
- We release our code (https://gitlab.com/distration/dsi-nlp-publib/-/tree/main/htc-survey-24, accessed on 17 March 2024) and dataset splits for public usage in research. The datasets are available on Zenodo [20], including two new benchmark datasets derived from existing collections;
- Lastly, we summarize our results and discuss current research challenges in the field.
1.4. Structure of the Article
2. NLP Background
2.1. Text Representation and Classification
2.1.1. Text Segmentation
2.1.2. Weighted Word Counts
2.1.3. Word Embeddings
2.1.4. Contextualized Language Models
2.1.5. Classification
2.2. Notable Neural Architectures
2.2.1. Recurrent Neural Networks
2.2.2. Convolutional Neural Networks
2.2.3. Transformer Networks and the Attention Mechanism
2.2.4. Graph Neural Networks
Message Passing
Graph Convolution
2.2.5. Capsule Networks
Capsules
- Recognizing the presence of a single entity (e.g., deciding how likely it is that an object, or piece-of, is present in an image);
- Computing a vector that describes the instantiation parameters of the entity (e.g., the spatial orientation of an object in an image or the local word ordering and semantics of a piece of text [88]).
Dynamic Routing
3. Hierarchical Text Classification
3.1. Types of Hierarchical Classification
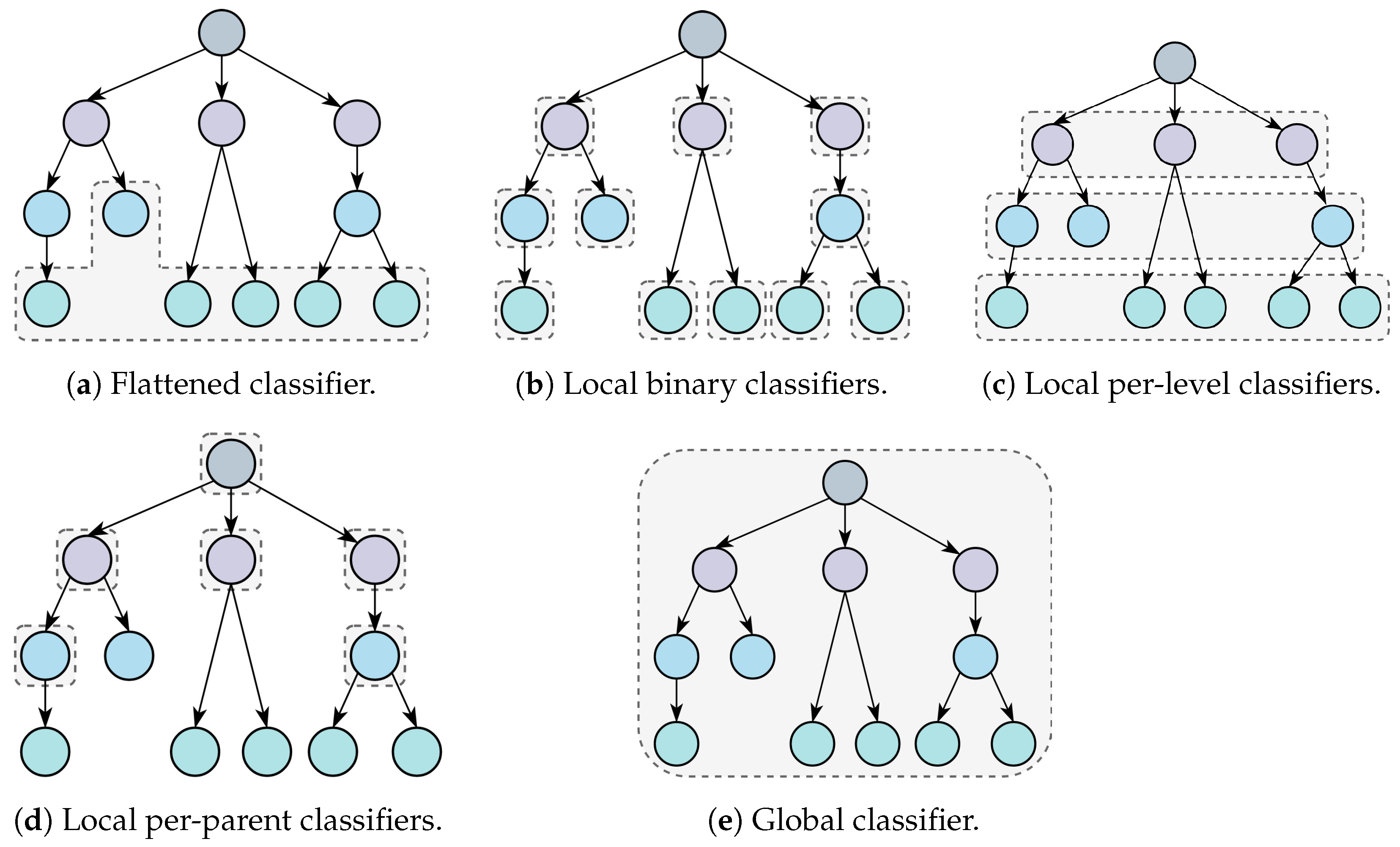
3.1.1. Flattened Classifiers
3.1.2. Local Classifiers
3.1.3. Global Classifiers
3.1.4. Training and Testing Local Classifiers
Testing
Training
3.2. Non-Mandatory Leaf Node Prediction and Blocking
3.2.1. Flattened Classifiers
3.2.2. Local Classifiers
3.2.3. Global Classifiers
3.3. Evaluation Measures
3.3.1. Standard Metrics
3.3.2. Hierarchical Metrics
3.3.3. Other Metrics
4. Hierarchical Text Classification Methods
4.1. Overview of Approaches
4.2. Recent Proposals
4.3. Analyzed Methods
4.3.1. HTrans
4.3.2. HiLAP
4.3.3. MATCH
4.3.4. HiAGM
4.3.5. RLHR
4.3.6. HiMatch
4.3.7. HE-AGCRCNN
4.3.8. CLED
4.3.9. ICD-Reranking
4.3.10. HGCLR
4.3.11. HIDDEN
4.3.12. CHAMP
4.3.13. HE-HMTC
4.3.14. HTCInfoMax
4.3.15. GACaps-HTC
4.3.16. HiDEC
4.3.17. K-HTC
4.3.18. HiTin
4.3.19. PeerHTC
4.3.20. HJCL
4.3.21. HBGL
4.3.22. HPT
4.3.23. HierVerb
4.3.24. P-Tuning-v2
4.4. Datasets Used in the HTC Literature

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Size | Depth | Labels (Overall) | Labels per Level |
|---|---|---|---|---|
| RCV1-v2 [214] | 804,414 | 4 | 103 | 4–55–43–1 |
| Web of Science (WOS-46,985) [215] | 46,985 | 2 | 145 | 7–138 |
| Blurb Genre Collection (BGC) [88] | 91,894 | 4 | 146 | 7–46–77–16 |
| 20Newsgroup (20NG) [216] | 18,846 | 2 | 20 | 6–20 |
| Arxiv Academic Paper (AAPD) [171,217] | 55,840 | 2 | 61 | 9–52 |
| Enron [94,218] | 1648 | 3 | 56 | 3–40–13 |
| Patent/USPTO [76] | 100,000 | 4 | 9162 | 9–128–661–8364 |
5. Experiments and Analysis
5.1. Datasets Used
5.1.1. Linux Bugs
| Listing 1. Linux bugs extracted from the Bugs dataset. |
 |
5.1.2. RCV1-v2
| Listing 2. A news article extracted from the RCV1 dataset. |
 |
5.1.3. Web of Science
| Listing 3. Abstract extracted from the WOS dataset. |
 |
5.1.4. Blurb Genre Collection
| Listing 4. Book sample extracted from the BGC dataset. |
 |
5.1.5. Amazon 5 × 5
| Listing 5. An example of user review in the Amazon dataset. |
 |
5.2. Models Implemented
5.2.1. HBGL
5.2.2. GACaps-HTC
5.2.3. MATCH
5.2.4. HiAGM
5.2.5. BERT
5.2.6. XML-CNN
5.2.7. CHAMP/MATCH Losses
5.2.8. SVM
5.3. Results
5.3.1. Comparison
5.3.2. Inference Time
5.4. Discussion
6. Future Work and Research Directions
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TC | Text Classification |
| NLP | Natural Language Processing |
| HTC | Hierarchical Text Classification |
| HMC | Hierarchical Multilabel Classification |
| BoW | Bag of Words |
| TF-IDF | Term Frequency - Inverse Document Frequency |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| BERT | Bidirectional Encoder Representations from Transformers |
| GPT | Generative Pre-trained Transformer |
| MLM | Masked Language Modeling |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| MHA | Multi-head Attention |
| CN | Capsule Network |
| DAG | Directed Acyclic Graph |
| (N)MLNP | (Non-)Mandatory Leaf Node Prediction |
| LCA | Lowest Common Ancestor |
| NDCG | Normalized Discounted Cumulative Gain |
| RCV1 | Reuters Corpus-V1 |
| WOS | Web Of Science |
| BGC | Blurb Genre Collection |
| 20NG | 20 NewsGroups |
| AAPD | ArXiv Academic Paper dataset |
| BCE | Binary Cross Entropy |
| KG | Knowledge Graph |
References
- Gasparetto, A.; Marcuzzo, M.; Zangari, A.; Albarelli, A. A Survey on Text Classification Algorithms: From Text to Predictions. Information 2022, 13, 83. [Google Scholar] [CrossRef]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Traditional to Deep Learning. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–41. [Google Scholar] [CrossRef]
- Sebastiani, F. Machine Learning in Automated Text Categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Vens, C.; Struyf, J.; Schietgat, L.; Džeroski, S.; Blockeel, H. Decision trees for hierarchical multi-label classification. Mach. Learn. 2008, 73, 185. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Schlegel, V.; Ramesh Kashyap, A.; Winkler, S. A Two-Stage Decoder for Efficient ICD Coding. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; pp. 4658–4665. [Google Scholar] [CrossRef]
- Tsai, S.C.; Huang, C.W.; Chen, Y.N. Modeling Diagnostic Label Correlation for Automatic ICD Coding. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 4043–4052. [Google Scholar] [CrossRef]
- Caled, D.; Won, M.; Martins, B.; Silva, M.J. A Hierarchical Label Network for Multi-label EuroVoc Classification of Legislative Contents. In Digital Libraries for Open Knowledge, Proceedings of the International Conference on Theory and Practice of Digital Libraries, Oslo, Norway, 9–12 September; Doucet, A., Isaac, A., Golub, K., Aalberg, T., Jatowt, A., Eds.; Springer: Cham, Switzerland, 2019; pp. 238–252. [Google Scholar] [CrossRef]
- Zhu, H.; He, C.; Fang, Y.; Ge, B.; Xing, M.; Xiao, W. Patent Automatic Classification Based on Symmetric Hierarchical Convolution Neural Network. Symmetry 2020, 12, 186. [Google Scholar] [CrossRef]
- Wahba, Y.; Madhavji, N.H.; Steinbacher, J. A Hybrid Continual Learning Approach for Efficient Hierarchical Classification of IT Support Tickets in the Presence of Class Overlap. In Proceedings of the 2023 IEEE International Conference on Industrial Technology (ICIT), Orlando, FL, USA, 4–6 April 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning–Based Text Classification: A Comprehensive Review. Acm Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Gasparetto, A.; Zangari, A.; Marcuzzo, M.; Albarelli, A. A survey on text classification: Practical perspectives on the Italian language. PLoS ONE 2022, 17, 1–46. [Google Scholar] [CrossRef]
- Koller, D.; Sahami, M. Hierarchically Classifying Documents Using Very Few Words. In Proceedings of the Fourteenth International Conference on Machine Learning, ICML ’97, San Francisco, CA, USA, 8–12 July 1997; pp. 170–178. [Google Scholar]
- Sun, A.; Lim, E.P. Hierarchical Text Classification and Evaluation. In Proceedings of the 2001 IEEE International Conference on Data Mining, ICDM ’01, San Jose, CA, USA, 29 November–2 December 2001; pp. 521–528. [Google Scholar]
- Sun, A.; Lim, E.P.; Ng, W.K. Hierarchical Text Classification Methods and Their Specification. In Cooperative Internet Computing; Springer: Boston, MA, USA, 2003; Chapter 14; pp. 236–256. [Google Scholar] [CrossRef]
- Silla, C.N.; Freitas, A.A. A survey of hierarchical classification across different application domains. Data Min. Knowl. Discov. 2011, 22, 31–72. [Google Scholar] [CrossRef]
- Stein, R.A.; Jaques, P.A.; Valiati, J.F. An analysis of hierarchical text classification using word embeddings. Inf. Sci. 2019, 471, 216–232. [Google Scholar] [CrossRef]
- Defiyanti, S.; Winarko, E.; Priyanta, S. A Survey of Hierarchical Classification Algorithms with Big-Bang Approach. In Proceedings of the 2019 5th International Conference on Science and Technology (ICST), Yogyakarta, Indonesia, 30–31 July 2019; Volume 1, pp. 1–6. [Google Scholar] [CrossRef]
- Zangari, A.; Marcuzzo, M.; Schiavinato, M.; Albarelli, A.; Gasparetto, A.; Rizzo, M. [Dataset] Hierarchical Text Classification Corpora (v.1). 2022. Available online: https://zenodo.org/records/7319519 (accessed on 21 March 2024).
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Toronto, ON, Canada, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Brooklyn, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Mielke, S.J.; Alyafeai, Z.; Salesky, E.; Raffel, C.; Dey, M.; Gallé, M.; Raja, A.; Si, C.; Lee, W.Y.; Sagot, B.; et al. Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP. arXiv 2021, arXiv:2112.10508. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 1715–1725. [Google Scholar] [CrossRef]
- Schuster, M.; Nakajima, K. Japanese and Korean voice search. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5149–5152. [Google Scholar] [CrossRef]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 66–71. [Google Scholar] [CrossRef]
- Graves, A. Generating Sequences With Recurrent Neural Networks. arXiv 2013, arXiv:1308.0850. [Google Scholar] [CrossRef]
- Salesky, E.; Etter, D.; Post, M. Robust Open-Vocabulary Translation from Visual Text Representations. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 7235–7252. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26, NIPS’13, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates, Inc.: Brooklyn, NY, USA, 2013; Volume 26, pp. 3111–3119. [Google Scholar]
- Jurafsky, D.; Martin, J. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 3rd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2020; pp. 30–35. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2 June 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 21 March 2024).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Curran Associates, Inc.: Brooklyn, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2015, arXiv:1409.0473. [Google Scholar] [CrossRef]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Kerrville, TX, USA, 2015; pp. 1412–1421. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; Volume 1: Foundations, Chapter 11; pp. 318–362. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 2, NIPS’14, Cambridge, MA, USA, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar] [CrossRef]
- Lepikhin, D.; Lee, H.; Xu, Y.; Chen, D.; Firat, O.; Huang, Y.; Krikun, M.; Shazeer, N.; Chen, Z. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. In Proceedings of the International Conference on Learning Representations (ICLR 2021), Vienna, Austria, 4 May 2021. [Google Scholar] [CrossRef]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. J. Mach. Learn. Res. 2022, 23, 1–39. [Google Scholar] [CrossRef]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Bhambhoria, R.; Chen, L.; Zhu, X. A Simple and Effective Framework for Strict Zero-Shot Hierarchical Classification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL 2023, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J.L., Okazaki, N., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 1782–1792. [Google Scholar] [CrossRef]
- Safavian, S.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man, Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QB, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V.N. Support-Vector Networks. Mach. Learning 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; Association for Computing Machinery: New York, NY, USA, 1992; pp. 144–152. [Google Scholar] [CrossRef]
- Xu, S.; Li, Y.; Wang, Z. Bayesian Multinomial Naïve Bayes Classifier to Text Classification. In Proceedings of the Advanced Multimedia and Ubiquitous Engineering, Seoul, Republic of Korea, 22–24 May 2017; Springer: Singapore, 2017; pp. 347–352. [Google Scholar] [CrossRef]
- van den Bosch, A. Hidden Markov Models. In Encyclopedia of Machine Learning and Data Mining; Chapter Hidden Markov Models; Springer: Boston, MA, USA, 2017; pp. 609–611. [Google Scholar] [CrossRef]
- Zhang, Y.; Wallace, B.C. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (IJCNLP), Taipei, Taiwan, 27 November–1 December 2017; Volume 1, pp. 253–263. [Google Scholar]
- Gasparetto, A.; Ressi, D.; Bergamasco, F.; Pistellato, M.; Cosmo, L.; Boschetti, M.; Ursella, E.; Albarelli, A. Cross-Dataset Data Augmentation for Convolutional Neural Networks Training. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 910–915. [Google Scholar] [CrossRef]
- Gasparetto, A.; Minello, G.; Torsello, A. Non-parametric Spectral Model for Shape Retrieval. In Proceedings of the 2015 International Conference on 3D Vision, Lyon, France, 19–22 October 2015; pp. 344–352. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Kerrville, TX, USA, 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Liu, P.; Qiu, X.; Huang, X. Recurrent Neural Network for Text Classification with Multi-Task Learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI’16, New York, NY, USA, 9–15 July 2016; AAAI Press: Washington, DC, USA, 2016; pp. 2873–2879. [Google Scholar]
- Gasparetto, A.; Cosmo, L.; Rodolà, E.; Bronstein, M.; Torsello, A. Spatial Maps: From Low Rank Spectral to Sparse Spatial Functional Representations. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 477–485. [Google Scholar] [CrossRef]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Jafari Meimandi, K.; Gerber, M.S.; Barnes, L.E. HDLTex: Hierarchical Deep Learning for Text Classification. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 364–371. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; Dasgupta, S., McAllester, D., Eds.; Volume 28, pp. 1310–1318. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; pp. 103–111. [Google Scholar] [CrossRef]
- Elman, J.L. Finding Structure in Time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Toronto, ON, Canada, 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1003–1012. [Google Scholar] [CrossRef]
- Yan, J.; Mu, L.; Wang, L.; Ranjan, R.; Zomaya, A.Y. Temporal Convolutional Networks for the Advance Prediction of ENSO. Sci. Rep. 2020, 10, 8055. [Google Scholar] [CrossRef] [PubMed]
- de Vries, W.; van Cranenburgh, A.; Nissim, M. What’s so special about BERT’s layers? A closer look at the NLP pipeline in monolingual and multilingual models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 4339–4350. [Google Scholar] [CrossRef]
- Jawahar, G.; Sagot, B.; Seddah, D. What Does BERT Learn about the Structure of Language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 29–31 July 2019; pp. 3651–3657. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Knight, K., Nenkova, A., Rambow, O., Eds.; pp. 1480–1489. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, J.; Zheng, S.; Xue, Y.; Hu, X. Hierarchical multi-attention networks for document classification. Int. J. Mach. Learn. Cybern. 2021, 12, 1639–1647. [Google Scholar] [CrossRef]
- Huang, W.; Chen, E.; Liu, Q.; Chen, Y.; Huang, Z.; Liu, Y.; Zhao, Z.; Zhang, D.; Wang, S. Hierarchical Multi-label Text Classification: An Attention-based Recurrent Network Approach. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM 2019, Beijing, China, 3–7 November 2019; Zhu, W., Tao, D., Cheng, X., Cui, P., Rundensteiner, E.A., Carmel, D., He, Q., Yu, J.X., Eds.; ACM: New York, NY, USA, 2019; pp. 1051–1060. [Google Scholar] [CrossRef]
- González, J.Á.; Segarra, E.; García-Granada, F.; Sanchis, E.; Hurtado, L.F. Attentional Extractive Summarization. Appl. Sci. 2023, 13, 1458. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural Message Passing for Quantum Chemistry. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; 2017; Volume 70, pp. 1263–1272. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 7370–7377. [Google Scholar] [CrossRef]
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef]
- Li, Q.; Han, Z.; Wu, X.M. Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, AAAI’18/IAAI’18/EAAI’18, New Orleans, LA, USA, 2–7 February 2018; pp. 3538–3545. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming Auto-Encoders. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2011, Espoo, Finland, 14–17 June 2011; Honkela, T., Duch, W., Girolami, M., Kaski, S., Eds.; pp. 44–51. [Google Scholar] [CrossRef]
- Xi, E.; Bing, S.; Jin, Y. Capsule Network Performance on Complex Data. arXiv 2017, arXiv:1712.03480. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, L.; Liu, B.; Chen, T.; Zhang, F.; Wang, D. Concept-Based Label Embedding via Dynamic Routing for Hierarchical Text Classification. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 5010–5019. [Google Scholar] [CrossRef]
- Aly, R.; Remus, S.; Biemann, C. Hierarchical Multi-label Classification of Text with Capsule Networks. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Alva-Manchego, F., Choi, E., Khashabi, D., Eds.; Volume 2: Student Research Workshop. Association for Computational Linguistics: Kerrville, TX, USA, 2019; pp. 323–330. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing between Capsules. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Red Hook, NY, USA, 4–9 December 2017; pp. 3859–3869. [Google Scholar]
- Hinton, G.E.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, Z.; Wang, P.; Huang, L.; Sun, X.; Wang, H. Incorporating Hierarchy into Text Encoder: A Contrastive Learning Approach for Hierarchical Text Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 7109–7119. [Google Scholar] [CrossRef]
- Peng, H.; Li, J.; He, Y.; Liu, Y.; Bao, M.; Wang, L.; Song, Y.; Yang, Q. Large-Scale Hierarchical Text Classification with Recursively Regularized Deep Graph-CNN. In Proceedings of the 2018 World Wide Web Conference, WWW ’18, Lyon, France, 23–27 April 2018; pp. 1063–1072. [Google Scholar] [CrossRef]
- Yu, C.; Shen, Y.; Mao, Y. Constrained Sequence-to-Tree Generation for Hierarchical Text Classification. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’22, New York, NY, USA, 11–15 July 2022; pp. 1865–1869. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, J.; Soh, C.; Chen, L. LA-HCN: Label-based Attention for Hierarchical Multi-label Text Classification Neural Network. Expert Syst. Appl. 2022, 187, 115922. [Google Scholar] [CrossRef]
- Punera, K.; Ghosh, J. Enhanced Hierarchical Classification via Isotonic Smoothing. In Proceedings of the 17th International Conference on World Wide Web, WWW ’08, New York, NY, USA, 26–30 October 2008; pp. 151–160. [Google Scholar] [CrossRef]
- Cerri, R.; Barros, R.C.; de Carvalho, A.C.P.L.F. Hierarchical multi-label classification for protein function prediction: A local approach based on neural networks. In Proceedings of the 2011 11th International Conference on Intelligent Systems Design and Applications, Cordoba, Spain, 22–24 November 2011; pp. 337–343. [Google Scholar] [CrossRef]
- Zhou, J.; Ma, C.; Long, D.; Xu, G.; Ding, N.; Zhang, H.; Xie, P.; Liu, G. Hierarchy-Aware Global Model for Hierarchical Text Classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2020; pp. 1106–1117. [Google Scholar] [CrossRef]
- Wehrmann, J.; Cerri, R.; Barros, R. Hierarchical Multi-Label Classification Networks. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Volume 80, pp. 5075–5084. [Google Scholar]
- Mao, Y.; Tian, J.; Han, J.; Ren, X. Hierarchical Text Classification with Reinforced Label Assignment. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2019; pp. 445–455. [Google Scholar] [CrossRef]
- Freitas, A.; de Carvalho, A. A Tutorial on Hierarchical Classification with Applications in Bioinformatics. In Research and Trends in Data Mining Technologies and Applications; IGI Global: Hershey, PA, USA, 2007. [Google Scholar] [CrossRef]
- Marcuzzo, M.; Zangari, A.; Schiavinato, M.; Giudice, L.; Gasparetto, A.; Albarelli, A. A multi-level approach for hierarchical Ticket Classification. In Proceedings of the Eighth Workshop on Noisy User-Generated Text (W-NUT 2022), Gyeongju, Republic of Korea, 12–17 October 2022; pp. 201–214. [Google Scholar]
- Ceci, M.; Malerba, D. Classifying web documents in a hierarchy of categories: A comprehensive study. J. Intell. Inf. Syst. 2007, 28, 37–78. [Google Scholar] [CrossRef]
- Sun, A.; Lim, E.P.; Ng, W.K.; Srivastava, J. Blocking reduction strategies in hierarchical text classification. IEEE Trans. Knowl. Data Eng. 2004, 16, 1305–1308. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Matwin, S.; Nock, R.; Famili, A.F. Learning and Evaluation in the Presence of Class Hierarchies: Application to Text Categorization. In Proceedings of the Advances in Artificial Intelligence, Hobart, Australia, 4–8 December 2006; Lamontagne, L., Marchand, M., Eds.; pp. 395–406. [Google Scholar]
- Kosmopoulos, A.; Partalas, I.; Gaussier, E.; Paliouras, G.; Androutsopoulos, I. Evaluation measures for hierarchical classification: A unified view and novel approaches. Data Min. Knowl. Discov. 2015, 29, 820–865. [Google Scholar] [CrossRef]
- Pistellato, M.; Cosmo, L.; Bergamasco, F.; Gasparetto, A.; Albarelli, A. Adaptive Albedo Compensation for Accurate Phase-Shift Coding. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2450–2455. [Google Scholar] [CrossRef]
- Vaswani, A.; Aggarwal, G.; Netrapalli, P.; Hegde, N.G. All Mistakes Are Not Equal: Comprehensive Hierarchy Aware Multi-label Predictions (CHAMP). arXiv 2022, arXiv:2206.08653. [Google Scholar] [CrossRef]
- Aho, A.V.; Hopcroft, J.E.; Ullman, J.D. On Finding Lowest Common Ancestors in Trees. SIAM J. Comput. 1976, 5, 115–132. [Google Scholar] [CrossRef]
- Sainte Fare Garnot, V.; Landrieu, L. Leveraging Class Hierarchies with Metric-Guided Prototype Learning. In Proceedings of the 32th British Machine Vision Conference, Online, 22–25 November 2021. [Google Scholar]
- Chen, B.; Huang, X.; Xiao, L.; Cai, Z.; Jing, L. Hyperbolic Interaction Model for Hierarchical Multi-Label Classification. Proc. AAAI Conf. Artif. Intell. 2020, 34, 7496–7503. [Google Scholar] [CrossRef]
- Gong, J.; Ma, H.; Teng, Z.; Teng, Q.; Zhang, H.; Du, L.; Chen, S.; Bhuiyan, M.Z.A.; Li, J.; Liu, M. Hierarchical Graph Transformer-Based Deep Learning Model for Large-Scale Multi-Label Text Classification. IEEE Access 2020, 8, 30885–30896. [Google Scholar] [CrossRef]
- Marcuzzo, M.; Zangari, A.; Albarelli, A.; Gasparetto, A. Recommendation Systems: An Insight Into Current Development and Future Research Challenges. IEEE Access 2022, 10, 86578–86623. [Google Scholar] [CrossRef]
- Ma, Y.; Zhao, J.; Jin, B. A Hierarchical Fine-Tuning Approach Based on Joint Embedding of Words and Parent Categories for Hierarchical Multi-label Text Classification. In Proceedings of the Artificial Neural Networks and Machine Learning - ICANN 2020—29th International Conference on Artificial Neural Networks, Bratislava, Slovakia, 15–18 September 2020; Farkas, I., Masulli, P., Wermter, S., Eds.; Proceedings, Part II; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2020; Volume 12397, pp. 746–757. [Google Scholar] [CrossRef]
- Dong, G.; Zhang, W.; Yadav, R.; Mu, X.; Zhou, Z. OWGC-HMC: An Online Web Genre Classification Model Based on Hierarchical Multilabel Classification. Secur. Commun. Netw. 2022, 2022, 7549880. [Google Scholar] [CrossRef]
- Yu, Y.; Sun, Z.; Sun, C.; Liu, W. Hierarchical Multilabel Text Classification via Multitask Learning. In Proceedings of the 33rd IEEE International Conference on Tools with Artificial Intelligence, ICTAI 2021, Washington, DC, USA, 1–3 November 2021; IEEE: New York, NY, USA, 2021; pp. 1138–1143. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. A Review on Multi-Label Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, G. Hierarchical Sequence-to-Sequence Model for Multi-Label Text Classification. IEEE Access 2019, 7, 153012–153020. [Google Scholar] [CrossRef]
- Zhao, W.; Gao, H.; Chen, S.; Wang, N. Generative Multi-Task Learning for Text Classification. IEEE Access 2020, 8, 86380–86387. [Google Scholar] [CrossRef]
- Rojas, K.R.; Bustamante, G.; Oncevay, A.; Cabezudo, M.A.S. Efficient Strategies for Hierarchical Text Classification: External Knowledge and Auxiliary Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2020; pp. 2252–2257. [Google Scholar] [CrossRef]
- Risch, J.; Garda, S.; Krestel, R. Hierarchical Document Classification as a Sequence Generation Task. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries in 2020, JCDL ’20, New York, NY, USA; 2020; pp. 147–155. [Google Scholar] [CrossRef]
- Yan, J.; Li, P.; Chen, H.; Zheng, J.; Ma, Q. Does the Order Matter? A Random Generative Way to Learn Label Hierarchy for Hierarchical Text Classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 276–285. [Google Scholar] [CrossRef]
- Kwon, J.; Kamigaito, H.; Song, Y.I.; Okumura, M. Hierarchical Label Generation for Text Classification. In Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; Vlachos, A., Augenstein, I., Eds.; pp. 625–632. [Google Scholar] [CrossRef]
- Liu, H.; Huang, X.; Liu, X. Improve label embedding quality through global sensitive GAT for hierarchical text classification. Expert Syst. Appl. 2024, 238, 122267. [Google Scholar] [CrossRef]
- Chen, H.; Ma, Q.; Lin, Z.; Yan, J. Hierarchy-aware Label Semantics Matching Network for Hierarchical Text Classification. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, Virtual Event, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2021; Volume 1: Long Papers, pp. 4370–4379. [Google Scholar] [CrossRef]
- Pal, A.; Selvakumar, M.; Sankarasubbu, M. MAGNET: Multi-Label Text Classification using Attention-based Graph Neural Network. In Proceedings of the 12th International Conference on Agents and Artificial Intelligence—Volume 2: ICAART, INSTICC, Valletta, Malta, 22–24 February 2020; SciTePress: Setubal, Portugal, 2020; pp. 494–505. [Google Scholar] [CrossRef]
- Zhao, R.; Wei, X.; Ding, C.; Chen, Y. Hierarchical Multi-label Text Classification: Self-adaption Semantic Awareness Network Integrating Text Topic and Label Level Information. In Proceedings of the Knowledge Science, Engineering and Management, Hangzhou, China, 28–30 August 2020; Qiu, H., Zhang, C., Fei, Z., Qiu, M., Kung, S.Y., Eds.; pp. 406–418. [Google Scholar] [CrossRef]
- Chen, J.; Zhao, S.; Lu, F.; Liu, F.; Zhang, Y. Research on patent classification based on hierarchical label semantics. In Proceedings of the 2022 3rd International Conference on Education, Knowledge and Information Management (ICEKIM), Harbin, China, 21–23 January 2022; pp. 1025–1032. [Google Scholar] [CrossRef]
- Yao, Z.; Chai, H.; Cui, J.; Tang, S.; Liao, Q. HITSZQ at SemEval-2023 Task 10: Category-aware Sexism Detection Model with Self-training Strategy. In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), Toronto, Canada, 13–14 July 2023; Ojha, A.K., Doğruöz, A.S., Da San Martino, G., Tayyar Madabushi, H., Kumar, R., Sartori, E., Eds.; pp. 934–940. [Google Scholar] [CrossRef]
- Ning, B.; Zhao, D.; Zhang, X.; Wang, C.; Song, S. UMP-MG: A Uni-directed Message-Passing Multi-label Generation Model for Hierarchical Text Classification. Data Sci. Eng. 2023, 8, 112–123. [Google Scholar] [CrossRef]
- Song, J.; Wang, F.; Yang, Y. Peer-Label Assisted Hierarchical Text Classification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; pp. 3747–3758. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In The Semantic Web. ISWC ASWC 2007 2007. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4825, pp. 722–735. [Google Scholar] [CrossRef]
- Speer, R.; Chin, J.; Havasi, C. ConceptNet 5.5: An Open Multilingual Graph of General Knowledge. Proc. AAAI Conf. Artif. Intell. 2017, 31, 1. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Burges, C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, AAAI’14, Quebec, QC, Canada, 27–31 July 2024; AAAI Press: Washington, DC, USA, 2014; pp. 1112–1119. [Google Scholar]
- Liu, Y.; Zhang, K.; Huang, Z.; Wang, K.; Zhang, Y.; Liu, Q.; Chen, E. Enhancing Hierarchical Text Classification through Knowledge Graph Integration. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; pp. 5797–5810. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, P.; Liu, T.; Lin, B.; Cao, Y.; Sui, Z.; Wang, H. HPT: Hierarchy-aware Prompt Tuning for Hierarchical Text Classification. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; pp. 3740–3751. [Google Scholar] [CrossRef]
- Ji, K.; Lian, Y.; Gao, J.; Wang, B. Hierarchical Verbalizer for Few-Shot Hierarchical Text Classification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Volume 1: Long Papers, pp. 2918–2933. [Google Scholar] [CrossRef]
- Chen, L.; Chou, H.; Zhu, X. Developing Prefix-Tuning Models for Hierarchical Text Classification. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Li, Y., Lazaridou, A., Eds.; pp. 390–397. [Google Scholar] [CrossRef]
- da Silva, L.V.M.; Cerri, R. Feature Selection for Hierarchical Multi-label Classification. In Proceedings of the Advances in Intelligent Data Analysis XIX, Porto, Portugal, 26–28 April 2021; Abreu, P.H., Rodrigues, P.P., Fernández, A., Gama, J., Eds.; pp. 196–208. [Google Scholar] [CrossRef]
- Stepišnik, T.; Kocev, D. Hyperbolic Embeddings for Hierarchical Multi-label Classification. In Proceedings of the Foundations of Intelligent Systems, Graz, Austria, 23–25 September 2020; Helic, D., Leitner, G., Stettinger, M., Felfernig, A., Raś, Z.W., Eds.; pp. 66–76. [Google Scholar] [CrossRef]
- Cerri, R.; Basgalupp, M.P.; Barros, R.C.; de Carvalho, A.C. Inducing Hierarchical Multi-label Classification rules with Genetic Algorithms. Appl. Soft Comput. 2019, 77, 584–604. [Google Scholar] [CrossRef]
- Romero, M.; Finke, J.; Rocha, C. A top-down supervised learning approach to hierarchical multi-label classification in networks. Appl. Netw. Sci. 2022, 7, 8. [Google Scholar] [CrossRef]
- Liu, J.; Xia, C.; Yan, H.; Xie, Z.; Sun, J. Hierarchical Comprehensive Context Modeling for Chinese Text Classification. IEEE Access 2019, 7, 154546–154559. [Google Scholar] [CrossRef]
- Gargiulo, F.; Silvestri, S.; Ciampi, M.; Pietro, G.D. Deep neural network for hierarchical extreme multi-label text classification. Appl. Soft Comput. 2019, 79, 125–138. [Google Scholar] [CrossRef]
- Masoudian, S.; Derhami, V.; Zarifzadeh, S. Hierarchical Persian Text Categorization in Absence of Labeled Data. In Proceedings of the 2019 27th Iranian Conference on Electrical Engineering (ICEE), Yazd, Iran, 30 April–2 May 2019; pp. 1951–1955. [Google Scholar] [CrossRef]
- Li, X.; Arora, K.; Alaniazar, S. Mixed-Model Text Classification Framework Considering the Practical Constraints. In Proceedings of the 2019 Second International Conference on Artificial Intelligence For Industries (AI4I 2019), Laguna Hills, CA, USA, 25–27 September 2019; IEEE: New York, NY, USA, 2019; pp. 67–70. [Google Scholar] [CrossRef]
- Meng, Y.; Shen, J.; Zhang, C.; Han, J. Weakly-Supervised Hierarchical Text Classification. In Proceedings of the The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Washington, DC, USA, 2019; pp. 6826–6833. [Google Scholar] [CrossRef]
- Banerjee, S.; Akkaya, C.; Perez-Sorrosal, F.; Tsioutsiouliklis, K. Hierarchical Transfer Learning for Multi-label Text Classification. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2019; Volume 1, pp. 6295–6300. [Google Scholar] [CrossRef]
- Liu, L.; Mu, F.; Li, P.; Mu, X.; Tang, J.; Ai, X.; Fu, R.; Wang, L.; Zhou, X. NeuralClassifier: An Open-source Neural Hierarchical Multi-label Text Classification Toolkit. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Costa-jussà, M.R., Alfonseca, E., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2019; Volume 3: System Demonstrations, pp. 87–92. [Google Scholar] [CrossRef]
- Prabowo, F.A.; Ibrohim, M.O.; Budi, I. Hierarchical Multi-label Classification to Identify Hate Speech and Abusive Language on Indonesian Twitter. In Proceedings of the 2019 6th International Conference on Information Technology, Computer and Electrical Engineering (ICITACEE), Semarang, Indonesia, 26–27 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Xiao, H.; Liu, X.; Song, Y. Efficient Path Prediction for Semi-Supervised and Weakly Supervised Hierarchical Text Classification. In Proceedings of the The World Wide Web Conference, WWW 2019, San Francisco, CA, USA, 13–17 May 2019; Liu, L., White, R.W., Mantrach, A., Silvestri, F., McAuley, J.J., Baeza-Yates, R., Zia, L., Eds.; ACM: New York, NY, USA, 2019; pp. 3370–3376. [Google Scholar] [CrossRef]
- Ciapetti, A.; Florio, R.D.; Lomasto, L.; Miscione, G.; Ruggiero, G.; Toti, D. NETHIC: A System for Automatic Text Classification using Neural Networks and Hierarchical Taxonomies. In Proceedings of the 21st International Conference on Enterprise Information Systems, ICEIS 2019, Crete, Greece, 3–5 May 2019; Filipe, J., Smialek, M., Brodsky, A., Hammoudi, S., Eds.; SciTePress: Setubal, Portugal, 2019; Volume 1, pp. 296–306. [Google Scholar] [CrossRef]
- Lomasto, L.; Di Florio, R.; Ciapetti, A.; Miscione, G.; Ruggiero, G.; Toti, D. An Automatic Text Classification Method Based on Hierarchical Taxonomies, Neural Networks and Document Embedding: The NETHIC Tool. In Proceedings of the Enterprise Information Systems, Virtual Event, 5–7 May 2020; Filipe, J., Śmiałek, M., Brodsky, A., Hammoudi, S., Eds.; pp. 57–77. [Google Scholar] [CrossRef]
- Xu, J.; Du, Q. Learning neural networks for text classification by exploiting label relations. Multimed. Tools Appl. 2020, 79, 22551–22567. [Google Scholar] [CrossRef]
- Nakano, F.K.; Cerri, R.; Vens, C. Active learning for hierarchical multi-label classification. Data Min. Knowl. Discov. 2020, 34, 1496–1530. [Google Scholar] [CrossRef]
- Addi, H.A.; Ezzahir, R.; Mahmoudi, A. Three-Level Binary Tree Structure for Sentiment Classification in Arabic Text. In Proceedings of the 3rd International Conference on Networking, Information Systems & Security, NISS2020, New York, NY, USA, 31 March–2 April 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Jiang, H.; Miao, Z.; Lin, Y.; Wang, C.; Ni, M.; Gao, J.; Lu, J.; Shi, G. Financial News Annotation by Weakly-Supervised Hierarchical Multi-label Learning. In Proceedings of the Second Workshop on Financial Technology and Natural Language Processing, Kyoto, Japan, 11–12 July 2020; pp. 1–7. [Google Scholar]
- Giunchiglia, E.; Lukasiewicz, T. Coherent Hierarchical Multi-Label Classification Networks. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 9662–9673. [Google Scholar]
- Krendzelak, M.; Jakab, F. Hierarchical Text Classification Using CNNS with Local Approaches. Comput. Inform. 2020, 39, 907–924. [Google Scholar] [CrossRef]
- Liang, X.; Cheng, D.; Yang, F.; Luo, Y.; Qian, W.; Zhou, A. F-HMTC: Detecting Financial Events for Investment Decisions Based on Neural Hierarchical Multi-Label Text Classification. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI, Yokohama, Japan, 7–15 January 2020; Bessiere, C., Ed.; pp. 4490–4496. [Google Scholar] [CrossRef]
- Li, R.A.; Hajjar, I.; Goldstein, F.; Choi, J.D. Analysis of Hierarchical Multi-Content Text Classification Model on B-SHARP Dataset for Early Detection of Alzheimer’s Disease. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, AACL/IJCNLP 2020, Suzhou, China, 4–7 December 2020; Wong, K., Knight, K., Wu, H., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2020; pp. 358–365. [Google Scholar]
- Xun, G.; Jha, K.; Sun, J.; Zhang, A. Correlation Networks for Extreme Multi-Label Text Classification. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’20, New York, NY, USA, 6–10 July 2020; pp. 1074–1082. [Google Scholar] [CrossRef]
- Masmoudi, A.; Bellaaj, H.; Drira, K.; Jmaiel, M. A co-training-based approach for the hierarchical multi-label classification of research papers. Expert Syst. 2021, 38, e12613. [Google Scholar] [CrossRef]
- Dong, H.; Wang, W.; Huang, K.; Coenen, F. Automated Social Text Annotation With Joint Multilabel Attention Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2224–2238. [Google Scholar] [CrossRef]
- Zhang, Y.; Shen, Z.; Dong, Y.; Wang, K.; Han, J. MATCH: Metadata-Aware Text Classification in A Large Hierarchy. In Proceedings of the Web Conference 2021, WWW ’21, New York, NY, USA, 19–23 April 2021; pp. 3246–3257. [Google Scholar] [CrossRef]
- Ye, C.; Zhang, L.; He, Y.; Zhou, D.; Wu, J. Beyond Text: Incorporating Metadata and Label Structure for Multi-Label Document Classification using Heterogeneous Graphs. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3162–3171. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, D.; Yin, B.; Zhu, X. Improving Pretrained Models for Zero-shot Multi-label Text Classification through Reinforced Label Hierarchy Reasoning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 1051–1062. [Google Scholar] [CrossRef]
- Wang, B.; Hu, X.; Li, P.; Yu, P.S. Cognitive structure learning model for hierarchical multi-label text classification. Knowl. Based Syst. 2021, 218, 106876. [Google Scholar] [CrossRef]
- Chatterjee, S.; Maheshwari, A.; Ramakrishnan, G.; Jagarlapudi, S.N. Joint Learning of Hyperbolic Label Embeddings for Hierarchical Multi-label Classification. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 21–23 April 2021; pp. 2829–2841. [Google Scholar] [CrossRef]
- Peng, H.; Li, J.; Wang, S.; Wang, L.; Gong, Q.; Yang, R.; Li, B.; Yu, P.S.; He, L. Hierarchical Taxonomy-Aware and Attentional Graph Capsule RCNNs for Large-Scale Multi-Label Text Classification. IEEE Trans. Knowl. Data Eng. 2021, 33, 2505–2519. [Google Scholar] [CrossRef]
- Xu, L.; Teng, S.; Zhao, R.; Guo, J.; Xiao, C.; Jiang, D.; Ren, B. Hierarchical Multi-label Text Classification with Horizontal and Vertical Category Correlations. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event/Punta Cana, Dominican Republic, 7–11 November 2021; Moens, M., Huang, X., Specia, L., Yih, S.W., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 2459–2468. [Google Scholar] [CrossRef]
- Falis, M.; Dong, H.; Birch, A.; Alex, B. CoPHE: A Count-Preserving Hierarchical Evaluation Metric in Large-Scale Multi-Label Text Classification. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Punta Cana, Dominican Republic, 7–11 November 2021; Moens, M., Huang, X., Specia, L., Yih, S.W., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 907–912. [Google Scholar] [CrossRef]
- Aljedani, N.; Alotaibi, R.; Taileb, M. HMATC: Hierarchical multi-label Arabic text classification model using machine learning. Egypt Inform. J. 2021, 22, 225–237. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, H.; Zhu, J.; Shi, W.; Guo, W.; Zhang, J. Effective Seed-Guided Topic Labeling for Dataless Hierarchical Short Text Classification. In Proceedings of the Web Engineering—21st International Conference, ICWE 2021, Biarritz, France, 18–21 May 2021; Brambilla, M., Chbeir, R., Frasincar, F., Manolescu, I., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2021; Volume 12706, pp. 271–285. [Google Scholar] [CrossRef]
- Pujari, S.C.; Friedrich, A.; Strötgen, J. A Multi-task Approach to Neural Multi-label Hierarchical Patent Classification Using Transformers. In Proceedings of the Advances in Information Retrieval, Virtual Event, 28 March–1 April 2021; Hiemstra, D., Moens, M.F., Mothe, J., Perego, R., Potthast, M., Sebastiani, F., Eds.; pp. 513–528. [Google Scholar]
- Shen, J.; Qiu, W.; Meng, Y.; Shang, J.; Ren, X.; Han, J. TaxoClass: Hierarchical Multi-Label Text Classification Using Only Class Names. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, 6–11 June 2021; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tür, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 4239–4249. [Google Scholar] [CrossRef]
- Deng, Z.; Peng, H.; He, D.; Li, J.; Yu, P.S. HTCInfoMax: A Global Model for Hierarchical Text Classification via Information Maximization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, 6–11 June 2021; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tür, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 3259–3265. [Google Scholar] [CrossRef]
- Huang, W.; Liu, C.; Xiao, B.; Zhao, Y.; Pan, Z.; Zhang, Z.; Yang, X.; Liu, G. Exploring Label Hierarchy in a Generative Way for Hierarchical Text Classification. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 1116–1127. [Google Scholar]
- Ma, Y.; Liu, X.; Zhao, L.; Liang, Y.; Zhang, P.; Jin, B. Hybrid embedding-based text representation for hierarchical multi-label text classification. Expert Syst. Appl. 2022, 187, 115905. [Google Scholar] [CrossRef]
- Jiang, T.; Wang, D.; Sun, L.; Chen, Z.; Zhuang, F.; Yang, Q. Exploiting Global and Local Hierarchies for Hierarchical Text Classification. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; pp. 4030–4039. [Google Scholar] [CrossRef]
- Song, Y.; Yan, Z.; Qin, Y.; Zhao, D.; Ye, X.; Chai, Y.; Ouyang, Y. Hierarchical Multi-label Text Classification based on a Matrix Factorization and Recursive-Attention Approach. In Proceedings of the 2022 7th International Conference on Big Data Analytics (ICBDA), Guangzhou, China, 4–6 March 2022; pp. 170–176. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, B.; Li, D.; Yue, X. Hierarchical multilabel classification by exploiting label correlations. Int. J. Mach. Learn. Cybern. 2022, 13, 115–131. [Google Scholar] [CrossRef]
- Mezza, S.; Wobcke, W.; Blair, A. A Multi-Dimensional, Cross-Domain and Hierarchy-Aware Neural Architecture for ISO-Standard Dialogue Act Tagging. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; Calzolari, N., Huang, C.R., Kim, H., Pustejovsky, J., Wanner, L., Choi, K.S., Ryu, P.M., Chen, H.H., Donatelli, L., Ji, H., et al., Eds.; pp. 542–552. [Google Scholar]
- Sadat, M.; Caragea, C. Hierarchical Multi-Label Classification of Scientific Documents. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; pp. 8923–8937. [Google Scholar] [CrossRef]
- Wang, Y.; Song, H.; Huo, P.; Xu, T.; Yang, J.; Chen, Y.; Zhao, T. Exploiting Dynamic and Fine-grained Semantic Scope for Extreme Multi-label Text Classification. In Proceedings of the Natural Language Processing and Chinese Computing, Guilin, China, 24–25 September 2022; Lu, W., Huang, S., Hong, Y., Zhou, X., Eds.; pp. 85–97. [Google Scholar]
- Zheng, S.; Zhou, J.; Meng, K.; Liu, G. Label-Dividing Gated Graph Neural Network for Hierarchical Text Classification. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–08. [Google Scholar] [CrossRef]
- Mallikarjuna, K.; Pasari, S.; Tiwari, K. Hierarchical Classification using Neighbourhood Exploration for Sparse Text Tweets. In Proceedings of the 2022 12th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Virtual Event, 27–28 January 2022; pp. 31–34. [Google Scholar] [CrossRef]
- Wunderlich, D.; Bernau, D.; Aldà, F.; Parra-Arnau, J.; Strufe, T. On the Privacy & Utility Trade-Off in Differentially Private Hierarchical Text Classification. Appl. Sci. 2022, 12, 11177. [Google Scholar]
- Liu, L.; Perez-Concha, O.; Nguyen, A.; Bennett, V.; Jorm, L. Automated ICD coding using extreme multi-label long text transformer-based models. Artif. Intell. Med. 2023, 144, 102662. [Google Scholar] [CrossRef]
- Agrawal, N.; Kumar, S.; Bhatt, P.; Agarwal, T. Hierarchical Text Classification Using Contrastive Learning Informed Path Guided Hierarchy. In Proceedings of the 26th European Conference on Artificial Intelligence, Krakow, Poland, 30 September–4 October 2023; IOS Press: Amsterdam, The Netherlands, 2023; pp. 19–26. [Google Scholar] [CrossRef]
- Bang, J.; Park, J.; Park, J. GACaps-HTC: Graph attention capsule network for hierarchical text classification. Appl. Intell. 2023, 53, 20577–20594. [Google Scholar] [CrossRef]
- Wang, X.; Guo, L. Multi-Label Classification of Chinese Rural Poverty Governance Texts Based on XLNet and Bi-LSTM Fused Hierarchical Attention Mechanism. Appl. Sci. 2023, 13, 7377. [Google Scholar] [CrossRef]
- Hunter, S.B.; Mathews, F.; Weeds, J. Using hierarchical text classification to investigate the utility of machine learning in automating online analyses of wildlife exploitation. Ecol. Inform. 2023, 75, 102076. [Google Scholar] [CrossRef]
- Im, S.; Kim, G.; Oh, H.S.; Jo, S.; Kim, D.H. Hierarchical Text Classification as Sub-hierarchy Sequence Generation. Proc. AAAI Conf. Artif. Intell. 2023, 37, 12933–12941. [Google Scholar] [CrossRef]
- Bongiovanni, L.; Bruno, L.; Dominici, F.; Rizzo, G. Zero-Shot Taxonomy Mapping for Document Classification. In Proceedings of the 38th ACM/SIGAPP Symposium on Applied Computing, SAC ’23, New York, NY, USA, 27 March–2 April 2023; pp. 911–918. [Google Scholar] [CrossRef]
- Ma, K.; Huang, Z.; Deng, X.; Guo, J.; Qiu, W. LED: Label Correlation Enhanced Decoder for Multi-Label Text Classification. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Li, F.; Chen, Z.; Wang, Y. HLC-KEPLM: Hierarchical Label Classification Based on Knowledge-Enhanced Pretrained Language Model for Chinese Telecom. In Proceedings of the 2023 4th International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI), Guangzhou, China, 4–6 August 2023; pp. 262–266. [Google Scholar] [CrossRef]
- Wang, Y.; Qiao, D.; Li, J.; Chang, J.; Zhang, Q.; Liu, Z.; Zhang, G.; Zhang, M. Towards Better Hierarchical Text Classification with Data Generation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 10–12 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; pp. 7722–7739. [Google Scholar] [CrossRef]
- Chen, C.Y.; Hung, T.M.; Hsu, Y.L.; Ku, L.W. Label-Aware Hyperbolic Embeddings for Fine-grained Emotion Classification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Volume 1: Long Papers, pp. 10947–10958. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, C.; Huang, J.; Wu, J.; Xu, K. HiTIN: Hierarchy-aware Tree Isomorphism Network for Hierarchical Text Classification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Volume 1: Long Papers, pp. 7809–7821. [Google Scholar] [CrossRef]
- Zhao, F.; Wu, Z.; He, L.; Dai, X.Y. Label-Correction Capsule Network for Hierarchical Text Classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 2158–2168. [Google Scholar] [CrossRef]
- Yu-Kun, C.; Zi-Yue, W.; Yi-jia, T.; Cheng-Kun, J. Hierarchical Label Text Classification Method with Deep-Level Label-Assisted Classification. In Proceedings of the 2023 IEEE 12th Data Driven Control and Learning Systems Conference (DDCLS), Xiangtan, China, 12–14 May 2023; pp. 1467–1474. [Google Scholar] [CrossRef]
- Li, H.; Yan, H.; Li, Y.; Qian, L.; He, Y.; Gui, L. Distinguishability Calibration to In-Context Learning. In Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; Vlachos, A., Augenstein, I., Eds.; pp. 1385–1397. [Google Scholar] [CrossRef]
- Fan, Q.; Qiu, C. Hierarchical Multi-label Text Classification Method Based On Multi-level Decoupling. In Proceedings of the 2023 3rd International Conference on Neural Networks, Information and Communication Engineering (NNICE), Guangzhou, China, 24–26 February 2023; pp. 453–457. [Google Scholar] [CrossRef]
- Cheng, Q.; Lin, Y. Multilevel Classification of Users’ Needs in Chinese Online Medical and Health Communities: Model Development and Evaluation Based on Graph Convolutional Network. JMIR Form Res. 2023, 7, e42297. [Google Scholar] [CrossRef]
- Yu, S.C.L.; He, J.; Basulto, V.; Pan, J. Instances and Labels: Hierarchy-aware Joint Supervised Contrastive Learning for Hierarchical Multi-Label Text Classification. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; pp. 8858–8875. [Google Scholar] [CrossRef]
- Chen, A.; Dhingra, B. Hierarchical Multi-Instance Multi-Label Learning for Detecting Propaganda Techniques. In Proceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023), Toronto, ON, Canada, 13 July 2023; Can, B., Mozes, M., Cahyawijaya, S., Saphra, N., Kassner, N., Ravfogel, S., Ravichander, A., Zhao, C., Augenstein, I., Rogers, A., et al., Eds.; pp. 155–163. [Google Scholar] [CrossRef]
- Ying, C.; Cai, T.; Luo, S.; Zheng, S.; Ke, G.; He, D.; Shen, Y.; Liu, T.Y. Do Transformers Really Perform Badly for Graph Representation? In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Long Beach, CA, USA, 2021; Volume 34, pp. 28877–28888. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural Deep Network Embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, New York, NY, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Red Hook, NY, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Su, J.; Zhu, M.; Murtadha, A.; Pan, S.; Wen, B.; Liu, Y. ZLPR: A Novel Loss for Multi-label Classification. arXiv 2022, arXiv:2208.02955. [Google Scholar]
- DBpedia. Available online: https://www.dbpedia.org/ (accessed on 15 November 2022).
- Wikimedia Downloads. Available online: https://www.wikimedia.org (accessed on 15 November 2022).
- Lewis, D.D.; Yang, Y.; Rose, T.G.; Li, F. RCV1: A New Benchmark Collection for Text Categorization Research. J. Mach. Learn. Res. 2004, 5, 361–397. [Google Scholar]
- Kowsari, K.; Brown, D.; Heidarysafa, M.; Jafari Meimandi, K.; Gerber, M.; Barnes, L. Web of Science Dataset. 2018. Available online: https://data.mendeley.com/datasets/9rw3vkcfy4/6 (accessed on 21 March 2024).
- Lang, K. NewsWeeder: Learning to Filter Netnews. In Proceedings of the Machine Learning 1995, Tahoe, CA, USA, 9–12 July 1995; Prieditis, A., Russell, S., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1995; pp. 331–339. [Google Scholar] [CrossRef]
- Yang, P.; Sun, X.; Li, W.; Ma, S.; Wu, W.; Wang, H. SGM: Sequence Generation Model for Multi-label Classification. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3915–3926. [Google Scholar]
- Klimt, B.; Yang, Y. The Enron Corpus: A New Dataset for Email Classification Research. In Proceedings of the 15th European Conference on Machine Learning, ECML’04, Berlin/Heidelberg, Germany, 20–24 September 2004; pp. 217–226. [Google Scholar] [CrossRef]
- Sandhaus, E. The New York Times Annotated Corpus LDC2008T19; Linguistic Data Consortium: Philadelphia, PA, USA, 2008. [Google Scholar] [CrossRef]
- McAuley, J.; Leskovec, J. Hidden Factors and Hidden Topics: Understanding Rating Dimensions with Review Text. In Proceedings of the 7th ACM Conference on Recommender Systems, RecSys’13, New York, NY, USA, 12–16 October 2013; pp. 165–172. [Google Scholar] [CrossRef]
- Lyubinets, V.; Boiko, T.; Nicholas, D. Automated Labeling of Bugs and Tickets Using Attention-Based Mechanisms in Recurrent Neural Networks. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 271–275. [Google Scholar] [CrossRef]
- Ni, J.; Li, J.; McAuley, J. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 188–197. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Kerrville, TX, USA, 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Tanaka, H.; Shinnou, H.; Cao, R.; Bai, J.; Ma, W. Document Classification by Word Embeddings of BERT. In Proceedings of the 16th International Conference of the Pacific Association for Computational Linguistics, PACLING 2019, Hanoi, Vietnam, 11–13 October 2019; Nguyen, L.M., Phan, X.H., Hasida, K., Tojo, S., Eds.; pp. 145–154. [Google Scholar] [CrossRef]
- Liu, J.; Chang, W.C.; Wu, Y.; Yang, Y. Deep Learning for Extreme Multi-Label Text Classification. In Proceedings of the SIGIR ’17 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 115–124. [Google Scholar] [CrossRef]
- Adhikari, A.; Ram, A.; Tang, R.; Lin, J. DocBERT: BERT for Document Classification. arXiv 2019, arXiv:1904.08398. [Google Scholar] [CrossRef]
- Jiang, Y.; Hu, C.; Xiao, T.; Zhang, C.; Zhu, J. Improved Differentiable Architecture Search for Language Modeling and Named Entity Recognition. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; pp. 3585–3590. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, Y.; Chen, Y.; Bai, J.; Zhang, C.; Su, G.; Kou, X.; Tong, Y.; Yang, M.; Zhou, L. TextNAS: A Neural Architecture Search Space Tailored for Text Representation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 9242–9249. [Google Scholar] [CrossRef]
- Chen, K.C.; Li, C.T.; Lee, K.J. DDNAS: Discretized Differentiable Neural Architecture Search for Text Classification. ACM Trans. Intell. Syst. Technol. 2023, 14, 1–22. [Google Scholar] [CrossRef]
- Samuel, D.; Atzmon, Y.; Chechik, G. From generalized zero-shot learning to long-tail with class descriptors. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 286–295. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 353–355. [Google Scholar] [CrossRef]
- Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 3266–3280. [Google Scholar]
- Tenney, I.; Wexler, J.; Bastings, J.; Bolukbasi, T.; Coenen, A.; Gehrmann, S.; Jiang, E.; Pushkarna, M.; Radebaugh, C.; Reif, E.; et al. The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 107–118. [Google Scholar] [CrossRef]
- Wu, T.; Ribeiro, M.T.; Heer, J.; Weld, D. Errudite: Scalable, Reproducible, and Testable Error Analysis. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 747–763. [Google Scholar] [CrossRef]
- Yuan, J.; Vig, J.; Rajani, N. ISEA: An Interactive Pipeline for Semantic Error Analysis of NLP Models. In Proceedings of the IUI ’22 27th International Conference on Intelligent User Interfaces, New York, NY, USA, 22–25 March 2022; pp. 878–888. [Google Scholar] [CrossRef]
- Scikit-learn.org. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html (accessed on 17 March 2024).








| Method | Base | Datasets | Code | Novelty |
|---|---|---|---|---|
| HCCMN [143] | TCN, LSTM, ATT | CRTEXT, Fudan, Sogou, TouTiao | ✗ | Combine TCN with LSTM for extraction of contextual information and temporal features from Chinese text |
| [117] | CNN, LSTM, ATT | RCV1, AAPD, Zhihu-QT | ✗ | Usage of local and global information, new Seq2seq model with CNN encoder and LSTM decoder |
| HLSE [144] | CNN | MeSH | ✗ | Hierarchical label set expansion for label regularization |
| [145] | k-means, SVM | Hamshahri | ✗ | HTC of Persian text with weak supervision using clustering |
| [146] | SVM, MLP | - | ✗ | Mixed deep learning and traditional methods for HTC in the automotive domain |
| WeSHClass [147] | CNN | NYT, AAPD, Yelp | ✓ | Weakly supervised HTC with pseudo-document generation |
| HMC-CAPS [88] | CN | BGC, WOS | ✓ | Compare CapsNets with other NNs |
| HTrans [148] | GRU, ATT | RCV1 | ✗ | Recursive training of LMs on branches of tree-shaped hierarchies of labels |
| NeuralClassifier [149] | - | RCV1, Yelp | ✓ | Toolkit to quickly set up HTC pipelines with multiple algorithms |
| HARNN [76] | RNN, ATT | Patent | ✓ | Hierarchical attention unit (HAM) |
| HiLAP [99] | BASE | RCV1, NYT, Yelp | ✓ | RL framework to learn a label assignment policy |
| HLAN [7] | LSTM, ATT | EURLEX, EURLEX-PT | ✓ | HTC of legal documents, new Portuguese corpus |
| [150] | RF, DT, NB, SVM | HS-Ind | ✓ | Categorization of hate speech expression in Indonesian tweets |
| HKUST [151] | NB, EM | RCV1, 20NG | ✓ | Path cost-sensitive learning algorithm to leverage structural information of hierarchy and unlabeled/weakly-labeled data |
| NETHIC [152,153] | MLP | DANTE | ✓ | DNN for efficient and scalable HTC |
| LSNN [154] | MLP | 20NG, DBpedia, YahooA | ✗ | Unsupervised clustering to exploit label relation, neural architectures to learn inter- and intra-label relations |
| HG-Transformer [111] | TRAN | RCV1, Amazon | ✗ | Transformer-based model, weighted loss using semantic distances |
| H-QBC [155] | QBC (AL) | Enron, Reuters | ✗ | Active learning framework for HTC for classification of datasets with few labeled samples |
| GMLC [118] | LSTM, ATT | - | ✗ | Seq2seq multi-task framework with hierarchical mask matrix to learn cross-task relations |
| 3LBT [156] | SVM, NB, DT, RF | HARD | ✗ | Framework for sentiment classification of Arabic texts using multi-level hierarchical classifiers, using SMOTE technique |
| [157] | FIN-NEWS-CN | ✗ | Weakly supervised model driven by user-generated keywords, adopting a confidence-enhancing method during training | |
| C-HMCNN [158] | MLP | Enron, 19 + | ✓ | Coherent predictions using a hierarchical constraint, usage of hierarchical information |
| HyperIM [110] | GRU | RCV1, Zhihu, WikiLSHTC | ✓ | Embedding of label hierarchy and document in the same hyperbolic space, with explicit modeling of label–word semantics |
| LCN [159] | CNN | 20NG | ✗ | Different approaches with CNNs for HTC |
| [119] | GRU, ATT | WOS, DBpedia | ✗ | Seq2seq model, auxiliary tasks, and beam search |
| HiAGM [97] | LSTM, GCN | RCV1, WOS, NYT | ✓ | Extraction of hierarchical label information |
| ONLSTM [113] | LSTM | WOS, DBpedia | ✓ | Sharing parameters for sequential prediction of next-level label |
| F-HMTC [160] | BERT | - | ✓ | BERT embeddings with hierarchy-based loss |
| [161] | TRAN | B-SHARP | ✗ | Hierarchical Transformer for classification based on ensemble of three models |
| CorNet [162] | BERT, CNN, RNN | EURLEX, Amazon, Wikipedia | ✓ | Model-agnostic architecture for MLTC to enhance label predictions to consider the labels’ correlation |
| MAGNET [125] | LSTM, GAT | Reuters, RCV1, AAPD, Slashdot, Toxic | ✓ | Improving GCN with GAT for considering label correlation and co-occurrence |
| Article | Base | Datasets | Code | Novelty |
|---|---|---|---|---|
| PAC-HCNN [8] | CNN, ATT, GLU | - | ✗ | Stacked hierarchical convolutional layers for HTC of Chinese patent dataset |
| [163] | Co-training | - | ✗ | Semi-supervised approach for HTC of research papers based on co-training algorithm |
| JMAN [164] | GRU | Bibsonomy, Zhihu, CiteULike | ✓ | Attention mechanism to mimic user annotation behavior, loss regularization to capture label co-occurrence relations |
| [120] | LSTM, TRAN | USPTO | ✗ | HTC as sequence generation, teacher forcing with scheduled sampling in training, beam search to choose output labels |
| MATCH [165] | TRAN (CorNet) | MAG-CS, PubMed | ✓ | E2E framework for classification with large hierarchies of labels and documents’ metadata |
| [166] | TRAN, GNN | MAG-CS, PubMed | ✗ | Incorporate text metadata and label structure using heterogeneous graphs |
| RLHR [167] | BERT, RL | WOS, Yelp, QCD | ✓ | Label structure modeling using Markov decision process and RL with pre-trained LMs for zero-shot TC |
| HCSM [168] | LSTM, CN | RCV1, EURLEX, WOS | ✗ | Combine global label structure and partial knowledge learning to emulate cognitive process |
| HiMatch [124] | BERT, GCN, GRU, CNN | RCV1, EURLEX, WOS | ✓ | Semantic matching method to learn relationship between labels and text |
| HIDDEN [169] | CNN | RCV1, NYT, Yelp | ✓ | Embed hierarchical label structure in label representation jointly training the classifier |
| HE-AGCRCNN [170] | CNN, ATT, CN, RNN | RCV1, 20NG | ✓ | Architecture, graph-of-words text representation, taxonomy-aware margin loss |
| HVHMC [171] | GCN | WOS, AAPD, Patent | ✗ | Loosely coupled GCN to capture word-to-word, label-to-word, and label-to-label associations, correlation matrix and hybrid algorithm to capture vertical and horizontal dependencies |
| CoPHE [172] | n/a | MIMIC-III | ✓ | New metrics for hierarchical classification for large label spaces |
| CLED [87] | CN, CNN, GRU | DBpedia, WOS | ✓ | Concept-based label embeddings to model sharing in hierarchical classes |
| HMATC [173] | Tree-based (HOMER) | MLAD | ✓ | HTC in multilabel setting for Arabic text, introduction of new Arabic corpus |
| ICD-RE [6] | AE, TRAN | MIMIC | ✓ | Re-ranking method to learn label co-occurrence with unknown label hierarchies |
| SASF [126] | GCN, GRU, CNN | WOS, BGC | ✗ | Hierarchy-aware label encoder and attention mechanism applied to document labels and words |
| L1-L2-3BERT [115] | BERT | - | ✗ | Hierarchical classification using multi-task training with penalty loss |
| HierSeedBTM [174] | HuffPost, 20NG | - | ✗ | Dataless hierarchical classification with iterative propagation mechanism to exploit hierarchical label structure |
| THMM [175] | ATT | Patent | ✗ | Pre-trained LM with multi-task architecture for efficient HTC |
| TaxoClass [176] | RoBERTa | Amazon-531, DBpedia-298 | ✗ | HMTC with class surface name as the only supervision signal |
| HTCInfoMax [177] | HiAGM-LA | RCV1, WOS | ✓ | Text-label mutual information maximization and label prior matching |
| PAAM-HiA-T5 [178] | T5 | RCV1, NYTimes, WOS | ✗ | Hierarchy aware T5, path-adaptive mask mechanism |
| HFT-ONLSTM [113] | LSTM | WOS, DBpedia | ✗ | Hierarchical fine-tuning approach with joint embedding learning based on labels and documents |
| HPT [136] | BERT, GAT | RCV1, WOS, NYT | ✓ | Hierarchy-aware prompt tuning and MLM suitable for handling label imbalance |
| Article | Base | Datasets | Code | Novelty |
|---|---|---|---|---|
| HE-HMTC [179] | BiGRU, SDNE | WOS, Amazon, DBpedia, WebService, BestBuy | ✓ | Level-by-level hybrid embeddings, graph embedding of category structure |
| LA-HCN [94] | ATT | RCV1, Enron, WIPO-alpha, BGC | ✗ | Label-based attention learned at different hierarchical levels, local and global text embedding |
| HGCLR [91] | TRAN | RCV1, WOS, NYT | ✓ | Contrastive learning, graph-based Transformers for sample generation |
| Seq2Tree [93] | T5 | RCV1, WOS, BGC | ✗ | Decoding strategy to ensure consistency in predicted labels across levels, new metrics for HTC |
| HBGL [180] | BERT | RCV1, WOS, NYT | ✓ | Hierarchical label embeddings encoding label structure using both local and global hierarchical data |
| MF-RA [181] | MF, ATT | - | ✗ | Recursive attention mechanism to capture relations between labels at different levels, applied to the MF algorithm |
| CHAMP [107] | n/a | RCV1, NYT | ✗ | Definition of new metrics and modified BCE loss for hierarchical classification |
| OWGC-HMC [114] | MLP | Aizhan | ✗ | Online classifier for genre classification based on entity extraction and embedding with hierarchical regularization term |
| HMC-CLC [182] | BN | RCV1, Enron, imclef07a | ✗ | Exploit label correlations for HTC with greedy label selection method to determine correlated labels dynamically |
| ML-BERT [101] | BERT | Linux Bugs | ✓ | Global approach with multiple BERT models trained on different hierarchy levels, test of document embedding strategies |
| DASHNet [183] | LSTM, GRU | DialogBank, GDC | ✓ | BiTree-LSTM computes prior probabilities of hierarchical label correlation, grammatical, lexical, and contextual encoding |
| P-tuning v2 [138] | BERT | WOS, Amazon | ✓ | Prefix tuning in local and global HTC methods to reduce parameters to fine-tune in pre-trained LMs |
| HR-SciBERT [184] | Bi-LSTM, BERT | WOS, CORA, MAG, SciHTC | ✓ | New dataset, multi-task learning jointly learns topic classification and keyword labeling |
| HLSPC [127] | GCN, Bi-LSTM, ATT | USPTO | ✗ | Leverage label descriptions of patents to find semantic correlation between texts and hierarchical label descriptions with attention |
| TReaderXML [185] | TRAN, ATT | RCV1, Amazon, EURLex | ✗ | Dual cooperative network based on multi-head self-attention, dynamic and fine-grained semantic scope from teacher knowledge to optimize text prior label semantic ranges |
| LD-GGNN [186] | GCN, BiGRU | RCV1, WOS, NYTimes | ✗ | Gated GNN as structure encoder with fine-grained adjacency matrix for better label dependence extraction and reduced over-smoothing, dynamic label dividing to differentiate sibling labels |
| [187] | MLP, BERT | Non-profit Tweets (private) | ✗ | Neighborhood exploration data augmentation, MLP blocks for each layer of the hierarchy with modular adapters |
| [188] | BoW, CNN, TRAN | RCV1, DBpedia, BestBuy | ✓ | Analyze and compare privacy–utility trade-off in DP HTC under a white-box MI adversary |
| LSE-HiAGM [123] | GCN, HiAGM | RCV1, WOS, NYTimes | ✗ | Introduce a common density coefficient of labels to measure their structural similarity, re-balance loss to alleviate label imbalance |
| Seq2Label [121] | BART | RCV1, WOS, BGC | ✗ | HTC as a sequence generation problem, novel Seq2Label framework to learn label hierarchy in a random generative way, hierarchy-aware negative sampling against error accumulation |
| XR-LAT [189] | TRAN | MIMIC-II/III | ✓ | Transformer recursively trained model chain on a predefined hierarchical code tree with dynamic negative label sampling |
| HTC-CLIP [190] | BERT | WOS, NYTimes | ✗ | Combines contrastive learning-guided hierarchy in a text encoder and a path-guided hierarchy |
| GACaps-HTC [191] | GAT, CN | RCV1, WOS | ✓ | A GAT extracts textual representations while integrating label hierarchy information, whereas CN learns latent label relationships to infer classification probabilities |
| Article | Base | Datasets | Code | Novelty |
|---|---|---|---|---|
| HTMC-PGT [192] | XLNet, LSTM | PGT (private) | ✗ | HTC as a parameter-solving problem for multiple multiclass classifiers in a classifier tree |
| [193] | BERT | Private | ✓ | Multi-per-level local classifiers based on BERT for analyses of wildlife exploitation |
| HiDEC [194] | ATT | RCV1, NYTimes, EURLEX | ✓ | HTC as a sub-hierarchy sequence generation, recursive hierarchy encoder–decoder with self-attention to exploit dependency between labels |
| UMP-MG [129] | GCN | E-commerce, WOS | ✗ | HTC as sequence generation through auto-regressive decoder, top-down and down-top unidirectional message-passing |
| Z-STC [195] | BERT | WOS, DBpedia, Amazon | ✓ | Zero-shot prior generation for labels based on semantic alignment of documents and labels, upwards score propagation (USP) to propagate confidence scores upwards in the taxonomy |
| LED [196] | BERT | RCV1, WOS, BGC, AAPD | ✗ | Hierarchy-aware attention module and pairwise matching task to capture hierarchical dependencies of labels |
| HLC-KEPLM [197] | BERT, RoBERTa | Private | ✗ | Knowledge-enhanced pre-trained language model that learns with multiple local classifiers with knowledge fusion |
| [198] | Graphormer, BERT, ATT | RCV1, WOS, NYTimes | ✗ | Generative data augmentation for HTC, leverages both semantic-level and phrase-level hierarchical label information to enhance the label controllability and text diversity |
| [5] | Bi-LSTM | MIMIC-III | ✗ | Two-stage decoding model for hierarchical 2-level ICD codes |
| K-HTC [135] | GCN, BERT | WOS, BGC | ✓ | Knowledge graph integration in text and label representation, contrastive learning with knowledge-aware encoder |
| [128] | BERT, GCN | EDOS SemEval-23 | ✗ | BERT to encode text and labels, hierarchy-relevant structure encoder to model relationships between classes, class-aware attention, self-training against imbalanced classes |
| HypEmo [199] | RoBERTa | GoEmotions, Emp. Dialogues | ✓ | Label embeddings learned in both Euclidean and hyperbolic space to combine LMs with hierarchy-aware representation |
| HiTIN [200] | TextRCNN, BERT | RCV1, WOS, NYTimes | ✓ | Structure encoder optimization for dual-encoder frameworks through the encoding of label hierarchies into unweighted trees |
| LCN [201] | CN | WOS, BGC | ✗ | Hierarchical capsule framework, each capsule classifies one label, same level labels correspond to groups of competing capsules |
| HierVerb [137] | BERT | RCV1, WOS, DBpedia | ✓ | Multi-verbalizer framework, learn vectors as verbalizers constrained by hierarchy and contrastive learning, path-based metric |
| DLAC [202] | Bi-LSTM, CNN | WOS, BGC, AAPD | ✗ | Dual-channel text classification, a global label classification channel, and a deep-level label-assisted classification channel |
| HOOM [9] | SVM | Private | ✗ | IT ticket classification, hybrid model based on SVM-based offline component and Passive Aggressive Classifier online component |
| PeerHTC [130] | GCN | WOS, BGC | ✓ | GCN to reinforce feature sharing among peer (same-level) labels, sample importance learning to alleviate label confusion |
| TML/TARA [203] | Base | WOS, Emotion, GoEmotions | ✓ | Calibration method for prompt-based learning, improve information diffusion and context shift issues in the output embeddings |
| Seq2Gen [122] | mBART | Blog (novel) | ✗ | Unseen label generation by considering label hierarchy as a sequence of labels, semi-supervised learning for better generation |
| MTMD [204] | Bi-LSTM, BERT | Private | ✗ | HTC as sequence generation, multilevel decoupling strategy to guide label generation |
| [205] | GCN | Private | ✗ | GCN-based multilevel classification for users’ needs in online medical communities to improve targeted information retrieval |
| HJCL [206] | BERT | RCV1, BGC, NYTimes, AAPD | ✓ | Instance-wise and label-wise contrastive learning techniques on hierarchy |
| [207] | RoBERTa | SemEval 20 T11 | ✓ | Multi-instance multilabel learning for propaganda classification, simultaneously classifies all spans in an article and incorporates the hierarchical label dependencies from the annotation process |
| Bugs | RCV1-v2 | WOS | BGC | Amazon | |
|---|---|---|---|---|---|
| Size | 35,050 | 804,414 | 46,960 | 91,894 | 500,000 |
| Depth | 2 | 4 ** | 2 | 4 | 2 |
| Labels overall | 102 | 103 * | 145 | 146 | 30 |
| Labels per level | 17–85 | 4–55–43–1 | 7–138 | 7–46–77–16 | 5–25 |
| Average # characters | 2026 | 1378 | 1376 | 996 | 2194 |
| Train | 18,692 | 23,149 | 31,306 | 58,715 | 266,666 |
| Validation | 4674 | n/a | 6262 | 14,785 | 66,667 |
| Test | 11,684 | 781,265 | 15,654 | 18,394 | 166,667 |
| MLNP | ✓ | ✗ | ✓ | ✗ | ✓ |
| Method | RCV1-v2 * | WOS ** | ||
|---|---|---|---|---|
| micro- | macro- | micro- | macro- | |
| HTrans [148] | 0.805 | 0.585 | - | - |
| NeuralClassifier (RCNN) [149] | 0.810 | 0.533 | - | - |
| HiLAP [99] | 0.833 | 0.601 | - | - |
| HiAGM-TP [97] | 0.840 | 0.634 | 0.858 | 0.803 |
| RLHR [167] | - | - | 0.785 | 0.792 |
| HCSM [168] | 0.858 | 0.609 | 0.921 | 0.807 |
| HiMatch [124] | 0.847 | 0.641 | 0.862 | 0.805 |
| HIDDEN [169] | 0.793 | 0.473 | - | - |
| HE-AGCRCNN [170] | 0.778 | 0.513 | - | - |
| HVHMC [171] | - | - | 0.743 | - |
| SASF [126] | - | - | 0.867 | 0.811 |
| HTCInfoMax [177] | 0.835 | 0.627 | 0.856 | 0.800 |
| PAAM-HiA-T5 [178] | 0.872 | 0.700 | 0.904 | 0.816 |
| HPT [136] | 0.873 | 0.695 | 0.872 | 0.819 |
| HGCLR [91] | 0.865 | 0.683 | 0.871 | 0.812 |
| Seq2Tree [93] | 0.869 | 0.700 | 0.872 | 0.825 |
| HBGL [180] | 0.872 | 0.711 | 0.874 | 0.820 |
| P-tuning v2 (SPP-tuning) [138] | - | - | 0.875 | 0.800 |
| LD-GGNN [186] | 0.842 | 0.641 | 0.851 | 0.805 |
| LSE-HiAGM [123] | 0.839 | 0.646 | 0.860 | 0.800 |
| Seq2Label [121] | 0.874 | 0.706 | 0.873 | 0.819 |
| HTC-CLIP [190] | - | - | 0.879 | 0.816 |
| GACaps [191] | 0.868 | 0.698 | 0.876 | 0.828 |
| HiDEC [194] | 0.855 | 0.651 | - | - |
| UMP-MG [129] | - | - | 0.859 | 0.813 |
| LED [196] | 0.883 | 0.697 | 0.870 | 0.813 |
| (HGCLR-based + aug) [198] | 0.862 | 0.679 | 0.874 | 0.821 |
| K-HTC [135] | - | - | 0.873 | 0.817 |
| HiTIN (BERT) [200] | 0.867 | 0.699 | 0.872 | 0.816 |
| HierVerb (few-shot) [137] | 0.655 | 0.351 | 0.809 | 0.738 |
| DLAC [202] | - | - | 0.868 | 0.810 |
| PeerHTC [130] | - | - | 0.742 | 0.674 |
| HJCL [206] | 0.870 | 0.705 | - | - |
| Model | Acc ↑ | F1 ↑ | h-F1 ↑ | AHC ↓ |
|---|---|---|---|---|
| Bugs | ||||
| MATCH | 0.3624 [±0.0491] | 0.3635 [±0.0559] | 0.3638 [±0.0560] | 0.5501 [±0.0834] |
| HiAGM | 0.4482 [±0.0069] | 0.5218 [±0.0045] | 0.5214 [±0.0046] | 0.7672 [±0.0527] |
| BERT + CL | 0.4822 [±0.0066] | 0.4965 [±0.0078] | 0.4968 [±0.0079] | 0.4047 [±0.0182] |
| BERT + ML | 0.5061 [±0.0099] | 0.5165 [±0.0095] | 0.5172 [±0.0096] | 0.4634 [±0.0238] |
| XML-CNN + CL | 0.2603 [±0.0037] | 0.2515 [±0.0062] | 0.2522 [±0.0247] | 0.2443 [±0.0052] |
| XML-CNN + ML | 0.2823 [±0.0110] | 0.2767 [±0.0058] | 0.2774 [±0.0057] | 0.2885 [±0.0188] |
| HBGL | 0.5763 [±0.0003] | 0.5709 [±0.0032] | 0.5710 [±0.0029] | 0.6320 [±0.0037] |
| GACaps | 0.4916 [±0.0052] | 0.5430 [±0.0110] | 0.5445 [±0.0110] | 0.6476 [±0.0725] |
| BERT | 0.5070 [±0.0113] | 0.5204 [±0.0093] | 0.5209 [±0.0091] | 0.4606 [±0.0119] |
| XML-CNN | 0.2800 [±0.0130] | 0.2710 [±0.0163] | 0.2716 [±0.0160] | 0.3000 [±0.0239] |
| SVM (MultiL) | 0.3029 [±0.0035] | 0.4187 [±0.0044] | 0.4207 [±0.0043] | 0.5254 [±0.0086] |
| SVM (MultiC) | 0.5496 [±0.0039] | 0.4724 [±0.0061] | - | - |
| WOS | ||||
| MATCH | 0.5932 [±0.0161] | 0.6672 [±0.0145] | 0.6674 [±0.0145] | 0.3891 [±0.0114] |
| HiAGM | 0.6513 [±0.0159] | 0.7544 [±0.0065] | 0.7541 [±0.0066] | 0.4272 [±0.0356] |
| BERT + CL | 0.7647 [±0.0064] | 0.7928 [±0.0066] | 0.7929 [±0.0066] | 0.1941 [±0.0130] |
| BERT + ML | 0.7718 [±0.0027] | 0.7974 [±0.0030] | 0.7974 [±0.0030] | 0.2120 [±0.0104] |
| XML-CNN + CL | 0.4488 [±0.0078] | 0.5408 [±0.0095] | 0.5410 [±0.0095] | 0.1853[±0.0091] |
| XML-CNN + ML | 0.4759 [±0.0109] | 0.5688 [±0.0057] | 0.5691 [±0.0057] | 0.2044 [±0.0097] |
| HBGL | 0.8014[±0.0002] | 0.8221[±0.0004] | 0.8221[±0.0004] | 0.2140 [±0.0024] |
| GACaps | 0.7376 [±0.0078] | 0.8063 [±0.0050] | 0.8067 [±0.0050] | 0.2753 [±0.0136] |
| BERT | 0.7712 [±0.0067] | 0.7981 [±0.0059] | 0.7981 [±0.0059] | 0.2087 [±0.0069] |
| XML-CNN | 0.4714 [±0.0115] | 0.5628 [±0.0085] | 0.5630 [±0.0085] | 0.1978 [±0.0105] |
| SVM (MultiL) | 0.5051 [±0.0026] | 0.6611 [±0.0018] | 0.6619 [±0.0018] | 0.2172 [±0.0061] |
| SVM (MultiC) | 0.7609 [±0.0033] | 0.7397 [±0.0045] | - | - |
| Amazon | ||||
| MATCH | 0.8717 [±0.0087] | 0.9039 [±0.0028] | 0.9039 [±0.0028] | 0.0801 [±0.0028] |
| HiAGM | 0.8735 [±0.0044] | 0.9029 [±0.0030] | 0.9029 [±0.0030] | 0.0858 [±0.0037] |
| BERT + CL | 0.8912 [±0.0019] | 0.9192 [±0.0015] | 0.9192 [±0.0015] | 0.0632 [±0.0016] |
| BERT + ML | 0.8960[±0.0021] | 0.9214[±0.0015] | 0.9214[±0.0015] | 0.0658 [±0.0020] |
| XML-CNN + CL | 0.8242 [±0.0038] | 0.8849 [±0.0018] | 0.8850 [±0.0018] | 0.0709 [±0.0015] |
| XML-CNN + ML | 0.8279 [±0.0036] | 0.8860 [±0.0021] | 0.8860 [±0.0021] | 0.0782 [±0.0011] |
| HBGL | 0.8405 [±0.0002] | 0.8796 [±0.0012] | 0.8796 [±0.0012] | 0.1134 [±0.0000] |
| GACaps | 0.8673 [±0.0019] | 0.9058 [±0.0010] | 0.9057 [±0.0011] | 0.0701 [±0.0005] |
| BERT | 0.8954 [±0.0020] | 0.9212 [±0.0014] | 0.9212 [±0.0014] | 0.0661 [±0.0008] |
| XML-CNN | 0.8290 [±0.0030] | 0.8867 [±0.0016] | 0.8867 [±0.0017] | 0.0774 [±0.0020] |
| SVM (MultiL) | 0.7340 [±0.0016] | 0.8491 [±0.0010] | 0.8492 [±0.0010] | 0.0628[±0.0010] |
| SVM (MultiC) | 0.8666 [±0.0007] | 0.8677 [±0.0007] | - | - |
| Model | Acc ↑ | F1 ↑ | h-F1 ↑ | AHC ↓ |
|---|---|---|---|---|
| RCV1-v2 | ||||
| MATCH | 0.5149 [±0.0010] | 0.5308 [±0.0056] | 0.5309 [±0.0056] | 0.3478 [±0.0005] |
| HiAGM | 0.6035 [±0.0064] | 0.6836 [±0.0075] | 0.6830 [±0.0083] | 0.3236 [±0.0001] |
| BERT + CL | 0.6409 [±0.0004] | 0.6612 [±0.0127] | 0.6613 [±0.0125] | 0.1929 [±0.0304] |
| BERT + ML | 0.6383 [±0.0059] | 0.6805 [±0.0073] | 0.6806 [±0.0073] | 0.2270 [±0.0076] |
| XML-CNN + CL | 0.5449 [±0.0099] | 0.4898 [±0.0058] | 0.4905 [±0.0055] | 0.1768 [±0.0121] |
| XML-CNN + ML | 0.5460 [±0.0089] | 0.4832 [±0.0161] | 0.4840 [±0.0164] | 0.1917 [±0.0156] |
| HBGL | 0.6588 [±0.0015] | 0.7284 [±0.0001] | 0.7285 [±0.0002] | 0.2312 [±0.0127] |
| GACaps | 0.6390 [±0.0012] | 0.7103 [±0.0060] | 0.7090 [±0.0057] | 0.2629 [±0.0118] |
| BERT | 0.6391 [±0.0036] | 0.6722 [±0.0305] | 0.6723 [±0.0304] | 0.1959 [±0.0480] |
| XML-CNN | 0.5516 [±0.0023] | 0.4923 [±0.0124] | 0.4932 [±0.0127] | 0.1815 [±0.0098] |
| SVM (MultiL) ** | 0.4971 | 0.5456 | 0.5472 | 0.2340 |
| SVM (MultiC) ** | 0.7289 | 0.4416 | - | - |
| BGC | ||||
| MATCH | 0.3876 [±0.0009] | 0.4800 [±0.0015] | 0.4802 [±0.0012] | 0.4793 [±0.0059] |
| HiAGM | 0.4112 [±0.0055] | 0.5483 [±0.0030] | 0.5484 [±0.0024] | 0.5483 [±0.0144] |
| BERT + CL | 0.4674 [±0.0008] | 0.6058 [±0.0156] | 0.6060 [±0.0155] | 0.3303 [±0.0017] |
| BERT + ML | 0.4740 [±0.0004] | 0.6116 [±0.0049] | 0.6119 [±0.3450] | 0.3450 [±0.0017] |
| XML-CNN + CL | 0.3544 [±0.0012] | 0.3870 [±0.0029] | 0.3873 [±0.0028] | 0.3054 [±0.0121] |
| XML-CNN + ML | 0.3549 [±0.0018] | 0.3798 [±0.0076] | 0.3803 [±0.0077] | 0.2875 [±0.0227] |
| HBGL | 0.5060 [±0.0006] | 0.6782[±0.0016] | 0.6779[±0.0015] | 0.3540 [±0.0032] |
| GACaps | 0.4527 [±0.0071] | 0.6459 [±0.0059] | 0.6446 [±0.0063] | 0.4517 [±0.0150] |
| BERT | 0.4711 [±0.0032] | 0.6100 [±0.0119] | 0.6102 [±0.0116] | 0.3490 [±0.0334] |
| XML-CNN | 0.3602 [±0.0028] | 0.3996 [±0.0092] | 0.4000 [±0.0091] | 0.3096 [±0.0073] |
| SVM (MultiL) ** | 0.3495 | 0.5129 | 0.5148 | 0.3985 |
| SVM (MultiC) ** | 0.6285 | 0.2792 | - | - |
| Method | RCV1-v2 | WOS | Amz | BGC | Bugs |
|---|---|---|---|---|---|
| MATCH | 0.5308 | 0.6719 | 0.9048 | 0.4800 | 0.4064 |
| HiAGM | 0.6836 | 0.7484 | 0.9041 | 0.5483 | 0.5263 |
| BERT + CL | 0.6612 | 0.7958 | 0.9200 | 0.6058 | 0.5046 |
| BERT + ML | 0.6805 | 0.8007 | 0.9214 | 0.6116 | 0.5218 |
| XML-CNN + CL | 0.4898 | 0.5471 | 0.8856 | 0.3870 | 0.2517 |
| XML-CNN + ML | 0.4832 | 0.5645 | 0.8863 | 0.3798 | 0.2784 |
| HBGL | 0.7284 | 0.8221 | 0.8794 | 0.6781 | 0.5710 |
| GACaps | 0.7095 | 0.8064 | 0.9058 | 0.6464 | 0.5433 |
| BERT | 0.6722 | 0.7991 | 0.9206 | 0.6100 | 0.5235 |
| XML-CNN | 0.4923 | 0.5631 | 0.8855 | 0.3996 | 0.2802 |
| SVM (MultiL) | 0.5456 | 0.6610 | 0.8484 | 0.5129 | 0.4184 |
| SVM (MultiC) | 0.4416 | 0.7438 | 0.8676 | 0.2792 | 0.4700 |
| Method | Time (ms) |
|---|---|
| MATCH | 8.55 × 10−3 |
| HiAGM | 2.13 × 10−1 |
| SVM | 2.68 × 10−2 |
| BERT | 1.13 × 101 |
| XML-CNN | 1.09 × 10−2 |
| HBGL | 7.38 × 101 |
| GACaps-HTC | 2.67 × 101 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zangari, A.; Marcuzzo, M.; Rizzo, M.; Giudice, L.; Albarelli, A.; Gasparetto, A. Hierarchical Text Classification and Its Foundations: A Review of Current Research. Electronics 2024, 13, 1199. https://doi.org/10.3390/electronics13071199
Zangari A, Marcuzzo M, Rizzo M, Giudice L, Albarelli A, Gasparetto A. Hierarchical Text Classification and Its Foundations: A Review of Current Research. Electronics. 2024; 13(7):1199. https://doi.org/10.3390/electronics13071199
Chicago/Turabian StyleZangari, Alessandro, Matteo Marcuzzo, Matteo Rizzo, Lorenzo Giudice, Andrea Albarelli, and Andrea Gasparetto. 2024. "Hierarchical Text Classification and Its Foundations: A Review of Current Research" Electronics 13, no. 7: 1199. https://doi.org/10.3390/electronics13071199
APA StyleZangari, A., Marcuzzo, M., Rizzo, M., Giudice, L., Albarelli, A., & Gasparetto, A. (2024). Hierarchical Text Classification and Its Foundations: A Review of Current Research. Electronics, 13(7), 1199. https://doi.org/10.3390/electronics13071199