The security threats facing network communication are complex and ever-changing. In this section, we choose to elaborate on the aspects of synchronicity, traceability, and anti-forgery. Through theoretical derivation and proof, we comprehensively validate the multiple security features of this model.
3.1. Synchronization
In this subsection, the synchronicity analysis of the memorable communication model is described through the following definitions and theoretical derivations. The synchronous nature of the memorable communication model is primarily demonstrated through logical reasoning and proof by contradiction. This establishes the foundation for the overall security attributes of the method.
Definition 2. If for any k, there is always a such that when . Then is said to be a negligible value with ϵ as the parameter.
Definition 3. is an RSA cryptographic accumulator. If it has the following three features, is a good RSA cryptographic accumulator.
(1) For a (·) in , if it can find in polynomial time such that the probability of (a) = is equal to , then the (·) in is said to be non-collision.
(2) It is assumed that adversary A can arbitrarily select the set (M is the range of accumulative values) of elements to be accumulated and initialize the accumulator. If A adds an arbitrary element x to X, A must generate corresponding evidence , which can be verified by the evidence update checking algorithm (output 1 means that the updated accumulated value and evidence are valid. An output of 0 indicates that the updated accumulative value and evidence are invalid. If the current accumulative value and , there is no updated accumulative value , can safely add elements.
(3) Suppose that there is an adversary A that can arbitrarily generate its member evidence for elements in the cumulative element set and can also generate non-member evidence for elements outside X. If the evidence generated by A is w for an element x, when and , the probability of is ; When and , the probability of is , is said to be undeniable in evidence calculation ( represents the evidence verification algorithm, and if the output is 1, it means that the member proof is valid; If the output is 0, the non-member proof is valid. If the output is ⊥, the evidence is invalid).
Definition 4. Please note that H is a hash function. H is said to be a good hash function if it has the following two features.
(1) Given a hash value h calculated using H, the H is said to be unidirectional if a particular input x can be found in polynomial time such that the probability of is , and given any y, it is easy to calculate .
(2) For a H, if it can find in polynomial time such that the probability of is equal to , then the H is said to be non-collision.
Definition 5. For the communication based on in this paper, the sender sends in the message sequence to the receiver one by one. When sending the message, the sender constructs based on and attaches it to the corresponding . The latest memory value constructed by the sender is recorded as . The receiver constructs the local according to the received mi’ and the local . The message sequence received by the receiver is denoted as , and the local latest memory value constructed is . If the receiver can ensure that the probability of is when is obtained, then the communication method based on the in this paper has synchronization.
Corollary 1. is a memory function constructed based on RSA cryptographic accumulator. If the RSA cryptographic accumulator that constitutes is a good RSA cryptographic accumulator, then the communication method based on in this scheme has synchronization.
Proof. Suppose the message sequence sent by the sender is , the sequence number is , the generated corresponding message element sequence is , and the generated memory value sequence is . The message sequence received by the receiver is , the generated message element sequence is , and the generated memory value sequence is . Assuming that the communication method based on in this paper does not have synchronization, i.e., when the RSA cryptographic accumulator used in is a good RSA cryptographic accumulator and the communication parties communicate according to the method in this paper, the communication parties still cannot ensure that the data sent and received are completely consistent, i.e., . Then there must be the following two situations:
(1) , when alone, it cannot be determined that the sequence of message elements in X and is consistent, i.e., it cannot be determined that the sequence of M and is consistent. However, in this paper, the receiver calculates the after sorting the messages according to , so can ensure the message sequence without being changed. If is attacked and the attacker forges as and make , then must exist. However, this is contrary to the fact that the RSA cryptographic accumulator used in is a good RSA cryptographic accumulator, so this situation is not tenable.
(2) If the attacker directly forges as and makes , then must exist. However, this also contradicts that the RSA cryptographic accumulator used in is a good RSA cryptographic accumulator, so this situation is not tenable.
In conclusion, the original hypothesis is not valid, i.e., when the RSA cryptographic accumulator used in is a good RSA cryptographic accumulator, the memory value comparison between the communication parties can ensure the consistency of the message. Therefore, the communication method based on in this paper has synchronization. □
Corollary 2. is a memory function constructed based on the message hash chain. If the hash function used in the message hash chain in this paper is good, then the communication method based on given in this paper has synchronization
Proof. It is assumed that the communication method based on in this paper does not have synchronization, i.e., when the hash function used in is a good hash function when the communication parties follow the way in this paper, the communication parties still cannot guarantee the message consistency, i.e., . Since , there is only the following situation. The attacker forges as and makes , then must exist, but this contradicts the hash function uses as a good hash function, so this situation is not valid. □
3.2. Traceability
This section presents a scheme for the traceability analysis of the memorable communication method. It mainly adopts logical reasoning and proof by contradiction to demonstrate that the memorable communication method has traceability, making ex-post facto network forensics possible.
Definition 6. For the communication based on a memory function given in the paper, if the sender or receiver can determine whether a message has been sent or received based on the memory function, the communication method based on the memory function given in the paper is said to have traceability.
Corollary 3. is a memory function constructed based on RSA cryptographic accumulator. If the RSA cryptographic accumulator that constitutes is a good RSA cryptographic accumulator, then the communication method based on in this scheme has traceability.
Proof. Assuming that the communication method of the base in this paper does not have traceability, i.e., the RSA cryptographic accumulator that constitutes the is a good RSA cryptographic accumulator, and both parties communicate according to the method given in this paper, both parties cannot correctly determine whether they have sent or received a certain message. Then there must be the following situation: the sender or receiver generates for , and the probability of is in the case of the corresponding . However, this situation is inconsistent with the RSA cryptographic accumulator used in as a good RSA cryptographic accumulator, so this situation is not true. In conclusion, the original hypothesis is not valid, and the communication method based on given in this paper has traceability. □
Corollary 4. is a memory function constructed based on the message hash chain. If the hash function used in the message hash chain in this paper is good, then the communication method based on given in this paper has traceability.
Proof. Assuming that the communication method based on in this paper does not have traceability, i.e., when the hash function used in is good, and the communication parties communicate according to the way given in this paper, the communication parties cannot correctly determine whether a certain message has been sent or received. Then there must be the following situation: The sender or receiver generates for , and occurs when is validated by (, , ). However, this situation is inconsistent with the hash function used in as a good hash function, so this situation is not true. In conclusion, the original hypothesis is not tenable, and the communication method based on given in this paper has traceability. □
3.3. Batch Signature and Authentication
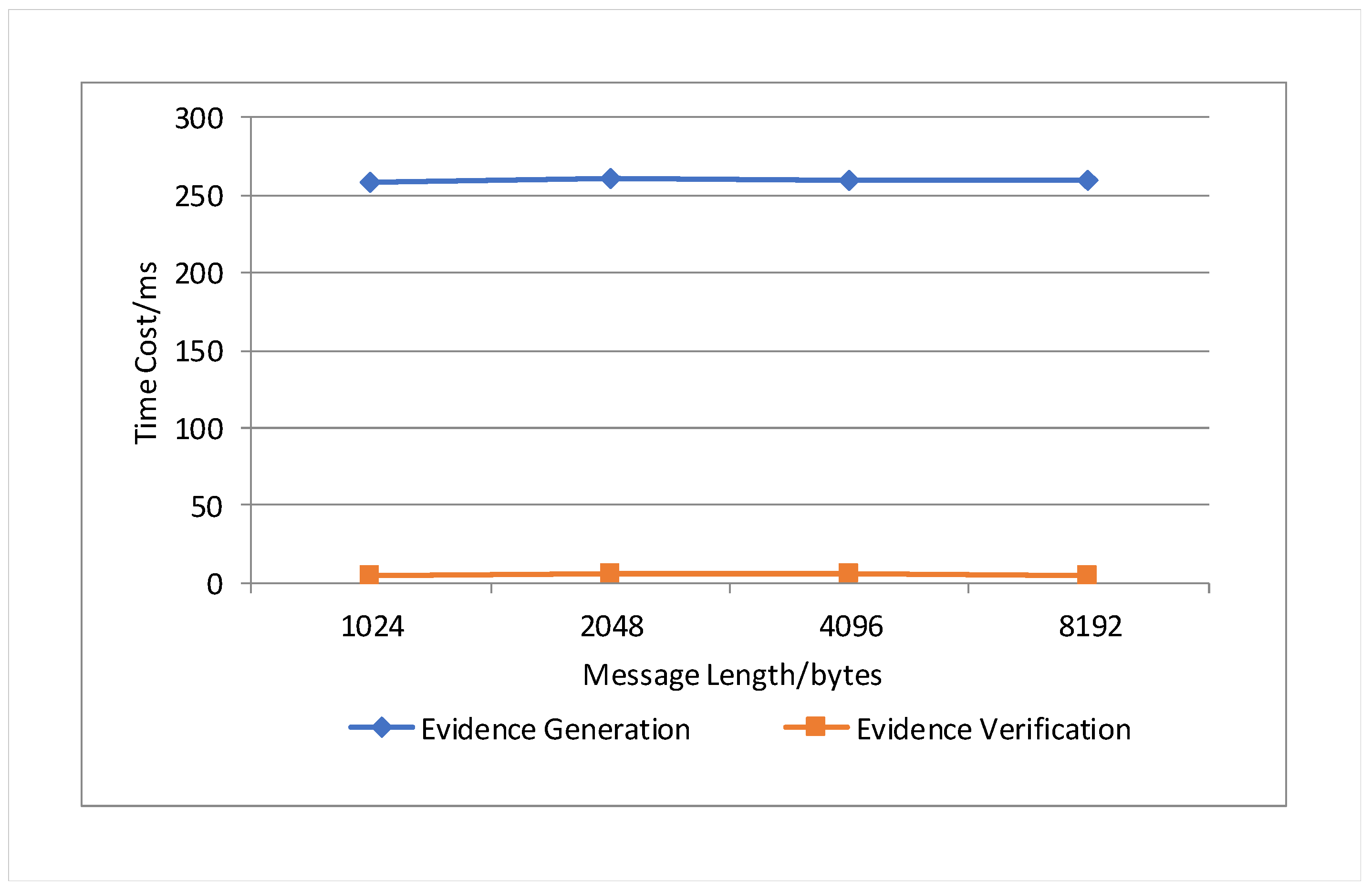
This subsection provides an analysis of batch signature authentication for the memorable communication model. Through the signing of memory values, the memorable communication model achieves efficient batch authentication, preventing threats such as man-in-the-middle attacks and ensuring communication security.
Definition 7. For a digital signature scheme , represents the asymmetric key generation algorithm, is the private key of the signature, and is the public key of the signature. Sign is the signature algorithm for a m, , s is its signature result, and is the signature verification algorithm. For the s and the key pair generated by , there is always . The digital signature scheme is said to be secure if the probability of a correct signature is only through to forge in polynomial time.
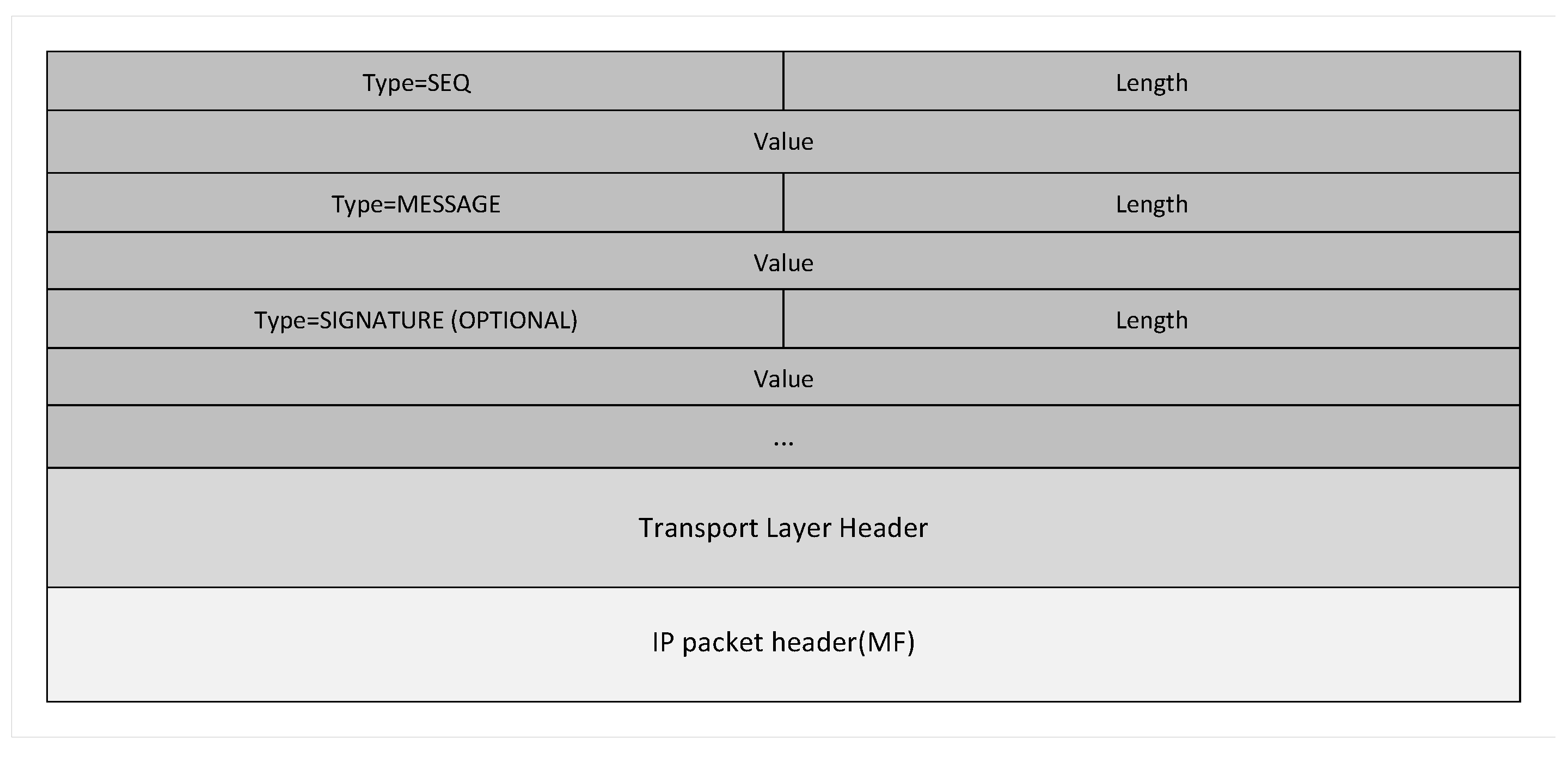
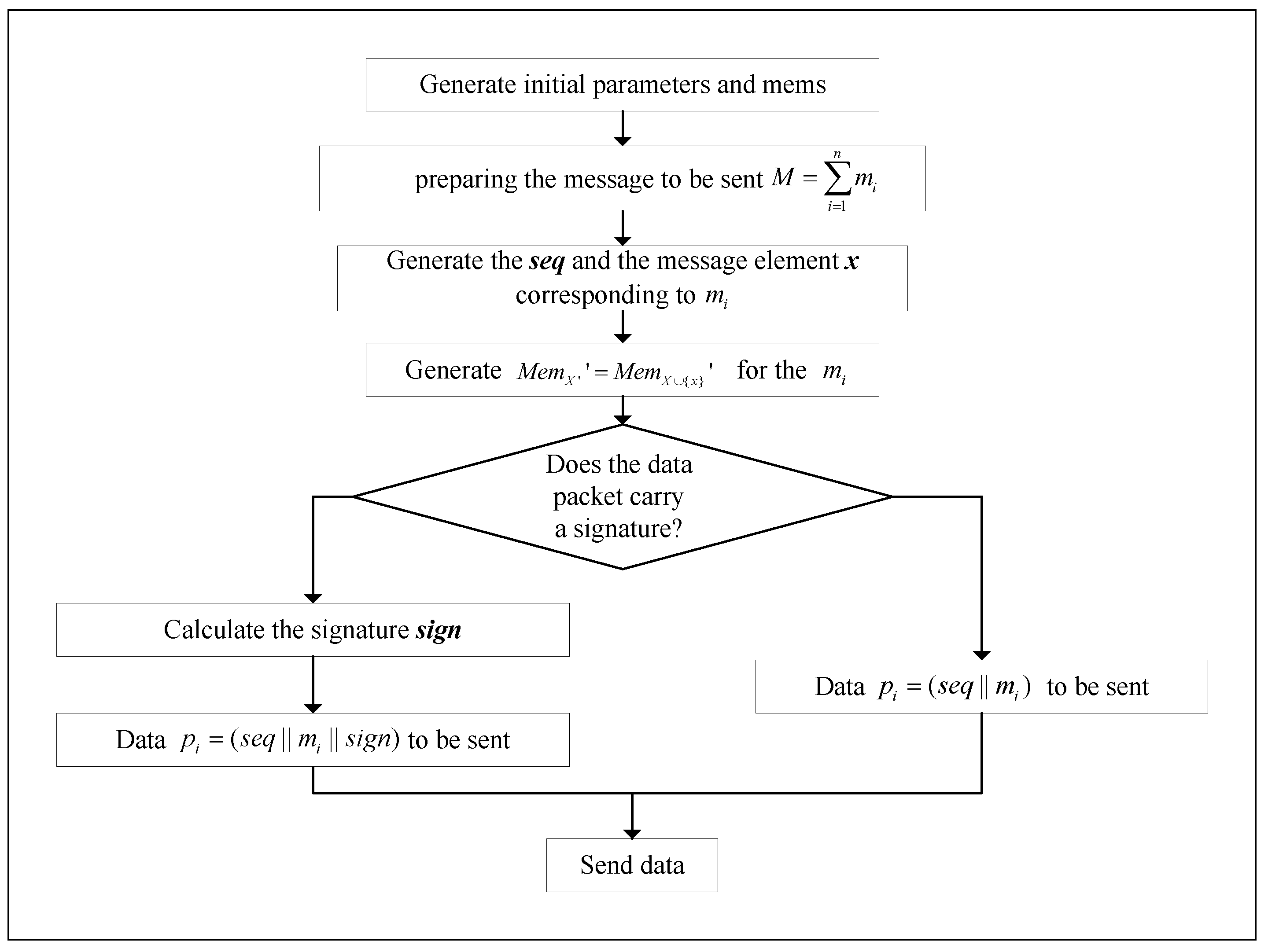
Definition 8. For the communication method based on in this paper, the sender sends in to the receiver one by one according to the method in the paper, and the memory value corresponding to is . On this basis, if the sender adopts a digital signature scheme, uses in the key pair to generate for , and sends to the receiver after is attached to the . The receiver only uses in the key pair to obtain , which can confirm the authenticity, non-repudiation, and integrity of in M. It can be said that the communication method based on in this paper has the feature of batch signature authentication.
Corollary 5. is a memory function constructed based on RSA cryptographic accumulator. Suppose the RSA cryptographic accumulator that constitutes is a good RSA cryptographic accumulator, and the signature scheme used in communication according to the method given in this paper is secure. In that case, the communication method with a signature based on in this scheme has the feature of batch signature and authentication.
Proof. Set the sequence of the message sent by the sender as , the sequence of the message elements generated as , the memory value corresponding to as , and the result of the sender signing as = (, ) . Assuming that the communication method with signature based on in this paper does not have the feature of batch signature authentication: under the condition that the RSA cryptographic accumulator that constitutes the is a good RSA cryptographic accumulator and the digital signature scheme is secure, the receiver cannot confirm the authenticity, non-repudiation, and integrity of in M only by calculating with . There must be the following in two situations:
(1) The attacker tampers M to and generates , so that and . However, the RSA cryptographic accumulator used in is a good RSA cryptographic accumulator, so this situation is not true.
(2) The attacker tampers M to and generate so that , and forges so that . However, this contradicts the premise that a digital signature scheme is secure, so this kind of situation is not tenable.
In summary, the hypothesis is not valid. In the form of the RSA cryptographic accumulator used in is a good RSA cryptographic accumulator, and the digital signature scheme is secure. The communication with signature based on in this paper has the feature of batch signature and authentication. □
Corollary 6. is a memory function constructed based on the message hash chain. If the hash function used in the message hash chain in this paper is a good hash function and the signature scheme used in communication according to the method given in this paper is secure, then the communication method with signature based on in this scheme has the feature of batch signature and authentication.
Proof. Assuming that the communication method with signature based on in this paper does not have the feature of batch signature authentication: under the condition that the hash function used in is a good hash function and the digital signature scheme is secure, the receiver cannot confirm the authenticity, non-repudiation, and integrity of in M only by calculating with . There must be the following two situations:
(1) The attacker tampers M to and generates so that and . However, as the hash function used in is a good hash function, this situation is not true.
(2) The attacker tampers M to and generate so that , and forges so that . However, this contradicts the premise that a digital signature scheme is secure, so this kind of situation is not tenable.
In summary, the hypothesis is not valid. Under the condition that the hash function used in is a good hash function and the digital signature scheme is secure, the communication method with signature based on in this paper has the feature of batch signature authentication. □
3.4. Randomness of Chain Keys
This section provides an analysis of the randomness among the keys generated based on the memory value in the chain-key generation. The analysis illustrates that the chain-key model based on strongly confused hashing possesses excellent random characteristics.
Data subjected to a strong mixing hash operation will be completely shuffled. The data before and after the strong mixing hash operation can be considered with a high probability of undergoing a random permutation, meaning non-randomness can be negligibly small.
Definition 9. There exist two keys. If key B is obtained by some complex transformation from key A and key B cannot be deduced from key A, then keys A and B are said to have a derived relationship. The process of derivation is called a derivation algorithm. Key A is referred to as the master key, and key B is referred to as the derived subkey.
For a master key A and a derived subkey B with a derived relationship, cracking key A can lead to obtaining key B. If key B cannot be obtained through any means other than cracking key A, then the difficulty of cracking key B is equivalent to the difficulty of cracking key A.
Definition 10. Computation Indistinguishability: Given two sequences and , if there is no effective algorithm that can distinguish between them, then it is said that these two sequences are computationally indistinguishable.
Definition 11. Statistical Distance: Assuming two populations and , represented by as the statistical distance between the two populations X and Y, the definition is as follows:
If is negligibly small, it is said that and are statistically close. If they are statistically close, then they are indistinguishable.
Based on the above theorems and definitions, the following two corollaries are derived:
Corollary 7. The intermediate key in the key chain and the initial key have a derived relationship. The difficulty for an attacker to obtain the intermediate key will not be less than , meaning that it is not feasible for an attacker to have a higher probability of obtaining the intermediate key when is unknown.
Using proof by contradiction, the proof is conducted as follows:
Proof. Assume that an attacker can crack the intermediate key with a higher probability when is unknown. Then, the attacker would need to acquire the correlation between at least two intermediate keys or more. Subsequently, employing analytical techniques such as differential analysis for key analysis would be required. Otherwise, this would contradict Shannon’s proof of perfect security—one-time pad’s absolute security. This implies that these two or more keys do not possess computational indistinguishability, meaning that statistically, is not negligible.
However, since the keys are computed through strong mixing hash operations, the conclusion that obtained in statistics is not negligibly small contradicts the conclusion of a random permutation with high probability as assumed by strong mixing hash operations. Therefore, the assumption is not valid, i.e., an attacker cannot crack the intermediate key with a higher probability when is unknown. □
Corollary 8. The security of keys in the key chain depends on the randomness of the hash function hash, the randomness of the plaintext sequence , and the confidentiality of the pre-shared key, independent of the intermediate key states.
Using mathematical induction, the proof is conducted as follows:
Proof. (1) The initial key is obtained through the hash operation of the pre-shared key . At this point, plaintext is not involved. Therefore, the security of the initial key depends on the randomness of the hash function and the confidentiality of the pre-shared key . The generation of the second key is jointly determined by the plaintext , the key , and the pseudo-random function H. Since is the result of a hash operation on the pre-shared key , satisfies Corollary.
(2) Assume that the key k satisfies the Corollary;
(3) For the key , its security is jointly determined by the key , the randomness of the hash function, the memory value of plaintext . Since satisfies Corollary, then also satisfies Corollary. In other words, the security of depends on the randomness of the hash function, the randomness of the plaintext sequence , and the confidentiality of the pre-shared key.
(4) From (1), (2), and (3), it can be concluded that the Corollary holds. □
3.5. Attacks Analysis
This section will analyze and explain common network communication attacks.
3.5.1. Man-In-The-Middle (MITM) Attacks
MITM (Man-in-the-Middle) attacks involve attackers secretly relaying and potentially altering communication between two parties who trust each other for direct communication. This model can resist MITM attacks due to the use of secure technologies such as cryptographic accumulators and batch signature authentication.
3.5.2. Spoofing Attacks
Deceptive attacks involve attackers impersonating other devices or users on the network to steal data, spread malware, or bypass access controls. This scheme mitigates this risk by:
The use of memory functions ensures that each participant in the communication has a verifiable and unique identity tied to their messages. This makes it much harder for an attacker to impersonate a legitimate user without access to their specific cryptographic materials.
The system’s traceability feature, which allows the sender and receiver to verify the origin and integrity of messages, acts as a deterrent to spoofing. Any discrepancy in the traceability check would indicate a potential spoofing attempt.
3.5.3. Session Hijacking
Session hijacking involves taking over a user’s session to gain unauthorized access to information or services. The proposed system counters this threat through:
Ensuring that messages are synchronized and cannot be repudiated helps in maintaining a secure and continuous session. Any attempt to hijack the session would be detected as an anomaly in the sequence of message exchanges, thanks to the cryptographic linkages provided by the memory functions.
By updating encryption keys per data packet based on the memory values, the system ensures that even if a session key is compromised, it cannot be used to hijack the session, as future communications will use different keys.
3.6. Quantum Resistance Analysis
Traditional information systems continue to confront threats from computer attacks, struggling to withstand cryptographic analyses and other attack methodologies executed by powerful computers. The emergence of quantum computing further exacerbates this threat.
The communication model designed in this paper, based on
, primarily relies on maintaining a memory function to ensure the integrity and consistency of data transmission while enabling the traceability of messages. The core concept of this model is relatively independent of specific network types and is theoretically applicable to various network environments, whether they be classical or quantum in nature. Additionally, unlike public-key cryptography, traditional hash functions are considered to be capable of resisting quantum attacks by increasing the length of the existing hash output [
20]. With the continuous development of quantum technology, numerous novel algorithms have emerged to counter quantum attacks, such as quantum digital signatures and certificates that prevent signature forgery [
21,
22], as well as new hash functions designed to resist quantum computing [
23]. In a quantum environment, these interchangeable algorithms can autonomously negotiate as needed. The model possesses the capability to resist quantum computing.
Various methods are usually available for the distribution of pre-shared keys. In a quantum network environment, quantum key distribution (QKD) is commonly employed to secure key distribution and resist quantum attacks.






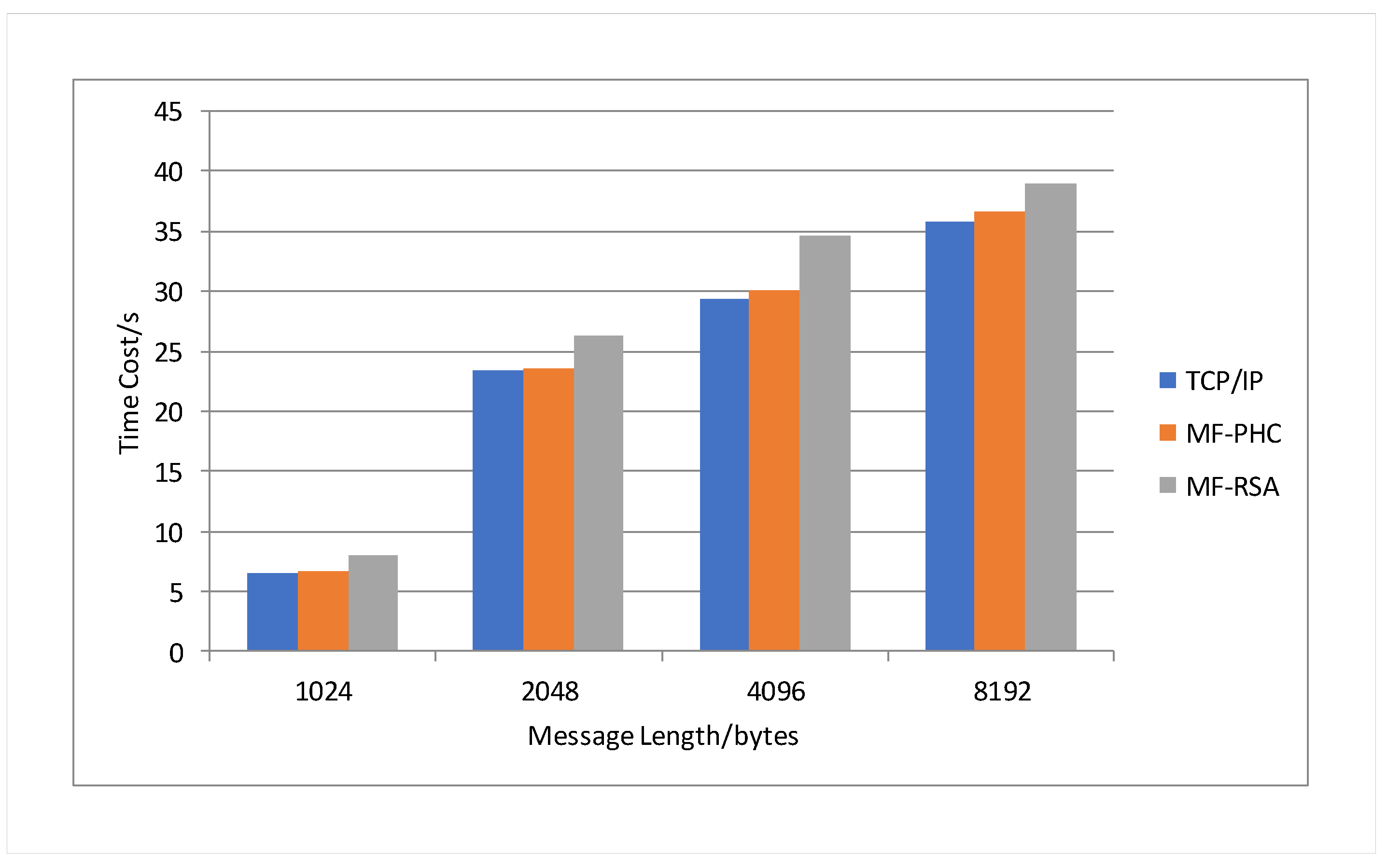





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}