


Deep Reinforcement Learning with Godot Game Engine


Abstract
1. Introduction
- 1.
- Complexity and overhead: Game engines are complex and designed to handle a wide range of tasks related to rendering, simulations, physical interactions, and user interactions. This complexity can introduce unnecessary overheads during DRL tasks, potentially slowing the learning process. In addition, integrating DRL algorithms or workflows with high-end game engines can be challenging.
- 2.
- Limited Customizations and Closed Sourced: As most game engines are designed for specific purposes, using them to perform simulations requires extending their features through APIs. However, most high-end game engines are proprietary and close-sourced, and they limit their ability to modify the core codebase, extend their features via APIs, and access low-level functionalities.
- 3.
- Resource intensiveness: High-end game engines can be resource-intensive, and they require powerful GPUs, CPUs, and significant computational resources to handle complex scenes. Resource intensiveness can cause scalability challenges, particularly when the access to high-end computational clusters is limited or expensive. In addition, performing DRL alongside the simulation could affect the overall learning owing to the delayed execution of actions and state observations.
- 4.
- Tradeoff between Realism and Simplicity: Most modern game engines are designed to simulate realistic immersion environments. However, DRL research requires simplicity and control over the simulation rather than realism. Simplifying the environment allows more control and customization options to be tailored to the specific requirements of reinforcement learning algorithms. Most existing virtual environments and physics engines require researchers to follow a specific structure to begin performing DRL. This restricts the ability to tailor the research.
2. Related Work
2.1. Deep Reinforcement Learning
2.2. Domain Randomization
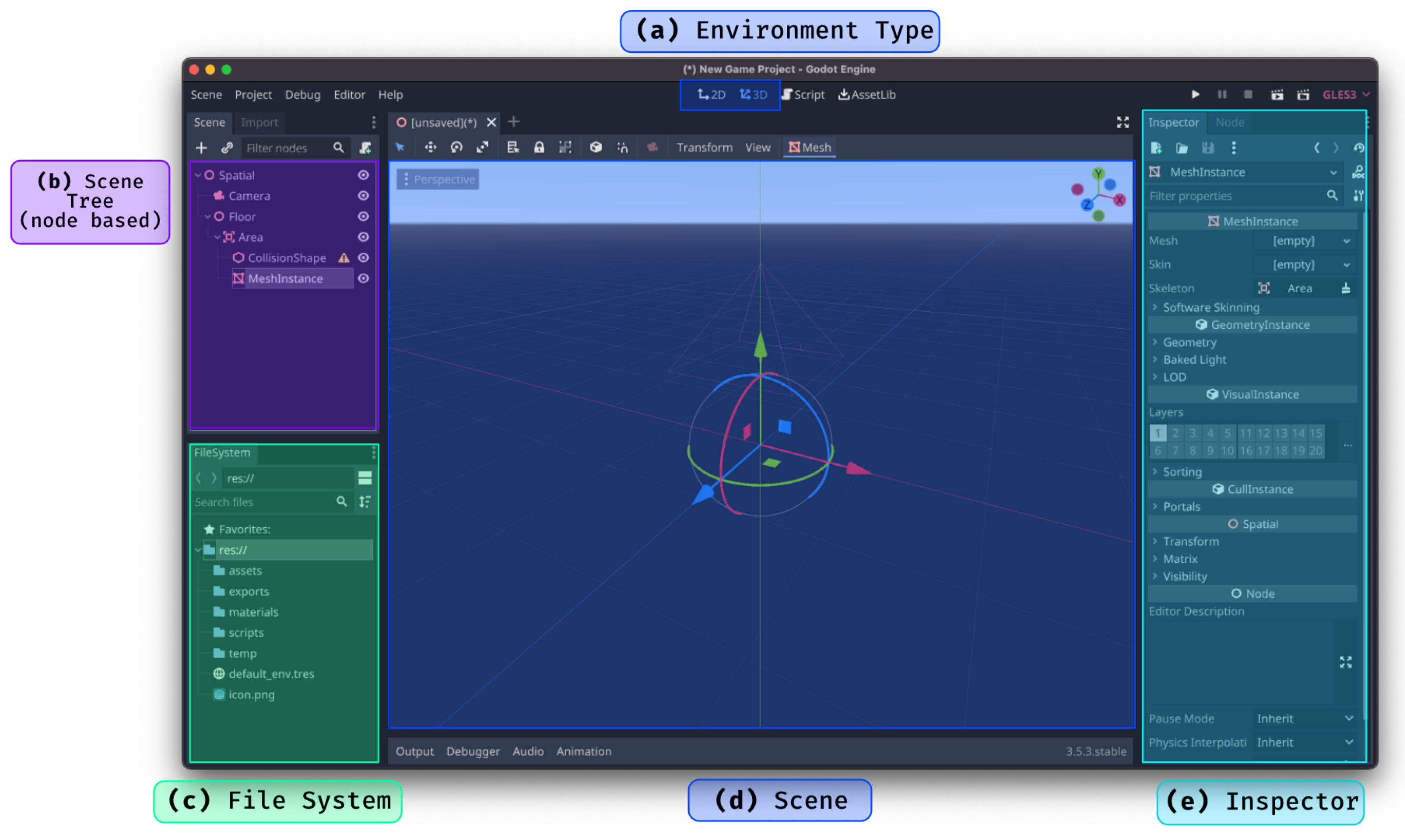
3. Godot Game Engine
3.1. Overview of the Game Engine
3.2. Features and Capabilities
- 1.
- Multi-platform support: Godot supports multiple platforms including Windows, MacOS, Linux, Android, and HTML. This allows developers to create training environments for their operating systems.
- 2.
- Open-Source: Godot is fully open-source, and developers release it under an MIT license. This enables developers and researchers to create applications without legal constraints. Godot can be customized because the source code is publicly available.
- 3.
- Scripting: Godot was developed in multiple languages. It has a built-in scripting language called GDScript, similar to Python. Additionally, it supports other development languages, such as C#, C++, and Visual Script. This provides a wide range of programming languages for work and development purposes.
- 4.
- Physics Engine: Godot includes both 2D and 2D physics engines. By default, Godot used a high-fidelity Bullet physics engine. In addition, it contains a low-fidelity physics engine called GodotPhysics.
- 5.
- Networking: The Godot engine provides extensive support for both the client-server and peer-to-peer networking for building multiplayer games.
- 6.
- Node-based scene system: The Godot engine allows for the construction of environments or scenes using node-based systems that create a hierarchy between nodes.
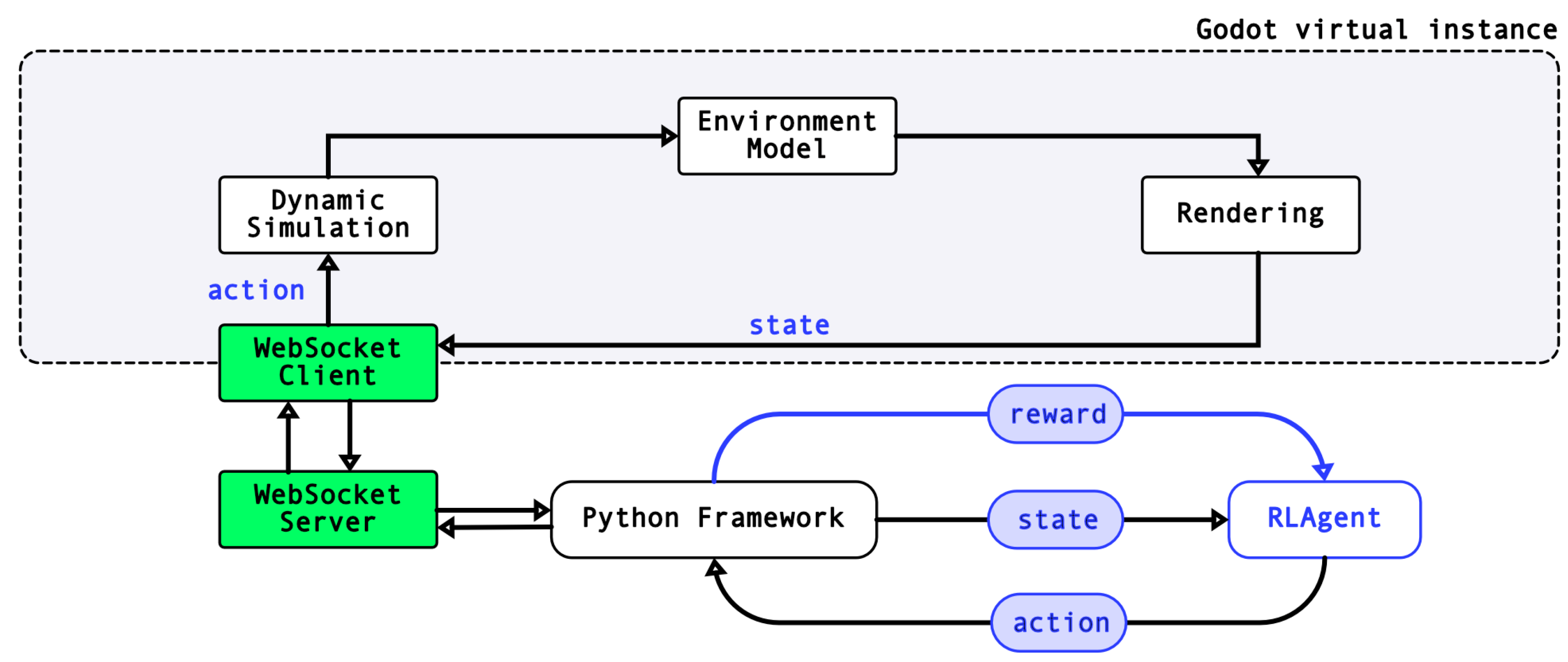
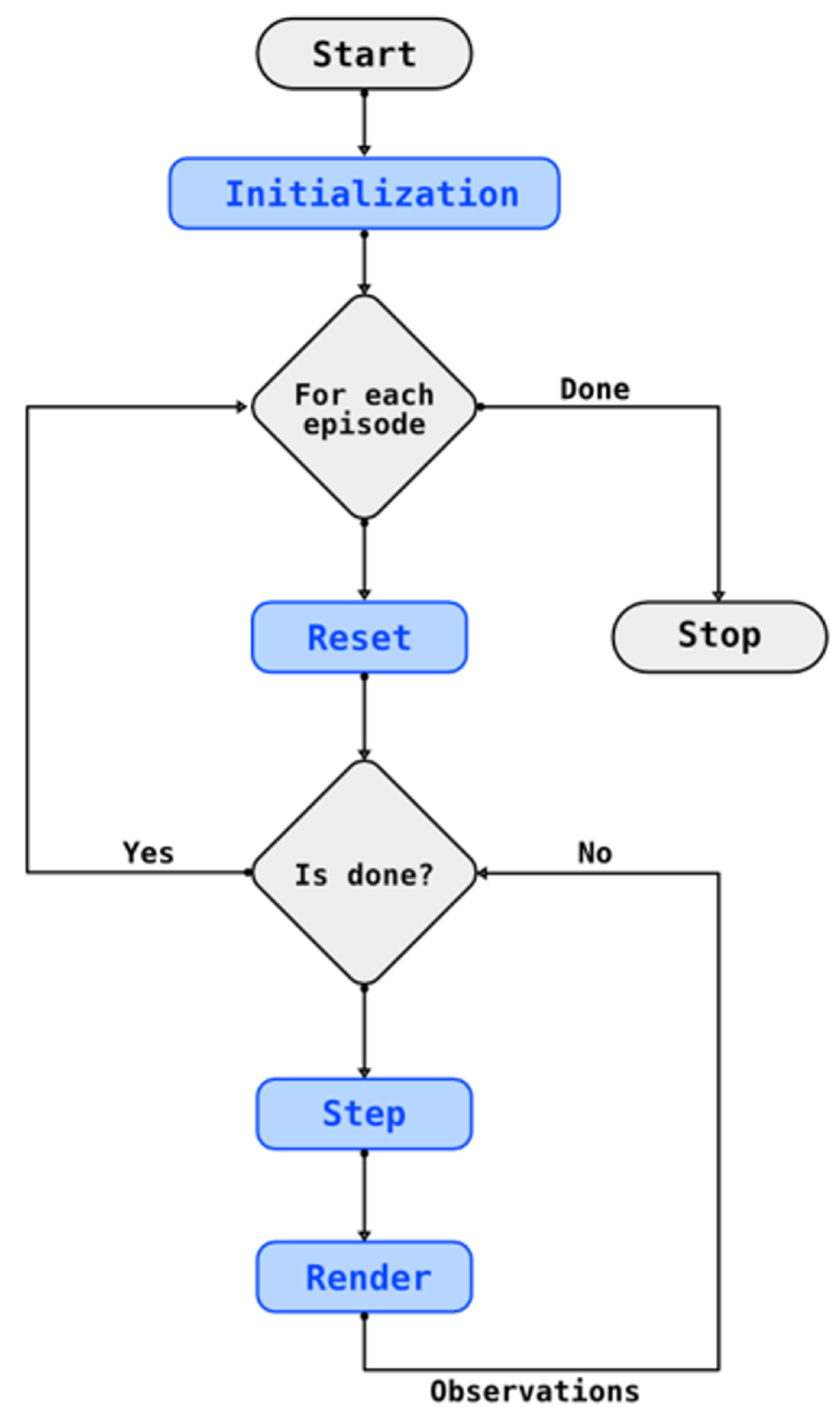
4. Methodology
4.1. Structure of the Framework
4.1.1. Establishing the WebSocket Connection
4.1.2. Interfacing with the Virtual Environment
4.1.3. Scalability and Fault Tolerance
4.1.4. Challenges and Difficulties
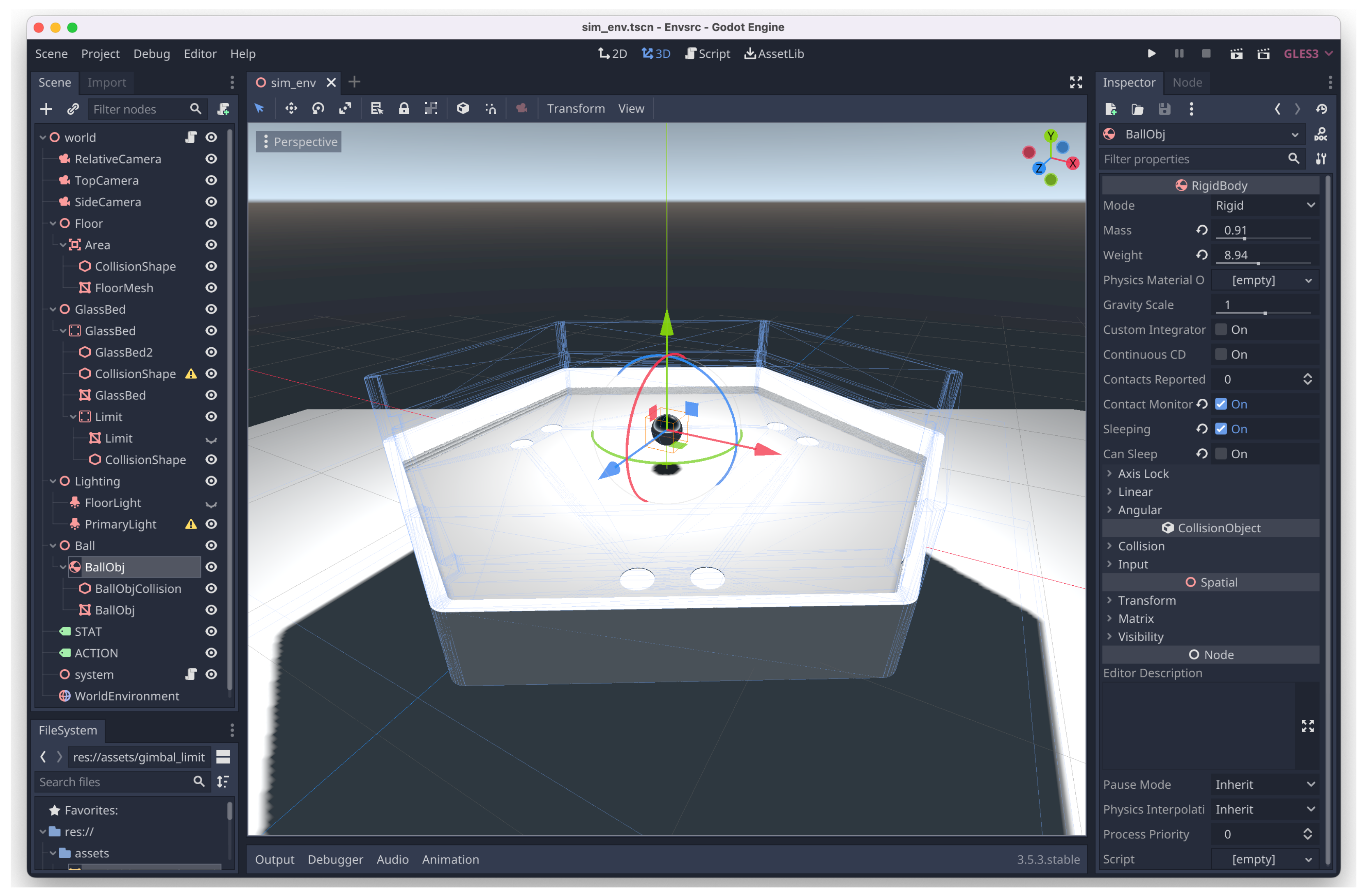
5. Experimentation
5.1. Deep Reinforcement Learning on a 3-DoF Stewart Platform
5.1.1. Defining the Action Space
5.1.2. Results
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Ranaweera, M.; Mahmoud, Q. Bridging Reality Gap Between Virtual and Physical Robot through Domain Randomization and Induced Noise. In Proceedings of the Canadian Conference on Artificial Intelligence, Virtual Online, 27 May 2022; Available online: https://caiac.pubpub.org/pub/kzx3gl4e (accessed on 12 January 2024).
- Wang, J.; Chen, Y.; Feng, W.; Yu, H.; Huang, M.; Yang, Q. Transfer Learning with Dynamic Distribution Adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–25. [Google Scholar] [CrossRef]
- Ranaweera, M.; Mahmoud, Q.H. Virtual to Real-World Transfer Learning: A Systematic Review. Electronics 2021, 10, 1491. [Google Scholar] [CrossRef]
- Petrenko, A.; Huang, Z.; Kumar, T.; Sukhatme, G.; Koltun, V. Sample Factory: Egocentric 3D Control from Pixels at 100000 FPS with Asynchronous Reinforcement Learning. arXiv 2020, arXiv:2006.11751. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Castro, P.S.; Moitra, S.; Gelada, C.; Kumar, S.; Bellemare, M.G. Dopamine: A Research Framework for Deep Reinforcement Learning. arXiv 2018, arXiv:1812.06110. [Google Scholar]
- Plappert, M. Keras-rl. 2016. Available online: https://github.com/keras-rl/keras-rl (accessed on 12 January 2024).
- Liang, E.; Liaw, R.; Moritz, P.; Nishihara, R.; Fox, R.; Goldberg, K.; Gonzalez, J.E.; Jordan, M.I.; Stoica, I. RLlib: Abstractions for Distributed Reinforcement Learning. arXiv 2018, arXiv:1712.09381. [Google Scholar]
- Beeching, E.; Debangoye, J.; Simonin, O.; Wolf, C. Godot Reinforcement Learning Agents. arXiv 2021, arXiv:2112.03636. [Google Scholar]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Huang, S.; Dossa, R.F.J.; Ye, C.; Braga, J. CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms. arXiv 2021, arXiv:2111.08819. [Google Scholar]
- Derevyanko, G. Lupoglaz/GodotAIGym. 2019. Available online: https://lupoglaz.github.io/GodotAIGym/ (accessed on 12 January 2024).
- Morais, G.; Loron, I.; Coletta, L.F.; da Silva, A.A.; Simões, A.; Gudwin, R.; Costa, P.D.P.; Colombini, E. CST-Godot: Bridging the Gap Between Game Engines and Cognitive Agents. In Proceedings of the 2022 21st Brazilian Symposium on Computer Games and Digital Entertainment (SBGames), Natal, Brazil, 24–27 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Bakhmadov, M.; Fridheim, M. Combining Reinforcement Learning and Unreal Engine’s AI-Tools to Create Intelligent Bots. Bachelor Thesis, NTNU, May 2020. Available online: https://ntnuopen.ntnu.no/ntnu-xmlui/handle/11250/2672159 (accessed on 12 January 2024).
- Boyd, R.A.; Barbosa, S.E. Reinforcement Learning for All: An Implementation Using Unreal Engine Blueprint. In Proceedings of the 2017 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2017; pp. 787–792. [Google Scholar] [CrossRef]
- Ward, T.; Bolt, A.; Hemmings, N.; Carter, S.; Sanchez, M.; Barreira, R.; Noury, S.; Anderson, K.; Lemmon, J.; Coe, J.; et al. Using Unity to Help Solve Intelligence. arXiv 2020, arXiv:2011.09294. [Google Scholar]
- Kar, A.; Prakash, A.; Liu, M.Y.; Cameracci, E.; Yuan, J.; Rusiniak, M.; Acuna, D.; Torralba, A.; Fidler, S. Meta-Sim: Learning to Generate Synthetic Datasets. arXiv 2019, arXiv:1904.11621. [Google Scholar]
- Todorov, E.; Erez, T.; Tassa, Y. MuJoCo: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 5026–5033. [Google Scholar] [CrossRef]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar] [CrossRef]
- Merschformann, M.; Xie, L.; Li, H. RAWSim-O: A Simulation Framework for Robotic Mobile Fulfillment Systems, 8th ed.; Bundesvereinigung Logistik (BVL) e.V: Bremen, Germany, 2018. [Google Scholar] [CrossRef]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24 September 2017; pp. 23–30. [Google Scholar]
- Park, S.; Kim, J.; Kim, H.J. Zero-Shot Transfer Learning of a Throwing Task via Domain Randomization. In Proceedings of the 2020 20th International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 13–16 October 2020; pp. 1026–1030. [Google Scholar] [CrossRef]
- Open, A.I.; Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; et al. Solving Rubik’s Cube with a Robot Hand. arXiv 2019, arXiv:1910.07113. [Google Scholar]
- Zakharov, S.; Ambrus, R.; Guizilini, V.; Kehl, W.; Gaidon, A. Photo-realistic Neural Domain Randomization. arXiv 2022, arXiv:2210.12682. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: A Survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; pp. 737–744. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, H.; Yau, W.Y.; Wan, K.W. A Brief Survey: Deep Reinforcement Learning in Mobile Robot Navigation. In Proceedings of the 2020 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 592–597. [Google Scholar] [CrossRef]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Ranaweera, M.; Mahmoud, Q.H. Bridging the Reality Gap Between Virtual and Physical Environments Through Reinforcement Learning. IEEE Access 2023, 11, 19914–19927. [Google Scholar] [CrossRef]
- Ranaweera, M.; Mahmoud, Q. Evaluation of Techniques for Sim2Real Reinforcement Learning. In The International FLAIRS Conference Proceedings; Open Journal System: Gainesville, FL, USA, 2023; Volume 36. [Google Scholar] [CrossRef]
- Vacaro, J.; Marques, G.; Oliveira, B.; Paz, G.; Paula, T.; Staehler, W.; Murphy, D. Sim-to-Real in Reinforcement Learning for Everyone. In Proceedings of the 2019 Latin American Robotics Symposium (LARS), 2019 Brazilian Symposium on Robotics (SBR) and 2019 Workshop on Robotics in Education (WRE), Rio Grande do Sul, Brazil, 23–25 October 2019; pp. 305–310. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
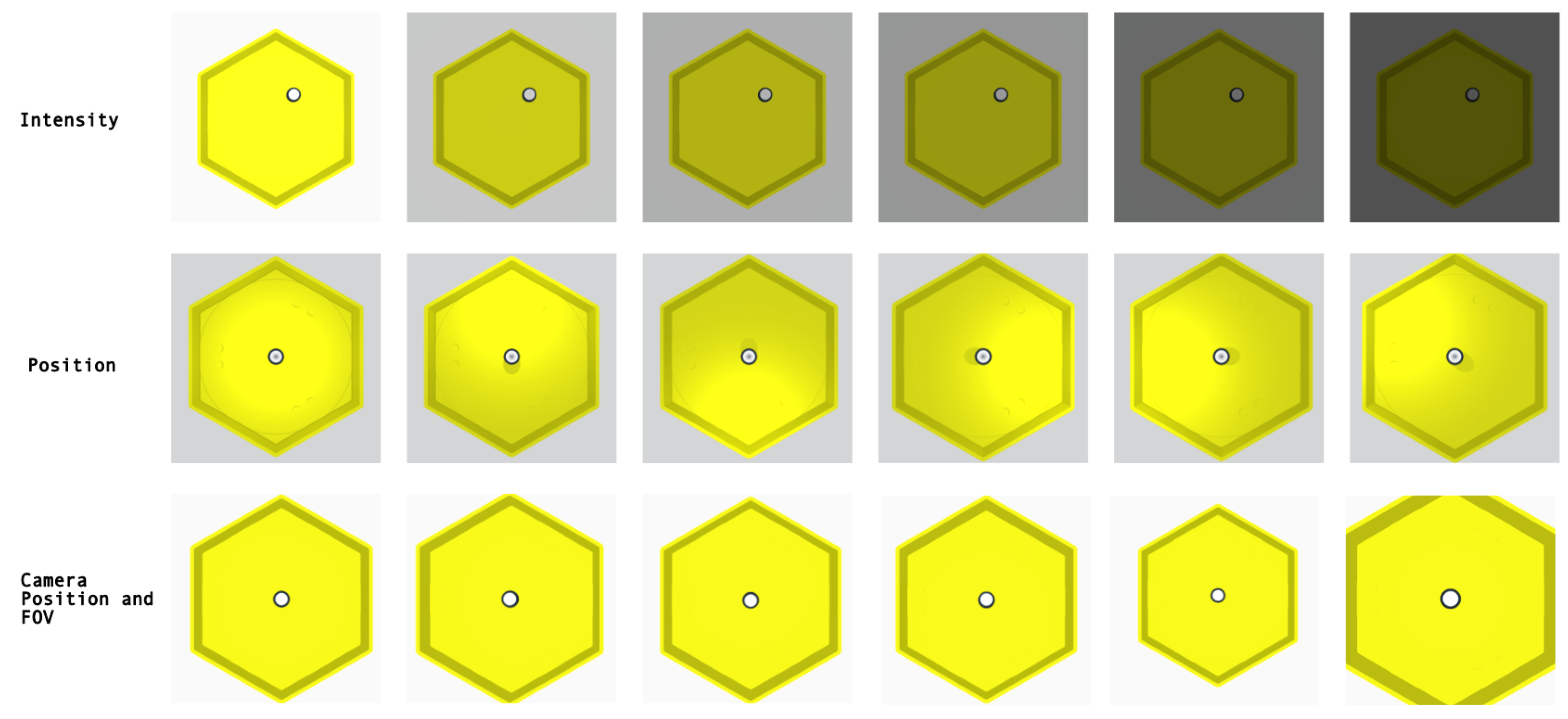
| Randomization | Value Range |
|---|---|
| Background (environment background) | Random RGB value, except dark colors |
| Platform surface | Random RGB value, except dark colors |
| Lighting position (x, y, z) | x = [−78, 78], y = [109, 109], z = [78, −78] |
| Lighting intensity | [0, 16] |
| Camera position (x, y, z) | x = [−20, 20], y = [0, 0], z = [−20, 20] |
| Camera FOV | [60, 90] degrees |
| Marble size (radius) | [1.5, 3.0] units |
| Marble mass | [4, 8] units |
| Marble position (x, y, z) | x = [−40, 40], y = [0, 0], z = [−40, 40] |
| Parameters | Deep Q-Learning | Actor-Critic |
|---|---|---|
| Num. Episodes | 1000 | 1000 |
| Gamma | 0.99 | 0.99 |
| Learning rate | 0.00025 | 0.001 |
| Batch Size | 4 | - |
| Loss Function | Huber | Huber |
| Max. frames per episode | 100,000–1 M | 100,000–1 M |
| Image Resolution | 84 × 84 | 360 × 360 |
| (A) Q-Learning | Virtual Environment | Physical Environment | ||
|---|---|---|---|---|
| Environment Configuration | Success Rate | Max. Reward | Success Rate | Max. Reward |
| No randomization | 50.85% | 2314 | 18.98% | 434 |
| Marble position | 85.56% | 6293 | 55.89% | 2783 |
| Camera position | 55.98% | 2804 | 34.34% | 964 |
| Marble and camera position | 88.45% | 5663 | 72.57% | 6024 |
| with DR | 86.67% | 6544 | 65.68% | 4538 |
| With DR and induced noise | 89.55% | 7944 | 78.56% | 6027 |
| (B) Actor-Critic | Virtual Environment | Physical Environment | ||
| Environment Configuration | Success Rate | Max. Reward | Success Rate | Max. Reward |
| Marble position | 92.87% | 9370 | 76.90% | 5811 |
| No induced noise | 88.44% | 5825 | 72.67% | 6167 |
| With induced noise | 99.49% | 9942 | 81.88% | 8726 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ranaweera, M.; Mahmoud, Q.H. Deep Reinforcement Learning with Godot Game Engine. Electronics 2024, 13, 985. https://doi.org/10.3390/electronics13050985
Ranaweera M, Mahmoud QH. Deep Reinforcement Learning with Godot Game Engine. Electronics. 2024; 13(5):985. https://doi.org/10.3390/electronics13050985
Chicago/Turabian StyleRanaweera, Mahesh, and Qusay H. Mahmoud. 2024. "Deep Reinforcement Learning with Godot Game Engine" Electronics 13, no. 5: 985. https://doi.org/10.3390/electronics13050985
APA StyleRanaweera, M., & Mahmoud, Q. H. (2024). Deep Reinforcement Learning with Godot Game Engine. Electronics, 13(5), 985. https://doi.org/10.3390/electronics13050985