In this section, we propose a task allocation algorithm based on Monte Carlo Tree Search. Specifically, we propose a centralized adaptive Monte Carlo Tree Search for small-scale tasks and a decentralized adaptive Monte Carlo Tree Search for large-scale tasks.
4.1. Task Allocation Based on Centralized Adaptive Monte Carlo Tree Search
Based on the different abilities possessed by different robots and the different abilities required for different task objectives, we need to design a capability analysis algorithm on the basis of MDP to traverse the set of all under different state .
In the multi-robot capability analysis algorithm of Algorithm 1, the first line of the algorithm inserts a special empty task item into the queue of unallocated tasks. The design intention of this step is to address certain situations, such as when a robot is unable to perform any other tasks in the current context, or when there is a more optimized solution, it can choose the option of wheel clearance. Next, in the second to third lines of the algorithm, this article traverses the robot queue, starting from the first robot, to find a task within its capability range. This process will continue until a suitable task is found or the aforementioned empty task is assigned. Once the appropriate task is identified, as shown in line 4, it is temporarily stored in an array named ‘actions’.
| Algorithm 1: Multi-robot Capability Analysis |
![Electronics 13 04943 i001]() |
Subsequently, the algorithm will create a new robot and task queue while removing the robots and tasks that have already been assigned from it in preparation for the next round of task allocation. As shown in line 7, when all robots have been assigned at least one task, the task allocation result of the current round will be added to set a. Subsequently, following the instructions on line 11, this article retrieves the actions that were recently added to the actions array and proceeds to the next iteration. If there are still robots that have not been assigned tasks, this article will use the updated robots and task queue to restart the entire allocation process.
Algorithm 1 provides an efficient method to ensure that each agent is assigned tasks reasonably according to its capabilities and the requirements of the current situation. By introducing empty task items, the algorithm enhances its flexibility and robustness, allowing agents to effectively take turns when there are no suitable tasks to allocate or better solutions available, avoiding performing tasks that are not suitable or inefficient. Furthermore, the algorithm ensures the continuity of the allocation process and the dynamic response capability of the system by continuously updating the robot and task queues. This method allows the algorithm to re-evaluate the task and robot status during each iteration, adapting to possible environmental changes or new task requirements, thereby optimizing the overall task allocation strategy.
After successfully initializing the state
(line 2), Algorithm 2 then uses Algorithm 1 to determine the possible actions a that can be taken in that state (line 3). In the generated tree structure, if there are unassigned tasks in the current state and there are still actions in the action set a that have not been explored, the algorithm will randomly select an untested action from among them and execute it to transition to a new state
. At this point, the algorithm will simulate the allocation of remaining tasks through a random task allocation process (simulation) and calculate the corresponding reward based on the final scheduled time (lines 5–7). If all possible actions in action set a have been explored, the algorithm will select those nodes with the highest historical reward values (line 9). This process will continue until all tasks have been assigned, at which point the system reaches a final state
. Once the final state
is reached, the algorithm starts the backpropagation process. In lines 10 to 13 of the algorithm, the number of visits to the final state
is incremented, and the reward value is updated. The reward value is calculated by dividing the sum of all rewards on the path to the final state by the number of visits to obtain the average reward. The same update process will also be applied to all ancestor nodes of the final state, ensuring that the information in the search tree is fully updated. This completes a complete iteration process, setting initial conditions for the next iteration and continuously optimizing the task allocation strategy.
| Algorithm 2: Use MCTS for multi-robot task allocation |
![Electronics 13 04943 i002]() |
In the MCTS algorithm, the traditional selection strategy often relies on the weighted mean of rewards for all possible actions in state . This approach performs well in scenarios like board games, where the outcome is relatively fixed—typically a binary result of winning or losing. In such cases, rewards are often represented as a final game result (e.g., 0 or 1), directly reflecting the winning probability. This concise reward mechanism effectively evaluates the potential value of actions and guides strategy selection. However, even in board games, intermediary rewards—such as features of the game state, like the number of opponent pieces on the board—can also play a crucial role in MCTS node evaluation, enhancing decision-making beyond the final outcome.
In multi-agent task allocation scenarios involving complex decisions and diverse factors, relying solely on traditional reward evaluation methods becomes insufficient. These methods may fail to capture key differences in task completion times, which often depend heavily on each robot’s initial state, target location, and the specific abilities required. To address this limitation, this study proposes a new reward calculation method that moves beyond simple weighted averages of all solutions, instead prioritizing specific choices likely to lead to optimal outcomes, enabling more accurate and adaptive task allocation in complex environments. Although determining an optimal solution is an NP-hard problem that involves extensive computational resources and time, we should not ignore the potential optimal potential just because some specific states may lead to suboptimal results. Instead, we should identify and prioritize those paths that have the potential to guide the system state to or near the optimal solution through a more refined reward system, as shown in Formula (1).
Using this strategy, we can more intensively use resources to pursue and achieve optimal solutions rather than considering all possible solutions equally, thereby more effectively guiding the development of algorithms toward the most advantageous state and improving the efficiency of solving problems.
In addition, using a reward system based on the best possible solution can also bring other benefits, including improving the transparency and predictability of the decision-making process and reducing the possibility of overlooking extreme but valuable strategies due to the pursuit of average. In practical operations, this means that the algorithm can converge to high-quality solutions faster while reducing ineffective exploration on the path to the optimal solution.
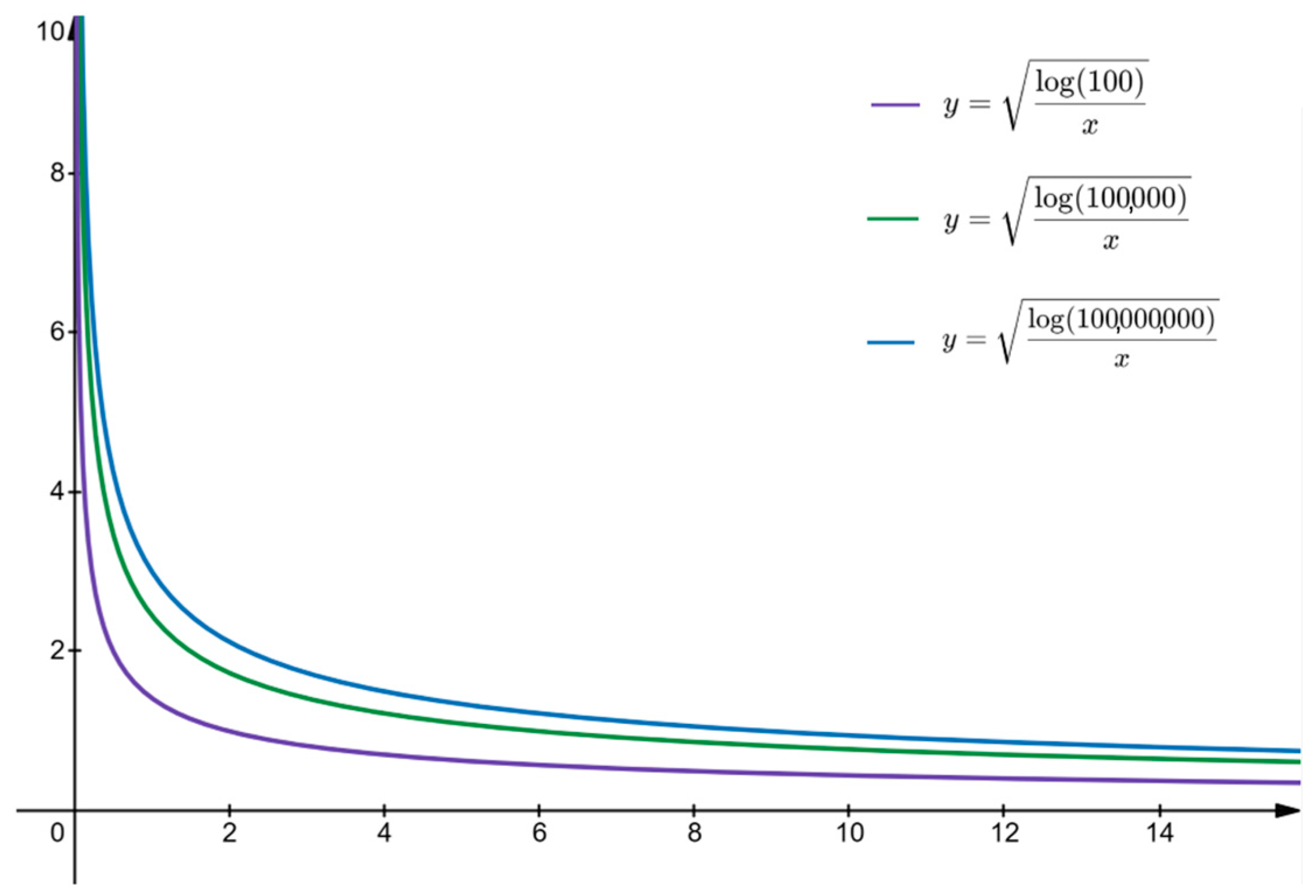
The exploration term in the UCT formula is designed to balance the relationship between exploration and exploitation, where c is the exploration coefficient, represents the total number of visits in state , and represents the number of visits in state when action is taken. This formula adjusts the exploration desire to make a trade-off between new or less explored actions and actions with higher known rewards.
Based on the analysis of
Figure 2, it can be found that when the proportion of the number of visits for a specific action to the total number of visits is too high, the value of the exploration item will significantly decrease, which reduces the algorithm’s willingness to explore actions that have not been fully explored. When the minimum number of visits to action
is 1, the exploration coefficient value will be a positive number greater than 0.5 and will increase logarithmically as the total number of visits increases. This leads to a potential problem: for actions with high reward values, even if their reward values are only slightly higher than other actions, the algorithm may not explore other possible actions for a long time, thus falling into local optima. For example, in the case of coefficient
c = 1, for action
with a reward value of 100 if the reward value of another action
is 102, it will take at least 1000 visits to re-explore
, which is clearly not the optimal choice in terms of decision-making.
Given the unique challenges of multi-agent task allocation, including the diversity in the total number of tasks and robots, as well as the dynamic nature of task reward values, this paper introduces a new dynamic UCT formula (3) to better accommodate this complexity. In this study, we develop an adaptive D-UBMCTS algorithm by introducing the dynamic UCT formula into traditional MCTS. The key to this algorithm is to dynamically adjust the balance between exploration and exploitation. The specific method is to adjust the exploration parameter c, which measures the proportion of the optimal reward value (max (Reward)) in each state to the total reward. The significant advantage of this strategy is that the algorithm can automatically adjust its behavior to maximize long-term gains regardless of the magnitude of the reward.
By calculating the percentage impact of reward values in real time, the D-UBMCTS algorithm can effectively adapt to task combinations of different sizes and complexities. This flexibility allows the algorithm to automatically find the optimal exploration and exploitation ratio without manually adjusting parameters when facing different task requirements, thus maintaining efficient decision-making capabilities in a changing environment. This not only optimizes the performance of the algorithm but also greatly enhances its adaptability, enabling it to achieve more accurate and efficient task allocation in a wide range of application scenarios. Therefore, the adaptive D-UBMCTS algorithm is not only theoretically innovative but also has great potential for practical application, especially in fields that require the handling of large-scale, highly complex decision-making problems.
4.2. Task Allocation Based on Decentralized Adaptive Monte Carlo Tree Search
When faced with larger task allocation problems, centralized algorithms may produce unstable results in a short period of time due to their inherent randomness. As the task size continues to increase, the variance of the results will become larger, and the allocation of preliminary solutions will have a huge impact on the total time result of the final solution.
4.2.1. Distributed Algorithm Implementation
Firstly, this article defines the action sequence of agent as , where represents the action of agent at time . For agent , all possible action sequences form a set , i.e., . Furthermore, this article defines as a set of action sequences jointly selected by multiple agents, i.e., , where is the total number of agents. Therefore, the set of action sequences for all agents except agent can be represented as .
We define the probability of agent taking a certain action sequence as . Furthermore, this article represents the probability distribution of agent for all possible action sequences as a binary This definition includes two important levels:
Domain of intent: This represents all feasible sequences of actions that the agent may take. This domain defines the scope of the agent’s behavior, that is, which action sequences it can choose to achieve its goals.
Distribution of intent: This represents the agent’s preference for different action sequences. That is to say, this distribution indicates which action sequences the agent tends to take and reflects this preference in the form of probability.
The same logic applies to other agents as well. Therefore, for agent , the set of intentions of all other agents except for itself . This collection provides agent with important information about the possible actions of other participants.
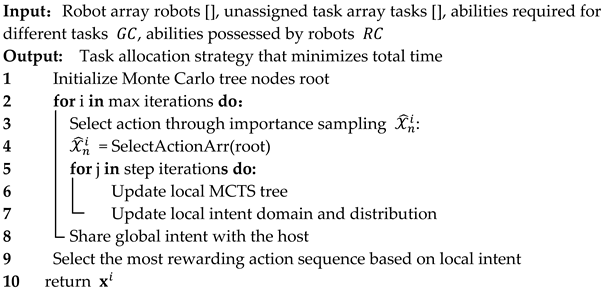
As shown in Algorithm 3, the optimization objectives of the Dec-MCTS algorithm are twofold. One is to optimize the action sequence set
selected through importance sampling in this paper, which is the domain of the action. The other is to iteratively optimize and update the selection probability of the sequence set, which is the distribution of the action. It can be divided into three steps: (1) expand the local Monte Carlo search tree; (2) update the action sequence set
and probability distribution through importance sampling; and (3) share and update global intent, as explained in detail below.
| Algorithm 3: Multi-robot task allocation based on Distributed Monte Carlo Tree Search (Dec-MCTS) |
![Electronics 13 04943 i003]() |
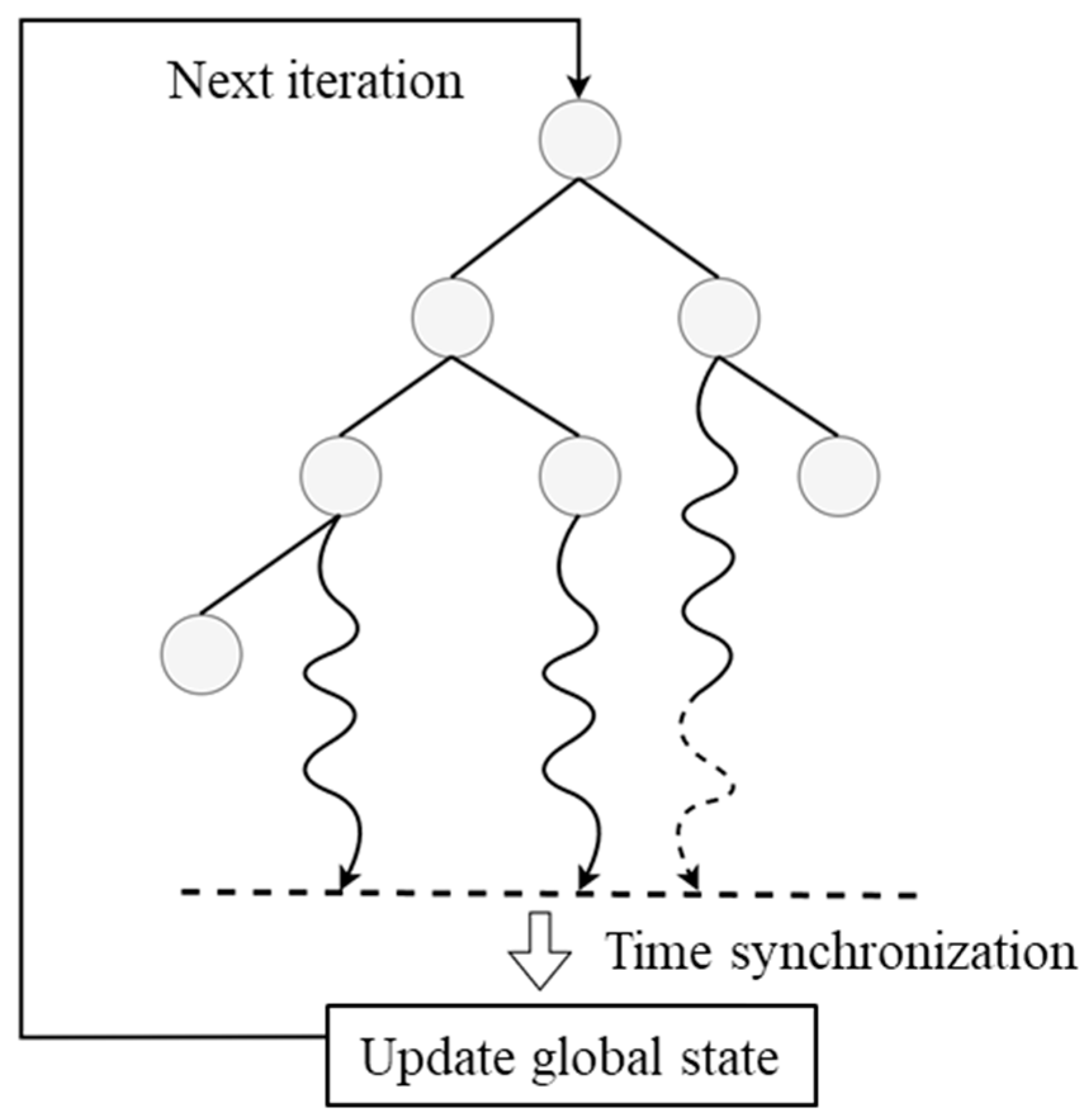
As shown in
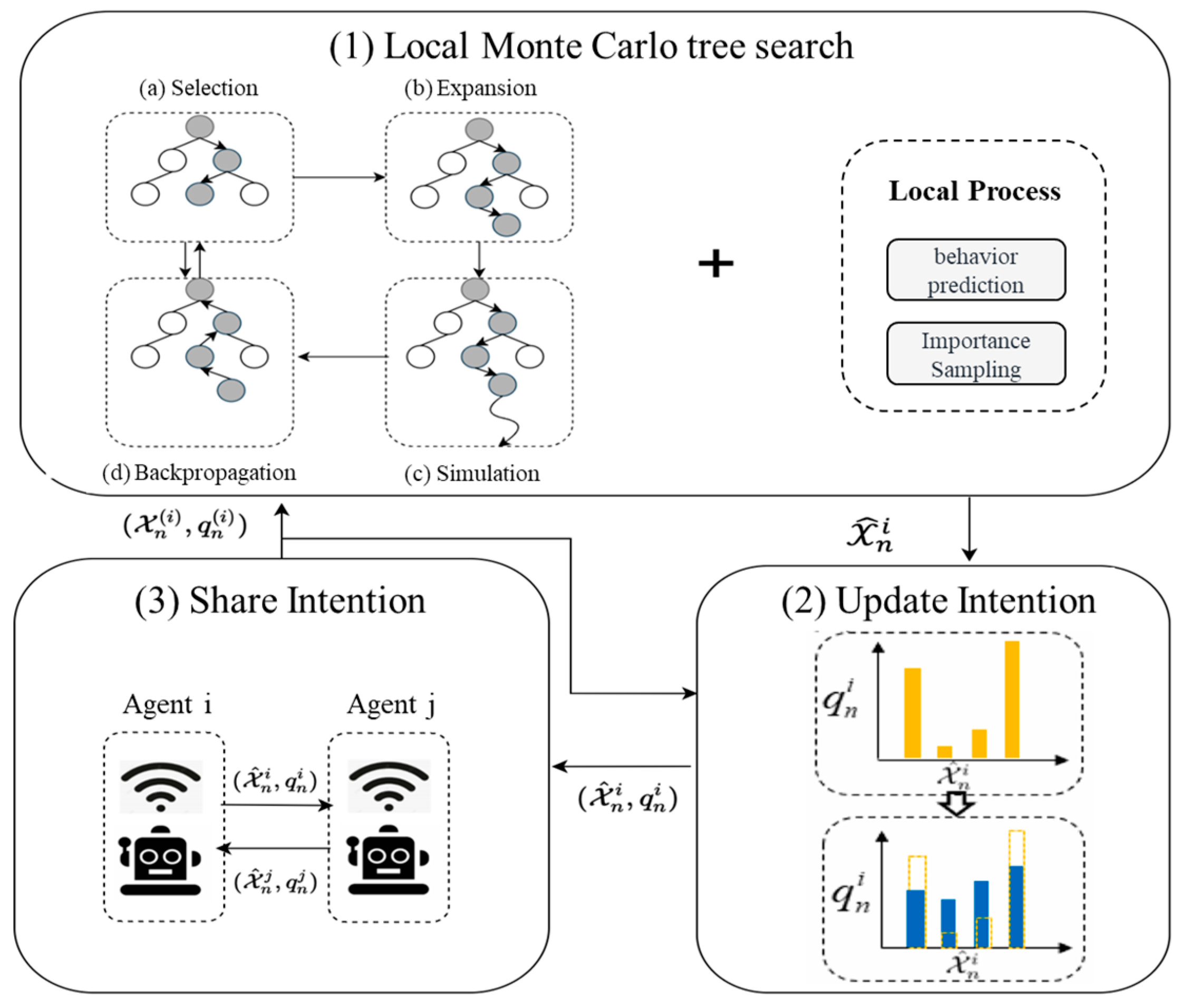
Figure 3 first, each agent initializes the root node of the Monte Carlo search tree based on the initial global task information, the specific capabilities required for the task, the set of capabilities it possesses, and the scarcity of each capability. This node grows rapidly through an iterative process, providing all the information required for initialization to a single agent (see line 1 of the algorithm). Then, each intelligent agent begins to execute the main process of the decentralized algorithm, which includes continuously looping steps.
Due to the increase in the number of tasks, the size of the set that can be composed of different action sequences grows exponentially. Therefore, this article will not sample and update the probability distribution of all updated action sequences. For a certain intelligent agent, this article only needs to select a part of the more feasible action sequence . This means that although this article abandons considering the distribution of all feasible scenarios, it reduces the originally exponential time complexity to a set constant level (for example, this article only considers the first four most feasible strategies). This process is referred to as importance sampling in the algorithm presented in this article (see line 3 of the algorithm), where the most likely sequence of actions will change as the shared information is updated. Once a new important action sequence is discovered in a certain iteration, this paper uses uniform distribution to initialize the new intent binary .
After each new intent distribution appears, this article will update based on a new round of agent negotiation (see lines 5 to 8 of the algorithm), where the agent first updates the existing Monte Carlo tree according to a specified number of iterations and returns an updated Monte Carlo tree (see line 6 of the algorithm). During the update process, two points should be noted: firstly, the intention set of all other agents except for the agent itself should be considered ; secondly, in the process of sharing, it is necessary to distribute the predicted additional budget among various agents; that is, each agent independently predicts its own path and synchronously shares it. Then, the intelligent agent shares its own intentions while receiving the latest teammate intentions .
Finally, after all rounds of negotiation, each individual agent will receive an action sequence and distribution probability that has been negotiated with all other agents. The action sequence with the highest probability is the final action decision result (line 10).
4.2.2. Importance Sampling
As mentioned earlier, it is impractical to consider all feasible action sequences
of agent
in each round of decentralized multi-agent negotiation, as the size of the intent domain increases exponentially with time steps. So, this article adopts the method of importance sampling, only considering a part of
in each round, that is,
, which is essentially a compromise sparse representation of the current search tree. Further explanation of importance sampling will be provided in conjunction with
Figure 4.
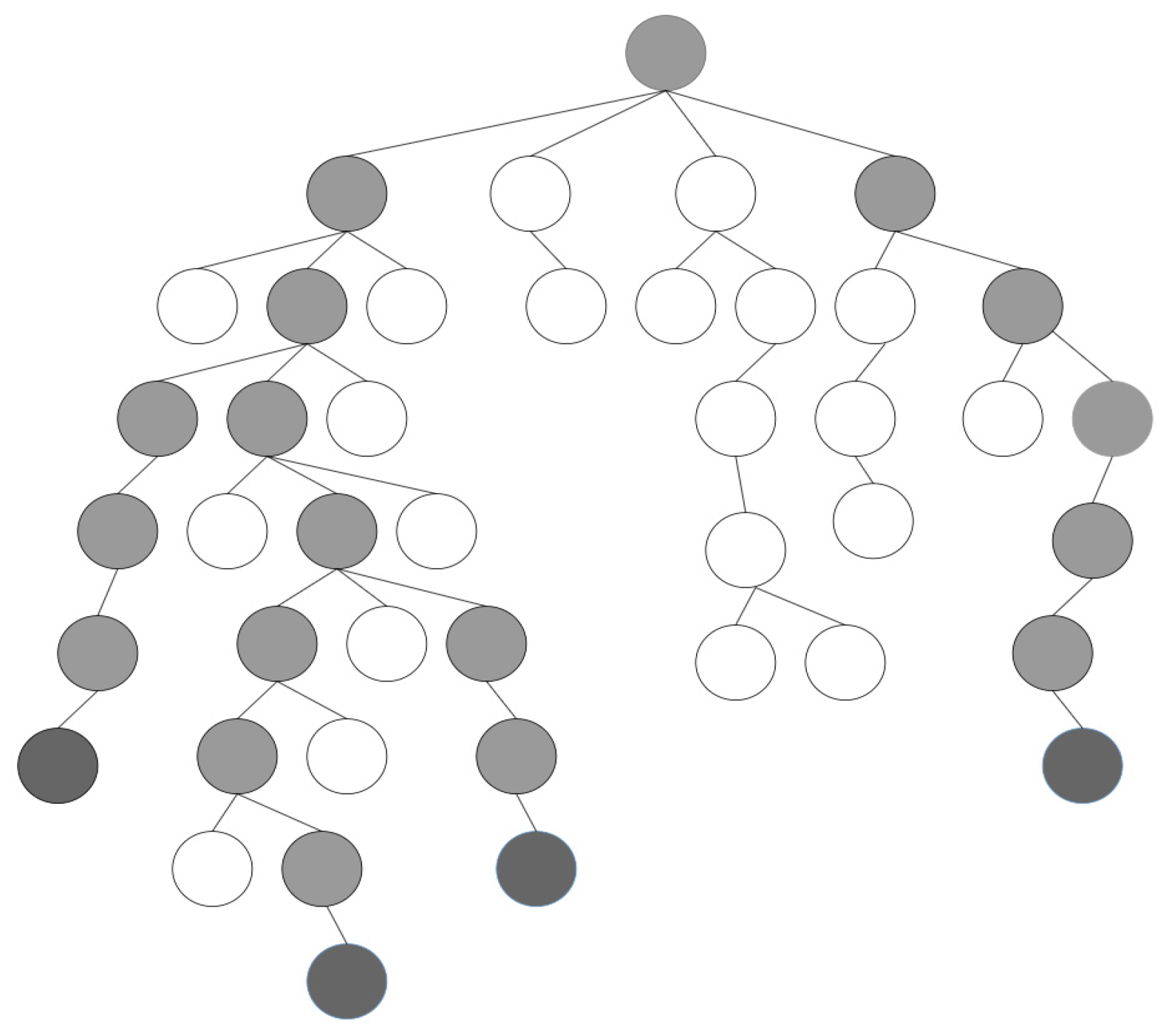
After running the Dec-MCTS algorithm for several rounds, an unbalanced and structurally complex search tree will be generated, as shown in
Figure 5. In this study, only four potential action sequences were considered in each round of negotiation, so the size of the intent domain
was set to y. This study first traverses the tree using a depth-first search method and then identifies all leaf nodes. Each leaf node contains the cumulative average reward evaluation value of its corresponding branch (action sequence). By comparing the average reward values of these leaf nodes, select the top y leaf nodes with the highest evaluation values (as shown in the dark gray nodes in the figure). Next, trace back from these selected nodes toward the root of the tree to identify the action sequence containing these leaf nodes (as shown by the light gray nodes in the figure).
In order to maintain the continuity of the negotiation process, it is necessary to extend these y action sequences to the Terminal State. Although the conventional approach is to expand the action sequence through random sampling, this method is less efficient. Therefore, this study adopted a method based on greedy heuristic factors to extend the action sequence, and the specific implementation details will be elaborated in the subsequent intention prediction section.
In the process of algorithm implementation, in order to save computation time, this study adopted the strategy of space for time. In the simulation phase of MCTS, combined with greedy heuristic intention prediction, the predicted action sequence is stored in the tree nodes so that it can be directly obtained when needed without recalculating.
Algorithm 4 provides a detailed description of the process of each importance sampling. In this process, for each newly discovered action sequence
located in the top y, first check whether the action sequence already exists in the current local intent domain. If
is not recorded in the local intent field, the algorithm will create a new intent binary for it. This newly created intent binary will be initialized to a uniform distribution to ensure that all possible action sequences have an equal probability of being explored in the initial stage (lines 1–3). Subsequently, during the sampling process, the algorithm will utilize the latest information shared from other nodes to recalculate all data within the local intent domain. This step ensures that the local intent domain can reflect the latest global information and changes, thereby adjusting and optimizing the probability distribution and priority of each action sequence (lines 4–6). After recalculating and updating the data, the algorithm will output the updated local intent domain. This output not only includes the newly added action sequence and its related data but also the information of the existing action sequence updated based on global information (line 7). In this way, the importance sampling algorithm ensures that the local intent domain remains up-to-date and accurately reflects the impact of data updates from other nodes, providing more accurate and effective data support for subsequent decisions. It should be pointed out that although there may be insufficient selection of action plans in the initial stage of local intent and even more conflicts between different agents, as the Dec-MCTS algorithm continues to run, the accumulated statistical information in the MCTS gradually improves and optimizes. The intention negotiation process between multiple agents is also constantly deepening, resulting in a more optimized action plan for
and a significant reduction in action plan conflicts between agents.
| Algorithm 4: Importance Sampling Intent Update |
![Electronics 13 04943 i004]() |
4.2.3. Heuristic Prediction Algorithm Based on the Rarity of Abilities
In the scenario of multi-robot collaborative work, accurately predicting the future actions of other robots is extremely difficult. This article proposes a heuristic prediction algorithm based on the rarity of abilities. This algorithm aims to predict and optimize the performance of different robots in tasks based on the rarity of the special equipment they are equipped with.
This article defines the concept of capability scarcity to evaluate the rarity of the abilities required by robots to complete specific tasks. For a specific ability cap1, the ability scarcity of robot i possessing that ability can be defined as Formula (2).
This value reflects the proportion of robots with this ability in the entire robot population relative to the importance of this ability in completing tasks. Among them, is the number of robots with this capability, is the total number of robots, and is the coefficient. By considering the degree of capability deficiency, this paper can allocate tasks more effectively, ensuring that robots equipped with rare but important equipment are prioritized for key tasks, thereby improving the efficiency and robustness of the entire multi-robot system.
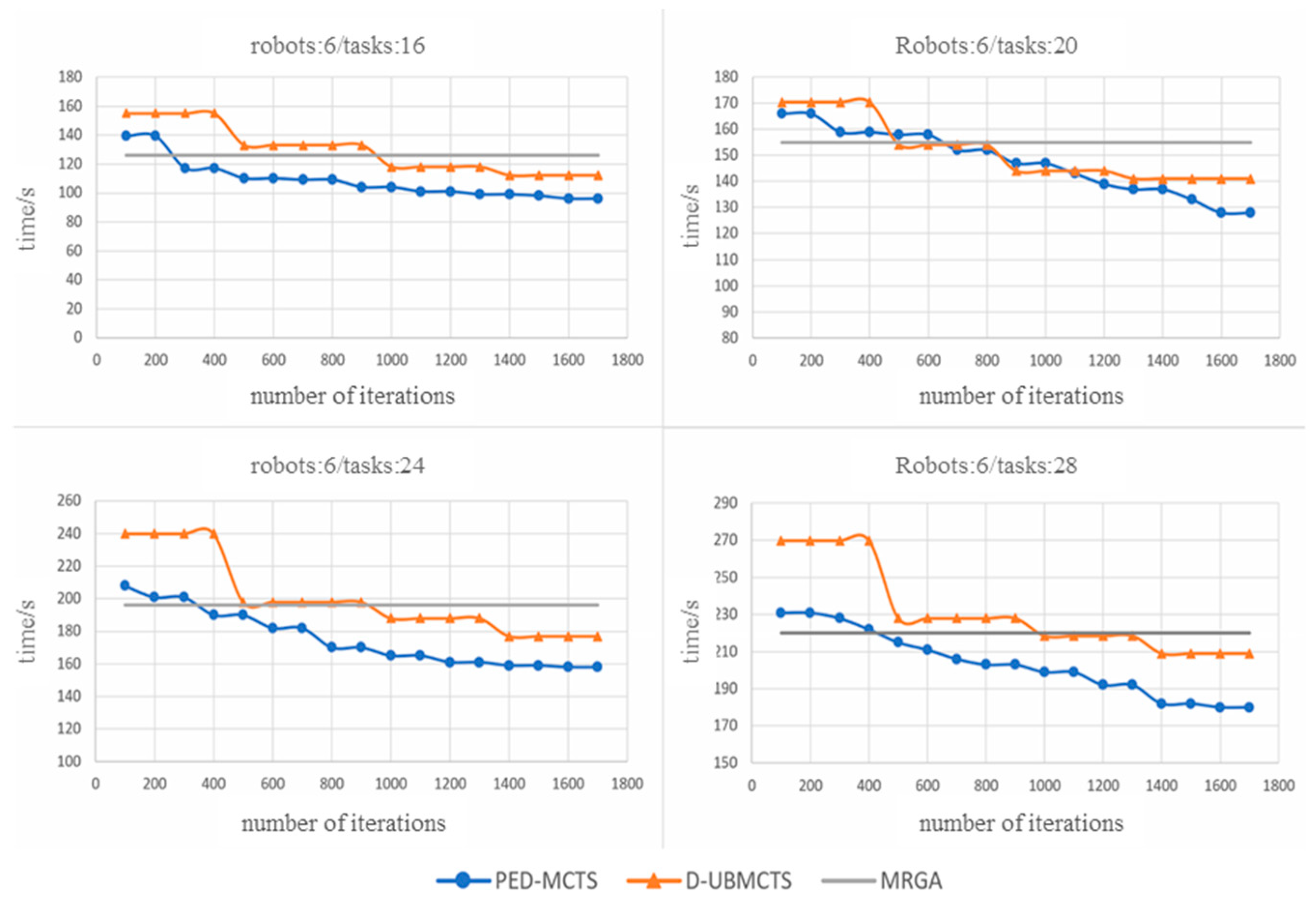
4.2.4. Parallel Enhanced Dec-MCTS (PED-MCTS) Algorithm
The root parallelization strategy refers to independently simulating leaf nodes for processes to achieve maximum depth, and each process independently simulates its assigned leaf nodes until the maximum depth is reached. Although this method cannot completely solve the problem of process synchronization, it can, to some extent, reduce the dependence on local optimal solutions, as it allows the system to explore multiple different search paths simultaneously. Root parallelization further promotes the diversity of the search process, and by exploring different decision paths in parallel, it can, to some extent, avoid overly focused searches on local regions.
As shown in
Figure 4, the root parallelization method creates
independent search trees, each of which is managed by a separate process. All processes run in independent environments to avoid the complexity of information sharing or mutual interference. The task of each process is to conduct an in-depth state simulation within a specified time
, and return the simulated state and results to the main process after the time is up. The responsibility of the main process is to aggregate the data returned by all child processes and form a comprehensive decision result through statistical analysis and synthesis. The significant advantage of this method is that it can significantly reduce the communication requirements between processes, as each process operates independently throughout the entire computation process, except for the initial task allocation and final result aggregation.
In addition, the effectiveness of this method largely depends on the settings of (number of processes) and (available time). Generally speaking, having more processes means being able to explore more state spaces simultaneously, and longer time allows each process to conduct more in-depth simulations, thereby increasing the likelihood of finding the optimal solution. However, this also means that more computing resources and time are required, so in practical applications, the selection of and needs to be carefully balanced based on available hardware resources, task size, and solution accuracy requirements.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}