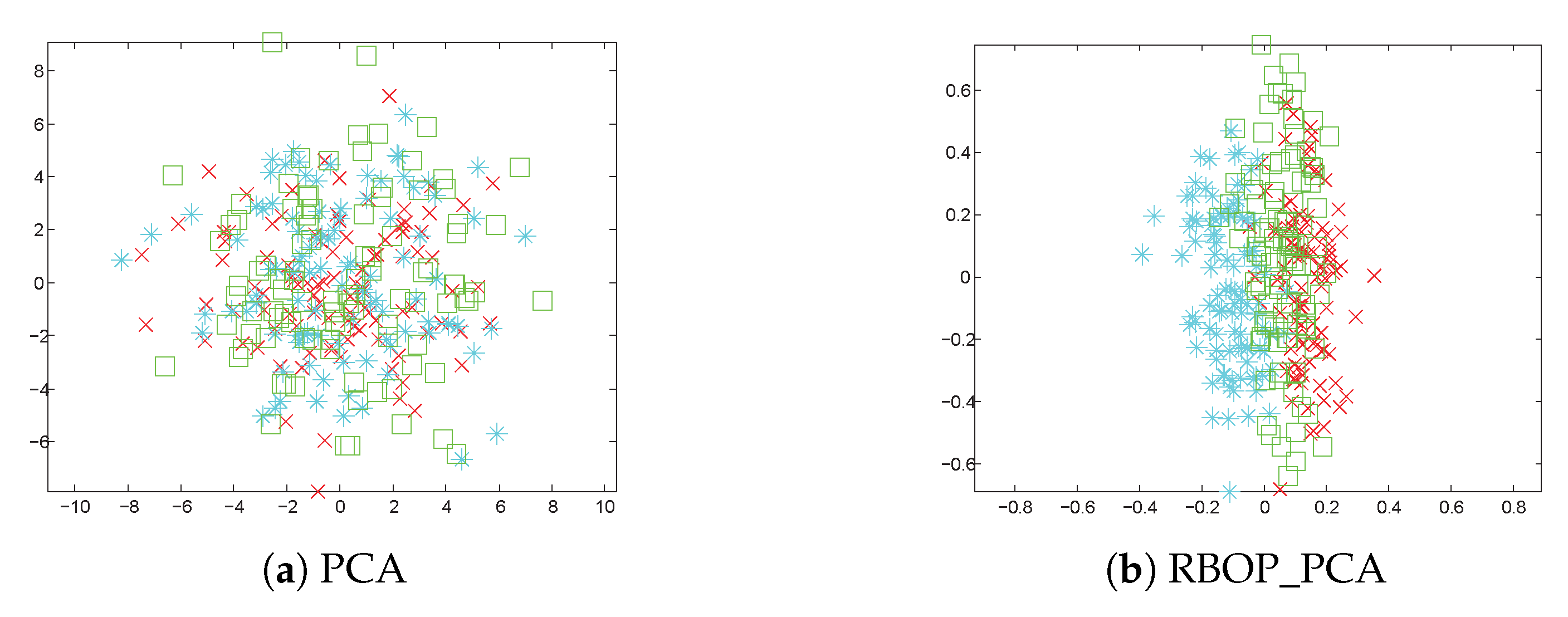1. Introduction
The curse of dimensionality represents a widespread hurdle in numerous real-world scenarios, particularly in applications involving high-dimensional data like facial and textual images. This problem can significantly hinder the efficacy of subspace learning methodologies owing to their excessive computational expenses and considerable memory demands. DR is crucial for tackling this issue, as it strives to preserve essential characteristics of the data in a lower-dimensional space. Since high-dimensional data typically arise from an underlying low-dimensional manifold structure [
1]; the objective of DR is to reveal these informative, compact, and meaningful low-dimensional structures that are embedded within the original high-dimensional space. This promotes enhanced classification and visualization capabilities [
2,
3,
4]. The desired attributes are usually specified by an objective function, and the task of DR can be formulated as an optimization problem [
5].
DR methods are generally divided into three types according to the label information used for training samples: supervised, semi-supervised, and unsupervised DR. Supervised DR methods leverage label information to learn a projection that enhances class discrimination. Notable examples include linear discriminant analysis (LDA) [
6,
7], local linear discriminant analysis (LLDA) [
8], sparse tensor discriminant analysis (STDA) [
9], locality sensitive discriminant analysis (LSDA) [
10], discriminative locality alignment (DLA) [
11], marginal Fisher analysis (MFA) [
12], and local discriminant embedding (LDE) [
13]. Each of these techniques has unique strengths, depending on their specific focus. LDA is a fundamental method, while LLDA, an extension of LDA, emphasizes the local separability between different classes, although it still faces the small-sample-size problem and handles intra-class data similarly to LDA. LLDA specifically concentrates on classes that are spatially proximate in the data space, with the assumption that this closeness enhances the probability of misclassification. Consequently, its objective is to optimize the separation between adjacent classes. LSDA endeavors to maximize the margins between distinct classes within every local region. It aims to project samples of the same class, which are neighboring in the high-dimensional space, to be nearer in the reduced space, while making sure that samples from various classes are distinctly separated, thus increasing the discriminative ability in the lower dimensions. DLA is designed to handle nonlinearly distributed data, preserving local discriminative information and avoiding issues with matrix singularity. MFA, on the other hand, is a linear feature extraction technique based on the Fisher criterion within a graph embedding framework. LDE prioritizes the local and class relationships among data points, preserving the internal proximity of points belonging to the same class while guaranteeing that points from distinct classes are not adjacent in the embedded space, thus enhancing class distinction.
The aim of DR techniques is to identify a discriminative projection that concurrently maximizes the separations between the centroids of distinct classes and reduces the proximity of data points belonging to the same class, employing Fisher’s criterion [
8]. However, high-quality labeled data are often scarce compared to the abundance of unlabeled data [
14]. Unlabeled data can be valuable for enhancing algorithm performance. Semi-supervised DR methodologies take advantage of the distribution and local structure of both labeled and unlabeled data, together with the labeling information from the labeled data, to boost performance. Semi-supervised discriminant analysis (SDA) strives to identify a discriminative projection that maximizes the separability of labeled data across distinct classes while estimating the intrinsic geometric structure of the unlabeled data [
15]. SDA makes use of both labeled and unlabeled samples. labeled samples serve to boost the separability among distinct classes, while unlabeled samples contribute to delineating the underlying data geometry. The objective is to learn a discriminant function that represents the data manifold as smoothly as possible. Constrained non-negative matrix factorization (CNMF) has been proposed to address the limitations of the original non-negative matrix factorization (NMF), which does not incorporate label information [
16]. CNMF purposefully employs the label information from the labeled samples to bolster the discriminative strength of the matrix decomposition. The label information is implemented as an extra hard restriction, ensuring that data points sharing the same label maintain their coherence in the newly reduced dimensional space. However, since there are no constraints on the unlabeled data, the performance of CNMF can be limited when the amount of label information is minimal. In cases where only one sample per class is labeled, the constraint matrix in the algorithm effectively becomes an identity matrix, rendering it ineffective.
Unsupervised DR methods aim to preserve the intrinsic manifold structure of the data by exploring the local relationships between data points and their neighbors. Key examples of such methods include locally linear embedding (LLE) [
17], Laplacian Eigenmaps (LEs) [
18], neighbor preserving embedding (NPE) [
19], orthogonal neighborhood preserving projection (ONPP) [
20], and locality preserving projection (LPP) [
21]. The LLE method [
17] is particularly effective for data with an overall nonlinear distribution, as it has a strong capability to maintain the original data structure, even for datasets with complex nonlinear structures. Similarly, LEs [
18] reconstruct the local structure of the data manifold by establishing a similarity graph, which effectively captures the intrinsic manifold structure. NPE [
19] focuses on preserving the locally linear structure of the manifold during the dimensionality reduction process, allowing it to extract useful information from the data. This method can capture both the nonlinear structure of manifolds and retain linear properties, making it suitable for generalization to new samples. Both ONPP [
20] and the LPP method [
21] employ learned projections to reduce the dimensionality of data in a space. These methods model the data manifold using a nearest-neighbor connection graph, which preserves the local structure of the data. The resulting projection subspaces are intended to maintain the nearest-neighbor associations, guaranteeing that the local geometry of the data is preserved within the reduced space.
Recently, Wang [
12] introduced a new graph embedding framework that unifies various DR methods, including LDA, ISOMAP, locally linear embedding (LLE), Laplacian Eigenmaps (LEs), and LPP. In this framework, the statistical and geometric properties of the data are encoded as graph relationships. PCA [
22] is a widely recognized method that maps high-dimensional data onto a lower-dimensional space by identifying the directions of maximum variance for optimal data reconstruction. Modified principal component analysis (MPCA) enhances PCA by employing various similarity metrics to more accurately capture the similarity structure of the data [
23], and sparse PCA (SPCA) [
24] has been introduced. From the overview of the three categories of DR methods, supervised, semi-supervised, and unsupervised, it is evident that obtaining labeled data samples in real-world scenarios can be costly and challenging. Therefore, this paper focuses on unsupervised DR methods. Nevertheless, current unsupervised DR techniques might possess the following possible disadvantages:
(1) Many unsupervised DR methods, such as LPP and NPE, rely on the similarity matrix (or affinity graph) of the input data. As a result, the quality of subspace learning is significantly influenced by the construction of this affinity graph. Furthermore, since similarity measurement and subspace learning are typically conducted in two distinct stages, the acquired data similarity may not be optimal for the subspace learning task. This can result in sub-optimal performance.
(2) These approaches generally learn just one projection throughout the dimensionality reduction procedure. This singular projection provides limited adaptability for attaining a more precise data transformation, which may result in a less effective representation within the lower-dimensional space.
To tackle these challenges, this paper introduces a new learning approach, RBOP, which is an extension of our previous work [
25]. In contrast to conventional methods that necessitate a similarity matrix of the data as input, RBOP employs sparse reconstruction to guarantee that the projected data retain sparsity, as shown in
Figure 1. The sparse reconstruction coefficient matrix serves to encode the local geometric characteristics of the data, effectively fulfilling the role of a similarity matrix. Through this method, the similarity matrix can be directly learned throughout the dimensionality reduction procedure. In contrast to traditional DR techniques that depend on a single projection, RBOP employs two separate projections: the “true” projection and the “counterfeit” projection. These two projections are orthogonal to one another. The “true” projection is afforded considerable latitude, allowing it to learn a more precise and effective data transformation. This dual-projection methodology boosts the adaptability and resilience of subspace learning, ultimately resulting in improved representation within the lower-dimensional space.
Moreover, drawing inspiration from the observation that the two projections exhibit a similar data structure, we stipulate that the data projected by these two techniques maintain this structural resemblance via two distinct reconstruction methodologies. We incorporate a sparse term for error compensation, which helps in learning robust projections by mitigating the impact of noise. This sparse term weakens the response to noise during the learning process, thereby enhancing the robustness of the projections. The proposed RBOP approach has the potential to expand several unsupervised dimensionality reduction methods into a robust and sparse embedding framework for subspace learning. We have devised an efficient and effective algorithm to address the optimization problem that arises. The efficacy of RBOP is substantiated by remarkable experimental outcomes, which exhibit considerable enhancements compared to prevailing methods.
This paper presents the following principal contributions:
(1) For the first time, we propose a novel concept and methodology for learning bi-orthogonal projections in the context of DR. Utilizing the inexact augmented Lagrange multiplier (iALM) technique as a foundation, we develop an efficient algorithm to tackle the optimization problem that ensues. Both theoretical validations and empirical assessments substantiate the effectiveness of the devised optimization algorithm.
(2) We approach the DR challenge from a fresh viewpoint by concurrently acquiring the data similarity matrix and the subspace via sparse reconstruction and the learning of two orthogonal projections. This methodology guarantees the preservation of the local geometric structure of the data while capitalizing on the complementary insights offered by the two projections.
(3) By employing the proposed RBOP, we extend several conventional DR methods into a robust and sparse embedding framework. This extension bolsters the resilience of these methods against various kinds of noisy data and allows them to learn more precise and meaningful subspaces.
The rest of this paper is structured in the following manner. In
Section 2, we conduct a comprehensive review of the existing literature and related studies. In
Section 3, we introduce the proposed theoretical framework and formulation. This is succeeded by a detailed examination of the optimization algorithm, computational complexity, and convergence analysis in
Section 4. To validate the efficacy of our approach, we present empirical results in
Section 5, which demonstrate the effectiveness of the proposed method. Lastly, we wrap up our discussion and draw conclusions in
Section 6.
4. Convergence Analysis and Complexity Analysis
For efficiency, we utilize the iALM to solve Equation (
8), as detailed in Algorithm 1. Here, matrices
A and
B vary depending on the specific subspace learning method employed. In steps
1 and
2, the variables
W and
P are essentially updated by solving the Sylvester equation. Steps
4 and
5 are handled using shrinkage minimization techniques, as described in reference [
33].
With respect to the iALM, its convergence properties have been extensively studied in [
34] for cases where the number of variables does not surpass two. However, Algorithm 1 involves five variables. Additionally, the objective function presented in Equation (
8) lacks smoothness. These two aspects complicate the assurance of convergence. Fortunately, reference [
35] offers two sufficient conditions: (1) the dictionary X must possess full-column rank; and (2) the optimal gap during each iteration must diminish monotonically. That is,
, where
,
,
, and
represent the solution obtained in the
k-th iteration. The first condition is readily satisfied [
30,
35]. The second condition presents a more substantial challenge to prove directly, but subsequent experimental evaluations on real-world applications indicate that it does indeed hold true.
Subsequently, we examine the computational complexity of Algorithm 1. The primary computational costs of Algorithm 1 are as follows:
(1) Sylvester equations in steps 1 and 2.
(2) Matrix multiplication and inverse operations in steps 3, 4, and 5.
We delve into each component in detail in the following. Initially, the complexity of the classical resolution for the Sylvester equation is
[
31]. Consequently, the overall computational complexity of steps
1 and
2 is approximately
. Secondly, the computational complexity of general matrix multiplication is
, and given that there are
multiplications, the total computational complexity of these operations is
. Thirdly, the inversion of an
matrix incurs a complexity of
. Therefore, the total computational complexity of steps
3,
4, and
5 is approximately
. The overall computational complexity for Algorithm 1 is roughly
, where
N denotes the number of iterations.
Our proposed method, while not on par with deep learning approaches in terms of performance metrics, possesses distinct characteristics that set it apart. Unlike deep learning techniques, which often require large datasets and substantial computational resources, our method is designed for scenarios where data are limited and computational efficiency is a priority. It leverages classical dimensionality reduction techniques and enhances them with robust bi-orthogonal projections, offering a more accessible and interpretable solution for certain applications. Our method is particularly adept at handling noise and maintaining data structure, which can be beneficial in environments where data integrity is compromised. Although it may not achieve the state-of-the-art results that deep learning models [
36] can, it provides a reliable and efficient alternative for users who value simplicity, reduced computational overhead, and the ability to work with smaller datasets.
5. Experiments
In this section, the performance of RBOP was assessed through the execution of seven experiments. Of these, five experiments were carried out on publicly available image datasets, namely, PIE (Pose, Illumination, and Expression) (
https://www.ri.cmu.edu/publications/the-cmu-pose-illumination-and-expression-pie-database-of-human-faces, accessed on 14 December 2024), Extended Yale B (
http://cvc.cs.yale.edu/cvc/projects/yalefaces/yalefaces.html, accessed on 14 December 2024), FERET (
https://www.nist.gov/programs-projects/face-recognition-technology-feret, accessed on 14 December 2024), COIL20 (
http://ccc.idiap.ch, accessed on 14 December 2024), and C-CUBE (
https://cave.cs.columbia.edu/repository/COIL-20, accessed on 14 December 2024). For comparative purposes, the remaining two experiments were conducted on either two or three Gaussian synthetic datasets.
5.1. Datasets
The CMU PIE face dataset consists of 41,368 images that capture 68 individuals exhibiting four unique expressions, 13 diverse poses, and under 43 different illumination conditions.
The Extended Yale B face dataset comprises around 2432 frontal face images, each resized to a pixel dimension, captured under 64 distinct lighting conditions.
The FERET face dataset holds 1400 images featuring 200 subjects portrayed in a range of poses, illuminations, and expressions.
The C-CUBE dataset encompasses over 50,000 handwritten letters, encompassing all 26 uppercase and 26 lowercase letters, derived from a multitude of cursive scripts.
The COIL20 object dataset is composed of 1440 images, capturing 20 different objects from various angles at 5-degree increments (with each object represented by 72 images). Sample images from these datasets are depicted in
Figure 2.
5.2. Experimental Settings
To streamline the experimental process, we preprocess the original images within the datasets by converting them into grayscale images beforehand. Subsequently, for each dataset (namely, PIE, Extended Yale B, FERET, C-CUBE, and COIL20) we rearrange the sample data as follows: We choose a limited number of samples per individual to serve as training samples, while the rest are utilized as testing samples. Both training and testing samples are considered as a single set of experimental data. By extension, we increase the number of samples selected from each person to form additional sets of experimental data. As a result, each dataset comprises a total of six sets of experimental data, with the quantity of training samples chosen following a principle of incremental increase. Take, for example, the PIE dataset. We pick out 25, 30, 40, 50, 60, or 70 samples for each person to be used as training samples. Meanwhile, the samples that have not been selected are then utilized as test samples. When it comes to the C-CUBE and COIL20 datasets, the same principle applies. Here, we choose 20, 30, 40, 50, 60, or 70 samples per person as training samples, and the samples left over are employed as test samples. Likewise, in the Extended Yale B dataset, we select 10, 20, 30, 40, 50, or 59 samples for every individual to serve as training samples, with the remaining ones acting as test samples. In the case of the FERET dataset, 1, 2, 3, 4, 5, or 6 samples per person are chosen as training samples, while the rest of the samples for each person are used as test samples.
Overall, this way of dividing the data into training and test sets for different datasets is a typical practice in tasks like machine learning or data analysis. It enables us to assess the performance of algorithms or models on data that have not been seen before (the test samples) after they have been trained on the selected training samples. The different numbers of training samples chosen per person for each dataset are probably meant to explore how the performance of the analysis varies depending on the quantity of available training data.
Before running the algorithms, we carefully chose parameter combinations from a set of potential optimal values to make sure that the algorithms could successfully learn the best projection matrix for feature extraction. To evaluate the robustness of the experimental outcomes, we performed ten-fold cross-validation for each algorithm, resulting in the mean and standard deviation of the classification accuracy (mean ± std%), as shown in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5. In the table, bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best classification results and dimensions within the same row.
5.3. Results and Analyses
We have documented the experimental results comparing the performance of our proposed RBOP methods (namely, RBOP_PCA, RBOP_NPE, and RBOP_LPP) with other conventional DR techniques (i.e., PCA, NPE, and LPP) across five public datasets, as detailed in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5. We provide the following observations and analyses.
Table 1.
Classification accuracy of all methods on PIE is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
Table 1.
Classification accuracy of all methods on PIE is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
| #Tr/s | PCA | RBOP_PCA | NPE | RBOP_NPE | LPP | RBOP_LPP |
|---|
| 25 | 67.12 ± 0.50 | 74.16 ± 1.64 (50) | 79.60 ± 0.84 | 82.45 ± 0.59 (30) | 86.58 ± 0.46 | * 88.20 ± 0.36 (90) |
| 30 | 72.25 ± 0.57 | 85.05 ± 1.69 (100) | 84.43 ± 0.68 | 86.76 ± 0.44 (100) | 87.27 ± 0.45 | * 90.50 ± 0.29 (100) |
| 40 | 79.13 ± 0.50 | 90.39 ± 0.27 (100) | 89.21 ± 0.44 | 90.47 ± 0.31 (50) | 90.71 ± 0.40 | * 92.91 ± 0.14 (100) |
| 50 | 83.51 ± 0.27 | 92.56 ± 0.39 (100) | 91.60 ± 0.27 | 92.86 ± 0.55 (50) | 92.59 ± 0.43 | * 94.47 ± 0.12 (300) |
| 60 | 87.06 ± 0.65 | 93.78 ± 0.49 (200) | 92.84 ± 0.20 | 93.85 ± 0.23 (50) | 93.79 ± 0.22 | * 95.00 ± 0.13 (200) |
| 70 | 89.33 ± 0.33 | 94.37 ± 0.26 (100) | 93.58 ± 0.23 | * 95.27 ± 0.10 (200) | 94.63 ± 0.32 | 94.93 ± 0.15 (200) |
(1) From
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5, it is evident that RBOP methods generally achieve superior results in the majority of cases, with the exception of scenarios where the number of training samples provided by each subject is limited. For instance, in
Table 2 when #Tr/s equals 10 and 20, or in
Table 3 when #Tr/s equals 1, the classification accuracy achieved by the RBOP methods is not as competitive as that of LPP, NPE, and PCA. This finding suggests that the effectiveness of RBOP methods on the Extended Yale B and FERET datasets may be somewhat compromised by an inadequate number of training samples. Nevertheless, as the number of training samples increases, our results demonstrate improvement, potentially increasing the classification accuracy by over 50% in the most favorable cases.
Table 2.
Classification accuracy of all methods on Extended Yale B is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
Table 2.
Classification accuracy of all methods on Extended Yale B is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
| #Tr/s | PCA | RBOP_PCA | NPE | RBOP_NPE | LPP | RBOP_LPP |
|---|
| 10 | 53.85 ± 1.47 | 62.54 ± 2.11 (100) | 80.38 ± 1.11 | 62.04 ± 1.47 (50) | * 89.07 ± 1.02 | 79.48 ± 0.59 (50) |
| 20 | 69.28 ± 1.09 | 80.87 ± 2.19 (100) | 78.39 ± 2.67 | 80.49 ± 1.10 (20) | * 90.88 ± 0.92 | 88.21 ± 0.26 (50) |
| 30 | 76.41 ± 1.43 | 89.61 ± 1.30 (200) | 65.68 ± 4.03 | 83.82 ± 0.77 (150) | 92.17 ± 0.36 | * 92.42 ± 0.51 (100) |
| 40 | 81.40 ± 0.86 | 90.86 ± 1.02 (100) | 71.86 ± 1.84 | 89.28 ± 0.54 (50) | 93.15 ± 0.78 | * 94.19 ± 0.34 (100) |
| 50 | 84.47 ± 1.95 | 94.23 ± 0.36 (200) | 78.79 ± 2.20 | 91.80 ± 0.94 (50) | 94.69 ± 0.47 | * 94.29 ± 0.26 (100) |
| 59 | 86.34 ± 1.35 | 93.75 ± 0.58 (300) | 94.53 ± 1.82 | 92.97 ± 1.07 (50) | 94.36 ± 2.39 | * 97.36 ± 0.54 (100) |
(2) Compared to PCA, RBOP_PCA delivers impressive results on both the PIE and Extended Yale B datasets. On the C-CUBE and COIL20 datasets, the benefits of RBOP_PCA are less pronounced, with its performance being nearly equivalent to that of PCA. However, the performance of RBOP_PCA on the FERET face dataset is not as strong, primarily due to a lack of sufficient training samples. As suggested by the classification accuracy rates in the tables, the scores vary between 12.47% and 56.50%, indicating that the overall performance is not ideal when only a limited number of training samples are available for each class.
Table 3.
Classification accuracy of all methods on FERET is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
Table 3.
Classification accuracy of all methods on FERET is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
| #Tr/s | PCA | RBOP_PCA | NPE | RBOP_NPE | LPP | RBOP_LPP |
|---|
| 1 | 17.55 ± 1.32 | 12.47 ± 0.53 (19) | 14.59 ± 0.59 | 14.52 ± 0.54 (20) | * 20.82 ± 0.40 | 16.87 ± 0.81 (20) |
| 2 | 25.05 ± 1.32 | 22.69 ± 0.20 (300) | 18.65 ± 1.01 | 23.60 ± 0.09 (300) | 25.39 ± 1.88 | * 28.63 ± 0.57 (100) |
| 3 | 31.15 ± 1.27 | 29.72 ± 0.28 (300) | 23.85 ± 1.95 | * 37.26 ± 1.32 (100) | 26.21 ± 0.83 | * 37.26 ± 1.32 (50) |
| 4 | 36.53 ± 1.48 | 38.01 ± 0.37 (200) | 27.93 ± 1.45 | 38.65 ± 0.62 (300) | 32.53 ± 0.96 | * 44.71 ± 1.57 (100) |
| 5 | 39.80 ± 1.93 | 40.96 ± 0.12 (200) | 30.05 ± 2.42 | 43.78 ± 1.29 (300) | 39.10 ± 1.38 | * 53.72 ± 2.93 (50) |
| 6 | 46.40 ± 2.42 | 42.15 ± 0.63 (300) | 28.35 ± 1.76 | 40.52 ± 0.82 (200) | 47.50 ± 2.01 | * 56.50 ± 1.56 (20) |
(3) In comparison to NPE, RBOP_NPE attains a slightly higher score on the PIE dataset, although the superiority is not significant. On the Extended Yale B dataset, RBOP_NPE demonstrates greater stability in its scores compared to NPE. Moreover, their scores are significantly higher when the number of training samples per person (i.e., #Tr/s) is 20, 30, 40, or 50, respectively. Conversely, when #Tr/s is 10 or 59, the score of RBOP_NPE is lower. On the FERET dataset, RBOP_NPE can achieve superior results even with a small number of training samples, indicating its effectiveness in such scenarios. On the COIL20 dataset, the performance of RBOP_NPE is relatively consistent, and it can achieve a high classification accuracy, close to 100%, when #Tr/s is 40. On the C-CUBE dataset, RBOP_NPE obtains slightly higher accuracy when #Tr/s is 20, 30, 40, or 50. However, its performance is unstable and prone to fluctuations when #Tr/s is 60 or 70, in comparison to NPE.
Table 4.
Classification accuracy of all methods on C-CUBE is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
Table 4.
Classification accuracy of all methods on C-CUBE is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
| #Tr/s | PCA | RBOP_PCA | NPE | RBOP_NPE | LPP | RBOP_LPP |
|---|
| 20 | 52.63 ± 1.04 | 53.84 ± 0.96 (100) | 50.72 ± 1.67 | * 54.03 ± 0.39 (200) | 46.08 ± 0.97 | 52.56 ± 0.51 (390) |
| 30 | 56.36 ± 1.33 | 57.91 ± 0.27 (395) | 52.99 ± 1.06 | * 58.41 ± 0.49 (300) | 46.40 ± 1.21 | 54.76 ± 1.07 (395) |
| 40 | 59.18 ± 1.50 | * 61.22 ± 0.37 (500) | 52.05 ± 1.13 | 59.22 ± 0.42 (300) | 43.71 ± 0.90 | 60.30 ± 0.23 (760) |
| 50 | 61.93 ± 1.34 | 60.63 ± 0.36 (600) | 59.20 ± 1.13 | * 62.94 ± 0.31 (600) | 47.21 ± 1.81 | 62.78 ± 0.51 (875) |
| 60 | 62.88 ± 1.36 | 63.59 ± 0.63 (500) | * 65.18 ± 1.58 | 64.23 ± 0.44 (780) | 53.85 ± 1.46 | 63.56 ± 0.34 (875) |
| 70 | 64.10 ± 1.52 | 64.58 ± 0.61 (600) | * 68.53 ± 1.45 | 63.94 ± 0.34 (700) | 57.90 ± 1.23 | 67.97 ± 0.50 (875) |
(4) Compared to LPP, RBOP_LPP generally achieves a higher score in most instances across
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5, with a few exceptions. For example, when the number of training samples per class (i.e., #Tr/s) is 10 or 20, LPP achieves higher scores on the Extended Yale B dataset, whereas when #Tr/s = 1, LPP surpasses RBOP_LPP on the FERET dataset. In the most favorable scenario, RBOP_LPP can enhance classification accuracy by 56.22% (calculated by (37.26−23.85)/23.85 when #Tr/s = 3); in the least favorable case, it can still boost accuracy by 18.95% (calculated by (56.50−47.50)/47.50 when #Tr/s = 6).
Table 5.
Classification accuracy of all methods on COIL20 is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
Table 5.
Classification accuracy of all methods on COIL20 is represented by mean ± std% (best dimension). Bold numbers indicate the best classification results and their corresponding dimensions compared between the 2nd/4th/6th and 3rd/5th/7th columns, while bold and asterisked marks denote the best among these 3 bold numbers.
| #Tr/s | PCA | RBOP_PCA | NPE | RBOP_NPE | LPP | RBOP_LPP |
|---|
| 20 | 95.06 ± 0.82 | 95.97 ± 0.42 (20) | 94.67 ± 0.79 | 95.67 ± 0.13 (20) | 93.10 ± 0.61 | * 100.00 ± 0.00 (200) |
| 30 | 97.21 ± 0.67 | 98.37 ± 0.76 (20) | 95.39 ± 0.79 | 98.49 ± 0.32 (20) | 96.35 ± 0.72 | * 97.98 ± 0.22 (100) |
| 40 | 98.69 ± 0.69 | 99.32 ± 0.20 (20) | 91.91 ± 1.01 | * 99.84 ± 0.03 (20) | 98.21 ± 0.80 | 97.77 ± 0.27 (300) |
| 50 | 99.18 ± 0.29 | 98.96 ± 0.11 (300) | 69.93 ± 3.91 | 99.39 ± 0.26 (20) | 99.22 ± 0.37 | * 99.93 ± 0.13 (200) |
| 60 | 99.38 ± 0.66 | * 100.00 ± 0.00 (50) | 93.67 ± 5.41 | 99.58 ± 0.00 (50) | 99.87 ± 0.20 | 99.48 ± 0.18 (200) |
| 70 | 99.75 ± 0.79 | * 100.00 ± 0.00 (20) | 99.00 ± 1.75 | * 100.00 ± 0.00 (20) | * 100.00 ± 0.00 | * 100.00 ± 0.00 (100) |
(5) As illustrated in
Table 5, when the number of training samples provided per class is sufficient (e.g., when #Tr/s = 20), all methods are capable of achieving high classification accuracy. This outcome is attributed to the fact that the object images in the COIL20 dataset are not afflicted by complex background information or over-illumination. Moreover, the majority of classification accuracies surpass 90%, with six reaching 100%. Simultaneously, we observe that when #Tr/s exceeds 20, the discrepancies in classification accuracy are not significant, suggesting that none of the methods require an excessive number of additional training samples on the COIL20 dataset to achieve high classification accuracy.
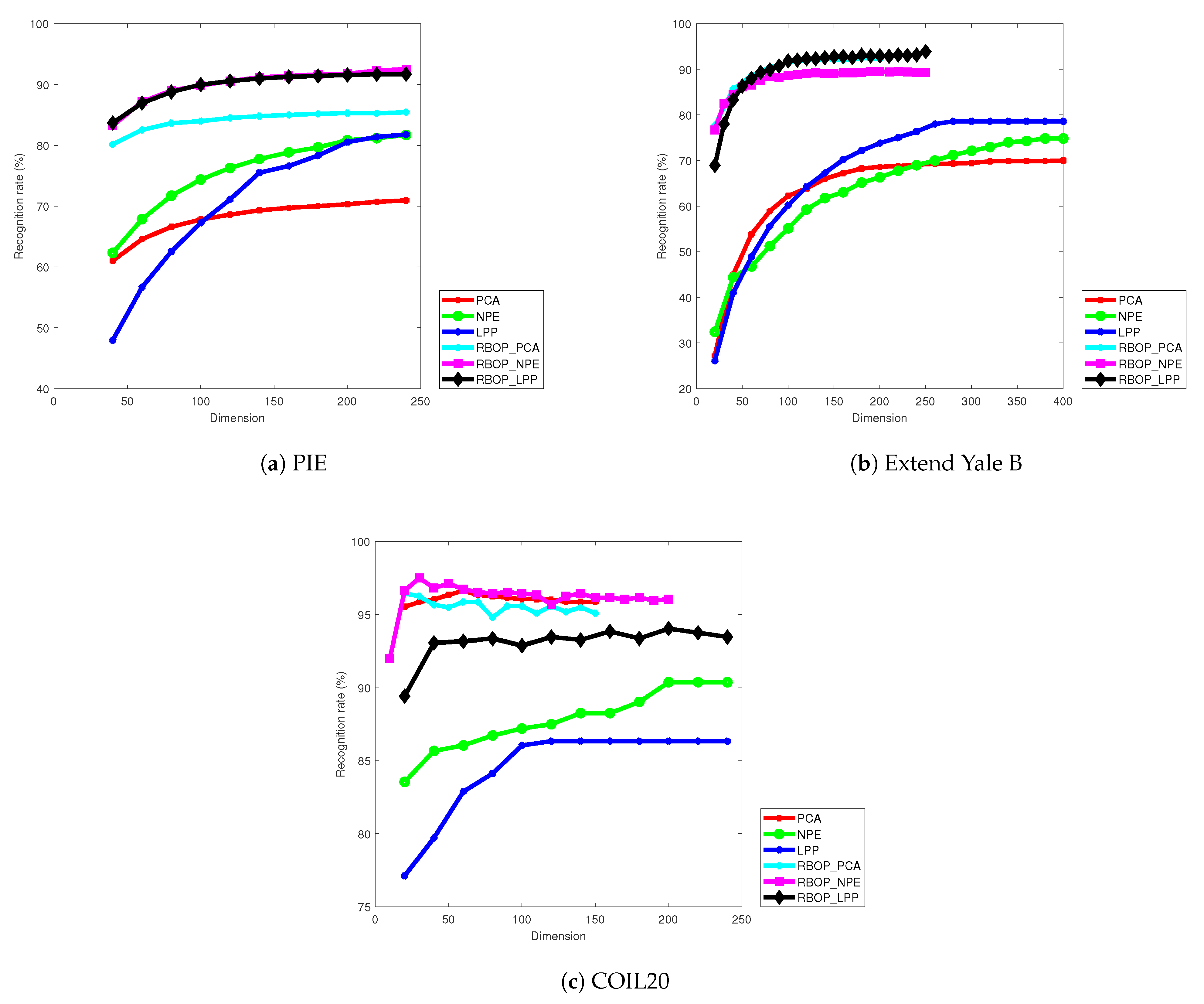
During the experimental phase, accurately presenting the experimental results of different methods under various dimensions is of crucial importance for algorithm evaluation and optimization. To this end, this paper selects three representative datasets, namely, PIE, Extended Yale B, and COIL20, to conduct experiments. The selection of samples strictly adheres to statistical norms. A total of 30 samples are randomly selected from each class in the PIE dataset, and 20 samples are randomly selected from each class in both the Extended Yale B and COIL20 datasets to form the training sample set, aiming to eliminate sample bias as much as possible.
Each group of experiments is run only once, with strict control over the consistency of conditions to reduce random errors. After completion, the focus is placed on the recognition accuracy rate and dimension changes, and the relationship between the two is precisely plotted in
Figure 3. Here, the number of dimensions refers to the number of column vectors in the projection matrix
P, which is related to dimensionality reduction and algorithm performance. By analyzing
Figure 3, it can be seen that the RBOP_PCA, RBOP_NPE, and RBOP_LPP methods exhibit excellent performance in recognition accuracy on the three datasets. On the COIL20 dataset, the PCA method also achieves relatively good results. Based on the comprehensive experiment, the proposed methods can not only efficiently project the original images into low-dimensional subspaces and reduce the number of dimensions but also lead their counterparts in convergence speed, quickly approaching the global optimal solution. Through strict argumentation, the efficiency and scientific nature of the proposed methods have been verified, providing strong support for technological innovation in related fields.
Subsequently, we showcase the results of applying various methods to three Gaussian synthetic datasets in
Figure 4.
Figure 4a,c,e display the classification outcomes utilizing PCA, NPE, and LPP. It is clear that these methods encounter difficulties in distinguishing between different objects (labeled as green squares, blue asterisks, and red crosses) based on the existing features.
Figure 4b portrays the classification results of RBOP_PCA on the same dataset: blue asterisks, green squares, and red crosses are arranged sequentially along the horizontal axis from left to right.
Figure 4d,f exhibit the classification results of RBOP_NPE and RBOP_LPP on the three Gaussian synthetic datasets. From this observation, we can identify three clear clusters, which further highlights that the performance of the proposed RBOP methods is superior to that of other traditional methods.
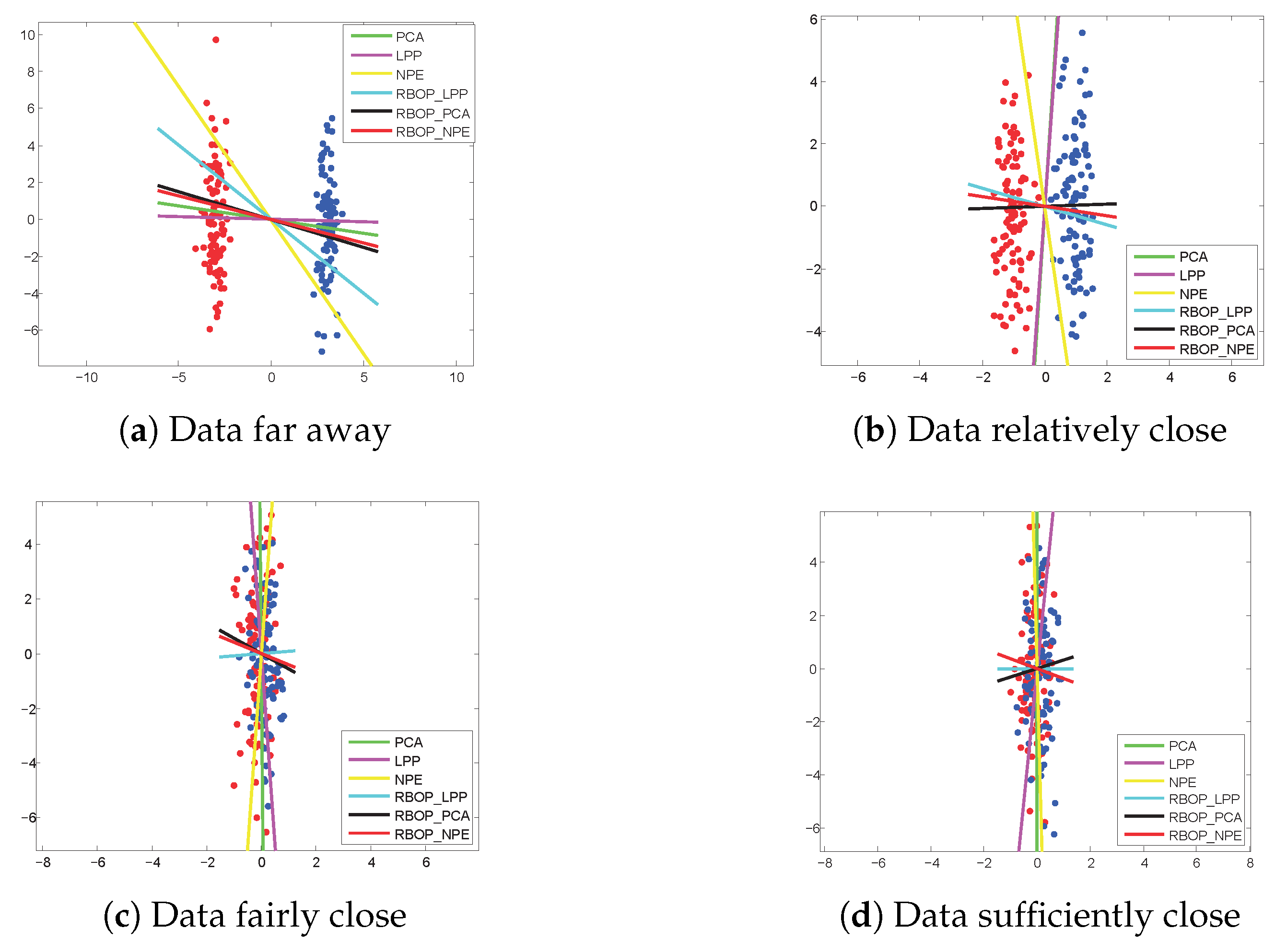
Finally, we illustrate the experimental outcomes of the two Gaussian synthetic datasets, as depicted in
Figure 5. Distinct colored lines represent different methods. To categorize the data, denoted by red and dark blue dots, we project them vertically onto a straight line and subsequently differentiate the two clusters based on their projection position—theoretically, the greater the number of horizontal lines, the higher the classification accuracy. The observations from
Figure 5a–d reveal that the proposed RBOP methods exhibit superior performance compared to traditional DR methods, particularly on data that are relatively, moderately, or sufficiently close.
5.4. Computational Efficiency Comparison
To showcase the computational efficiency of the proposed method, this subsection conducts a comparison of the runtime of this method with those of other benchmark methods. When setting up the experiment, a personal computer equipped with a 3.4 GHz central processing unit and 8 GB of memory serves as the hardware base. Windows 10 is chosen as the operating system, and Matlab 2015a is used to run all the methods. For simplicity and to focus on key data, the Extended Yale B dataset is selected for the experiment. By using a random sampling method, 30 images are randomly selected from the image set of each subject as training samples, so that the model can fully learn and extract key features. The remaining images are used as test samples to strictly verify the generalization performance and classification accuracy of the model. All data in each experiment link are collected and recorded meticulously. The key results are shown in
Table 6. It is found that the proposed methods take 55.16, 71.34, and 69.55 s, respectively, during different training rounds. As KNN is only used for image classification in the test set, and the running time of all methods is nearly the same in this regard, this part of the data is not recorded in detail. When making a horizontal comparison with classic methods like PCA, NPE, and LPP, the training time required by the proposed method is longer. However, it can achieve optimal classification results within about one minute. Therefore, in the pursuit of high-precision image classification, it is inevitable that a certain amount of computing time will be sacrificed. The proposed method has found a good balance, providing valuable reference for the design and improvement of similar algorithms.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}